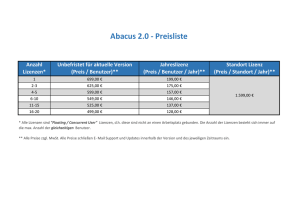
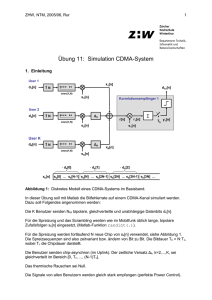
Projektarbeit
Werbung

Konzeption und Implementierung eines personalisierten Wissensnetzwerks. (Erstellung eines Software-Agenten zur Analyse des Benutzerverhaltens, Identifikation der Benutzerpräferenzen und Generierung von Vorschlägen zur sinnvollen Erweiterung des personalisierten Wissensnetzwerks) Projektarbeit Lehrstuhl Wirtschaftsinformatik II an der Wirtschafts- und Sozialwissenschaftlichen Fakultät Der Friedrich-Alexander-Universität Erlangen-Nürnberg Professor : Prof. Dr. F. Bodendorf Betreuer : Sascha Uelpenich Bearbeiter: René J. Soria Wolf Bearbeitungszeit: 01.06.2001 – 01.10.2001 1 Index 1. Einleitung 1.1. Das BrainSDK 1.2. Das vorhandene System 1.3. Das Ziel der Projektarbeit 2. Konzeption 2.1. Überblick 2.2. Profilierung als Grundlage 2.3. Quantitative Vorschlagsgenerierung 2.4. Qualitative Vorschlagsgenerierung 2.5. Einordnende Vorschlagsgenerierung 2.6. Protokolle des Beobachtungsagenten 3. Implementierung 3.1. Die Hilfsfunktionen 3.1.1. getProfileStringSize() 3.1.2. getNumberOfUsers() 3.1.3. getProfilString(int uid) 3.1.4. createProfilStringIntoDB(uid) 3.1.5. insertNewThoughtToProfilStringsInDB(uid) 3.1.6. writeDirectProfilIntoDB(currentProfilString, uid) 3.1.7. updateAllProfileStringsInDB() 3.1.8. getMatchingWert(profilString1, profilString2) 3.1.9. getProfilDifferenceString(profilStr1, profilStr2) 3.1.10. Sonstige Hilfsfunktionen... 3.2. Die Hauptfunktionen 3.2.1. matching(uid) 3.2.2. topten(uid) 3.2.3. suggest(uid, tid) 3.2.4. recents(uid) 3.2.5. update(uid) 4. Anhang 4.1. Erweiterungsmöglichkeiten des AnalyseAgenten 4.2. Hinweise 2 1. Einleitung 1.1 Das BrainSDK LASSO (Lehrmittel assoziativ suchen) basiert auf der Javatechnologie BrainSDK Version 2.1, ein Softwareentwicklungstool, dass die Benutzeroberfläche des Brains in Java-Applikationen oder Java-Applets zu integrieren ermöglicht. Ein Brain ist eine Sammlung von „Thoughts“ und ihre korrespondierenden Beziehungen zueinander. Ein Thought ist eine Abstraktion eines beliebigen Informationsobjekts, wie z.B. ein Konzept, ein Projekt, eine Person, ein Thema, ein Dokument, eine Webseite, eine Datei, ein Hyperlink oder alles was sich in Beziehung zu irgend etwas anderem befindet und so als Verknüpfung (link) dargestellt werden kann. TheBrain hat keine hierarchische Struktur. Es bildet Analog zum Gehirn viel mehr ein Netzwerk von Verknüpften Thoughts, das in seiner Verknüpfungsweise keinerlei Restriktionen kennt. Jeder Thought kann potentiell mit jedem anderem Verknüpft werden, wenn dies vom Benutzer gewünscht wird. Abbildung 1: BainSDK – graphische Oberfläche Die Idee eines Brains ist, die Nachteile einer hierarchischen Ordnung zu umgehen, da das hierarchische Konzept sehr oft den Wissensstrukturen nicht gerecht wird, die eher einer assoziativen Ordnung bedürfen. 3 Ein klarer Vorteil dieses Prinzips ist, dass keine Redundanz vorhanden sein muss, da jeder Thought eindeutig im Brain identifiziert und gespeichert ist und bei Bedarf von jeden anderen Thought aus, eine Beziehung zu diesem aufgebaut, er also verlinkt werden darf. Ein weiterer Vorteil ist, dass der Benutzer durch ein assoziatives Netzwerk intuitiv von vielen Stellen des Brains aus, zu einem gesuchten thouhgt finden kann. Dies wird ergänzt durch eine integrierte Suchfunktion, um Thoughts schneller zu finden. BrainSDK, stellt eine graphische Oberfläche zur Verfügung, in dem der Benutzer zwischen den Thoughts navigieren kann. Es gibt immer einen aktiven Thought, der in der Mitte dargestellt wird, die Position in der sich der Benutzer befindet. Möchte der Benutzer auf einen anderen Thought wechseln, muss er auf einen durch eine Gerade mit diesem verlinkten Thought klicken. Möchte der Benutzer den Inhalt eines aktiven Thoughts sehen, muss er diesen erneut anklicken. Der Inhalt wird dann in einem anderem Frame oder Browserwindow angezeigt. 4 1.2 Das vorhandene System Das System ist konzeptionell in drei Ebenen gegliedert. Auf der obersten Ebene ist das SuperBrain, dass alle Thoughts enthält. In der zweiten Ebene sind die GruppenBrains, die alle Thoughts enthält, die für eine bestimmte Benutzergruppe relevant sind. Diese beiden Ebenen werden von Brain-Administratoren verwaltet, die die Qualität des Brains sichern. Die Aufgaben sind insbesondere: Selektion, Aufnahme und Entsorgung von Thoughts. Auf der dritten Ebene befinden sich letztendlich die personalisierten Brains, die jedoch nur eine Sicht (view) auf die Zweite Ebene darstellen. Hier hat der Benutzer die Möglichkeit, Knoten aus dem Gruppennetzwerk zu übernehmen, aber auch eigene, nicht in seinem GruppenBrain vorhandene Thoughts, in sein personalisiertes Netzwerk aufzunehmen. Das können sowohl Links auf seine lokal gespeicherten Dateien, als auch Hyperlinks, die ins Internet verweisen, sein. Die folgende Abbildung 2 soll dies veranschaulichen: Abbildung 2: Konzeptionelles 3-Ebenen System. Die vorangehende Projektarbeit implementierte einen Beobachtungs- und Protokollierungsagenten, der das Verhalten der Benutzer zu jedem Zeitpunkt mitprotokolliert. Er ist auf der zweiten Ebene angesiedelt, da er sämtliche Ereignisse auf Gruppenebene mitverfolgt. Dies ist so gedacht, da er benutzerübergreifend, das Verhalten aller Benutzer einer Gruppe beobachten soll, um daraus später Möglichkeiten der Optimierung, für den einzelnen Benutzer, ableiten zu können. Dies soll vor allen durch 5 weitere Agenten, wie z.B. den AnalyseAgenten in dieser Projektarbeit, geleistet werden. Zu den protokollierten Informationen gehören: Datum beim Aktivieren eines Thoughts, die dazugehörige Benutzeridentität sowie die Thoughtidentität selbst. Diese Informationen werden in eine Oracle-Datenbank gespeichert und bilden die Grundlage für diese Projektarbeit, da der zu Implementierende AnalyseAgent auf die Informationen des Beobachtungs- und Protokollierungsagenten zugreift. Für das personalisierte Wissensnetzwerk wurde ein weiteres Datenbankmodell implementiert, da dies für die später im konzeptionellen Teil erklärte Benutzerprofilierung und für die benutzerspezifischen Daten notwendig erschien. Die Beschreibung des Datenbankmodells ist in der schriftlichen Ausarbeitung von Herrn T. Schnocklake nachzulesen. 6 1.3 Das Ziel der Projektarbeit Ziel der Projektarbeit ist es, für den individuellen Benutzer, auf Basis der jeweiligen Gruppennetzwerke, personalisierte Netzwerke nach seinen Bedürfnissen zu erstellen, konfigurieren und individuell zu erweitern. Um ein personalisiertes Netzwerk zu erstellen muss der Benutzer ein Login-Name und ein Passwort besitzen um sich in sein Netz einzuloggen. Dieses ist anfangs leer, und enthält nur einen Start-Thought “Willkommen“. An diesen kann der Benutzer nun Thoughts anfügen, die er entweder aus dem Gruppennetzwerk holt oder indem er eigene Thoughts hinzufügt. Eigene Thoughts wären z.B. Verweise auf eine Webseite im Internet oder auf eine Datei die sich lokal auf seinen Rechner befindet. Die Anordnung, bzw. Vernetzung in ihrer Struktur hängt frei vom Benutzer ab. Er kann sein Netzwerk so organisieren wie er das für richtig hält. An dieser Stelle findet der zu implementierende AnalyseAgent seine Aufgabe. Er soll den Benutzer unterstützen, damit dieser sein Wissensnetzwerk sinnvoll erweitern , sinnvoll strukturieren und gegebenenfalls reduzieren kann. Reduktion ist beispielsweise dann sinnvoll, wenn ein bestimmter Thought über einen sehr großen Zeitraum nicht mehr besucht worden ist. Der AnalyseAgent sollte dies erkennen und dem Benutzer mitteilen, bzw. vorschlagen, dass er diesen Thought vielleicht entfernen sollte. In der Strukturbildung des personalisierten Netzwerks, kann der AnalyseAgent insofern unterstützend wirken, indem er dem Benutzer diejenigen Thoughts im Netz vorschlägt, die sich am besten für das Anhängen eines neuen Thoghts eignen. Die sinnvolle Erweiterung des personalisierten Netzwerks wäre dann erfüllt, wenn der Agent dem Benutzer Thouhgts vorschlagen könnte, die er erstens noch nicht hat und man zweitens davon ausgehen kann, dass mit einer sehr hohen Wahrscheinlichkeit, dieser Thought-Vorschlag sinnvoll und bereichernd in sein personalisierten Netzwerk passen würde. Hier spielen die Konzepte der Benutzerprofilierung eine große Rolle, die im Konzeptionellen Teil ausführlich erklärt werden. Die gesamte Projektarbeit besteht aus zwei Teilen. Der Schwerpunkt liegt hier auf dem AnalyseAgenten, der unterstützende Funktionen für den Benutzer eines personalisierten Netzwerkes bereitstellt. Die Implementierung und Erklärung der Graphischen Oberfläche für das Login, das personalisierte Netzwerk selbst, die Dialoge und die Menüimplementierung sind nicht Gegenstand dieser Ausarbeitung. Diese ist bei der 7 schriftlichen Ausarbeitung von Herrn T. Schnocklake zu suchen. Sie bildet die visuelle Schnittstelle zum Benutzer (GUI). Die Algorithmen des AnalyseAgenten, bleiben so dem Benutzer verborgen. Er sieht letztendlich nur die Ergebnisse der Rechenprozesse, die über die graphische Oberfläche kommuniziert werden. 8 2. Konzeption 2.1 Überblick Die konzeptionelle Strategie steht auf zwei Säulen um ihr Ziel zu erreichen. Einmal wird der zu implementierende AnalyseAgent auf die Beobachtungsdaten des Beobachtungsagenten analysierend zugreifen, um aus diesen Konklusionen ziehen zu können. Da im Rahmen der Projektarbeit aber auch auf der personalisierten Ebene (3. Ebene), Daten in einer Datenbank verwaltet werden, greift der AnalyseAgent des weiteren auch auf diese zu und schreibt zum Teil auch eigene Daten rein. Jeder Benutzer hat in seinem personalisierten Wissensnetzwerk eine "Sicht" (einen sogenannten “View“) des Gruppennetzes, sowie weitere Thoughts die nicht im Gruppennetzwerk definiert sind und individuell hinzugefügt werden können. Dadurch ermöglicht es sich der Benutzer, das Netzwerk seinen Bedürfnissen anzupassen. Auch diese Daten werden auf der personalisierten Ebene in die Datenbank geschrieben. Diese beiden Säulen werden in 2.2 bis 2.5 (Verwendung der Daten auf der personalisierten Ebene) und in 2.6 (Verwendung der Beobachtungsdaten) eingehend erklärt. 9 2.2 Profilierung als Grundlage Auf der Ebene der personalisierten Wissensnetzwerke, werden Informationen in die Datenbank geschrieben. Diese sind: UserId, Passwort, alle Thoughts die auf personaliserter Ebene jemals angelegt worden sind (Thoughts aus dem Gruppennetz und benutzereigene Thoughts), Benutzer-Links (Verbindungen zwischen Thouhgts). Die Frage, wie der AnalyseAgent mit diesen Informationen die Benutzer sinnvoll unterstützen kann, sei es durch Vorschläge interessanter Thoughts und wo er diese in seinem Netzwerk integrieren sollte oder sei es nur ein Vorschlag der beliebtesten Thoughts die benutzerübergreifend in einem Gruppennetz von den einzelnen Benutzern gewählt worden sind, hat in dieser Projektarbeit die Profilierung als Antwort gefunden. Profilierung ist als eine Art binäre Codierung zu verstehen, auf der man arithmetische Operationen durchführen kann. Für jeden Benutzer wird ein Profil erstellt, das der AnalyseAgent in die Datenbank schreibt. Der binäre Code ist eine n-stellige Sequenz der Zahlen 0 oder 1. Die 0 an der Stelle x bedeutet dass der Benutzer den Thought x nicht in seinem personalisierten Netzwerk hat. Dementsprechend bedeutet 1 an der Stelle x, dass der Benutzer den Thought x in seinem personalisierten Netzwerk hat. Abbildung 3: Ein Profilstring. Die Länge einer binär kodierten Sequenz (ein sogenannter “Profilstring“), ist die Anzahl aller vorkommenden Thoughts, die auf der personalisierten Ebene von den Benutzern verwendet werden und deshalb in die Datenbank geschrieben werden. Mit anderen Worten, da alle Thoughts der personalisierten Netzwerke in eine Datenbank geschrieben werden, bestimmt die Anzahl der Thoughts in der Datenbank die Länge eines Profilstrings. 10 2.3 Quantitative Vorschlagsgenerierung Es werden unabhängig von der Ähnlichkeit der Profile, die am häufigsten vorkommenden Thoughts angeboten. Dies geschieht im ersten Schritt durch Aufsummierung der „1“-Bits in den einzelnen Profilstrings. Im zweiten Schritt wird dann noch verglichen, ob der Benutzer x diese Knoten schon selbst in seinem personalisierten Wissensnetzwerk hat. Ist dies der Fall werden diese Knoten nicht angeboten. So kann der Benutzer x sein Wissen (Thoughts) auch profilübergreifend erweitern. Abbildung 4: Quantitatives Konzept. 11 2.4 Qualitative Vorschlagsgenerierung Vorschläge die auf quantitativen Verfahren basieren, stellen eine durchaus gute Möglichkeit dar, das Wissen eines Benutzers zu erweitern. Allerdings erlauben sie keinerlei Rückschlüsse auf deren Wahrscheinlichkeit, wie sinnvoll eine Information für einen Benutzer ist oder wieso ein angebotener Thought überhaupt angeboten werden sollte, nur weil er sehr oft von anderen Benutzern in ihre Netze integriert worden ist. Qualitative Vorschläge müssen wenigstens ein Kriterium der Nachweisbarkeit erfüllen, um Vorschläge höherer Güte zusichern zu können. Die vorher erklärte Profilierung bietet die Möglichkeit auf sehr einfache Weise Benutzer zu vergleichen. Ein Benutzer a ist einem anderen Benutzer b dann sehr ähnlich, wenn die Anzahl der Thoughts die beide Profile gemeinsam haben, maximal groß ist. Das qualitative Kriterium ist hier also die „Ähnlichkeit“ der Benutzer untereinander. Abbildung 5: Qualitatives Konzept. Es wird ein Profil x eines Benutzers a mit allen anderen Profilen verglichen. Je mehr ein anderes Profil dem Profil x gleicht, desto ähnlicher ist dieser Benutzer dem Benutzer a. Dazu müssen im Profilstring nur die 1-Bits möglichst oft auch auf 1-Bits in dem zu vergleichenden, anderen Profil auftreten. Für jedes “matching“ zweier 1-Bits steigt der Ähnlichkeitswert des zu vergleichenden Benutzers. Am Ende dieses Prozesses sind die ähnlichsten Benutzer bekannt. Nun wird wieder auf ein rein quantitatives Verfahren gegriffen. Von den ähnlichsten Benutzern werden die Thoughts quantitativ aufaddiert, die der Benutzer noch 12 nicht in seinem personalisierten Netzwerk hat. Die dabei am häufigsten gezählten Thoughts, werden schließlich dem Benutzer vorgeschlagen. Dieses Vorgehen basiert auf der Annahme, dass die Ähnlichkeit bei der Wahl von Thoughts, die Benutzer individuell in ihrem Netzwerk gewählt haben, sinnvoll verwendet werden kann. Es kann so ähnliche Interessen und Wissen anderen Benutzern zugänglich machen, also, ihr eigenes Wissen sehr wahrscheinlich mit sinnvollen, ähnlichen Wissen bereichern. 13 2.5 Einordnende Vorschlagsgenerierung Der AnalyseAgent kann auf quantitative und auf qualitative Verfahren zurückgreifen, um den Benutzer Thought-Vorschläge zu geben. Diese vorgeschlagenen Thoughts müssen irgendwo in das existierende Wissensnetzwerk des Benutzers eingeordnet werden. Auch die Thoughts, die vom Benutzer aus dem Gruppennetzwerk übernommen werden, müssen in sein personalisierte Netzwerk an eine sinnvolle Position eingefügt werden, weil man nicht davon ausgehen darf, dass er die gleichen referenziellen Strukturen in seinem personalisierten Netzwerk vorfindet, wie diese im Gruppennetzwerk etabliert sind. Mit anderen Worten: es kann durchaus passieren, dass der Vater-Thought des hinzufügenden Thoughts im personalisierten Netzwerk nicht vorhanden ist. In der Datenbank auf der personalisierten Ebene sind die Informationen über die Links (Verknüpfungen) zwischen den Thoughts. In unserem Konzeptionellen Modell wurden nur die Vater-Kind-Beziehungen implementiert. Das heißt, das es für jeden Thouhgt im personalisierten Wissensnetzwerk eine eindeutige Zuordnung gibt. Der Start-Thought ist die einzige Ausnahme, da dieser keinen Vater-Thought hat, verweist er als Vater-Thought auf sich selbst. Damit sind alle Thoughts berücksichtigt. Es werden, wie in 2.4 erklärt, die ähnlichsten Profile ermittelt. Diese werden daraufhin untersucht ob diese den einzufügenden Thought besitzen und wenn dies der Fall ist, werden ihre Vater-Thoughts analysiert. Dies geschieht wieder rein quantitativ, wie in 2.3 erklärt. Die Vater-Thoughts werden also nach ihrem quantitativen Auftreten abgezählt. Die am häufigsten vorkommenden Vater-Thoughts werden nun dem Benutzer vorgeschlagen. Dieser hat dann eine Auswahl an möglichen Orten in seinem personalisierten Wissensnetzwerk, aus denen er sich die bestmögliche Lösung für sich wählen kann, aber auch nicht muss, denn zu keinem Zeitpunkt zwingt der AnalyseAgent den Benutzer etwas auf, das „ultima ratio“ bleibt beim Benutzer, der AnalyseAgent unterstützt durch Vorschlagsgenerierungen. Sollte einmal ein Thought vom Benutzer gelöscht werden, bestünde die Gefahr, dass der an ihm hängende Ast nicht mehr zugänglich wäre. Denn wenn ein Vater-Thought eines Thoughts gelöscht wird, ist er im Wissensnetzwerk nicht mehr auffindbar, es sei denn, dass ein anderer Thought noch auf diesen verweist. Dieses sollte jedoch nicht dem Zufall 14 überlassen werden. Der AnalyseAgent könnte nun für jeden Thought, der an dem zu löschenden Vater-Thought hängt, einen Vorschlag generieren, wo dieser im Netzwerk angehängt werden könnte. In dieser Projektarbeit ist dies nicht implementiert. Die einfachere Lösung der Vererbung wurde gewählt. Das heisst, dass alle Kinder-Thoughts, bei Verlust ihres Vater-Thoughts, an den Großvater-Thought vererbt werden, also mit diesem verknüpft werden. Sollte es mehrere Großvater-Thoughts geben, kann der Benutzer zwischen den verschiedenen Optionen wählen. 15 2.6 Protokolle des Beobachtungsagenten Die Protokolle des Beobachtungsagenten, der in der vorherigen Projektarbeit implementiert worden ist, ermächtigen den AnalyseAgenten weitere Funktionen anzubieten, die dem Benutzer auf der personalisierten Ebene weiter unterstützen können. Die Algorithmen sind hier eher als analysierend zu werten und bedürfen z.B. nicht einer binären Codierung(hier gemeint: die Profilierung). Diese Protokolle sind alle in der Datenbank gespeichert und können über Standard SQL Abfragen abgerufen werden. Eine Funktion des AnalyseAgeneten überprüft anhand der Daten der Protokolle, wie lange die Thoughts schon nicht mehr besucht worden sind. Wenn diese über einen bestimmten Zeitraum “unactivated“ waren, wird der AnalyseAgent dem Benutzer vorschlagen diese bestimmten Thoughts von seinem personalisierten Wissensnetzwerk zu entfernen. So wird garantiert, dass sich ein Wissnsnetzwerk mit der Zeit nicht mit “Informationsleichen“ füllt, sondern analog einer Pflanze sich von ihren toten Blättern befreit. Eine weitere Funktion ist eine quantitative Vorschlagsgenerierung, die jedoch nicht auf einer Profilierung basiert, sondern auf die Protokollierungsdaten zugreift, die sich ständig ändern. Vorgeschlagen werden sollen die Thoughts, die in letzter Zeit am häufigsten benutzerübergreifend besucht worden sind und die noch nicht in dem personalisierten Wissensnetzwerk des Benutzers integriert sind. In den Protkollierungsdaten werden die Thoughts, die das jüngste Datum bei einem “activate“ haben, ermittelt. 16 3. Implementierung Für die Implementierung des AnalyseAgenten, wurde Java und Java RMI gewählt. Die GUI des personalisierten Wissensnetzwerks kommuniziert über Remote Method Invocation mit dem Agenten, der auf dem RMI-Server bereitgestellt wird. Der Quellcode ist nach dem objektorientierten Paradigma programmiert und kommentiert. Name der Source: AnalyseAgent.java . Der AnalyseAgent greift auf die Oracle Datenbank zu, rechnet mit den gelesenen Daten und gibt die Ergebnisse an die GUI des personalisierten Wissensnetzwerks weiter. Die Hilfsfunktionen sind in erster Linie das “Rechenwerk“ des AnalyseAgenten, sie erfüllen viele Aufgaben, auf deren Resultate dann die Hauptfunktionen zugreifen können. Wie z.B. die Profilierung aller Benutzer, etc... Der AnalyseAgent wird a) beim Start des personalisierten Netzwerks sowie bei sämtlichen Funktionsaufrufen, die von der GUI über RMI an die Methoden des Agenten gelangen, aktiviert. b) beim Einfügen eines neuen Knotens aktiviert. 17 3.1 Hilfsfunktionen 3.1.1 getProfileStringSize() public int getProfilStringSize(), gibt die Länge(int) der Profilstrings zurück, also die Anzahl aller Thoughts auf der personalisierten Ebene, da es für jedes Bit in einem Profilstring einen zugeordneten Thought gibt. Dazu wird ein beliebiger Profilstring aus der Datenbank gelesen, das erledigt die Funktion getProfileString(uid). Der erhaltene String kann einfach auf seine Länge überprüft werden. 3.1.2 getNumberOfUsers() public int getNumberOfUsers(), gibt die Anzahl der Benutzer (int) zurück, die in einem Gruppennetzwerk vorhanden sind und ein personalisiertes Netzwerk haben. Das wird durch eine SQL Abfrage erreicht. 3.1.3 getProfilString(int uid) public String getProfilString(int uid), gibt einen Profilstring(String) eines bestimmten Benutzers mit der Identität uid zurück. Dieser wird einfach aus der Datenbank gelesen. 3.1.4 createProfilStringIntoDB(uid) public void createProfilStringIntoDB(int uid), generiert den Profilstring eines bestimmten Benutzers uid und schreibt ihn in die Datenbank. Der Proiflstring ist eine binäre Sequenz aus entweder 0-Bits oder 1-Bits. Es wird in der Datenbank abgefragt, welche Thoughts der Benutzer uid hat. Diese werden iterativ in einen Array, mit der Länge die aus der Funktion getProfileStringSize() als Rückgabewert ermittelt wird, geschrieben, wobei ein 0-Bit in den Array geschrieben wird, wenn der Benutzer diesen Thought nicht, bzw. einen 1-Bit wenn er diesen hat. Anschließend wird iterativ einfach ein Proiflstring generiert . 3.1.5 insertNewThoughtToProfilStringsInDB(uid) public void insertNewThoughtToProfilStringsInDB(int uid), diese Funktion fügt einen absolut neuen Thought in alle Profilstrings ein. Das heisst, dass alle Profilstrings um einen weitere Bit-Stelle erweitert werden müssen. Dem Benutzer uid wird dementsprechend ein 1er-Bit an seinem Profilstring angehängt, da er diesen Thought nun in seinem personalisierten Netzwerk hat. Alle anderen Profilstrings werden also um ein 0er-Bit ergänzt, da sie ihn potentiell haben könnten, ihn aber bis jetzt noch nicht in ihrem Netzwerk integriert haben. Damit nicht für jeden einzelnen Benutzer wieder jeder einzelne Profilstring 18 generiert werden muss, sondern die vorhandenen Profilstrings nur um 1 Bit erweitert werden müssen, ruft die Funktion die Funktion writeDirectProfilIntoDB(currentProfilString, uid) auf. Wobei sämtliche Benutzer(uid) durchlaufen werden und ihre korrespondierenden Profilstrings, schlicht als Parameter durch die Funktion getProfilString(uid) übergeben werden. 3.1.6 writeDirectProfilIntoDB(currentProfilString, uid) public void writeDirectProfilIntoDB(String currentProfilString, int uid), schreibt direkt einen Profilstring currentProfilString des Benutzers uid in die Datenbank. 3.1.7 updateAllProfileStringsInDB() public void updateAllProfileStringsInDB(), generiert für alle Benutzer alle Profilstrings neu. Diese Funktion ist eine Iteration aller Benutzer(uid), angewandt auf die Funktion createProfilStringIntoDB(uid). 3.1.8 getMatchingWert(profilString1, profilString2) public int getMatchingWert(String profilString1, String profilString2); Diese Funktion vergleicht zwei Profilstrings Character für Character und erhöht den zurückgebenden MatchingWert(int) immer dann um 1, wenn in beiden Profilstrings an gleicher Stelle, Beide ein 1er-Bit haben. Je höher der MatchingWert ist, desto ähnlicher sind sich beide Profile. 3.1.9 getProfilDifferenceString(profilStr1, profilStr2) public String getProfilDifferenceString(String profilStr1, String profilStr2); Diese Funktion generiert einen DifferenzProfilString und gibt diesen als Resultat zurück. Vom profilStr1 wird der ProfilStr2 “abgezogen“. Es wird wieder Charakter für Charakter verglichen. Wenn in einer beliebigen Position des ProfilStr1 eine 0 ist und im ProfilStr2 auch eine 0, so wird der Wert im DifferenzProfilStr auch zu 0. Steht im ProfilStr1 eine 0 und ProfilStr2 eine 1, so wird die Position im DifferenzProfilString zu 1. Steht im ProfilStr1 eine 1, so wird an dieser Position grundsätzlich in den DifferenzProfilString eine 0 geschrieben. Die Idee ist, für den ProfilStr1 die Thoughts herauszufinden, die er noch nicht hat, aber trotzdem im ProfilStr2 enthalten sind. 3.1.10 Sonstige Hilfsfunktionen... Es gibt noch einige weitere Funktionen, die hier nicht erklärt werden brauchen, sie sind ausreichend im Quellcode kommentiert und für das Verständnis nicht weiter notwendig. 19 3.2 Hauptfunktionen Sämtliche Hauptfunktionen sind von der GUI direkt abrufbar. Sie verwenden viele der vorangehend beschriebenen Hilfsfunktionen. 3.2.1 matching(int uid) public int[][] matching(int uid), liefert einen Array mit Thoughts-Vorschlägen zurück. Gemeint ist die Thought-Identity, die die Thoughts eindeutig identifiziert. Das “Matching“ verläuft über mehrere Schritte. Es basiert auf den qualitativen und quantitativen Konzepten. Es wird ein Profilstring x eines Benutzers uid itterativ mit allen restlichen Profilen über die Funktion getMatchingWert (uid) verglichen. Die resultierenden “MatchingWerte“ werden mit einem Sortieralgorithmus in einem Array der Größe nach geordnet. Die Profile mit den höchsten “MatchingWerten“ sind dem eigene Profil am ähnlichsten. Aus diesen Profilstrings sollen die Thoughts angeboten werden, die das eigene Profil noch nicht hat. Die Funktion getProfilDifferenceString(profilStr1, profilStr2) liefert uns die gewünschten Thoughts. Diese werden ein weiteres mal in einem Array der Größe nach geordnet. Damit haben wir jetzt die am häufigsten vorkommenden Thoughts von den Benutzern, die dem Benutzer uid am ähnlichsten sind. In dieser Funktion sind noch Schwellwertprüfungen implementiert. Am Ende der Sortieralgorithmen der Arrays wird überprüft, ob die größten Werte nicht einen gewissen Schwellwert unterschreiten. Dies dient der Qualitätssicherung der Vorschläge des AnalyseAgenten. 3.2.2 topten(int uid) public int[][] topten(int uid); Es werden, unabhängig von der Ähnlichkeit der Profile, die am häufigsten, quantitativ vorkommenden Thoughts angeboten. Eigene Thoughts des Benutzers uid werden ignoriert. Das konzeptionelle Vorgehen ist unter 2.3 geschildert. Auch hier gibt es eine Schwellwertüberprüfung. Die am häufigsten vorkommenden kumulierten Häufigkeiten der Thoughts sollten nicht unter einen definierten Wert liegen, sonst werden sie nicht vorgeschlagen. Der Name „topten“ soll lediglich suggerieren, dass es sich hier um ein „Ranking“ handelt. Es müssen nicht zehn Thoughts angeboten werden, allein schon deshalb nicht, weil bei einer Schwellwertunterschreitung, der Array mit den Vorschlägen jederzeit gekürzt werden kann. 20 3.2.3 suggest(int uid, int tid) public int[][] suggest(int uid, int tid), Bei den ersten beiden beschriebenen Hauptfunktionen geht es um die Generierung von Vorschlägen, d.h. es werden Thoughts angeboten. Es bleibt aber ungeklärt, an welcher Stelle diese Thoughts sinnvoll in das personalisierte Wissensnetzwerk Netzwerk integriert werden sollen. Die gleiche Frage stellt sich, wenn Knoten aus dem Gruppennetzwerk übernommen werden. Für die Annexion von komplett neuen Knoten in das personalisierte Netzwerk, kann der Agent keinen sinnvollen Vorschlag generieren, weil er keine Referenzen hat. Für die anderen beiden Problemstellungen wird folgendermaßen vorgegangen: Zuerst bekommt die Funktion eine Benutzer-ID uid und eine Thought-ID tid. Die tid ist der Thought, der sinnvoll verknüpft werden soll. In der Datenbank wird dieser Thought dem Benutzer zugeschrieben. Um den Thought an das personalisierte Wissensnetzwerk anzubinden, muss in die Link Tabelle(Verknüpfungen der Thoughts) geschrieben werden. Dazu muss der Agent wissen, welcher Thought der Vater-Thought des tid ist. Es werden nach dem qualitativen Konzept erst einmal die ähnlichsten Benutzer ermittelt. Hier kommt die Funktion getMatchingWert(profilString1, profilString2) zum Zuge. Diese werden der Größe nach geordnet, einer Schwellwertprüfung unterzogen und in ein Array geschrieben. Aus den gefundenen, ähnlichsten Profilen werden nun die gewählt, die den Thought tid auch haben. Dann werden in der Datenbank nun die Links zu diesem Thought betrachtet, gemeint sind die Vater-Thoughts. Das passiert mittels einer SQL Abfrage. Das Resultat dieses Arbeitsschritts wird von Duplikaten befreit und in ein Array ordnend geschrieben. Aus diesem werden noch diese Thoughts entfernt, die im Profilstring des Benutzers uid nicht vorkommen, da sie sonst nicht angehängt werden könnten. So erhält das personalisierte Netzwerk einen Array an Thoughts-Vorschlägen, wo es seine Thoughts sinnvoll integrieren kann. 3.2.4 recents(uid) public int[][] recents(int uid), ist eine Funktion, die auf der Arbeit des Beobachtungsagenten aufsetzt. Mit einer SQL-Abfrage in den Protokollierungsdaten, erhält man als Resultat, als Array, die in letzter Zeit am häufigsten besuchten Thoughts, die der Benutzer uid selbst noch nicht in seinem personalisiertem Wissensnetzwerk hat. 21 3.2.5 update(uid) public int[][] update(int uid), ist eine Funktion, die auf der Arbeit des Beobachtungsagenten aufsetzt. Mit einer SQL Abfrage in der Protokollierungsdatenbank, kann der AnalyseAgent erkennen, ob ein Thought im personalisierten Wissensnetzwerk des Benutzers uid, über eine bestimmte Zeitschwelle hinweg, nicht mehr besucht worden ist und ihm einen Array mit den Thoughts zurückgeben, damit dieser sie evtl. aus seinem Netzwerk entfernen kann. Das entfernen eines Thoughts ist eine der „Sonstigen Hilfsfunktionen“ und im Quellcode beschrieben. 22 4. Anhang 4.1 Erweiterungsmöglichkeiten des AnalyseAgenten Der AnalyseAgent könnte beim Anlegen von Thoughts noch zwischen privaten und öffentlichen Informationen unterscheiden. Es könnte ein Konfigurator programmiert werden, der es den Benutzern erlaubt ihre Thoughts frei zu Verknüpfen, auch über zwei Schritte hinweg Man könnte sich vorstellen, Thoughts anzubieten, die “right now“ von Benutzern gelesen werden. 4.2 Hinweise Die Software ist soweit wie möglich kommentiert und gegen Fehler geschützt. Das System oder nur bestimmte Funktionen sollten synchronisiert werden (secure transaction) um das Risiko der Inkonsistenz zu eliminieren. 23