Hauptseminar: Automatisches Beweisen
Werbung

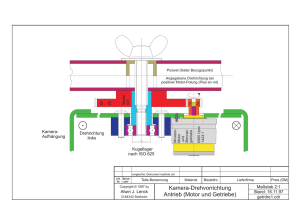
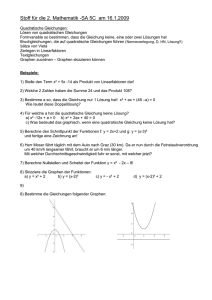
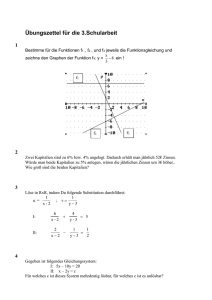
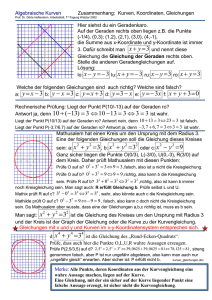
Hauptseminar: Automatisches Beweisen Kombination von Theorien nach Shostak Karolin Zabel [email protected] Aufbauend auf das Kongruenzabschlussverfahren wird Shostak’s Methode des automatischen Beweisens vorgestellt. Die Besonderheit an Shostak’s Verfahren ist, dass es nicht nur Probleme innerhalb einer Theorie lösen kann, sondern auch Kombinationen aus verschiedenen Theorien. Zunächst wird Shostak’s Verfahren für einzelne Theorien erklärt, anschließend für die Kombination mehrerer Shostak Theorien. 1. Historische Einordnung von Shostak’s Verfahren Anfang der 80er wurden vermehrt automatische Beweisverfahren für mathematische Beweise und Programm-Verifikationen entworfen. Dabei stellte sich häufig das Problem, dass die Formeln, die bewiesen werden sollten, Konstrukte aus verschiedenen semantischen Bereichen enthielten. Es entstanden zunächst Sonderlösungen für einzelne Misch-Theorien. Einer der ersten allgemeinen Ansätze für kombinierte Theorien stammt von Nelson und Oppen [NO]. Bei diesem Ansatz wurde die Information über die Gleichheit mittels gemeinsamer Variablen ausgetauscht. Robert E. Shostak folgte 1984 mit seiner Veröffentlichung „Deciding Combinations of Theories“[Sho84]. Sein Verfahren ist eine Abwandlung des Kongruenzabschluss Verfahrens und arbeitet mit einem sogenannten Kanonisierer. In seinem Papier mischt er die Theorie linearer Arithmetik mit cons, car und cdr aus der Theorie der Listen. Da in Shostak’s Original jedoch ein Fehler enthalten ist, stützt sich die folgende Ausführung auf [RS02]. 1 2. Begriffsdefinitionen In 2.1 werden allgemeine Grundbegriffe der Logik wiederholt. In 2.2 werden speziell für Shostak wichtige Definitionen gegeben. 2.1 Allgemeine Grundbegriffe der Logik Lineare Gleichungen werden auch als Gleichungen erster Ordnung bezeichnet, sie haben beispielsweise die Form a x + b = c x + d. In der Mathematik gibt es zwei verschiedene Quantoren, den Existenzquantor ∃ und den Allquantor∀. ∃ bedeutet ‚es gibt ein’ und ∀ heißt ‚für alle’. Die Junktoren sind T (verum, das Wahre) und ⊥ (falsum, das Falsche), ¬(nicht), ∧ (und), ∨ (oder) und → (wenn – dann). Das Zeichen ├ steht für Ableitbarkeit. S ├ F bedeutet: F ist aus S ableitbar. Für semantische Folgerungen steht das Zeichen |=. Die Notation S |= X bedeutet: Ist S eine Aussagenmenge und X eine Aussage, dann heißt X semantische Folgerung von S, wenn jede Aussage, die S wahr macht auch X wahr macht. |= X heißt „X ist gültig“. Von einer disjunktiven Normalform (DNF) spricht man, wenn eine Formel als Disjunktion von Konjunktionen vorliegt, z. B. (L11 ∧ . . . ∧ L1n) ∨ . . . ∨ (Lm1 ∧ . . . ∧ Lmn). Jede aussagenlogische Formel kann in disjunktive oder konjunktive Normalform gebracht werden. Äquivalenzrelationen sind reflexiv (x = x), symmetrisch (x = y ⇒ y = x) und transitiv (x = y ∧ y = z ⇒ x = z). 2.2 Begriffsdefinitionen für Shostak Shostak arbeitet mit der Prädikatenlogik. Daher werden hier nur einige wichtige Begriffe, die später verwendet werden kurz wiederholt. Eine Signatur Σ ist eine endliche Menge von Funktionssymbolen ΣF = { f, g, ...}und Prädikatssymbolen ΣP = {P, Q, ...}. Dabei wird n als die Stelligkeit (arity) der Funktion f(t1, .....tn) bezeichnet. Konstanten sind Funktionssymbole mit der Stelligkeit 0 und werden mit a, b,... bezeichnet. Eine atomare Formel oder ihre Negation wird als Literal bezeichnet. Ein Modell ist eine Interpretation einer Σ-Gleichung, wenn die Gleichung unter der Interpretation für jede Variablenbelegung erfüllt ist. 2 Eine Formel heißt gültig, wenn sie für jede Interpretation wahr ist, erfüllbar, wenn es eine Interpretation gibt, die sie wahr macht und unerfüllbar, wenn sie für keine Interpretation wahr ist. 3. Abstrakter Kongruenzabschluss vs. Shostak’s Verfahren Ganz allgemein ausgedrückt entscheiden beide Verfahren Aussagen der Form T ├ a = b, wobei T eine Sammlung von Gleichungen ist, und a und b Variablen und Funktionssymbole enthalten. Sind alle Funktionssymbole uninterpretiert, mit der Gleichheit (=) als einzigem Prädikat, reicht das Kongruenzabschlussverfahren aus, um die Subterme in Äquivalenzklassen einzuteilen. In der Praxis hat man es jedoch meist mit interpretierten und uninterpretierten Funktionssymbolen zu tun. Zum Beispiel ließe sich das Problem f3(x) = f(x) ├ f5(x) = f(x) mit dem Kongruenzabschlussverfahren lösen. Dagegen enthält f(x–1) –1 = x +1, f(y) + 1 = y –1, y + 1 = x ├ false Symbole aus verschiedenen Theorien: + und – kommen aus der linearen Arithmetik, f ist ein uninterpretiertes Funktionssymbol und false ist ein boolscher Ausdruck. Hier braucht man sowohl lineare Arithmetik, als auch das Kongruenzabschlussverfahren. Zunächst werden die Gleichungen mit linearer Arithmetik umgeformt: f(x–1) –1 = x +1 wird zu f(x–1) = x +2, f(y) + 1 = y –1 wird zu f(y) = y –2 und y+1=x wird zu x – 1 = y. Aus der Kongruenz folgt f(x-1) = f(y). Weiter mit linearer Arithmetik kommt man zu x + 2 = y – 2, was einen Widerspruch zu Gleichung drei, x – 1 = y, darstellt. Also ist false aus den drei Gleichungen ableitbar. Shostak bezieht sich in seinem Papier auf ein anderes Beispiel, anhand dessen später Shostak’s Algorithmus erklärt wird: 5 + car(x + 2) = cdr(x + 1) +3 Neben linearer Arithmetik ist hier auch noch die Theorie der Listen mit cons, car und cdr enthalten. Cons steht für construct pair, car liefert die erste Komponente zurück, cdr die zweite. Die Definition der Eigenschaften von cons, car und cdr lautet: (car (cons x1 x2)) = x1 (cdr (cons x1 x2)) = x2 (cons (car x) (cdr x)) = x Hat man zum Beispiel eine Liste primzahlen(2 3 5 7) definiert, liefert car primzahlen 2, cdr primzahlen (3 5 7) und car(cdr primzahlen)) 3. Shostak versuchte auch hier die Gleichung abwechselnd einen Schritt mit linearer Arithmetik und den nächsten nach der Theorie der Listen zu lösen. So soll die Gleichung nach x aufgelöst werden. (solveA) bzw. (solveL) heißt, die Gleichung wird arithmetisch bzw. nach der Theorie der Listen gelöst. 3 5 + car(x + 2) = cdr(x + 1) +3 (solveA) : (solveL) : (solveA) : car(x + 2) x+2 x = cdr(x + 1) – 2 = cons(cdr(x + 1) – 2, k) = cons(cdr(x + 1) – 2, k) – 2 In Zeile 2 wurde k eingeführt, weil man die rechte Seite von cons nicht kennt. k hat keine weitere Bedeutung. Da x jedoch am Ende immer noch auf der rechten Seite enthalten ist, hat man keine aufgelöste Form erreicht, d.h das Ergebnis ist nicht sinnvoll. Statt dessen bringt man beide Seiten in ihre kanonische Form. Die kanonische Form eines Ausdrucks ist eine spezielle Variante aus einer Menge äquivalenter Ausdrücke. Beispielsweise sind y + 1 = x, y = x – 1, y – x = -1 und x = y +1 äquivalent, wobei die letzte Variante hier die kanonische Form sei. Um die kanonische Form zu erhalten, substituiert man die einzelnen Terme durch neue Variablen. Diesen Vorgang bezeichnet man als Variablenabstraktion. So erhält man v3 = v6, mit v1 = x + 2, v2 = car(v1), v3 = v2 + 5, v4 = x + 1, v5 = cdr(v4) und v6 = v5 + 3. Im nächsten Schritt werden die Gleichungen in verschiedene Gruppen eingeteilt: S(SV ; SU ; SA ; SL ). In SV stehen die Gleichungen in kanonischer Form, SU enthält die uninterpretierten Funktionen, wie f und g, und ist in diesem Beispiel leer. SA enthält die Lösungen für die Theorie der linearen Arithmetik und SL die Lösungen für die Listentheorie. Dann ist SV = {x = x, v1 = v1 , v2 = v2 , v3 = v6 , v4 = v4 , v5 = v5 , v6 = v6}, SA = { v1 = x + 2, v3 = v2 + 5, v4 = x + 1, v6 = v5 + 3} und SL = { v2 = car(v1), v5 = cdr(v4)}. Da v3 und v6 in SV vereinigt werden, aber nicht in SA , lösen wir die Gleichung zwischen SA (v3) und SA (v6), d.h. solveA(v2 + 5 = v5 + 3). Das ergibt v2 = v5 – 2. Dieses Ergebnis wird in SA eingefügt: SA = { v1 = x + 2, v3 = v2 + 5, v4 = x + 1, v6 = v5 + 3, v2 = v5 – 2}. Es sind keine neuen Variablengleichungen mehr in SV ,SA oder SL . v2 und v5 haben beide verschiedene Formen in SA und SL . Das wird toleriert, da die Lösungen aus verschiedenen Theorien stammen und der Kanonisierer, der die Ausdrücke in ihre kanonische Form bringt, die jeweils passende Lösung auswählen kann. 4 Nun können wir überprüfen, ob der resultierende Lösungszustand die Originalgleichung verifiziert: Der Kanonisierer liefert v1 für x + 2 (aus SA ) und v2 für car(v1 ) (aus SL ). Der resultierende Term 5 + v2 wird zu v5 + 3, was die kanonische Form v6 (aus SA ) liefert. Auf der rechten Seite ist x + 1 äquivalent zu v4 in SA und car(v4) zu v5 mit SL . Die rechte Seite wird zu v5 + 3 vereinfacht und der Kanonisierer liefert daraus v6 (aus SA ). Die kanonischen Formen der linken und der rechten Seite sind also identisch. Damit hat man nachgewiesen, dass die Gleichung gültig ist. 4. Formale Methode nach Shostak Im Folgenden wird Shostak’s Methode formal beschrieben, zunächst für einzelne Shostak Theorien und im Anschluss für die Kombination mehrerer Theorien. 4.1 Einzelne Theorien nach Shostak Eine Theorie, die kanonisierbar und lösbar ist, heißt Shostak Theorie. Dazu zählen z.B. lineare Arithmetik, die Theorie der Listen und uninterpretierte Funktionen. Ein Kanonisierer σ bringt Terme in ihre Normalform, gleichbedeutende Terme werden in die selbe Form gebracht. Ein Terme ist kanonisch, wenn der Kanonisierer wieder die gleiche Form liefert σ(b) ≡ b. Ein Solver löst Gleichungen, indem er sie in gleichwertige Substitutionen abbildet. Eine Theorie T heißt kanonisierbar, wenn es ein berechenbares σ(a) gibt, so dass: • • • |= T a = b iff σ(a) = σ(b) vars(σ(a)) ⊆ vars(a) σ(b) ≡ b für jeden Subterm b von σ(a) Eine Gleichungsmenge E hat die Form {a1 = b1, ...., an = bn}. E ist funktional, wenn a1 = b1 , a2 = b2 ∈ E impliziert b1 ≡ b2 . Lookup liefert das kanonische Element zurück: b : a = b ∈ E Lookup: E (a) := a : sonst Anwendung: E[x] := E(x) E[f(a1, ...., an)] := E(f(E[a1], ...., E[an]) 5 Eine Lösungsmenge S ist eine funktionale Gleichungsmenge der Form: {x1 = b1,…., xn= bn}, mit xi ∉ vars(bj) für 1 ≤ i, j ≤ n. dom( ρ ) ist die Domain von ρ und definiert als {a | a = b ∈ ρ für jedes b}. Eine Variablenzuordnung ρ´ erweitert ρ , wenn dom( ρ ) ⊆ dom ( ρ´ ) und ρ (x) = ρ´ (x) für alle x ∈ dom( ρ ). Seien ψ ,ψ ´ Mengen von Literalen, dann gilt: ψ ´ bewahrt ψ , wenn vars(ψ ) ⊆ vars (ψ ´ ) und es für alle T-Interpretationen M und Zuordnungen ρ ein ρ´ gibt, welches ρ so erweitert, dass M, ρ |=T ψ iff M, ρ´|=T ψ ´ . In diesem Fall: |=Tψ ⇒ φ iff |=Tψ ´⇒ φ . Eine Theorie heißt lösbar, wenn es eine berechenbare Funktion solve(a = b) gibt: • • solve(a = b) = ⊥ iff a = b in T unlösbar ist sonst: solve( a = b) = S, wobei S eine Lösungsmenge ist, so dass dom(S) ⊆ vars (a = b) und S bewahrt a = b. Neue Variablen die noch nicht in vars(a = b) enthalten sind, können auf der rechten Seite eingefügt werden. Es sei T eine Shostak Theorie mit dem Kanonisierer σT(.) und dem Solver solveT(.). Für das Gültigkeitsproblem |=T E ⇒ a = b gehe wie folgt vor: 1. Bilde eine Lösungsmenge S:= process(idE, E), indem man eine endliche Menge von Umformungen anwendet, welche die Bedeutung von T nicht verändern. 2. Berechne die kanonischen Formen von a und b: a´:= S a , b´:= S b 3. Wenn die beiden kanonischen Formen die selben sind (a´≡b´), dann ist a = b aus E ableitbar. Die Kanonisierung ist definiert als S a := σ T ( S[a]) . Die Fusion ist S R := {a = R b | a = b ∈ S} . Die Kompositionen sind S ° ⊥ := ⊥, ⊥ ° S := ⊥ und S ° R := R ∪( S R ). Für bereits aufgelöste Formen ist S ° S = S. Die Konfiguration (S, E) enthält die Menge von Gleichungen E und die Lösungsmenge S. Die Lösungsmenge wird folgendermaßen konstruiert: Es gibt zwei Endzustände, die man erreichen kann: entweder es sind keine neuen Variablen mehr vorhanden, dann process(S, 0/ ) = S. Oder man trifft auf einen Widerspruch, dann process(⊥ , E) = ⊥. Solange man nicht bei einem dieser beiden Zustände ist berechne process(S, a = b ∪ E) = process(assert( a = b, S), E). Mit assert wird die bisher gefundene Lösungsmenge erweitert: für S´= process*(E, idE) assert(a = b, S) = S ° solve( S a = S b ) 6 |=T (E ⇒ a = b) iff entweder S´ = ⊥ oder S´ a ≡ S´ b Ein Beispiel für die Umwandlung von Gleichungen in ein Termersetzungssystem nach Shostak’s Verfahren mit nur einer Theorie ist E0 = {a = gab, fffa = fgab} Zunächst ersetzt man alles Ausdrücke aus E mit Variablenabstraktion: Aus a wird c1, fc1 wird zu c2, usw.. Man formt die Notation aus Gleichungen (=) in ein Termersetzungssystem (→) um. Man wandelt erst die erste Gleichung in ein Termersetzungssystem um. Anschließend verwendet man die Termersetzung aus Gleichung eins um die Gleichung zwei in ein Termersetzungssystem zu verwandeln. a = gab, fffa = fgab a → c1, b → c5, gc1c5 → c1 fffc1 = fc1 fc1 →c2, fc2 → c3, fc3 → c2 finaler Kongruenzabschluss { a → c1, b → c5, gc1c5 → c1, fc1 →c2, fc2 → c3, fc3 → c2 } 4.2 Kombination von Shostak Theorien Zwei Theorien T1 und T2 werden als unterschiedlich angesehen, wenn sie keine gemeinsamen Funktionssymbole haben. Sei σi der Kanonisierer für Ti, dann ist ein Term f(a1, ..., an) in Ti, wenn f in Ti ist; auch dann, wenn einige der ai Funktionssymbole enthalten, die nicht in Ti enthalten sind. Die Kanonisierer behandeln die Terme in der jeweils anderen Theorie als Variablen. Da σi nur i-Terme behandeln kann, muss er zunächst so angepasst werden, dass er Terme aus Tj als Variablen behandelt, wenn j ≠ i. Πi sei eine ausgewählte bijektive Menge von Gleichungen zwischen den Variablen X und der Menge {a | (∃j : j ≠ i ∧ a ∈Tj}. Uninterpretierte Funktionssymbole werden behandelt, als würden sie zu einer speziellen Theorie T0 gehören, in der σ0 (a) = a, für a ∈ T0. Der erweiterte Kanonisierer lautet dann σi´(a) = Πi [σi (a´)], 7 wenn a´: a´ ein i-Term ist, ist Πi [a´] ≡ a. Da die Bedingung immer erfüllt werden kann, lässt sich der kombinierte Kanonisierer so definieren: σ(x) = x σ(f(a1, ..., an)) = σi´(f(σ (a1) ,..., σ (an))), wenn i : f ist in Ti. Wie wir oben am Beispiel mit den Theorien der linearen Arithmetik TA und der Listen TL gesehen haben, lassen sich die Solver der einzelnen Theorien nicht einfach vermischen. Löst man 5 + car(x + 2) = cdr(x + 1) +3 mit einem gemeinsamen Solver erhält man: x = cons(cdr(x + 1) – 2, k) – 2. Die Idee oben war nun, dass man zwar einen gemeinsamen Kanonisierer verwendet, die Solver aber getrennt lässt: Man bringt beide Seiten der Gleichung in kanonische Form. Sind die kanonischen Formen identisch, so sind auch die Originalgleichungen gleich. Genau wie beim einfachen Shostak Verfahren ersetzt man die Ausdrücke durch neue Variablen. Diese Zuordnung zwischen den Ausdrücken und den neuen Variablen kommen in die Lösungsmenge S. Die Lösungsmenge wird in unserem Beispiel in vier Gruppen unterteilt: in SV stehen die Gleichungen in kanonischer Form. In SU die uninterpretierten Gleichungen, diese Menge ist bei unserem Beispiel leer. Sowie den arithmetischen Lösungen SA und den Lösungen nach der Theorie der Listen SL. Lösungen die in SV enthalten sind, aber nicht in SA oder SL werden dorthin übernommen. In unserem Beispiel war v3 = v6 in SV enthalten, nicht aber in SA. v3 = v6 wird auch in SA vereinigt: v3 = v2 + 5 und v6 = v5 + 3 wird zu v2 = v5 – 2. Diese neue Gleichung wird in SA aufgenommen. Dieses Vorgehen entspricht Punkt 4b von Shostak’s Algorithmus. Nachdem nun in keiner Menge aus S noch neue Gleichungen enthalten sind, arbeitet man nun mit dem Kanonisierer weiter und versucht die Originalgleichung zu verifizieren, indem man die Ausdrücke im Original durch die neuen Variablen ersetzt und in kanonische Form bringt. process(S, 0/ ) := S process(S:{a = b}∪ T) := process(assert(S; a = b); T) assert(S; a = b) := close*(merge(abstract*(S;S a = b ))) 1. Kanonisiere a = b um a´ = b´ zu erhalten. 2. mit Variablenabstraktion a´ = b´: Ersetze f(x1, ...., xn) durch ein neues x, und füge x = x in SV ein und x = f(x1, ...., xn) in Si . Die Iteration ergibt x = y aus a´ = b´ 3. vereinige x = y in S um SV ° {x = y} zu erhalten, es gelte x ≺ y 4. schließe S ab: wenn für x, y gilt a. Si (x) ≡ Si (y) und SV (x) ≡/ SV (y), merge x = y in S b. SV (x) ≡ SV (y) und Si (x) ≡/ Si (y), merge solve( Si ( x) = Si ( y )) in Si 8 5. Bedeutung von Shostak’s Verfahren Varianten von Shostak’s Algorithmus werden in verschiedenen Systemen eingesetzt, darunter STP, EHMD, PVS und SVC, obwohl lange Zeit ein Beweis für die Korrektheit des Verfahrens fehlte. Erst 1999 erkannte Jeremy Levitt die Schwierigkeiten, die sich bei Shostak’s Umgang mit getrennten Theorien ergaben. Shostak hatte behauptet, dass die Kanonisierer und Solver für getrennte Theorien einfach kombiniert werden könnten. Diese Behauptung war jedoch falsch. Die korrigierte Variante von Shostak’s Verfahren, die hier vorgestellt wurde, ist viel mehr eine Abwandlung der Nelson-Oppen Methode, da auch hier der Informationsaustausch über die Variablen realisiert wird. Sie wurde in ICS – Integrated Canonizer and Solver - implementiert. Momentan werden Gleichungen, Ungleichungen, rational und ganzzahlig lineare Arithmetik, Theorie der Tupel und S-Ausdrücke, boolesche Konstanten, Arrays und Bitvektoren unterstützt. ICS ist unter ics.csl.sri.com frei verfügbar. 9 Literatur [HE02] F.v. Henke, Maschinelles Beweisen. Universität Ulm, Vorlesungsskript WS 2002/03 [NO] G. Nelson and D.C. Oppen. Fast decision procedures based on congruence closure. JACM 27(2) (1980). 356-364. [RS] H. Rueß, N. Shankar, A. Tiwari. On Shostak’s Combination of Decision Procedures. Proc. Automated Deduction - CADE 13, LNAI (1104 )Springer Verlag ( 1996). 463-477 [RS01] Harald Rueß, Natarajan Shankar. Deconstructing Shostak. In 16th Annual IEEE Symposium on Logic in Computer Science, pages 19-28, Boston, MA, July 2001. IEEE Computer Society [RS02] H. Rueß, N. Shankar. Combinig Shostak Theories. RTA`02 [Sho84] R. E. Shostak. Deciding combinations of theories. Journal of the ACM, 31(1):12-12, January 1984 10