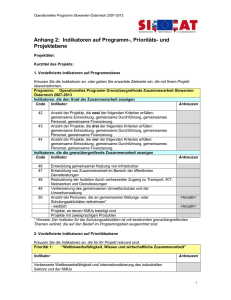
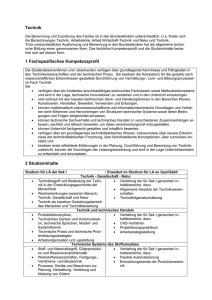
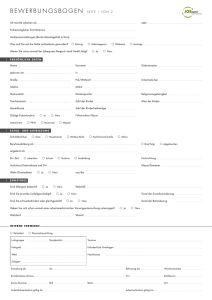
Beispiel für die Ermittlung der durchschnittlichen
Werbung

Behandlung von Leistungsproblemen bei Microsoft® Exchange 2000 Server Dylan Miller Behandlung von Leistungsproblemen bei Microsoft® Exchange 2000 Server Dylan Miller Copyright Die in diesem Dokument enthaltenen Informationen stellen die behandelten Themen aus der Sicht der Microsoft Corporation zum Zeitpunkt der Veröffentlichung dar. Da Microsoft auf sich ändernde Marktanforderungen reagieren muss, stellt dies keine Verpflichtung seitens Microsoft dar, und Microsoft kann die Richtigkeit der hier dargelegten Informationen nach dem Zeitpunkt der Veröffentlichung nicht garantieren. Dieses Whitepaper dient nur zu Informationszwecken. MICROSOFT SCHLIESST FÜR DIE INFORMATIONEN IN DIESEM DOKUMENT JEDE GEWÄHRLEISTUNG AUS, SEI SIE AUSDRÜCKLICH, KONKLUDENT ODER GESETZLICH FESTGELEGT. Die Benutzer/innen sind verpflichtet, sich an alle anwendbaren Urheberrechtsgesetze zu halten. Unabhängig von der Anwendbarkeit der entsprechenden Urheberrechtsgesetze darf ohne ausdrückliche schriftliche Erlaubnis der Microsoft Corporation kein Teil dieses Dokuments für irgendwelche Zwecke vervielfältigt oder in einem Datenempfangssystem gespeichert oder darin eingelesen werden, unabhängig davon, auf welche Art und Weise oder mit welchen Mitteln (elektronisch, mechanisch, durch Fotokopieren, Aufzeichnen, usw.) dies geschieht. Microsoft kann Inhaber von Patenten oder Patentanträgen, Marken, Urheberrechten oder anderen gewerblichen Schutzrechten sein, die den Inhalt dieses Dokuments betreffen. Die Bereitstellung dieses Dokuments gewährt keinerlei Lizenzrechte an diesen Patenten, Marken, Urheberrechten oder anderen gewerblichen Schutzrechten, es sei denn, dies wurde ausdrücklich durch einen schriftlichen Lizenzvertrag mit der Microsoft Corporation vereinbart. Die in diesem Dokument verwendeten Firmen, Organisationen, Produkte, Domänennamen, E-Mail-Adressen, Logos, Personen, Orte und Ereignisse sind frei erfunden, soweit nichts anderes angegeben ist. Jede Ähnlichkeit mit bestehenden Firmen, Organisationen, Produkten, Domänennamen, E-Mail-Adressen, Logos, Personen, Orten oder Ereignissen ist rein zufällig. 2002 Microsoft Corporation. Alle Rechte vorbehalten. Microsoft, Active Directory, Outlook, Windows und Windows NT sind entweder eingetragene Marken oder Marken der Microsoft Corporation in den USA und/oder anderen Ländern. Die in diesem Dokument aufgeführten Produkt- und Firmennamen sind möglicherweise Marken der jeweiligen Eigentümer. Veröffentlicht: September 2002 Gilt für: Exchange 2000 Server SP3 Projektredakteur: Susan Bradley Technische Lektoren: Dale Koetke, KC Lemson, Jim Lucey, Nick Rosenfeld, Jason Hill, Michael Palermiti, Charles McDaniels, Sameer Patel, Scott Landry Design: Kristie Smith Produktion: Stephanie Schroeder Inhalt Einführung 1 Ziele des Whitepapers .................................................................................... 1 Aufbau des Whitepapers ................................................................................. 2 Kapitel 1 Tools zur Behandlung von Leistungsproblemen............... 3 Systemmonitor ................................................................................................ 3 Leistungsdatenprotokolle und Warnungen ..................................................... 6 Microsoft Operations Manager 2000 ............................................................... 8 Ereignisanzeige ............................................................................................... 9 Netzwerkmonitor ........................................................................................... 12 Dateimonitor .................................................................................................. 12 Hinweise zur Notation ................................................................................... 13 Kapitel 2 Ermitteln der durchschnittlichen Serverleistung ............. 15 Minimaler Indikatorensatz ............................................................................. 15 Beispiel für die Ermittlung der durchschnittlichen Serverleistung ................. 19 Zu beantwortende Fragen ...................................................................... 20 Beispiele für den Systemmonitor ............................................................ 20 Kapitel 3 Behandeln von Leistungsproblemen.............................. 25 Ursachen für Leistungsprobleme .................................................................. 25 Art des Problems ........................................................................................... 29 Leistungsprobleme der CPU .................................................................. 30 CPU-Auslastung ............................................................................... 31 Isolieren von Threads ....................................................................... 33 Leistungsprobleme der Festplatte .......................................................... 33 Leistungsprobleme der Festplatte: Erster Ansatz................... 33 RAID-Ebenen ................................................................................... 34 Leistungsprobleme der Festplatte: Zweiter Ansatz ................ 37 Leistungsprobleme der Festplatte: Dritter Ansatz .................. 38 Wodurch wird die E/A aktiviert? ....................................................... 38 Probleme mit dem Arbeitsspeicher ......................................................... 40 ii Behandlung von Leistungsproblemen bei Microsoft Exchange 2000 Server Weitere Probleme.......................................................................................... 45 Active Directory....................................................................................... 45 DSAccess ............................................................................................... 45 Netzwerkprobleme .................................................................................. 46 Verwenden des Netzwerkmonitors .................................................. 46 Messen von Nicht-MAPI-Anforderungen ................................................ 49 Indikatoren für die Nachrichtenzustellung .............................................. 50 Anhang A 51 Leistungsindikatoren ..................................................................................... 52 Datenbankindikatoren ............................................................................. 53 Epoxy-Indikatoren ................................................................................... 54 Indikatoren für logische Datenträger ...................................................... 55 Indikatoren für den Arbeitsspeicher ........................................................ 57 Indikatoren für MSExchangeIS ............................................................... 59 Indikatoren für das MSExchangeIS-Postfach ......................................... 63 Indikatoren für die öffentlichen Ordner von MSExchangeIS .................. 64 Indikatoren für die Netzwerkschnittstelle ................................................ 65 Indikatoren für die Auslagerungsdatei .................................................... 66 Indikatoren für physikalische Datenträger .............................................. 66 Prozessindikatoren ................................................................................. 68 Prozessorindikatoren .............................................................................. 71 Indikatoren für den Redirectordienst ...................................................... 72 Serverindikatoren .................................................................................... 73 Indikatoren für die Serverwarteschlange ................................................ 74 Indikatoren für den SMTP-Server ........................................................... 75 Systemindikatoren .................................................................................. 76 TCP-Indikatoren ...................................................................................... 76 Threadindikatoren ................................................................................... 77 Weitere Quellen............................................................................................. 78 Whitepapers ............................................................................................ 78 Microsoft Knowledge Base-Artikel .......................................................... 79 i Einführung In diesem Whitepaper erhalten Sie eine Einführung in Tools und Konzepte sowie Empfehlungen für die Behandlung von Leistungsproblemen bei Microsoft® Exchange 2000 Server. Außerdem werden Möglichkeiten zur Überwachung der Server unter Exchange 2000 sowie zur Ermittlung der durchschnittlichen Serverleistung beschrieben. Dadurch können bei der Behandlung von Leistungsproblemen Abweichungen von der normalen Serverleistung gemessen werden. Ziele des Whitepapers Dieses Dokument enthält detaillierte Antworten zu folgenden Fragen: Welche Tools stehen für die Überwachung von Exchange 2000-Servern zur Verfügung? Wie kann die durchschnittliche Serverleistung ermittelt werden? Welche Schritte sind bei der Behandlung von Leistungsproblemen durchzuführen? Für welche weiteren Bereiche ist nach dem Ermitteln der durchschnittlichen Serverleistung eine Überwachung der Leistung möglich? 2 Behandlung von Leistungsproblemen bei Microsoft Exchange 2000 Server Aufbau des Whitepapers Das Dokument ist in drei Kapitel und einen Anhang unterteilt: Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ Dieses Kapitel enthält Informationen zu den für die Überwachung der Leistung von Exchange 2000-Servern zur Verfügung stehenden Tools. Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ Dieses Kapitel enthält allgemeine Informationen und Anweisungen zum Ermitteln der durchschnittlichen Serverleistung von Exchange 2000-Servern. Weiterhin enthält dieses Kapitel Beispiele für gesammelte Leistungsdaten. Kapitel 3: „Behandeln von Leistungsproblemen“ Dieses Kapitel enthält allgemeine Informationen und Anweisungen zur Behandlung von Leistungsproblemen. Dieses Kapitel enthält darüber hinaus Beispiele von Leistungsproblemen und gesammelte Leistungsdaten für viele unterschiedliche Bereiche, in denen Leistungsprobleme auftreten können. Anhang Dieser Abschnitt enthält zusätzliche Leistungsindikatoren, die überwacht werden können, wenn die durchschnittliche Serverleistung ermittelt oder die ordnungsgemäße Funktionsweise von Exchange 2000-Servern überwacht wird. Zusätzlich zu den in diesem Dokument aufgeführten Informationen stehen in der Microsoft Knowledge Base unter http://support.microsoft.com die aktuellsten Artikel zur Leistungsfähigkeit von Exchange 2000 Server zur Verfügung. Die Microsoft Knowledge Base enthält aktuelle und detaillierte Informationen zu spezifischen, die Systemleistung betreffenden Themen. Mit den in diesen Artikeln enthaltenen Informationen können die meisten bekannten Leistungsprobleme gelöst werden. 1 Tools zur Behandlung von Leistungsproblemen Mit Hilfe der folgenden Tools kann die Leistung von Exchange 2000 Server überwacht und mögliche Probleme behandelt werden: Systemmonitor Leistungsdatenprotokolle und Warnungen Microsoft Operations Manager 2000 Ereignisanzeige Netzwerkmonitor Dateimonitor Systemmonitor Der Systemmonitor ist ein Verwaltungs-Snap-In der Microsoft Management Console (MMC). Mit dem Systemmonitor kann die Leistung des eigenen oder anderer Computer des Netzwerks gemessen werden. Hinweis In der Titelleiste des Systemmonitors wird die Bezeichnung Leistung angezeigt. Der Name der ausführbaren Datei für den Systemmonitor lautet perfmon. 4 Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ In der folgenden Abbildung ist ein aktiver Systemmonitor dargestellt. Abbildung 1 Systemmonitor Mit dem Systemmonitor können folgende Aufgaben bearbeitet werden: Sammeln und Anzeigen von Leistungsdaten eines lokalen Computers oder von verschiedenen Remotecomputern in Echtzeit. Anzeigen aktueller oder älterer Daten, die in einem Indikatorprotokoll gesammelt wurden. Darstellen der Daten als druckbares Diagramm, Histogramm oder als Bericht. Erstellen von HTML-Seiten mit Leistungsdaten. Erstellen wieder verwendbarer Systemmonitorkonfigurationen, die mit Microsoft Management Console auf anderen Computern installiert werden können. Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ 5 Mit dem Systemmonitor können umfangreiche Daten über die Verwendung von Hardwareressourcen und über Systemdienstaktivitäten der verwalteten Computer gesammelt und angezeigt werden. Für das Sammeln der im Diagramm anzuzeigenden Daten können folgende unterschiedliche Definitionen vorgenommen werden: Datentyp Mit dem Systemmonitor können die Daten ausgewählt werden, die durch spezifische Leistungsobjekte, Leistungsindikatoren und Objektinstanzen gesammelt werden sollen. Einige Objekte stellen Daten über Systemressourcen (wie den Arbeitsspeicher) zur Verfügung. In anderen Objekten werden Daten zu Anwendungsoperationen gesammelt (z. B. von Exchange 2000). Datenquelle Mit dem Systemmonitor können Daten des lokalen Computers oder Daten anderer Computer des Netzwerks, für die Zugriffsrechte bestehen, gesammelt werden. Weiterhin kann das Sammeln von Echtzeitdaten oder älterer Daten mit Hilfe von Indikatorprotokollen erfolgen. Abtastparameter Mit dem Systemmonitor kann das Abtasten entweder manuell auf Anforderung oder automatisch auf Grundlage eines festgelegten Zeitintervalls erfolgen. Bei der Anzeige der protokollierten Daten können außerdem die Startzeit und die Endzeit festgelegt werden, so dass nur Daten eines bestimmten Zeitabschnitts dargestellt werden. Zusätzlich zu den Optionen zum Festlegen der Daten besteht eine hohe Flexibilität bei der Gestaltung der Anzeige im Systemmonitor: Anzeigetyp Die Anzeige im Systemmonitor kann entweder als Diagramm, Histogramm oder Bericht erfolgen. Standardmäßig ist die Diagrammanzeige aktiviert. Diese bietet eine Vielzahl an möglichen Einstellungen. Anzeigemerkmale Für jede dieser Anzeigen können Farbe und Schriftart festgelegt werden. In der Diagramm- und Histogrammansicht können für die Anzeige der Leistungsdaten zahlreiche unterschiedliche Optionen ausgewählt werden. Dazu zählen zum Beispiel: Festlegen eines Titels für das Diagramm bzw. Histogramm und Benennen der vertikalen Achse. Festlegen des Wertebereichs für das Diagramm bzw. Histogramm. Anpassen der Merkmale von Linien oder Balken zur Anzeige von Indikatorwerten, einschließlich Farbe, Breite, Stil usw. Weitere Informationen zum Systemmonitor finden Sie in der Hilfe zu Microsoft Windows® 2000 Server. 6 Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ Leistungsdatenprotokolle und Warnungen Leistungsdatenprotokolle und Warnungen sind Teil des Verwaltungs-Snap-Ins der Microsoft Management Console (MMC). Mit Hilfe von Leistungsdatenprotokollen und Warnungen können Leistungsdaten von lokalen Computern und Remotecomputern automatisch gesammelt werden. Die protokollierten Daten können mit Hilfe des Systemmonitors angezeigt werden. Sie können aber auch für die Analyse und das Erstellen von Berichten in eine Kalkulationstabelle oder eine Datenbank exportiert werden. Durch die Verwendung von Leistungsdatenprotokollen und Warnungen können folgende Aufgaben ausgeführt werden: Sammeln von Daten in einem durch Trennzeichen oder Tabstopps getrennten Format, so dass ein einfacher Import der Daten in eine Kalkulationstabelle möglich ist. Für die Umlaufprotokollierung oder für Protokollierinstanzen, wie z. B. Threads oder Prozesse, die erst nach dem Starten der Protokollierung aktiviert werden, können die Daten auch im Binärformat gesammelt werden. (Bei der Umlaufprotokollierung erfolgt eine kontinuierliche Protokollierung der Daten in einer einzigen Datei, wobei ältere Daten durch die neuen Daten überschrieben werden.) Sammeln von Indikatordaten, die während und nach dem Beenden der Protokollierung angezeigt werden. Ausführen von Leistungsdatenprotokollen und Warnungen als Dienst, so dass das Sammeln von Leistungsdaten auch dann möglich ist, wenn niemand am überwachten Computer angemeldet ist. Festlegen der Start- und Endzeit, des Dateinamens, der Dateigröße und anderer Parameter für die automatische Protokollierung. Verwalten mehrerer Protokollsitzungen von einem einzigen Konsolenfenster aus. Setzen einer Warnung auf einen Indikator. Wenn der im Indikator ausgewählte Wert eine bestimmte Einstellung über- oder unterschreitet, wird entweder eine Nachricht gesendet, ein Programm ausgeführt oder ein Protokoll gestartet. Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ 7 Ähnlich wie beim Systemmonitor unterstützen Leistungsdatenprotokolle und Warnungen die Definition von Leistungsobjekten, Leistungsindikatoren und Objektinstanzen. Außerdem können Abtastintervalle für die Überwachung von Daten von Hardwareressourcen und Systemdiensten eingerichtet werden. Weiterhin ermöglichen Leistungsdatenprotokolle und Warnungen die folgenden Optionen zum Aufzeichnen von Daten: Starten und Beenden der Protokollierung entweder manuell auf Anforderung oder automatisch auf der Grundlage eines benutzerdefinierten Zeitplans. Konfigurieren zusätzlicher Einstellungen für die automatische Protokollierung, wie z. B. das automatische Umbenennen der Datei, und Festlegen von Parametern zum Beenden und Starten eines Protokolls auf Grundlage der abgelaufenen Zeit oder der Dateigröße. Erstellen von Protokollen der Ablaufverfolgung. Bei Verwendung des standardmäßigen Systemdatenanbieters oder eines anderen Anbieters können mit Hilfe von Protokollen der Ablaufverfolgung bei bestimmten Aktivitäten, z. B. bei einer E/A-Operation auf der Festplatte oder einem Seitenfehler, entsprechende Daten aufgezeichnet werden. Wenn das Ereignis stattfindet, sendet der Anbieter die Daten zum Dienst für Leistungsdatenprotokolle und Warnungen. Darin liegt der Unterschied zu Indikatorprotokollen: Bei Verwendung von Indikatorprotokollen erhält der Dienst die entsprechenden Daten vom System nicht nach Auslösung eines bestimmten Ereignisses, sondern nach Ablauf des Aktualisierungsintervalls. Für die Interpretation der Ausgabe des Protokolls der Ablaufverfolgung wird ein Analysetool benötigt. Dieses Tool kann von Entwicklern unter Verwendung von Anwendungsprogrammierschnittstellen (APIs) erstellt werden, die auf der Website von Microsoft (http://msdn.microsoft.com/) verfügbar sind. Definieren eines Programms, das nach Abschluss der Protokollierung ausgeführt wird. Weitere Informationen zu Leistungsdatenprotokollen und Warnungen finden Sie in der Hilfe zu Windows 2000 Server. 8 Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ Microsoft Operations Manager 2000 Microsoft Operations Manager 2000 ermöglicht die umfassende Ereignisverwaltung, die effiziente Überwachung, das Senden von Warnungen sowie die Erstellung von Berichten und Trendanalysen. Application Management Pack ist die in Microsoft Operations Manager integrierte umfangreiche Knowledge Base für den Produktsupport. Dadurch können die täglich anfallenden Supportkosten reduziert werden, die beim Ausführen von Anwendungen und Diensten in einer auf Microsoft Windows basierenden Information Technology (IT)-Infrastruktur entstehen. Die Verwaltungspakete von Microsoft Operations Manager 2000 stellen das für die Verwendung von Windows 2000 Server und Exchange 2000 Server notwendige Wissen zur Verfügung. In der folgenden Abbildung werden Informationen dargestellt, die in Microsoft Operations Manager i. d. R. zur Verfügung stehen. Abbildung 2 Microsoft Operations Manager Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ 9 Mit Microsoft Operations Manager 2000 können folgende Aufgaben ausgeführt werden: Prüfen des Systemstatus über eine Webkonsole. Erstellen komplexer Regeln als Reaktion auf Ereignisse. Generieren benutzerdefinierter Berichte. Ausführen grundlegender Betriebsaufgaben unter Verwendung eines der integrierten Verwaltungspakete. Microsoft Operations Manager 2000 verfügt über einen vollständigen Satz von Features für die Unterstützung von Administratoren bei der Überwachung und Verwaltung sowohl von Ereignissen als auch der Leistung der auf Windows 2000 basierenden Serversysteme. Weitere Informationen zu Microsoft Operations Manager 2000 finden Sie auf der Produktwebsite unter http://www.microsoft.com/mom/. Ereignisanzeige Mit Hilfe der Ereignisprotokolle der Ereignisanzeige können Informationen zu Hardware-, Software- und Systemproblemen gesammelt sowie Sicherheitsereignisse von Windows 2000 überwacht werden. Der Ereignisprotokolldienst wird automatisch beim Starten von Windows 2000 ausgeführt und zeichnet Ereignisse in den drei in der folgenden Tabelle aufgeführten Protokollarten auf. 10 Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ Tabelle 1 Von der Ereignisanzeige verwendete Protokolle Protokoll Beschreibung Anwendungsprotokoll Das Anwendungsprotokoll enthält alle in Exchange 2000 und anderen Anwendungen protokollierten Ereignisse. Die meisten der in Exchange 2000 aufgetretenen Ereignisse werden im Anwendungsprotokoll aufgezeichnet. Systemprotokoll Das Systemprotokoll enthält Ereignisse, die von Windows 2000Systemkomponenten protokolliert werden. So werden im Systemprotokoll z. B. Fehler beim Laden eines Treibers oder anderer Systemkomponenten beim Systemstart aufgezeichnet. In Windows 2000 wird vorab festgelegt, welche Ereignistypen von den Systemkomponenten protokolliert werden. Sicherheitsprotokoll Mit dem Sicherheitsprotokoll können Sicherheitsereignisse, wie gültige und ungültige Anmeldeversuche, oder auch Ereignisse im Zusammenhang mit der Verwendung von Ressourcen, wie z. B. das Erstellen, Öffnen und Löschen von Dateien, aufgezeichnet werden. Der Administrator kann festlegen, welche Ereignisse im Sicherheitsprotokoll aufgezeichnet werden. Wenn beispielsweise die Überwachung der Anmeldeaktivitäten aktiviert wird, werden alle Versuche, sich am System anzumelden, im Sicherheitsprotokoll aufgezeichnet. Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ 11 In der Ereignisanzeige werden die in der folgenden Tabelle aufgeführten Ereignistypen angezeigt: Tabelle 2 In der Ereignisanzeige angezeigte Ereignisse Ereignis Beschreibung Fehler Zeigt ein erhebliches Problem an, z. B. den Verlust von Daten oder den Ausfall von Funktionen. Ein Fehler wird beispielsweise protokolliert, wenn ein Dienst beim Systemstart nicht geladen werden kann. Warnung Zeigt ein mögliches Problem an. Eine Warnung wird beispielsweise protokolliert, wenn auf der Festplatte nur noch wenig freier Speicherplatz zur Verfügung steht. Information Zeigt die erfolgreiche Ausführung einer Anwendung, eines Treibers oder eines Dienstes an. Ein Informationsereignis wird zum Beispiel protokolliert, wenn ein Netzwerktreiber erfolgreich geladen wurde. Erfolgsüberwachung Zeigt einen erfolgreich überwachten Versuch eines Sicherheitszugriffs an. Ein Erfolgsüberwachungsereignis wird zum Beispiel protokolliert, wenn die Anmeldung eines Anwenders am System erfolgreich war. Fehlerüberwachung Zeigt einen überwachten Zugriffsversuch an, der fehlerhaft war. Ein Fehlerüberwachungsereignis wird zum Beispiel protokolliert, wenn der Zugriffsversuch eines Anwenders auf ein Netzwerklaufwerk fehlgeschlagen ist. Weitere Informationen zur Ereignisanzeige finden Sie in der Hilfe zu Microsoft Windows® 2000 Server. 12 Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ Netzwerkmonitor Mit Hilfe des Netzwerkmonitors können Probleme im LAN ermittelt und behandelt werden. Folgende Aufgaben können mit dem Netzwerkmonitor ausgeführt werden: Identifizieren von Mustern des Netzwerkverkehrs und von Netzwerkproblemen. Beispielsweise können Probleme von Client-Server-Verbindungen lokalisiert, ein Computer mit einer überproportionalen Anzahl von Netzwerkanfragen gefunden und nicht autorisierte Anwender im Netzwerk identifiziert werden. Aufzeichnen von Frames (Paketen) direkt aus dem Netzwerk. Anzeigen, Filtern, Speichern und Drucken der aufgezeichneten Frames. Eine Anleitung zur Verwendung des Netzwerkmonitors für die Behandlung von Leistungsproblemen ist im Abschnitt „Behandeln von Leistungsproblemen“ weiter unten in diesem Dokument zu finden. Weitere Informationen zum Netzwerkmonitor finden Sie in folgenden Artikeln der Knowledge Base: Q294818 – „Frequently Asked Questions About Network Monitor“ (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q294818) (in englischer Sprache) Q148942 – „How to Capture Network Traffic with Network Monitor“ (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q148942) (in englischer Sprache) Dateimonitor Mit Hilfe des Dateimonitors von System Internals können die Aktivitäten des Dateisystems in Echtzeit überwacht und angezeigt werden. Mit seiner erweiterten Funktionalität stellt der Dateimonitor ein leistungsstarkes Tool dar, mit dem die Arbeitsweise von Windows untersucht, Dateien und DLLs hinsichtlich ihrer Verwendung durch die einzelnen Anwendungen analysiert und Konfigurationsprobleme von System- oder Anwendungsdateien festgestellt werden können. Durch Zeitstempelung wird im Dateimonitor genau angegeben, wann Dateien geöffnet, gelesen, geschrieben oder gelöscht wurden. In der Statusspalte wird dazu das entsprechende Ergebnis festgehalten. Die Überwachung durch den Dateimonitor beginnt, wenn dieser gestartet wird. Der Inhalt seines Ausgabefensters kann für die spätere Offline-Anzeige in einer Datei gespeichert werden. Der Dateimonitor verfügt über vollständige Such- und Filterfunktionen. Kapitel 1: „Tools zur Behandlung von Leistungsproblemen“ 13 Weitere Informationen zum Dateimonitor von System Internals finden Sie im Abschnitt „Behandeln von Leistungsproblemen“ weiter unten in diesem Dokument sowie im Internet unter: http://www.sysinternals.com. Hinweis Diese Kontaktinformationen von Drittanbietern werden bereitgestellt, um Ihnen die Suche nach technischer Unterstützung zu erleichtern. Diese Kontaktinformationen können ohne Vorankündigung geändert werden. Microsoft übernimmt keine Garantie für die Richtigkeit dieser Kontaktinformationen von Drittanbietern. Hinweise zur Notation In diesem Abschnitt werden viele Leistungsindikatoren vorgestellt. Leistungsindikatoren bestehen aus folgenden drei Teilen: Leistungsobjekt Teil des Computers, der überwacht wird. Einige der am häufigsten überwachten Objekte sind Prozessor, Arbeitsspeicher und physikalischer Datenträger. Nach dem Installieren von Exchange 2000 werden neue Objekte wie zum Beispiel MSExchangeIS zur Leistungsobjektliste hinzugefügt. Indikatoren Die für ein Leistungsobjekt zur Verfügung stehenden Indikatoren, die Teile des überwachten Objekts sind. Bei einem Arbeitsspeicherobjekt können beispielsweise die verfügbaren Bytes, Kilobytes und Megabytes des Arbeitsspeichers sowie die Seitenfehler pro Sekunde oder die Gesamtzahl von Seiten pro Sekunde überwacht werden. Instanzen Auf dem Computer befinden sich unter Umständen mehrere Objekte oder Indikatoren, die zu überwachen sind. Bei der Anzeige der Indikatoren des Prozessorobjekts eines Mehrprozessorsystems ist beispielsweise jeder Prozessor des Computers mit einer eigenen Instanz dargestellt. Es besteht die Möglichkeit einen einzelnen Prozessor oder alle Prozessoren zu überwachen. Die Referenz auf einen Leistungsindikator erfolgt in diesem Artikel durch folgendes Format: Leistungsobjekt(Instanz)\Indikator Hinweis Die Angabe der Instanz ist nicht zwingend erforderlich. Beispiel: Physikalischer Datenträger\Zeit (%) 2 Ermitteln der durchschnittlichen Serverleistung Zum Erkennen von Leistungsproblemen müssen die Exchange 2000-Server ständig überwacht und die durchschnittlichen Serverleistung ermittelt werden. Sofort nach dem Einrichten eines Exchange 2000-Servers sollten die in der folgenden Tabelle aufgelisteten Indikatoren für die Überwachung der Serverleistung verwendet und die durchschnittliche Serverleistung ermittelt werden. Minimaler Indikatorensatz Die folgenden Indikatoren bilden den Minimalsatz für die Ermittlung der durchschnittlichen Serverleistung und die Überwachung der Funktionstüchtigkeit des Servers. Für jeden Indikator ist eine Beschreibung und ein empfohlener Wert angegeben. Verwenden Sie für die Überwachung der Leistung bei jedem Indikator den empfohlenen Wert. Hinweis Für die Ermittlung der durchschnittlichen Serverleistung Ihrer Organisation und zur Überwachung der Leistung von Exchange 2000-Servern stehen zahlreiche Indikatoren zur Verfügung. Eine vollständige Liste der Indikatoren mit einer Beschreibung und einem empfohlenen Wert finden Sie im Anhang weiter unten in diesem Dokument. 16 Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ Tabelle 3 Minimaler Indikatorensatz Indikator Beschreibung Empfohlener Wert MSExchangeIS Postfach\Nachrichtenöffnungen/Sek. Rate, mit der Anfragen zum Öffnen von Nachrichten an den ExchangeInformationsspeicher übergeben werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. MSExchangeIS Postfach\ Ordneröffnungen/Sek. Rate, mit der Anfragen zum Öffnen von Ordnern an den ExchangeInformationsspeicher übergeben werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. MSExchangeIS Postfach\Lokale Übermittlungsrate Rate, mit der Nachrichten lokal übermittelt werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. MSExchangeIS\RPCOperationen/Sek. Rate, mit der Remote Procedure Call (RPC)Operationen erfolgen. Dieser Indikator zeigt die Anzahl der noch anstehenden RPCAnfragen an. Wenn die Benutzer durch Microsoft® Outlook® benachrichtigt werden, dass kein Kontakt zum Exchange-Server hergestellt werden konnte, zeigt dieser Wert meist signifikante Spitzen. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Bei Standardoperationen auf einem Computer mit 4 Prozessoren sollte dieser Wert 0 sein. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ 17 Tabelle 3 Minimaler Indikatorensatz (Fortsetzung) Indikator Beschreibung Empfohlener Wert MSExchangeIS\RPCAnfragen Anzahl von Clientanfragen, Der Wert dieses Indikators die aktuell vom Exchange- sollte 100 nicht Server verarbeitet werden. übersteigen. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. Physikalischer Datenträger(_Gesamt)\ Übertragungen/Sek. Anzahl der abgeschlossenen Leseund Schreibvorgänge pro Sekunde. Dieser Indikator misst die Zugriffe auf den Datenträger und wird als Prozentsatz ausgedrückt. Werte über 50 Prozent können anzeigen, dass der Datenträger einen Engpass darstellt. Der Wert dieses Indikators sollte unter 50 Prozent liegen. Verwenden Sie diesen Indikator für die Ermittlung der durchschnittlichen Serverleistung. Prozess (STORE.EXE)\ Prozessorzeit (%) Prozentwert der Prozessorzeit zum Ausführen von Threads, die sich nicht im Leerlauf befinden. Verwenden Sie diesen Indikator, um den Prozentwert für die Verwendung des Prozessors durch den Exchange-Dienst zu überwachen. Ein durchschnittlicher Wert unter 20 Prozent zeigt an, dass der Server nicht verwendet wird oder die Dienste nicht aktiv sind. Ein durchschnittlicher Wert, der beständig über 75 bis 80 Prozent liegt, zeigt an, dass der Server überlastet ist. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. 18 Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ Tabelle 3 Minimaler Indikatorensatz (Fortsetzung) Indikator Beschreibung Empfohlener Wert Prozessor (_Gesamt)\Prozessorzeit (%) Prozentwert der Prozessorzeit zum Ausführen von Threads, die sich nicht im Leerlauf befinden. Verwenden Sie diesen Indikator, um den Prozentwert für die Verwendung des Prozessors durch den Exchange-Dienst zu überwachen. Ein durchschnittlicher Wert unter 20 Prozent zeigt an, dass der Server nicht verwendet wird oder die Dienste nicht aktiv sind. Ein mittlerer Wert, der beständig über 75 bis 80 Prozent liegt, zeigt an, dass der Server überlastet ist. In diesem Fall sollten Benutzer auf einen anderen Server gelenkt werden. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. SMTP-Server\Lokale Warteschlangenlänge Anzahl von Nachrichten in der lokalen Simple Mail Transfer Protocol (SMTP)Warteschlange. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. SMTP-Server\Übermittelte Nachrichten/Sek. Rate, mit der Nachrichten an das lokale Postfach gesendet werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ 19 Tabelle 3 Minimaler Indikatorensatz (Fortsetzung) Indikator Beschreibung Empfohlener Wert SMTP-Server\Empfangene Rate, mit der Nachrichten Nachrichten/Sek. empfangen werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. SMTP-Server\Gesendete Nachrichten/Sek. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verwenden Sie diesen Indikator zur Ermittlung der durchschnittlichen Serverleistung. Rate, mit der Nachrichten gesendet werden. Hinweis Vor der Behandlung von Datenträgerproblemen sollte an der Eingabeaufforderung der Befehl diskperf –y ausgeführt werden, um den Indikator für logische Datenträger sowie für physikalische Datenträger zu aktivieren. Beispiel für die Ermittlung der durchschnittlichen Serverleistung Nach dem Beginn der Überwachung der Exchange 2000-Server kann mit Hilfe der gesammelten Daten die durchschnittliche Serverleistung ermittelt werden. Die im folgenden Abschnitt aufgeführten Fragen sollten vor dem Ermitteln der durchschnittlichen Serverleistung beantwortet werden. Außerdem sind Beispieldaten zum Systemmonitor aufgeführt. 20 Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ Zu beantwortende Fragen Vor Ermittlung der durchschnittlichen Serverleistung sollten die folgenden Fragen beantwortet werden. Die Antworten auf diese Fragen helfen Ihnen bei der Interpretation der aktuellen Leistungsdaten und bei der Untersuchung von Leistungsproblemen. Wie viele Nachrichten erhalten die Benutzer durchschnittlich pro Tag? Wie viele Nachrichten werden von den Benutzern geöffnet, und wie häufig werden Ordner geöffnet? Wie hoch ist die maximale Übertragungsrate? Zu welcher Tageszeit und an welchem Wochentag werden Spitzenlasten erreicht? Gibt es monatliche bzw. quartalsweise Spitzenlasten? Wie viele Benutzer können von den vorhandenen Servern zusätzlich bedient werden? Ziel ist es, die für typische Belastungszeiträume gesammelten Daten als durchschnittliche Serverleistung mit den aktuellen Leistungsdaten zu vergleichen. Beim Vergleich der Daten der durchschnittlichen Serverleistung mit den Daten der aktuellen Serverleistung kann festgestellt werden, ob der Server ordnungsgemäß funktioniert oder ob Leistungsprobleme auftreten. Die Beantwortung der oben gestellten Fragen hilft bei der Analyse der aktuellen Leistungsdaten und beim Erkennen von Leistungsproblemen. Beispiele für den Systemmonitor Im Folgenden sind Beispiele für Leistungsdaten aufgeführt, die durch den Systemmonitor gesammelt wurden. Bei einem Systemmonitor, der rund um die Uhr ausgeführt wird, werden Daten mit folgender Häufigkeitsrate gesammelt: 900 Sekunden bei einer 24-Stunden-Ansicht 60 Sekunden bei einer 1- bis 2-Stunden-Ansicht 10 Sekunden zur Erfassung von kurzzeitigen Belastungsspitzen Die folgenden Abbildungen des Systemmonitors wurden während der Überwachung eines Exchange 2000-Produktionsservers mit Service Pack 3 aufgezeichnet. In der ersten Abbildung sind Leistungsdaten in der 24-Stunden-Ansicht mit den Operationen zu Spitzen- und Nicht-Spitzenzeiten dargestellt. In der zweiten und dritten Abbildung werden die 1- bis 2-Stunden-Ansicht bzw. die Kurzzeit-Ansicht während der Hauptgeschäftszeit gezeigt. Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ In der folgenden Abbildung ist die Datenaufzeichnung des Systemmonitors in der 24-Stunden-Ansicht dargestellt. Abbildung 3 Daten des Systemmonitors in der 24-Stunden-Ansicht 21 22 Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ In der folgenden Abbildung ist die Datenaufzeichnung des Systemmonitors in der 1- bis 2-Stunden-Ansicht dargestellt. Abbildung 4 Daten des Systemmonitors in der 1- bis 2-Stunden-Ansicht Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ 23 In der folgenden Abbildung ist die Datenaufzeichnung des Systemmonitors im Abstand von 10 Sekunden zum Erfassen kurzzeitiger Belastungsspitzen dargestellt. Abbildung 5 Daten des Systemmonitors mit kurzzeitigen Spitzen 24 Kapitel 2: „Ermitteln der durchschnittlichen Serverleistung“ Bei der Leistungsüberwachung unter Verwendung der oben dargestellten Ansichten und des minimalen Indikatorsatzes kann die durchschnittliche Serverleistung ermittelt und die Leistung des Servers überwacht werden. Bei Verwendung der empfohlenen Werte für den minimalen Indikatorsatz als Richtlinie zeigt sich, dass der in Abbildung 5 dargestellte Server ordnungsgemäß funktioniert. Der Indikatorwert RPCOperationen/Sek. bleibt im Allgemeinen 0, der Indikatorwert RPC-Anfragen unter 100, der Indikatorwert Übertragungen/Sek. im Allgemeinen unter 50 Prozent und die Indikatorwerte Prozessorzeit (%) (_Gesamt) und Prozessorzeit (%) (STORE.EXE) unter 80 Prozent. Aus Abbildung 5 wird außerdem ersichtlich, dass Spitzen bei der Serverleistung normal sind. In Abbildung 5 ist zu erkennen, dass die Indikatorwerte Ordneröffnungen/Sek., Prozessorzeit (%) (STORE.EXE) und Prozessorzeit (%) (_Gesamt) zeitweise stark ansteigen, danach aber wieder auf ein niedriges Niveau zurückgehen. Hinweis Leistungsdaten können unter Verwendung von Leistungsdatenprotokollen und Warnungen in einer Protokolldatei gespeichert werden. Mit Leistungsdatenprotokollen und Warnungen können Leistungsdaten in Protokolldateien gespeichert werden, so dass die während der typischen Lastzeiten gespeicherten Leistungsdaten mit den aktuellen Leistungsdaten verglichen werden können. Die in den Protokolldateien gespeicherten Daten können anschließend mit dem Systemmonitor angezeigt werden. 3 Behandeln von Leistungsproblemen Nach Ermittlung der durchschnittlichen Serverleistung und Einrichten der Überwachung der Exchange 2000-Server können Leistungsprobleme erkannt werden. In den folgenden Abschnitten finden Sie Hilfe bei der Ermittlung von Leistungsproblemen. Ursachen für Leistungsprobleme Hinweise auf Leistungsprobleme erhalten Sie entweder mit Hilfe der überwachten Daten oder durch Benutzer, die Verzögerungen beim Mailverkehr melden. Der erste Schritt zum Eingrenzen der Leistungsprobleme von Exchange ist die Ermittlung der Problemquelle. Unter Verwendung einer eingehenden Nachricht als Beispiel (für den Erhalt einer Nachricht über das Netzwerk, seine Verarbeitung durch Exchange und für die Speicherung auf einem physikalischen Datenträger) kann ermittelt werden, ob das Problem vor der Verarbeitung durch Exchange auftritt, so dass es sich um ein Netzwerkproblem handeln muss, oder ob das Problem während oder erst nach der Verarbeitung durch Exchange auftritt, was auf ein Problem mit dem physikalischen Datenträger verweist. Mit Hilfe der folgenden Leistungsindikatoren kann festgestellt werden, ob die Clientanfragen den Exchange-Server überhaupt erreichen: MSExchangeIS\RPC-Anfragen MSExchangeIS\RPC-Operationen/Sek. Der Indikator MSExchangeIS\RPC-Anfragen zeigt die Anzahl der MAPI-RPCAnfragen an, die aktuell durch den Exchange-Informationsspeicher bedient werden. Vom Exchange-Informationsspeicher können nur 100 Anfragen gleichzeitig bedient werden. Der Indikator MSExchangeIS\RPC-Operationen/Sek. zeigt an, wie 26 Kapitel 3: „Behandeln von Leistungsproblemen“ viele RPC-Operationen vom Exchange-Informationsspeicher pro Sekunde angefragt, und wie viele davon pro Sekunde beantwortet werden. Kapitel 3: „Behandeln von Leistungsproblemen“ 27 Wenn der Wert für die RPC-Anfragen niedrig und der Wert für die RPCOperationen/Sek. (ausstehende Anfragen) gleich 0 ist, tritt das Leistungsproblem vor der Verarbeitung durch Exchange auf. Alle anderen Kombinationen verweisen auf ein Problem während oder nach der Verarbeitung durch Exchange. In der folgenden Abbildung wird eine Problemsituation mit Exchange gezeigt, die mit Hilfe der Indikatoren MSExchangeIS\RPC-Anfragen und MSExchangeIS\RPCOperationen/Sek. festgestellt wurde. Für eine Dauer von drei Minuten werden keine Operationen ausgeführt, obwohl beim Exchange-Informationsspeicher noch Anfragen vorliegen. Abbildung 6 Beispiel für ein Leistungsproblem bei Exchange 2000 28 Kapitel 3: „Behandeln von Leistungsproblemen“ In der folgenden Abbildung ist ein weiteres Leistungsproblem von Exchange zu sehen, das mit Hilfe der Indikatoren MSExchangeIS\RPC-Anfragen und MSExchangeIS\RPC-Operationen/Sek. festgestellt wurde. In der Abbildung werden vier Zeitabschnitte gezeigt, in denen sich die Anzahl der anstehenden Anfragen erhöht, während sich der Datendurchsatz verringert. Während dieser Zeitabschnitte erhöht sich zwar die Anzahl der RPC-Anfragen, aber der Wert für RPC-Operationen/Sek. passt sich dem nicht an. Bei der dritten Spitze der RPCAnfragen (dargestellt in Grün), steigt die Rate der RPC-Anfragen, aber die Rate für RPC-Operationen/Sek. (dargestellt in Rot) ist im Zeitraum der Spitze gleich null. Abbildung 7 Beispiel für ein Leistungsproblem bei Exchange 2000 Kapitel 3: „Behandeln von Leistungsproblemen“ 29 In der folgenden Abbildung ist ein Clientproblem dargestellt, das mit Hilfe der Indikatoren MSExchangeIS\RPC-Anfragen und MSExchangeIS\RPCOperationen/Sek. festgestellt wurde. Die Raten für RPC-Operationen/Sek. und RPC-Anfragen steigen gleichzeitig. Das kann bedeuten, dass ein Client ein Dienstprogramm oder Skript ausführt, bei dem viele Anfragen an den ExchangeInformationsspeicher gerichtet werden und der Exchange-Informationsspeicher versucht den zahlreichen Anfragen nachzukommen. In dieser Situation kann mit Hilfe des Netzwerkmonitors der Computer ermittelt werden, von dem aus die Anfragen gestellt werden. Abbildung 8 Beispiel für ein vom Client verursachtes Leistungsproblem 30 Kapitel 3: „Behandeln von Leistungsproblemen“ In der folgenden Abbildung ist ein Netzwerkproblem dargestellt, das mit Hilfe der Indikatoren MSExchangeIS\RPC-Anfragen und MSExchangeIS\RPCOperationen/Sek. festgestellt wurde. In zwei Fällen sind die Werte für RPCOperationen/Sek. und RPC-Anfragen gleich null. In dieser Situation wird der Empfang der Anfragen beim Exchange-Informationsspeicher verhindert. Mit Hilfe des Netzwerkmonitors kann festgestellt werden, ob Anfragen überhaupt den Server erreichen. Abbildung 9 Beispiel für ein vom Netzwerk verursachtes Leistungsproblem Art des Problems Nachdem festgestellt wurde, ob das Problem während, vor oder nach der Verarbeitung durch Exchange auftritt, müssen erst allgemeine Fragen beantwortet werden, um den nächsten Schritt festlegen zu können. Vor Beginn der Problembehandlung sollten die folgenden Fragen über die Clients und die Hardware des Servers, bei dem die Probleme aufgetreten sind, beantwortet werden: Ist das Verhalten der Clients deutlich verlangsamt, oder wurde die Bearbeitung sogar eingestellt? Trat das Problem bei einer bestimmten Clientoperation auf? Trat das Problem bei allen Clients gleichzeitig auf? Kapitel 3: „Behandeln von Leistungsproblemen“ 31 Mit welcher Häufigkeit tritt das Problem auf? Wie ist die Hardwareausstattung des Servers? Über wie viele Prozessoren verfügt der Server? Wie groß ist der Arbeitsspeicher des Servers? Wie viele Festplatten bestehen auf jedem physikalischen Datenträger, und wie sind diese konfiguriert (z. B. als RAID-0, RAID-1, RAID-5)? Welche Versionen von Exchange und Windows und welche jeweiligen Service Packs sind installiert, und sind die korrekten Versionen installiert? Erfüllt die Hardware des Servers die Hardwareanforderungen der installierten Software? Entspricht die Bandbreite den Anforderungen der Anwendung (z. B. bei Verwendung von Site Connector auf einer Leitung mit 56 kbit/s)? Entspricht das versuchte Szenario einem vom System unterstützten Szenario? Gibt es Probleme mit dem Netzwerk? Prüfen Sie alle IP-Informationen, einschließlich Windows Internet Name Service (WINS), Domain Name Server (DNS) und die Kommunikation mit dem globalen Katalog oder dem Domänencontroller. Leistungsprobleme der CPU Engpässe der CPU können sehr einfach festgestellt werden. Wenn sich der Wert des Indikators Prozessor(_Gesamt)\Prozessorzeit (%) 100 Prozent nähert, ist die CPU der Engpass. Wichtig Wenn auf dem Server der Indexdienst ausgeführt wird, verwendet dieser die gesamte CPU. Deaktivieren Sie während der Untersuchung der Leistungsprobleme den Indexdienst. Der Indexdienst nutzt die gesamte ungenutzte Prozessorleistung der CPU. Wenn ein anderer Prozess während der Ausführung des Indexdienstes zusätzliche Prozessorleistung vom System anfordert, überlässt die Indexdienst-Engine diesem Prozess die CPU. Wenn der Wert des Indikators Prozessor(_Gesamt)\Prozessorzeit (%) hoch ist, sollten Sie prüfen, ob sich der Wert des Indikators MSExchangeIS\RPC-Anfragen ebenfalls erhöht. Erreicht der Wert von MSExchangeIS\RPC-Anfragen das Maximum von 100, werden beim Client Timeouts verursacht. Vom ExchangeInformationsspeicher können gleichzeitig nur 100 RPC-Anfragen bedient werden. 32 Kapitel 3: „Behandeln von Leistungsproblemen“ In der folgenden Abbildung ist ein Leistungsproblem der CPU dargestellt. Sie zeigt einen plötzlichen Anstieg der lokalen Übermittlungsrate. Dadurch erhöht sich die Auslastung der CPU auf 100 Prozent. In dieser Situation arbeitet die CPU an der Kapazitätsgrenze, um lokale Nachrichten zu übermitteln. Abbildung 10 Beispiel für ein Leistungsproblem der CPU CPU-Auslastung Nach Eingrenzen des Problems auf die CPU sollte ermittelt werden, wodurch die hohe Auslastung der CPU verursacht wird. Mit den unten aufgeführten Indikatoren kann das Problem mit hoher Wahrscheinlichkeit aufgespürt werden, wobei der erste Indikator die höchste Wahrscheinlichkeit und der vierte Indikator die geringste Wahrscheinlichkeit besitzt. Die Prozesse dieser vier Indikatoren lasten die CPU normalerweise bis zu 90 Prozent aus. Prozess(STORE.EXE)\Prozessorzeit (%) Prozess(inetinfo)\Prozessorzeit (%) Prozess(emsmta)\Prozessorzeit (%) Prozess(system)\Prozessorzeit (%) Hinweis In den Wert eines Prozessindikators geht jede CPU des Servers mit 100 Prozent ein. Daher kann bei einem Computer mit acht Prozessoren der Wert jedes Prozessorindikators zwischen 0 und 800 Prozent liegen. Kapitel 3: „Behandeln von Leistungsproblemen“ 33 In der folgenden Abbildung ist eine Histogrammansicht der Prozesse gezeigt, die mit hoher Wahrscheinlichkeit die CPU-Auslastung verursachen. Der ExchangeInformationsspeicher verbraucht dabei die meiste CPU-Leistung. Werden neben den vier wahrscheinlichsten Prozessen andere Prozesse als Verursacher der CPU-Auslastung vermutet, sollten diese zur Histogrammansicht hinzugefügt werden. Abbildung 11 Histogrammansicht der wahrscheinlich für die CPU-Auslastung verantwortlichen Prozesse Hinweis Die Anzeige mehrerer Indikatoren in der Histogrammansicht des Systemmonitors ist ein einfacher Weg, um den Indikator zu ermitteln, der auf das Problem verweist. Folgende allgemeine Prozesse können die Auslastung der CPU verursachen: Sicherungsprogramme Überwachungsprogramme Tools für den Remotezugriff 34 Kapitel 3: „Behandeln von Leistungsproblemen“ Isolieren von Threads Ein weiterführender Schritt bei der Ermittlung des Prozesses, der für die Auslastung der CPU verantwortlich ist, ist die Überwachung der einzelnen Threads, die die CPU verwenden. Dabei können die entsprechenden Threads isoliert werden, die die CPUAuslastung verursachen. Verwenden Sie wiederum die Histogrammansicht des Systemmonitors, um wie bei der Untersuchung der Prozesse den entsprechenden Thread zu ermitteln, der die CPU auslastet. Fügen Sie alle Indikatoren Thread(Prozess/Threadnummer)\Prozessorzeit (%) des entsprechenden Prozesses zur Histogrammansicht des Systemmonitors hinzu. Ein Thread kann mit dem Indikator Thread\Prozess(Threadnummer)ThreadID identifiziert werden. Leistungsprobleme der Festplatte Anders als bei Leistungsproblemen der CPU können Leistungsprobleme der Festplatte nicht mit einem einzelnen Indikator erkannt werden, der einen Datenträgerengpass anzeigt. Hinweis Der Festplattenengpass kann auch durch Probleme mit dem Arbeitsspeicher verursacht werden. Er kann nicht einfach durch Hinzufügen weiterer Spindeln beseitigt werden. Stellen Sie sicher, dass bei der Konfiguration der Datenträger für Exchange 2000 auch für E/A-Vorgänge ausreichende Kapazität eingeplant wird und nicht nur für den Festplattenspeicher. Microsoft empfiehlt RAID-0+1, da diese Konfiguration zu einer höheren E/A-Kapazität führt als RAID-5. Hinweis Vor der Behandlung von Datenträgerproblemen sollte an der Eingabeaufforderung der Befehl diskperf –y ausgeführt werden, um den Indikator für logische Datenträger sowie für physikalische Datenträger zu aktivieren. Leistungsprobleme der Festplatte: Erster Ansatz Bei diesem ersten Ansatz kann ein Datenträgerproblem festgestellt werden, indem jedes physikalische Laufwerk durch folgende Indikatoren überwacht wird: Physikalischer Datenträger(Laufwerk:)\Schreibvorgänge/Sek. Physikalischer Datenträger(Laufwerk:)\Lesevorgänge/Sek. Hinweis Vor der Behandlung von Leistungsproblemen bei Datenträgern sollte an der Eingabeaufforderung der Befehl diskperf –y ausgeführt werden, um den Indikator für logische Datenträger sowie für physikalische Datenträger zu aktivieren. Kapitel 3: „Behandeln von Leistungsproblemen“ 35 Untersuchen Sie jedes Laufwerk, und vergleichen Sie es mit der gesamten Instanz, um den E/A-Vorgang zu lokalisieren. Verwenden Sie die unten aufgeführten Empfehlungen für den Vergleich und um festzustellen, ob ein Engpass vorliegt: RAID-0: Lesevorgänge/Sek. + Schreibvorgänge/Sek. < # Spindeln × 100 RAID-1: Lesevorgänge/Sek. + 2 * Schreibvorgänge/Sek. < # Spindeln × 100 (Jeder Schreibvorgang erfolgt auf jeden Spiegel des Arrays.) RAID-5: Lesevorgänge/Sek. + 4 * Schreibvorgänge/Sek. < # Spindeln × 100 (Jeder Schreibvorgang erfordert zwei Lese- und zwei Schreibvorgänge.) Hinweis Bei diesem Szenario wird angenommen, dass der Datendurchsatz des Datenträgers 100 zufällige E/A-Vorgänge pro Spindel beträgt. Weitere Informationen über RAID finden Sie im folgenden Abschnitt „RAID-Ebenen“. RAID-Ebenen Obwohl es viele verschiedene Implementierungen der RAID-Technologie gibt, verfügen alle über zwei gemeinsame Merkmale. Bei allen Implementierungen werden zur Verteilung der Daten mehrere physikalische Datenträger verwendet, und die Speicherung der Daten erfolgt auf der Grundlage einer Logik, die unabhängig von der Anwendung ist, deren Daten gespeichert werden. Dieser Abschnitt behandelt vier primäre RAID-Implementierungen: RAID-0, RAID-1, RAID-0+1 und RAID-5. Obwohl es viele weitere RAID-Implementierungen gibt, kann mit diesen vier Arten der Gesamtumfang der RAID-Lösungen dargestellt werden. RAID-0: Bei RAID-0 werden mehrere Festplatten eines Arrays als Stripeset-Laufwerk eingerichtet. Jeder Datenträger ist in logische Partitionen aufgeteilt. Das Striping erfolgt über alle Festplatten des Arrays zu einer einzigen logischen Partition. Wenn beispielsweise bei einem RAID-0-Array durch die Anwendung eine Datei auf Laufwerk D gespeichert wird, dann wird diese Datei über das gesamte logische Laufwerk D verteilt, wie in der folgenden Abbildung gezeigt. In diesem Beispiel wird die Datei auf alle sechs Festplatten verteilt. Abbildung 12 RAID-0-Festplattenarray 36 Kapitel 3: „Behandeln von Leistungsproblemen“ Aus Sicht der Leistungsfähigkeit ist RAID-0 die effizienteste RAID-Technologie, da gleichzeitig auf alle sechs Festplatten geschrieben wird. Wenn alle Festplatten gleichzeitig Daten speichern, wird eine hohe Effizienz bei der Verwendung der Festplatten erzielt. Der Nachteil der RAID-0-Technologie ist der Mangel an Zuverlässigkeit. Wenn die Exchange-Postfachdatenbank quer über ein RAID-0-Array gespeichert wird und eine einzige Festplatte ausfällt, müssen sowohl die Postfachdatenbank auf einem funktionierenden Festplattenarray als auch die Transaktionsprotokolldateien wiederhergestellt werden. Wurden auch die Transaktionsprotokolldateien in dieses Array gespeichert und eine Festplatte fällt aus, kann die Postfachdatenbank nur mit Hilfe der letzten Sicherung wiederhergestellt werden. RAID-1: RAID-1 ist ein gespiegeltes Festplattenarray, bei dem zwei Festplatten, wie in folgender Abbildung dargestellt, gespiegelt werden. Abbildung 13 RAID-1-Festplattenarray RAID-1 ist das zuverlässigste der drei RAID-Festplattenarrays, da alle Daten nach dem Schreiben gespiegelt werden. Daher kann nur die Hälfte des Speicherplatzes der Festplatten verwendet werden. Obwohl diese Variante ineffizient erscheint, wird RAID-1 insbesondere für Daten verwendet, die eine besonders hohe Zuverlässigkeit erfordern. Kapitel 3: „Behandeln von Leistungsproblemen“ 37 RAID-0+1 Mit einem RAID-0+1-Festplattenarray wird die beste Leistung bei gesicherter Redundanz erzielt. Dabei werden die Elemente von RAID-0 und RAID-1 kombiniert, wie in folgender Abbildung dargestellt. Abbildung 14 RAID-0+1-Festplattenarray In einem RAID-0+1-Festplattenarray werden die Daten auf beide Festplattensätze gespiegelt (RAID-1) und danach über Stripeset-Laufwerke verteilt (RAID-0). Jeder physikalische Datenträger wird im Array dupliziert. Bei einem RAID-0+1Festplattenarray mit sechs Festplatten können drei Festplatten als Datenspeicher verwendet werden. RAID-5 RAID-5 ist ein Stripeset-Festplattenarray, bei dem ähnlich wie bei RAID-0 die Daten über das gesamte Array verteilt werden, allerdings mit Parität. Das bedeutet, dass durch einen bestimmten Mechanismus die Integrität der im Array gespeicherten Daten erhalten bleibt. Dadurch können beim Ausfall einer Festplatte des Arrays die Daten mit Hilfe der anderen Festplatten wiederhergestellt werden, wie in folgender Abbildung dargestellt. Daher ist RAID-5 eine zuverlässige Speichervariante. Abbildung 15 RAID-5-Festplattenarray 38 Kapitel 3: „Behandeln von Leistungsproblemen“ Um die Parität zwischen den Festplatten zu gewährleisten, wird 1/n GB (Gigabyte) Festplattenspeicher benötigt (wobei n die Anzahl der Laufwerke des Arrays ist). Bei sechs Festplatten mit jeweils 9 GB stehen nur 45 GB nutzbarer Speicherplatz zur Verfügung. Zur Gewährleistung der Parität in einem RAID-5-Array wird ein Schreibenvorgang in zwei Schreib- und zwei Lesevorgänge umgewandelt. Dadurch verringert sich die Gesamtleistung des Systems. Der Vorteil einer RAID-5-Lösung gegenüber RAID-1 (und RAID-0+1) liegt in der hohen Zuverlässigkeit und der effizienteren Verwendung des verfügbaren Festplattenspeichers. Weitere Informationen zum Vergleich der verschiedenen RAID-Ebenen und RAIDVarianten sowie zu verschiedenen Speicherlösungen wie Storage Area Network (SAN, Speichernetzwerk) und Network Attached Storage (NAS, Netzwerkspeicher) finden Sie im Whitepaper Speicherlösungen für Microsoft® Exchange 2000 Server unter http://go.microsoft.com/fwlink/?LinkId=1715. Leistungsprobleme der Festplatte: Zweiter Ansatz Bei diesem Ansatz werden zum Feststellen eines Festplattenengpasses die noch nicht abgeschlossenen E/A-Anfragen untersucht. Dabei werden folgende Warteschlangenindikatoren verwendet: Physikalischer Datenträger(Laufwerk:)\Durchschnittl. Warteschlange des Datenträgers Physikalischer Datenträger(Laufwerk:)\Aktuelle Warteschlange des Datenträgers Der Wert des Indikators Physikalischer Datenträger(Laufwerk:)\Durchschnittl. Warteschlange des Datenträgers zeigt die durchschnittliche Länge der Warteschlange für das Abtastintervall an. Der Indikator Physikalischer Datenträger(Laufwerk:)\Aktuelle Warteschlange des Datenträgers enthält den Wert für die Länge der Warteschlange zum Abtastzeitpunkt. Kapitel 3: „Behandeln von Leistungsproblemen“ 39 Ein Festplattenengpass muss angenommen werden, wenn die durchschnittliche Warteschlangenlänge des Datenträgers größer als die Anzahl der Spindeln des Arrays ist und die aktuelle Warteschlangenlänge des Datenträgers nie 0 ist. Kurzzeitige Spitzen bei der Warteschlangenlänge können die durchschnittliche Warteschlangenlänge künstlich in die Höhe treiben, so dass die aktuelle Warteschlangenlänge überwacht werden muss. Wenn die Warteschlangenlänge regelmäßig auf null fällt, wird die Warteschlange geleert, so dass wahrscheinlich kein Festplattenengpass vorliegt. Hinweis Bei Verwendung dieses Ansatzes müssen die Spitzen der Warteschlangenlänge mit dem Indikator MSExchangeIS\RPC-Anfragen in Beziehung gesetzt werden, um die Auswirkungen auf die Clients zu prüfen. Leistungsprobleme der Festplatte: Dritter Ansatz Bei diesem Ansatz zum Erkennen eines Festplattenengpasses wird die E/A-Verzögerung untersucht, die die ordnungsgemäße Funktionsweise des Datenträgers anzeigt: Physikalischer Datenträger(Laufwerk:)\Mittlere Sek./Lesevorgang Physikalischer Datenträger(Laufwerk:)\Mittlere Sek./Schreibvorgang Ein typischer Wertebereich ist 0,005 bis 0,020 Sekunden für einen beliebigen E/A-Vorgang. Wenn im Array-Controller die Zurückschreibspeicherung aktiviert ist, sollte der Wert des Indikators Physikalischer Datenträger(Laufwerk:)\Mittlere Sek./Schreibvorgang unter 0,002 Sekunden liegen. Wenn diese Indikatoren Werte zwischen 0,020 und 0,050 Sekunden haben, liegt wahrscheinlich ein Festplattenengpass vor. Wenn die Indikatorwerte über 0,050 Sekunden liegen, liegt definitiv ein Festplattenengpass vor. Wodurch wird der E/A-Vorgang ausgelöst? Nachdem ein Festplattenproblem erkannt wurde, muss nun festgestellt werden, wodurch der E/A-Vorgang ausgelöst wurde. Zuerst muss das Laufwerk identifiziert werden, auf dem der E/A-Vorgang erfolgt. Durch Aussortieren der verschiedenen Exchange-Dateien auf verschiedene Datenträger kann einfacher festgestellt werden, ob der E/A-Vorgang durch die Auslagerungsdatei, die EDB-Datei (Exchange-Datenbank), die STM-Datei (Exchange-Streamingdatenbank), die LOG-Dateien (Protokolldateien) oder durch die Dateien der Routingwarteschlange aktiviert wurde. 40 Kapitel 3: „Behandeln von Leistungsproblemen“ Unter Microsoft® Windows® 2000 können folgende Indikatoren verwendet werden, um Prozesse zu erkennen, die E/A-Vorgänge auf der Festplatte verursachen: Prozess(Prozessname)\E/A-Lesevorgänge/Sek. Prozess(Prozessname)\E/A-Schreibvorgänge/Sek. Als Nächstes muss mit dem Dateimonitor von System Internals festgestellt werden, bei welchen Dateien E/A-Aktivitäten angezeigt werden. Wählen Sie die näher zu untersuchenden logischen Laufwerke aus, und zeigen Sie alle Lese- und Schreibvorgänge der Laufwerke an. Dieses Verfahren ist vor allem bei mehrfach benutzten Laufwerken wie Laufwerk C hilfreich, auf denen sich mehrere grundlegende, vom System und von Anwendungen verwendete Dateien befinden. Die folgende Abbildung zeigt den Dateimonitor von System Internals. Abbildung 16 Dateimonitor von System Internals. Im Ausgabefenster werden die E/A-Vorgänge von priv1.stm und priv1.edb angezeigt. Kapitel 3: „Behandeln von Leistungsproblemen“ 41 Hinweis Diese Kontaktinformationen von Drittanbietern werden bereitgestellt, um Ihnen die Suche nach technischer Unterstützung zu erleichtern. Diese Kontaktinformationen können ohne Vorankündigung geändert werden. Microsoft übernimmt keine Garantie für die Richtigkeit dieser Kontaktinformationen von Drittanbietern. Probleme mit dem Arbeitsspeicher Wenn Probleme mit dem Arbeitsspeicher untersucht werden, sollte zuerst der Indikator Arbeitsspeicher\Verfügbare MB für die Überwachung des physikalischen Arbeitsspeichers verwendet werden. Fällt der Wert des Indikators unter 4 MB, beginnt Windows mit der rigorosen Kürzung der Arbeitsseiten der laufenden Prozesse. Der Server funktioniert ordnungsgemäß, wenn der Indikator Arbeitsspeicher\Verfügbare MB mehr als 4 MB anzeigt. Primäre Indikatoren Die folgenden Indikatoren sind die primären Indikatoren bei der Untersuchung von Problemen mit dem Arbeitsspeicher. Mit ihnen kann festgestellt werden, ob die Probleme durch Auslagerung verursacht werden. Diese Indikatoren enthalten Informationen zu Hardwareseiten und zu Seiten, die Speicheraktivitäten zur Festplatte oder von der Festplatte verursachen. Arbeitsspeicher\Seiten/Sek. Arbeitsspeicher\Seitenlesevorgänge/Sek. Arbeitsspeicher\Seitenschreibvorgänge/Sek. Hinweis Die E/A-Auslagerung ist ein normaler Vorgang, da Exchange 2000 den WindowsSystemcache zum Rückspeichern der STM-Datei verwendet. Weitere Indikatoren Folgende Indikatoren können für eine weiterführende Untersuchung von Problemen mit dem Arbeitsspeicher verwendet werden: Arbeitsspeicher\Seitenfehler/Sek. Arbeitsspeicher\Cachefehler/Sek. Arbeitsspeicher\Übergangsfehler/Sek. Prozess(Prozess)\Seitenfehler/Sek. 42 Kapitel 3: „Behandeln von Leistungsproblemen“ Mit dem Indikator Arbeitsspeicher\Seitenfehler/Sek. können nur selten Probleme mit dem Arbeitsspeicher erkannt werden, da in diesem Wert auch der Indikatorwert Arbeitsspeicher\Cachefehler/Sek. enthalten ist und Cachefehler beim Betrieb von Exchange 2000 durch die STM-Datei verursacht werden. Außerdem enthalten die Indikatoren Arbeitsspeicher\Seitenfehler/Sek. und Arbeitsspeicher\Cachefehler/Sek. die Werte für Übergangsfehler des Indikators Arbeitsspeicher\Übergangsfehler/Sek. Übergangsfehler betreffen nicht die Festplatte, da die Verwaltung des Arbeitsspeichers Seiten auf der StandbyListe verwendet. Der Indikator Prozess(Prozess)\Seitenfehler/Sek. kann hilfreich sein, um Prozesse mit vielen Seitenfehlern zu erkennen. Die Prozesse werden in die Histogrammansicht des Systemmonitors übernommen, wo der Prozess mit der hohen Seitenfehlerrate schnell identifiziert werden kann. Diese Methode entspricht dem Vorgehen beim Ermitteln von Prozessen, die eine Auslastung der CPU verursachen. Dieses Vorgehen wird im Abschnitt „Leistungsprobleme der CPU“ weiter oben in diesem Artikel beschrieben. Hinweis Dieser Indikatorwert sollte als Richtwert verwendet werden. Seitenfehler verweisen nicht unbedingt auf Probleme mit dem Arbeitsspeicher. Dennoch erzeugt ein Prozess mit einer hohen Seitenfehlerrate wahrscheinlich auch viele Seitenlese- und Seitenschreibvorgänge. Ursache für den Verbrauch von Arbeitsspeicher Um festzustellen, wodurch Arbeitsspeicher verbraucht wird, werden die folgenden Indikatoren überwacht. Mit diesen Indikatoren und in der angegebenen Reihenfolge kann mit hoher Wahrscheinlichkeit die Ursache für den hohen Verbrauch von Arbeitsspeicher ermittelt werden: Prozess(STORE.EXE)\Arbeitsseiten Prozess(inetinfo)\Arbeitsseiten Prozess(emsmta)\Arbeitsseiten Arbeitsspeicher\Cachebytes Der durch den Indikator Prozess(STORE.EXE)\Arbeitsseiten überwachte Exchange-Informationsspeicher verbraucht mit hoher Wahrscheinlichkeit die meisten der zugesicherten Bytes. Ursache dafür ist der große Cache, der vom ExchangeInformationsspeicher verwendet wird. Mit dem Indikator Datenbank\Cachebytes kann die Situation dahingehend geprüft werden. Auch mit der Histogrammansicht des Systemmonitors können Prozesse mit großen Arbeitsseiten identifiziert werden. Diese Methode wird im Abschnitt „Leistungsprobleme der CPU“ weiter oben in diesem Artikel beschrieben. Kapitel 3: „Behandeln von Leistungsproblemen“ 43 Virtueller Speicher Besonders problematisch beim Skalieren von Exchange ist möglicherweise der Mangel an virtuellem Speicher für den Prozess STORE.EXE. Beim Anpassen des Servers an eine größere Anzahl von Benutzern und eine entsprechend höhere Auslastung verringert sich der zur Verfügung stehende virtuelle Speicher. Dieses Problem wird deutlich, wenn im Anwendungsprotokoll Ereignisse mit der ID 9582 zu finden sind. In einigen Fällen handelt es sich dabei um Informationen oder Routinen, die nicht beachtet werden müssen. In anderen Fällen kann der Mangel an virtuellem Speicher zu einer deutlichen Verringerung der Verarbeitungsgeschwindigkeit und zu Fehlern bei der Verarbeitung von Nachrichten führen (angezeigt durch Ereignisse mir der ID 12800). Im Folgenden ist ein Beispiel für Ereignisse mit der ID 9582 aufgeführt. Wenn der virtuelle Speicher des Exchange 2000-Servers übermäßig fragmentiert ist, werden durch den Informationsspeicherdienst folgende Ereignisse protokolliert: EreignisID=9582 Schweregrad=Warnung Einrichtung=Systemmonitor Sprache=Deutsch Der für die Ausführung des Exchange-Servers benötigte virtuelle Speicher ist so stark fragmentiert, dass Leistungsprobleme auftreten können. Es wird dringend empfohlen, alle Exchange-Dienste neu zu starten, um dieses Problem zu beheben. Hinweis Diese Warnung wird protokolliert, wenn der größte freie Block kleiner als 32 MB ist. EreignisID=9582 Schweregrad=Fehler Einrichtung=Systemmonitor Sprache=Deutsch Der für die Ausführung des Exchange-Servers benötigte virtuelle Speicher ist so stark fragmentiert, dass bei Standardoperationen Fehler auftreten können. Es wird dringend empfohlen, alle ExchangeDienste neu zu starten, um dieses Problem zu beheben. Hinweis Diese Warnung wird protokolliert, wenn der größte freie Block kleiner als 16 MB ist. 44 Kapitel 3: „Behandeln von Leistungsproblemen“ Es besteht praktisch kein Zusammenhang zwischen dem physikalischen und dem virtuellen Speicher. Fehler, die einen Mangel an virtuellem Speicher anzeigen, können nicht dadurch beseitigt werden, indem mehr physikalischer Speicher hinzugefügt wird. Weiterhin sind Fehler, die auf einen Mangel an virtuellem Speicher und auf seine Fragmentierung verweisen, nicht nur ein Merkmal von Clustern im Modus „Aktiv/Aktiv“. Bei Clustern im Modus „Aktiv/Passiv“ und bei Einzelrechnern können ebenfalls Probleme mit dem virtuellen Speicher auftreten. Probleme mit dem virtuellen Speicher treten dennoch häufiger bei Clustern auf, da allein stehende Server normalerweise nicht für einen Betrieb mit mehreren tausend Benutzern vorgesehen sind. So behandeln Sie Probleme mit dem virtuellen Speicher 1. Stellen Sie fest, ob auf dem Server Windows 2000 Server oder Microsoft® Windows® 2000 Advanced Server ausgeführt wird. Wenn Windows 2000 Server ausgeführt wird, müssen Sie sicherstellen, dass die Datei boot.ini nicht die Option „/3GB“ enthält. Wenn Windows 2000 Advanced Server ausgeführt wird und mehr als 1 GB physikalischer RAM installiert ist, müssen Sie sicherstellen, dass in der Datei boot.ini die Option „/3GB“ enthalten ist. Hinweis Da die zur Optimierung bestimmte Option „/3GB“ von Windows 2000 Server nicht unterstützt wird, sollten Einzelserver nicht als Host für mehrere tausend Benutzer eingerichtet werden. 2. Prüfen Sie das Anwendungsprotokoll auf Warnungen (keine Blöcke mit mehr als 32 MB virtuellem Speicher verfügbar) oder Fehler (keine Blöcke mit mehr als 16 MB virtuellem Speicher verfügbar) mit der ID 9582. Bei einigen großen Systemen ist es nicht ungewöhnlich, dass bei Spitzenbelastungen der Schwellenwert von 32 MB unterschritten wird. Außerhalb dieser Belastungszeiten sollte der Wert für den verfügbaren virtuellen Speicher allerdings deutlich höher liegen. 3. Prüfen Sie das Anwendungsprotokoll auf weitere Fehler, die fehlenden Speicher anzeigen können. Dazu zählen, zusätzlich zu den Warnungen mit der ID 9582, Fehler mit der ID 12800, die Verarbeitungsfehler von Multipurpose Internet Mail Extensions (MIME) anzeigen. Wenn die Warnungen mit anderen Fehlern verbunden sind, die auf fehlenden Speicher verweisen, haben die Benutzer möglicherweise keinen Zugriff auf Mails mehr. Treten keine weiteren Verarbeitungsfehler auf und empfangen die Benutzer weiterhin Mails, so können die Warnungen mit der ID 9582 als relativ unproblematisch eingeschätzt werden. Dennoch sollten Warnungen mit der ID 9582 auf möglichen Handlungsbedarf hin untersucht werden. Kapitel 3: „Behandeln von Leistungsproblemen“ 45 4. Überwachen Sie den Indikator MSExchangeIS\VM Größte Blockgröße. Mit Hilfe dieses Indikators können Probleme mit dem virtuellen Speicher am schnellsten erkannt werden. Dieser Indikator kann in Echtzeit oder in Intervallen von einer Minute überwacht werden. Sammeln Sie Daten für 18 bis 24 Stunden, um festzustellen, ob im Verlauf Speicher freigegeben wird. Überwachen Sie den Minimalwert, um festzustellen, ob dieser geringer wird. Bei großen Servern sollte dieser Minimalwert bei ungefähr 55 MB liegen. 5. Durch andere speicherintensive Prozesse wie Virenprüfung kann dieser Schwellenwert unterschritten werden. Solange aber für den Benutzer keine Leistungseinschränkungen festzustellen sind und die Blockgröße des virtuellen Arbeitsspeichers in belastungsfreien Zeiten wieder ansteigt, sind keine korrigierenden Maßnahmen notwendig. Wenn allerdings höhere Belastungen durch die Benutzer erwartet werden, sollte die Gesamtverbrauch an virtuellem Speicher verringert werden, so dass der Server die höhere Belastung aufnehmen kann. 6. Um den Verbrauch an virtuellem Arbeitsspeicher zu verringern, muss zuerst sichergestellt werden, dass auf dem Server Exchange 2000 Server Service Pack 3 (SP3) ausgeführt wird. Exchange SP3 verfügt über Funktionen zur Optimierung des virtuellen Speichers. 7. Wenn weiterhin Warnungen mit der ID 9582 protokolliert werden, muss eine Änderung der Registrierung durchgeführt werden. Diese Änderung der Registrierung ist zulässig, wenn auf dem Server ausreichend RAM zur Verfügung steht. Überwachen Sie den Indikator Arbeitsspeicher\Verfügbare Bytes. Stellen Sie sicher, dass der Wert des Indikators mehr als 200 MB beträgt. Ändern Sie den Wert von HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\HeapDeCommitFreeBlockThreshold in 262144. 8. Sollten Sie weiterhin Probleme mit dem virtuellen Speicher feststellen, muss entweder eine starke Auslastung des Systems oder ein Speicherverlust angenommen werden. Wenn Sie einen Speicherverlust vermuten, sollten Sie den Indikator Prozess(STORE.EXE)\Private Bytes überwachen, um festzustellen, ob dieser Wert über einen längeren Zeitraum ansteigt. Wenn Sie eine Überlastung des Systems vermuten, müssen Sie nach anderen Anzeichen suchen, wie beispielsweise einer hohen CPU-Auslastung. 46 Kapitel 3: „Behandeln von Leistungsproblemen“ 9. Wenn weiterhin Warnungen mit der ID 9582 angezeigt werden, prüfen Sie den Indikator Physikalischer Datenträger\Warteschlangenlänge des Datenträgers auf Probleme mit den Datenbank- und Transaktionsprotokolllaufwerken. (Führen Sie an der Eingabeaufforderung den Befehl diskperf –y aus, um diese Indikatoren anzuzeigen.) Die Warteschlangenlänge sollte nicht beständig größer als die Anzahl der Spindeln im Array sein. Bei Belastungsspitzen sind Werte im unteren Hunderterbereich zulässig. Wenn die Warteschlangenlänge beständig über 300 liegt, handelt es sich vielleicht um einen Festplattenengpass. 10. Sollten weiterhin Probleme mit dem virtuellen Speicher angezeigt werden, muss der Verbrauch von virtuellem Speicher noch weiter reduziert werden. So können Sie beispielsweise untersuchen, wie die Speichergruppe und die Datenbank konfiguriert wurden. Durch eine Reduzierung auf drei Speichergruppen kann möglicherweise der Verbrauch an virtuellem Speicher verringert werden. Weitere Probleme Wenn Sie Probleme mit Exchange, der CPU, den physikalischen Laufwerken und dem Arbeitsspeicher erfolgreich analysiert haben, der Server aber weiterhin langsam läuft, können Sie auch die folgenden Komponenten untersuchen. Active Directory Exchange 2000 Server ist abhängig vom Microsoft® Active Directory®-Verzeichnisdienst. Engpässe der CPU, der Festplatte sowie des Arbeitsspeichers können auf den Active Directory-Servern untersucht werden. Die meisten Techniken, die zur Identifizierung und Lösung von Problemen mit Exchange 2000-Servern verwendet werden, können auch bei Problemen mit Windows® 2000 Active Directory-Servern angewendet werden. DSAccess DSAccess ist der Cache des Exchange-Servers, auf welchem regelmäßig an Active Directory gestellte Abfragen desselben Servers gespeichert werden. Durch die Speicherung von Active Directory-Informationen ist es nicht notwendig, dass der Exchange-Server bei jeder Abfrage eine Verbindung zum Active Directory herstellt. Die folgenden Indikatoren sind hilfreich, wenn Probleme mit DSAccess untersucht werden: MSExchangeDSAccess Cache\Cachetreffer/Sek. MSExchangeDSAccess Caches\LDAP-Suchvorgänge/Sek. Vergleichen Sie diese aktuellen Indikatoren mit den Daten der durchschnittlichen Serverleistung anderer Server, die ordnungsgemäß funktionieren. Kapitel 3: „Behandeln von Leistungsproblemen“ 47 Netzwerkprobleme Durch Netzwerkprobleme kann es dazu kommen, dass Daten den Exchange-Server nicht erreichen. Die folgenden Indikatoren sind für die Analyse von Netzwerkproblemen hilfreich: Netzwerkkarte (netcard) Empfangene Bytes/Sek. Netzwerkkarte (netcard) Gesendete Bytes/Sek. In Data Center-Umgebungen bzw. in Umgebungen mit Verbindungen hoher Bandbreite sind Netzwerkprobleme selten. Allerdings kann es beispielsweise dann zu Netzwerkproblemen kommen, wenn Sie planen, Sicherungskopien tagsüber zu erstellen, obwohl diese eigentlich nachts erstellt werden sollten. Verwenden des Netzwerkmonitors Falls der Clientverkehr den Exchange-Server nicht erreicht, können Sie den Netzwerkmonitor zur Überprüfung des Datenverkehrs verwenden. Der Netzwerkmonitor ist ein Diagnoseprogramm, das lokale Netzwerke überwacht und Netzwerkstatistiken grafisch darstellt. Während der Zusammenstellung von Daten aus dem Datenstrom des Netzwerks werden vom Netzwerkmonitor folgende Arten von Daten angezeigt: Die Quelladresse des Computers, von dem aus ein Frame an das Netzwerk gesendet wurde. (Bei dieser Adresse handelt es sich um eine eindeutige hexadezimale Zahl (Basis 16), durch die dieser Computer im Netzwerk erkannt wird.) Die Zieladresse des Computers, der den Frame empfangen hat. Die Protokolle, mit denen der Frame gesendet wurde. Die gesendeten Daten oder ein Teil der gesendeten Nachricht. Der Prozess, mit dem der Netzwerkmonitor diese Daten zusammenstellt, heißt „Sammeln“. Standardmäßig werden in einem Sammlungspuffer durch den Netzwerkmonitor Statistiken zu allen Frames erstellt, die im Netzwerk erkannt werden. Der Sammlungspuffer ist ein reservierter Speicherbereich im Arbeitsspeicher. Wenn Statistiken nur von einer Untermenge von Frames erstellt werden sollen, können Sie zu diesem Zweck einen Sammlungsfilter erstellen. Sobald die Datensammlung abgeschlossen ist, können Sie einen Anzeigefilter erstellen und angeben, wie viele der gesammelten Daten im Fenster für die Frameansicht des Netzwerkmonitors angezeigt werden. 48 Kapitel 3: „Behandeln von Leistungsproblemen“ Damit ein Netzwerkmonitor verwendet werden kann, muss Ihr Computer mit einer Netzwerkkarte ausgerüstet sein, die den Promiscuous-Modus unterstützt. Wenn Sie einen Netzwerkmonitor auf einem Remotecomputer verwenden, muss nicht die lokale Arbeitsstation mit einer Netzwerkkarte ausgerüstet sein, die den Promiscuous-Modus unterstützt, sondern der Remotecomputer. Sobald die Daten entweder lokal oder remote gesammelt wurden, können Sie diese zur späteren Analyse in einer Text- oder Sammlungsdatei abspeichern. Hinweis Um mögliche Netzwerkprobleme mit Hilfe des Netzwerkmonitors vollständig behandeln zu können, sollten Sie den Netzwerkmonitor so konfigurieren, dass nicht nur Daten gesammelt werden, die vom Client gesendet und empfangen werden, sondern auch Daten, die vom Server gesendet und empfangen werden. Auch eine server- und clientseitige Ablaufverfolgung des Netzwerkverkehrs ist für die Behandlung von Netzwerkproblemen hilfreich. Erstellen einer Adressliste Um Adresspaare in einem Sammlungsfilter verwenden zu können, müssen Sie zunächst eine Adressdatenbank erstellen. Sobald Sie diese Datenbank erstellt haben, können Sie die darin aufgelisteten Adressen verwenden, um Adresspaare für den Sammlungsfilter zu bestimmen. 1. 2. 3. 4. 5. 6. 7. So erstellen Sie eine Adressliste Klicken Sie im Menü Sammeln auf Starten. Optional können Sie im Fenster für die Frameansicht auch eine CAP-Datei öffnen. Wenn Sie die Datensammlung beendet haben, klicken Sie im Menü Sammeln auf Beenden und Anzeigen, um das Fenster für die Frameansicht anzuzeigen. Klicken Sie im Menü Anzeige auf Alle Namen suchen. Der Netzwerkmonitor verarbeitet die Frames und fügt sie der Adressdatenbank hinzu. Schließen Sie das Fenster für die Frameansicht, und öffnen Sie das Fenster Sammeln. Klicken Sie im Menü Sammeln auf Filter, um das Dialogfeld Sammlungsfilter anzuzeigen. Doppelklicken Sie im Dialogfeld Sammlungsfilter auf Adresspaare. Alternativ können Sie im Dialogfeld Hinzufügen auf Adresse klicken. Die von Ihnen erstellte Adressdatenbank wird vom Netzwerkmonitor angezeigt. Sie können die in der Datenbank gespeicherten Namen verwenden, um Adresspaare für den Sammlungsfilter zu bestimmen. Kapitel 3: „Behandeln von Leistungsproblemen“ 49 So überwachen Sie den Datenverkehr zwischen zwei Computern 1. Klicken Sie im Menü Sammeln auf Filter, um das Dialogfeld Sammlungsfilter anzuzeigen. 2. Doppelklicken Sie auf ANY<->ANY, um das Dialogfeld Adressausdruck anzuzeigen. 3. Wählen Sie im linken Fenster des Dialogfelds Adressausdruck die Adresse eines Computers. 4. Wählen Sie nun im rechten Fenster des Dialogfelds Adressausdruck die Adresse eines Computers. 5. Wählen Sie unter Richtung eines der beiden Symbole: 6. Wählen Sie das Symbol <-->, um den Datenverkehr zu überwachen, der zwischen einer der beiden von Ihnen ausgewählten Adressen in beliebiger Richtung verläuft. 7. Wählen Sie das Symbol -->, um nur den Datenverkehr zu überwachen, der von der im linken Fenster ausgewählten Adresse zur der im rechten Fenster ausgewählten Adresse verläuft. 8. Wählen Sie das Symbol <--, um nur den Datenverkehr zu überwachen, der von der im rechten Fenster ausgewählten Adresse zur der im linken Fenster ausgewählten Adresse verläuft. 9. Klicken Sie auf OK. 10. Klicken Sie im Dialogfeld Sammlungsfilter auf OK. 11. Klicken Sie im Menü Sammeln auf Starten. Ablaufverfolgung in einer WAN-Umgebung Für die Behebung von Netzwerkproblemen müssen Sie ggf. eine Sammlungsdatei für den Netzwerkverkehr zwischen zwei bestimmten Computern erstellen, die durch einen oder mehrere Router voneinander getrennt sind. In diesem Fall empfiehlt es sich, den gesamten Netzwerkverkehr zwischen dem ersten Computer und seinem nächsten Router sowie den gesamten Netzwerkverkehr zwischen dem zweiten Computer und seinem nächstliegenden Router zu analysieren. In den meisten Fällen wird diese Analyse durchgeführt, um zu überprüfen, ob Netzwerkpakete zwischen den Routern beschädigt wurden oder verloren gegangen sind. Damit die Ablaufverfolgungen konsistent sind und Sie diese gleichzeitig lesen können, müssen die Systemzeiten zwischen den beiden Computern synchronisiert werden, bevor Sie die Ablaufverfolgung starten. 50 Kapitel 3: „Behandeln von Leistungsproblemen“ So synchronisieren Sie die Systemzeiten zweier Computer 1. Geben Sie bei dem Computer, den Sie synchronisieren wollen, an der Eingabeaufforderung net time \\ComputerName /set /yes ein, wobei ComputerName der Name des Computers ist, mit dem synchronisiert werden soll. 2. Stellen Sie sicher, dass die Computer dieselben Systemzeiten haben. Geben Sie dazu für jeden Computer an der Eingabeaufforderung TIME ein. 3. Fahren Sie mit der Ablaufverfolgung fort. Messen von Nicht-MAPI-Anforderungen Genauso wie Sie die RCP-Indikatoren verwendet haben, um zu überprüfen, wie der Informationsspeicher von MAPI-Clients wie z. B. Outlook verwendet wird, können Sie nun einen anderen Leistungsindikatorensatz für Warteschlangen verwenden, um zu überprüfen, wie der Exchange-Informationsspeicher durch Post Office Protocol 3 (POP3), Internet Message Access Protocol, Version 4, Revision 1 (IMAP4), SMTP, Distributed Authoring und Versioning (DAV) und Network News Transfer Protocol (NNTP)-Clients verwendet wird. Diese Indikatoren sind im Epoxy-Leistungsobjekt enthalten. Dabei handelt es sich um Warteschlangen, in denen Daten aus IIS (Internet Information Services) an den Exchange-Informationsspeicher gesendet werden und dann aus dem Exchange-Speicher wieder an IIS zurückgegeben werden. Zu diesen Warteschlangenindikatoren gehören: Epoxy(protocol)\Warteschlangenlänge ab Client Epoxy(protocol)\Warteschlangenlänge ab Informationsspeicher Der Indikator für Epoxy(protocol)\Client Out Que Len zeigt die Anzahl der Bearbeitungsanfragen durch den Exchange-Informationsspeicher in der Warteschlange, während der Indikator für Epoxy(protocol)\Store Out Que Len die Anzahl der Anfragen zur Weiterbearbeitung durch die IIS-Protokollhandler anzeigt. Mit Hilfe dieser Indikatoren können Sie untersuchen, welche Daten erfolgreich zwischen IIS und dem Exchange-Informationsspeicher ausgetauscht werden. Kapitel 3: „Behandeln von Leistungsproblemen“ 51 Leistungsindikatoren für die Nachrichtenzustellung Der Exchange-Informationsspeicher reagiert vorzugsweise auf Benutzeranfragen und erst dann auf Nachrichtenzustellung. Wenn Ihre Server beginnen, Warteschlangen für zu versendende Nachrichten zu erstellen, führt dies zu Überbuchungsproblemen. Es werden in so hoher Frequenz Benutzeranfragen empfangen, dass der Server die E-Mails nicht mehr effizient verarbeiten kann. Überwachen Sie die Nachrichtenzustellung mit Hilfe der folgenden Indikatoren: SMTP-Server\Lokale Warteschlangenlänge SMTP-Server\Übermittelte Nachrichten/Sek. Der Indikator für SMTP Server\Local Queue Length darf nicht kontinuierlich ansteigen. Dieser Indikator steigt während Spitzenlastenzeiten an, wobei Warteschlangenlängen von 0 bis 1000 unbedenklich sind. Der Indikator für SMTP Server\Übermittelte Nachrichten/Sek. sollte kontinuierlich ansteigen. Lücken ohne jegliche Nachrichtenzustellung, auf die Phasen mit besonders hohen Nachrichtenzustellungswerten folgen, weisen auf Engpässe hin. Anhang A Leistungsindikatoren Im folgenden Abschnitt werden zusätzliche Leistungsindikatoren beschrieben, die zur Überwachung der Funktionstüchtigkeit Ihrer Exchange 2000-Server oder zur Ermittlung der durchschnittlichen Serverleistung verwendet werden können. Die Indikatoren sind je nach Leistungsobjektbereich aufgeführt. Bei der Untersuchung eines Leistungsproblems können Sie diese Indikatoren verwenden, um weitere Informationen zu sammeln oder um diese der Minimalliste hinzuzufügen, die zur Ermittlung der durchschnittlichen Serverleistung verwendet werden soll. Hinweis Einige der Indikatoren zeigen keine empfohlenen Werte an, da es sich um spezifische Werte Ihrer Organisation handelt oder diese Indikatoren lediglich Zusatzinformationen liefern. 56 Anhang Datenbankindikatoren Im folgenden Abschnitt sind Leistungsindikatoren für Datenbanken (ExchangeInformationsspeicher) aufgeführt. Diese Indikatoren werden mit Hilfe der Informationsspeicherinstanz überwacht. Tabelle 4 Datenbankindikatoren (Exchange-Informationsspeicher) Indikator Beschreibung Empfohlener Wert Cachegröße der Datenbank Größe des Systemspeichers, der von der Cacheverwaltung zur Speicherung häufig verwendeter Informationen aus Datenbankdateien verwendet wird, ohne dass Dateioperationen durchgeführt werden müssen. Wenn die Größe des Datenbankcache für eine optimale Leistung zu klein und der verfügbare Arbeitsspeicher nicht groß genug ist (siehe Indikator für Arbeitsspeicher/Verfügbare Bytes), kann das Hinzufügen von Arbeitsspeicher die Leistungsfähigkeit steigern. Wenn genügend Arbeitsspeicher zur Verfügung steht und die Größe des Datenbankcache nicht über einen bestimmten Wert ansteigt, kann die Cachegröße auf niedrigem Niveau begrenzt werden. Durch das Erhöhen dieses Wertes kann die Systemleistung gesteigert werden. Dieser Indikator kann standardmäßig bis zu 900 MB groß werden. Überwachen Sie diesen Indikator, und stellen Sie sicher, dass dieser den Wert 900 MB nicht übersteigt. Protokoll Datensatzverzögerungen/ Sek. Dieser Indikator sollte stets null anzeigen. Anzahl der Protokolldatensätze, die den Protokollpuffern pro Sekunde nicht hinzugefügt werden können, da diese voll sind. Wenn der vom Indikator angezeigte Wert nicht stets null ist, ist die Protokollpuffergröße unter Umständen der Engpass. Anhang Tabelle 4 Datenbankindikatoren (Exchange-Informationsspeicher) (Fortsetzung) Indikator Beschreibung Empfohlener Wert Protokollschreiboperationen/Sek. Häufigkeit, mit der die Protokollpuffer pro Sekunde in die Protokolldateien geschriebenen werden. Wenn sich die Schreibrate dem maximalen Wert für das Medium nähert, in dem die Protokolldateien enthalten sind, kann dies ein Hinweis dafür sein, dass das Protokoll einen Engpass darstellt. Dieser Indikator sollte einen Wert anzeigen, der unterhalb der Schreibrate für das Medium liegt, in dem die Protokolldateien enthalten sind. Tabelle öffnen/Sek. Anzahl der pro Sekunde geöffneten Datenbanktabellen. Dieser Indikator eignet sich gut, um festzustellen, wie ausgelastet JET ist. Epoxy-Indikatoren Im folgenden Abschnitt sind Epoxy-Leistungsindikatoren aufgeführt. Tabelle 5 Epoxy-Indikatoren Indikator Beschreibung Empfohlener Wert Wartenschlangenlänge ab Client Anzahl der Anfragen in der Warteschlange zur Bearbeitung durch den ExchangeInformationsspeicher. Dieser Indikator sollte null anzeigen. Wartenschlangenlänge ab Informationsspeicher Anzahl der Anfragen in der Warteschlange für den Empfang durch IISProtokollhandler. Dieser Indikator sollte null anzeigen. 57 58 Anhang Indikatoren für logische Datenträger Im folgenden Abschnitt sind Leistungsindikatoren für logische Datenträger aufgeführt. Tabelle 6 Indikatoren für logische Datenträger Indikator Beschreibung Empfohlener Wert Zeit Datenträger (%) Prozentanteil der Der Wert dieses Indikators verstrichenen Zeit, die das sollte unter 90 Prozent ausgewählte Laufwerk mit liegen. dem Bearbeiten von Leseund Schreibanforderungen beschäftigt ist. Ein ständiger Wert über 90 Prozent deutet auf einen Leistungsengpass des Festplattenlaufwerks hin. Freier Speicherplatz (%) Das Verhältnis vom auf dem logischen Laufwerk verfügbaren freien Speicherplatz zum gesamten nutzbaren Speicherplatz auf dem gewählten logischen Laufwerk. Der empfohlene Schwellenwert für freien Speicherplatz liegt bei 15 Prozent. Dieser Indikator sollte stets über 15 Prozent anzeigen. Durchschn. Warteschlangenlänge des Datenträgers Durchschnittliche Anzahl der Lese- und Schreibanforderungen, die für den gewählten Datenträger während des Abtastintervalls in der Warteschlange aufgenommen wurden. Dieser Indikator sollte bei normalen Betriebsbedingungen unter dem Wert 2 liegen. Mittlere Sek./Lesevorgänge Durchschnittliche Dauer in Sekunden für das Lesen von Daten vom Datenträger. Dieser Indikator sollte einen Wert anzeigen, der unterhalb der Leserate liegt, die vom Hersteller für den Datenträger angegeben ist. Mittlere Sek./Schreibvorgänge Durchschnittliche Dauer in Sekunden für das Schreiben von Daten auf den Datenträger. Dieser Indikator sollte einen Wert anzeigen, der unterhalb der Schreibrate liegt, die vom Hersteller für den Datenträger angegeben ist. Mittlere Sek./Übertragung Die Dauer in Sekunden für eine durchschnittliche Datenträgerübertragung. Dieser Indikator sollte stets unterhalb der Übertragungsrate liegen, die für den Datenträger angegeben ist. Anhang Tabelle 6 Indikatoren für logische Datenträger (Fortsetzung) Indikator Beschreibung Aktuelle Warte- Die Interpretation dieses Indikators schlangenlänge richtet sich nach der Funktion des überwachten logischen Datenträgers. Auf den meisten Servern, auf denen Exchange ausgeführt wird, stehen zwei logische Datenträger zur Verfügung: einer für die Datenbanken und ein weiterer für die Transaktionsprotokolle. Der Indikator für die aktuelle Warteschlangenlänge muss auf den jeweiligen Datenträger bezogen interpretiert werden. Die Datenbank kann alle 30 Sekunden mit einem Spitzenwert an Schreibvorgängen belastet werden, wobei das Maximum bei 64 Schreibvorgängen liegt. Zwischen zwei solchen Spitzenzeiten werden von der E/A nur Lesevorgänge durchgeführt. Solche Spitzenzeiten liegen über der zulässigen Warteschlangenlänge, die in der Regel die Anzahl der Spindeln dividiert durch 2 (alle dreißig Sekunden) beträgt. Wenn die Warteschlangenlänge zwischen den Spitzenzeiten größer als die Hälfte der Spindelanzahl ist, deutet dies darauf hin, dass zu wenige E/As für Lesevorgänge zur Verfügung stehen, und weitere Spindeln hinzugefügt werden müssen. Um die Dauer solcher Spitzenzeiten mit maximalen Warteschlangenlängen zu verringern, müssen Sie eine Speicherung (Zurückschreiben) durchführen, die Anzahl der Spindeln erhöhen und ggf. von RAID-5 auf RAID-0+1 umstellen, falls sich der RAID-Gruppencontroller als zu schwach erweist. Die Warteschlange eines Transaktionsprotokolls darf den Wert 1 nicht übersteigen, da die E/A-Vorgänge synchron und im Single-Thread-Modus verlaufen. Auch wenn die Warteschlangenlänge den Wert kleiner oder gleich 1 hat, kann es ggf. zu Leistungsproblemen der Festplatte kommen. Die Warteschlangenlänge überschreitet bei Standardoperationen nie den Wert 1 (dies gilt nicht für das Erstellen von Sicherungskopien). Wenn ein Leistungsproblem bezüglich der Protokollgröße festgestellt wird, müssen Sie eine Speicherung (Zurückschreiben) durchführen. Empfohlener Wert Dieser Indikator sollte bei Exchange-Datenbanken stets unterhalb der Anzahl der Spindeln geteilt durch 2 bzw. für Transaktionsprotokolldatent räger unterhalb 1 liegen. 59 60 Anhang Tabelle 6 Indikatoren für logische Datenträger (Fortsetzung) Indikator Beschreibung Empfohlener Wert MB frei Auf dem Laufwerk nicht zugeordneter Speicherplatz (in MB). Warnungen müssen auf den Laufwerken konfiguriert sein, die ExchangeDatenbanken oder Protokolldateien enthalten, durch die Sie benachrichtigt werden, sobald sie sich der Kapazitätsgrenze nähern. Exchange wird beendet, sobald die Protokolldateien bzw. die Datenbanken keinen Speicherplatz mehr haben und nicht mehr größer werden können. Indikatoren für den Arbeitsspeicher Im folgenden Abschnitt sind Leistungsindikatoren für den Arbeitsspeicher aufgeführt. Tabelle 7 Indikatoren für den Arbeitsspeicher Indikator Beschreibung Empfohlener Wert Verfügbare Bytes Größe des physikalischen Speichers, der für Prozesse auf dem Computer zur Verfügung steht (in Byte). Dieser Indikator sollte stets einen Wert von über 4000 KB anzeigen. Zugesicherte Bytes Die Größe des virtuellen Speichers (in Byte), der zugesichert ist (im Gegensatz zu einem nur reservierten Speicher). Der zugesicherte Speicher muss über einen Sicherungsspeicher (Laufwerk) verfügen, oder es muss sichergestellt sein, dass kein weiterer Speicherplatz notwendig ist (da der Hauptspeicher groß genug ist). Dies ist ein unmittelbarer Indikator, kein Durchschnitt über ein Zeitintervall. Der zulässige Durchschnittswert muss kleiner sein als der physikalische Arbeitsspeicher des Servers. Allerdings sollten Sie zur Sicherheit die Indikatoren für Speicher\Seiten/Sek. und für Speicher\Seitenfehler/Sek. überprüfen. Wenn der Indikator für Speicher\Seiten/Sek. größer als 10 (10 ist ein geeigneter Leitwert, variiert jedoch je nach Laufwerktyp) und der Wert für Speicher\Seitenfehler/Sek. größer als der Wert für Speicher\Cachefehler/Sek. ist, ist der Umfang der Auslagerung zu groß Dieser Indikator sollte stets einen Wert anzeigen, der kleiner ist als der physikalische Arbeitsspeicher des Servers. Anhang Tabelle 7 Indikatoren für den Arbeitsspeicher (Fortsetzung) Indikator Beschreibung Empfohlener Wert Seitenfehler/ Sek. Gesamtrate, mit der Seitenfehler vom Prozessor verarbeitet werden. Ein Seitenfehler tritt auf, wenn für einen Prozess Code oder Daten erforderlich sind, die sich nicht in seiner Arbeitsseite befinden (fehlerhafte Seite befindet sich im physikalischen Speicher). Dieser Indikator zeigt sowohl Hardwarefehler (für die Zugriff auf den Datenträger erforderlich ist) als auch Softwarefehler an (die fehlerhafte Seite befindet sich im physikalischen Speicher). Die meisten Prozessoren können eine große Anzahl von Softwarefehlern problemlos verarbeiten. Hardwarefehler können jedoch wesentliche Verzögerungen verursachen. Dieser Indikator darf nie einen konstant hohen einstelligen Wert anzeigen. Seiten/Sek. Anzahl der Seiten, die gelesen oder auf den Datenträger geschrieben wurden, um Hardwareseitenfehler zu beheben. (Hardwareseitenfehler treten auf, wenn für einen Prozess Code oder Daten erforderlich sind, die sich nicht in der entsprechenden Arbeitsseite oder anderswo im physikalischen Speicher befinden. Der Code oder die Daten müssen dann vom Datenträger abgerufen werden). Dieser Indikator ist eine primäre Anzeige der Fehler, die Verzögerungen im System verursachen. Dabei handelt es sich um die Summe der Indikatoren Speicher\Seiteneingabe/Sek. und Speicher\Seitenausgabe/Sek. Hierbei wird die Anzahl der Seiten angegeben, so dass diese mit anderen Seitenindikatoren wie z. B. dem Indikator Speicher\Seitenfehler/Sek. verglichen werden kann, ohne dass eine Konvertierung notwendig ist. Der Indikator enthält die zum Beheben von Fehlern im Datencache abgerufenen Seiten (in der Regel für Anwendungen erforderlich). Dieser Indikator sollte stets kleiner als 20 sein. Eine idealer Wert liegt bei 5 Seiten/Sek. Sobald dieser Wert sich bei einem Durchschnittswert von 10 oder höher einpendelt, deutet dies auf eine erhebliche Leistungsverringerung und ggf. auf einen Datenträgerfehler hin. NichtAuslagerungsseiten (in Byte) Die Anzahl der Bytes im NichtAuslagerungsspeicher, einem Bereich im Systemspeicher für Objekte, die nicht auf den Datenträger geschrieben werden können (physikalischer Speicher wird vom Betriebssystem verwendet), aber über die gesamte Zuordnungsdauer im physikalischen Speicher verbleiben müssen. Dieser Indikator darf nicht schwanken. Wenn dieser Indikator stetig ansteigt, überprüfen Sie, ob ein Speicherverlust vorliegt. 61 62 Anhang Tabelle 7 Indikatoren für den Arbeitsspeicher (Fortsetzung) Indikator Beschreibung Empfohlener Wert Auslagerungsseiten (Bytes) Die Anzahl der Bytes im Auslagerungsspeicher; einem Bereich im Systemspeicher (vom Betriebssystem verwendeter physikalischer Speicher) für Objekte, die auf den Datenträger geschrieben werden können, wenn sie nicht verwendet werden. Dieser Indikator steigt in der Regel bei einer physikalischen Speichergröße von 1024 MB auf dem Server nicht über 196 MB, wenn er über einen /3GBSchaltersatz verfügt (270 MB ohne /3GBSchalter). Wenn dieser Indikator nicht weiter ansteigt, kann dies dazu führen, dass der Server nicht mehr reagiert. Falls dieser Wert ansteigt, kann dies auf Fehler bei Zugriffsnummern (überprüfen Sie dazu die Indikatoren für Zugriffsstatus) oder eine wachsende SMTPWarteschlange hindeuten. Indikatoren für MSExchangeIS Im folgenden Abschnitt sind MSExchangeIS-Leistungsindikatoren aufgeführt. Tabelle 8 MSExchangeIS-Indikatoren Indikator Beschreibung Empfohlener Wert Anzahl aktive Verbindungen Anzahl der Verbindungen zum ExchangeInformationsspeicher, die innerhalb der letzten zehn Minuten aktiv waren. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Anzahl aktive Benutzer Anzahl der Benutzerverbindungen, die innerhalb der letzten zehn Minuten aktiv waren. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Anzahl Verbindungen Anzahl der Clientprozesse, die mit dem ExchangeInformationsspeicher verbunden sind. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Anhang Tabelle 8 MSExchangeIS-Leistungsindikatoren (Fortsetzung) Indikator Beschreibung Empfohlener Wert RPC Durchschn. Verzögerung/Sek. Durchschnittliche RPCVerzögerung in Millisekunden für die letzten 1024 Pakete. Dieser Indikator sollte bei Standardoperationen stets einen Wert zwischen 10 und 20 Millisekunden anzeigen. RPC-Operationen/Sek. Rate, mit der RPCOperationen erfolgen. Dieser Indikator zeigt die Anzahl der noch anstehenden RPCAnfragen an. Wenn Outlook Benutzer benachrichtigt, zeigt dieser Indikator in der Regel signifikante Spitzen an. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. In der Regel sollte der Wert auf einem Computer mit 4 Prozessoren bei Standardoperationen stets 0 sein. RPC-Anfragen Anzahl von Clientanfragen, Dieser Indikator sollte nicht die aktuell vom Exchange- höher sein als 100. Informationsspeicher ausgeführt werden. Anzahl Benutzer Aktuelle Anzahl der Benutzer (nicht Verbindungen), die gerade den ExchangeInformationsspeicher nutzen. Die Leistungsüberprüfung und Interpretation dieses Indikators muss stets im Zusammenhang mit der aktuellen Anzahl der Benutzer gesehen werden. Warteschlangenlänge Virenüberprüfung Aktuelle Anzahl Der Wert dieses Indikators ausstehender Anfragen, die ist von Ihrer Organisation auf eine Virenüberprüfung abhängig. warten. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. 63 64 Anhang Tabelle 8 MSExchangeIS-Leistungsindikatoren (Fortsetzung) Indikator Beschreibung Empfohlener Wert Virtueller Speicher: größter freier Block Größe des größten freien Dieser Indikator sollte stets über 32 MB liegen. Blocks des virtuellen Speichers (in Byte). Dieser Indikator zeigt durch eine fallende Linie an, dass virtueller Speicher belegt wird. Wenn dieser Indikator niedriger als 32 MB ist, wird durch Exchange 2000 im Ereignisprotokoll eine Warnung protokolliert (Ereignis-ID=9582). Es wird ein Fehler protokolliert, wenn dieser Wert unter 16 MB fällt. Virtueller Speicher: gesamt Gesamtzahl freier virtueller Dieser Indikator sollte stets frei über 16 MB Speicherblöcke, die größer mehr als drei 16-MB-Blöcke anzeigen. sind als 16 MB oder die genau 16 MB groß sind. Bei der Überwachung dieses Indikators bildet die Linie die Form einer Pyramide. Diese Linie beginnt mit der Abbildung eines virtuellen Speicherblocks, der größer ist als 16 MB, und fährt mit den kleineren, über 16 MB liegenden Speicherblöcken fort. Durch die Überwachung des Verlaufs dieses Indikators lässt sich vorhersagen, wann die Anzahl der 16-MBSpeicherblöcke ungefähr unter die Zahl 3 fallen wird. Tritt dieser Fall ein, ist der Neustart aller Dienste auf dem Knoten empfehlenswert. Anhang Tabelle 8 MSExchangeIS-Leistungsindikatoren (Fortsetzung) Indikator Beschreibung Empfohlener Wert Virtueller Speicher: freie Blöcke gesamt Gesamtzahl freier virtueller Der Wert dieses Indikators Speicherblöcke, ist von Ihrer Organisation abhängig. unabhängig von der Speichergröße. Bei der Überwachung dieses Indikators bildet die Linie die Form einer Pyramide. Mit Hilfe dieses Indikators können Sie feststellen, wie hoch der Grad der Fragmentierung des verfügbaren virtuellen Speichers ist. Die durchschnittliche Speicherblockgröße ergibt sich aus der Instanz Prozess\Virtuelle Bytes\STORE.EXE dividiert durch MSExchangeIS\ Virtueller Speicher: freie Blöcke gesamt. Virtueller Speicher: freie Größe (in Byte) aller freien Dieser Indikator sollte stets Blöcke über 16 MB gesamt virtuellen Speicherblöcke, über 50 MB liegen. die größer sind als 16 MB bzw. genau 16 MB groß sind. Dieses Linie zeigt nach unten, wenn Speicherplatz belegt wird. Durch diesen Indikator lässt sich die Speicherfragmentierung überwachen. 65 66 Anhang Indikatoren für das MSExchangeIS-Postfach Im folgenden Abschnitt sind die Leistungsindikatoren für das MSExchangeIS-Postfach aufgeführt. Tabelle 9 Indikatoren für das MSExchangeIS-Postfach Indikator Beschreibung Empfohlener Wert Aktive Clients Anzahl der Clients, die innerhalb Der Wert dieses Indikators der letzten zehn Minuten eine ist von Ihrer Organisation abhängig. beliebige Aktion ausgeführt haben. Durchschnittliche Übermittlungszeit Durchschnittliche Zeit zwischen der Übermittlung einer Nachricht an den Postfachspeicher und die Übergabe an andere Speicherdienstanbieter für die letzten zehn Nachrichten. Ermitteln Sie anhand dieses Indikators die Verzögerungszeit, wenn die Serverbelastung gering ist. Ein hoher Wert kann darauf hinweisen, dass ein Leistungsproblem beim Message Transfer Agent (MTA)-Dienst vorliegt. Durchschnittliche Zeit für die lokale Übermittlung Durchschnittliche Zeit, die die letzten zehn Nachrichten für die Übermittlung in den Postfachspeicher bis zum Empfang durch alle lokalen Empfänger (Empfänger auf dem gleichen Server) benötigt haben. Ermitteln Sie anhand dieses Indikators die Verzögerungszeit, wenn die Serverbelastung gering ist. Ein hoher Wert weist ggf. auf ein Leistungsproblem des Postfachspeichers hin. Dieser Indikator darf nie für mehrere Sekunden einen Wert anzeigen, der ungleich null ist. Nachrichtenöffnungen/ Rate, mit der Anfragen zum Sek. Öffnen von Nachrichten an den Exchange-Speicher übergeben werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Größe Empfangswarteschlange Anzahl der Nachrichten in der Empfangswarteschlange des Postfachspeichers. Dieser Indikator sollte bei Standardoperationen stets null anzeigen. Größe der Sendewarteschlange Anzahl der Nachrichten in der Sendewarteschlange des Postfachspeichers. Dieser Indikator sollte bei Standardoperationen stets null anzeigen. Lokale Übermittlungsrate Rate, mit der Nachrichten lokal übermittelt werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Anhang 67 Indikatoren für die öffentlichen Ordner von MSExchangeIS Im folgenden Abschnitt sind die Leistungsindikatoren für die öffentlichen Ordner von MSExchangeIS aufgeführt. Tabelle 10 Indikatoren für die öffentlichen Ordner von MSExchangeIS Indikator Beschreibung Empfohlener Wert Durchschnittliche Übermittlungszeit Durchschnittliche Zeit zwischen der Übermittlung einer Nachricht an den öffentlichen Informationsspeicher und der Übergabe an andere Speicherdienstanbieter für die letzten zehn Nachrichten. Ermitteln Sie anhand dieses Indikators die Verzögerungszeit, wenn die Serverbelastung gering ist. Ein hoher Wert weist ggf. auf ein Leistungsproblem des MTA hin. Durchschnittliche Zeit für die lokale Übermittlung Durchschnittliche Zeit, die die letzten zehn Nachrichten von der Übermittlung in den öffentlichen Informationsspeicher bis zum Empfang durch alle lokalen Empfänger (Empfänger auf dem gleichen Server) benötigt haben. Ermitteln Sie anhand dieses Indikators die Verzögerungszeit, wenn die Serverbelastung gering ist. Ein hoher Wert weist ggf. auf ein Leistungsproblem des öffentlichen Informationsspeichers hin. Dieser Indikator darf nie für mehrere Sekunden einen Wert anzeigen, der ungleich null ist. Ordneranfragen/Sek. Rate, mit der Anfragen Der Wert dieses Indikators zum Öffnen von Ordnern ist von Ihrer Organisation an den Exchange-Speicher abhängig. übergeben werden. Nachrichtenanfragen/Sek. Rate, mit der Anfragen zum Öffnen von Nachrichten an den Exchange-Speicher übergeben werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Größe Empfangswarteschlange Anzahl der Nachrichten in der Empfangswarteschlange des öffentlichen Informationsspeichers. Dieser Indikator sollte bei Standardoperationen stets null anzeigen. Größe der Sendewarteschlange Anzahl der Nachrichten in der Sendewarteschlange des öffentlichen Informationsspeichers. Dieser Indikator sollte bei Standardoperationen stets null anzeigen. 68 Anhang Indikatoren für die Netzwerkschnittstelle Im folgenden Abschnitt sind Leistungsindikatoren für die Netzwerkschnittstelle aufgeführt. Diese Indikatoren werden anhand sämtlicher Instanzen überwacht. Tabelle 11 Indikatoren für die Netzwerkschnittstelle Indikator Beschreibung Empfohlener Wert Empfangene Bytes/Sek. Die Rate, mit der Bytes über die Schnittstelle empfangen werden (einschließlich Rahmenzeichen). Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Gesendete Bytes/Sek. Die Rate, mit der Bytes über die Schnittstelle gesendet werden (einschließlich Rahmenzeichen). Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Gesamtanzahl Bytes/Sek. Die Rate, mit der Bytes über die Schnittstelle gesendet und empfangen werden (einschließlich Rahmenzeichen). Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Ausgabewarteschlangenlänge Länge der Ausgabewarteschlange (in Paketen). Eine Warteschlangenlänge von 1 oder 2 ist unproblematisch. Längere Warteschlangen weisen darauf hin, dass der Adapter auf das Netzwerk wartet und mit dem Server zeitlich nicht abgestimmt ist. Dieser Indikator sollte stets einen Wert von weniger als 1 oder 2 anzeigen. Anhang Indikatoren für die Auslagerungsdatei Im folgenden Abschnitt sind Leistungsindikatoren für die Auslagerungsdatei aufgeführt. Tabelle 12 Indikatoren für die Auslagerungsdatei Indikator Beschreibung Empfohlener Wert Belegung (%) Angabe (in Prozent), wie Microsoft empfiehlt einen viel der Auslagerungsdatei Wert von unter 75 Prozent. während des Abtastintervalls verwendet wird. Ein hoher Wert deutet darauf hin, dass Sie die Auslagerungsdatei (Pagefile.sys) ggf. vergrößern oder mehr RAM hinzufügen müssen. Indikatoren für physikalische Datenträger Im folgenden Abschnitt sind Leistungsindikatoren für physikalische Datenträger aufgeführt. Tabelle 13 Indikatoren für physikalische Datenträger Indikator Beschreibung Empfohlener Wert Zeit (%) Prozentanteil der verstrichenen Zeit, die das ausgewählte Laufwerk mit dem Bearbeiten von Leseund Schreibanforderungen beschäftigt ist. Der Wert dieses Indikators sollte unter 50 Prozent liegen. Mittlere Sek./Lesevorgänge Durchschnittliche Dauer in Sekunden für das Lesen von Daten vom Datenträger. Stellen Sie sicher, dass diese Rate nicht höher ist als die spezifizierte Übertragungsrate Ihrer Festplatten. Einige SCSILaufwerke (small computer system interface) können 50 bis 70 E/A-Vorgänge pro Sekunde verarbeiten. Dieser Indikator sollte Werte anzeigen, die unter den Herstellerangaben liegen. Ein allgemeiner Schwellenwert ist 20 Millisekunden oder geringer. 69 70 Anhang Tabelle 13 Indikatoren für physikalische Datenträger (Fortsetzung) Indikator Beschreibung Empfohlener Wert Mittlere Sek./Übertragung Datenübertragungsgeschwi ndigkeit (in Sekunden). Ein hoher Wert zeigt ggf. an, dass das System wegen zu langer Warteschlangen Anforderungen erneut sendet. In seltenen Fällen kann es sich auch um einen Datenträgerfehler handeln. Mit Hilfe dieses Indikators lassen sich signifikante Abweichungen von den Daten der durchschnittlichen Serverleistung feststellen. Mittlere Sek./Schreibvorgänge Durchschnittliche Dauer in Sekunden für das Schreiben von Daten auf den Datenträger. Stellen Sie sicher, dass diese Rate nicht höher ist als die spezifizierte Schreibrate Ihrer Festplatten. Einige SCSI-Laufwerke können 50 bis 70 E/A-Vorgänge pro Sekunde verarbeiten. Dieser Indikator sollte Werte anzeigen, die unter den Herstellerspezifikationen liegen. Ein allgemeiner Schwellenwert ist 20 Millisekunden oder geringer. Aktuelle Warteschlangenlänge Weitere Informationen zu diesem Indikator finden Sie in der Zeile „Aktuelle Warteschlangenlänge“ in Tabelle 6 „Indikatoren für logische Datenträger“. Kein. Datenträgerübertragungen/ Anzahl der Der Wert dieses Indikators Sek. abgeschlossenen Lesesollte unter 50 Prozent liegen. und Schreibvorgänge pro Sekunde. Der Zähler misst die Verwendung des Datenträgers und drückt dies als Prozentsatz aus. Werte über 50 Prozent können anzeigen, dass der Datenträger einen Engpass darstellt. Anhang Prozessindikatoren Im folgenden Abschnitt sind Prozessindikatoren aufgeführt. Wählen Sie verschiedene Exchange-Prozesse aus, die Sie als Instanzen dieser Indikatoren überwachen möchten. Tabelle 14 Indikatoren für Prozessdatenträger Indikator Beschreibung Empfohlener Wert Prozessorzeit (%) Prozentwert der Prozessorzeit zum Ausführen eines Threads, der sich nicht im Leerlauf befindet. Mit diesem Indikator kann der Prozentwert für die Verwendung des Prozessors durch den Exchange-Dienst überwacht werden. Ein durchschnittlicher Wert unter 20 Prozent zeigt an, dass der Server nicht verwendet wird oder die Dienste nicht aktiv sind. Ein durchschnittlicher Wert, der beständig über 75 bis 80 Prozent liegt, zeigt an, dass der Server überlastet ist. Benutzerzeit (%) Prozentwert der verstrichenen Zeit, die Prozessthreads benötigt haben, um Code im Benutzermodus auszuführen. Die Ausführung von Code im Benutzermodus kann die Integrität von Windows NT® Executive, Kernel und Gerätetreibern nicht beeinträchtigen. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Verstrichene Zeit Gesamte Dauer (in Der Wert dieses Indikators Sekunden), die ein Prozess ist von Ihrer Organisation bereits läuft. Durch diesen abhängig. Indikator lässt sich schnell und ohne Überprüfung des Ereignisprotokolls feststellen, ob ein Server oder ein Dienst vor kurzer Zeit neu gestartet wurde. Ein Nullwert zeigt einen nicht aktiven Prozess an. Handleanzahl Gesamtzahl der von diesem Prozess aktuell geöffneten Handles. Die Anzahl ist die Summe der Handles, die von allen Threads in diesem Prozess geöffnet sind. Die Anzahl der von der Systemaufsicht, vom MTA, und dem ExchangeInformationsspeicher geöffneten Handles bleiben in der Regel relativ konstant. Die Zahl der Inetinfo-Handles kann bei der Bildung einer Warteschlange signifikant ansteigen. 71 72 Anhang Tabelle 14 Indikatoren für Prozessdatenträger (Fortsetzung) Indikator Beschreibung Empfohlener Wert Seitenfehler/Sek. Die Rate, mit der Seitenfehler in den Threads auftreten, die in diesem Prozess ausgeführt werden. Ein Seitenfehler tritt auf, wenn ein Thread auf eine virtuelle Speicherseite verweist, die sich nicht in seinen Arbeitsseiten im Hauptspeicher befindet. Ermitteln Sie mit Hilfe dieses Indikators Prozesse, die mehr virtuellen Speicher benötigen. Auslagerungsdatei (Byte) Die aktuelle Anzahl der Der Wert dieses Indikators Bytes, die dieser Prozess in ist von Ihrer Organisation abhängig. den Auslagerungsdateien verwendet hat. Auslagerungsdateien werden verwendet, um vom Prozess verwendete Speicherseiten zu speichern, die nicht in anderen Dateien enthalten sind. Auslagerungsdateien werden von allen Prozessen verwendet. Zu kleine Auslagerungsdateien können bewirken, dass die Speicherzuordnung für andere Prozesse unmöglich ist. Nicht-Auslagerungsseiten (Byte) Die Anzahl der Bytes im Der Wert dieses Indikators Nichtist von Ihrer Organisation abhängig. Auslagerungsspeicher, einem Bereich im Systemspeicher für Objekte, die nicht auf den Datenträger geschrieben werden können (physikalischer Speicher wird vom Betriebssystem verwendet), aber über die gesamte Zuordnungsdauer im physikalischen Speicher verbleiben müssen. Anhang Indikator Beschreibung Empfohlener Wert Private Bytes Die aktuelle Anzahl der vom Prozess reservierten Bytes, die nicht mit anderen Prozessen geteilt werden können. In der Regel bleibt die Anzahl der privaten Bytes der Systemaufsicht, des MTA und von Exchange konstant. Diese Regel gilt nicht, wenn Hintergrundaufgaben ausgeführt werden. Die Anzahl der privaten Bytes von Inetinfo kann bei der Bildung einer Warteschlange signifikant ansteigen. 73 74 Anhang Tabelle 14 Indikatoren für Prozessdatenträger (Fortsetzung) Indikator Beschreibung Empfohlener Wert Virtuelle Bytes Die aktuelle Größe des virtuellen Adressraums, den der Prozess verwendet, in Byte. Die Verwendung von virtuellem Adressraum bedeutet nicht unbedingt korrespondierende Verwendung von Datenträger- oder Arbeitsspeicherseiten. Virtueller Speicherplatz ist begrenzt, wenn zu viel belegt wird, können möglicherweise weniger Bibliotheken geladen werden. Die Anzahl virtueller Bytes muss während der Prozessausführungen konstant bleiben. Virtuelle Bytes spielen eine zentrale Rolle für Prozesse des ExchangeInformationsspeichers, dem ein virtueller Adressraum von nur 2 oder 3 GB Größe zur Verfügung steht (mit oder ohne /3GB-Schalter). Auf einem großen Server mit /3GB-Schalter sollte dieser Indikator einen Wert unter 2,8 GB anzeigen. Jedem Prozess, der auf einem Windows 2000Server ausgeführt wird, steht ein virtueller Speicher von 2 GB zur Verfügung. Falls der virtuelle Speicher des ExchangeInformationsspeichers seine Speichergrenze erreicht, wird ggf. zu wenig Speicherplatz festgestellt. Anhang Indikator Beschreibung Empfohlener Wert Arbeitsseiten Die aktuelle Anzahl der Bytes in den Arbeitsseiten des Prozesses. Die Arbeitsseiten sind ein Satz von Speicherseiten, die vor kurzem von den Threads eines Prozesses verwendet wurden. Wenn freier Speicher des Computers über einem Schwellenwert liegt, werden Speicherseiten in den Arbeitsseiten eines Prozesses belassen und zwar auch dann, wenn sie nicht verwendet werden. Wenn der freie Speicher unter einem Schwellenwert liegt, werden Seiten aus den Arbeitsseiten entfernt. Wenn diese Seiten benötigt werden, werden sie in die Arbeitsseiten zurückgeschrieben, bevor sie den Hauptspeicher verlassen. In der Regel bleibt die Anzahl der Arbeitsseiten der Systemaufsicht, des MTA und von Exchange konstant. Diese Regel gilt nicht, wenn Hintergrundaufgaben ausgeführt werden. Die Arbeitsseite von Inetinfo kann bei der Bildung einer Warteschlange signifikant größer werden. 75 76 Anhang Prozessorindikatoren Im folgenden Abschnitt sind Leistungsindikatoren für Prozessoren aufgeführt. Tabelle 15 Prozessorindikatoren Indikator Beschreibung Empfohlener Wert Privilegierte Zeit (%) Prozentwert der Dauer, Der Wert dieses Indikators während der sich der sollte unter 75 Prozent Prozessor im privilegierten liegen. Modus und nicht im Leerlauf befindet. Der Indikator für privilegierte Zeit zeigt auch die zum Bearbeiten von Interrupts erforderliche Zeit sowie Double-Byte-Zeichensätze an. Ein hoher Wert für privilegierte Zeit ist ggf. auf einen Geräteausfall zurückzuführen, der wiederum eine größere Anzahl von Interrupts verursacht. Dieser Indikator zeigt die durchschnittliche Aktivität als Prozentwert der Abtastzeit an. Prozessorzeit (%) Prozentwert der Prozessorzeit zum Ausführen eines Threads, der sich nicht im Leerlauf befindet. Mit diesem Indikator kann der Prozentwert für die Verwendung des Prozessors durch den Exchange-Dienst überwacht werden. Benutzerzeit (%) Prozentwert der Dauer, die Der Wert dieses Indikators sich ein Prozessor nicht im sollte unter 75 Prozent Leerlauf im Benutzermodus liegen. befindet. Ein durchschnittlicher Wert unter 20 Prozent zeigt an, dass der Server nicht verwendet wird oder die Dienste nicht aktiv sind. Ein durchschnittlicher Wert, der beständig über 75 bis 80 Prozent liegt, zeigt an, dass der Server überlastet ist. In diesem Fall sollten Benutzer auf einen anderen Server umgeleitet werden. Anhang Indikatoren für den Redirectordienst Im folgenden Abschnitt sind Leistungsindikatoren für den Redirectordienst aufgeführt. Tabelle 16 Indikatoren für den Redirectordienst Indikator Beschreibung Empfohlener Wert Gesamtanzahl Bytes/Sek. Rate, mit der der Redirectordienst Datenbytes verarbeitet. Solche verarbeiteten Daten sind zum Beispiel alle Anwendungs- und Dateidaten sowie Protokollinformationen (z. B. Paketheader). Vergleichen Sie den maximalen Datendurchsatz Ihrer Netzwerkkarte mit dem maximalen Wert dieses Indikators, um festzustellen, ob der Netzwerkverkehr in Ihrem System ein Engpass ist. Netzwerkfehler/Sek. Anzahl unerwarteter Dieser Indikator sollte stets null anzeigen. Fehlermeldungen, die der Redirectordienst empfängt. Wenn Sie Netzwerkprobleme vermuten, überprüfen Sie, ob dieser Wert über null liegt. Wenn dieser Wert über null liegt, überprüfen Sie das Ereignisprotokoll des Systems genau auf Angaben zu Netzwerkfehlern. Serverindikatoren Im folgenden Abschnitt sind Serverleistungsindikatoren aufgeführt. Tabelle 17 Serverindikatoren Indikator Beschreibung Empfohlener Wert Gesamtanzahl Bytes/Sek. Anzahl der Bytes, die der Server an das Netzwerk gesendet und vom Netzwerk empfangen hat. Dieser Wert gibt einen allgemeinen Hinweis, wie ausgelastet der Server ist. Falls dieser Indikator eine Bytezahl anzeigt, die etwa so hoch ist wie die maximale Übertragungsrate Ihres Netzwerks, müssen Sie Ihr Netzwerk ggf. segmentieren. Nicht-Auslagerungsseiten (Byte) Anzahl der Bytes nichtauslagerbaren Speichers, den der Server verwendet. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. 77 78 Anhang Tabelle 17 Serverindikatoren (Fortsetzung) Indikator Beschreibung Empfohlener Wert NichtAuslagerungsseitenfehler Häufigkeit fehlgeschlagener Der Wert dieses Indikators Zuweisungen aus dem ist von Ihrer Organisation abhängig. NichtAuslagerungsspeicher. Wenn dieser Wert hoch ist, ist entweder der Arbeitspeicher oder die Auslagerungsdatei zu klein (oder beides). Wenn dieser Wert konstant ansteigt, vergrößern Sie den physikalischen Arbeitsspeicher und die Auslagerungsdatei. Nicht genügend Arbeitselemente Angabe, wie häufig STATUS_DATA_NOT_AC CEPTED zur Empfangsanzeigezeit zurückgegeben wird. Dies tritt auf, wenn kein Arbeitselement verfügbar ist oder zum Verarbeiten der eingehenden Anforderung zugeordnet werden kann. Der Wert zeigt an, ob die Parameter „InitWorkItems“ oder „MaxWorkItems“ anders eingestellt werden sollten. Wenn der Wert sich dem empfohlenen Schwellenwert 3 nähert, passen Sie die Einträge „InitWorkItems“ oder „MaxWorkItems“ in der Registrierung an (unter HKEY_LOCAL_MACHINE\ SYSTEM\CurrentControlSe t\Services\lanmanserver\Pa rameters). Anhang Indikatoren für die Serverwarteschlange Im folgenden Abschnitt sind Leistungsindikatoren für die Serverwarteschlange aufgeführt. Tabelle 18 Indikatoren für die Serverwarteschlange Indikator Beschreibung Empfohlener Wert Aktive Threads Anzahl der Threads, die eine Anfrage Der Wert dieses des Server-Clients für diese CPU Indikators ist von Ihrer verarbeiten. Das System hält die Anzahl Organisation abhängig. möglichst gering, um unnötige Kontextumschaltungen zu vermeiden. Dies ist ein aktueller Wert für die CPU, nicht der Durchschnittswert über einen längeren Zeitraum. Gesendete Bytes/Sek. Rate, mit der der Server Bytes an die Netzwerkclients auf dieser CPU sendet. Dieser Wert zeigt an, wie ausgelastet der Server ist. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Länge der Warteschlange Aktuelle Länge der ServerWarteschlange für diese CPU. Eine andauernde Warteschlangenlänge über 4 weist ggf. auf eine Prozessorüberlastung hin. Die ist ein unmittelbarer Indikator. Sein Wert muss über mehrere Zeitintervalle beobachtet werden. Der Wert dieses Indikators sollte unter 4 liegen. Bytes gelesen/Sek. Geschwindigkeit, mit der der Server auf dieser CPU Daten aus Dateien für die Clients liest. Dieser Wert zeigt an, wie ausgelastet der Server ist. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Bytes Geschwindigkeit, mit der der Server auf geschrieben/Sek dieser CPU Daten in Dateien für die . Clients schreibt. Dieser Wert zeigt an, wie ausgelastet der Server ist. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Schreibvorgänge Geschwindigkeit, mit der der Server /Sek. Schreibvorgänge für die Clients auf dieser CPU ausführt. Dieser Wert zeigt an, wie ausgelastet der Server ist. Dieser Wert ist bei blockierten Warteschlangen immer null. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. 79 80 Anhang Indikatoren für den SMTP-Server Im folgenden Abschnitt sind Leistungsindikatoren für den SMTP-Server aufgeführt. Tabelle 19 Indikatoren für den SMTP-Server Indikator Beschreibung Empfohlener Wert Länge der Kategorisierungswarteschlange Angabe, wie gut LDAPDieser Indikator sollte stets Lookupvorgänge auf einen Wert von etwa null anzeigen. globalen Katalogservern durch SMTP verarbeitet werden. Dieser Wert sollte etwa bei null liegen, es sei denn, Sie erweitern gerade Verteilerlisten. In diesem Fall kann er ggf. abweichen. Dieser Indikator eignet sich ausgezeichnet, um festzustellen, wie funktionstüchtig Ihre globalen Kataloge sind. Wenn Ihre globalen Kataloge langsam sind, zeigt der Indikator einen hohen Wert an. Länge der lokalen Warteschlange Anzahl der Nachrichten in der lokalen SMTPWarteschlange. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Übermittelte Nachrichten/Sek. Rate, mit der Nachrichten an lokale Postfächer gesendet werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Empfangene Nachrichten/Sek. Rate, mit der Nachrichten empfangen werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Gesendete Nachrichten/Sek. Rate, mit der Nachrichten gesendet werden. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. Anhang Systemindikatoren Im folgenden Abschnitt sind System-Leistungsindikatoren aufgeführt. Tabelle 20 Systemindikatoren Indikator Beschreibung Empfohlener Wert ProzessorWarteschlangenlänge Anzahl der Threads in der Dieser Indikator sollte stets Prozessor-Warteschlange. Auch einen Wert von 2 oder geringer anzeigen. wenn mehrere Prozessoren vorhanden sind, wird eine einzelne Warteschlange für die Prozessorzeit verwendet. Dieser Indikator zählt nur abgeschlossene Threads, keine Threads, die aktuell ausgeführt werden. Der Wert sollte 2 oder niedriger betragen. Systembetriebszeit Gesamtzeit (in Sekunden), die der Computer seit dem letzten Starten in Betrieb war. Der Wert dieses Indikators ist von Ihrer Organisation abhängig. TCP-Indikatoren Im folgenden Abschnitt sind TCP-Leistungsindikatoren aufgeführt. Tabelle 21 TCP-Indikatoren Indikator Beschreibung Empfohlener Wert Segmente empfangen/Sek. Die Rate, mit der Segmente Ein niedriger Wert weist auf empfangen werden (einschließlich einen zu großen Broadcastverkehr hin. fehlerhaft empfangener Segmente). Dieser Indikator berücksichtigt Segmente, die auf aktuell eingerichteten Verbindungen empfangen werden. Ein niedriger Wert weist auf einen zu großen Broadcastverkehr hin. Erneut übertragene Segmente/Sek. Rate, mit der Segmente erneut übertragen werden, die ein oder mehrere bereits übertragene Bytes enthalten. Ein hoher Wert zeigt ggf. an, dass das Netzwerk überlastet ist oder ein Hardwareproblem vorliegt. Ein hoher Wert zeigt ggf. an, dass das Netzwerk überlastet ist oder ein Hardwareproblem vorliegt. 81 82 Anhang Threadindikatoren Im folgenden Abschnitt sind Thread-Leistungsindikatoren aufgeführt. Tabelle 22 Threadindikatoren Indikator Beschreibung Empfohlener Wert Prozessorzeit (%) Prozentanteil der verstrichenen Zeit, in der der Thread den Prozessor verwendet hat, um Anwendungen auszuführen. Achten Sie auf Threads, die viel Prozessorzeit benötigen. Threadkennung Die eindeutige Kennung dieses Threads. Threadkennungen werden wieder verwendet, so dass diese nur für die Lebensdauer des entsprechenden Threads gültig sind. Kein. Threadstatus Der aktuelle Status des Threads. Es gibt Kein. folgende Statusangaben: 0 = Initialisiert 1 = Bereit 2 = Wird ausgeführt 3 = Standby 4 = Abgebrochen 5 = Wartend 6 = Übergang 7 = Unbekannt Ein Thread mit dem Status „Wird ausgeführt“ verwendet einen Prozessor. Ein Thread mit dem Status „Standby“ wird in Kürze einen Prozessor verwenden. Ein Thread mit dem Status „Bereit“ wartet, bis ein Prozessor zur Verwendung frei wird. Ein Thread mit dem Status „Übergang“ wartet auf eine Ressource, um ausgeführt werden zu können. So benötigt er z. B. einen Ausführungsstack, der von der Festplatte ausgelagert werden muss. Ein Thread mit dem Status „Wartend“ verwendet den Prozessor noch nicht, da er auf den Abschluss eines peripheren Vorgangs oder eine frei werdende Ressource wartet. Anhang Tabelle 22 Threadindikatoren (Fortsetzung) Indikator Beschreibung Empfohlener Wert Threadverzögerungsursache Kein. Der Status „Threadverzögerungsursache“ wird nur angezeigt, wenn sich der Thread im Wartezustand befindet (siehe Threadstatus). Es gibt folgende Statusangaben: 0 oder 7 = Thread wartet auf die Ausführung 1 oder 8 = Wartet auf eine freie Seite 2 oder 9 = Wartet auf ein „Page In“ 3 oder 10 = Wartet auf eine Poolreservierung 4 oder 11 = Wartet auf eine Ausführungsverzögerung 5 oder 12 = Wartet auf eine Unterbrechung 6 oder 13 = Wartet auf eine Benutzeranforderung 14 = Wartet auf ein „Event Pair High“ 15 = Wartet auf ein „Event Pair Low“ 16 = Wartet auf einen LPC-Empfang 17 = Wartet auf eine LPC-Antwort 18 = Wartet auf virtuellen Speicher 19 = Wartet auf ein „Page Out“ 20 und höher sind zurzeit noch nicht zugewiesen. Ereignispaare werden zur Kommunikation mit geschützten Subsystemen verwendet. Weitere Quellen In den unten aufgeführten Whitepapers und Microsoft Knowledge Base-Artikeln finden Sie hilfreiche Informationen über die Behandlung von Exchange 2000-Leistungsproblemen. Whitepapers Die folgenden Whitepapers finden Sie im Web unter der Adresse http://www.microsoft.com/exchange Microsoft Exchange 2000 Internals: Quick Tuning Guide (in englischer Sprache) http://go.microsoft.com/fwlink/?LinkId=9942 Speicherlösungen für Microsoft® Exchange 2000 Server http://go.microsoft.com/fwlink/?LinkId=1715 83 84 Anhang Microsoft Knowledge Base-Artikel Die folgenden Microsoft Knowledge Base-Artikel finden Sie im Web unter der Adresse http://support.microsoft.com/: Q294818 – “Frequently Asked Questions About Network Monitor” (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q294818) (in englischer Sprache) Q148942 – “How to Capture Network Traffic with Network Monitor” (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q148942) (in englischer Sprache) Q317411 – “XADM: Gather Data to Troubleshoot Exchange Virtual Memory Issues” (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q317411) (in englischer Sprache) Q296073 – “XADM: Monitoring for Exchange 2000 Memory Fragmentation” (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q296073) (in englischer Sprache) Q266096 – “XGEN: Exchange 2000 Requires /3GB Switch with More Than 1 GB RAM” (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q266096) (in englischer Sprache) Q253251 – “Using Diskperf in Windows 2000” (http://go.microsoft.com/fwlink/?LinkId=3052&ID=Q253251) (in englischer Sprache) Weitere Informationen: http://www.microsoft.com/exchange. Sind die Informationen in diesem Whitepaper hilfreich für Sie? Senden Sie uns Ihr Feedback zu. Wo stufen Sie dieses Whitepaper auf einer Skala von 1 (schwach) bis 5 (hervorragend) ein? mailto:[email protected]?subject=Troubleshooting Microsoft Exchange 2000 Server Performance Problems