Data-Mining-Cup 2012
Werbung

Hochschule Wismar
University of Applied Sciences
Technology, Business and Design
Fakultät für Ingenieurwissenschaften, Bereich EuI
Data-Mining
Data-Mining-Cup 2012
Eingereicht am:
von:
13. Mai 2012
Merten Kopp, Henry Köhler, Hans Fanter
Szenario
Das Thema der automatischen Preisoptimierung im E-Commerce gewinnt zunehmend an Bedeutung. Dies ist insbesondere der Tatsache geschuldet, dass sich mittels
intelligenter Preisfestlegungen deutliche Margensteigerungen erzielen lassen. Neben
den Standardalgorithmen, die Einzelpreisoptimierungen für prinzipiell jedes Produkt eines Online-Shops vorsehen, werden spezielle Algorithmen entwickelt, die u.
a. dem gewinnorientierten Verkauf kombinierter Produkte oder dem zügigen Abverkauf schnell verderblicher Ware dienen. Die Zeit ist nun reif, das Thema der
automatischen Preisoptimierung in den Fokus der DMC-Aufgabe zu rücken. Diese besteht im Jahr 2012 wieder aus einem Offline-, sowie einem Online-Teil, die
unabhängig voneinander bewertet werden.
Aufgabenstellung
Im Offline-Teil, der ersten Aufgabe, werden zu ausgewählten Produkten Preise und
zugehörige Abverkaufszahlen für einen konkreten Zeitraum vorgegeben. Mit Hilfe
dieser Daten soll ein Modell entwickelt werden, das die Zusammenhänge zwischen
den Daten beschreibt. Auf Basis dieses Modells erfolgt dann in einer Anwendungsphase die Prognose von Abverkaufszahlen. Sieger der ersten Aufgabe ist das Team,
welches die Abverkaufszahlen möglichst genau voraussagt.
2
Inhaltsverzeichnis
Inhaltsverzeichnis
1
2
3
Ausgangspunkt
4
Analyse der Trainingsdaten
5
2.1
2.2
5
6
Programm zur Visualisierung der Trainingsdaten . . . . . . . . . . . .
Vorgedanken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Theoretische Grundlagen
3.1
3.2
8
Probalistische Neuronale Netze . . . . . . . . . . . . . . . . . . . . . 8
Lineare Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4
Vorverarbeitung
11
5
Lösungsvarianten
12
5.1
5.2
5.3
6
Probabilistische neuronale Netze . . . . . . . . . . . . . . . . . . . . . 12
Mittelwert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Lineare Regression . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Ergebnisse
15
Literaturverzeichnis
18
Abbildungsverzeichnis
19
Inhalt des Archivs
20
3
Kapitel 1. Ausgangspunkt
1 Ausgangspunkt
Gegeben sind zwei Tabellen die sich in vier Spalten unterteilen. Es sind fortlaufend
Tage gelistet, deren Items mit ihrer Preisentwicklung und ihren Verkaufszahlen zugeordnet sind. Die erste Tabelle ist zu 100% konsistent und dient als Trainingsmenge
für das Testen anwendbarer Algorithmen. Bei der zweiten Liste sollen die Verkaufszahlen der einzelnen Artikel ausgehend von der Preisentwicklung und dem aus der
Trainingsmenge gewonnenem Wissen vorhergesagt werden.
Um dies zu bewerkstelligen ist eine Vielzahl von Verarbeitungsschritten notwendig, um letzten Endes Schlussfolgerungen und Analogien zwischen den bekannten
Daten ziehen zu können und diese auf die unbekannte Menge anzuwenden. In den
folgenden Kapiteln werden diese Vorgänge und Arbeitsschritte näher beleuchtet und
verdeutlicht.
4
Kapitel 2. Analyse der Trainingsdaten
2 Analyse der Trainingsdaten
Um Rückschlüsse auf anwendbare Verfahren erhalten zu können, ist es sinnvoll die
gegebenen Daten zu analysieren und gewisse Gemeinsamkeiten der unterschiedlichen
Datensätze herzuleiten. In den folgenden Sektionen wird auf eine frühe Analyse
dieser Daten eingegangen.
2.1 Programm zur Visualisierung der Trainingsdaten
Um eine Übersicht über die gegebenen Daten zu erhalten, wurde zunächst ein
simples Programm umgesetzt, welches die Trainingsdaten verarbeitet und in einem Diagramm visualisiert. Hierzu wurde die Trainingstabelle mit diversen StringOperationen bearbeitet, sodass die einzelnen Daten in einer Liste aus Structs bereitgestellt werden konnten. Ausgehend von dieser Liste wurden die Werte für jedes
Item normalisiert.
1
2
3
4
5
6
7
8
9
public struct Eintrag
{
public int id ;
public int tag ;
public double preis ;
public int anzahl ;
public double preisNorm ;
public double anzahlNorm ;
}
Das Visualisierungs-Tool umfasst folgende Funktionen:
• Graph Tag/Preis für ein/alle Item(s) (absolut / normalisiert)
• Graph Tag/Anzahl für ein/alle Item(s) (absolut / normalisiert)
Der Zweck des Programms ist es dem Anwender logische Zusammenhänge leichter
erkennbar zu machen bzw. aufgestellte Thesen zu festigen oder zu verwerfen. Dabei
soll das Programm nur als unterstützendes Hilfsmittel dienen.
5
Kapitel 2. Analyse der Trainingsdaten
Bild 2.1: DMC-Viewer: Preis(blau), Anzahl(rot) normalisiert
2.2 Vorgedanken
Erste Theorien liefen darauf hinaus, dass die Werte wiederkehrende periodische Sequenzen aufweisen. Bei vielen Items ist ein sieben Tage Rhythmus zu erkennen.
(siehe Bild 2.1) Ein erster Schritt war es nun die Tage anhand eines Java-Snippets
in KNIME in Wochen und Wochentage aufzuteilen.
Zudem ist um den 11. und 41. Tag eine erhöhte Anzahl von Käufen zu beobachten,
was wiederum auf den Tag der Gehaltsausschüttung hindeuten könnte. So könnte
man diese Tage als Monatsende bzw. -anfang deklarieren. Teilweise erhalten Arbeitnehmer ihr Gehalt auch in der Mitte des Monats. So ist um den 25. Tag ein lokales
Maximum der Ausgaben zu erkennen. Ausgehend davon sollten die berechneten Ergebnisse an diesen Tagen des Monats stärker gewichtet werden.
Des Weiteren ist anzunehmen, dass sich die Items in bestimmte Gruppen einteilen
lassen:
Items in Abhängigkeit des Preises
Diese Sorte von Items werden nur gekauft, wenn der Preis ein relativ niedriges Niveau erreicht hat bzw. kurz nach einem Preissturz. Dabei ist ein Offset einzuplanen,
6
Kapitel 2. Analyse der Trainingsdaten
welcher der Reaktion des Marktes entspricht.
Bedarfsabhängige Items
Diese Gruppe von Items werden immer nach Bedarf gekauft. Sie sollten eine geringe
Varianz in der Preisentwicklung zeigen und dazu stetig bleibende Verkaufszahlen
aufweisen.
Items in Abhängigkeit anderer Items
Es sollten Produkte zu finden sein, die immer mit anderen Produkten zusammen
gekauft werden. Dabei ist darauf zu achten, dass Produkte oftmals vergessen und
nachgekauft werden (+/- 2 Tage). Die Items dieser Itemsets sollten ähnliche Verkaufsentwicklung aufzeigen. Zudem sollte es möglich sein, dass sich diese Menge mit
den Mengen der bedarfsabhängigen bzw. preisabhängigen Items überschneidet.
Bei weiteren Überlegungen und genauer Betrachtung der Graphenverläufe des Preisverhaltens und der Anzahl der Verkäufe wird jedoch schnell ersichtlich, dass sich
kaum Zusammenhänge zwischen den beiden Werteverläufen herstellen lassen können. Somit sollte dies zu der Entscheidung führen, gewisse Assoziationsregeln in den
Hintergrund für die geforderte Wertevorhersage zu rücken.
7
Kapitel 3. Theoretische Grundlagen
3 Theoretische Grundlagen
Im folgenden Kapitel werden einige anwendbare Techniken theoretisch beleuchtet
und erklärt. Diese Techniken könnten einen Teil zur Lösung des Problems beitragen.
3.1 Probalistische Neuronale Netze
Künstliche Neuronale Netze stellen Modelle dar, mit denen biologische neuronale
Netze nachgebildet werden sollen. Sie kommen in verschiedenen Bereichen zur Anwendung, wie bspw. bei Klassifikationszwecken. Das Netz besteht aus sogenannten
Neuronen, die mit Hilfe gewichteter Eingaben und einer Aktivierungsfunktion Ausgaben erzeugen. Grundsätzlich unterscheiden sich die Klassen der Netze vorwiegend
durch die unterschiedlichen Netztopologien und Verbindungsarten, wie bspw. einschichtige, mehrschichtige, Feedforward- oder Feedback-Netze.
Probabilistische neuronale Netze (PNN) gehören zur Klasse der Radial-Basis-Netze,
welche wiederum den neuronalen Feedforward Netzen zuzuordnen sind. Das Netz
besteht hierbei aus vier Schichten. Einer Eingabe- und einer Ausgabe-Schicht zur
Dateneingabe bzw. -ausgabe und den so genannten Hidden und Pattern Schichten.
Am Eingang des Neurons liegt ein Eingangsvektor x mit R Elementen an. Bei der
Eingabe werden die importierten Werte des Eingabevektors einzelnen Neuron zugeordnet, die später in der Hidden-Layer mit dem Gewichtsvektor ω verknüpft werden.
Die Gewichtsvektoren dienen als Kostenfaktoren, wodurch die Entscheidung nicht
anhand von reinen Wahrscheinlichkeiten sondern z.B. durch die zu erwartenden
Kosten getroffen werden. Die Verknüpfung mit dem Gewichtsvektor, der ebenfalls
R Elemente enthält, erfolgt als vektorielle Distanz d zwischen Eingangs- und Gewichtsvektor über den euklidischen Abstand.
8
Kapitel 3. Theoretische Grundlagen
Bild 3.1: PNN: Verfahrensweise
Den Netzeingang n erhält man durch Multiplikation der Distanz d mit dem Bias
b. Der Bias entspricht einem weiteren Gewicht mit dem Eingangswert 1. Der so erhaltene Netzeingang n wird als Argument der Radial-Basis-Funktion, die hier als
Aktivierungsfunktion f dient, übergeben. Die Radial-Basis-Transformation stellt eine gaußförmige Funktion mit dem Erwartungswert 0 dar. Die Aktivierungsfunktion
generiert die Ausgabe des Neurons, welche eben mittels ω und b beeinflusst werden
kann. Das Training des Netzes besteht darin, die Gewichte so anzupassen, dass die
gewünschte Ausgabe erzeugt wird. Der Netzausgangswert a des Neurons wird damit
maximal, wenn der Netzeingang n = 0 ist. Dies ist der Fall, wenn der Eingangsvektor
x und der Gewichtsvektor ω identisch sind. Das Neuron kann damit als ein Detektor
angesehen werden, der als Ausgang ein Ähnlichkeitsmaß für x und ω liefert. Die
Empfindlichkeit der Detektion kann dabei durch Anpassung des Bias-Wertes eingestellt werden. Bei den PNN wird eine normalisierende Aktivierungsfunktion in den
Ausgabeneuronen verwendet, wodurch die Summe der Ausgabe aller Neuronen gleich
1 ist. Folglich lässt sich die Ausgabe der Posteriori-Wahrscheinlichkeit für Cluster
bei Beobachtung der Muster interpretieren. Damit berechnet die Ausgabeschicht die
bedingte Wahrscheinlichkeit für eine Klasse.
9
Kapitel 3. Theoretische Grundlagen
3.2 Lineare Regression
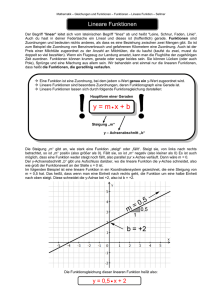
Die Lineare Regression ist ein konzeptuelles Modell zur Vorhersage einer abhängigen Variablen Y durch eine unabhängige Variable X. Bei der einfachen linearen
Regression ist der Ausprägungsgrad der Variable X bekannt, wodurch der Ausprägungsgrad der Variable Y vorhergesagt werden kann. Der Regressionskoeffizient ist
hierbei als Anstieg der Geraden zu betrachten, wodurch es möglich ist eine lineare
Funktion, die den Zusammenhang zwischen X und Y optimal beschreibt, zu finden.
Der Anstieg repräsentiert die durchschnittliche Veränderungsrate der Y -Werte pro
Zunahme einer Einheit von X -Werten.
Jede Gerade lässt sich mit einer Funktion vom Typ Y = bX + a abbilden. In der
Gleichung wird der Y -Wert zur Schätzung linear transformiert. Die Regressionsgerade entspricht dann dem Trend der Punkte im Streudiagramm. Jedoch liegen die
wenigsten Punkte genau auf der Geraden. Der Schätzfehler der Vorhersage eines
bestimmten Wertes Y ist als Differenz zwischen dem tatsächlichen und dem vorhergesagten Y -Wert definiert. Da alle anhand der Regressionsgleichung vorhergesagten
Werte auf der Regressionsgeraden liegen, ist ein Gesamtmaß für den Schätzfehler
der Regressionsgleichung nach dem Kriterium der kleinsten Quadrate die Summe
der quadrierten Abweichungen der vorhergesagten Werte Y von den tatsächlichen
gegebenen Werten. Dabei sollte der Anstieg so gewählt werden, das der quadratische
Fehler minimal ist.
Die lineare Regression geht über die reine Beschreibung der Daten hinaus. Sie kann
als Erklärungs- und auch als Prognosemodell eingesetzt werden. Dazu wird eine
Regressionsgerade gesucht, welche den Trend im Streudiagramm am besten wiedergibt.
10
Kapitel 4. Vorverarbeitung
4 Vorverarbeitung
Die Vorverarbeitung wurde in KNIME bewerkstelligt. Zunächst wurden alle Items
in einer Schleife normalisiert, um einen Wertebereich der Verkaufszahlen und Preise
zwischen 0 und 1 zu realisieren.
Da es anzunehmen ist, dass die Kurven der Attribute periodisch auftreten, wurden
diese in einem 7-Tage-Rhythmus in Wochen und Wochentage eingeteilt.
Bild 4.1: Vorverarbeitung
Für jeden Ansatz war es zudem wichtig die Datensätze in Trainings- und Testmenge
aufzuteilen. Die Trainingsmenge belief sich auf 28 Tage. Somit wurde auf den übrigen
14 Tagen getestet.
11
Kapitel 5. Lösungsvarianten
5 Lösungsvarianten
Im folgenden Kapitel werden Varianten zur Findung einer Lösung des genannten
Problems erklärt. Zudem wird hier auf die Anwendung der Methoden mittels KNIME eingegangen.
5.1 Probabilistische neuronale Netze
Ein Ansatz stellt die Anwendung von PNNs dar. Hierzu wurden die Daten zunächst
normalisiert und in Cluster mittels Kmeans aufgeteilt. Für das Clustering-Verfahren
wurden zunächst der Mittelwert und die Varianz eines jeden Items berechnet. Diese
zwei Merkmale dienten so als Kriterien für das Clustering-Verfahren. Jeder Cluster
beinhaltete also die Datensätze für den PNN-Learner. Das sich daraus ergebene
Modell wurde für die Vorhersage (PNN-Predictor) genutzt.
Bild 5.1: KNIME: Clustern & PNN
Ein Nachteil der gegebenen Datensätze stellt ihre Anzahl dar, speziell die Menge
an Tagen, die zum Trainieren gegeben war, bzw. die geringe Anzahl von 570 Items.
Bei einer Clusteranzahl von acht ergaben sich für den größten Cluster 115 und
12
Kapitel 5. Lösungsvarianten
für den kleinsten 49 Datensätze. Jedes Item besaß den Verlauf der Anzahl und
des Preises über 28 Tage. Somit ergaben sich für den Preis und die Anzahl des
größten Clusters zusammen 6440 Datensätze. Für solche geringen Mengen an Daten
in Verbindung mit der Komplexität des eigentlichen Problems stellen neuronalen
Netze keine verwendbare Lösung dar.
5.2 Mittelwert
Für die Menge an Items, deren Verkaufszahlen nicht ausreichend gut mit den oben
genannten Techniken vorhergesagt wurden, bediente man sich der Berechnung des
Mittelwertes.
Dazu wurden die Mittelwerte für jedes Item zum einen über die gesamte Zeit (s.
Abb. 5.2) berechnet und zum anderen für jeden einzelnen Wochentag (s. Abb. 5.3).
Bild 5.2: Knime: Mittelwertberechnung über alle Tage
Bild 5.3: Knime: Mittelwertberechnung über die einzelnen Wochentage
13
Kapitel 5. Lösungsvarianten
5.3 Lineare Regression
Um die Entwicklung über alle Items einschätzen zu können, wurde zunächst in
KNIME die lineare Regression angewendet. (s. Abb. 5.5)
Bild 5.4: Lineare Regression über alle Items
Diese Art der Regression wurde in einer Schleife in KNIME auf jedes Item angewendet, sodass mit den vorhergesagten Daten für jedes Item der Fehler berechnet
werden konnte. Dabei wurde zunächst die Anzahl der verkauften Produkte über den
Tag und den Preis vorhergesagt. Ignoriert man jedoch den Tag ergeben sich wesentlich geringere Fehlerwerte. Da ein Wert der Verkaufsanzahl nicht kleiner null sein
kann, wurden negative Werte auf Null gesetzt. Ein wesentlicher Vorteil der linearen
Regression ist die stärkere Gewichtung aktuellerer Daten, die durch den errechneten
Anstieg gegeben ist.
Bild 5.5: KNIME: Lineare Regression für jedes Item
14
Kapitel 6. Ergebnisse
6 Ergebnisse
Die Liste der vorhergesagten Ergebnisse setzt sich aus den „besten“ Vorhersagen
aller angewendeten Methoden zusammen.
Dazu wurde für jede Methode über jeden vorhergesagten Wert eines jeden Items die
Distanzen zum eigentlichen Wert berechnet und aufsummiert. Anschließend wurde
der Wert mit der kleinsten Distanzsumme in die endgültige Liste aufgenommen.
Eine weitere Spalte in der Ergebnisliste gibt an, mit welcher Methode die Werte des
jeweiligen Items vorhergesagt wurden.
Folgende Tabellen verdeutlichen die Ergebnisse der angewendeten Methoden:
Quadratischer Fehler
Manhatten Distanz
nicht gerundet
465,93
20789,20
abgerundet
473,06
20470
aufgerundet
464,53
21478
gerundet
467,04
20713
Tabelle 6.1: Ergebnisse: Lineare Regression
Quadratischer Fehler
Manhatten Distanz
nicht gerundet
489,44
21083,07
abgerundet
495,95
20756
aufgerundet
488,54
21774
gerundet
489,87
21018
Tabelle 6.2: Ergebnisse: Mittelwert über alle Tage
15
Kapitel 6. Ergebnisse
Quadratischer Fehler
Manhatten Distanz
nicht gerundet
485,35
20915
abgerundet
489,86
20682
aufgerundet
484,89
21316
gerundet
484,96
20872
Tabelle 6.3: Ergebnisse: Mittelwert über die jeweiligen Wochentage
Tabelle 6.1 zeigt einen Gegenüberstellung der Ergebnismengen der verschiedenen
Knime report powered by Birt
Methoden.
DataMining Cup 2012
"itemID"
"meanWeekday"
"linReg"
"mean"
"Winner_distance"
"Winner_name"
3
40
38.866
39.429
38.866
LinReg
69
30
30.85
32.714
30
MeanWeekDay
114
24.5
23.811
24.143
23.811
LinReg
249
15
13.223
13
13
Mean
271
58
59.814
57.429
57.429
Mean
287
19.5
14.563
19.429
14.563
LinReg
389
21
17.905
18.429
17.905
LinReg
445
17.5
14.034
14.5
14.034
LinReg
516
19.5
22.295
19
19
Mean
550
20
15.872
17.286
15.872
LinReg
Bild 6.1: Ergebnisgegenüberstellung der einzelnen Methoden an zufällig ausgewählten
Items
Date: 11.05.2012 12:37
Author: Team FKK
1
of
1
www.knime.org
16
Kapitel 6. Ergebnisse
Die besten Werte wurden über die lineare Regression und den Mittelwerten über
alle Tage, sowie die der Wochentage vorhergesagt.
In Tabelle 6.4 wurde der beste Wert durch das aufrunden der vorhergesagten Werte
erzielt (Kriterium: Quadratischer Fehler). Dabei wurden 167 Items mit der Linearen
Regression, 164 Items über den Mittelwert über alle Tage und 239 Items über den
Mittelwert über den jeweiligen Wochentag bestimmt.
Quadratischer Fehler
Manhatten Distanz
nicht gerundet
444,74
19249,54
abgerundet
451,84
19090
aufgerundet
443,07
19789
gerundet
444,57
19131
Tabelle 6.4: Ergebnisse: Lineare Regression in Verbindung mit Mittelwert über alle Tage
& Mittelwert über die jeweiligen Wochentage
17
Literaturverzeichnis
Literaturverzeichnis
[1] Mutz, Michael:
Universitaet Potsdam - Lineare Regressionsanalyse.
http://www.uni-potsdam.de/u/soziologie/methoden/mitarbeiter/
shk/Michael/1b/9_Zusammenfassung_Teil1.pdf, Abruf: 13. Mai 2012
[2] Universitaet Hamburg - Lineare Regression. http://www2.jura.uni-hamburg.
de/instkrim/kriminologie/Mitarbeiter/Enzmann/Lehre/StatIKrim/
Regression.pdf, Abruf: 13. Mai 2012
[3] Siebers, Stefan: Ein Konzept fà 41 r die merkmalsbasierte Tumor-Klassifikation
mit diagnotischem Ultraschall. Dissertation, 2008
[4] Berthold, M.:
Netzwerke mit radialen Basisfunktionen.
http:
//www.informatik.uni-konstanz.de/fileadmin/BioML/Lehre/SS_09/
DM2/VL06_RBF_PNN_details.pdf, Abruf: 13. Mai 2012
18
Abbildungsverzeichnis
Abbildungsverzeichnis
2.1
DMC-Viewer: Preis(blau), Anzahl(rot) normalisiert . . . . . . . . . .
6
3.1
PNN: Verfahrensweise . . . . . . . . . . . . . . . . . . . . . . . . . .
9
4.1
Vorverarbeitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
5.1
5.2
5.3
5.4
5.5
KNIME: Clustern & PNN . . . . . . . . . . . .
Knime: Mittelwertberechnung über alle Tage . .
Knime: Mittelwertberechnung über die einzelnen
Lineare Regression über alle Items . . . . . . . .
KNIME: Lineare Regression für jedes Item . . .
6.1
Ergebnisgegenüberstellung der einzelnen Methoden an zufällig ausgewählten Items . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
. . . . . . . .
. . . . . . . .
Wochentage .
. . . . . . . .
. . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
12
13
13
14
14
19
Inhalt des Archivs
Inhalt des Archivs
/
KNIME-Workflow
KNIME_LinReg_PNN_und_Mittelwert_Modelle.zip
KNIME_Modellaufbau_zur_Abgabe.zip
DMC-Viewer
DMC-Viewer.exe
ZedGraph.dll
Dokumentation.pdf
Ergebnisse
class.txt
Offizielle Aufgabe
class.txt
dmc2012_task.pdf
ShopAgentInterface.java
SimpleAgent.java
train.txt
20