Evolutionäre Algorithmen
Werbung

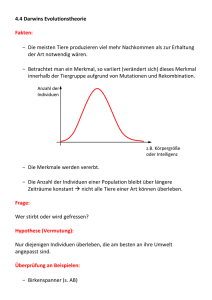
Evolutionäre Algorithmen Lukas Sikorski [email protected] Dieses Dokument ist eine Ausarbeitung zum Thema Evolutionäre Algorithmen (EA). Kernpunkt sind die vier Standardformen der Evolutionären Algorithmen: Genetische Algorithmen, Genetische Programmierung, Evolutionsstrategien und Evolutionäre Programmierung. Dazu wird für jeden dieser Standardalgorithmen das Grundkonzept erläutert. Anschließend werden die Standardalgorithmen gegenübergestellt und miteinander verglichen. Weiterhin wird ein Allgemeines Ablaufschema eines Evolutionären Algorithmus vorgestellt sowie die einzelnen Verfahren und Operatoren Evolutionärer Algorithmen beschrieben. 1 Einleitung Systeme bzw. Anwendungsprobleme hängen meistens von einer Anzahl von Entscheidungen und Variablen ab. Diese Entscheidungen oder Variablen können unterschiedliche Zustände annehmen. Je nach Wahl und Einstellung der Variablen zeigt das System unterschiedliches Verhalten. Auf der anderen Seite möchte der Nutzer des Systems, dass dieses eben ein bestimmtes Verhalten aufweist. Das System soll besonders gut an eine bestimmte Aufgabenstellung angepasst sein. Um dieses Ziel zu erreichen, sucht der Nutzer nach den Einstellungen der Variablen, die dieses bestimmte Verhalten hervorrufen. Dieser Prozess der Suche nach der gewünschten Einstellung der Variablen bezeichnet man als Optimierung. Betrachtet man ein Optimierungsverfahren rein technisch, so wird das Systemverhalten durch eine Zielfunktion beschrieben. Für jede Einstellung der Variablen lässt sich durch die Zielfunktion ein Zielfunktionswert bestimmen. Von den Variablen wird dabei ein Suchraum aufgespannt. Bei einem Blick in unsere Umgebung stellt man fest, dass wir von einer Vielzahl lebender Systeme umgeben sind. Bei näherer Betrachtung zeigt sich, wie gut die vielen Lebewesen an ihren jeweiligen Lebensraum angepasst sind. Ein Individuum stellt dabei eine Einstellung von Variablen dar. Der Lebensraum eines Individuums bildet die Zielfunktion. Der Zielfunktionswert ist die Überlebenschance eines Individuums und je besser ein Individuum an seinen Lebensraum angepasst ist, desto bessere Überlebens- und Fortpflanzungschancen hat es. Diese Anpassung ist ein Optimierungsprozess und man spricht von der Evolution. Das Gebiet der Evolutionären Algorithmen versucht die in der Natur vorhandenen Prinzipien und Mechanismen auf technische Systeme zu übertragen um damit komplexe Optimierungsprobleme zu bewältigen. In Kapitel 2 werden grundlegende Aspekte Evolutionärer Algorithmen vorgestellt. Zunächst werden Zusammenhänge zwischen natürlicher Evolution und den Evolutionären Algorithmen erläutert. Danach 1 wird das Allgemeine Ablaufschema eines evolutionären Algorithmus dargelegt. In Kapitel 3 werden die grundlegenden Verfahren und Operatoren evolutionärer Algorithmen vorgestellt. Aufbauend auf dem allgemeinem Ablaufschema eines evolutionären Algorithmus und den Verfahren und Operatoren wird in Kapitel 4 für jeden der vier Standardalgorithmen: „Genetische Algorithmen“, „Genetische Programmierung“, „Evolutionsstrategien“ und „Evolutionäre Programmierung“ ein Basisablauf vorgestellt. Danach werden die Standardalgorithmen gegenübergestellt und verglichen. Abschließend wird in Kapitel 5 ein Fazit gegeben. 2 Grundlegende Aspekte evolutionärer Algorithmen Der erste Abschnitt soll dazu dienen, einige grundlegende Zusammenhänge zwischen evolutionärer Algorithmen und der natürlichen Evolution zu erläutern. Danach wird ein allgemeines Ablaufschema eines evolutionären Algorithmus vorgestellt. 2.1 Evolutionäre Algorithmen und die natürliche Evolution Evolutionäre Algorithmen orientieren sich an unterschiedlichen Vorbildern der natürlichen Evolution. Begriffe und Vorgänge aus der Biologie werden übernommen um Methoden zur Lösung von Optimierungsproblemen zu beschreiben. Bei der natürlichen Evolution stehen Begriffe wie Selektion und Variation im Vordergrund. Prozesse der Selektion entscheiden unter anderem, welche Individuen überleben oder welche Individuen Nachkommen zeugen. Die Variation bestimmt wie aus den Eltern Nachkommen produziert werden. Individuen einer Population sind wegen ihrem begrenzten Lebensraum Wettkämpfen ausgesetzt. Dabei haben die Individuen, die besser an ihren Lebensraum angepasst sind, größere Überlebensund Fortpflanzungschancen. Evolutionäre Algorithmen sind stochastische Such- und Optimierungsverfahren, die an Prinzipien der natürlichen Evolution angelehnt sind. Sie arbeiten gleichzeitig auf einer Anzahl von potenziellen Lösungen (Individuen), die verschiedene Entscheidungsalternativen bzw. Lösungen des jeweiligen Optimierungsproblems darstellen. Auf diesen Individuen (Lösungen) wird das Prinzip „Der stärkere überlebt!“ angewendet. Dabei durchlaufen die Individuen einen iterativen Zyklus von Variation und Selektion. Die Variation setzt sich in der Regel zusammen aus Rekombination, in der Informationen zwischen Individuen ausgetauscht werden, und Mutation, in der die Individuen zufällig geringfügig verändert werden. Die Selektion entscheidet welche Individuen für die Fortpflanzung ausgewählt werden. Ziel ist es anhand einer Zielfunktion immer bessere Individuen zu erzeugen, die am Ende der Suche zu einer guten Lösung führen. Im Folgenden wird ein Allgemeines Ablaufschema eines evolutionären Algorithmus vorgestellt. 2.2 Allgemeines Ablaufschema eines Evolutionären Algorithmus Abbildung 1 zeigt das allgemeine Ablaufschema eines Evolutionären Algorithmus grafisch. 2 Initialisierung Ergebnis Zielfunktion ja nein Selektion Abbruchkriterium erfüllt Rekombination Umweltselektion Mutation Zielfunktion Abbildung 1: Allgemeines Ablaufschema eines Evolutionären Algorithmus Zuerst findet eine Initialisierung statt in der eine Anfangspopulation generiert wird. Diese Population enthält erste Lösungskandidaten (Individuen) die meist zufällig ausgewählt werden. Mittels einer Zielfunktion wird die neu generierte Population bewertet. Sie bestimmt die Güte (Fitness) der einzelnen Individuen. Dadurch ist die Population der ersten Generation erstellt. Es folgt ein Prozess über mehrere Generationen in dem die Suche nach besseren Individuen durchgeführt wird. In jeder Generation werden neue Lösungen erstellt. Entsprechend der Fitness werden Individuen (Eltern) ausgewählt (Selektion), die neue Individuen (Nachkommen) produzieren sollen. Die Produktion der neuen Individuen erfolgt durch Anwendung von Rekombination und Mutation. Die Rekombination erstellt Nachkommen und diese werden dann durch Mutation wieder verändert. Die neuen Individuen werden erneut durch die Zielfunktion bewertet und in die Population wieder eingefügt. Das Wiedereinfügen kann durch eine Umweltselektion erfolgen in der einzelne Individuen aus der Elternpopulation oder die gesamte Elternpopulation durch die neuen Individuen ersetzt werden. Zum Schluss entscheidet ein Abbruchkriterium ob das Ziel erreicht wurde oder der Prozess der Erstellung einer neuen Population von vorn beginnen soll [POHLHEIM 2000]. Die prinzipielle Vorgehensweise bei Evolutionären Algorithmen wird nochmals im folgenden Pseudocode gezeigt [NISSEN 1997]. 1. Wähle Strategieparameterwerte 2. Initialisiere Ausgangspopulation P(0) 3. t <- 0 4. Bewerte Individuen der Ausgangspopulation 5. Wiederhole (Generationszyklus) 6. t <- t+1 7. Selektion (Auswahl der Eltern) 8. Replikation (Nachkommen generieren) 9. Variation 3 10. Bewerten der Nachkommen 11. Bilden der neuen Population 12. bis tmax erreicht ist oder eine andere Abbruchbedingung erfüllt ist 13. Ausgabe der Ergebnisse 14. Stop 3 Verfahren und Operatoren evolutionärer Algorithmen Aufbauend auf dem allgemeinen Ablaufschema eines evolutionären Algorithmus werden nun die wichtigsten Verfahren und Operatoren eines evolutionären Algorithmus vorgestellt. 3.1 Initialisierung der Individuen Zu Beginn eines EA werden die Individuen der Anfangspopulation erstellt. Im Allgemeinen werden sie willkürlich aus dem vorgegebenen Suchraum ausgewählt. Sind allerdings Vorkenntnisse über das Optimierungsproblem in Form einiger bekannter guter Lösungen (Individuen) gegeben, so können und sollten sie in die Optimierung mit aufgenommen werden [POHLHEIM 2000]. Weiterhin können Ergebnisse anderer Optimierungsverfahren zur Initialisierung der Anfangspopulation verwendet werden. 3.2 Population In EA bezeichnet die Population eine Menge von Lösungskandidaten (Individuen). Diese Individuen können in der Population mehrfach vorkommen. Demnach ist die Angabe der Häufigkeit für jedes Individuum notwendig. Populationen werden üblicherweise als Tupel repräsentiert auch wenn sie nicht sortiert sind. Individuen können reellwertig als Vektoren oder binär als Null-Eins-Folgen dargestellt werden. 3.3 Fitness Jedem Individuum der Population wird eine Fitness zugewiesen. Sie wird allgemein errechnet aus dem Zielfunktionswert des Individuums und den Zielfunktionswerten aller anderen Individuen der Population. Gemäß dieser Fitness werden die Individuen (Eltern) ausgewählt die neue Individuen (Nachkommen) produzieren sollen. Die Fitness ist eine Aussage über die Güte einer Lösung und damit ein Vergleichskriterium zu anderen Lösungen. Sie soll die Evolution zu den besseren Lösungen im Suchraum führen [POHLHEIM 2000]. 3.4 Selektion Die Selektion legt fest, welche Individuen als Eltern für die Fortpflanzung ausgewählt werden. Die Auswahl erfolgt entsprechend ihrer Fitness. Das geläufigste Verfahren zur Auswahl von Individuen ist die Rouletteselektion. Hierbei werden die Individuen 4 einzelnen Abschnitten einer Linie zugeordnet. Die Länge eines jeden Abschnittes ist gleich der Fitness des Individuums. Danach wird eine Zufallszahl generiert, die sich im Bereich von null und der Länge der Linie gleichverteilt. Das Individuum wird ausgewählt, in dessen Abschnitt die Zufallszahl zeigt. Dieser Ablauf wird nun solange wiederholt bis alle Individuen ausgewählt sind. Damit ist die Rouletteselektion ein stochastisches Auswahlverfahren. Weitere Verfahren sind stochastic universal sampling, Turnierselektion oder Trunkation-Selektion [POHLHEIM 2000]. 3.5 Rekombination Nach der Selektion der Eltern erfolgt die Rekombination. Hierbei werden Nachkommen erzeugt indem man die Information der Eltern miteinander kombiniert. Es gibt verschiedene Verfahren zur Rekombination. Sie richten sich zum Einen nach der Repräsentation der Variablen in den Individuen. Die Variablen können reell, ganzzahlig oder binär sein. Zum Anderen entscheidet die Art der Zielfunktion über die Wahl des jeweiligen Verfahrens. Die Arten der Zielfunktion sind Parameteroptimierung und kombinatorische Optimierung. 3.6 Mutation Die Mutation findet nach der Rekombination statt. Die Nachkommen, die durch Rekombination der Eltern erzeugt wurden, werden in diesem Schritt einer Mutation unterzogen. Dies geschieht durch eine geringe Veränderung der Variablen der Nachkommen. Welche Verfahren zur Mutation gewählt werden, hängt wieder von der Repräsentation der Variablen und der Art der Zielfunktion ab. 3.7 Wiedereinfügen Nachdem die Produktion der Nachkommen durch Rekombination und Mutation und die Bewertung durch die Anwendung der Zielfunktion abgeschlossen ist, müssen die Nachkommen wieder in die Population eingefügt werden. Das Wiedereinfügen entscheidet darüber, wie viele und welche Nachkommen in die Population eingefügt werden und welche Individuen der Population durch die einzufügenden Nachkommen ersetzt werden. 3.8 Abbruchkriterium Ein Evolutionärer Algorithmus läuft solange bis ein definiertes Abbruchkriterium erfüllt wird. Das Kriterium sollte nach Möglichkeit so definiert sein, dass die Optimierung erst beendet wird, wenn ein ausreichend gutes Ergebnis erreicht wurde und nicht mehr Berechnungen durchgeführt werden, als notwendig zur Erreichung des Ziels. Abbruchkriterien werden unterschieden in direkte- und abgeleitete Kriterien. Direkte Abbruchkriterien ergeben sich sofort aus dem Zusammenhang der Optimierung. Ein Kriterium dieser Art greift, wenn eine maximale Anzahl von Generationen bzw. maximale Anzahl an Zielfunktionsberechnungen durchgeführt werden oder die maximale Rechenzeit oder ein „globales“ Optimum erreicht wird. Abgeleitete Kriterien ergeben sich aus der Berechnung von Hilfsgrößen. Beispielsweise werden aus allen 5 Zielfunktionswerten der aktuellen Generation deren Standardabweichung berechnet und mit dem vorgegebenem Abbruchwert verglichen. Erreicht der berechnete Wert den vorgegebenen Abbruchwert, so wird die Optimierung beendet.Weitere Hilfsgrößen neben der Standardabweichung sind „laufender Mittelwert“, „GuterSchlechtester“, „Phi“ und „Kappa“ [POHLHEIM 2000]. Bei der Anwendung Evolutionärer Algorithmen ist das am häufigsten verwendete Abbruchkriterium die maximale Anzahl von Generationen. Der Vorteil dieses Kriteriums ist die gute Überschaubarkeit und der garantierte Abbruch der Optimierung. Gleichzeitig lässt sich das Ende des Optimierungslaufes vorhersagen. Im Gegensatz ist die Entwicklung der abgeleiteten Abbruchkriterien während eines Optimierungslaufes fast nie genau vorhersehbar. 4 Standardalgorithmen In diesem Kapitel werden die vier Standardalgorithmen Genetische Algorithmen, Genetische Programmierung, Evolutionsstrategien und Evolutionäre Programmierung vorgestellt. Zunächst wird die historische Entwicklung dieser Standardalgorithmen erläutert. Genetische Algorithmen gehen auf Arbeiten von John Holland in den 60er Jahren zurück. Das Ziel von Holland war, Mechanismen adaptiver Systeme zu erklären und in Form von Genetischen Algorithmen auf Computern zu implementieren. Dabei diente ihm die natürliche Evolution als Vorbild. Heute sind Genetische Algorithmen in Forschung und Anwendung die zahlenmäßig dominierenden Verfahren der Evolutionären Algorithmen. Evolutionäre Programmierung geht auf Arbeiten von L.J. Fogel, A.J. Owens und M.J. Walsh Mitte der 60er Jahre zurück. Hier war das Ziel, mittels simulierter Evolution künstlich intelligente Automaten, heute als Agenten bezeichnet, zu erzeugen. Auch die Evolutionsstrategien entstanden in den 60er Jahren. Sie wurden von Rechenberg und Schwefel an der TU Berlin entwickelt. Damals ging es um Fragen der praktischen Optimierung im Rahmen ingenieurwissenschaftlicher Anwendungen. Schließlich beeinflusste J.R. Koza 1994 die Richtung der Genetischen Programmierung. Der Grundgedanke bestand darin, Lösungen in Form von Computerprogrammen zu repräsentieren, die dann mit den Mechanismen der Evolution verändert werden [NISSEN 1997]. Abbildung 2 zeigt die historische Entwicklung Evolutionärer Algorithmen grafisch. 6 Evolutionary Computing Genetische Algorithmen Evolutionäres Programmieren Holland (1962) Fogel, Owens, Walsh (1965) Evolutionsstrategien Rechenberg, Schwefel (1969) Genetisches Programmieren Koza (1994) Abbildung 2: Historische Entwicklung Evolutionärer Algorithmen Im Folgenden werden die Standardalgorithmen in einer Basisform dargestellt, die als Ausgangspunkt bei der Entwicklung eines leistungsfähigen Lösungsverfahrens zu sehen ist. 4.1 Genetische Algorithmen Im Folgenden wird ein Grundkonzept eines Genetischen Algorithmus vorgestellt. Genetische Algorithmen arbeiten oft mit der binären Lösungsrepräsentation. Damit ist die Repräsentation eines Individuums nicht immer identisch zur Repräsentation des zu lösenden Problems. Probleme, deren Variablen reelle oder ganzzahlige Zahlen sind, werden in eine binäre Repräsentation umgewandelt. Dazu werden verschiede Kodierungen eingesetzt. Üblicherweise sind es die binäre und die gray Kodierung [WEICKER 2002]. Jedes Individuum ist ein String bestehend aus einer Menge von Bits. Jeder String unterteilt sich außerdem in eine bestimmte Anzahl von Segmenten, die jeweils in Verbindung zu einer Variablen des Optimierungsproblems stehen. Damit enthält jedes Segment den Wert einer Entscheidungsvariablen des Optimierungsproblems in binär codierter Form. Die einzelnen Bits auf dem String werden als “Gene” und ihre Ausprägung als “Allel” bezeichnet [NISSEN 1997]. In Abbildung 3 wird die binäre Lösungscodierung beim Genetischen Algorithmus grafisch dargestellt. Die Initialisierung beim Genetischen Algorithmus erfolgt indem eine Anfangspopulation von Individuen stochastisch erzeugt wird. Dies geschieht indem die Bits aller Individuen der Population stochastisch unabhängig voneinander und mit gleicher Wahrscheinlichkeit entweder auf den Wert Eins oder Null gesetzt werden. Danach erfolgt die Bewertung der Ausgangslösungen um im anschließenden Selektionsschritt nach der Güte vergleichen zu können. Dies erfolgt durch Anwendung der Fitnessfunktion. Nach der Bewertung werden aus der aktuellen Population Individuen stochastisch gezogen und als Eltern ausgewählt. Es können Duplikate entstehen, da „mit Zurücklegen“ gezogen wird. Die Selektionswahrscheinlichkeit eines Individuums hängt von dem Funktionswert des Individuums und der Summe der Funktionswerte 7 aller anderen Individuen ab. Diese stochastische Selektion wird als fitnessproportionale Selektion bezeichnet und entspricht der in Abschnitt 3.4 beschriebenen Rouletteselektion. Alle Individuen haben eine positive Selektionswahrscheinlichkeit und können damit Nachkommen zeugen. Diese Eigenschaft ist bei Selektionsformen bei Evolutionsstrategien und Evolutionärer Programmierung nicht gegeben. String (Individuum) codierter Wert von Entscheidungsvariable xj … 0 1 1 0 0 1 0 1 codierter Wert von Entscheidungsvariable xj+1 1 0 Gen 0 0 0 1 1 0 0 1 … Allel (Wert) Abbildung 3: Binäre Lösungscodierung beim Genetischen Algorithmus Nach der Selektion werden Nachkommen erzeugt. Dazu wird aus der Menge der Eltern, die durch die Rouletteselektion entstanden ist, ein Elternpaar mit gleicher Wahrscheinlichkeit und ohne Zurücklegen gezogen. Aus diesem Elternpaar entstehen im weiteren Verlauf durch den Variationsoperator Crossover und Mutation zwei Nachkommen. In Genetischen Algorithmen ist die Rekombination eher der primäre Operator und die Mutation mehr ein Hintergrundoperator [NISSEN 1997]. In einem Basis-Genetischem-Algorithmus wird der 1-Punkt-Crossover angewendet. Dieser ist die einfachste Abwandlung des Crossover. Neben dem 1-Punkt-Crossover gibt es Varianten wie, N-Punkt-Crossover, Uniform Crossover, Shuffel Crossover sowie den Diagonal Crossover [NISSEN 1997]. Bei dem 1-Punkt-Crossover wird zunächst auf Basis der a-priori festgelegten Crossover-Wahrscheinlichkeit entschieden ob der Crossover zum Einsatz kommt. Der empfohlene Wahrscheinlichkeitswert ist größer oder gleich 0,6. Zum Vergleich wählt man eine Zufallsvariable aus dem Intervall [0,1[. Demnach findet ein Crossover statt, wenn der Wert der Zufallsvariablen kleiner oder gleich der Crossover-Wahrscheinlichkeit ist. In dem Fall, dass kein Crossover stattfindet, wird das Elternpaar unverändert weiter an den Mutationsoperator gegeben. Andernfalls wird der Crossover durchgeführt. Abbildung 4 zeigt den 1-Punkt-Crossover grafisch. Es wird eine Schnittposition gleichverteilt zufällig in den Elternindividuen ausgewählt. Nach dem Schnittpunkt werden die Variablen zwischen den Elternindividuen zur Bildung zweier Nachkommen ausgetauscht. Im nächsten Schritt erfolgt die Mutation vgl. Abbildung 5. Hierbei werden die Bits eines Individuums mit einer Mutationswahrscheinlichkeit, gleichverteilt zufällig, ausgewählt und invertiert. 8 Eltern Nachkommen Abbildung 4: 1-Punkt-Crossover vor der Mutation 1 0 0 1 0 nach der Mutation 1 1 1 0 0 0 0 1 1 Abbildung 5: Mutation beim Genetischen Algorithmus Der letzte Schritt beim Erzeugen neuer Nachkommen ist das Bewerten und das Ergänzen der neuen Population. Die nach der Mutation gewonnen Individuen werden mit der Fitnessfunktion bewertet und in die anfangs noch leere neue Population übernommen. Enthält diese Population genauso viele Elemente wie die bisherige Population, wird diese vollständig ersetzt. Der Genetische Algorithmus endet wenn ein Abbruchkriterium erfüllt wird, andernfalls wird eine neue Population generiert. Als resourcenabhängige Abbruchkriterien können gewählt werden: „Maximale Anzahl an Generationen erreicht“, „maximale Rechenzeit erreicht“. Andere Abbruchkriterien, die sich auf die erreichte Lösungsqualität beziehen sind: „Nach längerer Zeit wurde keine Verbesserung mehr beobachtet“, „Individuen der Population stimmen an vielen Bitpositionen überein (Ineffektivität des Crossover)“. Als Ergebnis bekommt der Nutzer die beste während des gesamten Laufes gefundene Lösung. 4.2 Genetische Programmierung Die Genetische Programmierung ist im Zusammenhang mit den genetischen Algorithmen entstanden. Ähnlich wie bei den genetischen Algorithmen ist die Rekombination der Hauptoperator während die Mutation nur als Hintergrundoperator wirkt. Charakteristisch für die Genetische Programmierung ist, dass die Repräsentation keine feste vorgeschriebene Größe hat. Die Individuen und Strukturen sind Computerprogramme unterschiedlicher Größe und Komplexität, die 9 aus Funktionen, Variablen und Konstanten bestehen. Nachfolgend wird das Grundkonzept der Genetischen Programmierung vorgestellt. Die Initialisierung Genetischer Programmierung erfolgt wie bei Genetischen Algorithmen indem eine Anfangspopulation von Individuen stochastisch erzeugt wird. In dem Fall sind die Individuen Programme. Sie werden gebildet aus den Elementen einer Menge problempassender elementarer Funktionen, dem sogenannten „function set“, sowie den Elementen einer Menge von problempassender Variablen und Konstanten, dem sogenannten „terminal set“ [NISSEN 1997]. Die Individuen werden allgemein als Syntaxbäume dargestellt. Diese können beliebige mathematische Ausdrücke oder auch beliebige Programme, beispielsweise durch die Verwendung der Sprache LISP, darstellen. Abbildung 6 zeigt ein Programmbaum und den zugehörigen LISP Ausdruck. * + 2 5 6 <=> (*(+254)6) 4 Abbildung 6: Programmbaum mit zugehörigem LISP-Ausdruck Jedes Programm wird generiert, indem man mit gleicherWahrscheinlichkeit zufällig eine Funktion aus dem function set auswählt und sie zur Wurzel des Programmbaumes bestimmt. Danach wird ein Element stochastisch und mit gleicher Wahrscheinlichkeit aus der Vereinigung des function set und des terminal set ausgewählt und zum Programmbaum hinzugefügt. Ist das Element eine Variable bzw. eine Konstante, ist der Generierungsprozess für diesen Ast beendet. Handelt es sich dagegen um eine weitere Funktion, so wird der Generierungsprozess rekursiv fortgesetzt. Zusätzlich wird noch eine maximale Baumtiefe festgelegt, um komplexe Bäume zu vermeiden [NISSEN 1997]. Im nächsten Schritt des Laufs von Genetischer Programmierung geht es um die Bewertung der Ausgangslösungen. Dies geschieht wieder mit einer Fitnessfunktion wie bei den Genetischen Algorithmen beschrieben. Im Allgemeinen sind die Fitnesswerte der Anfangspopulation bei Genetischer Programmierung ziemlich schlecht. Trotz alledem liegen bessere und schlechtere Lösungen vor, die sich gegeneinander abgrenzen. Nach dem Bewerten der Programme soll eine neue Population gebildet werden. Dazu werden die drei Schritte Operatorauswahl, stochastische Selektion und Replikation und Operatoranwendung und Ergänzen der neuen Population so oft durchlaufen, bis die Anzahl der Programme der zunächst leeren neuen Population 10 der Anzahl der Programme der aktuellen Population entspricht. Bei der Operatorauswahl geht es darum, probabilistisch zu entscheiden, welcher der beiden evolutionären Operatoren Reproduktion und Crossover zum Einsatz kommt. Die Auswahl der Individuen erfolgt dann auf Basis der Fitnesswerte und kann mittels der fitnessproportionalen Selektion erfolgen. Die ausgewählten Programme verbleiben gleichzeitig in der alten Population und es wird ausschließlich auf Duplikaten gearbeitet. Dieses Muster entspricht dem Ziehen mit Zurücklegen. Schließlich wird der zuvor ausgewählte Operator auf die eben selektierten Programmduplikate angewendet. Der Replikationsoperator kopiert ein Individuum unverändert in die neue Population. Der Crossover wird in Abbildung 7 grafisch aufgezeigt. In diesem Fall werden zwei Elternindividuen gewählt und in beiden stochastisch und unabhängig voneinander ein Crossover-Punkt bestimmt. Anschließend werden die mit dem Crossover-Punkt als Wurzelknoten beginnenden Teilbäume, zwischen den Eltern vertauscht und man erhält zwei Nachkommen. Diese werden hinsichtlich ihrer Fitness bewertet und zur neuen Population hinzugefügt. Eltern * + + 2 5 6 * 4 + 8 Nachkommen 5 7 6 + 8 4 + * 4 3 5 * + 2 * 5 * 3 4 7 Abbildung 7: Crossover bei Genetischer Programmierung Überschreitet ein Nachkomme die maximal erlaubte Baumhöhe, so wird dieser verworfen. Als Ersatz wird der dazugehörige Elter in die neue Population übernommen. Dieser Ablauf der Erstellung neuer Populationen wird so lange wiederholt bis ein vordefiniertes Abbruchkriterium erfüllt ist. Auf diese Weise entstehen aus den 11 zufälligen Ausgangslösungen schrittweise bessere Lösungen des gegebenen Anwendungsproblems. 4.3 Evolutionsstrategien Evolutionsstrategien werden Überwiegend zur Optimierung kontinuierlicher Entscheidungsvariablen verwendet. Im Folgenden wird ein Grundkonzept von Evolutionsstrategien vorgestellt, dabei soll eine Funktion F von n kontinuierlichen Entscheidungsvariablen optimiert werden: F : Rn → R Bei den Evolutionsstrategien werden im Allgemeinen Vektoren reeller Zahlen zur Lösungsrepräsentation verwendet. Jedes Individuum enthält Werte für alle Entscheidungsvariablen und eine bzw. mehrere Standardabweichungen, die für die Mutation von Bedeutung sind. Im Folgenden wird der Fall betrachtet, dass nur mit einer Standardabweichung σ gearbeitet wird. Die Initialisierung erfolgt durch die Erzeugung einer Anfangspopulation von µ Individuen. Dies kann für jede Entscheidungsvariable stochastisch auf Basis einer Gleichverteilung innerhalb definierter Ober- und Untergrenzen erfolgen. Ist die Initialisierungsphase abgeschlossen, so werden die Individuen der Anfangspopulation bewertet, indem jedem Individuum ein Fitnesswert zugeordnet wird. Nach der Bewertung der Lösungen folgt das Erzeugen neuer Nachkommen. In der Grundform der Evolutionsstrategien werden in einer Generation, aus µ Eltern λ Nachkommen erzeugt. Allgemein werden zunächst Eltern wiederholt ausgewählt, dies entspricht dem „Ziehen mit Zurücklegen“. Danach werden ihre Komponenten rekombiniert und der entstehende Nachkomme anschließend mutiert. Die nächsten vier Schritte werden zur Entstehung einer neuen Population λ-mal wiederholt. Schritt 1: Aus der aktuellen Population wird stochastisch ein Elternpaar bestimmt. Dabei haben alle Individuen die gleiche Selektionswahrscheinlichkeit. Schritt 2: Die Bestandteile der Elternvektoren werden rekombiniert. Dies kann beispielsweise mit der diskreten Rekombination durchgeführt werden. Dabei wird entweder der Wert des einen oder des anderen Elters mit gleicher Wahrscheinlichkeit gewählt und an den Nachkommen vererbt. Abbildung 8 zeigt die diskrete Rekombination grafisch. 12 Eltern 3,0 1,2 5,3 Nachkomme 2,4 0,6 3,0 2,3 4,0 0,8 6,2 4,0 5,3 6,2 0,5 0,5 Abbildung 8: Diskrete Rekombination Schritt 3: In diesem Schritt wird der Nachkomme mutiert. Zunächst wird die Standardabweichung σ durch Multiplikation mit einer logarithmisch normalverteilten Zufallszahl verändert. Anschließend wird zum Wert jeder Entscheidungsvariablen des Individuums eine normalverteilte Zufallsgröße mit Erwartungswert 0 und der veränderten Standardabweichung hinzuaddiert. Daraus folgt, dass kleine Veränderungen eine größere Wahrscheinlichkeit als große Veränderungen haben. Schritt 4: Im letzten Schritt wird der neu erzeugte Nachkomme mittels der Fitnessfunktion bewertet und zur neuen, anfangs noch leeren Zwischenpopulation hinzugefügt. Sobald die eben beschriebenen vier Schritte λ-mal durchlaufen wurden, existiert eine Zwischenpopulation mit λ Nachkommen. Aus den λ Nachkommen werden nun die bezogen auf ihre Fitness µ besten Individuen zur neuen Population. Man nennt diese Selektionsstrategie auch die Komma-Selektion ((µ; λ)-Evolutionsstrategie). Bei dieser Selektionsart wird standardmäßig ein Verhältnis µ/λ von 1/7 bis 1/5 empfohlen [WEICKER 2002]. Daneben gibt es auch die Plus- Selektion ((µ+λ) Evolutionsstrategie). Hierbei werden nicht nur aus den Kindern sondern auch aus den Eltern die Individuen der nächsten Generation ausgewählt. Bei der Komma Selektion hat man jedoch keine Garantie, dass die beste bis dahin gefundene Lösung auch in der Schlusspopulation enthalten ist. Daher wird empfohlen die bisherige beste Lösung gesondert zu speichern und laufend zu aktualisieren. Dieser iterative Prozess der Erzeugung neuer Populationen wird solange fortgesetzt bis eine Abbruchbedingung erfüllt ist. Bei den Evolutionsstrategien können Abbruchkriterien resourcenabhängig definiert oder auch erfolgsorientiert formuliert sein. Erfolgsorientiert bedeutet in diesem Zusammenhang, dass über einen gewissen Zeitraum keine besseren Lösungen mehr erzielt werden können. In [NISSEN 1997] wird das abgeleitete Abbruchkriterium „Guter-Schlechtester“ für Evolutionsstrategien vorgeschlagen, dabei wird die Differenz zwischen dem Zielfunktionswert des besten und schlechtesten Individuums der aktuellen Generation berechnet. Liegen die Zielfunktionswerte nah bei einander, so terminiert der Algorithmus. 4.4 Evolutionäre Programmierung Die heutigen Formen von Evolutionärer Programmierung wurden zur Optimierung insbesondere kontinuierlicher Entscheidungsgrößen entwickelt [NISSEN 1997]. Sie basieren auf der Annahme, die Evolution auf einer eher verhaltensbestimmten Ebene 13 nachzubilden, d.h. es wird kein Wert darauf gelegt, die genetischen Strukturen zu berücksichtigen, sondern ist die Ähnlichkeit zwischen Nachkommen und Eltern von Interesse. Aus diesem Grund wird in evolutionärer Programmierung keine Rekombination verwendet. Stattdessen kommt die Mutation als einziger Suchoperator zum Einsatz. Im folgenden Grundkonzept der evolutionären Programmierung [NISSEN 1997] soll die Minimierung einer Funktion F von n kontinuierlichen Variablen als Optimierungsproblem gelten: F : Rn → R Als Lösungsrepräsentation für die Optimierung kontinuierlicher Variablen wird ein Vektor reeller Zahlen verwendet. Demnach besteht ein Individuum aus Vektorelementen, die den Werten der n Entscheidungsvariablen entsprechen. Die Initialisierung erfolgt, indem eine Anfangspopulation von µ Individuen stochastisch erzeugt wird. Dabei werden die Werte des Individuums auf Basis einer Gleichverteilung innerhalb definierter Ober- und Untergrenzen festgelegt. Die Individuen werden wieder bewertet, indem ihnen ein Fitnesswert zugewiesen wird. Die bewerteten µ Individuen bilden die Menge der Eltern. Es folgt das Erzeugen von Nachkommen. Dazu werden die nächsten Schritte µ-mal durchlaufen. 1. Schritt: Es wird eine Kopie vom ersten Elter erstellt (Replikation). 2. Schritt: Diese Kopie wird mutiert, indem ihr eine normalverteilte Zufallszahl mit Erwartungswert Null und dynamisch veränderter Standardabweichung dazu addiert wird. Die Standardabweichung der Zufallszahl hängt dabei vom Fitnesswert des Elters ab. Der global optimale Fitnesswert ist Null. Dabei gilt die Annahme, dass die Optimierung effektiver werden soll, indem man die Standardabweichung bei Annäherung an das Optimum verkleinert. 3. Schritt: Dem Nachkommen wird ein Fitnesswert zugeordnet. Danach wird er in die Zwischenpopulation aufgenommen. Nachdem die 3 Schritte µ-mal durchlaufen wurden, bilden Eltern und Nachkommen eine Zwischenpopulation vom Umfang 2 × µ. Aus dieser Population wird stochastisch die bessere Hälfte als neue Elternpopulation für die nächste Generation selektiert. Dazu werden Turniere ausgetragen, bei denen Eltern und Nachkommen paarweise gegen h Gegner antreten, wobei h eine nutzerdefinierte natürliche Zahl größer oder gleich 1 ist. Häufig wird für die Zahl h der Wert 0; 05 × µ gewählt [NISSEN 1997]. Die Gegner werden dann auf Basis einer Gleichverteilung stochastisch aus der Zwischenpopulation gezogen. Sieger und Verlierer eines Turniers werden durch paarweises Vergleichen der Fitnesswerte bestimmt. “Ein Individuum erzielt den Sieg, wenn sein Fitnesswert mindestens so gut ist wie der des Gegners”. Nach dem Wettkampf werden die Individuen nach der Anzahl ihrer Siege sortiert und die µ besten anhand dieser Rangfolge als neue Population von Eltern ausgewählt. Bei gleicher Anzahl von Siegen werden die Fitnesswerte verglichen und danach entschieden welches Individuum in die neue Population aufgenommen wird. Bei dieser Selektionsart wird immer garantiert, dass das beste Individuum immer gewinnt, im Gegensatz zur Selektion bei den Evolutionsstrategien. 14 Der Generationsprozess wird mit einem Abbruchkriterium gestoppt. Abbruchkriterien können wieder resourcenabhängig gewählt werden oder sich am erreichten Niveau der besten gefundenen Lösung richten. Im Allgemeinen ist das Ergebnis die beste während des gesamten Laufes gefundene Lösung. 4.5 Unterschiede und Gemeinsamkeiten der Standardalgorithmen Die Standardalgorithmen sind als Instanzen des in Kapitel 2.2 vorgestellten allgemeinen Ablaufschemas zu sehen. Grundsätzlich stimmen sie hier überein. Jedoch ergeben sich zwischen den Standardalgorithmen methodische Unterschiede, die Abbildung 9 wiedergibt. Abbildung 9: Methodische Unterschiede zwischen den Standardalgorithmen Alle diese Standardalgorithmen imitieren das Evolutionsgeschehen auf unterschiedlichsten Abstraktionsebenen. Genetische Algorithmen und Genetische Programmierung unterstreichen genetische Mechanismen auf der Abstraktionsebene des Chromosoms, d.h. auf der codierten Ebene der Lösungen. Demgegenüber bilden Evolutionsstrategien das Evolutionsgeschehen auf der decodierten Ebene ab. Die Evolutionäre Programmierung betrachtet schließlich die Evolution auf der Ebene ganzer Populationen bzw. Arten. Demzufolge nimmt der Abstraktionsgrad von Genetischen Algorithmen über Evolutionsstrategien zu Evolutionärer Programmierung hin zu. 5 Fazit Evolutionäre Algorithmen bieten verschiedene Verfahren und Operatoren zur Lösung komplexer Problemstellungen. Die Basisformen der Standardalgorithmen können beliebig erweitert werden und somit neben einer Fülle von Optimierungsansätzen, leistungsfähige Lösungsverfahren entwickeln. Praktische Erfahrungen zeigen, dass Evolutionäre Algorithmen, soweit sie an die Struktur der Problemstellung angepasst 15 wurden, zuverlässige Lösungsverfahren für komplexe Optimierungsprobleme sind. Viele Optimierungsverfahren sind von einem Startpunkt der Optimierung abhängig. Bei Evolutionären Algorithmen hingegen verringert sich diese Abhängigkeit durch den Populationsansatz und die stochastischen Komponenten. Ein großer Vorteil von Evolutionären Algorithmen ist, dass sie sich sehr gut mit lokalen Verbesserungsverfahren kombinieren lassen. Es können nichtevolutionäre Komponenten in Evolutionäre Algorithmen integriert werden. Zusätzlich bestehen vielfältige Kombinationsmöglichkeiten mit künstlichen Neuronalen Netzen, regelbasierten Systemen und Fuzzy-Systemen. Auf der anderen Seite sind Evolutionäre Algorithmen oft rechenintensiv. Meistens durchlaufen sie viele Generationen um gute Lösungen zu finden. Alle Formen Evolutionärer Algorithmen benötigen außerdem eine große Anzahl von Zufallszahlen. Auch das erfordert Rechenzeit. Optimierungsanwendungen mit hoher Komplexität sowie auch mit stochastischen Einflüssen sind prinzipiell als geeignet für Evolutionäre Algorithmen anzusehen. Einen weiteren geeigneten Anwendungsbereich für Evolutionäre Algorithmen bilden die kombinatorischen Optimierungsprobleme. Zusätzliche Anwendungsmöglichkeiten gibt es im Rahmen lernender Classifier-Systeme, sowie im Bereich von Artificial Life. Literatur [DE JONG 2006] DE JONG, KENNETH A. (2006), Evolutionary Computation: A Unified Approach. A Unified Approach MIT Press. [GERDES 2004] GERDES, INGRID; KLAWONN, FRANK; KRUSE, RUDOLF (2004). Evolutionäre Algorithmen: Genetische Algorithmen- Strategien und Optimierungsverfahren- Beispielanwendungen. Vieweg +Teubner, Wiesbaden. [NISSEN 1997] NISSEN, VOLKER (1997). Einführung in evolutionäre Algorithmen: Optimierung nach dem Vorbild der Evolution. Vieweg, Braunschweig. [POHLHEIM 2000] POHLHEIM, HARTMUT (2000). Evolutionäre Algorithmen. Springer-Verlag, Berlin Heidelberg. [WEICKER 2002] WEICKER, KARSTEN (2002). Evolutionäre Algorithmen. B.G. Teubner Stuttgart, Leipzig, Wiesbaden. 16