PPT
Werbung

Validierung der
FH-Wsb.-Suchsite
Beispiel3.txt
Ü1/1
Übersicht
Diese Präsentation demonstriert den groben Ablauf der Skriptdatei zur
Validierung der FH-Wiesbaden Suchsite. Die auf den folgenden Seiten
befindlichen Referenzzahlen dienen als Querverweis
Zum Einstieg wird eine Führung durch die einzelnen Schritte unternommen.
Dabei wird immer eine Erläuterung, und je nach Bedarf einen Teil der
HTML-Site, HTML-Codes, Scriptdatei oder Scriptausgabe als Screenshot
dargestellt
Nun folgt der Flowchart, der sich auf nicht weniger als fünf Seiten erstreckt
Danach folgt eine Referenztabelle, die zur Zuweisung der Zahlen und
Farben dient
Anschließend wird die Skriptdatei in farblich unterlegte Abschnitte
dargestellt (ebenfalls fünf Seiten)
Abschließend werden auch die Ausgaben an einem Beispiel in farblich
unterlegte Abschnitte unterteilt und dargestellt
Bildlicher Ablauf des Skriptes 1/7
Man gibt diesen Link, wie in Abb. zu sehen, vor
HTML-Code:
Ablauf des Skriptes 2/7
Anschließen wird die Framesite geladen:
Man benötigt aber nur den Body (Body muss also vorhanden sein), deshalb muss nach dieser URL gesucht
werden und geladen werden:
Mit dieser URL erhält man die eigentliche Suchpage, hier muss auch „Fachhochschule durchsuchen“ vorkommen:
Ablauf des Skriptes 3/7
Nachdem die Website geladen wurde, erhält
man die erste Page der Suchtreffer: Wie man
auch sehen kann, erscheint nicht die
Fehlermeldung „Keine Dokumente gefunden“
Nun werden die Gesamttrefferanzahl
ermittelt. Hier im Beispiel sind es 20
Ablauf des Skriptes 4/7
Nun wird überprüft, ob der Weiterlink existiert. Wenn ja, wird auch gleich der Link einer Variablen
zugewiesen. Danach wird geprüft, ob das Copyright von „Thunderstone“ vorhanden ist.
Anschließend wird eine Linkliste erstellt
Ablauf des Skriptes 5/7
Nun wird die Linkliste geladen, und Link für Link getestet. Das geht
natürlich solange bis die Liste abgehandelt wurde. Bei jedem Link
wird das Resultat anhand eines Regexes verglichen, und
entschieden, ob dies ein Broken Link ist, eine PDF oder eine
normale HTML-Datei ist. Bei Link 7 ist ein Broken Link aufgetreten.
Brokenlinks werden samt Titel in einer Datei gespeichert.
Das Resultat wird sofort auf dem Bildschirm ausgegeben
Ablauf des Skriptes 6/7
Wir hatten uns gemerkt, ob ein Weiterlink vorhanden ist.
Je nachdem lädt man den neuen Link in den Speicher
und beginnt wieder von vorne. In diesem Fall war der
Weiterlink vorhanden.
Die neue URL wird geladen, jedoch ist auf dieser
der Weiterlink nicht mehr vorhanden. Nach
Überprüfung der Links verlässt das Skript die
Schleife.
Falls die zu Beginn ermittelte
Trefferanzahl ungleich der
überprüften Treffer sein sollten,
wird eine Warnung ausgegeben
und auf eine Bestätigung des
Users gewartet.
Ablauf des Skriptes 7/7
Nachdem alle Links überprüft worden
sind, erfolgt das Resumé, dh.
Zusammenfassung
Danach wird überprüft, ob Brokenlinks vorhanden waren.
Wenn ja, dann wird noch geschaut, ob noch weiter überprüft
werden soll. Es kann ja sein das beim nächsten mal ein
broken Link wieder funktioniert. In diesem Fall wird zur
Routine tryAgain gesprungen, ansonsten ist das Skript
fertig.
Wenn zu tryAgain gesprungen wird, wird überprüft,
ob sich die Anzahl der Brokenlinks seit dem letzten
mal sich verändert hat. Nur wenn sich nichts
geändert hat wird der Zähler decrementiert. Danach
wird als Linkliste die Brokenliste genommen, und es
werden alle Links überprüft, dh. es wird auf nextLink
zurückgesprungen.
Flowchart 1/5
F1/5
Start
A
Framesite laden
Existiert Body?
nein
ja
Existiert „keine Dokumente gefunden“ ?
ja
Bodysite laden
Existiert
„Fachhochschule
durchsuchen“?
nein
Gesamtanzahl
Treffer ermitteln
nein
URL mit dem SuchbegriffParameter posten
ja
A
Fehlermeldung,
Abbruch
B
Flowchart 2/5
F2/5
C
F
B
Linkliste der
Suchtreffer erstellen
Existiert der Link
„weiter“ ?
nein
Linkliste anzeigen
ja
Weiterlink
setzen
Weiterlink nicht
vorhanden
Linkliste laden
nein
Weitere Links
Vorhanden?
nein
Fehlermeldung,
Abbruch
„Thunderstone“
Vorhanden?
ja
Nächsten Link
laden
ja
C
G
D
Flowchart 3/5
F3/5
D
E
nein
Titel
vorhanden?
Linkcounter
erhöhen
ja
nein
Broken Link
o.ä. ?
PDFDatei?
ja
ja
nein
Infozeile
ausgeben
Count Error
Write Error
E
F
Flowchart 4/5
F4/5
G
Weiterlink
vorhanden?
ja
Weiterlink
laden
nein
nein
Linkcounter =
Anz. Treffer?
Warnung
ausgeben
ja
Auf Bestätigung
warten
B
Remumé,
Brokenlinks
Ausgeben usw.
H
Flowchart 5/5
F5/5
H
nein
nein
Veränderung
Brokenlinks?
Brokenlinks
Vorhanden?
Restliche
Überprüfungen
decrementieren
ja
ja
Noch weitere
Überprüfungen?
nein
Alles OK,
Ende
ja
Brokenlinkliste
laden
B
R1/1
Referenz Flowchartelemete<->Farben
1
5
9
13
17
21
25
29
33
37
2
6
10
14
18
22
26
30
34
38
3
7
11
15
19
23
27
31
35
4
8
12
16
20
24
28
32
36
Skript 1/5
// Dieses Beispiel demonstriet die Integrität der informatik.fh-wiesbaden - Suchseite
// Hinweis: In der letzten Zeit ging (vorallem) die Suchsite immer mal wieder für ein paar Minuten nicht, auch wenn man ganz normal den Internet Explorer verwendet!
// Bearbeitungszeitraum: 16.7.02-17.7.02
// Parameter: [retrys left] [Suchbegriff][,[Suchbegriff]]*
// Beispiel: 2 Weber1
// //////// Such-URL von Informatik.FH-Wiesbaden ermitteln //////////////////
print 1. lade Framesite...
url http://fh-web1.informatik.fh-wiesbaden.de/go.cfm?fb=6&action=search&sprachid=1&lpid=0&sid=0
// Body vom Frame herausfiltern
limit 515 <frame name="body".*>
limit 515 src=".*"
cleft 5
cright 1
jumpifnoi errNoBody 0
// "Fachhochschule durchsuchen" muss vorhanden sein
print 2. lade Body...
url http://fh-web1.informatik.fh-wiesbaden.de{!/0!}
vlimit 512 Fachhochschule durchsuchen
jumpifnoi errDurchsuche 0
init
// relative URL ermitteln
vlimit 515 <form.*>
vlimit 515 action=".*"
vlimit 515 ".*"
cleft 1
cright 1
// /////// Haupteil ////////////////////////////////////////////
// Initialisierungen
var s url = http://fh-web1.informatik.fh-wiesbaden.de{!/0!}
var i countError = 0
var i gesamtLink = 0
var i countGesamtLink = 0
var i retrysLeft = {!1!}
var i altCountError = 0
var i countRetrys = 0
var s aktlink = home
print 3. pruefe, ob Treffer vorhanden sind
post {!/url!} query={!2!}
vlimit 0 Keine Dokumente gefunden
jumpifi errTreffer 0
S1/5
Skript 2/5
S2/5
vlimit 0 [0-9]+.+bis.+[0-9]+.+von.+[0-9]+(,[0-9]+)?.+Treffern
vlimit 0 von.+[0-9]+(,[0-9]+)?
jumpifnoi errNoGesamttreffer 0
cleft 4
replace gesamtanzahl.tmp 0 , ""
load gesamtanzahl.tmp
limit 0 [0-9]+
var i gesamtLink = {!/0!}
var i aktGesamtLink = {!/0!}
post {!/url!} query={!2!}
run del gesamtanzahl.tmp
run del brokenlinks.tmp
run del linkliste.tmp
run cls
print Initialisierung abgeschlossen, suche nach broken Links ({!gesamtLink!} Links insgesamt):
print
print {!/url!} enthaelt folgende Links:
label nextPage:
var i countLink = 0
// Nach dem Link "weiter" suchen
limit 515 <A HREF=".*"> <FONT FACE="Helvetica">weiter</FONT>&gt;&gt;</A>
jumpifnoi keinWeiter 0
limit 515 <A HREF=".*">
limit 515 ".*"
cleft 1
cright 1
var s weiter = {!/0!}
var s weiter = nichts
label keinWeiter:
init
// nach erforderlichem Inhalt überprüfen
limit 0 Texis &amp; Webinator Copyright \(C\) 2\d{3,3} THUNDERSTONE - EPI, Inc."></A></H6>.\n</BODY></HTML>.$
jumpifnoi errCopyright 0
init
// Linkliste erstellen
limit 519 <A.*><STRONG>
limit 519 HREF="?http://.*("| |>|#)
cleft 5
// #, > " und amp; löschen
replace linkliste2.tmp 0 ("|>|#) ""
load linkliste2.tmp
cright 1
replace linkliste.tmp 0 &.*; &
run del linkliste2.tmp
load linkliste.tmp
limit 0 .+
show
Skript 3/5
label nextLink:
// Linkliste laden
load linkliste.tmp
limit 0 http.+
jumpifnoi lastLink {!countLink!}
// Links auf broken Links überprüfen
var s linkname = {!/{!countLink!}!}
url {!/{!countLink!}!}
limit 519 <title>.*</title>
cleft 7
cright 8
limit 0 .+
jumpifnoi warnNoTitle 0
var s linktest = OK: {!/0!}
jumpifnor countLink 519 (404 Not Found|File Not Found|Permission Failed|Forbidden|Server overloaded|no Serverresponse|Failed|verweigert|nicht gefunden|Fehler)
// broken Link zur broken Linkliste hinzufügen
label brokenLink:
var s linktest = {!/0!}
var i countError + 1
usestring NOT OK: {!/0!}: {!/linkname!}
write brokenlinks.tmp
// Linkcounter incrementieren
label countLink:
var i countLink + 1
var i countGesamtLink + 1
// Gebe Infozeile aus
print {!countLink!}: Link {!countGesamtLink!} von {!aktGesamtLink!} Links getestet, bisher {!countError!} broken Links, {!/linktest!}
jump nextLink
// Wenn der Weiterlink existiert, lade nächste Page, ansonsten Resumee
label lastLink:
usestring {!/weiter!}
jumpifr noMorePages 0 nichts
var s aktlink = http://fh-web1.informatik.fh-wiesbaden.de{!/weiter!}
url {!/aktlink!}
print
run del linkliste.tmp
print {!/weiter!} enthaelt folgende Links:
jump nextPage
// Wenn kein Weiterlink mehr vorhanden
label noMorePages:
usethis {!countGesamtLink!}
jumpifnor warnAnzLinks 0 {!aktGesamtLink!}
run cls
jump resumee
S3/5
Skript 4/5
//
S4/5
label tryAgain:
run cls
print
print noch mindestens {!retrysLeft!} Versuche...
var i countError = 0
var i countLink = 0
var i aktGesamtLink = 0
var i countGesamtLink = 0
// Nur retrysLeft decrementieren, wenn die Fehleranzahl gleich geblieben ist
usethis {!altCountError!}
jumpifnor ermGesamtanzahl 0 {!countError!}
var i retrysLeft - 1
var i altCountError = {!countError!}
// aktuelle Gesamtanzahl der Links ermitteln
label ermGesamtanzahl:
load brokenlinks.txt
limit 0 .+
label incLink:
var i aktGesamtLink + 1
jumpifi incLink {!aktGesamtLink!}
// Linkliste erstellen
init
limit 1 http.+
write linkliste.tmp
jump nextLink
label resumee:
var i countRetrys + 1
print Der Linkcheck mit dem Suchbegriff "{!2!}" ergab folgendes:
print
print {!countError!} broken Links von insgesammt {!gesamtLink!} Links, davon {!countGesamtLink!} getestet, {!countRetrys!}. Versuch
print zeige nun die sortierte und bereinigte broken Linkliste:
print
load brokenlinks.tmp
limit 0 NOT OK: .+
cleft 8
sort
show
run del brokenlinks.txt
write brokenlinks.txt
run del linkliste.tmp
// Wenn keine broken Links, dann fertig
usethis {!countError!}
jumpifr endPoint 0 ^.0$
// Broken Links erneut abchecken, wenn retrys left
usethis {!retrysLeft!}
jumpifr endPoint 0 ^.0$
jump tryAgain
Skript 5/5
S5/5
label errDurchsuche:
print
print Fachhochschule durchsuchen nicht gefunden
jump endpoint
label errTreffer:
print
print Suche ergab keine Treffer
jump endPoint
label errNoGesamttreffer:
print
print Gesamttrefferanzahl nicht gefunden, obwohl Treffer vorhanden sind:
show
jump endPoint
label errNoBody:
print
print Website enthaelt keinen Frame Namens Body (FH-Server down ?!)
init
show
jump endPoint
label errCopyright:
print
print Copyright nicht gefunden
jump endPoint
label warnAnzLinks:
run cls
print Warnung: Anzahl der ueberprueften Links ({!aktGesamtLink!) entspricht nicht der Gesamttrefferanzahl ({!gesamtLink!})
usethis {!/aktlink!}
jumpifr home 0 home
print Letzte URL: {!/aktlink!}
print HTML-Code der letzten Page:
url {!/aktlink!}
show
run waitinput.exe
jump resumee
label home:
print Letzte Page war die erste Suchsite
run waitinput.exe
jump resumee
// Kein Titel vorhanden, ist bei einer PDF-Datei OK
label warnNoTitle:
init
jumpifr pdf 0 PDF-[0-9]+\.[0-9]+
usethis Warnung: kein Titel
jump brokenLink
label pdf:
var s linktest = OK: PDF-Datei
jump countLink
label endPoint:
Bildschirmausgabe 1/2
Bildschirmausgabe anhand eines Beispiels
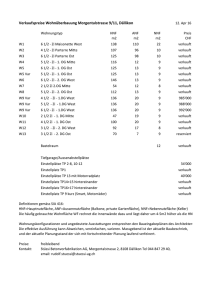
Parameter
•Maximal 2 Versuche, Suchstring: Koch
scanne nach Regex in 'beispiel3.txt' mit den Parametern
1. 1
2. Koch
1. lade Framesite...
2. lade Body...
OK:
Typ: 11 Optionen: 512 Regex: Fachhochschule durchsuchen
OK:
Typ: 11 Optionen: 515 Regex: <form.*>
OK:
Typ: 11 Optionen: 515 Regex: action=".*"
OK:
Typ: 11 Optionen: 515 Regex: ".*"
3. pruefe, ob Treffer vorhanden sind
NOT OK:
Typ: 11 Optionen: 0 Regex: Keine Dokumente gefunden
OK:
Typ: 11 Optionen: 0 Regex: [0-9]+.+bis.+[0-9]+.+von.+[0-9]+(,[0-9]+)?.+Treffern
OK:
Typ: 11 Optionen: 0 Regex: von.+[0-9]+(,[0-9]+)?
Initialisierung abgeschlossen, suche nach broken Links (20 Links insgesamt):
http://fh-web1.informatik.fh-wiesbaden.de/cgi-bin/texis.exe/webinator/search1/ enthaelt folgende Links:
1.
http://fh-web1.informatik.fh-wiesbaden.de/peopledetail.cfm?fb=0&sprachid=1
2.
http://fh-web1.informatik.fh-wiesbaden.de/peopledetail.cfm?fb=0&sprachid=2
3.
http://fh-web1.informatik.fh-wiesbaden.de/peopledetail.cfm?fb=3&sprachid=1
4.
http://fh-web1.informatik.fh-wiesbaden.de/peopledetail.cfm?fb=3&sprachid=2
5.
http://fh-web1.informatik.fh-wiesbaden.de/peopledetail-mtg.cfm?fb=3&pid=664
6.
http://fh-web1.informatik.fh-wiesbaden.de/peopledetail-mtg.cfm?fb=3&pid=664
7.
http://wwwsys.informatik.fh-wiesbaden.de/weber1/operetta/nacht/index.htm
8.
http://fh-web1.informatik.fh-wiesbaden.de/mitarbeiter.cfm?fb=0&sprachid=2
9.
http://fh-web1.informatik.fh-wiesbaden.de/mitarbeiter.cfm?fb=0&sprachid=1
10.
http://fh-web1.informatik.fh-wiesbaden.de/genpage.cfm?fb=0&vorgaenger=397,
1: Link 1 von 20 Links getestet, bisher 0 broken Links, OK: Mitarbeiterdetails
2: Link 2 von 20 Links getestet, bisher 0 broken Links, OK: Mitarbeiterdetails
3: Link 3 von 20 Links getestet, bisher 0 broken Links, OK: Mitarbeiterdetails
4: Link 4 von 20 Links getestet, bisher 0 broken Links, OK: Mitarbeiterdetails
5: Link 5 von 20 Links getestet, bisher 0 broken Links, OK: Mitarbeiterdetails Mitgliedschaften
6: Link 6 von 20 Links getestet, bisher 0 broken Links, OK: Mitarbeiterdetails Mitgliedschaften
7: Link 7 von 20 Links getestet, bisher 1 broken Links, 404 Not Found
8: Link 8 von 20 Links getestet, bisher 1 broken Links, OK: Mitarbeiter
9: Link 9 von 20 Links getestet, bisher 1 broken Links, OK: Mitarbeiter
10: Link 10 von 20 Links getestet, bisher 1 broken Links, OK: fhw - Organisation
A1/2
Bildschirmausgabe 2/2
/cgi-bin/texis.exe/webinator/search1//?query=koch&amp;db=db&jump=10 enthaelt folgende Links:
1.
http://fh-web1.informatik.fh-wiesbaden.de/mitarbeiter.cfm?fb=3&sprachid=2
2.
http://fh-web1.informatik.fh-wiesbaden.de/go.cfm?fb=0&sid=0
3.
http://fh-web1.informatik.fh-wiesbaden.de/go.cfm?fb=0&sid=0
4.
http://fh-web1.informatik.fh-wiesbaden.de/mitarbeiter.cfm?fb=3&sprachid=1
5.
http://fh-web1.informatik.fh-wiesbaden.de/go.cfm?fb=3&sid=0
6.
http://fh-web1.informatik.fh-wiesbaden.de/go.cfm?fb=3&sid=0
7.
http://www.informatik.fh-wiesbaden.de/~linn/vpdv01/cms/kapitel6.pdf
8.
http://www.informatik.fh-wiesbaden.de/~linn/c2.pdf
9.
http://wwwsys.informatik.fh-wiesbaden.de/weber1/opera/reference.html
10.
http://www-intern.informatik.fh-wiesbaden.de/doc/mysql/manual.html
1: Link 11 von 20 Links getestet, bisher 1 broken Links, OK: Mitarbeiter
2: Link 12 von 20 Links getestet, bisher 1 broken Links, OK: Fachhochschule Wiesbaden - FH Wiesbaden Homepage
3: Link 13 von 20 Links getestet, bisher 1 broken Links, OK: Fachhochschule Wiesbaden - FH Wiesbaden Homepage
4: Link 14 von 20 Links getestet, bisher 1 broken Links, OK: Mitarbeiter
5: Link 15 von 20 Links getestet, bisher 1 broken Links, OK: Fachhochschule Wiesbaden - Informationstechnologie und Elektrotechnik Homepage
6: Link 16 von 20 Links getestet, bisher 1 broken Links, OK: Fachhochschule Wiesbaden - Informationstechnologie und Elektrotechnik Homepage
7: Link 17 von 20 Links getestet, bisher 1 broken Links, OK: PDF-Datei
8: Link 18 von 20 Links getestet, bisher 1 broken Links, OK: PDF-Datei
9: Link 19 von 20 Links getestet, bisher 1 broken Links, OK: Must have opera recordings
10: Link 20 von 20 Links getestet, bisher 2 broken Links, Access forbidden!
Der Linkcheck mit dem Suchbegriff "koch" ergab folgendes:
2 broken Links von insgesammt 20 Links, davon 20 getestet, 1. Versuch
zeige nun die sortierte und bereinigte broken Linkliste:
1.
2.
404 Not Found: http://wwwsys.informatik.fh-wiesbaden.de/weber1/operetta/nacht/index.htm
Access forbidden!: http://www-intern.informatik.fh-wiesbaden.de/doc/mysql/manual.html
noch mindestens 1 Versuche...
1: Link 1 von 2 Links getestet, bisher 1 broken Links, 404 Not Found
2: Link 2 von 2 Links getestet, bisher 2 broken Links, Access forbidden!
Der Linkcheck mit dem Suchbegriff "koch" ergab folgendes:
2 broken Links von insgesammt 20 Links, davon 2 getestet, 2. Versuch
zeige nun die sortierte und bereinigte broken Linkliste:
1.
404 Not Found: http://wwwsys.informatik.fh-wiesbaden.de/weber1/operetta/nacht/index.htm
2.
Access forbidden!: http://www-intern.informatik.fh-wiesbaden.de/doc/mysql/manual.html
Press any key to continue
A2/2