Datenbankgestütztes Matching von Kartenobjekten Abstract
Werbung

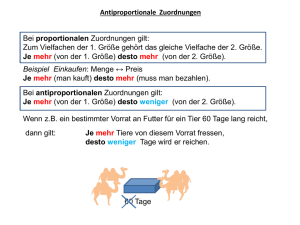
Daniela Mantel, Udo Lipeck Universität Hannover, Institut für Informationssysteme FG Datenbanksysteme Datenbankgestütztes Matching von Kartenobjekten Abstract: Nowadays cartographic objects of different resolutions are hold in different coexisting databases. This implies an extensive amount of work for updating an object in all resolutions. One way to reduce this is to build a multi-representation database which holds and links different representations of the real-world objects and allows to automatically pass updates to all linked representations (requiring the existence of algorithms for update propagation). In order to ensure the autonomy of applications on the local databases, we propose the architecture of a federated database for such a multi-representation database. A main requirement for setting up a multi-representation database is to “identify” the different representations of real-world objects. In this article we describe a multistage procedure for this “object identification” (matching). Zusammenfassung: Kartographische Objekte verschiedener Maßstäbe werden heute in vielen unabhängig existierenden und insbesondere unabhängig gepflegten Datenbanken gespeichert. Daraus entsteht bei Fortführungen ein hoher Aufwand für die Aktualisierung in allen Maßstäben. Eine Möglichkeit diesen Aufwand zu reduzieren besteht darin, die Daten unterschiedlicher Auflösung in einer integrierten Datenbank zu halten und Fortführungen zwischen den Maßstäben automatisch zu propagieren. Neben den benötigten Mechanismen zur Weitergabe von Aktualisierungen zwischen den Maßstäben, wird hierfür ein Konzept für die Realisierung einer Multi-Resolution Database (MRDB) benötigt. Um die Autonomie der bereits bestehenden Datenbanken und ihrer Anwendungen zu erhalten, schlagen wir als Architektur für eine MRDB das Konzept der föderierten Datenbank vor. Eine wichtige Aufgabe beim Aufbau einer föderierten Datenbank stellt dabei die Identifikation von Repräsentationen der gleichen Real-Welt-Objekte dar. Wir stellen in diesem Artikel ein mehrstufiges Verfahren für diese „Objektidentifikation“ (Matching) vor. 1. Einleitung Ausgangssituation ist das Vorliegen kartographischer Datenbestände desselben Gebietes in verschiedenen Maßstäben, die für maßstabsübergreifende Anfragen und Aktualisierungen integriert werden sollen. Innerhalb dieser Datenbestände werden RealWelt-Objekte unterschiedlich dargestellt. So kann es bei ATKIS-Daten, für die wir mit Daten des DLM 25, des DLM 250 und des DLM 1000 eine solche Integration durchgeführt haben, durch unterschiedliche Objektbildungsregeln dazu kommen, dass ein Straßenabschnitt im feineren Maßstab durch zwei, im gröberen Maßstab durch drei (Datenbank-) Objekte repräsentiert wird. Sollen diese Daten nun integriert zur Verfügung stehen, so sind folgende Aufgaben zu erfüllen: • Aufbau einer geeigneten Datenbank-Architektur • Aufbau einer Struktur zur Speicherung von Objektzuordnungen aller Kardinalitäten (1:1, 1:n, n:m) • Aufbau von Methoden bzw. Verfahren zur Objektidentifikation. • Dem entsprechend ist der vorliegende Artikel aufgebaut. 2. Architektur Um eine größtmögliche Autonomie der zugrunde liegenden Datenbestände zu gewährleisten und insbesondere eine weitere Nutzung der für diese implementierten („lokalen“) Anwendungen zu ermöglichen, eignet sich besonders die Architektur einer Föderierten Datenbank (siehe Abbildung 1). Ausgangspunkt für ein föderiertes Datenbanksystem [1] sind mehrere getrennt betriebene Datenbanken, die so miteinander gekoppelt werden sollen, dass Anfragen an den aus ihnen integrierten Datenbestand gestellt werden können und so globale Anwendungen ermöglicht werden. Daraus ergibt sich ein grundsätzlicher Aufbau wie in Abbildung 1: Über den zu föderierenden Datenbanken (Komponentendatenbanken) mit ihren Datenbankmanagementsystemen wird ein Föderierungsdienst gesetzt, der eine integrierte Zugriffsmöglichkeit auf die Datenbanken bietet. Die Komponentendatenbanken werden hierbei nicht verändert, so dass die lokalen Anwendungen nicht beeinflusst werden. Abbildung 1: Föderierte Datenbank Die Arbeitsdatenbank des Föderierungsdienstes dient zum einen der Verwaltung der benötigten Meta-Daten der Komponentendatenbanken, zum anderen werden hier die benötigten Parameter und Regeln für das Matching gespeichert. Daneben verfügt der Föderierungsdienst über eine Datenbank zur Speicherung der Verknüpfungen zwischen den Objekten der Komponentendatenbanken, also zwischen den unterschiedlichen Repräsentationen gleicher Real-Welt-Objekte. 3. Links Da in unterschiedlichen Maßstäben Real-Welt-Objekte durch unterschiedliche Objekteinteilungen (z. B. aufgrund von kartographischen Generalisierungen zu grobmaßstäblichen Repräsentationen oder wie im Falle von ATKIS-Daten durch unterschiedliche Objektbildungsregeln) dargestellt werden, muss das Modell für die Speicherung der Objektzuordnungen (Links) nicht nur 1:1-Zuordnungen sondern auch Zuordnungen anderer Kardinalitäten, also 1:n und n:m (siehe Abbildung 2a)), abbilden können. Dies wird dadurch realisiert, dass für die zuzuordnenden Repräsentationen eines Real-Welt-Objektes zunächst die zugehörigen Datenbankobjekte der jeweiligen Datenbestände zu je einem Objekt aggregiert werden (Klassen „aggregierte Objekte“ in Abbildung 2). Diese neu gebildeten Objekte werden dann einander zugeordnet (siehe „agg.Objektlinks“ in Abbildung 2b)). Zusätzlich werden die geometrischen Beziehungen (z. B. „a ist geometrisch Teil von b“) zwischen den einzelnen beteiligten Objekten in der Klasse „Objektlinks“ gespeichert. b) a) Abbildung 2: Objektlink und Linkstruktur 4. Matching 4.1 Stufen des Matching: Die Zuordnung der Objekte zueinander kann in mehreren Stufen erfolgen. Zunächst werden die Objekte der zugrunde liegenden Datenbestände so in Vergleichsmengen klassifiziert, dass Zuordnungen (Links) nur innerhalb einer Klassenzuordnung, bestehend aus zwei Vergleichsmengen, sinnvoll sind, also auch nur dort generiert werden müssen. Dann werden innerhalb dieser Klassenzuordnungen Kandidaten für die Zuordnungen gesucht („mögliche Zuordnungen“), und aus dieser Menge der möglichen Zuordnungen wird die gültige Kombination von Zuordnungen ermittelt. Die Ermittlung der gültigen Zuordnungen erfolgt dabei teilweise automatisiert, kommt aber nicht gänzlich ohne manuelle Nachbearbeitung aus. Der Ablauf des Matching-Prozesses ist also wie folgt: 1. 2. 3. 4. Semantische Filterung Ermittlung möglicher Zuordnungen Regelbasierte Auswahl Manuelle Nachbearbeitung 4.2 Semantische Filterung Zunächst werden die Objektarten, die in den beiden betrachteten Datenbanken vorkommen, miteinander verglichen und so festgestellt, welche Objektarten sich semantisch überlappen, also möglicherweise gleiche Real-Welt-Objekte modellieren können. Als Beispiel sind in Abbildung 3a für den Objektbereich Straßenverkehr des DLM250 und des DLM1000 die semantischen Überlappungen zwischen den Objektarten durch die durchgezogenen Linien dargestellt. Teilt man nun die Objektartenmengen der beiden betrachteten Datenmodelle (wie in Abbildung 3a)) so ein, dass semantische Überlappungen einer Objektartenmenge des ersten Datenmodells nur zu maximal einer Objektartenmenge des zweiten Datenmodells (und umgekehrt) existieren, so erhält man „grobe Klassenzuordnungen“ (1,2), auf die man sich bei der Objektidentifikation beschränken kann. a) Grobe Klassenzuordnungen b) Klassenzuordnungen Abbildung 3: Semantische Filterung Die groben Klassenzuordnungen lassen sich durch weitere partitionierende Attribute, im ATKIS-Modell beispielsweise durch die objektbildenden Attribute, an Hand der Attributwertübergänge weiter unterteilen, so dass die zuzuordnenden Mengen weiter beschränkt werden können („feine Klassenzuordnungen“). Für die grobe Klassenzuordnung „Straße“ im DLM 250 und DLM 1000 führt dieses, wie in Abbildung 3 b) dargestellt, mit dem Attribut Widmung zu vier Klassenzuordnungen (A,B,C,D). Dies ist in Abbildung 3 b) für die grobe Klassenzuordnung „Straße“ (1) im DLM250 und DLM 1000 für das Attribut Widmung dargestellt. Die Ermittlung der möglichen Zuordnungen Klassenzuordnungen beschränkt werden. kann nun auf diese feinen 4.3 Buffer Growing Ein Verfahren zur Ermittlung der möglichen Zuordnungen linienförmiger Objekte ist das in [8] vorgestellte Buffer Growing, das in [5] für die datenbankgestützte, das heißt mengenorientierte, Verarbeitung angepasst wurde. Dieses nutzt aus, dass die verschiedenen Repräsentationen eines Real-Welt-Objektes geometrisch ähnliche Größen und Positionen aufweisen. Hier wird vorausgesetzt, dass der jeweilige (aggregierte) Zuordnungspartner innerhalb eines vorgegebenen Puffers um das (aggregierte) Objekt liegt. Der Algorithmus arbeitet wie folgt: Zunächst wird um jedes Objekt (aus beiden Datenbeständen) ein Puffer gelegt. Alle in diesem Puffer vollständig enthaltenen Objekte des jeweils anderen Datenbestandes und deren geometrisch möglichen Aggregierungen sind dann die möglichen Zuordnungspartner des Objektes (siehe Abbildung 4 b)). Schneidet ein Objekt zwei Puffer um Objekte des anderen Datenbestandes, deren zugrunde liegenden Objekte zu einem aggregierbar sind, ohne ganz in einem der beiden Puffer enthalten zu sein, werden die den Puffern zugrunde liegende Objekte aggregiert und um das so entstandene Objekt ein Puffer gelegt. Dann werden wieder alle möglichen Aggregierungen von ganz in diesem neuen Puffer liegenden Objekten als mögliche Zuordnungen identifiziert (siehe Abbildung 4 c)). Dieses wird so lange wiederholt bis keine weiteren Schnitte vorhanden sind. Im Anschluss daran werden eventuell doppelt auftretende Zuordnungen (die daraus resultieren, dass mit der Pufferbildung um beide Datenbestände gearbeitet wird) eliminiert. Abbildung 4: Buffer Growing 4.5 Auswahlverfahren Da jedes Objekt in einer Datenbank nur zu einem Real-Welt-Objekt gehören darf, können innerhalb der Menge möglicher Zuordnungen Konflikte auftreten. Ein Konflikt zwischen zwei möglichen Zuordnungen besteht dann, wenn beide dasselbe (Datenbank-) Objekt enthalten. Dieses Prinzip kann man im Auswahlverfahren auf verschiedene Arten nutzen. Zum einen können durch das Bestätigen einer möglichen Zuordnung alle mit dieser Zuordnung in Konflikt stehenden Zuordnungen verworfen werden. In Abbildung 5 werden beispielsweise durch die Auswahl der Zuordnung a) die Zuordnungen b) und c) verworfen, da sie jeweils Objekte (B bzw. A, B und E) mit der Zuordnung a) gemeinsam haben. Abbildung 5: Zuordnungskonflikte Zum anderen können aber auch Zuordnungen, die nicht mit anderen in Konflikt stehen und festgesetzten (Qualitäts-) Kriterien entsprechen, als mit hoher Wahrscheinlichkeit gültig angenommen und so automatisch bestätigt werden. In Abbildung 5 kann nun beispielsweise die Zuordnung d) bestätigt werden, sofern sie allen Qualitätskriterien genügt. Diese Grundprinzipien lassen sich in einem regelbasierten Auswahlverfahren nutzen. Hier werden Qualitätskriterien an die Zuordnungen durch Regeln festgelegt. Eine solche Regel ist beispielsweise, dass die Längen einander zugeordneter Linienobjekte nur um einen festgelegten Prozentsatz differieren dürfen. Verwirft man mit solchen Regeln alle Zuordnungen, deren zugeordnete Objekte sich nicht genug „ähneln“, so wird die Menge der möglichen Zuordnungen dadurch auf solche Zuordnungen eingeschränkt, die die Kriterien erfüllen. Dadurch können Konflikte eliminiert werden und Zuordnungen, die ursprünglich im Konflikt mit anderen standen, nun konfliktfrei sein, also als gültig angenommen und automatisch bestätigt werden. Die Regelanwendung kann auch iterativ mit schwächer werdenden Kriterien erfolgen. Hier werden jeweils nach Anwendung eines Kriteriums alle in der Ergebnismenge konfliktfreien Zuordnungen bestätigt, dann die in der Gesamtmenge der möglichen Zuordnungen mit diesen in Konflikt stehenden Zuordnungen verworfen, und auf die übrige Menge der möglichen Zuordnungen das gleiche Kriterium mit abgeschwächten Parametern erneut angewandt. Diese Iteration kann dann bis zu einem festgelegten Schwellenwert für die Parameter erfolgen. Für eine solche iterative Regelanwendung erwies sich insbesondere das oben erwähnte Längendifferenzkriterium für das Linienmatching als gut geeignet. Mit den eben beschriebenen Methoden kann ein großer Teil der ermittelten möglichen Zuordnungen automatisch verworfen oder bestätigt werden. Für die verbleibende Menge müssen dann Software-Tools zur Verfügung stehen, die die manuelle Auswahl unterstützen. Dafür wird ein Visualisierer benötigt, der die Möglichkeit bietet Zuordnungen anzuzeigen und zu markieren („Paarmodus“). Markierte Zuordnungen müssen dann durch den Benutzer bestätigt oder verworfen werden können, wobei beim Bestätigen einer Zuordnung solche Zuordnungen, die mit dieser in Konflikt stehen, automatisch verworfen werden müssen. Des weiteren kann hierbei oder beim Verwerfen einer Zuordnung je nach Konfiguration des Tools ein weiterer automatischer Prozess angestoßen werden, der dann wieder alle durch diese Auswahl konfliktfreien Zuordnungen automatisch bestätigt. Abbildung 6 zeigt den im Fachgebiet Datenbanksysteme genutzten selbstentwickelten Visualisierer GisVisual mit der Erweiterung für die Auswahl von Zuordnungen in einer Testsituation. Abbildung 6: GisVisual mit Erweiterung geoFoed 5. Die Arbeitsdatenbank In Abbildung 7 ist das Schema der Arbeitsdatenbank für den Föderierungsdienst dargestellt. Im grün unterlegten Bereich werden die zur Föderierung gehörenden Datenbanken und deren Verknüpfungen („DB-Links“) registriert. Die für die semantische Filterung benötigten Daten, also die Einteilung in Klassenzuordnungen an Hand von Attributwerten, ist im gelb unterlegten Teil modelliert. Der blau unterlegte Teil schließlich dient der Speicherung der Matching-Parameter und der zu nutzenden Auswahlregeln. Die Objekte der Komponentendatenbanken sind über Importe in materialisierter Form oder Sichten in virtueller Form eingebunden. Für das Management der Datenbank wird eine objekt-relationale Datenbank mit einer erweiterung für räumliche Objekte und räumliche Operatoren (z. B. Oracle 8i) eingesetzt. Abbildung 7: Arbeitsdatenbank des Föderationsdienstes Der Zugriff auf die Arbeitsdatenbank erfolgt über eine SQL-Programmierschnittstelle, z. B. Oracle PL/SQL. Hier sind zum einen Funktionen zur Verwaltung der Datenbanken in der föderierten Datenbank, also solche die den Registrierungsbereich der Datenbank nutzen (Package GeoFoed in Abbildung 8), zur Verwaltung der semantischen Filterung und zur Steuerung des Matching-Verfahrens (Packages MatchingRules und MatchingTools) implementiert. Zum anderen werden Zugriffsfunktionen auf die Linkstruktur zur Verfügung gestellt, etwa zum Einfügen von Links oder zum Abfragen von an einem Link beteiligten Objekten. Die SteuerungsGUI in Abbildung 8 stellt das Benutzer-Interface zu allen Funktionen der SQL-Schnittstelle dar. Hier kann also beispielsweise die semantische Filterung konfiguriert werden (siehe Abbildung 9). Für die manuelle Auswahl von Zuordnungen wird eine Interaktion mit einem Visualisierer benötigt. Um diesen austauschbar zu halten und auch Änderungen an der SteuerungsGUI ohne Eingriffe in diese Steuerung zu ermöglichen, wird sowohl der Zugriff auf die PL/SQL-Schnittstelle als auch die Interaktion zwischen SteuerungsGUI und Visualisierer durch einen Connector realisiert. Abbildung 8: Programmstruktur Abbildung 9: Bearbeitung der Arbeitsdatenbank (bei Klassenzuordnungen) in der SteuerungsGUI 6. Ausblick Derzeit werden am Fachgebiet Datenbanksysteme der Universität Hannover weitere Matchingverfahren untersucht und Auswahlregeln getestet. Weitere Konzepte zur MRDB- Nutzung, insbesondere die datenbankseitige Unterstützung von regelbasierten Verfahren zur Propagierung von Updates, werden gemeinsam mit dem Institut für Kartographie und Geoinformatik der Universität Hannover entwickelt. Gefördert werden diese Arbeiten durch das Bundesamt für Kartographie und Geodäsie. Literatur: [1] Conrad, S.: Föderierte Datenbanksysteme. Springer-Verlag, Berlin, 1997. [2] Devogele, T., Parent, C. und Spaccapietra, S: On Spatial Database Integration. International Journal of Geographical Information Science, 12(4), 1998, pp. 335-352. [3] Kleiner, C., Lipeck, U.W. und Falke, S.: Objekt-Relationale Datenbanken zur Verwaltung von ATKISDaten. In: R.Bill, F.Schmidt (Hrsg.), ATKIS - Stand und Fortführung, Verlag Konrad Wittwer, Stuttgart, 2000, pp.169-177. [4] Kleiner, C. und Lipeck, U.W.: Web-Enabling Geographic Data with Object-Relational Databases. In: A. Heuer et al. (Hrsg.), Datenbanksysteme in Büro, Technik und Wissenschaft - 9. GI-Fachtagung BTW 2001, Springer-Verlag, Berlin, 2001, pp. 127-143. [5] Mantel, D.: Konzeption eines Föderierungsdienstes für geographische Datenbanken. Diplomarbeit, FB Informatik, Universität Hannover, 2002. [6] Sester, M., Anders, K.-H. und Walter,V.: Linking Objects of Different Spatial Data Sets by Integration and Aggregation. GeoInformatica, 2(4), 1999,pp. 335-358. [7] Sester, M.: Maßstabsabhängige Darstellungen in digitalen räumlichen Datenbeständen. Habilitationsschrift, Universität Stuttgart, 2000. [8] V. Walter: Zuordnung von raumbezogenen Daten - am Beispiel der Datenmodelle ATKIS und GDF. Dissertation, Universität Stuttgart, 1997.