Datenmanager - GDV
Werbung

Gesamtverband der Deutschen
Versicherungswirtschaft e.V.
Prozesse
Objekte
Funktionen
Daten
Komponenten
Request Broker
VA A
Edition
1999
Die Anwendungsarchitektur der Versicherungswirtschaft
DATENMANAGER
VERSION 2.1
PROZEDURAL
© GDV 1999
http://www.gdv.de/vaa
Autoren:
Das Projektteam "Datenmanager"
Administration, Koordination: Gesamtverband der Deutschen Versicherungswirtschaft e.V., Berlin
http://www.gdv.de/vaa
© GDV 1999
Datenmanager
Willkommen bei VAA Edition 1999!
Liebe Leserin, lieber Leser,
haben Sie bereits eine der Broschüren der VAA Edition 1999 gelesen? Wenn ja, können Sie gleich
weiter blättern, denn dieses Kapitel steht gleichlautend am Anfang jedes Dokuments dieser VAAEdition.
Ansonsten freuen wir uns über Ihr Interesse an der VAA und gratulieren Ihnen zu Ihrer Entscheidung,
sich mit diesem Thema zu beschäftigen, an dem wir seit Jahren mit großem Engagement und immer
noch mit viel Spaß arbeiten.
Mit WIR sind alle gemeint, die sich in den letzten Jahren direkt an der Arbeit in den VAA-Gremien
beteiligten. Um wen es sich dabei im einzelnen handelt, können Sie in einem Anhang der Broschüre
ANFORDERUNGEN UND PRINZIPIEN nachlesen, darüber hinaus werden die VAA-Gremien auf der neuen
VAA-CD und im Internet (Adresse http://www.gdv.de/vaa) vorgestellt.
Nun zur Sache:
Die VAA wurde in den vergangenen zwei Jahren in zwei Richtungen weiterentwickelt.
Der erste Schritt in Richtung Objektorientierung ist getan. Sie finden in der VAA Edition 1999 das
OBJEKTORIENTIERTE FACHLICHE
REFERENZMODELL und das OBJEKTORIENTIERTE TECHNISCHE
REFERENZMODELL der VAA. Das Geschäftsobjekt PRODUKT wurde bereits detailliert ausgearbeitet.
Die prozedurale Variante lebt weiter. Sie wurde ergänzt um eine weitere fachliche Komponente,
INKASSO/KONTOKORRENT.
Darüber hinaus wurden die aufgrund der Aufnahme der Objektorientierung notwendig gewordenen
Überarbeitungen und Ergänzungen der Dokumente der 2. Auflage von VAA vorgenommen. Es
entstand eine Vielzahl von zum Teil sehr umfangreichen Dokumenten, die auf drei Wegen
veröffentlicht werden: CD-ROM, Internet und als gebundene Broschüren in Papierform.
Um Ihnen die Orientierung zu erleichtern, haben wir als Übersicht über die verfügbaren
Dokumentationen der VAA Edition 1999 einen grafischen Wegweiser erstellt, den Sie auf der
nächsten Seite finden können. Vielleicht hilft er Ihnen, sich zurechtzufinden und Ihre
Schwerpunktthemen "herauszufischen".
Viel Spaß beim Studium des hier und in den übrigen Dokumenten zusammengestellten VAA-Wissens.
© GDV 1999
http://www.gdv.de/vaa
Datenmanager
Dokumentenstruktur der VAA Edition 1999
Anforderungen und Prinzipien
neu
Glossar
überarbeitet
VAA prozedural (pVAA) Version 2.1
Prozeduraler Rahmen
neu
Fachliche Beschreibung
Inkasso/Kontokorrent
neu
Partner
Partner/Anhang
Provision
überarbeitet
Schaden/Leistung
Vertrag
Technische Beschreibung
Datenmanager
Datenmanager/Anhang
Dialogmanager
Parametersystem
Workflow-/Vorgangsmanager
VAA objektorientiert (oVAA) Version 1.0
Objektorientiertes fachliches Referenzmodell
Hauptdokument
neu
Anhang A – Use-Case-Modell –
neu
Anhang B – Klassenmodell –
neu
Modell in Rational-Rose-Format
neu
Objektorientiertes technisches Referenzmodell
neu
Produkt
neu
http://www.gdv.de/vaa
© GDV 1999
Datenmanager
I.
Inhalt
Der Datenmanager (Überblick) ............................................................................ 5
I.1.
Einleitung und Problemstellung ..................................................................................................... 5
I.2.
Anforderungen .............................................................................................................................. 6
I.3.
Einbindung in die Gesamtarchitektur ............................................................................................ 7
I.4.
Grundstruktur des Datenmanagers ............................................................................................... 7
I.5.
Aufgaben des Datenmanagers ..................................................................................................... 9
I.5.1.
Bereitstellung von Daten ....................................................................................................... 9
I.5.2.
Änderung von Daten ............................................................................................................. 9
I.5.3.
Pufferung logischer Änderungen bis zum Konsistenzpunkt .................................................. 9
I.5.4.
Zwischenspeicherung von temporären Daten ..................................................................... 10
I.5.5.
Unterstützung der Zeitlogik ................................................................................................. 10
I.6.
Zusammenfassung...................................................................................................................... 10
II. Einbindung des Datenmanagers in die Gesamtarchitektur............................. 12
II.1.
Das Zusammenspiel mit anderen VAA-Komponenten ................................................................ 12
II.2.
Schnittstellen ............................................................................................................................... 12
II.2.1.
Die Schnittstelle zur Anwendung......................................................................................... 13
II.2.2.
Die Schnittstelle zum Parametersystem .............................................................................. 13
III.
Spezifikation des Datenmanagers ................................................................. 15
III.1.
Spezifikationsgrundsätze ........................................................................................................ 15
III.2.
Komponentenstruktur (Masterplan) ......................................................................................... 16
III.2.1.
Konfigurationskomponenten im Überblick ........................................................................... 16
III.2.2.
Buildtime-Komponenten im Überblick ................................................................................. 19
III.2.3.
Runtime-Komponenten im Überblick................................................................................... 19
III.2.4.
Beispiel der Datenbeschaffung durch einen Anwendungsbaustein .................................... 20
III.2.5.
Ablaufsteuerung für Veränderungen in der Datenbank ....................................................... 25
III.2.6.
Ablauf für Update des Vorgangsspeichers .......................................................................... 28
III.3.
Konfigurationskomponenten ................................................................................................... 28
III.3.1.
Logisches Datenmodell ....................................................................................................... 29
III.3.1.1.
E/R-Sprache................................................................................................................ 29
III.3.1.2.
Begriffserklärungen: Entity, Relationship, ................................................................... 29
III.3.1.3.
Anforderungen an die E/R-Sprache aus Sicht des Datenmanagers ........................... 31
III.3.1.4.
Festlegung der Minimal-Konstrukte einer E/R-Sprache .............................................. 32
III.3.1.5.
Beispiel eines E/R-Modells.......................................................................................... 35
III.3.2.
Physisches Datenmodell ..................................................................................................... 36
III.3.3.
Abbildung zwischen logischem und physischem Modell ..................................................... 36
III.3.3.1.
Abbildungsregeln ........................................................................................................ 38
III.3.3.2.
Optimierungskonstrukte .............................................................................................. 38
III.3.3.3.
Transformationsdokumentation ................................................................................... 40
III.3.4.
Logische Datensicht ............................................................................................................ 40
III.3.4.1.
Schnittstellenbeschreibung durch Datensichten.......................................................... 40
III.3.4.2.
Definition von Datensicht und Datensichtsprache ....................................................... 41
© GDV 1999
i
Inhalt
Datenmanager
III.3.4.3.
Anforderungen an eine Datensichtsprache ................................................................. 42
III.3.4.4.
Minimal-Konstrukte der Datensichtsprache ................................................................. 42
III.3.5.
Physische Datensicht .......................................................................................................... 65
III.3.6.
Zuordnung der logischen zur physischen Datensicht .......................................................... 65
III.3.7.
Werkzeuge .......................................................................................................................... 65
III.3.7.1.
Allgemeine Anforderungen an Werkzeuge .................................................................. 65
III.3.7.2.
Werkzeuge im VAA-Entwicklungsprozeß .................................................................... 66
III.3.8.
Organisation ........................................................................................................................ 68
III.3.8.1.
Überblick ..................................................................................................................... 68
III.3.8.2.
Prozessmodellierung ................................................................................................... 69
III.3.8.3.
Fachdesign .................................................................................................................. 69
III.3.8.4.
Realisierung ................................................................................................................ 70
III.3.8.5.
Betrieb ......................................................................................................................... 71
III.4.
Buildtime Komponenten .......................................................................................................... 71
III.4.1.
Der LDASI-Generator .......................................................................................................... 71
III.4.2.
Der PDASI-Generator.......................................................................................................... 72
III.4.2.1.
Erstellung eines Ablaufplans ....................................................................................... 73
III.4.2.2.
Auflösung der physischen Datensicht in I/O-Module ................................................... 74
III.4.2.3.
Datenzugriffsoptimierung............................................................................................. 74
III.5.
Runtime Komponenten ............................................................................................................ 75
III.5.1.
III.5.1.1.
Die Schnittstelle zum Anwendungsprogramm ............................................................. 77
III.5.1.2.
Speicherverwaltung (Vorgangs-/Hauptspeicher) ......................................................... 89
III.5.2.
Der Datenhandler ................................................................................................................ 91
III.5.2.1.
Schnittstelle zum Datensichtprozessor ........................................................................ 91
III.5.2.2.
Die Transformation ...................................................................................................... 92
III.5.2.3.
Die Ablaufsteuerung .................................................................................................... 92
III.5.2.4.
I/O-Module ................................................................................................................... 92
III.5.3.
IV.
Der Datensichtprozessor ..................................................................................................... 75
Datenbank-Verfügbarkeit..................................................................................................... 92
Abbildung der Zeitlogik .................................................................................. 94
IV.1.
Einleitung und Problemstellung ............................................................................................... 94
IV.2.
Unterstützung des Historienkonzepts durch den Datenmanager ............................................ 95
IV.2.1.
Die Bildung von Informationsobjekten ................................................................................. 95
IV.2.2.
Versionsbildung ................................................................................................................... 95
IV.2.3.
Definition eines Versionsbaums .......................................................................................... 95
V. Verteilung ............................................................................................................ 98
V.1.
Verteilte Datenbank ..................................................................................................................... 98
V.2.
Verteilung der I/O-Module ........................................................................................................... 98
V.3.
Verteilung der Anwendungs-Module ........................................................................................... 99
V.4.
Offline Verarbeitung .................................................................................................................... 99
VI.
ii
Migrationsverfahren ...................................................................................... 100
© GDV 1999
Datenmanager
VI.1.
Datenmigration ...................................................................................................................... 100
VI.2.
Verfahrensmigration durch Altdatenintegration ..................................................................... 101
VI.3.
Unterlegung von neuen Datenmodellen ................................................................................ 101
VI.4.
Migrationsverfahren bei der Württembergischen Versicherung ............................................ 101
VII.
VI.4.1.
Komplette Umstellung der Anwendung auf eine neue Architektur .................................... 101
VI.4.2.
Stufenweise Umstellung von Anwendungen ..................................................................... 102
VI.4.3.
Verwendung des Datenmanagers in bestehenden Anwendungen.................................... 102
Inhalt
Glossar........................................................................................................... 103
© GDV 1999
iii
Datenmanager
Der Datenmanager (Überblick)
I. Der Datenmanager (Überblick)
Die Datenanforderungen innerhalb der Versicherungsanwendungsarchitektur werden durch einen
Datenmanager abgewickelt. Dieser bildet die Schnittstelle zwischen Anwendungssystemen und den
extern gespeicherten Daten. Er entkoppelt die Anwendungen von den Details der physischen
Datenspeicherung, übernimmt den aufwendigen Teil der Beschaffung von komplexen Datenstrukturen
und erleichtert die Erstellung der in der Versicherungswirtschaft üblichen datenorientierten
Anwendungen signifikant.
Der Datenmanager stellt den Anwendungen eine logische und transparente Datenschnittstelle bereit.
Dazu muß er in der Lage sein, Konvertierungen von verschiedensten Datenspeicherungsformen auf
die von der Anwendungen angeforderten und effizient zu verarbeitenden Strukturen durchzuführen.
Diese Spezifikation beschreibt die grundlegenden Mechanismen und Aufgaben des Datenmanagers
und seine Schnittstellen innerhalb der Versicherungsanwendungsarchitektur (VAA).
I.1. Einleitung und Problemstellung
Anwendungssysteme innerhalb der Versicherungswirtschaft sind datenorientiert. Zu jedem
Geschäftsvorgang werden eine Vielzahl von Daten verarbeitet und gespeichert. Diese Daten sind
komplex strukturiert und werden in der Regel in Datenbanksystemen gespeichert. Das Spektrum der
verwendeten
Datenbanksysteme
reicht
von
Eigenentwicklungen
über
die
klassischen
Datenbanksysteme (wie IMS oder DB2) bis hin zu verteilten Datenbanksystemen.
Die Hauptaufgabe der Anwendungssysteme der Versicherungswirtschaft besteht in der Prüfung von
eingegebenen Daten, ihrer Ablage und in der Bereitstellung der gespeicherten Datenstrukturen in einer
dem Sachbearbeiter eingängigen Form. In den Standardisierungsbestrebungen einer
Versicherungsanwendungsarchitektur ist deshalb die Bereitstellung und Ablage von Daten eine
zentrale Dienstleistung, die effizient und in unterschiedlichsten technischen Gegebenheiten
abgewickelt werden muß. Diese zentrale Dienstleistung wird im sogenannten Datenmanager
umgesetzt, der seine Dienste allen Anwendungskomponenten zu Verfügung stellt. Eine Anwendung
besorgt sich die benötigten Daten nicht mehr selber durch aufwendige Leseoperationen. Sie teilt ihre
Anforderungen dem Datenmanager mit. Der Datenmanager überführt dann die physisch gespeicherten
Daten effizient und einfach nutzbar in die von Anwendungen angeforderte Form. Der
Anwendungsentwickler muß sich nicht mehr mit den internen Details der Datenspeicherung
auseinandersetzen. Diese häufig sehr aufwendige Aufgabe übernimmt der Datenmanager. Dadurch
wird die Wiederverwendbarkeit komplexer Anwendungsteile in wechselnden Umgebungen
sichergestellt und auf hohem Qualitätsniveau festgeschrieben.
Um einen groben Eindruck von der Leistungsfähigkeit eines Datenmanagers zu vermitteln, betrachten
wir den notwendige Datendurchsatz in einer gängigen Umgebung eines größeren
Versicherungsunternehmens:
In heutigen Dialogsystemen können wir von Spitzenbelastungen von ca. 100 Transaktionen per
Sekunde und mehr ausgehen. Bei ca. 15 Datenzugriffen pro Transaktion müssen mindestens 1500
Datensätze in einer Sekunde beschafft werden. Ausgehend von einer CPU-Zeit von 1/1000-Sekunde
© GDV 1999
5
Der Datenmanager (Überblick)
Datenmanager
pro Aktivität werden zur Abwicklung 1,5 Sekunden CPU-Zeit benötigt. Ohne Berücksichtigung der
tatsächlichen Verweilzeiten sind somit mindestens 1,5 Prozessoren eines Großrechners einzusetzen.
Das Inkasso einer Versicherung mit 3.000.000 K-Verträgen muß in einer Nachtschicht abgewickelt
werden können. Damit stehen ca. 8 Stunden reiner Laufzeit für die Durchführung des Inkassos zu
Verfügung. Bei Speicherung unter DB2 und durchschnittlich 5 zusätzlichen Lesezugriffen zur
Ermittlung des Ist-Status eines Vertrages ergeben sich in 8 Stunden 18.000.000 zu verarbeitende Sätze
aus DB2-Tabellen. Dies bedeutet, daß ca. 600-650 Sätze pro Sekunde zu Verfügung gestellt werden
müssen.
Diese Beispiele zeigen die hohe Lastanforderungen, die ein Datenmanager in einer gängigen
Umgebung erfüllen muß. Zusätzlich sind notwendige Eigenschaften wie Stabilität, Verfügbarkeit,
Datensicherheit usw. zu berücksichtigen.
Derartige Anforderungen lassen sich nur erfüllen, wenn der Datenmanager in hohem Maße eine
Optimierung der Datenzugriffe unterstützt. Allerdings ist der Datenmanager kein Datenbanksystem. Er
ist vielmehr eine allgemeingültig definierte Zugriffsschale über die derzeit benutzen Speicherformen,
die seinem Anwender die intimen Kenntnisse der verwendeten Datenspeicherungstechnologie
abnimmt und durch Normierung und Generalisierung die Qualität, die Wiederverwendbarkeit und die
Entkopplung von Anwendungen und Datenspeicherung garantiert.
I.2. Anforderungen
Die Funktionalität eines Datenmanagers ist typisch für alle DV-Systeme und nicht auf die
Versicherungswirtschaft beschränkt. Aus den Grundprinzipien der VAA können die wesentlichen
Anforderungen abgeleitet werden:
Der Datenmanager muß sämtliche Datenbeschaffungen innerhalb der VAA abwickeln. Davon
auszunehmen sind nur die Daten eines Parametersystems.
Die Datenbeschaffung durch den Datenmanger muß in der Lage sein, die heute in
Versicherungsunternehmen anfallenden hohen Transaktionsraten mit der notwendigen Response-Zeit
von unter einer Sekunde abzudecken. Aus den Charakteristika der notwendigen Batch-Aktivitäten
ergibt sich die Forderung nach einer wirksamen Unterstützung sequentieller Lesezugriffe in größerem
Umfang.
Die notwendigen Veränderungen in Datenbeständen sind ebenfalls Aufgabe des Datenmanagers. Dazu
gehört auch die Unterstützung sogenannter langer Transaktionen, d.h. Änderungen innerhalb eines
Vorgangs werden lokal auch über Transaktionsgrenzen hinweg vorgehalten und erst am Vorgangsende
auf den Datenbeständen fortgeschrieben und damit der Allgemeinheit zur Verfügung gestellt.
Eine Vielzahl von eingesetzten Programmiersprachen, Datenbanksystemen und physischen
Speicherungsformen muß durch den Datenmanager unterstützt werden. Zu erwähnen sind z.B. IMS,
DB2, UDS als Datenbanksysteme, PL/1, Cobol als Programmiersprachen und VSAM als häufig
eingesetzte Form der Datenspeicherung. Weniger häufige Speicherformen von Daten müssen durch
Erweiterungen an den Datenmanager angebunden werden können. In diesem Kontext von
verschiedensten Sprachen, Datenbanksystemen und Datenspeicherungsformen kommt einer
effizienten Anwendungsschnittstelle zentrale Bedeutung zu, die die in der Versicherungswirtschaft
üblichen hohen Kodierungsaufwände der Datenzugriffe durch geeignete Entkopplungsmechanismen
und wiederverwendbare Strukturen wirksam vermindert.
6
© GDV 1999
Datenmanager
Der Datenmanager (Überblick)
Durch den zunehmenden Einsatz von Rechnerverbund-Systemen ergibt sich die Forderung nach der
Unterstützung verteilter Datenhaltung.
I.3. Einbindung in die Gesamtarchitektur
Param ete rSyste m m it
Ge schäftsund Steue rungsParam ete rn
Datenm anage r
Steuerungs obje kte
Workflowmanager
3
1
Dialogsteuerung
1
Vorgangsspeicher
2
1
DV-Vorgangssteuerung
4
5
E/R Modellbeschreibung
Vorgangstabellen
Anw endungsbaus teine
3
Risikoprüfung
Beitrag
Provision
Police
2
usw .
logisches
Instanzenmodell
Bilddefinitionen
5
Tarifierungsmodelle
Die ns te
Fehlerbehandlung
Feldkonverter
Regelsystem
Präsentation
DBMSEntkopplung
usw .
Abb: Zusammenspiel der wichtigsten VAA-Komponenten
Zwischen den einzelnen Komponenten bestehen folgende Schnittstellenbeziehungen:
(1) Verbindung der zur Abwicklung eines Geschäftsprozesses notwendigen Steuerungsobjekten
(2) Beschaffung der für den Geschäftsprozeß benötigten Datenstrukturen.
(3) Beschaffung der für den Prozeß notwendigen Steuerungsdaten und Parameter.
(4) Aufruf
der
zur
Abwicklung
Anwendungsbausteinfunktionen.
der
fachlichen
Inhalte
notwendigen
(5) Nutzung der allgemein verfügbaren Dienste zur Abwicklung des Geschäftsprozesses.
I.4. Grundstruktur des Datenmanagers
Die obigen Anforderungen geben einen ersten Eindruck von der Bandbreite und Komplexität eines
Datenmanagers. Aufgrund der Leistungscharakteristika sollte der Datenmanager möglichst komplexe,
wiederverwendbare und nur einmal zu definierende Geschäftsobjekte an die Anwendungen
weiterreichen, die dann einfach verarbeitet werden können. Statt der Anwendung z.B. die
Zusammenstellung der benötigten Daten zu einem Versicherungsvertrag Datensatz um Datensatz zu
überlassen, stellt er alle in einer Datenanforderung benötigten Datensätze über allgemeine
Vertragsdaten, Risiko- und Unterrisikodaten und abweichenden Vereinbarungen immer in der
gleichen Form und Qualität zu Verfügung. Feldweiser Zugriff auf Datenelemente als allgemeine
Datenschnittstelle verbietet sich aus Effizienzgründen.
Anwendungen kommunizieren mit dem Datenmanager nicht auf der Ebene von Datenelementen,
sondern mittels komplex aufgebauter Datenstrukturen (sogenannte komplexe Objekte), die die innere
Ordnung der benötigten Daten widerspiegeln. Diese Datenstrukturen entsprechen im Idealfall den
auszugegebenden Strukturen z.B. eines Bildschirms oder einer Listendarstellung. Dadurch kann
© GDV 1999
7
Der Datenmanager (Überblick)
Datenmanager
erreicht werden, daß die Anwendung entsprechend definierte Objekte direkt und auf einfachste Weise
Datenmanager
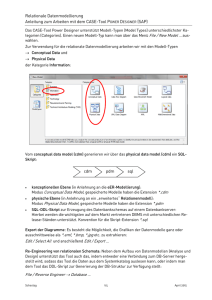
Datensichtprozessor
Anwendungskomponente
mit
Datenlesebzw. Updateanforderung
log.
Datenmodell
Datenhandler
phys.
Datenbank
phys.
Datenbank
Abb.: externe Schnittstellen des Datenmanagers
verarbeiten und darstellen kann.
Der Datenmanager liefert die von den Anwendungen durch sogenannte Datensichten angeforderten
Daten als komplexe Datenstrukturen, die aus den Entitäten eines logischen Datenmodells bestehen.
Dazu bedient er sich eines Datensichtprozessors.
Die fachliche Aufgabe des Datensichtprozessors besteht darin, Datenanforderungen
entgegenzunehmen und diese anhand des logischen Datenmodells in Aufträge für die
Datenbeschaffung zu übersetzen. Nach Bereitstellung der Entitäten stellt der Datensichtprozessor die
geforderten Daten in der gewünschten Reihenfolge zur Verfügung.
Die Abarbeitung einer Lese-Anforderung erfolgt in folgenden Schritten:
1. Ermittlung des angeforderten Datenumfangs.
2. Umsetzung der logischen Datenanforderung in physische Einheiten
3. Zugriff auf die Daten in den ermittelten Datenbanken und Dateien.
4. Umsetzung der gelesenen physischen Daten in logische Entitäten.
5. Rückgabe der Daten an die Anwendung in der angeforderten Struktur.
8
© GDV 1999
Datenmanager
Der Datenmanager (Überblick)
I.5. Aufgaben des Datenmanagers
I.5.1. Bereitstellung von Daten
Die Datenanforderungen erfolgen durch die Formulierung von Datensichten. Datensichten
beschreiben auf der Basis des logischen Datenmodells den Umfang und die Anordnung der Daten, die
eine Anwendung benötigt, sie werden im Laufe der Anwendungsentwicklung definiert. Grundsatz ist,
daß jede Anwendung nur die Daten zu Verfügung gestellt bekommt, die sie auch wirklich benötigt,
um sie auszuwerten oder zu ändern. Der Datenmanager setzt die Datenanforderungen in die
erforderlichen physischen Zugriffe um, d.h. für die Anwendung ist die konkrete physische Ablage der
Daten nicht relevant. Insofern hat auch eine Änderung der Datenspeicherung (z.B. durch Migration
von VSAM nach DB2) keine Auswirkungen auf die Anwendung.
I.5.2. Änderung von Daten
Analog zum lesenden Zugriff formuliert eine Anwendung Änderungen nur auf den Entitäten des
logischen Datenmodells. Die Änderungen auf den physisch gespeicherten Daten ist ausschließliche
Aufgabe des Datenmanagers.
I.5.3. Pufferung logischer Änderungen bis zum Konsistenzpunkt
Häufig existiert die Anforderung, daß mehrere zu einem Geschäftsprozeß gehörende Arbeitsschritte
nur zusammen wirksam werden oder gar nicht. Auch diese Aufgabe erledigt der Datenmanager. Er
kennzeichnet die Daten als vorläufig und stellt sie nur dem Geschäftsprozeß zur Verfügung, der diese
Daten erzeugt hat, bis das Kommando zum endgültigen Abspeichern kommt. Dann werden die Daten
allen anderen Geschäftsprozessen bekannt und allgemein gültig gemacht.
Bsp.: Beim Neugeschäft wird zum einen der Arbeitsschritt "Kunde erfassen" durchgeführt, zum
anderen der Arbeitsschritt "Vertragsdaten erfassen“. Die Anforderung kann dann lauten, daß auch die
Anschrift des Kunden erst dann wirksam wird, wenn der Vertrag von uns angenommen wird. Die
Daten der Anschrift müssen also solange zwischengepuffert werden, bis auch der Arbeitsschritt
"Vertragsdaten erfassen" korrekt beendet wurde. Gleichwohl müssen sie diesem Arbeitsschritt bekannt
gemacht werden, wenn er sie benötigt.
© GDV 1999
9
Der Datenmanager (Überblick)
Datenmanager
I.5.4. Zwischenspeicherung von temporären Daten
Im Rahmen der Anwendungsarchitektur ist es häufig notwendig, Daten in einen Speicher einzustellen
und sie zu einem späteren Zeitpunkt wieder zu lesen. Dies ist zum einen durch den verwendeten TPMonitor (z.B. CICS) bedingt, zum anderen durch die Geschäftsprozeß-orientierte Sachbearbeitung mit
der Möglichkeit des Unterbrechens und Terminierens von Geschäftsprozessen. Der Datenmanager
stellt eine Schnittstelle zur Verfügung, die es den anderen Architekturbausteinen und der Anwendung
ermöglicht, Daten einzustellen und zu einem späteren Zeitpunkt wieder zu bekommen.
I.5.5. Unterstützung der Zeitlogik
Der Datenmanager muß zeitpunktbezogene Datenanforderungen erfüllen, und zwar in zweierlei
Hinsicht:
Lieferung der zu einem bestimmten Zeitpunkt gültigen Daten
Lieferung der Daten, die zu einem bestimmten Zeitpunkt dem System bekannt waren.
Um dies zu gewährleisten, muß der Datenmanager ein durchgängiges Versionskonzept beinhalten, das
bei jedem Änderungsvorgang alle benötigten Informationen festhält.
I.6. Zusammenfassung
Der Datenmanager bildet die Schnittstelle zwischen den Anwendungen und den extern gespeicherten
Daten. Seine Aufgabe ist es, den Anwendungen eine abstrakte Datenschnittstelle zur Verfügung zu
stellen, so daß diese vollkommen befreit sind von dem Schema der darunterliegenden Datenbanken
und deren Zugriffslogik. Er beschafft die angeforderten Daten von externen Speichern, baut temporäre
Speicher auf, kontrolliert deren Inhalte, schreibt die temporären Daten fort und ändert
Datenbankinhalte. Er macht die Anwendungen unabhängig von der physischen Speicherungsform, von
den Zugriffsarten und dem eingesetzten Datenbankmanagementsystem. Die Anwendungen arbeiten
ausschließlich auf den logischen Datenmodell, das der Datensichtprozessor kennt und verwaltet. Über
eine zusätzliche Entkopplungsschicht wird das logische Datenmodell auf die physisch gespeicherten
Datenstrukturen abgebildet.. Der Datenmanager stellt dadurch standardisierte und wiederverwendbare
Strukturen auf hohem Qualitätsniveau zur Verfügung und erleichtert die Erstellung von
datenorientierten Anwendungen in erheblichem Ausmaß.
10
© GDV 1999
Datenmanager
© GDV 1999
Der Datenmanager (Überblick)
11
Einbindung des Datenmanagers in die Gesamtarchitektur
Datenmanager
II. Einbindung des Datenmanagers in die
Gesamtarchitektur
II.1. Das Zusammenspiel mit anderen VAA-Komponenten
Innerhalb der VAA-Architektur existieren zwei Dienste, die Daten aus persistenten Speichern
beschaffen. Dies sind:
der Datenmanager, der die benötigten operativen Daten für die einzelnen Anwendungsbausteine
besorgt und
das Parametersystem, welches die Konfigurationsdaten und generischen Parameter der einzelnen
Bausteine beschafft.
Das Zusammenwirken der einzelnen Teile der VAA wurde bereits anhand der Abbildung
Zusammenspiel der wichtigsten VAA-Komponenten erläutert. In dieser Spezifikation steht die
Schnittstelle (2) zwischen dem Datenmanager und den Steuerungsobjekten oder den
Anwendungsbausteinen im Vordergrund.
II.2. Schnittstellen
Betrachtet man den Datenmanager im Kontext der gesamten VA-Architektur, so hat er eine
Schnittstelle mit herausragender Bedeutung, die Schnittstelle zu den Anwendungsteilen, die Daten
anfordern oder entgegennehmen bzw. die Speicherung von Daten veranlassen. Die effziente und
performante Bedienung dieser Schnittstelle ist die zentrale Aufgabe des Datenmanagers.
Während der Konfigurationsphase und der Buildtime kommt dann als zweite Schnittstelle die zum
Parametersystem hinzu. (Vgl. Abbildung externe Schnittstellen des Datenmanagers.) Das
Parametersystem ist der Ablageort aller in diesen Phasen erstellten Datenmanager-Objekte (logisches
Datenmodell, Datensichten etc.). Auf das Parametersystem wird von den operativen Systemen zur
Laufzeit nur lesend zugegriffen.
Genaugenommen existiert noch eine dritte Schnittstelle, die zu den Datenbanken, in denen die zu
beschaffenden Daten abgelegt sind. In unserer Betrachtungsweise ist diese Schnittstelle aber
Datenmanager-intern, da außer dem Datenmanager niemand Kenntnis über die Spezifika dieser
Schnittstelle haben muß.
12
© GDV 1999
Datenmanager
Einbindung des Datenmanagers in die Gesamtarchitektur
II.2.1. Die Schnittstelle zur Anwendung
Die Schnittstelle des Datenmanagers zur Anwendung stellt in Bezug auf seine technische Realisierung
eine besondere Herausforderung dar. Wegen der Häufigkeit seiner Nutzung ist die Performance dieser
Schnittstelle von entscheidender Bedeutung.
Die Schnittstelle zur Anwendung wird durch den Datensichtprozessor, ein Subsystem innerhalb des
Datenmanagers realisiert. Die fachliche Aufgabe des Datensichtprozessors besteht darin, für die
Funktionsbausteine, die Steuerungskomponenten DV-Vorgangssteuerung und Dialogsteuerung oder
den Präsentationsmanager des Anwendungsprogrammes Daten im Vorgangsspeicher bereitzustellen
bzw. das Update/Insert/Delete von Daten zu veranlassen.
Anwendungsprogramme kommunizieren mit dem Datenmanager nicht auf der Ebene von
Datenelementen, sondern mittels logischer, komplexerer Strukturen, den „logischen Datensichten“.
Unter logischen Datensichten werden dabei hierarchische Bäume verstanden, die sich z.B. durch die
Jackson-Notation beschreiben lassen. Sie können als NF2-Strukturen aufgefaßt werden, die im
Idealfall direkt auszugegebenden Strukturen (Bildschirm, Liste, ...) entsprechen. Logische
Datensichten beschreiben die Daten also in der Form, wie das Anwendungsprogramm sie gerade
benötigt. Die logischen Datensichten werden in einer spezifischen Sprache formuliert.
Durch diese Art der Anwendungsschnittstelle werden die Anwendungsprogramme völlig von der
physischen Datenhaltung entkoppelt. Der Datensichtprozessor strukturiert und verwaltet die Daten
modellgerecht aufgrund der logischen Beschreibung der Datensichten und unter Kenntnis des
logischen
Datenmodells
in
einem
Trefferverzeichnis
im
Vorgangsspeicher.
Die
Anwendungsprogramme „greifen“ nicht auf die phsysische Datenhaltung durch.
II.2.2. Die Schnittstelle zum Parametersystem
In den ersten beiden Phasen des Arbeitens mit dem Datenmanager (Konfiguration, Buildtime) ist das
Parametersystem das zentrale Ablagesystem für alle Datenmanager-Informationen.
Dem Parametersystem werden während der Konfiguration alle Informationen zum logischen und
physischen Datenmodell und zur Abbildung zwischen diesen beiden, sowie deren grafische
Darstellung (in einem Textformat) übergeben.
Das Parametersystem stellt die gespeicherten Informationen bei Bedarf wieder zur Verfügung.
Während der Buildtime werden die Definitionen der logischen und physischen Datensichten, der
Zuordnung zwischen ihnen und deren grafische Darstellung im Paramtersystem abgelegt bzw. bei
Änderungen von dort beschafft.
Auf den dort abgelegten Informationen setzen dann der Datenmodell-Editor und die Generatoren für
die logischen und physischen Datensichten auf und generieren die zur Laufzeit verwendeten
Bausteine. Diese Bausteine werden dann in einer Ladebibliothek abgelegt.
Während der Runtime greift der Datenmanager auf das Paraametersystem lesend zu, um sich Inhalte
vom logischen Datenmodell, Datensichten usw. zu beschaffen.
© GDV 1999
13
Einbindung des Datenmanagers in die Gesamtarchitektur
Datenmanager
Anwendungsbausteine, die Daten aus dem Parametersystem benötigen, rufen es direkt über die
Parameterschnittstelle während der Laufzeit auf.
14
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III. Spezifikation des Datenmanagers
III.1. Spezifikationsgrundsätze
Die Beschreibung eines komplexen Systems, wie es der Datenmanager darstellt, kennt natürlich
verschiedene
Beschreibungsebenen
(Detaillierungsgrade).
Die
VAA-Arbeitsgruppe
DATENMANAGER hat sich entschieden, für die Beschreibung eine Ebene deutlich oberhalb dessen,
was für eine Programmvorgabe notwendig wäre, zu wählen. Eine stärkere Detaillierung war vom
vorgegebenen Zeitrahmen nicht machbar, außerdem hätte ein solches Dokument allein für den
Datenmanager mehrere hundert Seiten Umfang.
Die einzelnen Teile der Spezifikation sind bewußt unterschiedlich stark detailliert.
Die Stellen, die entweder dem Verständnis der Funktionalität oder der Beschreibung von
Schnittstellen dienen, haben wir näher und mit größerer Detailschärfe beschrieben . Bis auf die Ebene
der Definition von Datenstrukturen sind wir nur bei der Beschreibung der Schnittstelle zwischen
Anwendungsprogramm und Datenmanager gegangen, wobei die vorgestellte Struktur mehr
Beispielcharakter hat.
Wir stützen uns in der Spezifikation an vielen, nicht näher gekennzeichneten Stellen auf Erfahrungen
mit einer Implementierung eines Datenmanagers in der Württembergischen Versicherung, Stuttgart
und Ideen zur Weiterentwicklung dieses Systems.
Der Datenmanager ist eine (wesentliche) Komponente der Versicherungs-Anwendungs-Architektur,
kein neues Datenbanksystem. Deshalb werden Eigenschaften, die heutige Datenbanksysteme haben
oder regeln (z.B. verteilte Datenhaltung, stored procedures) genutzt, aber nicht neu entwickelt.
Fehlende Integrität von mehreren Datenbanksystemen untereinander (z.B. ADABAS und IMS) stellt
auch der Datenmanager nicht her.
Wir streben an, unser Konzept so datenbankunabhängig wie irgendmöglich zu beschreiben. Deshalb
haben wir so wenig wie möglich auf Eigenschaften einzelner Datenbanksysteme abgehoben, aber
immer die im Versicherungsumfeld marktgängigen DB-Systeme wie z.B. DB2, IMS oder ADABAS
als Beispiele für denkbare Umsetzungen herangezogen.
Techniken, die nur bestimmte Datenbanksystemklassen (z.B. relationale DBMS) zur Verfügung
stellen, sollten (wenn sinnvoll) nach unseren Überlegungen lokal, d.h. innerhalb einzelner
Datensichten verwendet werden, um die DB-Unabhängigkeit der erstellten Lösung sicherzustellen.
© GDV 1999
15
Spezifikation des Datenmanagers
Datenmanager
III.2. Komponentenstruktur (Masterplan)
Die Abbildung auf der nächsten Seite zeigt die einzelnen Komponenten in einer Übersicht
(Masterplan). Die folgenden Abschnitte dienen der Erläuterung.
III.2.1. Konfigurationskomponenten im Überblick
Graphische Editoren für die Erstellung von
logischen Datenmodellen (LDM - Editor)
physischen Datenmodellen (PDM - Editor)
Dabei werden die Definitionen der operationalen Datenbanken/Dateien verwendet, d.h. IMSDBDs, DB2-Table-Definitionen usw.
logischen Datensichten (LDaSi - Editor)
Dabei wird das zugrundegelegte logische Datenmodell verwendet.
physischen Datensichten (PDaSi - Editor)
Für jede logische Datensicht wird eine passende physische Datensicht definiert oder eine
bereits vorhandene zugeordnet, dabei werden die benötigten Ausschnitte des physischen
Datenmodells verwendet.
Abbildungen zwischen logischem und physischem Datenmodell
Jeder Entität des logischen Datenmodells ist seine physische Repräsentierung zuzuordnen.
Zuordnung logischer zu physischer Datensicht
Jeder logischen Datensicht wird eine physische Datensicht zugeordnet. Dabei werden auch
evtl. notwendige Umsetzungen von Ordnungsbegriffen und sonstigen Parametern definiert.
16
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
MetaInformationen
Definition
operationaler
Datenbestände
Abbildungs.Editor
K
o
n
f
i
g
u
r
a
t
i
o
n
log. Datenmodell
Abbildungsdefinition
phys. Datenmodell
LDM-Editor
PDM-Editor
log.Datensicht
Zuordnung
phys.Datensicht
LDasi-Editor
RuntimeBibliothek
B
u
i
l
d
T
i
m
e
R
u
n
T
i
m
e
PDasi-Editor
Operationale
Daten
Datenmod.Generator
Datenmodell-Baustein
LDASIGenerator
LDasi-Baustein
PDASIGenerator
Abbildungs/Zuordnungs
Generator
Transformations-Bausteine
Datenhandler-Bausteine
Ablaufplan
Abbildung
I/O-Modul
Zuordnung
I/O-Modul
Datenhandler
Anwendungs
-Programm
DatensichtProzessor
I/O-Modul
Transformation
Ablaufsteuerung
I/O-Modul
WV/pk96
© GDV 1999
17
Datenmanager
Spezifikation des Datenmanagers
III.2.2. Buildtime-Komponenten im Überblick
Aus den Ergebnissen der Konfigurationsprozesse werden durch Generatoren Bausteine erstellt, die für
den Einsatz zur Laufzeit optimiert sind.
Die erzeugten Bausteine können damit auf die jeweilige Runtime-Umgebung maßgeschneidert
werden.
Folgende Generatoren sind erforderlich:
LDaSi - Generator
PDaSi - Generator
erzeugt das Runtime-Modul für die Ablaufsteuerung und die I/O-Module
Datenmodell - Generator
stellt die Entitäten des LDM und ihre Beziehungen zur Verfügung
Abbildungs - bzw. Zuordnungs - Generator
enthält die Informationen für die Transformation
III.2.3. Runtime-Komponenten im Überblick
Datensichtprozessor
Der Datensichtprozessor wird von einer Anwendung (d.h.einem Funktionsbaustein oder einer
Komponente der Steuerungsebene) unter Angabe einer logischen Datensicht und der zur Ausführung
erforderlichen Parameter aufgerufen.
Lesender Aufruf (Datenbeschaffung):
Zunächst ruft er den Datenhandler zur Datenbeschaffung auf. Dabei werden der LDaSi-Name und die
Datensicht-Parameter mitgegeben.
Die zurückgelieferten Daten werden gemäß den Definitionen des logischen Datenmodells in den
Vorgangsspeicher eingestellt und alle im logischen Datenmodell definierten Beziehungen werden
aufgebaut.
Dann wird die logische Datensicht abgearbeitet, dabei werden die Daten in der definierten Reihenfolge
und im definierten Umfang in die Anwendungsschnittstelle eingetragen.
© GDV 1999
19
Spezifikation des Datenmanagers
Datenmanager
Update-Aufruf (Vorgangsspeicher):
Auf Anforderung werden im Vorgangsspeicher neue Versionen von Informationsobjekten oder neue
Existenzen von Datenmodell-Entitäten eingefügt oder bereits im Vorgangsspeicher vorhandene
Entitäten geändert oder gelöscht.
Commit - Aufruf (Update bei Vorgangsende):
Der Datenhandler wird unter Angabe eines LDaSi-Namens und der Datensicht-Parameter aufgerufen
und liefert einen Verarbeitungs-Status zurück.
Datenhandler
Zur Datenbeschaffung wird der Datenhandler vom Datensicht-Prozessor unter Angabe einer logischen
Datensicht aufgerufen. Die Transformation ermittelt die zugehörige physische Datensicht und führt die
erforderlichen Parameterumsetzungen durch. Aus der PDaSi werden die zur Ausführung anstehenden
Bausteine (Ablaufsteuerung, I/O-Module) ermittelt.
Die Ablaufsteuerung aktiviert die benötigten I/O-Module in der optimalen Reihenfolge. Die I/OModule führen die Datenbank-Zugriffe durch.
Dann erfolgt durch die Transformation die Aufbereitung der Daten, d.h. die Umsetzung in logische
Entitäten, und deren Übergabe an den Datensicht-Prozessor.
Zum Datenbank-Update wird der Datenhandler vom Datensicht-Prozessor unter Angabe einer
logischen (Update-)Datensicht aufgerufen. Die Transformation ermittelt die zugehörige physische
Datensicht und führt die erforderlichen Parameterumsetzungen durch.Außerdem setzt sie anhand der
Abbildungs-Definitionen alle logischen Entitäten in die physischen Datenstrukturen um.
Aus der PDaSi werden die zur Ausführung anstehenden Bausteine (Ablaufsteuerung, I/O-Module)
ermittelt.
Die Ablaufsteuerung steuert die I/O-Module an, die alle zur Änderung anstehenden Daten in die
entsprechenden Datenbanken schreiben, dann wird ein Verarbeitungsstatus an den
Datensichtprozessor zurückgeliefert.
III.2.4. Beispiel der Datenbeschaffung durch einen
Anwendungsbaustein
Um die Anforderungen und die daraus abgeleiteten Sprachkonstrukte besser nachvollziehen zu
können, wird das dynamische Verwendungsmodell des Datenmanagers kurz skizziert.
Mit Hilfe der Vorgangssteuerung werden betriebswirtschaftliche Transaktionen abgewickelt. Dabei
gelten folgende Prinzipien:
20
Transaktionsbeginn und Transaktionsende werden von der Vorgangssteuerung festgelegt.
Die Vorgangssteuerung
Vorgangsspeicher.
verwaltet
unter
Nutzung
der
Datenmanagerfunktionalität
den
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Die Vorgangssteuerung legt fest, welche Anwendungsbausteine in welcher Reihenfolge ausgeführt
werden. Für jeden Anwendungsbaustein existieren eine oder mehrere logische Datensichten, in
denen die benötigten Daten beschrieben sind.
Zur Datenbeschaffung bzw. Speicherung in einem persistenten Speicher bedient sich der
Anwendungsbaustein des Datenmanagers.
Die Anwendungsbausteine greifen nicht selbst auf Datenhaltungssysteme zu; sie operieren mit den
vom Datenmanager im Vorgangsspeicher zur Verfügung gestellten Daten und liefern Daten an den
Vorgangsspeicher zurück.
Der dynamische Ablauf des Aufrufs einer Anwendungsfunktion in einem Anwendungsbaustein sieht
wie folgt aus:
Ein Anwendungsbaustein ruft den Datenmanager auf und übergibt ihm den Namen der logischen
Datensicht und die aktuellen Werte in der Datensicht.
Die Komponente des Datenmanagers, die die logische Datensicht entgegennimmt, ist der
Datensichtprozessor. Er beschafft aus dem Parametersystem den Aufbau der logischen
Datensicht und prüft, ob die angeforderten Daten schon im Vorgangsspeicher vorhanden
sind.
Sind die Daten schon im Vorgangsspeicher vorhanden, werden sie (oder deren Adresse)
dem Anwendungsbaustein übergeben und die Datenbeschaffung ist beendet.
Sind die Daten nicht im Vorgangsspeicher vorhanden, so wird die logische Datensicht an
die Transformation in Datenhandler weitergereicht. Diese beschafft sich aus dem
Parametersystem die zur logischen Datensicht gehörige physische Datensicht und die
Ablaufplan-ID. Dann transformiert sie die vom Datensichtprozessor erhaltenen aktuellen
logischen Zugriffsparameter, soweit erforderlich, in physik-konforme und übergibt diese
der Ablaufsteuerung.
Diese wertet zunächst die vorhandenen Datenbank-Verfügbarkeitsinformationen aus und
lädt, falls alle geforderten Datenbanken verfügbar sind, den erforderlichen Ablaufplan.
Der Ablaufplan startet (u.U. an verschiedenen Lokationen und gegen verschiedene
Datenbanksysteme) die ihm zugeordneten I/O-Module zur Beschaffung der Daten.
Konnten alle Daten beschafft werden, geben die I/O-Module die einzelnen physischen
Entitäten an den Ablaufplan zurück. Dieser prüft die Vollständigkeit der Beschaffung und
füllt mit den Daten die von der Transformation übergebene physische Datensichtstruktur.
Die Transformation entnimmt dem Parameter-System die Abbildungsbausteine:
physisches
<->
logisches Modell,
physische
<->
logische Datensicht und
Datenmodellstruktur.
Hiermit setzt die Transformation die von der Ablaufsteuerung gelieferten Daten in eine Menge
logischer Entitäten mit allen Beziehungsinformationen für die geforderte logische Datensicht um und
übergibt sie dem Datensichtprozessor.
Dieser ergänzt unter Zuhilfenahme der aus dem Parameter-System beschafften logischen
Datensichtstruktur den Vorgangsspeicher und teilt der Anwendungsschnittstelle (z. B.
dem Funktionsbaustein) die Verfügbarkeit der gewünschten Daten mit.
© GDV 1999
21
Spezifikation des Datenmanagers
Datenmanager
Die Anwendungsbausteine arbeiten mit den im Vorgangsspeicher zur Verfügung gestellten Daten.
Damit dieses Verwendungsmodell funktionieren kann, wird also vorausgesetzt, daß ein logisches
Datenmodell existiert und die Schnittstellen der Funktionsbausteine auf logischer Ebene beschrieben
sind.
22
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Anwendungsschnittstelle
lDaSi - ID und
aktuelle logische Daten
z.B.:
lDasi = 4711
Ordbg = 15
Param = xy7z
aus Parameterund Regelsystem:
lDaSi-Struktur
Datensichtprozessor
Daten im
Vorgangsspeicher
?
Ja
Datenbeschaffung
beendet
Nein
Zuordnung
lDaSi <-> pDaSi
Beschaffung
Ablaufplan-ID
Transformation
pDaSi - ID und
aktuelle physische Daten
z.B.:
pDaSi = 1312
Ordbg = 151
Param = abx9
Ablaufsteuerung
-----------------------Ablaufplan
Laden Ablaufplan
--------------------Verfügbarkeitsinformationen
Input/OutputModul
Input/OutputModul
Input/OutputModul
Input/OutputModul
physische
Entität
(z.B. Tabelle)
physische
Entität
(z.B. IMSSegment)
physische
Entität
(z.B. ADABASFile)
physische
Entität
(z.B. DB2-View)
physische Daten
(einzeln, nacheinander)
Abb.: Datenbeschaffung, Lesezugriff auf mehrere Datenbanken
© GDV 1999
23
physische
Entität
(z.B. ADABASFile)
Input/OutputModul
Input/OutputModul
Input/OutputModul
physische
Entität
(z.B. DB2-View)
physische
Entität
(z.B. IMSSegment)
Datenmanager
physische
Entität
(z.B. Tabelle)
Spezifikation des Datenmanagers
Input/OutputModul
physische Entitäten
(einzeln)
Ablaufsteuerung
-------------------------------Ablaufplan
pDaSi
Transformation
Abbildungsbausteine
pDM <-> lDM
pDaSi <-> lDaSi
Menge aller logischen Entitäten
mit Beziehungsinfo für die geforderte lDaSi
Datenmodellbaustein
Datensichtprozessor
lDaSiBaustein
logische Entität mit
Beziehungsinfo
VorgangsspeicherErgänzung
lDaSi
Anwendungsschnittstelle
Abb.: Datenbeschaffung, Rücktransport der Daten aus den Datenbanken
24
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.2.5. Ablaufsteuerung für Veränderungen in der Datenbank
Dieser Abschnitt beschreibt den Ablauf im Datenmanager beim persistenten Wegschreiben von den in
einem Vorgang neu erfaßten/geänderten/gelöschten Daten.
Anwendungsbaustein
LDaSi = '4711'
Ordnungsbegriff = '15'
Parameter = 'xy'
Datensichtprozessor
LDaSi = '4711'
Ordnungsbegriff = '15'
Parameter = 'xy'
________________
logische Entitäten
Zuordnung
LDaSi <-> PDaSi
--------------------Abbildung
LDM <-> PDM
Datenhandler
------------------------------Transformation
PDaSi = '1312'
Ordnungsbegriff = '151'
Parameter = 'abc'
________________
physische Daten
Datenhandler
------------------------------Ablaufsteuerung
Ablaufplan
physische
Entität
(z.B. IMSSegment)
Input/OutputModul
Input/OutputModul
physische
Entität
(z.B. DB2View)
Input/OutputModul
physische
Entität
(z.B.
ADABASRecord)
Input/OutputModul
physische
Entität
(z.B. Tabelle)
physische Daten
(einzeln, nacheinander)
Abb.: Update auf mehrere Datenbanken
Die Anwendung ruft den Datensichtprozessor mit der Funktion DBCommit auf unter Angabe von
© GDV 1999
25
Spezifikation des Datenmanagers
Name der LDaSi,
Ordnungsbegriffen,
weiteren Parametern.
Datenmanager
Es wird offen gelassen, ob die Commit-Verarbeitung synchron oder asynchron erfolgt.
Der Datensichtprozessor stellt die logischen Entitäten aus dem Vorgangsspeicher gemäß der LDaSi
zusammen. Er übergibt diese Daten mit den sonst unveränderten Aufrufparametern an die
Transformation.
Die Transformation führt die Zuordnung der LDaSi in die entsprechende PDaSi durch (incl.
Parameter-Umsetzung).und setzt entsprechend den Abbildungsdefinitionen alle logischen Entitäten in
physische Daten um.
Dann ruft die Transformation mit der Funktion DB-Update die Ablaufsteuerung des Datenhandlers auf
und übergibt die physischen Daten sowie
Name der PDaSi,
Ordnungsbegriffe,
weitere Parameter.
Die Ablaufsteuerung ermittelt aus dem PDaSi-Namen den zugehörigen Ablaufplan und ruft alle
erforderlichen I/O-Module auf. Dabei liefert sie jedem I/O-Modul die von ihm zu verarbeitenden
Daten.
Die I/O-Module führen die DB-Updates durch. Jedes I/O-Modul gibt eine Statusinformation zurück.
Die Ablaufsteuerung interpretiert die gelieferten Statusinformationen der I/O-Module und gibt einen
Verarbeitungs-Status an die Transformation weiter.
Die Transformation gibt den Verarbeitungs-Status an den Datensichtprozessor weiter.
Vom Datensichtprozessor wird der Verarbeitungs-Status nochmals interpretiert und in aufbereiteter
Form an die Anwendung zurückgegeben.
26
© GDV 1999
Datenmanager
Input/OutputModul
Spezifikation des Datenmanagers
Input/OutputModul
Input/OutputModul
Input/OutputModul
VerarbeitungsStatus
Datenhandler
-------------------------------Ablaufsteuerung
VerarbeitungsStatus
Datenhandler
-------------------------------Transformation
VerarbeitungsStatus
Datensichtprozessor
VerarbeitungsStatus
Funktionsbaustein
(Anwendungsschnittstelle)
Abb.: Update, Rückgabe des Verarbeitungsstatus
© GDV 1999
27
Spezifikation des Datenmanagers
Datenmanager
III.2.6. Ablauf für Update des Vorgangsspeichers
Dieser Abschnitt beschreibt den Ablauf im Datenmanager beim lokalen Änderungen im
Vorgangsspeicher
Anwendungsbaustein
LDaSi = '4711'
______________
logische Entitäten
Datensichtprozessor
Vorgangsspeicher
logische Entitäten
mit ihren Beziehungen
Abb.: Update im Vorgangsspeicher
Die Anwendung ruft den Datensichtprozessor mit der Funktion Insert, Update oder Delete auf und
übergibt den Namen einer LDaSi sowie die zur Bearbeitung anstehenden logischen Entitäten.
Der Datensichtprozessor fügt neue logische Entitäten mit ihren Beziehungen in den Vorgangsspeicher
ein bzw. ändert oder löscht vorhandene Entitäten.
Vom Datensichtprozessor wird ein Verarbeitungs-Status an die Anwendung zurückgegeben.
III.3. Konfigurationskomponenten
Zur Konfiguration des Datenmanagers gehören die folgenden
Komponenten
eine Darstellung des logischen Datenmodells,
die logischen Datensichten,
eine Darstellung des physischen Datenmodells,
die physischen Datensichten,
die Abbildung des logischen auf das physische Datenmodell,
die Zuordnung der logischen zu den physischen Datensichten,
28
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
und die Werkzeuge
Editor zur Erstellung und Pflege des logischen Modells,
Editor zur Erstellung und Pflege des physischen Modells,
Editor für die physischen Datensichten,
Editor für die logischen Datensichten,
Editor zur Erstellung und Pflege der Abbildung des physischen auf das logische Modell
und
ein Generator zur erstmaligen
Datenbankdefinitionen.
Erstellung
des
Modells
aus
bestehenden
III.3.1. Logisches Datenmodell
In diesem Abschnitt werden Beschreibungsmittel zur Definition eines minimal notwendigen
Sprachschatzes zur logischen Beschreibung von E/R-Modellen benannt.
III.3.1.1. E/R-Sprache
Die E/R-Sprache ist die Modellierungs- bzw. Beschreibungssprache für das logische Datenmodell. Im
Gegensatz
zu
den
Datenbankmodellen
(Relationenmodell,
Netzwerkmodell,
hierarchisches
Datenmodell) ist das E/R-Modell ein „semantisches“ Datenmodell. Das semantische Datenmodell
übertrifft einerseits das Datenbankmodell an Ausdrucksfähigkeit, abstrahiert andererseits von der
technischen
Umsetzung
in
einem speziellen
Datenhaltungssystem,
ist
also
insbesondere
zugriffspfadunabhängig. Von Bedeutung sind:
Semantik als Beziehung zur Realität, d.h. die Verfügbarkeit eines Begriffssystems, das es gestattet,
einen relevanten Ausschnitt der Realität (Diskurswelt, Miniwelt) präzise und möglichst umfassend
durch Datenobjekte abzubilden.
Semantik der Daten in Bezug auf ihre zulässige Verwendung (Manipulation der Daten durch die
darauf operierenden Funktionen)
III.3.1.2. Begriffserklärungen: Entity, Relationship, ...
Ein Entity ist ein abgrenzbares „Objekt“ der Diskurswelt, das ein reales Objekt oder eine gedankliche
Abstraktion davon darstellt. Wichtig für die Datenmodellierung von Informationssystemen sind
folgende Kriterien:
Ein Entity muß wohlunterscheidbar und identifizierbar sein.
Ein Entity ist relevant für den Informationsbedarf.
Ein Entity wird selektiv durch die Ausprägung seiner bedeutungsvollen Attribute (Eigenschaften/Merkmale) beschrieben.
© GDV 1999
29
Spezifikation des Datenmanagers
Datenmanager
Was im konkreten Fall als Entity definiert wird, hängt vom Zweck des Systems ab. Beispielsweise
sind in einem Personalinformationssystem „Angestellte“ Entities des Unternehmens oder in einem
Versicherungssystem „Personen“ Entities des Unternehmens. Die für das jeweilige System
bedeutungsvollen Merkmale und der relevante Informationsbedarf werden sich unterscheiden, auch
wenn es sich in der Realität um denselben Menschen handeln sollte.
Gleichartige Entities eines Systems, die durch dieselben bedeutungsvollen Attribute (Eigenschaften/Merkmale) charakterisiert werden, werden zu Entitytypen (E-Typ) oder Entity-Mengen
zusammengefaßt. Jedes Entity läßt sich somit eindeutig einem Entitytypen zuordnen. Unterschiedliche
Entities, die demselben Entitytypen zuzuordnen sind, werden also durch dieselben Attribute
beschrieben, unterscheiden sich aber in den Attributwerten.
Eine (Entity-)Relationship ist eine Verknüpfung zwischen zwei (oder mehreren) Entities. Ansonsten
gelten sinngemäß dieselben Kriterien wie für ein Entity. Z.B. ist der „Auftrag“ eine Relation zwischen
einer Entity „Kunde“ und „Verkauf“, „Heirat“ die Relationship zwischen zwei „Personen“ oder
„Halter“ die Beziehung zwischen „Person“ und „Kfz“. Relationen können auch zwischen Relationen
oder Relationen und Entities bestehen.
Gleichartige Relationen eines Systems, die durch dieselben bedeutungsvollen Attribute (Eigenschaften/Merkmale) charakterisiert werden, werden zu (Entity-) Relationshiptypen (ER-Typ) oder
Relationship-Mengen zusammengefaßt. Jede Relation läßt sich somit eindeutig einem
Relationshiptypen zuordnen. Unterschiedliche Relationen, die demselben Relationshiptypen
zuzuordnen sind, werden also durch dieselben Attribute beschrieben, unterscheiden sich aber in den
Attributwerten.
Während Enitytypen Attribute zugeordnet sein müssen, können Relationshiptypen neben der
Verknüpfungseigenschaft weitere Attribute zugeordnet werden, müssen aber nicht. Z.B. kann das
Hochzeitsdatum weiteres Attribut des Relationshiptypen „Heirat“ sein.
Wichtig ist die Unterscheidung zwischen der Typ- oder Mengen-Ebene und der Ebene der konkreten
Ausprägung. Begriffe auf derselben Ebene sind jeweils:
Typ- oder Mengen-Ebene: Entitytyp oder Entity-Menge, Relationshiptyp oder Relationship-Menge,
Attribut
Beispiel: Entitytyp „Person“ charakterisiert durch die Attribute „Nachname“, „Vorname“,
„Personalnummer“
Ausprägungsebene: Entity, Relationship, Attributwert
Beispiel: konkrete Person „Schmidt, Willi, 4711“
Da in der Regel aus dem Kontext heraus klar ist, welche Ebene gemeint ist, ist der Sprachgebrauch
zuweilen lässig. Anstelle des Begriffs Entity oder Relationship werden auch die Begriffe „Instanz“,
„Objekt“, „Entität“ oder „Relation“ verwendet, anstelle der Entity- oder Relationshiptypen oder Mengen auch „Objekttyp“ oder „Klasse“.
Das E/R-Modell ist ein Modell, mit dem auf Typ-Ebene fachliche Zusammenhänge semantisch
beschrieben werden. Die Sprachmittel zur Modellierung von E/R-Modellen sind also Beschreibungsmittel für die Typ-Ebene.
Bei Relationships ist zwischen unterschiedlichen Abbildungstypen von Entitymengen zu unterscheiden:
30
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
1:1-Beziehung:
Die 1:1-Beziehung bedeutet, daß jedem Entity der einen Entitymenge höchstens ein Entity der
anderen Entitymenge zugeordnet ist und umgekehrt. Sie impliziert nicht, daß für jedes Entity der
einen Menge auch tatsächlich ein Entity der anderen Menge existiert.
Bsp.: Abteilungsleitung als Relationship zwischen Manager und Abteilung: Dabei wird
angenommen, daß jeder Manager höchstens eine Abteilung leitet und umgekehrt jede Abteilung
höchstens einen Manager hat. Aber nicht jede Abteilung hat einen Manager und nicht jeder
Manager ist Abteilungsleiter.
1:n-Beziehung:
Die 1:n-Beziehung bedeutet, daß jeder Entität der ersten Entity-Menge bis zu n Entitäten der
zweiten Entity-Menge zugeordnet werden, umgekehrt jedem Entity der zweiten Entity-Menge
höchstens 1 Entity der ersten EntityMenge zugeordnet wird.
Bsp.: Abteilungszugehörigkeit zwischen Abteilung und Personal: Jeder Abteilung sind bis zu n
Personen zugeordnet, jede Person gehört aber zu höchstens einer Abteilung.
n:m-Beziehung:
Bei der n:m-Beziehung gibt es keine Einschränkungen für die Menge der zulässigen Entity-Paare.
Bsp.: Projektmitarbeit zwischen Personal und Projekt: Eine Person kann in mehreren Projekten
eingesetzt sein. Einem Projekt können mehrere Personen zugeordnet sein.
Zusätzliche wichtige Eigenschaften von Relationships sind:
Eine Relationship-Menge kann auf einer einzigen Entity-Menge definiert sein. Bsp.:Heirat als 1:1Beziehung zwischen Person und Person
Eine Relationship-Menge kann auf mehr als zwei Entity-Mengen definiert sein. Bsp.: Lieferung als
Beziehung zwischen Lieferant, Artikel und Empfänger
Es können mehrere Relationship-Mengen auf den gleichen Entity-Mengen definiert sein. Bsp.:
Zwischen Personal und Projekt können die 1:n-Beziehung Projektleiter und die n:m-Beziehung
Projektmitarbeiter definiert sein.
Im Fall einer Spezialisierungs-bzw. Generalisierungsrelation (is_a) ist die eine Entity-Menge
Untermenge der anderen. Bsp.: is_a zwischen Manager und Personal
III.3.1.3. Anforderungen an die E/R-Sprache aus Sicht des Datenmanagers
Zur Festlegung der E/R-Sprache werden folgende Grundprinzipien eingehalten:
Es werden logische Datenmodelle für Versicherungs-Informationssysteme beschrieben.
Die Konstrukte der E/R-Sprache sind so zu wählen, daß die logischen Datenmodelle vollständig
beschrieben werden können. D.h. jedes aus fachlicher Sicht gestellte Problem muß sich im Modell
abbilden lassen.
Es wird Wert darauf gelegt, daß die Anzahl der Konstrukte so klein wie möglich gehalten wird.
D.h. es wird auf Sprachkonstrukte verzichtet, die sich durch andere im Minimalumfang
unverzichtbar enthaltene Konstrukte darstellen lassen.
© GDV 1999
31
Spezifikation des Datenmanagers
Datenmanager
Die Konstrukte sollen trotzdem selbsterklärend sein.
Darüber hinaus müssen folgende Anforderungen abgedeckt werden:
Es muß darstellbar sein, welche „Objekte“ derselben Zeitlogik (Versionsführung) unterliegen bzw.
welche nicht.
Existenzabhängige und existenzunabhängige „Objekte“ müssen unterscheidbar sein.
Unterschiedliche Beziehungstypen sind ausdrückbar.
Aufgrund dieser Anforderungen läßt sich eine minimale Liste von Sprachkonstrukten für die
semantische Datenmodellierung festlegen.
III.3.1.4. Festlegung der Minimal-Konstrukte einer E/R-Sprache
Aufgrund der Minimalitätsanforderungen an die festzulegende E/R-Sprache müssen im folgenden
nicht für alle möglichen Relationshiptypen eigene Sprachkonstrukte festgelegt werden.
Der Begriffe Entität und Relationship müssen nicht unbedingt auseinander gehalten werden. Eine
Relationship kann immer als „abhängige Entität“ von mindestens zwei Entitäten dargestellt
werden.
Eine n:m-Beziehung zwischen zwei Entitäten kann durch Einfügung einer Beziehungsentität, die
dann genau diese Ausgangsentitäten als „Parents“ hat, in „abhängige Entitäten“ mit zwei „Parents“
aufgelöst werden.
Eine Beziehung auf mehr als zwei Entity-Mengen kann stufenweise aufgelöst werden in
Beziehungen mit jeweils zwei Entity-Mengen. Dazu ist zwischen den ersten beiden eine
Beziehungsentität einzufügen, die dann in Beziehung zur dritten steht usw.
Aufgrund der Minimalitätsanforderung wird deshalb festgelegt,
daß zwischen Entity und Relationship nicht unterschieden wird,
daß eine Entität maximal zwei Parents haben darf, d.h. zwei Entitäten, von denen sie hierarchisch
abhängig ist,
daß die Spezialisierungs- bzw. Generalisierungsrelation nicht dargestellt wird.
Um Spezialisierungs- bzw. Generalisierungsrelationen zu realisieren, gibt es grundsätzlich zwei
Möglichkeiten: entweder sie werden im Modell bereits dargestellt und müssen in der Toolkette dann
entsprechend berücksichtigt werden, oder sie werden (erst) im variablen Teil der Implementierung
behandelt.
Damit sind als Minimalkonstrukte nur für folgende Entitytypen Sprachkonstrukte einzuführen:
Entitytyp einer unabhängigen Entität
Entitytyp einer abhängigen Entität in 1:n-Beziehung
Entitytyp einer abhängigen Entität mit zwei Parents
32
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Entitytyp einer abhängigen Entität mit doppelter Parent-Beziehung
Als Erweiterung der klassischen Datenmodellierungskonstrukte kommen zur Darstellung der Zeitlogik
das Sprachkonstrukt „Informationsobjekt“ und der Begriff „Existenz“ hinzu.
Diese Einschränkung auf die „Minimalkonstrukte“, also der Verzicht auf m:n-Beziehungen und Sub/Supertyp-Beziehungen hat zur Konsequenz, eine höhere Komplexität in den logischen Modelle
entsteht, oder die logischen Modelle auf einer abstrakten Ebene gehalten werden müssen. Dann muß
im Anwendungsprogramm die in der Konkretisierung steckende Komplexität abgefangen werden.
Grundsätzlich ist eine Transformationsleistung zu erbringen: Entweder ist die Auflösung der m:n- und
Sub-/Supertyp-Beziehungen oder die Ermittlung der „richtigen“, d.h. konkreten Enitäten zu
beschreiben. Dazu Parametersystem an.
III.3.1.4.1. Entitytyp einer unabhängigen Entität
Police, Person oder Objekt (Kfz, Haus, ...) sind sog.
unabhängige Entitäten. Ihre Anlage setzt nicht die Existenz
anderer Entitäten voraus.
Beispiel einer möglichen Darstellung einer unabhängigen
Entität: Alle anderen Entities sind ihrer Natur nach
Relationships und damit immer abhängig.
Entität 1
Abb.: Darstellung einer
unabhängigen Entität
III.3.1.4.2. Entitytyp einer abhängigen Entität in 1:n-Beziehung
Mit Hilfe der 1:n-Beziehung zwischen zwei Entitäten läßt sich zweierlei ausdrücken:
Existenzabhängigkeit
Beziehungstyp
Die Existenzabhängigkeit (Existenzvoraussetzung) drückt eine hierarchische Abhängigkeit aus, die :1Richtung ist immer eine Muß-Beziehung, die :n-Beziehung eine Kann-Beziehung. Diese
Existenzabhängigkeit besagt, daß ein Entity in der abhängigen Entitätenmenge (:n-Richtung) nicht
weiterexistieren kann, wenn das zugehörige Entity in der bestimmenden Menge (:1-Richtung)
verschwindet.
Der Beziehungstyp 1:n besagt, daß jeder Entität in der bestimmenden Menge bis zu n abhängige
Entitäten in der abhängigen Entitätenmenge zugeordnet werden können.
Beispiel einer möglichen Darstellung einer abhängigen Entität:
Zwischen Entität 1 und Entität 2 existiert eine 1:n-Beziehung
Entität 1
Entität 1 ist Parent von Entität 2, dadurch wird eine
hierarchische
Abhängigkeit
ausgedrückt
(Existenzvoraussetzung)
eine 1:1-Beziehung ist implizit enthalten
Entität 2
Abb.: Darstellung einer
abhängigen Entität
© GDV 1999
33
Spezifikation des Datenmanagers
Datenmanager
III.3.1.4.3. Entitytyp einer abhängigen Entität mit zwei Parents
Aufgrund der Minimalitätsanforderung wurde festgelegt, daß eine Entity maximal zwei Parents haben
soll. Beziehungen auf mehr als zwei Entity-Mengen und n:m-Beziehungen sollen durch Einführung
zusätzlicher Beziehungsentitäten aufgelöst werden.
Beispiel einer möglichen Darstellung einer abhängigen Entität mit zwei Parents:
es existiert jeweils eine 1:n-Beziehung zwischen Entität1 und
-3 sowie -2 und -3
Entität 1
Entität 2
jede Entität 3 muß genau einen Parent vom Typ Entität 1 und
genau einen Parent vom Typ Entität 2 haben
Entitäten vom Typ Entität 3 entstehen auch bei Auflösung
einer n:m-Beziehung zwischen Entität1 und -2 (Beziehungsentität)
Entität 3
Abb.: Entität mit zwei Parents
III.3.1.4.4. Entitytyp einer abhängigen Entität mit doppelter Parent-Beziehung
Als Spezialfall der Entität mit zwei Parents können diese auch vom selben Entitätstyp sein. Dieser Typ
entsteht auch bei der Auflösung einer rekursiven n:m-Beziehung
Beispiel einer möglichen Darstellung einer abhängigen Entität mit doppelter Parent-Beziehung:
Entität 1 ist Parent von Entität 2
Entität 1
jede Entität 2 hat genau zwei Parents vom Typ Entitität 1
es wird eine n:m-Beziehung zwischen Entitäten des Entitätstyps 1
ausgedrückt
III.3.1.4.5. Informationsobjekt
Entität 2
Abb.: abhängige Entität mit
doppelter ParentBeziehung
Es gibt Entitäten (und Relationships), die demselben zeitlichen
Änderungsdienst unterliegen. Deshalb muß es ein Sprachkonstrukt geben, das eine logische Klammer
für solche Entitäten und Relationships darstellt, das Informationsobjekt.
Das Informationsobjekt ist also die Zusammenfassung von Entitäten, die derselben Zeitlogik
(Versionsführung) unterliegen, und die einen gemeinsamen Änderungsdienst haben. Dadurch kann
sehr häufig auf eine Versionsbestimmung verzichtet werden.
34
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Jedes Informationsobjekt enthält genau eine Entität, die von keiner anderen Entität des gleichen
Informationsobjekts abhängig ist (Bezeichnung: z.B. Führungsentität).
Beispiel einer möglichen Darstellung eines Informationsobjekts:
alle Entitäten, die innerhalb eines Informationsobjektes
liegen,
unterliegen
derselben
Zeitlogik
(Versionsführung); d.h. sie werden alle geändert, wenn
eine der beteiligten Entitäten eine neue Version erhält.
jedes Informationsobjekt
Führungsentität (FE)
enthält
genau
eine
die FE ist von keiner innerhalb des Informationsobjektes liegenden Entität abhängig
Abb.: Darstellung eines
Informationsobjekts
III.3.1.5. Beispiel eines E/R-Modells
Um die Liste der Minimalkonstrukte anschaulich zu verdeutlichen zu können, wird ein vereinfachtes
Beispiel aus dem Versicherungsbereich erläutert.
Police
Person
Pol/Per
Objekt
Vertrag
Per/Obj
Gefahr
Gef/Per
Gef/Obj
Abb.: Beispiel eines ER-Modells
In diesem Beispiel wird folgender Sachverhalt dargestellt:
Eine Police enthält keinen oder mehrere Verträge.
Ein Vertrag bezieht sich auf keine oder mehrere abzusichernden Gefahren (Risiken).
Ein Vertrag kann mehrere Sonderbedingungen enthalten, z.B. Zu- und Abschläge für bestimmte
Personengruppen wie Garagenparker, Wenigfahrer usw.
Zwischen Police und Person besteht die n:m-Relationship Pol/Per,
z.B. Versicherungsnehmer.
© GDV 1999
35
Spezifikation des Datenmanagers
Datenmanager
Zwischen Gefahr und Person besteht die n:m-Relationship Gef/Per, z.B. Unfall oder Leben.
Zwischen Gefahr und Objekt (z.B. Haus oder Kfz) besteht die n:m-Relationship Gef/Obj, z.B.
Hausrat- oder Kfz-Versicherung.
Zwischen Person und Objekt besteht die n:m-Relationship Per/Obj, z.B. Eigentümer.
Eine Gefahr kann Nebengefahren (Gef/Gef) beinhalten, z.B. Glasgefahr im Hausrat.
Die Entitytypen (und Relationshipstypen) Police, Vertrag, Gefahr, Pol/Per, Gef/Per und Gef/Obj
besitzen dieselbe Zeitlogik-Klammer, ihre konkreten Entities unterliegen demselben zeitlichen
Änderungsdienst (Versionierung), befinden sich im selben Informationsobjekt.
Person und Per/Obj haben einen eigenen Änderungsdienst und Objekt besitzt wieder eine eigene
Versionierung. In diesem vereinfachten Beispiel lassen sich also alle Entitäten drei verschiedenen
Informationsobjekten mit den Führungsentitytypen Police, Person und Objekt zuordnen.
Dies ist plausibel, denn die Änderung in einer Police muß keine Änderungen der Personendaten
bedeuten, eine Änderung der Personendaten (Name, Adresse, ...) bedeutet umgekehrt keine Änderung
in Policen, abzusichernden Gefahren usw.
III.3.2. Physisches Datenmodell
Das physische Datenmodell enthält eine Beschreibung aller Tabellen, Segmente usw, die die Entitäten
des logischen Modells abbilden. DB2-Tabellen, IMS-Segmente, ADABAS-Files usw. fassen wir unter
dem Begriff „physische Entitäten“ zusammen.
Die Beschreibung des physischen Modells umfaßt dabei nur die Informationen, die für die
Generierung von physischen Datensichten notwendig sind.
Im Regelfall können aus dem physischen Modell keine Datenbanken erzeugt werden, da nicht alle der
für diesen Zweck erforderlichen Parameter Bestandteil des physischen Modells sind.
Im wesentlichen enthält das physische Datenmodell physische Entitäten mit der folgenden groben
Struktur je Entität:
Namen
Typ (z.B. IMS-.., DB2-..., Adabas-..., Oracle-..., ...)
Attribute der physischen Entität
Zugriffschlüssel (primary, alternate keys)
Beziehungen (Beziehungen der physischen Entitäten untereinander)
III.3.3. Abbildung zwischen logischem und physischem Modell
Bei dieser Abbildung werden logische Entitäten als Einheiten betrachtet und als Ganzes einer
physischen Entität zugeordnet.
36
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Grundsätzlich muß zwischen zwei verschiedenen Aufgabenstellungen unterschieden werden:
der Abbildung eines aus einer fachlichen Modellierung gewonnenen logischen Datenmodells auf
ein vorhandenes, nicht zu änderndes physisches Modell und
der Konstruktion und Definition eines neuen (oder zu ändernden) physischen Modells aus dem
logischen Modell.
Im ersten Fall besteht nur die Möglichkeit des Modellabgleichs und der Zuordnung der vorhandenen
physischen Strukturen zu den Entitäten des logischen Modells. Ob das zu realisierte System dann
performant läuft, hängt dann davon ab, ob die Punkte, die bei der Konstruktion des physischen
Modells die entscheidende Rolle spielen (s.u.), zu dem vorhandenen physischen Modell passen.
Im zweiten Fall der teilweisen oder vollständigen Neugestaltung des physischen Systemes aufgrund
eines neuen logischen Designs kann man zunächst mit der Grundannahme einer 1:1-Abbildung von
logischen Entitäten auf physische ausgehen und später gegebenenfalls auf der Grundlage der
folgenden Konstruktionsregeln die entstandenen physischen Entitäten. Dabei sind folgende Punkte zu
berücksichtigen:
Typ des Zieldatenbanksystems
Mächtigkeit der Zieldatenbanksysteme
Datenvolumina und -verteilung
Zugriffshäufigkeiten
Antwortzeitanforderungen
regionale Datenverfügbarkeitsanforderungen
reale Besetzungshäufigkeiten von Attributen und Relationen
Diese Anforderungen werden teilweise im Rahmen der Möglichkeiten des Zieldatenbanksystems
„unsichtbar“ für das Anwendungsprogramm / für den Datenmanager gelöst.
Nachdem der Datenmanager potentiell die unterschiedlichsten Datenbanksysteme unterstützen soll,
werden jedoch die Anforderungen an die Modelltransformation kaum verringert.
In Anbetracht der hohen Performanzanforderungen an Versicherungsanwendungen kommt der
Ausnutzung der realen Möglichkeiten der Zieldatenbanksysteme hohe Bedeutung zu.
© GDV 1999
37
Spezifikation des Datenmanagers
Datenmanager
III.3.3.1. Abbildungsregeln
Der Abbildungsvorgang stellt einen kreativen Entwicklungsschritt dar, und ist daher nicht durch
Generierung zu erledigen.
Die Rücksichtnahme auf effiziente Abbildungsmöglichkeiten des Zieldatenbanksystemtyps ist
essentiell. Dabei wird unterschieden in:
hierarchische DBMS (z.B. IMS-DB)
Netzwerk-DBMS (z.B. UDS)
relationale DBMS (z.B. Oracle, DB2)
relationales DBMS mit hierarchischen Erweiterungen (z.B. Adabas)
indizierte Dateien (z. B. VSAM, ISAM)
Folgende zusammenfassende Tabelle zeigt die wichtigsten Abbildungsregeln:
ERElement
hierarchis Netzwerk
relational
ch
relational
indizierte
mit
Dateien
hierar.
Erw.
unabhängi-
Segment
ge Entität
Record-
Tabelle
File
Datei
Type
abhängige
im
Set-Type
Tabelle
n-File
Datei oder
Entität
Segment
oder im
oder in
oder PE
in der Datei
(1:n-
der n-
Record-
Tabelle der
bzw. MU
der n-
n-Entität
in der 1-
Entität
Beziehung) Entität oder Type der
Child-
n-Entität
File
Segment
des 1Objekts
abhängige
Child-
Record-
Entität mit
Segment
Type mit
PE bzw.
zwei
unter dem
zwei Set-
MU in der
Parents
n- oder m-
Types
n- oder
Segment
Tabelle
File oder
Datei
m-File
III.3.3.2. Optimierungskonstrukte
Neben der rein logischen Abbildungsmöglichkeit im Ziel-DBMS ergeben sich aus der
Anwendungsstruktur und aus den realen Dateninhalten des Produktionssystems Optimierungsbedarfe.
38
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.3.2.1. 1:1 - Abbildung
Einer Entität des logischen Datenmodells ist genau ein Objekt des physischen Datenmodells (ein IMSSegment, eine DB2-Tabelle usw.) zugeordnet.
III.3.3.2.2. Aggregation
Mehrere Entitäten des logischen Datenmodells werden zu einer Einheit des physischen DM’s
zusammengefaßt.
Typ 1: Zusammenfassung von Entitäten einer Version.
Typ 2: Zusammenfassung von Entitäten mehrerer Versionen.
Achtung: Im Regelfall ergeben sich daraus zahlenmäßige Einschränkungen (z.B. nur x Vertreter pro
Vertrag möglich).
III.3.3.2.3. Vertikale Partitionierung
Eine Entität des logischen DM wird auf mehrere Einheiten des physischen DM’s verteilt, indem eine
Zuordnung auf Attributsebene erfolgt.
Beispiel: getrennte Speicherung von Attributen mit seltenen Zugriffen
III.3.3.2.4. Horizontale Partitionierung
Eine Entität des logischen DM wird auf mehrere Einheiten des physischen DM’s verteilt, indem eine
Zuordnung auf Schlüsselebene erfolgt.
Beispiel: Regionalisierung, Spartenordnung von Policen
III.3.3.2.5. Redundanz
Entitäten (oder Teile davon) werden physisch redundant gespeichert, d.h. es erfolgt eine parallele
Zuordnung zu mehreren physischen Einheiten.
Zweck: Vereinfachung des Zugriffs auf Daten für häufige Zugriffskombinationen.
Beispiel: Speicherung
von
expandierten
Textbausteinen
in
Archivdatenbanken
oder
Drucksteuerdateien.
Achtung:
Redundanz
erfordert
immer
organisatorische
Einschränkungen
oder
zusätzliche
Funktionalität zwecks Erhaltung der Konsistenz.
© GDV 1999
39
Spezifikation des Datenmanagers
Datenmanager
III.3.3.3. Transformationsdokumentation
Wie bereits festgehalten, stellt die Transformation vom logischen auf das physische DM einen
kreativen Designakt dar, der Stand heute nicht automatisierbar ist.
Neben dem Hauptergebnis physisches Datenmodell ist die Transformation selbst als wichtiges
Ergebnis festzuhalten, da diese Abbildungen einen wesentlichen Input für die automatisierte
Zuordnung von logischer auf physische Datensichten darstellen:
Logische Entität/Attribut x ist implementiert in physischem Objekt y, möglicherweise mit
Selektionskriterium (bei Partitionierung).
Relation x ist implementiert in Objekt/File/Set/Datei/Segment/Attribut y.
Redundanz entsteht dadurch, daß eine logische in mehrere physische Entitäten abgebildet
wird. Der Datenmanager muß die Konsistenz gewährleisten. Dazu sind funktionale
Abbildungsregeln festzulegen.
Diese Dokumentation hat zwecks maschineller Weiterbearbeitung im Parametersystem zu erfolgen.
Die Konsistenz zwischen dem logischen und physischen Modell ist sicherzustellen. Hilfestellung
hierbei gibt die ausschließliche Verwendung der obenbeschriebenen Konstruktionsregeln zur
Erstellung physischer Entitäten.
III.3.4. Logische Datensicht
III.3.4.1. Schnittstellenbeschreibung durch Datensichten
Ein wichtiges Ziel der VAA ist die Beschreibung einer komponentenbasierten Architektur, bei der die
Schnittstelle der einzelnen Bausteine auf logischer Ebene durch sog. „Datensichten“ beschrieben sind
und somit eine Abstraktion von technischen Gegebenheiten gewährleistet wird. Die Umsetzung der
logisch spezifizierten Funktionalität an der Schnittstelle in technische Programmaufrufe und physische
Datenbeschaffung muß durch Mittel des technischen Rahmenwerks, wie es von der VAA definiert
wird, bewerkstelligt werden. Dadurch wird die Integrationsfähigkeit von Funktionsbausteinen
gewährleistet und für die Anwendungsentwickler wesentlich erleichtert.
Um die an der Anwendungsschnittstelle bereitzustellenden Daten logisch beschreiben zu können,
bedarf
es
geeigneter
Beschreibungsmittel
(„Datensichtsprache“),
die
folgende
Darstellungsmöglichkeiten bietet:
Beschreibung, welche Datentypen (Festlegung des Modellausschnitts) und welche Datenmengen
(Selektionsbedingungen) an der Anwendungsschnittstelle zur Verfügung gestellt werden sollen
Beschreibung der Anordnung der Daten bzgl. Reihenfolge, Gruppierung, Hierarchie, Alternativen,
... (Struktur der Daten)
Einen guten Anhaltspunkt zur Definition einer solchen Datensichtsprache liefert die JacksonEntwurfsmethodik mit ihren Beschreibungsmitteln. Die Jackson-Entwurfsmethode verfolgt Ziele, die
40
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
ebenso durch die VAA-Anwendungsarchitektur erreicht werden sollen. Die wichtigsten Ziele der
Jackson-Methode sind:
Die Programmstruktur soll die Problemstruktur widerspiegeln.
Entwerfen heißt Struktur beschreiben und ermitteln.
Programmstrukturen sollen auf Datenstrukturen basieren; Programmkomponenten sollten 1:1 mit
den Datenkomponenten verbindbar sein.
Die Kernthese von Jackson ist, daß sich die folgenden 4 Komponententypen sowohl in den
Datenstrukturen als auch in den Programmstrukturen zeigen:
atomare Komponenten / einzelne Anweisungen (Funktionsmodule)
zusammengesetzte Komponenten
Sequenz
2 oder mehr je einmal vorkommende,
aufeinanderfolgende Teile
Sequenz
1 Teil, welches 0 oder mehrmals auftritt
Selektion
2 oder mehr Teile, von denen genau eines auftritt
Jackson macht für diese Komponenten auch einen Darstellungsvorschlag.
Jedes Programm (für eine serielle Maschine) kann durch eine Folge von Sequenzen, Iterationen und
Selektionen ausgedrückt werden. Die VAA stützt sich auf die Jackson-Thesen, nutzt dessen
Komponentenstrukturierung und orientiert sich für die Symbolik an den Jackson-Vorschlägen, die
natürlich nur Beschreibungsmöglichkeiten darstellen.
III.3.4.2. Definition von Datensicht und Datensichtsprache
Eine Datensicht beschreibt
1. einen bestimmten Ausschnitt von Entitäten aus dem logischen Datenmodell
2. die zu Treffern führenden Selektionsbedingungen (Datensicht-Selektion)
3. die von der Funktion angeforderte Anordnung dieser Treffer (Datensicht-Struktur)
4. Funktionalität zum Aufbau der Anwendungsschnittstelle
Die Datensicht-Selektion beschreibt die Regeln und Bedingungen, mit welchen die Treffer einer
Datensicht bestimmt werden. Es gibt vier Arten von Selektionsbedingungen:
Selektionsbedingungen, die sich auf das Vorhandensein von Entitäten oder Pfaden beziehen
Selektionsbedingungen, die sich auf Attributswerte beziehen und dadurch den Umfang der
Ausgabemenge definieren (Mengendefinitionen: Attributswert =, >, <, UND und ODERSchachtelungen)
Selektionsbedingungen, die sich auf bestimmte Eigenschaften der Entitäten/Instanzen in Bezug auf
andere Instanzen der Entitymenge beziehen (z.B. Versionsbedingungen: aktuelle, neueste, älteste,
... oder Zeitbedingungen: Vorgänger, Nachfolger, ...)
© GDV 1999
41
Spezifikation des Datenmanagers
Datenmanager
Selektionsbedingungen, die sich auf die Menge aller diese Entitymenge betreffenden Entitäten
beziehen (z.B. MINDESTENS-EIN, ALLE, NICHT-ALLE ... Entitäten, die eine bestimmte
Eigenschaft besitzen)
Die Datensicht-Struktur beschreibt die Anordnung (Reihenfolge, Gruppierung und Hierarchie,
Alternativen) der durch die Datensicht-Selektion ermittelten Instanzen von Entitytypen (Treffern), wie
sie von der Anwendung angefordert wird.
Mit Hilfe der Datensichtsprache wird eine Datensicht auf logischer Ebene formuliert.
III.3.4.3. Anforderungen an eine Datensichtsprache
Aufgrund der Definition der Datensicht und der Beschreibung ihres Verwendungszwecks ist dann
klar, welche Anforderungen an eine Datensichtsprache gestellt werden:
Die Reihenfolge, in der Instanzen bestimmter Entitytypen nach der Selektion geliefert werden, muß
definiert werden können.
Parameter, die für die Selektion von Entitäten entscheidend sind und die aus Anwendungsprogrammen mitgegeben werden, müssen festgelegt werden können.
Für die Selektion von Instanzen von Entitytypen müssen Attributsbedingungen formuliert werden
können.
Die Sprachsyntax muß sicherstellen, daß die Wege, die zwischen Entitäten zurückgelegt werden
sollen, vorgegeben werden können.
Die Sprache muß Möglichkeiten für die Zeitnavigation zwischen Informationsobjekten und für die
Zeitnavigation zwischen Entitätsversionen bereitstellen.
Die Sprache muß die Bildung von ‘UND-’ und ‘ODER-’Konstrukten zwischen Attributsbedingungen und Navigationswegen unterstützen, ebenso die Verschachtelung dieser Konstrukte.
Wie bei der Festlegung der Konstrukte der E/R-Sprache gilt auch hier eine entsprechende Minimalanforderung.
III.3.4.4. Minimal-Konstrukte der Datensichtsprache
III.3.4.4.1. Struktur-Elemente zur Beschreibung der logischen Datensicht
Eine Datensicht selbst wird gekennzeichnet durch:
ihren logischen Namen
einen Verweis auf das logische Datenmodell
einen Verweis auf die zugehörige Anwendungsschnittstelle
Eine mögliches Darstellungsymbol einer Datensicht ist der Datensicht-Label:
42
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Datensicht
z.B. Doku-Dasi: Datensicht, die die Daten zum
Ausdruck eines Versicherungs-Scheins bereitstellt.
Die wesentlichen Elemente, aus denen sich eine
Datensicht zusammensetzt sind die Entitätsmengen. Jedem Element der Ausgabestruktur kann eine
Entity-Menge des logischen Datenmodells zugeordnet werden. (Zur Laufzeit bestimmt die Menge der
den Selektionsbedingungen entsprechenden Daten den Umfang der Ausgabemenge.)
Dabei muß zwischen den Ausgabeentitätsmengen (AEM), die Daten in der Ausgabestruktur der
Anwendung beschreiben, und Datensichtentitäten (DSE), die nur innerhalb der Datensicht zur
Navigation zu den Daten oder zur Beschreibung von Selektionsbedingungen relevant sind,
unterschieden werden.
Mögliche Darstellungssymbole für diese Konstrukte sind:
Ausgabeentitätsmenge (AEM)alle
Daten,
Schnittstelle
werden
Datensichtentität (DSE)
Daten,
die
Schnittstelle
werden
die
nicht
an
die
übergeben
an
die
übergeben
Die Ausgabestruktur des Datenmanagers entspricht der Ausgabestruktur der Anwendung. Damit muß
die Datensichtsprache folgende Elemente abdecken:
Hierarchie
Sequenz
Alternative (Case-Konstrukt)
Iteration
Mit diesen Elementen wird die äußere Struktur einer Datensicht beschrieben, sie beziehen sich jeweils
auf die Gesamtheit der jeweiligen Entität (AEM oder DSE).
Mögliche Darstellungssymbole für diese Konstrukte Hierarchie, Sequenz, Alternative (CaseKonstrukt) und Iteration sind:
© GDV 1999
43
Spezifikation des Datenmanagers
Hierarchie
Sequenz
Datenmanager
Eine Sequenz wird z.B. durch nebeneinander angeordnete Entitäten (AEM) in der Ausgabestruktur
interpretiert.
44
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Alternative (Case-Konstrukt)
Die Abarbeitung des Case-Konstruktes erfolgt von links nach rechts, wobei die zuerst zutreffende
Alternative ausgewählt wird, die danach folgenden bleiben unberücksichtigt (exclusives Oder).
Iteration
Aufgrund der oben definierten Sprachkonstrukte
zeigt das folgende Beispiel eine AEM-Struktur
mit einer Sequenz aus zunächst drei AEM, wobei
die zweite AEM eine Hierarchie und die dritte
ein Case-Konstrukt enthält:
Die beiden folgenden Datensichten „Dasi XY“
und „Dasi YZ“ unterscheiden sich in der Frage,
ob der Vertrag zur Ausgabestruktur gehört oder
nicht zur Ausgabestruktur gehört und nur zur
Navigation zu den abhängigen Entity-Mengen
Gefahr
und
Sonderbedingungen-Vertrag
(SobVer) benötigt wird:
© GDV 1999
Abb.: Sequenz und Case-Konstrukt
45
Spezifikation des Datenmanagers
Datenmanager
Datensicht nur mit AEMs
Dasi XY
Police
Vertrag
SobVer
Gefahr
Datensicht mit AEMs und DSEs
Dasi YZ
Police
Vertrag
Gefahr
Vertrag
SobVer
Die folgende Datensicht „Dasi XZ“ zeigt eine Iteration mit AEM „Agentur“ und DSE „Ag-bez“:
Dasi XZ
Agentur
Ag-bez
Agentur
III.3.4.4.2. Strukturierung innerhalb einer AEM
Die folgenden Elemente betreffen die Strukturierung der Ergebnismengen.
Sortierung
Begrenzung der Ausgabe
46
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Erläuterung:
Auf ein Sprachelement für Gruppenwechsel wird verzichtet, weil es sich hier um kein
Minimalkonstrukt handelt. Da auf unterster Ebene immer konsolidiert (Eliminierung von
Mehrfachtreffern) wird, benötigt man auch kein eigenes Beschreibungselement dafür.
III.3.4.4.3. Selektionsbedingungen
Wie bei der Definition einer Datensicht beschrieben wurde, ist zwischen vier unterschiedlichen Arten
von Selektionsbedingungen in der Datensicht zu unterscheiden. Diese werden im folgenden behandelt.
III.3.4.4.3.1. Selektionsbedingungen durch Pfade
Pfade sind durch folgende Eigenschaften gekennzeichnet:
Pfade zeigen gerichtete Verbindungen, die die Ausgabeentitäten bestimmen.
Auf einem Pfad können mehrere Datenmodellentitäten angegeben sein
Ein Pfad kann sich aus mehreren Elementarpfaden zusammensetzen. (Ein Elementarpfad
beschreibt die direkte gerichtete Beziehung von Entitäten.)
Zwischen zwei Ausgabeentitäten können mehrere Pfade angegeben werden, die mit UND bzw.
ODER verknüpfbar sind.
Das UND-Konstrukt liefert eine Durchschnittsmenge als AEM, während das ODER-Konstrukt eine
Vereinigungsmenge als AEM liefert.
Schachtelungen von UND- und ODER-Konstrukten sind möglich.
© GDV 1999
47
Spezifikation des Datenmanagers
Datenmanager
Mögliche Darstellungen:
UND
Schachtelung von UND/ODER
ODER
Police
Police
Vertrag
Vertrag
Gefahr
Pol/Per
Gefahr
Pol/Per
Gef/Per
Gef/Per
Person
Person
In den obigen Beispielen wurden jeweils Pfade beschrieben, die die Navigation von einer Entität zu
einer Ausgabeentität beschreiben (Navigationspfad). Will man Bedingungen formulieren, wird von
der Ausgabeentität ausgehend eine Bedingung überprüft (Bedingungspfad).
Im folgenden Beispiel erfolgt eine Navigation von „Police“ über „Vertrag“ zur „Gefahr“; Die „GefahrObjekt“ Beziehung (Gef/Obj) stellt eine Bedingung für die AEM „Gefahr“ dar:
Police
NavigationsPfad
Vertrag
Gefahr
Gef/Obj
BedingungsPfad
Durch den Bedingungspfad von Gefahr zu Gef/Obj wird erreicht, daß nur solche Gefahren ausgewählt
werden, bei denen bestimmte Bedingungen, die sich auf die Entität Gef/Obj beziehen, erfüllt sind.
48
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Bedingungen können genauso durch UND und ODER verknüpft werden und Schachtelungen von
UND und ODER in Bedingungen sind möglich.
Beispiele:
UND
ODER
VTPlan
Police
Police
SobVer
SobVer
VTP/Ve
VTP/Ve
Vertrag
Vertrag
Gefahr
Gefahr
Schachtelung von UND und ODER
© GDV 1999
49
Spezifikation des Datenmanagers
Datenmanager
Nun muß noch unterschieden werden, ob die Pfade dadurch zustande kommen, daß Entity-Mengen im
logischen Datenmodell zueinander in Beziehung stehen (Modellpfad), oder dadurch, daß eine
Beziehung zwischen mehreren Versionen derselben Existenz bestehen (Zeitpfad). Dieser Unterschied
läßt sich z.B. durch andere Darstellung der Kanten ausdrücken:
Modellpfad
Zeitpfad
Zusammenfassung unterschiedlicher Pfadtypen in Datensichten:
Navigationspfad
Ein Navigationspfad ist ein Pfad, der von einer Ausgabeentität über beliebig
viele Datensichtentitäten zu einer Ausgabeentität führt.
Bedingungspfad
Ein Bedingungspfad ist ein Pfad, der von einer Ausgabeentität ausgeht.
Elementarpfad
Ein Elementarpfad beschreibt die direkte gerichtete Beziehung von Entitäten.
Modellpfad
Ein Modellpfad ist ein Elementarpfad, bei dem die direkte gerichtete Beziehung zwischen zwei Entity-Mengen im logischen Datenmodell besteht.
Zeitpfad
Ein Zeitpfad ist ein Elementarpfad, bei dem die direkte gerichtete Beziehung
zwischen mehreren Versionen derselben Existenz besteht.
III.3.4.4.3.2. Feldbezogene Selektionsbedingungen (Attributsbedingungen)
Attributsbedingungen sind durch folgende Eigenschaften gekennzeichnet:
Attributsbedingungen können für Entitäten des logischen Datenmodells formuliert werden.
Zulässige Vergleichs-Operatoren sind: =, >, <, >=, <=, N=.
Attributsbedingungen können mit 'UND' und 'ODER' verknüpft werden.
Attributsbedingungen können sich auf mehrere Felder beziehen.
Zulässige Vegleichs-Operanden sind: Literal, Parameter, Attribut.
50
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Schachtelungsmöglichkeiten der Attributsbedingungen: UND- und ODER- Klammern können
geschachtelt werden.
III.3.4.4.3.3. Entitätsbezogene Selektionsbedingungen
Bei den Entitätsbezogenen Selektionsbedingungen muß zwischen Versionsbedingungen und
Zeitbedingungen unterschieden werden:
Versionsbedingungen
Versionsbedingungen können für die der Ausgabeentität oder die einer Station des Pfades
zugeordnete Entität des logischen Datenmodells formuliert werden.
Zulässige Versionsbedingungen sind:
Aktuell
Neueste
Älteste
Stichtag
Version
Zeitbedingungen
Zeitbedingungen können bei Zeitpfaden verwendet werden.
Zeitbedingungen formulieren Bedingungen, die Versionen einer bestimmten Entität in Beziehung
setzen.
Voraussetzung ist, daß die zugeordneten Entitäten des logischen Datenmodells identisch sind.
Es gibt folgende Bedingungen:
Identität
Vorgänger
Nachfolger
alle Nachfolger
III.3.4.4.3.4. Mengenbedingungen
Mengenbedingungen für eine AEM beziehen sich auf die Menge aller von dieser AEM abhängigen
DSEs, die sich auf dem Bedingungspfad befinden, d. h. sie werden für Bedingungspfade formuliert.
Es gibt folgende Mengenbedingungen:
MINDESTENS-EINER
ALLE
NICHT-ALLE
KEINER
© GDV 1999
51
Spezifikation des Datenmanagers
Datenmanager
III.3.4.4.4. Beispiele von Datensichten
III.3.4.4.4.1. Beispiel für einen AEM-Baum ohne Verzweigung
Datenmodell:
Instanzen:
Pol2
Pol1
Pol
V
V1
V3
V2
V4
V7
V6
V5
G
G1
Datensicht:
G2
G3
G4
G5
G6
G7
G8
Treffer:
Pol1
Pol
V1
G1
V2
G2
G3
V3
G4
G5
G6
V
Pol2
V4
G7
V5
G8
V6
V7
G
Bei diesem Beispiel werden ausgehend von einem Pol alle zugehörigen V ermittelt, d. h. zu Pol1 sind das V1,
V2 und V3 und zu Pol2 sind das V4, V5, V6 und V7. Dann werden zu jedem V die zugehörigen G ermittelt.
52
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.4.4.4.2. Beispiel für einen AEM-Baum mit Verzweigung
Datenmodell:
Instanzen:
Pol2
Pol1
Pol
V4
V6
V5
V7
SOBV63
V
V1
G
V3
V2
G7
SOBV51
G8
SOBV62
SOBV61
SOBV
SOBV31
G3
G1
G2
SOBV12
G4
G6
G5
SOBV11
Datensicht:
Treffer:
Pol1
V1
Pol
SOBV11
SOBV12
G1
G2
V
V2
G3
V3
SOBV31
G4
G5
G6
SOBV
G
Pol2
V4
G7
V5
SOBV51
G8
V6
SOBV61
SOBV62
SOBV63
Bei diesem Beispiel werden ausgehend von
V7
einem Pol alle zugehörigen V ermittelt, d. h.
zu Pol1 sind das V1, V2 und V3 und zu Pol2 sind das V4, V5, V6 und V7. Dann werden zu jedem V
zuerst (Abarbeitung der Datensicht von links nach rechts) die zugehörigen SOBV und dann die
zugehörigen G ermittelt.
© GDV 1999
53
Spezifikation des Datenmanagers
Datenmanager
III.3.4.4.4.3. Beispiel für einen AEM-Baum mit einem CASE-Konstrukt
Datenmodell:
Instanzen:
Pol1
Pol2
P
Pol1P11
Pol
Pol1P21
Pol1P31
PolP
SOBV63
V
Pol2P11
Pol2P41
G
V7
V6
V5
V4
V3
G7
SOBV51
V1
SOBV62
SOBV61
G8
Pol2P42
P1
SOBV
V2
Pol2P51
P2
SOBV31
G3
P3
P4
P5
G2
G1
G4
G5
G6
SOBV12
SOBV11
Datensicht:
Treffer:
Pol1
V1
G1
G2
Pol
V2
G3
V3
G4
G5
G6
V
PolP
Pol2
G
SOBV
P
Pol1P11
P1
Pol1P21
P2
Pol1P31
P3
V4
G7
V5
G8
V6
SOBV61
SOBV62
SOBV63
Bei diesem Beispiel werden ausgehend von einem Pol alle
zugehörigen V und alle zugehörigen PolP ermittelt, d. h. zu Pol1
sind das sowohl V1, V2 und V3 als auch Pol1P11, Pol1P21 und
V7
Pol2P11
P1
Konstruktes bei V werden zunächst die zugehörigen G ermittelt,
Pol2P41
P4
gibt es solche, bleiben die SOBV unberücksichtigt: Zu V1 werden
Pol2P42
P4
Pol2P51
P5
Pol1P31. Analoge Ermittlung gilt für Pol2. Wegen des CASE-
deshalb nur G1 und G2 ermittelt. Nur wenn wenn es keine G gibt
,werden SOBV ermittelt, zu V6 gibt es deshalb SOBV61, SOBV62
und SOBV63.
Zu den PolP werden alle P ermittelt.
54
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.4.4.4.4. Beispiel für eine AEM, deren Instanzen sortiert werden (mit
Festlegung der maximal auszugebenden Instanzen)
Datenmodell:
Instanzen:
Pol1
P
Pol
Pol2
Pol1P11
Pol1P21
PolP
V4
V7
V6
V5
Pol1P31
V
V2
Pol2P11
SOBV63
G7
V3
KZA=3
SOBV51
KZA=1
V1
SOBV61
G8
KZA=2
Pol2P41
G
Pol2P42
P1
SOBV
SOBV62
Pol2P51
P2
SOBV31
G3
P3
G2
P4
G1
P5
G4
G5
G6
SOBV12
SOBV11
Datensicht:
Treffer:
Pol1
Pol
PolP
P
V
Pol2
V1
G1
V2
G3
V3
G4
V4
G7
V5
G8
V6
SOBV63
SOBV61
V7
MX:1
G
SD:KZA
MX:2
SOBV
MX:1 bzw. MX:2 beschränkt die Ausgabemenge auf 1 zw. 2 Treffer.
SD:KZA gibt das Sortierkriterium und die Sortierreihenfolge (D=descending) an.
© GDV 1999
55
Spezifikation des Datenmanagers
Datenmanager
III.3.4.4.4.5. Beispiel für ein Schnittmengen-Konstrukt
Datenmodell:
Instanzen:
Pol1
P1
P2
P3
P
Pol
V
V1 V2
PolP
Pol1P3
Pol1P1 Pol1P2
G
G1
GP
G2
G2P2
G1P1
Datensicht:
Treffer:
Pol1
Pol
P1
P2
PolP
V
G
GP
P
P3 erscheint nicht in der Ergebnismenge, weil P3 nicht über den Weg V > G > GP erreichbar ist (P3
ist von keinem GP erreichbar).
56
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.4.4.4.6. Beispiel für eine Schachtelung von einem SchnittmengenKonstrukt in einem Vereinigungsmengen-Konstrukt
Datenmodell:
Instanzen:
Pol1 Pol2 Pol3
P
Pol
V2
V1
V3
O1
V4
O2
O3
O4
O5
V
O
G
G1
G2
G3
G4
GP
G4O4
GPO
P1
P3
P2
GO
G2P1
G3P2
G4P3
G3O1
G2O2
G1O12
G1O11
G3O3
G1O12O3
G1O12O1
G4P3O5
GOO
G3P2O4
G2P1O3
G2P1O1
Datensicht:
Treffer:
Pol
Pol1
G1
G3
V
Pol2
G
G
GP
G4
Pol3
GO
GO
GPO
GOO
O
O
GO
G
Ausgangsbasis Pol1: Von Pol1 zu V1 (über V2 gibt es keine Treffer, weil V2 aus keine Beziehungen zu G
bestehen). Von V1 zu G1 und G2.
Von G1 zu G1O11 und G1O12. Von G1O11 zu O1, ebenso von G1O12 zu O1.
© GDV 1999
57
Spezifikation des Datenmanagers
Datenmanager
Von G1O11 aus ist kein GOO erreichbar, aber von G1O12 sind G1O12O1 und G1O12O3 erreichbar. Von
G1O12O1 aus kann wiederum O1 erreicht werden. Deshalb ist O1 eine ‘Zwischenlösung’.
Von O1 aus sind G1O11 und G1O12 erreichbar und von G1O11 aus gelangt man zu G1.Damit ist G1 ein
Treffer, der zu Pol1 gehört und über den rechten Pfad des Vereinigungskonstruktes erreicht wird.
Von Pol1 aus gelangt man über V1 zu G2, von G2 zu G2P1, von G2P1 zu G2P1O3, von G2P1O3 zu O3, von O3
zu G3O3 und G3O3 zu G3.
G4 wird über den linken Pfad erreicht.
58
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.4.4.4.7. Beispiel für eine Schachtelung von einem VereinigungsmengenKonstrukt in einem Schnittmengen-Konstrukt
Datenmodell:
Instanzen:
Pol1 Pol2 Pol3
P
Pol
V2
V1
V3
O1
V4
O2
O3
O4
O5
V
O
G
G1
G2
G3
G4
GP
G4O4
GPO
P1
P2
P3
GO
G2P1
G3P2
G4P3
G3O1
G2O2
G1O12
G1O11
G3O3
G1O12O3
G1O12O1
G4P3O5
GOO
G3P2O4
G2P1O3
G2P1O1
Datensicht:
Treffer:
Pol1
G1
G3
Pol
Pol2
V
Pol3
G
G
GP
GO
GO
GPO
GOO
O
O
GO
G
G4 ist nicht über den rechten Pfad erreichbar und deshalb nicht in der Ergebnismenge.
© GDV 1999
59
Spezifikation des Datenmanagers
Datenmanager
III.3.4.4.4.8. Beispiel für einen Bedingungspfad
Datenmodell:
Instanzen:
Pol1
V3
V1
Pol
V2
O1
O2
O
V
G3
G1
G
G4
G5
G6
O3
G7
G2
GO
G1O1
G2O1
G3O2
G4O3
G5O1
G6O3
G7O2
KZ=5
KZ=8
KZ=5
KZ=8
KZ=2
KZ=6
KZ=7
Datensicht:
Treffer:
Pol1
Pol
V2
G4
V3
G5
G6
O
GO
G7
KZ=8
G
V
G
Zuerst werden die Verträge ermittelt, bei denen für die abhängigen GOs gilt: KZ=8. Derartige
Verträge sind V2 und V3. Zu diesen werden jeweils alle Gefahren ermittelt.
60
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.4.4.4.9. Beispiel für ‘NICHT-ALLE’
Datenmodell:
Instanzen:
Pol1
Pol
V1 V2
V
O
G
G3
G1
G4
G5
G2
O1
O2 O3
O4
GO
G1O1
KZ=3
Datensicht:
G1O2
KZ=4
G2O3
KZ=5
G3O1
KZ=3
G3O2
KZ=3
G4O4
KZ=3
Treffer:
Pol1
V1
Pol
G1
G2
V2
G5
V
GO
KZ= 3
NICHT-ALLE
G
G1 gehört zur Ausgabemenge, weil nicht bei allen GOs gilt: KZ=3 (G1O2 hat KZ=4)
© GDV 1999
61
Spezifikation des Datenmanagers
Datenmanager
III.3.4.4.4.10. Beispiel für ‘KEINER’
Datenmodell:
Instanzen:
Pol1
Pol
V
V1
V2
V3
O
G
G1
GO
G1O1
G2 G3
KZ = KFZ
Datensicht:
G1O2
KZ = BUS
G4
G5
O1
G2O1
KZ = KFZ
G3O3
KZ = BUS
G4O3
KZ = LKW
O3
G4O2
KZ = LKW
Treffer:
Pol1
Pol
O2
V1
V2
V3
G3
G4
G5
V
GO
KZ= KFZ
KEINER
G
Über V1 gibt es kein G, weil sowohl bei G1O1 KZ=KFZ als auch bei G2O1 KZ=KFZ gilt. Über V2 gelangt man
zu genau G3, dazu gibt es genau ein GO bei dem die Bedingung efüllt ist. Ähnliches gilt für V3 mit G4. Ebenso
für V3 mit G5, weil über G5 keine GO erreichbar sind und folglich auch keine GO mit KZ=KFZ.
62
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.4.4.4.11. Beispiel für eine Versionsentwicklung
Für das folgende Beispiel ‘Nachfolger’ gelte:
Kenntnisstand
Existenz-Nr. = 4711
Datum
heute
9.
7.
8.
6.
5.
4.
2.
3.
1.
Stichtag='A'
© GDV 1999
Datum
heute
Gültigkeit
63
Spezifikation des Datenmanagers
Datenmanager
Beispiel für ‘Nachfolger’
Datenmodell:
Instanzen:
Version 9
Version 8
Pol1
Pol1
Version 7
Version 6
Version 5
Pol1
Pol1
Pol1
Version 4
Pol1
Version 3
Version 2
Version 1
Pol1
Pol1
Pol1
Pol
V
V1
V5 V6
V8
V6 V7
Datensicht 1:
V5 V6
V2
V1 V5
Pol
Pol
Version: 2
Nachfolger
Nachfolger
Pol
Pol
V
V
Treffer:
Pol1Version 7 Pol1Version 8 V5Version
V6Version 8
64
V2 V1
Datensicht 2:
Version: 7
Treffer:
V1
V2 V3
V4 V2
8
Pol1Version 2 Pol1Version4
V2Version4
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.5. Physische Datensicht
Eine physische Datensicht enthält all die physischen Entitäten, deren zugeordnete logischen Entitäten
zur der physischen Datensicht zugeordneten logischen Datensicht gehören.
Eine physische Datensicht hat grob folgende Struktur:
Namen der physischen Datensicht
Namen der physischen Entitäten, die zu dieser physischen Datensicht gehören
Navigationsdaten (Pfade durchs physische Datenmodell)
Zugriffschlüssel (aus der Menge der durch die physischen Entitäten zur Verfügung gestellten
Zugriffsschlüssel ausgewählt)
Aktionsparameter (LESEN, ÄNDERN, EINFÜGEN, LÖSCHEN)
Mengenbegrenzer (Anzahl Instanzen je Aufruf)
Filterfunktionen (nicht schlüsselorientierte Bedingungen)
III.3.6. Zuordnung der logischen zur physischen Datensicht
Eine logische Datensicht wird höchstens einer physischen Datensicht zugeordnet. Unter Umständen
können mehrere logische Datensichten die gleiche physische Datensicht verwenden. Hierbei sind die
logischen Schlüssel und Filter in die physischen umzusetzen.
Eine logische Datensicht hat dann keine physische Entsprechung, wenn alle für die logische Sicht
erforderlichen Daten im Vorgangsspeicher vorhanden sind, dies aus dem Ablauf bekannt ist und
deshalb keine Daten (physisch) beschafft werden müssen (z.B.: hat die Dokumentation eines Vertrages
alle Daten aus der vorangehenden Bearbeitung schon zur Verfügung).
III.3.7. Werkzeuge
III.3.7.1. Allgemeine Anforderungen an Werkzeuge
Computer Aided Software Engineering (CASE) setzt hohe Ansprüche an die Qualität der verwendeten
Werkzeuge. Allerdings stellt diese Technik auch höchste Ansprüche an die Struktur und Organisation
des Entwicklungsprozesses. Dies dürfte auch der Grund dafür sein, daß „vollintegrierte“ CASEEntwicklungen auch heute eher die Ausnahme denn die Regel sind.
Etabliert hat sich die Verwendung von „punktuell“ einsetzbaren, speziellen Entwicklungswerkzeugen
mit der Erfordernis von „manuell-organisatorischen“ Integrationsschritten.
© GDV 1999
65
Spezifikation des Datenmanagers
Datenmanager
Die Entwicklung von Datenmanager-Komponenten ist eine hochintegrative Aufgabe zwischen
Funktionsmodell und Datenmodell.
III.3.7.1.1. Technische Anforderungen
Oberflächenkomfort, graphische Benutzeroberfläche
Plattformunabhängigkeit
Entwicklunggsdatenbank (Repository)
III.3.7.1.2. Fachliche Anforderungen
Unterstützung eines semantischen Datenmodells
Normalisierung
Implementierung von DBMS-Strukturen
Einbindung in die Funktionsentwicklung
III.3.7.1.3. Anforderungen an den Benutzer
Mitarbeiterschulungen in „EDV“ und Fachbereich
klare Strategie
Organisatorischer Rahmen: Informationsmanagement, Datenmanagement, DB-management,
Prozessmanagement,
zentral koordinierte Dezentralisierung
III.3.7.2. Werkzeuge im VAA-Entwicklungsprozeß
Der gesamte Prozeß der Konfiguration der Datenmodelle, -sichten und Abbildungen zwischen ihnen
wird durch die folgenden Werkzeuge unterstützt:
Editor zur Erstellung und Pflege des logischen Modells,
Editor zur Erstellung und Pflege des physischen Modells,
Editor zur Erstellung und Pflege der Abbildung des physischen auf das logische Modell und
Editor für die logischen Datensichten,
Editor für die physischen Datensichten,
Editor zur Erstellung und Pflege der Abbildung der physischen auf die logischen Datensichten und
66
ein Generator zur erstmaligen Erstellung des Modells aus bestehenden IMS-oder DB2Datenbankdefinitionen (bzw. aus der DDL anderer DB-Systeme).
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.7.2.1. Editor für das logische Datenmodell
Dieser Editor gestattet die Erstellung und Beschreibung der logischen Entitäten und deren ERkonformen Beziehungen. Darüberhinaus gestattet er die Zusammenfassung von mehreren Entitäten zu
den oben beschriebenen Informationsobjekten.
Das logische Datenmodell wird im Parameter-System abgelegt.
III.3.7.2.2. Editor für das physische Datenmodell
Nachdem die physischen Entitäten über den Abbildungseditor aus den logischen erstellt sind oder über
den Generator aus den vorhandenen Datenbankdefinitionen erzeugt wurden, werden nun mit diesem
Editor die strukturellen Beziehungen zwischen den physischen Entitäten ergänzt (soweit notwendig),
unter Umständen nach den oben beschriebenen Regeln auch weitere physische Entitäten angelegt und
die physischen Eigenschaften der Entitäten beschrieben.
Welche Beziehungen zulässig sind, ist entscheidend vom Typ der physischen Entitäten abhängig (z.B.
DB2-Tabelle oder IMS-Segment).
Das physische Datenmodell wird im Parameter-System abgelegt.
III.3.7.2.3. Abbildungs-Editor logisches auf physisches Datenmodell
Dieser Editor bedient sich der grafischen Darstellungen des logischen und des physischen
Datenmodells und erlaubt hierauf die Definition der Beziehungen. Seine Hauptaufgabe ist die
Herstellung und Sicherung einer Konsistenz zwischen logischem und physischem Modell.
Die Ergebnisse werden im Parameter-System abgelegt.
III.3.7.2.4. Editor für die logische Datensicht
Bei der Definition einer logischen Datensicht übernimmt der Editor aus dem logischen Datenmodell
die Informationen über die für diese Sicht ausgewählten Entitäten und deren Beziehungen
untereinander. Der Editor unterstützt dann bei der Formulierung der komplexen Auswahl- und
Filterbedingungen, die in einer Mischform von Grafik und Text eingegeben werden.
Die erstellten logischen Datensichten werden im Parameter-System abgelegt.
III.3.7.2.5. Editor für die physische Datensicht
Der physische Datensicht-Editor operiert auf der grafischen Darstellung des physischen Datenmodells.
Durch Kennzeichnung der gewünschten physischen Entitäten und der Vergabe des Datensichtnamens
wird eine physische Datensicht definiert. Anschließend werden die erforderlichen Attribute der Sicht
erfaßt.
Die Beschreibungen der physischen Datensichten werden im Parameter-System abgelegt.
© GDV 1999
67
Spezifikation des Datenmanagers
Datenmanager
III.3.7.2.6. Editor für die Zuordnung der logischen zur physischen Datensicht
Die Beschreibung der Zuordnungen wird im Parameter-System abgelegt.
III.3.7.2.7. Generator für Umsetzung von DDL-Statements in ein physisches Modell
Zur Unterstützung der erst- und einmaligen Erstellung des physischen Modells ist ein Generator
notwendig, der aus vorhandenen DDL-Statements, wie sie zur Definition von z.B. IMS- oder DB2Datenbanken benötigt werden, das physische Modell für den Datenmanager erstellt.
Diese Vorgehensweise ist keine Alternative zur Erstellung eines physischen Datenmodells als
Ableitung aus einem logischen, sondern dient ausschließlich der Erstladung der Informationen über
vorhandene Datenbanken.
III.3.8. Organisation
III.3.8.1. Überblick
Der Entwicklungs-, Pflege- und Wartungsprozess von Anwendungssystemen erfolgt nach erweiterten
Wasserfallmodellen, die in verschiedenen Ausprägungen existieren, aber folgendes gemeinsam haben:
1. jede Stufe setzt auf den Ergebnissen der Vorgängerstufe auf
2. jede Stufe liefert die Voraussetzungen für die Nachfolgerstufe
3. im Fall von notwendigen Korrekturen kann auf die Vorgängerstufe zurückgekehrt werden
Die Phasen der Entwicklungsmodelle können in drei Hauptentwicklungsstufen eingeteilt werden:
Stufe
Hauptergebnis
Prozessanalyse
Prozessmodell
Fachdesign
Realisierung
Betrieb
Funktionenmodell
Anwendungssystem
Informationsmodell
(=log. Datenmodell)
Datenbankzugriffe
Datenbank
(incl. phys.
Datenmodell)
optimiertes Fach- und EDV-System
Die grau hinterlegten Teile der Tabelle bezeichnen das Planungsfeld des Datenmanagers.
68
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Phasensynchronisation
Innerhalb der genannten Entwicklungsstufen können in Abhängigkeit von der Problemstellung die
einzelnen Entwicklungsschritte teilweise zeitlich unsynchronisiert ablaufen. Die Konsistenz der
verschiedenen Teilergebnisse muß durch -ggf. toolgestützte Designabstimmungen- sichergestellt sein.
Beim Übergang zur nächsten Entwicklungsstufe müssen die systembestimmenden
Entwicklungsdokumente allerdings vorliegen.
III.3.8.2. Prozessmodellierung
Im Schritt der Prozessmodellierung werden die strategischen Anforderungen bestmöglich realisiert.
Oft sind dafür Wettbewerbs- und Rationalisierungsvorgaben maßgebend.
Das entwickelte Geschäftsprozessmodell beinhaltet Arbeitsschritte, die bestmöglich mit dem
Anwendungssystem abgedeckt werden sollen. Die Verkettung dieser Arbeitsschritte zu Abläufen ist
nicht Gegenstand der nachfolgend beschriebenen Entwicklungsprozesse. Diese wird vielmehr mit
Hilfe von Workflow-Systemen realisiert.
III.3.8.3. Fachdesign
Das Fachsystem definiert die EDV-Unterstützung der in der Prozessanalyse festgelegten
Arbeitsschritte der betrieblichen Geschäftsprozesse. Es besteht aus
Funktionsmodell und
Informationsmodell (logisches Datenmodell).
III.3.8.3.1. Funktionmodellierung
Die Fachfunktionen des Anwendungssystems werden hierarchisch gegliedert und mit ihrem
Informationsbedarf beschrieben. Die definierten Funktionen sind unabhängig voneinanderum den
Einsatz des übergeordneten Workflowmanagers zu ermöglichen. Die Funktionsgliederung beschränkt
sich im Regelfall auf die drei Stufen:
1. Anwendungssystem
2. Anwendungsbaustein
3. Funktionsbaustein
Der Informationsbedarf wird mit Hilfe der logischen Datensichten beschrieben. Diese stellen das
Abstimmungswerkzeug mit der getrennt abzuwickelnden Informationsmodellierung dar.
III.3.8.3.2. Informationsmodellierung
Das logische Datenmodell (= Informationsmodell) beschreibt alle Objekte der realen Welt des
Planungsfelds und deren Beziehungen zueinander in konsistenter, zusammenhängender Form. Es wird
© GDV 1999
69
Spezifikation des Datenmanagers
Datenmanager
in Entity Relationship Notation in dritter Normalform dargestellt. Durch dieses Modell wird die
„Potenz“ des Anwendungssystems determiniert. Jede Funktion existiert nur auf der Grundlage der von
Ihr bearbeiteten Informationsobjekte. Das logische Datenmodell bildet die Gesamtintegration über alle
Geschäftsprozesse.
Dieser Stellenwert des logischen Datenmodells wird durch die Zuständigkeit einer eigenen
Entwicklergruppe unterstrichen.
In objektorientierten Systemdesign wird die Gesamtfunktionalität als Methoden den Objekten des
Informationsmodells zugeordnet. Somit stellt eine solide Informationsmodellierung den besten Garant
für die Migrationsfähigkeit von Anwendungssystemen in die künftig erwartete Paradigmenwelt der
Objektorientierung dar.
III.3.8.4. Realisierung
III.3.8.4.1. Anwendungsrealisierung
Die Anwendungsrealisierung umfaßt:
Systemdesign:
beschreibt Modularität, Schnittstellen und Softwareschichtung. Darüberhinaus erfolgt die
Festlegung von Designkriterien für das Komponentendesign.
Komponentendesign
Realisierung
diverse Tests bis zum integrierten System
Inbetriebnahme
Als wichtiges Designkriterium sollen die Anwendungsfunktionen strukturell der modellierten
Fachfunktionalität entsprechen. Im Sinn eines effizienten Systembaues (z.B. Wiederverwendung von
Anwendungsbausteinen) kann dieses Prinzip jedoch durchbrochen werden. Ein Funktionsbaustein
funktioniert auf der Basis einer logischen Datensicht. Diese Festlegung erfolgt im Systemdesign.
III.3.8.4.2. Datenbankzugriffsrealisierung
Auf der Basis der maschinell verwertbaren Dokumentation der Datenmodelltransformation im
Parametersystem können die Datenbankzugriffsbausteine weitestgehend generativ erzeugt werden.
III.3.8.4.3. Datenbankrealisierung
Die Datenbankrealisierung liegt entweder vor, oder wird auf der Basis des physischen Datenmodells in
der Regel weitestgehend generativ.
70
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.3.8.4.4. Integration, Einführung und Inbetriebnahme
Die Systemkomponenten aus den Teilentwicklungen werden zu funktionsfähignen (Teil-) Systemen
integriert und getestet. In diese Phase fallen auch Fachorganisation, Schulung, Datenmigration und
Inbetriebnahme.
III.3.8.5. Betrieb
Während des Betriebs des Systems werden
Prozeßabläufe
Fachfunktionen
(Informationsmodell)
Anwendungssystem
Datenbankzugriffe
Datenbank
im Hinblick auf einen optimierten Einsatz (Performanz unter realen Last- und
Datenfüllungsbedingungen, schritthaltende Systemadaptionen entsprechend der sich wandelnden
betriebswirtschaftlichen Anforderungen und Basissysteme) laufend gewartet und gepflegt.
Diese Lebensphase des Systems erfordert ständige Anstrengungen, die Konsistenz der Anforderungsund Designunterlagen mit dem real implementierten System sicherzustellen. Einarbeitsteiliges
Vorgehen mit entsprechend gelebten Verantwortungsbereichen ist dafür Voraussetzung. Besonderes
Augenmerk genießt dabei die Trennung von Funktions- und Datenverantwortungsbereichen.
Die Betriebsphase endet mit dem „Systemrecycling“ zugunsten eines Nachfolgesystems.
III.4. Buildtime Komponenten
III.4.1. Der LDASI-Generator
Der LDASI-Generator ist zur Buildtime zuständig für die Kompilation der logischen Datensicht, die
mit dem LDASI-Editor erstellt wurde, in eine Form, die vom Datensicht-Prozessor abgearbeitet
werden kann. Dabei kann man sich drei Varianten des Vorgangs vorstellen:
1. Es wird eine interne Form der logischen Datensicht erzeugt, die interpretativ vom
Datensichtprozessor abgearbeitet werden kann. Beim Datensichtprozessor der Württembergischen
Versicherung wird dazu ein binäres Lademodul mit einer Internform der Datensicht erzeugt, das
dynamisch vom Datensichtprozessor angefordert wird. Zum Erzeugen der Treffertabelle wird diese
Internform vor dem Ablauf eines Funktionsbausteines vom Datensichtprozessor interpretiert. Diese
Methode ist vom Programmcode her sehr platzsparend aber im Ablauf sicher nicht die schnellste.
2. Anstatt einer Interpretation der Datensicht werden direkt die Aufrufe des Datensichtprozessors zum
Aufbau der Treffertabelle generiert und dieser Programmcode zum Funktionsbaustein dazugelinkt.
Dieses Vorgehen spart eine Interpretationssstufe und ist deshalb schneller als die erste Variante.
© GDV 1999
71
Spezifikation des Datenmanagers
Datenmanager
Ein fertig compilierter und gelinkter Funktionsbaustein für sich alleine gesehen wird aber dadurch
vom Code her etwas größer.
3. Als letzte Variante könnte man sich eine direkte Generierung des Teils des Datensichtprozessors
aus der vorgegebenen Datensicht vorstellen, der intern die Treffertabelle verwaltet und teilweise
auch den Vorgangsspeicher direkt manipuliert. Die Verwaltung des Vorgangsspeicher und die
Schnittstelle zum Datenhandler können natürlich nicht vom LDASI-Generator erzeugt werden und
sind als fest vorgegeben anzunehmen. Damit sind in jedem LDaSi-Baustein zum ProgrammAblaufzeitpunkt einige Teile des Datensichtprozessors einkompiliert.
Von den gerade besprochenen Varianten wird die erste sicher die Methode der Wahl sein, wenn der
Aufwand für die Implementierung des Datenmanagers in einem engen Rahmen gehalten werden soll.
Treibt man mehr Aufwand und legt man Wert auf allerhöchste Performannce, so sollte man sich für
eine der Versionen 2 oder 3 oder eine Mischform entscheiden.
Der LDASI-Generator ist als Teil der Entwicklungsumgebung im höchsten Maße abhängig vom
internen
Ablageformat
der
logischen
Datensicht
und
von
der
internen
Struktur
des
Datensichtprozessors.
Eine logische Datensicht, die für schreibende Zugriffe verwendet wird, läßt sich auf ähnliche Art und
Weise wie die lesende Datensicht durch den LDASI-Generator in einer der drei obigen Varianten in
eine Internform kompilieren.
III.4.2. Der PDASI-Generator
Während der Konfigurationszeit ist aus einer logischen Datensicht eine physische Datensicht
entstanden, welche den unmittelbaren Input für den PDASI-Generator darstellt.
Die physischen Komponenten, die im Rahmen der Datenmanager-Architektur während der Buildtime
die beherrschende Stellung einnehmen, umfassen den PDASI-Generator und dessen generierte
Konstrukte - das sind Ablaufplan und I/O-Module, die im wesentlichen DB-Zugriffsoperationen (zur
Navigation und zur Datenbeschaffung/Änderung) sowie Logikkomponenten enthalten. Der Ablaufplan
mit den I/O-Modulen ist letzten Endes die in die DB-Physik übersetzte physische Datensicht.
Der PDASI-Generator verarbeitet als Input eine physische Datensicht, welche zur Konfigurationszeit
aus einer logischen Datensicht in Berücksichtigung des physischen Datenmodells abgeleitet worden
ist.
Diese Ableitung ist unter Beachtung von Navigationsmöglichkeiten (siehe phys. DM) bzw. nach
Strukturmerkmalen des Ziel-Datenbanksystems unter Bewahrung der Semantik der logischen
Datensicht (s.a. Datensichtsprache) erfolgt.
Der PDASI-Generator hat für die Runtime-Phase (also die Ausführung des Datenmanagers) optimale
Vorbereitungen zu treffen - vorallem unter dem Gesichtspunkt massiver Batch I/Os: Ein nur
interpretatives Abarbeiten eines vom PDASI-Generator erstellten Ablaufplanes ist (ähnlich wie bei
einem dynamic plan im DB2) nur die zweitbeste Lösung. Weitergehende Optimierungen bzgl. der
DB-Zugriffe zur Laufzeit sollen dem Bufferhandling des jeweiligen DB-Systems überlassen bleiben.
72
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Der vom PDASI-Generator erstellte Ablaufplan wird zur Runtime unter Kontrolle der
Ablaufsteuerung ausgeführt.
III.4.2.1. Erstellung eines Ablaufplans
Zu jeder physischen Datensicht erstellt der PDASI-Generator einen Ablaufplan. Der Ablaufplan
enthält alle Datenbanksystem-übergreifenden Funktionen, um z.B. abhängig vom Inhalt eines IMSSegments eine bestimmte Auswahl aus einer DB2-Tabelle einzugrenzen.
Die Zugriffe auf ein DB-System sind in sogenannten I/O-Modulen (IOM) gekapselt, welche in den
Ablaufplan eingebunden werden.
Der Ablaufplan realisiert somit als eine Art Hauptprogramm die physische Datensicht (mit ihren
navigatorischen und selektiven Operationen) und ruft nacheinander u.U. mehrere IOMe als
Unterprogramme auf, um die Daten zu beschaffen, die indirekt zur Navigation oder direkt vom
Anwendungsbaustein benötigt werden.
Die I/O-Module haben DB-spezifische Sichten auf eine oder mehrere physische Entitäten und sind im
Prinzip wiederverwendbar, d.h. auch in andere Ablaufpläne einbindbar, wenn es deren Bedarf
entspricht. Die IOMe dienen damit der Vermeidung von Redundanzen - über alle Ablaufpläne hinweg
betrachtet.
Die IOMe liefern immer komplette physische Entitäten zurück.
Der Ablaufplan hat die IOMe mit Aufrufparametern zu versorgen; für lesende und schreibende IOMe
muß bsplw. die Übergabe des physischen Schlüssels erfolgen; für schreibende IOMe muß zusätzlich
eine Datenstruktur übergeben werden. Die von den IOMen gelieferten Daten müssen vom Ablaufplan
gemäß Anforderung der logischen Datensicht (s. Konfigurationszeit) gekettet werden.
Die dem Transformator übergebene Struktur muß „selbsterklärend“ sein, bzw. für den Transformator
mithilfe des Datenmodellbausteins und der Zuordnungstabelle interpretierbar sein.
Dabei ist es denkbar, den Datenelementen entweder technische Identifikatoren voranzustellen oder
Angaben über ihre occurrence (im Sinne eines Feldes, auf das sich eine occurrs depending on Klausel in COBOL bezieht) vorzunehmen, um der Ablaufsteuerung bzw. dem Datensichtprozessor die
eindeutige Interpretation dieser NF2-Strukturen zu ermöglichen.
Bezüglich des Zusammenspiels der vom PDASI-erstellten Komponenten ergibt sich zur Laufzeit
folgendes (exemplarisches) hierarchisches Bild:
Ablaufsteuerung
Ablaufplan 1
Ablaufplan 2
Ablaufplan 3
IOM i
IOM k
IOM i
IOM j
IOM j
IOM k
© GDV 1999
73
Spezifikation des Datenmanagers
Datenmanager
Die Ablaufsteuerung parametrisiert die Ablaufplanprogramme. Der Ablaufplan wertet die Return
Codes der I/O-Module aus und gibt selbst einen Return Code (bzw. Zustandscode) an seine
Kontrollinstanz (die Ablaufsteuerung) zur Laufzeit weiter.
III.4.2.2. Auflösung der physischen Datensicht in I/O-Module
I/O-Module (IOM) sind einfache DB-Zugriffsprogramme in dem Sinne, daß sie
nur auf ein DB-System zugreifen
komplette physische Entitäten zurückliefern
entweder nur Lesezugriff oder verändernden Zugriff durchführen
der Kontrolle des Ablaufplanprogramms unterliegen
Jeder physischen Entität ist mindestens ein IOM zugeordnet; unter den IOMen zu einer physischen
Entität gibt es genau eines, welches die gesamte Struktur der physischen Entität über den
Primärschlüssel zu reproduzieren vermag.
Es kann auch IOMe geben, die auf mehrere physische Entitäten genau eines DB-Systems zugreifen.
Für die Implementierung ist es vorstellbar, ein IOM durch z.B. eine DB2-View (über evtl. mehrere
Tables mit komplexer where-Bedingung) oder eine Datenbank-Prozedur zu realisieren; in der Regel
wird es sich um (in eine Programmiersprache eingebettete) native DB-Calls handeln.
I/O-Module sind als DB-Zugriffsprimitive einem Wiederverwendungskonzept zu unterwerfen,
welches es dem PDASI-Generator ermöglicht, fertige IOMe für einen Ablaufplan auszuwählen
(„component ware“), statt sie erst produzieren zu müssen.
Das Erstellen der IOMe ist als Aufgabe der Datenbankadministration im Zusammenhang mit der
Implementierung des physischen DB-Schemas zu sehen.
Es könnte idealerweise Aufgabe eines mustererkennenden Algorithmus innerhalb des PDASIGenerators sein, ein Verwendungsmuster einer oder mehrerer physischer Entitäten in der physischen
Datensicht zu erkennen und auf ein dazu bekanntes IOM abzubilden. Sollte dabei der Fall eintreten,
daß ein Matching nicht möglich ist, so muß seitens der Daten(bank)administration ein IOM
nachgerüstet werden.
III.4.2.3. Datenzugriffsoptimierung
Optimierungen bzgl. der DB-Zugriffe zur Laufzeit sollten dem Bufferhandling des jeweiligen DBSystems überlassen bleiben. Hier gibt es seitens der Hersteller von DB-Systemen, aber auch der
Hersteller von Plattenspeichern (z.B. Iceberg, EMC2) bereits hochperformante Lösungen.
Diese Betrachtung gilt mit Einschränkung, wenn wir uns in Client/Server-Architekturen bewegen, bei
denen ein Netzwerk zwischen Anwendungsbausteinen und Datenbanksystemkern als ein I/O-
74
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Bottleneck anzusehen ist. Hier kommt es vordringlich darauf an, den Datentransfer im Netz minimal
zu halten.
Wenn der Datenmanager zur Laufzeit jedoch beim Datenbankkern (auf der gleichen Plattform also)
angesiedelt ist, gilt wieder die erste Betrachtungsweise.
Dieses ist auch unsere Architekturempfehlung, weil zumindest der Datenhandler innerhalb des
Datenmanagers auf die Plattform gehört, auf der sich auch der Datenbankserver befindet.
III.5. Runtime Komponenten
III.5.1. Der Datensichtprozessor
Der Datensichtprozessor bildet im Datenmanager die Schnittstelle zwischen dem „eigentlichen“
Anwendungsprogramm und den physischen Zugriffen auf die Daten, die durch die Komponente
Datenhandler im Datenmanager realisiert wird. Insofern hat der Datensichtprozessor eine „externe“
Schnittstelle, die von den Funktionsbausteinen, den Steuerungskomponenten DV-Vorgangssteuerung
und Dialogsteuerung oder dem Präsentationsmanager des Anwendungsprogramms aufgerufen werden
kann, und eine „interne“ Schnittstelle innerhalb des Datenmanagers zum Datenhandler. Die
wesentlichen Aufgaben des Datensichtprozessors sind:
Bereitstellung von Daten für die Anwendungskomponenten aufgrund des Aufrufs mit Angabe des
Namens einer logischen Datensicht und Laufzeitparametern
Strukturierung der Daten in Form einer „Übergabetabelle“ für die Anwendungskomponenten
Modellgerechte Verwaltung der Daten im Vorgangsspeicher (Hauptspeicher)
Verwaltung des Speichers unter Kontrolle der DV-Vorgangssteuerung
Aufruf des Datenhandlers zur physischen Beschaffung der Daten
Aufruf des Datenhandlers zum Update/Insert/Delete von Daten
© GDV 1999
75
Spezifikation des Datenmanagers
Editformat
LDaSi
LDaSi
Generierung
Datenmanager
Anwendungen
Name LDaSi
+ Laufzeitparameter
Daten
und
Adressen
Abarbeiten Datensicht
Laufzeitformat
LDaSi
Basisfunktionen
vorläufige
Treffer
Modellgerechte Verwaltung
der Daten im Hauptspeicher
Anforderung
Adressen
Daten
Hauptspeicherverwaltung
Name PDaSi
+ Laufzeitparameter
Datenhandler
Abb.: Übersicht über die Laufzeitkomponenten des Datensichtprozessors
Auf die einzelnen Aufgaben wird im folgenden noch detaillierter eingegangen.
Die im folgenden angegebene Schnittstelle beschreibt notwendige Aufrufe. Für den Fall, daß ein
anderes als das einfache Verteilungsmodell (siehe Kapitel V) gewählt wird, können noch weitere,
technisch bedingte Aufrufe hinzukommen; die beschriebenen Aufrufe sollten jedoch Bestand haben.
76
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.5.1.1. Die Schnittstelle zum Anwendungsprogramm
Der Datensichtprozessor im Datenmanager wird vom Anwendungsprogramm zur Datenbeschaffung
und zum persistenten Wegschreiben (Update, Insert, Delete) von Daten aufgerufen. Diese Fälle führen
zu unterschiedlichen Funktionsaufrufen in der Anwendungsschnittstelle.
III.5.1.1.1. Daten-Beschaffung und -Bereitstellung im Vorgangsspeicher
Beim Aufruf des Datensichtprozessors zur Beschaffung und Bereitstellung der geforderten Daten im
Vorgangsspeicher werden mitgegeben:
ein Vorgangsidentifikator
der Name der logischen Datensicht
Laufzeitparameter, sofern in der Datensicht Parameter definiert wurden
Bsp.:
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zur DatenBeschaffung
und
-Bereitstellung
im
Vorgangsspeicher:
DMgetData
Deklaration
in
C-Systax:
HANDLE
DMgetData(hVorgang,
aLDaSi,
HANDLE
hVorgang;
//
LDASI
aLDaSi;
//
PARAM
aParamList;
// Liste mit Laufzeitparametern
aParamList)
Vorgangsidentifikator
logischer
Datensichtname
Zurückgegeben wird ein Identifikator (Pointer oder Handle) des Trefferverzeichnisses.
Aufrufbeispiel
in
einer
C-Funktion:
{
HANDLE
hData,
LDASI
aLDaSi;
PARAM
aParamList;
hVorgang;
...
hData = DMgetData(hVorgang, aLDaSi, aParamList);
...
}
© GDV 1999
77
Spezifikation des Datenmanagers
Datenmanager
Aufruf
in
CALL DATMAN
COBOL-Syntax:
USING
FKTGET
*
Funktionscode
Lesen
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator,
log.Datensichtname,
*
weitere
Laufzeitparameter)
TREFF-VERZ.
*
Trefferverzeichnis
Zurückgegeben wird das Trefferverzeichnis.
Das Ergebnis der Datenanforderung ist ein im Vorgangsspeicher zur Verfügung gestelltes, gefülltes
Trefferverzeichnis.
Die
Struktur
des
Trefferverzeichnisses
wird
zum
Zeitpunkt
der
Datensichterstellung festgelegt. Diese Struktur kann individuell für den jeweiligen Aufruf aufgebaut
werden. Die Anzahl und die Reihenfolge der Felder sind frei definierbar. Das Trefferverzeichnis kann
damit durchaus für mehrere Datensichten verwendet werden. Es bietet sich an, für jedes
Anwendungsgebiet (Tarifierung, Dokumentierung, ...) eine einheitliche Tabellenstruktur zu definieren;
dies ist aber nicht notwendig.
Bsp.:
Es wurde eine logische Datensicht mit dem Namen LDaSi123 definiert:
Police VS_NR = &P
POL
Bst
H-Ver SPKZ = H
VER
Bst
XY
H-Gef
GEF
Bst
Pol/Pers
PP
K-Ver SPKZ = K
VER
Bst
ZZ
Person
PERS
Bst
K-Gef
GEF
Bst
Abb.: Beispiel-Datensicht LDaSi123
78
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Dann könnte die Struktur des Trefferverzeichnis folgendermaßen definiert werden:
AE-Name
DME
Level
T-Adr
Bst-Name
Bst-Adr
...
Zusätzlich kann zu jeder Ausgabeentitätsmenge (AEM) im Trefferverzeichnis definiert werden,
welche in der Tabellenstruktur vorgesehenen Felder für diese AEM gefüllt werden sollen. Wird für
eine AEM der Datensicht kein Eintrag gekennzeichnet, also keine Spalte im Trefferverzeichnis
vorgesehen, so werden zu dieser AEM keine Daten an die Anwendung geliefert; im Beispiel die AEM
Person. (Für die sonstige Verarbeitung der Daten innerhalb der Datensicht wird diese AEM behandelt
wie jede andere AEM auch.)
Das Trefferverzeichnis kann aus zwei verschiedenen Typen von Daten bestehen:
Trefferdaten
Trefferdaten sind die Daten, die zur Laufzeit aufgrund des Datenbestands ernittelt werden.
Standardattribute für die Trefferdaten einer Ausgabeentitätsmenge sind:
Versionsidentifikator
(z.B. Kenntnisstand, Gültigkeitsstand, ...)
Strukturname
(Typinformation
für
die
z.B. Name der zugehörigen Datenstruktur,
der zugehörigen Copy-Strecke)
Trefferadresse
(Adresse,
an
cher stehen)
Längenadresse
(Adresse,
steht)
Bausteindatenadresse
(Adresse,
stehen)
an
wo
der
der
ggf.
Trefferdaten,
Trefferdaten
die
Länge
im
der
Bausteindaten
HauptspeiTrefferdaten
zur
AEM
Weitere Attribute sind denkbar, werden aber nicht als Minimalkonstrukte angesehen und
hängen von der jeweiligen Realisierung des Datensichtprozessors ab.
Wir gehen davon aus, daß der Datensichtprozessor und die aufrufende Komponente des
Anwendungsprogramms im selben Prozeß laufen, so daß auf Kopieren von Daten verzichtet
und mit Übergabe von Adresspointern gearbeitet werden kann.
Bzgl. der Bausteindaten sehen wir vor, daß sie in der Anwendungsschnittstelle nicht weiter
detailliert werden, sondern daß beim Füllen des Trefferverzeichnis ein Dienst mit Angabe des
Bausteinnamens und der Bausteindatenadresse aufgerufen wird. Dieser Dienst analysiert dann,
ob es sich um einen Textbaustein, eine Prüfroutine, ... handelt und ruft diesen auf. (Hier sind
natürlich auch andere Realisierungen denkbar.)
© GDV 1999
79
Spezifikation des Datenmanagers
Datenmanager
Definitionsdaten
Definitionsdaten sind Daten, die zum Zeitpunkt der Datensichterstellung festgelegt und zur
Laufzeit ins Anwendungsprogramm geliefert werden. Standardattribute für die Definitionsdaten
einer Ausgabeentitätsmenge sind:
Ausgabe-Entitäts-Name
(logischer
Name,
Anwendung
erhalten möchte)
unter
Level
(Hierarchiestufe für den gelieferten Treffer)
Kommentar
(Erfassung
Anwendung)
spezieller
dem
die
Trefferdaten
die
Informationen
für
eine
Datenmodellentitäts-Name
Bausteinname
(Bausteinname, z.B. eines Textbausteins)
Funktionscode
(z.B.
Insert
Existenz
als
sionsselektion
chen)
Version/Existenz
und
Delete
Minimalanforderung,
um
Verund
-navigation
zu
ermögli-
Im obigen Beispiel in c-Syntax könnte das Trefferverzeichnis mit dem Handle hData nach dem
Funktionsaufruf
hData
=
DMgetData(hVorgang,
LDaSi123,
P4711);
dann folgendermaßen aussehen:
AE-Name
DME
Level
T-Adr
Bst-Name
Bst-Adr
Police
POL
1
0001
PP
9001
H-Vertrag
VER
2
0100
XY
9100
H-Gefahr
GEF
3
0110
H-Gefahr
GEF
3
0120
K-Vertrag
VER
2
0200
ZZ
9200
K-Gefahr
GEF
3
0210
...
In der Police P4711 besteht unter anderem ein Haftpflicht-Vertrag mit zwei versicherten Gefahren und
ein Kraftfahrvertrag mit einer versicherten Gefahr. Ob noch weitere Verträge in der Police bestehen,
ist irrelevant, weil in der Datensicht nicht angefordert. Die angegebenen Hauptspeicheradressen
beziehen sich auf den durch den Vorgangsidentifikator ‘hVorgang’ zugeordneten Vorgangsspeicher.
80
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.5.1.1.2. Füllen des Trefferverzeichnises
Um die Daten für das Trefferverzeichnis im lesenden Zugriff zu ermitteln, werden vom
Datensichtprozessor die folgenden Schritte in der durch die Datensicht vorgegebenen Reihenfolge
ausgeführt (Umsetzung der Grafik in die Ablaufsteuerung):
Aufruf des Datenhandlers;
solange AEMs abzuarbeiten sind:
{
1. Interpretation der AEM-Struktur, um die Hierarchiestufen im Trefferverzeichnis
festzulegen (inklusive Gruppierung);
2. Feststellen, ob AEM nicht im Trefferverzeichnis aufscheinen sollen (Ausgabeunterdrückung);
3. Ermittlung aller Treffer (AEM-Instanzen) über Navigations- und Bedingungspfade und
Prüfung von Attributs- und Versionsbedingungen;
4. Konsolidierung (Vermeidung von Mehrfachnennungen);
5. Aufbereitung der ermittelten Treffer entsprechend den in der Datensicht angegebenen
Vorschriften (maximale Trefferzahl, Sortierung, Gruppenwechsel);
6. Insert jedes Treffers der AEM in den Vorgangsspeicher und Füllen der zugehörigen Zeile
im Trefferverzeichnis;
}
III.5.1.1.3. Update von Daten
Beim Aufruf des Datensichtprozessors zum Update von Daten im Vorgangsspeicher innerhalb eines
DV-Vorgangs (nicht DV-Vorgangsende!) werden mitgegeben:
der Vorgangsidentifikator
der Identifikator der Übergabetabelle
der Datenmodellentitätstyp
ggf. die Nummer des zu ändernden Datensatzes, falls nicht das komplette Trefferverzeichnis zu
ändern ist
Bsp.:
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zum Update des
kompletten
DMUpdateData
oder
bei
Trefferverzeichnis:
Update
einzelner
Datensätze:
DMUpdateDataRow
© GDV 1999
81
Spezifikation des Datenmanagers
Datenmanager
Deklaration
in
C-Systax:
HANDLE
DMUpdateData(hVorgang,
HANDLE
hVorgang;
HANDLE
hUpdateData; // Identifikator des Trefferverz.
oder
//
bei
HANDLE
hUpdateData)
Vorgangsidentifikator
Update
einzelner
Datensätze:
DMUpdateDataRow(hVorgang,
hData,
hDME,
HANDLE
hVorgang;
//
HANDLE
hData;
//
HDME
hDME;
//
WORD
wRow;
//
wRow)
Vorgangsidentifikator
Identifikator
des
Trefferverz.
Datenmodellentitätstyp
Nummer
des
geänderten
Daten-
// satzes im Trefferverzeichnis
Zurückgegeben wird der Vorgangsidentifikator hVorgang (oder NULL im Fehlerfalle.)
Aufrufbeispiel
in
einer
C-Funktion:
{
HANDLE
hData,
LDASI
aLDaSi;
PARAM
aParamList;
hUpdateData,
hVorgang;
...
hData = DMgetData(hVorgang, aLDaSi, aParamList);
...
// Kopieren und Ändern der Daten in hUpdateData
hData = DMUpdateData(hVorgang, hUpdateData);
...
}
82
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Aufrufe
in
CALL DATMAN
COBOL-Syntax:
USING
FKTUPD
*
Funktionscode
Ändern
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator,
weitere
Laufzeitparameter)
TREFF-VERZ
*
Trefferverzeichnis
RET-CODE.
*
Statusinformation
bzw.
CALL DATMAN
USING
FKTUPZ
*
Funktionscode
Ändern
Zeile
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator,
Datenmodellentitätstyp,
*
Nummer
im
des
Datensatzes
Trefferverz.)
TREFF-VERZ
*
Trefferverzeichnis
RET-CODE.
*
Statusinformation
Zurückgegeben wird eine Statusinformation.
Aufgrund dieser Aufrufe werden vom Datensichtprozessor im Vorgangsspeicher nur bereits
vorhandene Instanzen überschrieben. Das Bilden von neuen Instanzen (Versionen) muß generell über
die Insert-Funktion erfolgen.
III.5.1.1.4. Insert von Daten
Prinzipiell erfolgt der Insert von neuen Entitäten in den Vorgangsspeicher über die Funktionalität der
Datensicht, kann also bei jedem Aufruf des Datenmanagers zur Datenbeschaffung bereits integriert
werden. Dies gilt sowohl für das Einfügen einer neuen Version bereits vorhandener Daten als auch für
das Einfügen einer neuen Existenz einer Entität.
Die folgenden Ausführungen beschreiben eine Möglichkeit, wie die Funktionalität des Datenmanagers
bezüglich des Inserts von Existenzen erweitert werden könnte, wenn der Insert über Datensicht nicht
ausreicht.
© GDV 1999
83
Spezifikation des Datenmanagers
Datenmanager
Beim Aufruf des Datensichtprozessors zum Insert von Daten im Vorgangsspeicher innerhalb eines
DV-Vorgangs (nicht DV-Vorgangsende!) werden mitgegeben:
der Vorgangsidentifikator
der Identifikator des Trefferverzeichnis
der Datenmodellentitätstyp
die Nummer des Datensatzes, hinter dem eingefügt werden soll
Pointer auf einen einzufügenden Datenstrom mit Längenangabe
Bsp.:
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zum Insert:
DMInsertDataRow
Deklaration
HANDLE
in
C-Systax:
DMInsertDataRow(hVorgang,
hData,
hDME,
wRow,
lpData,
wLenData)
HANDLE
hVorgang;
//
Vorgangsidentifikator
HANDLE
hData;
//
HDME
hDME;
//
WORD
wRow;
//
Nummer
//
Trefferverz.,
Identifikator
des
Trefferverz.
Datenmodellentitätstyp
//
gefügt
Pointer
des
Datensatzes
hinter
dem
werden
LPDATA
lpData;
//
auf
WORD
wLenData;
// Länge des Datenstroms
im
einsoll
Datenstrom
Zurückgegeben wird der Vorgangsidentifikator hVorgang (oder NULL im Fehlerfalle.)
Aufruf
in
CALL DATMAN
COBOL-Syntax:
USING
FKTINS
*
Funktionscode
Einfügen
Zeile
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator,
Datenmodellentitätstyp,
*
Pointer
auf
Daten,
der
*
Nummer
im
Länge
Daten,
des
Datensatzes
Trefferverz.)
TREFF-VERZ
*
Trefferverzeichnis
RET-CODE.
*
84
Statusinformation
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Zurückgegeben wird eine Statusinformation
Aufgrund dieses Aufrufs wird vom Datensichtprozessor im Vorgangsspeicher eine neue Instanz der
betreffenden Datenmodellentität eingefügt.
III.5.1.1.5. Delete von Daten
Beim Aufruf des Datensichtprozessors zum Löschen von Daten im Vorgangsspeicher innerhalb eines
DV-Vorgangs (nicht DV-Vorgangsende!) werden mitgegeben:
der Vorgangsidentifikator
der Identifikator des Trefferverzeichnis
der Datenmodellentitätstyp
die Nummer des zu löschenden Datensatzes
Bsp.:
Name der Prozedur/funktion des Datensichtprozessors im Datenmanager zum Delete:
DMDeleteDataRow
Deklaration
HANDLE
in
C-Syntax:
DMDeleteDataRow(hVorgang,
hData,
hDME,
HANDLE
hVorgang;
//
HANDLE
hData;
//
HDME
hDME;
//
WORD
wRow;
//
wRow)
Vorgangsidentifikator
Identifikator
des
Trefferverz.
Datenmodellentitätstyp
Nummer
des
zu
löschenden
Da-
// tensatzes im Trefferverzeichnis
Zurückgegeben wird der Vorgangsidentifikator hVorgang (oder NULL im Fehlerfalle.)
Aufruf
in
CALL DATMAN
COBOL-Syntax:
USING
FKTDEL
*
Funktionscode
Löschen
Zeile
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator,
Datenmodellentitätstyp,
*
Nummer
im
des
Datensatzes
Trefferverz.)
TREFF-VERZ
*
Trefferverzeichnis
RET-CODE.
*
© GDV 1999
Statusinformation
85
Spezifikation des Datenmanagers
Datenmanager
Zurückgegeben wird eine Statusinformation.
Aufgrund dieses Aufrufs wird vom Datensichtprozessor die betreffende Instanz im Vorgangsspeicher
mit einem Löschflag versehen. Achtung: Auf Datenbankebene gibt es kein Löschen!
III.5.1.1.6. Initialisierung und Abschluß eines DV-Vorgangs
Bei der Initialisierung eines DV-Vorgangs muß auch ein zugehöriger Vorgangsspeicher initialisiert
werden. Dazu stellt der Datensichtprozessor im Datenmanager eine entsprechende Funktion zur
Verfügung.
Bsp.:
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zur Initialisierung
eines
Vorgangsspeichers:
DMInit
Deklaration
in
C-Syntax:
HANDLE
DMInit(aDefaultSize)
WORD
wDefaultSize; // Defaultgröße
Zurückgegeben wird der Vorgangsidentifikator (Handle) oder NULL im Fehlerfall.
Aufruf
in
CALL DATMAN
COBOL-Syntax:
USING
FKTINI
*
Funktionscode
Initialisieren
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator,
Größe),
RET-CODE.
*
Statusinformation
Zurückgegeben eine Statusinformation
Beim Aufruf des Datensichtprozessors zum persistenten Wegschreiben von den in einem Vorgang neu
erfaßten/geänderten/gelöschten Daten (i.w. bei Vorgangsabschluß) werden beim Aufruf mitgegeben:
ein Vorgangsidentifikator
der Name einer logischen Update-Datensicht
Laufzeitparameter, sofern in der Update-Datensicht Parameter definiert wurden
Wir gehen davon aus, daß zu jedem Vorgang eine zugehörige logische Update-Datensicht formuliert
wurde. Die zugehörigen Daten stehen im Vorgangsspeicher modellgerecht zur Verfügung.
Bsp.:
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zum persistenten
Wegschreiben
von
Daten:
DMCommit
86
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Deklaration
in
C-Syntax:
BOOL
DMCommit(hVorgang,
HANDLE
hVorgang;
//
LDASI
aLCtDaSi;
//
PARAM
aParamList;
// Liste mit Laufzeitparametern
Aufruf
aLCtDaSi,
aParamList)
Vorgangsidentifikator
logischer
Datensichtname
in
CALL DATMAN
COBOL-Syntax:
USING
FKTCOMM
*
Funktionscode
Commit
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator,
log.Datensichtname,
*
weitere
Laufzeitparameter)
RET-CODE.
*
Statusinformation
Aufgrund dieses Aufrufs wird der Datenhandler zum Wegschreiben der geänderten Daten in den
betreffenden Datenhaltungssystemen aufgerufen.
Soll der Vorgang abgebrochen werden, ohne daß die Daten im Vorgangsspeicher in die
Datenhaltungssysteme geschrieben werden, ist der Datenmanager mit dem entsprechenden
Vorgangsidentifikator aufzurufen.
Bsp.:
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zum Abbruch:
DMAbort
Deklaration
in
BOOL
DMAbort(hVorgang)
HANDLE
hVorgang;
Aufruf
C-Syntax:
// Vorgangsidentifikator
in
CALL DATMAN
COBOL-Syntax:
USING
FKTABO
*
Funktionscode
Abbrechen
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator)
RET-CODE.
*
Statusinformation
Aufgrund dieses Aufrufs wird der Datenhandler ebenfalls vom Abbruch informiert.
Soll ein Vorgang endgültig abgeschlossen werden und sollen alle Speicherbereiche freigegeben
werden ,so ist das System davon ebenfalls zu informieren.
© GDV 1999
87
Spezifikation des Datenmanagers
Bsp.:
Datenmanager
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zum Freigeben des
Vorgangsspeichers:
DMFree
Deklaration
in
BOOL
DMFree(hVorgang)
HANDLE
hVorgang;
Aufruf
C-Syntax:
// Vorgangsidentifikator
in
CALL DATMAN
COBOL-Syntax:
USING
FKTFREE
*
Funktionscode
Freigeben
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator)
RET-CODE.
*
Statusinformation
Aufgrund dieses Aufrufs wird der Vorgangsspeicher freigegeben; der Datenhandler wird ebenfalls
vom Abbruch informiert.
III.5.1.1.7. (Zwischen-) Speichern von Vorgangsdaten
Neben dem persistenten Speichern von Daten beim Abschluß eines Vorgangs stellt der
Datensichtprozessor Funktionalität zur Zwischenspeicherung von Vorgangsdaten (zur späteren
Weiterbearbeitung) und zur Speicherung über den Vorgangsabschluß hinweg zur Verfügung. Zum
speichern und Laden von Vorgangsdaten muß jeweils der Vorgangsidentifikator mitgegeben werden:
Bsp.:
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zum Speichern von
Vorgangsdaten:
DMStore
Deklaration
in
HANDLE
DMStore(hVorgang)
HANDLE
hVorgang;
C-Syntax:
// Vorgangsidentifikator
Zurückgegeben wird der Vorgangsidentifikator (oder NULL im Fehlerfall).
88
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
Aufruf
in
CALL DATMAN
COBOL-Syntax:
USING
FKTSAVE
*
Funktionscode
Speichern
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator)
RET-CODE.
*
Statusinformation
Name der Prozedur/Funktion des Datensichtprozessors im Datenmanager zum Laden von
Vorgangsdaten:
DMLoad
Deklaration
in
HANDLE
DMLoad(hVorgang)
HANDLE
hVorgang;
C-Syntax:
// Vorgangsidentifikator
Zurückgegeben wird der Vorgangsidentifikator (oder NULL im Fehlerfall).
Aufruf
in
CALL DATMAN
COBOL-Syntax:
USING
FKTLOAD
*
Funktionscode
Laden
PARAM-LIST
*
Parameterliste
(Vorgangsidentifikator)
RET-CODE.
*
Statusinformation
III.5.1.2. Speicherverwaltung (Vorgangs-/Hauptspeicher)
Die
Speicherverwaltung
hat
-
entsprechend
dem
Übersichtsbild
Übersicht
über
die
Laufzeitkomponenten des Datensichtprozessors zwei wesentliche Aufgaben:
die Datenmodell-gerechte Verwaltung der Daten im Vorgangs-/Hauptspeicher
die auf Performanz und Ressourcenoptimierung ausgerichtete Verwaltung des zur Verfügung
stehenden Vorgangs-/Hauptspeichers
III.5.1.2.1. Datenmodellgerechte Verwaltung der Daten im Speicher
Während des Vorgangs verwaltet der Datensichtprozessor die Daten entsprechend dem logischen
Datenmodell im Vorgangsspeicher. Er ist damit für die Einhaltung von Konsistenzregeln
verantwortlich und „verwaltet“ die folgenden Datenmodellelemente:
Informationsobjekte
© GDV 1999
89
Spezifikation des Datenmanagers
Versionen
Instanzen (ganze Entitäten)
Daten
Pfade
Modellpfade (zwischen Existenzen) und
Versionspfade
Datenmanager
Um die beschriebenen Funktionen der Anwendungsschnittstelle ausführen zu können, muß der
Datensichtprozessor deshalb intern mindestens die folgenden Funktionen realisieren:
Insert einer neuen Existenz
sowohl von abhängigen Entitäten
als auch von Führungsentitäten
Insert einer Version
Löschen von Instanzen
Modellnavigation
Versionsnavigation
Da der Datensichtprozessor während eines Vorgangs mehrfach zur Datenbeschaffung aufgerufen
werden kann, realisiert er einen „Nachlademechanismus“ in der Weise, daß die noch fehlenden Daten
nachgeladen und modellgerecht in den Hauptspeicher eingefügt werden.
Aus Performanz- und Ressourcen-Gründen
Reorganisationsfunktion zur Verfügung stellen.
wird
der
Datensichtprozessor
auch
eine
III.5.1.2.2. Verwaltung des Vorgangs-/Hauptspeichers
Die Vorgangs- bzw. Hauptspeicherverwaltung des Datensichtprozessors hat folgende Aufgaben:
Bereitstellen eines Speicherblocks bestimmter Größe
Vergrößern/Verkleinern eines Speicherplates
Zwischensichern von Speicherblöcken
wieder Laden von Speicherblöcken
Freigeben von Speicher
Liefern von Adresspointern
Aus Performanz- und Ressourcen-Gründen wird die Speicherverwaltung Funktionen zur
Partitionierung des Speichers anbieten, z.B. danach, welche Daten während eines Vorgangs gelöscht
und welche nicht gelöscht werden.
90
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
III.5.2. Der Datenhandler
Der Datenhandler teilt sich auf in die physischen Zugriffe auf die jeweiligen Datenbanken und den
Umbau der physischen in die logischen Entitäten. Im Folgenden wird der Teil der Zugriffe
Ablaufsteuerung und der Umbau der Entitäten Transformation genannt. Unterschieden werden die
Arbeitsgänge deshalb, weil für die verschiedenen Handler grundsätzlich unterschiedliche
Informationen aus den Konfigurations- und Buildtime-Ebenen erforderlich sind.
III.5.2.1. Schnittstelle zum Datensichtprozessor
Die Kommunikation zum Datensichtprozessor findet ausschließlich mit der Transformation statt, auch
wenn diese aufgrund der Daten nur eine Durchreichfunktion hat.
Unterschieden werden muß bei der Schnittstelle zwischen Ein- und Ausgabe, bzw. zwischen lesendem
und schreibendem Zugriff.
III.5.2.1.1. Eingabeschnittstelle bei lesendem Zugriff
Die Eingabe für die Transformation besteht nur aus dem Namen der logischen Datensicht und den
Parametern, die von der Anwendung übergeben wurden. Aus dieser Information ermittelt die
Transformation die zugehörige physische Datensicht, anhand derer die Zugriffe erfolgen können. Die
Parameter werden gegebenenfalls auch in physische Werte umgesetzt.
III.5.2.1.2. Ausgabeschnittstelle bei lesendem Zugriff
Die Transformation hat anhand der physischen Entitäten die logischen Entitäten ermittelt und reicht
diese unsortiert an den Datensichtprozessor weiter. Weiterhin werden anhand des logischen
Datenmodells die Beziehungen zwischen den Entitäten ermittelt und an den Datensichtprozessor
durchgereicht. Im Fehlerfall wird ein Zustandscode zurückgegeben, der von einer darüberliegenden
Schicht interpretiert werden muß.
III.5.2.1.3. Eingabeschnittstelle bei schreibendem Zugriff
Der Datensichtprozessor übergibt der Transformation eine logische Datensicht mit konkreten Inhalten
(Auszug aus dem Vorgangsspeicher). Hieraus ermittelt die Transformation die physische Datensicht
und baut die Inhalte in die physischen Entitäten um.
III.5.2.1.4. Ausgabeschnittstelle bei schreibendem Zugriff
Je nach Erfolg des Schreibens übergibt die Transformation einen Zustandscode an den
Datensichtprozessor.
© GDV 1999
91
Spezifikation des Datenmanagers
Datenmanager
III.5.2.2. Die Transformation
Die Transformation ist für den Umbau der logischen in die physischen Entitäten und umgekehrt
zuständig. Sie bildet also entsprechend der Konfigurationsschicht die Logik in die Physik und die
Physik in die Logik ab. Aus diesem Grunde ist es erforderlich, während der Runtime die betroffenen
Teile des logischen Datenmodells in maschinenlesbarer Form vorzufinden, so daß die Abbildung
funktioniert. Hierzu werden sogenannte Datenmodell-Bausteine benutzt, die gegebenenfalls auf Daten
im Parametersystem zugreifen (siehe Masterplan). Weiterhin ist es erforderlich die Zuordnung von
logischer zu physischer Datensicht während der Runtime zu kennen, da diese für die Verbindung
zwischen Logik und Physik elementar ist.
Die Transformation hat nichts mit der Anwendungsschnittstelle zu tun. Sie kümmert sich
dementsprechend also auch nicht um Sortierung, Mengen und Einzelattribute, sondern sie behandelt
nur ganze Entitäten in der von der Schnittstelle vorgegebenen Reihenfolge.
III.5.2.3. Die Ablaufsteuerung
Die Ablaufsteuerung behandelt nur physische Entitäten, die ihm die Transformation übergibt, oder die
aufgrund der Datenbankzugriffe ermittelt werden. Ihre Aufgabe ist es, die in der Buildtime generierten
Module wie Ablaufplan und I/O-Module aufzurufen und den Zustand nach deren Aufruf zu ermitteln
und weiterzugeben.
III.5.2.4. I/O-Module
I/O-Module werden in der Buildtime generiert und dienen dazu direkt auf Datenbanken zuzugreifen.
Für I/O-Module gelten folgende Festlegungen:
Jede physische Entität hat mindest ein I/O-Modul.
Unter den I/O-Modulen gibt es genau eins, welches die gesamte Struktur einer physischen Entität
über den Primary Key ausgibt.
Es kann auch I/O-Module geben, die auf mehrere physische Entitäten eines DB-Systems zugreifen.
Verändernde Zugriffe sollten von separaten I/O-Modulen durchgeführt werden.
Die I/O-Module können statisch in die Ablaufsteuerung generiert werden, um die Performance zu
erhöhen. Sie eignen sich allerdings auch dazu Verteilungsaspekte zu implementieren, in dem Sie z.B.
als RPC’s aufgerufen werden.
III.5.3. Datenbank-Verfügbarkeit
Das Thema Verfügbarkeit von Anwendungsresourcen, wie z.B. Datenbanken geht weit über die
Funktionalität eines Datenmanagers hinaus. Der Sachbearbeiter sollte zu einem möglichst frühen
Zeitpunkt auf Störungen in seinem Arbeitsprozeß hingewiesen werden. Aus diesem Grunde zieht sich
das Verfügbarkeitshandling von der Workflow-Steuerung bis zur Funktionsbaustein- und Dienstebene
92
© GDV 1999
Datenmanager
Spezifikation des Datenmanagers
durch. Im Folgenden werden die Auswirkungen eines Verfügbarkeitshandlings auf den Datenmanager
beschrieben, ohne die genaue Ausprägung des Handlings zu kennen.
Weiter darüber hinausgehende Funktionalitäten, die den Datenmanager betreffen, können nur über die
allgemeine Spezifikation eines Verfügbarkeitshandlings in der VAA-Architektur beschrieben werden.
III.5.3.1.1. Voraussetzungen für logische Verfügbarkeit
Um Geschäftsvorfälle durchgängig und ohne vergebliche Eingaben durchführen zu können, ist es
notwendig, Informationen über die Verfügbarkeit von benötigten Resourcen zu bekommen. Hierzu
gehören in erster Linie die Daten bzw. Datenbanken, ohne die ein Geschäftsvorfall nicht bearbeitet
werden kann.
Um ein logisches Verfügbarkeitshandling betreiben zu können, ist es notwendig, Daten über
Zusammenhänge
von
Anwendungssystemen
und
den
benötigten
Ressourcen
mit
ihrem
Verfügbarkeitsstatus zu speichern. Die Pflege dieser Bestände erfolgt hauptsächlich während des
normalen Betriebs eines Anwendungssystems, da auf Störungen sehr schnell reagiert werden muß.
III.5.3.1.2. Auswirkungen auf den Datenmanager
Die Hauptauswirkung des Verfügbarkeitshandlings wird in der Ablaufsteuerung realisiert. Vor dem
Aufruf eines I/O-Moduls muß anhand der Verfügbarkeitsdaten der Zustand der betroffenen
Datenbanken geprüft werden. Ist nun ein Teil der im I/O-Modul angesprochenen physischen Entitäten
nicht verfügbar, so wird das Modul nicht aufgerufen, und es muß mit einem entsprechenden
Fehlercode reagiert werden.
Sind aufgrund der Daten alle Ressourcen des I/O-Moduls verfügbar, so wird dieses aufgerufen. Stellt
nun das I/O-Modul eine technische Nichtverfügbarkeit einer Datenbank (z.B. IMD-DB gestoppt) fest,
so wird der ensprechende Fehlercode an die Ablaufsteuerung zurückgegeben. Diese muß nun die
technische Nichverfügbarkeit in die logische umbauen und die Pflege der Verfügbarkeitsdaten
übernehmen. Dies sollte allerdings nur in einem Aufruf eines Verfügbarkeitsmoduls bestehen, welches
als Service im Rahmen des gesamten Verfügbarkeitshandlings existieren muß.
© GDV 1999
93
Abbildung der Zeitlogik
Datenmanager
IV. Abbildung der Zeitlogik
IV.1. Einleitung und Problemstellung
In Versicherungsunternehmen fallen häufig Daten an, deren Änderungen im Laufe der Zeit
nachvollzogen werden müssen. Dies sind insbesondere Informationen über rechtlich wirksame
Vertragskonstellationen. Dieser Themenkomplex wird mit dem Schlagwort Historisierung tituliert.
Eine detaillierte Beschreibung zum Thema Historienkozept ist im Anhang dieses Dokuments
enthalten.
Unter zeitabhängiger Datenspeicherung wird die Speicherung von verschiedenen zeitlichen Zuständen
einer Entität verstanden. Generell lassen sich folgende Kategorien unterscheiden:
aktuelle Daten
zukünftige Daten
historische Daten
überschriebene Daten
Die Datenmodellierung betrachtet normalerweise nur eine Zeitebene. In der Realität ist die
Speicherung zeitlicher Entitätszustände allerdings in vielen Fällen notwendig. Beispiele sind:
Vergangene, aktuelle und zukünftige Vertragszustände
Zustände, auf denen Änderungen aufgesetzt werden.
Der Modellierungsansatz der VAA berücksichtigt durch das Konstrukt des Informationsobjekts die
Notwendigkeit der Versionsführung.
Die zeitabhängige Betrachtung von Entitäten kann zur Erfüllung verschiedener Anforderungen
konzipiert werden, z.B. könnte die Anforderung lauten:
Der (rechtlich wirksame) Stand der Entitäten muß zu jedem Zeitpunkt rekonstruiert werden
können. Damit müssen auch Werte, die im Nachhinein überschrieben worden sind, nachvollziehbar
sein.
Eine reduzierte Anforderung könnte sein:
Es müssen nur die derzeit gültigen Werte eines vergangenen, aktuellen oder zukünftigen Zeitpunkts
bekannt sein. Werte, die im Nachhinein geändert worden sind, müssen nicht rekonstruiert werden.
Der elementare Zugang zu einer Darstellung zeitlicher Abhängigkeiten ist der Baum möglicher
Änderungen einer Entität. Eine Entität nimmt im Laufe ihres Lebens verschiedene Zustände an. Ein
Zustand ist für einen bestimmten Zeitraum, die Gültigkeitsdauer, relevant.
Generell sind zwei Änderungsarten zu unterscheiden:
94
© GDV 1999
Datenmanager
Abbildung der Zeitlogik
Fortschreibungen, d.h. Änderungen des letzten gültigen Zustands einer Entität.
Rückwirkende Änderungen, die nicht auf dem letzten gültigen Zustand aufsetzen und damit eine
Reihe von Zuständen ungültig machen.
Dieser Änderungsbaum wird im folgenden Beispiel veranschaulicht.
Er wird von links nach rechts und von unten
nach oben fortgeschrieben. Aktuell ist
immer der obere Pfad mit all seinen Knoten.
Ausgehend von dem Zustand (a) einer
Entität werden die Zustände (b) - (e) im
Zuge der Zeit eingefügt. Hierdurch wird der
Pfad A gebildet, der durch die
Gültigkeitsfolge A repräsentiert wird. Im
Pfad B und C werden durch rückwirkende
Änderung bereits bestehende Zustände überschrieben.
Daraus
resultieren
die
Gültigkeitsfolgen B und C.
i
j
k
f
a
b
a
g
c
b
Pfad C
l
Pfad B
h
d
Pfad A
e
c
d
e
Gültigkeitsfolge A
rückw irkende Änderung
a
b
f
g
h
Gültigkeitsfolge B
rückw irkende Änderung
a
IV.2. Unterstützung des
Historienkonzepts durch
den Datenmanager
i
j
k
l
Gültigkeitsfolge C
Abb.: Änderungsbaum einer Entität
IV.2.1. Die Bildung von Informationsobjekten
Datenmodellentitäten, die in einem Informationsobjekt liegen, erfahren die gleiche zeitliche
Behandlung. Bei Änderung einer Entität im Informationsobjekt wird eine Version des gesamten
Informationsobjektes und damit eine Version aller darin enthaltenen Datenmodellentitäten erzeugt.
Bei Navigation zwischen Entitäten eines Informationsobjektes bewegt man sich in einer Zeitscheibe,
d.h. alle Entitäten haben dieselbe Version. Nur beim Übergang von einem Informationsobjekt in ein
anderes muß dann noch eine Aussage zur gewünschten Version gemacht werden.
IV.2.2. Versionsbildung
Jede Version wird durch ihre Versionsnummer eindeutig identifiziert. Eine neue Version wird immer
auf Basis einer bestehenden Version gebildet. Damit gibt es eine eindeutige Ursprungsversion, das ist
die Version, die bei der Erzeugung einer Informationsobjektexistenz entsteht.
IV.2.3. Definition eines Versionsbaums
Relevante Daten für die Versionsführung sind die Versionsnummer, das ‘Gültig-ab-Datum’
(Gültigkeitsdatum) der Version, das Datum der Versionsbildung (Wissensdatum) sowie die
Information, welche Version als Basis für eine neue Version gewählt wurde. In einem Diagramm mit
den beiden Datumsangaben als Achsen und einer Verbindungslinie zwischen jeder Version und ihrer
© GDV 1999
95
Abbildung der Zeitlogik
Datenmanager
Basis kann der sogenannte Versionsbaum dargestellt werden. Dieser stellt somit die auf die
Anforderungen des Datenmanagers angepaßte Art des o.g. Änderungsbaums dar.
Wissensdatum
Datum
9
heute
am Stichtag gültige Version:
7
aktuelle Version (heute gültig) :
8
neueste Version :
9
Vorgänger der Version 8 :
7
8
7
6
5
Abb.: Beispiel für einen Versionsbaum
4
3
Die Funktionalität des Datenmanagers setzt nur die2 im Versionsbaum
definierten Informationen
voraus, d.h.
1
die Versionsnummer,
die Versionsnummer der Basisversion (Vorgänger),
das Wissensdatum,
das Gültig-ab-Datum.
Stichtag
Datum
heute
Gültigkeits
datum
Die Korrektheit und Konsistenz dieser Daten wird vom Datenmanager sichergestellt.
Damit können alle üblichen Arten der Zeitlogik abgebildet werden. Die Definition und Sicherstellung
einer speziellen Historienführung ist aus Sicht des Datenmanagers Aufgabe einer
Anwendungsfunktion (z.B. des generellen Änderungsdienstes für ein Informationsobjekt).
96
© GDV 1999
Datenmanager
Abbildung der Zeitlogik
Beispiele für spezielle, in der Praxis oft gemachte Einschränkungen bei der Historienführung sind:
Rückwirkende
Änderungen
sind
nicht
zulässig.
Dann kann die Basis für eine neue Version immer nur die derzeit neueste Version eines
Informationsobjekts (bzw. einer Entität) sein.
Änderungen
in
der
Vergangenheit
sind
nicht
zulässig.
Das Gültig-ab-Datum darf nicht kleiner als das Wissensdatum (d.h. das Datum der Änderung) sein.
Die
Gültigkeitskette
muß
lückenlos
sein.
Für jede Version muß das Gültig-ab-Datum mit dem Ungültig-ab-Datum der Vorgänger-Version
übereinstimmen.
© GDV 1999
97
Verteilung
Datenmanager
V. Verteilung
Die EDV-Systeme, die heute neu konzipiert werden, sind meist keine reinen Host-Systeme mehr.
Stattdessen setzt sich die Verwendung von Client/Server-Systemen immer mehr durch, in denen die
Datenbank-Last von einem größeren Server (dem altgedienten Host) getragen wird und in dem die
meist graphische Benutzeroberfläche auf einem Client-PC abläuft. Die genaue Verteilung der
Anwendungs-Komponenten und der Datenbank-Zugriffsmodule ist vom Einzelfall abhängig. Auch der
VAA-Datenmanager sollte in einem solchen Umfeld einsetzbar sein. Deshalb geben wir hier
Vorschläge für eine mögliche Verteilung des VAA-Datenmanagers, die uns mit der heutigen
Technologie sinnvoll erscheinen. Zukünftige Entwicklungen auf dem Feld der verteiten Systeme
werden sicher bald neue Alternativen möglich und attraktiv machen.
Wir sehen für die Verteilung des VAA Datenmanagers folgende Ansätze:
V.1. Verteilte Datenbank
Heutzutage unterstützen bereits viele Datenbanken eine Verteilung der Daten auf mehrere Rechner,
die auf der Applikationsebene gar nicht mehr sichtbar wird. Diese Art der Verteilung muß natürlich
gut geplant sein, damit nicht zu viele Querbeziehungen zwischen den Daten auf den unterschiedlichen
Rechnern bestehen. Aus der architektonischen Sicht des Datenmanagers ist das aber wiederum
unproblematisch, da keine weiteren technischen Vorkehrungen zur Implementierung von DatenbankFeatures im Datenmanager selbst getroffen werden müssen.
V.2. Verteilung der I/O-Module
Die direkte Schnittstelle zur physischen Datenbank des Datenmanagers sind die I/O-Module. Man
könnte sich vorstellen, daß der Haupt-Anteil des Datenmanagers auf einem Rechner läuft, während die
Datenbank-I/O-Module auf verschiedene Rechner verteilt sind. Damit beim Zurückschreiben von
Daten aus dem Vorgangsspeicher in die beteiligten Datenbanken kein Datenverlust auftritt, müssen die
zugrundegelegten eventuell verschiedenen Datenbanken ein 2-Phasen-Commit unterstützen. Die
Verteilung von I/O-Modulen bedingt also, daß für Datenbank-übergreifende Operationen typische
Datenbank-Funktionalitäten reimplementiert werden.
98
© GDV 1999
Datenmanager
Verteilung
V.3. Verteilung der Anwendungs-Module
Für ein flexibles Design einer Anwendung wird eine weitergehende Verteilung benötigt. Oft sollen
Anwendungs-Bausteine auf verschiedene Rechner im Netz aufgeteilt werden, da spezialisierte
Applikations-Server für bestimmte Aufgaben existieren, die sich im Aufruf-Baum mit den Dialogen
der Benutzerschnittstelle abwechseln.
Dazu muß der Datenmanager auf jeder Plattform laufen, um den Inhalt des Vorgangsspeichers an den
jeweils aktiven Prozeß im Verteilungs-Szenario weiterzugeben. Mit Unterstützung moderner
Transaktionsmonitore ist dieses Szenario implementierbar, da Programmaufrufe über Rechnergrenzen
hinweg automatisch einen Transaktionsspeicher mitgeben können. Natürlich muß beim Einsatz auf
verschiedenen Hardware-Architekturen auf eine Hardware-unabhängige Speicherung der Daten im
Vorgangsspeicher oder auf eine entsprechende Konvertierung geachtet werden. Auch Zugriffe auf I/OModule, die sich auf verschiedenen Rechnern befinden, lassen sich mit diesem Vorgehen
implementieren.
Damit übernimmt der Transaktionsmonitor eine wesentliche Rolle im ganzen Szenario. Das setzt
voraus, daß die Verwaltung des Vorgangsspeichers und das Rollback der zugehörigen Datenbanken
vom Transaktionsmonitor gesteuert wird. Der Transaktionsmonitor ist dabei zusammen mit der
darunterliegenden Datenbank für das eventuell notwendige 2-Phasen-Commit zuständig. In diesem
Fall ergibt sich ein enges Zusammenspiel des Transaktionsmonitors mit den darunterliegenden
Datenbanken.
V.4. Offline Verarbeitung
Die Verwendung von mobilen offline-Clients (Notebooks) steigt auch in der Versicherungswirtschaft
stetig. Notebooks werden nur manchmal an das firmenweite Netz angeschlossen und müssen dann die
potentiell notwendigen Daten vom Datenbankserver holen und neu erfaßte Daten und Änderungen
zurückspielen. Bei Verwendung des Datenmanagers kann man sich dazu zwei mögliche ArchitekturVarianten vorstellen:
1. Das Notebook lädt bei der Verbindung mit dem Firmen-Netz alle Daten, die für die nächsten
Geschäftsvorfälle notwendig sein könnten, in einen eigenen Vorgangsspreicher. Im Offline-Betrieb
wird der Vorgangsspeicher gelesen, Schritt für Schritt modifiziert oder mit weiteren Daten gefüllt.
Erst wenn wieder eine Verbindung zur zentralen Datenbank hergestellt ist, kann der
Vorgangsspeicher auch zurückgeschrieben werden.
2. Man verwendet Replikations-Mechanismen einer Datenbank, um vor Einsatz eines Notebooks
relevante Teile der Datenbank auf den Offline-Client herunterzuladen. Die Offline-Verarbeitung
geschieht dann auf der lokalen Datenbank. Bei der nächsten Verbindung mit dem DatenbankServer müssen geeignete Replikationsmechanismen die gegenseitigen Änderungen der lokalen und
der Host-Datenbank nachführen.
Wie man sieht, ist die Verteilungsproblematik sehr komplex und muß auch im Gesamtumfeld von
VAA, also in der VAA-Gesamtarchitektur gelöst werden. Aus Sicht des VAA-Datenmanagers können
nur Vorschläge gemacht und Hinweise auf versteckte Probleme gegeben werden, leider aber keine
Patentlösungen vorgestellt werden.
© GDV 1999
99
Migrationsverfahren
Datenmanager
VI. Migrationsverfahren
Migration bezeichnet den einmaligen Übergang von einem Ausgangssystem in das Zielsystem.
Das Ausgangssystem hat üblicherweise zwei Softwareschichten:
1. Programmschicht, bestehend aus Präsentation, Steuerung, Funktion und Datenzugriff in
weitestgehend vermischter Form.
2. heterogen vermischte Datenbasis (hierarchisch, relational, (index)sequentiell)
Das Zielsystem gehorcht der VAA-Architektur und zeichnet sich durch das Vorhandensein des
entkoppelnden Datenmanagers aus.
Die Einführung eines VAA-Anwendungssystems erfordert in der Regel Migrationen in mehrfacher
Hinsicht:
Organisation
Anwendungssystem
Daten
In diesem Dokument wird die Organisationsmigration nicht betrachtet.
Zu unterscheiden ist die Migration von der Integration. Als Integration wird die Anbindung des neu
einzuführenden Systems an „fremde“ Verfahren (besonders Altverfahren) bezeichnet.
Üblicherweise gebietet die Mächtigkeit von Versicherungsanwendungssystemen die Systemmigration
in mehreren Etappen. Für jede „unvollständige“ Systemmigration wird ein Integrationsschritt
erforderlich, der die Kopplung zwischen migrierten und nicht migrierten Teilsystemen herstellt. Die
Logik „was nicht migriert wird, muß integriert werden“ legt die Wahl möglichst mächtiger
Migrationsetappen nahe.
Aufgrund der höheren Flexibilität des Neusystems scheiden Altsystemadaptionen meistens aus. Das
Konzept des VAA-Datenmanagers erleichtert die Migration erheblich, da Zugriffe auf „fremde“
Datenbasen relativ einfach möglich sind.
VI.1. Datenmigration
Die Datenmigration führt den Altdatenbestand in einer Stichtagsumstellung in die neue Datenbasis
über. Danach sollten die neuen Verfahren ohne spezielle Adaptionen betrieben werden können.
Als wesentlicher Designakt für die Datenmigration ist die Transformationsdokumentation vom ISTphysikalischen-Datenmodell auf das NEU-logische Datenmodell hervorzuheben. Die
Entwicklungswerkzeuge des Datenmanagers können hiebei von großem Nutzen sein.
Diese Vorgehensweise erfordert das gezielte Reengineering der vorhandenen Datenstrukturen im
Hinblick auf Befriedigung der Erfordernisse des neuen Datenmodells. Im Zuge dieses Reengineerings
100
© GDV 1999
Datenmanager
Migrationsverfahren
müssen üblicherweise Programme des Altsystems analysiert und dokumentiert werden, da sich die
Bedeutung vieler Datenfelder erst im Kontext mit ihrer Verarbeitungslogik erschließt.
Die Durchführung der Datenmigration muß möglichst schnell erfolgen, da währenddessen die
Datenbasis nicht verändert werden kann (= Betriebsstillstand). Aus diesem Grund bietet sich bei
großen Organisationen eine etappenweise Migration an (z.B. spartenweise erst Bestand, dann
Schaden, ...).
VI.2. Verfahrensmigration durch Altdatenintegration
Zugriff von neuen Verfahren auf Altdatenbestände. Diese Vorgehensweise wird durch das
Datenmanagerkonzept unterstützt. Idealerweise brauchen nur spezifische Zugriffsroutinen für die
Altdatenbasis verwendet werden und die neuen Verfahren funktionieren „ohne“ Migration. Sozusagen
wird die Migration ersetzt durch die (Online-) Integration der neuen Verfahren mit der Altdatenbasis.
Anzumerken ist allerdings, daß durch das schönste Neuverfahren die Altdatenbasis nicht besser wird.
Auch gelten alle Reengineeringanforderungen aus der Datenmigration für diese Vorgehensweise.
VI.3. Unterlegung von neuen Datenmodellen
Attraktive Altverfahrensfunktionalität kann durch Unterlegung der neuen Datenstrukturen erhalten
werden. Voraussetzung ist die strukturelle Eignung der Altprogramme für die Verwendung des
Datenmanagers (Datenzugriffsschicht!). Fehlt diese Voraussetzung, droht dieser Weg unwirtschaftlich
zu werden gegenüber einer Neuentwicklung.
VI.4. Migrationsverfahren bei der Württembergischen
Versicherung
Folgende Verfahren wurden bei der Württembergischen bei der Einführung ihres Datensichtprozessors
bereits erfolgreich angewendet:
VI.4.1. Komplette Umstellung der Anwendung auf eine neue
Architektur
Bei dieser Umstellung werden die Architurkomponenten Datenmanager, Dialogmanager und
Vorgangsmanager sowie die allgemeinen Anwendungsbausteine Tarifierung, Provisionierung,
Dokumentierung, Schnittstellenbelieferung und Prüfsystem verwendet.
Praktisch ist diese Art der Umstellung eine komplette Neuentwicklung des Anwendungssystems, bei
dem die bestehenden Daten übernommen und in das erforderliche Format konvertiert werden.
Die Vertragsverwaltung wurde bei der Württembergischen spartenweise in dieser Form umgestellt.
Dies erfolgte jeweils dann, wenn für die jeweilige Sparte ohnehin ein Redesign der Anwendungen
erforderlich war. Durch die Nutzung der Architekturkomponenten und dem damit verbundenen hohen
Wiederverwendungsgrad gelang es, diese Redesign-Projekte deutlich kostengünstiger zu realisieren.
© GDV 1999
101
Migrationsverfahren
Datenmanager
VI.4.2. Stufenweise Umstellung von Anwendungen
Bei einer Umstellung wird die Kernanwendung im Rahmen einer neuen Architektur entwickelt,
Teilsysteme können unverändert weitergenutzt werden.
Dazu müssen auch die Datenbestände ins Unternehmensdatenmodell integriert werden, die in der alten
Speicherungsform weiterverwendet werden. Durch die Trennung von logischem und physischem
Modell ist dies möglich, ohne im logischen Modell zu große Kompromisse einzugehen.
Bei der Württembergischen wurden die Systeme Kunde und Schaden zunächst nicht verändert. Aus
Sicht der neuen Anwendungen sind diese Systeme dennoch völlig integriert, d.h. die Kunden- und
Schadendaten werden bereits über den Datenmanager gelesen und verändert und die Anzeige der
Daten erfolgt bereits durch den neuen Dialogmanager.
VI.4.3. Verwendung des Datenmanagers in bestehenden
Anwendungen
Dies ist mit vertretbarem Aufwand immer dann möglich, wenn bereits zentrale Zugriffs- und
Updateroutinen für die Datenbestände existieren (was in vielen Firmen ja der Fall ist).
Die betreffenden Datenbestände werden neu modelliert und in das Unternehmensdatenmodell
integriert, die physische Struktur wird angepaßt und die alten Daten werden in die neue Form
konvertiert. Die bestehenden Zugriffs-und Updatemodule werden auf den Zugriff über den
Datensichtprozessor umgestellt. An die aufrufende Anwendung wird die gleich Schnittstelle wie
früher zurückgeliefert.
Bei der Württembergischen wurde dieses Verfahren verwendet, als das Kundensystem
weiterentwickelt wurde. Alle Anwendungen, die bereits auf die neue Architektur umgestellt waren,
greifen über den Datensichtprozessor direkt auf diese Kundendaten zu. „Alt“-Anwendungen rufen
nach wie vor die zentralen Kunden-Module auf und bekommen ihre Daten in der derselben Form wie
vorher.
102
© GDV 1999
Datenmanager
Glossar
VII. Glossar
Abbildung
Abbildungsvorschrift vom logischen auf das
physische Datenmodell
Ablaufplan
vom
PDaSi-Generator
erzeugtes
Zugriffsprogramm, welches alle Funktionen
enthält, die DB-übergreifend sind. Ruft die I/OModule auf
Ablaufsteuerung
Komponente im Datenhandler: aktiviert die
benötigten Ablaufpläne und darüber indirekt die
I/O-Module in der optimalen Reihenfolge
AEM
Ausgabeentitätsmenge
Aggregation
Mehrere Entitäten des logischen Datenmodells
werden zu einer Einheit des physischen
Datenmodells zusammengefaßt
Archiv
ein Hintergrund-Speicher
gewordenen
Zweige
Historienführung
Basisversion
Kopiervorlage zur Bildung einer neuen Version
Blättern, historisch
Lesen der Versionen eines
zeitlicher Reihenfolge
Buildtime
hier werden durch Generatoren Bausteine erstellt,
die für den Einsatz zur Laufzeit optimiert sind
Commit - Aufruf
Anforderung zur persistenten DB-Ablage bei
Vorgangsende
Datenhandler
DB-nahe Datenmanager-Komponente: funktionale
Hülle um Transformation und Ablaufsteuerung
Datenmanager
siehe Zusammenfassung am Ende des Kapitel I
Datensicht, logische
Logische Datensichten sind hierarchische Bäume,
die sich z.B. durch die Jackson-Notation
beschreiben lassen. Logische Datensichten
beschreiben die Daten in der Form, wie das
Anwendungsprogramm sie gerade benötigt.
Datensicht-Selektion
beschreibt die Regeln und Bedingungen, mit
welchen die Treffer einer Datensicht bestimmt
werden
© GDV 1999
für alle ungültig
innerhalb
der
Entitätstyps
in
103
Glossar
Datenmanager
Datensicht-Struktur
beschreibt
die
Anordnung
(Reihenfolge,
Gruppierung und Hierarchie, Alternativen) der
durch die Datensicht-Selektion ermittelten
Instanzen
Datensichtentität
siehe DSE
Datensichtprozessor
Datenmanager-Komponente: wird von einer
Anwendung (d.h.einem Funktionsbaustein oder
einer Komponente der Steuerungsebene) unter
Angabe einer logischen Datensicht und der zur
Ausführung erforderlichen Parameter aufgerufen
Datensichtsprache
Beschreibungsmittel
für
die
an
der
Anwendungsschnittstelle bereitzustellenden Daten
auf konzeptioneller Ebene (ERM)
DSE
Datensichtentität; wird innerhalb einer Datensicht
als Navigationsbrücke gebraucht
E/R-Modell
Entity-Relationship-Modell zur Beschreibung
fachlicher
Zusammenhänge
von
Unternehmensdaten
E/R-Sprache
Modellierungs- bzw. Beschreibungssprache für
das logische Datenmodell
Entität
siehe Entity
Entität, abhängige
Entität, die nicht Kernentität ist
Entity
ein abgrenzbares „Objekt“ der Diskurswelt, das
ein reales Objekt oder eine gedankliche
Abstraktion davon darstellt
Entity-Menge
im Sinne von Entitytyp
Entitytyp
Zusammenfassung unterschiedlicher Entities eines
Systems, die durch dieselben bedeutungsvollen
Attribute
(Eigenschaften/Merkmale)
charakterisiert werden
Existenz
alle Versionen zu einer bestimmten Instanz in
einer Zeitperiode
Führungsentität
Einstiegsentität in ein Informationsobjekt, die von
keiner
anderen
Entität
des
gleichen
Informationsobjekts abhängig ist
Gültigkeitsabschnitt
Zur Beschreibung von Gültigkeitsabschnitten sind
die zwei Attribute Beginn und Ende notwendig
104
© GDV 1999
Datenmanager
Glossar
Historie
die vergangenen Abschnitte des derzeit gültigen
aktuellen Zweigs einer Entität
Horizontale Partitionierung
Eine Entität des logischen DM wird auf mehrere
Einheiten des physischen DM’s verteilt, indem
eine Zuordnung auf Schlüsselebene erfolgt
I/O-Module
führen (in den Ablaufplan eingebunden) die
Datenbank-Zugriffe durch
Informationsobjekt
aggregierendes Konstrukt im Entity-Relationship
Modelling des VAA im Sinne einer
Zusammenfassung von Entitäten, die derselben
Zeitlogik gehorchen
Instanz
im Sinne von Entität, d.h. Ausprägung eines
Entity-Typs i.a. zum aktuellen Zeitpunkt
Jackson-Notation
Ein Programm wird baumstrukturartig durch eine
Folge von Sequenzen, Iterationen und Selektionen
dargestellt
Kernentität
unabhängige Entität, die von keiner anderen
Entität existentiell abhängig ist
Konfiguration
Zeitraum im Vorgehensmodell, in dem die
administrativen Voraussetzungen für den Betrieb
des Datenmanagers getroffen werden
Konfigurationsdaten
Daten zur Anpassung von Bausteinen in eine
techn. Umgebung; legen zu operativen Daten z.B.
Darstellungseigenschaften
auf
den
Ausgabemedien fest
LDaSi - Editor
graphischer Editor zur Definition einer logischen
Datensicht auf Basis des logischen Datenmodells
LDaSi - Generator
Der LDaSi-Generator ist zur Buildtime zuständig
für die Kompilation der logischen Datensicht, die
mit dem LDASI-Editor erstellt wurde, in eine
Form, die vom Datensicht-Prozessor abgearbeitet
werden kann
LDM - Editor
graphischer Editor zum Aufbau und zur Pflege des
logischen Datenmodells
NF2-Struktur
non-first-normal-form Datenstruktur mit multiplen
Bereichen (Tabellen) und Schachtelungen analog
zur Jackson-Notation
© GDV 1999
105
Glossar
Datenmanager
PDaSi - Editor
graphischer Editor zur Definition einer physischen
Datensicht auf Basis des physischen Datenmodells
(Datenbankschemas)
PDaSi - Generator
erzeugt das Ablaufplanprogramm (das RuntimeModul für die Ablaufsteuerung) und die I/OModule
PDM - Editor
graphischer Editor zum Aufbau und zur Pflege des
physischen Datenmodells
Redundanz
Entitäten (oder Teile davon) werden physisch
redundant gespeichert, d.h. es erfolgt eine
parallele Zuordnung zu mehreren physischen
Einheiten
Semantik
Bedeutungsumfang eines Modellkonstrukts für
den zugehörigen Realitätsausschnitt
Sicht, interne
technische Sicht der Daten aus der Perspektive
eines DBMS
Sicht, konzeptionelle
siehe Datensicht
Transformation
im Datenhandler: ermittelt die zugehörige
physische Datensicht und führt die erforderlichen
Parameterumsetzungen
durch.
Außerdem
Umsetzung der log. in phys. Entitäten anhand der
Abbildungsdefinition
Übergabetabelle
eine im Vorgangsspeicher als Ergebnis der
Datenanforderung zur Verfügung gestellte,
gefüllte Treffertabelle mit Referenzen auf die
gefundenen Instanzen
Version
zeitpunktbezogene Betrachtung einer Entität in
ihrem Lebenslauf
Versionsführung
im Sinne von Zeitlogik: Verwaltung zeitlich
unterschiedlicher Ausprägungen einer Entität
Vorgangsspeicher
benutzerspezifischer Hauptspeicherbereich, der
Instanzen enthält, die gemäß den im logischen
Datenmodell definierten Beziehungen aufgebaut
werden
Zeitbedingungen
Zeitbedingungen formulieren Bedingungen, die
Versionen einer bestimmten Entität in Beziehung
setzen
Zeitlogik
Zeitabhängige
106
Datenspeicherung,
siehe
auch
© GDV 1999
Datenmanager
Glossar
Versionsführung
Zuordnung
© GDV 1999
Baustein, der einer log. Datensicht eine physische
Datensicht zuordnet
107