Mixture Regression Modelle
Werbung

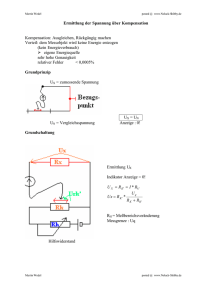
Mixture Regression Modelle Gründe für die Anwendung von Mixture Regression Modellen am Beispiel der Conjointanalyse Conjointanalyse: J Stimuli Stimulus 1 Stimulus J Stimulus 2 Pentium IV 2 GHZ Pentium IV 2,2 GHZ 512 MB Arbeitsspeicher 256 MB Arbeitsspeicher Preis: 1599 Preis: 1749 AMD Athlon 1,8 GHZ+ ... 512 MB Arbeitsspeicher Preis: 1549 werden durch I Befragte bewertet: Gesamtnutzenwerte yij Conjointanalyse: Beitrag von Merkmalsausprägungen 1 falls Stimulus j die Ausprägung n von Eigenschaf t m besitzt z(i ) jmn 0 sonst M Aus Nm yij imn z(i ) jmn m 1 n 1 erhält man die Teilnutzenwerte imn Problem: Datenaggregation Gemeinsame Analyse: setzt homogene Präferenzen voraus Individuallevelanalyse: wenig Freiheitsgrade der Schätzung führen zu nicht reliablen Schätzern Conjointanalyse und Marktsegmentierung • Zweistufig: • a-priori Segmentierung • post-hoc Segmentierung • Simultan: • Optimal Weighting • Clusterwise Regression • Mixture Regression Lineare multiple Regression yi 0 1 x1 k xk i i 1 I Y X ~ N 0, 2 OLS-Regression: ̂ X X 1 X Y ˆ 2 ˆˆ N k 1 y x x x x x x x x x x x x x x x x x x x x x x x x x x x y x x x x x x x x x x x x x x x x x x x x x x x x x x x ~ N 0, Y X f yi xi , , 2 2 Y ~ N X , 2 yi xi 2 exp 2 2 2 2 1 y E(y| x ) 1 x y x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x y x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x y x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x E(y| x ,s ) 1 2 E(y| x ,s ) 1 1 f 1 y i x, 1 , 12 f 2 y i x, 2 , 22 yi f s y i xi , s , 2 s yi s xi 2 exp 2 2 2 2 s s 1 f y i 1 f 1 y i xi , 1 , 12 2 f 2 y i xi , 2 , 22 f y i s f y i xi , s , S s 1 2 s S s 1 s 1 s : a priori Wahrscheinlichkeiten a posteriori Wahrscheinlichkeiten: pis s f y i xi , s , s2 f y S s 1 s i xi , s , s2 Schätzung der Parameter s , s , s2 Maximum Likelihood Schätzung EM-Algorithmus EM-Algorithmus Beginne mit beliebiger Partition. p11 p1S p p IS I1 s= Spaltenmittelwert Ermittle für alle Segmente s , s2 durch gewichtete KQ-Schätzung 2 und berechne f s yi x, s , s Ermittle neue Partition aus posteriori Wahrscheinlichkeiten pis s f yi s , s2 f y S s 1 s 2 , i s s Beispiele für Anwendungen im Marketing Conjointanalyse: Vriens et al. (1996): Monte Carlo Studie Überlegenheit simultaner gegenüber zweistufigen Verfahren Mixturemodell am besten geeignet DeSarbo et al. (1992): Remote Entry System für Automobile Kamakura et al. (1994): Bankdienstleistungen Teichert (2000): Wohnungen Jeweils 4 Segmente mit unterschiedlichen Präferenzen Baumgartner, B. (2002): Ein hodonisches Mixture Modell zur Aufdeckung latenter Preis-Leistungsstrukturen. In: Zeitschrift für Betriebswirtschaft, Jg. 72, H. 5, S. 477-496 DeSarbo, W.S.; Cron, W.L. (1988): A Maximum Likelihood Methodology for Clusterwise Linear Regression. In: Journal of Classification, Vol. 5, S. 249–282. DeSarbo, W.S.; Wedel, M.; Vriens, M.; Ramaswamy, V. (1992): Latent Class Metric Conjoint Analysis. In: Marketing Letters, Vol. 3, S. 273–288. Kamakura, W.A., Wedel, M.; Agrawal, J. (1994): Concomitant Variable Latent Class Models for Conjoint Analysis. In: International Journal of Research in Marketing, Vol. 11, S. 451–464. Ramaswamy, V.; DeSarbo, W.; Reibstein, D.J.; Robinson, W.T. (1993): An Empirical Pooling Approach for Estimating Marketing Mix Elasticities with PIMS Data. In: Marketing Science, Vol. 12, No. 1, S. 103-124. Teichert, T. (2000): Das Latent-Class Verfahren zur Segmentierung von wahlbasierten ConjointDaten: Befunde einer empirischen Anwendung. In: Marketing ZFP, Heft 3, S. 227–239. Vriens, M.; Wedel, M.; Wilms, T. (1996): Metric Conjoint Segmentation Methods: A Monte Carlo Comparison. In: Journal of Marketing Research, Vol. 33, S. 73–85. Wedel, M.; DeSarbo, W. (1995): A Mixture Likelihood Approach for Generalized Linear Models In: Journal of Classification, Vol. 12, S. 21 - 55. Wedel, M.; Kamakura, W.A. (1998): Market Segmentation. Conceptual and Methodological Foundations. International Series in Quantitative Marketing, Kluwer Academic Publishers, Boston, Dordrecht, London.