Datenbanken - computermusik.org
Werbung

Datenbanken
Daten sind nach DIN 4450 heißen Informationen die zum Zweck der Verarbeitung
gesammeln und gespeichert werden. Sie sind Zweckbezogenes wissen. Es sind Informationen
wo ein Kontext und ein Zweckbezug vorhanden ist. Informationen entstehen erst wenn diese
Zahlen zu einem Kontext gestellt wird
Information + Kontext = Daten
Wissen kann man als ein System von vernetzten Information ansehen. Den Vorgang bei dem
neue Information die diesem System mit bereits vorhandenen hinzugefügt wird, nennt man
Wissenserwerb.
Geschichtliche Entwicklung von Datenbanksystem
-
jedes Anwendungsprogramm verwaltete seine eigenen Daten inklusive der
Datendefinition und Befehle zum schreiben und lesen von Daten
Probleme beim Datenaustausch
Required parameters are missing or incorrect.
-
Redundanzen sind mehrfache Speicherung von gleichen Daten in verschieden
Dateien, da verschiedene Programme häufig gleiche Daten verarbeiten
Inkonsistenzen d.h. Widersprüche zwischen den in denen Dateien abgelegten
Daten
Logische und physische Datenabhängigkeit, die Änderung dieser Struktur hat eine
Änderung in allen Daten zufolge
Inflexibel
Grundidee
-
Zentrale und Anwendungsneutrale Verwaltung der Daten
Trennung von Benutzern und Anwendungssystemen sowie der Datenhaltung
Required parameters are missing or incorrect.
Hierarchisches Datenbankmodell
aus Wikipedia, der freien Enzyklopädie
Wechseln zu: Navigation, Suche
Hierarchisches Datenbankmodell
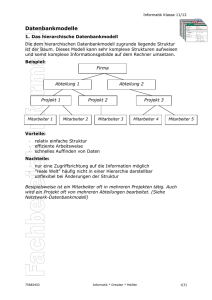
Ein Hierarchisches Datenbankmodell ist das älteste Datenbankmodell, es bildet die
reale Welt durch eine hierarchische Baumstruktur ab. Jeder Satz (Record) hat also
genau einen Vorgänger, mit Ausnahme genau eines Satzes, nämlich der Wurzel der
so entstehenden Baumstruktur.
Die Daten werden in einer Reihe von Datensätzen gespeichert, mit denen
verschiedene Felder verknüpft sind. Die Instanzen eines bestimmten Datensatzes
werden als Datensatzabbild zusammengefasst. Diese Datensatzabbilder sind
vergleichbar mit den Tabellen einer relationalen Datenbank.
Verknüpfungen zwischen den Datensatzabbildern werden in hierarchischen
Datenbanken als Eltern-Kind-Beziehungen (Parent-Child Relationships, PCR)
realisiert, die in einer Baumstruktur abgebildet werden. Der Nachteil von
hierarchischen Datenbanken ist, dass sie nur mit einem solchen Baum umgehen
können. Verknüpfungen zwischen verschiedenen Bäumen oder über mehrere
Ebenen innerhalb eines Baumes sind nicht möglich.
Mit den beiden Strukturelementen (Record-Typen und PCR-Typen) lassen sich
folgende minimale Bedingungen an ein hierarchisches Datenbankmodell stellen:
Ein Record-Typ muss das Wurzelelement darstellen, und tritt somit nicht als "Child"
in einer PCR-Beziehung auf.
Jeder andere Record-Typ tritt genau einmal als "Child" auf
Ein Record-Typ, der nicht als "Parent" in einem PCR-Typen auftritt, wird "Blatt"
genannt
Durch diese Baumstruktur lassen sich nur 1:1 und 1:n-Beziehungen darstellen (vgl.
Grafik). Die vielfach notwendigen n:m-Beziehungen können einerseits über
Redundanzen erreicht werden, besser aber über virtuelle Parent-Child-Relationships
(VPCR).
Das hierarchische Modell ist im Bereich der Datenbanksysteme heute weitgehend
von anderen Datenbankmodellen abgelöst worden.
Die Dateisysteme vieler Betriebssysteme sind näherungsweise hierarchische
Datenbanken: Dateien entsprechen Blättern, Verzeichnisse/Ordner entsprechen den
Knoten mit Kindern. Die Ähnlichkeit ist unvollständig, weil Verzeichnisse ohne
Dateien darin trotzdem keine Blätter (einfache Dateien) sind (real enthalten sie z.B.
Verweise auf sich selbst und den übergeordneten Knoten, nämlich mit "." und ".."),
und weil die Verwendung von Softlinks oder Hardlinks die Baumstruktur nicht erhält.
Eine Renaissance erlebt die hierarchische Datenspeicherung mit XML. Auch diverse
ältere Anwendungen bei Banken und Versicherungen benutzen noch heute
hierarchische Datenbanken. Das bekannteste hierarchisch organisierte
Datenbanksystem ist IMS/DB der Firma IBM.
Netzwerkdatenbankmodell
aus Wikipedia, der freien Enzyklopädie
Wechseln zu: Navigation, Suche
Das Netzwerkdatenbankmodell wurde von der Data Base Task Group (DBTG) des
Programming Language Committee (später COBOL Committee) der Conference on
Data Systems Language (CODASYL) vorgeschlagen, der Organisation die auch für
die Definition der Programmiersprache COBOL verantwortlich war. Es ist auch unter
den Namen "CODASYL Datenbankmodell" oder "DBTG Datenbankmodell" bekannt
und entsprechend stark von Cobol beeinflusst. Der fertige DBTG-Bericht wurde 1971,
etwa zur gleichen Zeit wie die ersten Veröffentlichungen über das relationale
Datenbankmodell, vorgestellt. Er enthielt Vorschläge für drei verschiedene
Datenbanksprachen: Eine Schema Data Description Language oder SchemaDatenbeschreibungssprache, eine Subschema Data Description Language oder
Subschema-Datenbeschreibungssprache und eine Data Manipulation Language
oder Datenmanipulationssprache.
Das Netzwerk-Modell fordert keine strenge Hierarchie sondern kann auch m:nBeziehungen abbilden, d. h. ein Datensatz kann mehrere Vorgänger haben. Auch
können mehrere Datensätze an oberster Stelle stehen. Es existieren meist
unterschiedliche Suchwege, um zu einem bestimmten Datensatz zu kommen. Man
kann es als eine Verallgemeinerung des hierarchischen Datenbankmodells sehen.
Das logische Datenmodell [Bearbeiten]
Netzwerkdatenbankmodell
Datenbanksätze [Bearbeiten]
Eine Netzwerkdatenbank besteht aus Datensätzen (Record), welche aus
verschiedenen Feldern (Data Item) bestehen. Ein Feld hat einen Namen und einen
Wert. Jeder Satz beschreibt eine Person, ein Objekt oder ein Ereignis (event).
Ein Netzwerk-Datenbankmanagementsystem (DBMS) bearbeitet Datensätze. Ein
Satz, oder genauer die Ausprägung eines Satzes (record occurrence) kann als
Ganzes in die Datenbank gespeichert (STORE), verändert (MODIFY) und wieder
gelöscht (DELETE) werden.
Ein CODASYL-Datensatz hat in der Regel eine innere Struktur. Felder können zu
Gruppenfeldern zusammengefasst werden und Gruppenfelder können nicht nur aus
Einzelfeldern sondern wiederum aus Gruppenfeldern bestehen.
Ein CODASYL-Satz kann sogenannte "Tabellen" enthalten, das sind mehrere Werte,
die unter einem Namen verwaltet werden. Die Einzelwerte oder Elemente der Tabelle
werden durch Subscripte adressiert, z. B. Kunde.Mayer.Monatsumsatz[0]. Es sind
auch doppelte Feldnamen erlaubt, sofern sie in unterschiedlichen Sätzen sind. Sie
müssen dann qualifiziert angesprochen werden, z. B. Kunde.Name und
Lieferant.Name.
Sätze einer Satzart (record type), die einen eindeutigen Namen haben muss, haben
die gleiche interne Struktur. Eine Satzart ist also eine allgemeine Beschreibung vieler
Datensätze, sprich Ausprägungen einer Satzart (record occurrence). Im
Datenbankschema werden alle Satzarten definiert.
Datenbankschlüssel [Bearbeiten]
Sätze innerhalb einer Datenbank können in allen Feldern gleiche Werte haben. Der
Datenbankschlüssel (Data Base Key (DBK)) dagegen ist ein interner, innerhalb einer
Datenbank eindeutiger Schlüssel, der beim erstmaligen Speichern des Satzes
vergeben wird.
Dataset [Bearbeiten]
Beziehungen zwischen Sätzen werden durch eine spezielle, Datenset (oder einfach
Set) genannte, Konstruktion bestimmt. Im einfachsten Fall besteht jedes Set aus
zwei verschiedenen Satzarten. Ein Daten-Set besteht aus genau einem Mitglied der
ersten Satzart, dem Owner des Daten-Set. Jedes Set kann keinen (leeres SetAuftreten), einen, oder mehrere Sätze der zweiten Satzart haben, die Member des
Daten-Set. Diese haben eine definierte Sortierfolge. Die eindeutig benannte Set-Art
(set type) beschreibt alle Mitglieder der gleichen Beziehung.
Die beiden Strukturtypen, die also das Netzwerkdatenbankmodell beschreiben, sind:
die Satzart (record type); mehrere Sätze einer Satzart nennt man record occurrence
Set-Art (set type); mehrere Ausprägungen einer Set-Art nennt man set occurrence
Alle Satzarten und alle Set-Arten müssen im Datenbankschema beschrieben sein.
Das Schema einer Datenbank wird grafisch als Bachmann-Diagramm
(Datenstrukturdiagramm) dargestellt, in dem jede Satzart als Rechteck (mit Satzart
und Attributnamen) und jede Set-Art als Pfeil vom Owner zum Member dargestellt ist.
Datenmanipulation [Bearbeiten]
Eine Datenmanipulationssprache besteht aus Updatefunktionen- und aus
Abfragefunktionen. Zu den Update-Funktionen gehört das Speichern neuer Sätze der
Satzart, das Ändern existierender Sätze, das Löschen existierender Sätze, das
Einfügen existierender Sätze einer Satzart als Member eines Data Set und das
Entfernen einer Satzart aus einem Data Set.
Ein Anwendungsprogramm benötigt gewöhnlich nur Teile einer Datenbank oder
eines Datenbankschemas. Deshalb definiert man Subschemas für Programme oder
Programmgruppen, die diese Teile der Datenbank manipulieren möchten.
Datensätze hinzufügen und verändern [Bearbeiten]
Hierfür gibt es verschiedene Befehle: Speichern (STORE) eines neuen Datensatzes,
Einfügen (INSERT) eines Datensatzes in einen Set, Entfernen (REMOVE) eines
Datensatzes aus einem Set, Löschen (DELETE) des derzeitigen Satzes (current
record) und Verändern (MODIFY) des derzeitigen Satzes. Alle Befehle haben viele
verschiedene Optionen, deren Einsatz stark von der jeweiligen Datenbankstruktur
(Schema) abhängt und im Einzelfall sehr komplex werden kann.
Um dem Anwendungsprogrammierer in der Praxis das Leben zu erleichtern haben
sich deshalb zwischen (z. B. COBOL-) Programm und Datenbank geschaltete I/OModule bewährt.
Das Netzwerkdatenbankmodell heute [Bearbeiten]
Nach der Vorstellung beider Datenbankmodelle (Relational vs. Netzwerk) anfang der
1970er Jahre gab es schon zwanzig Jahre lang hocheffiziente
Netzwerkdatenbanksysteme auf mittleren und großen Mainframes für höchste
Transaktionsraten, bis relationale Datenbanksysteme bezüglich der Performance
einigermaßen gleichziehen konnten. Nicht ohne Grund ist das hierarchische
Datenbanksystem von IBM von Ende der 1960er noch heute bei vielen IBM-Kunden
im Einsatz. Auch Abfragesprachen für Ad-hoc-Anfragen standen auf
Netzwerksystemen zur Verfügung, beispielsweise QLP/1100 von Sperry Rand. Heute
wird das Netzwerkdatenbankmodell hauptsächlich auf Großrechnern eingesetzt.
Bekannte Vertreter des Netzwerkdatenbankmodells sind UDS (Universal Datenbank
System) von Siemens, DMS (Database Management System) von Sperry Univac.
Mischformen zwischen Relationalen Datenbanken und Netzwerkdatenbanken
wurden entwickelt - z. B. von Sperry Univac (RDBMS Relational Database
Management System) und Siemens (UDS/SQL), mit der Absicht, die Vorteile beider
Modelle zu verbinden.
Seit den 1990er Jahren wird das Netzwerkdatenbankmodell vom relationalen
Datenbankmodell mehr und mehr verdrängt. Mit der Idee des semantischen Webs
gewinnt das Netzwerkdatenbankmodell wieder mehr an Bedeutung.
Relationales Datenbankmodell
Powerpointpräsentation dazu 3_Relat_DB.ppt
Datenbanken oder Data Dictionary
-
systematisch, strukturierte langfristige verfügbare Sammlung von Daten
einschließlich der zur sicheren Manipulation dieser Daten erforderlichen Software
DBMS
-
Verwaltungssoftware
DBS = DB + DBMS
Ziel der Trennung:
-
physische Datenunabhängigkeit (das Anwendungsprogramm benötigt keine
Kenntnisse über die physische Datenstruktur auf der festplatte)
alle Abfragen und Manipulationsanforderungen werden auf logischer Ebene
formuliert
Änderung an der physischen Struktur der Daten ziehen keine Änderungen an der
Anwendung nach sich
Logische Datenunabhängigkeit (die Entkopplung der externen Sicht, vom
konzeptionellen Schema bewirkt, das eine Erweiterung des konzeptionellen
Schema keine Anpassung der bestehenden Anwendungsprogramm fordert)
Anforderungen an ein Datenbanksystem
-
Redundanzfreiheit (kein Datenelement soll mehrfach gespeichert werden)
Vielfache Verwendbarkeit (anwendungsunabhängig)
Speicherunabhängigkeit (Speicherstruktur wird vom Datenbanksystem festgelegt
nicht von der Anwendung
Benutzerfreundlichkeit (Umgang mit Datenbank soll leicht erlernbar sein)
Flexibilität (es muss möglich sein die Struktur der Datenbank zu ändern wenn
erforderlich, um Änderungsaufwand an einer Anwendung zu minimieren)
Modularität (Funktionen des Datenbanksystems soll einzelnen Modulen
zugeordnet sein, so weit wie möglich)
Leistungsfähigkeit (wenig Speicher - Systemoverhead – benötigen, schnelle
Reaktionszeit bei anfragen)
Plattformunabhängigkeit
Geringe Betriebskosten
Grundsätze nach dem Manifesto von Kyoto (1987)
D1 = Dauerhaftigkeit (Daten müssen über längeren Zeitraum bestehen bleiben)
D2 = Große Datenbestände (effektiver zugriff auf Datenbestände über spezielle
Speicher und Zugriffalgorithmen)
D3 = Mehrbenutzerbetrieb (zugriff von mehreren Benutzern gleichzeitig,
Vermeidung von Inkonsistenz)
D4 = Widerherstellbarkeit (nach auftritt von Fehlern, müssen diese Automatisch
behoben werden)
D5 = Adhoc Abfragemöglichkeit (es muss eine Abfragesprache enthalten sein)
D1 bis D5 stellen die Anforderungen an ein Datenbanksystem.
Relationenmodell
Tabellen, bestehen aus Merkmalen
und Attribute(Anzahl beliebig)
R2 Primärschlüssel (einzelne
Merkmale und minimalste
Merkmalkombinationen
identifizieren einen Datensatz
innerhalb eine Tabelle eindeutig)
R3 Mengenorientierte Operationen
(Vereinigung, durchschnitt,
Differenz, usw. zu eine neuen
Tabelle kombiniert werden)
R4 Relationsorientierte Operationen
(einzelne Tabellen lassen sich
durch Fülloperation verändern,
Selektion, Projektion, Join)
R5 View-Konzept – gespeicherte
Abfrage (verlangt, das über
einzelne Tabellen beliebige sichten
gelegt werden können,
Ausblenden von spalten)
Relationales Datenbankmodell(RDBM)
= D1 bis D5 und R1 bis R5
R1
O1
Objektmodell
Komplexe Objekte
O2
Objektidentität
O3
Datenkapselung
O4
Typen und Klassen
O5
Vererbung
O6
O7
O8
Polymorphismus
Vollständigkeit
Erweiterbarkeit
Datenanalyse und Datenmodellierung mit Hilfe des ERM
Einheitlich standardisierte Modellierungshilfe für den Datenbankentwurf. Bei der
Datenmodellierung mit Hilfe des ERM entstehen grafische Darstellungen als ERMDiagramme.
Entitäten:
individuelles identifizierbares Exemplar, z.B. Personen, Gegenstände,
Ereignisse, diese werden beschrieben durch Eigenschaften
Entitätsmenge (Entity Set)
oder Entity-Typ
Zusammenfassung von Entitäten mit gleichartigen
Eigenschaften
Attribute
die Eigenschaften eines Entität-Types oder die Beziehung zwischen
zwei Entitäts-Typen werden durch Attribute beschrieben, alle Entitäten
eines Entitäts-Types werden durch die gleichen Attribute beschrieben
Übung:
Vorname und Nachname, Geburtsdatum, Beruf
Jedem Beruf ist eine Qualifikation zugeordnet
Vorgaben:
Facharbeiter(Geselle) (FA)
Meister (Mei)
Techniker (Tech)
Dipl. Ing. (BA)
Dipl. Ing FH (FH)
Dipl. Ing HS (HS)
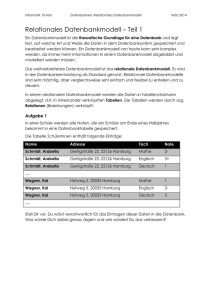
Tabelle 1 Personal
Pers-Nr Vorname
1
Heinz
2
Inge
3
Tom
4
Gina
Nachname
Müller
Beier
Balzer
Wild
Tabelle 2 Berufe
BKz
1
2
3
Bezeichnung
Maurer
Informatiker
Lehrer
Tabelle 3 Qualifikation
IDQual
Bezeichnung
1
Facharbeiter
2
Meister
3
Z_Berufe_Qualifikation
idZ_BQ
BKz
1
1
2
1
Z_Personal_ZBQ
Pers.-Nr
1
1
Geb.-Datum
05.06.1952
20.09.1958
27.03.1970
06.12.1970
Kürzel
FA
Mei
IDQual
1
2
idZBQ
1
2
Tabelle 1 Personal
Tabelle 2 Beruf
Personalnummer
Berufskenzeichen
Vorname
Nachname
Geburtsdatum
Unterteilung der Datenbanken in Analytische und operationale:
-
analytische DB sind statistische DB die nur gelesen werden können, sie dienen zur
Trendberechnung oder Ermittlung von Verkaufszahlen
analytische DB existieren als Data-Warehaus oder Data-Mining
auf analytische DB greifen wenige Benutzer zu, durch die Redundanzen existiert
eine hohe Performance
operationale DB (sind realtime DB) hier können Daten archiviert werden,
hinzugefügt und gelöscht
-
viele Nutzer, keine Redundanzen, geringere Performance zu analytischen DB
Datenbankentwurf
-
Modellierung eines Ausschnittes aus der modernen Welt, durch strukturelle
Abstraktion um eine Speicherung und Verarbeitung durch den Computer zu
ermöglichen und Fragen über die reale Welt mit Hilfe des Modells zu beantworten
Lebenszyklus einer Datenbank
1. Problemabgrenzung und Anforderungsanalyse
o Begin mit der Analyse der Spezifikation
o Welche Daten müssen erfasst werden?
o Welche Beziehungen
o Welche Transaktionen stehen zwischen den Daten
o Randbedingungen (Datenvolumen, Sicherheit, Plattform, Zeichensatz)
2. Entwurf des konzeptionellen Schemas
o Mittels ERM oder UML – formale Beschreibung der Datenobjekte und ihren
Beziehungen (Systemunabhängig)
o Integration verschiedener Sichten für die Nutzer
3. Entwurf des logischen Schemas und externen Schemata
o Transaktion des ERM in ein RDM (Systemabhängig)
o Festlegung des Primär. Sekundär und Fremdschlüssel
o Transaktionen definieren
o Spezifikation von Triggern
o Berechtigungssystem (Wer darf was?)
4. Entwurf des internen Schemas
o Einrichtung der DB
SQL – Structured Query Language → strukturierte Abfragesprache
Sprachumfang von SQL92 wurde in drei Level unterteilt
Entry-Lvl
Intermediate Lvl
- Wird von den meisten DB’s voll unterstützt
- er umfasst grundlegende befehle zum anlegen von DB und
Tabellen
- und zu deren bearbeitung und verwaltung
- Create, Select, Show
- zusätzliche funktionalitäten (Datums- Zeit und Datentypen,
Full-Lvl
Mengenoperationen, dynamische SQL
- enthält Funktionen welche nur unvollständige in die DB
implementiert sind (z.B.: Constraints über mehrere
Tabellen, Select-Befehle in der FROM-Klausel so
genannte Subselects)
4 Befehlgruppen
DDL (Data Definition Language)
DQL (Data Query Language)
DML (Data Maninpulate Language)
DCL (Data Control Language)
Befehle zum erstellen von
Datenbankentabellen und Relationen
Abfrage von Daten
Anlegen, ändern und löschen von Daten
Anlegen von Benutzern und die Vergabe von
Zugriffsrechten
Einführung SQL
-
Möglichkeiten zur Adhoc-abfrage
Lesende und schreibende Zugriffe
Anweisungen zur Erstellung eine DB
-
-
CREATE DATABASE [DB-Name]
(erstellen DB)
USE [DB-Name]
(Benutzen der DB)
SHOW DATABASES
(anzeigen von DB)
SHOW TABLES
(anzeigen von Tabellen)
DROP DATABASE [DB-Name]
(löschen einer DB)
DROP TABLE [Tabellenname]
(löschen von Tabellen)
CREATE TABLE [Tabellen-Name]
(erstellen von Spalten)
(
Datenfeld1, Datentyp {Default Standartwert | NULL | NOT NULL},
{Auto_Increment}, PRIMARY KEY(Datenfeld)
)
ef
01.10.09
Bsp.
Create table plz ort varchar (100)
ID INTEGER NOT NULL
ANZAHL INTEGER DEFAULT 1
CREATE TABLE ort varchar (100) DEFAULT Berlin
Bit = 2 bit 8 ^ 2
Bit = 32 bit 32 ^ 2
Datentyp
SMALLINT (GANZE
ZAHL)
Speicherbedarf
2 Byte
Wertebreich
- 32768 – 32767
INTEGER (GANZE ZAHL)
4 Byte
FLOAT (FLIESSKOMMA)
DOUBLE
(FLIESSKOMMA)
DECIAMAL
(FESTKOMMA)
4 Byte
8 Byte
DATE (Datum)
DATETIME (Datum + Zeit)
CHAR (Laenge) 1.255
ASCI Sortierung! – Aa - Bb
VARCHAR (Laenge) 1.255 (
mehr Perfomance noetig!
Variable, keine Leerzeichen,
mehr Speicherplatz!)
BLOB – Binary Large
Objects (Bilder, Videos)
TEXT (Gross und
Kleinschreibung egal .
Sourtierreihenfolge nach
Alphabet)
- 2.147.483648 2.147.483647
7 Signifikante Stellen
15 Signifikante Stellen
Praezision 1-15 (max 15
Stellen, Vorkommastellen)
Skalierung 1-15
(Nachkommastellen)
4 Byte
8 Byte
Bsp
Integer eignen sich gut fuer Identifikationsschluessel (Primaerschluessel fuer Tabelle)
Aggregatsfunktion
Funktion
COUNT ()
AVG ()
MIN ()
MAX ()
SUM ()
Erklaerung
Anzahl der Datensaetze (Zaehlt!)
Durchschnitt (Durchschnitts alter bsp.
Noten) – Nur Ausgabe!
Kleinste Wert
Groesste Wert
Summe von Werten
Spalten die nicht ueber Aggegatsfunktion zusammengefasst werden muessen kopiert
werden
0 Werte werden nicht bei Aggregratsfunktion mit einbezogen
xampp/mysql/bin
einloggen aus sql-shell
mysql –u root <dateiname>
use
describe
logfile anlegen; tee <pfad/xxx.log>
werte zaehlen
select count(*) as Anzahl titel from titel;
DESC - absteigend
ASC – aufsteigend
Limit 3 (die ersten drei)
Limit 3,5 (nach den ersten drei)
Unter mac osx:
./ mysql –u root