Definition (relative Häufigkeit)
Werbung
")
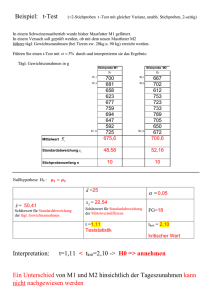
Stand: 02. Juli 2011 Grundkurs Mathematik Kurshalbjahr 11.1 Von Daten zu Funktionen 1. 2. 3. 4. Aufarbeitung und Darstellung statistischer Daten 1.1 Absolute und relative Häufigkeiten 1.2 Graphische Darstellung Maßzahlen zu Beschreibung statistischer Daten 2.1 Maße der zentralen Tendenz (Lagemaße) – Modus, Median, arithmetisches Mittel 2.2 Maße der Streuung: Spannweite, mittlere lineare Abweichung, mittlere quadratische Abweichung (Varianz), Standardabweichung Lineare Regression und Korrelation 3.1 Maße des Zusammenhangs (Korrelationsmaße) 3.1.1 Der Produkt-Moment-Korrelationskoeffizient (PMK) 3.1.2 Der Spearman’sche Rangkorrelationskoeffizient (SRK) 3.1.3 Der Kontingenzkoeffizient 3.1.4 Der Phi-Koeffizient 3.1.5 Korrelation und Kausalität 3.2 Lineare Regression Funktionen 4.1 Eindeutige Zuordnung, Definitionsmenge, Wertemenge 4.2 Darstellungen von Funktionen (Funktionsgleichung, Wertetabelle, Graph) 4.3 Ganzrationale Funktionen (Achsenabschnitte, Symmetrieeigenschaften, Monotonie) 4.3.1 Lineare Funktionen 4.3.2 Quadratische Funktionen 4.3.3 Ganzrationale Funktionen (mindestens bis Grad 4) Carsten Püttmann Document1 Seite 1 Stand: 02. Juli 2011 Kurshalbjahr 11.2 Von der mittleren zur lokalen Änderungsrate 5. 6. Ermittlung von Änderungsraten 5.1 Mittlere Änderungsrate, Differenzenquotient, Sekantensteigung 5.2 Deutung der Ableitung als lokale Änderungsrate und als Tagentensteigung Von der Änderungsrate zur Ableitungsfunktion 6.1 Ableitungsfunktion 6.2 Ableitungsregeln 6.2.1 Potenzregel 6.2.2 Faktorregel 6.2.3 Summenregel Lokale und globale Eigenschaften von Funktionen 7. Analyse von ganzrationalen Funktionen 7.1 Monotonie 7.2 Notwendiges und hinreichendes Kriterium für lokale Extremstellen 7.3 Krümmungsverhalten 7.4 Notwendiges und hinreichendes Kriterium für Wendestellen 7.5 Randverhalten Carsten Püttmann Document1 Seite 2 Stand: 02. Juli 2011 Kurshalbjahr 11.1 Von Daten zu Funktionen Die empirische Sozialforschung, die Biologie, die Medizin oder die Entwicklungspsychologie liefern wichtige Daten für die Erziehungswissenschaft: Wie ist der Wissenstand deutscher Schülerinnen und Schüler im internationalen Vergleich? Was bewirkt mediale Gewalt bei Kindern und Jugendlichen? Wie stark ist der Zusammenhang zwischen Einkommen der Eltern und Schulabschluss des Kindes? Diese und ähnliche Fragestellungen versucht die empirisch orientierte Pädagogik zu beantworten, um pädagogische Handlungsweisen bzw. Programme zu entwickeln, die die beobachteten Missstände beseitigen bzw. zu vermeiden helfen. Sie greift dabei auf Methoden der mathematischen Statistik zurück. Der Begriff Statistik umfasst alle quantitativen Modelle und Techniken, mittels derer empirische Daten zusammengefasst, geordnet und verdichtet werden können (Deskriptivstatistik bzw. beschreibende Statistik) bzw. durch die sich aufgrund empirischer Daten Aussagen über die Richtigkeit von Hypothesen formulieren lassen (Inferenzstatistik bzw. beurteilende Statistik). „Ziel jeder statistischen Analyse muss es sein, die in den Daten enthaltenen Informationen sichtbar zu machen und zu interpretieren, um auf dieser Grundlage angemessene Entscheidungen zu treffen. In diesem Sinne können die Modelle der Statistik auch verstanden werden als entscheidungsunterstützende Verfahren“ (Pfeiffer & Püttmann, 2011, S. 79). 1. Aufarbeitung und Darstellung statistischer Daten Täglich werden Millionen einzelner Daten gesammelt, beschrieben und analysiert. Auf ihrer Grundlage erhofft man sich Erkenntnisse über Eigenschaften und Tendenzen derjenigen Bereiche, aus denen die Daten stammen. Diese können dann wiederum als Grundlage für zukünftige Entscheidungen dienen. Denken Sie beispielsweise daran, welche Daten bei dem Gebrauch von Internetportalen, des I-Phones, bei der Zahlung mit der EC-Karte oder der zentralen Abschlussprüfungen gesammelt werden. In diesem Abschnitt werden die wichtigsten Grundbegriffe eingeführt und Möglichkeiten beschrieben, diese übersichtlich anzuordnen. Beispiel 1a (Merkmale und Merkmalsausprägungen) Bei ihren Aufnahmegesprächen wurden Schülerinnen (w) und Schüler (m) danach befragt, welche Note sie in der letzten Klassenarbeit in der Jahrgangsstufe 10 im Fach Mathematik erzielt haben. Darüber hinaus wollte der Schulleiter wissen, ob sie großes (g), wenig (w) oder kein (k) Interesse an mathematischen Inhalten haben. Die Daten sind in der untenstehenden Urliste ( Tab.1) zusammengefasst. Die 23 befragten Schülerinnen und Schüler bilden zusammen die Grundgesamtheit dieser statischen Erhebung. Jede einzelne Schülerin bzw. jeder einzelne Schüler ist als Element dieser Grundgesamtheit im Hinblick auf die Merkmale „Geschlecht“, „Mathematiknote der letzten Klassenarbeit der Jahrgangstufe 10“ und „Interesse an mathematischen Inhalten“ ein Merkmalsträger. Die Merkmale selbst kommen in verschiedenen Merkmalsausprägungen vor: Geschlecht Carsten Püttmann männlich, weiblich Document1 Seite 3 Stand: 02. Juli 2011 Mathematiknote 1, 2, 3, 4, 5, 6 Interesse groß, wenig, kein Tab.1: Urliste einer Schülerbefragung 1 Al l eri ch w 2 g 2 Ammerma nn w 2 g 3 Ba a rtel s w 3 g 4 Ba umei s ter m 4 w 5 Berthol d w 2 w 6 Bl ume w 5 k 7 Connra d m 4 k 8 Chri s topovi c m 2 g 9 Da mmers w 1 g 10 Derbol ov w 4 k 11 Dros te m 3 w 12 Eckbert m 2 g 13 Eggers w 3 w 14 Ewers w 4 w 15 Evers w 3 w 16 Fra nke w 2 g 17 Gottha rd m 6 k 18 Hei nri ch w 3 w 19 Kna pp m 2 g 20 Li eberknecht w 1 g 21 Mül l er m 2 g 22 Schmi dt w 3 g 23 Werner m 1 g 24 Wol f w 4 k 25 Zörner w 2 g Wir unterscheiden bei der Art der Merkmale zwischen quantitativen und qualitativen Merkmalen. Bei quantitativen Merkmalen lassen sich Merkmalsausprägungen durch Zahlen oder Größenwerte ausdrücken und dadurch in einer metrischen Skala sortieren. Wir unterscheiden dabei zwischen einer Intervallskala und einer Verhältnisskala bzw. Rationalskala. Qualitative Merkmale werden unterschieden in solche, bei denen die Merkmalsausprägungen in eine Reihenfolge (Rangskala bzw. Ordinalskala oder ordinale Skala) gebracht werden können, und solche, bei denen die Merkmalsausprägungen nicht abgestuft werden können (Nominalskala oder nominale Skala). Hinweis: Qualitative Merkmale werden in der EDV meistens codiert. Eine Zuordnung, ob ein Merkmal qualitativ oder quantitativ ist, muss daher von der ursprünglichen Merkmalsausprägung beurteilt werden. Bei Schulnoten unterscheiden wir grundsätzlich zwischen einer sehr guten (1) , einer guten (2), einer befriedigenden (3), einer ausreichenden (4), einer mangelhaften (5) oder ungenügenden (6) Leistung. Carsten Püttmann Document1 Seite 4 Stand: 02. Juli 2011 Konkreter lassen sich die vier Skalentypen bzw. Messniveaus wie folgt beschreiben: Nominalskala: Diese ist das niedrigste Messniveau und kommt bei kategorialen Begriffen zur Anwendung (Geschlecht, Familienstand). Hier werden Relationen gleichungleich angewendet. Die Zahlen haben nur Symbolcharakter: es können also auch beliebige, nicht numerische Symbole verwendet werden. Elemente, die im empirischen Relativ gleich sind, erhalten das gleiche Symbol und verschiedene Elemente dementsprechend verschiedene Symbole. Zulässige Transformationen sind alle die, welche die Ungleichheit oder Gleichheit der Objekte nicht ändern (streng symmetrische Transformationen). Ordinalskala: Die Ordinal- oder Rangskala bildet die Ausprägungen von komparativen Begriffen ab. Dabei werden nicht nur Gleich-Ungleich-Relationen sondern auch GrößerKleiner-Relationen abgebildet. Größere Zahlen bedeutet ein Mehr oder Weniger im empirischen Relativ. Es geht also um sortierte oder geordnete Beziehungen (Schulnoten, Schichtindex, Ranking). Zulässig sind hier nur streng monotone Transformationen, so dass die ermittelte Ordnung der Merkmale nicht verloren geht. Intervallskala: Hierbei handelt es sich im engeren Sinne um eine metrische Skala, bei der die Abstände zwischen den Zahlen eine Bedeutung haben. Der Nullpunkt und die Einheiten der Skala können jedoch willkürlich gewählt werden. Bekannteste Beispiele sind Temperaturskalen wie Celsius und Fahrenheit. Ob es sich bei den üblicherweise verwendeten Einstellungsskalen und Persönlichkeitstest um Intervallskalen handelt, wird in der Literatur unterschiedlich beurteilt. Verhältnisskala: Der Unterschied zur Intervallskala besteht darin, dass die Verhältnisskala einen natürlichen Nullpunkt hat. Null Einkommen bedeutet auch Null. Die vorgefundenen Verhältnisse der Zahlen haben eine empirische Bedeutung, d. h., wenn jemand doppelt soviel verdient, ist dies direkt am Einkommen in Zahlen ablesbar. Da eine Nullpunktverschiebung wegen des natürlichen Nullpunktes nicht möglich ist, sind nur Ähnlichkeitstransformationen zulässig. Für unsere Merkmale aus Beispiel 1.1 lässt sich somit zusammenfassend festhalten: Tab.2: Merkmal, Merkmalsausprägung, Skala Merkmal Merkmalsausprägung Art des Merkmals Art der Skala Geschlecht Männlich (m), Weiblich (w) qualitativ Nominalskala Note sehr gut (1), gut (2), befriedigend (3), ausreichend (4), mangelhaft (5), ungenügend (6) qualitativ Ordinalskala Interesse Groß (g), wenig (w), klein (k) qualitativ Ordinalskala Grundbegriffe statistischer Erhebungen, über die Sie nach der Lektüre verfügen sollten Grundgesamtheit, Merkmal, Merkmalsträger, Merkmalsausprägung, qualitatives Merkmal, quantitatives Merkmal, metrische Skala, Nominalskala, Ordinalskala, Intervallskala, Rationalskala Carsten Püttmann Document1 Seite 5 Stand: 02. Juli 2011 1.1 Absolute und relative Häufigkeiten Im Folgenden soll es darum gehen, wie statisch erhobene Daten aufbereitet bzw. dargestellt werden können, um sie beispielsweise in einer Präsentation oder in einem (Forschungs-)Bericht verwenden zu können. Die einfachste Form der Aufbereitung von Daten ist, festzuhalten, mit welcher Häufigkeit ein gemessenes Merkmal auftaucht. Dabei unterscheiden wir in der einfachsten Form zwischen absoluter und relativer Häufigkeit. Definition (absolute Häufigkeit) Die absolute Häufigkeit 𝐻(𝑥𝑖 ) einzelner Merkmalsausprägungen 𝑥𝑖 erhalten wir durch einfaches Zählen. Diese Anzahl gibt an, wie oft eine bestimmte Ausprägung eines bestimmten Merkmals vorkommt. Beispiel 1b (Notenspielgel: absolute Häufigkeit) Bei unserer Befragung aus Beispiel 1a ergibt sich der folgende Notenspiegel: Tab.3: Notenverteilung in einer Mathematikklausur Note 1 2 3 4 5 6 Summe Anzahl 3 9 6 5 1 1 25 Hier gilt: 𝐻(1) = 3 , 𝐻(2) = 9 , 𝐻(3) = 6 , 𝐻(4) = 5 , 𝐻(5) = 1 , 𝐻(6) = 1. Definition (relative Häufigkeit) Die relative Häufigkeit ℎ(𝑥𝑖 ) einer Merkmalsausprägung erhalten wir durch Quotientenbildung. Es ist: ℎ(𝑥𝑖 ) = 𝐻(𝑥𝑖 ) 𝑛 = 𝑎𝑏𝑠𝑜𝑙𝑢𝑡𝑒 𝐻ä𝑢𝑓𝑖𝑔𝑘𝑒𝑖𝑡 𝑑𝑒𝑟 𝑀𝑒𝑟𝑘𝑚𝑎𝑙𝑠𝑎𝑢𝑠𝑝𝑟ä𝑔𝑢𝑛𝑔 . 𝐺𝑒𝑠𝑎𝑚𝑡𝑧𝑎ℎ𝑙 𝑎𝑙𝑙𝑒𝑟 𝑀𝑒𝑟𝑘𝑚𝑎𝑙𝑠𝑡𝑟ä𝑔𝑒𝑟 Die relative Häufigkeit einer Merkmalsausprägung gibt also den Anteil an, den diese Ausprägung unter allen betrachteten Personen oder Objekten (Merkmalsträgern) hat. Diese Anteile werden durch gewöhnliche Brüche, Dezimalbrüche oder in Prozent angegeben. Dabei gilt für die Ermittlung des Prozentwertes: ℎ% (𝑥𝑖 ) = ℎ(𝑥𝑖 ) ∙ 100%. Beispiel 1c (absolute, relative und prozentuale Häufigkeit) Wir betrachten noch einmal unser Beispiel „Notenspiegel“. Insgesamt haben 25 Schülerinnen und Schüler die Mathematikklausur mitgeschrieben. Damit ergeben sich für die relativen Häufigkeiten die Werte Carsten Püttmann Document1 Seite 6 Stand: 02. Juli 2011 ℎ(1) = 𝐻(1) 25 = 3 25 = 0,12 ; ℎ(2) = 𝐻(2) 25 = 9 25 = 0,36 usw. Die entsprechenden prozentualen Häufigkeiten sind dann: ℎ% (1) = ℎ(1) ∙ 100% = 0,12 ∙ 100% = 12% ℎ% (2) = ℎ(2) ∙ 100% = 0,36 ∙ 100% = 36% usw. Insgesamt ergibt sich dann für das Beispiel die folgende Häufigkeitstabelle: Tab.4: Häufigkeiten in einer Mathematikklausur Note 1 2 3 4 5 6 Summe 𝑯 3 9 6 5 1 1 25 𝒉 0,12 0,36 0,24 0,2 0,04 0,04 1 𝒉% 12% 36% 24% 20% 4% 4% 100% Tab.4 zeigt die absoluten, die relativen und die prozentualen Häufigkeiten an. Es fällt auf, dass sich die Summe der absoluten Häufigkeiten gleich der Anzahl der Merkmalsträger (𝑛 = 25) ist. dass die Summe der relativen Häufigkeiten gleich 1 ist. dass die Summe der prozentualen Häufigkeiten gleich 100% ist. Mit dieser sogenannten Summenprobe kann die Vollständigkeit einer Erhebung oder die Richtigkeit einer Rechnung überprüft werden. Tabellen, in denen die verschiedenen Ausprägungen eines Merkmals zusammen mit den relativen (prozentualen) Häufigkeiten abgedruckt werden, bezeichnen wir als Häufigkeitsverteilung eines Merkmals. Die obigen Tabellen lassen sich ebenfalls verstehen als Wertetabellen einer Funktion ( Kap.4) Merkmalsausprägung Häufigkeit der Merkmalsausprägung. Wenn die Anzahl der Merkmalsträger zu gering oder die Anzahl der Merkmalsausprägungen zu hoch ist, kann es mitunter sinnvoll oder gar notwendig sein, verschiedene Merkmalsausprägungen zusammenzufassen. Dies kann geschehen bei metrischen Merkmalen, indem Intervalle von Messdaten gebildet werden, bei nominalen Merkmalen ohne natürliche Reihenfolge, indem mehrere Eigenschaften/ Kategorien zusammengefasst werden, bei Rangmerkmalen, indem die Anzahl der Ränge durch Zusammenfassung reduziert wird. Der Vorteil solcher Klassenbildungen besteht in der Übersichtlichkeit der Präsentation. Der Nachteil liegt darin, dass durch die Zusammenfassung Informationen verloren gehen, die für eine spätere Interpretation durchaus wichtig sein könnten. Carsten Püttmann Document1 Seite 7 Stand: 02. Juli 2011 Beispiel 1d (Klassenbildung) In der folgenden Tabelle wurde der Fernsehkonsum der Schülerinnen uns Schüler einer FOS12 Klasse an einem normalen Montag erfasst. Dabei ergaben sich folgende Werte [in Minuten]: Tab.5: Fernsehkonsum von Schülerinnen und Schüler der FOS12 95 135 160 80 90 65 120 95 110 100 75 80 90 150 195 120 45 90 105 85 95 70 105 130 115 85 95 55 75 95 Diese Variablen können z. B. zu folgenden Klassen zusammengefasst werden: weniger als eine Stunde: eine Stunde bis weniger als zwei Stunden: zwei Stunden bis weniger als drei Stunden: mehr als drei Stunden: Intervall: Intervall: Intervall: Intervall: 𝐼1 = [0; 60[ 𝐼2 = [60; 120[ 𝐼3 = [120; 180[ 𝐼4 = [180; 1440[ Hinweis: 120 Minuten gehören nach der obigen Einteilung zum Intervall 𝐼3 , nicht zum Intervall 𝐼2 . Grundbegriffe statistischer Erhebungen, über die Sie nach der Lektüre verfügen sollten Absolute Häufigkeit, relative Häufigkeit, Häufigkeitsverteilung, Klassenbildung prozentuale Häufigkeit, Summenregel, Übungsaufgabe Fertigen Sie für die obigen Intervalle eine Häufigkeitstabelle an, in der Sie die absoluten, die relativen und die prozentualen Häufigkeiten erfassen. Carsten Püttmann Document1 Seite 8 Stand: 02. Juli 2011 1.2 Graphische Darstellung Neben der Tabellenform lassen sich Daten auch graphisch darstellen. Die gängigsten Formen der graphischen Darstellungen wie Säulendiagramm, Balkendiagramm, Blockdiagramm, Kreisdiagramm bzw. Polygonzug werden im Folgenden exemplarisch dargestellt. Dabei wird für jede Darstellungsart auf die jeweiligen Vorteile hingewiesen. So zeigen beispielsweise Säulendiagramme sehr übersichtlich absolute und relative Häufigkeiten der einzelnen Merkmale einer Stichprobe und lassen einen einfachen Vergleich der Merkmalsausprägungen zu. lassen sich durch Kreisdiagramme deutlich die Anteile darstellen, die jedes einzelne Merkmal einer Stichprobe am Gesamtumfang hat. lässt sich die Verteilung eines Merkmals in verschiedenen Gruppen durch Blockdiagramme vergleichend visualisieren. Auf eine gesonderte Definition der verschiedenen Darstellungsarten werden wir jedoch verzichten. Ausgangspunkt für die Erstellung einer Graphik ist dabei stets ein konkretes Beispiel. Beispiel 1e (Säulendiagramm) In einer Kindertagesstätte beschweren sich die Erzieherinnen über verlängerte Arbeitszeiten, die durch die Häufigkeiten der Verspätungen der Eltern bei der Abholung ihre Kinder zu Erklären sind. In Vorbereitung auf einen Elternabend, an dem dieses diskutiert werden soll, werden diese nun festgehalten. Für die ersten vier Wochen im August 2010 berichtet die Einrichtungsleitung ihrem Team über die Verspätungen und geht dabei insbesondere auf die einzelnen Wochentage ein: Tab.6: Verspätungen Da tum 2. 3. 4. 5. 6. 9. 10. 11. 12. 13. 16. 17. 18. 19 20. 23. 24. 25. 26. 27. Wochenta g Mo Di Mi Do Fr Mo Di Mi Do Fr Mo Di Mi Do Fr Mo Di Mi Do Fr Anza hl 0 0 1 1 3 1 1 0 1 2 1 1 0 1 2 1 0 1 1 2 In einem ersten Schritt erstellen wir aus der Urliste ( Tab.6) eine Häufigkeitsverteilung in Abhängigkeit der Wochentage: Tab.7: Verspätungen je Wochentag Carsten Püttmann 𝒙𝒊 Mo Di Mi Do Fr Summe 𝑯 9 3 2 2 4 20 𝒉 0,45 0,15 0,1 0,1 0,2 1 Document1 Seite 9 Stand: 02. Juli 2011 10 0.5 8 0.4 6 0.3 4 0.2 2 0.1 0 0 Mo Di Mi Do Fr Mo Di Mi Do Fr Abb.1: Säulendiagramm mit absoluten bzw. mit relativen Häufigkeiten Säulendiagramme ( Abb.1) bestehen, wie wir sehen können, aus nebeneinander stehenden, gleich breiten Rechtecken; die Höhe der Rechtecke entspricht der absoluten oder der relativen Häufigkeit der jeweiligen Merkmalsausprägung. Erfolgt die Anordnung der Rechtecke nicht wie in Abb.1 nebeneinander, sondern übereinander, so dass die Häufigkeiten auf der x-Achse abgetragen werden, handelt es sich um ein Balkendiagramm ( Abb.2). Ein solches empfiehlt sich vor allem, wenn eine größere Anzahl von Kategorien vorliegt. Beispiel 1f (Balkendiagramm) Fr Do Mi Di Mo 0 2 4 6 8 10 Abb.2: Beispiel eines Balkendiagramms mit relativen Häufigkeiten Werden hingegen die Häufigkeiten von Merkmalsausprägungen übereinander oder nebeneinander zu einem Gesamtrechteck „gestapelt“, so dass sich die Beträge der einzelnen Werte mit dem Gesamtbetrag vergleichen lassen, dann spricht man von einem Blockdiagramm. Sind dabei die Prozentanteile der einzelnen Kategorien eingetragen, so müssen sich diese Anteile zu einem Rechteck summieren, dessen Gesamtlänge genau 100% entspricht. Ein Blockdiagramm ist vor allem sinnvoll, wenn die Verteilung eines Merkmals in verschiedenen Gruppen vergleichend visualisiert werden soll. Carsten Püttmann Document1 Seite 10 Stand: 02. Juli 2011 Bei Kreisdiagrammen ( Abb.3) wird jeder Merkmalsausprägung ein Kreissektor zugeordnet, dessen Mittelpunktswinkel 𝛼 (im Vergleich zum Vollwinkel von 360°) der relativen Häufigkeit der jeweiligen Ausprägung entspricht. Beispiel 1g (Kreisdiagramm) In der obigen Statistik ergibt sich beispielsweise für die Merkmalsausprägung „Mo“ ein Mittelpunktswinkel von 𝛼 = 360° ∙ 0,45 = 162°. Insgesamt ergibt sich so das folgende Kreisdiagramm: Fr, 0.2, 20% Mo, 0.45, 45% Do, 0.1, 10% Mi, 0.1, 10% Di, 0.15, 15% Abb.3: Kreisdiagramm Kreis- und Blockdiagramme geben also an, wie sich die Stichprobe bzgl. eines Merkmals zusammensetzt. Das bedeutet zwangsläufig, dass sich die betrachteten Merkmalsausprägungen gegenseitig ausschließen müssen. Das wiederum hat zur Folge, dass beispielsweise bei einer (schriftlichen) Befragung keine Mehrfachnennungen zugelassen werden dürfen. Kreisdiagramme eignen sich insbesondere dann, wenn vorliegende Mehrheitsverhältnisse verdeutlicht werden sollen; Blockdiagramme lassen eher den Vergleich der Ergebnisse aus verschiedenen Erhebungen zu. An Säulendiagrammen lassen sich hingegen leichter ablesen, welche Reihenfolge hinsichtlich ihrer Häufigkeiten die verschiedenen Ausprägungen haben. Hier sind im Gegensatz zu den beiden anderen Diagrammtypen auch Mehrfachnennungen darstellbar. Polygonzüge bzw. ein Liniendiagramm ( Abb.4) werden bevorzugt eingesetzt, wenn unterschiedliche Stichproben verglichen werden sollen. Dazu werden die Häufigkeiten als Punkte in ein Koordinatensystem eingetragen und mir Geraden verbunden. Polygonzüge finden wir z. B. bei Trendanalysen wie etwa im Politbarometer wieder, wobei hier die x-Achse die Zeitdimension repräsentiert. Carsten Püttmann Document1 Seite 11 Stand: 02. Juli 2011 Liegen die Daten in klassifizierter Form vor, ist es üblich, diese durch Histogramme ( Abb.4) darzustellen. Histogramme sind Säulendiagramme, bei denen keine Lücken zwischen den einzelnen Säulen gelassen werden. Die Breite der so entstandenen Rechtecke entspricht dabei den angegebenen Intervallbreiten und der Flächeninhalt der zugehörigen absoluten bzw. relativen Häufigkeit, mit der die Merkmalsausprägung auftritt. Bei unterschiedlichen Klassenbreiten ist darauf zu achten, dass die Flächeninhalte den Häufigkeiten entsprechen. Dann gilt: 𝑅𝑒𝑐ℎ𝑡𝑒𝑐𝑘ℎöℎ𝑒 = 𝐾𝑙𝑎𝑠𝑠𝑒𝑛ℎä𝑢𝑓𝑖𝑔𝑘𝑒𝑖𝑡 . 𝐾𝑙𝑎𝑠𝑠𝑒𝑛𝑏𝑟𝑒𝑖𝑡𝑒 Gelegentlich werden Polygonzüge und Histogramme Formen miteinander kombiniert. Beispiel 1h (Polygonzug und Histogramm) In einer Kindertagesstätte sind 15 Angestellte verschiedenen Alters beschäftigt: Tab.8: 15 Angestellte verschiedenen Alters Person A B C D E F G H I J K L M N O Alter 28 55 29 47 53 38 40 42 57 53 51 35 20 43 25 Um ein Histogramm zu erstellen bilden wir zunächst sinnvolle Altersklassen und im Anschluss eine Häufigkeitsverteilung: Tab.9: Häufigkeitsverteilung von 15 Angestellten verschiedenen Alters Alter 20-29 30-39 40-49 50-59 H 4 2 4 5 Verbinden wir die Mitten der oberen Seiten des Histogramms mit Geraden, dann erhalten wir auf der Basis des Histogramms ein so genanntes Häufigkeitspolynom ( Abb.4): 6 5 4 3 2 1 0 20-29 30-39 40-49 50-59 Abb.4: Histogramm und Polygonzug Carsten Püttmann Document1 Seite 12 Stand: 02. Juli 2011 Grundsätzlich gilt, dass Informationen durch geeignete grafische Darstellungsformen zwar leichter zu vermitteln sind, dass sie aber auch „bessere“ Möglichkeiten der Manipulation bieten. Dies gilt ganz besonders für die heute in Zeitungen und Zeitschriften oft und gerne verwendeten Piktogramme ( Abb.5), die mit Hilfe von Symbolen die betrachteten Größen veranschaulichen sollen. Durch diese Darstellungsformen gelingt es oft, die besondere Aufmerksamkeit des Lesers zu wecken. Dabei unterlaufen häufig – gewollt oder ungewollt – Fehler, die, wenn sie bewusst eingesetzt werden, die Meinung des Lesers beeinflussen können und sollen. Typische Fehler einer solchen grafischen Darstellung sind z. B. Verstöße gegen Proportionalität perspektivische Verzerrungen Stauchung oder Streckung von Achsen Verwendung von Polygonzügen anstelle von Säulendiagrammen Verwendung von dreidimensionalen anstelle von zweidimensionalen Formen etc. Aus Gründen der Vollständigkeit seien an dieser Stelle zwei Beispiele für Piktogramme, wie sie etwa in den bekannten Wochenzeitungen Spiegel oder Focus zu finden sind, ohne Kommentar aufgeführt. Abb.5: Beispiele für Piktogramme (aus: Griesel/Postel, 1999, S.111) Übungsaufgaben (Schöwe, 2011, S. 29) 1. Die folgende Tabelle gibt an, welche Zeit die Teilnehmer eines Volkslaufs für die Strecke benötigen. Zeit in Stunden 2 bis 2,5 2,5 bis 3 3 bis 3,5 3,5 bis 4 4 bis 4,5 Teilnehmerzahl 240 600 510 90 60 a) Stellen Sie die Häufigkeitsverteilung in einem Kreisdiagramm dar. b) Stellen Sie die relativen Häuf gkeiten in einem Histogramm dar. Bilden Sie das Häufigkeitspolygon. 2. 20 Würfe mit einem Würfel brachten folgende Augenzahlen: 6, 2, 4. 1. 14. 3. 3. 2. 1. 6. 5. 6. 3. 4. 1, 6. 2. 5. 3. a) Ermitteln Sie die absolute und die relative Häufigkeit der einzelnen Augenzahlen. Carsten Püttmann Document1 Seite 13 Stand: 02. Juli 2011 b) Stellen Sie die Häufigkeitsverteilung in einem Säulendiagramm dar. 3. Der Pinzgauer Zuchtverband veröffentlichte für ein Jahr die unten stehende statistische Aufstellung über den Milchertrag der steierischen Milchkühe. Erstellen Sie für die Häufigkeitsverteilung ein Histogramm. Mi chertra g i n 1 von … bi s unter Anza hl Kühe 0-1.000 4. 11 1.000-2.000 556 2.000-3.000 1.169 3.000-4.000 326 4.000-5.000 32 5.000-6.000 4 Bei Versuchen zur prophylaktischen Bekämpfung der Nonne (Raupenart) wurden an 30 Probestämmen die folgenden Anzahlen von Eiern gezählt: 125, 212, 284, 176, 100, 132, 52, 319, 410, 181, 273, 186, 43, 11, 109, 20, 76, 30, 73, 47, 121, 518, 129, 22, 314, 144, 38, 225, 257, 138. Überlegen Sie sich eine geeignete Klasseneinteilung, stellen Sie die dazu gehörende Häufigkeitsverteilung in einem Kreisdiagramm, Säulendiagramm sowie Histogramm dar und bilden Sie dazu das Häufigkeitspolygon. 5. Pa rtei In der Tabelle ist das Wahlergebnis der Bundestagswahl vom 18. September 2004 wiedergegeben. Ermitteln Sie die relative Häufigkeit in Prozent der abgegebenen Stimmen und stellen Sie das Ergebnis in einem Säulendiagramm dar. Geben Sie die Verteilung der Sitze in einem Kreisdiagramm wieder. SPD CDU CSU Sti mmen 16.194.665 13.136.740 3.494.309 Si tze Carsten Püttmann 222 180 46 Grüne FDP Di e Li nke Ungül ti ge und Sons ti ge 3.838.326 4.648.144 4.118.194 2.613.756 51 61 54 Document1 Seite 14 Stand: 02. Juli 2011 2. Maßzahlen zu Beschreibung statistischer Daten Die Daten einer statistischen Erhebung, die zum Beispiel mit Hilfe eines Fragebogens oder eines Interview erhoben werden, enthalten eine Vielzahl an Informationen, die, wenn es um schnelle Entscheidungen gehen soll oder aber auch um eine sinnvolle Beurteilung auf typische Kennzahlen (Lagemaße bzw. Streuungsmaße) reduziert werden. Je nachdem, für welche Eigenschaften der Grundgesamtheit man sich interessiert, welche Aussagen man treffen möchte, für wen die Daten aufbereitet werden, für welches Zweck usw. sind einige Informationen wichtig, andere eher nebensächlich. Also: Hinter jeder Reduzierung der Datenmenge steht eine Absicht. Wir betrachten im Folgenden aber zunächst nur die mathematische Seite. Dabei halten wir zu Beginn fest: Lagemaße beschreiben die Daten „im Mittel“ Streuungsmaße geben darüber Auskunft, welchen Schwankungen die Daten unterliegen und in welchem Bereich der größte Teil der Daten liegt. 2.1 Maße der zentralen Tendenz (Lagemaße) – Modus, Median, arithmetisches Mittel Maße der zentralen Tendenz fassen Häufigkeitsverteilungen in einer einzigen Kennzahl zusammen. Ziel dieser Datenreduktion ist es, die Häufigkeitsverteilung eines gemessenen Merkmals durch eine einzige Zahl zu charakterisieren. Somit geben Maße der zentralen Tendenz wichtige Informationen über ein betrachtetes Merkmal, indem sie die Gesamtzahl der Einzelinformationen zu einer einzigen statistischen Kennzahl verdichten – dem sogenannten Schwerpunkt oder Mittelpunkt einer Häufigkeitsverteilung; sie sind überschaubar und repräsentativ und lassen erste grobe Vergleiche zu. Die in der Statistik gebräuchlichsten Maße der zentralen Tendenz wie Modalwert (Mo), Median (Md) und arithmetisches Mittel (M) werden im Folgenden näher beschrieben. Definition (Modalwert) Der Modalwert bzw. Modus (𝑀𝑜) einer Verteilung ist derjenige Wert, der am häufigsten in einer Verteilung vorkommt, d. h. es ist die Merkmalsausprägung, die die meisten untersuchten Objekte aufweist. Bei der graphischen Darstellung einer Verteilung ist der Modalwert somit der Wert, bei dem die Häufigkeitsverteilung ihr Maximum besitzt. Carsten Püttmann Document1 Seite 15 Stand: 02. Juli 2011 Anmerkungen (1) (2) Bei klassierten Daten gilt die Klassenmitte der am häufigsten besetzten Kategorie als Modalwert. Mitunter kann es vorkommen, dass eine Verteilung mehr als ein lokales Maximum besitzt. Im Säulendiagramm bzw. Histogramm kommen somit zwei (oder mehr) unterschiedliche „Gipfel“ vor. Wir sprechen in einem solchen Fall von einer bimodalen (multimodalen) Verteilung. Definition (Median) Der Median 𝑀𝑑 ist der Wert, der die geordnete Datenreihe in zwei gleich große Hälften unterteilt, d. h. es liegen je 50% der Daten oberhalb und unterhalb des Medians. Ist die Anzahl 𝑛 der untersuchten Merkmalsträger ungerade, so lässt sich der Median bestimmen, indem die Messwerte der Größe nach geordnet und die unteren (𝑛 − 1)/2 Werte abgezählt werden. Der nächste Wert ist dann der gesuchte Median. Eine Alternative bietet die Formel 𝑴𝒅 = 𝒙𝒏+𝟏 . 𝟐 Ist die Anzahl 𝑛 der untersuchten Merkmalsträger gerade, so ist der Median nicht zwingend ein Wert der Datenreihe selbst. Er errechnet sich durch 1 𝑀𝑑 = 2 (𝑥𝑛 + 𝑥𝑛+1 ). 2 2 Definition (arithmetisches Mittel) Das arithmetische Mittel M ist das gebräuchlichste Maß zur Kennzeichnung der zentralen Tendenz. Es wird berechnet, indem die Summe aller Werte durch die Anzahl aller Werte dividiert wird. Mathematisch schreibt man dafür: 𝑛 1 1 𝑀 = ∑ 𝑥𝑖 = (𝑥1 + 𝑥2 + 𝑥3 + ⋯ 𝑥𝑛 ). 𝑛 𝑛 𝑖=1 Das arithmetische Mittel ist unter anderem dadurch gekennzeichnet, dass Abweichungen nach oben und nach unten ausgeglichen werden, d. h. die Summe aller Abweichungen vom arithmetischen Mittel ist 0: 𝑛 ∑(𝑥𝑖 − 𝑀) = 0. 𝑖=1 Carsten Püttmann Document1 Seite 16 Stand: 02. Juli 2011 Beispiel 2a (arithmetisches Mittel; Median; Modalwert) Eine Befragung von 20 Schülerinnen und Schüler der AHR11 über deren täglichen Fernsehkonsum in Minuten ergab folgende (ungeordnete) Datenreihe: 156 166 169 178 159 168 173 186 168 164 175 189 165 168 176 189 165 168 177 195 Das arithmetische Mittel errechnet sich hier zu 𝑛 1 1 1 (156 + 166 + 169 + ⋯ + 195) = 172,2. 𝑀 = ∑ 𝑥𝑖 = (𝑥1 + 𝑥2 + 𝑥3 + ⋯ 𝑥𝑛 ) = 𝑛 𝑛 20 𝑖=1 Ordnen wir die Daten der Größe nach, ergibt sich folgende geordnete Datenreihe: 156 159 164 165 165 166 168 168 168 168 169 173 175 176 177 178 186 189 189 198 Der Median ist dann 1 1 𝑀𝑑 = (𝑥𝑛 + 𝑥𝑛+1 ) = (168 + 169) = 168,5. 2 2 2 2 Die Merkmalsausprägung „168“ besitzt mit 4 die größte absolute Häufigkeit. Demnach ist 𝑀𝑜 = 168. Beispiel 2b (Arithmetisches Mittel, Median und Modalwert bei Klassenbildung) Die Ergebnisse einer Befragung von 20 Schülerinnen und Schüler der AHR11 über deren täglichen Fernsehkonsum wurden zu folgenden Klassen zusammengefasst: 𝐼1 = [150; 160[ ; 𝐼2 = [160; 170[ ; 𝐼3 = [170; 180[ ; 𝐼4 = [180; 190[ ; 𝐼5 = [190; 200[ Damit ergibt sich die folgende Häufigkeitstabelle: Tab.10: Klassenbildung bei einer Befragung zum Fernsehkonsum [150; 160[ [160; 170[ [170; 180[ [180; 190[ [190; 200[ 2 9 5 3 1 Werden mit dieser Häufigkeitstabelle die verschiedenen Mittelwerte bestimmt, so ist nicht mehr zu ermitteln, ob die Werte aus den verschiedenen Intervallen im Bereich der unteren oder der Carsten Püttmann Document1 Seite 17 Stand: 02. Juli 2011 oberen Intervallgrenze liegen. Somit muss die jeweilige Klassenmitte für die Berechnungen benutzt werden. Die Klassenmitte kann mit der folgenden Formel berechnet werden: 𝑙𝑖𝑛𝑘𝑒 𝐼𝑛𝑡𝑒𝑟𝑣𝑎𝑙𝑙𝑔𝑟𝑒𝑛𝑧𝑒+𝑟𝑒𝑐ℎ𝑡𝑒 𝐼𝑛𝑡𝑒𝑟𝑣𝑎𝑙𝑙𝑔𝑟𝑒𝑛𝑧𝑒 2 = 𝐾𝑙𝑎𝑠𝑠𝑒𝑛𝑚𝑖𝑡𝑡𝑒. Für die Klasse [150; 160[bedeutet das: 𝐾𝑙𝑎𝑠𝑠𝑒𝑛𝑚𝑖𝑡𝑡𝑒 = 150+160 2 = 155. Tab.11: Klassenbildung bei einer Befragung zum Fernsehkonsum mit der Angabe der Klassenmitte Klasse [150; 160[ [160; 170[ [170; 180[ [180; 190[ [190; 200[ Klassenmitte 155 165 175 185 195 Absolute Häufigkeit 2 9 5 3 1 Das arithmetische Mittel errechnet sich hier, indem wir die jeweiligen Klassenmitten mit ihren (absoluten) Häufigkeiten multiplizieren, die Ergebnisse addieren und durch die Gesamtzahl 𝑛 = 20 dividieren: 𝑛 1 1 𝑀 = ∑ 𝐻(𝑥𝑖 ) ∙ 𝑥𝑖 = (2 ∙ 155 + 9 ∙ 165 + 5 ∙ 175 + 3 ∙ 185 + 3 ∙ 195) = 171. 𝑛 20 𝑖=1 Der Median wird dann bestimmt durch: 1 1 𝑀𝑑 = (𝑥𝑛 + 𝑥𝑛+1 ) = (𝑥10 + 𝑥11 ). 2 2 2 2 Sowohl die Stelle 𝑥10 , als auch die Stelle 𝑥11 liegen in der Klasse [160; 170[ , denn die ersten beiden Werte liegen in der Klasse [150; 160[; die nächsten neun eben in [160; 170[. Der Median wird nun durch die Klassenmitte charakterisiert: 𝑀𝑑 = 165. Der Modalwert ergibt sich unmittelbar aus dem Vergleich der Häufigkeiten der verschiedenen Klassen. Er wird ebenfalls durch die Klassenmitte dargestellt: 𝑀𝑜 = 165. Hinweis Wir sehen beim zweiten Beispiel deutlich, dass durch die Klassenbildung zusätzlich weitere Informationen zu den erhobenen Daten verloren gehen: Obwohl die gleichen Ausgangsdaten wie Carsten Püttmann Document1 Seite 18 Stand: 02. Juli 2011 im ersten Beispiel benutzt werden, verändern sich alle Zentralwerte. Dieser Umstand sollte bei einer Klassenbildung stets bedacht werden. Es sei hier daran erinnert, dass aufgrund der Rechenoperationen, die zur Bestimmung der Maße der zentralen Tendenz durchgeführt werden, ein bestimmtes Skalenniveau des untersuchten Merkmals vorausgesetzt werden muss. Eine Übersicht bietet folgende Tabelle: Tab.12: Skalenniveaus der Maße der zentralen Tendenz Skala Nominal- Ordinal- Intervall- Verhältnis- Modalwert Mo Median Md - Arithmetisches Mittel M - - Anmerkungen (1) (2) (3) Im Vergleich zum arithmetischen Mittel ist der Median weniger empfindlich (robuster) gegenüber sogenannten Ausreißern (Extremwerten), da es bei der Medianbestimmung nicht auf jeden einzelnen Wert, sondern nur auf deren Reihenfolge ankommt. Bei der Erhebung von Daten wissen wir zunächst nicht, warum Ausreißer auftreten, ob sie vielleicht nur Messfehler darstellen, oder ob es sich um sehr spezielle Fälle handelt. Es ist daher sinnvoll, stets auch den Median anzugeben und Abweichungen vom arithmetischen Mittel und vom Median zu überprüfen. Zur genaueren Betrachtungsweise wird zusätzlich der Modalwert mit einbezogen. Die drei Maße der zentralen Tendenz unterscheiden sich, wie aus obiger Tabelle zu ersehen ist, zunächst hinsichtlich ihrer Anwendbarkeit auf den unterschiedlichen Skalenniveaus. Sind die Daten mindestens intervallskaliert, so ist eine Berechnung aller drei Maße sinnvoll. Übungsaufgabe Berechnen Sie das arithmetische Mittel, den Median und den Modus der folgenden Datenreihe (Anzahl der Gegentore in den ersten zehn Spielen des BSC Lippstadt in der vergangenen Saison): 2 Carsten Püttmann 0 2 3 2 0 Document1 3 2 1 3 Seite 19 Stand: 02. Juli 2011 2.2 Maße der Streuung: Spannweite, mittlere lineare Abweichung, mittlere quadratische Abweichung (Varianz), Standardabweichung Maße der Streuung bzw. Dispersionsmaße kennzeichnen die Streuung einer Häufigkeitsverteilung um den Mittelwert. Hier geht es um die Frage: Wie typisch ist der errechnete Mittelwert für die Gesamtreihe der Messwerte? Die einfache Überlegung ist: je geringer die Streuung der Messwerte, umso typischer ist der Mittelwert und umso homogener (gleichmäßiger zusammengesetzt) ist die Verteilung. Wie bei den Maßen der zentralen Tendenz ist auch für die Dispersionsmaße das Skalenniveau ausschlaggebend, welches Maß zur Beschreibung der Verteilung sinnvoll berechenbar ist. Tab.13: Skalenniveaus der Dispersionsmaße Skala Nominal- Ordinal- Intervall- Verhältnis- Variationsbreite SP - mittlere lineare Abweichung d - - Varianz s², Standardabweichung s - - Definition (Variationsbreite bzw. Spannweite) Die Variationsbreite bzw. Spannweite SP (englisch: range) ist das am einfachsten zu bestimmende Dispersionsmaß. Sie wird ermittelt, indem wir die Differenz aus dem größten und kleinsten Wert der Messreihe bilden: 𝑆𝑃 = 𝑥𝑚𝑎𝑥 − 𝑥𝑚𝑖𝑛 . Der Nachteil dieses Streuungsmaßes ist, dass es lediglich auf den beiden Extremwerten basiert und somit höchst unsicher ist; es sagt zudem nichts über die dazwischen liegenden Werte aus. Der Vorteil ist, dass wir die Spannweite schon bei ordinalskalierten Werten bestimmen können. Definition (Quartilsabstand) Der Quartilsabstand bezeichnet die Spannweite zwischen unterem und oberem Viertel einer Verteilung, d. h. er gibt den Abstand für die mittleren 50% der Fälle an. Auch dieses Maß eignet sich bereits für ordinale Größen. Definition (mittlere lineare Abweichung d) Die mittlere lineare Abweichung d (engl.: mean deviation) bietet sich bei metrisch skalierten Merkmalen als Streuungsmaß an. Sie ist das arithmetische Mittel der absoluten Abweichungen der einzelnen Messwerte vom Mittelwert. Carsten Püttmann Document1 Seite 20 Stand: 02. Juli 2011 Üblicherweise wird zur Berechnung das arithmetische Mittel als Mittelwert verwendet, so dass sich ergibt: 𝑛 1 𝑑 = ∑| 𝑥𝑖 − 𝑀 |. 𝑛 𝑖=1 Die mittlere lineare Abweichung vom arithmetischen Mittel wird in der Praxis selten benutzt; die ebenfalls mögliche lineare Abweichung vom Median fast überhaupt nicht. Dennoch sind diese Maße für Zwecke der Deskriptivstatistik brauchbare und anschaulich interpretierbare Kennzahlen zur Messung der Dispersion. Für den einfachen Vergleich von Stichprobenergebnissen wäre die Angabe und der Vergleich der mittleren linearen Abweichung durchaus ausreichend. Nicht zuletzt aus Gründen der Generalisierbarkeit von Stichprobenergebnissen ( Inferenzstatistik) werden allerdings andere Dispersionsmaße vorgezogen, nämlich die Varianz s² als mittlere quadratische Abweichung und ihre Wurzel, die Standardabweichung s. Definition (Varianz s²; Standardabweichung s) Die Varianz s² wird definiert als mittlere quadratische Abweichung vom arithmetischen Mittel. Ihre Wurzel wird als Standardabweichung s bezeichnet. 𝑛 1 𝑠 = ∑(𝑥𝑖 − 𝑀)2 𝑛 2 𝑖=1 bzw. 𝑛 1 𝑠 = √𝑠 2 = √ ∑(𝑥𝑖 − 𝑀)2 . 𝑛 𝑖=1 Durch das Quadrieren der Abweichungen vom arithmetischen Mittel werden negative Differenzen vermieden; die Standardabweichung wiederum erlaubt eine Interpretation des Ergebnisses in der ursprünglichen Dimension. Beispiel 2c (Varianz und Standardabweichung 1) Es liegen folgende zehn Werte vor: 26 ml; 28 ml; 26 ml; 31 ml; 29 ml; 23 ml; 36 ml; 24 ml; 32 ml; 25 ml Dies ergibt einen Mittelwert von: 𝑀 = 28 [𝑚𝑙]. Varianz und Standardabweichung errechnen sich wie folgt: 𝑠2 = Carsten Püttmann 1 [(26 − 28)² + (28 − 28)² + ⋯ + (32 − 28)² + (25 − 28)²] = 14,8 10 Document1 Seite 21 Stand: 02. Juli 2011 und 𝑠 = √14,8 ≈ 3,847. Häufig können wir uns die Berechnung mit Hilfe von Tabellen erleichtern: Beispiel 2d (Varianz und Standardabweichung 2) Gegeben ist folgende Tabelle: Tab.14: Beispiel Varianz und Standardabweichung VP xi xi M ( x i M)2 1. 123 -15,75 248,0625 2. 158 19,25 370,5625 3. 112 -26,75 715,5625 4. 162 23,25 540,5625 4 4 x i 555 4 ( xi M ) 0 i 1 i 1 ( x i M ) 2 1874 ,75 i 1 mit M 4 1 4 xi i 1 555 138,75 4 ergibt sich s² 4 1 4 x i M 2 i 1 1874,75 468,6875 4 bzw. s s² Carsten Püttmann 1 4 4 xi M 2 468,6875 21,65 i 1 Document1 Seite 22 Stand: 02. Juli 2011 Es bleibt zu klären, wie die errechneten Kenngrößen, wie die Varianz bzw. Standardabweichung zu interpretieren sind. Was bedeutet es beispielsweise, wenn in einem Test ein Mittelwert von 50 Punkten und eine Standardabweichung von 10 Punkten auftreten? Um hier eine Antwort geben zu können, betrachten wir die sogenannte Normalverteilung ( Abb.94): Diese Häufigkeitsverteilung hat einen unimodalen und glockenförmigen Verlauf. Abb.94: Normalverteilung Liegt annähernd eine Normalverteilung vor, dann gilt, dass im Intervall [M-s;M+s] ca. zwei Drittel aller untersuchten Fälle (68,27%) zu finden sind. Erweitern wir den Bereich auf zwei Standardabweichungen [ M - 2s ; M + 2s ], so befinden sich in diesem Intervall ca. 95% (95,45%) aller Fälle. Beispiel 2e (Normalverteilung) Bei einer schulinternen Studie wurde der Intelligenzquotient für jede Schülerin und jeden Schüler der FOS12 getestet. Dabei ergab sich ein arithmetisches Mittel von M = 95 und eine Standardabweichung von s = 9. Wir nehmen an, dass die Häufigkeitsverteilung annähernd normalverteilt ist, dann befinden sich im Intervall [95-9 ; 95+5 ] = [86 ; 104 ] ca. 68% aller Schülerinnen und Schüler der untersuchten Jahrgangsstufe. Umgekehrt lässt sich formulieren: Bei Vorliegen einer Normalverteilung ist die Wahrscheinlichkeit, dass ein Messwert um mehr als eine Standardabweichungseinheit vom Mittelwert abweicht, ca. 32%. Carsten Püttmann Document1 Seite 23 Stand: 02. Juli 2011 Übungaufgaben 1. Im Biologieunterricht wird in einer Klasse von jedem der 26 Schüler eine Bohne gepflanzt. Nach einiger Zeit wird die Länge der verschiedenen Ranken gemessen. Dabei ergeben sich die folgenden (ungeordneten) Daten (Angabe in mm): a. b. c. d. e. f. g. 2. 6,15 7,51 6,18 4,98 6,49 7,95 8,62 7,25 5,98 7,16 6,09 6,44 7,95 4,99 8,55 8,19 7,95 6,46 4,91 7,64 4,99 8,46 5,22 9,36 4,99 5,67 Bestimmen Sie den arithmetischen Mittelwert M. Bestimmen Sie den Median Md. Bestimmen Sie den Modalwert Mo. Bestimmen Sie die Spannweite der Werte aus der Tabelle. Bestimmen Sie die mittlere lineare Abweichung. Bestimmen Sie die Varianz. Bestimmen Sie die Standardabweichung. Bei einem Preisvergleich für ein neues Notebook im Internet ergaben sich folgende Preise in Euro: Preis H(x i ) 627 659 679 698 699 719 729 789 2 5 4 3 7 6 3 1 a. Berechnen Sie den arithmetischen Mittelwert. b. Bestimmen Sie die Varianz und die Standardabweichung. 3. In der folgenden Tabelle wurde der Fernsehkonsum der Schülerinnen und Schüler der Klasse FSP1 an einem Montag erfasst. Zur besseren Übersicht erfolgte eine Klasseneinteilung. Bestimmen Sie das arithmetische Mittel sowie Varianz und Standardabweichung. Halten Sie Ihre Ergebnisse in einem Kurzbericht fest. Zeit in min 0 – 59 60 – 119 120 – 179 180 - 239 H(x i ) 2 21 6 1 Klassenmitte 29,5 89,5 149,5 209,5 Referatsthema Insbesondere beim Vergleich von Messwerten interessiert man sich dafür. Wie dicht beieinander z. B. die mittleren 50% der Werte liegen. Dazu teilt man die Spannweite in vier Bereiche, die sog. Quartile. Stellen Sie da, wie man diese Quartile bestimmt und wie man diese mit Hilfe eines Boxplots darstellt. Gehen Sie dabei von einer Beispielsituation aus. Carsten Püttmann Document1 Seite 24 Stand: 02. Juli 2011 3. 4. Lineare Regression und Korrelation 3.1 Maße des Zusammenhangs (Korrelationsmaße) 3.1.1 Der Produkt-Moment-Korrelationskoeffizient (PMK) 3.1.2 Der Spearman’sche Rangkorrelationskoeffizient (SRK) 3.1.3 Der Kontingenzkoeffizient 3.1.4 Der Phi-Koeffizient 3.1.5 Korrelation und Kausalität 3.2 Lineare Regression Funktionen 4.1 Eindeutige Zuordnung, Definitionsmenge, Wertemenge 4.2 Darstellungen von Funktionen (Funktionsgleichung, Wertetabelle, Graph) 4.3 Ganzrationale Funktionen (Achsenabschnitte, Symmetrieeigenschaften, Monotonie) 4.3.1 Lineare Funktionen 4.3.2 Quadratische Funktionen 4.3.3 Ganzrationale Funktionen (mindestens bis Grad 4) Carsten Püttmann Document1 Seite 25