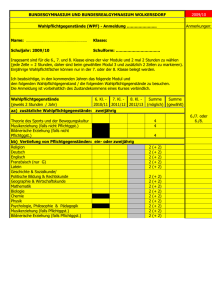
XML-Verarbeitung
Werbung

Wissens- und
Content Management
XML-Verarbeitung
Dr. Roman Schneider
Institut für Informatik
XML-Verarbeitung
Zielsetzung 1/4
„Techniken, um XML herum“ –
Möglichkeiten zur Verarbeitung von XML-Instanzen (in Datenbanken)
Analyse durch XML-Prozessoren
machen den Inhalt eines XML-Dokuments für die Weiterverarbeitung
verfügbar
nichtvalidierend / validierend in Bezug auf DTD oder XML Schema
standardisierte XML-Schnittstellen für zahlreiche
Programmiersprachen (Java, Python, C, C++, PL/SQL, ...)
SAX (Simple API for XML) – sequentielle ereignisorientierte
Verarbeitung
DOM (Document Object Model) - Manipulation von Baumstrukturen
Generierung von XML-Dokumenten
Transformation von XML-Dokumenten (Saxon, msxml, oraxml, ...)
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
2
XML-Verarbeitung
Zielsetzung 2/4
Schemabeschreibung
Modellierung
XML-Dokumente
Generierung
Transformation
Datenbank
XSLT
HTML
XML-Instanzen werden aus Datenbankinhalten generiert – oder...
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
3
XML-Verarbeitung
Zielsetzung 3/4
Schemabeschreibung
Modellierung
XML-Dokumente
Generierung
CMS / Datenbank
Transformation
XSLT
HTML
...XML-Instanzen werden in CMS/DBMS vorgehalten und verarbeitet.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
4
XML-Verarbeitung
Zielsetzung 4/4
Bedienung von Anfragen:
XML in => XML out oder XML in => SQL out oder SQL in => XML out
Speicherung
Generierung
XML-Anfragen
DB-Anfragen,
Updates,
Indizierung
XML –
Dokumentformat
Dr. Roman Schneider
Datenbanken (DBMS) –
Systeme zur Speicherung
großer Datenmengen
Modul Wissens- und Contentmanagement
5
XML-Verarbeitung
DBMS als Speicherungssystem
Gegenüber Standard-Dateisystemen haben DBMS-basierte
Lösungen „Datenbankvorteile“, z.B.:
– Datensicherheit, Konsistenzprüfung, Indizierung, Optimierung etc.
– (aber: neuere Dateisysteme evtl. spezialisiert, z.B. für parallele
Verarbeitung wie Map-Reduce)
Wahl des Systems hängt von konkreten Erfordernissen,
Verfügbarkeit, Vorkenntnissen ab
Beachten: langfristige Produktpflege, Änderungs-/Updatezyklus
(„Investitionssicherheit“)
=> Im Folgenden: Darstellung der XML-Verarbeitung in Oracle (ähnliche
Funktionalitäten existieren z.B. in IBM DB2, MS SQL-Server, ...)
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
6
XML-Verarbeitung
XML-Unterstützung in Oracle
Seit Oracle 9iR2 Vereinigung der
Daten- (Data) und
Inhaltsverarbeitung
(Content Processing)
ConText => Text, XMLDB
Grundlegende Funktionen:
– Ausgabe relationaler
Datenbankinhalten als XMLInstanzen (Baumstruktur!)
– Verschiedene (native) XMLSpeicherungsverfahren (werden
noch vorgestellt)
– Validierung
– Weiterverarbeitung (=> XDK)
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
7
XML-Verarbeitung
XML-DB und XML Developer's Kit (XDK) 1/2
XML-DB:
Repository für XML-Schemata,
Tabellen, Indizes, …
XML Developer's Kit (XDK):
Techn. Grundbausteine zum
- Lesen
- Manipulieren
- Transformieren
- Anzeigen
- Generieren
von XML-Dokumenten
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
8
XML-Verarbeitung
XML-DB und XML Developer's Kit (XDK) 2/2
XML Parser:
– DOM (einschließlich Version 3.0)
– SAX
XSLT Prozessor (mit XSLT 2.0 Java-Unterstützung)
XML Schema Prozessor: erlaubt Validierung gegen ein XML-Schema
XML Class Generator: generiert Java-Klassen aus DTDs oder XML-Schemata
XML SQL Utility:
– generiert XML-Dokumente, DTDs und Schemas aus SQL-Anfragen
– realisiert das “Insert” von XML-Instanzen in das RDBMS
direkter Zugriff auf XML-Dokumentstruktur durch Datentyp => XMLType
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
9
XML-Verarbeitung
Speicherung von XML in Oracle: XMLTYPE
XMLType ist ein spezieller Datentyp für XML-Instanzen in der Datenbank, kann
intern physikalisch auf drei verschiedene Arten realisiert werden:
Unstrukturierte Speicherung als CLOB
Strukturierte Speicherung in objektrelationalen Tabellen
Speicherung als binary
Wahl der Speicherungsoption ist für den Nutzer transparent, d.h. beeinflusst nicht
die Syntax der Weiterverarbeitung.
Nativ?
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
10
XML-Verarbeitung
XMLType als CLOB
Bei der unstrukturierten Speicherung werden die XML-Daten intern als Text in
einem CLOB abgelegt (ideal für eher dokumentenzentriertes Arbeiten).
Dazu wird zu jeder XMLType-Tabellenspalte intern eine CLOB-Spalte angelegt,
die für den Benutzer unsichtbar ist.
Die XMLType-Spalte enthält eine Referenz auf diese CLOB-Spalte.
Vorteil: XML-Instanz wird nicht manipuliert, d.h. zeichengenau mit Whitespace,
Zeilenumbrüchen etc. vorgehalten (instance fidelity)
Vorteil: Performantes Lesen / Update kompletter Instanzen.
Vorteil: Unterschiedliche XML-Strukturen in einem Datenfeld möglich
Nachteil: Suboptimale Performanz beim Zugriff auf einzelne XML-Fragmente.
CREATE TABLE tb_bib (
co_id NUMBER,
co_datum DATE,
co_literatur XMLTYPE)
XMLTYPE COLUMN co_literatur STORE AS CLOB;
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
11
XML-Verarbeitung
XMLType objekt-relational
Passendes XML-Schema muss verfügbar sein (=> einheitliche Struktur).
Aufgrund der Informationen aus dem XML-Schema werden entsprechende
objektrelationale Tabellen / Views erzeugt.
Knotenstruktur der Instanz sowie die Beziehungen zwischen den Knoten bleiben
erhalten (DOM fidelity).
Vorteil: Abspeichern und Zugriff ist wesentlich performanter, da nicht das ganze
XML-Dokument geschrieben/gelesen werden muss (piecewise update).
Vorteil: Indizierung der OR-Tabellen sorgt für bessere Performanz.
Vorteil: Benötigt weniger Speicherplatz, weil Element-/Attribut-Namen nicht
jedesmal gespeichert werden und Whitespace wegfällt.
Nachteil: XML-Instanz bleibt nicht intakt.
CREATE TABLE tb_bib (
co_id NUMBER,
co_datum DATE,
co_literatur XMLTYPE)
XMLTYPE COLUMN co_literatur STORE AS OBJECT RELATIONAL
XMLSCHEMA "http://localhost/myXMLSchema.xsd" ELEMENT "literatur";
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
12
XML-Verarbeitung
XMLType binary
Speziell entworfenes Binärformat für XML mit platzsparender Speicherung;
XMLDB Developers Guide: “Binary XML is compact, post-parse, XML
Schema-aware XML.”
Erlaubt die flexible Speicherung unterschiedlich strukturierter XML-Instanzen in
gemeinsamer XMLTYPE-Spalte (wie CLOB, aber performanter).
Kann mit oder ohne Angabe eines Schemas erfolgen.
CREATE TABLE tb_bib (
co_id NUMBER,
co_datum DATE,
co_literatur XMLTYPE)
XMLTYPE COLUMN co_literatur STORE AS BINARY XML XMLSCHEMA
"http://localhost/myXMLSchema.xsd" ALLOW ANYSCHEMA ALLOW NONSCHEMA;
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
13
XML-Verarbeitung
Schema-Registrierung in der Datenbank
Schema für XMLTypes muss der Datenbank bekannt sein.
Bei Anlegung Steuerung möglich, ob Objekttypen und Tabellen (für objektrelationale Speicherung) umgehend angelegt werden sollen.
Verwendung des Schemas kann (bei binary-Speicherung) aus
Effizienzgründen temporär deaktiviert werden.
Prüfung bei XML-Speicherung:
BEGIN
DBMS_XMLSCHEMA.registerSchema(
SCHEMAURL => 'http://localhost/myXMLSchema.xsd',
LOCAL
=> FALSE,
GENTYPES => TRUE,
GENTABLES => TRUE,
FORCE
=> FALSE,
OPTIONS
=> DBMS_XMLSCHEMA.REGISTER_BINARYXML,
OWNER
=> USER);
END;
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
14
XML-Verarbeitung
Objekt-relationale vs. Binary XML-Speicherung
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
15
XML-Verarbeitung
Einfügen von XML-Inhalten per SQL
Um Daten in eine XMLType-Spalte einzufügen, muss der Konstruktor
XMLType() verwendet werden.
XMLTYPE() wandelt Textstrings in XMLTYPE um.
Dabei können nur wohlgeformte (wenn Schema angegeben: nur gültige)
XML-Daten eingefügt werden!
INSERT INTO tb_bib
(co_id, co_datum, co_literatur)
VALUES (1, SYSDATE, XMLTYPE('
<literatur typ="monographie">
<autor><nachname>Schneider</nachname>
<vorname>Roman</vorname></autor>
<titel>Benutzeradaptive Systeme im Internet</titel>
<jahr>2004</jahr>
<ort>Mannheim</ort>
</literatur>
'));
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
16
XML-Verarbeitung
Einfügen von XML-Inhalten per SQL-Loader
Alternativ lassen sich XML-Dokumente direkt aus dem Dateisystem laden, für
größere Bestände ist dann der SQL Loader das Werkzeug der Wahl.
control=<steuerdatei> Name der Steuerdatei
log=<protokolldatei> Name der Protokolldatei
bad=<bad file> Name des bad file
data=<datendatei> Name der Datendatei
discard=<discard file> Name des discard file
discardmax=n nach n Datensätzen im discard file wird abgebrochen
skip=n überlese die ersten n Datensätze (hilfreich zum Wiederaufsetzen)
load=n lade maximal n Datensätze
errors=n breche nach n fehlerhaften Datensätzen ab
direct=<modus> Verwende den direkten Pfad (Modus=true) oder nicht (Modus=false)
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
17
XML-Verarbeitung
Einfügen von XML-Inhalten per PL/SQL
Kleinere XML-Bestände sind auch per PL/SQL (Procedural Language
/Structured Query Language) ladbar:
– Zunächst erzeugt man ein sogenanntes SQL Directory, d.h. den Zugang
zu einem auf dem Server existierenden Verzeichnis/Ordner.
– Anschließend lassen sich dort abgelegte Dateien öffnen und die XMLInhalte in die Beispieltabelle übernehmen:
CREATE DIRECTORY "xmldir" AS 'c:\xml';
DECLARE
datei BFILE := BFILENAME('xmldir', 'beispiel.xml');
inhalt CLOB := '';
BEGIN
DBMS_LOB.fileOpen (datei, DBMS_LOB.file_readonly);
DBMS_LOB.CREATETEMPORARY(inhalt, TRUE, 2);
DBMS_LOB.loadFromFile (inhalt, datei, DBMS_LOB.getLength(datei),1,1);
DBMS_LOB.fileClose (datei);
INSERT INTO tb_bib VALUES (1, SYSDATE, XMLTYPE(inhalt));
COMMIT;
END;
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
18
XML-Verarbeitung
Einfügen von XML-Inhalten per Web-Interface
Oracle XE (die freie Express Edition) bringt für den gelegentlichen Upload ein
einfaches Web-Frontend mit.
Automatisierte Weiterverarbeitung bspw. durch Tabellen-Trigger und PL/SQL.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
19
XML-Verarbeitung
Einfügen von XML-Inhalten aus Datenbanktabellen 1/5
Etwas anspruchsvoller gestaltet sich die Aufgabe, XML-Instanzen aus bereits
bestehenden (relationalen) Datenbanktabellen zu generieren.
=> SQL/XML (SQLX)-Funktionen produzieren wohlgeformte XMLFragmente für den Datentyp XMLTYPE.
Diese Funktionen können in den select-from-where-Block integriert werden
(Beispiel folgt).
SQLX
relationale
Datenbank
Dr. Roman Schneider
XML-“Sicht“
Modul Wissens- und Contentmanagement
XMLDokument
20
XML-Verarbeitung
Einfügen von XML-Inhalten aus Datenbanktabellen 2/5
Funktion xmlelement()
– erzeugt ein XML-Element und erwartet als Parameter einen Elementnamen
sowie optional mehrere Attributinhalte
Funktion xmlforest()
– Konstruktion einer Folge („Wald“) aus XML-Dokumenten
Funktion xmlagg()
– Aggregierungsfunktion für die Integration mehrerer Ergebniszeilen
Funktion xmlconcat()
– fügt mehrere XML-Fragmente zusammen
Weitere Funktionen:
–
–
–
–
xmlattributes()
xmlroot()
xmlcomment()
xmlpi()
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
21
XML-Verarbeitung
Einfügen von XML-Inhalten aus Datenbanktabellen 3/5
Anwendungsfall: Bibliografie mit zwei Ausgangstabellen
• In tb_titel liegen Publikationstyp, -titel, -jahr und -ort in
entsprechend benannten Spalten;
• Tabelle tb_autor speichert die Autorenangaben.
Beide Tabellen sind mittels eindeutiger IDs (Spalte co_id)
miteinander verknüpft.
=> SQL/XML-Funktionen sammeln, ordnen und formatieren
sämtliche für eine XML-Instanz erforderlichen Inhalte.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
22
XML-Verarbeitung
Einfügen von XML-Inhalten aus Datenbanktabellen 4/5
SELECT t1.co_id,
XMLELEMENT ("literatur",
XMLATTRIBUTES (t1.co_typ as "typ"),
XMLFOREST(t1.co_titel as "titel",
t1.co_jahr as "jahr", t1.co_ort as "ort"),
XMLELEMENT ("autor",
XMLAGG(
XMLCONCAT(
XMLELEMENT("nachname",t2.co_nachname),
XMLELEMENT("vorname",t2.co_vorname)))))
as "literatur"
FROM tb_titel t1, tb_autor t2
WHERE t1.co_id=t2.co_id
GROUP BY t1.co_typ,t1.co_titel,t1.co_jahr,t1.co_ort;
Die Aggregierungsfunktion XMLAGG wird genutzt, um Veröffentlichungen mit
mehreren beteiligten Autoren zu handhaben, d.h. um 1:n-Relationen zwischen
Publikationstitel und Verfasser im XML-Baum durch aneinander gereihte AutorElemente (sibblings) wiederzugeben.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
23
XML-Verarbeitung
Einfügen von XML-Inhalten aus Datenbanktabellen 5/5
CO_ID
literatur
----------------------------1 <literatur typ=“monographie“><titel>Benutzeradaptive Systeme im
Internet</titel><jahr>2004</jahr>
<autor><nachname>Schneider</nachname><vorname>Roman</vorname></auto
r></literatur>
2
<literatur typ=“nachschlagewerk“><titel>Bibliographie zur
deutschen Grammatik</titel><jahr>2003</jahr><ort>Mannheim</ort>
<autor><nachname>Frosch</nachname><vorname>Helmut</vorname></autor><a
utor><nachname>Schneider</nachname><vorname>Roman</vorname></autor><a
utor><nachname>Strecker</nachname><vorname>Bruno</vorname></autor><au
tor><nachname>Eisenberg</nachname><vorname>Peter</vorname></autor></l
iteratur>
Das Ergebnis dieser Abfrage besteht aus jeweils einer eindeutige ID kombiniert
mit einem Literatureintrag als wohlgeformter XML-Instanz.
=> Optionen zur Validierung?
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
24
XML-Verarbeitung
Validierung von XML-Instanzen (via XML-Schema)
Ähnlich wie für die Erzeugung stellt das DBMS auch für den
Strukturcheck von XML-Instanzen verschiedene Wege bereit.
Zumeist kommen dabei XML-Schemata zum Einsatz (wg. Datentypen).
In solchen Fällen kann der Anwender die Überprüfung recht einfach
automatisieren, indem er beim Anlegen einer XMLTYPE-Spalte ein
verbindliches Schema spezifiziert (s.o.).
Die Funktion isSchemaValid() startet darüber hinaus explizit einen
Validierungslauf (Rückgabewert „1“ wenn valide): SELECT
x.co_literatur.isSchemaValid('http://localhost/myXMLSchema.xsd',
'literatur') FROM tb_bib x;
Auf Kommandozeilenebene existiert mit „oraxml“ ein Frontend für
Oracles XML-Parser, das Dokumente gegen ein im Wurzelelement
referenziertes Schema validiert.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
25
XML-Verarbeitung
Validierung von XML-Instanzen (via DTD) 1/2
Die Erfahrung zeigt, dass sich nicht alle Anwender auf Schemata
verlegen wollen oder können (Übersichtlichkeit, ...).
Wer für die Beschreibung seiner XML-Strukturen ohne bestimmte
Features (Datentypen, XML-Syntax etc.) auskommt, wird in vielen
Fällen weiterhin gerne mit “einfachen” Document Type Definitions
(DTDs) arbeiten wollen.
Ob eine DTD im Dateisystem oder in der DB liegt, ist für deren
Nutzung zur XML-Validierung in der DB zweitrangig.
Aus DBA-Sicht wäre sicherlich die zweite Variante vorzuziehen, bei der sowohl XMLInstanz als auch Strukturbeschreibung von den Vorteilen der DBMS-gestützen
Speicherung profitieren – „all data in one place“.
Idealerweise sollte jede XML-Instanz unmittelbar vor dem Anlegen
eines neuen Datensatzes hinsichtlich ihrer Gültigkeit überprüft
werden. Hierfür bietet sich ein => BEFORE INSERT-Trigger an
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
26
XML-Verarbeitung
Validierung von XML-Instanzen (via DTD) 2/2
Der Trigger macht dem Parser die DTD bekannt und nimmt die Validierung
des Dokuments vor:
CREATE TRIGGER literaturvalidierung
BEFORE INSERT ON tb_bib FOR EACH ROW
DECLARE
parser xmlparser.parser;
dtd_quelle CLOB;
dtd_dokument xmldom.DOMDocumentType;
BEGIN
SELECT co_inhalt INTO dtd_quelle FROM tb_dtd
WHERE co_name='literatur.dtd';
parser := xmlparser.newParser;
xmlparser.setValidationMode(parser, false);
xmlparser.parseDTDClob(parser, dtd-quelle , 'literatur');
dtd_dokument := xmlparser.getDoctype(parser);
xmlparser.setValidationMode(parser, true);
xmlparser.setDoctype(parser, dtd_dokument);
xmlparser.parseClob(parser, :NEW.co_literatur.getClobVal());
xmlparser.freeParser(parser);
EXCEPTION
WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('Validierungs-Fehler!');
END;
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
27
XML-Verarbeitung
Recherche mit SQL/XML 1/3
Ist ein XML-Dokument artgerecht gespeichert, stellt sich die Frage nach
effizienter Recherche.
Neben einfachen Abfragen zur Ausgabe ganzer Instanzen à la SELECT
t.co_literatur.getClobVal() AS gesamtdokument FROM tb_bib t
interessiert meist die Extraktion, Zählung etc. einzelner Elemente.
Hierfür empfehlen sich XPath-basierte SQLX-Funktionen, die den präzisen
Zugriff auf XML-Fragmente erlauben:
existsNode() stellt fest, ob bestimmte Elemente existieren und liefert 0 oder 1 zurück
extract() extrahiert XML-Fragmente als XMLTYPE
extractValue() gibt den reinen Zeicheninhalt eines Knotens aus
Üblicherweise konstruiert eine SQLX-Funktion für jede XML-Instanz ein
DOM, unabhängig davon, ob die Instanz den gesuchten Wert enthält.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
28
XML-Verarbeitung
Recherche mit SQL/XML 2/3
ExtractValue
Liefert anhand eines XPath-Ausdrucks den Wert eines Knotens.
Extract
Extrahiert einen oder mehrere Äste eines XMLType-Objekts.
ExistsNode
Prüft, ob in einem XMLType-Objekt ein entsprechender Knoten
vorliegt.
GetRootElement
Gibt das Root-Element der XMLType-Instanz zurück.
GetSchemaURL
Gibt die URL der registrierten XML-Schema-Definition zurück. Wurde
kein XML-Schema registriert, so wird NULL zurück gegeben.
XMLTransform
Transformiert die übergebene XMLType-Instanz unter Einsatz einer
XSLT-Datei (als XMLType) in HTML, Text etc.
UpdateXML
Ändert Fragmente/Werte in einem XMLType-Objekt.
XMLSequence
Ermöglicht die Verarbeitung mehrerer Knoten eines XMLType-Objekts.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
29
XML-Verarbeitung
Recherche mit SQL/XML 3/3
Damit ein ein SQL-Statement wie
SELECT co_id FROM tb_bib WHERE extractValue (co_literatur,'/literatur@typ') =
'monographie';
möglichst schnell zum Ziel führt, empfiehlt sich bei häufig wiederkehrenden
XPath-Ausdrücken die Verwendung von Indizes.
Zum Einsatz kommen hier funktionale Indizes ("functional indexes"), die analog
zu den im RDBMS üblichen B-Tree-Indizes organisiert sind und von denen
mehrere gleichzeitig für dieselbe Instanz existieren dürfen.
CREATE INDEX idx_bib ON tb_bib (extractValue(co_literatur, '/literatur@typ'));
Alternative: Spezieller Indextyp „XMLIndex“ (indiziert grundsätzlich die
komplette XML-Instanz, aber Ausnahmen möglich).
Der kostenorientierter Optimierer des DBMS entscheidet von Fall zu Fall,
welcher Index beim Auswerten einer WHERE-Klausel zum Einsatz kommt.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
30
XML-Verarbeitung
Update mit SQL/XML
Für XML-Dokumente gilt wie für andere Formate: Nur in seltenen Fällen bleiben
Datenbankinhalte statisch.
Inhaltliche Korrekturen oder strukturelle Anpassungen erfordern Funktionen zum
Ersetzen einzelner Fragmente:
UpdateXML()
InsertChildXML()
InsertXMLBefore()
AppendChildXML()
DeleteXML()
Folgender Befehl modifiziert alle jahr-Elemente, indem er den Wert 1 addiert:
UPDATE tb_bib SET co_literatur=
updateXML (co_literatur,'/literatur/jahr',
'<jahr>'||
to_char(extractValue(co_literatur,'/literatur/jahr')+1)
||'</jahr>');
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
31
XML-Verarbeitung
Transformation mit SQL/XML 1/2
Oft reichen einzelne Änderungen an XML-Elementen nicht aus.
Der Datentransfer zwischen Softwaresystemen etwa erfordert nicht selten
die komplette Umgestaltung der XML-Struktur, also die Übersetzung aus
einer Markup-Sprache in eine andere.
Auch die Layout-Aufbereitung erfordert zusätzliche Arbeitsschritte.
In diese Kategorie fällt insbesondere die Transformation von XML nach
HTML mit XSL (XML Stylesheet Language) bzw. XSLT.
Zur Erinnerung:
XML beschreibt eine Datenstruktur
Aber: XML enthält keine Informationen über die Darstellung der Daten
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
32
XML-Verarbeitung
Transformation mit SQL/XML 2/2
Das DBMS enthält einen integrierten XSLT-Prozessor, den die Funktion
XMLTransform() startet. Er arbeitet in einer virtuellen XSLT-Maschine.
Der XSLT-Prozessor kompiliert Stylesheets als Bytecode, den er in einem
internen Cache speichert. Wiederholte Transformationen unter Verwendung
desselben Stylesheets lassen sich auf diese Weise beschleunigen.
Idealerweise liegt das XSLT-Stylesheet als natives XML in einer DB-Tabelle.
Beispiel: Tabelle tb_xsl mit den beiden Spalten co_name (zur eindeutigen
Benennung) und co_inhalt (Stylesheet als XMLTYPE).
XMLTransform() erhält als Parameter die Spaltennamen von XML-Instanz und
Stylesheet und erzeugt "on the fly" die gewünschte Ausgabe:
SELECT XMLTransform(t1.co_literatur, t2.co_inhalt)
FROM tb_bib t1, tb_xsl t2
WHERE t1.co_id=1 AND t2.co_name='literatur.xsl';
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
33
XML-Verarbeitung
Anwendungsfall: Datenbank Gesprochenes Deutsch (DGD) 1/5
Archiviert die bei Spracherhebungen erstellten Korpora von gesprochenem Deutsch
Text-Ton-Alignment (Synchronisierung von Transkripten und Audio)
Korpusübergreifender XML-Metadatenstandard
Stellt komplexe Inhalte für die weitere wissenschaftliche Auswertung zur Verfügung
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
34
XML-Verarbeitung
Anwendungsfall: Datenbank Gesprochenes Deutsch (DGD) 2/5
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
35
XML-Verarbeitung
Anwendungsfall: Datenbank Gesprochenes Deutsch (DGD) 3/5
Baum-Modell der Korpusdokumentation als Basis für Schemagenerierung
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
36
XML-Verarbeitung
Anwendungsfall: Datenbank Gesprochenes Deutsch (DGD) 4/5
Metadaten-Schema
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
37
XML-Verarbeitung
Anwendungsfall: Datenbank Gesprochenes Deutsch (DGD) 5/5
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
38
XML-Verarbeitung
XML-Retrieval mit Oracle Text 1/14
Oracle Text ist eine in den Datenbankkern integrierte XML-fähige Volltextsuche
(XML-)Dokumente lassen sich filtern, recherchieren und inhaltlich auswerten
Funktionen für Text Retrieval, Text Mining und Knowledge Management
Typische Anwendungsfälle: Verlags- bzw. Medienunternehmen sowie in
Branchen mit umfangreichem elektronischen Dokumentationsbedarf
kann mit (beinahe) allen gängigen Dokumentformaten umgehen: Filtertechnik
deckt mehr als 150 Dateitypen ab, incl. ASCII, PDF, Word, HTML oder XML
Unicode-Unterstützung
Der prominenteste Indextyp hört auf den Namen CONTEXT
Indextyp CTXCAT für Abfragen, die kürzere
(XML-)Dokumente sowie relationale Daten betreffen
Indextyp CTXRULE für die Klassifikation
von (XML-)Dokumenten
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
39
XML-Verarbeitung
XML-Retrieval mit Oracle Text 2/14
Beispiel: Tabelle TB_DOKUMENTE mit den Spalten
CO_ID (eindeutige IDs)
CO_INHALT (VARCHAR2, CLOB/BLOB oder XMLTYPE - erlaubt ist,
was sich für die Aufnahme von Fließtext eignet)
Für die Suche verwendet man nicht die üblichen SQL-Operatoren wie LIKE
oder =, sondern den Suchoperator CONTAINS
SELECT CO_ID
FROM TB_DOKUMENTE
WHERE CONTAINS (CO_INHALT, 'gehen')>0;
findet Dokumente, die "gehen" oder Zusammensetzungen wie "Zu-Fuß-Gehen" enthalten,
richtigerweise aber nicht "Wohlergehen" oder "umgehend“ (=> anpassbarer LEXER)
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
40
XML-Verarbeitung
XML-Retrieval mit Oracle Text 3/14
• Eine Erweiterung des Suchausdrucks auf $gehen schließt darüber hinaus
alle Beugungen, Ableitungen und Komposita ein.
SELECT CO_ID FROM TB_DOKUMENTE
WHERECONTAINS(CO_INHALT,‘$gehen')>0;
findet "geht", "ging", "gegangen" et cetera
•
•
•
Ist die Schreibweise zweifelhaft, findet ein dem Wort vorangestelltes ?
sämtliche ähnlichen Schreibungen (fuzzy search),
Beziehungsweise ein vorangestelltes ! auch ähnlich klingende Wörter auf
Basis des phonetischen SOUNDEX-Algorithmus.
Der NEAR-Operator legt einen Höchstabstand zwischen Fundstellen fest:
SELECT CO_ID
FROM TB_DOKUMENTE
WHERE CONTAINS(CO_INHALT,'NEAR((gehen, Büro),3)')>0;
findet Dokumente, in denen "gehen" und "Büro" durch höchstens drei Wörter getrennt sind
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
41
XML-Verarbeitung
XML-Retrieval mit Oracle Text 4/14
Query Relaxation: Mehr oder weniger exaktes Finden
erlaubt das sukzessive Abarbeiten mehrerer Suchanfragen gemäß einer vom
Anwender definierten Reihenfolge (XML-Syntax!)
zunächst kommt typischerweise die restriktivste Version zur Ausführung findet sie zu
wenige Treffer, folgen Schritt für Schritt die weiteren Anfragen
Folgendes Beispiel erweitert die Suche nach "gehen" zunächst um eine Wortstamm- und
anschließend um eine Fuzzy-Suche, bis 20 passende Dokumente gefunden sind:
SELECT CO_ID FROM TB_CLOB_1000 WHERE CONTAINS (CO_INHALT,
'<query>
<textquery lang="GERMAN" grammar="CONTEXT">
<progression>
<seq>gehen</seq>
<seq>$gehen</seq>
<seq>?gehen</seq>
</progression>
</textquery>
<score datatype="INTEGER" algorithm="COUNT"/>
</query>',1)>0 AND ROWNUM<20;
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
42
XML-Verarbeitung
XML-Retrieval mit Oracle Text 5/14
Anlegen eines rudimentären CONTEXT Index:
CREATE INDEX IDX_DOKUMENTE ON TB_DOKUMENTE(CO_INHALT)
INDEXTYPE IS CTXSYS.CONTEXT;
Indexierung findet in mehreren aufeinander aufbauenden Stufen statt ("IndexierungsPipeline"), => jeweils Feinjustierung möglich.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
43
XML-Verarbeitung
XML-Retrieval mit Oracle Text 6/14
•
„Preferences" und "Section Groups" parametrisieren jede Stufe
z.B. lässt sich für den Datastore festlegen, wo sich der zu indexierende Text befindet:
in der Regel eine Tabellenspalte, erlaubt sind aber auch lokale Dateien oder URLs
•
Die folgende Station, der Filter, übernimmt den Datenstream und wandelt die Inhalte
sofern erforderlich in Text, HTML oder XML um
•
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
44
XML-Verarbeitung
XML-Retrieval mit Oracle Text 7/14
Dritte Station ist der Sectioner, teilt die vom Filter gelieferten Texte in Bereiche auf.
Mehrere Section Groups sind vordefiniert:
•
NEWS_SECTION_GROUP für Newsgroup-Inhalte
•
XML_SECTION_GROUP für Attributwerte und Elementinhalte von XML-Instanzen
•
PATH_SECTION_GROUP für XML, wenn XPath-Abfragen mit INPATH- und HASPATH geplant
• AUTO_SECTION_GROUP
mit der Option, ausgewählte Bereichsinformationen (stop sections) explizit
aus dem Indexierungsprozess auszuschließen.
•
HTML_SECTION_GROUP für Webinhalte, wandelt HTML-Elemente in Bereichsgrenzen
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
45
XML-Verarbeitung
XML-Retrieval mit Oracle Text 8/14
PATH_SECTION_GROUP für XPath-Abfragen:
SELECT CO_ID FROM TB_DOKUMENTE
WHERE CONTAINS(CO_INHALT,
'hasPath(/dokument/absatz[@typ=“bsptyp"])')>0;
findet alle Dokumente, die direkt unterhalb eines dokument-Elements ein absatzElement enthalten, dessen Attribut typ den Wert bsptyp hat
SELECT CO_ID FROM TB_DOKUMENTE
WHERE CONTAINS(CO_INHALT,
'$gehen inPath (/dokument/absatz)') > 0;
liefert alle Dokumente, in denen eine beliebig flektierte Form von "gehen" im Text des
spezifizierten XML-Knotens vorkommt
Auf diese Weise lässt sich die Mächtigkeit von XPath mit den linguistischen Features
der Volltextrecherche kombinieren.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
46
XML-Verarbeitung
XML-Retrieval mit Oracle Text 9/14
Erstellung einer selbstdefinierten Section Group, die eine kombinierte Recherche in HTMLÜberschriften (H1 bis H4) erlaub:
BEGIN
CTX_DDL.CREATE_SECTION_GROUP('MY_GROUP', 'HTML_SECTION_GROUP');
CTX_DDL.ADD_ZONE_SECTION('MY_GROUP', 'UEBERSCHRIFT', 'H1');
CTX_DDL.ADD_ZONE_SECTION('MY_GROUP', 'UEBERSCHRIFT', 'H2');
CTX_DDL.ADD_ZONE_SECTION('MY_GROUP', 'UEBERSCHRIFT', 'H3');
CTX_DDL.ADD_ZONE_SECTION('MY_GROUP', 'UEBERSCHRIFT', 'H4');
END;
SELECT *
FROM TB_DOKUMENTE
WHERE CONTAINS(CO_INHALT,
'gehen WITHIN UEBERSCHRIFT')>0;
•
Kommentare, Scripts oder STYLE-Abschnitte lassen
sich im Sectioner automatisch entfernen.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
47
XML-Verarbeitung
XML-Retrieval mit Oracle Text 10/14
•
Die Bereichsinhalte reicht der Sectioner anschließend als Plain Text weiter
•
Der Lexer extrahiert nun sämtliche Wörter (tokens)
Wichtig: Unterstützung von Sprachen, in denen Leer- und Satzzeichen Wörter trennen,
aber auch andere (zum Beispiel asiatische) Sprachfamilien
•
Die Datenbank-Engine erstellt abschließend - gegebenenfalls unter Zuhilfenahme der
vom Sectioner ermittelten Bereichsgrenzen - einen invertierten Index
•
•
Diese Wortliste ordnet jedem Token eine Liste der zugehörigen Dokumente zu
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
48
XML-Verarbeitung
XML-Retrieval mit Oracle Text 11/14
Diskriminationskraft der
Terme
BEGIN
CTX_DDL.CREATE_STOPLIST('MY_STOPLIST');
CTX_DDL.ADD_STOPWORD('MY_STOPLIST','der');
CTX_DDL.ADD_STOPWORD('MY_STOPLIST','die');
CTX_DDL.ADD_STOPWORD('MY_STOPLIST','das');
END;
/
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
Stoppwortliste
zu seltene Terme
- Ausschließen von Stoppwörtern
(z.B. Funktionswörter wie Artikel,
Hilfsverben, Pronomen, ...)
zu häufige Terme
Anpassung eines CONTEXT-Index (STOPLIST):
abnehmende
Worthäufigkeit
49
XML-Verarbeitung
XML-Retrieval mit Oracle Text 12/14
Anpassung eines CONTEXT-Index (LEXER):
- ALTERNATE_SPELLING: Berücksichtigung der im Deutschen geläufigen Umschreibung von
Umlauten und ß als "ae", "ue, "oe" und "ss"
- NEW_GERMAN_SPELLING: durch die Rechtschreibreform erlaubte Schreibvarianten
- COMPOSITE: legt fest, ob Wortzusammensetzungen wie "Hauptbahnhofsgebäude" zerlegt
oder als Ganzes indexiert werden
- MIXED_CASE: regelt den Umgang mit Groß- und Kleinschreibung
- Weitere Optionen: z.B. SKIPJOINS, PRINTJOINS, WHITESPACE oder BASE_LETTER
BEGIN
CTX_DDL.CREATE_PREFERENCE('MY_LEXER','BASIC_LEXER');
CTX_DDL.SET_ATTRIBUTE('MY_LEXER','ALTERNATE_SPELLING', 'GERMAN');
CTX_DDL.SET_ATTRIBUTE('MY_LEXER','NEW_GERMAN_SPELLING', 'YES');
CTX_DDL.SET_ATTRIBUTE('MY_LEXER','COMPOSITE', 'GERMAN');
CTX_DDL.SET_ATTRIBUTE('MY_LEXER','MIXED_CASE', 'NO');
END;
/
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
50
XML-Verarbeitung
XML-Retrieval mit Oracle Text 13/14
Anpassung eines CONTEXT-Index (WORDLIST):
- STEMMER: regelt die Expansionsregeln für die Wortstamm-/Flexionssuche, orientiert sich
an den Eigenschaften der Dokumentensprache
- FUZZY_MATCH: initiiert fehlertolerante Suche, unterstützt auch OCR-Dokumente
- SUBSTRING-/PREFIX: beeinflussen Query-Performance für Anfragen mit Wildcards an
einem Ende des Suchbegriffs
- WILDCARD_MAXTERMS: legt die Obergrenze für Wildcard- Expansionen fest
- Einfluss auf Platzbedarf und Erstellungs- beziehungsweise Aktualisierungszeit!
BEGIN
CTX_DDL.CREATE_PREFERENCE('MY_WORDLIST', 'BASIC_WORDLIST');
CTX_DDL.SET_ATTRIBUTE('MY_WORDLIST','STEMMER', 'GERMAN');
CTX_DDL.SET_ATTRIBUTE('MY_WORDLIST','FUZZY_MATCH', 'GERMAN');
CTX_DDL.SET_ATTRIBUTE('MY_WORDLIST','SUBSTRING_INDEX','TRUE');
CTX_DDL.SET_ATTRIBUTE('MY_WORDLIST','PREFIX_INDEX','TRUE');
CTX_DDL.SET_ATTRIBUTE('MY_WORDLIST','PREFIX_MIN_LENGTH', '2');
CTX_DDL.SET_ATTRIBUTE('MY_WORDLIST','PREFIX_MAX_LENGTH', '10');
CTX_DDL.SET_ATTRIBUTE('MY_WORDLIST','WILDCARD_MAXTERMS','7000');
END;
/
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
51
XML-Verarbeitung
XML-Retrieval mit Oracle Text 14/14
Erstellung eines CONTEXT-Index mit Preferences:
CREATE INDEX IDX_DOKUMENTE
ON TB_DOKUMENTE (CO_INHALT)
INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS('
DATASTORE
CTXSYS.DEFAULT_DATASTORE
FILTER
CTXSYS.NULL_FILTER
SECTION GROUP
MY_GROUP
STOPLIST
MY_STOPLIST
LEXER
MY_LEXER
WORDLIST
MY_WORDLIST');
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
52
XML-Verarbeitung
Semantische Suchfunktionalitäten für XML-Instanzen
Anbindung von
Thesauri
für die semantische
Suche möglich.
ctx_thes.create_relation
('MY_THES', 'Stürmer',
'BT', 'Spieler');
select text from
TB_DOKUMENTE where
contains(CO_INHALT,
'NT(Spieler,10) inPath
(/dokument/absatz)') > 0;
Der Stürmer lieferte eine
Glanzleistung ab.
Dr. Roman Schneider
Modul Wissens- und Contentmanagement
53