Vorkurs Mathematik
Werbung

Vorkurs Mathematik
Thiemo Hustedt
September 2010
Vorkurs Mathematik
Dieser Text ist eine Ausarbeitung des Mathematikteils der Veranstaltung Vorkurs für
Informatik 2010 und nur für die Teilnehmer dieser Veranstaltung gedacht. Er lehnt
sich zu großen Teilen an ein Skript Vorkurs Mathematik, April 2009 von Lars Scheele
an, einige Passagen sind komplett übernommen. Dieser Text wird evtl. weiterhin
geändert bzw überarbeitet.
2
Inhaltsverzeichnis
1 Mengen und Logik
4
2 Die natürlichen Zahlen
9
2.1 Das Prinzip der Induktion . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Ganze Zahlen
18
4 Rationale Zahlen
20
5 Reelle Zahlen
22
6 Exkurs: Sinus und Cosinus
31
7 Komplexe Zahlen
33
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
7.1 Rechnen in
C
8 Abbildungen
37
8.1 Allgemeine Begriffe . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
8.2 Wichtige Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
9 Stetigkeit
42
10 Differenzierbarkeit
46
10.0.1 Rechenregeln für Ableitungen . . . . . . . . . . . . . . . . . . . 49
11 Gleichungen und Gleichungssysteme
11.1 Lineare Gleichungen . . . . . . .
11.1.1 Der Gauß-Algorithmus . .
11.2 Gleichungen höheren Grades . . .
11.3 Beispiel: Partialbruchzerlegung .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
12 Matrizenkalkül
.
.
.
.
52
52
54
55
56
58
If people do not believe that mathematics is simple, it is only because they
do not realize how complicated life is.
John v. Neumann
3
1 Mengen und Logik
In diesem Abschnitt soll eine kurze Einführung in die wesentlichen Begriffe der Logik
und der Mengenlehre gegeben werden. Mitunter lässt sich der ein oder andere von
dem formalen Rahmen etwas abschrecken. Es ist wichtig, dass man erkennt, dass
es sich um denkbar simple Begriffe handelt, die eigentlich intuitiv jedem sofort klar
sind.
Definition 1.1. Eine Aussage ist ein sprachliches Gebilde, von dem eindeutig
bestimmt werden kann, ob es wahr oder falsch ist.
Einer Aussage kann man also immer einen Wahrheitswert zuordnen. Dementsprechend wäre zum Beispiel “Hallo!” keine Aussage, “London ist die Hauptstadt Frankreichs” aber sehr wohl.
Wir wollen zu einer Aussage A ihre Negation ¬A definieren. Ist A wahr, so ist ¬A
falsch, ist A falsch, so ist ¬A wahr. Man kann diesen Sachverhalt auch in einer
Wahrheitstafel ausdrcken:
A ¬A
w f
f w
¬(¬A) hat dann wieder den gleichen Wahrheitswert wie A.
Zwei Aussagen A und B können mit “und” (Symbol “∧”, Konjunktion) oder
“oder” (Symbol “∨”, Disjunktion) verknüpft werden. Die zugehörigen Wahrheitstafeln sehen so aus:
A
w
w
f
f
B A∧B
w
w
f
f
w
f
f
f
A
w
w
f
f
B A∨B
w
w
f
w
w
w
f
f
Der Operator ∧ liefert also nur dann eine wahre Aussage, wenn A und B wahr sind,
∨ liefert eine wahre Aussage, wenn mindestens eine der beiden Aussagen wahr ist.
Die Implikation ⇒ kann durch folgende Wahrheitstafel definiert werden:
A
w
w
f
f
B A⇒B
w
w
f
f
w
w
f
w
Die Implikation können wir im Sprachgebrauch auch so beschreiben: A ⇒ B heißt
“Aus A folgt B”. Passt dies mit der Definition aus der Wahrheitstafel zusammen?
4
A ⇒ B ist wahr, wenn A wahr ist und B auch. Ist A wahr, B aber falsch, so
kann aus A wohl kaum B folgen, deswegen ist dann die zusammengesetzte Aussage
falsch. Was ist nun, wenn A falsch ist? Gemäß der Wahrheitstafel ist dann A ⇒ B
immer wahr. Dies ist mit der sprachlichen Beschreibung nicht so offensichtlich in
Einklang zu bringen. Man muss sich das so vorstellen: wenn A vorliegt und die
zusammengesetzte Aussage wahr sein soll, muss B wahr sein. Liegt A aber gar nicht
vor, kann die zusammengesetzte Aussage unabhängig vom Wahrheitswert von B
wahr sein!
Die Implikation A ⇒ B hat übrigens immer den gleichen Wahrheitswert wie die
Aussage (¬A) ∨ B. Dies mache man sich anhand einer Wahrheitstafel klar!
Sind die Aussagen A und B äquivalent, d.h. aus der Wahrheit von A folgt jene
von B und umgekehrt, schreibt man A ⇔ B. Formal kann man dies z.B. über die
Gleichung
(A ⇔ B) := (A ⇒ B) ∧ (B ⇒ A)
oder per Wahrheitstafel ausdrücken:
A
w
w
f
f
B A⇔B
w
w
f
f
w
f
f
w
Das nächste Lemma stellt ein beliebtes Hilfsmittel für Beweise zur Verfügung, die
sogenannte Kontraposition.
Lemma 1.2 (Kontraposition). Für Aussagen A und B gilt:
(A ⇒ B) = (¬B) ⇒ (¬A)
Beweis. Die linke Seite entspricht (¬A) ∨ B. Die rechte Seite entspricht ¬(¬B) ∨
(¬A) und wegen ¬(¬B) = B folgt die Behauptung.
Eine kleine Warnung zum Umgang mit Aussagenlogik: mit etwas Mogeln ist es
möglich, jeden Satz zu beweisen. Sei S ein beliebiger Satz, dann betrachte die Aussage:
“Entweder diese Aussage ist falsch oder der Satz S ist wahr.”
Nennt man die Aussage kurz A, so kann man dies logisch umformulieren zu:
A = (¬A ∧ ¬S) ∨ (A ∧ S)
Betrachte nun zwei Fälle:
Fall 1: A ist wahr. Dann folgt S, denn die Wahrheit von A lässt nur die zweite
Alternative zu.
Fall 2: A ist falsch. Wenn A falsch ist, dann gilt ¬A, was wegen
¬(A ∧ B) = (¬A) ∨ (¬B)
¬(A ∨ B) = (¬A) ∧ (¬B)
(Übung 1) bedeutet
(A ∨ S) ∧ (¬A ∨ ¬S)
Da dies wahr ist, müssen beide Klammern wahr sein, aber die vordere Klammer
kann nur wahr sein, wenn S wahr ist. Daher ist S wahr.
5
Die Aussage S war völlig beliebig. Der Grund, warum man auf diese Art eine beliebige Aussage beweisen kann liegt darin, dass die Aussage A einen Selbstbezug
enthält, etwas, das in der Aussagenlogik streng verboten ist.
Aussageformen
Wir betrachten den Ausdruck “x > 2”. Dies stellt keine Aussage im obigen Sinne
dar. Wir mssen erst festlegen, wofür x genau stehen soll. Wählen wir hier sinnvolle
Werte, z.B. Zahlen, so erhalten wir zu jedem bestimmten Wert eine Aussage. Dies
ist ein Beispiel für eine Aussageform.
Definition 1.3. Eine Aussageform ist ein sprachliches Gebilde mit mindestens einer Variablen. Durch Einsetzen von entsprechend vielen Elementen aus angegebenen
Einsetzungsbereichen wird daraus eine Aussage.
Mit einer Aussageform können wir also eine ganze Schar von Aussagen behandeln.
Betrachten wir die Aussageform A(x) = (x2 ≥ 0) mit dem Einsetzungsbereich
E=Menge aller reeller Zahlen. Die Aussagen sind für alle Werte aus dem Einsetzungsbereich wahr. Wir notieren dies mit dem sogenannten All-Quantor ∀:
∀x : A(x) “Für alle x gilt A(x).”
Um auszudrücken, dass mindestens ein Element aus dem Einsetzungsbereich existiert, für den die Aussageform wahr ist, benutzt man den Existenzquantor ∃. Sei
z.B. B(x) := (x2 = 4) und der Einsetzungsbereich wie oben, so können wir schreiben
∃ x : B(x) oder ∃ x : x2 = 4,
und lesen dies als “Es existiert ein x, für das B(x) gilt.
Eine Aussageform kann auch mehrere Variablen enthalten, z.B.
P (d, t) := ”Der Deckel d passt auf Topf t“
mit den Einsetzungsbereichen D Menge aller Topfdeckel in meinem Haushalt, T
Menge aller Töpfe in meinem Haushalt. Die Aussage ”Auf jeden Topf passt auch
ein Deckel“ liest sich dann folgendermaßen
∀t aus T ∃d aus D : P (d, t).
Hier kommt es entscheidend auf die Reihenfolge der Quantoren an, vertauschen wir
diese
∃d aus D ∀t aus T : P (d, t),
erhalten wir auf einmal eine völlig andere Aussage, in diesem Beispiel würde sie
bedeuten, dass es einen Deckel gibt, der auf jeden Topf passt.
Wollen wir eine Aussage, die mit Quantoren beschrieben wird, negieren, so müssen
wir den Existenz- und den All-Quantor einfach durch den jeweils anderen ersetzen.
Wollen wir sagen, dass es mindestens einen Topf gibt, auf den kein Deckel passt, so
schreiben wir:
¬(∀t aus T ∃d aus D : P (d, t)) = ∃t aus T ∀d aus D : ¬P (d, t).
6
Mengenlehre
Wir wollen nun noch kurz den elementaren Begriff der Menge wiederholen und die
wesentlichen Symbole und Operationen definieren.
Eine Menge M wird so beschrieben, dass man auf widerspruchsfreie (und möglichst
einfache) Weise genau angibt, welche Elemente sie enthalten soll. Ist x in M enthalten, so schreiben wir x ∈ M. Die Menge, die nichts enthält, heißt leere Menge
und wird mit ∅ oder {} notiert.
Enthält die Menge, die wir definieren, nur endlich viele Elemente, so kann man sie
z.B. einfach durch Auflistung ihrer Elemente in Mengenklammern beschreiben. Die
Menge, die die Buchstaben A, C, D und F enthält, beschreiben wir so:
{A, C, D, F } = {C, D, A, F } = {F, D, A, C}.
Die Reihenfolge der Elemente ist irrelevant. Oft ist eine solche Liste aber unhandlich
lang oder gar nicht zu erstellen, z.B. wenn wir eine Menge mit unendlich vielen Elementen beschreiben. Normalerweise kann man eine Menge durch eine Aussageform
A(x) spezifizieren. Die Menge, die alle Elemente enthält, für die die Aussageform
wahr ist, schreiben wir so:
{x : A(x)} oder {x|A(x)} oder {x; A(x)}.
Zum Beispiel
{x|x ist eine Quadratzahl kleiner als 70}
Die Beschreibung einer Menge kann allerdings auch in sich widersprüchlich sein.
Definiere die Menge Y := {X Menge|X ∈
/ X}, also die Menge aller Mengen, die sich
nicht selbst enthalten, so ist nicht klar, ob Y selbst Element von Y ist oder nicht.
Definition 1.4. Seien im Folgenden A und B Mengen.
1. A heißt Teilmenge von B, wenn gilt (a ∈ A ⇒ a ∈ B), d.h. wenn jedes Element
aus A auch in B liegt. Man schreibt A ⊆ B. Insbesondere ist die leere Menge
Teilmenge jeder Menge.
2. Der Schnitt A ∩ B von A und B ist die Menge aller Elemente, die sowohl in
A als auch in B liegen:
A ∩ B := {x|x ∈ A ∧ x ∈ B}
3. Die Vereinigung A ∪ B von A und B ist die Menge, die alle Elemente aus A
und B enthält:
A ∪ B := {x|x ∈ A ∨ x ∈ B}
4. Die Differenzmenge A \ B ist die Menge aller Elemente aus A, die nicht in B
liegen:
A \ B := {x ∈ A ∧ |x ∈
/ B}
5. Sei A ⊆ B. Dann ist das Komplement A von A in B die Menge aller Elemente
in B, die nicht in A liegen:
A := {x ∈ B|x ∈
/ a}
7
Für diese Verknüpfungen gelten die folgenden Gesetze:
Satz 1.5. Seien A, B, C Mengen. Dann gilt:
1. A ∩ B = B ∩ A
A ∪ B = B ∪ A (Kommutativität)
2. (A ∩ B) ∩ C = A ∩ (B ∩ C)
(A ∪ B) ∪ C = A ∪ (B ∪ C) (Assoziativität)
3. A∩(B∪C) = (A∩B)∪(A∩C) A∪(B∩C) = (A∪B)∩(A∪C) (Distributivität)
4. A \ (B ∪ C) = (A \ B) ∩ (A \ C)
A \ (B ∩ C) = (A \ B) ∪ (A \ C)
Auf die zugehörigen Beweise wollen wir hier verzichten, man möge sich die Gültigkeit
der Aussagen selbst kurzerhand klarmachen.
Eine Verknüpfung von Mengen ist das kartesische Produkt
A × B := {(a, b)|a ∈ A, b ∈ B}.
Die Elemente sind die Tupel (a, b), wobei der erste Eintrag aus dem ersten ”Faktor“,
hier A, der zweite Eintrag Element des zweiten ”Faktors“, hier also B, sein muss. Das
kartesische Produkt ist also auf keinen Fall mit der Vereinigung von zwei Mengen
zu verwechseln! Insbesondere kann man auch das kartesische Produkt einer Menge
mit sich selbst bilden, A × A. Hierfür schreibt man dann meist A2 . Wichtig ist:
die Reihenfolge der Einträge in den Elementen von A2 sind relevant! So sind z.B.
für a, b ∈ A, a 6= b die Elemente (a, b), (b, a) ∈ A2 , aber es gilt (a, b) 6= (b, a) (im
Gegensatz zu der Teilmenge {a, b} ⊂ A, wo {a, b} = {b, a} gilt).
Das kartesiche Produkt kann man auch für eine beliebige (endliche) Anzahl n von
Mengen definieren, in dem Fall bestehen die Elemente dann nicht aus Zweier-Tupeln,
sondern aus n-Tupeln. Aus der Schule evtl. schon bekannte Beispiele für das kartesische Produkt sind der 2 oder der 3 .
R
R
8
2 Die natürlichen Zahlen
Die natürlichen Zahlen hat der liebe Gott gemacht, der Rest ist Menschenwerk.
Leopold Kronecker
Spätestens seit der ersten Klasse sollten einem jeden von uns die natürlichen Zahlen
geläufig sein. Wir können sie aufzählen, 1, 2, 3, 4, 5, . . . , aber das werden wir in unserem Leben wohl kaum noch schaffen. Deswegen schreiben wir in diesem Vorkurs
für die Menge der natürlichen Zahlen das Symbol
N := {1, 2, 3, 4, 5, . . . }.
Manche Mathematiker nehmen die Null mit zu den natürlichen Zahlen, ich werde
dies in diesem Vorkurs nicht tun. Die natürlichen Zahlen mit Null werde ich mit
folgendem Symbol bezeichnen
N0 := {0, 1, 2, 3, 4, 5, . . . }.
Mit den natürlichen Zahlen können wir schon ein bisschen rechnen und folgende
Probleme aus unserem Alltag berechnen, wie z.B. A hat 3 Äpfel, B hat 5 Äpfel,
dann haben A und B zusammen 8 Äpfel. Oder: C hat 3 Packungen Äpfel mit jeweils
6 Stück, dann hat C insgesamt 18 Äpfel. Wir haben also die Verknüpfungen Addition
und Multiplikation, die folgende Eigenschaften erfüllen:
• Kommutativität: m + n = n + m, nm = mn
• Assoziativität: (k + m) + n = k + (m + n), (km)n = k(mn)
• Distributivität k(m + n) = km + kn.
Dies wirkt hinreichend simpel und trivial und sollte auch allgemein bekannt sein.
Im weiteren Verlauf Ihres Studiums werden Ihnen aber auf anderen Mengen Verknüpfungen begegnen, die diese Eigenschaften nur teilweise aufweisen.
Die Zahlen 0 und 1 spielen eine Sonderrolle, es gilt:
0 + n = n,
1n = n.
Man nennt die 0 deshalb neutrales Element der Addition, die 1 neutrales Element
der Multiplikation.
Eine weitere Verknüpfung auf den natürlichen Zahlen ist die Potenz. Wir definieren
sie rekursiv: Seien a, n ∈ . Dann ist
N
a0 := 1,
Es gelten die folgenden Regeln
an := an−1 · a.
am+n = am · an ;
(ab)n = an · bn .
Hieraus kann man noch folgende Regel ableiten:
(an )m = anm .
c
c
2
Hier muss man vorsichtig sein, man definiert ab := a(b ) . Denn z.B. ist 23 6= (23 )2 .
9
Zahlenfolgen
Typische Aufgaben in Tests, die unsere Intelligenz messen wollen, sind folgender
Art: Fügen Sie folgenden Zahlenfolgen die 3 logisch folgenden Zahlen an.
1. 3, 5, 7, 9, ?, ?, ?
2. 1, 1, 2, 3, 5, 8, 11, ?, ?, ?
3. 1, 3, 6, 10, ?, ?, ?
Die Aufgabe besteht also darin, in den Zahlenfolgen ein System zu erkennen, das
ihren Aufbau bestimmt. Schauen wir uns Zahlenfolge (i) noch einmal an. Auf den
ersten Blick sollte klar sein, wie wir sie fortsetzen, und zwar mit 11, 13, 15, indem
wir einfach zu jeder Zahl eine 2 addieren. Genauso gut könnten wir die Folge allerdings auch mit 11, 13, 17 fortsetzen, und zwar, wenn wir behaupten, die Folge
zähle sämtliche ungeraden Primzahlen auf. Für einen Mathematiker ist es deshalb
oft nicht hinreichend exakt, eine Zahlenfolge einfach nur mit ihren ersten Gliedern
anzudeuten. Wir würden (i) z.B auf folgende Art notieren: (an )n∈N mit an := 2n + 1
falls wir ungerade Zahlen aufzählen möchten, (bn )n∈N , bn := n-te ungerade Primzahl,
falls wir die ungeraden Primzahlen aufzählen wollen. Die Schreibweise (an )n∈N soll
andeuten, dass der Index n sämtliche natürlichen Zahlen durchläuft.
Entsprechend können wir (ii) mit (fn )n∈N , f1 = f2 = 1, fn = fn−1 + fn−2 für n ≥ 3
eindeutig notieren.
Definition 2.1. (an )n∈N mit an ∈ N, n ∈ N, ist eine Folge natürlicher Zahlen.
Eine Folge ist also einfach eine Aneinanderreihung nummerierter Zahlen. Wichtig
ist: die Wahl des Buchstabens a ist völlig willkürlich, genauso gut können wir eine
Folge mit b oder z oder Maus oder ähnlichem bezeichnen, auch der Index n kann
einen beliebigen anderen Namen haben, beliebt sind z.B. i, j, k oder l. Oft wird
sogar der Index einer Folge kurzfristig und stillschweigend umbenannt, wenn der
entsprechende Buchstabe schon anderweitig vergeben ist. Hieran muss man sich
einfach gewöhnen.
Summen und Produkte
Wir wissen jetzt, wie wir eine Folge von Zahlen vernünftig und eindeutig aufschreiben
wollen. Nun kann es aber vorkommen, dass wir an einer Summe von Folgengliedern
interessiert sind. Wir betrachten die Folge (an )n∈N , an := 2n − 1, d.h. die Folge der
ungerade Zahlen, und sind an der Summe ihrer ersten 10 Glieder interessiert, wir
schreiben:
1 + 3 + 5 + 7 + 9 + 11 + 13 + 15 + 17 + 19.
Dies bekommen wir gerade noch so hin, für die ersten 300 oder 5000 ungeraden Zahlen wäre diese Schreibweise aber doch zu aufwendig. Alternativ können wir natürlich
auch abkürzend schreiben:
1 + 3 + 5 + · · · + 19.
10
Nun müssen wir aber wieder einwenden, dass diese
P Schreibweise wohl kaum exakt
ist. Uns hilft eine Notation, das Summenzeichen , altgriechisch groß Sigma. Wir
schreiben für unsere gefragte Summe einfach
10
X
k=1
(2k − 1)
oder äquivalent
10
X
ak .
k=1
Diese Notation ist auf die folgende Art zu verstehen: Unter der Summe steht der
Laufindex k, der hier alle natürlichen Zahlen zwischen 1 und 10 durchläuft. Für jeden Wert von k wird der Term, der hinter dem Summenzeichen in Klammern steht,
ausgewertet. Z.B setzen wir für k = 3 ein: 2 · 3 − 1 = 5. Dann werden alle diese Werte aufaddiert. In dieser Schreibweise können wir also schnell und platzsparend eine
5000
P
beliebige Summation aufschreiben. So wäre also
ak die Summe über die ersten
k=1
5000 Folgenglieder oder
151
P
k=37
ak die Summe über sämtliche Folgenglieder von a37 an
bis a151 . Ein großer Vorteil dieser Notation liegt vor, wenn wir den Summationsbereich auf eine beliebige Obergrenze festlegen und entsprechend notieren wollen. Für
ein beliebig gewähltes n ∈ N schreiben wir für die Summe der ersten n ungeraden
Zahlen
n
X
(2k − 1).
k=1
Wie können wir nun folgende Summe schreiben
a7 + a15 + a31 ?
In diesem Fall kann man die Menge G := {7, 15, 31} definieren und wir schreiben
X
ak .
k∈G
Eine völlig analoge Notation gibt es auch für Produkte. Sind wir zum Beispiel an
dem Produkt der ersten n natürlichen Zahlen interessiert, welches man oft mit n!,
sprich “n Fakultät”, notiert, also an folgendem Ausdruck
n! := 1 · 2 · 3 · 4 · · · · · n,
so können wir ihn auf folgende Weise notieren:
n! :=
n
Y
k=1
11
k.
Indexverschiebung
Kommen wir nun zu einem etwas formaleren Aspekt der Notation mit Summenbzw. Produktzeichen. Dabei soll im Folgenden nur das Summenzeichen betrachtet
werden, die Überlegungen für das Produktzeichen laufen völlig analog.
Ausgangspunkt dieser Überlegung ist, dass die Wahl des Bereiches, die unsere Zählvariable durchläuft, etwas willkürlich ist. Das folgende Beispiel soll das illustrieren:
4
X
(k + 1)2 = 22 + 32 + 42 + 52 =
k=1
5
X
k2
k=2
Es ist offensichtlich, dass beide Notationen mit dem Summenzeichen die gleiche
Summe meinen. Der Unterschied besteht darin, dass der Laufindex k “verschoben”
wurde. In der zweiten Summe läuft er nicht von 1 bis 4, sondern von 2 bis 5 – dafür
muss zum Ausgleich in der Summe das k durch k − 1 ersetzt werden (bzw. k + 1
durch k).
Ein weiteres Beispiel ist:
X
X
7 3 3 X
1
1
1
=
=
2j
−
7
2(j
+
4)
−
7
2j + 1
j=5
j=1
j=1
Die wichtige Regel ist also: wird der Wertebereich des Laufindexes nach unten verschoben, so muss der Index selbst zum Ausgleich vergrößert werden und umgekehrt.
Als Anwendung der Indexverschiebung soll für eine reelle Zahl q 6= 1 die folgende
Formel bewiesen werden:
Für alle n ∈
n
X
N gilt:
qk =
k=0
1 − q n+1
1−q
Beweis. Nach Multiplikation mit dem Nenner genügt es zu zeigen:
(1 − q) ·
n
X
k=0
q k = 1 − q n+1
Multipliziere die linke Seite aus:
(1 − q) ·
n
X
q
k
=
k=0
=
=
n
X
k=0
n
X
k=0
n
X
k=0
k
(q ) − q ·
(q k ) −
(q k ) −
= 1+
n
X
n
X
k=0
n
X
k+1
q
k=0
n+1
X
k
= 1−q
12
qk
k=1
(q ) −
k=1
n+1
qk
n
X
k=1
k
(q ) + q
n+1
!
In diesem Beweis wird ein weiteres wichtiges Prinzip beim Rechnen mit Summen
deutlich: man kann Summanden abspalten und einzeln hinschreiben. So kann man
zum Beispiel die folgende Summe umschreiben:
n+1
X
k=1
n
X
(k 2 ) + (n + 1)2
k =
2
k=1
Oder die folgende elementare Formel für Fakultäten notieren:
(n + 1) · n! = (n + 1) ·
n
Y
i=
i=1
n+1
Y
i = (n + 1)!
i=1
Als Schlussbemerkung noch eine Konvention: taucht ein Summenzeichen auf, das
keine Summanden enthält, so wird dies die “leere Summe” genannt und bekommt
per Definition den Wert 0. Dies ergibt Sinn, weil 0 das “neutrale Element” der
Addition ist – die Addition einer 0 ändert den Wert einer Summe nicht.
Analog wird das “leere Produkt” als 1 definiert, da bei der Multiplikation die 1 das
neutrale Element ist. Als Konsequenz erhalten wir:
0! =
0
Y
i = 1.
i=1
2.1 Das Prinzip der Induktion
Weiter oben haben wir eine Notation für Summen kennengelernt, z.B. für die ersten
10 ungeraden Zahlen. Welchen Wert hat nun diese Summe? Nun, wir können dies
natürlich einfach ausrechnen, der Wert ergibt 100. Oft kann man für den Wert einer
solchen Summe aber auch eine allgemeine Formel, d.h. für eine beliebige Anzahl von
n Summanden, herleiten. Wir wollen uns also die Summen für n = 1, 2, 3, 4 mal
anschauen:
• n = 1: 1 = 12
• n = 2: 1 + 3 = 4 = 22
• n = 3: 1 + 3 + 5 = 9 = 32
• n = 4: 1 + 3 + 5 + 7 = 16 = 42
Aus der Beobachtung der ersten vier Summanden liegt die Vermutung nahe, dass
die Summe der ersten n ungeraden Zahlen n2 lautet.
Vermutung 2.2. Für alle n ∈ N gilt
n
X
k=1
(2k − 1) = n2 .
Wir schließen aus einigen Beobachtungen auf einen allgemeinen Fall. Diese Art zu
schlussfolgern nennt man induktiv.
Schlüsse dieser Art ziehen wir ständig (z.B. “Morgen geht die Sonne auf, weil das
auch gestern und vorgestern der Fall war.”). Logisch zulässig sind sie deswegen aber
noch lange nicht. Folgendes Beispiel soll dies verdeutlichen:
13
Beispiel 2.3 (Irrtum von Fermat). Pierre de Fermat (franz. Mathematiker) betrachtete Zahlen der Form
n
Fn = 22 + 1
n∈N
Die ersten dieser Zahlen lauten:
F0
F1
F2
F3
F4
=
=
=
=
=
3
5
17
257
65537
Dies sind alles Primzahlen und so vermutete Fermat im Jahre 1637, dass alle weiteren
Zahlen dieser Form ebenfalls Primzahlen seien. Etwa 100 Jahre nach der Vermutung
entdeckte Euler im Jahre 1732, dass die nächste Fermat-Zahl keine Primzahl ist:
F5 = 4294967297 = 641 · 6700417
Inzwischen wird sogar vermutet, dass alle weiteren Fermat-Zahlen Fn mit n ≥ 5
keine Primzahlen sind, aber ein formaler Beweis steht bislang noch aus.
Wie können wir denn nun aber unsere Vermutung 2.2 zweifelsfrei beweisen? Hier
hilft uns ein Beweisverfahren, das man vollständige Induktion nennt. kann es in
folgendem Fall anwenden. Wir haben eine Familie von Aussagen A(n), n ∈ N, d.h.
zu jedem n ∈ N gibt es eine Aussage A(n), deren Wahrheit wir nachweisen möchten.
Wir können auch sagen, wir haben eine Aussageform A mit Einsetzungsbereich .
hP
n
(2k−1) =
In unserem Beispiel mit den ungeraden Zahlen wäre A(n) die Aussage
k=1
i
n2 . Der Beweis geht nun in zwei Schritten.
N
1. Induktionsanfang Man beweist, dass A(1) gilt.
2. Induktionsschritt Man beweist, dass für jedes n ∈ N aus der Gültigkeit von
A(n) auch die Gültigkeit von A(n + 1) folgt.
Im Induktionsanfang zeigt man die Wahrheit für die erste Aussage. Dies ist oft
sehr einfach. Der Induktionsschritt sagt nun aus, dass insbesondere aus der ersten
Aussage A(1) die Aussage A(2) folgt. Aus dieser folgt nun aber wieder mit Induktionsschritt die nächste Aussage A(3). Somit können wir für ein beliebiges n ∈ N
die Aussage A(n) mit einer endlichen Zahl von Induktionsschritten jeweils aus der
Wahrheit der vorangehenden Aussagen schließen. Deshalb gilt dann A(n) für jedes
n.
Ein hilfreiches Bild ist vielleicht das Folgende: man stelle sich die Aussagen wie
Dominosteine vor, die aneinander gereiht sind. Wenn ein Dominostein umfällt, dann
soll das bedeuten, dass die Aussage wahr ist. Der Induktionsschritt formuliert nun
das Gesetz, dass ein fallender Dominostein seinen Nachbarn umstößt. (Wenn A(n)
gilt, dann auch A(n + 1).) Und der Induktionsanfang garantiert uns das Fallen des
ersten Steins – und damit fallen alle um.
Wir wollen nun unsere Vermutung 2.2 beweisen. Für den Induktionsanfang müssen
1
P
(2k − 1) = 12 . Nun gilt
wir die Wahrheit von A(1) beweisen, in unserem Fall also
k=1
14
dies offensichtlich:
1
P
(2k − 1) = 1 und 12 = 1. Als nächstes wollen wir nun zeigen,
k=1
dass aus A(n) auch A(n + 1) folgt, d.h. unter der Annahme, dass
n
P
(2k − 1) = n2
k=1
gilt, gilt dann auch
n+1
P
k=1
n+1
X
k=1
(2k − 1) = (n + 1)2 . Wir rechnen nach:
n
X
IV
(2k − 1) + 2(n + 1) − 1 = n2 + 2n + 1 = (n + 1)2 .
(2k − 1) =
k=1
Das kleine “IV” (Induktionsvoraussetzung) deutet die Stelle an, an der benutzt wird,
dass A(n) laut Annahme gilt.
Zusammenfassend kann man sagen, dass der eigentliche Trick der Induktion darin
besteht, den Schluss von einer Zahl auf ihren Nachfolger allgemein zu formulieren,
so dass dieser im Prinzip beliebig oft anwendbar ist.
Zum Schluss noch eine geometrische Anschauung der soeben bewiesenen Formel:
Beginnend mit einem Kästchen in der oberen linken Ecke, wird immer eine ungerade
Anzahl an Kästchen hinzugefügt und es entsteht jeweils wieder ein Quadrat.
Der kleine Gauß
Es wird eine Anekdote über den deutschen Mathematiker Carl-Friedrich Gauß erzählt, der im Alter von neun Jahren in der Schule die Strafarbeit aufbekam, die
natürlichen Zahlen von 1 bis 100 alle aufzuaddieren. Die abkürzende Notation benutzend sollte also die Summe
100
X
i
i=1
berechnet werden.
Laut der Anekdote soll der “kleine Gauß” seinen Lehrer damit überrascht haben, in
kürzester Zeit auf das (korrekte) Ergebnis 5050 zu kommen.
Aufgrund dieser Anekdote, deren Wahrheitsgehalt ungewiss ist, trägt die folgende
15
Formel den Namen “Gaußsche Summenformel” oder manchmal auch einfach “der
kleine Gauß”:
n
X
n(n + 1)
i=
2
i=1
Für n = 100 ergibt sich gerade 100·101
= 50 · 101 = 5050. Der Beweis der Formel
2
funktioniert über vollständige Induktion.
Beweis.
a) Induktionsanfang Sei n = 1. Dann steht auf der linken Seite
1·2
=1
2
Die Aussage ist also für n = 1 wahr.
b) Induktionsschritt Die Aussage gelte für n ∈
i=1
i=
n
X
i = 1 und auf
i=1
der rechten gerade
n+1
X
1
P
IV
i + (n + 1) =
i=1
N. Es folgt:
n · (n + 1) 2n + 2
n2 + 3n + 2
+
=
2
2
2
Andererseits gilt aber
n2 + 3n + 2
(n + 1)(n + 2)
=
2
2
Dies zeigt die Behauptung.
Alle Dinge sind gleich
Zum Schluss des Kapitels über vollständige Induktion noch eine kleine Warnung:
manchmal muss man bei solchen Beweisen sehr genau hinschauen, sonst können
sich Fehler einschleichen. Wir werden nun eine offensichtlich falsche Aussage mit
vollständiger Induktion beweisen. Die Aussage lautet:
“Alle Studierenden an der Universität Bielefeld studieren das Gleiche.”
Um diese Aussage mit Induktion angehen zu können, muss noch eine natürliche
Zahl n irgendwo auftauchen. Daher wird die Aussage in Abhängigkeit von n wie
folgt umformuliert:
“In einer beliebigen Menge von n Studierenden studieren alle das Gleiche.”
Dies soll die Aussage A(n) sein, die im Folgenden mit vollständiger Induktion bewiesen wird.
Beweis.
a) Induktionsanfang Sei n = 1. In einer beliebigen Menge, die nur einen Studenten
oder eine Studentin enthält, ist die Aussage klar.
16
N
b) Induktionsschritt Nehmen wir an, die Aussage sei für n ∈
bewiesen. Wir
nehmen uns nun eine beliebige Menge M her, in der n+1 Studierende sind und
wollen zeigen, dass die alle das Gleiche studieren. Geben wir den Elementen
von M Namen:
M = {a1 , a2 , . . . , an+1 }
Betrachten wir nun eine Teilmenge von M, in welcher der erste Studierende
fehlt:
M ′ = {a2 , a3 , . . . , an+1 }
M ′ enthält nur n Studierende und die studieren nach Induktionsvoraussetzung
alle das Gleiche. Fehlt noch a1 – aber zu diesem Zweck betrachten wir eine
zweite Teilmenge:
M̃ = {a1 , a2 , . . . , an }
Auch in dieser Menge sind nur n Studierende enthalten, die wieder nach Induktionsvoraussetzung alle das Gleiche studieren. Nehmen wir uns nun ein beliebiges Element ak aus dem Schnitt (also ein ak aus der Menge {a2 , . . . , an }),
so folgt, dass a1 das Gleiche studiert wie ak und ak das Gleiche wie an+1 , denn
a1 und ak liegen in M̃ und ak und an+1 liegen in M ′ .
Damit ist die Aussage bewiesen und alle Studierenden aus M studieren das
Gleiche.
Da an der Universität nur endlich viele Studierende eingeschrieben sind, muss man
n nur groß genug wählen und die Aussage A(n) für dieses n zeigt die Behauptung.
Natürlich kann man diesen Beweis nun für beliebige Dinge führen: Alle Bücher
heißen gleich, alle Menschen haben das gleiche Geschlecht, alle Häuser sind gleich
hoch...
Wo liegt also der Fehler im vorangegangenen “Beweis”?
17
3 Ganze Zahlen
Mit den natürlichen Zahlen können wir nun Dinge zählen. Wir betrachten aber mal
folgende Gleichung:
6 + x = 3.
Diese hat keine Lösung in den natürlichen Zahlen. Deswegen wollen wir die natürlichen Zahlen um negative Zahlen erweitern, wir definieren Z, die Menge der ganzen
Zahlen:
Z := {0, −1, 1, −2, 2, −3, 3, . . . }.
Für die ganzen Zahlen gilt eine Existenzaussage, die für die natürlichen Zahlen noch
falsch ist:
Zu jedem n ∈ Z existiert ein n′ ∈ Z mit n + n′ = 0.
Wir bezeichnen n′ mit −n und nennen −n das additive Inverse von n.
Somit können wir in Z obige Gleichung lösen, x = −3.
Auf den ganzen Zahlen haben wir wie auf den natürlichen auch die zweite Verknüpfung, die Multiplikation. Die Eigenschaften Kommutativität, Assoziativität und
Distributivität gelten hier genauso. Das folgende Lemma hält ein paar Rechenregeln
fest:
Lemma 3.1. Es seien a, b ∈ Z. Dann gilt:
1. 0b = 0
2. (−a)b = −ab
3. (−a)(−b) = ab.
Die Aussagen dieses Lemmas sollten niemanden überraschen. Wir wollen doch kurz
zeigen, wie sie aus den Eigenschaften der Assoziativität und Distributivität folgen.
Beweis: Zu (i): Es ist 0b = (0+0)b = 0b+0b. Wir addieren auf beiden Seiten −(0b).
Dies ergibt 0 = 0b.
Zu (ii): Wegen ab + (−a)b = (a − a)b = 0, ist (−a)b das additiv Inverse zu ab.
Zu (iii):Aus (ii) folgt: (−a)(−b) = −(a(−b)) = −(−(ab)) = ab.
Der Beweis zeigt: Will man Addition und Multiplikation auf einer Zahlenmenge
haben und soll das Distributivgesetz und Assoziativgesetz gelten, so ergibt sich
sofort die vermutlich hinlänglich bekannte Rechenregel “minus mal minus ergibt
plus”.
Wie gehen wir auf mit Potenzen um? Seien a, n natürliche Zahlen, was ist dann
(−a)n ? Nun, wenn wir unsere Rechenregeln für Potenzen auf den natürlichen Zahlen
auf diesen Fall erweitern, erhalten wir:
Z
(−a)n = ((−1)a)n = (−1)n an .
18
Mit Lemma 3.1 ergibt sich für (−1)n der Wert 1, falls n gerade und (−1), falls n
ungerade ist (wie zeigt man dies?). Was ist nun, wenn die Potenz negativ ist? Wenn
wir eine positive Potenz um 1 reduzieren, bedeutet dies, dass wir die Basis einmal weniger mit sich selbst multiplizieren, d.h. wir benötigen multiplikative Inverse.
Diese stehen uns in nicht zur Verfügung...
Z
Wie damals: Teilen mit Rest
Wir stehen vor der folgenden Rechenaufgabe: 21 : 5 =?. Im Bereich der ganzen
Zahlen können wir hier keine Antwort geben. Eine sinnvolle Angabe ist allerdings
die Antwort “4 Rest 1”: wir können 20 durch 5 teilen, es bleibt ein Rest von 1. Wir
können überlegen, welche (ganzen) Zahlen “geteilt durch 5 Rest 1” ergeben: R1 :=
{. . . , −9, −4, 1, 6, 11, . . . } oder allgemein: R1 := {n ∈ |∃m ∈ : n = 5m + 1}. Wir
wollen die Elemente von R1 gemäß der folgenden Schreibweise identifizieren, z.B.
Z
6≡1
Z
mod 5 “6 äquivalent 1 modulo 5.
Diese Schreibweise kann man so verstehen: bezüglich des Restes beim Teilen durch
5 (modulo 5) sind 6 und 1 gleich.
Ebenso wie R1 können wir auch die Mengen R0 , R2 , R3 , R4 aufschreiben (wie die
aussehen ist klar?). Diese sind paarweise disjunkt (d.h. der Schnitt von je zwei dieser
Mengen ist leer). Wie wirkt sich dies auf die Addition und Multiplikation aus? Wir
rechnen:
2 + 3 ≡ 0 mod 5, 2 · 3 ≡ 1 mod 5.
2 + 3 ergibt also auf einmal 0, 2 · 3 1! Bewzüglich ”modulo 5“ können wir also
auch Inverse zur Multiplikation definieren. Man mache sich klar, ob man für jedes
Element jeder Restklassenmenge Ri ein multiplikatives Inverses finden kann. Hierfür
stellen wir Verknüpfungstafeln für die Addition und die Multiplikation auf.
+
0
1
2
3
4
0
0
1
2
3
4
1
1
2
3
4
0
2
2
3
4
0
1
3
3
4
0
1
2
·
0
1
2
3
4
4
4
0
1
2
3
19
0
0
0
0
0
0
1
0
1
2
3
4
2
0
2
4
1
3
3
0
3
1
4
2
4
0
4
3
2
1
4 Rationale Zahlen
Mit den ganzen Zahlen können wir nun ein Inverses zu der Addition angeben. Oft
benötigen wir aber auch einen inversen Ausdruck zur Multiplikation, z.B. wenn wir
die Lösung der folgenden Gleichung angeben wollen:
bx = c.
Dem Problem begegnen wir zunächst auf simple Weise, wir definieren die multiplikativen Inversen einfach hinzu. Zu einer ganzen Zahl u sei u1 so, dass
u·
1
1
= · u = 1.
u
u
Zunächst einmal folgt mit Lemma 3.1, dass die 0 kein multiplikatives Inverses haben
kann. Dies zeigen wir über einen Widerspruch. Wir nehmen an, es existiere ein
multiplikatives Inverses zu 0 und zeigen dann, dass aus dieser Annahme zwingend
eine Aussage folgt, deren Unwahrheit wir kennen. Sei η also multiplikatives Inverses
zu 0, d.h.
0 · η = η · 0 = 1.
Andererseits gilt aber wegen Lemma 3.1, (i):
0 · η = 0.
Somit
0 = 0 · η = 1,
was wohl definitiv nicht stimmt. Wer genau hinschaut, wird hier einen Einspruch
erheben: das zitierte Lemma haben wir nur für ganze Zahlen formuliert. Es ist
allerdings aus dem Beweis unmittelbar ersichtlich, dass die Aussagen immer gelten,
wenn assoziative Addition und Multiplikation und das Distributivgesetz vorliegen.
Mit diesen neuen Zahlen u1 wollen wir auch wieder rechnen können, sie z.B. mit
ganzen Zahlen multiplizieren. Sei v ∈ Z, dann schreiben wir v · u1 =: uv . Aus dem
Distributivgesetz folgt dann sofort mit w ∈ Z:
v w
1
v+w
+ = (v + w) =
.
u u
u
u
Wir können nun die Menge Q der rationalen Zahlen definieren:
Q := { uv : u, v ∈ Z, v 6= 0}.
Z
Wie multiplizieren wir nun zwei Zahlen u1 , v1 mit u, v ∈ , u, v 6= 0? Nun, u1 ist das
multiplikative Inverse von u, 1v jenes von v. Wegen Kommutativität ist dann
uv
11
1 1
=u v = 1·1 =1
uv
u v
20
also das Produkt von
1
u
und
1
v
das multiplikative Inverse von uv und somit
11
1
=
.
uv
uv
Nun können wir mit unseren Rechenregeln auch das Produkt zweier rationaler Zaheln herleiten. Seien u, u′, v, v ′ ∈ , v, v ′ 6= 0. Dann ist
Z
uu
1 ′1
uu′
′1 1
=
u
u
=
uu
=
.
v v′
v v′
v v′
vv ′
Zwei Brüche kann man nun addieren, indem man sie auf einen gemeinsamen Nenner
erweitert:
u u′
v ′ u v u′
uv ′ + u′ v
+ ′ = ′ +
=
.
v v
v v v v′
vv ′
Die rationalen Zahlen weisen nun eine Eigenschaft auf, die wir von den natürlichen
oder ganzen Zahlen noch nicht kennen: zu je zwei Zahlen existiert auch immer eine
rationale Zahl, die dazwischen liegt (daraus folgt natürlich auch, dass zwischen zwei
rationalen Zahlen unendlich viele rationale Zahlen liegen). Wir formulieren diese
Aussage im folgenden Lemma.
′
Lemma 4.1. Seien p, q ∈
p < r < q.
Q mit p < q. Dann existiert eine rationale Zahl r mit
Beweis: Wir können a, b, c ∈
a < b gelten. Wegen
Z,
c > 0 finden, so dass
a
c
= p, cb = q. Dann muss
1
1
b a
− ≥ >
>0
c c
c
2c
1
ist z.B. ac + 2c
= 2a+1
∈ die gesuchte Zahl.
2c
Mit den rationalen Zahlen können wir nun auch die Frage der negativen Potenzen
klären, die im vorigen Kapitel noch offen geblieben ist. Seien a, n natürliche Zahlen, dann entspricht die Reduktion der Potenz in an um 1 der Multiplikation des
Ausdrucks mit dem Inversen: an−1 = a1 an . Es folgt sofort a0 = 1 und, dass es offensichtlich sinnvoll ist, a−n als multiplikatives Inverses zu an zu verstehen und somit
zu definieren:
1
a−n := n .
a
Folglich haben wir bei einer rationalen Basis
an
a
( )n := n .
b
b
Wie können wir nun mit rationalen Potenzen umgehen? Wir betrachten folgende
äquivalente Gleichungen
Q
2
1
1
1
2 = 21 = 2 2 = (2 2 )2 = 2 2 · 2 2
⇔
1
1
2 = (22 ) 2 = 4 2
Eien Basis a zur Potenz 21 kann man also als den Wert interpretieren, dessen Produkt
1
mit sich selbst die Basis ergibt, im Falle der Basis 4 ergibt sich also 4 2 = 2 und
allgemein für ein beliebiges a und n
n
Y
1
n
n
an .
a=a =
j=1
Wie wir im nächsten Kapitel sehen werden, sind diese Werte aber nicht alle unbedingt auch rationale Zahlen.
21
5 Reelle Zahlen
Man könnte nun meinen, die rationalen Zahlen füllten die ganze Zahlengerade aus,
denn zwischen zwei beliebigen rationalen Zahlen findet man immer wieder eine weitere. Dem ist aber nicht so. Wir stellen uns die Zahlengerade vor, malen ein Quadrat
über dem Intervall von 0 bis 1, setzen einen Zirkel in die Null und in die obere rechte
Ecke. Nach dem Satz von Pythagoras gilt, dass die Länge a dieser Strecke folgende
Gleichung erfüllt
a2 = 1 + 1 = 2.
Wenn wir nun mit dem Zirkel einen Kreis um die Null mit Radius a schlagen, liegt
die Länge a und damit auch die Zahl a auf der Zahlengeraden. Nun gilt aber folgende
Proposition:
Proposition 5.1. Es gibt keine rationale Zahl a mit a2 = 2.
Beweis: Angenommen es gibt eine positive Zahl a ∈
gekürzter Bruch mit pq = a. Es gilt
Q mit a2
= 2. Sei
p
q
ein
2
p
p2
a =
= 2 = 2 ⇐⇒ p2 = 2q 2
q
q
2
Damit ist p2 eine gerade Zahl. Dann muss aber auch p gerade sein, denn das Quadrat
einer ungeraden Zahl ist stets ungerade:
(2n + 1)2 = 4n2 + 4n + 1
Da also p selbst eine gerade Zahl ist, gibt es eine Zahl r ∈
eingesetzt ergibt:
Z mit p = 2r. Dies
(2r)2 = 2q 2 ⇐⇒ 4r 2 = 2q 2 ⇐⇒ 2r 2 = q 2
Also ist q 2 gerade und demnach, mit demselben Argument wie oben, auch q.
Das aber ist ein Widerspruch! Denn wenn p und q beide gerade sind, sind beide
durch 2 teilbar - wir hatten aber vorausgesetzt, dass die Darstellung von a als Bruch
gekürzt ist, d.h. p und q sollten teilerfremd sein.
Wieder haben wir also eine Größe, die in unserer bisherigen Zahlenmenge nicht
vorkommt. Aber die Prozedur√ist die gleiche wie vorher: wir erfinden ein Symbol für
diese Größe (in diesem Fall 2) und nehmen solcherlei Elemente einfach mit auf.
Die größere Menge, die wir enthalten, nennen wir dann : die Menge der reellen
Zahlen.
In Wahrheit ist die Konstruktion der reellen Zahlen aus den rationalen um einiges
komplizierter. Man kann es sich ungefähr so vorstellen: jede der neuen reellen Zahlen
kann man beliebig gut durch rationale Zahlen approximieren, d.h. annähern. Konkret heißt dies, dass in jeder noch so kleinen Umgebung einer reellen Zahl auf dem
R
22
Zahlenstrahl unendlich viele rationale Zahlen liegen. Die reellen Zahlen füllen quasi
die Lücken zwischen den rationalen Zahlen aus.
Eine andere Art die reellen Zahlen aufzufassen ist die Entwicklung als Dezimalbrüche: man betrachtet die Menge aller “Zahlen” der Form
ak ak−1 . . . a1 a0 , a−1 a−2 . . .
Dabei sind die ai ∈ {0, 1, . . . , 9} die Ziffern. Gemeint ist mit obigem Ausdruck
natürlich eigentlich folgende Reihe (den Begriff einer Reihe werden wir später definieren):
∞
X
a−i
i=−k
10i
Nicht alle Zahlen dieser Form sind rational: wann immer man von einem Bruch ausgeht, entsteht eine Dezimalzahl, die periodisch ist, also ab einem Punkt wiederholen
sich die Ziffernfolgen. Die reellen Zahlen kann man also als Menge aller (periodischer
und nicht periodischer) Dezimalzahlen auffassen.
Eine detailliertere Behandlung der reellen Zahlen würde den Rahmen des Vorkurses
bei Weitem sprengen. In beinahe jedem Lehrbuch der Analysis wird dieses Thema
mehr oder weniger ausführlich behandelt, Interessierte seien also darauf verwiesen.
Außerdem wird die Konstruktion der reellen Zahlen mit an Sicherheit grenzender
Wahrscheinlichkeit auch Gegenstand der Mathematikvorlesung im kommenden Semester sein.
Archimedisches Axiom
Die Zahlen, die wir bisher kennen, sind auf eine natürliche Art und Weise angeordnet,
wir bezeichnen dies durch die “größer-gleich” und “kleiner-gleich” Relationen “ ≥′′
bzw “ ≤′′ .
Für “ ≤′′ haben wir die folgenden Eigenschaften:
• total : a ≤ a, a ≤ b oder b ≤ a.
• scharf : Sind a ≤ b und b ≤ a, dann ist a = b.
• transitiv : Sind a ≤ b und b ≤ c, dann ist auch a ≤ c.
• verträglich mit Addition: aus a ≤ b folgt a + c ≤ b + c.
• verträglich mit Multiplikation: aus a ≤ b und 0 ≤ c folgt ac ≤ bc.
Wir schreiben a < b falls a ≤ b und a 6= b.
Eine wichtige Klasse von Teilmengen von
a, b ∈ ∪ {−∞, ∞} und a < b:
R
R sind die Intervalle: Wir definieren für
• abgeschlossenes Intervall: [a, b] := {x ∈
• halboffenes Intervall: [a, b) := {x ∈
b}
• offenes Intervall: (a, b) := {x ∈
R|a ≤ x ≤ b}
R|a ≤ x < b},
R|a < x < b}
23
(a, b] := {x ∈
R|a < x ≤
In den reellen Zahlen gilt das Archimedische Axiom: Zu allen positiven reellen
Zahlen a, b gibt es eine natürliche Zahl n, so dass na > b.
Die Gültigkeit dieser Aussage ist uns selbstverständlich. Wichtig ist eine weitere
Aussage, die zu dieser äquivalent ist:
Lemma 5.2. Zu dem archimedischen Axiom ist folgende Aussage äquivalent: Ist α
eine reelle Zahl, so dass 0 ≤ α < n1 für alle natürlichen Zahlen n ∈
gilt, so ist
α = 0.
N
Das archimedische Axiom und das Lemma sagen also, dass es weder unendlich kleine
noch unendlich große Zahlen gibt, und dass zwei reelle Zahlen, die beliebig nahe
beieinander liegen, gleich sein müssen. Das Axiom gilt natürlich auch schon für die
rationalen Zahlen. Wir wollen das Lemma noch beweisen:
Beweis: Wir zeigen zunächst, dass aus dem archimedischen Axiom das Lemma
mit nα > 1. Aber dann ist
folgt: Angenommen, α > 0. Dann existiert ein n ∈
1
α > n , was ein Widerspruch zur Annahme im Lemma ist.
Nun zeigen wir noch die Rückrichtung: Wäre na ≤ b ∀n ∈ , so erhielte man durch
1
Multiplikation mit der positiven Zahl nb
die Ungleichung ab ≤ n1 ∀n und somit aus
a
1
≤ n+1
die Ungleichung ab < n1 ∀n.
b
N
N
Betrag und Abstand
Im folgenden Abschnitt wird der Absolutbetrag von reellen Zahlen auftauchen. Die
formale Definition sieht folgendermaßen aus:
x
, falls x ≥ 0
|x| :=
−x , falls x < 0
Anschaulich gesprochen ignoriert der Absolutbetrag einfach das Vorzeichen einer
reellen Zahl: ist die Zahl positiv, bleibt sie erhalten, ist die Zahl negativ, wird ihr
Vorzeichen geändert.
Für Rechnen mit Beträgen bieten sich Fallunterscheidungen an. Wesentlich ist die
wichtige Dreiecksungleichung: für alle Zahlen x, y ∈ gilt:
R
|x + y| ≤ |x| + |y|
Der Beweis wird zur Übung überlassen. Eine direkte Folge der Dreiecksungleichung
ist die sogenannte “umgekehrte Dreiecksungleichung”:
|x − y| ≥ |x| − |y|.
Beweis. Seien x, y ∈
R beliebig. Aus der Dreiecksungleichung folgt:
|x| = |x − y + y| ≤ |x − y| + |y| ⇒ |x − y| ≥ |x| − |y|.
Ebenso folgt
|y| = |y − x + x| ≤ |y − x| + |x| ⇒ |x − y| ≥ |y| − |x|.
Insgesamt folgt die Behauptung, denn für alle reellen Zahlen a und b gilt:
a ≥ b und a ≥ −b ⇒ a ≥ |b|.
Die letzte Ungleichung ist klar, da der Betrag von b nach Definition ja entweder
gleich b oder gleich −b ist.
24
Mit dem Betrag wollen wir auch den Abstand d(a, b) zweier reeller Zahlen definieren,
und zwar
d(a, b) := |a − b| = |b − a|.
Aus der letzten Gleichung folgt trivialerweise auch d(a, b) = d(b, a), was man ja von
einem Abstandsbegriff auch erwarten möchte.
Konvergenz reeller Folgen
Wir haben schon den Begriff der Folge kennengelernt. Wir wollen uns drei Beispiele
reeller Folgen anschauen:
an =
1
n
bn = (−1)n
cn =
2n2 − 10n + 5
√
n
Wir schauen uns im ersten Beispiel die ersten paar Folgenglieder an
1 1 1 1 1
1, , , , , , . . .
2 3 4 5 6
Oder im zweiten Beispiel:
−1, 1, −1, 1, −1, 1, −1, 1, −1, 1, . . .
Wir sind am “Langzeitverhalten” solcher Folgen interessiert. Die Anschauung hilft
dabei, dieses schwammige Konzept ein wenig zu erläutern: bei näherer Betrachtung
der ersten Beispielfolge fällt auf, dass die Folgenglieder immer kleiner werden, sich
mit fortschreitendem n also der 0 nähern – und das obwohl die 0 selbst nicht Teil
der Folge ist, denn n1 > 0 für alle n ∈ .
N
Diese Beobachtung soll die folgende Definition motivieren:
Definition 5.3. Sei (an )n∈N eine reelle Folge. Diese heißt konvergent mit Grenzwert a ∈ , falls für jedes ε > 0 ein n0 ∈
existiert, so dass für alle natürlichen
Zahlen n ≥ n0 gilt: |an − a| < ε. Ist eine Folge konvergent gegen a, so schreibt man
auch
lim an = a.
R
N
n→∞
Diese Verklausulierung des anschaulichen Begriffs der Konvergenz einer Folge sieht
auf den ersten Blick furchterregend aus. Was heißt es also genau? Das Beispiel oben
zeigt, dass man im Allgemeinen nicht erwarten kann, dass eine Folge, die einem
Wert zustrebt diesen jemals erreicht, sie kommt ihm nur “immer näher”. Dies soll in
dieser Definition ausgedrückt werden: man verlangt nicht, dass irgendwann an = a
gilt, sondern nur, dass der “Fehler”, also die Differenz |an − a| beliebig klein wird,
Genau das steht in der Definition! Zu jedem Fehler ε, den man sich vorgibt (hierbei
stelle man sich ε als eine sehr kleine positive Zahl vor, z.B. 0, 000000001) gibt es
einen Index n0 (der natürlich von ε abhängt), so dass sich ab diesem Index alle
Folgenglieder um höchstens ε vom geforderten Grenzwert unterscheiden. Man achtet
also gar nicht auf den “Anfang” der Folge, die Elemente bis an0 (das sind “nur”
25
endlich viele), sondern trifft eine Aussage über die unendlich vielen Folgenglieder,
die noch kommen.
Es ist nicht schwer mit dieser Definition zu beweisen, dass die Beispielfolge an =
tatsächlich gegen 0 konvergiert:
1
n
Beweis. Sei ε > 0 beliebig vorgegeben. Zu zeigen ist, dass es eine natürliche Zahl n0
gibt, so dass für alle n ≥ n0 gilt: | n1 − 0| = n1 < ε. Betrachte dazu die reelle Zahl 1ε .
Diese kann man “aufrunden”, es gibt also eine natürliche Zahl n0 mit 1ε < n0 .
Ist nun n ≥ n0 , dann folgt auch n > 1ε , was nach Mulitplikation mit ε und Division
durch n äquivalent ist zu n1 < ε.
Leider ist nicht jede Folge auch konvergent. Wenn es keine Zahl a gibt, welche die
Eigenschaft aus der Definition besitzt, dann nennt man die Folge divergent. Ein
einfaches Beispiel für eine divergente Folge ist an = n die Folge der natürlichen
Zahlen. Diese strebt keinem Grenzwert zu, sondern überwindet jede Schranke. In
diesem Fall schreibt man
lim an = ∞
n→∞
Um sich klarzumachen, was man für die Divergenz einer Folge zeigen muss, notiert
man am besten die Definition der Konvergenz einer Folge (an ) gegen einen Grenzwert
a formal mit Quantoren:
∀ ε > 0 ∃ no ∈
N ∀ n ≥ n0 : |an − a| < ε.
Die Verneinung dieser Aussage sieht dann so aus. Eine Folge ist divergent, wenn für
alle a ∈ gilt:
∃ ε > 0 ∀ n0 ∈ ∃ n ≥ n0 : |an − a| ≥ ε.
R
N
Wie sieht es mit der Beispielfolge bn = (−1)n von oben aus? Diese ist divergent:
Beweis. Zunächst zeigen wir, dass die Zahl 1 als einziger möglicher Grenzwert in
Frage kommt. Sei nämlich a 6= 1 eine beliebige reelle Zahl, dann definieren wir
ε := |a−1|
> 0.
2
Ich behaupte, dass a nicht Grenzwert der Folge bn sein kann. Wäre dies nämlich der
Fall, dann gäbe es ein n0 , so dass |bn − a| < ε für alle n ≥ n0 . Ist aber n ≥ n0 eine
gerade Zahl, dann ist bn = 1 und es folgt |bn − a| = |a − 1| = 2ε > ε.
Damit kommt als einziger Grenzwert a = 1 in Frage. Dies erfüllt die Bedingung aber
auch nicht: wähle ε := 21 . Wäre a = 1 der Grenzwert, dann gäbe es wieder ein n0 , so
dass für alle n ≥ n0 gilt: |bn − 1| < ε. Ist n ≥ n0 aber ungerade, dann gilt bn = −1,
also |bn − 1| = | − 1 − 1| = | − 2| = 2 > 21 = ε.
Beachte, dass die Wahl des ε im zweiten Teil die pure Willkür ist: jedes ε mit ε < 2
leistet das Gewünschte.
Anschaulich gesprochen “springt” die Folge immer zwischen den Werten −1 und 1
hin und her und kann damit die Bedingung an Konvergenz nicht erfüllen, nämlich
dass zu gegebenem (winzigen) Fehler ε alle Folgenglieder ab einem Index so nahe
an dem Grenzwert liegen.
26
Noch eine Bemerkung: konvergente Folgen sind immer beschränkt, d.h. wenn (an )n∈N
eine Folge mit Grenzwert a ist, dann gibt es eine reelle Zahl M > 0 mit |an | < M
für jedes n ∈ . Der Grund dafür liegt darin, dass ab einem gewissen Index alle
Folgenglieder nahe bei a liegen (bis auf den Fehler ε) und die übrigen nur endlich viele
sind, also insbesondere ein Maximum haben. Betrachten wir ein weiteres Beispiel:
N
n
. Die ersten Glieder der Folge lauten
Beispiel 5.4. Betrachte die Folge an = n+1
also:
1
2
3
4
5
6
a1 = ; a2 = ; a3 = ; a4 = ; a5 = ; a6 = .
2
3
4
5
6
7
Es liegt die Vermutung nahe, dass diese Folge gegen 1 konvergiert, denn jeder der
Brüche ist kleiner als 1 (der Nenner ist immer um eins größer als der Zähler), aber
der Abstand wird immer geringer. Der formale Beweis sieht folgendermaßen aus:
Beweis. Sei ε > 0 beliebig. Betrachte
n
=1− n = n+1 − n = 1
−
1
n + 1
n+1
n+1 n+1
n+1
Da die Folge n1 n∈N wie oben gezeigt gegen 0 konvergiert, gibt es also ein N ∈
mit N1 < ε. Ist nun n > N − 1, also n + 1 > N, so folgt
N
1
1
<
< ε.
n+1
N
Also folgt für n0 := N − 1 das Gewünschte.
Rasante Schildkröten und 9er-Perioden
Der griechische Philosoph Zeno ersann folgendes Paradoxon: Angenommen der Held
Achilles läuft mit einer langsamen Schildkröte um die Wette. Um das Rennen fairer
zu gestalten, gewährt er dem Reptil einen Vorsprung. Beide starten zugleich und es
wird angenommen, dass sich beide die ganze Zeit über mit konstanter Geschwindigkeit bewegen, Achilles schneller als die Schildkröte. Dann wird er sie nie erreichen, so
der Philosoph: Sobald Achilles den Punkt erreicht, an dem die Schildkröte gestartet
ist, ist diese schon ein Stück weiter gekrochen. Erreicht der Held aber auch diesen
Punkt kurze Zeit später, so ist die Schildkröte wieder etwas weiter und so fort, so
dass er sie niemals erreicht.
Es hat mehrere Versuche gegeben, dieses Paradoxon argumentativ aufzuheben und
einer davon kommt aus der Mathematik und hat mit Folgen zu tun, genauer gesagt
mit der Tatsache, dass eine Folge bestehend aus unendlich vielen Folgengliedern
einen endlichen Grenzwert besitzen kann.
Zur Veranschaulichung führen wir einige Zahlen ein: nehmen wir einmal an, dass
Achilles der Schildkröte 90m Vorsprung gewährt. Er bewegt sich mit rasanten 10 ms
fort, wohingegen die Schildkröte nur 1 ms schafft (Es ist trotz allem eine recht schnelle
Schildkröte). Dann dauert es 9s bis Achilles die 90m Vorsprung überbrückt und den
Punkt erreicht, an dem die Schildkröte gestartet ist. Diesen Zeitpunkt (9s nach dem
Start) nennen wir t0 .
27
Nach 9s hat die Schildkröte 9m zurückgelegt. Um diese Strecke zu überbrücken
braucht Achilles weitere 0, 9s, also erreicht er diesen zweiten Punkt zum Zeitpunkt
t1 = 9s + 0, 9s = 9, 9s. Dann aber hat die Schildkröte weitere 0, 9m geschafft und
Achilles benötigt um diese Strecke aufzuholen wiederum 0, 09s, schafft dies also zum
Zeitpunkt t2 = 9s + 0, 9s + 0, 09s = 9, 99s usw.
Allgemein sieht die entstehende Folge also so aus:
n
X
9
tn = 9s + 0, 9s + · · · + 0, 00 . . . 09s = 9, 99 . . . 9s =
s
10k
k=0
Die (tn )n∈N0 bilden eine Folge und man kann sich jetzt fragen, ob diese einen Grenzwert besitzt und falls ja, wie dieser aussieht. Mit dem Satz aus Kapitel 2 können
wir obige Summe leicht umschreiben:
k
n 1 n+1
X
1 − 10
1
tn = 9 ·
s=9·
s
1
10
1
−
10
k=0
Um diesen Grenzwert in den Griff zu bekommen betrachten wir folgendes Hilfslemma
R
Lemma 5.5. Sei q ∈ eine reelle Zahl mit 0 < q < 1. Definiere die Folge (an )n∈N
durch an := q n . Dann ist an konvergent und es gilt
lim an = 0
n→∞
N
Beweis. Sei ε > 0 beliebig. Gesucht ist ein n0 ∈ , so dass für alle n ≥ n0 gilt:
q n < ε. Mit Hilfe der Logarithmusfunktion kann diese Gleichung umgestellt werden:
q n < ε ⇔ log q n < log ε ⇔ n · log q < log ε ⇔ n >
log ε
log q
Hierbei ist zu beachten, dass log q < 0 wegen q < 1 und daher dreht sich das
log ε
Ungleichungszeichen um. Wenn also n0 > log
gewählt wird, gilt die geforderte
q
Ungleichung.
Mit Hilfe von den Ergebnissen aus Übung 32 ergibt sich nun die Lösung: die Folge
der tn ist konvergent mit Grenzwert 10s.
Beweis. Es ist
1 n+1
1 − 10
9
lim tn = lim 9 ·
s = 9 s = 10s = 9, 9999s
1
n→∞
n→∞
1 − 10
10
Die Folge der betrachteten Zeitpunkte, obgleich “unendlich lang” hat also einen
endlichen Grenzwert. Und nach 10s hat Achilles rein rechnerisch tatsächlich 100m
zurückgelegt und die Schildkröte 10m, wodurch sie wegen der 90m Vorsprung auf
gleicher Höhe sind.
Zu beachten ist hierbei, dass dieses Paradoxon mathematisch befriedigend gelöst
28
sein mag, vom philosophischen Standpunkt aber noch Fragen offen bleiben. Wer
sich für solche Dinge interessiert, der sei auf Google und Wikipedia verwiesen, wo
die Problematik ausführlich diskutiert wird.
Eine Folge wie die der tn , die dadurch entsteht, dass immer mehr Terme aufsummiert
werden, trägt den Namen “Reihe”. Als Schreibweise hat sich Folgendes eingebürgert:
ist (ak )k∈N eine Folge, so entsteht die Reihe als Grenzwert der Folge der Partialsummen: setze
n
X
bn :=
ak
k=1
und definiere dann
∞
X
ak := lim
n→∞
k=1
n
X
ak = lim bn
n→∞
k=1
Dies ist natürlich nur dann definiert, wenn die Folge der (bn )n∈N auch konvergiert.
Die Folge (ak )k∈N wird auch unterliegende Folge der Reihe genannt.
Analog zu obigem Beispiel haben wir eine Reihe samt Grenzwert bereits kennengelernt:
Satz 5.6. Sei q ∈
R eine reelle Zahl mit 0 < q < 1. Dann gilt
∞
X
qk =
k=0
1
1−q
Beweis. Nach Kapitel 2 gilt
bn =
n
X
qk =
k=0
1 − q n+1
1−q
Wegen lim q n = 0 folgt die Behauptung.
n→∞
Die harmonische Reihe
Folgender Sachverhalt ist im Bezug auf Reihen und ihren unterliegenden Folgen
sofort einleuchtend:
∞
X
k=1
ak ist konvergent ⇒ lim ak = 0
k→∞
In Worten ausgedrückt: wenn eine Reihe konvergiert, dann muss ihre unterliegende
Folge eine Nullfolge sein. Denn Konvergenz der Reihe bedeutet ja, dass sich ab einem
Index n0 alles in einer ε-Umgebung eines Grenzwertes abspielt, insbesondere können
sich die Folgenglieder der Folge der Partialsummen nicht mehr viel voneinander
unterscheiden. Die Frage, die man sich nun stellen kann (und sollte) ist die Folgende:
gilt Äquivalenz, d.h. ist eine Reihe genau dann konvergent, wenn die unterliegende
Folge eine Nullfolge ist? Kann man Konvergenz von Reihen an diesem griffigen
Kriterium festmachen?
Die Antwort ist leider nein, wie folgendes Gegenbeispiel zeigt:
29
Satz 5.7. Die harmonische Reihe
∞
X
1
n
n=1
divergiert.
Beweis. Zunächst halten wir folgenden einfachen Sachverhalt fest: sind m und n
natürliche Zahlen mit m ≥ n, dann folgt m1 ≤ n1 . Betrachte nun eine natürliche Zahl
n und die zugehörige 2er Potenz 2n . Dann gilt:
n−1
n−1
2X
2X
1
1
1
2n−1
1
+
+
·
·
·
+
=
≥
=
=
2n−1 + 1 2n−1 + 2
2n
2n−1 + k
2n
2n
2
k=1
k=1
1
1
Der Sinn dieser Abschätzung liegt in folgender Beobachtung:
∞
X
1 1 1 1 1 1 1
1
= 1 + + + + + + + +···
n
2 |3 {z 4} |5 6 {z 7 8}
n=1
≥ 12
≥ 12
Die Terme zwischen zwei Kehrwerten einer 2er Potenz sind also aufsummiert immer
grösser als 21 . Damit ist die Folge der Partialsummen aber unbeschränkt und daraus
folgt die Divergenz der harmonischen Reihe.
30
6 Exkurs: Sinus und Cosinus
Gradmaß und Bogenmaß
Die trigonometrischen oder Winkelfunktionen Sinus, Cosinus und Tangens (um die
wichtigsten zu nennen) sind schon aus der Schule bekannt. Allerdings ist die Notation und der Gebrauch an der Uni etwas anders als gewohnt, weshalb hier kurz
darauf eingegangen werden soll.
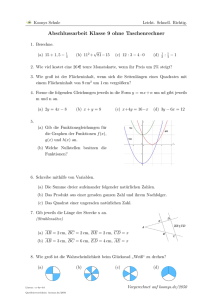
Es gibt eine ganze Reihe verschiedener Möglichkeiten, wie die Winkelfunktionen definiert werden. Im Rahmen des Vorkurses sollen sie als Funktionen am Einheitskreis
verstanden werden:
b
sin α
α
cos α
Der Vorteil hiervon ist, dass die Funktion sin und cos damit automatisch für alle
reellen Werte für α erklärt werden können, also auch für Winkel, die größer als 90◦
sind oder sogar für negative Winkel. Hierbei gilt, wie man direkt ablesen kann:
sin(−α) = − sin α
cos(−α) = cos α
Bleibt die Frage, in welcher Einheit der Winkel α angegeben werden soll. Gewöhnt
ist man hierbei das sogenannte Gradmaß, bei dem der Vollkreis in 360 Teile eingeteilt wird und die Winkel entsprechend in “Grad” angegeben werden, ein rechter
Winkel entspricht also zum Beispiel 90◦ .
Diese Art Winkel zu messen ist an der Uni allerdings unüblich. Statt dessen begegnet
einem hier in erster Linie das Bogenmaß. Bei dieser Einheit werden Winkel in der
31
Länge des Kreisbogens notiert, den sie abstecken, wobei angenommen wird, dass der
Kreis den Radius 1 hat. Dem Vollkreis entspricht also im Bogenmaß der Winkel 2π
(denn das ist genau der Umfang eines Kreises mit Radius 1) und ein rechter Winkel
wird als π2 notiert.
Das erscheint anfangs gewöhnungsbedürftig, ist aber keine große Sache, selbst der
Taschenrechner läßt sich per Knopfdruck umschalten. Und es ist ja auch nicht
schwer, zwischen den Maßen umzurechnen, der Faktor beträgt nämlich einfach
π
2π
=
360
180
π
Mit anderen Worten: ist ein Winkel im Gradmaß gegeben, so muss er nur mit 180
multipliziert werden und ist damit ins Bogenmaß umgerechnet. Umgekehrt geht es
natürlich genauso: ist ein Winkel im Bogenmaß notiert, so rechnet man ihn ins
Gradmaß um, indem man ihn mit 180
multipliziert.
π
Ein weiterer Vorteil der Definition von Sinus und Cosinus am Einheitskreis ist, dass
der Satz des Pythagoras eine wichtige Identität liefert. Für alle reellen Zahlen x gilt
nämlich:
sin2 x + cos2 x = 1
Hierbei ist mit sin2 x natürlich (sin x)2 gemeint.
Zum Schluss sei nochmal an die Additionstheoreme von Sinus und Cosinus verwiesen.
Es ist möglich (aber relativ aufwändig), diese mit geometrischen Mitteln zu beweisen.
Einfacher und eleganter sind Beweise mit Hilfe der komplexen Exponentialfunktion
oder Matrizenrechnung, auf die wir evtl. später noch eingehen.
sin(x + y) = sin x · cos y + cos x · sin y
cos(x + y) = cos x · cos y − sin x · sin y
Wer sich diese Formeln nicht ohne weiteres merken kann, der sei beruhigt: ich auch
nicht. Diese Formeln finden sich aber in jedem Nachschlagewerk.
32
7 Komplexe Zahlen
Schon in der Schule lernt man, dass das Produkt zweier negativer Zahlen positiv ist,
ebenso wie das Produkt zweier positiver Zahlen. Es folgt, dass für jede reelle Zahl
a ∈ gilt:
a2 ≥ 0
R
Das bedeutet auch, dass die Gleichung x2 + 1 = 0 keine Lösungen besitzt, oder
anders ausgedrückt: es existiert keine reelle Zahl, deren Quadrat gleich (−1) ist.
Diese Lücke schließen wir nun auf die gewohnte Art: wir führen eine neue Zahl i ein,
für die gelten soll:
i2 = −1
Diese Zahl heißt imaginäre Einheit. Den neu erschlossenen Zahlbereich nennen wir
dann Menge der komplexen Zahlen und kürzen diese mit dem Buchstaben ab:
C
C = {a + bi : a, b ∈ R}
Man kann also jede komplexe Zahl als Summe a + b · i darstellen, wobei a und b
reelle Zahlen sind. Man nennt a den Realteil und b den Imaginärteil der komplexen
Zahl z = a + ib.
Ist das Problem des Wurzelziehens denn nun vollständig gelöst? Die Wurzel aus
(−1) können wir ziehen, wie sieht es mit anderen negativen Zahlen aus? Sei dazu
a ∈ + eine beliebige positive Zahl. Dann können wir nun die Wurzel aus −a wie
folgt ziehen:
p
√
√
√
√
−a = (−1) · a = −1 · a = i · a ∈
R
C
Und wie sieht es mit unseren Verknüpfungen aus? Wenn man die üblichen Rechenregeln zugrundelegt, kann man Summe und Produkt von komplexen Zahlen ganz
einfach erklären:
(a + ib) + (c + id) = (a + c) + i · (b + d)
Und ebenso
(a + ib) · (c + id) = ac + iad + ibc + i2 bd = (ac − bd) + i · (ad + bc)
Es gibt auch die Möglichkeit, sich die komplexen Zahlen graphisch vorzustellen. Wo
die reellen Zahlen eine Zahlengerade bilden, sind die komplexen Zahlen Punkte in
einer Ebene:
33
i·
R
b+
b
|
a
a + ib
R
Man sieht: eine kanonische Anordnung ist nicht mehr gegeben, die Aussage z < z ′
für zwei komplexe Zahlen z, z ′ ergibt im Allgemeinen keinen Sinn.
Die Addition der komplexen Zahlen ist dann die gewöhnliche Vektoraddition, wie
sie in Kapitel ?? noch behandelt wird. Die Multiplikation hingegen ist ein wenig
komplizierter. Um sie besser zu verstehen, werden wir komplexe Zahlen später in
Polarkoordinaten betrachten.
i·
R
b
|z|
R
α
√
Ist z = a+ib eine komplexe Zahl, so nennt man die positive reelle Zahl |z| = a2 + b2
den Betrag von z. Konkret kann diese komplexe Zahl also geschrieben werden als
|z| · cos α + i · |z| · sin α = |z| · (cos α + i · sin α)
Für den wichtigen Ausdruck (cos α + i · sin α) hat sich die abkürzende Schreibweise
eiα eingebürgert. Die suggestive Schreibweise als Potenz macht Sinn, da folgendes
gilt:
eiα · eiβ = ei(α+β)
Wer mag, kann dies mit Hilfe der Additionstheoreme von Sinus und Cosinus nachrechnen. Diese Formeln erlauben aber jetzt die Interpretation der Multiplikation
komplexer Zahlen:
(r · eiα ) · (s · eiβ ) = (r · s) · ei(α+β)
34
In Worten: werden zwei komplexe Zahlen miteinander multipliziert, so multiplizieren
sich ihre Längen und ihre Winkel addieren sich.
√
Dies erlaubt uns, die Lösung des folgenden Problems zu erraten: was ist i? Müssen
wir hier schon wieder unsere Menge erweitern? Hört der Prozess erst auf, wenn uns
die Buchstaben ausgehen?
√
Zum Glück ist i wieder eine komplexe Zahl. Und die Formel der Multiplikation
oben verrät uns, dass sie die Länge 1 haben muss (denn i hat die Länge 1 und die
Längen multiplizieren sich ja) und einen Winkel von 45 Grad (oder π4 im Bogenmaß
ausgedrückt.) Und eine solche Zahl gibt es wirklich:
√
1+i
i= √
2
Die Probe zeigt, dass wir richtig liegen:
2
(1 + i)2
1+i
1 + 2i − 1
√
=
=
=i
2
2
2
7.1 Rechnen in
C
Um bequem mit komplexen Zahlen rechnen zu können, behandeln wir noch ein paar
Tricks. Eine wichtige Frage ist oft die Folgende: ist z = a+ ib gegeben, wie bestimme
ich dann z1 ? Oder konkreter ausgedrückt möchte man auch z1 gern in der Form c + id
schreiben, aber wie ermittelt man c und d?
Zu diesem Zweck ist es nützlich, die sogenannte komplexe Konjugation einer Zahl zu
betrachten. Dahinter verbirgt sich nichts Mysteriöses, es handelt sich lediglich um
eine Spiegelung an der reellen Achse: ist z = a + ib, so ist das komplex Konjugierte
z definiert durch
z = a + ib = a − ib
Mit anderen Worten: der Realteil bleibt erhalten, der Imaginärteil wird durch sein
Negatives ersetzt.
b+
i·
R
z = a + ib
b
a
−b +
b
35
z = a − ib
R
Auf den ersten Blick ist das nicht so spektakulär, aber die Wichtigkeit wird durch
folgende Formel deutlich:
z · z = (a + ib) · (a − ib) = a2 + b2 ∈
R+
Das Produkt einer Zahl mit ihrer komplex Konjugierten ist also reell und nichtnegativ. Wir definieren im Komplexen die Betragsfunktion folgendermaßen:
√
|z| := zz
und interpretieren diesen Wert als Abstand des Punktes z vom Ursprung.
Mit Hilfe dieses Tricks lässt sich die obige Aufgabe z1 zu finden aber leicht lösen: wir
erweitern den Bruch z1 einfach mit z:
1
a
−b
1
z
z
= =
= 2 = 2
+i 2
2
a + ib
z
z·z
|z|
a +b
a + b2
36
8 Abbildungen
8.1 Allgemeine Begriffe
Definition 8.1. Seien X, Y Mengen. Eine Abbildung f von X nach Y , schreibe
f : X → Y , ist eine Vorschrift, die jedem Element x aus X genau ein Element
in Y zuordnet. Dieses wird mit f (x) beteichnet. X heißt Definitionsmenge, Y Wertemenge.
Eine Abbildung liegt zum Beispiel vor, wenn wir jedem Studenten die Note seiner
Klausur zuordnen. Definitionsmenge sind dann die Teilnehmer an der Klausur, die
Wertemenge ist z.B. {1, 2, 3, 4, 5}. Jeder Student hat eindeutig eine Note; es kann
freilich vorkommen, dass mehrere Studenten die gleiche Note haben oder auch, dass
es eine Note gibt, die kein Student erhält. Die entscheidende Eigenschaft einer Abbildung ist also, dass jedem Element der Definitionsmenge genau ein Element aus
dem Wertebereich zugeordnet wird. Abbildungen, deren Definition in diesem Sinne
stimmig ist, nennt man übrigens wohldefiniert.
Eine Abbildung, wie sie aus der Schule typischerweise bekannt ist, ist zum Beispiel
das Quadrieren einer reellen Zahl:
f:
R → R,
f (x) := x2 .
Man muss bei einer Abbildung also immer den Definitions- und Wertebereich mit
angeben. Ist es aus dem Kontext klar, aus welchen Mengen man in welche abbildet,
so kann man die Zuordnungsvorschrift auch verkürzt schreiben:
f : x 7→ x2 .
Zu einer Teilmenge A ⊂ X des Definitionsbereichs können wir auch angeben, auf
welche Teilmenge des Wertebereichs Y ihre Elemente abgebildet werden. Man spricht
von dem Bild der Abbildung:
f (A) := {f (a) : a ∈ A}.
R
Das Bild des gesamten Definitionsbereichs in unserem Beispiel ist also f (X) = + :=
{x ∈ : x ≥ 0}.
Ähnlich wie das Bild kann man für Teilmengen B ⊆ Y das Urbild definieren:
R
f −1 (B) := {x ∈ X : f (x) ∈ B}
In Worten: das Urbild von B ist die Menge derjenigen Elemente aus X, die von f
in die Menge B abgebildet werden. Es ist klar (oder?), dass f −1 (Y ) = X gilt.
Wir rechnen einige Urbilder für unser Beispiel aus:
f −1 ({−1}) = ∅ f −1 ({4}) = {−2, 2} f −1 ([0, 9]) = [−3, 3]
37
Das Urbild kann also leer sein oder auch eine Menge mit (unendlich) vielen Elementen. Das Urbild selbst ist also keine Abbildung. Ferner sind Bild und Urbild immer
auch mengenwertig.
Abbildungen können verschiedene Eigenschaften haben. Es ist sehr nützlich, sich
mit einigen dieser Begriffe vertraut zu machen, wenngleich vielleicht nicht jedem
sofort deren praktischer Nutzen einleuchtet.
Definition 8.2. Seien X, Y Mengen. Eine Abbildung f : x → Y heißt injektiv, falls
für alle y ∈ Y gilt
|f −1 (y)| ≤ 1,
wobei für eine Menge M die Kardinalität |M| die Anzahl der Elemente in M bedeutet.
Eine injektive Abbildung ist also dadurch gekennzeichnet, dass unter ihr jeder Punkt
im Wertebereich höchstens einmal getroffen wird. Dies bedeutet, dass man aus einem
Funktionswert schon eindeutig auf das zugehörige Argument im Definitionsbereich
schließen kann. In unserem Beispiel f : IR → , f (x) = x2 liegt diese Eigenschaft
nicht vor, so hat z.B. {4} das Urbild {−2, 2}. Die Abbildung f˜ : + → , f (x) = x2
ist hingegen injektiv, wir wissen, dass das Urbild eines jeden Punktes y ∈ Y die
√
(positive) Wurzel y ist.
Unter f˜ können wir also jedem Punkt im Wertebereich höchstens einen Punkt im
Definitionsbereich zuordnen. Es gibt allerdings auch Punkte im Wertebereich, die
von f˜ gar nicht getroffen werden, nämlich alle negativen Zahlen.
R
R
R
Definition 8.3. Seine X, Y Mengen. Eine Abbildung f : X → Y heißt surjektiv, falls
gilt:
∀y ∈ Y ∃x ∈ X : f (x) = y,
d.h., jeder Punkt in Y wird auch von der Abbildung f getroffen. Äquivalent kann
man schreiben: f (X) = Y .
Eine surjektive Abbildung “füllt also ihren Wertebereich komplett aus”. Diese Eigenschaft kann sehr wichtig sein, z.B., wenn auf der Menge X eine Strukture definiert
ist, die in irgendeinem Sinne von f berücksichtigt wird. In diesem Fall “erbt” Y
dann die Struktur von X.
Die Abbildung f : → , f (x) = x2 ist offensichtlich nicht surjektiv, denn alle Argumente werden auf nichtnegative Zahlen abgebildet, die negativen Zahlen werden
nie getroffen. Betrachten wir hingegen die Abbildung f : → + , so ist diese surjektiv, jede nichtnegative Zahl wird mindestens einmal von der Abbildung getroffen.
Die beiden Eigenschaften “injektiv” und “surjektiv” charakterisieren Abbildungen
also jeweils unter dem Aspekt, wie oft Punkte aus dem Wertebereich unter der Abbildung getroffen werden, injektiv bedeutet höchstens ein Treffer, surjektiv mindestens
ein Treffer. Hat eine Abbildung beide Eigenschaften, so bedeutet dies offensichtlich,
dass jeder Punkt im Wertebereich genau einmal getroffen wird.
R R
R R
Definition 8.4. Eine Abbildung heißt bijektiv, wenn sie injektiv und surjektiv ist.
Zu einer bijektiven Abbildung f : X → Y kann man nun auch eine Abbildung
definieren, die diese rückgängig macht, die Umkehrabbildung: Sei g : Y → X mit
g(y) ∈ f −1 ({y}). Da das Urbild genau einelementig ist, ist diese Abbildung wohldefiniert. Die Umkehrabbildung bezeichnet man oft auch mit f −1 . Hier muss man
aufpassen, man kann dies leicht mit dem Urbild verwechseln.
38
R
R
R
R
√
Für die Funktion f : + → , f (x) = x2 ist g : + → + , g(x) = x die
Umkehrabbildung.
Zum Schluss des Abschnittes soll noch die Verkettung von Abbildungen definiert
werden. Seien X, Y und Z Mengen und seien Abbildungen f : X → Y und g : Y → Z
gegeben. Dann kann man die Verkettung (oder Verknüpfung) von f und g wie folgt
definieren: die verkettete Abbildung wird mit g ◦ f : X → Z bezeichnet und ist
definiert durch
(g ◦ f )(x) := g f (x)
Dies kann man sich leicht anhand des folgenden Diagramms vorstellen:
X
f
/
Y
g
7/
Z
g◦f
Zu guter Letzt noch eine spezielle Abbildung: ist X eine Menge, so gibt es stets die
Abbildung f : X → X mit f (x) = x für jedes x ∈ X. Diese Abbildung wird oft als
Identität auf X bezeichnet und mit 1IX notiert.
Mit Hilfe der Identität kann nun die Umkehrabbildung formal sauber definiert werden:
Definition 8.5. Seien X und Y Mengen und f : X → Y eine bijektive Abbildung.
Die Umkehrabbildung g : Y → X ist durch die Eigenschaften
g ◦ f = 1IX
und f ◦ g = 1IY
eindeutig bestimmt.
Mit anderen Worten: verkettet man eine bijektive Abbildung mit ihrer Umkehrabbildung, erhält man immer die Identität.
Weiter kann man auch ganz einfach eine Addition oder Multiplikation von Funktionen definieren, seien z.B. f, g : → Funktionen, so definieren wir
R R
f +g :
R → R, (f + g)(x) := f (x) + g(x)
f ·g :
R → R, (f · g)(x) := f (x)g(x).
8.2 Wichtige Beispiele
Abbildungen auf
N
Jede Folge lässt sich als Abbildung auf den natürlichen Zahlen verstehen und jede
Abbildung auf
als Folge schreiben: Sei (an )n∈N Folge von z.B. reellen Zahlen,
so per f :
→ , F (n) := an eine Abbildung definiert. Ist andersherum f eine
Abbildung auf , so ist per an = f (n) eine Folge gegeben.
Wir können eine Abbildung der natürlichen Zahlen in die ganzen Zahlen angeben,
die bijektiv ist:
n−1
, falls n ungerade
2
f : → , f (n) :=
− n2 , sonst
N
N
R
N
N Z
39
Mit einer geschickten Wahl der Folge, können wir sogar eine surjektive Abbildung
nach ∗+ := {q ∈ |q > 0} definieren. Betrachte folgendes Bild:
Q
Q
1
1
1
2
/
B
1
3
1
4
B
1
5
..
.
2
1
2
2
2
3
2
4
2
5
..
.
B
B
B
3
1
3
2
3
3
3
4
3
5
..
.
/
B
B
4
1
4
2
4
3
4
4
4
5
..
.
B
B
B
5
1
/ ···
5
2
·@ · ·
5
3
···
·@ · ·
5
4
5
5
···
..
.
..
.
Wir definieren eine Folge, indem wir links oben die 1 als a1 setzen und dann den
Pfeilen folgen. Auf diese Weise laufen wir ganz ∗+ ab.
Man kann sich nun überlegen, dass auch eine surjektive Abbildung in alle rationalen
Zahlen exisiteren muss. Somit gibt es also in gewissem Sinne überhaupt gar nicht
“mehr” rationale als natürliche Zahlen.
Eine surjektive Abbildung von den natürlichen Zahlen in die reeelen Zahlen existiert
aber nicht mehr. In diesem Sinne ist “mächtiger” als oder !
Q
R
Abbildungen auf
N
Q
R
Die denkbar einfachste Abbildung ist die konstante Abbildung: Sei c ∈
fc :
R → R, fc(x) := c.
eine oft gebrauchte Funktion ist die Indikatorabbildung IA . Sei A ⊂
1 , falls x ∈ A
IA : → , IA (x) :=
0 , falls x ∈
/A
R,
R, dann ist
R R
Die Identität ist schon bekannt, die Polynomfunktionen ergeben sich dann als Summen und Produkte der konstanten Funktionen und der Identität:
fp :
R → R,
fp (x) :=
n
X
ak xk ,
k=0
R
aj ∈ , j = 0, . . . , n.
Von gros̈ser allgemeiner Bedeutung ist die Exponentialfunktion exp,
exp :
R→R
∗
+,
exp(x) :=
∞
X
xn
n=0
40
n!
.
R
Man kan n zeigen, dass die Reihe für alle x ∈
konvergiert, somit die Funktion
wohldefiniert ist. Etwas umfangreicher ist der Beweis für die Funktionalgleichung
der Exponentialfunktion, den wir hier nicht führen wollen. Die Gleichung lautet
exp(x + y) = exp(x) exp(y) x, y ∈
R.
1
und
Wegen 1 = exp(0) = exp(x − x) = exp(x) exp(−x), ist exp(−x) = exp(x)
exp(x) > 0 für alle x ∈ . Wir definieren e := exp(1), dann folgt aus der Funktionalgleichung auch exp(n) = en für n ∈
und weiterhin exp(q) = eq für q ∈ .
Wegen der Stetigkeit (Kapitel 9) von exp können wir nun auch ex := exp(x) setzen.
Die Exponentialfunktion ist injektiv. Es reicht hierfür zu zeigen, dass nur die 0 auf
1 abgebildet wird, denn
R
N
Q
exp(x) = exp(y) ⇔ exp(x − y) = 0,
woraus dann x = y folgt. Sei nun aber exp(η) = 1 für ein η 6= 0, dann ist auch
exp(qη) = 1 für alle q ∈ und damit wegen der Stetigkeit von exp auch exp(x) = 1
für alle x ∈ . Dies ist aber nicht der Fall, offensichtlich ist exp(y > 1 für alle y > 0.
Die Exponentialfunktion ist auch surjektiv (dies zeigen wir hier nicht), als Umkehrfunktion definieren wir den Logarithmus log : ∗+ → . Dessen Funktionalgleichung
folgt direkt aus derjenigen der Exponentialfunktion:
R
Q
R
R
log(ab) = log(a) + log(b).
Ferner gilt log(ab ) = b log(a).
Für ein a ∈ ∗+ wollen wir nun noch folgende Funktion definieren f : → , x 7→
ax . Wir kennen bisher aber nur ax für rationales x. Wie definieren wir nun ax , wenn
x nicht rational ist? Wir können uns die Konstruktion der reellen Zaheln aus den
rationalen zunutze machen, wir wählen eine Folge von rationalen Zahlen xn mit
xn → x und definieren
ax := lim axn .
R
R R
n→∞
Dies ist aber nur wohldefiniert, wenn es nicht darauf ankommt, welche Folge, die
x approximiert, man konkret gewählt hat. Dies wollen wir hier nicht zeigen. Der
typische Umweg, den man zur Definition der allgemeinen Potenz geht, geht ohnehin
über die Exponentialfunktion und den Logarithmus:
ax := exp(ln(a)x)
41
9 Stetigkeit
Betrachten wir zunächst folgende Abbildungen:
f:
g:
R→R
R→R
gegeben durch f (x) =
gegeben durch g(x) =
−2 , falls x < 1
−1 , falls x ≥ 1
−x + 3 , falls x < 2
x−1
, falls x ≥ 2
Beide Graphen sind in folgendem Koordinatensystem dargestellt.
g
b
f
Auffällig ist, dass zwar beide Funktionen “stückweise” definiert sind, aber der Graph
von g eher “zusammenhängt”, d.h. in einem Stück gezeichnet werden kann, während
man beim Graphen von f eine Art Sprungstelle hat. Die Funktion f ist also unstetig
am Punkt 1, wohingegen g überall stetig ist. Formal definiert man den Begriff der
Stetigkeit folgendermaßen:
Kriterium I: Folgenstetigkeit Sei D ⊂ . Eine Funktion f : D →
heißt
stetig in a ∈ D, falls für jede Folgen (an )n∈N , die gegen a konvergiert, die Folge der
Funktionswerte gegen f (a) konvergiert, d.h. falls
R
R
∀(an )n∈N mit lim an = a : lim f (an ) = f (a).
n→∞
n→∞
Falls f in allen Punkten in D stetig ist, so nennt man f eine stetige Funktion.
In unserem Beispiel sehen wir also, dass die Funktion f im Punkt a = 1 nicht stetig
ist: Definieren wir nämlich die Folgen
an := 1 +
1
n
bn := 1 −
42
1
,
n
so ist
lim an = 1 = lim bn
n→∞
n→∞
aber f (an ) = −1 und f (bn = −2 für alle n ∈
ist f hingegen offensichtlich stetig.
R
R
R → R stetige Funktionen und α ∈ R eine
→
und g :
Satz 9.1. Seien f :
beliebige Zahl. Definiere dann
R R
R R
R R
(f + g) : →
(f · g) : →
(g ◦ f ) : →
N. In allen anderen Punkten hingegen
gegeben durch (f + g)(x) = f (x) + g(x)
gegeben durch (f · g)(x) = f (x) · g(x)
gegeben durch (g ◦ f )(x) = g(f (x)).
Diese Funktionen sind dann alle stetig.
Der Beweis bleibt als Übung. Beispiele
R → R, 1IR(x) = x ist stetig auf R.
f : R∗ → R, f (x) := x1 ist stetig. Denn: Sei a ∈ R∗ beliebig und (an )n∈N eine
Folge in R∗ , die gegen a konvergiert. Da |an − a| nach Voraussetzung beliebig
klein wird und wegen |a| > 0, gibt es ein n1 ∈ N mit
1. Die Identität 1IR :
2.
|an − a| ≤
|a|
2
für alle n ≥ n1 .
Verwende nun die umgekehrte Dreiecksungleichung:
|a| − |an | ≤ |an − a| ≤
|a|
|a|
⇒ |an | ≥
2
2
für alle n ≥ n1 .
Zu zeigen ist nun die Konvergenz der Folge f (an ) n∈N gegen den Wert f (a).
Sei ε > 0 beliebig. Es gilt:
1
|an − a|
1
2
|f (an ) − f (a)| = − =
≤ 2 · |an − a|.
an a
|an | · |a|
|a|
Diese Ungleichung gilt wiederum für alle n ≥ n1 . Nun verwenden wir erneut,
dass |an − a| beliebig klein wird, insbesondere gibt es ein n2 ∈ mit
N
|an − a| <
|a|2 · ε
2
für alle n ≥ n2 .
Sei nun n0 := max{n1 , n2 }. Dann folgt für alle n ≥ n0 nach der Ungleichung
oben:
2
2 |a|2 · ε
|f (an ) − f (a)| ≤ 2 · |an − a| ≤ 2 ·
= ε.
|a|
|a|
2
3. Polynomfunktionen sind auf
9.1.
R stetig. Dies folgt aus Beispiel (i) und dem Satz
43
4. Die Exponentialfunktion ist stetig. Wir zeigen aber nur, dass die Stetigkeit der
Funktion aus der Stetigkeit in 0 folgt. Um die Stetigkeit in 0 zu zeigen, muss
man die Exponentialreihe genauer betrachten. Sei xn → x. Dann ist
exp(xn ) = exp(x − x + xn ) = exp(x) exp(xn − x).
Kriterium II: ε − δ
Sei D ⊆ , f : D →
eine Abbildung und a ∈ D. Die Abbildung f heißt stetig
an der Stelle a, falls es für jedes ε > 0 ein δ > 0 gibt, so dass für alle x ∈ D mit
|x − a| < δ gilt: |f (x) − f (a)| < ε.
R
R
Satz 9.2. Die beiden Definitionen der Stetigkeit sind äquivalent.
Beweis. Nimm zunächst an, dass f stetig nach Kriterium II in a ist und sei (xn )n∈N
eine beliebige Folge in D mit lim xn = a. Zu zeigen ist:
n→∞
lim f (xn ) = f (a).
n→∞
Sei dazu ε > 0 beliebig. Wegen der Stetigkeit von f gibt es ein δ > 0, so dass für
alle x ∈ D mit |x − a| < δ gilt: f (x) − f (a)| < ε.
N
Da die Folge (xn )n∈N gegen a konvergiert, gibt es zu obigem δ > 0 ein n0 ∈ , so
dass für alle n ≥ n0 gilt: |xn − a| < δ. Damit aber folgt wiederum für alle n ≥ n0 :
|f (xn ) − f (a)| < ε.
Also konvergiert die Folge f (xn ) n∈N gegen f (a).
Sei nun umgekehrt das Folgenkriterium erfüllt, d.h. es gelte
lim f (x) = f (a).
x→a
Zu zeigen ist, dass f im Punkt a das Kriterium II erfüllt. Wir führen einen Beweis
durch Widerspruch: angenommen, f wäre nicht stetig im Punkt a. Dann würde es
ein ε > 0 geben, so dass es für alle δ > 0 einen Punkt x ∈ D mit |x − a| < δ gibt,
aber trotzdem |f (x) − f (a)| ≥ ε gilt.
N
Wähle zu n ∈
das δn := n1 und nenne das gefundene x einfach xn . Dann ergibt
sich eine Folge (xn )n∈N aus D mit folgenden Eigenschaften:
|xn − a| <
1
n
|f (xn ) − f (a)| ≥ ε.
und
Die erste Eigenschaft impliziert lim xn = a, aber die zweite zeigt lim f (xn ) 6= f (a).
n→∞
n→∞
Dies ist ein Widerspruch zur Annahme.
Wir zeigen
√ nun die Stetigkeit der Wurzelfunktion f :
f (x) = x mit dem Kriterium II.
44
R+
→
R+
gegeben durch
Beweis. Zeige zunächst Stetigkeit im Punkt a = 0. Sei ε > 0 beliebig und wähle
δ := ε2 . Dann ist δ > 0 und für x ∈ + mit |x − a| = |x| = x < δ gilt:
√
√
√
√
√
| x − 0| = x < δ = ε2 = ε
R
Also ist f stetig im Punkt a = 0.
√
Sei nun a > 0 beliebig, ebenso wie ε > 0. Wähle nun δ := ε a. Dann ist δ > 0. Sei
nun x ∈ + mit |x − a| < δ. Es folgt
√
x − a |x − a|
√
√
δ
ε a
√ ≤ √
|f (x) − f (a)| = | x − a| = √
< √ = √ = ε.
x + a
a
a
a
R
Also ist f stetig im Punkt a und da a > 0 beliebig war, ist f damit stetig auf ganz
+.
R
45
10 Differenzierbarkeit
Wir betrachten zunächst lineare Funktionen, also Funktionen der Form
f:
R→R
f (x) = ax + b mit a, b ∈
gegeben durch
R.
Diese sind durch die Parameter a (Steigung) und b (y-Achsenabschnitt) eindeutig
bestimmt. Ist eine lineare Funktion f gegeben, so gilt natürlich b = f (0). Die Steigung a kann ermittelt werden, indem zwei beliebige Punkte x0 , x1 ∈ mit x0 6= x1
gewählt werden. Dann gilt nämlich
R
f (x1 ) − f (x0 ) = ax1 + b − ax0 − b = a(x1 − x0 )
⇔
a=
f (x1 ) − f (x0 )
.
x1 − x0
Der Ausdruck rechts heißt auch Differenzenquotient. Seine geometrische Bedeutung liegt in der Interpretation als Steigungsdreieck:
b
f (x1 ) − f (x0 )
b
x1 − x0
x0
x1
Dieser Wert des Differenzenquotienten ist bei linearen Funktionen unabhängig von
der Wahl der Punkte x0 und x1 . Anders sieht es aus, wenn wir denselben Ausdruck
für beliebige Funktionen f :
→
betrachten (nur der Einfachheit halber, denn
mit D ⊆
zugelassen). Ein Bild soll
natürlich sind auch Funktionen f : D →
das verdeutlichen:
R
R
R
R
b
b
b
x0
x1
x2
R R
Der hier abgebildete Graph gehört zur Funktion f : → gegeben durch f (x) =
x2
− x + 74 mit x0 = 1, x1 = 3 und x2 = 5. Die verschiedenen Differenzenquotienten
4
46
entsprechen den Steigungen der Sekanten durch die entsprechenden Punkte:
f (x1 ) − f (x0 )
=
x1 − x0
9
4
Und ebenso ergibt sich
f (x2 ) − f (x0 )
=
x2 − x0
25
4
− 3 + 74 − 14 + 1 −
3−1
−5+
7
4
− 41 + 1 −
5−1
7
4
7
4
=
0
=0
2
=
2
1
=
4
2
In diesem Fall ist der Differenzenquotient also nicht unabhängig von der Wahl der
Punkte. Trotzdem ist es in vielen Fällen hilfreich, die Funktion f linear zu approxi-
mieren, d.h. anzunähern. Gesucht ist also eine Gerade, die sich im Punkt x0 , f (x0 )
möglichst gut an f “anschmiegt”, man sucht also die Tangente.
Anschaulich gesprochen kann man die Steigung der Tangente (im Bild gestrichelt
markiert) bestimmen, indem man Sekantensteigungen betrachtet und den zweiten
Punkt gegen x0 gehen lässt.
Man betrachtet also folgenden Grenzwert:
f (x) − f (x0 )
.
x→x0
x − x0
lim
Falls dieser existiert (wiederum: für alle Folgen (xn )n∈N , die gegen x0 konvergieren
muss der Grenzwert existieren und alle diese Folgen müssen den gleichen Grenzwert
liefern), so wird er als Steigung der Tangente oder auch Ableitung im Punkt x0
bezeichnet. Die Schreibweise dafür ist f ′ (x0 ) und die Funktion f heißt dann im
Punkt x0 differenzierbar. Wie bei Stetigkeit auch nennt man eine Funktion schlicht
differenzierbar, wenn sie in jedem ihrer Punkte differenzierbar ist.
Für das obige Rechenbeispiel ergibt sich:
f (x) − f (x0 )
=
x − x0
Also gilt
x2
4
− x + 47 − 14 + 1 −
x−1
7
4
f (x) − f (x0 )
f (x0 ) = lim
= lim
x→x0
x→1
x − x0
′
=
1 x2 − 1 x − 1
x+1
·
−
=
− 1.
4 x−1
x−1
4
x+1
−1
4
R
R
=
2
1
−1=− .
4
2
Die Tangente ist also eine lineare Funktion t : → , die den Graphen von f im
Punkt x0 , f (x0 ) berührt (d.h. es gilt t(x0 ) = f (x0 )) und die Steigung von t ist so
gewählt, dass die Funktion f gut approximiert wird. Was das heißt zeigt folgende
Überlegung:
Angenommen f :
R → R ist im Punkt x0 differenzierbar mit Ableitung
f (x) − f (x0 )
.
x→x0
x − x0
f ′ (x0 ) = lim
Diesen Grenzwertprozess kann man folgendermaßen umschreiben: für x 6= x0 setze
ϕ(x) :=
f (x) − f (x0 )
− f ′ (x0 ).
x − x0
47
R
R
Dann ist ϕ : \{x0 } →
eine Funktion (in gewisser Weise der “Fehler” der gemacht wird, wenn man die Ableitung über einen Differenzenquotienten, also eine
Sekantensteigung annähert) mit der Eigenschaft:
lim ϕ(x) = 0.
x→x0
Dies sagt nämlich gerade, dass dieser Fehler verschwindet, wenn x gegen x0 läuft.
Was ist nun die Gleichung der Tangente t : → im Punkt x0 ? Die Tangente ist
eine lineare Funktion mit Steigung f ′ (x0 ), d.h. sie hat die Form
R R
t(x) = f ′ (x0 ) · x + b für einen y-Achsenabschnitt b.
Wegen t(x0 ) = f (x0 ) kann man das b berechnen:
Es folgt:
f (x0 ) = f ′ (x0 ) · x0 + b
⇔
b = f (x0 ) − f ′ (x0 ) · x0 .
t(x) = f ′ (x0 ) · x + f (x0 ) − f ′ (x0 ) · x0 = f (x0 ) + f ′ (x0 ) · (x − x0 ).
Betrachte nun erneut die Definition von ϕ und multipliziere diese mit dem Nenner
(x − x0 ), dann ergibt sich:
f (x) − f (x0 )
−f ′ (x0 ) ⇔ (x−x0 )·ϕ(x) = f (x)−f (x0 )−f ′ (x0 )·(x−x0 ).
x − x0
Löst man diese Gleichung nach f (x) auf, so ergibt sich:
ϕ(x) =
f (x) = f (x0 ) + f ′ (x0 ) · (x − x0 ) + (x − x0 ) · ϕ(x) = t(x) + ψ(x)
{z
} |
{z
}
|
=t(x)
=:ψ(x)
Die neu eingeführte Funktion ψ bestimmt also die Abweichung zwischen der Funktion f und ihrer Tangente t. Wegen ψ(x) = (x − x0 ) · ϕ(x) gilt:
ψ(x)
= lim ϕ(x) = 0.
x→x0 x − x0
x→x0
Der Fehler ψ(x) geht also nicht einfach gegen 0, wenn das x gegen x0 läuft, sondern
sogar dann noch, wenn erschwerend durch (x − x0 ) dividiert wird. Man sagt, ψ geht
schneller als linear gegen 0.
lim
R
R
und f : D →
eine Funktion, die im Punkt x0 ∈ D
Satz 10.1. Sei D ⊆
differenzierbar ist. Dann ist f stetig in x0 .
R R
Beweis. Die Tangente t : → an den Punkt x0 ist linear, also ein Polynom und
daher stetig. Daher gilt nach obiger Beschreibung
lim f (x) = lim t(x) + ψ(x) = t(x0 ) = f (x0 ).
x→x0
x→x0
Daher ist f stetig nach dem Folgenkriterium.
Vorsicht! Die Umkehrung dieses Satzes gilt im Allgemeinen nicht, es gibt Funktionen, die zwar stetig an einem Punkt a sind, dort aber nicht differenzierbar.
Noch eine Bemerkung: manchmal nennt man den Term x−x0 einfach h, man definiert
also h := x − x0 . Dann sieht der Differenzenquotient etwas anders aus, beschreibt
aber genau den gleichen Sachverhalt, es ist nämlich
f (x0 + h) − f (x0 )
f (x) − f (x0 )
= lim
.
x→x0
h→0
x − x0
h
f ′ (x0 ) = lim
48
10.0.1 Rechenregeln für Ableitungen
Schon Übung 62 zeigt, wie mühsam es manchmal ist, Ableitungen direkt mit dem
Differenzenquotienten zu bestimmen. Zum Glück gibt es einige Rechenregeln, die
einem das Leben erleichtern. Diese wiederum werden natürlich mit Hilfe des Differenzenquotienten bewiesen.
R R
R R differenzierbare Funktionen und α ∈ R
Satz 10.2. Seien f : → und g : →
beliebig. Es gelten die folgenden Regeln:
(f + g)′ = f ′ + g ′ (Summenregel)
(α · f )′ = α · f ′ (Faktorrregel).
BeweisÜbung 63.
Nicht ganz so elementar ist die folgende Regel:
R
R
→
und g :
Satz 10.3 (Produktregel). Seien f :
Funktionen. Dann gilt:
(f · g)′ = f ′ · g + f · g ′
R
→
R differenzierbare
R
Beweis. Sei x0 ∈
beliebig und betrachte die Ableitung von (f · g) an der Stelle
x0 . Für den Differenzenquotienten gilt:
f (x) · g(x) − f (x0 ) · g(x0 )
(f · g)(x) − (f · g)(x0 )
=
x − x0
x − x0
f (x) · g(x) − f (x0 ) · g(x) + f (x0 ) · g(x) − f (x0 ) · g(x0 )
=
x − x0
f (x) − f (x0 )
g(x) − g(x0 )
=
· g(x) + f (x0 ) ·
x − x0
x − x0
Bildet man vom letzten Ausdruck den Grenzwert für x gegen x0 , so ergibt sich
f ′ (x0 ) · g(x0 ) + f (x0 ) · g ′ (x0 ), da f und g nach Voraussetzung in x0 differenzierbar
sind und weil g nach Satz 10.1 stetig in x0 ist.
Eine weitere wichtige Regel zur Bestimmung von Ableitungen ist die Quotientenregel. Folgendes Lemma hilft beim Beweis:
Lemma 10.4. Sei f :
R → R differenzierbar und betrachte die Menge
D := {x ∈ R : f (x) 6= 0} ⊆ R.
Falls D 6= ∅ kann man den Kehrwert von f definieren durch
1
1
1
(x) =
:D→
f
f
f (x)
R
Dann gilt
′
1
f′
=− 2
f
f
49
Beweis. Sei x0 ∈ D. Betrachte den Differenzenquotienten:
1
f (x)
−
1
f (x0 )
f (x0 )
f (x)·f (x0 )
−
f (x)
f (x)·f (x0 )
=
x − x0
x − x0
f (x) − f (x0 )
1
f (x0 ) − f (x)
=−
·
=
f (x) · f (x0 ) · (x − x0 )
x − x0
f (x) · f (x0 )
Bildet man nun den Grenzwert für x gegen x0 ergibt sich das Gewünschte, da f nach
Voraussetzung in x0 differenzierbar und damit nach Satz 10.1 auch stetig ist.
R R
R R
Satz 10.5 (Quotientenregel). Seien f : → und g : → differenzierbar und
betrachte wieder D = {x ∈ : g(x) 6= 0}. Dann ist die Funktion
f
f (x)
f
(x) =
:D→
g
g
g(x)
R
R
differenzierbar und es gilt
′
f
f ′ · g − f · g′
=
g
g2
Beweis. Das folgt direkt nach Lemma 10.4 und der Produktregel:
′
′
′ g
f ′ · g f · g′
f ′ · g − f · g′
1
f
′ 1
= f·
=f · +f · − 2 = 2 − 2 =
g
g
g
g
g
g
g2
Jetzt haben wir fast alle wichtigen Regeln, beisammen, es fehlt allerdings noch die
Regel zur Ableitung von verketteten Abbildungen, die (wie üblich) mit Hilfe des
Differenzenquotienten bewiesen werden kann.
Satz 10.6 (Kettenregel). Seien f :
auch (f ◦ g) und es gilt:
R → R und g : R → R differenzierbar, dann
(f ◦ g)′ (x0 ) = g ′(x0 ) · f ′ g(x0 )
Beweis. Es gilt
f g(x) − f g(x0 )
g(x) − g(x0 ) f g(x) − f g(x0 )
=
·
x − x0
x − x0
g(x) − g(x0 )
Bildet man wieder den Grenzwert, so geht der erste Faktor gegen g ′(x0 ) und für den
zweiten Faktor gilt, dass wegen der Stetigkeit von g in x0 (erneut Satz 10.1) folgt:
falls x gegen x0 geht, dann geht g(x) gegen g(x0 ). Daher geht der zweite Faktor
gegen f ′ g(x0 ) .
An dieser Stelle noch eine kurze Bemerkung zur Kettenregel: sind f :
g : → zwei lineare Funktionen, also
R R
f (x) = ax + b
und
50
g(x) = cx + d,
R → R und
dann gilt für ihre Verkettung:
(f ◦ g)(x) = a · g(x) + b = a · (cx + d) + b = (ac) · x + ad + b.
Man sieht sofort, dass (f ◦g) wieder linear ist und die Steigung ist gerade das Produkt
der Steigungen von f und g. Für allgemeine Funktionen gilt dies ebenso: approximiert man mit der Tangenten an einen Punkt und setzt die Funktionen ineinander
ein, so ergibt sich für die Verkettung als Tangente gerade die Verkettung der Tangenten und daher ist die Ableitung der Verkettung das Produkt der Ableitungen an
den entsprechenden Punkten.
Zum Abschluss betrachten wir die Ableitung der Umkehrfunktion. Angenommen
f : → ist differenzierbar und bijektiv, so dass die Umkehrabbildung f −1 auch
differenzierbar ist. Dann gilt folgende Regel für die Ableitung der Umkehrabbildung:
R
R
(f −1 )′ =
(f ′
1
◦ f −1 )
Beweis. Nach Definition der Umkehrabbildung gilt (f ◦ f −1 ) = idR , also folgt nach
der Kettenregel, wenn auf beiden Seiten die Ableitung gebildet wird für alle x0 ∈ :
R
(f −1 )′ (x0 ) · f ′ f −1 (x0 ) = 1
⇔
(f −1 )′ (x0 ) =
1
(f ′
R
◦ f −1 )(x0 )
R
Als Anwendung betrachte die Exponentialfunktion exp :
→ ∗+ gegeben durch
x
exp(x) = e . Diese ist dadurch gekennzeichnet, dass gilt exp′ = exp, was hier
nicht bewiesen werden soll. Ihre Umkehrabbildung ist der (natürliche) Logarithmus log : ∗+ → .
R
R
Eine Anmerkung zur Notation: manchmal ist auch die Schreibweise ln (Logarithmus
naturalis) für den natürlichen Logarithmus in Gebrauch, allerdings ist in mathematischen Vorlesungen meistens genau dieser gemeint, wenn log an der Tafel steht und
nicht etwa wie aus der Schule gewohnt der Logarithmus zur Basis 10.
Mit obiger Regel fällt es nun leicht, die Ableitung des Logarithmus zu bestimmen:
(log)′ (x0 ) =
exp′
1
1
1
=
=
x0
log(x0 )
exp log(x0 )
Die Ableitung des Logarithmus ist also die Funktion, die jedem positiven Wert x
seinen Kehrwert x1 zuordnet.
51
11 Gleichungen und
Gleichungssysteme
In diesem Kapitel beschäftigen wir uns mit Gleichungen. Wir verstehen darunter
einen mathematischen Ausdruck, in dem eine Unbekannte vorkommt (wir werden
diese meist mit x bezeichnen), deren mögliche Werte durch diesen Ausdruck bestimmt werden. Diese nennen wir Lösungen. Wir sind daran interssiert, ob es Lösungen gibt, wieviele und welche Werte diese annehmen. Wir wenden uns zunächst der
einfachsten Klasse von Gleichungen zu, den linearen Gleichungen.
11.1 Lineare Gleichungen
Eine lineare Gleichung ist zum Beispiel
5x = 10.
Die Lösung ist offensichtlich x = 2. Wir wollen uns gleich den allgemeinen Fall
anschauen. Gegeben seine zwei reelle Zahlen a, b. Wir betrachten die Gleichung
ax = b.
Die Gleichung heis̈st linear, weil die Unbekannte x nur mit dem Koeffizienten a
multipliziert wird. Gleichungen wie
5x2 = 14,
ex = 1
sind also nichtlinear. Wir sind nun an den Lösungen von unserer linearen Gleichung
interessiert. Hier müssen wir verschiedene Fälle betrachten:
Fall 1: a 6= 0. Dann ist x =
b
a
die einzige Lösung.
Fall 2: a = 0. Hier braucht man eine weitere Fallunterscheidung:
Fall 2a: b 6= 0. Dann gibt es keine Lösung, denn die Gleichung 0 · x = b
ist für kein x ∈ erfüllt.
Fall 2b: b = 0. In diesem Fall ist jedes x ∈ eine Lösung, denn 0 · x = 0
ist für alle x ∈ erfüllt.
R
R
R
Wir haben also drei verschiedene Fälle, die Unbekannte kann durch die Gleichung
eindeutig bestimmt sein, es kann der Fall auftreten, dass gar keine Lösung existiert
oder viele (sogar unendlich viele) Werte sind als Lösung möglich.
52
Wir verallgemeinern nun den Spezialfall von einer Gleichung mit nur einer Unbekannten auf den Fall von m Gleichungen mit n Unbekannten.
a1,1 x1 + a1,2 x2 + · · · + a1,n xn = b1
a2,1 x1 + a2,2 x2 + · · · + a2,n xn = b2
..
.
am,1 x1 + am,2 x2 + · · · + am,n xn = bm
R
R
Hierbei gilt wieder ai,j ∈ und bi ∈ und gesucht sind alle Werte für x1 , . . . , xn ,
die alle Gleichungen simultan erfüllen.
Um sich Notationsarbeit zu sparen, schreibt man auch oft nur die Koeffizienten in
eine Tabelle und nennt dieses Konstrukt dann Matrix. Allgemein sieht das dann
so aus:
a1,1 a1,2 · · · a1,n b1
a2,1 a2,2 · · · a2,n b2
..
..
.
.
.
.
.
am,1 am,2 · · · am,n bm
Diese Matrix heißt auch erweiterte Koeffizientenmatrix. Erweitert deshalb, weil
die Spalte mit den bi aufgenommen wurde, kommt diese nicht vor, spricht man
schlicht von der Koeffizientenmatrix.
Es handelt sich hierbei lediglich um eine geschickte Art der Notation, die überflüssige
Schreibarbeit ersparen soll. Um ein Gleichungssystem aber lösen zu können, muss
man mit den Gleichungen, also den Matrizen rechnen können. Zu diesem Zweck
betrachtet man sogenannte elementare Zeilenumformungen, die in vier Typen
daher kommen.
Typ 1: Multiplikation einer Zeile der Matrix mit einer reellen Zahl λ 6= 0. Diese
Operation entspricht der Multiplikation der entsprechenden Gleichung mit λ
und führt zu einer äquivalenten Gleichung.
Typ 2: Addition einer Zeile zu einer anderen. Diese Operation entspricht der
Addition der Gleichungen.
Typ 3: Addition des λ-fachen einer Zeile zu einer anderen. Dies ist keine wirklich neue Zeilenoperation, sondern schlicht eine Kombination der ersten beiden
Typen.
Typ 4: Vertauschung zweier Zeilen. Dies entspricht lediglich einer Vertauschung
zweier Gleichungen.
Wie man sofort sieht, ändern diese Operationen zwar die Matrix, nicht aber die
Lösungsmenge des Gleichungssystems. Die Frage ist jetzt, ob es eine Möglichkeit
gibt, mit Hilfe der Zeilenumformungen die Matrix in eine Gestalt zu bringen, die es
direkt erlaubt, die Lösungen zu bestimmen. Es gibt verschiedene Varianten dies zu
tun und eine davon ist der sogenannte Gauß-Algorithmus.
53
11.1.1 Der Gauß-Algorithmus
Gegeben sei ein Gleichungssystem mit m Gleichungen und n Variablen und die erweiterte Koeffizientenmatrix wie oben. Der Algorithmus funktioniert folgendermaßen.
Schritt 1: Suche die erste Spalte mit einem von 0 verschiedenen Eintrag. Sollte
es keine geben, ist der Algorithmus am Ende, die erweiterte Koeffizientenmatrix ist dann die sogenannte Nullmatrix, in der alle Einträge gleich 0 sind.
Angenommen die erste Spalte mit einem von 0 verschiedenen Eintrag ist die
Spalte j.
Schritt 2: Falls a1,j = 0 führe eine Vertauschung von Zeilen (Typ 4) durch, so
dass a1,j 6= 0.
Schritt 3: Führe wiederholt Zeilenumformungen vom Typ 3 durch, um alle
ai,j
Einträge ai,j mit i ≥ 2 zu 0 zu machen, indem zur Zeile i das − a1,j
-fache von
Zeile 1 addiert wird.
Schritt 4: Wende den Algorithmus auf die Untermatrix an, die aus der erweiterten Koeffizientenmatrix entsteht, indem die erste Zeile und die ersten j
Spalten fortgelassen werden.
Am Ende des Algorithmus hat die Matrix eine spezielle Gestalt, die Zeilenstufenform genannt wird. Schreibt man diese wieder in Gleichungen um, so sieht man,
dass sich die Zahl der Unbekannten von Gleichung zu Gleichung jedes Mal um mindestens eine reduziert. Hier ein Beispiel einer Matrix in Zeilenstufenform:
0 0 4 1 0 −5 9
0 0 0 0 −2 0 −10
0 0 0 0 0 14
2
0 0 0 0 0
0
0
0 0 0 0 0
0
0
Die fettgedruckten Elemente sind jeweils die Stufen des Systems und heißen auch
Pivot-Elemente der Matrix. Sie sind per Definition von 0 verschieden.
Anhand der Zeilenstufenform ist es nun nicht schwer, das System zu lösen:
Falls die letzte Spalte ein Pivot-Element b enthält, ist das System nicht lösbar, denn
die entstehende Gleichung lautet
0 · x1 + 0 · x2 + · · · + 0 · xn = b
Wegen b 6= 0 ist diese Gleichung nie erfüllt.
Enthält die letzte Spalte kein Pivot-Element, so ist das System lösbar. Jede Variable, die zu einer Spalte mit Pivot-Element gehört heißt gebundene Variable,
die anderen heißen freie Variablen. Letztere können wie der Name schon sagt frei
gewählt werden. Es gilt: Ein lösbares System hat genau dann unendlich viele Lösungen, wenn freie Variablen existieren, ansonsten ist die Lösung eindeutig bestimmt.
Die Ermittlung der Lösung geschieht mittels “rückwärts einsetzen”: Betrachte die
54
unterste Zeile, die keine Nullzeile ist (sagen wir Zeile i). Nimm an, dass die Spalte
j das Pivot-Element enthält, dann ergibt sich die Gleichung
ai,j xj + ai,j+1 xj+1 + · · · + ai,n xn = bi
mit ai,j 6= 0
Werden nun xj+1 bis xn beliebig gewählt (als freie Variablen), so ist xj dadurch
eindeutig bestimmt:
bi − ai,j+1 xj+1 − · · · − ai,n xn
xj =
ai,j
Auf diese Weise erhält man alle Lösungen des Gleichungssystems.
11.2 Gleichungen höheren Grades
Wir betrachten die Gleichung
x2 + px + q = 0.
Diese Gleichung nennt man quadratisch oder Gleichung zweiten Grades, da die Unbekannte x nur quadratisch und linear vorkommt. Zu ihrer Lösung bedient man sich
eines kleinen Tricks, man addiert auf beiden Seiten einen Term hinzu, so dass die
linke Seite mittels binomischer Formel vereinfacht werden kann:
p 2
p 2
x2 + px +
+q =
2
2
2
2
p
p
x+
−q
=
2
4
r
p2
p − q.
x + =
2
4
q
2
Auflösen des Betrags ergibt dann die Lösungen x = 2p ± p4 − q. Für den Fall,
dass das Argument der Wurzel positiv ist, haben wir zwei reelle Lösungen, ist das
Argument Null, liegt eine Lösung vor, ist das Argument negativ, existieren keine
reellen Lösungen, wohl aber komplexwertige (in diesem Fall ist die eine Lösung die
komplex konjugierte der anderen).
Allgemeine Lösungsformeln (die man sich aber nicht unbedingt zu merken braucht,
und die man nicht mehr ganz so einfach herleiten kann) gibt es auch fr̈ Gleichungen
dritten und vierten Grades. Die Lösungen von Gleichungen vom fünften Grad an
lassen sich nicht mehr auf eine allgemeine Weise lösen. Dies liegt nicht daran, dass die
Mathematiker bislang unfḧig gewesen wären, einen Lösungsweg zu finden, sondern
hat fundamentale Gründe.
Allgemein gilt aber folgendes: der Ausdruck xn + an−1 xn−1 + · · · + a1 x + a0 lässt sich
eindeutig als folgender Term schreiben:
n
n−1
x + an−1 x
n
Y
+ · · · + a1 x + a0 =
(x − αj ),
j=1
wobei die αj nicht alle verschieden sein müsssen und eventuell komplex sind. Sie
sind die Lösungen der Gleichung
xn + an−1 xn−1 + · · · + a1 x + a0 = 0.
55
Eine Gleichung vom Grad n hat also höchstens n verschiedene Lösungen. Die Faktoren (x − αj nennt man Linearfaktoren.
Ausdrücke der Form xn +an−1 xn−1 +· · ·+a1 x+a0 nennt man Polynome. Oftmals kann
man Gleichungen höheren Grades vereinfachen, wenn man schon einzelne Lösungen
kennt. Dies funktioniert mit Hilfe der Polynomdivision. Man stelle sich das so vor:
n
Q
das Polynom xn + an−1 xn−1 + · · · + a1 x + a0 entspricht dem Produkt
(x − αj ).
j=1
Kennt man schon einen Faktor aus diesem Produkt, so kann man ihn “herausteilen”
und erhält ein einfacheres Polynom (dieses hat dann eine um 1 niedrigere höchste
Potenz. Dann kann man versuchen, die weiteren Lösungen aus diesem einfacheren
Polynom abzulesen. Wir wollen das an einem Beispiel veranschaulichen. Wir sind
an der Lösung der Gleichung
x3 − 7x + 6 = 0
interessiert. Wir sehen schnell, dass 1 eine Lösung der Gleichung ist. Folglich können
wir x − 1 aus dem Polynom herausteilen:
x3
− 7x + 6 : x − 1 = x2 + x − 6
− x3 + x2
x2 − 7x
− x2 + x
− 6x + 6
6x − 6
0
Die weiteren Lösungen können wir nun mit Hilfe der allgemeinen Formel (oder einfach auch per Hingucken) ermitteln.
11.3 Beispiel: Partialbruchzerlegung
Wir betrachten folgenden Term:
6x2 − x + 1
.
x3 − x
Das Polynom im Nenner hat die Nullstellen 0, 1 und −1. Oftmals kann es nützlich
sein, den obigen Term als Summe von Brüchen zu schreiben, deren Nenner die
Linearfaktoren x, (x − 1) und (x + 1) sind. Wir machen folgenden Ansatz
A
B
C
6x2 − x + 1
=
+
+
x3 − x
x x−1 x+1
und müssen nun die Unbekannten A, B und C bestimmen. Diese müssen so gewählt
werden, dass die Gleichheit gilt. Wir bringen die drei Brüche wieder auf einen gemeinsamen Nenner und vergleichen ihn mit dem Ausgangsterm:
A(x2 − 1) + Bx(x + 1) + Cx(x − 1)
6x2 − x + 1
=
.
x3 − x
x3 − x
56
Die Koeffizienten von x2 , x und der konstante Term müssen auf der linken und
rechten Seite übereinstimmen. Wir erhalten die Gleichungen
A + B + C =6
B−C =−1
−A
=1.
Dies ist ein lineares Gleichungssystem!
In dem ersten Beispiel gab es nur einfache Nullstellen. Kommen Nullstellen mehrfach
vor, muss man einen etwas anderen Ansatz wählen:
x+1
A
B1
B2
B2
= +
+
+
.
3
2
x(x − 1)
x
x − 1 (x − 1)
(x − 1)3
Die Methode funktioniert ansonsten wie oben, man bringt die linke Seite wieder auf
einen gemeinsamen Nenner und vergleicht die Koeffizienten.
In diesen Beispielen hatte das Polynom im Nenner nur reelle Nullstellen. Treten
auch nichtreelle Nullstellen auf, ist ein etwas anderer Ansatz zu wählen. Darauf soll
hier aber nicht eingegangen werden.
57
12 Matrizenkalkül
Addition und Multiplikation von Matrizen
Nachdem im letzten Abschnitt eine Matrix als Notationshilfe eingeführt wurde, soll
hier nun mit Matrizen abstrakt gerechnet werden. Die Menge aller Matrizen mit m
Zeilen und n Spalten (wobei m, n ∈ ) und reellen Einträgen soll mit M(m × n, )
bezeichnet werden.
N
R
Zur Notation: eine Matrix A mit m Zeilen und n Spalten (oder kurz: eine m × nMatrix) soll kurz A = (aij )i,j geschrieben werden, wobei sich aij ∈ auf den Eintrag
in Zeile i und Spalte j bezieht.
R
R
Definition 12.1. Auf der Menge der m×n Matrizen M(m×n, ) wird die Addition
komponentenweise definiert, d.h. für A = (aij )i,j und B = (bij )i,j setzt man
A + B = C = (aij + bij )i,j
In Worten: der Eintrag in Zeile i und Spalte j der Summenmatrix entsteht, indem
die Einträge der Summanden an den entsprechen Stellen addiert werden.
Neben der Addition definiert man auch die Multiplikation von Matrizen. Diese ist
nicht komponentenweise definiert und sieht auf den ersten Blick furchtbar kompliziert aus, ist aber ungemein praktisch, wie sich später zeigen wird.
N
R
Definition 12.2. Seien m, n, r ∈
und A = (aij )i,j ∈ M(m × n, ) und B =
(bij )i,j ∈ M(n × r, ) Matrizen. Dann ist A · B folgendermaßen definiert :
R
R
A · B = C = (cij )i,j ∈ M(m × r, )
mit cij =
n
X
aik bkj
k=1
Bildlich gesprochen geschieht hier folgendes: multipliziert werden dürfen Matrizen,
bei denen die Anzahl der Spalten der ersten Matrix A mit der Anzahl der Zeilen der
zweiten Matrix B übereinstimmt. Die Produktmatrix hat dann genausoviele Zeilen
wie A und genauso viele Spalten wie B. Der Eintrag in Zeile i und Spalte j des
Produktes wird gebildet, indem Zeile i von Matrix A und Spalte j von Matrix B
(beide haben gleich viele Einträge!) eintragsweise multipliziert und dann aufaddiert
werden.
b
1j
···
b2j
c11 · · · c1r
..
.
.
.
.
.
.
.
.
n Zeilen
C = . cij
.
.
. = ai1 ai2 · · · ai,n−1 ain ·
.
bn−1,j
cm1 · · · cmr
···
bnj
{z
}
|
n Spalten
58
Um sich mit diesem seltsamen Konzept vertraut zu machen hilft es, zur Übung einige
Matrizen zu multiplizieren.
Eine erste Anwendung, die zeigen soll, wie praktisch dieses Konzept der Multiplikation sein kann, ist Folgende: betrachte erneut ein Gleichungssystem wie oben:
a1,1 x1 + a1,2 x2 + · · · + a1,n xn = b1
a2,1 x1 + a2,2 x2 + · · · + a2,n xn = b2
..
.
am,1 x1 + am,2 x2 + · · · + am,n xn = bm
Mit Hilfe der Multiplikation von Matrizen kann dies nun anders geschrieben werden.
Setze nämlich A := (aij )i,j ∈ M(m×n, ) und definiere zwei Matrizen mit nur einer
Spalte x := (xi )i ∈ M(n × 1, ), sowie b = (bi )i ∈ M(m × 1, ), dann schreibt sich
das System kurz als
A·x= b
R
R
R
Und wer das nicht glaubt, rechnet’s nach.
Noch eine kleine Anmerkung: Matrizen mit nur einer Spalte nennt man auch Vektoren (oder um ganz genau zu sein Spaltenvektoren zur Unterscheidung von
Zeilenvektoren, also Matrizen mit nur einer Zeile).
Rechenregeln
Im Folgenden sollen einige Rechenregeln für Matrizen erarbeitet werden. Dazu ist es
zweckmässig für n ∈ nur sogenannte quadratische Matrizen, also n×n-Matrizen
zu betrachten. Die Regeln haben zwar allgemeinere Gültigkeit, allerdings muss man
im allgemeinen Fall sehr viel genauer darauf achten, welche Produkte man bilden
kann und welche nicht. Quadratische Matrizen kann man untereinander beliebig
addieren und multiplizieren und es ergeben sich in jedem Fall wieder quadratische
Matrizen.
Diese Übung zeigt, dass Matrizenmultiplikation nicht kommutativ ist. Hingegen gilt:
N
Satz 12.3. Sei n ∈
N und A, B, C ∈ M(n × n, R). Dann gelten die Gleichungen
(A · B) · C = A · (B · C)
A · (B + C) = A · B + A · C
(A + B) · C = A · C + B · C
(Assoziativität)
(Distributivität)
Beweis. Setze D = (dij )i,j := (A · B) · C und E = (eij )i,j = A · (B · C). Dann gilt
für i, j ∈ {1, . . . , n}:
!
n
n
n
X
X
X
aik bkl clj =
aik bkl clj .
dij =
l=1
k=1
k,l=1
Diese Notation in der Summe bedeutet, dass die Indizes k und l unabhängig von
1 bis n laufen, also alle Kombinationen gebildet und aufsummiert werden. Für die
59
Matrix E ergibt sich entsprechend
eij =
n
X
n
X
aik
k=1
bkl clj
l=1
!
=
n
X
aik bkl clj = dij .
k,l=1
Es folgt D = E.
Betrachte nun F = (fij )i,j = A·(B +C) und G = (gij )i,j = A·B +A·C. Nachrechnen
ergibt
fij =
n
X
k=1
aik · (bkj + ckj ) =
n
X
k=1
(aik · bkj + aik · ckj ) =
n
X
k=1
aik bkj +
n
X
aik ckj = gij .
k=1
Insgesamt ergibt sich wieder F = G. Die zweite Distributivitätsgleichung folgt analog.
Die Multiplikation stellt neben der Addition eine zweite Verknüpfung auf der Menge
der quadratischen Matrizen dar. Aber wie reiht sich diese Menge in unsere bekannten Strukturen ein, bilden die Matrizen vielleicht einen Körper? Zu diesem Zweck
brauchen wir zunächst ein neutrales Element der Multiplikation.
Definition 12.4. Sei n ∈
N. Definiere die Einheitsmatrix durch
R
In = (δij )i,j ∈ M(n × n, ) , wobei δij =
1 , falls i = j
0 , falls i =
6 j
Die Einheitsmatrix hat also auf der Diagonalen lauter Einsen und ansonsten nur
Nullen. Eine kleine Bemerkung: es ist kein Zufall, dass die Einträge mit δ bezeichnet
sind, die Notation ist auch als “Kronecker-δ” bekannt.
1 0 ··· 0
. . ..
. .
0 1
In = . .
.
.. . . . . 0
0 ··· 0 1
Diese Einheitsmatrix ist das neutrale Element der Matrizenmultiplikation: für eine
beliebige Matrix A = (aij )i,j ∈ M(n × n, ) gilt:
R
A · In = In · A = A
Beweis. Setze B = (bij )i,j = A · In . Dann gilt
bij =
n
X
k=1
aik δkj = aij · δjj = aij
Also ist A · In = A. Die andere Gleichung folgt analog.
R
Die Menge der n×n Matrizen mit Einträgen in bilden also einen Monoid bzgl. der
Matrizenmultiplikation. Damit sie eine Gruppe bilden können, muss jede Matrix, die
nicht die Nullmatrix ist, ein inverses Element besitzen. Dies ist leider nicht der Fall,
wie folgendes Beispiel zeigt:
60
Satz 12.5. Die 2 × 2-Matrix
A=
0 1
0 0
R
ist nicht invertierbar, d.h. es gibt keine Matrix B ∈ M(2 × 2, ) mit A · B = I2 .
R
Beweis. Für jedes B = (bij )i,j ∈ M(2 × 2, ) gilt:
0 1
b11 b12
b21 b22
A·B =
·
=
0 0
b21 b22
0
0
Insbesondere ist der Eintrag in Zeile 2 und Spalte 2 des Produktes immer 0, also
kann nie die Einheitsmatrix I2 herauskommen.
Die Menge der Matrizen ohne die Nullmatrix bildet also keine Gruppe bezüglich
der Multiplikation, daher ist die Struktur der Menge nur die eines Ringes und sie
bildet keinen Körper. Am Rande: auch die ganzen Zahlen bilden einen Ring, bei
dem die Multiplikation allerdings kommutativ ist.
Z
61
Übungsaufgaben
Die Übungsaufgaben sollen helfen, sich mit dem Stoff der Vorlesung auseinanderzusetzen und ein tieferes Verständnis desselben zu gewinnen. Hierfür sind sie nahezu
unerlässlich. Es ist auch empfehlenswert, sie in einer kleinen Gruppe zu bearbeiten.
Sollte man selbst nicht auf die Lösung kommen, sollte man zumindest versuchen,
sie zu verstehen. Ob dies gelungen ist, stellt man übrigens grundsätzlich immer am
besten im Gespräch mit Kommilitonen fest; kann man einem anderen einen Sachverhalt erklären, so hat man ihn selbst meist auch begriffen!
Manche Aufgaben sind mit einem * markiert. Ich empfehle, zunächst die anderen
zu bearbeiten, die * Aufgaben sind als Bonusaufgaben zu sehen.
zu Logik und Mengen
Übung 1. Zeige mit Hilfe von Wahrheitstafeln die folgenden Regeln für Aussagen
A und B:
¬(A ∧ B) = (¬A) ∨ (¬B)
¬(A ∨ B) = (¬A) ∧ (¬B)
Übung 2. Seien A, B Aussagen. Zeige: (A ⇒ B) = (¬A) ∨ B.
Übung 3. Die Aussage E(x, y) ist wie unten angegeben. Formuliere dann auf
Deutsch
∀x∃y : E(x, y); ∃y∀x : E(x, y); ∃x∀y : E(y, x)
Die Aussage lautet: “Studentin x hat sich in Student y verliebt.
Übung 4. Wir definieren die folgenden Mengen: A := {NWI, KOI, BIG, MIG, andere},
B := {m,w}, C := {ABI2010, ABI2009, sonstige},
D := {gelangweilt, überfordert, interessiert, geht niemanden was an}. Nenne das
Element aus A × B × C × D, mit dem Du Dich identifizierst.
Übung 5. * Ist die folgende Aussage immer wahr? Beweise Deine Behauptung.
(¬A ∧ ¬B) ⇒ (B ⇒ A)
Übung 6. * Du sprichst mit drei Personen A, B und C, die über einander die
folgenden Aussagen treffen: A sagt, dass B lügt, B sagt, dass C lügt, C sagt, dass A
und B lügen. Sagt hier irgendjemand noch die Wahrheit? Begründe Deine Antwort.
Übung 7. * Seien A := {1, 2, 3}, B := {2, 4, 6, 8, 10}. Gib den Schnitt, die Vereinigung dieser Mengen und A \ B, B \ A an.
62
Übung 8. Seien A, B, C Teilmengen von G. Vereinfache die folgenden Ausdrücke
M = ((A ∩ B) ∪ (A ∩ B)) ∪ (A ∩ B))
N = [(A ∩ (A ∪ B)) ∪ (B ∩ (B ∪ C))] ∪ [B ∩ C]
Übung 9. * Ein Meinungsforscher teilt seinem Chef das Ergebnis einer Umfrage
über die Beliebtheit von Bier und Wein mit. Von 99 Befragten sagten 75, dass sie
gerne Bier und 68, dass sie gerne Wein trinken. Sowohl Bier also auch Wein trinken
42 Befragte. Einen Tag später erhält der Mann seine Kündigung. Was ist dem Chef
aufgefallen?
zu Natürliche Zahlen
Übung 10. Gib allgemeine Formeln für (a + b)3 und (a + b)4 an.
Übung 11. Definiere formal die Folge (an )n∈N für die gilt, dass jedes Folgenglied
das Quadrat seines Vorgängers ist und a1 = 4
a) rekursiv,
b) per expliziter Formel.
Punkt b) gelingt evtl erst, wenn man schon etwas über Induktion weiß.
Übung 12. Wir betrachten eine Kaninchenpopulation, die sich nach den folgenden
Regeln vermehrt.
• Zu Beginn gibt es ein Paar geschlechtsreifer Kaninchen.
• Jedes neugeborene Paar wird im zweiten Lebensmonat geschlechtsreif.
• Jedes geschlechtsreife Paar wirft pro Monat ein weiteres Paar.
• Die Tiere befinden sich in einem abgeschlossenen Raum (?in quodam loco, qui
erat undique pariete circundatus?), so dass kein Tier die Population verlassen
und keines von außen hinzukommen kann.
Definiere eine Folge, die die Anzahl der Paare im n−ten Monat beschreibt.
Übung 13. Berechne die folgenden Summen:
7
X
(k 2 − k)
k=3
7 X
j=5
6
X
1
2j − 7
2α
α=0
63
Übung 14. Berechne folgenden Ausdruck:
10
X
k=1
30
X
(k 7 − k 5 + k) +
(k − 20)5 − (k − 20)7
k=21
Hinweis: Indexverschiebung
Übung 15. Zeige mit vollständiger Induktion:
n
X
j=1
Übung 16. * Seien a, d ∈
j2 =
n(n + 1)(2n + 1)
6
N. Gesucht ist eine geschlossene Formel für den Ausdruck
n
X
(a + kd)
k=0
Stelle eine Vermutung auf und beweise sie mit vollständiger Induktion.
N
Übung 17. * Sei M eine Menge mit n Elementen für ein n ∈ . Zeige mit vollständiger Induktion: Die Menge aller Teilmengen von M enthält 2n Elemente. Beachte,
dass auch die leere Menge ∅ := {} und M selbst Teilmengen von M sind.
Übung 18. In der Vorlesung habe ich ”bewiesen“, dass alle Dinge gleich sind. Das
kommt mir komisch vor. Siehst Du einen Fehler in meiner Argumentation?
zu Rechnen mit Rest
Übung 19. Stelle die Verknüpfungstafeln aus der Vorlesung im Falle modulo 6 auf!
Haben jetzt noch alle Restklassen multiplikative Inverse? Woran mag das leigen?
Übung 20. Zeige: Zu jeder ungeraden natürlichen Zahl u gibt es eine natürliche
Zahl m mit u2 = 8m + 1.
zu Rationale Zahlen
Übung 21. Eine Aktie hat den Wert 100. Am nächsten Tag gewinnt (verliert) sie
10 Prozent an Wert, am Folgetag verliert (gewinnt) sie 10 Prozent an Wert. Welchen
Wert hat sie nun? Wie erklrt sich die Gleichheit der Ergebnisse?
Übung 22. Vergleiche die beiden Terme
3
2
7
Übung 23. Berechne
3
und 2
3
2
2
3
7
+
+
64
5
7
7
5
Übung 24. Finde ganze Zahlen m, n mit
m n
1
+ =
3
5
15
und natürliche Zahlen k, l mit
k
l
14
+ =
3 5
15
Übung 25. Proportionen: Zeige, dass für ganze Zahlen a1 , . . . , an , b1 , . . . , bn gilt
aj
a1
a + · · · + an
a1
= ∀j = 1, . . . , n ⇒
= 1
b1
bj
b1
b1 + · · · + bn
Übung 26. Zeige, dass
a
b
+
b
a
> 2 für a > b > 0.
Übung 27. * Ein Kaufmann hat 100 kg Gurken. Diese bestehen hinsichtlich ihres
Gewichts zu 99% aus Wasser. Wieviel kg Wasser müssen sie durch Austrocknen
verlieren, damit sie nur noch zu 98% aus Wasser bestehen?
zu Reelle Zahlen
Übung 28. Wir kennen die Vereinigung zweier Mengen A∪B. Analog zum Summenzeichen können wir auch die Vereinigung über einer Schar von Mengen An , n ∈
definieren:
m
[
An := {a : ∃n : a ∈ An }.
N
n=1
Der Schnitt geht analog. Gib nun Schnitt
An und Vereinigung
n=1
Mengen An an:
a) An := [1, 1 +
∞
T
∞
S
An folgender
n=1
1
1
1
] b) An := [1, 1 + ) c) An := (1, 1 + )
n
n
n
Übung 29. Zeige die Dreiecksungleichung.
Übung 30. Untersuche diese Folgen auf Konvergenz und ermittele ggf. den Grenzwert.
a) an =
1
n2
b) an =
n2 −1
n+1
c) an = c für eine reelle Zahl c.
(−1)n/2
, falls n gerade
n
d) an =
0
, falls n ungerade
Übung 31. Zeige:limn→∞ nn!n = 0.
Übung 32. Seien (an )n∈N und (bn )n∈N konvergente Folgen mit Grenzwert a bzw.
b. Zeige, dass die Folge (cn )n∈N gegeben durch cn = an + bn konvergent ist mit
Grenzwert a + b. Hat die Folge (dn )n∈N mit dn = an · bn entsprechend auch den
Grenzwert a · b?
Übung 33. Gibt es irrationale Zahlen a, b ∈
65
R\Q mit ab ∈ Q?
zu Komplexe Zahlen
Übung 34. Schreibe folgende komplexe Zahlen in der Form a + ib:
1
,
3 − 4i
2 + 7i
,
−1 − 2i
1
i
Manchmal gibt es mehr als eine Lösung. Dann reicht eine beliebige.
Übung 35. Bestimme alle Lösungen der Gleichung z 4 = 1. Was fällt auf? Wo liegen
die Ergebnisse geometrisch?
Übung 36. Löse die Gleichung (a + ib)2 = i algebraisch. Wieviele Lösungen gibt
es? Wo liegen sie in der Ebene?
C
N
und
Übung 37. * Sei ζ ∈ (Zeta) eine komplexe Zahl mit ζ n = 1 für ein n ∈
ζ 6= 1. (Eine solche Zahl heißt auch n-te Einheitswurzel.) Berechne den folgenden
Ausdruck:
n−1
X
ζk
k=0
zu Gleichungen und Gleichungssysteme
Übung 38. Finde alle Lösungen für folgendes Gleichungssystem.
x2 + 3x3 + 3x4
x1 + 3x2 − 5x3 + 9x4
−2x1 − 5x2 + 12x3 − 23x4
3x1 + 11x2 − 8x3 + 41x4
2x1 + 7x2 − 7x3 + 22x4
=
=
=
=
=
1
−3
8
−8
0
Übung 39. Aus Quarz (SiO2 ) und Natronlauge (NaOH) entsteht Natriumsilikat
(Na2 SiO3 ) und Wasser (H2 O):
x1 SiO2 + x2 NaOH → x3 Na2 SiO3 + x4 H2 O.
Bestimme kleinstmögliche natürliche Zahlen x1 , x2 , x3 , x4 , so dass die Reaktionsgleichung erfüllt ist.
Übung 40. * Gegeben sei ein Quadrat mit 3 × 3 Kästchen:
66
Diese Kästchen sollen mit rationalen Zahlen gefüllt werden, so dass die Summe in
horizontaler, vertikaler und diagonaler Richtung stets den gleichen Wert a ∈
ergibt. Geht das für jeden Wert a? Wieviele Möglichkeiten gibt es für gegebenes a?
Für welche a können die Einträge ganzzahlig gewählt werden?
Q
Übung 41. Ein Student spart für den nächsten Urlaub, 1 Euro am ersten Tag, 2
am zweiten, 3 am dritten usw. Wie lange muss er das aushalten, bis er 1000 Euro
zusammen hat?
2
x
. Vereinfache ihn zunächst
Übung 42. Zerlege folgenden Term in Partialbrüche: x2 −2x+1
per Polynomdivision: x2 : (x2 − 2x + 1) =?. Achtung: Bei dieser bleibt ein Rest über!
zu Abbildungen
Übung 43. Gegeben sei die Abbildung
f : {−2, 0, 1, 2, 3} → {−16, −1, 0, 1, 4, 16, 81, 256}
durch x 7→ x4
Bestimme folgende Mengen:
f ({0, 3}),
f ({−2, 2}),
f −1 ({−16, 0, 16}),
f −1 ({−1, 4, 256}),
f −1 ({−1, 1, 81}).
Übung 44. Gib Mengen X und Y und eine Abbildung f : X → Y , sowie Teilmengen A ⊆ X und B ⊆ Y an mit
f −1 f (A) 6= A
und
f f −1 (B) =
6 B
Übung 45. Seien X und Y Mengen, f : X → Y eine Abbildung und A, B ⊆ Y .
Zeige:
f −1 (A ∪ B) = f −1 (A) ∪ f −1 (B)
f −1 (A ∩ B) = f −1 (A) ∩ f −1 (B)
Übung 46. Gib eine (möglichst einfache) Menge X und zwei Abbildungen f : X →
X und g : X → X an, so dass gilt f ◦ g 6= g ◦ f . Ist es auch möglich, f und g bijektiv
mit dieser Eigenschaft zu wählen?
Übung 47. Welche der folgenden Abbildungen sind injektiv, surjektiv bzw. bijektiv?
N → N mit f (n) = n + 1.
f : R → R mit f (n) = n + 1.
f : N → N mit f (n) = n2 .
f : R → R+ mit f (x) = x2 .
f : R → R mit f (x) = sin(x).
f : R+ → R mit f (x) = 3x − 7.
a) f :
b)
c)
d)
e)
f)
67
Übung 48. Seien X, Y und Z Mengen und f : X → Y und g : Y → Z bijektive
Abbildungen. Zeige: dann ist auch (g ◦ f ) : X → Z bijektiv.
Übung 49. Gegeben sei die Abbildung
f : {−5, −3, −2, −1, 0, 2, 5} → {−7, 0, 2, 3, 4, 5, 7, 9, 12, 15, 16, 19, 25, 26, 28, 30}
durch f (x) := x2 + 3. Verkleinere Definitionsmenge und Wertemenge so, dass f
bijektiv wird und gib eine Umkehrabbildung an.
Übung 50. * Sei X eine Menge und P(X) := {A Menge : A ⊂ X} die Menge der
Teilmengen von X. Zeige: Es existiert keine surjektive Abbildung f : X → P(X).
Hinweis: Betrachte folgende Menge B := {x ∈ X : x ∈
/ f (x)}.
√
Übung 51. Es seien a, b ∈
mit a + b 2 = 0. Zeige, dass√dann a = b = 0 sein
muss (hierbei sollte man sich an den Beweis erinnern, dass √
2 nicht rational ist).
2
→ , (a, b) 7→ a + b 2 injektiv ist.
Folgere daraus, dass die Abbildung f :
Q
Q
R
Übung 52. Zeige: Es gibt eine surjektive Abbildung f :
N → Q.
Übung 53. Hilberts Hotel. * Die folgende Übung ist der interessante Vergleich
von Hilbert zum Thema Unendlichkeit, der als “Hilberts Hotel” bekannt geworden
Zimmer hat, also für jede natürliche
ist. Dieses Hotel ist ein fiktiver Ort, der
Zahl ein Zimmer, mit anderen Worten: unendlich viele. Stellen wir uns vor, dass alle
Zimmer belegt sind, das Hotel also restlos ausgebucht ist.
N
Trotzdem hat der Portier die Anweisung, alle neu ankommenden Gäste unterzubringen ohne bereits vorhandene Gäste ausquartieren zu müssen. Umquartieren innerhalb des Hotels ist ihm aber erlaubt. Wie kommt er mit folgenden Situationen
klar?
a) Ein neuer Gast kommt an.
b) Es kommen n Gäste an, wobei n ∈
c) Ein Großraumbus mit
N eine natürliche Zahl ist.
N Gästen kommt an.
d) Es kommen n Großraumbusse an.
e) Eine Kolonne mit
N Großraumbussen kommt an.
68
zu Stetigkeit
Übung 54. In der Vorlesung wurde behauptet, dass die Summe, das Produkt und
die Verkettung stetiger Funktionen selbst wieder stetige Funktionen sind. Beweise
diese Aussagen. Dabei dürfen die Ergebnisse von Übung 32 verwendet werden.
Übung 55. Notiere das Kriterium II für die Stetigkeit einer Funktion f formal mit
Quantoren. Verneine diese Aussage dann ebenfalls formal.
R
R
R
R
Übung 56. Sei f :
→
stetig und sei a ∈
mit f (a) 6= 0. Zeige: es gibt ein
δ > 0, so dass für alle x ∈
mit |x − a| < δ gilt: f (x) 6= 0. Man sagt, dass f in
einer Umgebung von a von 0 verschieden ist.
Übung 57. Untersuche die Gauß-Klammer
[·] :
R→R
gegeben durch
[x] = max{a ∈
Z : a ≤ x}
auf Stetigkeit, d.h. gib die Menge aller Punkte an, an denen die Funktion stetig ist
und die Menge aller Punkte, an denen sie unstetig ist (mit Beweis).
Übung 58. Zeige, dass die Betragsfunktion auf
R
R
R
R
R stetig ist.
→
und g :
→
stetig. Beweise die Stetigkeit von
Übung 59. Seien f :
(g ◦ f ) mit dem Folgenkriterium und mit dem ε-δ-Kriterium.
R R
Übung 60. * Betrachte die Funktion f : → mit f (0) = 0 und f (x) = xα sin( x1 )
für x 6= 0. Begründe, warum die Funktion für α = 1 stetig, für α = 0 jedoch
nichtstetig in 0 ist.
zu Differenzierbare Funktionen
Übung 61. Betrachte die Betragsfunktion. Zur Erinnerung: diese war definiert
durch
−x , falls x < 0.
|·|: →
mit |x| =
x
, falls x ≥ 0.
R R
Zeige: die Betragsfunktion ist im Punkt 0 stetig, dort aber nicht differenzierbar.
N
R R
Übung 62. Sei n ∈ und f : → gegeben durch f (x) = x4 . Bestimme für einen
beliebigen Punkt x0 ∈ die Ableitung von f mit Hilfe des Differenzenquotienten.
R
: R → R und g : R → R differenzierbare Funktionen und
Übung 63. Seien f
α ∈ beliebig. Zeige die folgenden Regeln:
R
(f + g)′ = f ′ + g ′ (Summenregel)
(α · f )′ = α · f ′ (Faktorrregel)
Übung 64. Berechne die Ableitung der Funktionen f :
f (x) = xn für alle n ∈ .
N
Übung 65. Bestimme die Ableitung der Funktion f :
→
R gegeben durch
R → R gegeben durch
f (x) = (x2 + 3x − 2) · (x4 + x − 2)
69
R
Übung 66. Bestimme die Ableitung der Funktion f :
durch
4x3 + 9
f (x) = 2
6x − 2x
Übung 67. Bestimme die Ableitung der Funktion f :
R\
1
0, 3 →
R gegeben
R → R gegeben durch
f (x) = (x + 2)17
R
R
√
Übung 68. Betrachte die Wurzelfunktion f : + →
mit f (x) = x. Was ist
f ′ (x) für x ∈ ∗+
? Wie sieht es für x = 0 aus? Und was ist die Ableitung der n-ten
√
n
Wurzel f (x) = x?
R
Übung 69. Sei a ∈
R∗+ beliebig und betrachte f : R → R gegeben durch
f (x) = ax
Bestimme die Ableitung von f .
(Hinweis: Schreibe f mit Hilfe der Rechenregeln für Potenzen und des Logarithmus
so um, dass die Exponentialfunktion vorkommt.)
R
Übung 70. * Sei a ∈ ∗+ eine positive reelle Zahl. Das Quadrat mit Seitenlänge a
hat dann die Fläche a2 , man kann also die Fläche des Quadrates als Funktion der
Seitenlänge ausdrücken:
AQ (a) = a2
A′Q (a) = 2a
Die Ableitung ist die Hälfte des Umfangs UQ (a) = 4a = 2 · A′Q (a).
Betrachtet man den Kreis mit Radius r ∈ ∗+ , so ist seine Fläche gerade πr 2 , es gilt
also
AK (r) = πr 2
A′K (r) = 2πr = UK (r).
R
In diesem Fall ist die Ableitung der Flächenfunktion identisch mit der Umfangsfunktion. Woran liegt das? Und wie kann man den Zusammenhang zwischen Fläche
und Umfang geometrisch deuten?
Das gleiche Phänomen tritt übrigens in 3 Dimensionen auch auf: für das Volumen
des Würfels mit Kantenlänge a gilt
VW (a) = a3
VW′ (a) = 3a2 =
1
· OW (a).
2
Die Ableitung des Volumens gibt hier die Hälfte der Oberfläche. Bei der Kugel mit
Radius r sieht das anders aus:
4
VK (r) = πr 3
3
VK′ (r) = 4πr 2 = OK (r).
Was ist der Grund?
70
zu Matrizen
R
Übung 71. Zeige: In der Menge M(m × n, ) existieren bezüglich der Verknüpfung
+ ein neutrales Element und inverse Elemente.
Übung 72. Bilde die folgenden Matrizenprodukte, sofern dies möglich ist.
2
0
3
3
−5 · 17 , −2 · 1 0 4 ,
1 0 4 · −2
1
−8
0
0
−2 5
0
1
3
2
0
7
−2
2
9
−3
2
4 10 ·
, −2 0 ·
1 −4 0
3 −1 6 −9
0 −4 −1
4 −7
Übung 73. Finde (möglichst einfache) quadratische Matrizen A und B für die gilt:
AB 6= BA
(Hinweis: Das geht schon für n = 2.)
Übung 74. Für eine n × n Matrix A und ein k ∈
A0 := In
A1 := A
N definiere Ak induktiv:
Ak := A · Ak−1
für k > 1.
Sei A = (aij )i,j gegeben durch
aij =
1 , falls j − i = 1
0 , falls j − i 6= 1
Zeige: An = 0n , wobei 0n die Nullmatrix bezeichnet. Eine solche Matrix, bei der eine
Potenz gleich der Nullmatrix ist, heißt nilpotent.
N
Übung 75. Sei n ∈ . Eine n × n Matrix A heißt invertierbar, wenn es eine
n × n-Matrix A−1 gibt mit A · A−1 = A−1 · A = In .
R
Betrachte nun folgende Relation ∼ auf der Menge M(n × n, ):
R
A ∼ B ⇔ ∃ P ∈ M(n × n, ) invertierbar, mit A = P BP −1
Zeige: A ∼ A, A ∼ B ⇔ B ∼ A, A ∼ B, B ∼ C ⇒ A ∼ C. Eine Relation, die diese
Eigenschaften erfüllt, nennt man übrigens Äquivalenzrelation.
71