DNA Replikation, Rekombination und Reparatur
Werbung

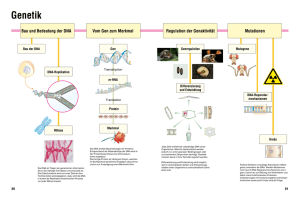
Zusammenfassung Biochemie, Kapitel 27 DNA Replikation, Rekombination und Reparatur 1953 veröffentlichten J. Watson und F. Crick das Strukturmodel der DNA. Sie fanden heraus, dass die DNA in einer rechtsdrehenden Doppelhelix vorliegt. Gleichzeitig erkannten sie, dass auf Grund der Struktur ein logischer Replikationsmechanismus vorhanden sein musste. Wie können DNA Stränge verdoppelt werden? Eine Übersicht: 1) Da die beiden DNA Stränge aufgrund der H-Brücken sehr gut zusammenhalten, braucht es einen Mechanismus, der die Stränge in einer bestimmten Region auseinandertrennt. Die Helikase (Enzym) übernimmt diesen Schritt. Sie benützt freie Energie aus der ATP-Hydrolyse, um an der Doppelhelix entlang zu wandern und die Stränge zu teilen. 2) Die DNA Helix muss entwunden werden, um in zwei Stränge geteilt werden zu können. Durch lokale Entwindung, entsteht eine Spannung. Spezielle Enzyme, die Topoisomerasen führen Supercoils ein, welche die Trennung in zwei Stränge erleichtern. 3) Die DNA Replikation ist sehr wichtig. Deshalb dürfen möglichst keine Fehler unterlaufen. Diese wären nämlich fatal. Es braucht folglich auch einen Korrekturmechanismus, um Fehler zu minimieren. 4) Die DNA Replikation muss schnell ablaufen. 5) Polymerasen (Enzyme, welche komplementäre Basen anlagern), können DNA nur in 5’ -> 3’ Richtung synthetisieren. Somit muss ein Strang diskontinuierlich erstellt werden. Zusätzlich braucht es ein kurzes RNA Stück, um den Start festzulegen (dies übernimmt die Primase, ein Enzym das den Primer synthetisiert) und einen „genetischen Kleber“ (Ligase) um die einzelnen Stücke zusammenzufügen. 6) An den Enden einer linearen DNA findet man spezielle Strukturen, die Telomere. Diese garantieren, dass bei der Replikation keine Stücke verloren gehen. 7) Um eine optimale Anpassung an die Umwelt zu erreichen, ist es nötig, dass DNA neu rekombiniert wird. Spezifische Enzyme, die Rekombinasen erleichtern diesen Prozess. 8) Nach der Replikation ist es möglich, dass die DNA Schäden trägt, welche ausgelöst werden durch ultraviolettes Licht oder chemische Stoffe (Krebs!). Alle Organismen haben jedoch Enzyme, die solche Mängel entdecken und auch reparieren können. 1 Zusammenfassung Biochemie, Kapitel 27 Aufbau der DNA: 1) DNA besteht aus zwei polynucleotid Ketten, welche gegenläufig sind (5’-> 3’ und 3’ -> 5’). Zusammen formen sie eine rechtshändige Doppelhelix (Bild s.S. 122) 2) Purin (A, G)und Pyrimidin (C, T) Basen befinden sich im Innern der Helix. Phosphat und Deoxyribose Einheiten bilden aussen das Rückgrat. 3) In der DNA paaren sich A und T (verbunden durch 2 H-Brücken), sowie C und G (verbunden durch 3 H-Brücken) (Chargaff Regel). Die DNA Struktur ist variabel: 3 verschiedene Konformationen sind bekannt: 1) B-DNA 2) A-DNA 4) Z-DNA B-DNA: - ist die biologisch häufigste Form - B-Form ist wie auch die A-Form eine rechtsdrehende Doppelhelix, deren beiden Stränge durch die Basenpaarung zusammengehalten werden - die glykosidischen Bindungen der C1’ Atome in der Deoxyribose haben eine übereinstimmende Lage. Dadurch sind die Basenpaare etwa 36 Grad gegeneinander versetzt (Propeller twist) - das C2’ Atom liegt ausserhalb der Ebene (C2’-endo).(Unterschied zu A-Form) - in der Struktur der DNA unterscheidet man zwischen grosser und kleiner Furche (major and minor groove). Diese entstehen, da sich die glykosidischen Bindungen der Basenpaare nicht genau diametrisch gegenüber liegen. Somit entstehen eine grössere und eine kleinere Region - in der grossen Furche gibt es nun mehr Möglichkeiten für Interaktionen mit Proteinen, welche spezifische DNA Sequenzen erkennen können A-DNA: 2 Zusammenfassung Biochemie, Kapitel 27 - Dehydrierung begünstigt die A-Form der DNA, da in dieser Konformation die Phosphatgruppe weniger Wasser bindet - A-DNA ist ebenfalls eine rechtsdrehende Doppelhelix (wie B-Form) mit zwei antiparallelen Strängen - das C3’ Atom liegt ausserhalb der Ebene (C3’-endo). Dies hat zur Folge, dass die Phosphatgruppen näher beieinander liegen, als bei der B-Form - die A-Form ist im vergleich zur B-Form breiter, aber dafür auch kürzer - die Basenpaare der A-DNA sind um 19 Grad zur Helixachse gegenüber der Senkrechten geneigt Z-DNA: - treten in GC reichen Teilsequenzen innerhalb von B-DNA auf - die Doppelhelix ist linksgängig - das Rückgrat der Z-DNA hat eine charakteristische Zickzack Form - DNA Abschnitte in der Z- Konformation haben wahrscheinlich physiologische Bedeutung, Details sind aber noch nicht bekannt. (Zur Übersicht der 3 Konformationen siehe BC S.750 Table 27.1) 3 Zusammenfassung Biochemie, Kapitel 27 Replikation: Helikase: Um eine DNA Doppelhelix zu replizieren, muss sie zuerst in die Teilstränge zerlegt werden. Nur so können beide Stränge als Templates dienen. Solche spontanen Strang-Separationen sind relativ selten. Deshalb gibt es spezifische Enzyme, die Helikasen, welche die Energie von ATP nützen um die Stränge auseinander zunehmen. Der detaillierte Mechanismus der menschlichen Helikase ist noch nicht ganz bekannt, jedoch konnte die bakterielle Helikase (PcrA) weitgehend erforscht werden. PcrA besteht aus vier Domänen (A1, A2, B1, B2) und teilt die Stränge in 3’ -> 5’ Richtung auf:: - Die Untereinheit A1 enthält ein „P-loop NTPase fold“, welcher an der Bindung und Hydrolyse von ATP beteiligt ist. - Die Untereinheit B1 ist homolog zu A1, enthält jedoch keine P-loop. - A2 und B2 haben genau den gleichen Aufbau. (Siehe BC S.753 Figure 27.16) A1 und B1 können DNA Einzelstränge binden. Wenn ATP fehlt, sind sie an die DNA gebunden. Lagert sich ATP an, löst dies eine konformelle Änderung der Ploop und denn danebenliegenden Regionen aus. Darauf folgt, dass sich die A1 Untereinheit löst und an der DNA entlang gleitet. Somit nähert sich A1 der B1 Domäne. ATP wird nun hydrolysiert in ADP und Orthophosphat. Dies hat zur Folge, dass sich wieder ein Spalt zwischen den Untereinheiten bildet. Da aber A1 den besseren Griff hat, wird der DNA Strang durch die B1 Domäne Richtung A1 gestossen. So wird also die DNA in Teilstränge zerlegt. (Siehe BC S. 753 Figure 27.17) DNA Supercoils: Wenn die DNA lokal entwunden wird, hat dies entweder eine Überwindung oder ein Supercoiling der umliegenden Regionen zur Folge. Um die Überwindungsspannung zu umgehen, sind spezielle Enzyme vorhanden, welche DNA Supercoils einführen. Wichtige topologische Daten der zirkulären DNA sind: - linking number (Lk): Verwindungszahl der DNA Einzelstränge. Moleküle, die sich nur in der Lk unterscheiden sind Topoisomere. Topoisomere von DNA können nur ineinander umgewandelt werden, indem man einen oder beide DNA Stränge durchschneidet und sie dann wieder zusammensetzt. - twist (Tw): Anzahl der Helikalen Windungen der DNA Stränge umeinander - writhe (Wr): Anzahl der Supercoilings (negativ = rechtsdrehend, positiv = linksdrehend) 4 Zusammenfassung Biochemie, Kapitel 27 Zusammenhang zwischen diesen Grössen: Lk = Tw + Wr Moleküle, welche sich nicht in Lk unterscheiden, können ohne Durchschneidung eines Stranges ineinander übergeführt werden. Eine DNA mit Supercoils ist kompakter als eine ungespannte DNA derselben Länge. Also kondensieren Supercoils die DNA. Viele natürlich vorkommende DNA’s sind negativ supercoiled. Dies, da es durch das negative Supercoiling einfacher ist, die Stränge zu entwinden. Positives Supercoiling kondensiert die DNA effektiv, was die Separation der Stränge schwieriger gestaltet. Topoisomerase 1: Diese Enzyme verändern die Linking Number der DNA, um sie während der Auftrennung in zwei Stränge zu entspannen. Dies tun sie in drei Schritten: 1. Aufschneiden eines DNA Einzelstränges 2. Durchziehen des anderen Stranges durch diese Lücke 3. Wiederzusammenfügen der DNA Bruchstücke Topo 1 katalysiert also die Relaxation der supercoiled DNA. Dies ist ein energetisch günstiger Prozess, welcher keine Energie verbraucht! (Siehe BC S. 757 Figure 27.22) Die Menschliche Topo 1 besteht aus vier Untereinheiten, welche sich um einen zentralen Hohlraum anordnen. Dieser besitzt einen Durchmesser von ca. 20 A, was exakt genügend Platz für eine doppelsträngige DNA bietet. In diesem Hohlraum befindet sich ein Tyrosinresiduum (siehe BC S.757). Dessen –OH Gruppe greift die Phosphatgruppe des einen DNA Rückgrades an und formt dann eine Phosphodiesterbindung zwischen dem Enzym und der DNA. Dies hat zur Folge, dass die DNA aufgeschnitten wird und eine freie 5’ Hydoxylgruppe entsteht. Nun rotiert die DNA, kontrolliert vom Enzym, um den anderen Strang. Dies ist möglich, da Energie frei wird, welche beim Supercoiling gespeichert wurde. Durch diese Rotation entwindet sich das Supercoiling. Darauf greift die Hydroxylgruppe das Phosphotyrosin an und das Tyrosin wird wieder freigelassen. Schlussendlich liegt die DNA also ungespannt vor. Topoisomerase 2 (Gyrase): Typ 2 Topoisomerasen katalysiert das Supercoiling. Um dies durchführen zu können, wird Energie von ATP benötigt. Topo 2 ist ein Dimer und hat die Form eines Herzen. Es besitzt wie Topo 1 einen grossen Hohlraum in der Mitte (siehe BC S. 758 Figure 27.23). Die Reaktion beginnt mit der Bindung einer Doppelhelix. Beide Stränge befinden sich in der Nähe eines Tyrosinresiduums. Diesen ist es möglich eine kovalente 5 Zusammenfassung Biochemie, Kapitel 27 Bindung mit dem DNA Rückgrat zu formen (G Segment). Dieser Komplex bindet dann schwach eine zweite Doppelhelix (T Segment). Beide Monomere besitzen Domänen, welche ATP binden können. Dies löst dann konformelle Änderungen aus und hat zur Folge, dass die beiden Monomere näher zusammen kommen. Geschieht dies, wird das T Segment in der Mitte gefangen genommen. Die konformelle Änderung bewirkt gleichzeitig auch die Separation und Aufschneidung beider Stränge des G Segments. Jeder Strang bindet sich nun durch eine tyrosin-phosphodiester Bindung an das Enzym. Das T Segment passiert dann das gespaltene G Segment und gelangt in den zentralen Hohlraum. Von dort aus gelangt es wieder aus dem Enzym. ADP und Pi wird freigesetzt und die ATP Bindungsdomänen gehen wieder auseinander. Nun kann der ganze Prozess wieder von vorne beginnen. Gesamthaft gesehen senkt Topo 2 die Lk um 2. Die Mengen an Topo 1 und Topo 2 werden reguliert, um einen angemessenen Grad an negativen Supercoilings zu erhalten. DNA Polymerasen brauchen eine Vorlage und einen Primer: DNA Polymerasen katalysieren die Formation einer Polynukleotidkette. Diese Reaktion kann aber nur stattfinden, wenn eine DNA Vorlage (Template) existiert. Jedes Nukleosid - Triphosphat formt zuerst ein Basenpaar mit der Base auf dem Template. Erst dann verknüpft die Polymerase die einkommende Base mit der Vorgängerbase zu einer Kette. DNA Polymerasen sind also Template abhängige Enzyme. DNA-Poly. hängt Nukleotide an die 3’ Enden von Polynukleotidketten. Um dies zu können, braucht es einen Primer mit einer freien 3’-Hydroxylgruppe, welcher bereits komplementär ist zum Template. DNA-Poly. kann also nicht einfach so Nukleotide an einen freien DNA Einzelstrang anheften. Wir unterscheiden zwei verschiedene Arten von Polymerasen: Poly. I: Schneidet den Primer aus und lagert die fehlenden Nukleotide dieser Sequenz wieder an. Zudem besitz Poly. I eine Korrekturuntereinheit. Poly. III: Lagert die Nukleotide an den Primer an. Diese Poly. ist viel schneller und effektiver als Poly. I. Aufbau einer Polymerase: Alle Polymerasen haben etwa den gleichen Grundaufbau. Die dreidimensionale Struktur gleicht einer rechten Hand. Wobei die Untereinheiten der Polymerase die Finger symbolisieren (siehe BC S.750 Figure 27.11). Mit diesen „Fingern“ kann sich die Polymerase um die DNA winden und so besser agieren. Um die Aktivität zu garantieren, braucht die Polymerase 2 Metall Ionen im aktiven Zentrum (Mg 2+). Ein Metall Ion bindet beide, das Deoxynukleotid - Triphosphat (dNTP) und die 3’Hydroxyl-Gruppe des Primers, während das andere Metall Ion nur mit der 3’Hydroxyl –Gruppe koordiniert. 6 Zusammenfassung Biochemie, Kapitel 27 Die Phosphat Gruppe des Nucleosid-Triphosphats bildet die Brücke zwischen den beiden Metallionen. Die Hydroxyl-Gruppe des Primers attackiert die PhosphatGruppe um eine neue O-P Bindung zu formen. (genauer: BC S. 751 Abs. 27.2.2) DNA muss mit grosser Genauigkeit repliziert werden. Die Paarung von G-C und A-T wird dadurch erreicht, dass in dieser Anordnung die besten Interaktionen erreicht werden können. Dies ist aber nicht der einzige Mechanismus, um eine korrekte Replikation zu garantieren. Zwei weitere, jedoch komplizierte, existieren (BC S. 751f). Viele Poly. haben zusätzlich noch einen Kontrollmechanismus. Dies minimiert Fehler in der Replikation. So besitzt z.B. DNA Poly. I eine ExonukleaseUntereinheit, welche nicht direkt am Replikationsvorgang beteiligt ist. Diese Untereinheit ist dazu da, falsche Nukleotide vom 3’ Ende der DNA zu entfernen. Dies geschieht durch Hydrolyse. Die Exonuklease Untereinheit befindet sich etwa 35 A weg vom aktiven Zentrum der Polymerase. Wird nun ein falsches Nukleotid eingebaut, erhöht sich die Möglichkeit, dass dieses Nukleotid aus dem aktiven Zentrum der Poly. rutscht und so in die Exonuklease Untereinheit gelangt. Wie weiss nun die Poly. ob ein falsches Nukleotid eingebaut wurde? 1) Falls ein falsches Nukleotid eingebaut worden ist, stimmt die Chargaff Regel nicht mehr. Die H-Brücken sind nicht ideal ausgebaut. Dies hat eine weniger starke Bindung der Basen zur Folge. 2) Durch ein falsches Nukleotid, ist die Wechselwirkung mit der Minor groove nicht mehr optimal. Dieser Korrekturmechanismus verringert Fehler um den Faktor 1000. (Siehe BC S. 752 Figure 27.15) DNA Polymerase III: Um ein gesamtes Genom zu replizieren braucht es schnelle, korrekt arbeitende Enzyme. Eines davon ist die DNA Poly. III. Dieses Enzym ist verantwortlich für die Anlagerung der Nukleotide. Der Trick der Poly. III ist, dass sie das Substrat gebunden hält und währenddessen mehrere Reaktionen damit durchführt. Anders gesagt hält die DNA Poly. den Template fest, bis das ganze Teilstück repliziert wurde. So kann sie bis zu 1000 Nukleotide pro Sekunde anlagern und verliert keine Zeit um immer wieder an den Template zu binden. Aufbau DNA Polymerase III: Um diese Funktion auszuführen braucht das Enzym eine spezielle 3 dimensionale Form. DNA Poly. III besteht aus 10 verschiedenen Polypeptidketten, und hat eine Masse von etwa 900 Kd. Der Aufbau ist asymmetrisch, da ja der Leit- und Folgestrang nicht identisch repliziert werden (Aufbau siehe BC S.763 Figure 27.30, Funktion der Untereinheiten siehe Skript Gruissem DNA Replikation S. 6)). 7 Zusammenfassung Biochemie, Kapitel 27 Damit die DNA Poly. III aber beide Stränge gleichzeitig replizieren kann, bildet der Folgestrang eine Schleife. So wird ebenfalls eine 5’ -> 3’ Richtung erreicht. Nach etwa 1000 Nukleotiden wird der Folgestrang losgelassen und eine neue Schleife wird gebildet. Nun kann die DNA Poly III beim neuen Primer fortfahren. Primase: Auch mit vorhandenem Template ist es der DNA Poly. noch nicht möglich, einen neuen Strang zu synthetisieren. Ein Primer ist nötig. Dies ist ein kurzes RNA Stück (etwa 5 Nukleotide), welches von der Primase erzeugt wird (Primosom). Dieses Stück ist komplementär zum Template. So entsteht ein Anfang (freie 3’Hydroxyl-Gruppe), welche jetzt von DNA Poly. zu einer Kette verlängert werden kann. Der Primer bleibt aber nicht erhalten. Er wird von der DNA Poly. I hydrolysiert und wird später durch DNA ersetzt. Beide Stränge der DNA dienen als Templates für die Synthese neuer DNA. Da aber die Polymerase DNA nur in 5’ -> 3’ Richtung synthetisieren kann, können nicht beide Stränge kontinuierlich aufgebaut werden. Im Folgenden unterscheiden wir also zwischen Leitstrang und Folgestrang. Der Leitstrang wird kontinuierlich, der Folgestrang diskontinuierlich synthetisiert. Replikationsgabel: Auf dem Folgestrang mussen also mehrere Primer synthetisiert werden. Diese werden dann von der DNA Poly. III verlängert, bis wieder ein nächster Primer folgt. Solch ein Stück nennt man Okazaki Fragment. Es besteht zirka aus 1000 Nukleotiden. Später wird der Primer abgebaut (DNA Poly I), durch neue DNA ersetzt (DNA Poly. II). Die „Schnittstellen“ werden durch die DNA Ligase verbunden. Somit scheint auch der Folgestrang in dieselbe Richtung synthetisiert zu werden wie der Leitstrang. 8 Zusammenfassung Biochemie, Kapitel 27 Telomerase: Da die menschliche DNA linear vorliegt, ergeben sich einige Probleme bei der Replikation. Es ist z.B. nicht einfach, die Enden der DNA (Telomere) vollständig zu replizieren, da die Polymerase ja nur in 5’ -> 3’ Richtung arbeiten kann. Der Folgestrang würde folglich ein inkomplettes 5’ Ende haben, nachdem der Primer entfernt wurde. So wäre dieser Strang von Replikation zu Replikation kürzer. Telomerische DNA besteht aus hunderten sich wiederholenden hexanukleotiden Sequenzen. Ein Strang ist am 3’ Ende G- reich (AGGGTT) und ein wenig länger als der andere Strang. Eine Idee der Wissenschaftler war nun, dass die Telomere eine Art Schleife bilden, welche durch Telomerbindungsproteine geformt und stabilisiert wird. Solch eine Struktur würde die Chromosomenenden schön schützen und abdecken. Wie werden nun die Telomere repliziert? Dies übernehmen die Telomerasen. Sie besitzen eine zur telomerischen DNA homologe RNA Untereinheit. Diese kann an die DNA binden und so eine Verlängerung der Telomer- Sequenzeinheit am 3’ Ende der DNA bewirken. Diese verlängerten 3’ Enden können nachher von DNA Poly. repliziert werden. (siehe BC S. 766 Figure 27.36) (Siehe auch www.uni-stuttgart.de/bio/zoologie/telomerase7.htm) DNA Ligase: Dieses Enzym katalysiert die Formation einer Phosphodiesterbindung zwischen der 3’Hydroxyl-Gruppe am Ende der DNA Kette und der 5’Phosphat-Gruppe am Ende einer anderen Kette. Um dies durchführen zu können wird Energie benötigt. In Eukaryoten und Archaea ist dies ATP, in Bakterien NAD+. (genaue Reaktion BC S. 761f) 9 Zusammenfassung Biochemie, Kapitel 27 Gesamtablauf der Replikation: Der Leit- und Folgestrang werden gleichzeitig repliziert. Die Doppelhelix wird zuerst aufgewunden. Dies übernimmt eine ATP getriebene Helikase. Einzelstrang-Bindungsproteine lagern sich an den einzelnen Strängen an, um ein erneutes binden zu verhindern. Nun kann die DNA Poly. III den Primer, welcher von der Primase hergestellt wurde, verlängern. Das Template wird nicht losgelassen, bis die Replikation abgeschlossen ist. Topoisomerase II (DNA Gyrase) führt rechtsdrehende (negative) Supercoils ein, um zu verhindern, dass eine grosse Spannung eintritt. Da der Folgestrang diskontinuierlich synthetisiert wird, sind mehrere Primer nötig. Diese werden dann alle zu Okazakifragmenten verlängert. Die DNA Poly. I schneidet nachher alle Primer aus und lagert die Nukleotide an. DNA Ligase verbindet die einzelnen Fragmente zu einer ganzen Kette. Eukaryoten – Prokaryoten: Grundsätzlich verläuft die Replikation bei Eu- und Prokaryoten gleich. Es gibt trotzdem ein paar Änderungen: - die Länge der DNA ist bei den Eukaryoten viel grösser - die Information ist auf mehrere Chromosomen verteilt - die DNA liegt linear vor und nicht als zirkuläre Einheit Um die DNA trotzdem relativ schnell zu replizieren, findet man bei den Eukaryoten mehrere Ori’s (origin of replication). Der Ori ist ein ganz bestimmer Ort auf der DNA, welcher anzeigt, wo die Replikation gestartet wird und wo dann schlussendlich die Primase den Primer synthetisieren kann. Jeder Ori repräsentiert also eine eigene Replikationseinheit (genannt Replicon). Die DNA Sequenz des Oris ist eine „autonomously replicating sequenz“ (ARS) und ist besonders AT-reich. Diese ARS ist eine Andockstation für den ORC (origin of replication complex). ORC rekrutiert andere Proteine um den Prereplikationskomplex zu bilden. Mehrere dieser rekrutierten Proteine nennt man „licensing factors“, weil sie die Bildung des Initiationskomplexes fördern. Sie garantieren auch, dass jedes Replicon genau einmal repliziert wird. (mehr zu den licensing factors siehe BC S. 764f) Beim Menschen findet man nun ca. 30'000 Ori’s, welche je ca. 30-300 kbp auseinander liegen. Dies hat zur Folge, dass die Replikation an mehreren Stellen gleichzeitig voranschreitet und so natürlich beschleunigt werden kann. Um sicher zu gehen, dass schlussendlich die ganze DNA repliziert wird, ist dieser Vorgang an den Zellzyklus (siehe BC S. 764 Figure 27.34) gekoppelt. Dieser enthält mehrere Checkpoints, welche passiert werden müssen. Ist die DNA also noch nicht vollständig repliziert, schreitet der Zyklus nicht fort. 10 Zusammenfassung Biochemie, Kapitel 27 Rekombination: Wo ist die DNA Rekombination eine wichtige Funktion? (siehe Gruissem Skript DNA Reparatur und Rekombination S. 10) Rekomination ist am effizientesten zwischen DNA Molekülen, welche die gleiche Sequenz tragen (homologe Rekombination). Rekombinasen katalysieren den Austausch des genetischen Materials in der Rekombination. Eine Schlüsselrolle in diesem Mechanismus nehmen die Holliday junctions ein, welche aus vier Polynukleotidketten geformt werden. Solche Junctions können sich aber nur formen, wenn die Nukleotidsequenzen in der Region der Rekombination sehr ähnlich oder identisch sind auf den beiden Doppelsträngen. Dies ist so, da sich Basenpaare bilden müssen zwischen den beiden parentalen Doppelsträngen. Mechanismus: (siehe BC. S. 767 Figure 27.38, 27.39) Zuerst lagern sich 4 Cre-Rekombinasen an die DNA’s an. So formt sich eine Rekombinase Synapse. Die Reaktion beginnt, indem je ein Strang der Doppelhelix aufgeschnitten wird. Die 5’ Hydroxylgruppen bleiben frei, während die 3’ Phosphorylgruppen sich an ein spezifisches Tyrosinresiduum in der Rekombinase binden. Die freien 5’ Enden attackieren die DNA-Tyrosin Einheit der anderen Doppelhelix und formen so eine neue Phosphodiesterbindung. Das Tyrosinresiduum kommt so wieder frei. Das Resultat dieses Prozesses ist die Holliday junction. Nun isomerisiert das Ganze und der Ablauf wird wiederholt. Das Resultat ist dann eine Synapse, welche die beiden rekombinierten Doppelhelices enthält. Durch Dissoziation dieser Komplexe entstehen die fertig rekombinierten Produkte. Mutationen: 1) Substitution (ein Basenpaar wird durch ein anderes ausgetauscht) 2) Deletion (ein oder mehrere Basenpaare gehen verloren) 3) Insertion (ein oder mehrere Basenpaare werden eingefügt) Punktmutationen: Zwei Arten von Substitution sind bekannt : - Transition A-T T-A G-C C-G Pyrimidin wird durch Pyrimidin ausgetauscht (Analog mit Purin) 11 Zusammenfassung Biochemie, Kapitel 27 Basen Analoga (z.B. 5-Bromouracil, 2-Aminopurine) können in die DNA eingebaut werden. 5-Bromuracil, welches analog zu Thymin ist, würde eigentlich mit Adenin paaren. Tatsächlich paart es sich aber mit Guanin und wird in Form des Enol Tautomers sogar noch mit grösserer Wahrscheinlichkeit eingebaut, als Thymin. Dies, da das Brom Atom des 5-Bromouracil elektronegativer ist als die Methylgruppe des Thymins (siehe BC S 769 Figure 27.42) T-A wird also zu C-G. Andere Mutagene wirken, indem sie die Basen chemisch verändern. Dies ist bei HNO2 der Fall. Adenin wird zu Hypoxanthin umgewandelt und paart sich folglich nicht mehr mit Thymin, sondern mit Cytosin. A-T wird also zu G-C - Transversion A-T T-A C-G G-C Purin wird durch Pyrimidin ausgetauscht (oder umgekehrt) Watson und Crick erkannten bereits das Problem der Transversion. Sie erklärten dies so, dass es möglich ist für die Basen, Tautomere auszubilden. So entstehen folglich aus: Amino -> Imino Keto -> Enol. Die Tautomere können trotzdem H-Brücken ausbilden (nicht genau so wie in der Normalform), welche auch genau in die Doppelhelix hineinpassen. So würde sich ein A* mit einem C paaren anstelle eines T’s. Durch die Replikation wird dieser Fehler nun an die Tochter DNA weitergegeben, falls er nicht korrigiert wird. Rastermutationen: Flache aromatische Moleküle (Acridines) lagern sich zwischen den Basen ein. Dies hat zur Folge, dass ein weiteres Basenpaar eingefügt wird, oder ein Paar verloren geht. Logischerweise wird durch diese Veränderung das Leseraster der Translation verschoben. Dies hat krasse Auswirkungen auf den ganzen Organismus. Ultraviolettes Licht kann ebenfalls mutationsfördernd wirken. Durch die Strahlung werden kovalente Bindungen ausgebildet zwischen benachbarten Pyrimidinresiduen. Solch ein Pyrimidindimer passt nun nicht mehr in die Doppelhelix und dadurch wird die Replikation und Genexpression blockiert, bis die Verknüpfung abgebaut wird. 12 Zusammenfassung Biochemie, Kapitel 27 Reparaturmechanismen der DNA: 3 verschiedene Mechanismen sind bekannt: - Base-excision repair: die kaputte Base wird herausgeschnitten und ersetzt. - Repair: Die kaputte Base wird direkt repariert. -Nucleotide-excision repair: die gesamte Region um die kaputte Base herum wird herausgeschnitten und ersetzt. (Wichtig: Beispiele dazu siehe BC S. 770 Punkt 27.6.3) Einbau von Uracil in die DNA anstelle von Thymin: Uracil kommt normalerweise nur in der RNA vor und besitzt am C-5 ein H Atom. Thymin dagegen ist Bestandteil der DNA und trägt eine Mehtylgruppe. Beide Basen paaren sich mit Adenin. Cytosin kann nun spontan deaminieren, was zur Folge hat, dass anstelle eines C’s ein U in der DNA vorkommt. Die Tochterstränge würden dann nicht ein C-G Basenpaar enthalten, sondern ein U-A. Diese Mutation wird aber vom Reparatursystem der DNA erkannt (siehe BC S. 772 Figure 27.50). Uracil-DNAGlykosylase erkennt die U’s in der DNA und schneidet sie aus. T-haltige Nukleotide werden in Ruhe gelassen. Diese garantieren nämlich die Genauigkeit der genetischen Nachricht. Im Unterschied dazu wird RNA nicht repariert und Uracil wird benutzt, weil dies ein weniger „teurer“ Baustein ist. Krebs wird häufig durch Mutationen ausgelöst, weil dort die Wachstumsgene mutiert werden. So teilen sich die Zellen unkontrolliert und wuchern aus. Defekte im Reparatursystem der DNA steigern die Frequenz von Mutationen und somit auch die Wahrscheinlichkeit von Krebs. Ames Test: Mutierte Salmonella Bakterien werden in einer Petrischale gezüchtet. Diese Bakterien sind nicht mehr in der Lage Histidin zu produzieren und können folglich auch nicht wachsen. Nun wird ein chemisches Mutagen in die Mitte der Platte gegeben. Dies hat zur Folge, dass einige Bakterien mutieren und wieder in der Lage sind, Histidin zu produzieren. Somit werden sich diskrete Bakterienkolonien bilden. Die Grösse dieser Kolonien sagt nun etwas darüber aus, wie mutagen eine Substanz ist. 13