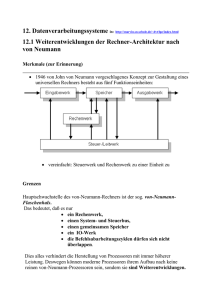
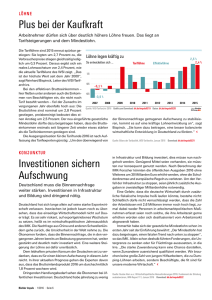
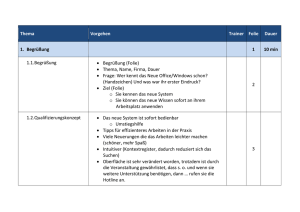
DOCX - Technische Universität Chemnitz
Werbung

Komponenten und Architekturen Skript Vorlesung und Übung (Bilder und Übungsmaterialien der Professur nicht enthalten) Inhaltsverzeichnis 1. 2. 3. Einführung .......................................................................................................................... 4 1.1 Begriffsbildung ............................................................................................................ 4 1.2 Aufgaben und Ziele von Rechnerarchitekturen ........................................................... 6 1.3 Leitlinien und Phasen des Rechnerentwurfs ................................................................ 6 1.4 Phasen des Rechnerentwurfs ....................................................................................... 7 1.4.1 Phase 1: Anforderungsanalyse und –definition .................................................... 8 1.4.2 Phase 2: Definition der Globalstruktur (System Level Design) ........................... 9 1.4.3 Phase 3: Definition der Befehlssatzebene (ISA Level Design) ............................ 9 1.4.4 Phase 3*: Auswahl von CPU- und Verarbeitungskomponenten ........................ 10 1.4.5 Phase 4: Definition der Mikroarchitektur (Micro Architecture Design) ............ 10 1.4.6 Phase 5: Hardware-Design ................................................................................. 11 1.4.7 Phase 6: Prototyp ................................................................................................ 11 1.4.8 Phase 7: Übergabe in die Produktion ................................................................. 12 1.4.9 Begleitende Architekturüberprüfung.................................................................. 12 Grundlagen, Architekturklassen und –merkmale von MP ............................................... 13 2.1 Allgemeines zur MP-Architektur .............................................................................. 13 2.2 Von-Neumann-Rechner, Harvard-/ Princeton-Architektur ....................................... 13 2.3 Möglichkeiten der Klassifizierung ............................................................................ 14 2.3.1 Rechnerklassifikation nach Flynn ...................................................................... 14 2.3.2 Erlanger Klassifikationssystem ECS .................................................................. 15 2.3.3 Klassifizierung nach Giloi .................................................................................. 17 2.3.4 Architekturklassen bei Prozessoren.................................................................... 17 Grundkomponenten von Prozessoren............................................................................... 19 3.1 Hardwaregrundlagen, Komponenten ......................................................................... 19 3.1.1 Schaltnetze ......................................................................................................... 19 3.1.2 Schaltwerke ........................................................................................................ 19 3.2 Leitwerke ................................................................................................................... 19 3.2.1 Allgemeines ........................................................................................................ 19 3.2.2 Mikrobefehle und Mikroprogramme .................................................................. 20 3.2.3 Mikrobefehlserzeugung ...................................................................................... 21 3.3 Varianten von Rechnerarchitekturen ......................................................................... 23 3.3.1 Befehlssatzarchitektur (ISA) vs. Mikroarchitektur ............................................ 23 3.3.2 CISC-Prozessoren und Mikroprogrammierung ................................................. 23 3.3.3 Entstehung der RISC-Technologie ..................................................................... 24 3.3.4 Phasenpipeline-Mikroarchitekturen ................................................................... 27 2 3.4 4. Rechenwerke ............................................................................................................. 30 3.4.1 Addierer .............................................................................................................. 31 3.4.2 Subtrahierer ........................................................................................................ 31 3.4.3 Multiplizierer ...................................................................................................... 32 3.4.4 Dividierer ........................................................................................................... 33 Übung ............................................................................................................................... 34 4.1 Materialien ................................................................................................................. 34 4.2 Adder ......................................................................................................................... 34 4.2.1 Halfadder (2, 2) ohne Carry In ........................................................................... 34 4.2.2 Fulladder (3, 2) mit Carry In .............................................................................. 34 4.2.3 Ripple Carry Adder ............................................................................................ 35 4.2.4 Manchester Carry Chain ..................................................................................... 35 4.2.5 Carry Skip Adder ............................................................................................... 36 4.2.6 Carry Look Ahead Adder (CLA) ....................................................................... 36 4.2.7 Carry Select Adder ............................................................................................. 37 4.2.8 Serial Adder ........................................................................................................ 37 4.3 Selbst zu entwerfende Komponente .......................................................................... 38 4.3.1 Bedingungen und Hinweise ............................................................................... 38 4.3.2 Eigene Komponente ........................................................................................... 38 4.4 Prozessoren ................................................................................................................ 40 4.4.1 Alignment ........................................................................................................... 40 4.4.2 Schaltung gegen Spikes ...................................................................................... 40 4.4.3 Dauer von Maschinenbefehle → CPI................................................................. 40 4.4.4 Pipeline Aufgabe 2 ............................................................................................. 40 4.4.5 Pipeline Aufgabe 4 ............................................................................................. 41 4.4.6 Pipeline Aufgabe 5 ............................................................................................. 41 4.4.7 Score-Boarding................................................................................................... 42 4.4.8 Tomasulo ............................................................................................................ 42 4.4.9 DLX Aufgaben aus Teil 2 .................................................................................. 43 4.5 Prüfungsinhalte .......................................................................................................... 44 3 1. 1.1 Einführung Anforderungen an Computerleistung wachsen mit enormer Geschwindigkeit Rechnerarchitekten und Chipentwerfer stehen vor der Herausforderung o immer kompaktere Computergenerationen, o mit spektakulär erscheinender Systemleistung, o zu einem vertretbaren Preis, o in zunehmend kürzeren Abstand auf den Markt zu bringen nicht nur Computer- und Chipentwickler, auch Wirtschaftsinformatiker, IT-Spezialisten, Marketing-Fachleute und Anwender müssen sich mit Rechnerarchitekturen auseinandersetzen → fachliche Beurteilung von IT-Entscheidungen wichtig: im globalen Umfeld vor allem wirtschaftliche Erfolgskriterien Prozessor-/Rechnerentwurf, immer höheres Integrationsniveau Aspekte des Rechnerentwurfs sind vielfältig: o Befehlssatzentwurf o funktionelle Organisation o Logikentwurf o Implementierung (z.B. Schaltkreisentwurf, Packaging, Spannungsversorgung, Kühlung, …) Optimierung eines Entwurfs muss über alle Ebenen erfolgen (Hardware, Software, Systementwurf → Layout → fertiges Produkt) Kenntnisse: Technologie, Compiler, OS, Logikentwurf, GT, … Begriffsbildung frühere RA-Definition umfasste nur die Sicht des Programmierers auf die konzeptionellen und funktionalen Eigenschaften des Systems interne Organisationsstruktur und Informationsfluss blieben unberücksichtigt Architekturbeschreibung eines Rechners sollte insbesondere die Möglichkeit seiner Programmierschnittstelle ausdrücken o Maschinenbefehlssatz o Registerstruktur o Adressierungsmodi o Behandlung von Interrupts durch den Programmierer wird heute als Befehlssatzarchitektur (ISA, Instruction Set Architecture) bezeichnet Moderne RA-Definition umfasst heute o Analyse, o Bewertung, o Entwurf, o und Synthese von Rechnern und Komponenten fächerübergreifend, dazu folgende Aspekte berücksichtigen: o strukturelle o organisatorische o implementierungstechnische diese Aspekte sind zu untersuchen auf o globaler Systemebene o Maschinenbefehlssatzebene o Mikroarchitekturebene 4 Rückkopplungen, Wechselwirkungen → Informatik, Ingenieurund Naturwissenschaften, Mathematik (siehe Bild K+A-1_F 1) Vorteile dieser Betrachtungsweise: o Begriffsmodell ist nach Teilbereichen und Beschreibungsebenen strukturiert o lässt sich auf existierende oder zu entwickelnde RA (Rechnerarchitekturen) abbilden o lässt leicht Teilprobleme benennen, die beim Vergleich oder Untersuchung vorliegender Rechner oder beim Entwurf neuer zu lösen sind o Modell erlaubt, erforderliches Spezialwissen, benötigte Analyse- und Entwurfstechniken und verfügbare Tools den zu bearbeitenden Teilaufgaben zuzuordnen RA hat folgende Teilbereiche abzudecken o Struktur: Eigenschaften, wie z.B. Zahl der Prozessoren in einem System oder Aufbau der Speicherhierarchie o Organisation: Steuerung und Vor- bzw. Nachteile logischer Organisationsformen z.B. für Caches o Implementierungstechnik: Möglichkeiten und Probleme der konkreten Realisierung bestimmter Struktur- und Organisationsformen und erzielbarer Leistung „Rechnerarchitekt“ hat Entscheidungen innerhalb von drei Beschreibungsebenen zu treffen: o Systemebene (System Level Architecture), Entscheidungen beziehen sich auf die Konfiguration von Prozessoren, Speicher, Verbindungs- und E/A-Systeme o Befehlssatzebene (ISA-Level), Entscheidungen betreffen hier Befehlssatz eines Computers (Zielrichtung?) (CISC, RISC, VLIW), sind für Software des Systems sichtbar, beeinflussen vor allem Zusammenarbeit des Systems mit OS und Compilern o Mikroarchitekturebene (Microarchitecture Level), Entscheidungen beziehen sich auf Prozessorimplementierung, nur teilweise für Systemsoftware sichtbar, dienen der Optimierung der Leistungseigenschaften und technologischen Aspekte des Systems (siehe Bild K+A-1_F 2) Nutzen des Begriffsmodells: o Gliederung nach Ebenen und Teilbereichen erlaubt schnellen Übergang von sehr speziellen Architekturkriterien zu abstrakteren und globalen Fragestellungen o Überschneidungen mit anderen Fachdisziplinen und Teilbereichen der RA auf unterschiedlichen Abstraktionsebenen erkennbar und je nach Anforderung auswertbar o Begriffsmodell verkörpert gleichermaßen Gerüst und äußeren Rahmen für systematische Auseinandersetzung mit analytischen und synthetischen Fragen der RA o für Behandlung detaillierter Aufgabenstellungen bei Analyse und Entwurf von Rechnersystemen, außerdem Methoden und Verfahren zur Klassifikation, Beschreibung, Modellierung von Rechnern und deren internen Verarbeitungsabläufen erforderlich o RA und beteiligte Fachrichtungen ergänzen sich o Ist RA zukunftsfähig? Neue Anforderungen wegen immer größeren Datenmengen (Multimedia, Internet) 5 1.2 1.3 Aufgaben und Ziele von Rechnerarchitekturen Rechnerarchitektur als praxisnahe Forschungsdisziplin, folgende Schwerpunktaufgaben: o Analyse der Architekturen existierender Computersysteme und Rechnerbausteine wie Prozessoren, Speicher, Logikbausteine, Verbindungsstrukturen, E/ASubsysteme, Peripherieansteuerung o Klassifikation von Rechnerarchitekturen o Beobachtung der Evolution von Rechnerfamilien und Architekturklassen o rechtzeitiges Erkennen erfolgversprechender neuartiger Ansätze, Verarbeitungsprinzipien und Überprüfung auf Umsetzbarkeit o Entwurf und Synthese leistungsfähiger, universeller und/oder spezialisierter Rechnersysteme aus neuen oder vorhandenen Standard- oder Spezialbausteinen; dabei Anwendung leistungsfähiger Entwurfsmethoden und CAD o Umsetzung von Leistungsanforderungen, die heute weitgehend von der Software und den Anwendungsbereichen vorgegeben werden, in geeignete Strukturen und Organisationsformen für Rechner und Komponenten (SoC) wichtige Ziele von Rechnerarchitekturen und –entwicklungen: o weitere Leistungssteigerung durch Architekturverbesserung o Erfüllung anerkannter Qualitätskriterien für Entwurf und Realisierung o Steigerung der Benutzerfreundlichkeit, z.B. Hardware-Komponenten für die MMK (Mensch-Maschine-Kommunikation: Benutzeroberfläche, Sprache, Animation, Video, VR, …) o Entwurf evolutionsfähiger Architekturkonzepte, die über einen längeren Zeitraum zu konkurrenzfähigen Implementierungen führen können → Reduzierung der durchschnittlichen Entwicklungskosten o Förderung sinnvoller und zukunftssicherer Industriestandards (nicht zu Lasten der Entwurfsziele und –qualität) o Streben nach ausgewogenen, in allen HW- und SW-Komponenten aufeinander abgestimmten Systemen o Nutzung von Synergie-Effekten mit Anwendungsgebieten im Sinne des Begriffsmodells, noch bessere Gesamtlösung o intensiveres Zusammenwirken mit Anwendern und Systemanalytikern o Berücksichtigung neuer Ergebnisse und Philosophien aus dem Softwarebereich Leitlinien und Phasen des Rechnerentwurfs Rechnerentwurf erfolgt entsprechend den Beschreibungshierarchien einer hierarchischen Vorgehensweise, 2 Wege: o Top-Down, Entwurf der Globalstruktur → Entwurf der Befehlssatz- und Mikroarchitekturebene → Festlegung der Logikebene und der Technologie o Bottom-Up, verfügbare Schaltkreistechnologie bzw. erhältliche Baustein-Basis der Architektur → Entwurfsziel ist die Gesamtstruktur in der Praxis gemischte Strategien statt rein sequentiellen Ablauf auch mehrere Phasen parallel bearbeiten Rechnerentwurf ist ein flexibel organisierter Prozess o Teilaufgaben untergliedern o Änderungen in der Reihenfolge o Anpassung an konkrete Entwurfsumgebungen o Reaktion auf technologische Anforderungen 6 1.4 o Beobachtung von Marketingvorgaben allgemeine Gestaltungsrichtlinien für Rechnerentwurf o Ausgewogenheit: Systemkomponenten in Leistung und Kosten aufeinander abstimmen o Verständlichkeit: überschaubare Funktionalität des Systems, Nachvollziehbarkeit des Systemverhaltens, steigende Komplexität erfordert umfangreiche intelligente und ergonomische Unterstützungs- und Hilfswerkzeuge o Konfigurierungsflexibilität, Offenheit, Skalierbarkeit: Anpassung des Systems in Funktion und Leistung an die Wünsche der Nutzer und Anforderungen der Softwareumgebung o Berücksichtigung von Industriestandards und Kompatibilität: sinnvolle Standards nutzen bereits im Systementwurf (Zielleistung und Funktionalität des Systems nicht beeinträchtigen) o Rapid Prototyping: schnelle Verfügbarkeit von Zwischenergebnissen (Simulationen, Modelle) → Evaluierung → Grundlage für weiteres Vorgehen o Systemdenken und Kooperation beim Rechnerentwurf notwendig, Anforderungen aus vielen Bereichen (Hard-, Software, Kosten, Technologie, Stromverbrauch, …) aktuelle technologische Trends: o Bedeutungsrückgang von traditionellen Großrechnern mit herstellerspezifischen OS o Konzentration auf Arbeits(platz)rechner, Server, tragbare Systeme, herstellerübergreifende OS, Standardisierung (GUI, HW (Busse), OS, …) o Behauptung von Superrechnern (Vektor-, Multiprozessorarchitektur) o starke Zunahme paralleler Strukturen o Vernetzung, Kommunikationsfähigkeit, Parallelisierung von Anwendungssytemen o intelligente Kommunikation zwischen Mensch und Maschine o neue Entwicklungen im industriellen Bereich (Robotik) o Architektur-Philosophie für CPU: CISC ↔ RISC o Steigerung Integrationsdichte o Komplexe Architekturen auf einem Chip Phasen des Rechnerentwurfs wichtige Trends, die sich auf die Rechnerarchitektur und damit auch auf die Phasen des Entwurfs auswirken Internet-Anwendungen: o nahezu gigantische Informations- und Datenmengen (hunderte Terabyte pro Tag, 2002 insgesamt 5 Exabyte) o neben Schrott auch seriöse Anwendungen z.B. öffentliche/ kommunale Dienstleistungen, Suchmaschinen, Hot Spots → Probleme mit der Bandbreite und Prozessorleistung o Zahl der vernetzten Rechner steigt ständig o gewisse Homogenisierung → Lösungen des Internets auch im Intranet Net-PC: nach anfänglicher Euphorie jetzt wenig relevant, weil Rechenleistung/ Speicherplatz geometrisch klein, low-power, billig (auch das Geräuschargument (Platten, Lüfter) spielt geringe Rolle) Internet Appliances: z.B. Smart Cards mit MC und Flash, MP3-Player, UMTS, Datenraten bis 2MBit/s → SoC 7 1.4.1 Internet-Server: Leistungsfähigkeit → hochparallel, zuverlässig, Prämisse ist RAS (reliability, availability, serviceability) zum RASUM ( …, usability, manageability) Software-Schnittstellen (Einheit von HW und SW): multimediafähig, GUI, objektorientierte Programmiersprachen Video/3D-Graphik: schnellste Graphikverarbeitung → sehr rechenintensiv, innovative HW/SW-Lösung Phase 1: Anforderungsanalyse und –definition Hier wird der Entwurfsrahmen abgesteckt, besonders zu klären: wer stellt Entwurfsanforderung? o das technologische Marketing: Markt, Standards, Trend-, Konkurrenzanalyse o die Entwicklungsabteilung: Berücksichtigung bereits laufender, geplanter, notwendiger interner Komponenten-/ Systementwicklungen o der Kunde: Speziallösungen, -anforderungen, Software-Anregungen, spezifische SW-Kompetenz, Anwendungs-Know-how o die Produktionstechnologie: vorhandene, erwartete VLSI-Produktionsprozesse, Baugruppen, Packaging-/ Gehäusung-, Kühltechnologie, Stromversorgung wie ist das zu entwickelnde System einzuordnen? o Untersuchung möglicher Einteilungskriterien (Preis, Leistung, Technologie) o Entwurf eines kompletten Rechnersystems oder einzelner Komponenten o Verwendung vorhandener und/ oder neu zu entwickelnder HW-SW-Module o Einsatzgebiet (z.B. Universal-, Spezialrechner, vorhandene/ neue (OS-)SW, Anwendungs-SW, Transaktionsverarbeitung) welche Leistungsanforderungen soll das Zielsystem erfüllen? o Vergleich von Entwicklungs-, Marketing-, Kundenvorstellungen o Abschätzung der zum Zielzeitpunkt erforderlichen Leistung (dabei ca. ½ bis 3 Jahre Entwicklungshorizont, je nach Architekturphilosophie, Projektumfang, Innovationsgrad) o Funktionalitätsanforderungen o Aufgabenspezifische Anforderungen an HW und SW o Real-time-Anforderungen o E/A und Kommunikation bei Vielzahl von Schnittstellen (Platten und andere Laufwerke, drahtlose/ -gebundene Interfaces wie WLAN und USB) o Zuverlässigkeit, Fehlertoleranz (MTBF, MTTR, MTBSC), Umgebungsanforderungen Kosten, Ressourcen, Planung o Projektumfang in Personenjahren, Anteil der Eigen- und Fremdentwicklungen o Projektleitung, -organisation, beteiligte Partner/ Einrichtungen/ Behörden o Abschätzen der Entwicklungskosten (HW, SW, Firmware, Forschung, Produktion, Prozesstechnologien, Ressourcen) o globale Festlegung der Entwurfsressourcen (Rechner, SW, Tools, …) Ergebnisse der ersten Phase fließen in verbindliche Spezifikationen ein. Angestrebt wird ein Optimum zwischen Entwicklungskosten, Leistungszielen, Zeitplan. 8 1.4.2 1.4.3 Phase 2: Definition der Globalstruktur (System Level Design) Festlegung der globalen Struktur des Systems Umsetzung der aus Phase 1 übernommenen Anforderungsspezifikationen in technologisch, kostentechnisch und zeitlich machbare Konzepte → Festlegung welche Systembestandteile als Reuse- bzw. Neu-/ Eigenentwicklungsteile benötigt werden → Systementwurf Globalentwurf bildet Grundlage für erste Abschätzung hinsichtlich der Erfüllung der Anforderungen, eventuell Modifikation der Spezifikation oder des Globalentwurfs möglichst (idealer Weise) gleichzeitig dazu Definition/ Erstellung/ Beschaffung der endgültig benötigten Simulations- und Entwicklungswerkzeuge soweit bereits möglich Definition globaler Systemschnittstellen zwischen den Komponenten (untereinander) und zur (OS-) Systemsoftware Phase 3: Definition der Befehlssatzebene (ISA Level Design) falls lediglich Auswahl und keine Entwicklung von CPUs bzw. sonstigen Komponenten (z.B. Coprozessor), Phase 3* Definition der Philosophie des Befehlssatzes o RISC, CISC, Kombination von beiden, alternatives Design o Einfluss von Leistungsvorgaben auf den Befehlssatz → Zyklen pro Befehl o Speichermodell (Load/ Store, Register-Stack-Orientierung, Speicheroperanden, Anzahl der Operandenadressen je Befehl, Mischung von Speicher- und Registeroperanden in Befehlen usw.) o Festlegung, welche Aufgaben durch Maschinenbefehle unterstützt werden, welche Aufgaben vom Leitwerk, welche vom Compiler zu übernehmen sind o Festlegung, wie offen die HW für den Programmierer sein soll, Klärung welche Befehle nötig sind, damit er z.B. im Compiler auf die HW zugreifen kann (Manipulation von MMU, Cache-, Pipelinesteuerung, Beeinflussung interner Parallelität, Verändern der Befehlsreihenfolge) o Unterstützung von Techniken zur Leistungssteigerung durch den Befehlssatz: Parallelität (Synchronisation, Kommunikation, Datenzugriff), Vektorverarbeitung, Programmiersprachen, OS-Unterstützung o Festlegung der Registersätze des Prozessors o Definition von modifizierbaren CPU-Statusinformationen o Festlegung möglicher HW- und SW-Unterbrechungstypen Definition des Befehlssatzes o Festlegung des Befehlssatzformates (OPCODE, Länge, Bitgruppen variabel oder fest) und der direkt unterstützten Datenformate o Definition der Beschreibungssprache für den Befehlssatz: bei Mikroprogrammierung Nutzung der Mikroprogrammsprache zur algorithmischen und logischen Beschreibung des Befehlsverhaltens bei HW-Realisierung des Befehlssatzes geeignete Sprache zur algorithmischen und logischen Verhaltensbeschreibung der Befehle, gegebenenfalls kompletten Interpreter angeben (auch später nutzbar, z.B. HW-Synthese, Phase 5) o Festlegung von Befehlsgruppen o Definition der einzelnen Maschinenbefehle: Format, Beschreibung o Simulation des Befehlsabarbeitungszyklus durch geeignete Modelle 9 1.4.4 1.4.5 Phase 3*: Auswahl von CPU- und Verarbeitungskomponenten wird i.a. (Europa) oft anstelle Phase 3 absolviert Auswahl der CPU und anderer für die Verarbeitung benötigten Komponenten (Coprozessoren, Graphik, E/A-Controller) und Subsysteme für die Auswahl Anwendung technologischer und kostenorientierter Kriterien, Beachtung von Architekturleitlinien und technologischen Rahmenbedingungen sowie die unter Phase 3 und 4 genannten Punkten große Sorgfalt und architektonisches Know-how Phase 4: Definition der Mikroarchitektur (Micro Architecture Design) Hier Festlegung, wie die durch die technologischen Rahmenbedingungen und allgemeinen Architekturrichtlinien aus Phase 2 und 3 vorgegebenen Entwurfsziele in eine Mikroarchitektur umgesetzt werden können (Phase entfällt bei 3*). Zwischen Phase 3 und 4 Überlappungen und Wechselwirkungen möglich. Umsetzung der Architekturphilosophie und Detail-Spezifikation der CPU-Umsetzung: Definition der Ausführungssteuerung im Leitwerk (Control Unit), z.B. HW, Mikrocode, gemischte Lösungen, Delegation von Steuerungsaufgaben an den Compiler Aufbau der Phasenpipeline zur Befehlsabarbeitung o Welche Stufen vorgesehen? o Zwischen den Stufen Register für Zwischenergebnisse vorsehen? o Ausgewogenheit der Phasen hinsichtlich ihrer Komplexität (gleichlange Ausführungsdauer) o Welche Befehle überspringen eine/ mehrere Stufen? o Wie Auslastung der Pipeline bei Sprungbefehlen Steigerung der Abarbeitungs- und Ausführungsgeschwindigkeit, z.B.: o Festlegen der Taktzykluszeit o Ausführung der meisten Befehle in einem oder mehreren Taktzyklen (je nach Architekturphilosophie), entsprechend Abstimmung des Taktzyklus, eventuell entfernen komplexer Befehle, um Zykluszeit einhalten zu können → Speicherschnittstelle schnell genug? o Superskalares Rechenwerk (Parallelität der Befehlsverarbeitung und –ausführung, statisches und dynamisches Scheduling) erforderlich/ wünschenswert? → wenn ja, wie erfolgt dann das Holen, Dekodieren, Auswählen und Verteilen der Befehle auf die Funktionseinheiten (FE) [statisches Scheduling: starten mehrerer Befehle (issue) in einer logischen Reihenfolge und Ausführung (in-order execution)] [dynamisches Scheduling: Auswahl aus einem Pool bereits decodierter Befehle, starten und ausführen out-of-order] o Erhöhung der Pipeline internen Taktung möglich? → Konsequenzen o CPU als Multiprozessorbaustein verwendbar? Auswirkungen auf Mikroarchitektur Mechanismen zur Ausführungssteuerung und Befehlsauswahl (z.B. ScoreboardTechniken, Ressourcen-Verfügbarkeit, Datenabhängigkeitsund Kontrollflusstechniken, usw.) [Scoreboard verwaltet über mehrere zentral im Leitwerk realisierte HW-Tabellen den Bearbeitungsstand bereits decodierter Befehle. (Zustände jedes Befehls: Start (issue), Operanden gelesen, Operation ausgeführt, Ergebnis geschrieben) Das Scoreboard prüft dabei die Verfügbarkeit geeigneter FE, ob die benötigten Operanden bereitstehen, von welcher FE sie kommen, ob Ergebnisregister frei sind, wer diese blockiert …] 10 1.4.6 Art und Weise der Implementierung von Rechenwerken und FE → Standardbausteine verwendbar? Einsatz arithmetischer Pipelines für bestimmte Befehle? Welches Speicherdesign unterstützt den bisher vorliegenden Entwurf am besten? o ein oder mehrere interne und/ oder externe Caches? o Arbeitsspeicher-Entwurf Verbindungsstruktur für das CPU-Speicher-Subsystem (z.B. Art, Anzahl und Struktur der lokalen Busse auf dem CPU-Chip und zwischen Chips) Festlegung der für die Prozessorentwicklung genutzten VLSI-Technologie, z.B.: o Strukturbreiten, Schaltzeiten, Gatterlaufzeiten, elektrisches Verhalten, usw. o Bestimmung der maximal möglichen Anzahl von Gattern pro Chip Partitionierung der Mikroarchitektur, mögliche Aspekte dabei: o optimale Nutzung von Chipfläche/ Gatteranzahl o Einteilung in Funktionsgruppen (FG) wie Leitwerk, Rechenwerk mit FE, Mikroprogrammwerk, Registersätze, MMU, Cache(s), Coprozessoren o Single-Chip-Prozessor oder Chipset, Kostenabschätzungen für unterschiedliche Partitionierung und verwendete Prozesstechnologie o Welche FG können mit auf CPU-Chip angeordnet werden? Dabei verschiedene Kombinationen/ Kompromisse möglich? o Abschätzung Gatteranzahl/ Modul inklusive Verbindungshardware o Welche Busse und Signalverbindungen werden zwischen FG benötigt? o Wahl eines Maximums (bzgl. Leistung) aus der Menge der Partitionierungslösungen. Welche führt zur größten Funktionalität bzw. Flexibilität? Setzen von Prioritäten, Entscheidung für (möglichst) optimale Lösung Phase 5: Hardware-Design Umsetzung der bisher getroffenen Entwurfsentscheidungen in HW, bis hin zum Board: endgültige Festlegung des neu zu entwickelnden Chips HW-Struktur des Gesamtsystems HW/SW-Schnittstellen und Protokolle zwischen den Bausteinen (HW/SW-Codedesign) Realisierungstechnologie o Wahl der Prozesstechnologie (z.B. CMOS) o Plattform: StaZ (Standardzelle), GA (Gate Array), Structured ASIC, FPGA EDA-Tools wählen VLSI-Entwurf Wahl der geeigneten AVT, Kühlung für Chips und Board o Standardtechniken z.B. SMD o Hochleistungsbaugruppen, Multi-Chip-Module o Kühlung z.B. Luft/ Gase, Wasser Board-Entwurf mit entsprechenden CAD Tools o Layout, Backplanes o Board Simulation 1.4.7 Phase 6: Prototyp nach Abschluss des Entwurfs folgt Realisierung eines Prototyps → Emulator enthält Implementierungen von (allen) Schaltkreisteilen z.B. in einem/ mehreren FPGAs kann auch begleitend zum Entwurf einzelner Schaltungsteile erfolgen 11 1.4.8 1.4.9 ausführliche Simulation, Ziel: möglichst viele Fehler in diesem Stadium finden und beheben → Iteration Prototyp-Fertigung weitere Verifikation, Evaluierung, gegebenenfalls Iteration bis zurück zum Entwurf Phase 7: Übergabe in die Produktion Beginn der Fertigung begleitende Unterstützung durch Entwicklungsabteilung letzte Möglichkeit, vor der Auslieferung Fehler zu erkennen Begleitende Architekturüberprüfung in allen Phasen ständige Überprüfung von Entwurfsentscheidungen, eventuell Änderungen/ Korrekturen so früh wie möglich → je später desto teurer/ aufwendiger möglichst vermeiden von Nebeneffekten durch Änderungen → Prüfen jeder Entwurfsprozess ist ein rückgekoppelter Vorgang 12 2. Grundlagen, Architekturklassen und – merkmale von MP 2.1 Allgemeines zur MP-Architektur 2.2 Begriff MP-Architektur wird für die übergreifende, d.h. von den Einzelheiten abstrahierende Darstellung des inneren Aufbaus von MP verwendet Operationsprinzip und Programmiermodell des Prozessors lassen sich als blockartiger Aufbau darstellen Programmiermodell besitzt in der Regel für jeden MP eine eigenständige Ausprägung Architekturmerkmale → Klassifizierung Architekturklassen von MP resultieren aus historischen und technologischen Gründen Von-Neumann-Rechner, Architektur Harvard-/ Princeton- siehe Bild K+A-2_F 2 und 3 Rechner besteht aus den Grundbestandteilen: o CPU mit Steuer-(Leit-)werk (Control Unit, CU) und Rechenwerk (Arithmetik Logic Unit, ALU) o Speicher o Ein-/ Ausgabe-Einheit o Bussystem Struktur des Rechners unabhängig vom zu bearbeitenden Problem → für jedes neues Problem ein neues Programm, deshalb auch Bezeichnung „Programmgesteuerter Universalrechner“ (Stored Program Machine) Programm und Daten standen im selben Speicher o Speicherplätze besitzen feste Wortlänge, einzeln über Adresse ansprechbar o nur Programmkontext entscheidet, ob Inhalt Programm oder Daten ist im Laufe der Entwicklung 2 Varianten für Struktur des Speichers o Princeton-Architektur gemeinsamer Hauptspeicher für Daten und Programm → kommt VonNeumann-Konzept am nächsten Vereinfachung im Aufbau, aber geringere Kommunikationsleistung o Harvard-Architektur getrennter Speicher für Daten und Programm paralleler Zugriff auf Daten und Programm möglich separate Busse häufig bei DSPs unabhängig von Speicherstruktur, aber gleiches Operationsprinzip die Struktur der CPU korrespondiert direkt mit der sequentiellen Abarbeitung von Instruktionen in 2 Phasen (Operationsprinzip des Von-Neumann-Rechners), siehe Bild K+A-2_F 4 o Phase 1: Befehl wird aus Speicher in Steuerwerk geladen, Zählwerk in der CPU (Programm-, Befehlszähler) wird mit dem Programmfluss weitergezählt 13 o 2.3 2.3.1 Phase 2: Bearbeitung des Befehls benötigte Daten in Rechenwerk laden und entsprechend Opcode verarbeiten, dann Resultat gespeichert danach Laden des nächsten Befehls Möglichkeiten der Klassifizierung Von-Neumann-Rechner gekennzeichnet durch: o ein Leitwerk (LW) für Steuerung o ein Rechenwerk (RW) für die Ausführung der Operationen o ein Speicherwerk (Hauptspeicher, HS) für Ablage von Programm und Daten o ein E/A-Werk für Ansteuerung von Peripherie o gemeinsamer Bus für die Übertragung von Daten und Befehlen Befehlsabarbeitungszyklus in 2 nichtüberlappte Teilphasen unterteilt → Beschränkung der Rechenleistung durch „Flaschenhals“ durch Verfeinerung, evolutionäre Veränderungen oder durch radikale Abkehr vom VonNeumann-Prinzip beträchtliche Fortschritte Rechnerklassifikation nach Flynn einfacher Ansatz: Rechner werden auf Basis von Befehls- und Datenströmen beschrieben Befehlsstrom: Maschinenbefehle werden vom HS ins LW und von dort als entschlüsselte Steuerinformationen an das Rechenwerk weitergeleitet Datenstrom: Daten, die als Operanden für arithmetische und logische Operationen oder als deren Ergebnis zwischen HS und RW übertragen werden Klassifikation: einfaches/ mehrfaches Auftreten von Daten- und Befehlsströmen nur 4 Kategorien zur Eingruppierung von Rechnern (siehe Bild K+A-2_F 5) SISD (Single Instruction Single Data), siehe Bild K+A-2_F 6 o klassischer Universalrechner o durch Ausführung des Programms erzeugt ein LW einen Befehlsstrom, dessen Befehle einzeln, nacheinander vom RW ausgeführt werden o benötigte Operanden/ Ergebnisse werden über einen bidirektionalen Datenstrom vom HS in ein RW geholt bzw. in HS zurückgeschrieben o Klassifikation erfasst nur Grobstruktur, keine weitgehende Differenzierung innerhalb SISD o nicht erkennbar, ob sich Phasen des Befehlsabarbeitungszyklus überlappen oder nicht o E/A-Aufgaben werden nicht von eigenen Prozessoren sondern von CPU bzw. intelligenten Controllern ausgeführt o z.B. PCs auf Mikroprozessorbasis, ältere Mainframes und Minicomputer, teilweise auch Vektor- und Pipelinerechner SIMD (Single Instruction Multiple Data), siehe Bild K+A-2_F 7 o besitzen ebenfalls nur ein LW o vom Leitwerk entschlüsselter Befehl kann gleichzeitig auf mehrere Operanden in mehreren RWs (VE, processing elements) angewendet werden (sogenanntes Instruction Broadcasting) o jede VE verfügt über einen eigenen bidirektionalen Datenpfad zum HS 14 o o 2.3.2 HS häufig in unabhängige Einzelmodule unterteilt SIMD-Rechner erweitern die Von-Neumann-Struktur durch Vervielfachung der Anzahl der RW o z.B. Arrayprozessoren, Vektorprozessoren MIMD (Multiple Instruction Multiple Data), siehe Bild K+A-2_F 8 o auch als Multiprozessorsysteme bezeichnet o verfügen über mehrere vollständige Prozessoren, es existieren unterschiedliche Architekturvarianten o Komponenten über vielfältige Verbindungstopologien gekoppelt o mehrere Befehls- und Datenströme aus gemeinsamen physikalischen HS oder unabhängigen Speichermodulen MISD (Multiple Instruction Single Data), siehe Bild K+A-2_F 9 o nur wenige Rechner, kaum kommerziell erfolgreich o Ausnahme: systolische Arrays, die heute zur Bearbeitung eines komplexen Datenstroms (MPEG, und ähnliche) mit mehreren gleichartigen Rechnern genutzt werden, z.B. auch als eingebettete Systeme in FPGAs Einschätzung: o Klassifikation nach Flynn liefert keine detaillierten Informationen über Rechnerstruktur o quantitative Aussagen über Rechneraufbau, Leistung und topologische Aspekte sind nicht möglich Erlanger Klassifikationssystem ECS geht erheblich weiter als Flynn Zielstellung: Steuerung der Ausdrucksmöglichkeiten bei der Beschreibung von Parallelarbeit in Rechnerstrukturen, ohne unnötige komplexe Darstellung eignet sich zur Beschreibung wichtiger quantitativer Eigenschaften von Rechnern mit Nebenläufigkeiten und Pipelining Parallelität liegt dann vor, wenn – bezogen auf ein bestimmtes Abstraktionsniveau – zu einem Zeitpunkt mehr als eine Aktion durchgeführt werden kann Serialität liegt dann vor, wenn diese Aktionen nicht gleichzeitig ausführbar sind, d.h. höchstens 1 durchgeführt werden kann in ECS werden 3 Ebenen einer Rechnerstruktur unterschieden o LW-Ebene (Prozessor-, Programmebene) o RW-Ebene (Befehlsausführungs-, ALU-Ebene) o Wortebene (Ebene der elementaren Verarbeitungsstellen) auf diesen Ebenen existieren unterschiedliche Arten von Nebenläufigkeiten und Pipelining, mit ECS quantitativ erfassbar Definition Nebenläufigkeit: o auf einer Strukturebene können zu einem Zeitpunkt mehrere in ihrer Art vergleichbare Aufgaben durchgeführt werden, da mehrere hierfür geeignete Ressourcen vorhanden sind o typische Aufgaben: z.B. Programme, Prozesse, einzelner Befehle, Threads o Parallelität wird als Nebenläufigkeit bezeichnet, wenn die Ressourcen des zu beschreibenden Rechners das gleichzeitige Ausführen vollständiger, auf diesem Niveau definierter (gleicher) Aktionen erlauben Definition Pipelining 15 o Aufgaben werden innerhalb einer Strukturebene eines Rechners in gleiche oder variabel viele nacheinander auszuführende einfache Teilschritte zerlegt, wobei für die Ausführung eines Teilschritts jeweils ein eigenes Teil-RW zuständig ist o alle Teilwerke können dabei gleichzeitig Teilschritte aus unterschiedlichen Aufgaben ausführen o nach Vorliegen des Ergebnisses eines Teilschritts gegebenenfalls weiterreichen an nächstes Teilwerk o Teilwerke können auch übersprungen werden, wenn sie für die Bearbeitung einer Aufgabe nicht benötigt werden o Endergebnis liegt vor, wenn alle benötigten TW durchlaufen wurden o wichtig: sind n Teilwerke vorhanden, so ist bei gleichlangen Teilschritten und voll ausgelasteter Pipeline eine maximale Beschleunigung der Rechengeschwindigkeit auf das n-fache möglich ECS-Tripel o zur Klassifikation eines Rechners bzw. Beschreibung einer Rechnerstruktur o jedes Tripelelement steht für den Grad der Parallelität in einer Rechnerbetrachtungsebene. 𝑡Rechner ≔ (𝑙Rechner , 𝑟Rechner , 𝑤Rechner ). Jeder Rechner besteht aus einer bestimmten Zahl l von Leitwerken, die ihrerseits eine bestimmte Zahl r von Rechenwerken mit einer Zahl w von elementaren Stellen umfassen [statt l auch k bzw. statt r auch d]. Die Zahlen l, r, w definieren dabei auch den Umfang der Nebenläufigkeit des Rechners auf der jeweiligen Betrachtungsebene. o Beispiel: 𝑡re1 = (4, 1, 32) → Rechner mit 4 Leitwerken (jeweils ein Rechenwerk mit einer Wortlänge von 32), 𝑡ILLIAC IV ≔ (1, 64, 64) → Arrayrechner mit 1 LW (64 RW und 64 Bit), 𝑡KI ≔ (1, 1, 64) → klassischer SIMD-Rechner o Erweiterung des ECS-Tripels für Pipelineorganisation können l’ spezialisierte Teilleitwerke, r’ spezialisierte Teilrechenwerke und w’ spezialisierte elementare Teilwerke zusammenarbeiten o 𝑡Rechner ≔ (𝑙Rechner ∗ 𝑙′Rechner , 𝑟Rechner ∗ 𝑟′Rechner , 𝑤Rechner ∗ 𝑤′Rechner ), der Operator * (concatenation) beschreibt dabei die echte, sich gegenseitig nicht beeinflussende Parallelität der jeweiligen HW → Verbesserung der Beschreibungsgenauigkeit Zusammenfassende Erläuterung der Tripelelemente: o l: Grad der Nebenläufigkeit auf LW-Ebene (Zahl der im System vorhandenen LW oder Prozessoren, bzw. die Zahl der echt parallel ausführbaren Programme) o l’: Grad des Makropipelinings, Betriebsart von Multiprozessorsystemen, bei denen mehrere CPUs gleichzeitig auf einem sequentiell an den Prozessoren vorbei fließenden Datenstrom verschiedene Bearbeitungsschritte ausführen o r: Anzahl der RW, die jeweils einem LW zugeordnet sind. Ein Prozessor verfügt über mindestens 1 LW und über 1 oder mehrere zugeordnete RW o r’: maximale Ausprägung einer Eigenschaft, die bei ECS als Funktionspipelining bezeichnet wird (maximal r’ sequentiell aufeinanderfolgende Befehle aus einem Programmfragment können dann gleichzeitig ausgeführt werden, wenn sie frei von Datenabhängigkeiten sind und entsprechend viele Funktionseinheiten (FE) verfügbar sind, die vom Typ her zu den ausführbereiten Befehlen passen) [heute: Nebenläufigkeit auf der Ebene von FE] → tritt bei Superskalar-Architekturen und anderen auf o w: Wortbreite des Rechners, Parallelität auf Wortebene o w’: Grad des Phasenpipelinings innerhalb der Mikroarchitektur eines Rechners oder innerhalb einer einzeln beschriebenen Teileinheit der Mikroarchitektur weitere Detaillierung: Operatoren wie +, ∨, ~ aus heutiger Sicht mit ECS 4 Arten von Nebenläufigkeit unterscheidbar: 16 2.3.3 2.3.4 o Nebenläufigkeit auf LW-Ebene, l > 1 o auf RW-Ebene, r > 1 o auf FE-Ebene, l’ > 1 o auf Wortebene, w > 1 Beispiel: 𝑡Pentium III ≔ (1, 1 ∗ 5, 32) → 1 Leitwerk (5 dekodierte Befehle pro Takt ausführbar, 32 Bit Wortbreite) Klassifizierung nach Giloi Unterscheidungskriterien: nach Operationsprinzip oder HW-Struktur nach Operationsprinzip, es wird das funktionelle Verhalten des Prozessors bestimmt, 3 Gruppen: o Von-Neumann-Prinzip (starres 2-Phasenschema, streng sequentielle Ausführung) o Operationsprinzip des impliziten Parallelismus die den Programmen gegebenen Möglichkeiten zur parallelen Ausführung werden genutzt auf verschiedenen Ebenen angelegt (z.B. Operations-, Anweisungs-, Prozessebene) o Operationsprinzip des expliziten Parallelismus Programm- und Datenstrukturen werden so angelegt, dass Parallelarbeit unmittelbar vorgezeichnet ist nach HW-Struktur, Unterscheidung von 5 Alternativen: o Einprozessorsystem (den Von-Neumann Prozessen entsprechend) o Arrays von gleichartigen Bearbeitungselementen (Prozessorteile mit echter Parallelität) o Pipelines aus verschiedenartigen Bearbeitungselementen (spezialisierte Prozessorteile, die gleichzeitig nutzbar sind, aber verschiedene Aufgaben ausführen) o homogene Multiprozessorsysteme o inhomogene Multiprozessorsysteme CCM (Customized Computing Machine), Coprozessoransatz für applikationsspezifische Prozessoren als HW-Beschleuniger Superskalare Prozessoren verarbeiten mehr als einen Befehl pro Takt d-Paradigma in Verbindung mit CCM → neuere Entwicklung zur weiteren Leistungssteigerung Architekturklassen bei Prozessoren Klassifizierung der Prozessoren nach ihrem internen Speichermodell Speichermodell in engem Zusammenhang mit Codierungsformat Aussagen, wie die für Datenoperationen benötigen Operanden vor und nach der Operation im Zugriffsbereich des Prozessors liegen 3 grundsätzliche Methoden o Stack-Architektur: Quell- und Zieloperanden werden auf dem Stack gespeichert, wo auf sie zugegriffen wird Zugriff seitens des Prozessors kann implizit erfolgen, z.B. in exakt festgelegter Reihenfolge 17 o o o o Akkumulator-Architektur Prozessor besitzt einen, gegebenenfalls wenig mehr Akkumulatoren als zentrale(s) Register in Befehlscodierung wird bereits festgelegt (implizit), welches Register als Quelle/ Ziel für Operation genutzt wird (general purpose) Register-Architektur mindestens 1 Operand wird aus einem internen Prozessorregister bezogen (muss im Befehl explizit angegeben werden) Register-Speicher-Architektur (Erweiterung der Akkumulator-Architektur) Load-Store-Architektur 18 3. Grundkomponenten von Prozessoren Hauptkomponenten der CPU bilden Leit- oder Steuerwerk (Control Unit) und Rechenwerk (ALU) 3.1 Hardwaregrundlagen, Komponenten Technische Systeme der Informationsverarbeitung werden unterteilt in Schaltnetze und Schaltwerke, siehe Bild K+A-3.1+3.2_F 1. 3.1.1 3.1.2 Schaltnetze siehe Bilder K+A-3.1+3.2_F 2 bis 4 Entwurf und Beschreibung mittels Boolescher Algebra analytische Beschreibung mit logischen Variablen und Operatoren häufig mit Wahrheitstabellen entworfen → Schaltfunktion auslesen (Terme → DNF (Disjunktive Normalform), KNF (Konjunktive)) besitzt keine Rückführungen, 𝑦 = 𝑓(𝑥) Schaltwerke siehe Bild K+A-3.1+3.2_F 5 𝑦 = 𝑓(𝑥, 𝑦′), aktueller Zustand vom vorangegangenen abhängig → Rückführung (Rückkopplung) Folgezustand hängt vom aktuellen Eingangszustand und dem momentan inneren Zustand ab, die von vorherigen Eingangsbelegungen herrühren besitzt endliche Zahl von Eingangsbelegungen und Zuständen, (endlicher, determinierter) Automat (Finite State Machine, FSM) Verhalten lässt sich in Graphenform darstellen (Knoten = Zustände, Kanten = Übergänge) Unterscheidung von 3 Typen: Mealy, Moore, Medwedjew zeitliche Abhängigkeit des Momentanzustandes von vorangegangenen bzw. des Folgezustandes vom aktuellen lässt sich auch durch Einfügen eines „Speichers“ in den Rückkopplungszweig vom Ausgang auf den Eingang darstellen Einsatz von Schaltwerken z.B. in der Zyklussteuerung der CPU 3.2 Leitwerke 3.2.1 Allgemeines übernehmen Ablaufsteuerung in RW und Operandentransport Steuerwerk, Befehlsprozessor, Control Unit unterschiedliche Typen: o Schrittleitwerk o JK-FF-LW o Matrix-LW 19 3.2.2 o Multiplexer-LW Matrix-LW dominieren bei MP legen folgendes fest: o Was ist in jedem Augenblick der Befehlsausführung zu tun? o Wo sind die vom Befehl abhängigen Aktionen auszulösen? Befehlsregister stellt Schnittstelle zwischen ALU und LW dar, indem es den Opcode bis zum Ende der Ausführung zwischenspeichert zusätzliche Informationen für das LW können die aus dem RW oder den Flags eingespeisten Statusmeldungen Zi sein Mikrobefehle und Mikroprogramme Makrobefehle sind durch das Programm vorgegeben und werden durch Compiler und Assembler letztlich in Opcode umgewandelt, stehen im Speicher, liegen im allgemeinen als Byte/ Wort/ Doppelwort/ … vor Mikrobefehle (micro instructions) entstehen aus einem einzigen Makrobefehl, stellen eigentliche Steuerbitmuster für das LW bereit, wie Makrobefehle binär codierte Worte, allerdings mit Wortbreiten zwischen 20 … 100 Bit, ein einziger Makrobefehl aktiviert meist eine ganze Mikrobefehlsfolge = Mikroprogramm Mikroprogramm: o ist die Darstellung eines HW-Algorithmus, der von den Funktionseinheiten der Prozessor-HW ausgeführt wird o besteht aus Mikrobefehlen, die jede Maschinenaktion zeitlich exakt steuern o auf der untersten HW-Ebene des Prozessors implementiert o eine FE im LW stellt die Mikrobefehle abrufbar bereit oder erzeugt sie unmittelbar o Bereitstellung über einen adressierbaren Mikrocodespeicher (ROM, EPROM) oder von PLA oder Mealy-Automat generativ übernommen mikroprogrammierte und festverdrahtete LW o mikroprogrammierte LW: Mikrobefehle werden aus Mikrocodespeicher geholt vorrangig auf CISC-Architekturen o festverdrahtete LW: in modernen RISC-Architekturen häufig, schaltungstechnisch höherer Aufwand, dafür schneller höherer HW-Aufwand wird durch reduzierten Befehlssatz (weniger Mikrobefehlsaufwand) kompensiert o Nutzung von PLAs für beide LW-Typen möglich, in dem Mikrobefehle direkt aus Oder-Feld ausgegeben werden (mikroprogrammiertes LW) bestimmte Automaten(teil)funktionen werden direkt zur Erzeugung/ Ausgabe der Mikrobefehle benutzt Formate von Mikrobefehle sehr unterschiedlich, Prozessor-LW möglichst redundanzfrei anlegen (Chipfläche) horizontale Mikrobefehlsstrukturen o einfachste Variante o nahezu alle Bitpositionen des Befehlsformats wird eine spezifische Steuerfunktion zugeordnet o dadurch Notwendigkeit eines breiten Mikrobefehlsformats (>100 Bit) und eines relativ großen Mikrobefehlsspeichers 20 Mikrobefehlsoperanden werden in codierter Form OPC0 … OPCi im Mikrobefehlsregister MBR bereitgestellt o Steuersignale S0 … Si werden an prozessorinternen Aktionspunkten (z.B. „Tore“) sowie auch auf dem externen Systembus wirksam zur Verringerung der Mikrobefehlsbreite (und damit Größe des Mikroprogrammspeichers) Codierung der den einzelnen FE zugeordneten Steuersignale in Gruppen, verkürztes Format = „quasihorizontales“ Mikrobefehlsformat nachfolgend aber Decodierung notwendig, dadurch zusätzliche Gatterlaufzeiten Extremfall: „vertikales“ Mikrobefehlsformat, die beim quasihorizontalen Format gebildeten Steuersignalgruppen wirken ihrerseits wiederum als Code für noch feinere Mikrobefehls, dadurch noch geringere Wortbreite (z.B. 40 Bit) Beispiel für die Abarbeitung eines Mikroprogramms (quasihorizontal) o Makrobefehl „ADD A, M“ steht im Befehlsregister (Register A = Akku, Speicher M, Ergebnis nach A) o Abarbeitung beginnt damit, dass Makrobefehl vollständig in CPU geholt wird („fetching“), ebenfalls mikroprogrammgesteuert o Annahme: „ADD A, M“ bereits im Befehlsregister BR verfügbar, in BR steht also Opcode von ADD, die (binär codierte) Adresse des Register A, sowie die Information, dass in Memory-Adressregister MAR die Adresse des Speicheroperanden M vorliegt o Opcode von ADD ist Einsprungadresse in Mikrobefehlsspeicher, hier steht erster Mikrobefehl → wird ins Mikrobefehlsregister MBR übernommen (verbleibt dort während gesamter Abarbeitungszeit), siehe Bild K+A-3.1+3.2_F 13 o 1. Mikrobefehl: MAR auf internen Systembus legen interner Systembus auf externen Adressbus legen Lesesignal über externen Steuerbus an Arbeitsspeicher legen o 2. Mikrobefehl: Speicherausgang über den Datenbus an internen Systembus legen interner Systembus an das Memory-Datenregister MDR legen o 3. Mikrobefehl: Akku (Register A) an ALU legen MDR an ALU legen in ALU Funktion ADD einstellen ALU-Ausgang an Akku legen (= Ergebnisregister) o 3.2.3 Mikrobefehlserzeugung 3.2.3.1 Leitwerksprinzip nach Wilkes Prinzip seit 1953 LW organisiert Verwaltung sowie Bereitstellung der Mikrobefehle läuft streng synchron zum Prozessortakt ab beschreibt LW in seiner allgemeinsten Form, kann auch als Mealy Automat aufgefasst werden Prinzip: o Eingangsworte für LW: Opcode, Parameter des Makrobefehls, aus ALU zurückgemeldete Statussignale Zi o Ausgangswerte: Steuersignale Si sowie Steuerinformationen innerhalb des LW selbst 21 o o o o o o diese letzteren werden als Zusatzinformation oder auch Adressen für die Zustandsüberführungsfunktion f erzeugt, gesamte CPU (= ALU und LW) liegt am gleichen Takt jedem „Informationspaar“ (= Opcode des aktuellen Makrobefehls und im Zustandsregister abgelegter Code im Automatenzustandes) wird genau eine Spalte am Ausgang des 1-aus-n Decoders zugewiesen und diese Spalte als aktive Leitung in die Zustandsüberführungsmatrix geschaltet jede Spalte entspricht dann auch genau einem Element aus der Produktmenge 𝑄 ⋅ 𝑋 des Automaten, wobei Q die Menge aller zugelassenen Zustandscodes und X die Menge aller binären Eingangsvektoren repräsentiert obere Matrix realisiert die Menge der Automatenfunktion f: 𝑄 ⋅ 𝑋 → 1𝑄 untere Matrix generiert die Ausgangsfunktion g: 𝑄 ⋅ 𝑋 → 𝑌 Menge Y enthalte alle vom LW generierten Mikrobefehle 3.2.3.2 Mikroprogrammierte Leitwerke Mikrobefehlsspeicher, Mikrobefehlsregister o der Kern mikroprogrammierter LW baut auf zweistufiger Logik auf, die mit PLAs oder ROMs realisiert wird o wenn Mikrobefehlsspeicher aus E(E)PROMs aufgebaut, dann „mikroprogrammierbarer Prozessor“ o Mikrocode-ROM muss wie jeder andere Speicher auch adressierbar sein, d.h. aus Opcode des Makrobefehls wird über Decoder Anfangsadresse für Mikrobefehl abgeleitet die folgenden Mikrobefehlsadressen werden erzeugt durch konstantes Inkrement im MAR oder durch zusätzlich im Mikrocode-ROM abgelegte Folgeadressen → auch im Mikroprogramm sind Verzweigungen möglich o Abbruch dieser Verzweigungszyklen durch Steuersignal Zi aus RW/ ALU Mikrobefehlsregister MBR, siehe Bild K+A-3.1+3.2_F 15 jeweils aktueller Mikrobefehl wird nach Bereitstellung in das MBR übernommen Funktionsweise: o Makrobefehl steht im Befehlsregister, durch UT1 an Adressauswahllogik PLA1 gelegt (durch „direktes Einlaufen“ des Makrobefehls in PLA1 erhält man redundanzfreien Befehlssatz, bei n-formatigen Opcode → 2n unterschiedliche Makrobefehle) o wenn jeder Makrobefehl genau eine Spalte im Oder-Feld des PLA1 aktiviert → auf dieser Spalte echte Einsprungadresse des Mikroprogramms codierbar o über MUX wird diese Adresse mit UT2 ins MAR geschrieben o wenn Startadresse des aktuellen Mikroprogramms steht, wird über Und-Feld von PLA2 die Spalte des ersten Mikrobefehls aktiv und die im Oder-Feld liegende Bitstruktur dieses Befehls am Ausgang von PLA2 verfügbar o Übernahme in MBR mit UT3 o gleichzeitig steuert S den MUX, eventuelle Folgeadresse liegt am MAR an o nächster Mikrobefehl oder Ende des Mikroprogramms 3.2.3.3 Festverdrahtete Leitwerke besitzt im Gegensatz zu mikroprogrammierbaren LW keinen Mikrocode-ROM oder ähnliches, Makrobefehle werden direkt über einen Mealy-Automaten auf die HW abgebildet („Ablaufsteuerung“), festverdrahtet („hard wire control“), nicht/ nur mit 22 großem Aufwand änder-/ anpassbar, Befehlssatz des Prozessors kann im allgemeinen nicht geändert werden, siehe Bild K+A-3.1+3.2_F 16 einfachste Realisierung: ein Automat bildet auf der untersten Prozessorebene die Makrobefehle auf die HW ab enthält Befehlsregister, -decoder Automat verarbeitet einen Makrobefehl, nachdem er vom Befehlsdecoder in einen definierten Anfangszustand versetzt, gestartet und dann so lange getaktet wird, bis Makrobefehl abgearbeitet ist, danach deaktiviert komfortable Lösung: jedem Makrobefehl wird ein eigener Automat zugeordnet o Ausgabe streng taktsynchron o mit jedem Takt wird neuer Mikrobefehl bereitgestellt o LW ist sehr schnell, eignet sich besonders zur Steuerung von Phasenpipelines 3.3 Varianten von Rechnerarchitekturen 3.3.1 Befehlssatzarchitektur (ISA) vs. Mikroarchitektur 3.3.2 ISA definiert Schnittstelle eines Rechners zur System- und Anwendungssoftware beim ISA-Entwurf: Spezifizierung der Befehlsformate und Maschinenbefehlstypen des Prozessors sowie der von der Software aus sichtbare Registersatz Entwurfsunterscheidung auf ISA-Level beeinflussen Zusammenspiel CPU-Architektur mit Compilern und OS ISA arbeitet mit Mikroarchitektur zusammen, beeinflussen sich gegenseitig Ziel: möglichst optimale Abstimmung aufeinander („Balance“) CISC-Prozessoren und Mikroprogrammierung 3.3.2.1 Allgemeines zur CISC-Philosophie CISC-Philosophie historisch durch die von IBM ausgehende Entwicklung kompatibler Computergenerationen begründet, Vorbild auch für andere wie Intel Grundlage der Softwarekompatibilität der IBM-Rechner: fest vorgegebener Standardbefehlssatz und ein Satz von Standardregistern, Speicheradressierungsschema der jeweiligen Vorläufer-Prozessoren muss von den kompatiblen Nachfolgern zumindest als „Architekturmodus“ unterstützt werden Problem: Entwicklungsfortschritte, effizientere Lösungen auf Befehlssatzebene, trotzdem muss alter Architekturballast weiter mitgeschleppt und weitervererbt werden → neue Befehle, Register, Adressierungsmodi können immer nur zusätzlich bereitgestellt werden Folge: Komplexität nimmt zu, Großteil der Entwicklungsressourcen muss für Kompatibilitätserhalt verwendet werden, Verbesserungen der Technologie müssen zum Teil der Kompatibilität geopfert werden Aufwand lohnt sich trotzdem: Software-Investitionen werden geschützt bis etwa 1980 Leistungssteigerung durch immer (neue) umfangreiche/ komplexere Maschinenbefehlssätze dafür folgende Gründe: o Geschwindigkeitsunterschied zwischen CPU und Hauptspeicher, deshalb Ziel möglichst viele miteinander zusammenhängende Aktionen in einem Maschinenbefehl codieren o kompaktere Codierung spart HS-Platz 23 o Mikroprogrammierung ermöglichte Aufwärtskompatibilität o durch spezielle Befehle Unterstützung der Compilertechnologie Gemeinsamkeiten aller CISC-Architekturen: o häufig mikroprogrammiert o Aufgaben der Compiler in Mikroprogramme umgesetzt o komplexe Software-Generationen (wie kombinierte arithmetische Befehle) in einem einzigen Befehl zusammengefasst o umfangreicher Maschinenbefehlssatz o kompakter Programmcode 3.3.2.2 Eigenschaften der CISC-Architektur 3.3.3 CISC-ISAs enthalten eigene Befehle zur Vereinfachung der Realisierung von OSKomponenten per SW, Hochsprachencompilern, Datenstrukturen, Adressierungsmodi Ziel: Steigerung der SW-Produktivität, kürzere elegante Programme, besseres Laufzeitverhalten Vervollständigung der CISC-Befehlssätze durch ergänzende Gleitkommabefehlssätze aber: zunehmende strukturelle und organisatorische Komplexität der CPU und Mikroprogrammwerke, dadurch Einschränkung des Leistungspotenzials o z.B. für ein Maschinenbefehl ca. 10 Mikrobefehle o für Ausführung eines Befehlstyp mehr als 10 Taktzyklen bei früheren Mikroprozessoren reichten 100000 Transistoren nicht für eine überzeugende Leistung aus, heute bis zu eine Milliarde Transistoren und Taktfrequenzen über 3GHz Entstehung der RISC-Technologie Zielstellung: einfachere Befehlssätze, ca. 40 bis 80 Befehlstypen und –formate einfache Hardwaresteuerung ohne Mikroprogrammierung effiziente Phasenpipelines mit gleichlangen, eintaktigen Stufen Befehle, die üblicherweise in einem Takt ausgeführt werden können Datenzugriffe durch Load/Store-Befehle größere Registersätze Optimierung des Befehlsdurchsatzes durch Compiler 3.3.3.1 Eigenschaften der RISC-Architektur keine unveränderliche feste Definition von RISC, folgende allgemeine Eigenschaften: o Ausführung nahezu aller Maschinenbefehle in einem Taktzyklus o HS-Zugriffe nur mittels Load und Store o alle anderen Operationen ausschließlich auf Registeroperanden o wenige Befehlstypen und Adressierungsarten, Konzentration auf Notwendiges o möglichst einheitliches Befehlsformat, gleichbleibende Bedeutung (inhaltlich) der Bitfelder o möglichst geringer Decodieraufwand für alle Befehle o Verzicht auf Mikrobefehlsebene o festverdrahtete HW-Steuereung des LW o Verringerung HW-Komplexität, dafür muss nun Compiler mehr übernehmen 24 Befehlsformate, Befehlssatz, Befehlsvorrat o RISC-Prozessoren verfügen nicht grundsätzlich über einen reduzierten Befehlssatz o RISC mehr im Sinne einer Reduktion der pro typischer Aufgabe benötigten Befehlszyklen o Reduced Instruction Set Cycles o RISC-Befehlsformate besitzen meist einheitliche Länge von 32 Bit, Vorteil: leichter decodierbar, einheitliches Befehlsformat o Befehlslänge 32 Bit entspricht Breite früherer Speicherzugriffsports, pro Speicherzugriff immer einen vollständigen Befehl übertragen o einheitliche Länge vereinfacht Zuordnung von „Bedeutungsträgern“ an feste Bitfelder o Veränderungen/ Modernisierung auch bei RISC o viele CPUs implementieren echte 64 Bit ISA und Mikroarchitekturen, mehrstufige Caches, größere Breite der Datenzugriffswege, häufig unabhängige Wege zu externen Cache und HS o Zusammenhang zwischen Wortbreite Prozessor und Breite der Datenwege: Weg zum HS: doppelt so breit wie Prozessorwortbreite (128 Bit bei 64 Bit CPU) Weg zum L2-Cache 4 mal so breit (256 Bit bei 64 Bit CPU) RISC-Vorteil: o RISC-Befehle unabhängig von Prozessorwortlänge nach wie vor 32 Bit lang, bei externen Zugriff auf Befehle werden immer bestimmte Vielfache der Prozessorwortlänge in die CPU geholt und dort an L1-Cache gegeben o L1-Cache so organisiert, dass immer die gleiche Anzahl 32 Bit breiter Befehle hineinpasst o z.B. holen Superskalare RISC-Prozessoren (verarbeiten ohnehin mehrere Befehle gleichzeitig) aus dem L1-Cache über einen 256 Bit breiten Zugriffsweg 8 Befehle in einem Pufferbereich o ein paralleler Decodierer (gleichzeitig 4 Befehle decodierbar) greift dann auf 4 Befehle (128 Bit breiter Block des Puffers) zu Beispiel: Alpha, 64 Bit RISC ISA o verwendet straffes, leicht zu decodierendes Befehlsformat o trotzdem „Programmierkomfort“ für kommerzielle Anwendungen o neuere Vertreter sind OOO-Superskalar-Prozessoren (out of order) o Kennzeichen der Befehlsformate, siehe Bild K+A-3.3_F 3 6 Bit breiter Opcode (Bit 31 bis 26 für alle Formate) bei Verknüpfungsoperationen durch 11 Bit breites Funktionsfeld (Bit 15 bis 5) genauer spezifiziert Befehle können zwischen 0 und 3 Registerfelder zur Spezifizierung von Operanden- und Ergebnisregistern enthalten Verknüpfungsoperationen im allgemeinen 3 Registeradressen, 3-AdressMaschine o Arten der Befehlsformate PAL Code-Format, eine Privileged Architecture Library umfasst Unterprogramme, die zu einer typischen Betriebssystemimplementierung gehören. Sie werden durch Hardware-Interrupts oder Call_PAL-Befehle aufgerufen Branch-Format wird von bedingten Sprüngen und UP-Aufrufen benutzt Memory-Format wird verwendet für 8, 16, 32, 64 Bit Load/Store Befehle zwischen Registern und Speicher 25 Operate-Format wird von allen arithmetischen, logischen, „Multimedia“Verknüpfungsoperationen und sonstigen Befehlen zur Datenmanipulation verwendet Befehlsformat o bei allen RISC-Architekturen unmittelbarer Zusammenhang zwischen Befehlsformat und –vorrat o folgende Befehlsgruppen unterscheidbar: Load/Store: Alle Speicherzugriffe über Load/Store-Operationen (verschiedene Datenformate). Load/Store-Instruktionen auch möglich für Adressen, Statusregister, mehrere Register, Gleitkommaregister. Integer-Arithmetik: Sollte generell in einem Taktzyklus ausführbar sein, deshalb manchmal nur Add, Sub, Mul im Befehlssatz. Bei neueren Architekturen auch Div. logische, Shift-, Bitmanipulationsbefehle: Verschiedenste logische Verknüpfungen, Shift-Operation, Byte-, Bit-Manipulation innerhalb eines Registerwortes. Maskierung von Registerinhalten durch Bitmasken. Verzweigungsoperationen: unbedingte Sprünge (Jump), bedingte Sprünge (Branch), UP-Aufrufe (Call), Rücksprung (Return) Gleitkommabefehle: bei allen neueren RISC-CPUs, arithmetische Operationen auf Gleitkommaregistern, Vergleichs-, Vorzeichenoperationen, Gleitkomma-Steuerbefehle Spezialbefehle: Registerorientierung und Load/ Store-Architektur o bei Load/Store-Architektur ist ausschließliches Interface zwischen internen Prozessorregistern und externen Speicher o Operationen nur zwischen Registern o RISC-Architekturen nutzen großen Teil der Chipfläche, um Registersätze mit schnellen Zugriffszeiten zu implementieren. Dadurch benötigen Operationen auf Register üblicherweise nur 1 Takt für Ausführungsphase. o Um Pipeline nicht zu blockieren, werden Registeroperanden bereits während der Befehlsdecodierungsphase aus den Registern gelesen und an das RW bzw. FE übertragen. Dort werden sie in Latches für ALU-Operation bereitgehalten. o nach der Operation wird Ergebnis zunächst in Puffer zwischengespeichert und im nächsten Takt zurückgeschrieben Unterschiede bei den CPUs hinsichtlich Anzahl und Organisationsform der Register o MIPS4000: 32 Bit Mode: 32x32 Bit Universalregister, 16x64 Bit Gleitkommaregister 64 Bit Mode: 32x64 Bit Universalregister, 16x64 Bit Gleitkommaregister o Intel i860: 32x32 Bit Integerregister, 32x32 Bit Gleitkommaregister RISC Auswirkungen auf Prozessor-Mikroarchitektur: o hohe Anforderungen an Speicherbandbreite, Grund: hohe Verarbeitungsgeschwindigkeit, nur durch mehrstufige Speicherhierarchie zu erfüllen o alle RISC-CPUs verwenden (große) Register „files“, dadurch Reduzierung der Speicherzugriffe o RISC-Architekturen reduzieren die Zahl pro Instruktion benötigten Taktzyklen auf einen Wert knapp über 1, Superskalar deutlich unter 1 o deshalb pro Taktzyklus ein oder mehrere Befehle zur CPU bringen und verarbeiten o Befehlscache mit hoher Kapazität, möglichst nur ein Taktzyklus pro Zugriff o mehrfach Datenbusse zur Steigerung der Transfergeschwindigkeit 26 3.3.4 Phasenpipeline-Mikroarchitekturen 3.3.4.1 Allgemeines zu Phasenpipelining wichtiges Kennzeichen einer Phasenpipeline: die Stufen, die zur kompletten Verarbeitung eines Befehls erforderlich sind, werden nacheinander abgearbeitet Festlegung der grundlegenden Struktur während Entwurf der Mikroarchitektur grundsätzlich 2 Varianten: o Ausstattung der Pipeline mit wenigen aber mächtigen Teilstufen o Ausstattung der Pipeline mit vielen aber einfachen Teilstufen heute: beide Ansätze, bei Hochleistungsarchitekturen eher lange „Superpipelines“ (8 bis über 20 Stufen), Grund: hohe Taktfrequenz (Gatterlaufzeiten), dadurch aber komplexes Pipelinemanagement und mehr Nebenläufigkeit Beispiel: Intel P4 (1,5 GHz Taktfrequenz), Standardpipeline 20 Stufen, Integer ALUs mit doppelter Taktfrequenz getaktet, sind aller 0,33ns mit neuen Operanden zu versorgen kurze Pipelines überwiegen bei einfachen, langsameren getakteten Mikroarchitekturen (z.B. DSP, Mikrocontroller), erledigen mehr Einzelaufgaben pro Stufe als Superpipelines, müssen jedoch bei Verzweigungen weniger neue Befehle nachladen, benötigen deshalb keine so komplexen Sprungvorhersagetechniken Pipelinekriterien: o hohe Leistungen und effizientes Pipelinedesign eng verbunden o Pipelineorganisation im Vordergrund beim Entwurf der Mikroarchitektur o zwecks Optimierung und Auslastungsrate einer Pipeline folgende Architektureigenschaften und Organisationskriterien berücksichtigen/ abstimmen: Art und Anzahl der Pipelinestufen Dauer einer Pipelinephase Befehlsformat Befehlsarten und –komplexität Registersatz und –organisation Zugriff auf Befehls- und Datencaches Implementierung von Verzweigungsbefehlen und Sprungvorhersagetechniken Implementierung von Load/ Store – Operationen Nutzung von Codeoptimierungsmöglichkeiten moderner Compiler Hardware-Steuerungsmechanismen zur Pipelinesynchronisation Lösung von Daten- und Ressourcenkonflikten Befehlsverarbeitung und Pipelinestrukturen, wichtiges Kennzeichen: Prozessoren mit Phasenpipelining überlappen „fließbandartig“ unterschiedliche Verarbeitungsphasen der sequentiell angeordneten Befehle eines Programms Phasenaufteilung: o jede Phase umfasst neben eigentliche Verarbeitungslogik auch Logik und Zwischenregister (Kommunikation mit vorheriger und folgender Phase) o bei einfachen Prozessoren Aufteilung in 4 oder 5 Phasen üblich o diese sind nicht unbedingt gleich lang, z.B. Befehlsholphase (2 Takte) Decodierphase (1 Takt) Operandenholphase (2 Takte) Ausführungsphase (variabel lang) Ergebnis-Rückschreibungsphase (2 Takte) 27 effiziente Pipelinehardware setzt gleichlange Phasen voraus (Synchronisation und Signalkommunikation zwischen exakt überlappbaren Phasen einfacher) Arbeitsweise von Pipelines: o bei ausgelasteter Pipeline arbeiten alle Stufen parallel an unterschiedlichen Befehlen o pro Taktzyklus verlässt ein Ergebnis die Pipeline sofern keine unbedingten Sprünge (Jump, Call, Return), bedingte Verzweigungen (Branch) oder durch andere Konfliktarten verursachte Verzögerungen auftreten o für Ausführung eines Befehls minimal nur ein Taktzyklus erforderlich o wichtiges Maß für Beschreibung der Leistung eines Prozessors: Cycles per Instruction, CPI o für Phasenpipelining ideal CPI = 1 o Befehlssatz gilt als ausgewogen, wenn ≥ 90% aller Befehle in einem Taktzyklus ausgeführt werden können o nicht realisierbar für Speicherzugriffe, Sprünge und die meisten Gleitkommaoperationen → mehrtaktige Ausführungsphasen o nachfolgende Befehle stauen sich dadurch in der Pipeline, besser: verursachenden komplexen Befehl an ein unabhängig weiterarbeitendes Verarbeitungswerk delegieren, welches ebenfalls als Pipeline realisiert sein kann, von der Hauptpipeline abzweigt und parallel zu dieser weiterläuft → eine Art von Nebenläufigkeit auf Befehlsebene Pipelinevarianten: o klassische fünfstufige Aufteilung (z.B. Intel 486) 1. Befehl holen (IF – instruction fetch) 2. Befehl decodieren/ Steuerinformation generieren (ID – instruction decode) 3. Registeroperanden holen und/ oder physikalische Speicheradresse ermitteln (OF – operand fetch) 4. Befehlsausführung oder Cachezugriff (Ex – Execute) 5. Ergebnis zurück schreiben (WB – write back) o Verweildauer des Befehl im Prozessor beträgt 5 Taktzyklen (wenn es ein Befehl ist, der in einem Taktzyklus ausgeführt werden kann, bzw. der Cache-Zugriff/ Load/Store erfolgreich ist) o kurze Pipelines, bei einigen RISC-Architekturen gelingt es ID und ID/OF zu kombinieren, 4 Phasen o lange Pipelines R4000, erste „Superpipeline“ siehe Bild K+A-3.3_F 7 Superskalare CPU-Implementierung ermöglichen, dass gleichzeitig mehrere Befehlsfolgen durch nebenläufige Teilpipelines der CPU laufen Pipeline-Implementierung: o zur Überlappung aller Pipelinephasen Orientierung der Länge einer Pipelinephase und damit des Prozessortaktes daran, wie viel Zeit der aufwendigste Teilschritt des Befehlszyklus minimal für seine Abarbeitung benötigt o auch kürzeren Teilschritten steht deshalb immer eine ganze Pipelinephase zur Verfügung (obwohl eigentlich nicht erforderlich) o Zwischenergebnis einer Phase wird bis zum Beginn der nächsten Phase intern Zwischengespeichert (Register) o bei einer vollausgelasteten n-stufigen Pipeline ergibt sich wegen dieser „Verschwendung“/ dieses „Verschnitts“ nicht automatisch ein n-facher Speedup gegenüber einer nicht überlappten Ausführung 28 Pipelineoptimierung: o während jedes Taktzyklus sind alle Pipelinestufen aktiv, deshalb muss Befehlszähler bereits in der Befehlsholphase des aktuellen Befehls auf Adresse des nächsten weitergeschaltet werden o interne Register vorsehen zur Wiederverwendung von Ergebnissen in nachfolgenden Pipelinestufen Speicher von ALU-Ergebnis aus Ausführungsphase ohne Rückschreiben in „sichtbares“ Register, um in nachfolgenden Befehlen verwendet zu werden da gleichzeitig mehrere Load oder Store Befehle in der Pipeline sein können, muss man dafür zwei separate Speicherregister vorsehen Architekturen mit nebenläufigen Pipelines benötigen mehrere derartige Zwischenregister o komplexe Befehle erfordern größeren Verarbeitungsaufwand, deshalb mehrere Ausführungstakte o eine eintaktige Befehlsausführungsphase ist nur erreichbar bei Verzicht auf Implementierung komplexer Maschinenbefehle oder nicht durch allgemeine Phasenpipeline leiten o häufig Realisierung durch Makros aus einfachen Befehlen Mehrfach-Load/Store-Befehle, Verzweigungen können dazu führen, dass bereits geladene Befehle ungültig werden → Pipelinefluss wird unterbrochen, es entsteht eine Auslastungslücke (pipeline bubble) Leistungssteigerung (Speedup) o mit Länge der Pipeline auch Speedup möglich, Geschwindigkeitserhöhung o fast alle neueren Prozessoren verwenden längere (tiefere) Pipelines (z.B. 8 und mehr Stufen, Intel P6: Länge variiert von 12 bis 17, Intel P4: 20 Phasen zu je einen Taktzyklus) o wichtig: beliebige Steigerung der Pipelinetiefe nicht erreichbar technische Grenzen: Gatterlaufzeiten (Kann pro Pipelinestufe überhaupt die für Teiloperationen benötigte Zahl von Gattern durchlaufen werden?), Probleme durch Clock Skew organisatorische Grenzen hervorgerufen durch Pipelinekonflikte, je länger Pipeline desto stärkere Auswirkung, 4 Arten: unbedingte Sprünge und ausgeführte bedingte Verzweigungen (control hazards) Datenkonflikte (data hazards) durch verzögerten Speicherzugriff Ressourcenkonflikte (structural hazards) Datenkonflikte in Rechenwerken oder Funktionseinheiten 3.3.4.2 Multiple Instruction Issue durch effizientes Phasenpipelining erreichen viele RISC Strukturen CPI Werte zwischen 1 und 1,5 RISC Architekturen werden wegen des Zieles (CPI = 1) als skalare Architekturen bezeichnet verschiedene Techniken möglich, um mit einem Prozessor pro Taktzyklus mehr als ein Ergebnis zu erhalten (CPI < 1), „multiple instruction issue“ Anstoß der Ausführungsphase von mehr als einem Befehl innerhalb eines Taktzyklus z.B. mit Superskalararchitekturen mehr als eine Instruktion pro Taktzyklus es müssen intern 2 (oder mehr) Befehle in echter Nebenläufigkeit zueinander verarbeitet werden, Abkehr vom Von-Neumann Paradigma 29 3.4 bisher: innerhalb eines RISC-Prozessors befinden sich mehrere Befehle quasi parallel in der Ausführung, in verschiedenen zeitlich aufeinander folgenden Phasen nun: die superskalare Ausführung des Programms bedeutet jedoch, dass Instruktionen zur gleichen Zeit abgearbeitet werden, im Extremfall sogar in invertierter zeitlicher Reihenfolge (out of order execution (ooo)), ersetzen der Befehlssequentialität durch die „Ergebnissequentialität“ wichtig ist nicht mehr, in welcher Reihenfolge etwas berechnet wird, sondern wie es berechnet wird → zusätzliche Hardware erforderlich, siehe Bild K+A-3.3_F 9 Prinzip: o Predecode-Unit erzeugt zusätzliche Informationen für die aus HS geladenen Befehle, werden im Instruction Cache gespeichert → Zweck: später benötigte Informationen möglichst schnell verfügbar haben o zwischen Instruction Cache und Instruction Buffer mehrere Datenpfade, um die benötigte Anzahl von Befehlen pro Takt in die Verarbeitung laden zu können, Anzahl muss mindestens der internen Parallelität (z.B. Anzahl der ALUs) entsprechen o während im Instruction Cache Blöcke von Instruktionen mit aufeinanderfolgenden Adressen stehen, lädt der Prozessor diese Instruktionen in logischen Zusammenhang in den Instruction Buffer o doppelte Pufferung soll möglichst viele Möglichkeiten zum Ausgleich von Fehlzugriffen (cache misses) oder Instruktionsflussänderungen bieten o Decode-, Rename-, Dispatch Unit führt in Zusammenarbeit mit den Instruction Buffer eine erste Bearbeitung von Kontrollflussänderungen durch → wie soll z.B. bei bedingten Sprüngen/ Verzweigungen Prozessor den Programmverlauf weiterverfolgen? Außerdem Kontrolle von Datenabhängigkeiten, Maßnahmen zur Behebung. o danach Übergabe der Instruktionen gemäß Zuteilungsalgorithmus an die ausführenden Einheiten o Ausführende Einheiten: ALUs für Operationen, Load/Store-Pipelines für Speicherzugriffe o Reorder-, Commit Unit verantwortlich für Ergebnissequentialität, sämtliche Ausführung von Befehlen die spekulativ durchgeführt wurden bzw. in Zusammenhang mit Datenabhängigkeiten standen, werden hier abschließend bestätigt oder verworfen VLIW-Architekturen (very long instruction word) o Variation der Superskalararchitekturen o können mehrere in einem Wort codierte Maschinenbefehle parallel zueinander ausführen o es werden Hardwarearchitekturen mit parallelen Rechenwerken/ FE benötigt o spezieller Compiler packt jeweils n unabhängige Befehle eines Programms in ein VLIW (Befehlswort z.B. 512 Bit) o jedes spezifische Feld mehrerer aufeinanderfolgender VLIWs enthält eine Operation aus einer sequentiellen Operationsfolge für eine der FEn des Prozessors Rechenwerke parallele RW: o parallele Operationen auf Bit-Formaten unterschiedlicher Breite (Byte, Word, …) o alle beteiligten Bit-Positionen werden gleichzeitig behandelt 30 3.4.1 o prinzipiell höherer Datendurchsatz pro Zeiteinheit als bei seriellen RW o Nachteil: höherer HW-Aufwand serielle RW: o jedes einzelne Operanden-Bit wird separat verarbeitet, auftretende Überträge müssen über mindestens eine Taktperiode zwischengespeichert werden o getaktete Schaltungen erforderlich o Operationszeit wird größer, größere Operandenformate o Operationszeit kann bei manchen seriellen RW auch von Operandenstruktur (0-1Verteilung) abhängen o Vorteil (meist) geringerer Implementierungsaufwand Addierer 3.4.1.1 Parallele Addierer Ripple-Carry-Addierer (RCA), siehe Bild K+A-3.4_F 1 o einfachster parallel arbeitender Addierer für 2 n-Bit breite Operanden A und B mit den Bitkomponenten an-1 … a0 und bn-1 … b0 o nach Anlegen der Operanden A und B wird Summe erst dann gültig, wenn der durch alle Adder laufende Übertrag bei der werthöchsten Bitstelle angekommen ist o vollständige Summe erst nach 𝑡 = (2𝑛 + 1) ∙ 𝜏 verfügbar, τ = Gatterlaufzeit Carry-Look-Ahead-Addierer (CLA), siehe Bild K+A-3.4_F 2 o Vorausberechnung des Übertrags ci in geringerer und von n nahezu unabhängiger Zeit o gilt auch für die Stellensummen si o Übertrag kann separat – aber in jeder Bitstelle einheitlich – nach einer Zeit von t = 3τ bereitgestellt werden o Schaltungsaufwand kann erheblich größer werden als bei RCA (bei gleicher Bitstellenzahl) o Berechnung der Stellensummen ebenfalls einheitlich, in jeder Bitstelle t = 6τ o für größere Bitstellen sehr hoher Implementierungsaufwand, Kompromiss: kaskadierter CLA-Addierer, siehe Bild K+A-3.4_F 3 3.4.1.2 Serielle Addierer 3.4.2 siehe Bild K+A-3.4_F 4 Schaltwerke als 1 Bit-Addierer serielle Addierer sind getaktete Schaltwerke, die mit jedem Takt genau 1 Bit der beteiligten n-stelligen Operanden verarbeiten Abarbeitung beginnt beim niederwertigsten Bit Addierer benötigt 2 n-stellige voreinstellbare Schieberegister, einen Volladder sowie einen 1-Bit-Zwischenspeicher für Carry Summe und Übertrag stehen nach n+2 Takten zur Verfügung (Register A, ZS) Steueraufwand größer als bei paralleler Addition insgesamt erforderliche Schaltungsaufwand bei größeren n erheblich geringer Subtrahierer siehe Bild K+A-3.4_F 5 31 3.4.3 Paralleladdierer kann auch Subtraktion der Operanden A und B realisieren, wenn bei 𝐷 = 𝐴 − 𝐵 der Subtrahend B als vorzeichenbehaftete negative Dualzahl interpretiert und dann addiert wird 𝐴 + (−𝐵) einführen von Steuerinformation AS in Addierschaltung, 0/1-Belegung von AS bestimmt ausführende Operation vorzeichenbehaftete Zahlen werden unterschiedlich codiert o Einerkomplement: bitweises Invertieren o Zweierkomplement: zunächst Einerkomplement bilden dann +1 addieren, Assembler benutzen allgemein das Zweierkomplement Multiplizierer 3.4.3.1 Parallele Multiplizierer siehe Bild K+A-3.4_F 6 und fortführend duale Multiplikation, ähnliche Rechenregeln wie duale Addition, Stellenmultiplikation über Und-Verknüpfung zusätzlicher HW-Aufwand für Zeilenverschiebungen und nachfolgend erforderliche Spaltenaddition Produkt P bei n-stelligem „Multiplikanden“ B und „Multiplikator“ A immer 2n Stellen groß konkreter Multiplizierer erfordert 𝑛 ∙ 𝑛 Und-Glieder sowie (𝑛 − 1) ∙ 𝑛 Volladdierer („parallel“ = Verknüpfung aller Bitstellen beginnt gleichzeitig), arbeitet relativ schnell keine internen Steuersignale größere Operandenbreiten (16x16 Bit ca. 4200 Gatter, 32x32 Bit ca. 253000 Gatter) benötigen mehr Chipfläche, Energie 3.4.3.2 Matrixmultiplikation Kompromiss zwischen Flächen-/ Gatterbedarf und Rechenzeit enthält ROM-Tabelle, deren Zeilen und Spalten direkt von den Operanden über Decoder angesteuert werden, entsprechendes Feld enthält Produkt Matrixinhalte sind Tetraden 0x0 … 0xF, symmetrisch zu Hauptdiagonalen (von unten links nach oben rechts), siehe Bild K+A-3.4_F 8 erweiterbar für 2 Byte Operanden, 32000 Produkte zu je 16 Bit mit bestimmten Multiplikationsverfahren wird nur konstante Taktzahl für Produktbildung benötigt arbeitet nebenläufig mit Operandenteilen auf Produktmatrix, Taktzahl von Operandenstruktur unabhängig, für Pipelines in RISC-Prozessoren geeignet 3.4.3.3 Serielle Multiplizierer siehe Bild K+A-3.4_F 9 verarbeiten jedes Bit einzeln Vorteil: HW Aufwand geringer Nachteil: komplizierte Taktsteuerung 32 3.4.3.4 Multiplikation mit CISC-Architekturen 3.4.4 Steuerung der inneren Abläufe durch Mikrobefehlsspeicher → Bereitstellen Steuersignale si Multiplizieren benötigen n unterschiedlich lange Zyklen für die Ausführung, Dauer sowohl von Operandenstruktur als auch von n abhängig, Multiplikationszeit wächst mit Anzahl der Einsen im Multiplikator „Strukturabhängigkeit“, nur für CISCArchitekturen geeignet Dividierer aus algebraischer Sicht Umkehroperation zur Multiplikation (2 n-stellige Operanden, 2n Produkt) bei paralleler Division muss Dividend 2n-stellig und Divisor n stellig sein berechnet Quotient und Rest, Rest ≥ 0 aber kleiner als Divisor Rückführung auf Operationen Subtraktion und Verschiebung 33 4. Übung 4.1 Materialien http://www-user.tu-chemnitz.de/~erma/dienst/lehre/ John L. Hennessy; David A. Patterson: Computer Architecture. Rechnerarchitektur) Morgan Kaufmann; Peter Ashenden: The Designer's Guide to VHDL 4.2 Adder 4.2.1 Halfadder (2, 2) ohne Carry In (deutsch: 2 Eingänge: a, b 2 Ausgänge: s, cout (Carry Out) Mathematische Funktionen: 𝑠 = (𝑎 + 𝑏) mod 2 𝑐out = ⌊(𝑎 + 𝑏)/2⌋ ←Zeichen für Abrunden Logische Funktionen: 𝑠 = 𝑎 ≁ 𝑏 = 𝑎̅𝑏 + 𝑎𝑏̅ (zwei Und-Verknüpfungen verbunden über Oder-Verknüpfung) 𝑐out = 𝑎𝑏 (Und-Verknüpfung) a =1 s & cout b 4.2.2 Fulladder (3, 2) mit Carry In 3 Eingänge: a, b, cin 2 Ausgänge: s, cout (Carry Out) Mathematische Funktionen: 𝑠 = (𝑎 + 𝑏 + 𝑐in ) mod 2 𝑐out = ⌊(𝑎 + 𝑏 + 𝑐in )/2⌋ Logische Funktionen: ̅ ̅̅̅ 𝑠 = 𝑎 ≁ 𝑏 ≁ 𝑐in = 𝑎̅𝑏̅𝑐in + 𝑎̅𝑏𝑐̅̅̅ in + 𝑎𝑏𝑐 in + 𝑎𝑏𝑐in 34 cin 0 0 0 1 0 1 0 1 0 0 cout 1 1 1 1 0 1 0 1 a b 𝑐out = 𝑎𝑏 + 𝑏𝑐in + 𝑎𝑐in = 𝑎𝑏 + 𝑐in (𝑎 + 𝑏) = Halfadder a b generate HA HA propagate s a ~ b ~ cin 4.2.3 Ripple Carry Adder bi-1 ai-1 ci-1 b 1 a1 FA b 0 a0 0 FA si-1 c2 FA s1 c1 s0 Manchester Carry Chain p schaltet wenn p=0 g cout HA p p p transmission gate cin p schaltet wenn p=1 Wenn p=1 ist cout nur noch von cin abhängig 𝑐out = 𝑎𝑏 ⏟ + 𝑐in (𝑎 ⏟ ≁ 𝑏) = 𝑔 + 𝑐in 𝑝 𝑔 cout cin a ~ b cin a b ab cin a ~ b generate a ~ b 4.2.4 ≥1 ab propagate ci (𝑎 𝑎𝑏 ⏟ + 𝑐in ⋅ ⏟ ≁ 𝑏) carry generate carry propagate 𝑝 35 4.2.5 Carry Skip Adder 𝑝=𝑎≁𝑏 𝑔 = 𝑎𝑏 𝑠 = 𝑐in ≁ 𝑝 𝑐out = 𝑔 + 𝑝𝑐in Annahme: 𝑝 = 1 → 𝑔 = 0 (wenn 𝑝 = 1 ist g immer gleich 0) cin FA a0 b0 =1 FA a1 b1 ≥1 FA a2 cout b2 =1 =1 & & Längster Pfad (wenn alle 𝑎𝑖 = 1, 𝑏𝑖 = 0, 𝑐in = 1) wird verkürzt, andere Fälle nicht unbedingt. 4.2.6 Carry Look Ahead Adder (CLA) Berechnet letztes Carry schneller. Zwischen-Carrys aber weiterhin nötig für Summe. 𝑝 =𝑎+𝑏 𝑔 = 𝑎𝑏 𝑠 = 𝑐in ≁ 𝑝 ≁ 𝑔 𝑐out = 𝑔 + 𝑝𝑐in Beispiel für 4 Bit: 𝑐1 = 𝑐2 = 𝑐3 = 𝑐out = 𝑔0 + 𝑝0 𝑐0 𝑔1 + 𝑝1 (𝑔0 + 𝑝0 𝑐0 ) 𝑔2 + 𝑝2 (𝑔1 + 𝑝1 (𝑔0 + 𝑝0 𝑐0 )) 𝑔3 + 𝑝3 (𝑔2 + 𝑝2 (𝑔1 + 𝑝1 (𝑔0 + 𝑝0 𝑐0 ))) = 𝑎3 𝑏3 + (𝑎3 + 𝑏3 ) (𝑎2 𝑏2 + (𝑎2 + 𝑏2 )(𝑎1 𝑏1 + (𝑎1 + 𝑏1 )(𝑎0 𝑏0 + (𝑎0 + 𝑏0 )𝑐0 ))) → cout ist nicht mehr abhängig von Zwischen-Carrys 36 g0 p0 g1 p1 g2 p2 c1 c0 g3 p3 c2 s0 c3 s1 a0 b 0 s2 a1 b 1 a2 b 2 cout s3 a3 b 3 𝑐out = 𝑎3 𝑏3 + 𝑎3 𝑎2 𝑏2 + 𝑏3 𝑎2 𝑏2 + ⋯ + 𝑏3 𝑏2 𝑏1 𝑏0 𝑐0 positiv: zweistufige Logik negativ: viele Eingänge (hoher fan in) macht es groß und langsam, komplexe Verdrahtung (Routing Problem) Baumstrukturen verwenden, Regularität 4.2.7 Carry Select Adder Z.B. aus einem 8 Bit Adder zwei 4 Bit Adder machen. Da vordere 4 Bit vom Carry Out der hinteren 4 Bit abhängen, werden die vorderen 4 Bit für beide Fälle des Carrys (0, 1) berechnet und über MUX am Ende entschieden, welches Ergebnis als korrektes genommen wird. b7…b4 a7…a4 c4=1 b7…b4 a7…a4 c4=0 4 Bit Adder 4 Bit Adder b3…b0 a3…a0 cout, s7…s4 cout, s7…s4 MUX 4 Bit Adder c4 cout, s7…s4 4.2.8 c0 s3…s0 Serial Adder D a b FA cin Clk D Clk & Q sum Q cout damit nicht Carry von alter Addition übernommen wird Bitstellen von a und b gelangen über Schieberegister rein, Bitstellen von sum über Schieberegister raus. Erstes cin vor a und b in FA reinschieben. 37 4.3 Selbst zu entwerfende Komponente 4.3.1 Bedingungen und Hinweise logische oder arithmetische Schaltung zwei 8 Bit breite Eingangswerte oder einen 16 Bit breiten erlaubt sind nur Grundgatter vom Typ UND, ODER, NAND, NOR und NOT mit höchstens 2 Eingängen VHDL Modell und Testbench entwerfen alle Gatter besitzen Laufzeit von 5ns in Entwurfssimulation für Simulation nach Implementierung müssen Ein- und Ausgangsregister angehängt werden, entfernen der 5ns pro Gatter und simulieren der echten Verzögerungszeiten dem Lehrer das Modell demonstrieren (Powerpoint-)Präsentation vor Lehrer und anderen Studenten längsten Pfad erklären zum Entwerfen können z.B. Praktikumsrechner benutzt oder auf privaten Rechner das Xilinx Web Pack installiert werden Umgebungsdateien holen über: gtar xvfz /home/4all/tmp/vje/component_template.tgz Quelldateien in dc.script in Anführungsstrichen eintragen, durch Komma getrennt im Makefile eventuell Componentennamen ändern dc_shell –f dc.script ¦ tee synthesis.log 4.3.2 Eigene Komponente 8-Bit-BCD-Adder gewählt, berechnet aus zwei 8-Bit-BCD Zahlen + Carry In eine 8 Bit BCD Summe mit Carry Out berechnet nur mit BCD Zahlen an den Eingängen korrekte Ergebnisse Zerlegung der Addition auf zwei 4-Bit-BCD-Adder für Erläuterung zum längsten Pfad siehe Präsentationen Aus Eingangswerten werden zunächst über normale Full Adder eine Zwischensumme Z und ein Zwischen-Carry CO berechnet. Gleichungen für Full Adder: CI 0 0 1 1 1 0 0 1 0 0 Z 0 1 1 1 1 0 0 1 a b CI 0 0 0 1 0 1 0 1 0 0 CO 1 1 1 1 0 1 0 1 a b 𝑍 = 𝑎 ≁ 𝑏 ≁ 𝐶𝐼 = (𝑎̅𝑏 ∨ 𝑎𝑏̅) ≁ 𝐶𝐼 = 𝑎̅𝑏𝐶̅𝐼 ∨ 𝑎𝑏̅𝐶̅𝐼 ∨ 𝑎𝑏𝐶𝐼 ∨ 𝑎̅𝑏̅𝐶𝐼 𝐶𝑂 = 𝑎𝑏 ∨ 𝑎𝐶𝐼 ∨ 𝑏𝐶𝐼 Zwischen-Carry wird an nachfolgenden Full Adder weiter gereicht. Aus Zwischensummen und Zwischen-Carry des vierten Full Adders (CO3) werden die BCD-Summe s und das Carry Out des 4-Bit-BCD-Adders berechnet. Gleichungen für Summe und Carry Out: 38 Z3 0 0 1 1 Z2 0 1 1 0 Z3 0 0 1 1 Z2 0 1 1 0 Z3 0 0 1 1 Z2 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 0 1 1 1 1 1 1 0 1 0 1 s0 0 0 Z1 0 Z0 1 CO3 Z3 Z2 0 0 0 1 1 1 1 0 0 1 0 0 0 0 0 0 1 1 0 1 0 0 0 1 1 0 1 1 0 0 1 0 0 0 1 0 1 0 1 1 0 1 1 1 0 1 0 1 s2 1 0 Z1 0 Z0 1 CO3 Z3 Z2 0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 1 1 0 0 1 0 0 1 1 0 0 1 1 0 0 0 1 0 0 1 0 1 0 1 1 0 1 1 1 0 1 0 1 s1 1 0 Z1 0 Z0 1 CO3 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 1 0 1 0 0 0 1 1 1 1 1 1 1 1 0 1 s3 0 0 Z1 0 Z0 1 CO3 cout 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 1 1 1 1 0 0 0 1 0 0 1 0 1 0 1 1 1 1 1 1 1 1 0 1 1 0 Z1 0 Z0 1 CO3 𝑠0 = 𝑍0 ̅̅̅1 𝐶𝑂3 ∨ 𝑍3 𝑍2 ̅̅̅ 𝑠1 = ̅̅̅ 𝑍3 𝑍1 ̅̅̅̅̅ 𝐶𝑂3 ∨ 𝑍 𝑍1 ̅̅̅ ̅̅̅ 𝑠2 = 𝑍1 𝐶𝑂3 ∨ 𝑍3 𝑍2 ∨ 𝑍2 𝑍1 𝑠3 = 𝑍1 𝐶𝑂3 ∨ 𝑍3 ̅̅̅ 𝑍2 ̅̅̅ 𝑍1 𝑐out = 𝐶𝑂3 ∨ 𝑍3 𝑍2 ∨ 𝑍3 𝑍1 Beide 4-Bit-BCD-Adder werden über Carry Out des ersten Adders zu einem 8-Bit-BCDAdder verknüpft. Tipp: Für Suche nach längstem Pfad nicht nur Eingangsbelegung betrachten, sondern Wechsel von einer bestimmten Eingangsbelegung zu einer anderen bestimmten → bei 9900 möglichen Eingangsbelegungspaarungen (für a und b Zahlen von 0 bis 99, ohne doppelte Paarungen, mit Carry In) ergeben sich 9900 ⋅ 9900 = 98010000 mögliche Wechsel. 39 4.4 Prozessoren 4.4.1 Alignment 0 8 16 24 Byte 1 Byte 2 Byte 3 Byte 4 Wort nicht möglich, da Beginn immer bei Vielfachen der Länge kein Wort Wort Speicherzugriffe müssen ausgerichtet sein. 4.4.2 Schaltung gegen Spikes Din & Clk & 1 Clk 4.4.3 gegen Spikes, die durch Verzögerungen des Negators entstehen ≥1 Z & Dauer von Maschinenbefehle → CPI 𝑛 𝐶𝑃𝐼 = ∑ Takte für Befehl i ⋅ Häufigkeit des Befehls i 𝑖=0 Summe der Häufigkeiten aller Befehle ergibt 1. Befehl Takte Häufigkeit Takte ∙ Häufigkeit Laden 8 0,21 1,68 Speichern 7 0,12 0,84 ALU 6 0,37 2,22 Vergleiche 7 0,06 0,42 Sprünge 4 0,02 0,08 UP-Sprünge 6 0 0 ausgeführt 5 0,12 0,6 Verzweigungen nicht ausgeführt 4 0,11 0,44 6,28 4.4.4 Pipeline Aufgabe 2 Pipeline mit 10 Stufen. 9 Stufen benötigen 50ns, eine benötigt 70ns. Pro Stufe zusätzliche Verzögerung von 10ns. Alternative Pipeline mit 9 Stufen. 8 Stufen benötigen 55ns, eine 40 benötigt 65ns (keine zusätzliche Verzögerung hier?). Vergleiche Befehlsdurchsatz für sequentielle Abarbeitung und berechne Beschleunigung für beide Varianten. Serielle Abarbeitung eines Befehls nach dem anderen (ohne Pipeline): erste Pipeline: 9 ⋅ 50𝑛𝑠 + 70𝑛𝑠 = 520𝑛𝑠 pro Befehl zweite Pipeline: 8 ⋅ 55𝑛𝑠 + 65𝑛𝑠 = 505𝑛𝑠 pro Befehl Abarbeitung in Pipeline (alle Stufen müssen sich nach langsamster Stufe richten): erste Pipeline: 10 ⋅ (70 + 10)𝑛𝑠 = 800𝑛𝑠 → pro Stufe 80ns zweite Pipeline: 9 ∙ 65𝑛𝑠 = 585𝑛𝑠 → pro Stufe 65ns Abarbeitung ohne Pipeline Zeit pro Pipelinestufe 520𝑛𝑠 erste Pipeline: 80𝑛𝑠 = 6,5 Beschleunigung = zweite Pipeline: 505𝑛𝑠 65𝑛𝑠 = 7,77 Zweite Pipelinevariante ist schneller und besitzt zudem weniger Stufen (weniger Hazards). 4.4.5 Pipeline Aufgabe 4 Pipeline der Tiefe 4 mit folgenden Hazards zwischen Befehl i und seinen Nachfolgern: Befehl Hazard-Häufigkeit Anzahl der Wartezyklen i+1 (ohne i+2) 20% 2 i+2 5% 1 Wie groß ist Leistungserhöhung des Pipelinings mit und ohne Hazards? CPI ohne Verzögerungen = 1 𝐶𝑃𝐼 = 1 + 0,2 ∙ 2 + 0,05 ∙ 1 = 1,45 Beschleunigung ohne Verzögerung = 4 Beschleunigung mit Verzögerung 4.4.6 Beschleunigung ohne Verzögerung CPI Dauer ohne Pipeline 4 = = = 2,76 Dauer mit Pipeline 1,45 = Pipeline Aufgabe 5 Verzweigungshäufigkeit: bedingte Verzweigungen = 20% (davon werden 60% ausgeführt) Sprünge und Unterprogrammaufrufe = 5% Pipeline der Tiefe 4. Unbedingte Verzweigungen am Ende des zweiten Zyklus entschieden, bedingte Verzweigungen am Ende des dritten Zyklus entschieden. Erste Pipelinestufe immer ausgeführt. Wie viel schneller ohne Verzweige-Hazards? 𝐶𝑃𝐼 = 1 + 0,05 ∙ 1 ⏟ Sprünge 1 Wartezyklus + 0,2 ∙ 0,4 ∙ 1 ⏟ + bedingte Verzweigungen nicht ausgeführt → 1 Wartezyklus 41 0,2 ∙ 0,6 ∙ 2 ⏟ bedingte Verzweigungen ausgeführt → 2 Wartezyklen = 1,37 Ohne Verzweigungen wäre Abarbeitung 1,37-mal schneller. 4.4.7 Score-Boarding Befehlsstatus Befehl Übergabe Opcode lesen Ausführung beendet Ergebnis schnreiben ld f2,32(r0) x x x x ld f4,40(r0) x x x - (x) multd f6,f4,f2 x - (x) subd f8,f2,f2 x x divd f4,f2,f8 - (x) (-) addd f10,f6,f4 - 1. Befehl 2: Ausführung beendet 2. Befehl 2 (in Klammern): Ergebnis schreiben Status FE FE Busy Op Fres Fj Fk Qj Qk Rj Rk INT x Load F4 r0 Mul1 x Multd F6 F4 F2 Integer (-) 1 (-) Mul2 Add x Subd F8 F2 F2 Div - (x) - (Divd) (F4) (F2) (F8) (-) (Add) (-) (1) Ergebnisstatus F0 F2 F4 F6 F8 F10 FE - Integer Mul1 Add - 4.4.8 Tomasulo Res-Tabelle Name Busy Op Vj Vk Qj Qk Add1 x Sub [Load1] [Load1] Add2 x Add Mult1 Mult2 Add3 Mult1 x Mult - ([Load2]) [Load1] [Load2] (-) Mult2 x Div [Load1] Add1 Erklärung: [Load1] = Wert kommt von erster Ladeeinheit Registerstatus F0 F2 F4 F6 F8 F10 Qi - Mult2 Mult1 Add1 Add2 Busy x x x x bzgl. (Qi, F4): Mult2 → Scoreboard: Int(WAW-Hazard) 42 4.4.9 DLX Aufgaben aus Teil 2 zu 2a) Basic Pipeline: 1515 Zyklen Scorboarding mit 2 Integer Units: 2425 Zyklen → Scorboarding nutzt nur bei genügend Hardware, kein Forwarding Scoreboarding mit 5 Integer Units: 1526 Zyklen Scoreboarding mit 8 Integer Units: 1364 Zyklen Tomasulo mit 2 Integer Units: 1718 Zyklen → Tomasulo langsamer trotz Forwarding, da hier Forwarding ein Takt mehr benötigt als bei Basic Pipeline (Ergebnis steht im selben Taktschritt zur Verfügung) Tomasulo mit 5 und 8 Integer Units und 2 FP: 1011 zu 2b) Vorteile Scoreboard: Außer-Reihe-Ausführung des Codes, Pipeline bleibt länger. addf f0, f3, f4 subf f6, f5, f0 addf f10, f8, f9 → Außer-Reihe-Ausführung Vorteile Pipeline: Forwarding addf f0, f3, f4 subf f6, f5, f0 → Ergebnis von f0 steht gleich zur Verfügung zu 2c) Bei viel paralleler Hardware lohnt sich Scoreboarding. Mehraufwand: Steuerung, WAW/WAR-Erkennung, Queues. zu 3b) Vorteile Tomasulo: Außer-Reihe-Ausführung, siehe Quellcode von vorhin. Dynamisches Register-Renaming das Hazards erspart (WAW). multd f6, f2, f2 addd f2, f0, f6 addd f8, f0, f6 Beide addd Befehle durch dynamisches Register-Renaming hazardfrei. Vorteile Pipeline: Schnelleres Forwarding. Tomasulo stoppt bei voller Reservation Station. zu 3e) Bei zu wenigen Reservation Stations wird es eng, lieber ein paar mehr. 43 zu 3f) Steuerung, Reservation Stations, Common Data Bus (CDB) zu 4) Vorteil Tomasulo: Forwarding, dynamisches Register-Renaming ein Befehl pro CDB → da nur ein CDB vorhanden kann auch nur ein Befehl pro Taktschritt fertig werden → ein zweiter Befehl müsste warten zu 5) Register umbenennen zu 6) formales Aufrollen streiche Sprünge und Vergleiche Anpassung Indizes/Adressoffsets Codeumwandlung zur Optimierung/Stall Vermeidung → 8,67 pro Iteration (3 Iterationen → 3-mal Aufrollen) 4.5 Prüfungsinhalte Vorlesung 5-stufiges Pipelining, DLX, Hazards, Forwarding, Scoreboarding, Tomasulo (Overhead, Common Data Bus, Reservation Station), Unterschiede zwischen Verfahren 44