T - Allgemeines - Hochschule RheinMain
Werbung

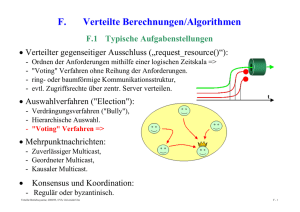
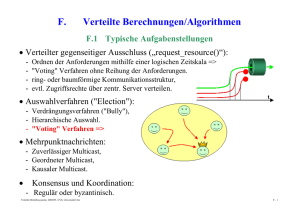
Kap. 9: Verteilte Transaktionsmechanismen 91 9.1 Einführung 9.2 Transaktionskonzept 93 9.3 Stellenlokale Commit Commit-Verfahren Verfahren 9.4 Das 2-Phasen Commit-Protokoll 95 9.5 X/O X/Open Distributed Di t ib t d Transaction T ti Processing P i © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-1 9.1 Einführung • Neues Problem bei der Entwicklung verteilter Anwendungen – Ausfall von einzelnen Komponenten des verteilten Systems (partial failure property) ⇒ komplexe Fehlersituationen in verteilten Anwendungsprogrammen • Motivation für Transaktionen – Atomare Aktionen als Erweiterung des DB-Tansaktionskonzepts zu allgemeinem Programmierkonstrukt – Reduktion der Komplexität der Anwendungsprogrammierung in Gegenwart von Fehlern und Nebenläufigkeit – Bessere Einsicht in die Wirkungsweise eines Programms – Automatisches Backward Error Recovery, Kombination mit Forward Error Recovery-Verfahren möglich © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-2 9.2 Transaktionskonzept • Eine Transaktion ist die Zusammenfassung einer Menge von Aktionen (Operationen auf log. Betriebsmitteln) mit folgenden Eigenschaften (ACID): – Atomicity = Atomarität im Fehlerfall (Alles-oder-Nichts): » T Transaktion kti entweder t d vollständig ll tä di ausgeführt füh t oder erscheint, als ob nie begonnen » Kein Zwischenzustand zwischen Anfangs- und Endzustand sichtbar – Consistency = Konsistenz: » Allgemein: Erfüllung aller Anwendungs-Constraints g Verhaltens » Erreicht durch Serialisierbarkeit des nebenläufigen (vgl. Datenbanken) (Schwächeres Kriterium als Determiniertheit) – Isolation: » Verhalten jeder Transaktion als ob "allein allein auf der Welt Welt" – Durability= Dauerhaftigkeit (Permanenz der Wirkung): » Wirkung abgeschlossener Transaktionen geht nicht verloren (selbst bei Auftreten aller erlaubten Fehler eines Fehlermodells) © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-3 Bemerkungen 9.2 • Isolierte Behandlung des Abbruchs einzelner Transaktionen – oft als Transaktionseigenschaft angesehen – ist jedoch Konsequenz einer strategischen Entscheidung im Spektrum Recovery ↔ Synchronisation (vgl nicht (vgl. nicht-striktes striktes 2 2-Phasen-Locking) Phasen Locking) – Nicht-isoliertes Recovery führt zu kaskadierenden Aborts und erfordert zur korrekten Behandlung das Halten eines Abhä i k it Abhängigkeitsgraphen h (R (Recovery-Graph) G h) • Transaktionen beinhalten vorgeplante Recovery-Linien © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-4 Lokale / Verteilte Transaktionen • Lokale Transaktion 9.2 • Zustandsdiagramm – Wirkung auf einzelnes Rechensystem beschränkt b i begin active commit abort committed • Verteilte V t ilt T Transaktion kti – Wirkung auf mehreren Stellen eines verteilten Rechensystems © R. Kröger, Hochschule RheinMain aborted ? im weiteren zu entwickeln Verteilte Systeme 9-5 Fehlermodell 9.2 • Fehlermodell beschreibt alle vorhergesehenen Fehler, auf die ein System geordnet reagiert, alle anderen heißen Katastrophen. • Transaktionsfehler (transaction abort): – Zurücksetzen einzelner Transaktionen, z.B. durch » Expliziter Abbruch durch Benutzer pp p g » Fehler im Applikationsprogramm » als Folge einer Deadlockauflösung • Stellenfehler (site failure): – Ausfall eines beteiligten Rechensystems, z.B. durch » Transiente oder permanente Hardware-Fehler (auch Stromausfall) y mit reboot » Betriebssystemabsturz – Alle laufenden Prozesse stürzen ab – Alle Transaktionen im Zustand active gehen in den Zustand aborted über © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-6 Fehlermodell (2) 9.2 • Medienfehler: – Nicht-behebbarer Fehler auf nicht-flüchtigem Speichermedium, Speichermedium das von Transaktionsverarbeitung genutzt wird, z.B. » Magnetplatte (genutzt für Speicherung der log. Daten) » Magnetband M tb d (genutzt ( t t für fü Logging) L i ) – Standardbehandlung durch stabilen Speicher (redundante Speicherung auf mehreren Medien, z.B. Spiegelplatten, RAID, ...) – hier nicht weiter betrachtet • Kommunikationsfehler: – F Fehler hl im i Nachrichtensystem N h i ht t führen füh zum Verlust V l t von Nachrichten – Partitionierung: Zerfall des Netzes in mehrere isolierte Teilnetze © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-7 Flache / Geschachtelte Transaktionen 9.2 • Flache Transaktionen – klassisches Modell aus DBKontext – Transaktion involviert Menge von Objekten (log. (log Betriebsmitteln) – Transaktionen können Objekte gemeinsam nutzen ( (geregelt lt durch d h Concurrency C Control- Mechanismen) TA1 TA2 involvierte Objekte – Transaktionen können nicht geschachtelt werden © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-8 Flache / Geschachtelte Transaktionen (2) 9.2 • Geschachtelte Transaktionen (Nested Transactions) – Eine Transaktion kann (auch zu einem Zeitpunkt) innere Transaktionen (Subtransaktionen) besitzen Top-Level T L l Transaktion – isolierte Zurücksetzbarkeit innerer Transaktionen: Abort einer inneren TA führt zu Exception beim Vater (nicht zu dessen Abbruch!) – Abort einer TA führt zum Abort aller i inneren TAen TA – Commitment relativ zum Vater (endgültig erst mit Commitment der Top-Level TA) TA1 TA11 TA12 TA121 TA122 – Nebenläufigkeitskontrolle auf jeder Schachtelungsebene g © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-9 9.3 Stellenlokale Commit-Verfahren • Verfahren zur lokalen Bereitstellung von Atomarität im Fehlerfall und Permanenz der Wirkung: – Intention Lists (Lampson 1981) – Shadowing (Gray 1981) – Write-Ahead Logging © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-10 Intention Lists 9.3 • Vorgehensweise – Beabsichtigte Veränderungen auf Datenobjekten werden in Liste gesammelt (d.h. Arbeiten auf Kopien der Originaldaten) – Liste wird in stabilen Speicher geschrieben – Entscheidung (committed-aborted) treffen – Falls aborted: Liste verwerfen – Falls committed: Originale der Objekte in nicht-flüchtigem Speicher aktualisieren. • Nach Stellenfehler – Analysieren der Listen in stabilem Speicher – Falls keine Liste vorhanden oder Liste unvollständig ((Stellenfehler beim Schreiben der Liste): ) Transaktion ist aborted und Liste löschen – Falls Liste vollständig: Aktualisieren der Objekte gemäß Liste (idempotent) und abschließend Löschen der Liste © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-11 Shadowing 9.3 • Vorgehensweise – Nichtflüchtiger Speicher als Baumstruktur mit Verweisblöcken (entsprechend UNIXDateisystem) angenommen – After Images aller Blöcke als Shadow ShadowVersion bis zur Wurzel anlegen – Entscheidung (committed-aborted) treffen d durch h atomaren t Pointer-Swap P i t S in i RootR t Block (Schreiben eines Blockes) root atomic pointer swap – Falls aborted: Shadow-Struktur verwerfen – Falls committed: ehemalige OriginalBlöcke freigeben, Shadow-Blöcke sind jjetzt die Originale g • Nach Stellenfehler – Entweder alter Zustand oder neuer Z t d ist Zustand i t etabliert t bli t © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-12 Shadowing (2) 9.3 • Vorteile – Atomarer Zustandswechsel durch Schreiben eines/des Root-Blockes • Nachteile – keine Nebenläufigkeit von Commit-Vorgängen – Physische Anordnung der Datenblöcke zueinander geht durch Commit-Vorgänge Commit Vorgänge verloren, da Shadow-Blöcke Shadow Blöcke aus der Frei Frei-Liste Liste genommen werden müssen. © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-13 Write-Ahead Logging 9.3 • Log-Grundlagen – Log besteht logisch aus Folge von sogenannten Log Records variabler Länge identifiziert durch Log Sequence Number LSN (Byte Offset im Log-Strom analog TCP Sequenznummer) – Log ist gemeinsam genutzt innerhalb eines Knotens – Verkettung von zusammengehörigen Log-Einträgen eines Commit-Vorgangs – Realisierung des Logs in replizierten Dateien (stabiler Speicher) und mehreren Generationen von Log-Files – Übergeordnete Tabelle mit Log-Einträgen Log Einträgen und SQL-Zugriff SQL Zugriff in Datenbanken üblich Blockstruktur des Mediums ... LSN 1000 älter 2000 3800 4000 5000 Schreibrichtung © R. Kröger, Hochschule RheinMain 7000 7200 7400 jünger Verteilte Systeme 9-14 Write-Ahead Logging (2) 9.3 • Schreiben von Log-Einträgen – Nur sequentielles Schreiben der Log Files (hohe Performance) – Gepuffertes Schreiben von Log-Einträgen im Arbeitsspeicher – Forced Write eines Log-Eintrags erzwingt Ablage aller vorangegangenen Log-Einträge (mit kleinerer LSN) und Rückkehr aus der Operation, nachdem Block physich auf dem Medium steht • Lesen von Log-Einträgen – Nur im Fall von Stellenfehlern und evtl. bei Transaktionsfehlern (s u ) (s.u.) • Log-Verkürzung – Log kann logisch beliebig lang werden, aber Restart-Dauer nach Stellenfehler muss begrenzt werden – Nutzung von Checkpoints © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-15 Write-Ahead Logging (3) 9.3 • Nutzung von Log-Einträgen im Rahmen des lokalen Commitments – Log Records einer Transaktion sind untereinander verkettet – Schreiben von Before Images (Undo Records) für alle Objekte, d deren persistenter i t t O Originalzustand i i l t d durch d h die di Transaktion T kti im i Zustand active geändert werden (Update in Place). – Schreiben von After Images (Redo Records) für alle erarbeiteten finalen Objektzustände der Transaktion – Ablegen eines finalen Outcome Records mittels Forced Write: » erzwingt Ablage aller zugehörigen Log-Einträge Log Einträge » erscheint dieser im Log, ist das Commitment vollzogen » kann auch als Flag im letzten Block realisiert sein • Write-Ahead W it Ah d Logging L i Protocol P t l – Gesichertes Schreiben von Log Records vor Modifikation des g persistenten Zustands originalen © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-16 Write-Ahead Logging (4) 9.3 • Behandlung von Transaktionsfehlern – (Eventuell) "Aborted" Aborted Outcome Record erzeugen und ablegen – Falls Before Records geschrieben wurden, deren Inhalte wieder als persistenten Objektzustand etablieren • Behandlung von Stellenfehlern – Lesen des Logs – Für alle nicht abgeschlossenen Transaktionen evtl. evtl vorhandene Before Images etablieren – Für alle Transaktionen mit vorhandenem "Committed" Outcome R Record d das d jeweils j il letzte l t t After Aft Image I aller ll Objekte Obj kt (irgendwann) (i d ) als persistenten Objektzustand etablieren (Idempotenz) © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-17 Write-Ahead Logging (5) 9.3 • Vorteile – Mehrere ineinander verzahnte Commit-Vorgänge können gleichzeitig stattfinden – Hohe I/O-Performance durch Buffering und Sequentielles Schreiben des Logs – Anordnung der Datenblöcke des persistenten Zustands bleibt erhalten (Update in Place) – Parallelisierung des Logs möglich – Nach Stellenfehler und anschließendem Neustart muss nur der Log analysiert werden – Log kann auch von Commit-Protokollen mitgenutzt werden (s.u.) © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-18 9.4 Das 2-Phasen Commit-Protokoll • Commit-Protokolle – dienen dazu, dazu in einer verteilten Umgebung die Commit/AbortEntscheidung einer Menge von Prozessen zu koordinieren – z.B. für Durchsetzung von Atomarität im Fehlerfall und Dauerhaftigkeit für verteilte Transaktionsumgebung – sind Spezialfälle sog. Konsensus-Protokolle (hier: ja/nein) • 2-P-C-Protokoll 2 P C Protokoll – ist das am weitesten verbreitete Protokoll – von hoher praktischer Bedeutung und auch in zahlreichen P d kt enthalten Produkten th lt – im weiteren besprochen • Allgemeinere Theorie – Mehrphasen-Commit-Protokolle (z.B. Skeen, 1981) – schwache / starke Terminierungsbedingungen führen zu bl ki blockierenden d / nichtblockierenden i h bl ki d Commit-Algorithmen C i Al ih © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-19 Eigenschaften eines Commit-Algorithmus • 9.4 Ein Commit-Algorithmus für eine Menge von Prozessen besitzt folgende Eigenschaften: 1. Alle Prozesse, die eine Entscheidung treffen, treffen die gleiche Entscheidung 2 Ei 2. Eine einmal i l getroffene t ff Entscheidung E t h id ist i t bindend bi d d für fü jeden j d Prozess und kann nicht widerrufen werden 3. Nur wenn alle Prozesse für Commit entscheiden, lautet die gemeinsame Entscheidung auf Commit, d.h. auch: sobald ein Prozess auf Abort entscheidet, muss die gemeinsame Entscheidung auf Abort lauten 4. Wenn zu einem Zeitpunkt alle aufgetretenen Fehler repariert sind und hinreichend lange keine neuen Fehler auftreten, erreichen die Prozesse eine gemeinsame Entscheidung. © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-20 Begriffe • 9.4 Fenster der Verwundbarkeit (des Commit-Protokolls) – Zeitspanne zwischen der lokalen Commit Commit-Enscheidung Enscheidung eines Prozesses und Kenntnis der Gesamtentscheidung – wird auch Unsicherheitsperiode des Prozesses (Uncertaincy Period)) g genannt • Blockierendes Protokoll – Protokoll sieht vor, dass ein Prozess die Reparatur eines Fehlers abwarten muss • Unabhängiges Recovery – Prozess kann nach einem Fehler eine Entscheidung treffen, ohne mit it anderen d Prozessen P zu kommunizieren k i i • Teilhaber (Participants) – Prozesse,, die Commit-Protokoll abwickeln • (vgl. auch eLearning-Modul "Verteilte Algorithmen") © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-21 Background • 9.4 Sätze: – Wenn Kommunikationsfehler oder Gesamtsystemfehler möglich sind, gibt es kein Commit-Protokoll, das keinen Prozess blockiert Bemerkung: nicht ausgeschlossen ist die Existenz eines nichtblockierenden Commit-Protokolls, wenn nur einzelne Stellen ausfallen – Kein Commit-Protokoll kann unabhängiges Recovery ausgefallener Prozesse garantieren Bemerkung: Es gibt kein Commit-Protokolls ohne Unsicherheitsperiode für Teilhaber © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-22 Grundlagen des 2-P-C-Protokolls 9.4 • J. Gray, 1978 • Blockierender Commit Commit-Algorithmus Algorithmus mit schwacher Terminierungseigenschaft ( ⇒ treten keine Fehler auf, treffen alle Prozesse irgendwann eine Entscheidung). • Rollen – Teilhaber /Teilnehmer – Koordinator als ausgezeichneter Teilhaber Teilhaber, der Abwicklung des Protokolls steuert Bemerkung: i.d.R. Teilhaber der Ursprungsstelle der Transaktion, d Commit-Vorgang der C it V iinitiiert itii t – Koordinator kennt alle Teilhaber – Teilhaber kennen nur ihren Koordinator, aber sich nicht gegenseitig • Nutzung von jeweils lokalem Log jedes Teilhabers zur Fortschreibung des Zustands des Commit-Vorgangs Commit Vorgangs © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-23 2-P-C-Protokoll • 9.4 Nachrichtenfluss (Normalfall ohne Fehler) K prepare (TID) T1 T2 ... Tn prepared (ok|failed) 1. Phase Abstimmung K 2. Phase Entscheidung commit | abort T1 T2 ... Tn done (optional) K © R. Kröger, Hochschule RheinMain K Koordinator Ti Teilhaber Verteilte Systeme 9-24 2-P-C-Protokoll (2) • 9.4 Zustandsdiagramm des Koordinators begin active K prepare wait decide(ok) abort b t decide(failed) committed aborted commit prepare (TID) Auffordern abort wait Warten auf Antworten T1 Tn prepared lokale Entscheidung des Koordinators K commit | abort Verbreiten Warten auf Bestätigung T1 Tn done (optional) done done © R. Kröger, Hochschule RheinMain Vergessen K Verteilte Systeme 9-25 2-P-C-Protokoll (3) • 9.4 Zustandsdiagramm der Teilhaber begin K active prepare (TID) prepare prepared prepared d ((ok) k) Fenster der Verwundbarkeit prepared d (f (failed) il d) abort b t committed T1 aborted done done © R. Kröger, Hochschule RheinMain Aktionen entsprechend Entscheidung ausführen Ende mitteilen Tn prepared d Warten auf Entscheidung des Koordinators wait commit lokales Vorbereiten K T1 commit | abort b t Tn done (optional) K Verteilte Systeme 9-26 2-P-C-Protokoll (4) • 9.4 Logging des Koordinators K TID: begin (T1 , ..., Tn) prepare p p (TID) ( ) Auffordern Warten auf Antworten entscheidet den Ausgang "forced write" TID: committed TID: aborted T1 Tn prepared Lokale Entscheidung des Koordinators K commit | abort Verbreiten Warten auf Bestätigung T1 Tn done (optional) TID: done © R. Kröger, Hochschule RheinMain Vergessen g K Verteilte Systeme 9-27 2-P-C-Protokoll (5) • 9.4 Logging der Teilhaber TID: begin (coord K) K prepare p p (TID) ( ) TID: after image TID: after image TID: after image "forced write" TID: prepared TID: committed TID: aborted Lokales Vorbereiten Aktionen entsprechend Entscheidung ausführen entsprechend bei einseitigem Abort Ende mitteilen Tn prepared Warten auf Entscheidung des Koordinators ! TID: done © R. Kröger, Hochschule RheinMain T1 K T1 commit | abort Tn done (optional) K Verteilte Systeme 9-28 2-P-C-Protokoll (6) • 9.4 zusammenfassendes Zustandsdiagramm für verteilte Transaktionen begin active prepare neuer Zustand prepared commit abort abort committed © R. Kröger, Hochschule RheinMain aborted Verteilte Systeme 9-29 2-P-C-Protokoll (7) 9.4 • Behandlung von Transaktionsfehlern – Übergang von aktiven Transaktionen in den Zustand aborted – unilaterale Abort-Entscheidung von Koordinator und jedem Teilhaber möglich » Koordinator sendet später abort, auch wenn alle Teilhaber mit prepared geantwortet haben » Teilhaber antworten auf prepare-Request des Koordinators mit prepared (failed) (failed). • Behandlung von Kommunikationsfehlern bei aktiven Transaktionen – Erkennung (wie auch anderer Vorkommnisse) durch Timeouts – Überführung in Transaktionsfehler mit Behandlung wie oben © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-30 2-P-C-Protokoll (8) 9.4 • Beispiel für Abort-Entscheidung des Koordinators K prepare (TID) Auffordern Warten auf Antworten T1 Tn prepared AbortEntscheidung des Koordinators Timeout K abort Verbreiten T1 © R. Kröger, Hochschule RheinMain Tn Verteilte Systeme 9-31 2-P-C-Protokoll (9) 9.4 • Beispiel für Abort-Entscheidung eines Teilhabers K Ti Timeout t prepare (TID) T1 Tn prepared (ok) Lokale Abort-Aktionen schon hier prepared (failed) K abort T1 © R. Kröger, Hochschule RheinMain Tn Verteilte Systeme 9-32 2-P-C-Protokoll (10) 9.4 • Behandlung eines Stellenfehlers des Koordinators – Vorgehensweise abhängig von Information im Log (a) TID: begin (T1 , ..., Tn) ⇒ abort-Entscheidung, Protokoll fortsetzen (b) TID: begin (T1 , ..., Tn) ⇒ wurde vor Stellenfehler bereits entschieden TID: committed TID: aborted (c) Protokoll fortsetzen: sende commit / abort-Nachricht an alle Teilhaber TID: begin (T1 , ..., Tn) TID: committed ⇒ nichts zu tun TID: done © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-33 2-P-C-Protokoll (11) 9.4 • Behandlung eines Stellenfehlers eines Teilhabers – Vorgehensweise ebenfalls abhängig von Information im Log (a) TID: begin (coord K) (b) TID: begin (coord K) ⇒ abort ⇒ abort b t TID: after image TID: after image (c) TID: begin (coord K) ⇒ keine unilaterale Entscheidung möglich TID: after image TID: after image TID: after image Nachfrage bei Koordinator K getDecision(TID) TID: prepared P t k ll fortsetzen Protokoll f t t © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-34 2-P-C-Protokoll (11) 9.4 • Behandlung eines Stellenfehlers eines Teilhabers (2) (d) TID: begin (coord K) TID: after image TID: after image TID: after image TID: prepared ⇒ unabhängiges Recovery möglich lokale commit / abort-Aktionen wiederholen Protokoll fortsetzen TID: committed TID: aborted (e) TID: begin (coord K) ... ⇒ nichts zu tun TID: done © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-35 Erweiterungen 9.4 • Coordinator Migration – Die Koordinator-Rolle wird einem hoch zuverlässigen Rechner übertragen – Damit wird Blockierung der Teilhaber bei Ausfall des Koordinators unwahrscheinlicher • Group Commitment – Gemeinsames Commitment mehrerer Transaktionen – Weniger forced write-Operationen – Durchsatzsteigerung bei geringfügig erhöhter Ausführungszeit d Protokolls des P t k ll • Kooperative Terminierung – Teilhaber kennen sich gegenseitig – Nach Stellenfehler kann Nachfrage bei anderen Teilhabern die Blockierung vermindern, falls jetzt Koordinator ausgefallen ist © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-36 Erweiterungen (2) 9.4 • Presumed Abort / Presumed Commit – Default-Wert für Ausgang der Transaktion angenommen angenommen, wenn kein spezifischer Outcome Record im Log vorhanden ist – Vereinfachungen bei Log-Verkürzung möglich • Dezentrales 2-Phasen-Commit-Protokoll – Kein zentraler Koordinator – Kommunikation der Teilhaber untereinander, untereinander z.b. z b vorteilhaft über Broadcast-Protokoll – Verringert Zeitkomplexität © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-37 9.5 X/Open Distributed Transaction Processing • X/Open – Historisches Industriekonsortium zur Förderung offener Systeme – Bildet 1996 zusammen mit Open Software Foundation (OSF) die Open Group • Modell für Transaktionsverarbeitung in offenen verteilten Umgebungen (OLTP) • Überwindung von Hersteller-spezifischen Lösungen der Transaktionssteuerung • Anwendung des 2-Phasen-Commit-Protokolls • Kommerziell ausgerichtet auf RDBMSe • Problem klassischer lokaler Datenbanksysteme – enge innere Verquickung der verschiedenen Funktionsbereiche – Unterstützung für verteilte Transaktionen erfordert Auftrennung zwischen Prepare-Aktivitäten p und Commit-Entscheidung g – Commit-Entscheidung muss auch extern getroffen werden können © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-38 Architekturüberblick 9.5 • Homogener Fall Verteilte Applikation begin commit abort TX Transaction Manager TM SQL ... XA Resource Manager Resource (RM) Manager Resource (RM) Manager RM SQL ... Resource Manager Resource (RM) Manager Resource (RM) Manager RM entfernter tf t Z Zugriff iff begin commit abort TX XA Transaction Manager TM 2-Phasen-Commit-Protokoll TM-spezifische TM spezifische Variante – RM kapseln log. Betriebsmittel (DB-Tupel, Dateien, Messages, Objekte, ...) – TM kapselt Transaktionssteuerung – für identische TMs, unterschiedliche RMs © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-39 Architekturüberblick (2) 9.5 • Heterogener Fall Verteilte Applikation begin commit abort SQL ... TX XA Transaction Manager SQL ... Resource Manager Resource (RM) Manager Resource (RM) Manager RM TX Resource Manager Resource (RM) Manager Resource (RM) Manager RM XA Transaction Manager entfernter tf t Z Zugriff iff TM A XA+ Communication Manager KM OSI TP Communication Manager KM begin commit abort TM B XA+ 2 P C Variante 2-P-C-Variante mit Coordinator Migration © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-40 Beispiele 9.5 • X/Open DTP-konforme Transaction Manager – Tuxedo » historischer De-Facto-Standard » von USL, jetzt BEA, jetzt Oracle » nur flache Transaktionen – Encina » unterstützt auch g genestete Transaktionen » nutzt OSF DCE » von Transarc (Ausgründung CMU), jetzt eingegliedert in IBM – CICS/6000 » CICS: IBM Host-Standard » Encina für AIX (RS 6000) – NCR Top End © R. Kröger, Hochschule RheinMain Verteilte Systeme 9-41 Beispiele (2) 9.5 • Transaction Manager in CORBA- und J2EE-Produkten – BEA Weblogic: Tuxedo – IONA Orbix: Encina – Heute i.d.R. in Applikationsserver mit integriert • X/Open DTP-konforme Resource Manager (XA-Schnittstelle) – Relationale DBMSe » historisch erstes System mit XA-Schnittstelle: Informix großen DB-Systemen y unterstützt » heute von allen g » selbst bei Microsoft (MS DTC) – Message Queueing Systeme » MQ Series S i » Swift MQ – Dateisysteme » ISAM XA (Gresham Computing) © R. Kröger, Hochschule RheinMain – ... Verteilte Systeme 9-42