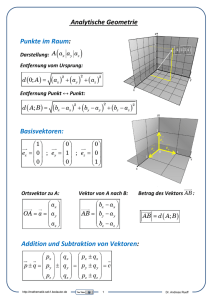
Vektor 1 - Universität der Bundeswehr München
Werbung

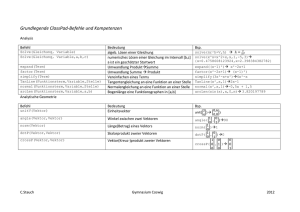
Einführung Clusteranalyse PostgreSQL Geo Web Services OpenLayers Dipl.- Ing. Eva Nuhn Dipl.- Geogr. Stephan Schmid Dipl.- Ing (FH) Steffen Schwarz Arbeitsgemeinschaft GIS Universität der Bundeswehr München Einführung in die Clusteranalyse Inhalt • Einführung in die Clusteranalyse • Proximitätsmaße • Clusteralgorithmen • Methoden zur Bestimmung der Clusteranzahl • Anwendungsbeispiel • • • • Forschungsprojekt EGIFF Auswahl eines Proximitätsmaßes Auswahl eines Clusteralgorithmus Auswahl einer Methode zur Bestimmung der Clusteranzahl Data Mining • „Schürfen“ oder „Graben“ von Daten, wobei das, wonach „gegraben“ wird, Informationen bzw. Wissen ist • Extraktion von neuen Zusammenhängen, Mustern oder Trends in großen Datenmengen Einleitung: Ein klassisches Beispiel für räumliche Datenanalyse Dr. John Snow Krankheitshäufung Untersuchung der Ursachen einer Coleraepidemie London, September 1854 Infizierte Wasserpumpe? SRC: M. May, 6. Seminar GIS im Internet/Intranet v. 06. bis 08. Oktober 2003 – UniBwMünchen Michael May Ziele des Spatial Data Mining • Räumliche Muster erkennen • Objekte erkennen, die solche Muster möglicherweise verursachen • Information extrahieren, die für die Erklärung der Muster relevant ist (und irrelvante Information wegfiltern) Data Mining • Typische Aufgabenstellungen • • • • • Klassifizierungsanalysen Segmentierungsanalysen Prognoseanalysen Abhängigkeitsanalysen Abweichungsanalysen Data Mining • Klassifizierung • Objekte werden einer vorher bestimmten Klasse zugeordnet • Zuordnung findet aufgrund der Parameter und der Klasseneigenschaften statt • Anzahl an Klassen bekannt • Informationen sind vorab bekannt • Segmentierung • Objekte werden in Gruppen zusammengefasst, welche vorher nicht bekannt sind • Anzahl an Gruppen zu Beginn unbekannt • Datenabhängige Einteilung objektiv nachvollziehbar und reproduzierbar • Werden verwendet, wenn wenige Informationen vorab vorliegen Data Mining • Das am Häufigsten verwendete Verfahren der Segmentierung ist die Clusteranalyse • Definition (Steinhausen und Langer, 1977): • Clusteranalyse steht „für eine Reihe unterschiedlicher mathematischstatistischer und heuristischer Verfahren, deren Ziel darin besteht, eine meist umfangreiche Menge von Elementen durch Konstruktion homogener Klassen, Gruppen oder Cluster optimal zu strukturieren“. Clusteranalyse • Objekte innerhalb eines Clusters sollen möglichst ähnlich sein (Homogenität in den Clustern) • Cluster untereinander sollen möglichst unähnlich sein (Heterogenität zwischen den Clustern) Ablauf der Clusteranalyse Analyse und Präzisierung der Fragestellung Modifikation, Korrektur Auswahl der Parameter Wahl eines Proximitätsmaßes Bestimmung des Algorithmus Bestimmung der Clusteranzahl Technische Durchführung Analyse der Ergebnisse Auswahl der Parameter • Clusteranalyse fordert kein spezielles Skalenniveau • Beachten: • Wahl von zu vielen Parametern zusammenfassen ließen • Wahl von zu wenigen Parametern ausdifferenzieren ließen viele Cluster, die sich weiter wenige Cluster, die sich weiter • Gute Auswahl der Parameter = einfaches und leicht verständliches Clusterergebnis • Schlechte Auswahl der Parameter = komplexes Clusterergebnis, dessen wahre Struktur oft schwierig oder unmöglich zu erkennen ist Auswahl der Parameter • Aufstellen der Rohdatenmatrix • Objekte • Parameter Vektoren Parameter Vektor 1 Vektor 2 Vektor Vektor 1 Vektor 2 Vektor 3 ...3 VektorVektor n n X [m] 249,7211,562 240,0351,673245,546 1,757 ... 242,098 1,604 Y [m] 549,2720,856 548,2721,923562,186 0,968 ... 536,249 -0,065 20,883 1,499 20,883 1,49920,883... Länge [m] 1,499 14,8040,315 Richtung [°]-2,423 ... 204,137-2,423 203,137-2,423 204,136 -0,640 267,832 Ablauf der Clusteranalyse Analyse und Präzisierung der Fragestellung Auswahl der Parameter Wahl eines Proximitätsmaßes Bestimmung des Algorithmus Bestimmung der Clusteranzahl Technische Durchführung Analyse der Ergebnisse Auswahl eines Proximitätsmaßes • Quantifizierung der Ähnlichkeiten zwischen den in der Clusteranalyse berücksichtigten Objekten durch eine statistische Maßzahl • Ähnlichkeitsmaße • Drücken die Ähnlichkeit zwischen zwei Objekten aus • Ein großer Wert beschreibt eine hohe Ähnlichkeit • Distanzmaße • Drücken die Unähnlichkeit zwischen zwei Objekten aus • Ein großer Wert beschreibt eine niedrige Ähnlichkeit • Bei identischen Objekten ist die Distanz Null Distanzmaße • Werden hauptsächlich bei quantitativen Parametern verwendet • Die am häufigsten verwendeten basieren auf der Minkowski-Metrik • r=1 • r=2 • … City-Block-Metrik Euklidische Distanz Auswahl Proximitätsmaß • Standardisierte Rohdatenmatrix wird in Distanzmatrix überführt Vektoren Vektoren Vektor 1 Vektor 2 Vektor 3 Vektor 1 0 Vektor 2 0,225 0 Vektor 3 0,959 1,073 0 Vektor n 2,381 2,330 2,922 Vektor n 0 Ähnlichkeitsmaße • Werden hauptsächlich bei qualitativen Parametern verwendet • • • • • Tanimoto-Koeffizient M-Koeffizient Dice-Koeffizient Sokal & Sneath … • Ähnlichkeitsmaß für quantitative Parameter • Q-Korrelations-Koeffizient Ähnlichkeitsmaße • Standardisierte Rohdatenmatrix wird in Ähnlichkeitsmatrix überführt Vektoren Vektoren Vektor 1 Vektor 2 Vektor 3 Vektor n Vektor 1 1 Vektor 2 0,33 1 Vektor 3 … … 1 Vektor n … … … 1 Ablauf der Clusteranalyse Analyse und Präzisierung der Fragestellung Auswahl der Parameter Wahl eines Proximitätsmaßes Bestimmung des Algorithmus Bestimmung der Clusteranzahl Technische Durchführung Analyse der Ergebnisse Clusteralgorithmus Cluster-Algorithmen Hierarchisch Partitionierend agglomerativ divisiv Partitionierende Clustermethoden • • • • Gehen von einer gegebenen Startgruppierung aus Die Startgruppierung muss vom Nutzer geschätzt werden Alle Objekte werden zu Beginn einem Cluster zugeordnet Prominentes Beispiel: K-Means K-means • Distanzmaß: quadrierte euklidische Distanz K-means • So viele Wiederholungen bis keine oder nur noch minimale Verschiebungen von Objekten in andere Cluster mehr • Lösung ist stark abhängig von den gewählten Clusterzentren • Anzahl Clusterzentren muss vorab bekannt sein • Bei Verwendung eines anderen k‘s kann sich eine komplett andere Lösung ergeben Hierarchische Clusteralgorithmen • Divisive Verfahren • Zu Beginn bilden alle Objekte ein einziges großes Cluster • Das Cluster wird Schritt für Schritt aufgeteilt, indem die unähnlichsten Objekte voneinander getrennt werden • Lässt sich solange fortsetzen, bis am Schluss alle Objekte ein eigenes Cluster bilden • Sehr rechenaufwändig daher kaum Einsatz in der Praxis • Agglomerative Verfahren • Zu Beginn bildet jedes Objekt ein Cluster • Schritt für Schritt werden die jeweils ähnlichsten Cluster zu einem neuen Cluster zusammengefügt • Lässt sich solange fortsetzen, bis sich alle Objekte in einem Cluster befinden Hierarchische Clusteralgorithmen 1. 2. Erstellen einer Distanzmatrix mit den Distanzen der einzelnen Cluster zueinander Zusammenfassen der Cluster, die den kleinsten Distanzwert haben 3. Update der Distanzmatrix Vektoren Vektor 1 Vektor 2 Vektor 3 Vektor n Vektoren Vektor 1 0 Vektor 2 0,225 0 Vektor 3 0,959 1,073 0 Vektor n 2,381 2,330 2,922 0 Vektoren Vektoren Vektor 1/ Vektor 3 Vektor 2 Vektor 1/ Vektor2 Vektor n 0 Vektor 3 0 Vektor n 2,922 0 Hierarchische Clusteralgorithmen • Agglomerative Clusterverfahren unterscheiden sich durch die Berechnung der Distanz zwischen den neugebildeten und den übrigen Clustern • Single Linkage • Minimale Distanz • Complete Linkage • Maximale Distanz • Average Linkage • Durchschnittliche Distanz • … Hierarchische Clustermethoden • Single Linkage Vektoren Vektor 1 Vektor 2 Vektor 3 ... Vektoren Vektor 1 0 Vektor 2 0,225 0 Vektor 3 0,959 1,073 0 Vektor n 2,381 2,330 2,922 Vektor n ... 0 Vektoren Vektoren Vektor 1/ Vektor 3 Vektor 2 Vektor 1/ Vektor2 Vektor n 0 Vektor 3 0,959 0 Vektor n 2,330 2,922 0 Hierarchische Clustermethoden Complete Linkage = dilatierendes Verfahren Single Linkage = kontrahierendes Verfahren (Chaining Effekt) Ablauf der Clusteranalyse Analyse und Präzisierung der Fragestellung Auswahl der Parameter Wahl eines Proximitätsmaßes Bestimmung des Algorithmus Bestimmung der Clusteranzahl Technische Durchführung Analyse der Ergebnisse Bestimmung der Clusteranzahl • Aufteilung in zu viele Cluster verkompliziert das Ergebnis • Aufteilung in zu wenige Cluster kann einen Informationsverlust verursachen • Bei agglomerativen Verfahren bildet zu Beginn jedes Objekt ein eigenständiges Cluster • Der Algorithmus endet mit der Zusammenfassung aller Objekte in einem großen Cluster • Im letzten Schritt muss entschieden werden, welche Anzahl von Clustern als die „beste“ anzusehen ist Bestimmung der Clusteranzahl • Subjektive Methode Vektor 1 Vektor 2 Vektor 3 Vektor 1 0 Vektor 2 0,225 0 Vektor 3 0,959 1,073 0 Vektor n 2,381 2,330 2,922 Vektor n 0 Dendrogramm Vektor 1/ Vektor 2 Vektor 3 ... Vektor 1 / Vektor 2 0 Vektor 3 0,959 0 ... ... ... 0 Vektor n 2,330 2,922 ... Vektor 1/ Vektor 2/ Vektor 3 ... Vektor 1 / Vektor 2 / Vektor 3 0 ... ... 0 Vektor n 2,330 ... Vektor n 0 Vektor n 2,330 2 1 0,959 0 0,225 1 2 3 n Stopping Rule von Mojena • Objektive Methode • Stopping Rule von Mojena • Basiert auf der relativen Größe der unterschiedlichen Aggregationslevel im Dendrogramm • Als Indikator für eine gute Cluster-Lösung gilt diejenige Clusteranzahl bei der gilt: Stopping Rule von Mojena • 2,330 2 1 0,959 0,225 1 2 3 n ANWENDUNGSBEISPIEL Anwendungsgebiete • • • • • Differenzieren von Bevölkerungsgruppen Auswertung von Satellitenbildern Klassifikation von Dokumenten Marktforschung (z.B. Makler bei Analyse von Haustypen) … Project EGIFF Joint Project: “Development of suitable Information Systems for Early Warning Systems” Funded by the German Ministry of Education and Research (BMBF) within the GEOTECHNOLOGIEN initiative Landslide Early Warning System Development of components of an information system for the early recognition of landslides http://carletong.files.wordpre ss.com/2009/04/landslid e1.jpg Novel combination of GIS, Finite Element Simulations, Geodatabases, Spatial Data Mining, linguistic Methods Objectives of Subproject 1 • Early recognition of geological hazards • Extension of warning time • Approaches • Conception, • Prototypically implementation and • Evaluation of an interlinked GIS and numerical simulation system (SIMS) for analysis of mass movements • Benefits of a linked GIS and SIMS • Application of numerical simulations to precalculate outcomes of various scenarios on physically well-founded models • Application of GIS for integration of user-guidance components and for the simplification of SIMS applications Testgebiet „Isarhänge Grünwald“ Neugrünwald Pullach Untersuchungsgebiet Datenquelle: LVG Bayern (Quelle: Google Earth) Interconnection of GIS and Simulation System Simulationsergebnisse FE-Netz Verschiebungsvektoren Aufbereitung der Simulationsergebnisse im GIS Bestimmung von Verformungsbereichen: Methoden der Clusteranalyse Bestimmung des Rutschkörpers Simulationsergebnisse für den Rutschkörper Methoden der Clusteranalyse Analyse und Präzisierung der Fragestellung - Lage - Richtung - Länge Auswahl der Parameter Wahl eines Proximitätsmaßes - Ähnlichkeitsmaße - Distanzmaße Bestimmung des Algorithmus Bestimmung der Clusteranzahl Technische Durchführung Analyse der Ergebnisse Euklidische Distanz Auwahlkriterien • Clusterform • Verarbeitung von hochdimensionalen Daten (räumliche, zeitliche, weitere Parameter) • Nutzerfreundlichkeit (Anzahl der Cluster ist zu Beginn unbekannt ) • Möglichkeit zur Aufdeckung von Ausreißern • (Anforderungen an Speicherplatz und an Rechenzeit ) Clusteralgorithmus Single Linkage Complete Linkage k-means Verarbeitung von + + + Nutzerfreundlichkeit + + - Clusterform + - - Ausreißer + - - Speicherplatzbedarf - - + Rechenzeit - - + hochdimensionalen Daten möglich Methoden der Clusteranalyse Analyse und Präzisierung der Fragestellung Auswahl der Parameter Wahl eines Proximitätsmaßes Bestimmung des Algorithmus Bestimmung der Clusteranzahl - Subjektive Methoden - Objektive Methoden Technische Durchführung Stopping Rule von Mojena Analyse der Ergebnisse Methoden der Clusteranalyse • Multivariate Clusteranalyse Einfluss der Lage zu groß! d = ( a − b )² + (a − b )² + ... + (a − b )² = 1 1 2 2 n n ( X − X )² + (Y − Y )² + ( L − L )² + ( R − R )² 1 2 1 2 1 2 1 2 Methoden der Clusteranalyse Lösungsmöglichkeit verworfen • Zweifache bivariate Clusteranalyse d = (a − b )² + (a − b )² + ... + (a − b )² = 1 1 2 n 2 n ( L − L )² + ( R − R )² 1 2 1 2 Bivariate Clusteranalyse nach Länge und Richtung d = (a − b )² + (a − b )² + ... + (a − b )² = 1 1 2 2 ( X − X )² + (Y − Y )² 1 Bivariate Clusteranalyse nach der Lage 2 1 2 n n Methoden der Clusteranalyse • Bivariate Clusteranalyse mit Nachbarschaftsbetrachtung d = (a − b )² + (a − b )² + ... + (a − b )² = 1 1 2 2 ( L − L )² + ( R − R )² 1 Bivariate Clusteranalyse nach Länge und Richtung Nachbarschaftsbetrachtung 2 1 2 n n Preparation for Decision Support PostgreSQL Übungstermine Insgesamt stehen vier Übungstermine fest. Zu jedem Termin ist eine Hausaufgabe anzufertigen • • • • 24.11 01.12 08.12 15.12 Abgabe der Aufgaben erfolgt per E-Mail an: [email protected] PostgreSQL • Objektrelationale Datenbank (ORDBMS) • OpenSource • Zugriff über Client-Server Modell • Client und Server laufen selten auf derselben Maschine Zugriff über TCP/IP • bekanntester Client: pgadmin Leistungsdaten PostgreSQL • Größe von Datenbank: unbegrenzt • Größe von Tabelle: max. 32 TerraByte • Anzahl an Datensätzen in Tabelle: unbegrenzt • Maximale Größe eines Datensatzes: 1,6 TB • Anzahl Spalten in Tabelle: begrenzt, abhängig von verwendeten Datentypen • Anzahl Indizes pro Tabelle: unbegrenzt • Vergleich Microsoft Access • Größe von Datenbank: max. 2 GB • Größe von Tabelle: max. 1 GB Erweiterung PostGIS • Es heißt 80 Prozent aller Daten besitzen einen Raumbezug • Speicherung raumbezogener Daten in PostgreSQL PostGIS • Erweiterung um geographische Objekte und Funktionen • Implementierung der Simple-Feature Access Spezifikation von OGC • Betreuung und Pflege durch Open Source Geospatial Foundation Geometrietypen PostGIS • OpenGIS Well-Known Text (WKT) / Well-Known Binary (WKB) • Point, Linestring, Polygon, Multipoint, Multilinestring, Multipolygon und Geometrycollection • Extended WKT / Extended WKB • Erweiterung von WKT bzw. WKB um Höheninformation • SQL/MM (noch nicht vollständig unterstützt) • Circularstring, Compoundcurve, Curvepolygon, Multicurve, Multisurface Geometrietypen Funktionen und Operatoren PostGIS • Räumliche Funktionen: • Berechnung von Flächen und Distanzen • Verschneidung • Berechnung von Pufferzonen etc. • Räumliche Operatoren: • Overlaps, Within, Contains etc. • Funktionen für die Erstellung von Geometrien: • GeometryFromText • shp2pgsql • Funktionen für die Abfrage von Geometrien in den Formaten WKT, WKB, GML, SVG, KML • Räumliche Indizierung mit dem GiST-Index GiST-Index • • • GiST Generalized Search Tree Index basiert auf R-Tree Index CREATE INDEX [indexname] ON [tablename] USING GIST ( [geometrycolumn] ); • GiST Indizes arbeiten mit dem “Lossiness” Prinzip • nur der “wichtige” Teil einer Spalte wird indiziert Geometriespalten: Bounding Box • Frühere PostGIS Versionen verwendeten R-Tree Index • Nachteile R-Tree Index • R-Tree Indizes können keine GIS-Objekte größer 8 KB indizieren • Dank “lossines” Eigenschaft von GIST Indizes ist dies möglich • R-Tree Indizes schlagen fehl, falls zu einem Datensatz keine Geometrie vorhanden ist • GIST-Indizes ignorieren dies Implementierung PostGIS in PostgreSQL • zusätzliche Anlage der Datenbank template_postgis • vorgefertigte Geometriefunktionen • zwei Systemtabellen geometry_columns spatial_ref_sys • geometry_columns • Verwaltung der Tabellen, die mit Hilfe von PostGIS-Funktionen erstellt wurden. • spatial_ref_sys • Auflistung von EPSG-Codes und Bezeichnung • Außerdem Projektionsparameter für Transformation der Geometrien. Aufbau PostgreSQL Datenbankserver Datenbank Schema Funktionen, Tabellen, … Anlegen von Datenbank, Tabellen immer nutzerabhängig Geometrietabelle / Spalte anlegen • • • Tabelle erstellen (ohne Geometriespalte) Geometriespalte hinzufügen AddGeometryColumn Anfügen der Geometriespalte in Tabelle • Tabellenname, Spaltenname, SRID, (-1: kein Referenzsystem, 4326: EPSG Code 4326: WGS 84), Geometrietyp, Dimension • SELECT AddGeometryColumn ( 'strassen', 'geom', -1, 'LINESTRING', 2 ); • Funktion GeometryFromText erzeugt ein Objekt vom Typ Geometry • Geometriedaten werden im WKT-Format übergeben • text, SRID • INSERT INTO strassen VALUES ( 4567, 'Hofweg', GeometryFromText ( 'LINESTRING ( 30 35, 45 57, 60 83 )', -1 ) ); EPSG Code • Daten mit Raumbezug benötigen Referenzsystem EPSG-Codes • eindeutige Angabe des räumlichen Bezugs von Geodaten • 4- bis 5-stellige Schlüsselnummern • In Deutschland • Gauß-Krüger-Zonen 2 bis 5 des Deutschen Hauptdreiecksnetzes • EPSG-Codes 31466 bis 31469. • WGS 84 (EPSG:4326) • World Geodetic System 1984 • am häufigsten verwendete EPSG-Code • weltweites zweidimensionales geodätisches Referenzsystem • Basis für GPS Koordinaten EPSG Auszug aus Tabelle spatial_ref_sys Geo Web Services Geo Web Services • • • • Maps are „cool“ (Schuyler D. Erle-FossGIS 2006) Abstrakte Zusammenhänge lassen sich leicht erkennen GIS 2.0 Crowd source data – Jeder kann mitmachen Gesteigertes Interesse an Geodaten im Internet Geo Web Services Geo Web Services Geoinformatik 2 (Geo) Web Service • Web Service • Web Service nimmt Anfragen über ein Netzwerk entgegen • verschiedene Anwendungen können mit Hilfe von XML-basierten (Extensible Markup Language) Nachrichten miteinander kommunizieren • Austausch über standardisierte Protokolle, wie zum Beispiel HTTP. • Geo Web Service • • • • besondere Ausprägung der Web Services speziell auf Geodaten ausgerichtet sind Zugriff auf geografische Informationen komplexe Berechnungen auf Grundlage der Geometrie von geografischen Objekten und ihren räumlichen und zeitlichen Ausbreitungen durchzuführen. Web Services • Grundlage Client Server Modell Vorteile (Geo) Web Services • • • • • • Reduzierung der Kosten durch günstige Entwicklung Einfachere Instandhaltung Flexibel und Anpassungsfähig Verschiedene Übertragungsprotokolle möglich (HTTP, FTP…) Unabhängig von einer Programmiersprache Standards gewährleisten Interoperabilität Web Map Service • Visualisierung von Vektordaten und Rasterdaten • kein Zugriff auf die zugrundeliegenden Daten ermöglicht • visuelle Repräsentation der angeforderten Informationen in Form einer digitalen Karte bereitgestellt • 3 definierte Operationen • GetCapabilities • GetFeatureInfo • GetMap Web Map Service (WMS 1.3) • Basic WMS Unterstützung GetCapabilities & GetMap • Queryable WMS • Unterstützung für GetFeatureInfo Alle output Formate mit MIME Type erlaubt • Besonderheiten: DGIWG 1.3 Profil Weniger als 20 Layer MaxWidth & MaxHeight > 800px Bestimmte Style Vorgaben für Höhendaten und bathymetrische Daten Unterstützung EPSG:4326 & 3395 (world mercator) PNG & JPEG & GIF output • GetCapabilities • http://137.193.149.11:8082/geoserver/wms?request=GetCapabilitie s&service=WMS • DescribeFeatureInfo http://137.193.149.11:8082/geoserver/wms?bbox=-130,24,66,50&styles=population&format=jpeg&info_format=text/plain& request=GetFeatureInfo&layers=topp:states&query_layers=top p:states&width=550&height=250&x=170&y=160 • GetMap http://137.193.149.11:8082 /geoserver/wms?service= WMS&version=1.1.0&requ est=GetMap&layers=UniB w:BadenWuertemberg_points&style s=&bbox=7.512,47.527,10. 482,49.8&width=512&heig ht=391&srs=EPSG:4326&f ormat=image/png Web Feature Service (WFS 2.0) • Acht Operationen möglich • GetCapabilities/ DescribeFeatureType /GetFeature • GetPropertyValue Ermöglicht die Abfrage von Werten eines Feature Attributes über ein Abfrage Statement • LockFeature • GetFeatureWithLock • Stored Query Management Vordefinierte Feature Operationen Z.B. ExtractPointSeries Ähnlich einem View einer Datenbank CreateStoredQuery DropStoredQuery ListStoredQueries DescribeStoredQueries • Transaction (insert, update, delete) • GetCapabilities • http://137.193.149.11:80 80/geoserver/wfs?reque st=GetCapabilities&serv ice=WFS • DescribeFeatureType • http://137.193.149.11:8082/geoserver/wms? Service=WFS&request=DescribeFeatureType&UniBw:BadenWuertemberg_points • GetFeature • http://137.193.149.11:8082/geoserver/wfs?service=WFS&Req uest=GetFeature&typeName=UniBw:BadenWuertemberg_natural Web Coverage Service (WCS 2.0) • WCS Core GetCapabilities DescriveCoverage GetCoverage • WCS Extensions WCPS (1.0) ProcessCoverages processing of multi-dimensional grid coverage WCS-T (1.1.4) add, modify, and/or delete coverages Transaction Operation - zwei Modi: Synchronous Mode: direkte Bearbeitung der Anfragen vom Client mit direkter Antwort Asynchronous Mode: Senden einer Bestätigung, Bearbeitung der Anfrage wenn der Server Zeit hat. Keine Timeout Web Coverage Service (WCS 2.0) • WCS: erlaubt den Zugriff auf große, multidimensionale Rasterarchive • GetCapabilities • DescribeCoverage • GetCoverage Coverages • Spezieller Typ zur Repräsentation raumbezogener Informationen • Abbildung von variierenden Attributwerten in Abhängigkeit der Position • Besteht aus einer Geometrie und einer Menge von Attributwerten Web Processing Service (WPS 1.0) • Bereitgestellte rechen und modellierungs Algorithmen • Daten auf Server oder Upload der Daten möglich, • Drei Operationen • GetCapabilities • Describe Process • Execute Process • Generisches Modell keine vordefinierten Prozesse, keine Implementierungsvorgaben der Prozesse • Ableitung Profile nötig Interoperabilität Geoserver • • • • Freie GIS Server Software Unterstützt WMS, WFS, WCS, (WPS über Plug-In) Programmiersprache: JAVA Nutzerfreundlich durch graphische Benutzeroberfläche • Benutzeroberfläche: Wicket (Projekt der Apache Software Foundation) • • • • Über Plug-Ins erweiterbar Software zum Caching der Inhalte integriert (GeoWebCache) Integrierter SLD Editor mit Validator Verschiedene Security Optionen • User • Data • Service Medium Term Project (2.1.x) • • • • • 3-D, 4-D, n-D Coverage Support (Core) WMS 1.3 (Standards Implementation) WFS 2.0 (Standards Implementation) WPS 1.0 CS-W 2.0 integration (Standards Implementation) OpenLayers OpenLayers • JavaScript Bibliothek • Entwicklung von Web Mapping Anwendungen • Flexibles Kartenwerkzeug • Open-Source Projekt (http://www.openlayers.org/) • Ansprechen eines GIS-Servers (z. B. Geoserver) über OpenLayers • Abrufen der Daten über WebServices (z. B. WMS, WFS) • Freie Software unter BSD (Berkeley Software Distribution) Lizenz • Freie Verwendung • Kopieren, verändern und verbreiten erlaubt • Nur Copyright muss angegeben werden Warum OpenLayers? • Integration zahlreicher Geodatenformate • Einfache Erstellung von Anwendungen nur wenig Code muss geändert werden • Geoserver verwendet OL zur Kartenvorschau • OSM verwendet OL zur Kartendarstellung Fortbildung – OpenLayers und Integration in Dienste Fortbildung – OpenLayers und Integration in Dienste Beispiel – Erzeugen einer Karte Fortbildung – OpenLayers und Integration in Dienste Vielen Dank für die Aufmerksamkeit