Lineare Diskriminanzfunktionen
Werbung

Maschinelles
Lernen
Metriken für Nearest Neighbour-Verfahren
Lineare Diskriminanzfunktionen
Metriken
Bei nearest-neighbour-Verfahren wird der Klassifikator einzig durch die
Daten und das Distanzmaß festgelegt. Expertenwissen kann hier
ausschließlich durch die Wahl des Distanzmaßes einfließen!
(Vergleiche: Bei einem parametrischen Modell wird der Klassifikator
durch die Daten und das Verfahren zur Parameterschätzung festgelegt)
Definition Distanzmaß: Eine Funktion d: X x X → ℝ heißt Distanzmaß
oder Metrik auf X, wenn gilt:
1. d(a,b) ≥ 0 für alle a,b∊X (Nicht-Negativität)
2. d(a,b) = 0 genau wenn a=b (Definitheit)
3. d(a,b) = d(b,a) für alle a,b∊X (Symmetrie)
4. d(a,b)+d(b,c) ≥ d(a,b) für alle a,b,c∊X
(Dreiecksungleichung)
(Anm.: Axiom 1 folgt aus den restlichen Axiomen)
Seite
5/16/2016|
2
Metriken
Beispiele:
1/ p
p
x p ( x1 ,..., xn ) p x j
Die
auf
(p≥1) :
j 1
d
(
x
,
y
)
x
y
induziert eine Metrik
p
n
Lp-Norm
ℝn
Einheitskugeln
verschiedener
Lp-Normen
Für 0<p<1 ist die analog
definierte Funktion d
keine Metrik (wieso?).
Seite
5/16/2016|
3
(Manhattan Distanz)
Metriken
Mahalanobis Distanz:
Sei < , > ein postitiv definites Skalarprodukt im ℝn. Dann lässt sich dies
darstellen durch
<x,y> = xTAy mit einer geeigneten symmetrischen, positiv definiten Matrix
A ∊ ℝnxn. Dies induziert eine Norm
x x, x
und somit eine Metrik d ( x, y) x y ( x y)T A( x y)
Verbindungen zur Diskriminanzanalyse:
Nimmt man an, dass die Daten einer Klasse ω einer
multivariaten Normalverteilung entspringen, z.B.
1
p ( x) exp( 0.5 ( x )T ( x ))
so kann man μω,Σω durch den Mittelwert bzw. die
Kovarianzmatrix der Daten in Klasse ω schätzen. Ein
neuer Punkt x wird dann in die Klasse ω klassifiziert,
für die die Mahalanobis-Distanz
Seite
5/16/2016|
4
d ( x, ) ( x )T 1 x )
d=1
1 3
3 1
minimal ist (sofern die Streuung |Σω| für alle
Gruppen gleich ist)
Metriken
Canberra Distanz:
Sind alle Features eines Datenpunktes x=(x1,…,xn) nicht-negativ, d.h. gilt
xj≥0 für alle j, dann ist
n |x y |
d ( x, y )
j 1
j
j
xj yj
eine Metrik, die Canberra-Metrik.
Hamming Distanz:
Sind alle Features eines Datenpunktes x=(x1,…,xn) binär, dann ist
d ( x, y ) | { j | x j y j } |
eine Distanzfunktion, die Hamming-Distanz. Fasst man die binären Werte 0
bzw. 1 als reelle Zahlen auf, so ist dies gerade die Manhattan Distanz.
(Pearson-)Korrelationsdistanz:
Für reelle Features und für das euklidische Skalarprodukt samt zugehöriger
Norm sei
Z ( x) ( x x ) / x x
Dann heißt
r ( x, y) Z ( x), Z ( y) / n die Pearson-Korrelation von x und y,
und d ( x, y ) 1 r ( x, y ) ist eine Metrik, die Korrelationsmetrik.
Seite
5/16/2016|
5
Metriken
Tanimoto Distanz:
Sind alle Features eines Datenpunktes x=(x1,…,xn) binär, dann ist
d ( x, y )
|{ j | x j y j}|
| { j | x j 1 oder y j 1} |
eine Distanzfunktion, die Tanimoto-Distanz.
Will man Teilmengen X bzw. Y einer Menge M vergleichen, so betrachtet
man x=(xj)j∊M, mit xj=1 genau wenn j∊X; y wird analog definiert. Dann ist
die Tanimoto Distanz von x und y:
d ( x, y )
| X \Y | |Y \ X |
| X Y |
Es wird also eine Ähnlichkeit von X und Y gemessen.
Seite
5/16/2016|
6
Metriken
Tangentendistanz (kommt of in der Bildanalyse zum Einsatz):
Eine Beobachtung x∊X (z.B. ein Bild) definiert eine ganze Menge von
x , d.h. P(ω|x) = P(ω|m) für alle m∊ ~x (z.B. könnte
„äquivalenten“ Beobachtungen ~
~x die Menge aller horizontal oder vertikal verschobenen Bilder von x sein).
Trainingspunkt x1
Trainingspunkt x2
Seite
5/16/2016|
7
Testpunkt y
Naive Verwendung eines Abstandsmaßes
führt dazu, dass ein verschobenes Muster
fehlklassifiziert wird. In diesem Beispiel
wäre ein vernünftiges Abstandsmaß
invariant gegenüber Translationen.
Metriken
Tangentendistanz (kommt of in der Bildanalyse zum Einsatz):
Eine Beobachtung x∊X (z.B. ein Bild) definiert eine ganze Menge von
x , d.h. P(ω|x) = P(ω|m) für alle m∊ ~x (z.B. könnte
„äquivalenten“ Beobachtungen ~
~x die Menge aller horizontal oder vertikal verschobenen Bilder von x sein).
Mit n Beobachtungen x1,…xn und deren Klassenzugehörigkeiten ω1,… ω n hat
man de facto die Beobachtungen ~x j mit den Klassenzugehörigkeiten ωj,
j = 1,…,n gemacht. Zur nearest neighbour Klassifikation einer neuen Beobachtung
y sucht man daher den kleinsten Abstand y zu den Vertretern aus ~x jd.h. man sucht
d ( y, ~x j ) inf~ d ( y, a)
ax j
x j zu aufwändig oder unmöglich ist,
Da die komplette Aufzählung aller a ~
nähert man xj durch einen affinen Raum an, indem man sich ~x j durch
„differentielle Operationen“ entstanden denkt, d.h. man berechnet
k x kj x j
x kj Nahe Umgebung ( ~
x j ) , k 1,..., K
und mit der Matrix ( k ) k 1... K (die man nur ein Mal bei der Präprozessierung berechnet) nähert man
d ( y, ~x j ) inf~ d ( y, a) inf K d ( y, x j a) d ( y, x j R k )
Seite
5/16/2016|
8
ax j
aR
Metriken
Die Idee hierbei ist, dass die Tangenten-Näherung für Punkte, die sich nahe bei der
neuen Beobachtung y befinden, gut ist. Für weit entfernte Punkte muss die
Näherung gar nicht gut sein, da diese Punkte sowieso als Nachbarn von y
ausgeschlossen werden sollen. Die Gefahr, dass durch die Tangenten-Näherung
ein weit entfernter Punkt (bzw. seine Äquivalenzklasse) fälschlicherweise als
benachbart zu y bewertet wird, ist dagegen gering.
Δa
Δ2
Δ1
Seite
5/16/2016|
9
Bem.: Ist d z.B. der euklidische
Abstand, so lässt sich das Minimum der
quadratischen Funktion d 2 ( y, x j Rk )
schnell berechnen.
~
x'
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
10
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
11
Lineare Diskriminanzfunktionen
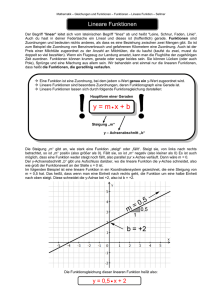
g ( x) wT x w0 w0 x0 w1 x1 ... wn xn
Seite
5/16/2016|
12
Aus: Duda, Hart, Stork. Pattern Classification
Lineare Diskriminanzfunktionen
g ( x) wT x w0
Seite
5/16/2016|
13
Lineare Diskriminanzfunktionen
g ( x) wT x w0
Seite
5/16/2016|
14
Lineare Diskriminanzfunktionen
Mehr als zwei Klassen
Paarweises Lernen I:
Entscheide, ob x∊ωj
oder x∉ωj , j=1,…,n.
Paarweises Lernen II:
Entscheide, ob x∊ωj
oder x ∊ωk , j,k =
1,…,n, j≠k.
Seite
5/16/2016|
15
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
16
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
17
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
18
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
19
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
20
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
21
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
22
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
23
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
24
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
25
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
26
Lineare Diskriminanzfunktionen
Seite
5/16/2016|
27