Einfache Statistiken in Excel - Bergische Universität Wuppertal
Werbung

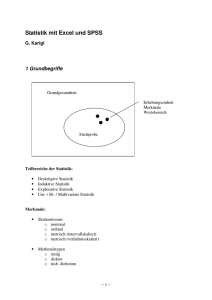
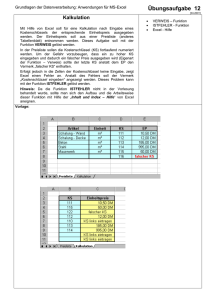
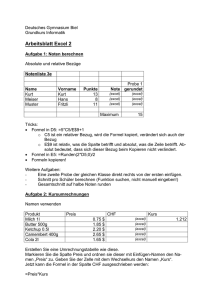
Einfache Statistiken in Excel Dipl.-Volkswirtin Anna Miller Bergische Universität Wuppertal Schumpeter School of Business and Economics Lehrstuhl für Internationale Wirtschaft und Regionalökonomik Raum P.08.16 [email protected] Inhalt • Statistiksoftware • Excel • Abbildungen • Lage- und Streuungsmaßzahlen • Verteilung • Kovarianz • Korrelation • T-Statistik • Regression 2 Statistiksoftware • Stata • SPSS • Eviews • Freeware • – R – PSPP – Statistiklabor – Gretl Tabellenkalkulationsprogramme – Excel – OpenOffice 3 Excel • Tabellenkalkulationsprogramm; Bestandteil von MS Office • Eingeschränkte Statistikanwendungen • Einfache Statistiken und Abbildungen erstellen • Add-Ins; RExcel • Analyse-Funktionen Add-Ins verfügbar – Daten → Datenanalyse Analyse-Funktionen Add-Ins laden: • – Registerkarte Datei → Optionen → Add-Ins – Im Feld Verwalten → Excel Add-Ins → Gehe zu – Verfügbare Add-Ins: Kontrollkästchen Analyse-Funktionen aktivieren, OK klicken 4 Diagramme in Excel • Grafische Darstellung der Daten • Erleichtert das Verständnis großer Datenmengen • Erstellen – Daten markieren (Zeilenbeschriftung links, Spaltenbeschriftung über) – Registerkarte Einfügen ->Diagramme 5 Diagramme in Excel • Weitere Typen im Dialogfeld Diagramm • Diagrammtools • – Titel und Datenbeschriftungen hinzufügen – Entwurf, Layout oder Format ändern Formatierung: schlichte Designs vorziehen 6 Diagramme in Excel • Säulendiagramme • Liniendiagramme • Kreisdiagramme • Balkendiagramme • Flächendiagramme • Punkt (XY) -Diagramme • Kursdiagramme • Oberflächendiagramme • Ringdiagramme • Blasendiagramme • Netzdiagramme 7 Histogramm • • • Darstellung der Häufigkeit für alle Werte innerhalb einer Klasse – Absolute Häufigkeit – Relative Häufigkeit Klassieren – Klasseneinteilung und -grenzen – Klassenanzahl (k ≈√n) Erstellen – Daten markieren – Klassenbereich eingeben (optional) – Daten → Datenanalyse → Analysetools → Histogramm 8 Deskriptive Statistik • Aufgabe: Daten beschreiben • Methoden: – Tabellen und graphische Darstellungen – Kenngrößen – Lagemaße – Streuungsmaße 9 Deskriptive Statistik • Lagemaßzahlen – beschreiben zentrale Eigenschaften einer Verteilung – Stichprobe vom Umfang n • Erwartungswert • Arithmetisches Mittel – Gibt viel Gewicht extremen Werten – Funktion MITTELWERT 10 Deskriptive Statistik • • Median – Mittlere Beobachtungen der nach Größe sortierten Daten – Unempfindlich gegenüber Ausreißer – Lokationsmaß für schiefe Verteilungen – Funktion MEDIAN Modalwert – Kommt am häufigsten in der Messwertreihe vor 11 Deskriptive Statistik • α-Quantil – Mindestens α% der Werte ≤ diesem Wert sind – 1 Quartil (α =0.25), Median (α =0.5), 3 Quartil (α =0.75) – Funktion QUANTIL Maßzahlen der Streuung • – Spannweite: R = Maximum – Minimum (extreme Werte) – Quartilsabstand: 3 Quartil – 1 Quartil 12 Deskriptive Statistik • • Varianz – Durchschnittliche quadrierte Abweichung der Messwerte vom arithmetischen Mittel – Funktion VAR.S (VARIANZ): auf Grundlage der Stichprobe Standardabweichung: – Bessere Einschätzung der Variabilität – Abhängig von Mittelwert – Funktion STDEV.S (STABW) 13 Deskriptive Statistik • • Schiefe – Beschreibt eingipfelige Verteilung (Symmetrie) – Funktion SCHIEFE Wölbung (Kurtosis) – Funktion KURT 14 Verteilung • • • Normalverteilung – Mittelwert = µ; Varianz = σ2; Schiefe = 0; Kurtosis = 3 – NORM.DIST (NORVERT) – Symmetrisch, glockenförmig – Modalwert, Median, Erwartungswert fallen zusammen Standardnormalverteilung – Mittelwert = 0; Varianz = 1 – NORM.S.DIST (STANDNORMVERT) Andere Verteilungstypen – T.DIST; BINOM.DIST; CHISQ.DIST usw. 15 Kovarianz • Maßzahl für den Zusammenhang zweier statistischer Zufallsvariablen (X und Y) • Richtung der Beziehung • Nicht standartisiert • Funktion COVARIANCE (KOVAR) 16 Korrelation • Beziehung zwischen statistischen Zufallsvariablen (X und Y) • Korrelation und Kausalität (Scheinkorrelationen) • Korrelationskoeffizient • – Maß für den Grad des linearen Zusammenhangs – ρ (X,Y) ϵ [-1,1] – dimensionslos Funktionen KORREL; PEARSON 17 Konfidenzinterval • Konfidenzinterval – schließt einen Bereich um den geschätzten Wert des Parameters ein, der mit einer zuvor festgelegten Wahrscheinlichkeit die wahre Lage des Parameters trifft – CONFIDENCE.NORM, CONFIDENCE.T (KONFIDENZ) – Angeben: α (Konfidenzniveau), σ (Standardabweichung), n (Stichprobenumfang) 18 T-Test • Testen einer Hypothese, dass Wert a mit x übereinstimmt • t = (a-x)/σ; • t größer als Wert in der Tabelle => Hypothese abgelehnt • Konfidenzinterval konstruieren • T-Wert berechnen • Signifikanz prüfen – t ≈ 2 → 5% Signifikanz – t ≈ 3 → 1% Signifikanz 19 Regression • Einfluss der Werte unabhängiger Variable auf abhängige Variable • Regressionsgerade • Methode der kleinsten Quadrate • Funktionen – KKLEINSTE – T.TEST; T.DIST • R2 gibt an wie viel Prozent der Streuung erklärt werden – Bestimmtheitsmaß – Qualität der linearen Approximation 20 Daten • Zeitreihe (Time Series): zeitabhängige Reihe von Datenpunkten (diskret; in endlichen zeitlichen Abständen anfallen) • Zeitreihenanalyse – Beschreibung; Erkennung von Veränderungen und Trends – Prognose • Querschnitt (Cross-sectional data): mehrere Beobachtungen zu einem Zeitpunkt • Längsschnittsstudie: dieselbe empirische Studie zu mehreren Zeitpunktenngsschnittstudie • Paneldaten (Panel Data) – multidimensional; – Beobachtungen mehrerer Untersuchungsobjekten zu verschiedenen Zeitpunkten 21 Daten • http://www.imf.org/external/data.htm • http://unctadstat.unctad.org/ReportFolders/reportFolders.aspx • http://www.internationaldata.org • http://pwt.econ.upenn.edu/ • http://data.worldbank.org/data-catalog • http://www.nber.org/data/ • http://stats.oecd.org/Index.aspx 22 23 24