Grundlagen der Statistical Process Control (SPC) – statistische
Werbung
 – statistische")
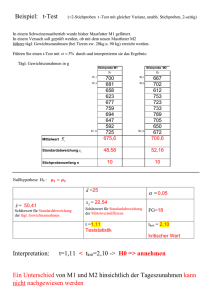
Grundlagen der Statistical Process Control (SPC) – statistische Prozesslenkung Eine der am weitesten verbreiteten Methoden zur Verbesserung von Produktionsprozessen ist die statistische Prozesslenkung, die „Statistical Process Control (SPC)“. Sie dient dazu, das Streuungsverhalten von Prozessen zu erfassen und zu bewerten, und liefert so einen maßgeblichen Beitrag zur Begrenzung von Ausschuss, Nacharbeit und fehlerhaften Produkten. Ausschuss Unter Ausschuss versteht man solche Produkte oder Zwischenprodukte, die nicht weiterverwendet werden können, weil sie nicht den Spezifikationen entsprechen. Die Mängel von Ausschuss sind in der Regel zurückzuführen auf Konstruktionsfehler, Materialfehler, Transport- und Lagerfehler, vor allem aber auf Fehler in der Bearbeitung. Durch Ausschuss gehen die Kosten für das eingesetzte Material verloren, aber auch die Kosten für die eingesetzten Maschinen und den Maschinenbediener einschließlich aller damit verbundenen Kosten wie Hilfsstoffe, Energie, Verschleißteile usw. Es ist also wichtig, dass ein Arbeitsvorgang so durchgeführt wird, dass die zulässigen Grenzen nicht unterschritten werden, weil es sonst zu Ausschuss kommt. Nacharbeit Als Nacharbeit werden alle Tätigkeiten nach oder während eines Produktionsprozesses verstanden, die der Beseitigung von Mängeln jeglicher Art (Fehler oder Minderqualität) an einem Produkt dienen. Nacharbeit ist ungeplant, erzeugt also Mehrkosten. Es handelt sich um ungeplante Korrekturmaßnahmen, die bei einem einwandfreien Produktionsprozess nicht anfallen sollten. Die Ursachen für Nacharbeit können in Konstruktionsfehlern, Materialfehlern, Transportund Lagerungsfehlern, sehr häufig aber in Bearbeitungsfehlern liegen. Eine typische Ursache ist die Über- oder Unterschreitung der Soll-Maße bei der Produktion. Abwägung zwischen Ausschuss und Nacharbeit Kann man eine Abweichung von den Soll-Maßen nicht mehr korrigieren (oder wäre dies zu teuer), so kommt es zu Ausschuss, ist eine Korrektur möglich und wirtschaftlich sinnvoll, so entsteht Nacharbeit. Die Kosten von Ausschuss Die Kosten für Ausschuss setzen sich zunächst wie folgt zusammen: Kosten des verbrauchten Materials im Ausschuss Kosten der verfahrenen Personalstunden Kosten der verfahrenen Maschinenstunden Wenn das verlorene Produkt oder Zwischenprodukt ersetzt werden muss, können durch die zusätzlichen Dispositionstätigkeiten, Produktionsplananpassungen, Umrüstungen der Maschinen oder Überstunden ebenfalls erhebliche Kosten entstehen. Der Aufwand zur Herstellung einzelner Ersatzteile kann – je Einzelstück – deutlich teurer sein als die Herstellung der Serienteile. Die Kosten von Nacharbeit Die Kosten für Nacharbeit entstehen durch die zusätzlichen Tätigkeiten (Verbesserungsmaßnahmen) am fehlerhaften Produkt oder Zwischenprodukt. Hierzu können gehören: Kosten für zusätzliches Material Kosten der zusätzlichen Personalstunden Kosten der zusätzlichen Maschinenstunden 1 Kosten der Produktionsplanänderung/Umrüstungen Kosten für Überstunden Die Verantwortung jedes Einzelnen Deshalb hat jeder Mitarbeiter im Produktionsprozess eine eigene Verantwortung, dass fehlerhafte Produkte seinen Bereich nicht verlassen. Die Kollegen, die das Produkt weiter bearbeiten, leisten sonst Arbeiten, die verloren sind. Früher wurde häufig versucht Fehler zu vertuschen. Heute ist klar, dass unentdeckte Fehler um ein Vielfaches teurer werden können als entdeckte und beseitigte Fehler. Praktisch jeder Prozess streut. Wie diese beiden Beispiele zeigen, ist es nicht möglich, einen Prozess ohne jede Streuung zu beherrschen. Links: Auto in der Garage Ganz gleich, wie gut der Fahrer des Autos ist, er wird immer ein wenig links oder rechts von der Mittellinie parken. Je besser der Fahrer ist (und das Auto), desto geringer werden diese Abweichungen von der Mittellinie, aber sie werden nie ganz verschwinden. Rechts: Boot auf dem Kanal Auch der Steuermann dieses Boots kann sich aufs Beste bemühen: Es wird ihm nicht gelingen, präzise auf der Mittellinie des Kanals zu fahren. Je besser er steuert, desto näher kommt er an die Mittellinie, aber das Boot wird immer ein wenig schlingern – schon weil Wind und Wellen seinen Weg beeinflussen. Einflüsse Einflüsse auf den Verlauf oder das Ergebnis eines Prozesses lassen sich nie vollständig ausschließen. Der Fahrer dieses Autos wird nicht immer präzise die Mittellinie treffen, sondern die Parkpositionen werden streuen. Diese Streuungen sind auf zufällige und systematische Einflüsse zurückzuführen. 2 Zufällige Einflüsse Bei zufälligen Einflüssen streuen die Parkpositionen gleichmäßig nach links und nach rechts (bzw. nach oben und nach unten). Auch der beste Sportschütze mit einem perfekten Gewehr weiß, dass seine Schüsse immer ein wenig streuen. Je besser der Schütze und das Gewehr, desto weniger streuen sie – aber sie streuen. Systematische Einflüsse Die folgende Grafik zeigt eine Verschiebung der Häufigkeitsverteilung, d.h., dass das Auto häufiger links als rechts von der Mittellinie geparkt hat. Eine solche Verteilung ist auf systematische Einflüsse zurückzuführen. In unserem Beispiel könnten das eine verstellte Spur des Autos, defekte Reifen, ein ungeübter Fahrer, eine ungünstige Zufahrt zur Garage und viele andere Bedingungen sein. Das Entscheidende hieran ist: Alle diese systematischen Einflüsse lassen sich beseitigen (ob technisch sinnvoll und bezahlbar oder nicht, sei dahingestellt). Wenn man alle diese systematischen Einflüsse beseitigt hat, dann sollte sich wieder eine Verteilung ergeben, auf die nur zufällige Einflüsse wirken. Zufällige und systematische Einflüsse Diese Merksätze sind wichtig: Systematische Einflüsse bewirken eine Verschiebung von der Mittellinie. Sie lassen sich grundsätzlich beseitigen. Zufällige Einflüsse führen zu einer (meist) symmetrischen Streuung um die Mittellinie. Sie lassen sich nicht vollständig beseitigen, sondern nur verringern. Auf diese Weise erhält man einen Prozess, der nur geringfügig um den Mittelwert streut. Die Bedeutung der Toleranzen Toleranzen sind zulässige Streuungen um den Soll-Wert (Mittelwert). Werden sie überschritten, so führt dies in der Regel zu Schäden, Ausschuss oder Nacharbeit. 3 Betrachtet man die Häufigkeitsverteilung, so heißt dies, dass die Häufigkeitsverteilung der Parkpositionen innerhalb der Toleranzen bleiben muss – andernfalls fährt es an oder gegen die Garagenwand. Das gleiche Prinzip gilt für Herstellungsprozesse: Die Häufigkeitsverteilung muss innerhalb der Toleranzen bleiben, um Über- und Unterschreitungen zu vermeiden. Aufschreibung Um zu ermitteln, wie gut ein Prozess beherrscht wird, misst man die Ergebnisse des Prozesses. Hierzu kann die Aufschreibung eingesetzt werden: Die Aufschreibung ist die ursprünglichste Aufzeichnung von Messdaten. Die Einzelwerte werden aufgeschrieben und Überschreitungen der Toleranzen können markiert werden. Vor- und Nachteile der Aufschreibung: Vorteil: Alle Einzeldaten bleiben individuell erhalten, sodass Sie später auch präzise Auswertungen durchführen können. Nachteil: Die Daten sind unübersichtlich. Die Aufschreibung bietet häufig die Grundlage für weitere Auswertungen. Strichliste Bei der Strichliste werden die Messdaten sofort in Klassen eingetragen. Dabei werden die einzelnen Messdaten nicht dokumentiert, sondern es ist später nur die Häufigkeit von Messdaten innerhalb bestimmter Klassen erkennbar. Vor- und Nachteile der Strichliste: Vorteil: einfache, wenig aufwendige Aufzeichnung, Übersichtlichkeit der Messdatenverteilung Nachteil: keine nachträgliche Analyse der Einzeldaten möglich 4 Säulendiagramm Das Säulendiagramm (auch als Histogramm bezeichnet) lässt sich unmittelbar aus der Strichliste ableiten oder auf Basis der Aufschreibung erstellen. Vorteil: einfache, wenig aufwendige Aufzeichnung, Übersichtlichkeit der Messdatenverteilung Nachteil: keine nachträgliche Analyse der Einzeldaten möglich Bei der Gestaltung von Histogrammen (und von Strichlisten) stellt sich die Frage nach der richtigen Klasseneinteilung. Hierfür gelten folgende Regeln: Um eine geeignete Aufteilung der Klassen zu finden, sollte man zunächst die Anzahl der Klassen (k) festlegen. Man sollte sie aus der Anzahl der Messwerte (n) herleiten: k n Die Breite der einzelnen Klassen (H) ergibt sich dann aus dem Verhältnis von Spannweite (R = Differenz zwischen größtem und kleinstem Einzelmesswert) und der Anzahl der Klassen (k): H R k Die untere Grenze der kleinsten Klasse muss kleiner sein als der kleinste Einzelmesswert, die obere Grenze der größten Klasse muss auch den größten Messwert einschließen. Man sollte die Klassengrenzen genauso runden wie die Messwerte, damit die Zuordnung eindeutig ist. Verteilungen – Streuung, Form, Lage Bislang haben wir uns mit Verteilungen von Stichproben beschäftigt. Bei der statistischen Prozessregelung geht es darum, aus diesen Stichproben auf den gesamten Prozess zu schließen. Die Frage lautet also beispielsweise: Wenn wir in einem Prozess 10.000 Teile herstellen, aber nur 50 Teile als Stichprobe entnehmen, dann kennen wir zwar die Verteilung der Stichprobe (siehe Säulendiagramm), aber wie ist dann die Verteilung aller 10.000 Teile? Lösung: Man schließt von der Stichprobenverteilung auf die Verteilung der so genannten Grundgesamtheit. Aus dem Säulendiagramm wird dann eine Kurve (siehe Folie). Auf die mathematischen Zusammenhänge gehen wir hier nicht ein. Um eine Verteilung zu beschreiben, braucht man drei Kriterien: Streuung: Wie flach ist die Kurve? Je flacher die Kurve, umso größer die Streuung. Lage: Liegt die Kurve über der Mittellinie oder ist sie zu einer Seite verschoben? Form: Hat die Kurve die Form einer Glocke oder eine andere Form? Gaußsche Normalverteilung Die gaußsche Normalverteilung ist die wichtigste Verteilungsform von Messwerten. Sie hat die Form einer symmetrischen Glockenkurve. Berechnung der statistischen Größen Mittelwert und Standardabweichung: 5 Hinweis zur Bezeichnung: Bei der Stichprobe werden Mittelwert und Standardabweichung mit x und s bezeichnet, bei der Grundgesamtheit mit µ und . Für die gaußsche Normalverteilung gilt: Der Anteil der Messwerte, die innerhalb der Standardabweichung liegen (1 ), beträgt 68,26%. Der Anteil der Messwerte, die innerhalb der dreifachen Standardabweichung (3 liegen, beträgt 99,73%. Das bedeutet, dass nur 0,27% aller Messwerte außerhalb der dreifachen Standardabweichung (3 liegen. Dies hat man zum Anlass genommen, an Prozesse die Anforderung zu stellen, dass der Bereich von 3 innerhalb der Toleranzen liegen muss. So ist gewährleistet, dass höchstens 0,27% der vom Prozess produzierten Teile die Toleranzen überschreiten. Prozessfähigkeit: cp-Werte Um zu überwachen, ob ein Prozess fähig ist, werden zwei Werte betrachtet, nämlich der cp- und der cpk-Wert. Die cp-Werte dienen der Überprüfung, ob die Streuung eines Prozesses klein genug ist. Der cp-Wert ist der Quotient aus der Spanne zwischen der unteren (UTG) und der oberen Toleranzgrenze (OTG) (Zähler) und der sechsfachen Standardabweichung (3 , Nenner). Ist dieser Quotient größer als 4/3, dann spricht man von Prozessfähigkeit, weil die Streuung des Prozesses innerhalb der Toleranzen liegt. Liegt der Quotient zwischen 4/3 und 1, so kann es zu Verletzungen der Toleranzen kommen. Man spricht dann von bedingter Prozessfähigkeit. Ist der Quotient kleiner als 1, so werden die Toleranzen verletzt und der Prozess ist nicht fähig. Prozessfähigkeit: cpk-Werte Die cpk-Werte dienen der Überprüfung, ob die Lage des Prozesses, kombiniert mit seiner Streuung, dazu führen kann, dass er die Toleranzgrenzen verletzt. Das Kriterium hierfür ist der Quotient aus dem Abstand zwischen dem Mittelwert der Verteilung ( x ) und der näheren Toleranzgrenze (Zähler) und der dreifachen Standardabweichung (Nenner). 6 Ist dieser Quotient größer als 4/3, dann spricht man von Prozessfähigkeit, weil es nicht zu einer Verletzung der Toleranzen kommen wird. Liegt der Quotient zwischen 4/3 und 1, so kann es zu Verletzungen der Toleranzen kommen. Man spricht dann von bedingter Prozessfähigkeit. Ist der Quotient kleiner als 1, so werden die Toleranzen verletzt und der Prozess ist nicht fähig. Was sind Prozessregelkarten? Um das Verhalten von Prozessen über längere Zeiträume zu verfolgen (und nicht nur einmalige Messungen vorzunehmen), werden Prozessregelkarten eingesetzt. Sie sind Datenblätter, auf denen in zeitlichen Intervallen Messwerte aus Stichprobenuntersuchungen protokolliert und deren Verteilungsparameter (Lage, Streuung) in zeitliche Verläufe übertragen werden. Prozessregelkarten erlauben so eine statistische Betrachtung des Prozessverhaltens, indem sie prüfen, wie sich die Lage und Streuung der untersuchten Stichproben verhalten. Damit sind Prozessregelkarten ein zentrales Werkzeug innerhalb der statistischen Prozessregelung (Statistical Process Control, SPC). Durch ihre Anwendung wird es möglich, auf eine aufwendige 100-%-Prüfung zu verzichten und stattdessen Stichproben zu entnehmen und diese zu untersuchen. Aufbau von Prozessregelkarten Prozessregelkarten bestehen aus drei Teilen. In jedem dieser Teile werden zu jeder Stichprobenmessung die Ergebnisse eingetragen. Jede Stichprobe wird in eine Spalte eingetragen, sodass sich die Regelkarte nach und nach von links nach rechts füllt. 1. Kartenkopf: Der Kartenkopf enthält die allgemeinen Daten zum Prozess, zur Stichprobenanweisung (Intervall der Stichprobenentnahme, Stichprobenumfang, Stichprobenuntersuchung usw.), zu Prozessverantwortlichen usw. Er enthält darunter die Tabelle der Stichprobenergebnisse: Diese Tabelle enthält zunächst die Einzelwerte jeder Stichprobe und darunter die Daten zu Lage und Streuung der Stichprobe. 2. Lagespur: In der Lagespur werden die ausgewerteten Daten zur Lage der Stichprobe (Median oder Mittelwert) eingetragen. 3. Streuungsspur: In der Streuungsspur werden die ausgewerteten Daten zur Streuung der Stichprobe (Spannweite oder Standardabweichung) eingetragen. 7 Auswahl von Prozessregelkarten Es gibt eine Reihe unterschiedlicher Prozessregelkarten. Man muss die für den betreffenden Prozess passende auswählen. Man unterscheidet zunächst nach Prozessregelkarten für attributive Daten und variable Daten. Attributive Daten: Bei den Prozessregelkarten für attributive Daten werden die Fehler oder fehlerhaften Einheiten gezählt. Eine solche Regelkarte ist sinnvoll, wenn keine variablen Daten gemessen werden können, wie Länge, Höhe, Gewicht usw. Variable Daten: Bei den Prozessregelkarten für variable Daten werden messbare Daten wie Länge, Höhe, Gewicht erfasst und ausgewertet. Für die Auswahl der geeigneten Prozessregelkarte ist dann der Umfang der Stichproben (SPU) ausschlaggebend (siehe Folie). Erfassung attributiver Daten (Zählung) Fehler: Will man die Anzahl der Fehler auf einer Prozessregelkarte erfassen, dann kommen hierfür zwei Regelkarten infrage: Umfasst der Stichprobenumfang immer die gleiche Anzahl von Teilen (aber mehr als fünf), dann verwendet man die c-Karte. Variiert der Stichprobenumfang von Stichprobe zu Stichprobe, dann verwendet man die uKarte. Fehlerhafte Einheiten: Will man die Anzahl der fehlerhaften Einheiten auf einer Prozessregelkarte erfassen, dann kommen hierfür zwei Regelkarten infrage: 8 Umfasst der Stichprobenumfang immer die gleiche Anzahl von Teilen (aber mindestens 50), dann verwendet man die np-Karte. Variiert der Stichprobenumfang von Stichprobe zu Stichprobe, dann verwendet man die pKarte. Erfassung variabler Daten (Messung): Die richtige Regelkarte findet man, nachdem man den Stichprobenumfang festgelegt hat. Stichprobenumfang = 1: Einzelwert (X) und Spannweite (Rm) ~ Stichprobenumfang 3 bis 9: Median ( X ) und Spannweite (R) Stichprobenumfang mindestens 10: arithmetischer Mittelwert ( X ) und Standardabweichung (s) Stichprobenumfang 3 bis 5: arithmetischer Mittelwert ( X ) und Spannweite (R) Erstellung von Prozessregelkarten Bei der Erstellung von Prozessregelkarten ist folgende Vorgehensweise erforderlich: 1. Prozessvorlauf: Zunächst werden möglichst 20 oder mehr Stichproben zu je fünf Einheiten entnommen. Hieraus werden die Mittelwerte und Spannweiten/Standardabweichungen je Stichprobe berechnet. Anmerkung: Häufig ist es wegen des großen Aufwands nicht möglich, eine so hohe Zahl von Stichproben schon zu Beginn zu entnehmen. Dann werden zunächst weniger Stichproben entnommen und ausgewertet. Man berechnet Mittelwerte und Spannweiten/Standardabweichungen auf Basis dieser Daten. Berechnet man dann auf Basis dieser Daten die Mittellinie und die Eingriffsgrenzen (siehe Schritt 2), dann kennzeichnet man sie als vorläufig. Sie werden später, wenn weitere 20 Stichproben vorliegen, ausgetauscht. 2. Berechnung der Mittellinie und der Eingriffsgrenzen der Streuungsspur (wird auf der folgenden Folie erklärt) (Falls eine Stichprobe diese Eingriffsgrenzen verletzt, wird diese Stichprobe gelöscht und die Eingriffsgrenzen neu berechnet.) 3. Berechnung der Mittellinie und der Eingriffsgrenzen der Lagespur (wird auf der folgenden Folie erklärt) 4. Erstellung der Diagramme Berechnung von Mittellinien und Eingriffsgrenzen Übersicht über die Vorgehensweise: 1. Auswahl der richtigen Prozessregelkarte (siehe oben) 2. Entnahme von Stichproben 3. Ermittlung der Mittelwerte und Spannweiten der Stichproben 4. Nachschlagen der Formel für Mittellinien und Eingriffsgrenzen in den Tabellen - für attributive Daten (siehe Tabelle A) und - für variable Daten (siehe Tabelle B) 5. Nachschlagen der Konstanten für die Formeln in der Konstantentabelle (siehe Tabelle C) 6. Eintragen der Konstanten in die Formeln und Berechnen der Mittellinien und Eingriffsgrenzen 9 10 Analyse von Prozessregelkarten Ein Prozess wird als beherrscht bezeichnet, wenn die Eingriffsgrenzen nicht über- bzw. unterschritten werden und keine auffälligen Muster auftreten. Um Muster besser erkennen zu können, wird in der Lage- und in der Streuungsspur der Bereich zwischen den beiden Eingriffsgrenzen in sechs Abschnitte unterteilt. Diese Abschnitte werden A-, B- und C-Zone genannt. Die Grenzen der Zonen entsprechen der einfachen und zweifachen Standardabweichung (1 , 2 ). Die dreifache Standardabweichung (3 entspricht den Eingriffsgrenzen. Diese Einteilung dient der Identifikation besonderer Muster, die auf den folgenden Folien beschrieben werden. Nicht beherrschte Prozesse Die acht Muster zeigen nicht beherrschte Prozesse. 11 Ausreißer: Ein Punkt der Lage- oder Streuungsspur liegt außerhalb der Eingriffsgrenzen. Run/Lauf: Mindestens acht aufeinander folgende Punkte liegen auf der gleichen Seite der Mittellinie. 4er-Run/4er-Lauf: Mindestens vier von fünf aufeinander folgenden Punkten liegen auf einer Seite der Mittellinie in den Zonen B oder A. 2er-Run/2er-Lauf im Außenbereich: Mindestens zwei von drei aufeinander folgenden Punkten liegen in der Zone A derselben Seite. 12 Innenbereich: 15 Punkte in Reihe oder mindestens 68 % aller Punkte liegen in Zone C. Tritt dieses Muster auf, sollten die Eingriffsgrenzen neu berechnet werden. Trend: Sechs aufeinander folgende Punkte fallen bzw. steigen. Alternation: Zwischen 14 aufeinander folgenden Punkten findet abwechselnd Steigen und Fallen statt. Zyklus: Die Aufzeichnung zeigt ein wiederkehrendes Muster. 13