PDF file
Werbung

RHEINISCHE FRIEDRICH-WILHELMS-UNIVERSITÄT BONN
Institut für Informatik III
Diplomarbeit
ProteinDB und ProteinWeb: Entwurf und Implementierung
einer prototypischen Informationssystems
für die Verwaltung von Proteinsequenzdaten
Shiyang Yu
31.März 2007
Betreuer: Prof. Dr. R. Manthey
Danksagung
Mein herzliches Dankeschön gilt Herrn Prof. Dr. Rainer Manthey. Bei der Betreuung meiner Diplomarbeit hat er mich mit seinem fachlichen und praktischen Rat und seiner Erfahrung unterstützt.
Dafür und dafür, dass er mir im Rahmen dieser Arbeit Gelegenheit gegeben hat, im Bereich der
Biochemie und Bioinformatik zu forschen, bin ich ihm sehr dankbar.
Inhaltsverzeichnis
Kapitel 1 Einleitung ...............................................................................1
Kapitel 2 Grundlagen aus der Biochemie ............................................4
2.1
2.2
2.3
2.4
Proteine und Aminosäuren .........................................................................................4
Proteinstruktur............................................................................................................9
Nucleinsäuren und Nucleotide .................................................................................12
Proteinbiosynthese ....................................................................................................15
2.4.1
Transkription.................................................................................................15
2.4.2
Translation .....................................................................................................16
Kapitel 3 Grundlagen aus der Informatik .........................................22
3.1
Datenbankenwurfsphasen ........................................................................................22
3.1.1
Konzeptueller Entwurf .................................................................................22
3.1.2
Logischer Entwurf.........................................................................................24
3.2
SQL.............................................................................................................................25
3.2.1
DDL ................................................................................................................26
3.2.2
DML ...............................................................................................................28
3.3
Java.............................................................................................................................29
3.3.1
Überblick über Java......................................................................................29
3.3.2
Java Servlets ..................................................................................................30
3.3.3
Java Server Pages..........................................................................................31
3.3.4
Apache Tomcat ..............................................................................................31
3.4
JDBC ..........................................................................................................................32
Kapitel 4 Proteindatenbanken ............................................................35
4.1
4.2
4.3
Protein-Sequenzdatenbanken ..................................................................................36
Protein-Strukturdatenbanken..................................................................................44
Protein-Sekundärdatenbanken ................................................................................50
Kapitel 5 Entwurf der ProteinDB.......................................................51
5.1
Konzeptueller Entwurf .............................................................................................51
5.1.1
Normaler Entwurf.........................................................................................51
5.1.2
Spezieller Entwurf.........................................................................................52
5.2
Logischer Entwurf.....................................................................................................57
5.2.1
Normale Umsetzung......................................................................................57
5.2.2
Spezielle Umsetzung......................................................................................58
I
Kapitel 6 Architektur und Funktionalität von ProteinWeb.............62
6.1
6.2
6.3
Architektur ................................................................................................................62
Implementierungs- und Entwicklungsumgebung ..................................................63
Realisierung von ProteinWeb...................................................................................63
6.3.1
Datenimport in die ProteinDB .....................................................................63
6.3.2
Kommunikationsmodul ................................................................................67
6.4
Verwendung von ProteinWeb...................................................................................70
Kapitel 7 Zusammenfassung und Ausblick .......................................75
Literaturverzeichnis ...............................................................................77
II
Kapitel 1
Einleitung
Biologie ist bereits heute eine datenreiche Wissenschaft, und immer mehr Daten werden mit Hilfe
der modernen Methoden produziert. Somit ist der Bedarf an sinnvoller Nutzung und Verwaltung
der unvorstellbar großen Datenmengen enorm gewachsen. Aus dieser Anforderung hat sich die
Bioinformatik als interdisziplinäre Wissenschaft entwickelt. In der Bioinformatik werden unter
Einsatz moderner Methoden der Datenverarbeitung komplexe biologische Sachverhalte analysiert.
Es handelt sich um eines der zentralen Gebiete der Naturwissenschaft im 21. Jahrhundert.
In den vergangenen zehn bis fünfzehn Jahren haben sich zur Sammlung biologischer Daten diverse molekularbiologische Datenbanken entwickelt. Die biologischen Daten in diesen Datenbanken
kann man zusammenfassen und klassifizieren [1] in folgende Typen:
Nucleotidsequenzen,
Proteinsequenzen,
Muster1 („patterns“) oder Motive2 („motifs“) der Proteinsequenz,
3D-Struktur des Moleküls,
Daten für Genexpression3 („gene expression data“),
Stoffwechselwege („metabolic pathways“).
Molekularbiologische Datenbanken sind sehr heterogen in ihren Zielen, Formen und Verwendungsgebieten [15]. Die vorhandenen biologischen Datenbanken kann man grob in vier Typen
klassifizieren [13]:
1.
2.
3.
4.
Genomdatenbanken (z.B., GDB, AceDB),
Sequenzdatenbanken von Nucleinsäuren und Proteine (z.B., GenBank, EMBL, SWISSPROT, PIR)
3D-Strukturdatenbanken von Hochmolekülen (z.B., PDB, SCOP, CATH)
sekundäre Datenbanken, die auf den oben genannten drei Typen Datenbanken basieren
(z.B., PROSITE, Pfam).
Die ersten drei Typen enthalten die grundsätzlichen Datenressourcen in molekularer Biologie und
werden primäre Datenbanken genannt. Gemäß den konkreten Bedürfnissen verschiedener Anwendungsgebiete in der Biologie werden viele sekundäre Datenbanken durch Analyse und Zusammenfassung primärer Datenbanken abgeleitet (s. Abb. 1-1). Zurzeit kooperieren Biologen und
Informatiker aus vielen Ländern der Welt und haben hunderte sekundäre Datenbanken entwickelt.
So kann man sich vorstellen, dass der Umfang der molekularbiologischen Datenbank ein ziemlich
unstabiles und sich schnell fortentwickelndes Gebiet ist.
1
„Der Begriff Muster (engl. pattern) bezeichnet allgemein eine gleich bleibende Struktur, die einer sich wiederholenden Sache zugrunde liegt, bzw. einen Handlungsablauf oder eine Denk-, Gestaltungs- oder Verhaltensweise,
die zur gleichförmigen Wiederholung bestimmt ist.“ [aus Wikipedia: Muster]
2
„Motiv ist eine Sequenz, die charakterisiert ist durch ein Muster.“ [aus Wikipedia: Motiv]
„Genexpression bezeichnet die Synthese von Proteinen aus den genetischen Informationen.“ [ aus Wikipedia:
Genexpression]
3
1
sekundäre Genom-DB
Colibri, TRANSFAC
sekundäre Sequenz-DB
PROSITE, Pfam,…
sekundäre Struktur-DB
DSSP, FSSP,...
sekundäre DB
analysieren und zusammenfassen
Genom-DB
GDB, AceDB,…
Sequenz-DB
GenBank, EMBL,
SWISS-PROT,…
Abb. 1-1
Struktur-DB
PDB, SCOP, CATH,…
primäre DB
biologische Datenbanken
Daraus resultiert, dass Biologen und Informatiker gemeinsam Konzepte für „optimale“ biologische Datenbanken entwickeln müssen. Tatsächlich fehlen aber den meisten Biologen Grundkenntnisse der Informatik, während die meisten Informatiker mit den biologischen Konzepten nicht
vertraut sind. So gibt es auch wenig Literatur über Datenbanken und Datenbankmanagementsysteme, die sich mit Molekularbiologie befasst.
Außerdem sind viele molekularbiologischen Datenbanken mit außerordentlich wertvollen Daten
nur eine Sammlung von „flat files“. In der Anfangszeit der Molekularbiologie-Datenbanken wurden Datenbankmanagementsysteme (DBMS) selten benutzt. Stattdessen wurden molekularbiologische Datenbanken von indizierten ASCII-Textdateien, den sog. „flat files“, aufgebaut. Später in
den 80er und 90er Jahren, als DBMSe – besonders relationale DBMSe – immer häufiger für
Molekularbiologie-Datenbanken benutzt wurden, blieben viele Molekularbiologie-Datenbanken
dennoch nur Kollektionen von „flat files“. Ein Grund besteht darin, dass die Kosten für das Importieren eines existierenden „flat files“ in eine relationale Datenbank normalerweise sehr hoch
sind. Ein anderer überzeugender Grund ist, dass Molekularbiologie-Daten oft sehr komplex sind,
so dass solche Datentypen nicht einfach in relationalen und objektorientierten DBMSen repräsentiert werden können [15]. Glücklicherweise haben solche „flat files“ immer bestimmte Muster.
Ihre Einträge sind gewöhnlich entweder implizit oder explizit durch Suchindexe strukturiert. Die
meisten Kollektionen von „flat files“ sind mit Hilfe von Schlüsselwörtern, die als Suchindizes
benutzt werden, explizit strukturiert. Die Schlüsselwörter können Zeichenfolgen mit zwei Buchstaben (z.B., in SWISS-PROT) oder mit variabler Länge (z.B., in PDB) sein. Heutzutage sind „flat
files“ der Standard zum Datenaustausch in Molekularbiologie.
Proteindatenbanken, die zur Speicherung und Verwaltung der sehr großen Datenmengen über Proteine dienen, spielen eine wichtige Rolle unter den zahlreichen molekularbiologischen Datenbanken. Um für die Verwendung der Vielzahl der vorhandenen Proteindatenbanken eine praktikable
Lösung zu finden, bietet sich die Entwicklung einer relationalen Datenbank mit der Möglichkeit
der Integration vorhandener Datenmengen an. Diese Diplomarbeit zielt auf die Modellierung und
2
Erstellung einer prototypischen Datenbank für didaktische Zwecke ab. Mit Hilfe dieser Datenbank,
mit dem Namen ProteinDB, wird beschrieben, wie man eine relationale Proteindatenbank entwerfen kann und wie die Daten aus auf „flat files“ basierenden Proteindatenbanken in einer relationalen Datenbank importiert werden können. Eine weitere nützliche Technik besteht darin, dass viele
wichtige biologische Datenbanken webbasierte Benutzerinterfaces entwickeln. Mit solchen Benutzerinterfaces lassen sich im Internet diese biologischen Datenbanken besuchen und die benötigten Informationen in den Datenbanken abfragen. Aus diesem Grund wurde zusätzlich ein webbasiertes Benutzerinterface ProteinWeb mit Hilfe von Java, JSP und JDBC-Technik entwickelt.
ProteinWeb erlaubt nicht nur die Ausführung fixer Anfragen, sondern auch die Ausführung freier
Anfragen, die in SWISS-PROT nicht realisiert wird.
Kapitel 2 beschreibt die wichtigsten Grundlagen aus der Biochemie. Um die in den folgenden Kapiteln verwendeten biologischen Fachbegriffe verständlich zu machen, werden für den Bereich der
Proteindatenbanken die Konzepte Protein, Aminosäure und Nucleinsäure und der Zusammenhang
zwischen Nucleinsäuren und Proteinen, also die Proteinbiosynthese, erklärt. Kapitel 3 beschreibt
die wichtigen Grundlagen aus der Informatik. Es beinhaltet die Theorie des Datenbankentwurfs,
die Grundlage der relationalen Anfragesprache SQL, die Grundlagen von Java, Java Servlets, Java
Server Pages, Apache Tomcat und die JDBC-Technik. Kapitel 4 stellt die Proteindatenbanken vor.
Hier werden die die wichtigen existierenden Proteindatenbanken klassifiziert. Kapitel 5 beschreibt
die Erstellung der Proteindatenbank ProteinDB mit Hilfe von Microsoft Access. Es beinhaltet den
konzeptuellen und relationalen Entwurf der Proteindatenbank. Kapitel 6 beschreibt die Bearbeitung der Daten aus den „flat files“ zum Import in die ProteinDB und den Entwurf des webbasierten Benutzerinterface: ProteinWeb. Architektur und Funktionalität von ProteinWeb werden hier
diskutiert. Kapitel 7 gibt zur vorliegenden Arbeit eine Zusammenfassung und einen Ausblick.
Hier werden die Vorteile und Nachteile von ProteinDB und ProteinWeb beschrieben und ihre Verbesserungsmethode diskutiert.
3
Kapitel 2 Grundlagen aus der Biochemie
Ziel dieses Kapitels ist es, Informatikern, denen biochemische Grundlagen fehlen, eine kurze Einführung in die Biochemie anzubieten. Damit sollen die in den späteren Kapiteln beschriebenen
biochemischen Konzepte besser verständlich werden. Für dieses Kapitel wurde Literatur
[20]-[32] über Protein und Nucleinsäure ausgewertet und daraus die wichtigen Grundlagen zusammengefasst.
2.1 Proteine und Aminosäuren
Proteine sind die zentralen Makromoleküle des Lebens und bilden den größten Teil der Trockenmasse einer Zelle. Das Wort Protein wurde im Jahr 1836 von Jönes J. Berzelius vom griechischen
Wort proteios (Bedeutet „erstrangig“, „wichtigst“) abgeleitet, um die Wichtigkeit der Proteine für
das Leben zu betonen. Zurzeit sind mehr als 10.000 Proteine bekannt. Sie sind weit verteilt, so
dass nahezu alle Organe Proteine enthalten und einen engen Zusammenhang mit allen Lebensaktivitäten haben. Proteine sind nicht nur die Bauteile der Zellen, sondern führen auch nahezu alle
Zellfunktionen aus. Proteine spielen im Organismus vielfältige Rollen:
Enzymatische Katalyse
Transport und Speicherung
Koordinierte Bewegung
Mechanische Stützfunktion
Immunabwehr
Erzeugung und Übertragung von Nervenimplusen
Kontrolle von Wachstum und Differenzierung
Proteine bestehen hauptsächlich aus fünf chemischen Elementen: Kohlenstoff (C), Wasserstoff (H),
Sauerstoff (O), Stickstoff (N) und Schwefel (S). Die Grundbausteine der Proteine sind 20 verschiedene Aminosäuren, von denen jede ihre eigenen chemischen Eigenschaften besitzt. Aminosäuren sind eine Klasse kleiner organischer Moleküle und enthalten mindestens eine Carboxylgruppe (COOH) und eine Aminogruppe (NH2). Nach der Stellung der Aminogruppe relativ zur
Carboxylgruppe werden die Aminosäuren in α-Aminosäure, β-Aminosäure, γ- Aminosäure, usw.
klassifiziert (s. Abb. 2-1).
Eine α-Aminosäure besteht aus
einer Aminogruppe (NH2),
einer Carboxylgruppe (COOH),
einem Wasserstoffatom (H),
einer variable Seitenkette (auch Rest genannt) (R),
die alle an ein C-Atom (auch α-Kohlenstoffatom genannt) gebunden sind (s. Abb. 2-2).
4
Abb. 2-1
Grundstrukturen einiger Aminosäuren
Abb. 2-2
Allgemeine Formel der Aminosäure
(aus [20])
(aus [22])
Da α-Kohlenstoffatom asymmetrisch ist, gibt es zwei optische Isomeren. Die beiden spiegelbildlichen Formen bezeichnet man als L- und D-Isomere:
Abb. 2-3
Optische Isomeren (aus [22])
Es gibt ca. 600 verschiedene Aminosäuren, von denen nur 20 L-α-Aminosäuren (auch proteinogene Aminosäuren genannt) Bausteine der Proteine aller Lebewesen (vom Bakterium bis zum
Menschen) auf der Erde sind. Im Folgenden wird daher immer auf die L-Form der Aminosäuren
Bezug genommen, wenn nicht ausdrücklich anders gesagt.
Alle Aminosäuren in Proteinen haben die gleiche Grundstruktur. Sie unterscheiden sich nur in 20
verschiedenen Aminosäure-Seitenketten. Die gewöhnlichen Aminosäuren werden nach den Eigenschaften ihrer Seitenketten sowie elektrische Polarität bzw. Ladung, chemische Reaktivität und
Wasserstoffbindungsfähigkeit eingeteilt in saure, basische, ungeladen polare, unpolare Aminosäuren. Abb. 2-4 zeigt die Strukturformeln der 20 Aminosäuren und die für sie verwendeten Drei- und
Ein-Buchstaben-Abkürzungen.
5
Abb. 2-4
20 Aminosäuren der Proteine (aus [21])
6
Ein Proteinmolekül besteht aus einer langen Aminosäurenkette, in der jede Aminosäure mit ihren
Nachbarn über eine Peptidbindung verknüpft ist. Die α-Carboxylgruppe einer ersten Aminosäure
bindet an die α-Aminogruppe einer zweiten Aminosäure unter Wasserabspaltung (s. Abb. 2-5). Die
resultierende -CO-NH-Verknüpfung wird Peptidbindung genannt.
Abb. 2-5
Bindung eines Dipeptids aus zwei Aminosäuren (aus [23])
Ein Peptid ist eine organische chemische Verbindung, die durch Verknüpfung mehrerer
Aminosäuren entsteht. Generell bezeichnet man die Anzahl der Aminosäuren im Peptid auch als
Kettenlänge: 2 Aminosäuren bilden ein Dipeptid, 3 Aminosäuren bilden ein Tripeptid, … usw.
Peptide mit bis zu 10 Aminosäuren heißen Oligopeptide, Peptide mit mehr als 10 Aminosäuren
heißen Polypeptide. Polypeptide mit über 100 Aminosäuren nennt man Proteine.
Eine Polypeptidkette besteht aus einem Rückgrat aus sich wiederholenden Untereinheiten und
unterschiedlichen Seitenketten (R1, R2, R3). Die sich wiederholende Abfolge von Atomen entlang
dem Rückgrat einer Polypeptidkette nennt man Polypeptid-Grundgerüst.
Abb. 2-6
Polypeptidkette (aus [23])
Eine Polypeptidkette hat eine bestimmte Richtung. Vereinbarungsgemäß beginnt eine Polypeptidkette mit dem aminoendständigen Rest (N-Terminus) und endet mit dem carboxylendständigen
Rest (C-Terminus). Das Peptid, das in Abb. 2-7 gezeigt wird, besitzt eine Aminosäuresequenz
Thy-Gly-Tyr-Ala-Leu.
Abb. 2-7
Peptid Thy-Gly-Tyr-Ala-Leu (aus [28])
7
In Proteinen geht es um folgende chemische Bindungen (s. Abb. 2-8):
Kovalente Bindung ist eine stabile chemische Bindung zwischen zwei Atomen durch
Anteiligkeit eines oder mehrerer Elektronenpaare.
Nicht kovalente Bindung ist im Gegensatz zur konvalenten Bindung eine schwache
Bindung, bei der keine Elektronen anteilig sind.
Ionische Bindung ist eine chemische Bindung zwischen zwei Atomen, eines mit positiver, das andere mit negativer Ladung. Sie gehört zu einem Typ der nicht kovalenten
Bindung.
Disulfidbrücke ist eine kovalente Bindung zwischen zwei Schwefel-Atomen, die in
Aminosäureseitenketten von zwei Cystein-Resten vorkommen. Disulfidbrücken sind von großer
Bedeutung für die Proteinstruktur, weil sie zusätzlich kovalente Bindungen innerhalb eines Proteins, aber auch zwischen Proteinen ermöglichen.
Wasserstoffbindung ist eine nicht kovalente Bindung, die ein elektropositives Wasserstoffatom
(H) teilweise mit zwei elektronegativen Atomen (X, Y) schwach verbindet. Man bezeichnet sie als
X-H…Y. Innerhalb der Peptidketten kommen Wasserstoffbindungen zwischen der N-H-Gruppen
und der C=O-Gruppen vor.
Salzbrücke ist eine ionische Bindung, bei der eine Carboxylgruppe mit einer Aminogruppe verbunden wird.
Van-der-Waals-Anziehungskraft ist eine Art nicht konvalenter Wechselwirkung, die auf kurze
Entfernung zwischen nicht polaren Atomen wirksam wird.
Hydrophobe Kraft ist eine Wechselwirkung zwischen Kohlenwasserstoff-Gruppen. In Proteinen
sind die wasserscheuen Bindungen zwischen nicht polaren Aminosäureseitenketten wie z.B. Alanin, Leucin,…usw.
Abb. 2-8
Die Bindungen und Kräfte in Proteine (aus [29])
8
2.2 Proteinstruktur
Die Proteinstruktur lässt sich auf vier Betrachtungsebenen beschreiben:
1. Die Primärstruktur ist die Aminosäuresequenz der Polypeptidkette.
2. Als Sekundärstruktur werden Abschnitte der α-Helices oder β-Faltblätter bildende Polypeptidkette bezeichnet.
3. Die vollständige dreidimensionale Organisation einer Polypeptidkette heißt Tertiärstruktur.
4. Wenn ein Proteinmolekül aus mehreren Polypeptidketten zusammengesetzt ist, heißt das
Ganze Quartärstruktur.
Abb. 2-9
Vier-Ebenen-Struktur der Proteine ([30])
Um die dreidimensionale Struktur von Proteinen zu stabilisieren, spielen viele verschiedene Bindungskräfte und Wechselwirkungen in Proteinen eine wichtige Rolle.
In der Primärstruktur: Peptidbindungen, Disulfidbrücken.
In der Sekundärstruktur: Wasserstoffbindungen.
In der Tertiärstruktur: Van-der-Waals-Anziehungskräfte, Salzbrücken, Wasserstoffbindungen, hydrophobe Kräfte.
In der Quartärstruktur: Van-der-Waals-Anziehungskräfte, Salzbrücken.
Man bezeichnet die Sequenz der Aminosäuren innerhalb der Polypeptidkette als Primärstruktur
der Proteine. Im Jahr 1953 bestimmte Frederick Sanger die Rheinfolge der Aminosäuren von Insulin und zeigte erstmalig, dass ein Protein eine präzise definierte Aminosäuresequenz besitzt, die
von Genen bestimmt wird. Diese Entdeckung war ein Markstein der Biochemie. Bis jetzt sind die
Primärstrukturen von ca. 1000 Proteinen bestimmt.
Die Primärstruktur enthält die Aminosäuresequenz der Polypeptidkette und die Anzahl und die
Stellung von Disulfidbrücken, falls solche vorhanden sind. Jedes Protein hat seinen eigenen spezifischen Aminosäurebestandteil und Aminosäuresequenz. Die räumliche Struktur (Sekundär-, Tertiär-, Quartärstruktur) hängt von der Primärstruktur ab. Die folgende Abbildung zeigt die Primärstruktur des Insulins. Insulin besteht aus 51 Aminosäuren und enthält zwei Ketten A und B. Die
9
A-Kette enthält 21 und die B-Kette 30 Aminosäuren. Die A-Kette wird durch Disulfidbrücken mit
der B-Kette verbunden. Innerhalb der A-Kette existiert eine zusätzliche Disulfidbrücke.
Abb. 2-10
Primärstruktur des menschlichen Insulins (aus [25])
In der Sekundärstruktur der Proteine werden die Schraubung und die Faltung der Polypeptidkette beschrieben. Hier bezieht es sich nur auf die lokale räumliche Anordnung von Atomen im
Polypeptid-Grundgerüst, aber nicht auf die räumliche Anordnung von Seitenketten. Es geht um die
Wasserstoffbindung in Intra- und Inter-Polypeptidkette. Die wichtigen Sekundärstrukturtypen sind
α-Helix, β-Faltblatt und β-Schleife, die häufig in Proteinen vorkommen, weil sie sich allein durch
Wasserstoffbindungen zwischen den N-H-Gruppen und den C=O-Gruppen im Polypeptid-Grundgerüst ausbilden, ohne die Seitenketten der Aminosäuren einzubeziehen.
Die α-Helix, die zum ersten Mal im Protein α-Keratin gefunden wurde, beschreibt die Schraubung
der Primärstruktur. Die α-Helix entsteht in Intra-Polypeptidkette. Zwischen jeder vierten Peptidbindung wird eine Wasserstoffbindung ausgebildet, die die N-H-Gruppe einer Peptidbindung mit
der C=O-Gruppe der nächst vierten Peptidbindung verbindet (s. Abb.2-11 (A)). Durch viele Wasserstoffbindungen in der Peptidkette entsteht eine regelmäßige Schraube und konstruiert eine stabile α-Helix-Struktur. Der Abstand zwischen zwei benachbarten Windungen beträgt 0,54nm und
jede Windung hat 3,6 Aminosäure-Reste. Eine Helix kann entweder ein Rechts- oder ein Linksgewinde haben (s. Abb. 2-11 (B)). Die α-Helix in Proteinmoleküle hat das Rechtsgewinde.
Abb. 2-11
α-Helix (aus [31])
10
Das β-Faltblatt, das ein Jahr nach der Entdeckung der α-Helix in Haarprotein β-Keratin gefunden
wurde, beschreibt parallel verlaufende Primärstrukturbereiche. Das β-Faltblatt entsteht in Inter-Polypeptidkette. Beim β-Faltblatt sind zwei oder mehrere Polypeptidketten in bestimmter dreidimensionaler Struktur wie ein mehrfach gefaltetes Blatt angeordnet (s. Abb. 2-12 (A)) und sind
ebenfalls durch Wasserstoffbindungen miteinander verbunden. Im β-Faltblatt liegen α-C-Atome
immer in den Kanten eines mehrfach gefalteten Blattes. Die Aminosäurenseiten R, die sich mit
α-C-Atome verbinden, liegen in der senkrechten Richtung der Kante. Es gibt zwei Typen von
β-Faltblättern (s. Abb. 2-12 (B)). Die beiden β-Faltblatt-Typen werden durch Wasserstoffbindungen stabilisiert, die in Zweierpaaren im Abstand von 0,7nm vorkommen.
Parallele Faltung: Die nebeneinander liegenden Polypeptidketten verlaufen in die gleiche Richtung.
Antiparallele Faltung: In einer sich hin und zurück faltenden Polypeptidkette läuft jeder
Kettenabschnitt in die Gegenrichtung zu seinem unmittelbaren Nachbarn.
Abb. 2-12
β-Faltblatt (aus [31])
Im Proteinmolekül können Peptidketten ihre Richtung umkehren, indem sie β-Schleife ausbilden.
Bei dieser Schleifenstruktur wird die C=O-Gruppe des Aminosäurerestes n durch eine Wasserstoffbindung mit der N-H-Gruppe des Aminosäurerestes (n+3) verbunden, so dass eine stabile
Struktur erzeugt wird (s. Abb. 2-13).
Abb. 2-13
β-Schleife (aus [28])
11
Die Tertiärstruktur beschreibt, dass Polypeptidketten, die auf die Sekundärstruktur basieren, sich
durch verschiedene Bindungskräfte und Wechselwirkungen weiter schrauben und falten. Unter
dieser Struktur versteht man die räumliche Struktur aller Atome nicht nur von dem Polypeptid-Grundgerüst sondern auch von den Aminosäureseitenketten. Die Tertiärstruktur eines Proteins
muss mit Hilfe der Röntgenstrukturanalyse aufgeklärt werden. Die Röntgenstrukturanalyse bestimmt die Struktur eines kristallinen Proteins durch das Beugungsbild und gibt Informationen
über die Art der Atome und über die Atomabstände. Das Myoglobin ist das erste Protein, dessen
räumliche Struktur 1960 bekannt wurde. Die 3D-Struktur von Myoglobin stellt sich wie Abb. 2-14
dar.
Durch die Untersuchung zahlreicher einheitlicher Proteine aus verschiedener Herkunft erkennt
man, dass viele Proteine aus mehr als einer Polypeptidkette bestehen. Jede Polypeptidkette eines
solchen Proteins wird als Untereinheit bezeichnet. Die Quartärstruktur beschreibt den räumlichen Aufbau solcher Untereinheiten und die Art ihrer Kontakte. Mehrere Untereinheiten können
sich zusammen verbinden, was man auch Polymer nennt. Polymer kann nach der Anzahl der Untereinheiten klassifiziert werden als Monomer, Dimer, … usw. Abb. 2-15 zeigt die Quartärstruktur
von Hämoglobin, der Sauerstofftransporter in roten Blutkörperchen ist. Hämoglobin ist ein Tetramer, der aus vier Untereinheiten besteht. Die Untereinheiten von Hämoglobin sind nicht über Peptidbindungen oder Disulfidbrücken, sondern vornehmlich über ionische Interaktionen und Wasserstoffbrücken miteinander verbunden.
Abb. 2-14
3D-Struktur von Myoglobin ohne Häm
Abb. 2-15
(aus [32])
2.3
Quartärstruktur von Hämoglobin
(aus [21])
Nucleinsäuren und Nucleotide
Nucleinsäuren sind Moleküle, die die Erbinformationen speichern. Es gibt zwei Typen von Nucleinsäuren: DNA (Desoxyribonucleinsäure, engl. deoxyribonucleic acid) und RNA (Ribonucleinsäure, engl. ribonucleic acid). Nucleinsäuren bestehen hauptsächlich aus fünf chemischen Elementen: Kohlenstoff (C), Wasserstoff (H), Sauerstoff (O), Stickstoff (N) und Phosphor (P). DNA
und RNA sind lineare Polymere, die aus Nucleotiden bestehen.
12
Ein Nucleotid besteht aus
einem Phosphat-Rest (P) (Monophosphat, Diphosphat oder Triphosphat),
einer der fünf Nucleinsäure-Basen,
einem Zucker (Monosaccharid) mit fünf C-Atomen, auch Pentose (Z) genannt, das als
Fünfring bezeichnet wird (siehe Abb. 2-16).
Abb. 2-16
Ein Nucleotid (aus [26])
Abb. 2-17
Der Zucker (aus [26])
In der DNA ist der Zucker immer Desoxyribose, in der RNA immer Ribose. Beide Zucker sind
Zucker mit fünf C-Atomen. Desoxyribose hat ein Element Sauerstoff weniger als Ribose (s. Abb.
2-17).
Es gibt fünf verschiedene Typen von Basen in Nucleinsäure: Adenin (Ade, A), Guanin (Gua, G),
Cytosin (Cyt, C), Uracil (Ura, U) und Thymin (Thy, T). Man benutzt normalerweise die
Ein-Buchstaben-Abkürzung. DNA und RNA. Beide haben vier Basen. DNA enthält A, G, C, T,
während RNA A, G, C, U enthält. Die Nucleinsäure-Basen sind in zwei Klasse: Purin- und Pyrimidin-Basen klassifiziert. Die kleinen Pyrimidein-Basen (C, U, T) enthalten einen einzigen Kreis,
während die Puin-Basen (A, G) einen abgesicherten Doppelkreis (s. Abb. 2-18) haben.
Abb. 2-18
Fünf Nucleinsäure-Basen (aus[16])
13
Verknüpft man eine Nucleinsäure-Base mit Ribose oder Desoxyribose, erhält man ein Nucleosid
oder Desoxynucleosid. Verknüpft man ein (Desoxy)nucleosid mit einer Phosphorsäure, erhält man
ein Nucleotid. Folgende Tabelle (aus [26]) zeigt die Basen, Nucleoside und Nucleotide:
Base
Nucleosid
Nucleotid
Adenin (A)
Guanin (G)
Cytosin (C)
Thymin(T)
Uracil (U)
Adenosin
Guanosin
Cytidin
Thymidin
Uridin
Adenosinmonophosphat (AMP)
Guanosinmonophosphat (GMP)
Cytidinmonophosphat (CMP)
Thymidinmonophosphat (TMP)
Uridinmonophosphat (UMP)
Ein DNA-Molekül besteht aus zwei langen Nucleotidketten. Jede dieser Ketten wird als
DNA-Strang bezeichnet, in dem jedes Nucleotid mit seinem Nachbarn über eine Phosphodiesterbindung verknüpft ist. Eine Nucleotidkette hat eine bestimmte Richtung. Definitionsgemäß ist die
Direktionalität der Kette immer von 5’-Ende bis 3’-Ende. Die zwei DNA-Stränge werden über
Wasserstoffbrücken zwischen den Basen der verschiedenen Stränge nach dem Prinzip der komplementären Basenpaarung antiparallel verbunden und formen die DNA-Doppelhelix. Die komplementäre Basenpaarung in DNA ist A mit T und C mit G.
Abb. 2-19
Doppelhelix von DANN (aus[26])
Ein RNA-Molekül besteht nur aus einer Nucleotidkette. Die komplementäre Basenpaarung in
der RNA ist A mit U, G mit C und G mit U. Es gibt drei Hauptarten von RNA: mRNA (Messenger-RNA) dient als Matrize der Proteinbiosynthese; rRNA (Transfer-RNA) wirkt als Adapter zwischen mRNA und Aminosäuren bei der Proteinbiosynthese; rRNA (Ribosomale RNA) ist das Bestandteil des Ribosoms, das als Proteinfabrik an der Proteinbiosynthese beteiligt. Die genauen
Funktionen der RNA werden später in Abschnitt 2.4 Proteinbiosynthese beschrieben.
14
2.4 Proteinbiosynthese
Proteinbiosynthese beschreibt, wie ein Protein oder ein Polypeptid in Lebewesen hergestellt wird.
Im Abschnitt 2.1 haben wir schon gesehen, dass Proteine oder Polypeptide sich in der Länge und
der Anordnung ihrer Aminosäurenketten unterscheiden. Die Anordnung jeder Aminosäurenkette
ist nicht willkürlich, sondern wird durch die Anordnung der Basen in Gene streng gebildet. Ein
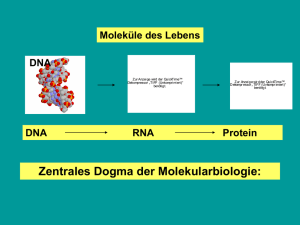
Gen ist ein Abschnitt auf der DNA, der die Grundinformationen zur Herstellung einer RNA speichert. Die genetischen Informationen werden von der DNA über die RNA zum Protein übertragen.
Proteinbiosynthese lässt sich in zwei Schritte einteilen: Transkription (von DNA zu RNA) und
Translation (von RNA zu Protein). Der vereinfachte Prozess der Proteinbiosynthese wird in Abb.
2-20 angegeben. Das Ziel dieses Abschnitts ist es, die zwei Schritte von Proteinbiosynthese zu
erklären.
Abb. 2-20
2.4.1
Vereinfachter Prozess der Proteinbiosynthese (aus [24])
Transkription
Die genetischen Informationen in dem entsprechenden Abschnitt der DNA-Nucleotidsequenz,
dem Gen, werden auf eine RNA-Nucleotidsequenz übertragen. Dieser Vorgang wird Transkription
genannt, weil die Informationen im Gen und in der RNA immer noch in derselben Sprache von
Nucleotiden geschrieben werden. Das Produkt der Transkription ist eine RNA-Kette, die
RNA-Transkript genannt wird. Die Transkription liefert drei Haupttypen von RNA: mRNA,
tRNA und rRNA.
Die Transkription wird mit Hilfe von einem Enzym, RNA-Polymerase genannt, durchgeführt. Die
RNA-Polymerase dient zur Aufschraubung der Doppelhelix der DNA. Einer der beiden Stränge
der DNA-Doppelhelix dient als Matrize für die Transkription und wird Matrizenstrang genannt.
Der andere gegenüberliegende Strang wird codierender Strang genannt. Die Transkription wird
in drei Phasen eingeteilt:
1. Initiation: Die Transkription beginnt mit einem kleinen Abschnitt von Nucleotidsequenzen in
der DNA, dem sogenannte Promotor (Startsignal). Der Einfachheit halber markiert man die
Startposition der Transkription mit +1. Nucleotidsequenzen, die in der Transkriptionsrichtung
(5’Æ3’) stromaufwärts von der Startposition liegen, haben negative Vorzeichen. Umgekehrt
haben sie positive Vorzeichen. Der Promotor sind Nucleotidsequenzen zwischen -35 und +1.
Die Initiationsphase unterscheidet sich in Eukaryonten und in Prokaryonten. In Prokaryonten
bindet die RNA-Polymerase zuerst an dem Promotor an und öffnet die DNA-Doppelhelix.
15
Abb. 2-21
Initiation bei der Transkription (aus [26])
2. Elongation: Vom Promotor aus bewegt sich die RNA-Polymerase immer um ein Nucleotid in
der Richtung 3’Æ5’ auf dem Matrizenstrang entlang und liest jedes Nucleotid des Matrizenstrangs. Auf dieser Weise wird die wachsende RNA-Kette immer um ein Nucleotid nach dem
Prinzip der komplementären Basenpaarung in der Richtung 5’Æ3’ verlängert (s. Abb. 2-22).
3. Termination: Die Verlängerung der wachsende RNA-Kette wird durchgeführt, wenn die
RNA-Polymerase ein Terminationssignal (Stopsignal) trifft. Schließlich werden die durch
Transkription erzeugte RNA-Kette und die RNA-Polymerase entlassen. Die Doppelhelix von
der DNA wird wieder hergestellt.
Abb. 2-22
2.4.2
Elongation bei der Transkription (aus [25])
Translation
Die Übertragung der genetischen Informationen in der mRNA-Nucleotidsequenz auf die Aminosäuresequenz eines Proteins wird Translation genannt, weil die genetischen Informationen in der
mRNA und im Protein mit verschiedenen Sprachen geschrieben werden. Also werden Informationen in der Sprache von Nucleotiden in die Sprache von Aminosäuren übersetzt. Bei der Translation arbeiten vier wesentliche beteiligte Komponenten zusammen:
16
Zwanzig proteinogene Aminosäure sind Rohmaterialien von Proteinen.
mRNA dient als die Matrizen der Proteinsynthese. Die Anordnung der Aminosäuren im
Protein wird durch die Nucleotidsequenz in mRNA bestimmt. Da es in der mRNA nur
vier verschiedene Nucleotide gibt, während es im Protein zwanzig verschiedene proteinogene Aminosäuren gibt, kann ein Nucleotid in der mRNA nicht direkt Eins-zu-Eins in
eine Aminosäure im Protein übersetzt werden. Auf der mRNA in der Richtung 5’Æ 3’
werden nach dem Startcodon AUG jede drei aufeinander folgende Nucleotide als ein
Codon gruppiert. Da die vier verschiedenen Nucleotide aus mRNA beliebig zu drei
kombinieren können, gibt es 43 = 64 mögliche Codonkombinationen. Diese Codons
repräsentieren nicht nur die zwanzig proteinogenen Aminosäuren, sondern bestimmen
auch die Anfangs- und Endposition bei der Transaktion. Jede Aminosöure hat mindestens ein Codon und meistens sechs Codons. In den frühen sechziger Jahren wurde der
genetische Code mit Experimenten entziffert. Nach dem genetischen Code (s. Abb.
2-23) wird die Nucleotidsequenz eines Gens über die RNA in die Aminosäuresequenz
eines Proteins übersetzt. Wir können sehen, dass 61 von den 64 Codonkombinationen
die Aminosäuren entschlüsseln und 3 davon ein Stopcodon bezeichnen, bei dem die
Proteinsynthese endet.
Abb. 2-23
Genetischer Code (aus [25])
Die tRNA dient als Adapter, der auf der einen Seite eine Aminosäure auswählt und auf
der anderen Seite im Ribosom an der richtigen Stelle zum Aufbau eines Proteins landet.
Da Codons in einer mRNA Aminosäuren nicht direkt erkennen, besteht zwischen der
mRNA und der Aminosäure keine Beziehung. Es wird also ein Bindeglied benötigt, um
die mRNA mit der Aminosäure indirekt zu verbinden. Die tRNA spielt hier genau diese
Rolle. Die Struktur einer tRNA sieht wie ein Kleeblatt aus (s. Abb. 2-24 (A) (C)). Das
Anticodon unten in der tRNA ist eine Folge von drei aufeinander folgenden Nucleotiden,
die nach der komplementären Basenpaarung mit einem Codon in der mRNA verbunden
sind. Die Bindungsstelle für die Aminosäure oben in der tRNA wählt eine Aminosöure,
die zum Codon in der mRNA passt. Jedes 3’-Ende von tRNA ist CCA. Der Einfachheit
halber wird normalerweise das in Abb. 2-24 (B) gegebene vereinfachte Zeichen von
tRNA bei der Translation verwendet.
17
Abb. 2-24
Struktur einer tRNA (aus [24])
Das Ribosom dient als Proteinfabrik bei der Translation. Das Ribosom ist ein riesiger
Komplex, der aus Proteinen und rRNAs besteht. Das Ribosom eines jeden Lebewesens
setzt sich aus einer großen und einer kleinen Untereinheit zusammen. Die kleine Untereinheit ist für die Verbindung der tRNA mit den Codons der mRNA verantwortlich. Die
große Untereinheit katalysiert die Bindung der Peptidbindung, die die Aminosäure zu
einer Polypeptidkette verbindet [30]. Für die tRNA gibt es in jedem Ribosom drei Bindungsstellen („site“), die A-, P-, E-Bindungsstellen. A-Stelle ist die Position auf dem
Ribosom für die tRNA, welche die nächstfolgende Aminosäure trägt. P-Stelle ist die Position für die Initiator-tRNA und die tRNA, welche später die wachsende Peptidkette
trägt. Jedes Ribosom hat auch eine mRNA-Bindungsstelle (s. Abb. 2-25). An der
E-Stelle verlässt eine bereits entladene tRNA das Ribosom. Für die mRNA gibt es in jedem Ribosom eine mRNA-Bindungsstelle.
Abb. 2-25
Darstellung des Ribosoms (aus [24])
18
Mit Hilfe der oben genannten wesentlichen Komponenten kann die Translation in folgenden vier
Phasen durchgeführt werden:
1. Aminosäure-Aktivierung: In dieser Phase geht es darum, wie eine tRNA ihre richtige Aminosäure erkennt und sich mit diese Aminosäure verbindet. Bei der Erkennung und Verbindung
der richtigen Aminosäure werden bestimmte Enzyme, die Aminoacyl-tRNA-Synthetasen, gebraucht. Eine tRNA, die eine Aminosäure trägt, wird als Aminoacyl-tRNA genannt. Jede
Aminosäure hat ihre eigene Synthetase, d.h. für 20 proteinogene Aminosäuren gibt es 20 verschiedene Synthetasen. Diese Synthetase dient hier als ein Vermittler, da sie auf der einen
Seite die entsprechende Aminosäure mit Hilfe von Energie (ATP) aufnimmt (s. Abb. 2-26 (A))
und auf der anderen Seite die richtige tRNA erkennt (s. Abb. 2-26 (B)).
Abb. 2-26
Aktivierung der Aminosäuren und ihre Koppelung an der tRNA (aus [33])
2. Initiation: Die Translation beginnt immer mit dem AUG-Codon. Für das AUG-Codon brauchen wir hier eine mit der Aminosäure Methionin beladene tRNA (die so genannte Initiator-tRNA). Da die Strukturen von eukaryontischen und prokaryontischen mRNA-Molekülen
(s. Abb. 2-27) unterschiedlich sind, unterscheidet sich die Initiationsphase in Eukaryonten und
in Prokaryonten. In Eukaryonten (s. Abb. 2-28) wird die Initiator-tRNA mit zusätzlichen Proteinen (so genannten Initiationsfaktoren) zuerst an der P-Stelle der kleinen Ribosomenuntereinheit verbunden. Diese beladene kleine Ribosomenuntereinheit wird dann am 5’-Ende eines mRNA-Moleküls angekoppelt und bewegt sich als nächstes auf der mRNA von 5’-Ende
zum 3’-Ende, bis das erste AUG-Codon gefunden wird. Wird ein solches AUG-Codon gefunden, koppelt es an die große Ribosomenuntereinheit an. Jetzt ist die Initiationsphase fertig und
19
es beginnt die Elongationsphase. Im Gegensatz zu eukaryontischen Ribosomen binden sich
prokaryontische Ribosomen am Anfang nicht an das 5’-Ende eines mRNA-Moleküls an, sondern direkt an der Ribosomenbindungsstelle vor dem AUG-Codon eines mRNA-Moleküls. Da
es viele Ribosomenbindungsstellen in einem prokaryontischen mRNA-Molekül gibt, können
Prokaryonten mehr als ein Protein von einer einzigen mRNA-Species synthetisieren.
Abb. 2-27
Vergleich der Strukturen von prokaryontischen und eukaryontischen mRNA-Molekülen
(aus [24])
Abb. 2-28
Initiation bei der Translation (aus [24])
3. Elongation: Am Anfang der Elongation steht eine Aminoacyl-tRNA (Nach der Initiation ist
diese Aminoacyl-tRNA Initiator-tRNA.) an der P-Stelle des Ribosoms, und die A-Stelle ist
noch frei. Die nächste Aminoacyl-tRNA wandert in das Ribosom und bindet zuerst nach dem
Prinzip der komplementären Basenpaarung durch ihr Anticodon an die A-Stelle des Ribosoms.
Bis jetzt sind P- und A-Stelle des Ribosoms besetzt (s. Abb. 2-29: Schritt 1). Dann verbindet
die Aminosäure auf der Aminoacyl-tRNA an der P-Stelle mit der Aminosäure auf der Aminoacyl-tRNA an der A-Stelle und eine Peptidbindung wird aufgebaut. Die große Untereinheit
des Ribosoms bewegt sich um ein Codon in der Richtung 5’Æ3’ und die Aminoacyl-tRNA
links besetzt die E-Stelle bzw. die Aminoacyl-tRNA rechts die P-Stelle (s. Schritt 2). Als
20
nächstes bewegt sich die kleine Untereinheit des Ribosoms um ein Codon in der Richtung
5’Æ3’ und die Aminoacyl-tRNA an der E-Stelle wird entlassen. Nun ist die A-Stelle wieder
frei und für die Bindung der nächsten Aminoacyl-tRNA bereit (s. Schritt 3). Dann laufen die
Schritte 1 bis 3 um.
Abb. 2-29
Elongation bei der Translation (aus [24])
4. Termination: Die Elongation des Polypeptids beendet, wenn ein Stopcodon sich an der
A-Stelle befindet. Dann bindet der so genannte Release-Faktor an der A-Stelle und das Polypeptid wird entlassen. Dieses Polypeptid faltet sich und formt ein Protein. Schließlich trennen sich die zwei Untereinheiten des Ribosoms, so dass die tRNA, die mRNA und der Release-Faktor entlassen werden. Nun ist die Biosynthese eines Proteins fertig.
Abb. 2-30
Termination bei der Translation aus [24]
21
Kapitel 3 Grundlagen aus der Informatik
Dieses Kapitel besteht aus sechs Abschnitten. Im Abschnitt 3.1 werden die Phasen des Datenbankentwurfs vorgestellt. Im Abschnitt 3.2 folgt eine kurze Beschreibung der relationalen Datenbanksprache SQL. Im Abschnitt 3.3 werden die Grundlagen von Java erläutet, inklusive Java
Servlet und Java Server Page, die für die Entwicklung der Web-Anwendung eine wichtige Rolle
spielen, sowie ihr Web-Container Apache Tomcat. Schließlich wird im Abschnitt 3.4 die
JDBC-Technik zur Bindung von Java an die Datenbank erklärt. Der Abschnitt 3.1 und Abschnitt
3.2 orientiert sich an [35]-[38], der Abschnitt 3.3 an [34], [42]-[45] und der Abschnitt 3.4 an [34],
[40], [41].
3.1 Datenbankenwurfsphasen
Der Datenbankentwurf kann in vier Phasen eingeteilt werden. Die erste Phase ist die Anforderungsanalyse, die im Dialog zwischen DB-Nutzer und DB-Designer erstellt wird. In dieser Phase
ermitteln die DB-Designer bei den zukünftigen DB-Nutzern ihre Anforderungen an die Datenbank.
Diese Anforderungen werden in einer vollständigen und ausführlichen Dokumentation (sog.
Pflichtenheft) beschrieben. Die zweite Phase ist der konzeptuelle Entwurf. In dieser Phase werden die aus der Anforderungsanalyse resultierenden Informationen mittels eines semantischen
Datenmodells (meistens Entity-Relationship-Modell) in eine formale Darstellung, das so genannte
konzeptuelle Schema umgesetzt. Der konzeptuelle Entwurf ist DBMS-unabhängig. DB-Designer
beschäftigen sich nur mit der Spezifikation der zu speichernden Daten, ohne die Speicherungsdetails zu berücksichtigen. Mit Hilfe des konzeptuellen Schemas kann man sicherstellen, dass alle
Anforderungen der DB-Nutzer erfüllt und die Gesetzmäßigkeiten des Anwendungsgebiets nicht
verletzt werden. Der Logische Entwurf ist die dritte Phase des Datenbankentwurfs. Hier wird das
konzeptuelle Schema mit Hilfe eines relationalen Datenmodells in einem relationalen Schema
umgesetzt. Das für diese Phase häufig verwendete Datenmodell ist das Relationenmodell. Unter
Verwendung eines kommerziellen DBMS ist der logische Entwurf DBMS-spezifisch. Schließlich
folgt der physische Entwurf. Es geht bei dieser Phase um die internen Speicherstrukturen,
Zugriffspfade und Dateiorganisationen im Rechner [38].
3.1.1
Konzeptueller Entwurf
Das Entity-Relationship-Modell (ER-Modell) ist ein populäres Datenmodell für den konzeptuellen
Entwurf. Es bietet einige nützliche Konzepte, mit denen die unformale Darstellung aus einer gegebenen Realwelt in eine präzisere formale Darstellung umgesetzt wird. Als nächstes werden diese grundlegende Konzepte näher erläutet.
Entities (Gegenstände) sind „wohlunterscheidbare physisch oder gedanklich existierende Konzepte der zu modellierenden Welt“ [46]. Ein Entity kann ein physisch existierendes Objekt sein,
z.B. ein Protein, eine Aminosäure, eine Person oder ein gedanklich existierendes Objekt, z.B. eine
Firma, eine Vorlesung. Jedes Entity ist durch seine Attribute mit Attributwerte charakterisiert.
22
Die Menge alle möglichen Werte wird Wertebereich genannt. Entity-Typen sind Sammlungen
von Entities mit identischer Attributstruktur. Jedes zu einem Entity-Typ gehörende Entity wird
Instanz dieses Typs genannt. Die Menge aller Instanzen eines Entity-Types heißt Population. Es
gibt im ER-Modell auch spezielle Entity-Typen; sie heißen schwache Entity-Typen. Ein schwacher Entity-Typ hängt stark von seinem übergeordneten Entity-Typ ab. „Instanzen eines schwachen Entity-Typs existieren nur dann, wenn sie in einer bestimmten Beziehung zu einer Instanz
eines übergeordneten Entity-Typs stehen“ [35]. Um die einzelnen Instanzen pro Entity-Typ eindeutig zu identifizieren, ist normalerweise nicht die Angabe aller Attributwerte erforderlich. Ein
Attribut oder eine minimale Menge von Attributen pro Entity-Typ, deren Werte die Identifikationseigenschaft besitzt, heißt Primärschlüssel. Ein Fremdschlüssel eines Entity-Typs A ist ein
Primärschlüssel eines anderen Entity-Typ B, wenn A B referenziert.
Relationships (Beziehungen) beschreiben die Zusammenhang zwischen zwei oder mehreren Entities. Ein Relationship kann auch seine eigenen Attribute besitzen. Relationship-Typen sind
Sammlungen von Relationships mit sowohl identischer Attributstruktur als auch identischen Typen und identischer Anzahl der beteiligten Entities. Jede zu einem Relationship-Typ gehörende
Relationship zwischen ihren beteiligten Entities ist eine Instanz dieses Typs. Im ER-Modell kann
die Beziehungen zwischen beteiligten Entity-Typen beschränkt werden. Solche Beschränkungen
sind so genannte Funktionalitäten [35] und werden durch die Annotationen an den Kanten zwischen beteiligten Entity-Typen und Relationship-Typen ausgedrückt. Es gibt vier verschiedene
Formen von binären Beziehungen: 1:1 1:N, N:1, N:M.
Die geschilderten Modellierungskonzepte reichen noch nicht aus, bestimmte spezielle Beziehungen zu modellieren. Dann wird das ER-Modell erweitert und das EER-Modell (Extended
ER-Modell) wird eingeführt. Um die Population eines Entity-Typs zu klassifizieren, wird die Generalisierung (IS-A-Beziehung) eingeführt. Sie beschreibt, dass die Population der Untertyps
Teilmengen der Population des Obertyps sind, z.B. die Beziehung zwischen Protein und Polymer.
Eine andere Erweiterung des ER.Modells ist die Aggregierung (IS-PART-OF-Beziehung). Sie
beschreibt, dass die Instanzen der Untertypen Bestandteile von Instanzen des Obertyps sind, z. B.
die Beziehung zwischen Gen und DNA.
Die graphische Notation des ER-Modells basiert auf einem Skript [35]. Ein Entity-Typ wird als
Rechteck bezeichnet, in das man den Namen des Entity-Tys schreibt. Ein schwacher Entity-Typ
wird als Rechteck mit doppelter Linie bezeichnet. Normalerweise werden als Namen der Entity-Typen Substantive verwendet. Der Wertebereich eines Attributs wird als Oval bezeichnet, in das
man einen Wertbereichsnamen (z.B., Int, String, usw.) schreibt. Mit einem Pfeil wird ein Entity-Typ mit dem Wertebereich seines Attributs verbunden, und der Pfeil wird mit diesen Attributnamen markiert. Wertbereichsnamen, die offensichtlich oder nicht wichtig sind, werden häufig
ausgelassen. Stattdessen werden die Attribute in das Oval geschrieben oder einfach ohne Oval
unter den Entity-Typ geschrieben. Schlüsselattribute werden durch Attributname mit Unterstrich
bezeichnet. Ein Relationship-Typ wird als Raute bezeichnet, die mit dem Namen des Relationship-Typs markiert wird. Normalerweise verwendet man Verben oder Substantive mit Präpositionen als Namen der Relationship-Typen. IS-A-Beziehung wird als Sechseck bezeichnet, die mit
dem Namen „is_a“ markiert wird. Außerdem werden Pfeile über IS-A-Beziehung von Untertypen
23
nach Obertypen bezeichnet. Für IS-PART-OF-Beziehung wird auch eine Raute verwendet, die mit
dem Namen „is_part_of “ makiert wird.
3.1.2
Logischer Entwurf
Beim logischen Entwurf wird das aus dem konzeptuellen Entwurf resultierende ER-Modell ins
relationale Datenmodell übersetzt. In relationalen Datenbanken, die das relationale Datenmodell
unterstützt, werden die Daten in Relationen gespeichert. Im Allgemeinen können relationale Datenbanken als Kollektionen von Relationen vorgestellt werden. Jede Relation wird als eine
zwei-dimensionale Tabelle dargestellt. Die Zeilen der Tabelle entsprechen Entities und die Spalten
entsprechen Attributen. Die Spezifikation einer Relation – das relationale Schema – besteht aus
der Spezifikation, dem Namen und der Struktur einer Relation. Das relationale Modell ist eine
Kollektion relationaler Schemata.
Die Umsetzung der ER-Schemata in relationale Schemata geschieht nach folgenden Regeln[35]:
Regel 1: Entity-Typen werden in Relationen (Tabellen) umgesetzt. Die Attribute eines Entity-Typs
sind Attribute (Spalten) der Relation. Schwache Entity-Typen werden genau so wie normale Entity-Typen in Relationen umgesetzt. Hier bilden jedoch die Schlüsselattribute des
übergeordneten Entity-Typs und die Attribute eines schwachen Entity-Typs zusammen
den Schlüssel dieses schwachen Entity-Typs.
Regel 2: Nicht alle Relationship-Typen werden in Relationen umgesetzt. Für 1:1 RelationshipTypen kann die Beziehungsinformation in beliebigen beteiligten Entity-Typ eingebettet
sein. Der Primärschlüssel eines beteiligten Entity-Typs wird Fremdschlüssel in einem
anderen Entity-Typ, welcher die Beziehungsinformation speichert.
Regel 3: Ähnlich wie 1:1 Relationship-Typen werden 1:N Relationship-Typen auch nicht in Relationen umgesetzt. Die Beziehungsinformation wird in den mit N markierten Entity-Typ
eingebettet. Der Primärschlüssel des mit 1 markierten Entity-Typs wird Fremdschlüssel
in dem mit N markierten Entity-Typ.
Regel 4: M:N Relationship-Typen werden in Relationen umgesetzt. Die Primarschlüssel der beteiligten Entity-Typen bilden in Kombination den Primärschlüssel dieser Relation.
Regel 5: Für die Umsetzung der IS-A-Beziehung gibt es drei Lösungsmöglichkeiten. Es wird angenommen, dass eine IS-A-Beziehung zwischen Entity-Typ E1 und E2 besteht. Dabei ist
E1 ider Obertyp von E2.
Alternative 1: Eine Lösung nach der Regel 1 besteht darin, dass eine Relation E1 mit ihren eigenen Attributen A1, A2, … und eine Relation E2 mit den von E1 vererbten Attributen A1, A2, … und ihren eigenen Attributen B1, B2, … erstellt wird. Mit dieser Lösung
kann der Zugriff auf die Attribute sehr schnell erfolgen, jedoch wird der Platzbedarf erhöht, da Werte der vererbten Attribute immer in der Relation E1 und E2 doppelt gespeichert werden.
Alternative 2: Um redundante Speicherung der vererbten Attribute zu vermeiden, wird
nur der Schlüssel von E1 zur Verknüpfung in E2 modelliert. Dann werden die Relation E1
mit den Attributen A1, A2, … und die Relation E2-lokal nur mit dem Schlüsselattribut A1
von E1 und ihrer eigenen Attributen B1, B2, ….erstellt. Durch JOIN-Operation zwischen
E1 und E2-lokal wird eine Sicht E2-global für die vollständige E2-Population erstellt. Mit
24
dieser Lösung wird die redundante Speicherung der vererbten Attributwerte stark reduziert, nur Schlüsselattributwerte werden doppelt gespeichert. Wegen der JOIN-Operation
ist der Zugriff auf E2-Attribute jedoch langsamer als bei der ersten Alternative. Die
SQL-Anweisung aus [35] für diese Lösung ist:
CREATE VIEW E2-global AS
(SELECT *
FROM E1 INNER JOIN E2-lokal ON E1. A1 = E2-loka. A1)
Alternative 3: Werte der vererbten Attribute A1, A2, … werden verteilt und in verschiedenen Relationen E1-lokal und E2 gespeichert. Die Relation E2 mit den Attributen A1,
A2, …, B1, B2, … und E1-lokal mit den Attributen A1, A2, … werden erstellt. Dann wird
durch eine Union-Operation die E2-Population mit der E1-lokal-Population vereinigt,
und die gesamte Population wird über eine Sicht E1-global realisiert. Hier müssen die
E2-Population und die E1-lokal-Population ohne Überlappung die E1-global-Population
vollständig überdecken. Der Vorteil dieser Lösung besteht darin, dass es keine doppelte
Speicherung der Attributwerte mehr gibt. Wegen der Union-Operation ist der Zugriff auf
die E1-Attribute jedoch langsamer als bei der zweiten Alternative. Die SQL-Anweisung
aus [35] für diese Lösung ist:
CREATE VIEW E1-global AS
(TABLE E1-lokal)
UNION
(SELECT A1, A2, … FROM E2)
3.2 SQL
SQL (Abkürzung für „Structured Query Language“) ist eine umfassende und populäre Datenbanksprache zum Zugriff und Manipulieren von relationalen Datenbanken. Ursprünglich wurde
SQL von IBM in den 1970er Jahren [38] entwickelt und als Sprache für das experimentelle relationale DBMS „System R“ implementiert. Damals wurde SQL als SEQUEL (Abkürzung für
„Structured English Query Language“) bezeichnet. Ab 1986 wurden viele Versionen von SQL
entwickelt. SQL1 (SQL-86) ist die erste Standardversion von SQL. SQL2 (SQL-92) ist ein revidierter und deutlich erweiterter Standard. Heute ist SQL2 üblich und für alle aktuellen Datenbank-Produkte standardisiert. Der neue Standard SQL3 (SQL:1999) wurde für objektorientierte
und andere Datenbankkonzepte entwickelt. Er ist noch nicht in allen Datenbank-Produkten implementiert. Die meisten kommerziellen Datenbank-Produkte haben ihre eigenen Erweiterungen
zusätzlich zum SQL-Standard, die in der Regel mehr oder weniger gut mit dem SQL-Standard
kompatibel sind.
In der vorliegenden Arbeit wird Microsoft Access als DBMS eingesetzt, um eine Proteindatenbank
aufzubauen und zu verwalten. Deshalb wird zuerst der Zusammenhang zwischen Microsoft Access und SQL dargestellt. Einerseits bringt Microsoft Access viele neue Eigenschaften mit, um mit
25
dem Standard SQL-92 so eng wie möglich überein zu stimmen; andererseits hat Access einige
noch nicht von SQL-92 definierte spezielle Eigenschaften, die die Leistung von SQL erweitern
[36].
Bei der Anwendung von Access tritt SQL nicht in Erscheinung, weil Access für jede Daten-orientierte Aufforderung SQL automatisch, verdeckt anwendet und zwar nicht nur für den
Aufbau von Tabellen und Abfragen, sondern auch für den Aufbau von Berichten, Formularen,
Seiten, usw. Wegen der verbreiteten Verwendung von SQL überall in Access, ist es nötig, SQL zu
verstehen.
SQL setzen sich aus einer Datendefinitionssprache (DDL) und einer Datenmanipulationssprache
(DML) zusammen. Die DDL dient zum Erstellen und Verändern von Datenbankschemata. Die
DML dient zum Formulieren von Anfragen und Änderungen von Datenbankzuständen. Alle
SQL-Befehle bestehen aus englischen Schlüsselwörtern, die nicht an anderer Stelle wie z.B. als
Tabellen- oder Spaltennamen verwendet werden dürfen. Als nächstes werden die DDL und die
DML ausführlich beschrieben.
3.2.1
DDL
Die SQL-Befehle für Datendefinitionen sind CREATE, ALTER, DROP. Eine neue Tabelle wird
mit dem Befehl „CREATE TABLE“ erzeugt. Die Anweisung [37] ist:
Die Elemente einer Tabelle sind Spaltendefinitionen und Definitionen der Integritätsbedingungen.
Bei der Spaltendefinition bezeichnet jeder Spaltenname eine Spalte der Tabelle und jeder Datentyp
bezeichnet den zugehörigen Wertebereich. Integritätsbedingungen haben zwei Typen: Attributsbeschränkungen (column-constrains) und Tabellenbeschränkungen (table-constraints). Jede Attributsbeschränkung schreibt man normalerweise in jeder Spalte hinter jeder Attribut-Definition.
Ganz unten hinter allen Attribut-Definitionen einer Tabelle schreibt man Tabellenbeschränkungen.
Das zusammengefasste Format einer Tabellen-Definition [35] ist:
Syntax von Attributsbeschränkungen bzw. Tabellenbeschränkungen [35] ist:
26
In SQL ist die Definition mehrerer Schlüssel für eine Tabelle (Schlüsselkandidaten) möglich. Einer von den Schlüsselkandidaten wird als Primärschlüssel bezeichnet. Die UNIQUE-Klausel dient
zur Definition von Schlüsselkandidaten. Ein Einspaltiger Schlüsselkandidat wird in Attributbeschränkung angegeben mit dem Format: column-name … UNIQUE. Ein mehrspaltiger Schlüsselkandidat wird in der UNIQUE-Klausel der Tabellenbeschränkung angegeben mit dem Format:
UNIQUE (list-of-column-names). Die PIMARY KEY-Klausel gibt den Primärschlüssel einer Tabelle an. In einer Tabelle kann der Primärschlüssel aus einem Attribut oder mehreren Attributen
bestehen. Die FOREIGN KEY-Klausel gibt den Fremdschlüssel einer Tabelle an, der auch ein oder mehrere Attribute enthalten kann. Die REFERENCES-Klausel beschreibt die Schlüsselkandidaten oder Primärschlüssel einer anderen Tabelle, welche die Spalte der gerade deklarierten Tabelle referenziert. CHECK-Klausel gibt die erlaubten Werte an. Die UNIQUE-, PRRIMARY
KEY-, REFERENCES- und CHECK-Klausel kann entweder für jede Spalte einer Tabelle oder für
eine Tabelle als Ganzes definiert werden. NULL bezeichnet einen Nullwert und DEFAULT bezeichnet einen automatisch eingesetzten Wert einer Spalte, wenn eine Spalte keinen expliziten
gegebenen Wert hat.
Der ALTER TABLE-Befehl dient zur Änderung einer existierenden Tabelle. Die Anweisung [35]
ist:
Die Änderungsaktion beinhaltet:
Einfügen einer Spalte mit der Anweisung: ADD COLUMN column-definition,
Änderung eine Spalte mit der Anweisung: ALTER COLUMN column-name,
Löschen eine Spalte mit der Anweisung: DROP COLUMN column-name,
Einfügen einer Spaltenbeschränkung mit der Anweisung:
ADD CONSTRAINT column-constraint
Löschen einer Spaltenbeschränkung mit der Anweisung:
DROP CONSTRAINT column-constraint
Der DROP TABLE-Befehl dient zum Löschen einer existierenden Tabelle. Die Anweisung [35]
ist:
RESTRICT-Option bedeutet, dass DROP-Befehl erfolglos ist, wenn diese Tabelle noch auf andere
Tabelle referenziert. CASCADE-Option bedeutet, dass Löschung kaskadierend realisiert wird.
Eine Sicht ist im Gegensatz zu einer Basistabelle eine virtuelle Tabelle und wird aus einer oder
mehreren Basistabellen abgeleitet. Die Sicht-Definition dient zur Erzeugung einer neuen
SQL-Anfrage. Die Anweisung [37] ist:
SQL-Anfrage (select-expression) wird mit den SELECT-FROM-WHERE-Befehlen angeben, die
später in DML ausführlich beschrieben werden.
27
3.2.2
DML
Die SQL-Befehle für Datenmanipulationen bestehen aus Datenbank-Anfragen-Befehlen und Datenbank-Änderungen-Befehlen. Mit SELECT-FROM-WHERE-Befehlen kann man Anfragen
formulieren. Mit INSERT, DELETE und UPDATE kann man Datenbank-Änderungen wie Einfügungen, Löschungen und Modifikationen durchführen. Das Format [37] der Anfragen ist:
Einfache Anfragen
Eine einfache Anfrage enthält nur SELECT- und FROM-Klauseln. Die SELECT-Klausel bezeichnet den anzuzeigenden Spaltennamen einer oder mehrerer Tabellen, die in der FROM-Klausel angegeben werden. DISTINCT-Option bedeutet, dass identische Zeilen nur einmal angezeigt werden.
In der SELECT-Klausel kann auch die Aggregatfunktionen angewendet werden. Aggregatfunktionen sind COUNT, SUM, AVG, MAX und MIN. COUNT zählt alle Zeilen (wenn ein * angegeben
wird) oder alle nichtleeren Zeilen (wenn ein Spaltenname angegeben wird). SUM berechnet die
Summe aller Werte eines Spaltennamens. AVG bestimmt den Durchschnitt der Werte eines Spaltennamens. MIN und MAX berechnen den Minimum- bzw. Maximumwert eines Spaltennamens.
Anfragen mit Bedingungen
Die WHERE-Klausel bezeichnet die Selektionsbedingungen. Die Selektionsbedingungen können
mit folgenden Vergleichsoperatoren formuliert werden: =, >, <, >=, <=, <>. Die Schlüsselwörter
AND, OR, und NOT werden verwendet, um die weiteren Bedingungen zu konstruieren. Außerdem wird der Operator LIKE häufig verwendet, um die Zeichenfolgen, die mit einem gegebenen
Muster übereinstimmen, zu suchen.
Datensätze sortieren und gruppieren
Die GROUP BY-Klausel dient zur Gruppierung der Datensätze gemäß den in der HAVING-Klausel angegebenen Bedingungen. Die ORDER BY-Klausel dient zur Sortierung der Datensätze. Die DESC- und ASC-Option bezeichnet die Sortierungsrichtung absteigend bzw. aufsteigend.
Verschachtelte Anfragen (Unterfragen)
Nicht selten basieren Anfragen auf dem Ergebnis vorheriger Anfragen. Diese Unteranfragen können in FROM- oder WHERE-Klauseln vorkommen. Das Syntaxformat ist:
28
Algebraische Operatoren in SQL-Anfragen
Jede der zwei Anfragen kann algebraische Operationen mit den Anweisungen UNION, INTERSECT, MINUS und JOIN durchführen. UNION, INTERSECT und MINUS dürfen nicht in der
FROM-Klausel vorkommen. JOIN darf nur in der FROM-Klausel vorkommen. Das Syntaxformat
ist:
Syntaxformat [35] für die Einfügungen einer Tabelle ist:
Die Einfügung einer Tabelle hat zwei Formen:
Einfügung einer oder mehrerer Zeilen mit der Anweisung: VALUES (data-items),
Einfügung der Zeilen über eine Anfrage mit den SELECT-FROM-WHERE-Befehlen.
Syntaxformate [35] für Löschungen und Modifikationen einer Tabelle sind:
In diesem Abschnitt wurden die Grundlagen von SQL vorgestellt, um einen kompakten Überblick
über SQL zu geben. Ein empfehlenswertes Buch über SQL ist [39].
3.3 Java
3.3.1
Überblick über Java
Java ist eine objektorientierte Programmiersprache, die 1993 von der Firma Sun Microsystems
entwickelt wurde. Parallel zur Entwicklung des World Wide Web entwickelte sich Java als geeignete Programmiersprache für die Anforderungen des WWW. Der Grund der umfangreichen Verwendung von Java im Internet besteht darin, dass Java-Quellecodes zuerst mit einem Compiler,
dem so genannten JAVAC, in nicht direkt ausführbaren Bytecodes (Dateiendung .class) übersetzt
und dann in einer speziellen Umgebung ausgeführt werden, die so genannte Java- Laufzeitumgebung (Java Runtime Eviroment, JRE) oder Java-Plattform. Der wichtigste Bestandteil der Java-Plattform ist die Ablaufumgebung (Java Virtual Maschine, JVM), die zur Interpretierung der
29
Bytecodes und zur Ausführung der Java-Programme dient. So werden Java-Programme nur einmal kompiliert und können auf allen Betriebssystemen laufen, die eine JRE besitzen.
Mit der Anwendung von Java 2 wurde die Java-Plattform in drei Editionen unterteilt:
Die J2ME (Java 2 Platform Micro Edition) dient zur die Entwicklung der Software resourcenabhängiger Geräte z.B., PDAs, Mobiltelefon.
Die J2SE (Java 2 Plattform Standard Edition) dient als Grundlagen für J2EE und J2ME.
Sie definiert die Anwendungsprogrammierschnittstellen (API) zur Realisierung von
Softwareprojekten. Die J2EE enthält alle Klassen der J2SE und ist um zahlreiche zusätzliche Klassen und Schnittstellen erweitert – insbesondere für die Programme, die im
Server ausgeführt werden.
Die J2EE (Java 2 Plattform Enterprise Edition) dient der Entwicklung und Ausführung
der unterschiedlichen Unternehmensanwendungen, die auf den im Server ausgeführten
Software- Komponenten basieren. Die J2EE-API beinhaltet viele verschiedne Techniken.
In den folgenden Abschnitten werden die Techniken Servlet, JSP, JDBC verwendet, die
im Folgenden näher vorgestellt werden.
3.3.2
Java Servlets
Parallel zur Entwicklung der Web-Technik haben sich die Webseiten von einfachen und statischen
Seiten zu vielgestaltigen und dynamischen Seiten entwickelt. Anfangs waren CGI-Skripts (Common Gateway Interface Scripts) die hauptsächliche Technik, die verwendet wurde, um dynamische Web-Inhalte zu erstellen. Die CGI-Technik hat jedoch viele Nachteile, wie z.B. Plattform-Abhängigkeit und mangelnde Skalierbarkeit. Um solche Probleme zu lösen, wurde Java
Servlet als effizientere und überzeugendere Lösung zur Erstellung dynamischer Web-Inhalte entwickelt.
Java Servlets sind Java-Programme, die via ein Request-Response-Modell im Server ausführen.
Servlets dienen zur Erweiterung der Leistungsfähigkeit der Server und zur Erstellung dynamischer
Web-Inhalte. Obwohl Servlets irgendeinen Typ von Abfrage beantworten können, werden sie üblich verwendet, um die Anwendungen in den Web-Server zu erweiten. Für solche Anwendungen
definiert die Servlet-Technik HTTP-spezifische Servlet-Klassen. Die Pakete javax.servlet und javax.servlet.http bieten die Schnittstellen und die Klassen an, um Servlets zu schreiben. Alle Servlets müssen die Schnittstelle Servlet implementieren. Die Schnittstelle Servlet definiert drei elementare Methoden für die Initialisierung eines Servlets (init), die Betreuung der Abfragen (service)
und die Entfernung eines Servlet aus dem Server (destroy). Der Ablauf dieser Methoden heißt
Lebenszyklus eines Servlets [34]. Für die Implementierung eines generischen Service kann man
die Klasse GenericServlet von Java Servlet-API verwenden. Die Klasse HttpServlet bietet die
Methode, z.B. doGet und doPost, um HTTP-spezifische Service zu bearbeiten.
Java Servlet ist zurzeit in Version 2.5 und ein Teil von J2EE (Java 2 Enterprise Edition). J2SE
(Java 2 Standard Edition) enthält keine Servlet-API, aber die offizielle Servlet-API kann auf der
Webseite http://java.sun.com/products/servlet/ gefunden oder mit J2EE gebündelt werden.
30
3.3.3
Java Server Pages
Java Servlets und Java Server Pages (JSP) sind zwei komplementäre Techniken zur Erzeugung
dynamischer Webseiten via Java. Servlets sind reine Java-Programme. Wenn man HTML ausgeben möchte, muss dies mittels Methode out.println() geschehen. Das macht die Ausgabe der
HTML-Codes kompliziert und erzeugt sehr oft Fehler. Die JSP-Technik ermöglicht dagegen eine
leichte Erstellung der Web-Inhalte, die aus statischen und dynamischen Komponenten bestehen.
Die JSP-Technik hat alle dynamischen Leistungsfähigkeiten der Servlet-Technik und bietet zusätzlich eine leicht verständliche Methode zur Erstellung statischer Web-Inhalte an. Eine JSP-Seite
ist ein Text-Dokument mit der Endung .jsp, die zwei Typen von Text enthält: statische Daten,
welche mit einer Makeup-Sprache (z.B. HTML, XML) formuliert werden können, und
JSP-Elemente, welche Java-Codes sind, die mit <% beginnen und mit %> enden und dynamische
Web-Inhalte konstruieren.
JSP hat einen ähnlichen Lebenszyklus wie Servlet, jedoch haben die drei Methoden im Vergleich
zu Servlet unterschiedliche Namen. Die Initialisierung einer JSP entspricht der Methode jspInit(),
die Betreuung der Abfragen entspricht der Methode _jspService() und die Entfernung einer JSP
aus dem Server entspricht der Methode jspDestroy().
Alle JSP-Programme werden vom Server automatisch in Servlets übersetzt. Deswegen haben JSP
und Servlet eine ähnliche Leistungsfähigkeit. Tatsächlich können JSP und Servlet separat verwendet werden. Normalerweise kombinieren wir JSP und Servlet zusammen und trennen ihre
Aufgaben. JSP dient hauptsächlich zur Visualisierung der Webseiten während Servlet die Rechenlogik bearbeitet.
3.3.4
Apache Tomcat
Um Servlets und JSPs im Web-Server auszuführen wird ein Web-Container benötigt. Ein
Web-Container ist eine Software, die für Beladung, Ausführung und Ausladung von Servlets und
JSPs verantwortlich ist und den Lebenszyklus von Servlets und JSPs verwaltet. Es gibt viele Container von verschiedenen Herstellern. Für meine Software ProteinWeb habe ich den Container
Apache Tomcat gewählt.
Apache Tomcat wird von dem Jakarta-Projekt der Apache Software Foundation entwickelt. Es ist
der Web-Container, der in der offiziellen Referenzimplementierung für Servlet- und
JSP-Techniken verwendet wird. Zurzeit gibt es vier Versionen von Tomcat. Die folgende Tabelle
aus [44] zeigt die vier Versionen und ihre Unterstützung der Servlet/JSP-Spezifikationen.
Apache Tomcat Version
Servlet-Spezifikation
JSP-Spezifikation
6.0.10
2.5
2.1
5.5.23
2.4
2.0
4.1.34
2.3
1.2
3.3.2
2.2
1.1
31
3.4 JDBC
JDBC (Java Database Connectivity) ist eine Programmierschnittstelle (API, Application Programming Interface), mit der Java und relationale Datenbanken miteinander kommunizieren können. Die JDBC-API hat die Aufgaben, Verbindungen zu Datenbanken aufzubauen,
SQL-Anweisungen abzusenden und Resultate der SQL-Anweisungen zu bearbeiten. Um JDBC zu
benutzen, brauchen wir eine Plattform von Java 2 (j2sdk), ein DBMS und einen JDBC-Treiber,
der die JDBC-API implementiert. Die JDBC-API ist Datenbank-unabhängig und bietet eine einheitliche Schnittstelle für Datenbanken an. Soll das vorher benutzte DBMS geändert werden und
ein anderes DBMS benutzt werden, so ist im Java-Programm lediglich der entsprechende Treiber
zu ändern. Jede spezifische DBMS hat ihren eigenen Treiber. Sun bietet momentan unter
http://developers.sun.com/product/jdbc/drivers 221 JDBC-Treiber für populäre relationale DBMS.
Wir können einen davon wählen für unser DBMS. Es gibt vier folgenden Typen von
JDBC-Treiber. Die deutschen Namen der vier Typen sind dem Abschnitt 20.4 von [34] entnommen.
Typ 1: Die JDBC-ODBC-Brücke ermöglicht den Zugang zur Datenbank über einen
ODBC-Treiber. ODBC (Open Database Connectivity) ist eine API von Microsoft zum
Besuchen der DBMSe. Da ODBC systembezogen ist, müssen außerdem der Binär-Code
des ODBC-Treibers und in vielen Fällen die Datenbank-API auf der Client-Seite geladen werden. Wegen dieses Nachteils ist dieser Treiber nur für experimentelle Anwendung und für Situationen geeignet, in denen kein anderer Treiber verfügbar ist.
Typ 2: Der Native plattformeigene JDBC-Treiber wandelt die JDBC-Aufrufe direkt
in Aufrufe der Datenbank-API auf der Client-Seite für Oracle, Sybase, Informix, DB2
oder andere DBMSe um [40]. Ähnlich wie der JDBC-ODBC-Brücke-Treiber benötigt
dieser Treiber für jede Betriebssystem-Plattform eine zusätzliche Programmbibliothek.
Typ 3: Der Direkte Netzwerktreiber übersetzt zuerst JDBC-Aufrufe in das Middleware-Protokoll, welches dann in ein DBMS-Protokoll durch einen Middleware-Server
übersetzt wird. Die Middleware bietet Verbindung zu vielen verschiedenen Datenbanken
an. Da das Middleware-Protokoll unabhängig von der Datenbank ist, wird keine plattformspezifische Programmbibliothek auf der Client-Seite benötigt. Deswegen hat dieser
Treibe für Internet-Anwendung einen großen Vorteil.
Typ 4: Der Universelle JDBC-Treiber übersetzt JDBC-Aufrufe direkt in ein DBMSProtokoll. Da hier keine Middleware verwendet wird, ist dieser Treiber schneller als Typ
3. Zur Nutzung schneller Netzwerkprotokolle ist Typ 4 eine gute Lösung. Jedoch ist Typ
4 nicht immer realisierbar [34], weil manche DBMS wie Microsoft Access, dBase oder
Paradox kein entsprechendes Netzwerkprotokoll definieren.
Da sich die hier entworfene Proteindatenbank ProteinDB an Microsoft Access orientiert und der
JDBC-Treiber von Access JDBC-ODBC-Brücke eingesetzt wird, wird im Folgenden ausführlich
beschrieben, wie eine Access-Datenbank aufzubauen und ODBC einzurichten ist.
32
Das Erstellen einer Access-Datenbank ist unkompliziert: Zunächst wird Microsoft Access, unter
dem Menüpunkt Datei Æ Neu geöffnet, dann Leere Datenbank gewählt. Dann im Dialogfenster
Neue Datenbankdatei ein Name mit einem Suffix .mdb wie z.B. ProteinDB.mdb eingegeben und
der Pfad dieser neu erstellten Datei gewählt. Mit dem Drücken von OK ist eine Access-Datenbank
erstellt.
Die Einrichtung einer ODBC-Datenquelle wird in folgenden Schritten durchgeführt:
1. Zunächst wird über das Windows-Startmenü der Programmpunkt Datenquellen (ODBC)
gewählt. Dieser Programmpunkt ist bei den verschiedenen Betriebssystemen unterschiedlich, beispielsweise bei Windows XP nach dem Pfad „Start \ Einstellungen \ Systemsteuerung \ Verwaltung “.
2. Im Dialogfenster ODBC-Datenquellen-Adiministrator wird die Karteikarte System
DSN gewählt und Hinzufügen geklickt.
3. Im Dialogfenster Neue Datenquelle erstellen wird der Microsoft Access-Treiber ausgewählt und auf Fertigstellen geklickt.
4. Im Dialogfenster ODBC Microsoft Access Setup wird unter Datenquellenname ein
Name für die Datenquelle eingegeben. Sodann wird auf Auswählen geklickt und die zu
verwendende Datenbank ausgewählt.
5. Mit Schließen der Dialogfenster ist die ODBC-Datenquelle eingerichtet.
In der Java-API bietet das Paket java.sql die JDBC-API für den Zugriff und die Bearbeitung der
Daten, die in einer Datenquelle gespeichert werden. Alle Klassen und Schnittstellen des Pakets
müssen am Anfang eines Java-Programms importiert werden, damit sie später in diesem Java-Programm verwendet werden können. Die Anweisung zum Import eine Klasse vom Paket java.sql ist import java.sql.Klassename. Mit der Anweisung import java.sql.* kann man alle Klassen
und Schnittstellen von dem Paket importieren. Die Ausführung der JDBC bei der Datenbank-Anwendung beinhaltet folgende Aufgaben:
1. Java-Datenbank-Verbindung über JDBC
Der erste Schritt der Datenbank-Anwendung ist die Datenbankverbindung als Basis für alle
anderen Aufgaben. Beim Aufbau der Datenbankverbindung werden die Java-Schnittstelle java.sql.Connection und die Java-Klassen java.sql.DriverManger und java.lang.Class verwendet.
Laden eines JDBC-Treibers
Im ersten Schritt muss der entsprechende Datenbanktreiber vor der Verbindung einer
speziellen Datenbank geladen werden. Mit einer einfachen Methode Class.forName()
kann ein JDBC-Treiber geladen werden. Beispielweise ist die JDBC-ODBC-Brücke ein
entsprechender Treiber für Microsoft Access. Die Anweisung für das Laden dieses Treibers lautet: Class.forName(“sun.jdbc.odbc.JdbcOdbcDriver“);
Verbindung zur Datenbank
Um als nächstes die Datenbankverbindung aufzubauen, wird die Methode getConnection() der Java-Klasse DriverManger verwendet. Der Treibermanager dient zur Samm33
lung aller Datenbanktreiber. Wenn die Methode getConnection() aufgerufen wird, sucht
der Treibermanager aus allen Datenbanktreibern, die bei der Initialisierung geladen wurden, einen passenden Treiber. Die getConnection() Methode braucht drei Parameter: url
bezeichnet die URL der Datenbank, user und password bezeichnen den Benutzername
und das Passwort für die Datenbankanmeldung. Die Anweisung für die Datenbankverbindung ist: Connection conn= DriverManger.getConnection(url, user, password);
Abschluss der Datenbankverbindung
Wenn nicht mehr auf die Datenquelle zugegriffen wird, wird die aufgebaute Datenbankverbindung vor dem Abschluss des Java-Programms geschlossen. Für den Abschluss der
Datenbankverbindung wird die Methode close() verwendet. Die Anweisung für den Abschluss ist: conn.close();
2. Datenbankmanipulation
Die Datenbankanfragen, sowie Aktualisieren, Einfügen und Löschen der Datensätze werden
in einer relationalen Datenbank durch verschiedene SQL-Anweisungen realisiert. Um solche
SQL-Anweisungen durchzuführen, finden die vier Java-Schnittstellen Connection, Statement, und ResultSet Anwendung.
Erzeugen eines Statement-Objekts
Vor der Ausführung eine SQL-Anfrage wird ein Statement-Objekt mit der Methode
creatStatement() der Java-Schnittstelle Connection erzeugt. Die Anweisung hier ist:
Statement stmt= conn.creatStatement();
Ausführen einer SQL-Anweisung
Um eine SQL-Anweisung auszuführen wird die Methode executeQuery() oder excuteUpdate() der Java-Schnittstelle Statement verwendet, wobei die Methode executeQuery() für die Anfragen-Operation dient und die Methode excuteUpdate() für die Aktualisierungs-, Einfügen- und Löschen-Operation. Die beiden Methoden erfordern einen
Parameter, dessen Datentyp String ist und die auszuführende SQL-Anweisung bezeichnet.
Der Rückgabewert beider Methoden ist entweder eine Ergebnistabelle in Form eines
Resultat-Objekts oder die Anzahl der geänderten Datensätze vom Typ int. Wenn die
Ausführung fehlerhaft war, wird zusätzlich die Ausnahme SQLException erzeugt. Der
Programmierer muss sodann die SQLException auffangen. Die Anweisungen beider
Methoden sind: ResultSet rs=stmt.executeQuery(sql);
int rowCount=stmt.executeUpdate(sql);
Abschluss des Statement-Objekts
Ein Statement-Objekt muss geschlossen werden, wenn es nicht mehr verwendet wird.
Die Methode close() von Java-Klasse Statement dient zum Abschluss des Statement-Objekts. Nach dem Abschluss des Statement-Objekts wird das ResultSet-Objekt
automatisch geschlossen.
34
Kapitel 4
Proteindatenbanken
Proteindatenbanken dienen zur Speicherung und Verwaltung der riesigen Datenmengen über Proteine. Die Auswahl der Datenbanken hängt stark davon ab, welche Arten von Informationen gebraucht werden. Sequenzdatenbanken wie z.B. SWISS-PROT, TrEMBL, und PIR werden benutzt,
um die primären Strukturen (Aminosäuren-Sequenzen) von Proteinen zu bekommen. Strukturdatenbanken wie z.B. PDB enthalten präzise Informationen über drei-dimensionale Strukturen von
Proteinen. SCOP und CATH dienen zur Klassifikation von Proteinstrukturen. Durch Analyse der
primären Datenbanken entstehen viele sekundäre Datenbanken, z.B., PROSITE, Pfam, Blocks.
In diesem Kapitel werden die verschiedenen repräsentativen Proteindatenbanken nach ihrem Verwendungsgebiet mittels Literatur- und Webrecherche ([1], [13], [14]) klassifiziert (s. Abb. 4-1)
und ihre wesentlichen Informationen vorgestellt. Proteindatenbanken repräsentieren ein umfangreiches Angebot, das sich in Primärdatenbanken und Sekundärdatenbanken unterteilen lässt. Dabei
basieren die Sekundärdatenbanken auf den Primärdatenbanken. Sequenzdatenbanken und Strukturdatenbanken sind Primärdatenbanken. Die Daten einer Sequenzdatenbank kommen aus der Sequenzanalyse; die Daten der Strukturdatenbanken aus der Strukturanalyse mittels Röntgenstrahlen- und NMR-Technik (Nuclear Magnetic resonance). In diesen beiden Datenbanken werden die
wesentlichen Protein-relevanten Daten angeboten. Strukturdatenbanken bestehen aus 3D-Strukturdatenbanken und Strukturklassifizierungsdatenbanken, die Proteine nach deren Strukturen klassifizieren. Sekundärdatenbanken bestehen aus Struktur-Sekundärdatenbanken und Sequenz- Sekundärdatenbanken, die auf Strukturdatenbanken bzw. Sequenzdatenbanken basieren. In den folgenden Unterabschnitten werden die Sequenzdatenbanken und Strukturdatenbanken ausführlich erläutert, weil deren Daten als Basis für die Weiterentwicklung anderer Sekundärdatenbanken wichtig sind. Andere Datenbanken, die sich auf spezielle Forschungsgebiete der Proteine beziehen,
werden kurz vorgestellt.
Struktur-DB
PDB
Sequenz-DB
Swiss-Prot
CATH
PIR
SCOP
TrEMBL
NRDB
NRL-3D
Sekundär-DB
OWL
PROSITE
Pfam
FSSP
BLOCKS
HSSP
PRINTS
DSSP
Abb. 4-1
PRODOM
Übersicht über die Proteindatenbanken
35
4.1
Protein-Sequenzdatenbanken
Protein-Sequenzdatenbanken speichern und verwalten die riesigen Datenmengen der Sequenzanalyse. Das größte Problem der umfangreichen Sequenzdatenbanken besteht darin, dass die Daten aus sehr unterschiedlichen wissenschaftlichen Veröffentlichungen kommen, aus Datenquellen individueller Forschungen bis hin zu großen Genom-Sequenzierungszentren. Die Qualität dieser Daten ist nicht garantiert. Es gibt darüber hinaus viele redundante Sequenzen, die identisch
oder fast identisch sind. SWISS-PROT und PIR sind die meist verwendeten Datenbanken, weil sie
beide „curated“ sind, d.h. Gruppen von ernannten Kuratoren (Wissenschaftler) erstellen die Einträge aus der Literatur und/oder Kontakten mit externen Experten. SWISS-PROT darüber hinaus
bekannt dafür, die Redundanzen der Sequenzen zu minimieren und eine sehr hohe Datenqualität
zu bieten.
1.
SWISS-PROT, TrEMBL [www.expasy.ch/sprot]
SWISS-PROT ist eine annotierte Protein-Sequenzdatenbank. Sie ist bekannt für ihre ausführliche
Annotation auf hohem Niveau, die Integration anderer Datenbanken und ihre minimale Redundanz. Sie wurde 1986 von Amos Bairoch in der Abteilung Medizinische Biochemie an der Uni
Genf in der Schweiz aufgebaut. Diese Datenbank wird im Hinblick auf die Qualität der Annotation als eine der besten Protein-Sequenzdatenbanken angesehen.
Für die Benutzer der biomolekularen Datenbanken ist ein hohes Maß an Integration zwischen
den verschiedenen sequenzbezogenen Datenbanken (Nucleinsäuredatenbanken, Proteinsequenzdatenbanken und Proteinstrukturdatenbanken) unerlässlich. SWISS-PROT enthält zurzeit die
Kreuzverweise auf mehr als 50 verschiedene Datenbanken. Damit lassen sich die entsprechenden
Einträge in den anderen Datenbanken direkt aufrufen. Ein solches umfangreiches Datenbanknetzwerk verleiht SWISS-PROT eine bedeutende Rolle bei der Integration von biomolekularen Datenbanken. So enthielt das Release 50.6 vom 05. Sep. 2006 von SWISS-PROT 231434 Sequenzeinträge. Das Wachstum der Datenbank ist wie folgt dargestellt:
Abb. 4-2
Anzahl der Einträge in SWISS-PROT (aus [53] )
36
Die Sequenzeinträge in SWISS-PROT sind so strukturiert, dass sie nicht nur für Menschen, sondern auch für Computerprogramme benutzbar sind. Die Erklärungen, Beschreibungen, Klassifikationen und anderen Kommentare sind überwiegend in Englisch gehalten. Jeder Sequenzeintrag
besteht aus verschiedenen Zeilenarten, die ihre eigenen Formate haben. Jeder Eintrag beginnt mit
einer Identifikationszeile (ID) und endet mit einer Abschlusszeile (//). Ein Beispiel-Sequenzeintrag
ist in Abb. 2-3 abgekürzt angezeigt.
Abb. 2-3
Sequenzeintrag in SWISS-PROT (aus [53])
Jede Zeile beginnt mit einer mit zwei Buchstaben bezeichneten Zeilenart, die die Art der in dieser
Zeile enthaltenen Daten angibt. Alle Zeilenarten und ihre Vorkommen in einem Eintrag werden in
folgender Tabelle angezeigt:
37
Tabelle 2-1
Zeilenarten in SWISS-PROT (aus [53])
Im Folgenden werden die Zeilenarten und ihre Struktur näher erläutet:
Die ID-Zeile ist immer die erste Zeile eines Eintrags. Das Format der ID-Zeile ist:
ID
ENTRY_NAME; DATA_CLASS; MOLECULE_TYPE; SEQUENCE_LENGTH.
‘ENTRY_NAME’ repräsentiert den Eintragsnamen, der eine Sequenz identifiziert. Dieser Name ist kein stabiles Identifizierungsmerkmal wie etwa die Eintragsnummer. Der
Eintragsname besteht höchstens aus 11 Großbuchstaben. SWISS-PROT verwendet eine
universelle Namenskonvention, die als X_Y symbolisiert werden kann, wobei
- X ein Code von höchstens 5 alphanumerischen Buchstaben ist, der den Proteinnamen repräsentiert,
- das Zeichen ‘_’ als Trennzeichen dient,
- Y ein Code von höchstens 5 alphanumerischen Buchstaben ist, der die biologische Quelle des Proteins repräsentiert. Im Allgemeinen besteht dieser Kode aus
den ersten drei Buchstaben der Gattung und den ersten zwei Buchstaben der
Art.
38
‘DATA_CLASS’ bezeichnet die Datenklasse eines Eintrags. Es gibt zwei Datenklassen:
„Reviewed“ und „Unreviewed“. „Reviewed“ bezeichnet die Einträge, die durch Fachleute von Hand geprüft und annotiert geworden sind. „Unreviewed“ bezeichnet die
Computer-annotierten Einträge, die nicht durch Fachleute geprüft worden sind. Alle
Einträge in SWISS-PROT sind „Reviewed“. Alle Einträge in TrEMBL sind “Unreviewed”.
‘MOLECULE_TYPE’ ist ein Code auf drei Buchstaben, der den Molekültyp eines Eintrags bezeichnet. In SWISS-PROT ist dies immer ‘PRT’ (für Protein).
‘SEQUENCE_LENGTH’ repräsentiert die Länge eines Moleküls, d.h. die Anzahl an
Aminosäuren in der Sequenz. Im unbestimmten Fall ist ‘X’ eingetragen. Die Längenangabe wird durch den Buchstabencode ‘AA’ (für Aminosäuren) abgeschlossen. (siehe
Abb. 2-3)
Die AC-Zeile bezeichnet die Eintragsnummern, die mit einem Eintrag verbunden sind. Das Format der AC-Zeile ist:
AC
AC_number_1;[ AC_number_2;]...[ AC_number_N;]
Semikolons trennen die Eintragsnummern und ein Semikolon beendet die Liste. Einträge haben
mehr als eine Eintragsnummer, wenn sie gemischt oder gesplittert worden sind. Die erste Eintragsnummer ist die primäre Nummer, die anderen sind alphanumerisch sortierte, sekundäre
Nummern. Wenn es nötig ist, kann mehr als eine AC-Zeile benutzt werden. Eintragsnummern bieten einen stabilen Weg an, um Einträge zu identifizieren. Eintragsnummern bestehen aus 6 alphanumerischen Buchstaben (s. Abb. 3-2) im folgenden Format:
Die DT-Zeile zeigt das Datum der Neueinrichtung und der letzten Änderung des Datenbankeintrags. Das Format der DT-Zeile ist:
DT
DD-MMM-YYYY, integrated into UniProtKB/database_name.
DT
DD-MMM-YYYY, sequence version x.
DT
DD-MMM-YYYY, entry version x.
Wobei ‘DD’ der Tag ist, ‘MMM’ der Monat, ‘YYYY’ das Jahr.
Die Daten, die in der DT-Zeile gezeigt werden, entsprechen dem Datum von dem Release alle
zwei Wochen, in der ein Eintrag integriert oder aktualisiert wurde. Es gibt immer drei DT-Zeilen
zu jedem Eintrag, jede mit einer spezifischen Bemerkung:
39
Die erste DT-Zeile zeigt, wann der Eintrag zum ersten Mal in der Datenbank auftrat. Die
zugehörige Bemerkung ‘integrated into UniProtKB/database_name’ zeigt, in welchem
Abschnitt von UniProtKB, SWISS-PROT, oder TrEMBL der Eintrag gefunden werden
kann.
Die zweite DT-Zeile zeigt, wann die Sequenzdaten zuletzt modifiziert wurden. Die zugehörige Bemerkung ‘sequence version x’ zeigt die Versionsnummer der Sequenz.
Die dritte DT-Zeile zeigt, wann die Daten anders als die Sequenz zuletzt modifiziert
wurden. Die zugehörige Bemerkung ‘entry version x’ zeigt die Versionsnummer des
Eintrags.
Die DE-Zeile enthält allgemeine Beschreibungsinformationen über die gespeicherte Sequenz.
Diese Informationen reichen im Allgemeinen aus, um das Protein genau zu identifizieren. Das
Format der DE-Zeile ist:
DE
Description.
Die Beschreibung ist überwiegend in Englisch geschrieben und hat ein freies Format. Es ist möglich, dass mehr als eine DE-Zeile ein Eintrag enthält. Die Beschreibung beginnt mit dem empfohlenen Namen des Proteins. Alternative Namen werden zwischen Rundklammern angezeigt.
Falls ein Protein sich in mehre funktionale Komponenten gliedert, beginnt die Beschreibung mit dem Namen vom Precursor des Proteins, gefolgt von einem Abschnitt
abgrenzt durch ‚[Contains: …]’. Alle individuellen Komponenten sind in diesem Abschnitt aufgelistet und werden durch Semikolons getrennt. Synonyme sind auf der Ebene
von Precursor und für jede individuelle Komponente erlaubt. Beispiel:
DE
DE
DE
DE
DE
DE
Corticotropin-lipotropin precursor (Pro-opiomelanocortin) (POMC)
[Contains: NPP; Melanotropin gamma (Gamma-MSH); Potential peptide;
Corticotropin (Adrenocorticotropic hormone) (ACTH); Melanotropin alpha
(Alpha-MSH); Corticotropin-like intermediary peptide (CLIP);
Lipotropin beta (Beta-LPH); Lipotropin gamma (Gamma-LPH); Melanotropin
beta (Beta-MSH); Beta-endorphin; Met-enkephalin].
Falls ein Protein mehre funktionale Domänen enthält, von denen jede durch verschiedene Namen beschrieben wird, beginnt die Beschreibung mit dem Name von globalem
Protein gefolgt durch einen Abschnitt abgrenzt durch ‚[Includes: …]’. Alle Domänen
sind in diesem Abschnitt aufgelistet und werden durch Semikolons getrennt. Synonyme
sind erlaubt auf der Ebene von Protein und für jede individuelle Domäne.
Beispiel:
DE
CAD protein [Includes: Glutamine-dependent carbamoyl-phosphate
DE
synthase (EC 6.3.5.5); Aspartate carbamoyltransferase (EC 2.1.3.2);
DE
Dihydroorotase (EC 3.5.2.3)].
40
In den seltenen Fällen, in denen die funktionalen Domänen eines Enzyms geteilt werden,
werden solche Proteine in der DE-Zeile durch eine Kombination von sowohl ‚[Contains: …]’ als auch ‚[Includes: …]’ beschrieben.
Beispiel:
DE Arginine biosynthesis bifunctional protein argJ [Includes: Glutamate
DE
N-acetyltransferase (EC 2.3.1.35) (Ornithine acetyltransferase)
DE
(Ornithine transacetylase) (OATase); Amino-acid acetyltransferase
DE
(EC 2.3.1.1) (N-acetylglutamate synthase) (AGS)] [Contains: Arginine
DE
biosynthesis bifunctional protein argJ alpha chain; Arginine
DE
biosynthesis bifunctional protein argJ beta chain].
Falls die vollständige Sequenz noch nicht bestimmt wurde, wird ‚(Fragment)’ oder
‚(Fragments)’ am Ende der DE-Zeile gegeben.
Beispiel:
DE
Dihydrodipicolinate reductase (EC 1.3.1.26) (DHPR) (Fragment).
Die GN-Zeile bezeichnet den Namen eines Gens, das die gespeicherte Proteinsequenz kodiert Das
Format der GN-Zeile ist:
GN GeneName=<name>; Synonyms=<name1>[, <name2>...]; OrderedLocusNames=<name1>[,<name2>...];
GN ORFNames=<name1>[, <name2>...];
Die GN-Zeile enthält drei Arten von Informationen:
‘GeneName’ bezeichnet den Namen eines Gens. Weil es mehr als einen Namen für ein
Gen geben kann, bezeichnet ‘GeneName’ den offiziellen Namen eines Gens während
‘Synonyms’ weitere Name eines Gens bezeichnet.
‘OrderedLocusNames’ wird verwendet um einen ORF (open reading frame) in einem
vollständig sequentierten Genom oder Chromosom zu bezeichnen.
‘ORFNames’ bezeichnet einen vorläufigen Namen von ORF in einem Sequenz-Projekt.
ORF (Open reading frame) wird derjenige Bereich der DNA bzw. mRNA genannt, der
zwischen einem Start-Codon und einem Stop-Codon liegt.
Die OS-Zeile beschreibt den Organismus, der die Quelle der gespeicherten Sequenz war. Das
Format der OS-Zeile ist:
OS
Species
‘Species’ besteht aus Namen (offizieller Name in Latein, gebräuchlicher Name in Englisch, Synonym in Englisch) der Gattung und Arten. Für Viren wird stets nur der lateinische ‚’Name angegeben.
41
Beispiel:
OS
Solanum melongena (Eggplant) (Aubergine).
OS
Escherichia coli.
Die OG-Zeile zeigt an, falls die Kodierung des Gens für ein Protein von der Mitochondrien, der
Chloroplast, der ‘cyanelle’, der ‘nucleomorph’ oder eines Plasmids stammt. Das Format der
OG-Zeile ist:
OG
Hydrogenosome.
Die OC-Zeile enthält die taxonomische Klassifikation der Organismusquelle. Das Format der
OC-Zeile ist:
OC
Node[; Node...].
Die OX-Zeile zeigt das Identifizierungsmerkmal eines spezifischen Organismus in einer taxonomischen Datenbank. Das Format der OX-Zeile ist:
OX
Taxonomy_database_Qualifier=Taxonomic code;
Die OH-Zeile ist wahlfrei und kommt nur in den Viruseinträgen vor. Sie zeigt die Wirtorganismen,
die durch den Virus angesteckt werden können. Das Format der OH-Zeile ist:
OH
NCBI_TaxID=TaxID; HostName.
Die Referenzzeilen beinhalten die Literaturzitate. Sie geben Auskunft über die Quellen, aus denen
die Daten stammen. Die Referenzzeilen für ein Zitat erscheinen im Block und zwar immer in der
Reihenfolge RN, RP, RC, RX, RG, RA, RT und RL:
RN (Reference Number) bezeichnet die laufende Nummer des Referenzzitats in einem
Eintrag. Diese Nummer wird für die Referenz in den Kommentarzeilen (CC) und in der
Featuretabelle (FT) verwendet.
RP (Reference Position) beschreibt den Arbeitsgebiet der Autoren.
RC (Reference Comment) beschreibt die referenzrelevanten Bemerkungen.
RX (Reference cross-reference) zeigt das Identifizierungsmerkmal für eine spezifische
Referenz in einer bibliographischen Datenbank.
RG (Reference Group) beschreibt den Namen der Arbeitsgemeinschaft für ein Zitat.
RA (Reference Author) beschreibt die Autoren der wissenschaftlichen Veröffentlichung.
RT (Reference Title) beschreibt den Titel der wissenschaftlichen Veröffentlichung.
RL (Reference Location) beschreibt die übliche Quelle der Referenz.
Die CC-Zeilen sind freie Text-Bemerkungen und beschreiben beliebige nützliche Informationen.
Die Bemerkungen sind in Bemerkungsblöcke zusammengruppiert. Die erste Zeile des Blocks beginnt mit dem Zeichen ‘-!-’. Das Format eines Bemerkungsblocks ist:
42
CC
CC
-!- TOPIC: First line of a comment block;
second and subsequent lines of a comment block.
Die DR-Zeilen beschreiben die Kreuzverweise in SWISS-PROT auf die entsprechenden Einträge in anderen Datenbanken. Das Format der DR-Zeile ist:
DR
DATABASE_IDENTIFIER; PRIMARY_IDENTIFIER; SECONDARY_IDENTIFIER[; TERTIARY_IDENTIFIER][; QUATERNARY_IDENTIFIER].
‘DATABASE_IDENTIFIER’ bezeichnet den abgekürzten Namen der Datenbank.
‘PRIMARY_IDENTIFIER’ bietet den Weblink zur anderen Datenbank.
‘SECONDARY_IDENTIFIER’ und ‘TERTIARY_IDENTIFIER’ bezeichnen die zusätzlichen Bemerkungen.
Die KW-Zeilen bieten Informationen an, die verwendet werden können, um Indizes der Sequenzeinträge zu generieren, die auf funktionellen, strukturellen oder anderen Kategorien basieren. Das
Format der KW-Zeile ist:
KW
Keyword[; Keyword...].
Die FT-Zeilen zeigen die Annotation der Sequenzdaten an. Die Schlüsselwörter für die Featuretabelle sind z.B., CHAIN, PEPTIDE, DISULFID, … usw.
Die SQ-Zeile bezeichnet den Anfang der Sequenzdaten und bietet eine Kurzfassung der Sequenz
an. Das Format der SQ-Zeile ist:
SQ
SEQUENCE XXXX AA; XXXXX MW; XXXXXXXXXXXXXXXX CRC64;
MTILASICKL GNTKSTSSSI
NVDGLLGAIG
GSSYSSAVSF GSNSVSCGEC GGDGPSFPNA SPRTGVKAGV
KTVNGMLISP NGGGGGMGMG
GGSCGCI
Diese Zeile enthält die Länge der Sequenz in Aminosäuren (‘AA’), das Gewicht der Moleküle
(‘MW’) und den 64-Bit Wert der zyklischen Redundanzprüfung (‘CRC64’)für die Sequenz. Die
Sequenzdaten-Zeile hat einen Code, der aus zwei Blanks besteht. Jede Zeile enthält 60 Aminosäuren der Sequenz, wobei 10 Aminosäuren in einer Gruppe sind. Z.B.,
Die Abschlusszeile (//) enthält keine Daten oder Bemerkungen und bezeichnet das Ende eines
Eintrags.
43
TrEMBL ist ein Computer-annotiertes Supplement von Swiss-Prot. Es enthält alle Übersetzungen
von Nucleotidsequenzeinträgen in EMBL, die noch nicht in Swiss-Prot integriert sind.
SWISS-PROT und TrEMBL werden heute von der Arbeitsgemeinschaft UniProt gepflegt, die eine
Zusammenarbeit zwischen SIB (Swiss Institute of Bioinformatics) und EBI (European Bioinformatics Institute) und PIR (Protein Information Resource) darstellt. Auf diese zwei Datenbanken
kann entweder durch das SRS System an ExPASy zugegriffen werden, oder man kann die vollständige Datenbank als „flat file“ herunterladen. Die SWISS-PROT Datenbank hat einige gesetzliche Beschränkungen: die Einträge selbst sind urheberrechtlich geschützt, aber frei zugänglich
und nutzbar von akademischen Forschern. Wirtschaftliche Unternehmen müssen, um
SWISS-PROT benutzen zu können, eine Lizenzgebühr an das SIB bezahlen, [1]. Die weitere Literatur zu SWISS-PROT und TrEMBL ist [2-7].
2. PIR [pir.georgetown.edu]
PIR steht für „Protein Information Resource“ und bezeichnet eine Abteilung der NBRF (National
Biomedical Research Foundation) in den USA. Sie arbeitet mit dem MIPS (Munich Information
Center for Protein Sequences) und der JIPID (Japan International Protein Sequence Database) zusammen. PIR wurde von Margaret Dayhoff Mitte der 1960er Jahre entwickelt mit dem Bestreben
nach einer umfangreichen, gut organisierten, richtigen und konsistenten Annotation. Dennoch erreicht PIR nicht das Niveau von Vollständigkeit in der Annotation wie SWISS-PROT. Obwohl
SWISS-PROT und PIR umfangreich überlappen, gibt es noch viele Sequenzen, die sich nur in
einer von beiden finden. Man kann in der PIR Seite nach Einträgen suchen oder nach Sequenzähnlichkeit forschen. Die Datenbank kann aber komplett herunter geladen werden. Die weitere
Literatur zu PIR ist [8].
4.2
1.
Protein-Strukturdatenbanken
PDB [www.rcsb.org/pdb/]
PDB ist die einzige zentrale und weltweite Datenbank für experimentell ermittelten 3D-Strukturen
von biologischen Makromolekülen (inklusiv Proteine und Nucleinsäuren), die durch X-Ray Kristallographie und NMR (Nuclear Magnetic Resonance) bestimmt werden. Diese Moleküle werden
in sämtlichen Organismen inklusive Bakterien, Hefen, Pflanzen, Fliegen, Mäusen sowie in gesunden und kranken Menschen gefunden. PDB wurde 1971 in den BNL (Brookhaven Nationale Laboratories) in den USA aufgebaut und wird heute von RCSB (Research Collaboratory for Structural Bioinformatics) betreut [1]. Die letzte Aktualisierung von PDB am 12. Sep. 2006 enthielt
38729 Struktureinträge.
Die Einträge in PDB enthalten die Atomkoordinaten und einige strukturelle Parameter, die mit den
Atomen verbunden werden, oder aus den Sekundärstrukturen berechnet werden. Die Einträge enthalten einige Annotationen, jedoch nicht so umfangreich wie in SWISS-PROT. Hier helfen jedoch
die Kreuzverweise zwischen den Datenbanken. Für die Benutzung der PDB-Daten gibt es keine
gesetzlichen Beschränkungen. Die weitere Literatur zu PDB ist [9].
44
Jeder Eintrag besteht aus verschiedenen Zeilenarten, die ihre eigenen Formate haben. Ein beispielhafter Sequenzeintrag wird abgekürzt in Abb. 3-4 dargestellt. Jeder Eintrag beginnt mit einer
Anfangszeile (HEADER) und endet mit einer Abschlusszeile (END).
Abb. 2-5
ein Sequenzeintrag in PDB (aus [www.rcsb.org/pdb/])
Der Titel-Teil enthält die Zeilen, die das im Eintrag enthaltende Experiment und die biologischen
Makromoleküle beschreiben. Dieser Teil beinhaltet die grundlegenden Informationen und besteht
aus den Zeilenarten: HEADER, OBSLTE, TITLE, CAVEAT, COMPND, SOURCE, KEYWDS,
EXPDTA, AUTHOR, REVDAT, SPRSDE, JRNL und REMARK.
45
Die HEADER-Zeile enthält eine Klassifikation des Eintrags, den einzelnen Identifikationskode in PDB und das Ablagerungsdatum in PDB.
Die OBSLTE-Zeile kommt in den Einträgen vor, die von dem vollständigen Release der
PDB zurückgenommen worden sind. Sie enthält den Identifizierungscode eines ersetzten
Eintrags, den Identifizierungscode eines ersetzenden Eintrags und das Ersetzdatum.
Die TITLE-Zeile enthält einen Titel für das Experiment oder die Analyse eines Eintrags.
Diese Zeile kann einen Eintrag in PDB identifizieren.
Die CAVEAT-Zeile beschreibt die Warnung von einigen Fehlern in einem Eintrag.
Die COMPND-Zeile beschreibt die hochmolekularen Inhalte eines Eintrags.
Die SOURCE-Zeile beschreibt die biologische und/oder chemische Quelle von jedem
biologischen Molekül eines Eintrags. Die Quellen werden durch den allgemein gebräuchlichen und den wissenschaftlichen Namen beschrieben.
Die KEYWDS-Zeile enthält eintragsrelevante Schlüsselwörter, die verwendet werden,
um Einträge zu klassifizieren und Indexdateien zu generieren.
Die EXPDTA-Zeile bietet Informationen über die Experimente, nämlich einige experimentelle Techniken für die Strukturanalyse. Z.B., ELECTRON DIFFRACTION, FIBER
DIFFRACTION, FLUORESCENCE TRANSFER, NEUTRON DIFFRACTION, NMR,
THEORETICAL MODEL, X-RAY DIFFRACTION.
Die AUTHOR-Zeile enthält die Namen der für die Inhalte des Eintrags verantwortlichen Autoren.
Die REVDAT-Zeilen enthalten die Modifikations-Historie eines Eintrags.
Die SPRSDE-Zeilen enthalten eine Liste von den ungültigen Identifizierungscodes und
die sie ersetzenden Identifizierungscodes.
Die JRNL-Zeile enthält das primäre Literaturzitat.. Es gibt höchstens eine
JRNL-Referenz pro Eintrag. Falls es keine primäre Referenz gibt, entfällt die
JRNL-Zeile. Andere Referenzen werden in REMARK-Zeilen angeboten.
Die REMARK-Zeilen beschreiben die experimentellen Details, Annotationen, Kommentare und Informationen, die nicht in anderen Zeilen beinhaltet werden.
Der Primärstruktur-Teil enthält die Sequenz der Aminosäurereste in jeder Proteinkette. Dieser
Teil besteht aus den Zeilenarten: DBREF, SEQADV, SEQRES, MODRES.
Die DBREF-Zeile bietet die Weblinks der Kreuzverweise zu anderen Datenbanken an.
Die SEQADV-Zeile zeigt die Abweichungen der Sequenzinformationen in der ATOM-Zeile zwischen PDB und anderen Sequenzdatenbanken in DBREF-Zeilen.
Die SEQRES-Zeilen enthalten die Sequenz der Aminosäurereste oder der Nukleinsäurereste in jeder Kette des Makromoleküls.
46
Die MODRES-Zeile bietet die Beschreibungen der chemischen oder posttranslationalen
Modifikationen für Aminosäurereste und Nukleinsäurereste an.
Der Heterogen-Teil enthält die vollständige Beschreibung der nicht standardisierten Reste im
Eintrag. Er besteht aus den Zeilenarten: HET, HETNAM, HETSYN, FORMUL.
Die HET-Zeile beschreibt die nicht standardisierten Reste.
Die HETNAM-Zeile beschreibt den chemischen Namen der Verbindung.
Die HETSYN-Zeile bietet die Synonyme der Verbindung in der HETNAM-Zeile an.
Die FORMUL-Zeile beschreibt die chemische Formel.
Der Sekunkärstruktur-Teil beschreibt die Helices, Faltblätter und Schleifen, die im Protein gefunden wurden. Drei Zeilenarten: HELIX, SHEET, TURN werden verwendet, um die Namen und
Positionen dieser drei Faltungsmuster zu beschreiben.
Der Verbindungskraftannotation-Teil beschreibt die Existenz und die Positionen der Disulfidbrücken, der Verbindungskräfte zwischen Resten, der Wasserstoffbindungen, Salzbrücken und
anderen Verbindungskräften durch die Zeilenarten: SSBOND, LINK, HYDBND, SLTBRG, CISPEP.
Der sonstige Feature-Teil beschreibt die Features im Molekül wie zum Beispiel Bindungsstelle
(engl. site) durch die Zeile SITE.
Der kristallographische Teil und Koordinatentransformation beschreibt die Geometrie des
kristallographischen Experiments und die Koordinatentransformationen durch die Zeilenarten:
CRYST1, ORIGXn, SCALEn, MTRIXn, TVECT.
Der Koordinaten-Teil enthält die Kollektion von Koordinaten der Atome durch die Zeilenarten:
MODEL, ATOM, SIGATM, ANISOU, SIGUIJ, TER, HETATM, ENDMDL.
Der Verbindung-Teil beschreibt die Informationen über die chemische Verbindung, die schon in
den Zeilen LINK, HYDBND, SLTBRG, und CISPEP gefunden sind. Die Zeile hier ist CONECT.
Der Buchführung-Teil beschreibt einige Abschlussinformationen über die Datei selbst. Es besteht
aus den Zeilenarten: MASTER und END.
Die MASTER-Zeile ist eine Kontrollzeile für Buchführung.
Die END-Zeile bezeichnet das Ende der PDB-Datei.
47
2.
SCOP [scop.mrc-lmb.cam.ac.uk/scop/]
Die Proteine in der PDB-Datenbank haben strukturelle Ähnlichkeiten mit anderen Proteinen und
in vielen Fällen einen gemeinsamen evolutionären Ursprung. Um den Zugriff auf diese Information zu erleichtern, wurde die SCOP-Datenbank konstruiert [10].
SCOP steht für „Structural Classification of Proteins“ und wurde von Alexey Murzin im Jahre
1994 (Lab of Molecular Biology, MRC, Cambridge, UK) aufgebaut [1]. Ziel von SCOP ist es,
3D-Strukturen von Proteinen in ein hierarchisches Schema von strukturellen Klassen einzuordnen. Die Erstellung wurde von Experten (von Hand) unterstützt, und sämtliche Proteinstrukturen in PDB sind dort klassifiziert. SCOP ist eine typische Sekundärdatenbank, die auf
den Daten einer Primärdatenbank (hier PDB) basiert. Klassifiziert sind nicht nur die Proteine
aus der PDB-Datenbank, sondern auch viele Proteine, für die es bekannte Beschreibungen gibt,
ohne dass deren Koordinaten vorhanden sind. SCOP wird durch visuelle Inspektion und Vergleich
der Proteinstrukturen aufgebaut. Die Einheit der Klassifikation ist üblicherweise Protein-Domäne.
Proteine mit mehren Domänen werden gesplittet und getrennt klassifiziert. Die Klassifikation
von 3D-Strukturen des Proteins in PDB ist ein hierarchisches Schema von „class“, „common
fold“, „superfamily“ und „family“. Die weitere Literatur zu SCOP ist [11].
3.
„Family“: Proteine werden in Familien zusammen gruppiert – basierend auf einem von
zwei Kriterien: erstens, alle Proteine mit 30%igen und größeren Sequenzidentitäten;
zweitens, Proteine mit niedrigen Sequenzidentitäten aber ähnlichen Funktionen und
Strukturen. Proteine einer Familie haben alle einen gemeinsamen evolutionären Ursprung.
„Superfamily“: Familien, deren Proteine niedrig Sequenzidentitäten haben, aber deren
Strukturen und in vielen Fällen funktionelle Eigenschaften zeigen, dass sie einen gemeinsamen evolutionären Ursprung haben, werden in Superfamilien zusammengestellt.
„Common fold“: Superfamilien und Familien werden definiert als „common fold“,
wenn ihre Proteine die gleiche Hauptsekundärstrukturen in der gleichen Anordnung und
mit der gleichen Topologie haben.
„Class“: Die verschiedenen Faltungen werden in Klassen gruppiert. Die meisten Faltungen gehören zu einer der fünf strukturellen Klassen:
1. all-α: Proteine, deren Struktur hauptsächlich durch α-Helices gebildet wird.
2. all-ß: Proteine, deren Struktur hauptsächlich durch ß-Faltblätter gebildet wird.
3. α/ß: Proteine mit α-Helices und ß-Faltblätter.
4. α+ß: Proteine, in denen α-Helices und ß-Faltblätter größtenteils isoliert werden.
5. multi-domain: Proteine mit Domänen von verschiedene „fold“.
CATH [www.biochem.ucl.ac.uk/bsm/cath]
Die CATH Datenbank dient einer hierarchischen Klassifikation von Protein-Domänen durch einen
Sequenz- und Strukturvergleich, der Proteine auf vier hauptsächlichen Ebenen clustert [12]: C
(Class), A (Architecture), T (Topology), H (Homologous Superfamily). Obwohl das Ziel von
48
CATH sehr ähnlich wie SCOP ist, ist das Schema unterschiedlich. CATH ist von Christine Orengo in Janet Thornton’s Lab (University College London) im Jahre 1996 aufgebaut [1]. Die weitere
Literatur zu CATH ist [12].
„Class“ (C-level) beschreibt den Aufbau und die Beziehungen der Sekundärstruktur.
Proteine werden in vier Hauptklasse klassifiziert: „mainly α“, „mainly β“, α-β, „few secondary structures“ [12].
„Architecture“ (A-level) beschreibt die grobe Anordnung von Sekundärenstrukturen,
unabhängig von ihren Konnektivität. Diese Ebene unterscheidet die Strukturen in der
gleichen Klasse mit verschiedenen Architekturen, ohne Berücksichtigung der Konnektivitäten zwischen den Sekundärstruktur-Elementen, z.B., Sandwich, TIM barrel.
„Topology“ (T-level): Strukturen, die auf T-Ebene gruppiert werden, haben die
gleiche Falte. D.h., sie haben eine ähnliche Anzahl und Anordnung von Sekundärstrukturen, und die Konnektivität zwischen den Elementen der Sekundärstruktur ist
gleich. Proteine mit den gleichen CAT-Nummern haben die gleiche Klasse, Architektur und Topologie. Sie gehören aber nicht unbedingt zur gleichen „homologous
superfamily“. Innerhalb einer gegebenen Topolgie-Ebene sind die Strukturen ähnlich, haben aber möglicherweise verschiedene Funktionen.
„Homologous Superfamily“ (H-level): Auf der H-Ebene werden Strukturen durch ihre
hohe strukturelle Ähnlichkeit und ähnliche Funktionen gruppiert. Es erscheint naheliegend, dass sie aus einem gemeinsamen Vorfahr entstanden sind.
Abb. 4-3
schematische Darstellung von C-, A- und T-Ebene in CATH (aus [12])
49
4.3
1.
Protein-Sekundärdatenbanken
Pfam [www.sanger.ac.uk/Software/Pfam/, www.cgr.ki.se/Pfam]
Pfam ist eine Datenbank von Proteinfamilien, die als Domäne definiert werden. Jede Domäne
enthält ein Multipelalignment4 von einer Menge von definierenden Sequenzen (die Samen) und
anderer Sequenzen in SWISS-PROT und TrEMBL [1]. Die Pfam Datenbank wurde 1996 aufgebaut und wird von einer Arbeitsgemeinschaft von Wissenschaftlern unterstützt – unter ihnen Erik
Sonnhammer (CGR, KI, Sweden), Sean Eddy (WashU, St Louis USA), Richard Durbin, Alan Bateman und Ewan Birnez (Sanger Centre, UK). Die Pfam Datenbank kann durchsucht oder benutzt
werden, um die Domäne einer Sequenz zu identifizieren, oder aus den Webseiten oben herunter
geladen werden. Die Alignments können in Hidden Markov Model (HMM) umgewandelt werden,
die benutzt werden können, um nach der Domäne in einer angefragten Proteinsequenz zu forschen.
Die Software HMMER (von Sean Eddy) ist die Rechenbasis für Pfam. Die Domänestruktur von
Proteinsequenzen in SWISS-PROT und TrEMBL sind direkt aus der Webseite von Pfam verfügbar,
und es ist auch möglich, in anderen Sequenzen nach Servern oder Webseiten zu suchen. Die weitere Literatur zu Pfam ist [18].
2.
PROSITE [www.expasy.ch/prosite/]
PROSITE ist eine Datenbank von Proteinfamilien und Domänen. Sie besteht aus biologisch wichtigen Bindungsstellen, Muster und Profile, die helfen, zuverlässig zu identifizieren, zu welcher
bekannten Proteinfamilie eine neue Sequenz gehört. PROSITE wurde von Amos Bairoch aufgebaut, ist ein Teil von SWISS-PROT und wird ebenso unterstützt. Die Basis sind reguläre Ausdrücke, die die typischen Subsequenzen von spezifischen Proteinfamilien oder Domänen beschreiben.
PROSITE ist durch einige Profile erweitert worden, die als Muster für spezifische Proteinsequenzfamilien beschrieben werden können. Die oben genannte Webseite kann benutzt werden
zum Durchsuchen nach Schlüsselwörtern oder anderen Texten, nach einem Muster in einer Sequenz, oder nach Proteinen in SWISS-PROT, die zu einem Muster passen. Die weitere Literatur
zu PROSITE ist [19].
4
„Für den Vergleich der Sequenzen wird ein Alignment erstellt, bei dem die Proteinsequenzen zweier oder mehrerer Proteine im Einbuchstabencode untereinander geschrieben werden. (engl. to align, in Reih und Glied aufstellen).“ (aus [25])
50
Kapitel 5
Entwurf der ProteinDB
ProteinDB ist eine relationale prototypische Protein-Sequenzdatenbank für didaktische Zwecke
und wird durch das DBMS Microsoft Access verwaltet. In diesem Kapitel werden der konzeptuelle und relationale Entwurf von ProteinDB näher beschrieben und die Lösungsmöglichkeiten des
Entwurfs diskutiert.
5.1 Konzeptueller Entwurf
Beim konzeptuellen Entwurf der ProteinDB wird ein konzeptuelles Modell unter Verwendung des
in Kapitel 3 vorgestellten ER-Modells entwickelt. Konzeptuelle Modelle sind finden als eine bewährte Technik seit Jahren in zahlreichen Software-Projekten Anwendung. Allerdings werden sie
für biologische und biochemische Daten bisher noch nicht in demselben Umfang eingesetzt, trotz
der wachsende Anzahl und Komplexität der Informationsressourcen in diesen Gebieten [47]. In
diesem Abschnitt soll dargelegt werden, welche Rolle das ER-Modell bei der Beschreibung und
der Strukturanalyse biologischer Daten spielen könnte. Hier werden die wichtigen Gegenstände
und ihre untereinander bestehenden Beziehungen in der Proteinwelt, die in Kapitel 2 ausgearbeitet
worden sind, modelliert.
Zur Erstellung des ER-Modells für eine Proteindatenbank sind folgende Designentscheidungen zu
treffen:
Soll ein Konzept als ein Entity-Typ oder als ein Attribut modelliert werden?
Welche Entity-Typen sind an einem Relationship-Typ beteiligt?
Soll ein Konzept als ein schwacher Entity-Typ modelliert werden?
Soll Generalisierung verwendet werden?
Als nächstes werden diese Fragen zu den Designentscheidungen diskutiert.
5.1.1
Normaler Entwurf
Modellierung der Proteine
Jedes Protein ist ein Entity und wird mit seinen Eigenschaften einschließlich Name, Gewicht,
Primärstruktur (Sequenz), Sequenzlänge, Sekundärstruktur und Spezies, aus der ein Protein
kommt, charakterisiert. Die Sammlung aller Proteine kann durch ein Entity-Typ Protein modelliert werden. Bei der Entscheidung der Attribute von Protein ist es manchmal nicht ganz klar, ob
eine Eigenschaft als ein Entity-Typ oder als ein Attribut modelliert werden soll. Die Eigenschaften
Gewicht und Sequenzlänge sind ganz klar durch Attribute weight bzw. length modelliert. Um jede
Instanz von Protein zu identifizieren, wird hier ein Attribut protein_AC (Zugriffsnummer) als Identifizierungsmerkmal erwartet. Dieses Attribut dient nicht zur Beschreibung eines Proteins
selbst, sondern zum Zugriff in der Proteindatenbank. Die anderen oben gezeigten Attribute haben
eine komplexe Struktur und sollen durch Entity-Typen modelliert werden. Als nächstes werden die
Details des Entwurfs näher erläutert.
51
Modellierung der Spezies
Proteine mit demselben Name unterscheiden sich durch ihre unterschiedlichen Speziesquellen.
Jede Spezies von Proteinen kann einen offiziellen Namen, einen alternativen Namen und ein
Synonym haben. Dann ist die Spezies kein atomares Attribut und soll als ein Entity-Typ Species
mit den Attributen official_name, alternative_name und synonym modelliert werden. Außerdem
hat Species ein Attribut Code als Identifizierungsmerkmal von jeder Instanz. Die Beziehungen
zwischen Species und Protein werden mit einem Relationship-Typ comes_from modelliert. Da
mehrere Proteine aus einer gemeinsamen Spezies kommen können und jedes Protein aus nur einer
Spezies, ist die Beziehung N:1.
Modellierung der Literaturhinweise
Die meisten Daten über Proteine kommen aus mehreren wissenschaftlichen Veröffentlichungen.
Deswegen soll ein Entity-Typ Reference erstellt werden, um die Literaturzitate zu den Proteinen
zu speichern. Der Relationship-Typ zwischen Protein und Reference ist cited_in. Da die wissenschaftlichen Veröffentlichungen in einer speziellen Datenbank gespeichert werden und der Entwurf einer solchen Literaturdatenbank kein Thema dieser Diplomarbeit ist, wird hier nur eine
kurze Version von Literatur modelliert. Das Attribute RT beschreibt den Titel einer wissenschaftlichen Veröffentlichung und RL ihre Quelle.
Modellierung der Schlüsselwörte
Außerdem wird ein Entity-Typ Keyword erstellt, um Indizes der Proteineinträge in der Datenbank
zu generieren, die auf funktionellen, strukturellen oder anderen Kategorien basieren. Das Attribut
keyword_ID bezeichnet das Identifizierungsmerkmal eines Schlüsselworts und definition bietet
seine Definition an. Der Relationship-Typ has_keyword beschreibt die N:M Beziehung zwischen
Protein und Keyword.
5.1.2
Spezieller Entwurf
Modellierung der Proteinnamen
Jedes Protein kann mehrer Namen haben. Dann ist der Name kein atomares Attribut und als ein
52
Entity-Typ Name modelliert. Alle Namen eines Proteins unterscheiden sich wieder in zwei Teile:
ein einziger empfohlener Primärname und viele andere alternative Namen. Dies berücksichtigend
gibt es zwei Lösungsmöglichkeiten:
Alternative 1: Der Entity-Typ Name hat ein String-Attribut name und ein Diskriminatorattribut primary. Der Relationship-Typ has_protein_name modelliert die Beziehung zwischen
Protein und Name. Da jedes Protein mehrere Namen haben kann und ein Name mehrere Proteine bezeichnen kann, ist die Beziehung N:M. Alle Instanzen von Name sind synonym, deswegen wird die Beziehungen zwischen den Instanzen und sich selbst durch den Relationship-Typ synonym_of modelliert.
Alternative 2: Da die alternativen Namen keine direkte Beziehung zum Protein haben, sondern eine direkte Beziehung zum Primärname dieses Proteins, werden zwei Entity-Typen
Primary Name und Alternative Name erstellt, deren Attribute nur aus einem String-Attribut
name bestehen. Diese zwei Entity-Typen sind Untertypen des Entity-Typ Name. Der Relationship-Typ has_protein_name beschreibt die Beziehung zwischen Protein und Primary Name. Da jedes Protein nur einen einzigen Primärnamen hat und ein Primärname mehrere Proteine bezeichnen kann, ist die Beziehung zwischen Protein und Primary Name N:1. Die Beziehung zwischen Primary Name und Alternative Name wird mit einem Relationship-Typ
synonym_of beschrieben. Die Beziehung zwischen Primary Name und Alternative Name
wird nicht beschränkt, deswegen ist sie M:N.
Designentscheidung: Im Vergleich mit der ersten Alternative ist die zweite Alternative zu bevorzugen, weil die Speicherstruktur der zweiten Alternative klarer und einfacher ist (s. folgende Abbildung).
53
Bei der zweiten Alternative wird has_protein_name wegen der N:1-Beziehung beim späteren
logischen Entwurf nur durch die Fremdschlüssel-Beziehung in Protein modelliert. Der Speicherplatz wird gespart, weil has_protein_name nicht in eine Relation umgesetzt wird.
Bei der ersten Alternative wird has_protein_name wegen der N:M-Beziehung im späteren
logischen Entwurf in eine Relation umgesetzt, sodass jede Beziehung zwischen den Proteinen
und ihren Namen gespeichert werden muss. Das beansprucht sehr viel Speicherplatz. Um
außerdem den Speicherplatz von synonym_of zu sparen, wird auch dem Relationship-Typ
synonym_of eine Beschränkung insofern auferlegt, als nur die Beziehungen zwischen dem
Primärnamen und dem alternativen Namen dargestellt werden.
Modellierung der Proteinsequenzen
Zum Modellieren der Sequenz eines Proteins gibt es zwei Lösungsmöglichkeiten:
Alternative 1: Die ganze Aminosäuresequenz mit Reihenfolge wird als Attribut eines Proteins
explizit gespeichert.
Alternative 2: Ein Entity-Typ Amino Acid wird erstellt, dessen Attribute name (Name einer
Aminosäure), 3_letter_code (3-Buchstaben-Code), 1_letter_code (1-Buchstaben-Code), PH
(Säuergrad) und polarity (Polarität) sind. Ein neuer Relation-Typ aa_lies_in_protein mit dem
Attribut position beschreibt die Beziehung zwischen Amino Acid und Protein. Hier werden
die Positionen aller Aminosäuren in jedem Protein dargestellt. Da jedes Protein aus mehreren
Aminosäuren bestehen und jede Aminosäure in mehreren Proteinen entstehen kann, ist diese
Beziehung N:M. Dann wird die Aminosäuresequenz eines Proteins implizit gespeichert.
Designentscheidung: Die erste Alternative ist für den direkten Zugriff auf die Sequenz geeignet.
Wenn man jedoch einen bestimmten Abschnitt von zwei Sequenzen vergleichen möchte, spielt die
Position der Aminosäure in einem Protein eine wichtige Rolle. Dann ist die zweite Alternative
geeignet. Da die zwei Alternativen ihre eigenen Vorteile haben, werden sie jeweils für verschiedene Anfragen verwendet (s. unten).
Modellierung der Sekundärstrukturen
Die Sekundärstruktur eines Proteins wird durch die drei hauptsächlichen Elementen Helix, Faltblatt und Schleife beschrieben. Hier kann die Sekundärstruktur als ein normaler Entity-Typ modelliert werden. Wenn aber ein Protein nicht mehr existiert, existieren auch die SekundärstrukturElemente dieses Proteins nicht mehr. Um die Abhängigkeit von Proteinen und ihrer Sekundärstrukturen exakt zu modellieren, werden die Sekundärstrukturen als ein schwacher Entity-Typ Secondary Structure Element modelliert, der von dem Entity-Typ Protein abhängt. Die Attribute
54
type bezeichnen den Typ eines Sekundärstruktur-Elements, begin und end beschreiben die Anfangs- bzw. Endposition eines Sekundärstruktur-Elements. Der schwache Relationship-Typ
has_ss_element beschreibt die Beziehung zwischen Protein und Secondary Structure Element. Da
jedes Protein mehrere Sekundärstruktur- Elemente hat, ist die Beziehung 1:N.
Generalisierung und Aggregierung
Auf der Basis der Grundlage von Proteinbiosynthese, die in Abschnitt 2.4 ausgearbeitet wurde,
kann auch die Beziehung zwischen Nucleinsäuren und Proteinen modelliert werden. An der Proteinbiosynthese sind die mRNA, tRNA, rRNA und das Gen beteiligt. Die mRNA, tRNA und
rRNA sind Untertypen des Entitity-Typ RNA. Die Beziehung zwischen der RNA und ihren drei
Untertypen ist die IS-A-Beziehung. Ein Gen ist ein Abschnitt einer DNA, deswegen ist die Beziehung zwischen den zwei Entity-Typen DNA und Gene die IS-PART-OF-Beziehung. DNA und
RNA sind zwei Untertypen des Entity-Typ Nucleic Acid. Ein Gen wird zuerst in eine oder mehrerer mRNA transkribiert, deswegen ist der Relationship-Typ transcibes_into zwischen Gene und
mRNA 1:N. Da eine mRNA in eine oder mehrere Proteine übersetzt wird, ist der Relationship-Typ
translates_into zwischen mRNA und Protein auch 1:N. In der vorliegenden Diplomarbeit werden
die oben gezeigten Entity-Typen und Relationship-Typen nur ohne Attribute modelliert (s. Abb.
5-1 rechts unten), weil sie zum Thema Entwurf der Nucleinsäuredatenbank gehören.
Proteine, Aminosäuren, Nucleinsäuren und Nucleotide gehören alle zu den Biomolekülen. Sie gehören aber zu verschiedenen Arten von Biomolekülen. Es gibt drei Arten von Biomolekülen: kleine Moleküle, Monomere, Polymere. Aminosäuren und Nucleotide gehören zu den Monomeren.
Proteine und Nucleinsäuren gehören zu den Polymeren. Um solche Klassen auszudrücken, werden
die IS-A-Beziehungen benötigt. Dann sind die Entity-Typen Protein und Nucleic Acid Untertypen
des Entity-Typ Polymer mit den Attributen AC, name und type. Die Entity-Typen Amino Acid und
Nucleotid sind Untertypen des Entity-Typ Monomer mit den Attributen code, name und type. Polymer und Monomer sind Untertypen des Entity-Typ Biomolecule mit den Attributen AC, name
und type. (s. Abb. 5-1)
Bis jetzt wurden alle Konzepte der Proteinwelt im ER-Modell modelliert. Abb. 5-1 zeigt das zusammengefasste ER-Schema der ProteinDB.
55
e
s
ha
m
na
n_
i
te
ro
p
_
tra
56
ns
es
la t
_ in
to
5.2 Logischer Entwurf
Nach dem konzeptuellen Entwurf wird das ER-Schema der ProteinDB mittels der die im Abschnitt 3.1.2 ausgearbeiteten Regeln in ein relationales Schema umgesetzt. Das ER-Schema der
ProteinDB ist Datenbank-unabhängig, während das relationale Schema stark von DBMS abhängt.
In diesem Abschnitt werden alle Relationen (Tabellen in Access) der ProteinDB näher erläutet.
Zur Umsetzung von ER-Schemata in relationale Schemata sind folgende Designentscheidungen zu
treffen:
Sollen alle Entity-Typen in Tabellen umgesetzt werden?
Sollen alle Relationship-Typen in Tabellen umgesetzt werden?
Wie sollen die Generalisierungshierarchien dargestellt werden?
Als nächstes werden diese Fragen zum logischen Entwurf diskutiert.
5.2.1
Normale Umsetzung
Umsetzung der Entity-Typen
Bei der Umsetzung der Entity-Typen Protein, Amino Acid, Species, Secondary Structure Element,
Keyword und Reference ist klar, dass jeder Entity-Typ in eine Tabelle umgesetzt wird. Die Namen
der Tabellen sind die Namen der Entity-Typen. Die Attribute werden in den Spaltennamen dieser
Tabelle umgesetzt. Die Tabellen solcher Entity-Typen sind:
Protein (protein_AC, length, weight, sequence)
Amino Acid (1_letter_code, name, 3_letter_code, PH, polarity)
Species (code, official_name, common_name, synonym)
Secondary Structure Element (type, begin, end, description)
Keyword (keyword_ID, definition)
Reference (RL, RT)
Umsetzung der 1:N- und N:1-Beziehungen
Für die speziellen Funktionalitäten (1:N, N:1 und 1:1) werden die Relationship-Typen nicht in
Tabellen umgesetzt. Stattdessen werden die Beziehungen zwischen den beteiligten Entity-Typen
mit Hilfe von Fremdschlüssel-Beziehungen realisiert. Dann wird der Primärschlüssel des mit 1
markierten Entity-Typs als Fremdschlüssel in die Tabelle des mit N markierten Entity-Typs eingebettet. Für die Relationship-Typen comes_from und has_protein_name zwischen Protein und
Species bzw. Primary Name, werden die Spaltennamen Species.code bzw. [Primary Name].name
in Protein eingebettet.
Protein (protein_AC, length, weight, sequence, Species.code, [Primary Name].name)
Für die schwachen Relationship-Typen has_ss_element wird Protein.protein_AC in Secondary
Structure Element eingebettet. Protein.protein_AC und der Schlüssel von Secondary Structure
57
Element zusammen bilden den Schlüssel von Secondary Structure Element.
Secondary Structure Element (Protein.protein_AC, type, begin, end, description)
Umsetzung der M:N-Beziehungen
Für die M:N-Beziehungen werden sowohl die Relationship-Typen als auch die Entity-Typen in
Tabellen umgesetzt. Nicht nur die Spaltennamen der Relationship-Typen werden in Tabellen umgesetzt, sondern auch die Primärschlüssel der beteiligten Entity-Typen werden in Relationship-Tabellen eingebettet. Die Tabellen solcher Relationship-Typen sind:
aa_lies_in_protein (Protein.protein_AC, position, [Amino Acid].1_letter_code)
cited_in (Protein.protein_AC, Reference.RL)
has_keyword (Protein.protein_AC, Keyword.keyword_ID)
synonym_of (primary_name, alternative_name)
5.2.2
Spezielle Umsetzung
Für die relationale Darstellung von Generalisierungshierarchien gibt es drei Lösungsmöglichkeiten. Als nächstes wird die Umsetzung der vier vorliegenden IS-A-Beziehungen diskutiert.
Für die Darstellung des Obertyps Name und der zwei Untertypen Primary Name sowie Alternative
Name gibt es drei Lösungsmöglichkeiten:
Alternative1: Name, Primary Name und Alternative Name werden in drei Tabellen umgesetzt.
Name (name, primary)
Primary Name (name)
Alternative Name (name)
Alternative2: Name wird in eine Tabelle umgesetzt. Primary Name und Alternative Name
werden durch zwei Sichten dargestellt. Die SQL-Anweisungen sind:
CREATE VIEW Primary Name AS
(SELECT Name.name
FROM Name
WHERE (Name.primary = Yes))
CREATE VIEW Alternative Name AS
(SELECT Name.name
FROM Name
WHERE (Name.primary = No))
58
Alternative 3: Primary Name und Alternative Name werden in zwei Tabellen umgesetzt. Name wird durch eine Sicht dargestellt. Die SQL-Anweisungen sind:
CREATE VIEW Name AS
((SELECT [Primary Name].name, "Yes" AS primary
FROM [Primary Name])
UNION
(SELECT [Alternative Name].name, "No" AS primary
FROM [Alternative Name]))
Designentscheidung: Im Vergleich mit der Alternative 1 und 3 ist die Alternative 2 zu bevorzugen.
Für die erste Alternative ist die Zugriffszeit schneller ohne Tabellenvereinigung. Aber wegen der
redundanten Speicherung des vererbten Attributs name erhöht sich der Platzbedarf in der Datenbank. Für die dritte Alternative gibt es keine Duplizierung von vererbten Attributwerten. Aber
wegen der Projektion und Vereinigung ist die Zugriffszeit langsamer. Die zweite Alternative balanciert die Nachteile und Vorteile der anderen zwei Alternativen aus. Hier wird nur eine Basis-Tabelle erstellt und dadurch Speicherplatz gespart. Wegen der Projektion ist der Zugriff auf
Attribut name ein bisschen langsamer aber trotzdem schneller als bei der dritten Alternative.
Für die Darstellung der Drei-Schichten-Generalisierungshierarchien der Entity-Typen Biomolecule,
Monomer, Polymer, Protein und Amino Acid gibt es drei Lösungsmöglichkeiten:
Alternative 1: Alle Entity-Typen werden in Tabellen umgesetzt.
Biomolecule (AC, name, type)
Monomer (code, name, type)
Polymer (AC, name, type)
Protein (protein_AC, length, weight, sequence, Species.code, [Primary Name].name)
Amino Acid (1_letter_code, name, 3_letter_code, PH, polarity)
Alternative 2: Die Bearbeitung der Drei-Schichten-Generalisierungshierarchien von oben
nach unten. Der Entity-Typ Biomolecule wird in Tabellen umgesetzt. Da die zwei Untertypen
Polymer und Momomer alle Attribute von Biomolecule erben, wird Monomer und Polymer
durch zwei Sichten dargestellt. Die SQL-Anweisung sind:
CREATE VIEW Monomer AS
(SELECT * FROM Biomolecule
WHERE (type=“monomer“)
CREATE VIEW Polymer AS
(SELECT * FROM Biomolecule
WHERE (type=”polymer”)
Da der Entity-Typ Protein außer den zwei vererbten Attributen: AC und name von Polymer
auch seine eigene Attribute hat, wird eine zusätzliche Tabelle Protein_local zur Speicherung
seiner eigenen Attributwerte erstellt, deren Attribute aus AC - der Schlüssel von Polymer 59
und den eigenen Attributen bestehen. Dann wird die Protein-Populaton vollständig über eine
Sicht realisiert, die durch JOIN-Verknüpfung die vererbten und die eigenen Attribute wieder
zusammenführt. Die Tabelle und die SQL-Anweisungen sind:
Protein_local (AC, length, weight, sequence, Species.code, [Primary Name].name)
CREATE VIEW Protein AS
(SELECT Polymer.name, Protein_local.*
FROM Protein_local INNER JOIN Polymer
ON Protein_local.AC=Polymer.AC)
Die Darstellung des Entity-Typs Amino Acid ist dann ähnlich wie Protein. Die Tabelle und
die SQL-Anweisungen sind:
Amino Acid_local (1_letter_code, 3_letter_code, PH, polarity)
CREATE VIEW Amino Acid AS
(SELECT Monomer.name, [Amino Acid_local].*
FROM [Amino Acid_local] INNER JOIN Monomer
ON [Amino Acid_local].1_letter_code=Monomer.code)
Alternative 3: Die Bearbeitung der Drei-Schichten-Generalisierungshierarchien von unten
nach oben. Die Untertypen Protein und Amino Acid werden in Tabellen umgesetzt. Zusätzlich
werden die zwei Tabellen Polymer_local, Monomer_local und Biomolecule_local erstellt, die
die anderen Polymere, Monomere und Biomoleküle speichern. Die Obertypen Polymer, Monomer und Biomolecule werden durch drei Sichten dargestellt. Die Tabellen und die
SQL-Anweisungen sind:
Polymer_local (AC, primary_name, type)
Monomer_local (code, name, type)
Biomolecule_local (AC, primary_name, type)
CREATE VIEW Polymer AS
((SELECT protein_AC AS AC, primary_name, "protein" AS type
FROM Protein)
UNION
(SELECT *
FROM Polymer_local))
CREATE VIEW Monomer AS
((SELECT 1_letter_code AS code, name, "amino acid" AS type
FROM [Amino Acid])
UNION
(SELECT *
FROM Monomer_local))
60
CREATE VIEW Biomolecule AS
((SELECT code AS AC, name AS primary_name, “monomer” AS type
FROM Monomer)
UNION
(SELECT AC, primary_name, “polymer” AS type
FROM Polymer)
UNION
(SELECT * FROM Biomolecule_local))
Designentscheidung: In Vergleich mit der Alternative 1 und 2 ist die Alternative 3 zu bevorzugen.
Die erste Alternative besetzt wegen der redundanten Speicherung der vererbten Attributwerte zu
viel Speicherplatz. Obwohl bei der zweiten Alternative die redundante Speicherung der vererbten
Attributwerte stark reduziert wird, wird wegen der enormen Anzahl der Proteine und der Polymere ebenfalls viel Speicherplatz beansprucht. Der Zugriff auf die Attribute von Protein ist langsamer wegen der Projektion und der JOIN-Verknüpfung. Die dritte Alternative enthält dagegen gar
keine redundante Speicherung von Attributwerten. Der Zugriff auf die Attribute von Polymer,
Monomer und Biomolekule ist langsamer wegen Projektion und Vereinigung. Aber da Protein und
Amino Acid als Basistabelle dargestellt wird, ist der Zugriff auf die Attribute von Protein und Amino Acid als die zentralen Entity-Typen der Proteindatenbank schneller.
61
Kapitel 6
Architektur und Funktionalität von ProteinWeb
Um ein webbasiertes Benutzerinterface zu realisieren, wird die Software ProteinWeb entwickelt.
Mit diesem Benutzerinterface kann man komfortabel mittels Browser über Internet die Datenbank
ProteinDB besuchen und die benötigen Informationen in den Datenbanken abfragen. Im Abschnitt
6.1 wird zuerst die Architektur von ProteinWeb vorgestellt. Dann wird im Abschnitt 6.2 die benötigte Software zur Entwicklung von ProteinWeb und der Aufbau der Entwicklungsumgebung erklärt. Die ausführliche Realisierung von ProteinWeb wird in Abschnitt 6.3 beschrieben und diskutiert. Schließlich wird die Verwendung von ProteinWeb erklärt.
6.1 Architektur
Der beste Weg zum Aufbau von ProteinWeb ist die Drei-Komponenten-Architektur [48], welche
die drei Komponenten Benutzeroberfläche, Rechenlogik und Datenspeicher trennt (s. Abb.6-1).
Die Client-Seite dient zur Visualisierung der Benutzeroberfläche. Die Entwicklung der Rechenlogik wird auf der Server-Seite realisiert. Das Datenbanksystem ist für den Datenspeicher und die
Datenverwaltung verantwortlich.
Abb. 6-1
globale Komponentenarchitektur
Bei dieser Drei-Komponenten-Architektur kann jede Komponente einzeln entwickelt werden, so
dass die Entwicklung flexibler wird. Der Web-Browser auf der Client-Seite bietet Benutzern eine
einheitliche Benutzeroberfläche. Die Benutzer können mittels dieser Benutzeroberfläche die Programme auf der Server-Seite aufrufen (HTTP-Request). Der Server dient als Brücke zwischen
dem Client und dem Datenbanksystem. Er nimmt die Abfragen der Benutzer an und übergibt sie
über JDBC dem Datenbanksystem. Nach der Bearbeitung durch das Datenbanksystem werden die
Resultate über den Server zurück an den Client geschickt (HTTP-Response).
62
Die Entwicklung der Server-Seite wird durch zwei Module realisiert. Das Datenimportmodul erhält die Dateien von den externen Datenbanken als Eingabe und gibt die Dateien aus, die in ProteinDB importiert werden. Das Kommunikationsmodul kommuniziert mit der Client-Seite über
HTTP und mit dem Datenbanksystem über JDBC. Die Server-Seite enthält verschiedene Techniken – wie zum Beispiel Java Servlet, Java Server Page (JSP), Java Bean, usw. In den folgenden
Unterabschnitten wird die Entwicklung der Software ProteinWeb ausführlich erläutet.
6.2 Implementierungs- und Entwicklungsumgebung
Um die Entwicklungsumgebung aufzubauen, wird für ProteinWeb folgende Software verwendet:
J2EE 1.4.2: Java 2 Plattform Enterprise Edition, die Servlets und JSPs unterstützt.
Herunterladen von http://java.sun.com
Eclipse-SDK-3.1.1: die Entwicklungsumgebung für Java.
Herunterladen von http://www.eclipse.org/downloads/index.php
Apache Tomcat 5.5.12: Servlet-/JSP-Container.
Herunterladen von http://tomcat.apache.org/download-55.cgi
Sysdeo Eclipse Tomcat Laucher Plugin 3.1.0 beta: ist für Starten, Stoppen und Restarten
des Servers in Eclipse verantwortlich.
Herunterladen von http://www.sysdeo.com/eclipse/tomcatplugin
Mit den Installationsprogrammen der ersten drei Softwares lassen sich J2EE, Eclipse und Apache
Tomcat unkompliziert installieren. Das Sysdeo Tomcat Plugin wird im Ordner eclipse\plugins\
entpackt werden. Mit dem Öffnen von Eclipse erscheinen drei Karter-Zeichen in dem Menü der
Eclipse-Plattform. Die drei Kater-Zeichen bedeuten in der Reihenfolge von Links nach Rechts:
Starten, Stoppen und neu Starten. Als nächstes gehen wir in der Eclipse-Plattform in das Menü
WindowÆPerferences. Dort im Menüpunkt Tomcat tragen wir die Version von Tomcat (die 5er
Version) ein. In das Feld Tomcat Home geben wir das Verzeichnis ein, in das Tomcat installiert
wurde. Der Pfad zur Konfigurationsdatei server.xml wird nach der Eingabe des Tomcat Home automatisch ergänzt. Jetzt können wir probehalber Tomcat starten. Wir verbinden uns mit dem
Browser auf http://localhost:8080/ und alles ist in Ordnung, wenn die Startseite von Apache Tomcat erscheint. Somit ist die Entwicklungsumgebung für ProteinWeb bereitgestellt.
6.3 Realisierung von ProteinWeb
6.3.1
Datenimport in die ProteinDB
Nach der Erstellung des Datenbankschemas von ProteinDB sollen die biologischen Daten in entsprechenden Tabellen gespeichert werden. In den vorhandenen Proteindatenbanken ist zu Proteinen bereits eine Fülle von Daten gespeichert. Da diese Daten meistens in „flat files“ gespeichert
sind, passen sie nicht in das relationale Schema. Das Problem besteht darin, solche Daten in eine
relationale Datenbank zu importieren.
63
Aus den in Kapitel 4 vorgestellten Proteindatenbanken wurde SWISS-PROT als Datenquelle für
ProteinDB ausgewählt. SWISS-PROT ist eine repräsentative primäre Proteindatenbank, welche
die grundsätzlichen Datenressourcen über Proteinsequenzen enthält. In SWISS-PROT wird jedes
Protein durch ausführliche Annotationen beschrieben. Um die Redundanz der Datenbank weitgehendest zu minimieren, werden die Daten verschiedener Sequenzdatenbanken durch die Zusammenarbeit vieler Wissenschaftler zusammengefasst. Das sorgt für eine hohe Datenqualität. Ferner
enthält SWISS-PROT zurzeit die Kreuzverweise auf mehr als 50 verschiedene Datenbanken.
Durch diese Kreuzverweise bei den Einträgen in SWISS-PROT lassen sich die entsprechenden
Einträge in anderen Datenbanken direkt aufrufen. Ein solches umfangreiches Datenbanknetzwerk
verleiht SWISS-PROT eine bedeutende Rolle bei der Integration von biomolekularen Datenbanken. Im Vergleich mit SWISS-PROT orientieren sich Protein-Strukturdatenbanken z.B., PDB an
der Beschreibung der 3D-Struktur von Proteinen und Daten aus den Experimenten. Die Protein-Sekundärdatenbanken – wie zum Beispiel Sequenzmotivdatenbanken und Protein-Protein-Interaktionsdatenbanken enthalten darüber hinaus spezielle Daten für bestimmte Anwendungsgebiete.
Für den Aufbau einer prototypischen Datenbank für didaktische Zwecke sind sie deswegen nicht
geeignet.
Vor der Realisierung des Datenimport-Moduls ist zu entscheiden, welcher Datei-Typ in Access
importiert werden soll. MS Access akzeptiert sowohl XML-Datei als auch Textdateien. Für ProteinWeb wird zum Import in Access eine Textdatei ausgewählt, da der Algorithmus für die Umschreibung der „flat files“ in Textdateien deutlich einfacher ist als in XML-Dateien.
Für das Datenimport-Modul arbeitet das Paket handleTXT (s. Abb.6-2). Die Eingaben dieses Pakets sind „flat files“ und Textdateien über alle Spezies (speclist.txt) und Schlüsselwörter (keywlist.txt) aus SWISS-PROT. Die Ausgaben sind Textdateien mit gezieltem Format, die den Tabellen
in ProteinDB entsprechen. Im Paket handleTXT befinden sind zwei Klassen:
1. Die Klasse FileHandle.java dient zur Verwaltung aller Dateien und bietet drei Methoden für
verschiedene Verwaltungsaufgaben an.
Die Methode getAllFiles (String path) holt alle Dateien in einem vorgegebenen Dateipfad und liefert ein Array von Dateien zurück. Der Parameter „path“ bezeichnet einen
Dateipfad.
Die Methode getAllFileNames (String path, String expandedName) holt alle Datei- namen mit einer bestimmten Dateiendung und liefert eine Arrayliste von Dateinamen zurück. Der Parameter „path“ bezeichnet einen Dateipfad und „expandedName“ eine Dateiendung.
Die Methode creatFile (String filename, String text, boolean append) dient zur Erstellung einer neuen Datei. Der Parameter „filename“ bezeichnet den Pfad und den Namen
der neu erstellten Datei. Der Parameter „text“ ist der Inhalt der Datei. Der boolesche Parameter „append“ bestimmt, ob „text“ hinter die Datei oder an deren Anfang geschrieben
wird.
64
Abb.6-2
Datenimport in ProteinDB
2. Die Klasse Rewrite.java dient zur Umschreibung der „flat files“, „speclist.txt“ und „keywlist.txt“ aus SWISS-PROT in Textdateien mit gezieltem Format, die in ProteinDB importiert
werden. Hier werden drei Methoden angeboten, um drei verschiedene Dateitypen zu bearbeiten. In dieser Klasse werden die oben definierten drei Methoden von der Klasse FileHandle.java aufgerufen.
Um die originalen Textdateien in die zu importierenden Textdateien umzuwandeln, werden die
Formate der originalen und der gezielten Textdateien verglichen. Das Format der „flat files“ von Proteinen wurde in Abschnitt 4.1 dargestellt. Für das Format der in die Datenbank zu
importierenden Textdateien werden folgende Eigenschaften definiert:
Jede Textdatei entspricht einer Tabelle in ProteinDB.
Jeder Zeile einer Textdatei entspricht ein Datensatz einer Tabelle in ProteinDB.
Jede durch ein spezifisches Trennzeichen getrennte Spalte einer Zeile entspricht einem Attributwerte eines Datensatzes.
Nach dem Vergleich der Strukturen der originalen und der gezielten Textdateien werden die
originalen Textdateien aus SWISS-PROT mittels folgender drei Methoden umgeschrieben.
Die Methode rewriteFlatFiles () dient zur Umschreibung der „flat files“. Für jedes „flat
file“ werden folgende Zeilencode bearbeitet: ID, DE, RN bis RL, KW, FT, SQ. Die Ausgabe dieser Methode sind sechs gezielte Textdateien: aa_lies_in_protein.txt, cited_in.txt,
Feature.txt, Protein.txt, has_keyword.txt und Synonym.txt, die in folgenden Tabellen
importiert werden:
65
Protein (protein_AC, length, weight, sequence, species_code, primary_name)
Feature (protein_AC, type, begin, end, description)
protein_cited_in_Reference (protein_AC, RN, RP, RC, RX, RG, RA, RT, RL)
has_keyword (protein_AC, keyword_ID)
synonym_of (primary_name, alternative_name)
aa_lies_in_protein (protein_AC, position, 1_letter_code)
Die Werte vom Attribut protein_AC für jede Tabelle kommen aus den Dateinamen der
„flat files“, da jeder Name von „flat file“ das Format AC.txt hat. Für die Tabelle Protein
kommen die Werte von den Attributen length, weight und sequence aus den SQ-Zeilen,
die Werte vom Attribut species_code aus den ID-Zeilen, die Werte vom Attribut primary_name aus den DE-Zeilen. Für die Tabelle Feature kommen die Werte von den Attributen type, begin, end und description aus den FT-Zeilen. Für die Tabelle cited_in
kommen die Werte von den Attributen RN, RP, RC, RX, RG, RA, RT und RL aus den RNbis RL-Zeilen. Für die Tabelle has_keyword kommen die Werte vom Attribut keyword_ID aus den KW-Zeilen. Für die Tabelle synonym_of kommen die Werte von den
Attributen primary_name und alternative_name aus den DE-Zeilen. Für die Tabelle
aa_lies_in_protein kommen die Werte vom Attribut 1_letter_code aus SQ-Zeilen. Die
Werte vom Attribut position werden durch Durchzählen der Aminosäurecodes auf den
Sequenzen automatisch erzeugt. (s. die Quellcodes in der CD der Diplomarbeit)
Die Tabellen Secondary Structure Element, cited_in, und Reference werden dann durch
folgende Tabellenerstellungsabfragen (s. ProteinDB in der CD) von MS Access erzeugt.
Abfrage: create Secondary Structure Element
SELECT protein_AC, type, begin, end, description
INTO [Secondary Structure Element]
FROM Feature
WHERE ((type="HELIX") Or (type="TURN") Or (type="STRAND"));
Abfrage: create cited_in
SELECT protein_AC, RL INTO cited_in
FROM protein_cited_in_Reference;
Abfrage: create Reference
SELECT DISTINCT RL, RT INTO Reference
FROM protein_cited_in_Reference;
Die Methode rewriteSpeclist () dient zur Umschreibung „speclist.txt“ aus SWISSPROT. Die Ausgabe dieser Methode ist die gezielte Textdatei Species.txt, die in die folgende Tabelle Species importiert wird:
Species (code, official_name, common_name, synonym)
Die Textdatei „speclist.txt“ hat ein festes Format (s. folgende Abbildung links). Jede
Spezies beginnt mit einer 5-Buchstaben-Zeichenkett, die als Attributwerte von code gespeichert werden. Die Werte von den Attributen official_name, common_name und synonym kommen aus den Zeilen, die mit „N=“, „C=“ bzw. „S=“ beginnen.
66
Die Methode rewriteKeywlist () dient zur Umschreibung „keywlist.txt“ aus SWISSPROT. Die Ausgabe dieser Methode ist Keyword.txt, die in die folgende Tabelle Keyword importiert wird.
Keyword (keyword_ID, definition)
In „keywlist.txt“ (s. folgende Abbildung rechts) wird jedes Schlüsselwort in einem Zeilenblock ID bis // gespeichert. Die Werte vom Attribut keyword_ID kommen aus den
ID-Zeilen. Die Werte vom Attribut definition kommen aus den DE-Zeilen.
6.3.2
Kommunikationsmodul
Die Entwicklung der Server-Seite kann beliebig komplex sein, und auch die Server-Seite selbst
kann mehrer Schichten enthält. Die Web-Anwendungsprogramme von ProteinWeb werden in zwei
Schichten eingeteilt: die JSP-Dateien und das Paket handleDB (s. Abb. 6-3). JSP-Dateien in der
ersten Schicht kommunizieren über HTTP mit der Client-Seite. Sie überbringen dann die Parameter aus der Client-Seite dem Paket handleDB in der zweiten Schicht. Das Paket handleDB ermöglicht mittels JDBC-Technik den Besuch des Datenbanksystems. Die Idee solcher 2-SchichtenArchitektur besteht darin, dass JSP-Dateien das Datenbanksystem nicht direkt mittels
JDBC-Technik besuchen, sondern über das Paket handleDB, die das Datenbanksystem direkt besuchen. Vorteil dieser Architektur ist, dass eine ähnliche Methode zur Kommunikation mit der
Datenbank in dem Paket handleDB eingepackt wird, welches mehrmals von allen JSP-Dateien
verwendet werden können. So werden in JSP-Dateien solche Java-Codes für Verbindungen zur
Datenbank gespart.
Abb. 6-3
Innere Struktur der JSP-Dateien und dem Packet handleDB
67
Package handleDB
Die Klasse DBBean.java im Paket handleDB dient zur Erstellung der Verbindung zur Datenbank
und Ausführung der Anfragen. Hier werden zwei Methoden definiert:
Die Methode DBBean() ist eine Konstruktor dieser Klasse. Hier wird der JDBC-Treiber für
MS Access (JDBC-ODBC-Brücke) geladen mittels der Anweisung:
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver")
Methode executeQuery (String sql) dient zur Verbindung zur Datenbank und Ausführung
einer gegebenen SQL-Anfrage. Der Parameter „sql“ bezeichnet die gegebenen SQL- Anweisungen. Diese Methode liefert ein Objekt der Schnittstelle ResultSet zurück, welches eine
Tabelle von Anfrageresultaten repräsentiert. Das Programm dieser Methode ist:
public ResultSet executeQuery(String sql) {
rs = null;
try {
//Aufbau der Verbindung zur Datenbank
conn = DriverManager.getConnection("jdbc:odbc:ProteinDB");
// Erstellung eines Statement-Objekts
Statement stmt = conn.createStatement();
// Ausführung der Anfragen
rs = stmt.executeQuery(sql);
}catch(SQLException ex) {
System.err.println("db.executeQuery: " + ex.getMessage());}
return rs;
}
JSP-Dateien
ProteinWeb realisiert sowohl fixe als auch freie Anfragen nach ProteiDB. Für die Realisierung der
freien Anfragen werden freeQuery.jsp und queryFreeText.jsp eingesetzt. Die anderen JSP-Dateien
dienen zur Realisierung der fixen Anfragen. Die in den JSP-Dateien eingebetteten HTML-Codes
dienen der Oberfläche und werden in diesem Abschnitt nicht beschrieben. Jede graphische Oberfläche wird in Abschnitt 6.4 gezeigt. In diesem Abschnitt werden die in diesen JSP-Dateien eingebetteten Java-Codes für die Ausführung der Anfragen und dynamische Visualisierung der Anfrageergebnisse beschrieben. Die innere Struktur der JSP-Dateien wird in Abb. 6-3 gezeigt. Die
Richtung der Pfeile zeigt die Reihenfolge der Aufrufe zwischen allen JSP-Dateien. Die Aufrufe
zwischen verschiedenen JSP-Dateien werden normalerweise durch HTML-Codes realisiert. Z.B.,
speciesList.jsp ruft querySpecies.jsp auf, dann soll folgende HTML-Codes in speciesList.jsp eingebettet werden:
<form id="form1" name="form1" method="post" action="/ProteinWeb/querySpecies.jsp">
Unter allen JSP-Dateien sind zwei JSP-Dateien: queryForm.jsp und queryFreeText.jsp spezifisch.
Sie beide dienen nicht zur Ausführung der Anfragen und Visualisierung der Anfrageergebnisse,
sondern zur Kontrollierung der Aufrufe anderen JSP-Dateien. Die queryForm.jsp bearbeitet die
Parameter aus proteinDB.jsp, die eine Auswahlsliste angeboten hat, und kontrolliert, welche
68
JSP-Datei als nächstes aufgerufen werden soll. Z.B., Wenn man in der Auswahlsliste von proteinDB.jsp „Protein AC“ wählt, wird queryForm.jsp aufgerufen und überprüft diese Parameter.
Dann wird proteinInfo.jsp durch queryForm.jsp aufgerufen. Die queryFreeText.jsp erhält die von
Benutzer eingegebene freie Anfrage aus freeQuery.jsp und führt diese Anfrage aus. Das Anfrageresultat wird dann freeQuery.jsp zurückgeliefert. Die queryForm.jsp und queryFreeText.jsp rufen
die anderen JSP-Dateien mittels der Schnittstelle RequestDispatcher und ServletContext vom Paket javax.servlet aus Java-API auf. Für jeden Aufruf der JSP-Dateien ist das folgende Programmstück zu verwenden:
ServletContext context = getServletContext();
RequestDispatcher dispatcher = context.getRequestDispatcher("/ ***.jsp");
dispatcher.forward(request,response);}
Die Methode executeQuery() der Klasse DBBean.java wird von den JSP-Dateien verwendet, um
SQL-Anfragen auszuführen. Deswegen soll das folgende Programmstück in jeder JSP-Datei verwendet werden, um ein Objekt von der Klasse DBBean.java zu deklarieren.
<jsp:useBean id="db" class="handleDB.DBBean" scope="application">
</jsp:useBean>
Mit dem deklarierten Objekt “db“ kann die Methode excuteQuery () in jeder JSP-Datei aufgerufen
werden. Um das Anfrageresultat-Tabelle zu bekommen, soll in jeder JSP-Datei ein Objekt von der
Schnittstelle ResultSet deklariert wird. Ein ResultSet-Objekt enthält einen Cursor, welcher sich auf
die aktuelle Zeile der Anfrageresultate richtet. Anfangs wird dieser Cursor vor der ersten Zeile
positioniert. Die Methode next() von ResultSet verschiebt den Cursor zur nächsten Zeile. Sie liefert „false“ zurück, wenn es in ResultSet-Objekt keine Zeile mehr gibt. Aus diesem Grund kann
sie in einer While-Schleife verwendet werden, um die Anfrageresultate zu iterieren. Die Methode
getString(i) von ResultSet dient zur Holung des Wertes der Spalte i. Beispielweise wird die abgekürzte Version von proteinInfo.jsp unten gezeigt. Die anderen JSP-Dateien sind ähnlich und werden hier nicht alle gezeigt. Die Quellcodes finden sich in der CD dieser Diplomarbeit.
proteinInfo.jsp
<!- - Deklariere ein Objekt von Klasse DBBean.java- ->
<jsp:useBean id="db" class="handleDB.DBBean" scope="application">
</jsp:useBean>
(HTML-Codes)
<% // Java-Codes
// SQL-Anfrage
String sql1="select protein_AC, primary_name, length, weight, sequence, species_code "
+ "from Protein "
+ "WHERE protein_AC='"+proteinACParam+"'";
// Erstelle ein Objekt von der Schnittstelle ResultSet und führe die SQL-Anweisungen aus.
ResultSet rs1 = db.executeQuery(sql1);
// Iteriere die Anfrageergebnisse
while(rs1.next()){ // für jede Zeile der Resultat-Tabelle
String proteinAC=rs1.getString(1); // Hole den Werte der ersten Spalte.
String primaryName=rs1.getString(2);// Hole den Werte der zweiten Spalte, usw.
69
String length=rs1.getString(3);
String weight=rs1.getString(4);
String sequence=rs1.getString(5);
String speciesCode=rs1.getString(6);
……………..
}%>
<%=proteinAC%> // Einbette String in HTML
……………….
(HTML-Codes)
6.4 Verwendung von ProteinWeb
Die Startseite von ProteinWeb ist proteinDB.jsp, die man durch Eingabe der URL
http://Domainname/ProteinWeb/proteinDB.jsp im Web-Browser clientseitig aufruft. Mit ProteinWeb kann man die angebotenen fixen Datenbank-Anfragen ausführen oder feie SQL-Anfragen
erstellen und ausführen.
Für die fixen Anfragen wählt man Im Bereich „Query by“ eine von fünf Optionen und gibt den
Anfragetext ein. Bei der Optionen Protein AC, Primary name wird das Protein mit einer eingegebenen Zugriffsnummer bzw. einem eingegebenen Primärnamen abgefragt. Bei der Optionen Species, Reference, Keyword werden alle Proteine aus einer eingegebenen Spezies, einer eingegebenen Zitierungsquelle bzw. einem eingegebenen Schlüsselwort abgefragt.
proteinDB.jsp
Wenn man z.B. die Option Protein AC auswählt und eine Zugriffsnummer „P02649“ eingibt, wird
dann proteinInfo.jsp aufgerufen. Die proteinInfo.jsp zeigt alle Informationen über dieses Protein
mit der Zugriffsnummer „P02649“ (s. folgenden Screenshot).
70
proteinInfo.jsp
Wenn man die Option Keyword auswählt und ein Schlüsselwort eingibt, wird dann queryKeyword.jsp aufgerufen. queryKeyword.jsp zeigt alle Zugriffsnummern von Proteinen mit einem gemeinsamen eingegebenen Schlüsselwort. Hier kann man ein Protein durch seine Zugriffsnummer
wählen, dann wird proteinInfo.jsp aufgerufen, das die Information des gewählten Proteins anzeigt.
Z.B., In proteinDB.jsp wird die Option Keyword ausgewählt und der Anfragetext
„3D-Strukture“ eingeben. Dann wird queryKezword.jsp aufgeruft, in der die Anfrage „alle Proteine mit dem Schlüsselwort 3D-Struktur“ ausgeführt und visualisiert wird (s. folgenden Screenshot).
71
queryKeyword.jsp
Die Bearbeitung der anderen Optionen ist ähnlich wie die Option Keyword, dann werden hier
nicht alle JSP- Dateien angezeigt.
Die Startseite proteinDB.jsp bietet ein nutzerfreundliches Menü an. Über die Menüpunkte Keywords List, Species List, Protein primary names List und References werden Wörterverzeichnisse
von Schlüsselwörtern, Spezies, Proteinnamen bzw. Literatur angeboten, mit dessen Hilfe der Benutzer seinen Anfragetext formulieren kann. Wenn man eine der vier Optionen wählt, wird keywordList.jsp, speciesList.jsp, primaryNamesList.jsp oder referencesList.jsp aufgerufen. Die vier
JSP-Dateien zeigen die entsprechenden Wörterverzeichnisse und bieten für jedes Wort einen Link,
durch den die Anfrage nach diesem Wort ausgeführt wird. Z.B., In proteinDB.jsp wird das Menüpunkt Keywords List ausgewählt. Dann wird keywordList.jsp aufgerufen, in der die Anfrage „alle
verfügbaren Schlüsselwörter“ ausgeführt und visualisiert wird. Durch das Anklicken „3D- Struktur“ wird queryKeyword.jsp aufgerufen, in der die Anfrage „alle Proteine mit dem Schlüsselwort
3D-Struktur“ ausgeführt und das Anfrageergebnis visualisiert wird. Folgende Screenshots zeigen
die graphischen Oberflächen von den vier JSP-Dateien.
keywordList.jsp
72
speciesList.jsp
primaryNamesList.jsp
referencesList.jsp
73
Eine weitere Funktionalität von ProteinWeb erlaubt die Ausführung freier SQL-Anfragen. Alle
Tabellenstrukturen von ProteinDB werden in freeQuery.jsp angegeben. Dann im Bereich „Query
for“ kann man ein SQL-Anfrage eingeben. Durch das Anklicken des Druckknopt „Search“ wird
diese Anfrage ausgeführt und die Anfrageergebnisse werden visualisiert.
freeQuery.jsp
74
Kapitel 7
Zusammenfassung und Ausblick
Proteindatenbanken spielen bei der Speicherung und Verwaltung der Informationen über Proteine
eine wichtige Rolle. Für verschiedene Forschungsgebiete der Proteine existiert heute bereits eine
Vielzahl von Proteindatenbanken. Die meisten dieser Proteindatenbanken sind zunächst als Kollektionen von „flat files“ implementiert worden. Mitte der 1990er Jahre wurden viele auf „flat files“ basierende Datenbanken mit einer relationalen, objektorientierten oder objektrelationalen
DMBS neu implementiert. Auf dem relationalen Modell basierende Proteindatenbanken haben
sehr komplexe Schemata, deswegen können sie nur schwierig administriert und angefragt werden.
Trotzdem werden viele wichtige Proteindatenbanken heute mit weit verbreitetem relationalen
DBMS implementiert, wie z.B. Oracle, Sybase oder MySQL.
Das Hauptziel dieser Arbeit besteht darin, Daten aus auf „flat files“ basierenden Datenbanken in
einer relationalen Datenbank neu zu modellieren und zu verwalten. In Kapitel 2 und 3 der vorliegenden Arbeit werden die Grundlagen aus der Biochemie und der Informatik beschrieben, die für
Entwicklung der Proteindatenbank nötig sind. Im Kapitel 4 werden die vorhandenen repräsentativen Proteindatenbanken klassifiziert und ausführlich vorgestellt, insbesondere SWISS-PROT und
PDB. Basierend auf den „flat files“ von SWISS-PROT wird eine relationale prototypische Proteindatenbank ProteinDB für didaktische Zwecke mit dem relationalen DBMS Microsoft Access
aufgebaut. Die definierten Probleme und ihre Lösungsmöglichkeiten beim Entwurf der Datenbank
werden in Kapitel 5 ausführlich diskutiert. Schließlich wird eine Software ProteinWeb entwickelt,
die aus zwei Modulen besteht. Ein Datenimportmodul mittels Java-Technik realisiert die Umwandelung der „flat files“ aus SWISS-PROT in gezielte Textdateien, die in ProteinDB importiert
werden. Das Kommunikationsmodul realisiert ein web-basiertes Benutzerinterface für ProteinDB
mittels JSP-Technik. Ein großer Vorteil von ProteinWeb besteht darin, dass es die Ausführung freier SQL-Anfragen erlaubt, die in SWISS-PROT nicht realisiert wird. Die Realisierung des ProteinWeb und die gewählten Technikschwerpunkte werden in Kapitel 7 näher erläutet.
ProteinDB und ProteinWeb können auch weiter entwickelt werden. Die „flat files“ von
SWISS-PROT enthalten mehrere Daten zur Erstellung einer Proteindatenbank, wie z.B., in der
DR-Zeile bietet es die Kreuzverweise auf mehr als 50 verschiedene Datenbanken. SWISS-PROT
realisiert durch solche Kreuzverweise die Integration mit anderen Datenbanken. In der CC-Zeile
gibt es auch viele nützliche Informationen über Funktionen und Klassen der Proteine. Wegen der
komplexen Strukturen der DR-Zeile und CC-Zeile werden solche Informationen nicht bearbeitet
und in ProteinDB importiert. Die Software ProteinWeb dient clientseitig nur zu Anfragen der Datenbanken. Die Änderungen der Datenbank (inklusiv Einfügen, Löschen und Modifikation) wurden auf der Client-Seite noch nicht in ProteinWeb realisiert.
Die Erstellung einer Proteindatenbank mittels relationaler DBMS ist wegen der Komplexität der
vorhandenen Datenmenge ein komplexer und langwieriger Prozess. Die zurzeit vorhandenen Proteindatenbanken speichern schon viele nützliche Daten über Proteine. Deswegen ist die Integration
der Daten mit unterschiedlicher Qualität aus den heterogenen Proteindatenbanken die zukünftige
Entwicklungsrichtung.
75
Die vorliegende Diplomarbeit ist im Hinblick auf die Anforderungen von Bioinformatikern geschrieben. Sie bietet Bioinformatikern, die sich mit der Erstellung von Proteindatenbanken beschäftigen, Ideen und Lösungsmöglichkeiten für den Datenbankentwurf an. Die Lösungsmethoden
zur Umwandelung der „flat files“ aus SWISS-PROT können auch für die Umwandelung der „flat
files“ aus anderen Proteindatenbanken als Beispiel dienen.
76
Literaturverzeichnis
Quellen über Proteindatenbanken:
1. www.sbc.su.se/~pjk/molbioinfo2001/databases.html
Databases in bioinformatics
2. Amos Bairoch and Rolf Apweiler. The SWISS-PROT protein sequence data bank and its
supplement TrEMBL. Nucleic Acids Research, 1997, Vol. 25, No. 1, 31-36.
3. Amos Bairoch and Rolf Apweiler. The SWISS-PROT protein sequence data bank and its
supplement TrEMBL in 1999. Nucleic Acids Research, 1999, Vol. 27, No. 1, 49-54.
4. Amos Bairoch and Rolf Apweiler. The SWISS-PROT protein sequence data bank and its
supplement TrEMBL in 2000. Nucleic Acids Research, 2000, Vol. 28, No. 1, 45-48.
5. Amos Bairoch and Rolf Apweiler. The SWISS-PROT protein sequence data bank and its
supplement TrEMBL in 2003. Nucleic Acids Research, 2003, Vol. 31, No. 1, 365-370.
6. Michele Magrane and Rolf Apweiler. ORGANISATION AND STANDARDISATION OF
INFORMATION IN SWISS-PROT AND TREMBL. Data Science Journal, Vol. 1 (2002),
pp. 13-18.
7. Amos Bairoch and Brigitte Boeckmann. The SWISS-PROT protein sequence data bank.
Nucleic Acids Research, Vol. 20, Supplement ,2019-2022.
8. Winona C. Barker, John S. Garavelli, Hongzhan Huang, Peter B. McGarvey, Bruce C. Orcutt,
Geetha Y. Srinivasarao, Chunlin Xiao, Lai-Su L. Yeh, Robert S. Ledley, Joseph F. Janda,
Friedhelm Pfeiffer, Hans-Werner Mewes, Akira Tsugita and Cathy Wu. The Protein Information Resource (PIR). Nucleic Acids Research,2000, Vol. 28, No.1, 41-44.
9. Helen M. Berman, John Westbrook, Zukang Feng, Gary Gilliland, T. N. Bhat, Helge Weissig,
Ilya N. Shindyalov and Philip E. Bourne. The Protein Data Bank. Nucleic Acids Reasearch,
2000, vol. 28, N0.1, 235-242.
10. Loredana Lo Conte, Bart Ailey, Tim J. P. Hubbard, Steben E. Brenner, Alexey G. Murzin and
Cyrus Chothia. SCOP: a Structural Classification of Proteins database. Nucleic Acids Research, 2000, Vol. 28, No. 1, 257-259.
11. Alexey G. Muryin, Steven E. Brenner, Tim Hubbard and Cyrus Chothia. SCOP: A Structural
Classification of Proteins Database for the Investigation of Sequences and Structures. J.
Mol. Biol. (1995) 247, 536-540.
12. CA Orengo, AD Michie, S Jones, DT Jones, MB Swindells and JM Thornton. CATH – a hierarchic classification of protein domain structures. Research Article 1093.
77
13. Guopin Zhao. Bioinformatics. Science Publishing House. (auf Chinesisch)
14. Daniela Faust. Proteindatenbanken.
http://lips.informatik.uni-leipzig.de/htdig/documents/2003/46/2/4/10/5/1/6/46.6.pdf.gz , 2006.
15. Francois Bry, Peer Kröger. A Molecular Biology Database Digest.
http://www.pms.ifi.lmu.de/publikationen/PMS-FB/PMS-FB-2001-3.pdf , 2006.
16. Stephan Kühn. Einführung in die Bioinformatik und die Bio-Datenbanken.
http://dbs.uni-leipzig.de/html/seminararbeiten/semWS0203/arbeit1/ausarbeitung.pdf , 2006.
17. Maik Röder. Sequenz- und Strukturdatenbanken mit einer Einführung in molekularbiologische Algorithmen.
http://www.informatik.uni-bonn.de/III/lehre/seminare/Molekularbiologische-Datenbanken/SS
96/ausarbeitungen/2.1_roeder.ps.gz , 2006.
18. A. Bateman et al. The Pfam Protein Families Database. Nucleic Acids Research, 2004, vol.
32, Database issue DOI: 10.1093/nar/gkh121.
19. Laurent Falquet, Marco Pagni, Philipp Bucher, Nicolas Hulo, Christian J. A. Sigrist, Kay
Hofmann and Amos Bairoch. The PROSITE database, its status in 2002. Nucleic Acids Research, 2002, vol. 30, No, 1 235-238.
Quellen zur Biochemie:
20. Wikipedia: Aminosäuren.
21. Biokurs 2007: http://www.biokurs.de/skripten/bs11.htm?bs11-7.htm .
22. Bruce Alberts, Alexander Johnson, Julian Lewis. Molekularbiologie der Zelle. Übersetzung
herausgegeben von L. Jaenicke. 4. Auflage, 2004, WILEY-VCH.
23. Lubert Stryer. Biochemie. Aus dem Amerikanischen übersetzt von Brigitte Pfeiffer und Johannes Guglielmi. 4.Auflage, 2003, Spektrum.
24. B. Alberts, D. Bray, A. Johnson, J. Lewis, M.Raff, K. Roberts, P. Walter. Lehrbuch der Molekularen Zellbiologie. 1999, WILEY-VCH.
25. Werner Müller-Esterl. Biochemie - Eine Einführung für Mediziner und Naturwissenschaftler. 1.Auflage, 2004, Spektrum..
26. David P.Clark. Molecular Biology - Das Original mit Übersetzungshilfen. 1.Auflage, 2006,
Spektrum.
78
27. E.Buddecke, Grundriss der Biochemie, 9. Auflage, deGruyter.
28. Biochemie: http://etc.lyac.edu.cn/ .
29. http://hpdb.hbu.edu.cn .
30. Wikipedia: Protein.
31. Biochemistry: http://www.ccty.org/Soft/soft7/soft75/200701/164.html. (auf Chinesisch)
32. Wikipedia: Myoglobin.
33. Aminosäure-Aktivierung: http://www.webmic.de/proteinbiosynthese.htm .
Quellen zu Grundlagen der Informatik:
34. Christian Ullenboom. Java ist auch eine Insel. 5.Auflage, 2006, Galileo Computing.
35. Prof. Dr. R. Manthey. Skript: Informationssysteme WS 2004/05.
36. Fundamental Microsoft Jet SQL for Access 2000.
http://msdn2.microsoft.com/en-us/library/aa140011(office.10).aspx .
37. Gottfried Vossen. Datenmodelle, Datenbanksprachen und Datenbank-Management-Systeme, 2. Auflage, 1994, ADDISON-WESLEY.
38. Chris Date, Hugh Darwen. SQL-Der Standard. 2002, ADDISON-WESLEY.
39. Ramez A. Elmasri, Shamkant B. Navathe. Grundlagen von Datenbanksystemen. 3. überarbeitete Auflage, 2005, ADDISON-WESLEY.
40. JDBC Overview: http://java.sun.com/products/jdbc/overview.html .
41. Banggui Xia, Fanxin Liu. JDBC API Database Programming Instance Course. 2001, Beijing Hope Electronic Press.
42. The J2EE 1.4 Tutorial: http://java.sun.com/j2ee/1.4/docs/tutorial/doc/ .
43. Jayson Falkner, Kevin Jones. Servlets and JavaServer Pages - The J2EE Technology Web
Tier.2003, ADDISON-WESLEY.
44. Apache Tomcat: http://tomcat.apache.org/ .
45. Wikipedia: Apache Tomcat.
79
46. Alfons Kemper, Andre Eickler. Datenbanksysteme - Eine Einführung. 5. überarbeitete und
erweiterte Auflage, 2001, Oldenbourg.
Quellen über konzeptuellen Entwurf:
47. Erich Bornberg-Bauer and Norman W. Paton. Conceptual data modelling for bioinformatics. Briefings in Bioinformatics, (13)2, 2002, pp. 166-180.
48. Haya EL-Ghalayini, Mohammed Odeh and Richard McClatchey. Centre for Complex Cooperative Systems, Faculty of CEMS, University of the West of England. Dawn Arnold. Centre
for Research in Plant Science, Faculty of Applied Science, University of the West of England.
Deriving Conceptual Data Models from Domain Ontologies for Bioinformatics.
Information and Communication Technologies, 2006. ICTTA '06. 2nd, Volume 2, 3562- 3567.
49. Beate Marx. Introduction to Database Modeling in Bioinformatics.
http://www.ebi.ac.uk/swissprot/Publications/mbd2.html , 2006
50. Kristian Rother, Heiko Müller, Silke Trissl, Ina Koch, Thomas Steinke, Robert Preissner,
Cornelius Frömmel, Ulf Leser. COLUMBA: Multidimensional Data Integration of Protein
Annotations. In DILS, Volume 2994 of Lecture Notes in Computer Science Edited by: Rahm E.
Springer; 2004: 156-171.
51. Silke Trißl, Kristian Rother, Heiko Müller, Thomas Steinke, Ina Koch, Robert Preissner, Cornelius Frömmel and Ulf Leser. Columba: an integrated database of proteins, structures
and annotations. BMC Bioinformatics 2005, 6:81 doi:10.1186/1471-2105-6-81.
52. Guochun Xie, Reynold DeMarco, Richard Blevins and Yuhong Wang. Storing biological sequence databases in relational form. Bioinformatics, Vol 16, No. 2, pp. 288-289.
53. Swiss-Prot Protein Knowledgebase - User Manual Release 9.3 of 12-Dec-2006
http://www.expasy.org/sprot/userman.html .
54. Tom Myers, Alexander Nakhimovsky. Übergesetzt von Hui Wang, Xiaohui Zhang. Professional Java XML Programming with Servlets and JSP). 2001, PUBLISHING HOUSE OF
ELECTRONICS INDUSTRY.
80
Erklärung
Hiermit versichere ich, dass ich diese Diplomarbeit selbständig verfasst habe. Ich habe dazu keine
anderen als die angegebenen Quellen und Hilfsmittel verwendet.
Bonn, den 31.03.2007
Shiyang Yu