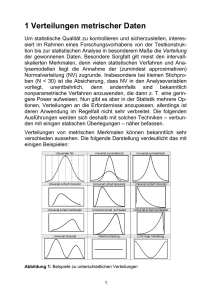
Statistische Methoden der Datenanalyse
Werbung

Statistische Metoden der Datenanalyse R. Frühwirth Statistische Methoden der Datenanalyse R. Frühwirth [email protected] VO 142.340 http://tinyurl.com/TU142340VO Oktober 2010 R. Frühwirth Statistische Metodender Datenanalyse 1/584 Übersicht über die Vorlesung Statistische Metoden der Datenanalyse R. Frühwirth Teil 1: Deskriptive Statistik Teil 2: Wahrscheinlichkeitsrechnung Teil 3: Zufallsvariable und Verteilungen Teil 4: Schätzen von Parametern R. Frühwirth Statistische Metodender Datenanalyse 2/584 Übersicht über die Vorlesung Statistische Metoden der Datenanalyse R. Frühwirth Teil 5: Testen von Hypothesen Teil 6: Regression und lineare Modelle Teil 7: Einführung in die Bayes-Statistik Teil 8: Simulation von Experimenten R. Frühwirth Statistische Metodender Datenanalyse 3/584 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Teil 1 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Deskriptive Statistik Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 4/584 Übersicht Teil 1 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung Eindimensionale Merkmale 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 5/584 Abschnitt 1: Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 6/584 Unterabschnitt: Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 7/584 Grundbegriffe Statistische Metoden der Datenanalyse Definition von Statistik R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 1 Die Erhebung und Speicherung von Daten, z.B. durch statistische Ämter 2 Die mathematische Auswertung von Daten, z.B. die Berechnung von Maß- und Kennzahlen Deskriptive Statistik Beschreibung von vorhandenen Daten durch Maßzahlen, Tabellen, Graphiken Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 8/584 Grundbegriffe Statistische Metoden der Datenanalyse Induktive Statistik R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Untersuchung von Gesetzmäßigkeiten und Ursachen, die hinter den Daten stehen und die Daten (teilweise) erklären. Explorative Datenanalyse: Ziel ist, Hypothesen für die Theoriebildung zu gewinnen Konfirmative Datenanalyse: Ziel ist, vorhandene Theorien zu prüfen, z.B. durch Schätzen von Parametern oder Testen von Hypothesen Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 9/584 Unterabschnitt: Merkmal- und Skalentypen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 10/584 Merkmal- und Skalentypen Statistische Metoden der Datenanalyse Qualitative Merkmale R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale binär (ja/nein). Beispiel: EU-Bürgerschaft. kategorial (Klassifizierung). Beispiel: ledig/geschieden/verheiratet/verwitwet. ordinal (Rang). Beispiel: Noten 1–5. Quantitative Merkmale diskret (ganzzahlig). Beispiel: Zählvorgang. kontinuierlich (reellwertig). Beispiel: Messvorgang. Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 11/584 Merkmal- und Skalentypen Statistische Metoden der Datenanalyse Skalentypen R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Nominalskala: Zahlenwerte sind nur Bezeichnung für sich ausschließende Kategorien. Ordinalskala: Ordnung der Zahlen ist wesentlich. Intervallskala: Ordnung und Differenzen zwischen den Werten sind sinnvoll interpretierbar, der Nullpunkt ist willkürlich festgelegt. Verhältnisskala: Ordnung, Differenzen und Größenverhältnisse sind sinnvoll interpretierbar, es gibt einen absoluten Nullpunkt. R. Frühwirth Statistische Metodender Datenanalyse 12/584 Merkmal- und Skalentypen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Beispiel 1 Der Familienstand einer Person wird durch Zahlen kodiert (1=ledig, 2=verheiratet, 3=geschieden, 4=verwitwet). Nominalskala. 2 Der Stand einer Mannschaft in der Meisterschaft wird durch den Rang in der Liga angegeben. Ordinalskala. 3 Die Jahreszahlen (2007, 2008, . . . ) bilden eine Intervallskala, da der Nullpunkt willkürlich festgelegt ist. 4 Die Celsius-Skala der Temperatur ist eine Intervallskala, da der Nullpunkt willkürlich festgelegt ist. 5 Die Kelvin-Skala der Temperatur ist eine Verhältnisskala, da der Nullpunkt physikalisch festgelegt ist. 6 Die Größe einer Person wird in cm angegeben. Es liegt eine Verhältnisskala vor, da ein natürlicher Nullpunkt existiert. Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 13/584 Merkmal- und Skalentypen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Beispiel In der folgenden Datenmatrix D sind Merkmale von acht Personen zusammengestellt. Nummer 1 2 3 4 5 6 7 8 Geschlecht 1 2 2 1 1 1 2 2 Alter 34 54 46 27 38 31 48 51 Ausbildung 2 1 3 4 2 3 4 2 Geschlecht: 1=W, 2=M, Alter: in Jahren Ausbildung: 1=Pflichtschule, 2=Höhere Schule, 3=Bachelor, 4=Master R. Frühwirth Statistische Metodender Datenanalyse 14/584 Unterabschnitt: Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 15/584 Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse Der Begriff der Aussage R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Eine Aussage ist eine Feststellung über Eigenschaften der Untersuchungsobjekte. Eine Aussage kann wahr oder falsch sein. Beispiel Die Aussage “Vier der Personen in Matrix D sind weiblich” ist wahr. Beispiel Die Aussage “Drei der Personen in Matrix D sind über 50 Jahre alt” ist falsch. R. Frühwirth Statistische Metodender Datenanalyse 16/584 Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse Verknüpfung von Aussagen R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Es seien A und B zwei Aussagen. Symbol A∪B A∩B A0 A⊆B Name Disjunktion Konjunktion Negation Implikation Bedeutung A oder B (oder beide) A und B (sowohl A als auch B) nicht A (das Gegenteil von A) aus A folgt B (A0 ∪ B) Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 17/584 Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Beispiel Es seien A, B, C drei Aussagen. Wir können mittels Verknüpfungen die folgenden Aussagen formulieren: 1 Alle drei Aussagen treffen zu: A∩B∩C Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 2 A und C treffen zu, B nicht: A ∩0 ∩C 3 Qualitative Merkmale Quantitative Merkmale Korrelation Genau zwei der Aussagen treffen zu: (A ∩ B ∩ C 0 ) ∪ (A ∩ B 0 ∩ C) ∪ (A0 ∩ B ∩ C) 4 Höchstens eine der Aussagen trifft zu: (A ∩ B 0 ∩ C 0 ) ∪ (A0 ∩ B ∩ C 0 ) ∪ (A0 ∩ B 0 ∩ C) ∪ (A0 ∩ B 0 ∩ C 0 ) R. Frühwirth Statistische Metodender Datenanalyse 18/584 Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Definition (Absolute Häufigkeit) Es sei A eine Aussage über eine Menge von Objekten. Die absolute Häufigkeit h(A) von A ist die Anzahl der Objekte, für die A zutrifft. Beispiel A ist die Aussage “Die Person in Matrix D hat zumindest Bakkalaureat”. Dann ist h(A) = 4. Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 19/584 Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Definition (Relative Häufigkeit) Es sei A eine Aussage über eine Menge von Objekten. Die relative Häufigkeit f (A) = h(A)/n von A ist die Anzahl der Objekte, für die A zutrifft, dividiert durch die Gesamtanzahl der Objekte. Beispiel A ist die Aussage “Die untersuchte Person ist älter als dreißig Jahre”. Dann ist f (A) = 7/8. Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 20/584 Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse Spezielle Aussagen R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale A = ∅: A trifft niemals zu, h(A) = f (A) = 0. A = Ω: A trifft immer zu, h(A) = n, f (A) = 1. Rechengesetze für Häufigkeiten Additionsgesetz ( h(A ∪ B) = h(A) + h(B) A ∩ B = ∅ =⇒ f (A ∪ B) = f (A) + f (B) Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 21/584 Aussagen und Häufigkeiten Statistische Metoden der Datenanalyse R. Frühwirth Siebformel Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten h(A ∪ B) = h(A) + h(B) − h(A ∩ B) f (A ∪ B) = f (A) + f (B) − f (A ∩ B) Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Beispiel 33% der Kunden einer Bank haben einen Wohnungskredit, 24% haben einen Kredit zur Finanzierung von Konsumgütern, 11% haben beides. Wie groß ist der Anteil der Kunden, die weder Wohnungs- noch Konsumgüterkredit haben? R. Frühwirth Statistische Metodender Datenanalyse 22/584 Abschnitt 2: Eindimensionale Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung 2 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 23/584 Unterabschnitt: Graphische Darstellung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung 2 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 24/584 Graphische Darstellung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Ein Bild sagt mehr als tausend Worte! Graphische Darstellungen von Datensätzen sind daher äußerst beliebt und nützlich. Qualitative Variable: Häufigkeitstabelle, Tortendiagramm, Stabdiagramm Quantitative Variable: gruppierte Häufigkeitstabelle, Histogramm, Boxplot, empirische Verteilungsfunktion Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 25/584 Graphische Darstellung Statistische Metoden der Datenanalyse Datensatz 1 (500 normalverteilte Werte): R. Frühwirth Datensatz 1 45 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 40 35 Eindimensionale Merkmale Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 30 Häufigkeit Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 25 20 15 10 5 0 0 1 2 3 4 5 x 6 7 8 9 10 Histogramm R. Frühwirth Statistische Metodender Datenanalyse 26/584 Graphische Darstellung Statistische Metoden der Datenanalyse Datensatz 2 = Datensatz 1 + Kontamination (100 Werte): R. Frühwirth Datensatz 2 45 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 40 35 Eindimensionale Merkmale Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 30 Häufigkeit Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 25 20 15 10 5 0 0 5 10 15 x Histogramm R. Frühwirth Statistische Metodender Datenanalyse 27/584 Graphische Darstellung Statistische Metoden der Datenanalyse Datensatz 3 (50 Püfungsnoten): R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Note k 1 2 3 4 5 Zweidimensionale Merkmale h(k) 5 8 22 5 10 50 f (k) 0.10 0.16 0.44 0.10 0.20 1.00 Häufigkeitstabelle Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: make dataset3 R. Frühwirth Statistische Metodender Datenanalyse 28/584 Graphische Darstellung Statistische Metoden der Datenanalyse Datensatz 3 (50 Püfungsnoten): R. Frühwirth 1 5 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 2 Eindimensionale Merkmale 4 Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 3 Qualitative Merkmale Quantitative Merkmale Korrelation Tortendiagramm Matlab: make dataset3 R. Frühwirth Statistische Metodender Datenanalyse 29/584 Graphische Darstellung Statistische Metoden der Datenanalyse Datensatz 3 (50 Püfungsnoten): R. Frühwirth 25 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Häufigkeit Eindimensionale Merkmale 20 15 10 5 0 1 2 3 x 4 5 Stabdiagramm Matlab: make dataset3 R. Frühwirth Statistische Metodender Datenanalyse 30/584 Graphische Darstellung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Der Boxplot ist die graphische Darstellung des five point summary. Datensatz 2 (500 Werte + Kontamination): Datensatz 2 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 1 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 0 5 10 15 x Boxplot Matlab: make dataset2 R. Frühwirth Statistische Metodender Datenanalyse 31/584 Unterabschnitt: Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung 2 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 32/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Ab Ordinalskala ist es sinnvoll, die Daten zu ordnen. Die Häufigkeitstabelle kann durch Summenhäufigkeiten ergänzt werden. Datensatz 3 (50 Prüfungsnoten): Note k 1 2 3 4 5 h(k) 5 8 22 5 10 H(k) 5 13 35 40 50 f (k) 0.10 0.16 0.44 0.10 0.20 F (k) 0.10 0.26 0.70 0.80 1.00 Häufigkeitstabelle mit Summenhäufigkeiten Matlab: make dataset3 R. Frühwirth Statistische Metodender Datenanalyse 33/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse R. Frühwirth Die graphische Darstellung der Summenhäufigkeiten wird die empirische Verteilungsfunktion der Datenliste genannt. Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Definition (Empirische Verteilungsfunktion) Die empirische Verteilungsfunktion Fn (x) der Datenliste ~x = (x1 , . . . , xn ) ist der Anteil der Daten, die kleiner oder gleich x sind: Fn (x) = f (~x ≤ x). Ist xi ≤ x < xi+1 , gilt Fn (x) = f (x1 ) + · · · + f (xi ). Fn ist eine Sprungfunktion. Die Sprungstellen sind die Datenpunkte, die Sprunghöhen sind die relativen Häufigkeiten der Datenpunkte. R. Frühwirth Statistische Metodender Datenanalyse 34/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse Datensatz 3: (50 Prüfungsnoten): R. Frühwirth Empirische Verteilungsfunktion 1 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 0.9 Eindimensionale Merkmale 0.6 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 0.7 F(x) Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 0.8 0.5 0.4 0.3 0.2 0.1 0 1 2 3 x 4 5 Empirische Verteilungsfunktion Matlab: make dataset3 R. Frühwirth Statistische Metodender Datenanalyse 35/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse Datensatz 2 (500 Werte + Kontamination): R. Frühwirth Datensatz 2 1 Einleitung 0.9 Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 0.8 0.7 Eindimensionale Merkmale Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 0.6 F(x) Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 0.5 0.4 0.3 0.2 0.1 0 0 5 10 15 x Empirische Verteilungsfunktion Matlab: make dataset2 R. Frühwirth Statistische Metodender Datenanalyse 36/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Aus der empirischen Verteilungsfunktion können Quantile einfach abgelesen werden. Median von Datensatz 2: Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 0.9 Eindimensionale Merkmale 0.8 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 0.7 0.6 F(x) Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Datensatz 2 1 0.5 0.4 0.3 0.2 0.1 0 0 5 10 15 x Empirische Verteilungsfunktion R. Frühwirth Statistische Metodender Datenanalyse 37/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Aus der empirischen Verteilungsfunktion können Quantile einfach abgelesen werden. Median von Datensatz 2: Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 0.9 Eindimensionale Merkmale 0.8 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 0.7 0.6 F(x) Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Datensatz 2 1 0.5 0.4 0.3 0.2 0.1 0 0 5 10 15 x Empirische Verteilungsfunktion R. Frühwirth Statistische Metodender Datenanalyse 37/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Es können auch Unter- und Überschreitungshäufigkeiten abgelesen werden. Welcher Anteil der Daten ist kleiner oder gleich 6? Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Datensatz 2 1 0.9 Eindimensionale Merkmale Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 0.8 0.7 0.6 F(x) Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 0.5 0.4 0.3 0.2 0.1 0 0 5 10 15 x Empirische Verteilungsfunktion R. Frühwirth Statistische Metodender Datenanalyse 38/584 Empirische Verteilungsfunktion Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Es können auch Unter- und Überschreitungshäufigkeiten abgelesen werden. Welcher Anteil der Daten ist kleiner oder gleich 6? Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Datensatz 2 1 0.9 Eindimensionale Merkmale Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 0.8 0.7 0.6 F(x) Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 0.5 0.4 0.3 0.2 0.1 0 0 5 10 15 x Empirische Verteilungsfunktion R. Frühwirth Statistische Metodender Datenanalyse 38/584 Unterabschnitt: Kernschätzer Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung 2 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 39/584 Kernschätzer Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Die Häufigkeitsverteilung (Histogramm) kann mit einem Kern- oder Dichteschätzer geglättet werden. Die Dichte des beobachteten Merkmals wird dabei durch eine Summe von Kernen K(·) approximiert: n 1 X fˆ(x) = K nh i=1 x − xi h h ist die Bandbreite des Kernschätzers. Der beliebteste Kern ist der Gaußkern: 2 1 x K(x) = √ exp − 2 2π R. Frühwirth Statistische Metodender Datenanalyse 40/584 Kernschätzer Statistische Metoden der Datenanalyse Datensatz 2: R. Frühwirth Datensatz 2 0.4 Relative Häufigkeit Kernschätzer Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 0.35 Eindimensionale Merkmale 0.25 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation f(x) Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 0.3 0.2 0.15 0.1 0.05 0 0 5 10 15 x Glättung des Histogramms durch Kernschätzer Matlab: make dataset2 R. Frühwirth Statistische Metodender Datenanalyse 41/584 Unterabschnitt: Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung 2 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 42/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Datenlisten sind oft so umfangreich, dass ihr Inhalt in einigen wenigen Maßzahlen zusammgefasst wird oder werden muss. Welche Maßzahlen dabei sinnvoll sind, hängt vom Skalentyp ab. Manche Maßzahlen gehen von der geordneten Datenliste x(1) , . . . , x(n) aus. Wir unterscheiden Lage-, Streuungs-, und Schiefemaße. Ein Lagemaß gibt an, um welchen Wert die Daten konzentriert sind. Ein Streuungsmaß gibt an, wie groß die Schwankungen der Daten um ihren zentralen Wert sind. Ein Schiefemaß gibt an, wie symmetrisch die Daten um ihren zentralen Wert liegen. R. Frühwirth Statistische Metodender Datenanalyse 43/584 Maßzahlen Statistische Metoden der Datenanalyse Lagemaße R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Definition (Lagemaß) Es sei x = (x1 , . . . , xn ) eine Datenliste. Die Funktion `(x) heißt ein Lagemaß für x, wenn gilt: `(ax + b) = a`(x) + b min x ≤ `(x) ≤ max(x) Sinnvolle Lagemaße geben den “typischen” oder “zentralen” Wert der Datenliste an. Je nach Skala sind verschiedene Lagemaße sinnvoll. R. Frühwirth Statistische Metodender Datenanalyse 44/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Mittelwert n 1X xi x̄ = n i=1 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Sinnvoll für Intervall- und Verhältnisskala. Der Mittelwert minimiert die folgende Funktion: x̄ = argx min n X (xi − x)2 i=1 Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: xbar=mean(x) R. Frühwirth Statistische Metodender Datenanalyse 45/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Median x̃ = x(n/2) Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Der Median teilt die geordnete Liste in zwei gleich große Teile. Sinnvoll für Ordinal-, Intervall- und Verhältnisskala. Der Median minimiert die folgende Funktion: x̃ = argx min n X |xi − x| i=1 Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: xmed=median(x) R. Frühwirth Statistische Metodender Datenanalyse 46/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Der Median ist ein Spezialfall eines allgemeineren Begriffs, des Quantils. α-Quantil Qα = x(αn) Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Das α-Quantil teilt die geordnete Liste im Verhältnis α : 1 − α. Sinnvoll für Ordinal-, Intervall- und Verhältnisskala. Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: qa=quantile(x,alpha) Q0 ist der kleinste Wert, Q1 ist der größte Wert der Datenliste. Q0.5 ist der Median. Die fünf Quartile Q0 , Q0.25 , Q0.5 , Q0.75 , Q1 bilden das five point summary der Datenliste. R. Frühwirth Statistische Metodender Datenanalyse Matlab: fps=quantile(x,[0 0.25 0.5 0.75 1]) 47/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation LMS (Least Median of Squares) Der LMS-Wert ist der Mittelpunkt des kürzesten Intervalls, das h = bn/2c + 1 Datenpunkte enthält. Der LMS-Wert ist extrem unempfindlich gegen fehlerhafte oder untypische Daten. Der LMS-Wert minimiert die folgende Funktion: x̃ = argx min medni=1 (xi − x)2 Ein verwandtes Lagemaß ist der “shorth”, der Mittelwert aller Daten im kürzesten Intervall, das h Datenpunkte enthält. Matlab: xlms=lms(x) Matlab: xshorth=shorth(x) R. Frühwirth Statistische Metodender Datenanalyse 48/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Modus Der Modus ist der häufigste Wert einer Datenliste Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Sinnvoll vor allem für qualitative Merkmale. Für quantitative Merkmale kann der Modus aus dem Kernschätzer der Dichte bestimmt werden. Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: xmode=mode(x) HSM (Half-sample mode) 1 Bestimme das kürzeste Intervall, das h = bn/2c + 1 Datenpunkte enthält. 2 Wiederhole den Vorgang auf den Daten in diesem Intervall, bis zwei Datenpunkte übrig sind. 3 Der HSM-Wert ist das Mittel der beiden letzten Daten. R. Frühwirth Statistische Metodender Datenanalyse 49/584 Maßzahlen Statistische Metoden der Datenanalyse Streuungsmaße R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Definition (Streuungsmaß) Es sei x = (x1 , . . . , xn ) eine Datenliste. Die Funktion σ(x) heißt ein Streuungsmaß für x, wenn gilt: σ(x) ≥ 0 σ(ax + b) = |a| σ(x) Sinnvolle Streuungsmaße messen die Abweichung der Daten von ihrem zentralen Wert. Streuungsmaße sind invariant unter Verschiebung der Daten. Je nach Skala sind verschiedene Streuungsmaße sinnvoll. R. Frühwirth Statistische Metodender Datenanalyse 50/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Standardabweichung v u n u1 X (xi − x̄)2 s=t n i=1 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Sinnvoll für Intervall- und Verhältnisskala. Die Standardabweichung hat die gleiche Dimension wie die Daten. Das Quadrat der Standardabweichung heißt Varianz. Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: xstd=std(x,1) Matlab: xvar=var(x,1) R. Frühwirth Statistische Metodender Datenanalyse 51/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Interquartilsdistanz IQR = Q0.75 − Q0.25 Die Interquartilsdistanz ist die Länge des Intervalls, das die zentralen 50% der Daten enthält. Sinnvoll für Ordinal-, Intervall- und Verhältnisskala. Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: xiqr=iqr(x) R. Frühwirth Statistische Metodender Datenanalyse 52/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale LoS (Length of the Shorth) LoS ist die Länge des kürzesten Intervalls, das h = bn/2c + 1 Datenpunkte enthält. Sinnvoll für Ordinal-, Intervall- und Verhältnisskala. Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: xlos=LoS(x) R. Frühwirth Statistische Metodender Datenanalyse 53/584 Maßzahlen Statistische Metoden der Datenanalyse Schiefemaße R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Definition (Schiefemaß) Es sei x = (x1 , . . . , xn ) eine Datenliste. Die Funktion s(x) heißt ein Schiefemaß für x, wenn gilt: s(ax + b) = sgn(a) s(x) s(x) = 0, wenn ∃b : x − b = b − x Sinnvolle Schiefemaße messen die Asymmetrie der Daten. Schiefemaße sind invariant unter Verschiebung der Daten. Je nach Skala sind verschiedene Schiefemaße sinnvoll. R. Frühwirth Statistische Metodender Datenanalyse 54/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Schiefe γ= 1 n Pn i=1 (xi s3 − x̄)3 Die Schiefe γ ist gleich 0 für symmetrische Daten. Ist γ < 0, heißen die Daten linksschief. Ist γ > 0, heißen die Daten rechtsschief. Sinnvoll für Intervall- und Verhältnisskala. Qualitative Merkmale Quantitative Merkmale Korrelation Matlab: xgamma=skewness(x,1) R. Frühwirth Statistische Metodender Datenanalyse 55/584 Maßzahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Schiefekoeffizient R−L R+L mit R = Q0.75 − Q0.5 , L = Q0.5 − Q0.25 . SK = SK liegt zwischen −1 (R = 0) und +1 (L = 0). Der Schiefekoeffizient ist gleich 0 für symmetrische Daten. Ist SK < 0, heißen die Daten linksschief. Ist SK > 0, heißen die Daten rechtsschief. Sinnvoll für Ordinal-, Intervall- und Verhältnisskala. Matlab: xsk=SK(x) R. Frühwirth Statistische Metodender Datenanalyse 56/584 Unterabschnitt: Beispiele Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 1 Einleitung 2 Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 3 Zweidimensionale Merkmale Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 57/584 Beispiele Statistische Metoden der Datenanalyse Datensatz 1: Symmetrisch, 500 Werte R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Lagemaße: Mittelwert: Median: LMS: Shorth: HSM: Schiefemaße: Schiefe: Schiefekoeffizient: 4.9532 4.9518 4.8080 4.8002 5.0830 0.0375 0.0258 Streuungsmaße: Standardabweichung: Interquartilsdistanz: Length of the Shorth: R. Frühwirth 1.0255 1.4168 1.3520 Statistische Metodender Datenanalyse 58/584 Beispiele Statistische Metoden der Datenanalyse Datensatz 1 R. Frühwirth 45 Mean Median LMS Shorth HSM Einleitung 40 Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 35 30 Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Häufigkeit Eindimensionale Merkmale 25 20 15 10 5 0 0 1 2 3 4 5 x 6 7 8 9 10 Datensatz 1: Mittelwert, Median, LMS, Shorth, HSM R. Frühwirth Statistische Metodender Datenanalyse 59/584 Beispiele Statistische Metoden der Datenanalyse Datensatz 2: Datensatz 1 + Kontamination (100 Werte) R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Lagemaße: Mittelwert: Median: LMS: Shorth: HSM: Schiefemaße: Schiefe: Schiefekoeffizient: 5.4343 5.0777 5.1100 5.0740 4.9985 1.7696 0.1046 Streuungsmaße: Standardabweichung: Interquartilsdistanz: Length of the Shorth: R. Frühwirth 1.8959 1.6152 1.5918 Statistische Metodender Datenanalyse 60/584 Beispiele Statistische Metoden der Datenanalyse Datensatz 2 R. Frühwirth 45 Mean Median LMS Shorth HSM Einleitung 40 Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 35 30 Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Häufigkeit Eindimensionale Merkmale 25 20 15 10 5 0 0 5 10 15 x Datensatz 2: Mittelwert, Median, LMS, Shorth, HSM R. Frühwirth Statistische Metodender Datenanalyse 61/584 Beispiele Statistische Metoden der Datenanalyse Datensatz 3: 50 Prüfungsnoten R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Lagemaße: Mittelwert: Median: Modus: Schiefemaße: Schiefe: Schiefekoeffizient: 5.4343 5.0777 5.1100 1.7696 0.1046 Streuungsmaße: Standardabweichung: Interquartilsdistanz: 1.8959 1.6152 Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 62/584 Beispiele Statistische Metoden der Datenanalyse 25 Mean Median Mode R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Häufigkeit Eindimensionale Merkmale 20 15 10 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 5 0 1 2 3 x 4 5 Datensatz 3: Mittelwert, Median, Modus R. Frühwirth Statistische Metodender Datenanalyse 63/584 Abschnitt 3: Zweidimensionale Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 1 Einleitung 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 64/584 Zweidimensionale Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Oft werden zwei oder mehr Merkmale eines Objekts gleichzeitig beobachtet. Beispiele: Körpergröße und Gewicht einer Person Alter und Einkommen einer Person Schulbildung und Geschlecht einer Person Der Zusammenhang zwischen den beiden Merkmalen gibt zusätzliche Information. Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 65/584 Unterabschnitt: Qualitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 1 Einleitung 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 66/584 Qualitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Wir betrachten zunächst zwei binäre Merkmale A und B. Die Häufigkeit des Eintretens von A und B kann in einer Vierfeldertafel oder Kontingenztafel zusammengefasst werden. Beispiel: A=“Die Person ist weiblich“ B=“Die Person ist Raucher/in“ Vierfeldertafel für 1000 Personen: Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation A A0 R. Frühwirth B 228 136 364 B0 372 600 264 400 636 1000 Statistische Metodender Datenanalyse 67/584 Qualitative Merkmale Statistische Metoden der Datenanalyse Allgemeiner Aufbau einer Vierfeldertafel: R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale A A0 B B0 h(A ∩ B) h(A ∩ B 0 ) h(A) h(A0 ∩ B) h(A0 ∩ B 0 ) h(A0 ) h(B) h(B 0 ) n Zeilen- und Spaltensummen sind die Häufigkeiten der Ausprägungen A, A0 und B, B 0 . Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 68/584 Qualitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Die Vierfeldertafel kann mittels Division durch n auf relative Häufigkeiten umgerechnet werden: Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale A A0 B B0 f (A ∩ B) f (A ∩ B 0 ) f (A) f (A0 ∩ B) f (A0 ∩ B 0 ) f (A0 ) f (B) f (B 0 ) 1 Zeilen- und Spaltensummen sind die relativen Häufigkeiten der Ausprägungen A, A0 und B, B 0 . Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 69/584 Qualitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Der Zusammenhang der beiden Merkmale kann durch die Vierfelderkorrelation gemessen werden: Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Vierfelderkorrelation f (A ∩ B) − f (A)f (B) ρ(A, B) = p f (A)f (A0 )f (B)f (B 0 ) Es gilt stets: −1 ≤ ρ(A, B) ≤ 1 Ist ρ(A, B) > 0, heißen A und B positiv gekoppelt. Ist ρ(A, B) < 0, heißen A und B negativ gekoppelt. R. Frühwirth Statistische Metodender Datenanalyse 70/584 Qualitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Das Vorzeichen von ρ(A, B) gibt die Richtung der Koppelung an. Der Betrag von ρ(A, B) gibt die Stärke der Koppelung an. Speziell gilt: Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation A = B =⇒ ρ(A, B) = 1 A = B 0 =⇒ ρ(A, B) = −1 Eine bestehende Koppelung ist kein Beweis für einen kausalen Zusammenhang! Die Koppelung kann auch durch eine gemeinsame Ursache für beide Merkmale entstehen. R. Frühwirth Statistische Metodender Datenanalyse 71/584 Unterabschnitt: Quantitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 1 Einleitung 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 72/584 Quantitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Bevorzugte Darstellung von zweidimensionalen Merkmalen: Streudiagramm (Scatter Plot) Jeder Punkt entspricht einem Objekt. Die beobachteten Merkmale bestimmen die Position des Punktes in der x-y-Ebene. Höherdimensionale Merkmale können durch Histogramme und Streudiagramme dargestellt werden. Dabei geht natürlich ein Teil der Information verloren. Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 73/584 Quantitative Merkmale Statistische Metoden der Datenanalyse Datensatz 4: Körpergröße und Gewicht von 100 Personen R. Frühwirth Datensatz 4 90 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 80 Gewicht (kg) Eindimensionale Merkmale 85 75 70 65 60 55 140 150 160 170 Körpergröße (cm) 180 190 Streudiagramm Matlab: make dataset4 R. Frühwirth Statistische Metodender Datenanalyse 74/584 Quantitative Merkmale Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Datensatz 5: Körpergröße, Gewicht und Alter von 100 Personen Merkmal x1 : Merkmal x2 : Merkmal x3 : Körpergröße (in cm) Gewicht (in kg) Alter (in Jahren) Matlab: make dataset5 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 75/584 Quantitative Merkmale Statistische Metoden der Datenanalyse 15 80 10 70 80 70 x3 x2 50 60 40 0 140 150 160 170 180 190 x1 50 140 150 160 170 180 190 x1 20 140 150 160 170 180 190 x1 20 80 30 190 x1 180 170 160 140 50 60 70 0 50 80 x2 Qualitative Merkmale Quantitative Merkmale Korrelation 60 10 50 40 5 150 Zweidimensionale Merkmale 70 15 x3 Eindimensionale Merkmale 30 60 70 20 50 80 60 x2 190 70 80 x2 80 15 x1 180 70 170 160 60 Häufigkeit Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele 60 5 Häufigkeit Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten x2 Einleitung Häufigkeit R. Frühwirth 10 5 150 140 20 30 40 50 60 70 80 x3 R. Frühwirth 50 20 30 40 50 60 70 80 x3 0 20 30 40 50 60 70 80 x3 Statistische Metodender Datenanalyse 76/584 Unterabschnitt: Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 1 Einleitung 2 Eindimensionale Merkmale 3 Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 77/584 Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Eigenschaften des Streudiagramms 1 (x̄, ȳ) ist der Mittelpunkt der Punktwolke. 2 Die Projektion der Punktwolke auf die x-Achse ergibt das Punktediagramm der Datenliste x1 , . . . , xn . 3 Die Projektion der Punktwolke auf die y-Achse ergibt das Punktediagramm der Datenliste y1 , . . . , yn . Aus dem Streudiagramm von Datensatz 4 ist ersichtlich, dass tendenziell größere Körpergröße mit größerem Gewicht einhergeht. Zwischen den beiden Merkmalen x und y besteht offensichtlich ein Zusammenhang, der auch intuitiv völlig klar ist. R. Frühwirth Statistische Metodender Datenanalyse 78/584 Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Wir brauchen eine Maßzahl für diesen Zusammenhang. Eine nützliche Maßzahl ist der empirische Korrelationskoeffizient. Sei (x1 , y1 ), . . . , (xn , yn ) eine bivariate Stichprobe. Wir berechnen die Standardscores: Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele zx,i = zy,i = yi − ȳ sy Wir erinnern uns, dass Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation xi − x̄ , sx n s2x = 1X (xi − x̄)2 n i=1 n und s2y = 1X (yi − ȳ)2 n i=1 Der empirische Korrelationskoeffizient ist der Mittelwert der Produkte der Standardscores. R. Frühwirth Statistische Metodender Datenanalyse 79/584 Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Definition (Empirischer Korrelationskoeffizient) Der empirische Korrelationskoeffizient rxy ist definiert als n rxy = 1X 1 zx,i zy,i = (zx,1 zy,1 + · · · + zx,n zy,n ) n i=1 n Es gilt immer: Zweidimensionale Merkmale −1 ≤ rxy ≤ 1 Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 80/584 Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale rxy ist positiv, wenn viele Produkte positiv sind, d.h. viele Paare von Standscores das gleiche Vorzeichen haben. Das ist der Fall, wenn die Paare der Standardscores vorwiegend im 1. oder 3. Quadranten liegen. x und y heißen dann positiv korreliert. rxy ist negativ, wenn viele Produkte negativ sind, d.h. viele Paare von Standscores verschiedenes Vorzeichen haben. Das ist der Fall, wenn die Paare der Standardscores vorwiegend im 2. oder 4. Quadranten liegen. x und y heißen dann negativ korreliert. Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 81/584 Korrelation Statistische Metoden der Datenanalyse Streudiagramm der Standardscores von Datensatz 4: R. Frühwirth Datensatz 4 Einleitung Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation 4 3 Standardscore des Gewichts Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 2 1 0 −1 −2 −3 −4 −4 −2 0 2 Standardscore der Körpergröße 4 Offensichtlich sind x und y positiv korreliert, da die meisten Punkte im 1. und 3. Quadranten liegen. rxy = 0.5562 R. Frühwirth Statistische Metodender Datenanalyse 82/584 Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Eine positive Korrelation muss nicht unbedingt einen kausalen Zusammenhang bedeuten. Die positive Korrelation kann auch durch eine gemeinsame Ursache oder einen parallel laufenden Trend verursacht sein. Beispiel Zwischen der Kinderzahl und der Anzahl der Störche in Österreich in den letzten 30 Jahren besteht eine positive Korrelation. Warum? Beispiel Zwischen dem Butterpreis und dem Brotpreis der letzten 20 Jahre besteht eine positive Korrelation. Warum? R. Frühwirth Statistische Metodender Datenanalyse 83/584 Korrelation Statistische Metoden der Datenanalyse 4 Qualitative Merkmale Quantitative Merkmale Korrelation 0 zx 2 −2 0 zx 2 −4 −4 4 4 rxy=0.6 2 0 −2 0 zx 2 4 −2 0 zx 2 4 0 zx 2 4 rxy=0.9 2 0 −2 −2 0 −2 4 rxy=0.3 zy zy 0 −4 −4 4 2 −4 −4 zy zy 4 −2 rxy=0 2 −2 −4 −4 Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 0 −2 Eindimensionale Merkmale 4 rxy=−0.4 2 zy 2 Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 4 rxy=−0.8 zy R. Frühwirth 0 −2 −4 −4 −2 0 zx 2 4 −4 −4 −2 Standardscores mit verschiedenen Korrelationskoeffizienten R. Frühwirth Statistische Metodender Datenanalyse 84/584 Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Der Korrelationskoeffizient misst die Korrelation der Daten. Die Korrelation gibt die Bindung der Punktwolke an eine steigende oder fallende Gerade, die Hauptachse an. Die Korrelation gibt also das Ausmaß der linearen Koppelung an. Besteht zwischen x und y ein starker, aber nichtlinearer Zusammenhang, kann die Korrelation trotzdem sehr klein sein. Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 85/584 Korrelation Statistische Metoden der Datenanalyse 4 R. Frühwirth 4 rxy=−0.00168 rxy=0.00987 Einleitung Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale 2 zy 2 zy Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten 0 −2 −4 −4 0 −2 −2 0 zx 2 4 −4 −4 −2 0 zx 2 4 Nichtlinearer Zusammenhang zwischen x und y Qualitative Merkmale Quantitative Merkmale Korrelation R. Frühwirth Statistische Metodender Datenanalyse 86/584 Korrelation Statistische Metoden der Datenanalyse R. Frühwirth Der Korrelationskoeffizient kann auch direkt aus der Stichprobe berechnet werden: Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und Häufigkeiten rxy = sxy sx sy Eindimensionale Merkmale Graphische Darstellung Empirische Verteilungsfunktion Kernschätzer Maßzahlen Beispiele Zweidimensionale Merkmale Qualitative Merkmale Quantitative Merkmale Korrelation Definition (Kovarianz der Daten) Die Größe n sxy = 1X (xi − x̄)(yi − ȳ) n i=1 heißt die Kovarianz der Daten. R. Frühwirth Statistische Metodender Datenanalyse 87/584 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Teil 2 Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Wahrscheinlichkeitsrechnung Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 88/584 Übersicht Teil 2 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 89/584 Abschnitt 4: Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 90/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Der konkrete Ausgang eines Experiments kann im Allgemeinen nicht genau vorausgesagt werden. Die möglichen Ausgänge sind jedoch bekannt. Ziel der Wahrscheinlichkeitsrechnung ist es, den Ausgängen Wahrscheinlichkeiten zuzuweisen. Zwei Interpretationen der Wahrscheinlichkeit möglich. Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 91/584 Einleitung Statistische Metoden der Datenanalyse Häufigkeitsinterpretation R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Die Wahrscheinlichkeit eines Ausgangs ist die Häufigkeit des Ausgangs, wenn das Experiment sehr oft unter den gleichen Bedingungen wiederholt wird. Die darauf basierende Statistik wird frequentistisch“ ” genannt. Beispiel Die Wahrscheinlichkeit des Ausgangs 1“ beim Würfeln ist der ” Grenzwert der Häufigkeit für eine große Zahl von Würfen. R. Frühwirth Statistische Metodender Datenanalyse 92/584 Einleitung Statistische Metoden der Datenanalyse Subjektive Interpretation R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Die Wahrscheinlichkeit eines Ausgangs ist eine Aussage über den Glauben der Person, die die Wahrscheinlichkeit angibt. Die darauf basierende Statistik wird bayesianisch“ genannt. ” Beispiel Die Wahrscheinlichkeit, dass es morgen regnet, ist 40 Prozent“ ist ein ” Aussage über den Glauben der Person, die diese Aussage tätigt. Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 93/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen In der Praxis ist der Übergang zwischen den beiden Ansätzen oft fließend. In vielen Fällen sind die Resultate identisch, nur die Interpretation ist verschieden. Der bayesianische Ansatz ist umfassender und flexibler. Der frequentistische Ansatz ist meist einfacher, aber beschränkter. Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 94/584 Abschnitt 5: Ereignisse Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 95/584 Unterabschnitt: Der Ereignisraum Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 96/584 Der Ereignisraum Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Grundlegend für die Statistik ist der Begriff des (zufälligen) Ereignisses. Für den Physiker der Ausgang eines Experiments, dessen Ergebnis nicht genau vorausgesagt werden kann. Mehrere Gründe: Die beobachteten Objekte sind eine zufällige Auswahl aus einer größeren Grundgesamtheit. Der beobachtete Prozess ist prinzipiell indeterministisch (Quantenmechanik). Messfehler geben dem Ergebnis einen stochastischen Charakter. Mangelnde Kenntnis des Anfangszustandes. R. Frühwirth Statistische Metodender Datenanalyse 97/584 Der Ereignisraum Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Die Menge Ω aller möglichen Ausgänge heißt Ereignisraum oder Stichprobenraum. Der Ereignisraum Ω kann endlich, abzählbar unendlich oder überabzählbar unendlich sein. Beispiel Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Beim Roulette gibt es 37 mögliche Ausgänge. Der Ereignisraum ist endlich. Wird eine radioaktive Quelle beobachtet, ist die Anzahl der Zerfälle pro Sekunde im Prinzip unbeschränkt. Der Ereignisraum ist abzählbar unendlich. Die Wartezeit zwischen zwei Zerfällen kann jeden beliebigen Wert annehmen. Der Ereignisraum ist überabzählbar unendlich. R. Frühwirth Statistische Metodender Datenanalyse 98/584 Unterabschnitt: Die Ereignisalgebra Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 99/584 Die Ereignisalgebra Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Definition (Ereignis) Ein Ereignis E ist eine Teilmenge des Ereignisraums Ω. Ein Ereignis E tritt ein, wenn E den Ausgang ω ∈ Ω des Experiments enthält. Beispiel Der Wurf mit einem Würfel hat den Ereignisraum Ω = {1, 2, 3, 4, 5, 6}. Das Ereignis G (gerade Zahl) ist die Teilmenge Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit G = {2, 4, 6} G tritt ein, wenn eine gerade Zahl geworfen wird. R. Frühwirth Statistische Metodender Datenanalyse 100/584 Die Ereignisalgebra Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Definition (Ereignisalgebra) Die Menge aller Ereignisse des Ereignisraums Ω heißt die Ereignisalgebra Σ(Ω). Im endlichen oder abzählbar unendlichen Fall kann jede Teilmenge als Ereignis betrachtet werden. Die Ereignisalgebra heißt diskret. Im überabzählbar unendlichen Fall müssen gewisse pathologische (nicht messbare) Teilmengen ausgeschlossen werden. Die Ereignisalgebra heißt kontinuierlich oder stetig. Zwei Ereignisse A ∈ Σ und B ∈ Σ können logisch verknüpft werden. R. Frühwirth Statistische Metodender Datenanalyse 101/584 Die Ereignisalgebra Statistische Metoden der Datenanalyse Verknüpfung von Ereignissen R. Frühwirth Einleitung Disjunktion Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Symbol A∪B Name Disjunktion Bedeutung A oder B (oder beide) Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Konjunktion Symbol A∩B Name Konjunktion Bedeutung A und B (sowohl A als auch B) Negation Symbol A0 Name Negation R. Frühwirth Bedeutung nicht A (das Gegenteil von A) Statistische Metodender Datenanalyse 102/584 Die Ereignisalgebra Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Implikation Symbol A⊆B Name Implikation Bedeutung aus A folgt B (A0 ∪ B) Mit diesen Verknüpfungen ist Σ ist eine Boole’sche Algebra: distributiver komplementärer Verbands mit Nullund Einselement. Das Nullelement 0 = ∅ ist das unmögliche Ereignis. Das Einselement 1 = Ω ist das sichere Ereignis. Ein Ereignis, das nur aus einem möglichen Ausgang besteht, heißt ein Elementarereignis. R. Frühwirth Statistische Metodender Datenanalyse 103/584 Die Ereignisalgebra Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Rechengesetze für Ereignisse Σ ist abgeschlossen: Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Assoziativgesetze : Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Verschmelzungsgesetze: Distributivgesetze: Regeln von de Morgan: Verneinung: R. Frühwirth A, B ∈ Σ =⇒ A ∩ B ∈ Σ A, B ∈ Σ =⇒ A ∪ B ∈ Σ (A ∩ B) ∩ C = A ∩ (B ∩ C) (A ∪ B) ∪ C = A ∪ (B ∪ C) A ∩ (A ∪ B) = A A ∪ (A ∩ B) = A A ∩ (B ∪ C) = (A ∩ B) ∪ (A ∩ C) A ∪ (B ∩ C) = (A ∪ B) ∩ (A ∪ C) (A ∩ B)0 = A0 ∪ B 0 (A ∪ B)0 = A0 ∩ B 0 A ∩ A0 = 0, A ∪ A0 = 1 = Ω Statistische Metodender Datenanalyse 104/584 Die Ereignisalgebra Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Ist Ω (abzählbar oder überabzählbar) unendlich, verlangt man, dass auch abzählbar viele Vereinigungen und Durchschnitte gebildet werden können. Der Ereignisraum ist dann eine sogenannte σ-Algebra. Ist überabzählbaren Fall ist die Ereignisalgebra Σ ist die kleinste σ-Algebra, die alle Teilintervalle von Ω enthält. Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 105/584 Unterabschnitt: Wiederholte Experimente Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 106/584 Wiederholte Experimente Statistische Metoden der Datenanalyse Der Wurf mit einem Würfel hat den Ereignisraum R. Frühwirth Ω = {1, 2, 3, 4, 5, 6} Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Die Ereignisalgebra Σ(Ω) hat folglich sechs Elementarereignisse: e1 = {1}, e2 = {2}, e3 = {3}, e4 {4}, e5 = {5}, e6 = {6} und insgesamt 26 = 64 Ereignisse (Teilmengen von Ω). Der Ereignisraum des zweimaligen Würfelns ist das kartesische Produkt Ω × Ω: Ω × Ω = {(i, j)|i, j = 1, . . . , 6} Das geordnete Paar (i, j) bedeutet: i beim ersten Wurf, j beim zweiten Wurf. Die Ereignisalgebra Σ(Ω × Ω) hat folglich 36 Elementarereignisse eij : e11 = {(1, 1)}, . . . , e36 = {(6, 6)} R. Frühwirth Statistische Metodender Datenanalyse 107/584 Wiederholte Experimente Statistische Metoden der Datenanalyse R. Frühwirth Analog ist beim n-maligen Würfeln der Ereignisraum das n-fache kartesische Produkt Ω × Ω × . . . × Ω. Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Beispiel (Ereignisalgebra des Doppelwurfs) Beispiele für Elemente der Ereignisalgebra des Doppelwurfs sind: 6 beim ersten Wurf: 6 beim zweiten Wurf: Beide Würfe gleich: Summe der Würfe gleich 7: {(6, 1), (6, 2), . . . , (6, 6)} {(1, 6), (2, 6), . . . , (6, 6)} {(1, 1), (2, 2), . . . , (6, 6)} {(1, 6), (2, 5), . . . , (6, 1)} Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 108/584 Wiederholte Experimente Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Beispiel (Wiederholter Alternativversuch) Ein Experiment, das nur zwei mögliche Ergebnisse hat, heißt ein Alternativversuch. Es gibt zwei Ausgänge, 0 und 1. Wird ein Alternativversuch n-mal durchgeführt, ergibt sich eine Ereignisraum mit 2n Ausgängen, nämlich den Folgen der Form (i1 , . . . , in ) mit ij = 0 oder 1. In der Regel interessiert aber nur die Häufigkeit des Eintretens von 1 (oder 0). Dann gibt es nur mehr n + 1 Ausgänge: 1 tritt 0, 1, 2, . . . oder n-mal ein. Bezeichnet das Ereignis E1 das einmalige Eintreten von 1, so ist E1 die ∪-Verbindung mehrerer Elementarereignisse der ursprünglichen Ereignisalgebra: E1 = {(e1 , e0 , . . . , e0 ), (e0 , e1 , e0 , . . . , e0 ), . . . , (e0 , . . . , e0 , e1 )} Ein Beispiel ist das n-malige Werfen einer Münze. R. Frühwirth Statistische Metodender Datenanalyse 109/584 Abschnitt 6: Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen 7 Bedingte Wahrscheinlichkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 110/584 Unterabschnitt: Wahrscheinlichkeitsmaße Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen 7 Bedingte Wahrscheinlichkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 111/584 Wahrscheinlichkeitsmaße Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Definition (Wahrscheinlichkeitsmaß) Es sei Σ eine Ereignisalgebra, A und B Ereignisse in Σ, und W eine Abbildung von Σ in R. W heißt ein Wahrscheinlichkeitsmaß, wenn gilt: 1. Positivität: 2. Additivität: 3. Normierung: R. Frühwirth W (A) ≥ 0 ∀A ∈ Σ A ∩ B = 0 =⇒ W (A ∪ B) = W (A) + W (B) W (1) = 1 Statistische Metodender Datenanalyse 112/584 Wahrscheinlichkeitsmaße Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Definition (Wahrscheinlichkeitsraum) Ist Σ eine σ-Algebra, was für unendliche Ereignisräume vorausgesetzt werden muss, verlangt man für abzählbares J: 4. σ-Additivität: Ai ∈ Σ, i ∈ J; Ai ∩ Aj = 0, i 6= j =⇒ [ X W ( Ai ) = W (Ai ) Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit i∈J i∈J Σ heißt dann normiert, und (Σ, W ) ein Wahrscheinlichkeitsraum. W wird auch als Wahrscheinlichkeitsverteilung bezeichnet. R. Frühwirth Statistische Metodender Datenanalyse 113/584 Wahrscheinlichkeitsmaße Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Rechengesetze für Wahrscheinlichkeit Ist (Σ, W ) ein Wahrscheinlichkeitsraum, so gilt: 1 W (A0 ) = 1 − W (A), ∀A ∈ Σ 2 W (0) = 0 3 A ⊆ B =⇒ W (A) ≤ W (B), ∀A, B ∈ Σ 4 W (A) ≤ 1, ∀A ∈ Σ 5 W (A ∪ B) = W (A) + W (B) − W (A ∩ B), ∀A, B ∈ Σ 6 Hat Σ höchstens abzählbar viele Elementarereignisse P {ei | i ∈ I}, so ist i∈I W (ei ) = 1. Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 114/584 Wahrscheinlichkeitsmaße Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit In einer diskreten Ereignisalgebra ist die Wahrscheinlichkeit eines Ereignisses gleich der Summe der Wahrscheinlichkeiten der Elementarereignisse, deren ∪-Verbindung es ist. Daher ist ein Wahrscheinlichkeitsmaß durch die Werte, die es den Elementarereignissen zuordnet, eindeutig bestimmt. Andererseits kann jede positive Funktion, die auf der Menge der Elementarereignisse definiert ist und Punkt 6 erfüllt, eindeutig zu einem Wahrscheinlichkeitsmaß fortgesetzt werden. Man kann also auf einer diskreten Ereignisalgebra Σ unendlich viele Verteilungen definieren. R. Frühwirth Statistische Metodender Datenanalyse 115/584 Wahrscheinlichkeitsmaße Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit In einer kontinuierlichen Ereignisalgebra ist die Wahrscheinlichkeit jedes Elementarereignisses gleich 0. Die Wahrscheinlichkeit eines Ereignisses kann daher nicht mehr durch Summation ermittlet werden. Statt dessen wird eine Dichtefunktion f (x) angegeben, die jedem Elementarereignis x einen nichtnegativen Wert f (x) zuordnet. Die Dichtefunktion muss normiert sein: Z f (x) dx = 1 R Die Wahrscheinlichkeit eines Ereignisses A wird durch Integration über die Dichte ermittelt: Z W (A) = f (x) dx A Die Dichte muss so beschaffen sein, dass das Integral für alle zugelassenen Ereignisse existiert. R. Frühwirth Statistische Metodender Datenanalyse 116/584 Unterabschnitt: Gesetz der großen Zahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen 7 Bedingte Wahrscheinlichkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 117/584 Gesetz der großen Zahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Betrachten einfaches Zufallsexperiment: Münzwurf Zwei mögliche Ergebnisse: Kopf (K), Zahl (Z) Annahme: Münze symmetrisch, K und Z gleichwahrscheinlich Experiment wird n-mal wiederholt n 10 100 500 1000 5000 hn (K) 6 51 252 488 2533 fn (K) 0.6 0.51 0.504 0.488 0.5066 |fn (K) − 0.5| 0.1 0.01 0.004 0.012 0.0066 Häufigkeitstabelle Matlab: make coin R. Frühwirth Statistische Metodender Datenanalyse 118/584 Gesetz der großen Zahlen Statistische Metoden der Datenanalyse 1 R. Frühwirth Einleitung 0.8 Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit f(K) Ereignisse 0.6 0.4 0.2 0 0 100 200 300 400 500 n Entwicklung der relativen Häufigkeit von K R. Frühwirth Statistische Metodender Datenanalyse 119/584 Gesetz der großen Zahlen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Die relative Häufigkeit des Ereignisses K scheint gegen den Grenzwert 0.5 zu streben. Dieser Grenzwert wird als die Wahrscheinlichkeit W (K) bezeichnet. Empirisches Gesetz der großen Zahlen lim fn (K) = W (K) n→∞ Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Das mathematische Problem dieser Definition liegt darin, dass die Existenz des Grenzwerts von vornherein nicht einzusehen ist und im klassisch analytischen Sinn tatsächlich nicht gegeben sein muss, sondern nur in einem weiteren, statistischen Sinn. R. Frühwirth Statistische Metodender Datenanalyse 120/584 Abschnitt 7: Bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 121/584 Unterabschnitt: Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 122/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Wir betrachten jetzt zwei Ereignisse A und B, die bei einem Experiment eintreten können. Frage: Besteht ein Zusammenhang zwischen den Ereignissen? Ein solcher Zusammenhang wird Koppelung genannt. Positive Koppelung: Je öfter A eintritt, desto öfter tritt tendenziell auch B ein. Negative Koppelung: Je öfter A eintritt, desto seltener tritt tendenziell auch B ein. Quantifizierung von oft“ und selten“ erfolgt durch ” ” Häufigkeitstabelle. R. Frühwirth Statistische Metodender Datenanalyse 123/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Die Häufigkeit des Eintretens von A und B kann in einer Vierfeldertafel oder Kontingenztafel zusammengefasst werden. Beispiel: A=“Eine untersuchte Person ist weiblich“ B=“Eine untersuchte Person hat Diabetes“ Vierfeldertafel für 1000 Personen: Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit A A0 R. Frühwirth B 19 26 45 B0 526 429 955 545 455 1000 Statistische Metodender Datenanalyse 124/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Gewöhnliche relative Häufigkeiten werden auf den Umfang n des gesamten Datensatzes bezogen: Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit f (A ∩ B) = h(A ∩ B) n Bedingte relative Häufigkeiten werden auf das Eintreten des anderen Merkmals bezogen: f (A|B) = h(A ∩ B) f (A ∩ B) = h(B) f (B) f (A|B) heißt die bedingte relative Häufigkeit von A unter der Bedingung B. R. Frühwirth Statistische Metodender Datenanalyse 125/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Die Vierfeldertafel U gibt folgende bedingte relative Häufigkeiten: Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit f (A|B) = 19 = 0.422, 45 f (A|B 0 ) = 526 = 0.551 955 Es ist somit zu vermuten, dass die beiden Merkmale gekoppelt sind. f (A|B) > f (A) deutet auf eine positive Koppelung, f (A|B) < f (A) auf eine negative Koppelung. Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 126/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Stammen die Daten aus einem Zufallsexperiment, dann besitzen die Ereigniskombinationen auch Wahrscheinlichkeiten. Wahrscheinlichkeitstabelle: Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit A A0 B B0 W (A ∩ B) W (A ∩ B 0 ) W (A) W (A0 ∩ B) W (A0 ∩ B 0 ) W (A0 ) W (B) W (B 0 ) 1 Nach dem empirischen Gesetz der großen Zahl sind diese Wahrscheinlichkeiten die Grenzwerte der entsprechenden relativen Häufigkeiten. R. Frühwirth Statistische Metodender Datenanalyse 127/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Die bedingten relativen Häufigkeiten konvergieren für n → ∞ gegen einen Grenzwert: Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit fn (A|B) = W (A ∩ B) fn (A ∩ B) → W (A|B) = fn (B) W (B) Definition (Bedingte Wahrscheinlichkeit) W (A|B) = W (A ∩ B) W (B) heißt die bedingte Wahrscheinlichkeit von A unter der Bedingung B, sofern W (B) 6= 0. R. Frühwirth Statistische Metodender Datenanalyse 128/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Beispiel (Der symmetrische Würfel) Ist der Würfel völlig symmetrisch, werden den Elementarereignissen ei = {i} gleiche Wahrscheinlichkeiten zugeordnet: Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente W (ei ) = 1 , 1≤i≤6 6 Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Wir definieren die folgenden Ereignisse: U = {1, 3, 5}, G = {2, 4, 6} Dann gilt zum Beispiel W (e1 ∩ U ) W (e1 ) 1 = = W (U ) W (U ) 3 W (e1 ∩ G) W (0) W (e1 |G) = = =0 W (U ) W (U ) W (e1 |U ) = R. Frühwirth Statistische Metodender Datenanalyse 129/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Beispiel (Fortsetzung) Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen W (e1 ∩ U ) W (e1 ) = =1 W (e1 ) W (e1 ) W (e1 ∪ e3 ) W ((e1 ∪ e3 ) ∩ U ) 2 = = W (e1 ∪ e3 |U ) = W (U ) W (U ) 3 W ((e1 ∪ e2 ) ∩ U ) W (e1 ) 1 W (e1 ∪ e2 |U ) = = = W (U ) W (U ) 3 W (U |e1 ) = Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 130/584 Kopplung und bedingte Wahrscheinlichkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Aus der Definition der bedingten Wahrscheinlichkeit folgt sofort die Produktformel W (A ∩ B) = W (A|B)W (B) = W (B|A)W (A) Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit und die Formel für die Inverse Wahrscheinlichkeit W (B|A) = W (A|B)W (B) W (A) Beide Formeln gelten auch für relative Häufigkeiten! R. Frühwirth Statistische Metodender Datenanalyse 131/584 Unterabschnitt: Satz von Bayes Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 132/584 Satz von Bayes Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Definition (Zerlegung) Die Ereignisse B1 , B2 , . . . , Bm bilden eine Zerlegung des Ereignisraums Ω, wenn gilt: 1 Unvereinbarkeit: Bi ∩ Bj = ∅, i 6= j 2 Vollständigkeit: B1 ∪ B2 ∪ . . . ∪ Bm = Ω Satz Bilden die Ereignisse B1 , B2 , . . . , Bm eine Zerlegung des Ereignisraums Ω, dann gilt: W (B1 ) + W (B2 ) + . . . + W (Bm ) = W (Ω) = 1 R. Frühwirth Statistische Metodender Datenanalyse 133/584 Satz von Bayes Statistische Metoden der Datenanalyse Es sei B1 , . . . , Bm eine Zerlegung. Dann gilt: R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Totale Wahrscheinlichkeit W (A) = W (A|B1 )W (B1 ) + . . . + W (A|Bm )W (Bm ) Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Beispiel Ein Betrieb erzeugt Glühbirnen mit 40W (35% der Produktion), mit 60W (45%) und mit 100W (20%). Nach einem Jahr sind noch 98% der 40W-Birnen funktionsfähig, 96% der 60W-Birnen, und 92% der 100W-Birnen. Welcher Anteil an allen Glühbirnen ist nach einem Jahr noch funktionsfähig? R. Frühwirth Statistische Metodender Datenanalyse 134/584 Satz von Bayes Statistische Metoden der Datenanalyse Es sei B1 , . . . , Bm eine Zerlegung. Dann gilt: R. Frühwirth Einleitung Satz von Bayes Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen W (A|Bi )W (Bi ) W (A) W (A|Bi )W (Bi ) = W (A|B1 )W (B1 ) + . . . + W (A|Bm )W (Bm ) W (Bi |A) = Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit W (Bi ) wird die a-priori Wahrscheinlichkeit von B genannt, W (Bi |A) die a-posteriori Wahrscheinlichkeit. R. Frühwirth Statistische Metodender Datenanalyse 135/584 Satz von Bayes Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Beispiel Ein Betrieb kauft Bauteile von zwei Anbietern, wobei der Anteil des ersten 65% beträgt. Erfahrungsgemäß ist der Ausschussanteil bei Anbieter 1 gleich 3% und bei Anbieter 2 gleich 4%. 1 Wie groß ist der totale Ausschussanteil? 2 Wie groß ist die Wahrscheinlichkeit, daß ein einwandfreier Bauteil von Anbieter 2 kommt? 3 Wie groß ist die Wahrscheinlichkeit, daß ein mangelhafter Bauteil von Anbieter 1 kommt? Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 136/584 Satz von Bayes Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Beispiel Ein Bauteil wird von vier Firmen geliefert, und zwar kommen 20% von Firma 1, 30% von Firma 2, 35% von Firma 3, und 15% von Firma 4. Die Wahrscheinlichkeit, dass der Bauteil im Testbetreib innerhalb von 24 Stunden ausfällt, ist 0.02 für Firma 1, 0.015 für Firma 2, 0.025 für Firma 3, und 0.02 für Firma 4. Ein Bauteil fällt im Testbetrieb nach 16 Stunden aus. Die Wahrscheinlichkeit, dass er von Firma i kommt, ist mittel des Satzes von Bayes zu berechnen. Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 137/584 Unterabschnitt: Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 4 Einleitung 5 Ereignisse 6 Wahrscheinlichkeit 7 Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 138/584 Unabhängigkeit Statistische Metoden der Datenanalyse Zwei Ereignisse sind positiv gekoppelt, wenn R. Frühwirth Einleitung W (A|B) > W (A) oder W (A ∩ B) > W (A)W (B) Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Zwei Ereignisse sind negativ gekoppelt, wenn W (A|B) < W (A) oder W (A ∩ B) < W (A)W (B) Liegt weder positive noch negative Kopppelung vor, sind A und B unabhängig. Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 139/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Definition (Unabhängigkeit) Zwei Ereignisse A und B heißen stochastisch unabhängig, wenn W (A ∩ B) = W (A)W (B) Die Ereignisse A1 , A2 , . . . , An heißen unabhängig, wenn gilt: W (A1 ∩ . . . ∩ An ) = W (A1 ) · . . . · W (An ) Dazu genügt nicht, dass je zwei Ereignisse Ai und Aj paarweise unabhängig sind! R. Frühwirth Statistische Metodender Datenanalyse 140/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Beispiel Wir betrachten den zweimaligen Wurf einer Münze (Kopf/Zahl). Die möglichen Ausgänge sind Ω = {KK, KZ, ZK, ZZ}. Ferner definieren wir die Ereignisse: Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente E1 = {KK, KZ} . . . Kopf beim ersten Wurf E2 = {KK, ZK} . . . Kopf beim zweiten Wurf Wahrscheinlichkeit E3 = {KK, ZZ} . . . Gerade Zahl von Köpfen Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Dann gilt für alle i 6= j Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit W (Ei ∩ Ej ) = 1 = W (Ei ) · W (Ej ) 4 aber W (E1 ∩ E2 ∩ E3 ) = R. Frühwirth 1 1 6= = W (E1 ) · W (E2 ) · W (E3 ) 4 8 Statistische Metodender Datenanalyse 141/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Sind A und B unabhängig, gilt W (A|B) = W (A) und W (B|A) = W (B). Die Vierfeldertafel für zwei unabhängige Ereignisse: Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit A A0 B B0 W (A)W (B) W (A)W (B 0 ) W (A) W (A0 )W (B) W (A0 )W (B 0 ) W (A0 ) W (B) W (B 0 ) 1 R. Frühwirth Statistische Metodender Datenanalyse 142/584 Unabhängigkeit Statistische Metoden der Datenanalyse Die Koppelung kann durch die Vierfelderkorrelation gemessen werden: R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Vierfelderkorrelation W (A ∩ B) − W (A)W (B) ρ(A, B) = p W (A)W (A0 )W (B)W (B 0 ) Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Eigenschaften der Vierfelderkorrelation 1 −1 ≤ ρ(A, B) ≤ 1 2 ρ(A, B) = 0 ⇐⇒ A und B unabhängig 3 ρ(A, B) > 0 ⇐⇒ A und B positiv gekoppelt 4 ρ(A, B) < 0 ⇐⇒ A und B negativ gekoppelt R. Frühwirth Statistische Metodender Datenanalyse 143/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Das Vorzeichen von ρ(A, B) gibt die Richtung der Koppelung an. Der Betrag von ρ(A, B) gibt die Stärke der Koppelung an. Speziell gilt: Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit A = B =⇒ ρ(A, B) = 1 A = B 0 =⇒ ρ(A, B) = −1 Eine bestehende Koppelung ist kein Beweis für einen kausalen Zusammenhang! Die Koppelung kann auch durch eine gemeinsame Ursache für beide Ereignisse entstehen. R. Frühwirth Statistische Metodender Datenanalyse 144/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Zwei physikalische Ereignisse können als unabhängig postuliert werden, wenn zwischen ihnen keine wie immer geartete Verbindung besteht, da dann das Eintreten des einen Ereignisses die Wahrscheinlichkeit des anderen nicht beeinflussen kann. Zwei Elementarereignisse sind niemals unabhängig, da ihre ∩-Verbindung stets das unmögliche Ereignis ist. Zwei Elementarereignisse sind sogar höchst abhängig“, weil ” das Eintreten des einen das Eintreten des anderen mit Sicherheit ausschließt. Sind E1 und E2 zwei unaghängige Ereignisse eines Wahrscheinlichkeitsraumes (Σ, W ), so sind auch E1 und E20 , E10 und E2 , sowie E10 und E20 unabhängig. R. Frühwirth Statistische Metodender Datenanalyse 145/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Beispiel (Wurf mit zwei unterscheidbaren Würfeln) Es gibt 36 Elementarereignisse eij = {(i, j)}, 1 ≤ i, j ≤ 6. Das Ereignis Ei1 , beim ersten Wurf eine i zu würfeln, setzt sich so zusammen: Ei1 = ei1 ∪ ei2 ∪ . . . ∪ ei6 und analog Ej2 = e1j ∪ e2j ∪ . . . ∪ e6j Klarerweise gilt Ei1 ∩ Ej2 = eij . Kann man annehmen, dass alle Elementarereignisse gleichwahrscheinlich sind, so gilt: 1 1 , W (Ej2 ) = 6 6 1 1 2 W (Ei ∩ Ej ) = W (eij ) = = W (Ei1 ) · W (Ej2 ) 36 W (Ei1 ) = R. Frühwirth Statistische Metodender Datenanalyse 146/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit Beispiel (Fortsetzung) In diesem Fall sind also auch die Elementarereignisse des einfachen Wurfes gleichwahrscheinlich und die beiden Teilwürfe sind unabhängig. Setzt man umgekehrt voraus, dass für beide Teilwürfe die Elementarereignisse gleichwahrscheinlich sind, und dass Ei1 und Ej2 für alle i und j unabhängig sind, so sind die eij gleichwahrscheinlich. Sind die Teilwürfe nicht unabhängig, so sind die eij trotz der Gleichwahrscheinlichkeit der ei und ej nicht mehr gleichwahrscheinlich. Ein Beispiel dafür ist der Wurf“ mit einem sehr ” großen Würfel, der jedesmal bloß um 90o gedreht werden kann. Das Elementarereignis e34 ist hier unmöglich und muss daher die Wahrscheinlichkeit 0 zugewiesen bekommen. R. Frühwirth Statistische Metodender Datenanalyse 147/584 Unabhängigkeit Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ereignisse Der Ereignisraum Die Ereignisalgebra Wiederholte Experimente Wahrscheinlichkeit Wahrscheinlichkeitsmaße Gesetz der großen Zahlen Bedingte Wahrscheinlichkeit Beispiel (Wiederholung eines Alternativversuchs) Die Ereignisalgebra hat 2n Elementarereignisse, nämlich die Folgen der Form (i1 , . . . , in ), ij = 0 oder 1. Sind die Wiederholungen unabhängig, und bezeichnet p die Wahrscheinlichkeit des Eintretens von 1, ist die Wahrscheinlichkeit einer Folge W ({(i1 , . . . , in )}) = pn1 (1 − p)n0 wo n0 bzw. n1 die Anzahl des Eintretens von 0 bzw. 1 angibt. Klarerweise gilt n0 + n1 = n. Kopplung und bedingte Wahrscheinlichkeit Satz von Bayes Unabhängigkeit R. Frühwirth Statistische Metodender Datenanalyse 148/584 Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Teil 3 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Zufallsvariable und Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 149/584 Übersicht Teil 3 Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 150/584 Abschnitt 8: Eindimensionale Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 151/584 Unterabschnitt: Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 152/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Zufallsvariable) Eine Abbildung X: ω ∈ Ω 7→ x = X(ω) ∈ R die jedem Element ω des Ereignisraums Ω eine reelle Zahl zuordnet, heißt eine (eindimensionale) Zufallsvariable. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Ist Ω endlich oder abzählbar unendlich, ist jede beliebige Abbildung X zugelassen. Ist Ω überabzählbar unendlich, muss X eine messbare Abbildung sein. Da der Wert einer Zufallsvariablen vom Ausgang des Experiments abhängt, kann man den möglichen Werten Wahrscheinlichkeiten zuschreiben. R. Frühwirth Statistische Metodender Datenanalyse 153/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Nimmt die Zufallsvariable X nur endlich oder abzählbar unendlich viele Werte an, heißt sie diskret. Nimmt die Zufallsvariable X ein Kontinuum von Werte an, heißt sie kontinuierlich. Beispiel Die Abbildung, die beim Würfeln dem Elementarereignis ei die Augenzahl i zuordnet, ist eine diskrete Zufallsvariable. Natürlich wäre auch die Abbildung ei :−→ 7 − i eine diskrete Zufallsvariable. Beispiel Die Abbildung, die dem Zerfall eines Teilchens die Lebensdauer x zuordnet, ist eine kontinuierliche Zufallsvariable. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 154/584 Unterabschnitt: Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 155/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Diskrete Zufallsvariable sind oft das Resultat von Zählvorgängen. In der physikalischen Praxis kommen diskrete Zufallsvariable häufig vor: man denke an das Zählen von Ereignissen in einem festen Zeitintervall (Poissonverteilung), an das Abzählen von Alternativversuchen (Binomialverteilung), oder auch an die Besetzungshäufigkeit der diskreten Energieniveaus des Wasserstoffatoms. Im folgenden nehmen wir an, dass die Werte einer diskreten Zufallsvariablen nichtnegative ganze Zahlen sind. Dies ist keine Einschränkung, weil jede abzählbare Menge von reellen Zahlen bijektiv auf (eine Teilmenge von) N0 abgebildet werden kann. Die Ereignisalgebra ist die Potenzmenge (Menge aller Teilmengen) P von N0 . R. Frühwirth Statistische Metodender Datenanalyse 156/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Ist auf der Ereignisalgebra Σ(Ω) ein Wahrscheinlichkeitsmaß W definiert, so kann man mit Hilfe der Zufallsvariablen X auf der Potenzmenge P von N0 ebenfalls ein Wahrscheinlichkeitsmaß definieren. Definition (Verteilung einer diskreten Zufallsvariablen) Es sei Σ(Ω) eine diskrete Ereignisalgebra. Die diskrete Zufallsvariable X : Ω 7→ N0 induziert ein Wahrscheinlichkeitsmaß auf N0 mittels WX ({k}) = W (X −1 (k)) = W ({ω|X(ω) = k}) WX wird als die Verteilung von X bezeichnet, und zwar als diskrete oder Spektralverteilung. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 157/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Beispiel Wir ordnen den geraden Augenzahlen des Würfels die Zahl 0 zu, den ungeraden die Zahl 1: X : ω 7→ mod (ω, 2) Die Verteilung von X ist dann gegeben durch 1 2 1 WX (1) = W (X −1 (1)) = W ({1, 3, 5}) = 2 WX (0) = W (X −1 (0)) = W ({2, 4, 6}) = Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 158/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Beispiel Wir ordnen dem Ausgang eines Doppelwurfs die Summe der Augenzahlen zu: Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe X : (i, j) 7→ i + j Die Werte von X sind die natürlichen Zahlen von 2 bis 12. Die Verteilung von X ist dann gegeben durch k−1 , k≤7 X −1 36 WX (k) = W (X (k)) = W ({(i, j)}) = i+j=k 13 − k , k ≥ 7 36 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 159/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Die Zahlen WX (k) können als Funktionswerte einer Spektralfunktion fX angesehen werden: ( WX (k), wenn x = k fX (x) = 0, sonst Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Definition (Diskrete Dichtefunktion) Die Funktion fX (k) wird als Wahrscheinlichkeitsdichtefunktion oder kurz Dichte der Zufallsvariablen X bezeichnet. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 160/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse Die Dichte der Zufallsvariablen X = i + j: R. Frühwirth Dichtefunktion Eindimensionale Zufallsvariable 0.18 Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.16 0.14 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe 0.1 f(x) Wichtige Verteilungen 0.12 0.08 0.06 0.04 0.02 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0 2 3 R. Frühwirth 4 5 6 7 x 8 9 10 Statistische Metodender Datenanalyse 11 12 161/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Die Wahrscheinlichkeit WX (E) eines Ereignisses E lässt sich bequem mit Hilfe der Dichte von X berechnen: X WX (E) = fX (k) k∈E Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Definition (Diskrete Verteilungsfunktion) Ist X eine diskrete Zufallsvariable, so ist die Verteilungsfunktion FX von X definiert durch: FX (x) = W (X ≤ x) Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Es gilt offenbar: FX (x) = X k≤x R. Frühwirth fX (k) = X WX ({k}) k≤x Statistische Metodender Datenanalyse 162/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eigenschaften einer diskreten Verteilungsfunktion F 1 F hat eine Sprungstelle in allen Punkten des Wertebereichs 2 Die Sprunghöhe im Punkt k ist gleich fX (k) 3 0 ≤ F (x) ≤ 1 ∀x ∈ R 4 x ≤ y =⇒ F (x) ≤ F (y) ∀x, y ∈ R Grundbegriffe Randverteilungen und bedingte Verteilungen 5 limx→−∞ F (x) = 0; limx→∞ F (x) = 1 Wichtige Verteilungen 6 Die Wahrscheinlichkeit, dass r in das Intervall (a, b] fällt, ist F (b) − F (a): Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen W (r ≤ a) + W (a < r ≤ b) = W (r ≤ b) =⇒ Momente Erwartung Varianz Schiefe W (a < r ≤ b) = F (b) − F (a) Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 163/584 Diskrete Zufallsvariable Statistische Metoden der Datenanalyse Die Verteilungsfunktion der Zufallsvariablen X = i + j: R. Frühwirth Verteilungsfunktion Eindimensionale Zufallsvariable 1 Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.9 0.8 Mehrdimensionale Zufallsvariable 0.7 Grundbegriffe Randverteilungen und bedingte Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.6 F(x) Wichtige Verteilungen 0.5 0.4 0.3 Momente Erwartung Varianz Schiefe 0.2 0.1 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0 2 3 4 R. Frühwirth 5 6 7 x 8 9 Statistische Metodender Datenanalyse 10 11 12 164/584 Unterabschnitt: Stetige Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 165/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Bisher wurden nur solche Zufallsvariable behandelt, die auf diskreten Ereignisalgebren definiert waren. Diese Beschränkung soll nun fallengelassen werden, d.h es werden jetzt überabzählbar viele Elementarereignisse zugelassen. Das ist notwendig, wenn nicht nur Zählvorgänge, sondern beliebige Messvorgänge zugelassen werden. Eine Funktion X, die auf einer solchen überabzählbaren Menge von Elementarereignissen definiert ist, kann beliebige reelle Werte annehmen. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 166/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Definition (Stetige Verteilungsfunktion) Es sei (Σ, W ) ein Wahrscheinlichkeitsraum über einem überabzählbaren Ereignisraum Ω. X sei eine Zufallsvariable, also eine (messbare) Funktion von Ω in R. Die Funktion FX , definiert durch: FX (x) = W (X ≤ x) heißt die Verteilungsfunktion von X. Die Wahrscheinlichkeit, dass X in ein Intervall (x, x + ∆x] fällt, ist dann: W (x < X ≤ x + ∆x) = FX (x + ∆x) − FX (x) = ∆FX . Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 167/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Eigenschaften einer stetigen Verteilungsfunktion 1 0 ≤ F (x) ≤ 1 ∀x ∈ R 2 x1 ≤ x2 =⇒ F (x1 ) ≤ F (x2 ) ∀x1 , x2 ∈ R 3 limx→−∞ F (x) = 0; limx→∞ F (x) = 1 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Definition (Quantil) Es sei FX (x) eine stetige Verteilungsfunktion. Der Wert xα , für den FX (xα ) = α, 0 < α < 1 gilt, heißt das α-Quantil der Verteilung von X. Die Funktion −1 x = FX (α), 0<α<1 heißt die Quantilsfunktion der Verteilung von X. R. Frühwirth Statistische Metodender Datenanalyse 168/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Quartil) Die Quantile zu den Werten α = 0.25, 0.5, 0.75 heißen Quartile. Das Quantil zum Wert α = 0.5 heißt Median der Verteilung. Quantile können auch für diskrete Verteilungen definiert werden, jedoch sind sie dann nicht immer eindeutig. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 169/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Definition (Stetige Dichtefunktion) Ist FX differenzierbar, heißt X eine stetige Zufallsvariable. Für die Verteilung von X gilt nach dem Hauptsatz der Integralrechnung: Z x2 WX (x1 < X ≤ x2 ) = FX (x2 ) − FX (x1 ) = fX (x) dx x1 0 wobei fX (x) = FX (x) ist. Die Ableitung der Verteilungsfunktion, die Funktion fX , wird als Wahrscheinlichkeitsdichtefunktion oder wieder kurz Dichte von X bezeichnet. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 170/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Das Wahrscheinlichkeitsmaß WX heißt die Verteilung von X. Es ist auf einer Ereignisalgebra Σ definiert, die aus Mengen reeller Zahlen besteht und zumindest alle Intervalle und deren Vereinigungen als Elemente enthält. Ähnlich wie bei diskreten Zufallsvariablen lässt sich die Wahrscheinlichkeit WX einer Menge M ∈ Σ leicht mit Hilfe der Dichte angeben: Z WX (M ) = fX (x) dx M Die Wahrscheinlichkeit eines einzelnen Punktes ist immer gleich 0: Z x WX ({x}) = fX (x) dx = 0 x R. Frühwirth Statistische Metodender Datenanalyse 171/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse Daher ist auch R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen WX ((x1 , x2 ]) = WX ((x1 , x2 )) = WX ([x1 , x2 ]). Ganz allgemein erhält man eine Aussage über stetige Zufallsvariable dadurch, dass man in einer Aussage über diskrete Zufallsvariable die Summation durch eine Integration ersetzt. Gilt zum Beispiel für eine diskrete Dichte f : X f (k) = 1 k∈N0 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze so gilt für eine stetige Dichte f : Z ∞ f (x) dx = 1 −∞ R. Frühwirth Statistische Metodender Datenanalyse 172/584 Stetige Zufallsvariable Statistische Metoden der Datenanalyse Dichtefunktion Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen f(x) Mehrdimensionale Zufallsvariable Verteilungsfunktion 0.2 1 0.18 0.9 0.16 0.8 0.14 0.7 0.12 0.6 F(x) R. Frühwirth 0.1 0.5 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.08 0.4 0.06 0.3 0.04 0.2 0.02 0.1 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0 0 5 10 x R. Frühwirth 15 20 0 0 5 Statistische Metodender Datenanalyse 10 x 15 20 173/584 Abschnitt 9: Mehrdimensionale Zufallsvariable Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 174/584 Unterabschnitt: Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 175/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Zufallsvariable) Eine Abbildung X: ω ∈ Ω 7→ x = X(ω) ∈ Rd die jedem Element ω des Ereignisraums Ω einen reellen Vektor x ∈ Rd zuordnet, heißt eine d-dimensionale Zufallsvariable. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Mehrdimensionale Zufallsvariablen können diskret oder stetig sein. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 176/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Verteilungsfunktion) Ist X = (X1 , . . . , Xd ) eine d-dimensionale Zufallsvariable, so ist die Verteilungsfunktion FX durch FX (x1 , . . . , xd ) = W (X1 ≤ x1 ∩ . . . ∩ Xd ≤ xd ) definiert. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Definition (Dichtefunktion) Ist X = (X1 , . . . , Xd ) eine d-dimensionale diskrete Zufallsvariable, so ist die Dichtefunktion fX durch fX (x1 , . . . , xd ) = W (X1 = x1 ∩ . . . ∩ Xd = xd ) Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze definiert. R. Frühwirth Statistische Metodender Datenanalyse 177/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Beispiel Die zweidimensionale Zufallsvariable X = (X1 , X2 ) ordnet dem Ergebnis des Wurfs mit zwei Würfeln die Augenzahlen (i, j) zu. Sind alle Ausgänge gleichwahrscheinlich, so ist WX gegeben durch: 1 WX {(i, j)} = 36 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Die Dichte fX lautet: ( fX (x1 , x2 ) = 1 , 36 0, x1 ∈ {1, . . . , 6} ∩ x2 ∈ {1, . . . , 6} sonst Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 178/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable 0.03 Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe 0.02 w(x1,x2) Mehrdimensionale Zufallsvariable 0.025 0.015 0.01 0.005 0 1 2 3 5 4 5 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 6 4 3 6 x2 R. Frühwirth 2 1 x1 Statistische Metodender Datenanalyse 179/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Beispiel (Fortsetzung) Die Verteilungsfunktion F ist daher: F (x1 , x2 ) = W (X1 ≤ x1 ∩ X2 ≤ x2 ) = X f (i, j) i≤x1 ∩j≤x2 Beispielsweise ist F (3, 4) = 1 i≤3∩j≤4 36 P = 12 36 = 13 . Wegen der Abzählbarkeit der Elementarereignisse können diese auch durch eine eindimensionale Zufallsvariable Y eindeutig in R abgebildet werden, z. B.: Y : (ei , ej ) −→ 6i + j − 6 Der Wertevorrat von Y sind die natürlichen Zahlen zwischen 1 und 36, und WY ist gegeben durch: 1 WY {k} = , 1 ≤ k ≤ 36 36 R. Frühwirth Statistische Metodender Datenanalyse 180/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Definition (Dichtefunktion) Ist X = (X1 , . . . , Xd ) eine d-dimensionale stetige Zufallsvariable, so ist die Dichtefunktion fX durch fX (x1 , . . . , xd ) = Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen ∂ d FX ∂x1 . . . ∂xd definiert. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 181/584 Unterabschnitt: Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 182/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Sind X1 und X2 zwei (diskrete oder stetige) 1-dimensionale Zufallsvariable, so ist X = (X1 , X2 ) eine zweidimensionale Zufallsvariable. Die Verteilung (Verteilungsfunktion, Dichte) von X heißt auch die gemeinsame Verteilung (Verteilungsfunktion, Dichte) von X1 und X2 . Es stellt sich nun das folgende Problem: Kann man die Verteilung von X1 bzw. X2 aus der gemeinsamen Verteilung berechnen? Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 183/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Es sei F die Verteilungsfunktion und f die Dichte der stetigen Zufallsvariablen X = (X1 , X2 ). Dann ist die Verteilungsfunktion F1 von X1 gegeben durch: F1 (x1 ) = W (X1 ≤ x1 ) = W (X1 ≤ x1 ∩ −∞ < X2 < ∞) = Z x1 Z ∞ = f (x1 , x2 ) dx2 dx1 −∞ −∞ Daraus folgt: Z f (x1 , x2 ) dx2 −∞ Momente Erwartung Varianz Schiefe ∞ f1 (x1 ) = ist die Dichte von X1 . Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 184/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Randverteilung) Es sei X = (X1 , X2 ) eine zweidimensionale stetige Zufallsvariable mit der Verteilungsfunktion F und der Dichte f . Die Verteilung von X1 heißt die Randverteilung von X1 bezüglich X. Ihre Dichte f1 lautet: Z ∞ f1 (x1 ) = f (x1 , x2 ) dx2 . −∞ Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Ist X = (X1 , X2 ) diskret mit der Dichte f , so ist analog die Dichte f1 der Randverteilung von X1 bezüglich X gegeben durch: X f1 (k1 ) = f (k1 , k2 ) Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze k2 R. Frühwirth Statistische Metodender Datenanalyse 185/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Die Verteilungen von X1 und X2 lassen sich also aus der gemeinsamen Verteilung von X1 und X2 berechnen. Der umgekehrte Vorgang ist im allgemeinen nicht möglich, da die gemeinsame Verteilung auch Information über mögliche Zusammenhänge (Kopplung) zwischen X1 und X2 enthält. Es seien X1 und X2 zwei diskrete Zufallsvariable mit der gemeinsamen Dichte f (k1 , k2 ) und den Randverteilungsdichten f1 (k1 ) und f2 (k2 ). Dann ist die bedingte Wahrscheinlichkeit des Ereignisses X1 = k1 unter der Bedingung X2 = k2 gegeben durch: Momente Erwartung Varianz Schiefe W (X1 = k1 |X2 = k2 ) = Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth W (X1 = k1 ∩ X2 = k2 ) f (k1 , k2 ) = W (X2 = k2 ) f2 (k2 ) Statistische Metodender Datenanalyse 186/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Definition (Bedingte Dichte) Es sei X = (X1 , X2 ) eine 2-dimensionale diskrete Zufallsvariable mit der Dichte f (k1 , k2 ) und den Randverteilungsdichten f1 (k1 ) bzw. f2 (k2 ). Die Funktion f (k1 |k2 ), definiert durch: Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe f (k1 |k2 ) = f (k1 , k2 ) f2 (k2 ) heißt die durch X2 bedingte Dichte von X1 . Die bedingte Dichte ist für festes k2 die Dichte eine Verteilung, der durch X2 = k2 bedingten Verteilung von X1 . Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 187/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Ist X = (X1 , X2 ) stetig, so ist analog f (x1 |x2 ) definiert durch: f (x1 |x2 ) = f (x1 , x2 ) (f2 (x2 ) 6= 0) f2 (x2 ) f (x1 |x2 ) ist für festes x2 die Dichte einer Verteilung, der durch X2 = x2 bedingten Verteilung von X1 . Dass f (x1 |x2 ) tatsächlich eine Dichte ist, läßt sich leicht nachprüfen: Z ∞ Z ∞ f (x1 , x2 ) f2 (x2 ) f (x1 |x2 ) dx1 = dx1 = =1 f (x ) f2 (x2 ) 2 2 −∞ −∞ und analog für diskretes X. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 188/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse Es gilt: R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen f (x1 , x2 ) = f (x1 |x2 ) · f2 (x2 ) Z ∞ f1 (x1 ) = f (x1 |x2 ) · f2 (x2 ) dx2 −∞ und analog für diskrete Dichten. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Definition (Unabhängigkeit von Zufallsvariablen) Ist die (unbedingte) Dichte der Randverteilung von X1 gleich der durch X2 bedingten Dichte, so heißen X1 und X2 unabhängig. X1 und X2 unabhängig ⇐⇒ f (x1 |x2 ) = f1 (x1 ) R. Frühwirth Statistische Metodender Datenanalyse 189/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse Für unabhängige Zufallsvariablen X1 und X2 gilt: R. Frühwirth Eindimensionale Zufallsvariable f (x1 |x2 ) = f1 (x1 ) ⇐⇒ f (x2 |x1 ) = f2 (x1 ) ⇐⇒ f (x1 , x2 ) = f1 (x1 ) · f2 (x2 ) Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente und analog für diskretes X. Für unabhängige Zufallsvariable X1 ,X2 ist also die Dichte der gemeinsamen Verteilung gleich dem Produkt der einzelnen Dichten. Ist X = (X1 , . . . , Xd ), d > 2, so müssen die Definitionen der Randverteilung, der bedingten Dichten und der Unabhängigkeit entsprechend verallgemeinert werden. Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 190/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Die Dichte der Randverteilung von Xi1 , . . . , Xim ist gegeben durch: fi1 ,...,im (xi1 , . . . , xim ) Z ∞ Z ∞ = ... f (x1 , . . . , xn ) dxim+1 . . . dxin −∞ −∞ Die durch Xj bedingte Dichte von Xi ist gegeben durch: Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen f (xi |xj ) = Momente Erwartung Varianz Schiefe fi,j (xi , xj ) fj (xj ) wobei fi,j (xi , xj ) die Randverteilungsdichte von Xi , Xj ist. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 191/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Xi1 , . . . , Xik heißen unabhängig, wenn die Dichte der Randverteilung von Xi1 , . . . , Xik das Produkt der Dichten der Randverteilungen der einzelnen Xij ist. Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 192/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Beispiel (Die Akzeptanz oder Nachweiswahrscheinlichkeit) X sei eine Zufallsvariable mit der Dichte f (x). Nimmt X den Wert x an, so gibt es eine Wahrscheinlichkeit a(x) dafür, dass x auch tatsächlich beobachtet wird. Man definiert nun eine Zufallsvariable I, die 1 ist, wenn x beobachtet wird, und 0 sonst. Dann ist I unter der Bedingung X = x alternativ nach Aa(x) verteilt: W (I = 1|X = x) = a(x) W (I = 0|X = x) = 1 − a(x) Die gemeinsame Dichte von X und I ist daher: f (x, 1) = a(x)f (x) f (x, 0) = [1 − a(x)]f (x) Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 193/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Beispiel (Fortsetzung) Da der Experimentator nur mit beobachteten Größen arbeiten kann, schränkt er seine Grundgesamtheit auf die nachgewiesenen Ereignisse ein, d.h. er braucht die Dichte von X unter der Bedingung, dass X beobachtet wird: Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze fA (x) = f (x|I = 1) = f (x, 1) a(x)f (x) = R f2 (1) a(x)f (x) dx Als konkretes Beispiel diene die Messung einer Lebensdauer. Die Messung möge bei tmin beginnen und bei tmax enden. Dann hat a(t) die folgende Gestalt: 0, für t ≤ tmin a(t) = 1, für tmin < t ≤ tmax 0, für t > tmax R. Frühwirth Statistische Metodender Datenanalyse 194/584 Randverteilungen und bedingte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Beispiel (Fortsetzung) Für die gemessene Wahrscheinlichkeitsdichte gilt: 0, t ≤ tmin 1 exp(−t/τ ) τ fA (t) = , tmin ≤ t < tmax exp(−t /τ ) − exp(−tmax /τ ) min 0, t > t max Der Faktor 1/[exp(−tmin /τ ) − exp(−tmax /τ )] korrigiert für jene Teilchen, die vor tmin oder nach tmax zerfallen. Die Nachweiswahrscheinlichkeit a(t) kann auch von der Geometrie des Detektors oder deren Ansprechwahrscheinlichkeit bestimmt werden und eine komplizierte Abhängigkeit von t haben. So kann es etwa von der Konfiguration der Zerfallsprodukte abhängen, ob ein Zerfall bei t beobachtet werden kann oder nicht. R. Frühwirth Statistische Metodender Datenanalyse 195/584 Abschnitt 10: Wichtige Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 196/584 Unterabschnitt: Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 197/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Die diskrete Gleichverteilung auf n Punkten, Gl(n) Die Verteilung einer Zufallsvariablen X, die die Werte 1, . . . , n mit gleicher Wahrscheinlichkeit annimmt.. Die Dichte fX lautet: ( fX = Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 1 n, 0, x ∈ {1, . . . , n} sonst Die Verteilungsfunktion FX ist eine Stufenfunktion mit Sprüngen der Größe n1 in den Punkten 1, . . . , n. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 198/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Die Alternativ- oder Bernoulliverteilung Al(p) Die Verteilung einer Zufallsvariablen, die den Ausgängen eines Alternativversuchs die Werte 1 (Erfolg) bzw. 0 (Misserfolg) zuordnet. Die Dichte fX lautet: Grundbegriffe Randverteilungen und bedingte Verteilungen fX (0) = 1 − p, fX (1) = p Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente oder fX (x) = px (1 − p)1−x , x ∈ {0, 1} Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 199/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Die Binomialverteilung Bi(n, p) Wird der Alternativversuch n mal unabhängig durchgeführt, so gibt es 2n Elementarereignisse, nämlich die Folgen der Form e = (ei1 , . . . , ein ), ij = 0 oder 1. Die diskrete Zufallsvariable X bildet die Folge e auf die Häufigkeit von e1 ab: Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze X(e) = n X ij j=1 Der Wertebereich von X ist die Menge {0, 1, . . . , n}. Auf die Zahl k (0 ≤ k ≤ n) werden alle Folgen abgebildet, bei denen e1 genau k-mal eintritt. Es gibt Ckn solche Folgen, und jede hat die Wahrscheinlichkeit pk (1 − p)n−k . R. Frühwirth Statistische Metodender Datenanalyse 200/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Die Dichte fX ist daher: ! n k fX (k) = p (1 − p)n−k , 0 ≤ k ≤ n k Die Verteilung von X wird als Binomialverteilung Bi(n, p) mit den Parametern n und p bezeichnet. Es gilt Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen ! n X n k p (1 − p)n−k = 1 fX (k) = k k=0 k=0 n X Momente Erwartung Varianz Schiefe Das ist gerade der binomische Lehrsatz. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 201/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse Der Modus m (der wahrscheinlichste Wert) ist gleich R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe b(n + 1)pc, (n + 1)p und m= (n + 1)p − 1, 1, wenn p = 0 oder (n + 1)p ∈ /N wenn (n + 1)p ∈ {1, . . . , n} wenn p = 1 Die Verteilungsfunktion kann durch die unvollständige regularisierte Betafunktion β(x; a, b) ausgedrückt werden: FX (k; n, p) = W (X ≤ k) = β(1 − p; n − k, k + 1) Z 1−p n−k−1 t (1 − t)k = dt B(n − k, k + 1) 0 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 202/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse 0.4 R. Frühwirth 0.4 Bi(10,0.3) 0.2 0.1 Mehrdimensionale Zufallsvariable 0 Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen 0.2 0.1 0 1 2 3 4 5 k 6 7 8 9 0 10 0.4 0 1 2 3 4 5 k 6 7 8 9 10 2 3 4 5 k 6 7 8 9 10 0.4 Bi(10,0.7) Bi(10,0.9) 0.3 P(k) 0.3 P(k) Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.3 P(k) P(k) Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Bi(10,0.5) 0.3 Eindimensionale Zufallsvariable 0.2 0.2 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0.1 0 0.1 0 1 2 3 4 5 k 6 7 R. Frühwirth 8 9 10 0 0 1 Statistische Metodender Datenanalyse 203/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse Die negative Binomialverteilung R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Ein Alternativversuch wird solange wiederholt, bis r Erfolge eingetreten sind. Die Verteilung der dazu benötigten Anzahl X von Misserfolgen wird als negative Binomialverteilung Nb(r, p) bezeichnet. Ihre Dichte lautet: ! r+k−1 r fX (k) = p (1 − p)k , k ≥ 0 k Der Modus m (der wahrscheinlichste Wert) ist gleich ( b(r − 1) 1−p p c, wenn r > 1 m= 0, wenn r = 0 Ist m ∈ N, so ist auch m − 1 ein Modus. R. Frühwirth Statistische Metodender Datenanalyse 204/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse 0.2 R. Frühwirth Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze P(k) P(k) 0.02 0 Wichtige Verteilungen Erwartung Varianz Schiefe 0.06 0.04 Grundbegriffe Randverteilungen und bedingte Verteilungen Momente 0.1 0.05 Mehrdimensionale Zufallsvariable 0 1 2 3 4 5 k 6 7 8 0 9 10 11 12 5 10 15 20 0.1 Nb(6,0.3) Nb(8,0.3) 0.08 0.06 0.06 P(k) 0.08 0.04 0.04 0.02 0.02 0 0 k 0.1 P(k) Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Nb(4,0.3) 0.08 0.15 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.1 Nb(2,0.3) 0 10 20 30 0 0 10 k R. Frühwirth 20 30 40 k Statistische Metodender Datenanalyse 205/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse 0.3 0.5 R. Frühwirth Nb(2,0.6) Nb(4,0.6) 0.25 0.4 Eindimensionale Zufallsvariable 0.15 0.2 0.1 0.1 Mehrdimensionale Zufallsvariable 0.05 0 Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen 0 1 2 k 3 4 5 0 6 0.2 0 1 2 3 4 5 k 6 7 8 9 10 11 12 0.2 Nb(6,0.6) Nb(8,0.6) 0.15 P(k) 0.15 P(k) Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.3 P(k) P(k) Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.2 0.1 0.1 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0.05 0 0.05 0 5 10 15 0 0 5 k R. Frühwirth 10 15 20 k Statistische Metodender Datenanalyse 206/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Die Multinomialverteilung Mu(n, p1 , . . . , pd ) Der Alternativversuch kann dahingehend verallgemeinert werden, dass man nicht nur zwei, sondern d Elementarereignisse e1 , . . . , ed zulässt, denen die Wahrscheinlichkeiten p1 , . . . , pd zugeordnet werden, die nur Grundbegriffe Randverteilungen und bedingte Verteilungen d X Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe pi = 1 i=1 erfüllen müssen. Führt man den verallgemeinerten Alternativversuch n-mal durch, so sind die Elementarereignisse die Folgen der Form: Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze (ei1 , . . . , ein ), 1 ≤ ij ≤ d R. Frühwirth Statistische Metodender Datenanalyse 207/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse Sind die n Teilversuche unabhängig, gilt: R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze W (ei1 , . . . , ein ) = n Y W (eij ) = j=1 n Y pij = j=1 d Y pni i i=1 wobei ni die Anzahl des Eintretens von ei ist. Die Summe der ni ist daher n. Die d-dimensionale Zufallsvariable X = (X1 , . . . , Xd ) bildet die Folge (ei1 , . . . , ein ) auf den Vektor (n1 , . . . , nd ) ab. Dabei werden n!/(n1 !· · ·nd !) Folgen auf den gleichen Vektor abgebildet. Die Dichte von X lautet daher: fX (n1 , . . . , nd ) = R. Frühwirth d d d Y X X n! pni i , ni = n, pi = 1 n1 ! . . . nd ! i=1 i=1 i=1 Statistische Metodender Datenanalyse 208/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Die Verteilung von X wird als Multinomialverteilung mit den Parametern n und p1 , . . . , pd bezeichnet: WX = Mu(n, p1 , . . . , pd ) Das klassische Beispiel einer multinomialverteilten Zufallsvariablen ist das Histogramm (gruppierte Häufigkeitsverteilung), das zur graphischen Darstellung der (absoluten) experimentellen Häufigkeit verwendet wird. Xi ist die Anzahl der Fälle, in denen die Zufallsvariable R, das experimentelle Ergebnis, in Gruppe i fällt. Die Wahrscheinlichkeit, dass R in Gruppe i fällt, sei gleich pi . Werden in das Histogramm n Ergebnisse eingefüllt, so sind die Gruppeninhalte (X1 , . . . , Xd ) multinomial nach Mu(n, p1 , . . . , pd ) verteilt. R. Frühwirth Statistische Metodender Datenanalyse 209/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse Ein Histogramm R. Frühwirth 25 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 20 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente ni Wichtige Verteilungen 15 10 5 Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0 0 1 2 R. Frühwirth 3 4 5 x 6 7 Statistische Metodender Datenanalyse 8 9 10 210/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Die Poissonverteilung Po(λ) Die Poissonverteilung entsteht aus der Binomialverteilung durch den Grenzübergang n → ∞ unter der Bedingung n · p = λ. Das klassische Beispiel einer Poissonverteilten Zufallsvariablen ist die Anzahl der Zerfälle pro Zeiteinheit in einer radioaktiven Quelle. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Allgemein gilt: Ist die Wartezeit zwischen zwei Ereignissen eines Zufallsprozesses exponentialverteilt, so ist die Anzahl der Ereignisse pro Zeiteinheit Poissonverteilt. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 211/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Die Dichte der Poissonverteilung folgt aus der Berechnung des Grenzwertes: Pλ (k) = lim Bn; λ (k) n→∞ = lim n→∞ Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen = n n! k!(n − k)! k n−k λ λ 1− = n n λk −λ ·e k! Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Der Modus m (der wahrscheinlichste Wert) ist gleich wenn λ ∈ /N bλc, m = λ und λ − 1, wenn λ ∈ N 0, wenn λ = 0 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 212/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse 0.4 R. Frühwirth w(k) 0.2 0.1 0 Grundbegriffe Randverteilungen und bedingte Verteilungen 0 1 2 3 4 5 6 7 8 9 0 10 0 1 2 3 4 k Wichtige Verteilungen 5 6 7 8 9 10 k 0.2 0.2 Po(5) Po(10) 0.15 w(k) 0.15 w(k) Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.2 0.1 Mehrdimensionale Zufallsvariable Po(2) 0.3 w(k) 0.3 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.4 Po(1) 0.1 0.1 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0.05 0 0.05 0 5 10 15 0 0 5 k R. Frühwirth 10 15 20 25 k Statistische Metodender Datenanalyse 213/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Die hypergeometrische Verteilung Hy(N, M, n) Grundgesamtheit von N Objekten, davon haben M eine bestimmte Eigenschaft E. Es werden n Objekte gezogen, wobei jedes Objekt die gleiche Wahrscheinlickeit hat, gezogen zu werden. Einmal gezogene Objekte werden nicht zurückgelegt. Die Anzahl der gezogenen Objekte mit der Eigenschaft E ist eine Zufallsvariable X. Die Verteilung von X wird hypergeometrische Verteilung Hy(N, M, n) genannt. Ihre Dichte lautet: M N −M m n−m , 0 ≤ m ≤ min(n, M ) f (m) = N n R. Frühwirth Statistische Metodender Datenanalyse 214/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Der Modus m (der wahrscheinlichste Wert) ist gleich (n + 1)(M + 1) m= N +2 Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 215/584 Diskrete Verteilungen Statistische Metoden der Datenanalyse 0.5 Mehrdimensionale Zufallsvariable Bi(10,0.6) 0.4 0.4 0.3 0.3 P(k) Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable P(k) Eindimensionale Zufallsvariable 0.5 Hy(20,12,10) R. Frühwirth 0.2 0.2 0.1 0.1 0 0 1 2 3 4 Grundbegriffe Randverteilungen und bedingte Verteilungen 5 k 6 7 8 9 0 10 0.4 Wichtige Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 2 3 4 5 k 6 7 8 9 10 2 3 4 5 k 6 7 8 9 10 Bi(10,0.4) 0.3 P(k) 0.3 0.2 0.1 0 1 0.4 Hy(100,40,10) P(k) Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0 0.2 0.1 0 1 2 3 4 5 k 6 7 8 9 10 0 0 1 Zwei Hypergeometrische Verteilungen und die entsprechenden Binomialverteilungen R. Frühwirth Statistische Metodender Datenanalyse 216/584 Unterabschnitt: Stetige Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 217/584 Stetige Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Die stetige Gleichverteilung Un(a, b) Die stetige Gleichverteilung auf dem Intervall [a, b] hat die Dichte: 0, x < a 1 f (x|a, b) = I[a,b] = 1/(b − a), a ≤ x ≤ b b−a 0, b < x Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Dichtefunktion der Gleichverteilung Un(0,1) Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 1.2 1 1 0.8 0.8 F(x) f(x) Momente Erwartung Varianz Schiefe Verteilungsfunktion der Gleichverteilung Un(0,1) 1.2 0.6 0.4 0.4 0.2 0 −0.5 0.6 0.2 0 0.5 x R. Frühwirth 1 1.5 0 −0.5 0 Statistische Metodender Datenanalyse 0.5 x 1 1.5 218/584 Stetige Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Die Gauß- oder Normalverteilung No(µ, σ 2 ) Die Normalverteilung ist eine der wichtigsten Verteilungen in Wissenschaft und Technik. Ihre Dichte lautet: Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen f (x|µ, σ 2 ) = √ (x−µ)2 1 e− 2σ2 2πσ Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Im Fall von µ = 0, σ = 1 heißt sie Standardnormalverteilung. Die Verteilungsfunktion Φ(x) ist nicht durch elementare Funktionen darstellbar. Der Modus m (das Maximum der Dichtefunktion) ist bei m = µ. R. Frühwirth Statistische Metodender Datenanalyse 219/584 Stetige Verteilungen Statistische Metoden der Datenanalyse Dichtefunktion der Standardnormalverteilung R. Frühwirth Eindimensionale Zufallsvariable 0.45 1 0.4 Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.35 Mehrdimensionale Zufallsvariable Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe 0.8 F(x) 0.3 f(x) Grundbegriffe Randverteilungen und bedingte Verteilungen Verteilungsfunktion der Standardnormalverteilung 0.5 0.25 0.6 0.2 0.4 0.15 0.1 0.2 0.05 0 −5 0 x 5 0 −5 0 x 5 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 220/584 Stetige Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Die Exponentialverteilung Ex(τ ) Die Exponentialverteilung ist die Wartezeitverteilung des radioaktiven Zerfalls von Atomen und allgemein des Zerfalls von Elementarteilchen. Ihre Dichte lautet: f (x|τ ) = 1 −x/τ e · I[0,∞) (x) τ Ihre Verteilungsfunktion lautet: F (x|τ ) = 1 − e−x/τ · I[0,∞) (x) Der Modus m ist bei m = 0. R. Frühwirth Statistische Metodender Datenanalyse 221/584 Stetige Verteilungen Statistische Metoden der Datenanalyse Dichtefunktion der Exponentialverteilung Ex(2) R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Verteilungsfunktion der Exponentialverteilung Ex(2) 0.5 1 0.4 0.8 F(x) Grundbegriffe Randverteilungen und bedingte Verteilungen f(x) Mehrdimensionale Zufallsvariable 0.3 0.6 Wichtige Verteilungen 0.2 0.4 Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.1 0.2 Momente Erwartung Varianz Schiefe 0 0 2 4 6 8 10 0 0 2 x 4 6 8 10 x Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 222/584 Stetige Verteilungen Statistische Metoden der Datenanalyse Der Poissonprozess R. Frühwirth Wir beobachten einen Prozess, bei dem gewisse Ereignisse zu zufälligen Zeitpunkten eintreten. Ist die Anzahl der Ereignisse pro Zeiteinheit unabhängig und Poisson-verteilt gemäß Po(λ), sprechen wir von einem Poissonprozess mit Intensität λ. Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Eigenschaften eines Poissonprozesses 1 Die Anzahl der Ereignisse in einem Zeitintervall der Länge T ist Poisson-verteilt gemäß Po(λT ). 2 Die Wartezeit zwischen zwei aufeinanderfolgenden Ereignissen ist exponentialverteilt gemäß Ex(1/λ). 3 Sind die Wartezeiten eines Prozesses unabhängig und exponentialverteilt gemäß Ex(τ ), so ist der Prozess ein Poissonprozess mit Intensität λ = 1/τ . R. Frühwirth Statistische Metodender Datenanalyse 223/584 Stetige Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Die Gammaverteilung Ga(a, b) Die Exponentialverteilung ist ein Spezialfall einer allgemeineren Familie von Verteilungen, der Gammaverteilung. Die Dichte der Gammaverteilung lautet: Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze f (x|a, b) = xa−1 e−x/b · I[0,∞) (x) ba Γ(a) Ihre Verteilungsfunktion ist die regularisierte unvollständige Gammafunktion: Z x a−1 −t/b t e γ(a, x/b) F (x|a, b) = dt = a b Γ(a) Γ(a) 0 Der Modus m ist bei m = (a − 1)b, wenn a ≥ 1. R. Frühwirth Statistische Metodender Datenanalyse 224/584 Stetige Verteilungen Statistische Metoden der Datenanalyse 0 0 f(x) Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0.5 1 0 0 1.5 1 x Wichtige Verteilungen Rechnen mit Verteilungen 0.5 1 Grundbegriffe Randverteilungen und bedingte Verteilungen Erwartung Varianz Schiefe 1 2 Mehrdimensionale Zufallsvariable Momente Dichtefunktion der Gammaverteilung Ga(a,b) 2 a=1 b=0.5 a=1 b=1 1.5 a=1 b=2 Dichtefunktion der Gammaverteilung Ga(a,b) 1 a=2 b=0.5 a=2 b=1 0.8 a=2 b=2 0.6 0.2 0.2 0.1 2 3 Dichtefunktion der Gammaverteilung Ga(a,b) 0.5 a=5 b=0.5 a=5 b=1 0.4 a=5 b=2 0.3 0.4 0 0 2 x f(x) Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable f(x) Eindimensionale Zufallsvariable Dichtefunktion der Gammaverteilung Ga(a,b) 5 a=0.5 b=0.5 a=0.5 b=1 4 a=0.5 b=2 3 f(x) R. Frühwirth 4 6 0 0 5 x R. Frühwirth 10 15 x Statistische Metodender Datenanalyse 225/584 Stetige Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Die Betaverteilung Beta(a, b) Die Gleichverteilung ist ein Spezialfall einer allgemeineren Familie von Verteilungen, der Betaverteilung. Die Dichte der Betaverteilung lautet: Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen f (x|a, b) = xa−1 (1 − x)b−1 · I[0,1] (x), B(a, b) B(a, b) = Γ(a)Γ(b) Γ(a + b) Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Ihre Verteilungsfunktion ist die regularisierte unvollständige Betafunktion: Z x 1 F (x|a, b) = ta−1 (1 − t)b−1 dt B(a, b) 0 Der Modus m ist bei m = (a − 1)/(a + b − 2), wenn a, b > 1. R. Frühwirth Statistische Metodender Datenanalyse 226/584 Stetige Verteilungen Statistische Metoden der Datenanalyse Dichtefunktion der Betaverteilung Beta(a,b) R. Frühwirth f(x) Grundbegriffe Randverteilungen und bedingte Verteilungen 3 2 1 Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0.2 0.4 0.6 0.8 0 0 1 0.2 0.4 x 1 5 a=2 b=0.5 a=2 b=1 a=2 b=2 a=2 b=3 3 3 2 2 1 1 0.2 0.4 0.6 a=3 b=0.5 a=3 b=1 a=3 b=2 a=3 b=3 4 f(x) 4 f(x) 0.8 Dichtefunktion der Betaverteilung Beta(a,b) 5 0 0 0.6 x Dichtefunktion der Betaverteilung Beta(a,b) Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Rechnen mit Verteilungen 3 1 0 0 a=1 b=0.5 a=1 b=1 a=1 b=2 a=1 b=3 4 2 Wichtige Verteilungen Erwartung Varianz Schiefe a=0.5 b=0.5 a=0.5 b=1 a=0.5 b=2 a=0.5 b=3 4 Mehrdimensionale Zufallsvariable Momente 5 f(x) Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Dichtefunktion der Betaverteilung Beta(a,b) 5 0.8 1 0 0 0.2 0.4 x R. Frühwirth 0.6 0.8 1 x Statistische Metodender Datenanalyse 227/584 Unterabschnitt: Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 11 Momente 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 228/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse Die eindimensionale Normalverteilung R. Frühwirth Eindimensionale Zufallsvariable Ihre Dichte ist die bekannte Gauß’sche Glockenkurve: Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable f (x) = Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen (x−µ)2 1 √ e− 2σ2 σ 2π Das Maximum ist bei x = µ, die Wendepunkte bei x = µ ± σ. Die √ halbe Breite auf halber Höhe (HWHM) ist gleich σ 2 ln 2 ≈ 1, 177σ. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 229/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse 0.5 R. Frühwirth Eindimensionale Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen fmax=0.39894 0.4 f((x−µ)/σ) Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.3 HWHM 0.2 0.1 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente 0 −4 −3 −2 −1 0 (x−µ)/σ 1 2 3 4 Eindimensionale Normalverteilung, gelber Bereich = 68.2% Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 230/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Es gilt: W (|r − µ| ≥ σ) W (|r − µ| ≥ 2σ) W (|r − µ| ≥ 3σ) = 31.8% = 4.6% = 0.2% Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 231/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Die d-dimensionale Normalverteilung No(µ, V) Ihre Dichte lautet: 1 1 T −1 exp − (x − µ) V (x − µ) f (x) = dp 2 (2π) 2 |V| V und V−1 sind symmetrische positiv definite d × d-Matrizen. Ist X normalverteilt gemäß No(µ, V) und H eine m × d Matrix, so ist Y = HX normalverteilt gemäß No(Hµ, HVHT ). Jede Randverteilung einer Normalverteilung ist wieder eine Normalverteilung. Mittelwert und Matrix der Randverteilung entstehen durch Streichen der Spalten und Zeilen der restlichen Variablen. R. Frühwirth Statistische Metodender Datenanalyse 232/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Jede bedingte Verteilung einer Normalverteilung ist wieder eine Normalverteilung. Ist X normalverteilt gemäß No(µ, V), so kann V als positiv definite symmetrische Matrix mittels einer orthogonalen Transformation auf Diagonalform gebracht werden: Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen UVUT = D2 Alle Digonalelemente von D2 sind positiv. Die Zufallsvariable Y = DU(X − µ) ist dann standardnormalverteilt. Die Drehung U heißt Hauptachsentransformation. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 233/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse Die zweidimensionale Normalverteilung R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Für d = 2 und µ = 0 kann die Dichte folgendermaßen angeschrieben werden: 2 h x1 1√ 1 f (x1 , x2 ) = exp − 2(1−ρ − 2 σρ 1xσ1 2x2 + 2) σ2 2 2πσ1 σ2 1−ρ 1 x22 σ22 i ρ = σ12 /(σ1 σ2 ) ist der Korrelationskoeffizient. Sind X1 und X2 unkorreliert, also ρ = 0, folgt: 1 x21 x22 1 f (x1 , x2 ) = exp − + 2 = f1 (x1 ) · f2 (x2 ) 2πσ1 σ2 2 σ12 σ2 Zwei unkorrelierte normalverteilte Zufallsvariable mit gemeinsamer Normalverteilung sind daher unabhängig. R. Frühwirth Statistische Metodender Datenanalyse 234/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse σ1=1, σ2=1, ρ=0.6 R. Frühwirth 3 Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable 0.2 2 0.15 1 0.1 0 Grundbegriffe Randverteilungen und bedingte Verteilungen 0.05 Wichtige Verteilungen 0 Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen −1 −2 2 2 0 0 −2 −3 −3 −2 −1 0 1 2 3 −2 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 235/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse Die bedingte Dichte f (x1 |x2 ) ist gegeben durch R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen f (x1 |x2 ) = f (x1 , x2 ) = f (x2 ) " 1 1 p exp − =√ 2 σ12 (1 − ρ2 ) 2πσ1 1 − ρ2 2 # ρ x2 σ1 x1 − σ2 X1 |X2 = x2 ist also eine normalverteilte Zufallsvariable mit der Erwartung E[X1 |X2 ] = ρx2 σ1 /σ2 Momente Erwartung Varianz Schiefe E[X1 |X2 ] heißt die bedingte Erwartung. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 236/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Je nach Vorzeichen von ρ fällt oder wächst die bedingte Erwartung von X1 , wenn X2 wächst. Ist ρ = 1, sind X1 und X2 proportional: X1 = X2 σ1 /σ2 . Die Höhenschichtlinien der Dichtefunktion sind Ellipsen. Die Hauptachsentransformation ist jene Drehung, die die Ellipsen in achsenparallele Lage bringt. Sie hängt im Fall d = 2 nur von ρ ab. Ist ρ = 0, sind X1 und X2 bereits unabhängig, und der Drehwinkel ist gleich 0. Ist ρ 6= 0, ist die Drehmatrix U gleich ! cos ϕ − sin ϕ 1 σ 2 − σ12 U= mit ϕ = − arccot 2 2 2ρσ1 σ2 sin ϕ cos ϕ Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 237/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Die t-Verteilung t(n) Die Dichte der t-Verteilung mit n Freiheitsgraden lautet: −(n+1)/2 Γ( n+1 ) x2 f (x|n) = √ 2 n 1+ n nπ Γ( 2 ) Die χ2 -Verteilung χ2 (n) Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Die Dichte der χ2 -Verteilung mit n Freiheitsgraden lautet: f (x|n) = 1 2n/2 Γ( n2 ) xn/2−1 e−x/2 · I[0,∞) (x) Sie ist die Gammaverteilung Ga(n/2, 2). Ist X standardnormalverteilt, so ist Y = X 2 χ2 -verteilt mit einem Freiheitsgrad. R. Frühwirth Statistische Metodender Datenanalyse 238/584 Die Normalverteilung und verwandte Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Die F-Verteilung F(n, m) Die Dichte der F-Verteilung (Fisher-Snedecor-Verteilung) mit n bzw. m Freiheitsgraden lautet: f (x|n, m) = n/2 m/2 Γ( n+m m xn/2−1 2 )n · I[0,∞) (x) n m Γ( 2 )Γ( 2 ) (m + nx)(n+m)/2 Sind X und Y unabhängig und χ2 -verteilt mit n bzw. n Freiheitsgraden, so ist F = Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze X/n Y /m verteilt gemäß F(n, m). R. Frühwirth Statistische Metodender Datenanalyse 239/584 Abschnitt 11: Momente Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente Erwartung Varianz Schiefe 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 240/584 Unterabschnitt: Erwartung Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente Erwartung Varianz Schiefe 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 241/584 Erwartung Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Erwartung) Es sei X eine (diskrete oder stetige) Zufallsvariable mit der Dichte f (x). Ferner sei g eine beliebige stetige reelle oder komplexe Funktion. Man definiert EX [g] = E[g(X)] durch: Z ∞ X g(x)f (x) dx g(k)f (k) bzw. E[g(X)] = E[g(X)] = −∞ k∈N0 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente EX [g] = E[g(X)] heißt die Erwartung von g(X). Ist g ein k-dimensionaler Vektor von Funktionen, dann ist auch E[g(X)] ein k-dimensionaler Vektor. Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 242/584 Erwartung Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Definition (Erwartung einer Zufallsvariablen) Ist g(x) = x, so heißt E[g(X)] = E[X] die Erwartung oder der Mittelwert von X. Z ∞ X E[X] = xf (x) dx bzw. E[X] = k f (k) −∞ k∈N0 Ist X = (X1 , . . . , Xd ), wird die Erwartung entsprechend verallgemeinert: Z ∞ Z ∞ ... g(x1 , . . . , xd ) f (x1 , . . . , xd ) dx1 . . . dxd EX [g] = −∞ −∞ Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 243/584 Erwartung Statistische Metoden der Datenanalyse Die Erwartung ist ein Lageparameter. R. Frühwirth Die Erwartung braucht nicht zu existieren. Ein Beispiel ist die Cauchy-Verteilung (t-Verteilung mit einem Freiheitsgrad) mit der Dichte Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable f (x) = Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 1 , x∈R π(1 + x2 ) Eigenschaften der Erwartung 1 E[c] = c, c ∈ R 2 E[aX + b] = aE[X] + b 3 E[X1 + X2 ] = E[X1 ] + E[X2 ] 4 X1 und X2 unabhängig =⇒ E[X1 X2 ] = E[X1 ] · E[X2 ] R. Frühwirth Statistische Metodender Datenanalyse 244/584 Erwartung Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Die Erwartung von diskreten Zufallsvariablen Gleichverteilung Gl(n) Alternativverteilung Al(p) Binomialverteilung Bi(n, p) Negative Binomialverteilung Nb(r, p) Poissonverteilung Po(λ) Hypergeometrische Verteilung Hy(N, M, n) Multinomialverteilung Mu(n, p1 , . . . , pd ) E[X] = n+1 2 E[X] = p E[X] = np E[X] = r(1−p) p E[X] = λ E[X] = nM N E[Xi ] = npi Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 245/584 Erwartung Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Die Erwartung von stetigen Zufallsvariablen Stetige Gleichverteilung Un(a, b) Exponentialverteilung Ex(τ ) Normalverteilung No(µ, σ 2 ) Normalverteilung No(µ, V) Gammaverteilung Ga(a, b) Betaverteilung Beta(a, b) χ2 -Verteilung χ2 (n) t-Verteilung t(n) F-Verteilung F(n, m) E[X] = a+b 2 E[X] = τ E[X] = µ E[X] = µ E[X] = ab a E[X] = a+b E[X] = n E[X] = 0, n > 1 m E[X] = m−2 ,m > 2 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 246/584 Erwartung Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Definition (Momente) Sei X eine Zufallsvariable. Die Erwartung von g(x) = (x − a)k , sofern sie existiert, heißt k-tes Moment von X um a. Das k-te Moment um 0 wird mit µ0k bezeichnet. Das k-te Moment um den Erwartungswert E[X] wird als zentrales Moment µk bezeichnet. Die zentralen Momente µ1 , . . . , µk können aus den Momenten um 0 µ01 , . . . , µ0k berechnet werden, und umgekehrt. Selbst wenn alle Momente einer Verteilung existieren, ist sie dadurch nicht eindeutig bestimmt. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 247/584 Unterabschnitt: Varianz Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente Erwartung Varianz Schiefe 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 248/584 Varianz Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Definition (Varianz) Das zweite zentrale Moment µ2 heißt die Varianz von X, bezeichnet mit var[X]. Die Wurzel aus der Varianz heißt die Standardabweichung von X, bezeichnet mit σ[X]. Die Standardabweichung ist ein Skalenparameter, der die Breite der Verteilung beschreiben. Die Standardabweichung hat die gleiche Dimension wie die Zufallsvariable. Varianz und Standardabweichung sind (wie alle zentralen Momente) invariant gegen Translationen. Die Varianz braucht nicht zu existieren. Ein Beispiel ist die t-Verteilung mit zwei Freiheitsgraden mit der Dichte Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze f (x) = R. Frühwirth 1 , x∈R (2 + x2 )3/2 Statistische Metodender Datenanalyse 249/584 Varianz Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Die Tschebyscheff’sche Ungleichung Es sei X eine Zufallsvariable mit der Erwartung E[X] = µ und der Varianz var[X] = σ 2 . Für g > 0 gilt: W (|X − µ| > gσ) ≤ 1 g2 Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 250/584 Varianz Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Definition (Kovarianz) Sei X = (X1 , . . . , Xn ) eine n-dimensionale Zufallsvariable und E[Xi ] = µ0i . cov[Xi , Xj ] = E[(Xi − µ0i )(Xj − µ0j )] = Z = (xi − µ0i )(xj − µ0j ) f (x1 , . . . xn ) dx1 . . . dxn = n ZR∞ Z ∞ (xi − µ0i )(xj − µ0j ) fij (xi , xj ) dxi dxj = −∞ −∞ heißt die Kovarianz von Xi und Xj , auch σij geschrieben. Die Matrix V mit Vij = cov[Xi , Xj ] heißt die Kovarianzmatrix von X, bezeichnet mit Cov[X]. Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 251/584 Varianz Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Eigenschaften der Varianz bzw. der Kovarianz 1 var[X] = E[r2 ] − (E[X])2 2 cov[X1 , X2 ] = E[X1 X2 ] − E[X1 ] · E[X2 ] 3 var[aX + b] = a2 var[X] 4 Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 5 var[a1 X1 + a2 X2 ] = a21 var[X1 ] + a22 var[X2 ] + 2a1 a2 cov[X1 , X2 ] " n # n X n X X var Xi = cov[Xi , Xj ] = i=1 n X Momente Erwartung Varianz Schiefe i=1 i=1 j=1 var[Xi ] + 2 n n X X cov[Xi , Xj ] i=1 j=i+1 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 252/584 Varianz Statistische Metoden der Datenanalyse Für unabhängige Zufallsgrößen gilt: R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen 1 X1 , X2 unabhängig =⇒ cov[X1 , X2 ] = 0 2 X1 , . . . , Xn unabhängig: " n # n X X var Xi = var[Xi ] i=1 i=1 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 253/584 Varianz Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Korrelationskoeffizient) σij heißt der Korrelationskoeffizient von Xi Die Größe ρij = σi σj und Xj . Eigenschaften des Korrelationskoeffizienten 1 Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 2 −1 ≤ ρij ≤ 1 Ist |ρij | = 1, so sind Xi und Xj linear abhängig. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 254/584 Varianz Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Die Varianz von diskreten Zufallsvariablen 2 Gleichvt. Gl(n) Alternativvt. Al(p) Binomialvt. Bi(n, p) var[X] = n 12−1 var[X] = p(1 − p) var[X] = np(1 − p) Negative Binomialvt. Nb(r, p) Poissonvt. Po(λ) Hypergeom. Vt. Hy(N, M, n) var[X] = r(1−p) p var[X] = λ −n)(N −M ) var[X] = nM (N N 2 (N −1) Multinomialvt. Mu(n, p1 , . . . , pd ) cov[Xi , Xj ] = δij npi − npi pj 2 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 255/584 Varianz Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Die Varianz von stetigen Zufallsvariablen 2 Gleichverteilung Un(a, b) Exponentialverteilung Ex(τ ) Normalverteilung No(µ, σ 2 ) Normalverteilung No(µ, V) Gammaverteilung Ga(a, b) Betaverteilung Beta(a, b) var[X] = (b−a) 12 var[X] = τ 2 var[X] = σ 2 Cov[X] = V var[X] = ab2 var[X] = (a+b)2ab (a+b+1) χ2 -Verteilung χ2 (n) t-Verteilung t(n) var[X] = 2 n n var[X] = n−2 ,n > 2 F-Verteilung F(n, m) var[X] = 2m2 (n+m−2) n(m−2)2 (m−4) , m >4 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 256/584 Unterabschnitt: Schiefe Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente Erwartung Varianz Schiefe 12 Rechnen mit Verteilungen Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 257/584 Schiefe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Definition (Schiefe) Das reduzierte dritte zentrale Moment γ = µ3 /σ 3 heißt die Schiefe. Die Schiefe misst die Asymmetrie einer Verteilung. Ist die Schiefe positiv (negativ), heißt die Verteilung rechtsschief (linksschief). Für symmetrische Verteilungen ist sie 0. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Beispiel (Die Schiefe der Exponentialverteilung) µ3 = E[(X − E[X])3 ] = ∞ Z 0 (t − τ )3 −t/τ e dt = 2τ 3 τ Die Schiefe ist daher gleich γ = 2. R. Frühwirth Statistische Metodender Datenanalyse 258/584 Schiefe Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Beispiel (Die Schiefe der Gammaverteilung) ∞ (x − ab)3 a−1 −x/b x e dx = 2ab3 ba Γ(a) 0 √ Die Schiefe ist daher gleich γ = 2/ a und strebt für a → ∞ gegen 0. µ3 = E[(X − E[X])3 ] = Z Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 259/584 Abschnitt 12: Rechnen mit Verteilungen Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 260/584 Unterabschnitt: Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 261/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Definition (Faltung) Es seien X1 und X2 zwei unabhängige Zufallsvariablen. Die Summe X = X1 + X2 heißt die Faltung von X1 und X2 . Satz Sind X1 und X2 zwei unabhängige Zufallsvariable mit der gemeinsamen Dichte f (x1 , x2 ) = f1 (x1 ) · f2 (x2 ), so hat ihre Summe X = X1 + X2 die Dichte Z ∞ f1 (x − x2 ) · f2 (x2 ) dx2 = g(x) = −∞ Z ∞ = f1 (x1 ) · f2 (x − x1 ) dx1 −∞ R. Frühwirth Statistische Metodender Datenanalyse 262/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Die Dichte g wird als Faltungsprodukt von f1 und f2 bezeichnet: g = f1 ∗ f2 . Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Beispiel (Faltung von zwei Exponentialverteilungen) Es seien X1 und X2 exponentialverteilt gemäß Eτ . Die Summe X = X1 + X2 hat die folgende Dichte: Z ∞ g(t) = f1 (t − t2 )f2 (t2 ) dt2 = Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Z −∞ t = 0 = Erwartung Varianz Schiefe 1 (t2 −t)/τ −t2 /τ e e dt2 = τ2 1 −t/τ te τ2 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 263/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Beispiel (Faltung von zwei Gleichverteilungen) Es seien X1 und X2 gleichverteilt im Intervall [0, 1]. Die Summe X = X1 + X2 hat die folgende Dichte: Z ∞ g(x) = f1 (x − x2 )f2 (x2 ) dx2 −∞ Das Produkt der Dichten ist nur ungleich 0, wenn 0 ≤ x − x2 ≤ 1 und 0 ≤ x2 ≤ 1 gilt. Die effektiven Integrationsgrenzen sind daher xmin = max(0, x − 1) und xmax = min(x, 1). Ist 0 ≤ x ≤ 1, ist xmin = 0 und xmax = x; ist 1 ≤ x ≤ 2, ist xmin = x − 1 und xmax = 1. Die Dichte g(x) lautet daher: wenn 0 ≤ x ≤ 1 x, g(x) = 2 − x, wenn 1 ≤ x ≤ 2 0, sonst Die Summenverteilung heißt Dreiecksverteilung. R. Frühwirth Statistische Metodender Datenanalyse 264/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Zwei Eigenschaften der Normalverteilung 1 Die Faltung zweier Normalverteilungen ist wieder eine Normalverteilung. 2 Ist die Faltung von zwei Verteilungen eine Normalverteilung, so sind auch die beiden Summanden Normalverteilungen. Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 265/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Beispiel (Der Messfehler) Es wird eine Zufallsgröße X beobachtet. Der Messfehler wird durch eine bedingte Dichte b(x0 |x) beschrieben, die die Wahrscheinlichkeit angibt, dass x0 bei der Messung registriert wird, wenn X den Wert x annimmt. Für die gemessene Verteilung gilt dann: Z ∞ Z ∞ f (x0 , x) dx b(x0 |x)f (x) dx = fM (x0 ) = −∞ −∞ Im günstigsten Fall hängt b nur von der Differenz x0 − x ab, oder eine weitere explizite Abhängigkeit von x ist vernachlässigbar. Dann wird aus dem Integral ein Faltungsintegral. Dies ist genau dann der Fall, wenn der Messfehler und die Messung unabhängig sind. Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 266/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Die Faltung von zwei Zufallsvariablen X1 und X2 kann auch mit Hilfe ihrer charakteristischen Funktionen berechnet werden. Definition (Charakteristische Funktion) Es sei X eine Zufallsvariable. Die charakteristische Funktion von X ist definiert durch: ϕX (t) = E[ exp(itX) ], t ∈ R Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Satz Ist X = X1 + X2 die Faltung von X1 und X2 , so gilt: ϕX (t) = ϕX1 (t) · ϕX2 (t) R. Frühwirth Statistische Metodender Datenanalyse 267/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Beispiel (Faltung von zwei Poissonverteilungen) Es seien X1 und X2 Poisson-verteilt gemäß Po(λ1 ) bzw. Po(λ2 ). Die charakteristische Funktion von Xi lautet: ϕXi (t) = ∞ X eikt λki e−λi = exp[λi (eit − 1)] k! k=0 Die charakteristische Funktion von X = X1 + X2 ist daher gleich Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen ϕX (t) = exp[λ1 (eit − 1)] exp[λ2 (eit − 1)] = exp[(λ1 + λ2 )(eit − 1)] X ist also Poisson-verteilt gemäß Po(λ) mit λ = λ1 + λ2 . Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 268/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Beispiel (Faltung von zwei χ2 -Verteilungen) Es seien X1 und X2 χ2 -verteilt mit n1 bzw. n2 Freiheitsgraden. Die charakteristische Funktion von Xi lautet: ϕXi (t) = Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Die charakteristische Funktion von X = X1 + X2 ist daher gleich Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 1 (1 − 2it)ni /2 ϕX (t) = 1 1 = (1 − 2it)n1 /2 (1 − 2it)n2 /2 (1 − 2it)(n1 +n2 )/2 X ist also χ2 -verteilt mit n = n1 + n2 Freiheitsgraden. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 269/584 Faltung und Messfehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Zwei Eigenschaften der Normalverteilung 1 Die Faltung zweier Normalverteilungen ist wieder eine Normalverteilung. 2 Ist die Faltung von zwei Verteilungen eine Normalverteilung, so sind auch die beiden Summanden Normalverteilungen. Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 270/584 Unterabschnitt: Fehlerfortpflanzung, Transformation von Dichten Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 271/584 Fehlerfortpflanzung, Transformation von Dichten Statistische Metoden der Datenanalyse Im folgenden Abschnitt sollen Linearkombinationen von — nicht notwendig unabhängigen — Zufallsvariablen betrachtet werden. R. Frühwirth Eindimensionale Zufallsvariable Es sei X = (X1 , . . . , Xn ) eine n-dimensionale Zufallsvariable und H eine m × n - Matrix. Dann ist Y = (Y1 , . . . Ym ) = HX — wie jede deterministische Funktion einer Zufallsvariablen — wieder eine Zufallsvariable. Wie ist Y verteilt? Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Es gilt exakt: Lineare Transformation von Erwartung und Varianz Momente Erwartung Varianz Schiefe 1 E[Y ] ≈ H · E[X] 2 Cov[Y ] ≈ H · Cov[X] · HT Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 272/584 Fehlerfortpflanzung, Transformation von Dichten Statistische Metoden der Datenanalyse Es soll nun statt der linearen Abbildung H eine allgemeine Funktion h = (h1 , . . . , hm ) betrachtet werden. R. Frühwirth Eindimensionale Zufallsvariable Es wird angenommen, dass h in jenem Bereich, in dem die Dichte von X signifikant von 0 verschieden ist, genügend gut durch eine lineare Funktion angenähert werden kann. Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Entwickelt man h an der Stelle E[X], so gilt in 1. Näherung: Lineare Fehlerfortpflanzung 1 2 E[Y ] = h(E[X]) T ∂h ∂h Cov[Y ] = · Cov[X] · ∂x ∂x Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 273/584 Fehlerfortpflanzung, Transformation von Dichten Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Ist h = (h1 , . . . , hn ) eine umkehrbar eindeutige Abbildung h : Rn → Rn , so läßt sich die Dichte von Y = (Y1 , . . . , Yn ) = h(X1 , . . . , Xn ) berechnen. Es sei X = (X1 , . . . , Xd ) eine d-dimensionale Zufallsvariable mit der Dichte fX (x1 , . . . , xd ), h eine umkehrbare Abbildung h : Rd → Rd , g die Umkehrfunktion von h, Y = h(X) und fY (y1 , . . . , yd ) die Dichte von Y . Dann gilt: Transformation der Dichte ∂g fY (y1 , . . . , yd ) = fX (g(y1 , . . . , yd )) · ∂y ∂g wobei der Betrag der Funktionaldeterminante ist. ∂y R. Frühwirth Statistische Metodender Datenanalyse 274/584 Fehlerfortpflanzung, Transformation von Dichten Statistische Metoden der Datenanalyse Beispiel (Transformation unter einer affinen Abbildung) R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Es sei X eine d-dimensionale Zufallsvariable mit Dichte fX (x) und Y = AX + b. Ist A regulär, ist die Dichte von Y gegeben durch: fY (y) = fX (A−1 (y − b)) · Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe 1 |A| Beispiel (Transformation mit der Verteilungsfunktion) Es sei X eine stetige Zufallsvariable mit der Dichte f (x) und der Verteilungsfunktion F (x), und Y = F (X). Dann ist die Dichte von Y gegeben durch: dF −1 = f (x)/f (x) = 1 g(y) = f (x) · dy Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Y ist also gleichverteilt im Intervall [0, 1]. Y wird als p-Wert (probability transform) von X bezeichnet. R. Frühwirth Statistische Metodender Datenanalyse 275/584 Fehlerfortpflanzung, Transformation von Dichten Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Beispiel (Transformation mit der inversen Verteilungsfunktion) Es sei U gleichverteilt im Intervall [0, 1], F (x) (f (x)) die Verteilungsfunktion (Dichtefunktion) einer stetigen Verteilung, und X = F −1 (U ). Dann ist die Dichte von X gegeben durch: dF = f (x) g(x) = 1 · dx X ist also verteilt mit der Verteilungsfunktion F und der Dichte f . Beispiel Es sei X gleichverteilt im Intervall [0, 1] und Y = − ln(X). Dann ist g(y) = exp(−y) und dg = e−y fY (y) = fX (exp(−y)) · dy Y ist daher exponentialverteilt mit τ = 1. R. Frühwirth Statistische Metodender Datenanalyse 276/584 Fehlerfortpflanzung, Transformation von Dichten Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Beispiel (Der Kehrwert einer gammaverteilten Zufallsvariablen) Es sei X Gammaverteilt gemäß Ga(a, b). Wir suchen die Verteilung von Y = 1/X. Es gilt: fY (y) = fX (1/y) · (1/y)a+1 e−b/x 1 = 2 y ba Γ(a) Die Verteilung von Y wird als inverse Gammaverteilung IG(a, b) bezeichnet. Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 277/584 Unterabschnitt: Systematische Fehler Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 278/584 Systematische Fehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Kann der Messfehler durch eine Zufallsvariable mit Mittel 0 beschrieben werden, hat die Messung nur einen statistischen Fehler. Die Messung kann jedoch durch eine falsche Kalibration (z.B. Skalenfehler oder Nullpunktfehler) des Messgeräts verfälscht sein. Solche Fehler werden systematische Fehler genannt. Systematische Fehler werden durch Vergrößerung der Stichprobe nicht kleiner! Die Korrektur von systematischen Fehlern erfordert solgfältige Kalibaration der Messaparatur, Überprüfung von theoretischen Annahmen, etc. Das Gesetz der Fehlerfortpflanzung gilt nicht für systematische Fehler! R. Frühwirth Statistische Metodender Datenanalyse 279/584 Systematische Fehler Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Beispiel Wir messen zwei Spannungen U1 , U2 mit dem gleichen Messgerät. Durch fehlerhafte Kalibration misst das Gerät statt der wahren Spannung U die Spannung Um = aU + b + ε, mit a = 0.99, b = 0.05, σ[ε] = 0.03 V. Der Mittelwert Ū der beiden Spannungen hat dann einen statistischen Fehler von 0.02 V. Der systematische Fehler des Mittelwerts wird beschrieben durch Ūm = aŪ + b, ist also der der Einzelmessung. Der systematische Fehler der Differenz ∆U wird beschrieben durch ∆Um = a∆U . Der Nullpunktfehler ist verschwunden. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 280/584 Unterabschnitt: Grenzverteilungssätze Statistische Metoden der Datenanalyse R. Frühwirth 8 Eindimensionale Zufallsvariable 9 Mehrdimensionale Zufallsvariable 10 Wichtige Verteilungen 11 Momente 12 Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 281/584 Grenzverteilungssätze Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Zentraler Grenzwertsatz für identisch verteilte Folgen von Zufallsvariablen Sei (Xi )i∈N eine Folge von unabhängigen Zufallsvariablen, die die gleiche Verteilung besitzen, mit endlicher Erwartung µ und endlicher Varianz σ 2 . Definiert man Sn und Un durch: Sn = n X Xi , Un = i=1 Sn − E[Sn ] Sn − nµ = √ σ[Sn ] n·σ so ist U = limn→∞ Un standardnormalverteilt. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 282/584 Grenzverteilungssätze Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Zentraler Grenzwertsatz für beliebig verteilte Folgen von Zufallsvariablen Sei (Xi )i∈N eine Folge von unabhängigen Zufallsvariablen mit beliebigen Verteilungen. µi = E[Xi ] und σi2 = var[Xi ] seien endlich für alle i ∈ N. Definiert man für jedes n ∈ N Ui und Yn durch: n X Xi − µi , Yn = Ui Ui = √ nσi i=1 so ist Y = limn→∞ Yn standardnormalverteilt. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze Der zentrale Grenzwertsatz erklärt, warum die Normalverteilung in der Natur eine so bedeutende Rolle spielt, etwa bei der Verteilung der Impulskomponenten von Gasmolekülen, die das Ergebnis von zahlreichen Stößen ist. R. Frühwirth Statistische Metodender Datenanalyse 283/584 Grenzverteilungssätze Statistische Metoden der Datenanalyse R. Frühwirth Auch bei relativ kleinem n ist die Normalverteilung of eine gute Näherung für die Summe von Zufallsvariablen. Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Beispiel (Binomialverteilung für großes n) Da eine gemäß Bi(n, p) verteilte Zufallsvariable als Summe von n alternativverteilten Zufallsvariablen dargestellt werden kann, muss die Binomialverteilung für n → ∞ gegen eine Normalverteilung streben. Die Abbildung zeigt die Verteilungsfunktion der Binomialverteilung Bi(n, p) mit n = 200 und p = 0.1, sowie die Verteilungsfunktion der Normalverteilung No(µ, σ 2 ) mit µ = np = 20 und σ 2 = np(1 − p) = 18. Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 284/584 Grenzverteilungssätze Statistische Metoden der Datenanalyse 1 R. Frühwirth 0.8 Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.7 Mehrdimensionale Zufallsvariable Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.6 F(x) Grundbegriffe Randverteilungen und bedingte Verteilungen Bi(200,0.1) No(20,18) 0.9 Eindimensionale Zufallsvariable 0.5 0.4 0.3 0.2 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0.1 0 0 5 10 R. Frühwirth 15 20 x 25 Statistische Metodender Datenanalyse 30 35 40 285/584 Grenzverteilungssätze Statistische Metoden der Datenanalyse R. Frühwirth Eindimensionale Zufallsvariable Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable Mehrdimensionale Zufallsvariable Grundbegriffe Randverteilungen und bedingte Verteilungen Beispiel (Poissonverteilung für großes n) Da eine gemäß Po(λ) verteilte Zufallsvariable als Summe von λ P (1)-verteilten Zufallsvariablen dargestellt werden kann, muss die Poissonverteilung für λ → ∞ gegen eine Normalverteilung streben. Die Abbildung zeigt die Verteilungsfunktion der Poissonverteilung Po(λ) mit λ = 25, sowie die Verteilungsfunktion der Normalverteilung No(µ, σ 2 ) mit µ = λ = 25 und σ 2 = λ = 25. Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze R. Frühwirth Statistische Metodender Datenanalyse 286/584 Grenzverteilungssätze Statistische Metoden der Datenanalyse 1 R. Frühwirth 0.8 Grundbegriffe Diskrete Zufallsvariable Stetige Zufallsvariable 0.7 Mehrdimensionale Zufallsvariable Wichtige Verteilungen Diskrete Verteilungen Stetige Verteilungen Die Normalverteilung und verwandte Verteilungen 0.6 F(x) Grundbegriffe Randverteilungen und bedingte Verteilungen Po(25) N(25,25) 0.9 Eindimensionale Zufallsvariable 0.5 0.4 0.3 0.2 Momente Erwartung Varianz Schiefe Rechnen mit Verteilungen Faltung und Messfehler Fehlerfortpflanzung, Transformation von Dichten Systematische Fehler Grenzverteilungssätze 0.1 0 0 5 10 15 R. Frühwirth 20 25 x 30 35 Statistische Metodender Datenanalyse 40 45 50 287/584 Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Teil 4 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Schätzen von Parametern Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 288/584 Übersicht Teil 4 Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 289/584 Abschnitt 13: Stichprobenfunktionen Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 14 Punktschätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 290/584 Unterabschnitt: Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 14 Punktschätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 291/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian X1 , . . . , Xn seien unabhängige Zufallsvariable, die alle die gleiche Verteilung F haben. Sie bilden dann eine zufällige Stichprobe der Verteilung F . Eine Zufallsvariable Y = h(X1 , . . . , Xn ) Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer heißt eine Stichprobenfunktion. In vielen Fällen sind Momente oder die Verteilung von Y zu bestimmen. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 292/584 Unterabschnitt: Stichprobenmittel Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 14 Punktschätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 293/584 Stichprobenmittel Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Definition (Stichprobenmittel) Das Stichprobenmittel X der Stichprobe X1 , . . . , Xn ist definiert durch n 1X X= Xi n i=1 Momente des Stichprobenmittels Hat F das Mittel µ und die Varianz σ 2 , gilt: 1 E[X] = µ 2 var[X] = 3 σ2 n Ist F eine Normalverteilung, so ist X normalverteilt. R. Frühwirth Statistische Metodender Datenanalyse 294/584 Stichprobenmittel Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Zentraler Grenzwertsatz 1 Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Hat F das Mittel µ und die Varianz σ 2 , so konvergiert die Verteilung von X −µ √ U= σ/ n gegen die Standardnormalverteilung. 2 Ist F eine Normalverteilung, ist U für alle n standardnormalverteilt. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 295/584 Unterabschnitt: Stichprobenvarianz Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 14 Punktschätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 296/584 Stichprobenvarianz Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Definition (Stichprobenvarianz) Die Stichprobenvarianz S 2 der Stichprobe X1 , . . . , Xn ist definiert durch n 1 X (Xi − X)2 S2 = n − 1 i=1 Erwartung der Stichprobenvarianz Hat F die Varianz σ 2 , gilt: Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung E[S 2 ] = σ 2 R. Frühwirth Statistische Metodender Datenanalyse 297/584 Stichprobenvarianz Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Satz Ist F eine Normalverteilung mit Mittel µ und Varianz σ 2 , so gilt: 1 (n − 1)S 2 /σ 2 ist χ2 -verteilt mit n − 1 Freiheitsgraden. 2 X und S 2 sind unabhängig. 3 Die Varianz von S 2 ist gegeben durch var[S 2 ] = 4 2σ 4 n−1 Die Größe T = X −µ √ S/ n ist t-verteilt mit n − 1 Freiheitsgraden. R. Frühwirth Statistische Metodender Datenanalyse 298/584 Unterabschnitt: Stichprobenmedian Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 14 Punktschätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 299/584 Stichprobenmedian Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Definition (Stichprobenmedian) Der Stichprobenmedian X̃ der Stichprobe X1 , . . . , Xn ist definiert durch X((n+1)/2) , n ungerade X̃ = 1 X (n/2) + X(n/2+1) , n gerade 2 Momente des Stichprobenmedians Hat F den Median m und die Dichte f , gilt: 1 lim E[X̃] = m n→∞ 2 lim var[X̃] = n→∞ 3 1 , 4 nf 2 (m) wenn f (m) > 0 X̃ ist asymptotisch normalverteilt. R. Frühwirth Statistische Metodender Datenanalyse 300/584 Abschnitt 14: Punktschätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen 14 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-Likelihood-Schätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 301/584 Unterabschnitt: Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen 14 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-Likelihood-Schätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 302/584 Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Ein Punktschätzer ist eine Stichprobenfunktion, die einen möglichst genauen Näherungswert für einen unbekannten Verteilungsparameter ϑ liefern soll: Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung T = g(X1 , . . . , Xn ) Die Funktion g(x1 , . . . , xn ) wird die Schätzfunktion genannt. Die Konstruktion von sinnvollen Punktschätzern für einen Parameter ϑ ist Aufgabe der Schätztheorie. Für einen Parameter ϑ sind viele Punktschätzer möglich. Ein guter“ Punktschätzer sollte jedoch gewisse Anforderungen ” erfüllen. R. Frühwirth Statistische Metodender Datenanalyse 303/584 Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Definition (Erwartungstreue) Ein Punktschätzer T für den Parameter ϑ heißt erwartungstreu oder unverzerrt, wenn für alle zulässigen Werte von ϑ gilt: Eϑ [T ] = ϑ Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer T heißt asymptotisch erwartungstreu, wenn gilt: lim Eϑ [T ] = ϑ n→∞ Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Ist der unbekannte Parameter gleich ϑ, dann ist die Erwartung des Punktschätzers gleich ϑ. Ein erwartungstreuer Punktschätzer hat zwar zufällige Abweichungen vom wahren Wert ϑ, aber keine systematische Verzerrung. R. Frühwirth Statistische Metodender Datenanalyse 304/584 Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Definition (MSE) Die mittlere quadratische Abweichung (mean squared error, MSE) eines Punktschätzers T für den Parameter ϑ ist definiert durch: MSE[T ] = Eϑ [(T − ϑ)2 ] Definition (MSE-Konsistenz) Ein Punktschätzer T für den Parameter ϑ heißt konsistent im quadratischen Mittel (MSE-konsistent), wenn gilt: lim MSE[T ] = 0 n→∞ R. Frühwirth Statistische Metodender Datenanalyse 305/584 Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Definition (MSE-Effizienz) Ein Punktschätzer T1 heißt MSE-effizienter als der Punktschätzer T2 , wenn für alle zulässigen ϑ gilt: MSE[T1 ] ≤ MSE[T2 ] Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Definition (Effizienz) Ein erwartungstreuer Punktschätzer T1 heißt effizienter als der erwartungstreue Punktschätzer T2 , wenn für alle zulässigen ϑ gilt: var[T1 ] ≤ var[T2 ] Ein erwartungstreuer Punktschätzer T heißt effizient, wenn seine Varianz den kleinsten möglichen Wert annimmt. R. Frühwirth Statistische Metodender Datenanalyse 306/584 Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Definition (Fisher-Information) Es sei X1 , . . . , Xn eine Stichprobe mit der gemeinsamen Dichte g(x1 , . . . , xn |ϑ). Die Erwartung 2 ∂ ln g(X1 , . . . , Xn |ϑ) Iϑ = E − ∂ϑ2 heißt die Fisher-Information der Stichprobe. Satz von Rao und Cramèr Es sei X1 , . . . , Xn eine Stichprobe mit der gemeinsamen Dichte g(x1 , . . . , xn |ϑ). Die Varianz eines erwartungstreuen Schätzers T für den Parameter ϑ ist nach unten beschränkt durch: var[T ] ≥ 1/Iϑ R. Frühwirth Statistische Metodender Datenanalyse 307/584 Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel Es sei X1 , . . . , Xn eine Stichprobe aus der Exponentialverteilung Ex(τ ). Die gemeinsame Dichte ist dann gleich ! n X 1 g(x1 , . . . , xn |τ ) = n exp − xi /τ τ i=1 Daraus folgt: ln g(x1 , . . . , xn |τ ) = − n ln τ − Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung ∂2 ln g(x1 , . . . , xn |τ ) = ∂τ 2 2 ∂ E ln g(X , . . . , X |τ ) = 1 n ∂τ 2 R. Frühwirth n X xi /τ i=1 P 2 n i=1 τ3 xi n − τ2 n 2 nτ n − 3 −=− 2 τ2 τ τ Statistische Metodender Datenanalyse 308/584 Eigenschaften von Punktschätzern Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Beispiel (Fortsetzung) Die Information ist also gleich Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Iτ = n τ2 Für jeden erwartungstreuen Schätzer T von τ gilt folglich: var[T ] ≥ τ2 n Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 309/584 Unterabschnitt: Schätzung des Mittelwerts Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen 14 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-Likelihood-Schätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 310/584 Schätzung des Mittelwerts Statistische Metoden der Datenanalyse R. Frühwirth Satz 1 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 2 Es sei X1 , . . . , Xn eine Stichprobe aus der Verteilung F mit Erwartung µ. Dann ist das Stichprobenmittel X ein erwartungstreuer Punktschätzer von µ. Hat F die endliche Varianz σ 2 , so ist X MSE-konsistent. Beispiel Ist F die Normalverteilung No(µ, σ 2 ), so ist X normalverteilt gemäß No(µ, σ 2 /n). Da die Fisher-Information für µ gleich Iµ = n/σ 2 ist, ist X effizient für µ. Beispiel Ist F die Exponentialverteilung Ex(τ ), so ist X Gamma-verteilt mit Mittel τ und Varianz τ 2 /n. Da die Fisher-Information für τ gleich Iτ = n/τ 2 ist, ist X effizient für τ . R. Frühwirth Statistische Metodender Datenanalyse 311/584 Schätzung des Mittelwerts Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Beispiel Ist F die Poissonverteilung Po(λ), hat X Mittel λ und Varianz λ/n. Da die Fisher-Information für λ gleich Iλ = n/λ ist, ist X effizient für λ. Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel Ist F die Alternativverteilung Al(p), hat X Mittel p und Varianz p(1 − p)/n. Da die Fisher-Information für p gleich Ip = n/[p(1 − p)] ist, ist X effizient für p. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 312/584 Unterabschnitt: Schätzung der Varianz Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen 14 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-Likelihood-Schätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 313/584 Schätzung der Varianz Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Satz 1 Es sei X1 , . . . , Xn eine Stichprobe aus der Verteilung F mit Erwartung µ und Varianz σ 2 . Dann ist die Stichprobenvarianz S 2 ein erwartungstreuer Punktschätzer von σ 2 . 2 Hat F das endliche vierte zentrale Moment µ4 , so ist Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer var(S 2 ) = Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 3 µ4 (n − 3)µ22 − n n(n − 1) In diesem Fall ist S 2 MSE-konsistent. R. Frühwirth Statistische Metodender Datenanalyse 314/584 Schätzung der Varianz Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Beispiel Ist F die Normalverteilung No(µ, σ 2 ), so ist (n − 1)S 2 /σ 2 χ2 -verteilt mit n − 1 Freiheitsgraden. Die Varianz von S 2 ist dann gleich var(S 2 ) = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 2σ 4 n−1 Die Fisher-Information für σ 2 ist gleich Iσ2 = n 2σ 4 S 2 ist also ein asymptotisch effizienter Punktschätzer für σ 2 . R. Frühwirth Statistische Metodender Datenanalyse 315/584 Unterabschnitt: Schätzung des Medians Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen 14 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-Likelihood-Schätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 316/584 Schätzung des Medians Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Satz 1 Es sei X1 , . . . , Xn eine Stichprobe aus der stetigen Verteilung F mit Median m und Dichte f . Dann ist der Stichprobenmedian X̃ ein asymptotisch erwartungstreuer Punktschätzer von m. 2 Für symmetrisches F ist X̃ erwartungstreu. 3 Der Stichprobenmedian X̃ hat asymptotisch die Varianz Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer var(X̃) ≈ Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 4 1 4nf (m)2 Der Stichprobenmedian ist MSE-konsistent, sofern f (m) > 0. R. Frühwirth Statistische Metodender Datenanalyse 317/584 Schätzung des Medians Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Beispiel Es sei X1 , . . . , Xn eine Stichprobe aus der Normalverteilung No(µ, σ 2 ). Die Varianz von X ist gleich var(X) = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer σ2 n Die Varianz von X̃ ist für großes n gleich var(X̃) = 2 πσ 2 σ2 ≈ 1.57 4n n Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Sie ist also um mehr als 50 Prozent größer als die Varianz von X. R. Frühwirth Statistische Metodender Datenanalyse 318/584 Schätzung des Medians Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel Es sei X1 , . . . , Xn eine Stichprobe aus der t-Verteilung t(3). Die Varianz von X ist gleich 3 var(X) = n Die Varianz von X̃ ist für großes n gleich var(X̃) = 1 1.8506 3 = ≈ 0.62 4 nf (0)2 n n Sie ist also fast um 40 Prozent kleiner als die Varianz von X. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 319/584 Unterabschnitt: Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 13 Stichprobenfunktionen 14 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-Likelihood-Schätzer 15 Intervallschätzer Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 320/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Definition (ML-Schätzer) 1 Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian L(ϑ|X1 , . . . , Xn ) = g(X1 , . . . , Xn |ϑ) Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Es sei X1 , . . . , Xn eine Stichprobe mit der gemeinsamen Dichte g(x1 , . . . , xn |ϑ). Die Funktion 2 heißt die Likelihoodfunktion der Stichprobe. Der plausible oder Maximum-Likelihood-Schätzer ϑ̂ ist jener Wert von ϑ, der die Likelihoodfunktion der Stichprobe maximiert. Oft wird statt der Likelihoodfunktion ihr Logarithmus, die Log-Likelihoodfunktion `(ϑ) = ln L(ϑ) maximiert. R. Frühwirth Statistische Metodender Datenanalyse 321/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Beispiel (ML-Schätzung eines Bernoulli-Parameters) Es sei X1 , . . . , Xn eine Stichprobe aus der Alternativverteilung Al(p). Die gemeinsame Dichte lautet: g(x1 , . . . , xn |p) = n Y pxi (1 − p)1−xi = p P xi P (1 − p)n− xi i=1 Die Log-Likelihoodfunktion ist daher: `(p) = n X Xi ln p + i=1 n− n X ! Xi ln(1 − p) i=1 Ableiten nach p ergibt: n ∂`(p) 1X 1 = Xi − ∂p p i=1 1−p R. Frühwirth n− n X ! Xi i=1 Statistische Metodender Datenanalyse 322/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Beispiel (Fortsetzung) Nullsetzen der Ableitung und Auflösen nach p ergibt: Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian p̂ = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer n 1X Xi = X n i=1 Der ML-Schätzer ist unverzerrt und effizient. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 323/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel (ML-Schätzung eines Poisson-Parameters) Es sei X1 , . . . , Xn eine Stichprobe aus der Poissonverteilung Po(λ). Die gemeinsame Dichte lautet: g(x1 , . . . , xn |λ) = Die Log-Likelihoodfunktion ist daher: `(λ) = Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung n Y λxi e−λ xi ! i=1 n X [Xi ln λ − λ − ln(xi !)] i=1 Ableiten nach λ ergibt: n ∂`(λ) 1X = Xi − n ∂λ λ i=1 R. Frühwirth Statistische Metodender Datenanalyse 324/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Beispiel (Fortsetzung) Nullsetzen der Ableitung und Auflösen nach λ ergibt: Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian λ̂ = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer n 1X Xi = X n i=1 Der ML-Schätzer ist unverzerrt und effizient. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 325/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel (ML-Schätzung einer mittleren Lebensdauer) Es sei X1 , . . . , Xn eine Stichprobe aus der Exponentialverteilung Ex(τ ). Die gemeinsame Dichte lautet: g(x1 , . . . , xn |τ ) = Die Log-Likelihoodfunktion ist daher: `(τ ) = Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung n Y e−xi /τ τ i=1 n n X 1X [− ln τ − Xi ] τ i=1 i=1 Ableiten nach τ ergibt: n ∂`(τ ) n 1 X =− + 2 Xi ∂τ τ τ i=1 R. Frühwirth Statistische Metodender Datenanalyse 326/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Beispiel (Fortsetzung) Nullsetzen der Ableitung und Auflösen nach τ ergibt: Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian τ̂ = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer n 1X Xi = X n i=1 Der ML-Schätzer ist unverzerrt und effizient. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 327/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Beispiel (ML-Schätzung der Parameter einer Normalverteilung) Es sei X1 , . . . , Xn eine Stichprobe aus der Normalverteilung No(µ, σ 2 ). Die gemeinsame Dichte lautet: 2 g(x1 , . . . , xn |µ, σ ) = n Y i=1 (xi − µ)2 1 √ exp − 2 σ2 2πσ Die Log-Likelihoodfunktion ist daher: n X √ (xi − µ)2 1 `(µ, σ 2 ) = − ln 2π − ln σ 2 − 2 2 σ2 i=1 Ableiten nach µ und σ 2 ergibt: n X xi − µ ∂`(µ, σ 2 ) = , ∂µ σ2 i=1 R. Frühwirth n X ∂`(µ, σ 2 ) (xi − µ)2 1 = − + ∂σ 2 2 σ2 2 σ4 i=1 Statistische Metodender Datenanalyse 328/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Beispiel (Fortsetzung) Nullsetzen der Ableitungen und Auflösen nach µ und σ 2 ergibt: µ̂ = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer σ̂ 2 = n 1X Xi = X n i=1 n 1X n−1 2 (Xi − X)2 = S n i=1 n Der ML-Schätzer von µ ist unverzerrt und effizient. Der ML-Schätzer von σ 2 ist asymptotisch unverzerrt und asymptotisch effizient. Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 329/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Die normierte Likelihoodfunktion kann als a-posteriori Verteilung des geschätzten Parameters interpretiert werden. Für großes n kann man die Varianz der Likelihoodschätzung ϑ̂ daher aus dem zweiten zentralen Moment der normierten Likelihoodfunktion ablesen. Ist des geschätzte Parameter ϑ das Mittel einer Normalverteilung, so ist diese Vorgangsweise für beliebiges n exakt: 1 1X n 2 2 L(ϑ) = (xi − ϑ̂) √ n exp − 2 (ϑ̂ − ϑ) + 2σ n σn 2 π Wird L(ϑ) normiert, so entsteht die Dichte“ einer ” 2 Normalverteilung mit Mittel ϑ̂ und Varianz σn , also gerade P die Varianz der Schätzung ϑ̂ = n1 xi . R. Frühwirth Statistische Metodender Datenanalyse 330/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Beispiel (Schätzung des Parameters a einer Gammaverteilung) Die Stichprobe X1 , . . . , Xn besteht aus n = 200 Werten, die unabhängig aus einer Γa,1 -Verteilung gezogen werden: f (xi |a) = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung xa−1 e−xi i , Γ(a) i = 1, . . . , n Der (unbekannte) wahre Wert von a ist aw = 2. Die Log-Likelihoodfunktion lautet ln L(a|x) = n X ln f (xi |a) = (a − 1) i=1 R. Frühwirth n X i=1 ln xi − n X xi − n ln Γ(a) i=1 Statistische Metodender Datenanalyse 331/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel (Fortsetzung) Numerische Maximierung von ln L(a) gibt die Maximum Likelihood-Schätzung â. Das Experiment wird N -mal wiederholt und die Schätzungen der einzelnen Experimente (â(k) , k = 1, . . . , N ) werden histogrammiert. Der Vergleich der individuellen (normierten) Likelihoodfunktion mit dem Histogramm (N = 500) zeigt gute Übereinstimmung der Standardabweichungen. Matlab: make ML gamma Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 332/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 1 0.9 Histogram: σ=0.08575 0.8 LF: σ=0.08502 0.7 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer 0.6 0.5 0.4 0.3 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 0.2 0.1 0 1.5 1.6 1.7 1.8 R. Frühwirth 1.9 2 2.1 2.2 Statistische Metodender Datenanalyse 2.3 2.4 2.5 333/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse Der ML-Schätzer hat die folgende wichtige Eigenschaft: R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Satz Existieren die ersten beiden Ableitungen von L(ϑ), existiert die Information Ig (ϑ) für alle ϑ und ist E [(ln L)0 ] = 0, so ist die Likelihoodschätzung ϑ̂ asymptotisch normalverteilt mit Mittel ϑ und Varianz 1/Ig (ϑ). ϑ̂ ist daher asymptotisch erwartungstreu und asymptotisch effizient. Daraus folgt sofort die nächste Eigenschaft: Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Satz Der Likelihoodschätzer ϑ̂ ist (unter den selben Voraussetzungen) konsistent. R. Frühwirth Statistische Metodender Datenanalyse 334/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Beispiel (ML-Schätzung des Lageparameters einer Cauchyverteilung) Es sei X1 , . . . , Xn eine Stichprobe aus der Cauchyverteilung t(1) mit Lageparameter µ. Die gemeinsame Dichte lautet: Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung g(x1 , . . . , xn |µ) = n Y i=1 1 π[1 + (xi − µ)2 ] Die Log-Likelihoodfunktion ist daher: `(µ) = −n ln π − n X ln[1 + (xi − µ)2 ] i=1 Das Maximum µ̂ von `(µ) muss numerisch gefunden werden. Matlab: make ML cauchy R. Frühwirth Statistische Metodender Datenanalyse 335/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Beispiel (Fortsetzung) Man kann zeigen, dass die Fisherinformation der Stichprobe gleich Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Iµ = n 2 ist. Für große Stichproben muss daher die Varianz des ML-Schätzers µ̂ ungefähr gleich 2/n sein. Der Stichprobenmedian x̃ ist ebenfalls ein konsistenter Schätzer für µ. Seine Varianz ist asymptotisch gleich π 2 /(4n) ≈ 2.47/n. Sie ist also um etwa 23 Prozent größer als die Varianz des ML-Schätzers. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 336/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse Simulation von 10000 Stichproben der Größe n = 100: R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 1400 1500 1200 µ=0.9998 µ=1.001 σ=0.1588 σ=0.1435 1000 1000 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 800 600 500 400 200 0 0 0.5 1 1.5 Stichprobenmedian 2 0 0 0.5 1 1.5 ML−Schätzer 2 Die Korrelation zwischen x̃ und µ̂ ist etwa 90%. R. Frühwirth Statistische Metodender Datenanalyse 337/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Die Standardabweichung des ML-Schätzers kann wieder näherungsweise aus der normierten Likelihoodfunktion einer Stichprobe abgelesen werden: Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Log−Likelihoodfunktion Normierte Likelihoodfunktion 0 3.5 −5 3 −10 2.5 −15 2 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung L(µ) Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer log L(µ) Punktschätzer −20 1.5 −25 1 −30 0.5 −35 0 0.5 1 µ R. Frühwirth 1.5 2 0 0 σ=0.1314 0.5 Statistische Metodender Datenanalyse 1 µ 1.5 2 338/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Beispiel (ML-Schätzung des Obergrenze einer Gleichverteilung) Es sei X1 , . . . , Xn eine Stichprobe aus der Gleichverteilung Un(0, b) mit Obergrenze b. Die gemeinsame Dichte lautet: g(x1 , . . . , xn |b) = 1 , 0 ≤ x1 , . . . , xn ≤ b bn Der größte Wert der Likelihoodfunktion ist daher bei b̂ = max Xi i Da ein Randmaximum vorliegt, gelten die üblichen asymptotischen Eigenschaften nicht. R. Frühwirth Statistische Metodender Datenanalyse 339/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Beispiel (Fortsetzung) Die Dichte von b̂ = max Xi lautet: i Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian f (x) = Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung nxn−1 bn Daraus können Erwartung und Varianz berechnet werden: E[b̂] = n , n+1 var[b̂] = b2 n (n + 2)(n + 1)2 Der Schätzer ist asymptotisch erwartungstreu, die Varianz geht aber wie 1/n2 gegen Null! Der Schätzer ist auch nicht asymptotisch normalverteilt. Matlab: make ML uniform R. Frühwirth Statistische Metodender Datenanalyse 340/584 Maximum-Likelihood-Schätzer Statistische Metoden der Datenanalyse R. Frühwirth Simulation von 10000 Stichproben (b = 1) der Größe n = 25 bzw. n = 100: Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer n=25 n=100 2500 7000 µ=0.9617 σ=0.03632 2000 5000 1500 4000 3000 1000 2000 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung µ=0.9902 σ=0.009755 6000 500 1000 0 0.8 1 ML−Schätzer R. Frühwirth 1.2 0 0.8 1 ML−Schätzer Statistische Metodender Datenanalyse 1.2 341/584 Abschnitt 15: Intervallschätzer Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 342/584 Unterabschnitt: Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 343/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Neben dem Schätzwert selbst ist auch seine Streuung um den wahren Wert von Interesse. Wir wollen aus einer Stichprobe ein Intervall bestimmen, das den wahren Wert mit einer gewissen Wahrscheinlichkeit enthält. Definition (Konfidenzintervall) Es sei X1 , . . . , Xn eine Stichprobe aus der Verteilung F mit dem unbekannten Parameter ϑ. Ein Intervall mit den Grenzen G1 = g1 (X1 , . . . , Xn ) und G2 = g2 (X1 , . . . , Xn ) heißt ein Konfidenzintervall mit Sicherheit 1 − α, wenn gilt: W (G1 ≤ G2) = 1 W (G1 ≤ ϑ ≤ G2) ≥ 1 − α Ein solches Intervall wird kurz als (1 − α)-Konfidenzintervall bezeichnet. R. Frühwirth Statistische Metodender Datenanalyse 344/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Zu jedem Wert der Sicherheit 1 − α gibt es viele verschiedene Konfidenzintervalle. Ist F stetig, gibt es unendlich viele Konfidenzintervalle mit Sicherheit 1 − α. Ist F diskret, ist die Sicherheit in der Regel größer als 1 − α. Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Ein symmetrisches Konfidenzintervall liegt vor, wenn gilt: W (ϑ ≤ G1 ) = W (ϑ ≥ G2 ) Ein einseitiges Konfidenzintervall liegt vor, wenn gilt: Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung W (ϑ ≤ G2 ) ≥ 1 − α R. Frühwirth oder W (G1 ≤ ϑ) ≥ 1 − α Statistische Metodender Datenanalyse 345/584 Unterabschnitt: Allgemeine Konstruktion nach Neyman Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 346/584 Allgemeine Konstruktion nach Neyman Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Es sei Y = h(X1 , . . . , Xn ) eine Stichprobenfunktion. Die Verteilung G von Y hängt dann ebenfalls vom unbekannten Parameter ϑ ab. Für jeden Wert von ϑ bestimmen wir ein Prognoseintervall [y1 (ϑ), y2 (ϑ)] vom Niveau 1 − α: Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer W (y1 (ϑ) ≤ Y ≤ y2 (ϑ)) ≥ 1 − α Ist die Beobachtung gleich Y = y0 , so ist das Konfidenzintervall [G1 (Y ), G2 (Y )] gegeben durch: Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung G1 = min{ϑ|y1 (ϑ) ≤ y0 ≤ y2 (ϑ)} ϑ G2 = max{ϑ|y1 (ϑ) ≤ y0 ≤ y2 (ϑ)} ϑ R. Frühwirth Statistische Metodender Datenanalyse 347/584 Allgemeine Konstruktion nach Neyman Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel Es sei X1 , . . . , Xn eine Stichprobe aus No(0, σ 2 ) mit unbekannter Varianz σ. Dann ist (n − 1)S 2 /σ 2 χ2 -verteilt mit n − 1 Freiheitsgraden. Für Varianz σ 2 und Y = S 2 ist daher ! σ 2 χ2α/2,n−1 σ 2 χ21−α/2,n−1 W =1−α ≤ S2 ≤ n−1 n−1 Der Ausdruck in der Klammer kann umgeformt werden zu: (n − 1)S 2 (n − 1)S 2 ≤ σ2 ≤ 2 2 χ1−α/2,n−1 χα/2,n−1 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Daraus folgt G1 = (n − 1)S 2 , χ21−α/2,n−1 R. Frühwirth G2 = (n − 1)S 2 χ2α/2,n−1 Statistische Metodender Datenanalyse 348/584 Allgemeine Konstruktion nach Neyman Statistische Metoden der Datenanalyse 10 R. Frühwirth 9 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 8 7 Punktschätzer 6 σ2 Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer 5 4 3 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 2 1 0 0 2 4 6 8 10 S2 Blau: Prognoseintervall für σ 2 = 3; rot: Konfidenzintervall für S 2 = 5 R. Frühwirth Statistische Metodender Datenanalyse 349/584 Unterabschnitt: Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 350/584 Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Es sei k eine Beobachtung aus der Binomialverteilung Bi(n, p). Wir suchen ein Konfidenzintervall für p. Je nach Konstruktion des Prognoseintervalls y1 (p), y2 (p) ergeben sich verschiedene Konfidenzintervalle. Intervall nach Clopper und Pearson y1 (p), y2 (p) sind die Quantile der Binomialverteilung Bi(n, p): y1 (p) = max k y2 (p) = min k R. Frühwirth k X i=0 n X W (k; n, p) ≤ α/2 W (k; n, p) ≤ α/2 i=k Statistische Metodender Datenanalyse 351/584 Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Für die praktische Berechnung des Konfidenzintervalls können die Quantile der Betaverteilung benützt werden: Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian G1 (k) = max(Bα/2,k,n−k+1 , 0) G2 (k) = min(B1−α/2,k+1,n−k , 1) Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Dieses Intervall ist konservativ in dem Sinn, dass die Sicherheit praktisch immer größer als 1 − α ist. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 352/584 Binomialverteilung Statistische Metoden der Datenanalyse Approximation durch Normalverteilung R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Für genügend großes n ist p̂ = k/n annähernd normalverteilt gemäß No(p, p(1 − p)/n). Das Standardscore Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Z= ist dann annähernd standardnormalverteilt. Aus W (−z1−α/2 ≤ Z ≤ z1−α/2 ) = 1 − α Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung p̂ − p σ[p̂] folgt W (p̂ − z1−α/2 σ[p̂] ≤ p ≤ p̂ + z1−α/2 σ[p̂]) = 1 − α R. Frühwirth Statistische Metodender Datenanalyse 353/584 Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Da p nicht bekannt ist, muss σ[p̂] näherungsweise bestimmt werden. Bootstrap-Verfahren: p wird durch p̂ angenähert. Robustes Verfahren: p wird so gewählt, dass σ[p̂] maximal ist, also p = 0.5. Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Korrektur gemäß Agresti-Coull Das Intervall nach dem Bootstrap-Verfahren kann eine kleinere Sicherheit als 1 − α haben. Eine Verbesserung wird durch die Definition p̂ = k+2 n+4 erzielt. R. Frühwirth Statistische Metodender Datenanalyse 354/584 Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Beispiel Angabe: Bei einer Umfrage unter n = 400 Personen geben k = 157 Personen an, Produkt X zu kennen. Wir suchen ein 95%-Konfidenzintervalle für den Bekanntheitsgrad p. Clopper-Pearson: Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung G1 (k) = B0.025,157,244 = 0.3443 G2 (k) = B0.975,158,243 = 0.4423 Approximation durch Normalverteilung: Es gilt p̂ = 0.3925 und z0.975 = 1.96. Mit dem Bootstrap-Verfahren ergibt sich σ[p̂] = 0.0244. Die Grenzen des Konfidenzintervalls sind daher G1 =0.3925 − 1.96 · 0.0244 = 0.3446 G2 =0.3925 + 1.96 · 0.0244 = 0.4404 R. Frühwirth Statistische Metodender Datenanalyse 355/584 Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Beispiel (Fortsetzung) Mit dem robusten Verfahren ergibt sich σ[p̂] = 0.025 und die Grenzen G1 =0.3925 − 1.96 · 0.025 = 0.3435 G2 =0.3925 + 1.96 · 0.025 = 0.4415 Das robuste Intervall ist nur unwesentlich länger als das Bootstrap-Intervall. Mit der Korrektur von Agresti-Coull ergibt sich p̂ = 0.3936. Die Grenzen des Konfidenzintervalls sind dann G1 =0.3936 − 1.96 · 0.0244 = 0.3457 G2 =0.3936 + 1.96 · 0.0244 = 0.4414 Matlab: make KI binomial R. Frühwirth Statistische Metodender Datenanalyse 356/584 Binomialverteilung Statistische Metoden der Datenanalyse Sicherheit der Konfidenzintervalle R. Frühwirth 1 Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 0.95 0.9 Punktschätzer 0.85 1−α Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer 0.8 0.75 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 0.7 Clopper−Pearson Bootstrap Robust Agresti−Coull 0.65 0.6 0 0.1 0.2 R. Frühwirth 0.3 0.4 0.5 p 0.6 0.7 Statistische Metodender Datenanalyse 0.8 0.9 1 357/584 Unterabschnitt: Poissonverteilung Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 358/584 Poissonverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Es sei k eine Beobachtung aus der Poissonverteilung Po(λ). Wir suchen ein Konfidenzintervall für λ. Je nach Konstruktion des Prognoseintervalls [y1 (λ), y2 (λ)] ergeben sich verschiedene Konfidenzintervalle. Symmetrisches Intervall y1 (λ), y2 (λ) sind die Quantile der Poissonverteilung Po(λ): y1 (p) = max k y2 (p) = min k R. Frühwirth k X i=0 ∞ X W (k; λ) ≤ α/2 W (k; λ) ≤ α/2 i=k Statistische Metodender Datenanalyse 359/584 Poissonverteilung Statistische Metoden der Datenanalyse R. Frühwirth Für die praktische Berechnung des Konfidenzintervalls können die Quantile der Gammaverteilung benützt werden: Stichprobenfunktionen G1 (k) = Γα/2,k,1 Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian G2 (k) = Γ1−α/2,k+1,1 Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Dieses Intervall ist konservativ in dem Sinn, dass die Sicherheit praktisch immer größer als 1 − α ist. P Liegen n Beobachtungen k1 , . . . , kn vor, so ist k = ki Poissonverteilt mit Mittel nλ. Das symmetrische Konfidenzintervall für λ ist daher: G1 (k) = Γα/2,k,1/n G2 (k) = Γ1−α/2,k+1,1/n R. Frühwirth Statistische Metodender Datenanalyse 360/584 Poissonverteilung Statistische Metoden der Datenanalyse Sicherheit des symmetrischen Konfidenzintervalls R. Frühwirth 1 Stichprobenfunktionen 0.99 Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 0.98 0.97 Punktschätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 0.96 1−α Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer 0.95 0.94 0.93 0.92 n=1 n=5 n=25 0.91 0.9 0 10 20 R. Frühwirth 30 40 50 λ 60 70 Statistische Metodender Datenanalyse 80 90 100 361/584 Poissonverteilung Statistische Metoden der Datenanalyse Linksseitiges Intervall R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Eine Beobachtung k: y1 (λ) = 0, y2 (λ) = min k ∞ X W (k; λ) ≤ α i=k Praktische Berechnung: G1 (k) = 0, G2 (k) = Γ1−α,k+1,1 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung n Beobachtungen k1 , . . . , kn : G1 (k) = 0, R. Frühwirth G2 (k) = Γ1−α,k+1,1/n Statistische Metodender Datenanalyse 362/584 Poissonverteilung Statistische Metoden der Datenanalyse Sicherheit des linksseitigen Konfidenzintervalls R. Frühwirth 1 Stichprobenfunktionen 0.99 Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian 0.98 0.97 Punktschätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung 0.96 1−α Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer 0.95 0.94 0.93 0.92 n=1 n=5 n=25 0.91 0.9 0 10 20 R. Frühwirth 30 40 50 λ 60 70 Statistische Metodender Datenanalyse 80 90 100 363/584 Unterabschnitt: Exponentialverteilung Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 364/584 Exponentialverteilung Statistische Metoden der Datenanalyse Symmetrisches Intervall für den Mittelwert R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Es sei X1 , . . . , Xn eine Stichprobe aus der Exponentialverteilung Ex(τ ). Pn Das Stichprobenmittel X = n1 i=1 Xi hat die folgende Dichte: xn−1 x f (x) = exp − (τ /n)n Γ(n) τ /n X ist also Gamma-verteilt gemäß Ga(n, τ /n). Für jedes τ gilt: W γα/2,n,τ /n ≤ X ≤ γ1−α/2,n,τ /n = 1 − α R. Frühwirth Statistische Metodender Datenanalyse 365/584 Exponentialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Daraus folgt X ≤ γ1−α/2,n,1/n = 1 − α W γα/2,n,1/n ≤ τ und W X γ1−α/2,n,1/n ≤τ ≤ X γα/2,n,1/n =1−α Damit gilt: Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung G1 (X) = G2 (X) = R. Frühwirth X γ1−α/2,n,1/n X γα/2,n,1/n Statistische Metodender Datenanalyse 366/584 Exponentialverteilung Statistische Metoden der Datenanalyse Linksseitiges Intervall für den Mittelwert R. Frühwirth Stichprobenfunktionen Für jedes τ gilt: Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung W γα,n,τ /n ≤ X = 1 − α Daraus folgt W γα,n,1/n ≤ X τ =1−α und W 0≤τ ≤ X γα,n,1/n =1−α Rechtsseitiges Intervall für den Mittelwert X W ≤τ =1−α γ1−α,n,1/n R. Frühwirth Statistische Metodender Datenanalyse 367/584 Unterabschnitt: Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 368/584 Normalverteilung Statistische Metoden der Datenanalyse Konfidenzintervall für den Mittelwert R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Es sei X1 , . . . , Xn eine Stichprobe aus der Normalverteilung No(µ, σ 2 ). X ist normalverteilt gemäß No(µ, σ 2 /n). Ist σ 2 bekannt, ist das Standardscore Z= X −µ √ σ/ n standardnormalverteilt. Aus W (−z1−α/2 ≤ Z ≤ z1−α/2 ) = 1 − α folgt √ √ W (X − z1−α/2 σ/ n ≤ µ ≤ X + z1−α/2 σ/ n) = 1 − α R. Frühwirth Statistische Metodender Datenanalyse 369/584 Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Ist σ 2 unbekannt, wird σ 2 durch die Stichprobenvarianz geschätzt, und das Standardscore Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung T = X −µ √ S/ n ist t-verteilt mit n − 1 Freiheitsgraden. Aus n−1 W (−tn−1 1−α/2 ≤ T ≤ t1−α/2 ) = 1 − α folgt √ √ n−1 W (X − tn−1 1−α/2 S/ n ≤ µ ≤ X + t1−α/2 S/ n) = 1 − α R. Frühwirth Statistische Metodender Datenanalyse 370/584 Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Beispiel Eine Stichprobe vom Umfang n = 50 aus der Standardnormalverteilung hat das Stichprobenmittel X = 0.0540 und die Stichprobenvarianz S 2 = 1.0987. Wird die Varianz als bekannt vorausgesetzt, lautet das symmetrische 95%-Konfidenzintervall für µ: √ G1 =0.0540 − 1.96/ 50 = −0.2232 √ G2 =0.0540 + 1.96/ 50 = 0.3312 Wird die Varianz als unbekannt angenommen, lautet das symmetrische 95%-Konfidenzintervall für µ: √ G1 =0.0540 − 2.01 · 1.0482/ 50 = −0.2439 √ G2 =0.0540 + 2.01 · 1.0482/ 50 = 0.3519 Matlab: make KI normal R. Frühwirth Statistische Metodender Datenanalyse 371/584 Normalverteilung Statistische Metoden der Datenanalyse Konfidenzintervall für die Varianz R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Es sei X1 , . . . , Xn eine Stichprobe aus der Normalverteilung No(µ, σ 2 ). (n − 1)S 2 /σ 2 ist χ2 -verteilt mit n − 1 Freiheitsgraden. Aus W χ2α/2,n−1 (n − 1)S 2 ≤ χ21−α/2,n−1 ≤ σ2 =1−α folgt W (n − 1)S 2 (n − 1)S 2 ≤ σ2 ≤ 2 2 χ1−α/2,n−1 χα/2,n−1 R. Frühwirth Statistische Metodender Datenanalyse ! =1−α 372/584 Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Beispiel Eine Stichprobe vom Umfang n = 50 aus der Normalverteilung No(0, 4) hat die Stichprobenvarianz S 2 = 4.3949. Das symmetrische 95%-Konfidenzintervall für σ 2 lautet: G1 =49 · 4.3949/70.2224 = 3.0667 G2 =49 · 4.3949/31.5549 = 6.8246 Werden die Quantile der χ2 -Verteilung χ2 (n − 1) durch die Quantile der Normalverteilung No(n − 1, 2(n − 1)) ersetzt, laute das Konfidenzintervall: G1 =49 · 4.3949/68.4027 = 3.1483 G2 =49 · 4.3949/29.5973 = 7.2760 Matlab: make KI normal varianz.m R. Frühwirth Statistische Metodender Datenanalyse 373/584 Normalverteilung Statistische Metoden der Datenanalyse Konfidenzintervall für die Differenz von zwei Mittelwerten R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Es seien X1 , . . . , Xn und Y1 , . . . , Ym zwei unabhängige Stichproben aus den Normalverteilungen No(µx , σx2 ) bzw. No(µy , σy2 ). Wir suchen ein Konfidenzintervall für µx − µy . Die Differenz D = X − Y ist normalverteilt gemäß No(µx − µy , σ 2 ), mit 2 σD = σx2 /n + σy2 /m. Sind die Varianzen bekannt, ist das Standardscore von D standardnormalverteilt. Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Aus W D − (µx − µy ) −z1−α/2 ≤ ≤ z1−α/2 = 1 − α σD folgt R. Frühwirth Statistische Metodender Datenanalyse 374/584 Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung W D − z1−α/2 σD ≤ µx − µy ≤ D + z1−α/2 σD = 1 − α Sind die Varianzen unbekannt und gleich, ist S2 = (n − 1)Sx2 + (m − 1)Sy2 n+m−2 χ2 -verteilt mit m + n − 2 Freiheitsgraden. Das Standardscore T = D − (µx − µy ) SD p mit SD = S 1/n + 1/m ist daher t-verteilt mit n + m − 2 Freiheitsgraden. R. Frühwirth Statistische Metodender Datenanalyse 375/584 Normalverteilung Statistische Metoden der Datenanalyse Aus R. Frühwirth W −t1−α/2,n+m−2 ≤ T ≤ t1−α/2,n+m−2 = 1 − α Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung folgt W D − t1−α/2,n+m−2 SD ≤ µx − µy ≤ D + t1−α/2,n+m−2 SD = 1−α Beispiel Eine Stichprobe aus No(2, 4) vom Umfang n = 50 hat Stichprobenmittel X = 2.1080 und Stichprobenvarianz Sx2 = 4.3949; eine zweite Stichprobe aus No(1, 4) vom Umfang m = 25 hat Stichprobenmittel X = 1.6692 und Stichprobenvarianz Sx2 = 5.2220. Werden die Varianzen als bekannt vorausgesetzt, lautet das 95%=Konfidenzintervall für µx − µy : G1 =0.4388 − 1.96 · 0.4899 = −0.5213 G2 =0.4388 + 1.96 · 0.4899 = 1.3990 R. Frühwirth Statistische Metodender Datenanalyse 376/584 Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel (Fortsetzung) Werden die Varianzen als unbekannt angenommen, ist S 2 = 4.6668 und SD = 0.5292. Das 95%=Konfidenzintervall für µx − µy lautet dann: G1 =0.4388 − 1.993 · 0.5292 = −0.6158 G2 =0.4388 + 1.993 · 0.5292 = 1.4935 Matlab: make KI normal difference.m Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 377/584 Unterabschnitt: Mittelwert einer beliebigen Verteilung Statistische Metoden der Datenanalyse R. Frühwirth 13 Stichprobenfunktionen 14 Punktschätzer 15 Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 378/584 Mittelwert einer beliebigen Verteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Es sei X1 , . . . , Xn eine Stichprobe aus der Verteilung F mit Mittel µ und Varianz σ 2 . Aufgrund des zentralen Grenzwertsatzes ist das Standardscore Z des Stichprobenmittels: Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung Z= X −µ √ σ/ n für große Stichproben annähernd normalverteilt. Es gilt also näherungsweise: √ √ W (X − z1−α/2 S/ n ≤ µ ≤ X + z1−α/2 S/ n) ≈ 1 − α R. Frühwirth Statistische Metodender Datenanalyse 379/584 Mittelwert einer beliebigen Verteilung Statistische Metoden der Datenanalyse R. Frühwirth Stichprobenfunktionen Grundbegriffe Stichprobenmittel Stichprobenvarianz Stichprobenmedian Punktschätzer Eigenschaften von Punktschätzern Schätzung des Mittelwerts Schätzung der Varianz Schätzung des Medians Maximum-LikelihoodSchätzer Beispiel Für exponentialverteilte Stichproben vom Umfang n gibt die folgende Tabelle die Sicherheit des 95%-Konfidenzintervalls in Näherung durch Normalverteilung, geschätzt aus N = 20000 Stichproben: n 1−α 25 50 100 200 400 0.9112 0.9289 0.9408 0.9473 0.9476 Matlab: make KI exponential Intervallschätzer Grundbegriffe Allgemeine Konstruktion nach Neyman Binomialverteilung Poissonverteilung Exponentialverteilung Normalverteilung Mittelwert einer beliebigen Verteilung R. Frühwirth Statistische Metodender Datenanalyse 380/584 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Teil 5 Testen von Hypothesen Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 381/584 Übersicht Teil 5 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 16 Einleitung 17 Parametrische Tests 18 Anpassungstests R. Frühwirth Statistische Metodender Datenanalyse 382/584 Abschnitt 16: Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 16 Einleitung 17 Parametrische Tests 18 Anpassungstests R. Frühwirth Statistische Metodender Datenanalyse 383/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Wir beobachten eine Stichprobe X1 , . . . , Xn aus einer Verteilung F . Ein Test soll feststellen, ob die Beobachtungen mit einer gewissen Annahme über F verträglich sind. Die Annahme wird als Nullhypothese H0 bezeichnet. Ist die Form von F bis auf einen oder mehrere Parameter spezifiziert, heißt der Test parametrisch. Ist die Form von F nicht spezifiziert, heißt der Test nichtparametrisch oder parameterfrei. Der Test entscheidet, ob die Stichprobe mit der Hypothese vereinbar ist, nicht ob die Hypothese richtig ist! R. Frühwirth Statistische Metodender Datenanalyse 384/584 Einleitung Statistische Metoden der Datenanalyse Allgemeine Vorgangsweise R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Aus der Stichprobe wird eine Testgröße (Teststatistik) T berechnet. Der Wertebereich von T wird, in Abhängigkeit von H0 , in einen Ablehnungsbereich (kritischen Bereich) C und einen Annahmebereich C 0 unterteilt. Der Annahmebereich ist meist ein Prognoseintervall für T . Fällt der Wert von T in den Ablehnungsbereich, wird H0 verworfen. Andernfalls wird H0 vorläufig beibehalten. Das ist jedoch keine Bestätigung von H0 . Es heißt lediglich, dass die Daten mit der Hypothese vereinbar sind. R. Frühwirth Statistische Metodender Datenanalyse 385/584 Einleitung Statistische Metoden der Datenanalyse Einseitige und zweiseitige Tests R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Ist der Annahmebereich das symmetrische Prognoseintervall für T , wird der Test zweiseitig genannt. Der kritische Bereich zerfällt dann in zwei Teilintervalle. Ist der Annahmebereich ein Intervall der Form T ≤ c oder T ≥ c, wird der Test einseitig genannt. Der kritische Bereich ist dann ein Intervall der Form T > c bzw. T < c. Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 386/584 Einleitung Statistische Metoden der Datenanalyse Der p-Wert R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Der Test kann alternativ auch unter Benütung des p-Werts P (T ) durchgeführt werden. Der p-Wert gibt an, wie wahrscheinlich es ist, unter Annahme der Nullhypothese mindestens den Wert T bzw. höchstens den Wert T zu beobachten. Zweiseitiger Test: Ist F0 (x) die Verteilungsfunktion von T unter der Nullhypothese, so ist der p-Wert gleich P (T ) = 2 min(F0 (T ), 1 − F0 (T )) Einseitiger Test: Ist F0 (x) die Verteilungsfunktion von T unter der Nullhypothese, so ist der p-Wert gleich P (T ) = F0 (T ) bzw. p = 1 − F0 (T ) Die Nullhypothese wird verworfen, wenn P (T ) < α. R. Frühwirth Statistische Metodender Datenanalyse 387/584 Einleitung Statistische Metoden der Datenanalyse Signifikanz und Güte R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Bei jedem Testverfahren sind zwei Arten von Fehlern möglich. 1 Fehler 1. Art: Die Hypothese H0 wird abgelehnt, obwohl sie zutrifft. 2 Fehler 2. Art: Die Hypothese H0 wird beibehalten, obwohl sie nicht zutrifft. Die Verteilung von T unter Annahme von H0 wird bestimmt. Der Ablehnungsbereich wird so festgelegt, dass die Wahrscheinlichkeit eines Fehlers 1. Art maximal gleich einem Wert α ist. α heißt das Signifikanzniveau des Tests. Gängige Werte sind α = 0.05, 0.01, 0.005. R. Frühwirth Statistische Metodender Datenanalyse 388/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Ist der Ablehnungsbereich festgelegt, kann für eine Gegenhypothese H1 die Wahrscheinlichkeit β(H1 ) eines Fehlers 2. Art berechnet werden. 1 − β(H1 ) heißt die Güte des Tests für H1 . Die Güte sollte nie kleiner als α sein. Ist die Güte nie kleiner als α, heißt der Test unverzerrt. Ein Ziel der Testtheorie ist es, unverzerrte Tests mit maximaler Güte (UMPU) zu konstruieren. R. Frühwirth Statistische Metodender Datenanalyse 389/584 Abschnitt 17: Parametrische Tests Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 16 Einleitung 17 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen 18 Anpassungstests Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 390/584 Unterabschnitt: Grundlagen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 16 Einleitung 17 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen 18 Anpassungstests Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 391/584 Grundlagen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Wir betrachten eine Stichprobe X1 , . . . , Xn aus einer Verteilung F , die bis auf einen oder mehrere Parameter spezifiziert ist. Tests von Hypothesen über F heißen parametrisch. Eine Nullhypothese H0 kann als eine Teilmenge des Parameterraums Θ aufgefasst werden. Der Test entscheidet, ob die Stichprobe mit der Hypothese vereinbar ist. Vor der Anwendung ist zu klären, ob die angenommene parametrische Form plausibel ist. R. Frühwirth Statistische Metodender Datenanalyse 392/584 Grundlagen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Zunächst wird die Teststatistik T und das Signifikanzniveau α gewählt. Dann wird der kritische Bereich C so festgelegt, dass Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test W (T ∈ C|ϑ ∈ H0 ) ≤ α Zu einer Nullhypothese H0 kann eine Gegenhypothese H1 formuliert werden. H1 kann ebenfalls als Teilmenge des Parameterraums Θ aufgefasst werden. Ist das Signifikanzniveau α festgelegt, kann für jedes ϑ ∈ H1 die Güte berechnet werden: 1 − β(ϑ) = W (T ∈ C|ϑ ∈ H1 ) 1 − β(ϑ) heißt die Gütefunktion des Tests. R. Frühwirth Statistische Metodender Datenanalyse 393/584 Grundlagen Statistische Metoden der Datenanalyse Beispiel mit Exponentialverteilung R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test X1 , . . . , Xn ist eine exponentialverteilte Stichprobe aus Ex(τ ). Die Hypothese H0 : τ = τ0 soll anhand der Stichprobe getestet werden. Als Teststatistik T wählen wir das Stichprobenmittel: T = X. Unter Annahme von H0 hat T die folgende Dichte: tn−1 t f (t) = exp − (τ0 /n)n Γ(n) τ0 /n T ist also verteilt gemäß Ga(n, τ0 /n). Das symmetrische Prognoseintervall [y1 (τ0 ), y2 (τ0 )] für T zum Niveau 1 − α erhält man mit: y1 (τ0 ) = γα/2,n,τ0 /n , R. Frühwirth y2 (τ0 ) = γ1−α/2,n,τ0 /n Statistische Metodender Datenanalyse 394/584 Grundlagen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Der Verwerfungsbereich mit Signifikanzniveau α ist daher die Menge C = [0, y1 (τ0 )] ∪ [y2 (τ0 ), ∞[ H0 wird also abgelehnt, wenn T “weit entfernt” vom hypothetischen Wert τ0 ist. Die Gütefunktion für einen Wert τ ergibt sich durch: 1 − β(τ ) = W (T ∈ C) = G(y1 (τ0 )) + 1 − G(y2 (τ0 )) wo G die Verteilungsfunktion der Ga(n, τ /n)-Verteilung ist. Der Test ist nicht unverzerrt, da z.B. für τ0 = 1 und n = 25 1 − β(0.986) = 0.0495 < α Matlab: make test exponential mean.m R. Frühwirth Statistische Metodender Datenanalyse 395/584 Grundlagen Statistische Metoden der Datenanalyse Dichte des Stichprobenmittels (τ0=1) und kritische Bereiche R. Frühwirth 4.5 n=25 n=100 Einleitung 4 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Der Chiquadrat-Test Der KolmogorovSmirnov-Test 3 2.5 f(T) Anpassungstests 3.5 2 1.5 1 0.5 0 0 0.2 0.4 0.6 R. Frühwirth 0.8 1 T 1.2 1.4 Statistische Metodender Datenanalyse 1.6 1.8 2 396/584 Grundlagen Statistische Metoden der Datenanalyse Gütefunktion (τ0=1) R. Frühwirth 1 Einleitung 0.9 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Der Chiquadrat-Test Der KolmogorovSmirnov-Test 0.7 0.6 1−β(τ) Anpassungstests 0.8 0.5 0.4 0.3 0.2 0.1 0 0.5 n=25 n=100 0.6 0.7 0.8 R. Frühwirth 0.9 1 τ 1.1 1.2 Statistische Metodender Datenanalyse 1.3 1.4 1.5 397/584 Unterabschnitt: Tests für binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 16 Einleitung 17 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen 18 Anpassungstests Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 398/584 Tests für binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse Zweiseitiger Test für den Parameter p R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test k ist eine Beobachtung aus der Binomialverteilung Bi(n, p). Die Hypothese H0 : p = p0 soll anhand der Beobachtung gegen die Alternativhypothese H1 : p 6= p0 getestet werden. H0 wird abgelehnt, wenn k unter Annahme von H0 nicht im symmetrischen Prognoseintervall [y1 (p0 ), y2 (p0 )] liegt, also zu klein“ oder zu groß“ ist. ” ” Das ist der Fall, wenn entweder k X n i p0 (1 − p0 )n−i = β(p0 ; k, n − k + 1) < α/2 i i=0 oder n X n i p (1 − p0 )n−i = β(1 − p0 ; n − k, k + 1) < α/2 i 0 i=k gilt. R. Frühwirth Statistische Metodender Datenanalyse 399/584 Tests für binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse Einseitiger Test für den Parameter p R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Hypothese H0 : p ≤ p0 soll anhand der Beobachtung k gegen die Alternativhypothese H1 : p > p0 getestet werden. H0 wird abgelehnt, wenn k zu groß“ ist und damit der ” p-Wert zu klein: P (k) = n X n i i=k pi0 (1 − p0 )n−i = β(p0 ; k, n − k + 1) < α Die Hypothese H0 : p ≥ p0 wird abgelehnt, wenn k zu ” klein“ ist und damit auch der p-Wert zu klein: P (k) = k X n i=0 i pi0 (1 − p0 )n−i = β(1 − p0 ; n − k, k + 1) < α R. Frühwirth Statistische Metodender Datenanalyse 400/584 Tests für binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Beispiel Ein Hersteller behauptet, dass nicht mehr als 2 Prozent eines gewissen Bauteils fehlerhaft sind. In einer Stichprobe vom Umfang 300 sind 9 Stück defekt. Kann die Behauptung des Herstellers widerlegt werden? Es gilt: ! 300 X 300 P (k) = 0.02i 0.98300−i = 0.1507 i i=9 Die Behauptung des Herstellers lässt sich also auf einem Signifikanzniveau von 5 Prozent nicht widerlegen. Matlab: make test binomial.m R. Frühwirth Statistische Metodender Datenanalyse 401/584 Tests für binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse Näherung durch Normalverteilung R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Ist n genügend groß, kann die Verteilung von k durch eine Normalverteilung No(np, np(1 − p)) angenähert werden. H0 wird abgelehnt, wenn das Standardscore k − np0 Z=p np(1 − p0 ) Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test nicht in einem Prognoseintervall vom Niveau 1 − α der Standardnormalverteilung liegt. Zweiseitiger Test: H0 wird abgelehnt wenn Z < zα/2 oder Z > z1−α/2 Einseitiger Test: H0 wird abgelehnt wenn Z < zα bzw. Z > z1−α R. Frühwirth Statistische Metodender Datenanalyse 402/584 Tests für binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Beispiel Mit der Angabe des letzten Beispiels ergibt die Näherung: Z = 1.2372 < z0.95 = 1.6449 Die Hypothese kann also nicht abgelehnt werden. Matlab: make test binomial.m Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 403/584 Unterabschnitt: Tests für Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 16 Einleitung 17 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen 18 Anpassungstests Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 404/584 Tests für Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse Zweiseitiger Test auf den Erwartungswert R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen X1 , . . . , Xn ist eine Poissonverteilte Stichprobe aus Po(λ). Die Hypothese H0 : λ = λ0 soll anhand der Stichprobe gegen die Alternativhypothese H1 : λ 6= λ0 getestet werden. Als Teststatistik T wählen wir die Stichprobensumme: T = Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test n X Xi i=1 T ist Poissonverteilt gemäß Po(nλ). H0 wird abgelehnt, wenn T zu klein“ oder zu groß“ ist, ” ” also wenn T X (nλ0 )k e−nλ0 k=0 k! R. Frühwirth < α/2 oder ∞ X (nλ0 )k e−nλ0 < α/2 k! k=T Statistische Metodender Datenanalyse 405/584 Tests für Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse Einseitiger Test auf den Erwartungswert R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Hypothese H0 : λ ≤ λ0 wird abgelehnt, wenn T zu ” groß“ ist und damit der p-Wert zu klein: ∞ X (nλ0 )k e−nλ0 P (T ) = <α k! k=T Die Hypothese H0 : λ ≥ λ0 wird abgelehnt, wenn T zu ” klein“ ist und damit auch der p-Wert zu klein: P (T ) = T X (nλ0 )k e−nλ0 k=0 R. Frühwirth k! <α Statistische Metodender Datenanalyse 406/584 Tests für Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Beispiel Ein Hersteller strebt an, dass in einer Fabrik täglich im Mittel nicht mehr als 25 defekte Bauteile hergestellt werden. Eine Stichprobe von 5 Tagen ergibt 28,34,32,38 und 22 defekte Bauteile. Hat der Hersteller sein Ziel erreicht? Es gilt: Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test T = 154, P (T ) = ∞ X (125)k e−125 = 0.0067 k! k=T Die Hypothese lässt sich also auf einem Signifikanzniveau von 1 Prozent widerlegen. Matlab: make test poisson mean.m R. Frühwirth Statistische Metodender Datenanalyse 407/584 Tests für Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse Näherung durch Normalverteilung R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Ist n genügend groß, kann die Verteilung von T durch eine Normalverteilung No(nλ, nλ) angenähert werden. H0 wird abgelehnt, wenn das Standardscore T − nλ0 Z= √ nλ0 nicht in einem Prognoseintervall vom Niveau 1 − α der Standardnormalverteilung liegt. Beispiel Mit der Angabe des letzten Beispiels ergibt die Näherung: Z = 2.5938 > z0.99 = 2.3263 Die Hypothese kann also auf einem Signifikanzniveau von 1 Prozent abgelehnt werden. R. Frühwirth Statistische Metodender Datenanalyse 408/584 Unterabschnitt: Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 16 Einleitung 17 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen 18 Anpassungstests Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 409/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Erwartungswert bei bekannter Varianz R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test X1 , . . . , Xn ist eine normalverteilte Stichprobe aus No(µ, σ 2 ) mit bekanntem σ 2 . Die Hypothese H0 : µ = µ0 soll anhand der Stichprobe gegen die Alternativhypothese H1 : µ 6= µ0 getestet werden. Als Teststatistik T wählen wir das Standardscore des Stichprobenmittels: √ n(X − µ0 ) T = σ Unter Annahme von H0 ist T verteilt gemäß No(0, 1). H0 wird abgelehnt, wenn T nicht in einem Prognoseintervall vom Niveau 1 − α der Standardnormalverteilung liegt. R. Frühwirth Statistische Metodender Datenanalyse 410/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Zweiseitiger Test R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Hypothese H0 wird abgelehnt, wenn √ n X − µ0 |T | = > z1−α/2 σ Die Gütefunktion für einen Wert µ ergibt sich durch: 1 − β(µ) = W (T ∈ C) = G(zα/2 ) + 1 − G(z(1−α)/2 ) √ wo G die Verteilungsfunktion der No( n(µ − µ0 )/σ, 1)Verteilung ist. Der Test ist unverzerrt. Matlab: make test normal mean.m R. Frühwirth Statistische Metodender Datenanalyse 411/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Gütefunktion des zweiseitigen Tests (µ0=1) R. Frühwirth 1 Einleitung 0.9 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Der Chiquadrat-Test Der KolmogorovSmirnov-Test 0.7 0.6 1−β(µ) Anpassungstests 0.8 0.5 0.4 0.3 0.2 0.1 0 0.5 n=25 n=100 0.6 0.7 0.8 R. Frühwirth 0.9 1 µ 1.1 1.2 Statistische Metodender Datenanalyse 1.3 1.4 1.5 412/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Einseitiger Test R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Hypothese H0 : µ ≤ µ0 soll mit der Teststatistik T gegen die Alternativhypothese H1 : µ > µ0 getestet werden. H0 wird abgelehnt, wenn T zu groß“ ist. ” Ein Verwerfungsbereich mit Signifikanzniveau α ist die Menge C = [z1−α , ∞[ Die Hypothese H0 wird also abgelehnt, wenn √ n X − µ0 > z1−α T = σ R. Frühwirth Statistische Metodender Datenanalyse 413/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Die Gütefunktion für einen Wert µ > µ0 ergibt sich durch: R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 1 − β(τ ) = W (T ∈ C) = 1 − G(z1−α ) √ wo G die Verteilungsfunktion der No( n(µ − µ0 )/σ, 1)Verteilung ist. Analog verläuft der Test mit H0 : µ ≥ µ0 und H1 : µ < µ0 . Matlab: make test normal mean.m R. Frühwirth Statistische Metodender Datenanalyse 414/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Gütefunktion des einseitigen Tests (µ0=1) R. Frühwirth 1 Einleitung 0.9 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Der Chiquadrat-Test Der KolmogorovSmirnov-Test 0.7 0.6 1−β(µ) Anpassungstests 0.8 0.5 0.4 0.3 0.2 0.1 0 1 n=25 n=100 1.1 1.2 1.3 R. Frühwirth 1.4 1.5 µ 1.6 1.7 Statistische Metodender Datenanalyse 1.8 1.9 2 415/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Erwartungswert bei unbekannter Varianz: t-Test R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test X1 , . . . , Xn ist eine normalverteilte Stichprobe aus No(µ, σ 2 ) mit unbekanntem σ 2 . Die Hypothese H0 : µ = µ0 soll anhand der Stichprobe gegen die Alternativhypothese H1 : µ 6= µ0 getestet werden. Als Teststatistik T wählen wir das Standardscore des Stichprobenmittels, unter Benützung der Stichprobenvarianz S2: √ n(X − µ0 ) T = S Unter Annahme von H0 ist T verteilt gemäß t(n − 1). R. Frühwirth Statistische Metodender Datenanalyse 416/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test H0 wird abgelehnt, wenn T nicht in einem Prognoseintervall vom Niveau 1 − α der t-Verteilung mit n − 1 Freiheitsgraden liegt. Ein Verwerfungsbereich mit Signifikanzniveau α ist die Menge n−1 C =] − ∞, tn−1 α/2 ] ∪ [t1−α/2 , ∞[ wo tn−1 das Quantil der t-Verteilung mit n − 1 p Freiheitsgraden zum Niveau p ist. Die Hypothese H0 wird also abgelehnt, wenn √ n X − µ0 |T | = > tn−1 1−α/2 S R. Frühwirth Statistische Metodender Datenanalyse 417/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Die Gütefunktion für einen Wert µ ergibt sich durch: R. Frühwirth 1 − β(τ ) = W (T ∈ C) = G(zα/2 ) + 1 − G(z(1−α)/2 ) Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen wo G die Verteilungsfunktion der nichtzentralen t(n − 1, δ)-Verteilung mit √ δ = n(µ − µ0 )/σ Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test ist. Der Test ist unverzerrt. Matlab: make test normal mean.m R. Frühwirth Statistische Metodender Datenanalyse 418/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Gütefunktion des zweiseitigen t−Tests (µ0=1) R. Frühwirth 1 Einleitung 0.9 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Der Chiquadrat-Test Der KolmogorovSmirnov-Test 0.7 0.6 1−β(µ) Anpassungstests 0.8 0.5 0.4 0.3 0.2 0.1 0 0.5 n=25 n=100 0.6 0.7 0.8 R. Frühwirth 0.9 1 µ 1.1 1.2 Statistische Metodender Datenanalyse 1.3 1.4 1.5 419/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Gleichheit von zwei Erwartungswerten R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test X1 , . . . , Xn und Y1 , . . . , Ym sind zwei unabhängige normalverteilte Stichprobe aus No(µx , σx2 ) bzw. No(µy , σy2 ). Die Hypothese H0 : µx = µy soll anhand der Stichproben gegen die Alternativhypothese H1 : µx 6= µy getestet werden. Sind die Varianzen bekannt, wählen wir als Teststatistik T die Differenz der Stichprobenmittel: T =X −Y Unter Annahme von H0 ist T verteilt gemäß No(0, σx2 /n + σy2 /m). R. Frühwirth Statistische Metodender Datenanalyse 420/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Das Standardscore R. Frühwirth Z=q Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen σx2 /n + σy2 /m ist dann standardnormalverteilt. Die Hypothese H0 wird also abgelehnt, wenn Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test T |Z| > z1−α/2 oder |X − Y | q R. Frühwirth σx2 /n + σy2 /m > z1−α/2 Statistische Metodender Datenanalyse 421/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Sind die Varianzen unbekannt und gleich, kann die Varianz aus der kombinierten ( gepoolten“) Stichprobe ” geschätzt werden: Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen S2 = (n − 1)Sx2 + (m − 1)Sy2 n+m−2 Unter Annahme von H0 ist Anpassungstests T =p Der Chiquadrat-Test Der KolmogorovSmirnov-Test X −Y S 2 (1/n + 1/m) t-verteilt mit n + m − 2 Freiheitsgraden. Die Hypothese H0 wird also abgelehnt, wenn |T | > tn+m−2 1−α/2 wo tn+m−2 1−α/2 das Quantil der t-Verteilung mit n + m − 2 Freiheitsgraden ist. R. Frühwirth Statistische Metodender Datenanalyse 422/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse t-Test für gepaarte Stichproben R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Gepaarte Stichproben (X1 , Y1 ), . . . , (Xn , Yn ) entstehen, wenn für jedes beobachtete Objekt die selbe Größe zweimal gemessen wird, vor und nach einer bestimmten Intervention. Die Wirkung der Intervention wird durch die Differenzen Wi = Yi − Xi , i = 1, . . . , n beschrieben. Wir nehmen an, dass W1 , . . . , Wn normalverteilt mit Mittel 2 µw und unbekannter Varianz σw ist. Die Hypothese H0 : µw = 0 (keine Wirkung der Intervention) soll anhand der Stichprobe gegen die Alternativhypothese H1 : µw 6= 0 getestet werden. Dies erfolgt mit dem t-Test für einzelne Stichproben. R. Frühwirth Statistische Metodender Datenanalyse 423/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Test der Varianz R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test X1 , . . . , Xn ist eine normalverteilte Stichprobe mit unbekanntem Erwartungswert µ und unbekannter Varianz σ2 . Die Hypothese H0 : σ 2 = σ02 soll anhand der Stichprobe gegen die Alternativhypothese H1 : σ 2 6= σ02 getestet werden. Als Teststatistik T wählen wir: T = (n − 1)S 2 σ02 Unter Annahme von H0 ist T χ2 -verteilt mit n − 1 Freiheitsgraden. R. Frühwirth Statistische Metodender Datenanalyse 424/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Die Hypothese H0 wird also abgelehnt, wenn R. Frühwirth Einleitung T < χ2α/2,n−1 oder T > χ21−α/2,n−1 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test wo χ2p,k das Quantil der χ2 -Verteilung mit k Freiheitsgraden zum Niveau p ist. Die Gütefunktion für einen Wert σ 2 ergibt sich durch: 1 − β(σ 2 ) = G(σ02 /σ 2 · χ2α/2 ) + 1 − G(σ02 /σ 2 · χ2(1−α)/2 ) wo G die Verteilungsfunktion der χ2 (n − 1)Verteilung ist. Der Test ist nicht unverzerrt. Matlab: make test normal variance.m R. Frühwirth Statistische Metodender Datenanalyse 425/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Gütefunktion des zweiseitigen Tests (σ20=1) R. Frühwirth 1 Einleitung 0.9 Parametrische Tests Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 0.8 0.7 0.6 1−β(σ2) Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen 0.5 0.4 0.3 0.2 0.1 0 0.5 n=25 n=100 0.6 0.7 0.8 R. Frühwirth 0.9 1 σ2 1.1 1.2 Statistische Metodender Datenanalyse 1.3 1.4 1.5 426/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Gleichheit von zwei Varianzen R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test X1 , . . . , Xn und Y1 , . . . , Ym sind zwei unabhängige normalverteilte Stichprobe aus No(µx , σx2 ) bzw. No(µy , σy2 ). Die Hypothese H0 : σx2 = σy2 soll anhand der Stichproben gegen die Alternativhypothese H1 : σx2 6= σy2 getestet werden. Die Teststatistik T ist das Verhältnis der Stichprobenvarianzen: T = Sx2 Sy2 Unter Annahme von H0 ist T F-verteilt gemäß F(n − 1, m − 1). R. Frühwirth Statistische Metodender Datenanalyse 427/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Die Hypothese H0 wird also abgelehnt, wenn R. Frühwirth Einleitung T < Fα/2 oder T > F1−α/2 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen wo Fp das Quantil der F-Verteilung mit n − 1 bzw. m − 1 Freiheitsgraden zum Niveau p ist. Ist σy2 = kσx2 , ergibt sich die Gütefunktion für einen Wert k ergibt durch: Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 1 − β(τ ) = G(σ02 /σ 2 · Fα/2 ) + 1 − G(σ02 /σ 2 · F(1−α)/2 ) wo G die Verteilungsfunktion der F(n − 1, m − 1)Verteilung ist. Der Test ist unverzerrt. Matlab: make test normal variance.m R. Frühwirth Statistische Metodender Datenanalyse 428/584 Tests für normalverteilte Beobachtungen Statistische Metoden der Datenanalyse Gütefunktion des zweiseitigen Tests (σ2x =σ2y ) R. Frühwirth 1 Einleitung 0.9 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Der Chiquadrat-Test Der KolmogorovSmirnov-Test 0.7 0.6 1−β(k) Anpassungstests 0.8 0.5 0.4 0.3 0.2 0.1 0 n=25 n=100 −0.6 −0.4 R. Frühwirth −0.2 0 ln k=ln(σ2y /σ2x ) 0.2 Statistische Metodender Datenanalyse 0.4 0.6 429/584 Abschnitt 18: Anpassungstests Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 16 Einleitung 17 Parametrische Tests 18 Anpassungstests Der Chiquadrat-Test Der Kolmogorov-Smirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 430/584 Anpassungstests Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Ein Test, der die Hypothese überprüft, ob die Daten einer gewissen Verteilung entstammen können, heißt ein Anpassungstest. Die Verteilung kann völlig oder bis auf unbekannte Parameter bestimmt sein. Ein Anpassungstest kann einem parametrischen Test vorausgehen, um dessen Anwendbarkeit zu überprüfen. Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 431/584 Unterabschnitt: Der Chiquadrat-Test Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 16 Einleitung 17 Parametrische Tests 18 Anpassungstests Der Chiquadrat-Test Der Kolmogorov-Smirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 432/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse Der Chiquadrat-Test für diskrete Beobachtungen R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Die Stichprobe X1 , . . . , Xn entstammt einer diskreten Verteilung mit Wertebereich {1, . . . , k}. Wir testen die Hypothese H0 , dass die Dichte f die Werte f (j) = pj , j = 1, . . . , k hat: H0 : W (Xi = j) = pj , j = 1, . . . , k Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test gegen H1 : W (Xi = j) 6= pj , für ein j Es sei Yj die Zahl der Beobachtungen, die gleich j sind. Unter der Nullhypothese ist Y1 , . . . , Yk multinomial verteilt gemäß Mu(n, p1 , . . . , pk ) und E[Yj ] = npj . R. Frühwirth Statistische Metodender Datenanalyse 433/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse R. Frühwirth Die Testgröße vergleicht die beobachteten Häufigkeiten Yj mit ihren Erwartungswerten: Einleitung k X (Yj − npj )2 T = npj j=1 Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Nullhypothese wird verworfen, wenn T groß ist. Der kritische Bereich kann nach dem folgenden Ergebnis bestimmt werden. Satz Unter Annahme der Nullhypothese ist die Zufallsvariable T asymptotisch, d.h. für n → ∞, χ2 -verteilt mit k − 1 Freiheitsgraden. R. Frühwirth Statistische Metodender Datenanalyse 434/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Soll der Test Signifikanzniveau α haben, wird H0 abgelehnt, wenn T ≥ χ21−α,k−1 wo χ21−α,k das Quantil der χ2 -Verteilung mit k − 1 Freiheitsgraden zum Niveau 1 − α ist. Der Grund dafür, dass T nur k − 1 Freiheitsgrade hat, ist der lineare Zusammenhang zwischen den Yj : Anpassungstests k X Der Chiquadrat-Test Der KolmogorovSmirnov-Test Yj = n j=1 Als Faustregel gilt: n sollte so groß sein, dass npj > 5, j = 1, . . . , k. Ist das nicht erfüllt, sollte der Ablehnungsbereich durch Simulation bestimmt werden. R. Frühwirth Statistische Metodender Datenanalyse 435/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Beispiel Wir testen anhand einer Stichprobe vom Umfang 50, ob ein Würfel symmetrisch ist, d.h. ob die Augenzahl X folgende Verteilung hat: W (X = 1) = . . . = W (X = 6) = 1 6 Eine Simulation von N = 100000 Stichproben ergibt: T = 5.000, ST2 = 9.789 Das 0.95-Quantil der χ2 -Verteilung mit fünf Freiheitsgraden ist χ20.95,5 = 11.07, und W (T ≥ 11.07) = 0.048 Matlab: make chi2test wuerfel.m R. Frühwirth Statistische Metodender Datenanalyse 436/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse Der Chiquadrat-Test für stetige Beobachtungen R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Stichprobe X1 , . . . , Xn entstammt einer stetigen Verteilung F . Wir testen die Hypothese H0 : F (x) = F0 (x). Dazu wird der Wertebereich von X in k Gruppen G1 , . . . , Gk eingeteilt. Es sei Yj die Zahl der Beobachtungen in Gruppe Gj . Unter der Nullhypothese ist Y1 , . . . , Yk multinomial verteilt gemäß Mu(n, p1 , . . . , pk ) und E[Yj ] = npj , mit pj = W (X ∈ Gj |H0 ) Der Test verläuft weiter wie im diskreten Fall. R. Frühwirth Statistische Metodender Datenanalyse 437/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse Unbekannte Parameter R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Nullhypothese muss nicht vollständig spezifiziert sein. Wir betrachten den Fall, dass die pj noch von unbekannten Parametern ϑ abhängen: W (X ∈ Gj ) = pj (ϑ) Die Statistik T ist nun eine Funktion der unbekannten Parameter: k X (Yj − npj (ϑ))2 T (ϑ) = npj (ϑ) j=1 Zunächst werden die Parameter geschätzt, durch ML-Schätzung oder Minimierung von T : ϑ̃ = arg min T (ϑ) ϑ R. Frühwirth Statistische Metodender Datenanalyse 438/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse Der kritische Bereich kann nach dem folgenden Ergebnis bestimmt werden. R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Satz Werden m Parameter aus der Stichprobe geschätzt, so ist T (ϑ̃) asymptotisch χ2 -verteilt mit k − 1 − m Freiheitsgraden. Soll der Test Signifikanzniveau α haben, wird H0 abgelehnt, wenn T ≥ χ21−α,k−1−m wo χ21−α,k das Quantil der χ2 -Verteilung mit k − 1 − m Freiheitsgraden zum Niveau 1 − α ist. R. Frühwirth Statistische Metodender Datenanalyse 439/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Beispiel Angabe: Die Zahl der Arbeitsunfälle wurde in einem großen Betrieb über 30 Wochen erhoben. Es ergaben sich folgende Werte: X ={8, 0, 0, 1, 3, 4, 0, 2, 12, 5, 1, 8, 0, 2, 0, 1, 9, 3, 4, 5, 3, 3, 4, 7, 4, 0, 1, 2, 1, 2} Es soll die Hypothese überprüft werden, dass die Beobachtungen Poisson-verteilt gemäß Po(λ) sind. Lösung: Die Beobachtungen werden in fünf Gruppen eingeteilt: Gruppe 1 2 3 4 5 X 0 1 2–3 4–5 >5 Die Häufigkeiten der Gruppen sind: Y1 = 6, Y2 = 5, Y3 = 8, Y4 = 6, Y5 = 5 R. Frühwirth Statistische Metodender Datenanalyse 440/584 Der Chiquadrat-Test Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Beispiel (Fortsetzung) Der Schätzwert für λ ist das Stichprobenmittel: Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test λ̃ = 3.1667 Die Erwartungswerte der Yj unter Annahme von H0 = Po(λ̃) sind: j 1 2 3 4 5 E[Y1 ] 1.2643 4.0037 13.0304 8.6522 3.0493 Die Testgröße T ist gleich T = 21.99 Das 99%-Quantil der χ2 -Verteilung mit drei Freiheitsgraden ist gleich χ20.99,3 = 11.35. Die Hypothese, dass die Beobachtungen Poisson-verteilt sind, ist also abzulehnen. Matlab: make chi2test poisson.m R. Frühwirth Statistische Metodender Datenanalyse 441/584 Unterabschnitt: Der Kolmogorov-Smirnov-Test Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test 16 Einleitung 17 Parametrische Tests 18 Anpassungstests Der Chiquadrat-Test Der Kolmogorov-Smirnov-Test R. Frühwirth Statistische Metodender Datenanalyse 442/584 Der Kolmogorov-Smirnov-Test Statistische Metoden der Datenanalyse Eine Stichprobe R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Die Stichprobe X1 , . . . , Xn ist aus der stetigen Verteilung mit Verteilungsfunktion F . Wir testen die Hypothese H0 : F (x) = F0 (x). Die Testgröße Dn ist die maximale absolute Abweichung der empirischen Verteilungsfunktion Fn (x) der Stichprobe von der hypothetischen Verteilungsfunktion F0 (x): Dn = max |Fn (x) − F0 (x)| x Für Stichproben aus F0 ist die Verteilung von Dn unabhängig von F0 ! Für √ Stichproben aus F0 strebt die Verteilungsfunktion von nD für n → ∞ gegen: K(x) = 1 − 2 ∞ X (−1)k−1 e−2k 2 x2 k=1 R. Frühwirth Statistische Metodender Datenanalyse 443/584 Der Kolmogorov-Smirnov-Test Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Aus der asymptotischen Verteilungsfunktion können Quantile K1−α berechnet werden. Die Nullhypothese wird abgelehnt, wenn √ nDn > K1−α Werden vor dem Test Parameter von F0 geschätzt, sind die Quantile nicht mehr gültig. In diesem Fall muss der Ablehnungsbereich durch Simulation ermittelt werden. Matlab: Funktion kstest R. Frühwirth Statistische Metodender Datenanalyse 444/584 Der Kolmogorov-Smirnov-Test Statistische Metoden der Datenanalyse Zwei Stichproben R. Frühwirth Einleitung Parametrische Tests Grundlagen Tests für binomialverteilte Beobachtungen Tests für Poissonverteilte Beobachtungen Tests für normalverteilte Beobachtungen Anpassungstests Der Chiquadrat-Test Der KolmogorovSmirnov-Test Wir testen, ob zwei Stichproben vom Umfang n bzw. m aus der gleichen Verteilung F stammen. Die Testgröße ist die maximale absolute Differenz der empirischen Verteilungsfunktionen: 2 Dn,m = max |Fn1 (x) − Fm (x)| x Die Nullhypothese wird abgelehnt, wenn r nm Dn,m > K1−α n+m Matlab: Funktion kstest2 R. Frühwirth Statistische Metodender Datenanalyse 445/584 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Teil 6 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Regression und lineare Modelle R. Frühwirth Statistische Metodender Datenanalyse 446/584 Übersicht Teil 6 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 19 Einleitung 20 Einfache Regression 21 Mehrfache Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 447/584 Abschnitt 19: Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 19 Einleitung 20 Einfache Regression 21 Mehrfache Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 448/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Regressionsanalyse untersucht die Abhängigkeit der Beobachtungen von diversen Variablen. Einflussvariable (unabhängige Variable) x = (x1 , . . . , xr ). Ergebnisvariable (abhängige Variable) Y . Regressionsmodell: Y = f (β, x) + ε Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression mit Regressionskoeffizienten β und Fehlerterm ε. Ziel ist die Schätzung von β anhand von Beobachtungen Y1 , . . . , Yn . Eine Einflussvariable: einfache Regression; Mehrere Einflussvariable: mehrfache (multiple) Regression. R. Frühwirth Statistische Metodender Datenanalyse 449/584 Abschnitt 20: Einfache Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 21 Mehrfache Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 450/584 Unterabschnitt: Lineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 21 Mehrfache Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 451/584 Lineare Regression Statistische Metoden der Datenanalyse Das einfachste Regressionsmodell ist eine Gerade: R. Frühwirth Einleitung Y = α + βx + ε, E[ε] = 0, var[ε] = σ 2 Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Es seien nun Y1 , . . . , Yn die Ergebnisse für die Werte x1 , . . . , xn der Einflussvariablen x. Die Schätzung von α und β kann nach dem Prinzip der kleinsten Fehlerquadrate erfolgen. Die folgende Zielfunktion wird minimiert: SS = n X (Yi − α − βxi )2 i=1 Gradient von SS: n n X X ∂SS ∂SS = −2 (Yi − α − βxi ), = −2 xi (Yi − α − βxi ) ∂α ∂β i=1 i=1 R. Frühwirth Statistische Metodender Datenanalyse 452/584 Lineare Regression Statistische Metoden der Datenanalyse Nullsetzen des Gradienten gibt die Normalgleichungen: R. Frühwirth Einleitung n X Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Yi = nα + β i=1 n X n X xi i=1 xi Yi = α i=1 n X i=1 xi + β n X x2i i=1 Die geschätzten Regressionskoeffizienten lauten: Pn Pn xi Yi − x̄ i=1 Yi i=1 Pn β̂ = 2 2 i=1 xi − nx̄ α̂ = Y − β̂ x̄ Es gilt E[α̂] = α und E[β̂] = β. R. Frühwirth Statistische Metodender Datenanalyse 453/584 Lineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Die Varianz des Fehlerterms wird erwartungstreu geschätzt durch: n 1 X 2 r σ̂ 2 = n − 2 i=1 i mit ri = Yi − Ŷi , Ŷi = α̂ + β̂xi Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Kovarianzmatrix der geschätzten Regressionkoeffizienten: P 2 P x xi P 2 i P − n ( x − nx̄2 ) n ( x2i − nx̄2 ) i 2 Cov[α̂, β̂] = σ P xi 1 P − P 2 n ( xi − nx̄2 ) x2i − nx̄2 R. Frühwirth Statistische Metodender Datenanalyse 454/584 Lineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Beispiel Datensatz 4: x̄ = 167.60 ȳ = 76.16 sx = 8.348 sy = 4.727 rxy = 0.5562 â = 0.3150 b̂ = 23.37 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Matlab: make dataset4 R. Frühwirth Statistische Metodender Datenanalyse 455/584 Lineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Beispiel (Fortsetzung) Datensatz 4: Einfache Regression Datensatz 4 Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 90 85 Mehrfache Regression 80 Gewicht (kg) Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression 75 70 65 60 55 140 150 R. Frühwirth 160 170 Körpergröße (cm) 180 Statistische Metodender Datenanalyse 190 456/584 Lineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Die Streuung der Werte Yi hat im Regressionsmodell unterschiedliche Ursachen. Einerseits gibt es systematische Unterschiede durch unterschiedliche Werte von x. Dazu kommt noch die zufällige Streuung der Daten. Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Erklärbare Streuung SS ∗ = n X 2 (Ŷi − Y )2 = rxy ns2Y i=1 n X 2 (Yi − Ŷi )2 = (1 − rxy )ns2Y Reststreuung SSR = Totale Streuung n X SST = (yi − Y )2 = ns2Y i=1 i=1 R. Frühwirth Statistische Metodender Datenanalyse 457/584 Lineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Streuungszerlegung SST = SS ∗ + SSR Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Die Güte der Regressionsgeraden kann durch das Bestimmtheitsmaß angegeben werden: Bestimmheitsmaß der Regression B= SS ∗ 2 = rxy SST Es gibt an, welcher Anteil an der Gesamtstreuung durch die Korrelation von x und Y erklärt werden kann. R. Frühwirth Statistische Metodender Datenanalyse 458/584 Unterabschnitt: Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 21 Mehrfache Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 459/584 Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Ist β = 0, hängt das Ergebnis überhaupt nicht von den Einflussvariablen ab. Ein Test der Nullhypothese H0 : β = 0 gegen H1 : β 6= 0 beruht auf dem folgenden Satz. Satz Ist ε normalverteilt, so sind Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression α̂ − α , σ̂α̂ β̂ − β σ̂β̂ t-verteilt mit n − 2 Freiheitsgraden, wobei P σ̂ 2 x2i σ̂ 2 2 2 P P 2 σ̂α̂ = , σ̂ = β̂ n ( xi − nx̄2 ) x2i − nx̄2 R. Frühwirth Statistische Metodender Datenanalyse 460/584 Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Die Nullhypothese H0 : β = 0 wird abgelehnt, wenn die Testgröße β̂ T = σ̂β̂ relativ klein oder relativ groß ist, also wenn |β̂| > tn−2 1−α/2 σ̂β̂ Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression wo tn−2 das Quantil der t-Verteilung mit n − 2 p Freiheitsgraden zum Niveau p ist. Ein analoger Test kann für die Nullhypothese H0 : α = 0 durchgeführt werden. R. Frühwirth Statistische Metodender Datenanalyse 461/584 Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Die symmetrischen Konfidenzintervalle mit 95% Sicherheit lauten: n−2 α̂ ± σ̂α̂ · tn−2 β̂ ± σ̂β̂ · t1−α/2 1−α/2 , Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Für n > 30 können die Quantile der t-Verteilung durch Quantile der Standardnormalverteilung ersetzt werden. Es soll nun das Ergebnis Y0 = Y (x0 ) für einen bestimmten Wert x0 der Einflussvariablen x prognostiziert werden. Der Erwartungswert von Y0 ist E[Y0 ] = α̂ + β̂x0 Die Varianz von E[Y0 ] ergibt sich mittels Fehlerfortpflanzung: (x̄ − x0 )2 2 1 var[E[Y0 ]] = σ +P 2 n xi − nx̄2 R. Frühwirth Statistische Metodender Datenanalyse 462/584 Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Da Y0 um seinen Erwartungswert mit Varianz σ 2 streut, ergibt sich: (x̄ − x0 )2 2 n+1 +P 2 var[Y0 ] = σ n xi − nx̄2 Das symmetrische Prognoseintervall für Y0 mit Sicherheit α ist daher gleich: s n+1 (x̄ − x0 )2 n−2 +P 2 α̂ + β̂x0 ± t1−α/2 σ̂ n xi − nx̄2 R. Frühwirth Statistische Metodender Datenanalyse 463/584 Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Die Angemessenheit des Modells kann durch Untersuchung der studentisierten Residuen (Restfehler) überprüft werden. Das Residuum rk hat die Varianz 1 (xk − x̄)2 var[rk ] = σ 2 1 − − P 2 n xi − nx̄2 Das studentisierte Residuum ist dann rk rk0 = σ̂ q 1− 1 n − (xk −x̄)2 P x2i −nx̄2 Es hat Erwartung 0 und Varianz 1. Matlab: make regression diagnostics R. Frühwirth Statistische Metodender Datenanalyse 464/584 Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse 2.5 R. Frühwirth 40 2 Einleitung 35 1.5 Einfache Regression 30 1 25 r’ 0.5 y Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 20 0 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression 15 −0.5 10 −1 5 0 −1.5 0 5 10 x 15 20 −2 0 5 10 x 15 20 Regressionsgerade und studentisierte Residuen R. Frühwirth Statistische Metodender Datenanalyse 465/584 Tests, Konfidenz- und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth 40 3 35 2.5 Einleitung 30 Einfache Regression 2 25 1.5 20 r’ 1 y Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 15 0.5 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression 10 0 5 −0.5 0 −1 −5 0 5 10 x 15 20 −1.5 0 5 10 x 15 20 Regressionsgerade und studentisierte Residuen R. Frühwirth Statistische Metodender Datenanalyse 466/584 Unterabschnitt: Robuste Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 21 Mehrfache Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 467/584 Robuste Regression Statistische Metoden der Datenanalyse Als LS-Schätzer ist die Regressionsgerade nicht robust, d.h. empfindlich gegen Ausreißer. R. Frühwirth Einleitung Einfache Regression Matlab: make regression outliers Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 150 160 150 130 140 y 120 y Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Data Outlier LS w/o outlier LS with outlier 170 140 Mehrfache Regression 130 110 120 100 110 100 90 90 80 40 45 50 x 55 60 40 50 60 70 80 90 100 110 x Lineare Regression mit Ausreißern R. Frühwirth Statistische Metodender Datenanalyse 468/584 Robuste Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression LMS (Least Median of Squares): Anstatt der Summe der Fehlerquadrate wird der Median der Fehlerquadrate minimiert. “Exact fit property”: Die LMS-Gerade geht durch zwei Datenpunkte. Berechnung kombinatorisch. LTS (Least Trimmed Squares): Es wird die Summe einer festen Anzahl h ≤ n von Fehlerquadraten minimiert. Berechnung iterativ (FAST-LTS). Beide Methoden gehen auf P. Rousseeuw zurück. Matlab: make robust regression R. Frühwirth Statistische Metodender Datenanalyse 469/584 Robuste Regression Statistische Metoden der Datenanalyse 150 R. Frühwirth Einfache Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression 160 150 130 140 y 120 y Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Data Outlier LS w/o outlier LS with outlier LMS LTS (75%) 170 140 Einleitung 130 110 120 100 110 100 90 90 80 40 45 50 x 55 60 40 50 60 70 80 90 100 110 x Robuste Regression mit Ausreißern R. Frühwirth Statistische Metodender Datenanalyse 470/584 Unterabschnitt: Polynomiale Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression 21 Mehrfache Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 471/584 Polynomiale Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Ist der Zusammenhang zwischen x und Y nicht annähernd linear, kann man versuchen, ein Polynom anzupassen. Das Modell lautet dann: Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Y = β0 +β1 x+β2 x2 +· · ·+βr xr +ε, E[ε] = 0, var[ε] = σ 2 Es seien wieder Y1 , . . . , Yn die Ergebnisse für die Werte x1 , . . . , xn der Einflussvariablen x. In Matrix-Vektor-Schreibweise: Y = Xβ + ε mit 1 1 X= .. . 1 R. Frühwirth x1 x2 .. . xn x21 x22 .. . x2n ··· ··· .. . ··· xr1 xr2 .. . xrn Statistische Metodender Datenanalyse 472/584 Polynomiale Regression Statistische Metoden der Datenanalyse Die folgende Zielfunktion wird minimiert: R. Frühwirth Einleitung SS = (Y − Xβ)T (Y − Xβ) Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Gradient von SS: ∂SS = −2XT (Y − Xβ) ∂β Nullsetzen des Gradienten gibt die Normalgleichungen: XT Y = XT Xβ Die Lösung lautet: β̂ = XT X R. Frühwirth −1 XT Y Statistische Metodender Datenanalyse 473/584 Polynomiale Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Die Varianz des Fehlerterms wird erwartungstreu geschätzt durch: n X 1 r2 σ̂ 2 = n − r − 1 i=1 i mit r = Y − Ŷ , Ŷ = Xβ̂ Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Kovarianzmatrix der geschätzten Regressionkoeffizienten: Cov[β̂] = σ 2 XT X −1 Kovarianzmatrix der Residuen r: Cov[β̂] = σ 2 I − X XT X −1 XT R. Frühwirth Statistische Metodender Datenanalyse 474/584 Polynomiale Regression Statistische Metoden der Datenanalyse R. Frühwirth 45 2 40 1.5 Einleitung 35 1 Einfache Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression 30 0.5 25 0 20 r’ y Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression −0.5 15 −1 10 −1.5 5 0 −2 −5 −2.5 0 5 10 x 15 20 0 5 10 x 15 20 Regressionsparabel und studentisierte Residuen R. Frühwirth Statistische Metodender Datenanalyse 475/584 Abschnitt 21: Mehrfache Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression 21 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 476/584 Unterabschnitt: Das lineare Modell Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression 21 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 477/584 Das lineare Modell Statistische Metoden der Datenanalyse R. Frühwirth Hängt das Ergebnis Y von mehreren Einflussvariablen ab, lautet das einfachste lineare Regressionmodell: Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Y = β0 +β1 x1 +β2 x1 +· · ·+βr xr +ε, E[ε] = 0, var[ε] = σ 2 Es seien wieder Y1 , . . . , Yn die Ergebnisse für n Werte x1 , . . . , xn der Einflussvariablen x = (x1 , . . . , xr ). In Matrix-Vektor-Schreibweise: Y = Xβ + ε mit 1 1 X= .. . 1 R. Frühwirth x1,1 x2,1 .. . xn,1 x1,2 x2,2 .. . xn,2 ··· ··· .. . ··· x1,r x2,r .. . xn,r Statistische Metodender Datenanalyse 478/584 Unterabschnitt: Schätzung, Tests und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression 21 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 479/584 Schätzung, Tests und Prognoseintervalle Statistische Metoden der Datenanalyse Die folgende Zielfunktion wird minimiert: R. Frühwirth Einleitung SS = (Y − Xβ)T (Y − Xβ) Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Gradient von SS: ∂SS = −2XT (Y − Xβ) ∂β Nullsetzen des Gradienten gibt die Normalgleichungen: XT Y = XT Xβ Die Lösung lautet: β̂ = XT X R. Frühwirth −1 XT Y Statistische Metodender Datenanalyse 480/584 Schätzung, Tests und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Die Varianz des Fehlerterms wird erwartungstreu geschätzt durch: n X 1 r2 σ̂ 2 = n − r − 1 i=1 i mit r = Y − Ŷ , Ŷ = Xβ̂ Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Kovarianzmatrix der geschätzten Regressionkoeffizienten: Cov[β̂] = σ 2 XT X −1 Kovarianzmatrix der Residuen r: Cov[β̂] = σ 2 I − X XT X −1 XT R. Frühwirth Statistische Metodender Datenanalyse 481/584 Schätzung, Tests und Prognoseintervalle Statistische Metoden der Datenanalyse Ist βk = 0, hängt das Ergebnis überhaupt nicht von den Einflussvariablen xk ab. Ein Test der Nullhypothese H0 : βk = 0 gegen H1 : βk 6= 0 beruht auf dem folgenden Satz. R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Satz Ist ε normalverteilt, so ist Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression β̂k − βk σ̂β̂k t-verteilt mit n − r − 1 Freiheitsgraden, wobei σ̂β̂2 das k-te k Diagonalelement der geschätzten Kovarianzmatrix σ̂ 2 XT X −1 ist. R. Frühwirth Statistische Metodender Datenanalyse 482/584 Schätzung, Tests und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Die Nullhypothese H0 : βk = 0 wird abgelehnt, wenn die Testgröße β̂k T = σ̂β̂k relativ klein oder relativ groß ist, also wenn |β̂k | > tn−r−1 1−α/2 σ̂β̂k Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression wo tn−2 das Quantil der t-Verteilung mit n − 2 p Freiheitsgraden zum Niveau p ist. Das symmetrische Konfidenzintervall für βk mit 95% Sicherheit lautet: β̂k ± σ̂β̂k · tn−r−1 1−α/2 R. Frühwirth Statistische Metodender Datenanalyse 483/584 Schätzung, Tests und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Es soll nun das Ergebnis Y0 = Y (x0 ) für einen bestimmten Wert x0 = (x01 , . . . , x0r ) der Einflussvariablen prognostiziert werden. Wir erweitern x0 um den Wert 1: x+ = (1, x01 , . . . , x0r ). Der Erwartungswert von Y0 ist dann E[Y0 ] = x+ · β̂ Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Die Varianz von E[Y0 ] ergibt sich mittels Fehlerfortpflanzung: var[E[Y0 ]] = σ 2 x+ XT X −1 x+ T R. Frühwirth Statistische Metodender Datenanalyse 484/584 Schätzung, Tests und Prognoseintervalle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Da Y0 um seinen Erwartungswert mit Varianz σ 2 streut, ergibt sich: var[E[Y0 ]] = σ 2 1 + x+ XT X −1 x+ T Das symmetrische Prognoseintervall für Y0 mit Sicherheit α ist daher gleich: q x+ · β̂ ± tn−k−1 σ̂ 1 + x+ (XT X) −1 x+ T 1−α/2 R. Frühwirth Statistische Metodender Datenanalyse 485/584 Unterabschnitt: Gewichtete Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression 21 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 486/584 Gewichtete Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Im allgemeinen Fall können die Fehlerterme eine beliebige Kovarianzmatrix haben: Y = Xβ + ε, Cov[ε] = V Ist V bekannt, lautet die Zielfunktion: SS = (Y − Xβ)T G(Y − Xβ), G = V−1 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Gradient von SS: ∂SS = −2XT G(Y − Xβ) ∂β Nullsetzen des Gradienten gibt die Normalgleichungen: XT GY = XT GXβ Die Lösung lautet: β̂ = XT GX −1 XT GY R. Frühwirth Statistische Metodender Datenanalyse 487/584 Gewichtete Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Kovarianzmatrix der geschätzten Regressionkoeffizienten: Cov[β̂] = σ 2 XT GX −1 Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Kovarianzmatrix der Residuen r: Cov[β̂] = σ 2 I − X XT GX −1 XT Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Tests und Prognoseintervalle können entsprechend modifizert werden. R. Frühwirth Statistische Metodender Datenanalyse 488/584 Unterabschnitt: Nichtlineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 19 Einleitung 20 Einfache Regression 21 Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression R. Frühwirth Statistische Metodender Datenanalyse 489/584 Nichtlineare Regression Statistische Metoden der Datenanalyse R. Frühwirth In der Praxis ist die Abhängigkeit der Ergebnisse von den Regressionskoeffizienten oft nichtlinear: Einleitung Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression Y = h(β) + ε, Cov[ε] = V Ist V bekannt, lautet die Zielfunktion: SS = [Y − h(β)]T G[Y − h(β)], G = V−1 SS kann mit dem Gauß-Newton-Verfahren minimiert werden. Dazu wird h an einer Stelle β0 linearisiert: h(β) ≈ h(β0 ) + H(β − β0 ) = c + Hβ, R. Frühwirth Statistische Metodender Datenanalyse H= ∂h ∂β β0 490/584 Nichtlineare Regression Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Die Schätzung von β lautet: β̂ = HT GH −1 HT G(Y − c) Einfache Regression Lineare Regression Tests, Konfidenz- und Prognoseintervalle Robuste Regression Polynomiale Regression Mehrfache Regression Das lineare Modell Schätzung, Tests und Prognoseintervalle Gewichtete Regression Nichtlineare Regression h wird neuerlich an der Stelle β1 = β̂ linearisiert. Das Verfahren wird iteriert, bis die Schätzung sich nicht mehr wesentlich ändert. Viele andere Methoden zur Minimierung von SS verfügbar. R. Frühwirth Statistische Metodender Datenanalyse 491/584 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Teil 7 Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Einführung in die Bayes-Statistik R. Frühwirth Statistische Metodender Datenanalyse 492/584 Übersicht Teil 7 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle 25 Stetige Modelle Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 493/584 Abschnitt 22: Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle 25 Stetige Modelle Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 494/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe In der Bayes-Statistik werden Wahrscheinlichkeiten als rationale Einschätzungen von Sachverhalten interpretiert. Neben den Beobachtungen werden auch unbekannte Parameter von Verteilungen als Zufallsvariable betrachtet. Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Die Vorinformation über die Parameter werden in einer a-priori-Verteilung zusammengefasst. Die Information in den Beobachtungen führt durch Anwendung des Bayes-Theorems zu einer verbesserten Information über die Parameter, die durch die a-posteriori-Verteilung ausgedrückt wird. Die a-posteriori Verteilung kann zum Schätzen von Parametern, zur Berechnung von Vertrauensintervallen, zum Testen, zur Prognose, zur Modellwahl etc. verwendet werden. R. Frühwirth Statistische Metodender Datenanalyse 495/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Durch die Wahl der a-priori-Verteilung wird eine subjektive Komponente in die Datenanalyse eingeführt. Dies kann besonders bei sehr kleiner Anzahl der Beobachtungen einen merkbaren Einfluss auf das Resultat haben. Es gibt jedoch Verfahren zur Konstruktion von a-priori-Dichten, die diesen Einfluss minimieren. Liegen viele Beobachtungen vor, wird der Einfluss der a-priori-Verteilung vernachlässigbar. In diesem Fall liefert die Bayes-Analyse annähernd die gleichen Resultate wie klassische “frequentistische” Verfahren. In der a-posteriori-Verteilung ist jedoch mehr Information enthalten als in klassischen Punkt- oder Intervallschätzern. R. Frühwirth Statistische Metodender Datenanalyse 496/584 Abschnitt 23: Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle 25 Stetige Modelle Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 497/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Der Stichprobenraum Y ist die Menge aller möglichen Stichproben y. Der Parameterraum Θ ist die Menge aller möglichen Werte des Parameters ϑ. Die a-priori-Verteilung p(ϑ) beschreibt unsere Einschätzung, ob ein bestimmter Wert ϑ die wahre Verteilung der Beobachtungen beschreibt. Die Likelihoodfunktion p(y|ϑ) beschreibt unsere Einschätzung, dass die Stichprobe y beobachtet wird, wenn ϑ wahr ist. Wird y beobachtet, kann unsere Einschätzung von ϑ aktualisiert werden, indem die a-posteriori-Verteilung berechnet wird: p(y|ϑ)p(ϑ) p(y|θ)p(θ) dθ Θ p(ϑ|y) = R R. Frühwirth Statistische Metodender Datenanalyse 498/584 Grundbegriffe Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Die a-posteriori-Verteilung beschreibt unsere Einschätzung von ϑ im Lichte der Beobachtungen y. Kommen neue Beobachtungen dazu, kann die a-posteriori-Verteilung als die neue a-priori-Verteilung benützt werden. Kann das Integral im Nenner nicht analytisch gelöst werden, muss man zu Monte-Carlo-Methoden greifen. Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 499/584 Abschnitt 24: Diskrete Modelle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 25 Stetige Modelle Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 500/584 Unterabschnitt: Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 25 Stetige Modelle Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 501/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Wir betrachten einen n mal wiederholten Alternativversuch mit Erfolgswahrscheinlichkeit ϑ. Die Anzahl Y der Erfolge ist dann binomialverteilt gemäß Bi(n, ϑ). Wir wollen aus einer Beobachtung y eine Einschätzung der Erfolgswahrscheinlichkeit ϑ gewinnen. Dazu brauchen wir eine a-priori-Verteilung von ϑ. In Abwesenheit jeglicher Vorinformation über den tatsächlichen Wert von ϑ können wir die Gleichverteilung Un(0, 1) als a-priori-Verteilung wählen: p(ϑ) = I[0,1] (ϑ) Die Likelihoodfunktion ist gleich ! n p(y|ϑ) = ϑy (1 − ϑ)n−y y R. Frühwirth Statistische Metodender Datenanalyse 502/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse Der Satz von Bayes liefert die a-posteriori-Dichte: R. Frühwirth Einleitung p(ϑ|y) ∝ ϑy (1 − ϑ)n−y I[0,1] (ϑ) Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Da die a-posteriori-Dichte proportional zur Dichte der Betaverteilung Beta(y + 1, n − y + 1) ist, muss sie mit dieser identisch sein. Der Erwartungswert der a-posteriori-Verteilung ist gleich E[ϑ|y] = y+1 n+2 Der Modus der a-posteriori-Verteilung ist gleich ϑ̂ = y n und damit der Maximum-Likelihood-Schätzer von ϑ. R. Frühwirth Statistische Metodender Datenanalyse 503/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse A−priori und a−posteriori−Dichte von ϑ mit n=20 R. Frühwirth 25 y=0 y=1 y=2 y=5 y=10 Einleitung Grundbegriffe 20 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 15 Normalverteilte Beobachtungen p(ϑ|y) Stetige Modelle 10 5 0 0 0.1 0.2 0.3 R. Frühwirth 0.4 0.5 ϑ 0.6 0.7 Statistische Metodender Datenanalyse 0.8 0.9 1 504/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Liegt Vorinformation über ϑ vor, kann diese durch eine geeignete a-priori-Dichte inkludiert werden. Die mathematisch einfachste Behandlung ergibt sich, wenn auch die a-priori-Verteilung eine Betaverteilung ist. Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Sei also p(ϑ) = Normalverteilte Beobachtungen ϑa−1 (1 − ϑ)b−1 B(a, b) Dann ist die a-posteriori-Dichte gleich p(ϑ|y) ∝ϑy (1 − ϑ)n−y ϑa−1 (1 − ϑ)b−1 =ϑy+a−1 (1 − ϑ)n−y+b−1 Die a-posteriori-Verteilung ist wieder eine Betaverteilung, nämlich Beta(y + a, n − y + b). R. Frühwirth Statistische Metodender Datenanalyse 505/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Offenbar gibt eine a-priori Betaverteilung mit einer Binomial-Likelihoodfunktion wieder eine a-posteriori Betaverteilung. Die Betaverteilung wird daher als konjugiert zur Binomialverteilung bezeichnet. Der Erwartungswert der a-posteriori-Verteilung ist gleich Stetige Modelle Normalverteilte Beobachtungen E[ϑ|y] = a+y a+b+n Der Modus der a-posteriori-Verteilung ist gleich ϑ̂ = R. Frühwirth a+y−1 a+b+n−2 Statistische Metodender Datenanalyse 506/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Der Erwartungswert der a-posteriori-Verteilung kann als gewichtetes Mittel aus a-priori-Information und Daten angeschrieben werden: Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen a+b a n y a+y = + a+b+n a+b+na+b a+b+nn a+b = × a-priori-Erwartung a+b+n n + × Mittel der Daten a+b+n E[ϑ|y] = a und b können als “a-priori-Daten” interpetiert werden: a b a+b R. Frühwirth Anzahl der Erfolge a-priori Anzahl der Misserfolge a-priori Anzahl der Versuche a-priori Statistische Metodender Datenanalyse 507/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse A−priori und a−posteriori−Dichte von ϑ mit n=10, y=3 R. Frühwirth 3.5 a=1, b=1 a=1, b=2 a=1, b=3 a=2, b=1 a=2, b=2 a=2, b=3 Einleitung 3 Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 2.5 Stetige Modelle 2 p(ϑ|y) Normalverteilte Beobachtungen 1.5 1 0.5 0 0 0.1 0.2 R. Frühwirth 0.3 0.4 0.5 ϑ 0.6 0.7 Statistische Metodender Datenanalyse 0.8 0.9 1 508/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse A−priori und a−posteriori−Dichte von ϑ mit n=100, y=30 R. Frühwirth 9 a=1, b=1 a=1, b=2 a=1, b=3 a=2, b=1 a=2, b=2 a=2, b=3 Einleitung 8 Grundbegriffe Diskrete Modelle 7 Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 6 Normalverteilte Beobachtungen p(ϑ|y) Stetige Modelle 5 4 3 2 1 0 0 0.1 0.2 0.3 R. Frühwirth 0.4 0.5 ϑ 0.6 0.7 Statistische Metodender Datenanalyse 0.8 0.9 1 509/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Wir wollen nun Teilbereiche des Parameterraums Θ konstruieren, die den wahren Wert von ϑ mit großer Sicherheit 1 − α enthalten. Ein solcher Bereich wird ein Vertrauensbereich genannt. Er ist meistens ein Intervall (Vertrauensintervall). Die einfachste Konstruktion eines Vertrauensintervalls [ϑ1 (y), ϑ2 (y)] benützt die Quantile der a-posteriori-Verteilung. Das symmetrische Vertrauensintervall lautet: ϑ1 (y) = qα/2 , ϑ1 (y) = q1−α/2 wo qp das p-Quantil der a-posteriori-Verteilung p(ϑ|y) ist. R. Frühwirth Statistische Metodender Datenanalyse 510/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Beispiel Es sei y = 4 die Anzahl der Erfolge in n = 20 unabhängigen Alternativversuchen mit Erfolgswahrscheinlichkeit ϑ. Mit der Gleichverteilung als a-priori-Verteilung ist die a-posteriori-Verteilung von ϑ eine Beta(5, 17)-Verteilung. Das symmetrische Vertrauensintervall mit 1 − α = 0.95 hat dann die Grenzen ϑ1 (y) = B0.025 (5, 17) = 0.08218, ϑ2 (y) = B0.975 (5, 17) = 0.4191 Der Erwartungswert der a-posteriori-Verteilung ist gleich E[ϑ|y] = 5 = 0.2273 22 Der Modus der a-posteriori-Verteilung ist gleich ϑ̂ = R. Frühwirth 4 = 0.2 20 Statistische Metodender Datenanalyse 511/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse A−posteriori−Dichte von ϑ mit n=20, y=4 R. Frühwirth 5 Einleitung A−posteriori−Dichte Vertrauensintervall 4.5 Grundbegriffe 4 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 3.5 3 Normalverteilte Beobachtungen p(ϑ|y) Stetige Modelle 2.5 2 1.5 1 0.5 0 0 0.1 0.2 R. Frühwirth 0.3 0.4 0.5 ϑ 0.6 0.7 Statistische Metodender Datenanalyse 0.8 0.9 1 512/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Das symmetrische Vertrauensintervall enthält Werte von ϑ, die geringere a-posteriori-Wahrscheinlichkeit haben als manche Punkte außerhalb des Intervalls. Ein Bereich, in dem alle Werte von ϑ höhere a-posteriori-Wahrscheinlichkeit haben als alle Werte außerhalb des Bereichs, heißt ein HighPosteriorDensity-Bereich, kurz HPD-Bereich. Ist die a-posteriori-Dichte unimodal, ist der HPD-Bereich ein HPD-Intervall. In diesem Fall erhält man die Grenzen ϑ1 , ϑ2 des HPD-Intervalls als Lösung des Gleichungssystems: p(ϑ2 |y) − p(ϑ1 |y) = 0 F (ϑ2 |y) − F (ϑ1 |y) = 1 − α Hier ist F (ϑ|y) die a-posteriori-Verteilungsfunktion. R. Frühwirth Statistische Metodender Datenanalyse 513/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Das Gleichungssystem muss in der Regel numerisch gelöst werden. Einleitung Grundbegriffe Beispiel (Fortsetzung) Diskrete Modelle Das HPD-Intervall mit 1 − α = 0.95 hat die Grenzen Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen ϑ1 (y) = 0.06921, ϑ1 (y) = 0.3995 Stetige Modelle Normalverteilte Beobachtungen Es ist mit einer Länge von 0.3303 kürzer als das symmetrische Vertrauensintervall, das eine Länge von 0.3369 hat. Matlab: make posterior binomial R. Frühwirth Statistische Metodender Datenanalyse 514/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse A−posteriori−Dichte von ϑ mit n=20, y=4 R. Frühwirth 5 Einleitung A−posteriori−Dichte Vertrauensintervall HPD−Intervall 4.5 Grundbegriffe 4 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 3.5 3 Normalverteilte Beobachtungen p(ϑ|y) Stetige Modelle 2.5 2 1.5 1 0.5 0 0 0.1 0.2 R. Frühwirth 0.3 0.4 0.5 ϑ 0.6 0.7 Statistische Metodender Datenanalyse 0.8 0.9 1 515/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Beispiel Ein Alternativversuch wird n = 20 mal wiederholt und ergibt keinen einzigen Erfolg (k = 0). Was kann man über die Erfolgswahrscheinlichkeit ϑ aussagen? Mit der a-priori-Dichte p(ϑ) = 1 ist die a-posteriori-Verteilung Beta(1, 21). Der Modus ist gleich 0, der Erwartungswert ist gleich 0.0455. Das HPD-Intervall mit 1 − α = 0.95 ist gleich [0, 0.1329]. Ist bekannt, dass ϑ eher klein ist, kann z.B. Beta(1, 5) als a-priori-Verteilung gewählt werden. Die a-posteriori-Verteilung ist dann Beta(1, 25). Der Modus ist gleich 0, der Erwartungswert gleich 0.0385, und das HPD-Intervall gleich [0, 0.1129]. R. Frühwirth Statistische Metodender Datenanalyse 516/584 Binomialverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Beispiel (Fortsetzung) Einleitung Der Likelihoodschätzer von ϑ ist gleich 0. Grundbegriffe Das einseitige Konfidenzintervall nach Clopper-Pearson ist gleich [0, 0.1391]. Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Die Näherung durch Normalverteilung ist nur sinnvoll mit der Korrektur gemäß Agresti-Coull, das sonst das Konfidenzintervall auf den Nullpunkt schrumpft. Die Schätzung ist ϑ̂ = 0.0833, das symmetrische Konfidenzintervall ist [−0.0378, 0.2045], das linksseitige Konfidenzintervall ist [−∞, 0.1850]. R. Frühwirth Statistische Metodender Datenanalyse 517/584 Unterabschnitt: Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 25 Stetige Modelle Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 518/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Die Beobachtung eines Poissonprozesses ergibt die Werte y = y1 , . . . , yn . Wir wollen aus den Beobachtungen eine Einschätzung der Intensität λ des Prozesses gewinnen. Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Die Likelihoodfunktion lautet: p(y|λ) = Normalverteilte Beobachtungen n Y λyi e−λ i=1 yi ! P ∝λ yi −nλ e Sie hängt von den Beobachtungen nur über s = P yi ab. Ist keine Vorinformation über λ verfügbar, setzen wir p(λ) = 1. Die a-priori-“Dichte” kann nicht normiert werden und wird uneigentlich (improper) genannt. R. Frühwirth Statistische Metodender Datenanalyse 519/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Die a-posteriori-Dichte ist dann proportional zur Likelihoodfunktion: p(λ|s) ∝ λs e−nλ Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Da die a-posteriori-Dichte proportional zur Dichte der Gammaverteilung Ga(s + 1, 1/n) ist, muss sie mit dieser identisch sein: λs e−nλ p(λ|s) = −(s+1) n Γ(s + 1) Der Erwartungswert der a-posteriori-Verteilung ist gleich s+1 E[λ|s] = n Der Modus der a-posteriori-Verteilung ist gleich s λ̂ = n und damit der Maximum-Likelihood-Schätzer von λ. R. Frühwirth Statistische Metodender Datenanalyse 520/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse A−posteriori−Dichte von λ mit n=1 R. Frühwirth 1 Einleitung y=0 y=1 y=2 y=5 y=10 0.9 Grundbegriffe 0.8 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 0.7 0.6 Normalverteilte Beobachtungen p(λ|y) Stetige Modelle 0.5 0.4 0.3 0.2 0.1 0 0 5 R. Frühwirth 10 λ 15 Statistische Metodender Datenanalyse 20 25 521/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Liegt Vorinformation über λ vor, kann diese durch eine geeignete a-priori-Dichte inkludiert werden. Die mathematisch einfachste Behandlung ergibt sich, wenn die a-priori-Verteilung eine Gammaverteilung ist. Sei also p(λ) = Stetige Modelle Normalverteilte Beobachtungen ba λa−1 e−bλ Γ(a) Dies ist die Dichte der Gammaverteilung Ga(a, 1/b). Dann ist die a-posteriori-Dichte gleich p(λ|s) ∝ λs e−nλ λa−1 e−bλ = λs+a−1 e−(b+n)λ Die a-posteriori-Verteilung ist die Gammaverteilung Ga(a + s, 1/(b + n)). Die Gammaverteilung ist also konjugiert zur Poissonverteilung. R. Frühwirth Statistische Metodender Datenanalyse 522/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse A−priori und a−posteriori−Dichte von λ mit n=10, s=30 R. Frühwirth 1 Einleitung a=1, b=1 a=2, b=1 a=3, b=1 a=4, b=1 a=5, b=1 0.9 Grundbegriffe 0.8 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 0.7 0.6 Normalverteilte Beobachtungen p(λ|s) Stetige Modelle 0.5 0.4 0.3 0.2 0.1 0 0 0.5 1 R. Frühwirth 1.5 2 2.5 λ 3 3.5 Statistische Metodender Datenanalyse 4 4.5 5 523/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Der Erwartungswert der a-posteriori-Verteilung ist gleich a+s E[λ|s] = b+n Der Modus der a-posteriori-Verteilung ist gleich a+s−1 b+n Der Erwartungswert der a-posteriori-Verteilung kann als gewichtetes Mittel aus a-priori-Information und Daten angeschrieben werden: λ̂ = a+s b a n s = + b+n b+n b b+nn b × a-priori-Erwartung = b+n n + × Mittel der Daten b+n E[λ|s] = R. Frühwirth Statistische Metodender Datenanalyse 524/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Die a-priori-Parameter a und b können folgendermaßen interpetiert werden: a b Summe der Beobachtungen a-priori Anzahl der Beobachtungen a-priori Ist n b, dominieren die Beobachtungen: E[λ|s] ≈ Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth s n Statistische Metodender Datenanalyse 525/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse A−priori und a−posteriori−Dichte von λ mit n=100, s=300 R. Frühwirth 2.5 a=1, b=2 a=2, b=2 a=3, b=2 a=4, b=2 a=5, b=2 Einleitung Grundbegriffe 2 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 1.5 Normalverteilte Beobachtungen p(λ|s) Stetige Modelle 1 0.5 0 0 0.5 1 R. Frühwirth 1.5 2 2.5 λ 3 3.5 Statistische Metodender Datenanalyse 4 4.5 5 526/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Vertrauensintervalle [λ1 (s), λ2 (s)] können leicht mittels der Quantile der a-posteriori-Gammaverteilung konstruiert werden. Das symmetrische Vertrauensintervall ist gleich Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen [Γα/2,a+s,1/(b+n) , Γ1−α/2,a+s,1/(b+n) ] Die einseitigen Vertrauensintervalle sind [0, Γα,a+s,1/(b+n) ] bzw. [Γα,a+s,1/(b+n) , ∞] HPD-Bereiche können mit numerischen Methoden bestimmt werden. R. Frühwirth Statistische Metodender Datenanalyse 527/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Beispiel Sie messen die Hintergrundstrahlung in einem Labor über eine Periode von 20 Sekunden. Die Zählwerte sind 6, 2, 6, 1, 6, 8, 5, 3, 8, 4, 2, 5, 7, 8, 5, 4, 7, 9, 4, 4 Ihre Summe ist gleich s = 104. Mit der uneigentlichen a-priori-Verteilung p(λ) = 1 ist die a-posteriori-Verteilung die Gammaverteilung Ga(105, 0.05). Ihre Erwartung ist 5.25, ihr Modus ist 5.20. Das symmetrische Vertrauensintervall mit 1 − α = 0.95 ist [4.2940, 6.3007], das HPD-Intervall ist [4.2629, 6.2653]. Da die Verteilung fast symmetrisch ist, sind die beiden Intervalle praktisch gleich lang. Matlab: make posterior poisson R. Frühwirth Statistische Metodender Datenanalyse 528/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse A−posteriori−Dichte von λ mit n=20, s=104 R. Frühwirth 0.8 A−posteriori−Dichte Vertrauensintervall HPD−Intervall Einleitung 0.7 Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 0.6 0.5 Normalverteilte Beobachtungen p(λ|y) Stetige Modelle 0.4 0.3 0.2 0.1 0 2 3 R. Frühwirth 4 5 λ 6 Statistische Metodender Datenanalyse 7 8 529/584 Poissonverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Beispiel Eine Beboachtung aus einer Poissonverteilung hat den Wert k = 0. Was kann über den Mittelwert λ ausgesagt werden? Mit der uneigentlichen a-priori-Dichte p(λ) = 1 ist die a-posteriori-Verteilung Ga(1, 1). Der Modus ist gleich 0, der Erwartungswert ist gleich 1. Das HPD-Intervall mit 1 − α = 0.95 ist gleich [0, 2.9957]. Ist bekannt, dass λ deutlich kleiner als 1 ist, kann z.B. Ga(0.5, 0.5) als a-priori-Verteilung gewählt werden. Die a-posteriori-Verteilung ist dann Ga(0.5, 0.6667). Der Modus ist gleich 0, der Erwartungswert gleich 0.3333, und das HPD-Intervall gleich [0, 1.2805]. Der Likelihoodschätzer von λ ist gleich 0. Das linksseitige Konfidenzintervall ist gleich [0, 2.9957], ist also identisch mit dem HPD-Intervall mit uneigentlicher a-priori-Dichte. R. Frühwirth Statistische Metodender Datenanalyse 530/584 Abschnitt 25: Stetige Modelle Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle 25 Stetige Modelle Normalverteilte Beobachtungen Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 531/584 Unterabschnitt: Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe 22 Einleitung 23 Grundbegriffe 24 Diskrete Modelle 25 Stetige Modelle Normalverteilte Beobachtungen Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 532/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Wir betrachten eine normalverteilte Stichprobe y = y1 , . . . , yn . Wir wollen eine Einschätzung von Mittelwert und Varianz der Verteilung gewinnen, aus der die Beobachtungen stammen. Wir nehmen zunächst an, dass die Varianz σ 2 bekannt ist. Dann lautet die Likelihoodfunktion: Normalverteilte Beobachtungen n Y 1 (yi − µ)2 √ p(y|µ, σ ) = exp − 2 σ2 2πσ i=1 2 In Abwesenheit jeglicher Vorinformation über den tatsächlichen Wert von µ wählen wir die uneigentliche a-priori-Dichte p(µ) = 1. R. Frühwirth Statistische Metodender Datenanalyse 533/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Dann ist die a-posteriori-Dichte gleich n Y (yi − µ)2 1 √ exp − p(µ|y, σ 2 ) ∝ 2 σ2 2πσ i=1 n(µ − ȳ)2 ∝ exp − 2 σ2 Stetige Modelle Normalverteilte Beobachtungen Da die a-posteriori-Dichte proportional zur Dichte der Normalverteilung No(ȳ, σ 2 /n) ist, muss sie mit dieser identisch sein. Der Erwartungswert der a-posteriori-Verteilung ist gleich E[µ|y] = ȳ und damit der Maximum-Likelihood-Schätzer von µ. Der Modus ist ebenfalls gleich ȳ. R. Frühwirth Statistische Metodender Datenanalyse 534/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Liegt Vorinformation über µ vor, kann diese durch eine geeignete a-priori-Dichte inkludiert werden. Die mathematisch einfachste Behandlung ergibt sich, wenn die a-priori-Verteilung ebenfalls eine Normalverteilung ist. Sei also 1 (µ − µ0 )2 2 p(µ|σ ) = √ exp − 2 τ02 2πτ0 Dann ist die a-posteriori-Dichte gleich n(µ − ȳ)2 (µ − µ0 )2 p(µ|y, σ 2 ) ∝ exp − exp − 2 σ2 2 τ02 a(µ − b/a)2 ∝ exp − 2 mit R. Frühwirth Statistische Metodender Datenanalyse 535/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe a= 1 n + 2 τ02 σ und b = nȳ µ0 + 2 τ02 σ Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Die a-posteriori-Verteilung ist daher die Normalverteilung No(µn , τn2 ) mit b µn = = a µ0 τ02 1 τ02 + + nȳ σ2 n σ2 , τn2 = 1 = a 1 τ02 1 + n σ2 Der Mittelwert µn ist das gewichtete Mittel aus der Vorinformation µ0 und dem Mittelwert der Daten ȳ, wobei die Gewichte durch die Präzision, d.h. die inverse Varianz gegeben sind. R. Frühwirth Statistische Metodender Datenanalyse 536/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Die Präzision 1/τn2 ist die Summe der Präzision der Vorinformation µ0 und der Präzision des Mittelwerts der Daten ȳ. Je kleiner die Präzision der Vorinformation ist, d.h. je größer τ02 ist, desto kleiner ist der Einfluss der Vorinformation auf die a-posteriori-Verteilung. Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 537/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Ist die Präzision σ 2 unbekannt, brauchen wir eine gemeinsame a-priori-Dichte für µ und σ 2 . Die Rechnung ist einfacher, wenn wir statt der Varianz σ 2 die Präzision z = 1/σ 2 verwenden. Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Eine mögliche Wahl ist die uneigentliche a-priori-Dichte p(µ, z) = Stetige Modelle Normalverteilte Beobachtungen 1 z Dann gilt: " # n n 1 Y√ zX 2 p(µ, z|y) ∝ z exp − (yi − µ) z i=1 2 i=1 " # n zX n/2−1 2 ∝z exp − (yi − µ) 2 i=1 R. Frühwirth Statistische Metodender Datenanalyse 538/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Integration über µ gibt die a-posteriori-Dichte von z: # " Z n zX 2 n/2−1 (yi − µ) dµ p(z|y) ∝ z exp − 2 i=1 " # n zX (n−3)/2 2 ∝z exp − (yi − ȳ) 2 i=1 z ist daher a-posteriori P Gammaverteilt gemäß Ga((n − 1)/2, 2/ (yi − ȳ)2 ). Wegen X X (yi − ȳ)2 = yi2 − nȳ 2 P P 2 hängt die Verteilung nur von s1 = yi und s2 = yi bzw. nur vom Stichprobenmittel ȳ und der Stichprobenvarianz S 2 ab. R. Frühwirth Statistische Metodender Datenanalyse 539/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Die a-posteriori-Dichte von σ 2 erhält man durch die Transformation σ 2 = 1/z: Einleitung Grundbegriffe g(σ 2 ) = Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen p(1/σ 2 |y) σ2 Die Verteilung von σ 2 ist eine inverse Gammaverteilung. Stetige Modelle Normalverteilte Beobachtungen R. Frühwirth Statistische Metodender Datenanalyse 540/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Die Inverse Gammaverteilung IG(a, b) Die Dichte der inversen Gammaverteilung lautet: Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen f (x|a, b) = (1/x)a+1 e−x/b · I[0,∞) (x) ba Γ(a) Ihre Verteilungsfunktion lautet: F (x|a, b) = 1 − γ(a, 1/(xb)) Γ(a) Der Mittelwert ist 1/(b(a − 1)), wenn a > 1; der Modus ist m = 1/(b(a + 1)). R. Frühwirth Statistische Metodender Datenanalyse 541/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Die durch z bedingte a-posteriori-Verteilung von µ erhalten wir aus p(µ, z|y) p(z|y) n z hX io X 1/2 ∝ z exp − (yi − µ)2 − (yi − ȳ)2 2 h nz i 1/2 ∝ z exp − (µ − ȳ)2 2 h n i 1 = exp − 2 (µ − ȳ)2 σ 2σ p(µ|z, y) = Das ist die Normalverteilung No(ȳ, σ 2 /n). R. Frühwirth Statistische Metodender Datenanalyse 542/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Schließlich erhalten wir die a-posteriori-Verteilung von µ durch Integration über z: # " Z n zX n/2−1 2 p(µ|y) ∝ z exp − (yi − µ) dz 2 i=1 1 ∝ P n/2 [ (µ − yi )2 ] Daraus folgt durch Umformung, dass das Standardscore t= µ − ȳ √ S/ n a-posteriori t-verteilt mit n − 1 Freiheitsgraden ist. R. Frühwirth Statistische Metodender Datenanalyse 543/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Will man eine eigentliche a-priori-Dichte für z, bietet sich die Gammaverteilung an, da diese die konjugierte Verteilung ist. Die a-posteriori-Verteilung p(z|y) ist dann wieder eine Gammaverteilung. Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Stetige Modelle Normalverteilte Beobachtungen Beispiel Von einem √ normalverteilten Datensatz des Umfangs n = 100 aus No(10, 2) sind ȳ = 9.906 und S = 1.34981 gegeben. Die √ a-posteriori-Dichte von µ ist eine mit S/ n skalierte und um ȳ verschobene t(n − 1)-Verteilung. Das HPD-Intervalls mit 1 − α = 0.95 ist gleich [9.6382, 10.1739]. Matlab: make posterior normal R. Frühwirth Statistische Metodender Datenanalyse 544/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse A−posteriori−Dichte von µ R. Frühwirth 3.5 A−posteriori−Dichte HPD−Intervall Einleitung 3 Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 2.5 Stetige Modelle 2 p(µ|y) Normalverteilte Beobachtungen 1.5 1 0.5 0 9.2 9.4 9.6 R. Frühwirth 9.8 10 µ 10.2 10.4 Statistische Metodender Datenanalyse 10.6 10.8 545/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Grundbegriffe Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen Beispiel (Fortsetzung) Die a-posteriori-Dichte p(σ 2 |y) der Varianz z ist die inverse Gammaverteilung IG((n − 1)/2, 2/(S 2 (n − 1))) = IG(49.5, 0.0110879) Das HPD-Intervall mit 1 − α = 0.95 ist gleich [1.3645, 2.4002]. Stetige Modelle Normalverteilte Beobachtungen Matlab: make posterior normal R. Frühwirth Statistische Metodender Datenanalyse 546/584 Normalverteilte Beobachtungen Statistische Metoden der Datenanalyse A−posteriori−Dichte von 1/σ2 R. Frühwirth 2 Einleitung A−posteriori−Dichte HPD−Intervall 1.8 Grundbegriffe 1.6 Diskrete Modelle Binomialverteilte Beobachtungen Poissonverteilte Beobachtungen 1.4 1.2 Normalverteilte Beobachtungen p(σ2|y) Stetige Modelle 1 0.8 0.6 0.4 0.2 0 0 0.5 1 R. Frühwirth 1.5 2 σ2 2.5 Statistische Metodender Datenanalyse 3 3.5 4 547/584 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Teil 8 Simulation von Experimenten Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 548/584 Übersicht Teil 8 Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen R. Frühwirth Statistische Metodender Datenanalyse 549/584 Abschnitt 26: Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen R. Frühwirth Statistische Metodender Datenanalyse 550/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Um das Ergebnis eines Experiments korrekt interpretieren zu können, muss der Einfluss des experimentellen Aufbaues auf die zu messenden Verteilungen berücksichtigt werden. Dabei bedient sich die experimentelle Mathematik einer statistischen Methode, der nach dem Roulette benannten Monte Carlo-Methode. Es wird ein Modell des Experiments erstellt, das sowohl die deterministischen Abläufe als auch die stochastischen Einflüsse (quantenmechanische Prozesse, Messfehler) modelliert. R. Frühwirth Statistische Metodender Datenanalyse 551/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Dabei können Teile des Systems (Experiments) nur global in ihrer Auswirkung oder in realistisch detaillierter Form behandelt werden. Zum Beispiel kann der Messfehler durch eine detaillierte Simulation der Messapparatur oder durch eine einfache Normalverteilung erzeugt werden. Wesentlich ist, dass bei Eingabe von Daten eines korrekten Datenmodells die nach der Simulation des Ablaufes entstehende Datenreihe statistisch gesehen die gleichen Eigenschaften aufweist wie die Messdaten. R. Frühwirth Statistische Metodender Datenanalyse 552/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Schon in der Planungsphase eines Experiments empfiehlt es sich, eine möglichst realistische Simulation. Die Kernfrage ist natürlich, ob und in welcher Messzeit das geplante Experiment eine genügend genaue Antwort auf die Problemstellung gibt. Durch wiederholte Simulation kann die Streuung und eine eventuelle Verzerrung der Schätzung der gesuchten Parameter studiert werden. Dabei kann auch der wahre Wert der Paramer variiert werden, um eine gewisse Kenntnis der systematischen Fehler der gewählten Auswertemethode erlangt werden. Ferner wird die Auswertemethode auf ihre Korrektheit überprüft. R. Frühwirth Statistische Metodender Datenanalyse 553/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Erscheint nun die Durchführung des Experiments als sinnvoll (Messdauer, Beherrschung des Untergrundes etc.), so wird die aus dem simulierten Experiment gewonnene Erfahrung sicherlich eine gewisse Rückwirkung auf das geplante Experiment haben, etwa auf die angestrebte Genauigkeit, die Anzahl, die Positionierung und das erforderliche Ansprechvermögen der Detektoren; auf das Unterdrücken oder auf das Erkennen des Untergrundes; auf die Optimierung der Auswertemethoden und der dazu erforderlichen Rechenzeit. R. Frühwirth Statistische Metodender Datenanalyse 554/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Natürlich wird eine gewisse Unsicherheit bei der Simulation des Experiments verbleiben; denn erstens können nicht alle kleinsten Details in einem Simulationsprogramm berücksichtigt werden, und zweitens sind die Detektoren häufig noch im Entwicklungsstadium, sodass ihr endgültiges Verhalten noch nicht gemessen und daher auch nicht in die Simulation eingegeben werden kann. Auf jeden Fall sollte der Simulation des Experiments größte Aufmerksamkeit geschenkt werden, und spätestens bei der Auswertung der echten Messergebnisse wird das Simulationsprogramm neuerlich wichtige Informationen liefern, nachdem es an Hand der realen experimentellen Gegebenheiten laufend angepasst wurde. R. Frühwirth Statistische Metodender Datenanalyse 555/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Die Simulation von stochastischen Prozessen benötigt Zufallszahlen mit vorgegebener Verteilung. Diese werden aus Zufallszahlen berechnet, die aus der Gleichverteilung Un(0, 1) gezogen werden. Auf jedem Rechner steht heute ein (Pseudo-) Zufallszahlengenerator zur Verfügung. Tatsächlich handelt es sich dabei um diskrete Werte. Wegen der großen Wortlänge moderner Maschinen kann dieser Wertevorrat für die meisten Anwendungen als quasi-kontinuierlich betrachtet werden. R. Frühwirth Statistische Metodender Datenanalyse 556/584 Einleitung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Die erzeugten Werte werden mit einer deterministischen Funktion generiert und sind daher Pseudozufallszahlen. Darunter versteht man eine Zahlenreihe, die statistisch gesehen ein ähnliches Verhalten zeigt wie eine Zahlenreihe echter Zufallszahlen, in Wahrheit jedoch deterministisch und wiederholbar ist. Der Zufallszahlengenerator hat periodisches Verhalten. Die Periode sollte möglichst lang sein. Ein Simulationsvorgang kann, wenn gewünscht, reproduziert werden, wenn der Zufallszahlengenerator mit dem gleichen Startwert aufgerufen wird. Die Qualität der erzeugten Zahlenreihe muss mit statistischen Tests überprüft werden. R. Frühwirth Statistische Metodender Datenanalyse 557/584 Abschnitt 27: Simulation von diskreten Zufallsvariablen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung 28 Simulation von stetigen Zufallsvariablen Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 558/584 Unterabschnitt: Allgemeine Methoden Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung 28 Simulation von stetigen Zufallsvariablen Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 559/584 Allgemeine Methoden Statistische Metoden der Datenanalyse Die Verteilungsfunktion einer diskreten Verteilung lautet X F (x) = f (k) R. Frühwirth Einleitung k≤x Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung F (x) ist eine monotone Stufenfunktion, die jeweils an den Werten k um f (k) springt. Die Wahrscheinlichkeit, dass eine Zufallszahl aus der Gleichverteilung in das Intervall [F (k − 1), F (k)) fällt, ist gerade gleich f (k). Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Satz Wird k so bestimmt, dass eine im Intervall [0, 1] gleichverteilte Zufallszahl im Intervall [F (k − 1), F (k)) liegt, so gehorcht k der Verteilung mit der Verteilungsfunktion F (x). R. Frühwirth Statistische Metodender Datenanalyse 560/584 Allgemeine Methoden Statistische Metoden der Datenanalyse In Matlab: R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen % Z u f a l l s z a h l e n aus einer d i s k r e t e n V e r t e i l u n g function x = s i m u l a t e _ d i s c r e t e (p ,m , n ) % p ... V e r t e i l u n g % x ... Matrix der Größe m mal n u = rand (m , n ); x = ones (m , n ); p = cumsum ( p ); for i =1: length ( p ) -1 x (u > p ( i ))= i +1; end Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 561/584 Unterabschnitt: Alternativverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung 28 Simulation von stetigen Zufallsvariablen Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 562/584 Alternativverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Vergleiche gleichverteilte Zufallszahl mit der Erfolgswahrscheinlichkeit p. In Matlab: % Z u f a l l s z a h l e n aus einer A l t e r n a t i v v e r t e i l u n g function x = s i m u l a t e _ a l t e r n a t i v e (p ,m , n ) % p ... E r f o l g s w a h r s c h e i n l i c h k e i t % x ... Matrix der Größe m mal n u = rand (m , n ); x =u < p ; Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 563/584 Unterabschnitt: Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung 28 Simulation von stetigen Zufallsvariablen Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 564/584 Binomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Wiederholter Alternativversuch. In Matlab: Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung % Z u f a l l s z a h l e n aus einer B i n o m i a l v e r t e i l u n g function x = s i m u l a t e _ b i n o m i a l (p ,N ,m , n ) % p ... E r f o l g s w a h r s c h e i n l i c h k e i t % N ... Anzahl der A l t e r n a t i v v e r s u c h e % x ... Matrix der Größe m mal n u = rand (m ,n , N ); x = sum (u <p ,3); Standard: Funktion binornd R. Frühwirth Statistische Metodender Datenanalyse 565/584 Unterabschnitt: Poissonverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung 28 Simulation von stetigen Zufallsvariablen Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 566/584 Poissonverteilung Statistische Metoden der Datenanalyse Eine Möglichkeit beruht auf dem folgenden Satz. R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Satz Es sei u1 , u2 , . . . eine Folge von gleichverteilten Zufallszahlen und λ > 0. Ist k die kleinste Zahl, sodass k Y Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung ui ≤ e−λ i=1 dann ist k − 1 Poisson-verteilt gemäß Po(λ). R. Frühwirth Statistische Metodender Datenanalyse 567/584 Poissonverteilung Statistische Metoden der Datenanalyse In Matlab: R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung % Z u f a l l s z a h l e n aus einer P o i s s o n v e r t e i l u n g function x = s i m u l a t e _ p o i s s o n ( lam ,m , n ) % lam ... I n t e n s i t ä t % x ... Matrix der Größe m mal n z = exp ( - lam ); u = ones (m , n ); x = - ones (m , n ); k =0; while any ( x (:) <0) k = k +1; u = u .* rand ( size ( u )); x (u <= z & x <0)= k -1; end Standard: Funktion poissrnd R. Frühwirth Statistische Metodender Datenanalyse 568/584 Unterabschnitt: Multinomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung 28 Simulation von stetigen Zufallsvariablen Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 569/584 Multinomialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Wiederholter verallgemeinerter Alternativversuch In Matlab: Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung % Z u f a l l s z a h l e n aus einer P o i s s o n v e r t e i l u n g function x = s i m u l a t e _ m u l t i n o m i a l (p ,N , n ) % p ... r K l a s s e n w a h r s c h e i n l i c h k e i t e n % N ... Anzahl der V e r s u c h e % x ... Feld der Größe r mal n u = rand (n , N ); p =[0 cumsum ( p )]; for i =1: length ( p ) -1 x (i ,:)= sum ( p ( i ) < u & u <= p ( i +1) ,2); end Standard: Funktion mnrnd R. Frühwirth Statistische Metodender Datenanalyse 570/584 Abschnitt 28: Simulation von stetigen Zufallsvariablen Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 571/584 Unterabschnitt: Allgemeine Methoden Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 572/584 Allgemeine Methoden Statistische Metoden der Datenanalyse Die Verteilungsfunktion einer stetigen Verteilung lautet Z x F (x) = f (x) dx R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen −∞ Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung F (x) ist eine monotone und stetige Funktion. F (x) ist daher umkehrbar. Satz Ist u eine im Intervall [0, 1] gleichverteilte Zufallszahl, so ist x = F −1 (u) verteilt mit der Verteilungsfunktion F (x). R. Frühwirth Statistische Metodender Datenanalyse 573/584 Allgemeine Methoden Statistische Metoden der Datenanalyse In Matlab: R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung % Z u f a l l s z a h l e n aus einer s t e t i g e n V e r t e i l u n g function r = s i m u l a t e _ c o n t i n u o u s (x ,F ,m , n ) % x ... x - Werte der V e r t e i l u n g s f u n k t i o n % F ... y - Werte der V e r t e i l u n g s f u n k t i o n % r ... Matrix der Größe m mal n u = rand (m , n ); r = interp1 (F ,x , u ); Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 574/584 Unterabschnitt: Exponentialverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 575/584 Exponentialverteilung Statistische Metoden der Datenanalyse Die Verteilungsfunktion der Exponentialverteilung Ex(τ ) ist R. Frühwirth F (x) = 1 − e−x/τ Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Ist u gleichverteilt im Intervall [0, 1], so ist x = −τ ln u verteilt gemäß Ex(τ ). In Matlab: % Z u f a l l s z a h l e n aus einer E x p o n e n t i a l v e r t e i l u n g function r = s i m u l a t e _ e x p o n e n t i a l ( tau ,m , n ) % tau ... M i t t e l w e r t % r ... Matrix der Größe m mal n r = - tau * log ( rand (m , n )); Standard: Funktion exprnd R. Frühwirth Statistische Metodender Datenanalyse 576/584 Unterabschnitt: Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 577/584 Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Verfahren von Box und Muller Sind u1 und u2 zwei unabhängige, gleichverteilte Zufallsgrößen, so sind p x1 = −2 ln u1 cos(2πu2 ) p x2 = −2 ln u1 sin(2πu2 ) standardnormalverteilt und unabhängig. In Matlab: % Z u f a l l s z a h l e n aus der S t a n d a r d n o r m a l v e r t e i l u n g % Box - Muller - V e r f a h r e n function r = s i m u l a t e _ b o x m u l l e r ( n ) % r ... Matrix der Größe 2 mal n u = rand (2 , n ); z = sqrt ( -2* log ( u (1 ,:))); r (1 ,:)= z .* cos (2* pi * u (2 ,:)); r (2 ,:)= z .* sin (2* pi * u (2 ,:)); R. Frühwirth Statistische Metodender Datenanalyse 578/584 Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Erzeugung mit dem zentralen Grenzwertsatz Sind u1 , . . . , u12 unabhängig und gleichverteilt in [−1/2, 1/2], so ist Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung x= 12 X ui i=1 in guter Näherung standardnormalverteilt. In Matlab: % Z u f a l l s z a h l e n aus der S t a n d a r d n o r m a l v e r t e i l u n g % Box - Muller - V e r f a h r e n function r = s i m u l a t e _ n o r m a l _ z g w s (m , n ) % r ... Matrix der Größe m mal n r = sum ( rand (m ,n ,12) -0.5 ,3); Standard: Funktion normrnd R. Frühwirth Statistische Metodender Datenanalyse 579/584 Normalverteilung Statistische Metoden der Datenanalyse 0.4 R. Frühwirth Faltungsdichte Exakte Dichte Einleitung 0.35 Simulation von diskreten Zufallsvariablen 0.3 Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung f(x) Simulation von stetigen Zufallsvariablen 0.25 0.2 0.15 0.1 0.05 0 −4 −3 R. Frühwirth −2 −1 0 x 1 2 Statistische Metodender Datenanalyse 3 4 580/584 Unterabschnitt: Multivariate Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 581/584 Multivariate Normalverteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Satz Es sei V eine (positiv definite) Kovarianzmatrix der Dimension n × n, µ ein Vektor der Dimension n × 1 und Q eine Matrix mit QQT = V. Ist U ein standardnormalverteilter Vektor der Dimension n × 1, so ist X = QU + µ Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung normalverteilt mit Mittel µ und Kovarianzmatrix V. Q kann mittels Choleskyzerlegung oder Hauptachsentransformation berechnent werden. In Matlab: Funktion mvnrnd R. Frühwirth Statistische Metodender Datenanalyse 582/584 Unterabschnitt: Gamma-,χ2 -, t- und F-Verteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung 26 Einleitung 27 Simulation von diskreten Zufallsvariablen 28 Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 583/584 Gamma-,χ2 -, t- und F-Verteilung Statistische Metoden der Datenanalyse R. Frühwirth Einleitung Simulation von diskreten Zufallsvariablen Allgemeine Methoden Alternativverteilung Binomialverteilung Poissonverteilung Multinomialverteilung Funktion gamrnd Funktion chi2rnd Funktion trnd Funktion frnd Simulation von stetigen Zufallsvariablen Allgemeine Methoden Exponentialverteilung Normalverteilung Multivariate Normalverteilung Gamma-,χ2 -, t- und F-Verteilung R. Frühwirth Statistische Metodender Datenanalyse 584/584