Datenanalyse01
Werbung

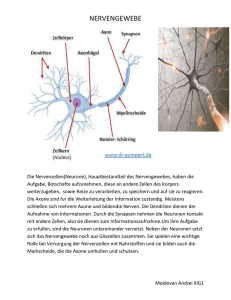
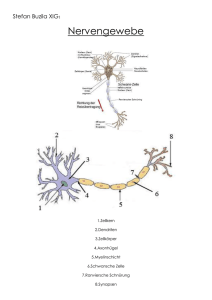
Neuronale Netzwerke Biologisches Vorbild Grundlagen Was sind künstliche neuronale Netzwerke? • Neuronale Netzwerke (NN, oft auch künstliche Neuronale Netzwerke KNN bezeichnet) sind Computerprogramme, die die Arbeitsweise natürlicher Neuronen nachahmen. • Zwecke dieser Programme können sein – Modellierung tatsächlicher neuronaler Vorgänge in der Biologie – Einsatz der Möglichkeiten neuronaler Systeme in Computerprogrammen WS 2010/11 H. Werner : Datenalyse §1 : 2 Das biologische Vorbild • Biologisches Vorbild der künstlichen Neuronalen Netze sind die Neuronen-geflechte, wie sie in menschlichen und Tierischen Nervenbahnen und Gehirnen vorkommen. Ein menschliches Gehirn besteht aus ca. 100 Billionen Neuronen, die mit ihren Axonen und Dendriten über Synapsen zusammengeschaltet sind. WS 2010/11 H. Werner : Datenalyse §1 : 3 Arbeitsweise • Die Arbeitsweise Neuronaler Netzwerke ist bestimmt durch – massiv parallele Informationsverarbeitung in den Neuronen – Propagierung der Informationen über die Synapsen (Neuronenverbindungen) – Vorbereitung der Netze für ihre Arbeitsphase (Propagierung) durch die Aufbauphase (Netztopologie) und eine Trainingsphase (kein Programmieren!) WS 2010/11 H. Werner : Datenalyse §1 : 4 Biologie der Nervenzellen • • • • Eine biologische Nervenzelle besteht aus dem eigentlichen Zellkörper (Soma), den Dendriten, das sind kurze Leitungen (um 0.4 mm), über die Reize in die Nervenzelle gelangen können, dem Axon, das ist die Leitung (mm-Bruchteil bis mehrere m lang), über die Zellaktivität an andere Zellen weitergeleitet wird, und schließlich den Synapsen, das sind die Kontaktstellen zwischen Axonen und Dendriten bzw. Soma. Da Dendriten und Axon stark verästeln, entstehen die hohen Verbindungszahlen biologischer Nervensysteme. Wird das Soma über einen gewissen Schwellwert hinaus über die Dendriten aufgeladen, so entlädt sich die Zelle einen kurzzeitigen elektrischen Impuls (Spike), der vom Axon an andere Zellen übertragen wird. Da die biologische Information nicht in der Amplitude der Spikes sondern in deren Frequenz codiert ist, können diese Spikes ohne weiteren Verstärkungsmechanismus auf alle Verzweigungen des Axons weitergeleitet werden. Die Synapsen sind chemische Kontakte, die auf einen Spike mit der Ausschüttung gewisser Ionen (Neurotransmitter) reagieren, die dann wiederum Potentialänderungen (und damit Spikes) in den Dendriten erzeugen. Die neue Spikefrequenz ist dann in Abhängigkeit von der Stärke des Kontaktes (Synapsengewicht) proportional zur ankommenden Spikefrequenz. Dabei können die Spikes zur Anregung des Somas beitragen (exzitatorische Synapsen) oder im Gegenteil hemmend wirken (inhibitorische Synapsen). WS 2010/11 H. Werner : Datenalyse §1 : 5 McCulloch-Pitts (1940) • (W.McCulloch, W.Pitts: A logical calculus of the ideas immanent in nervous activity. Bull. of Math. Biophysics 5, 1943, 115-133) • Dieses einfache Modell sieht die Neuronen als Input-abhängige 0-1Signalgeber, die intern einen Schwellwert a haben. Wenn der Gesamtinput diesen Schwellwert erreicht oder überschreitet gibt das Neuron 1 aus (spike) und sonst 0. Der Input kommt über Leitungen, die excitatorisch (anregend) oder inhibitorisch (hindernd) sein können, jedes Neuron ermittelt nun seinen Gesamtinput als die Summe aller Signale auf den excitatorischen Leitungen vermindert um die Summe aller Signale auf den inhibitorischen Leitungen zu dem Neuron. Erstes Ergebnis dieser Untersuchungen war, daß die durch solche Neuronalen Netze (am grünen Tisch durch Programme) realisierbaren Funktionen genau die im mathematischen Sinne berechenbaren Funktionen sind. Dieser Netztyp realisiert aber noch keine Anpassung (Training/Lernen) an ein gegebenes Problem. • WS 2010/11 H. Werner : Datenalyse §1 : 6 Neuronen Der Input ist gekennzeichnet durch die Aktivierungs-Funktion. Diese legt fest, wie die über die Verbindungen eingehenden Reize xi mit den Gewichten wi zu einem Gesamtreiz (Aktivierung) zusammengefaßt werden. Die Output-Funktion legt fest, wie der Output aus dem oben berechneten Gesamtreiz ermittelt wird. In dieser Funktion spielt ggf. ein besonderer Parameter Schwellwert eine Rolle. Der Output wird dann über die Verbindungen als Reiz an andere Neuronen geleitet WS 2010/11 H. Werner : Datenalyse §1 : 7 Topologie • Ein neuronales Netzwerk besteht aus einer Anzahl von Neuronen (bildlich durch kleine Kreise dargestellt), die untereinander verbunden sein können (die Verbindungen werden hier durch Pfeile dargestellt). • Die Struktur aller vorhandener Verbindungen heißt die Topologie des Netzwerks. Sie gibt also Antwort auf die Frage, welches Neuron ist mit welchem Neuron direkt verbunden. • Zur Topologie gehört noch die Festlegung, welche Neuronen Input von aussen bekommen bzw. Output nach aussen weitergeben WS 2010/11 H. Werner : Datenalyse §1 : 8 Propagierung • Das Verhalten eines neuronalen Netzwerks ist bestimmt durch die Gewichte seiner Verbindungen. – eine passende Folge von Werten wird in die Input-Neuronen eingegeben – die Neuronen berechnen ihren Output und geben den über die Verbindungen an andere Neuronen weiter – Dieser Schritt wird solange wiederholt, bis sich bei keinem Neuron der Input mehr verändert – Der Netz-Output ist nun die Folge der Outputs der speziellen Output-Neuronen • Bei geschichteten Netzen muss der Input nur von einer Schicht zur jeweils nächsten Schicht weitergegeben (propagiert) werden . • Bei Netzen mit Rückkopplungen (zyklen) läuft die Weitergabe so lange, bis das Netz stabil wird, d.h. die Aktivitäten der Neuronen ändern sich nicht mehr. (Es ist mathematisch nicht zwingend, dass ein stabiler Zustand überhaupt erreicht wird!) WS 2010/11 H. Werner : Datenalyse §1 : 9 Modellierung • Damit zeigt ein neuronales Netzwerk ein bestimmtes (von den Gewichten abhängiges) Input- Output-Verhalten, das bei hinreichender Ähnlichkeit als Modell für das Input- OutputVerhalten eines Prozesses genommen werden kann. • Ziel einer Modellierung ist es also für einen gegebenen Prozess ein geeignetes Netzwerk und darin geeignete Gewichte zu finden, damit der Prozess genau genug beschrieben (simuliert) wird. WS 2010/11 H. Werner : Datenalyse §1 : 10 Training • Hat man ein Netzwerk entworfen, das die richtige Anzahl von Input- und Output-Neuronen besitzt, besteht die Aufgabe darin, die Gewichte geeignet zu bestimmen, dies nennt man Training des Netzwerks. • Dazu benötigt man zunächst einen Satz Prozessdaten, in denen das Input-Output- Verhalten des Prozesses dokumentiert ist. • Die Datensätze des Prozesses gibt man nun in das Netzwerk, das zunächst mit beliebigen Gewichten initialisiert wurde, und vergleicht den Netz-Output mit dem Prozessoutput. • Es müssen nun Lernregeln entwickelt werden, die eine Veränderung der Gewichte in so einer Weise erzeugen, dass bei der nächsten Eingabe desselben Datensatzes der gemachte Fehler geringer wird. WS 2010/11 H. Werner : Datenalyse §1 : 11 D-Regel • Ein einfaches Beispiel ist die D-Regel, bei der das Gewicht einer Verbindung vergrößert (verkleinert) wird, wenn der Output zu klein (zu groß) ist. • Dies ist eine Fehler-orientierte (supervised) Lernregel WS 2010/11 H. Werner : Datenalyse §1 : 12 Hebb-Regel • Die Hebb-Regel belohnt (verstärkt) Verbindungen, bei denen beide Neuronen starke Aktivität zeigen. • Dies ist eine selbst-organisierte (unsupervised) Lernregel WS 2010/11 H. Werner : Datenalyse §1 : 13 Lernparadigmen 1. 2. 3. Überwachtes Lernen (supervised, mit Lehrer, output-oriented) Das Netzwerk verarbeitet den Trainingsinput und liefert sein Ergebnis, das ein Lehrer mit dem gewünschten Output vergleicht. In Abhängigkeit von dem Fehler wird das Netzwerk so verändert, daß dieser Fehler verringert wird. Unüberwachtes Lernen (selforganized, durch Gewöhnung, input-oriented) Das Netzwerk verarbeitet die Inputs und verändert sich dabei so, daß es auf die präsentierten Inputs immer stärker reagiert. verstärkendes Lernen (reinforced, mit Belohnung, behavior-oriented) Das Netzwerk verarbeitet die Inputs und überprüft, ob seine Aktivitäten eine bestimmte vorgegebene Form haben. Im positiven Fall wird das Verhalten des Netzwerks verstärkt. online-(Einzelschritt)-learning : nach jeder Eingabe wird gelernt offline(Gesamtschritt)-learning: nach Eingabe aller Datensätze der Trainingsdatei wird ein Anpassungsschritt gemacht. WS 2010/11 H. Werner : Datenalyse §1 : 14 Generalisierungstest • • Die vorhandenen Daten werden in zwei Gruppen geteilt, die Trainingsdaten und die Testdaten Nach erfolgreichem Training mit den Trainingsdaten wird mit den Testdaten überprüft, ob das Netz auch auf diesen zufriedenstellend arbeitet. WS 2010/11 H. Werner : Datenalyse §1 : 15 das Perceptron • Ein Perceptron verfügt x1 x2 x3 ... über eine Input-Schicht, über die n Inputs als Vektor x=(x1,..,xn) eingegeben werden. • Es hat n Verbindungen zu dem Output-Neuron mit dem s Gewichtsvektor w=(w1,..,wn). • Das Output-Neuron hat den Schwellwert s, errechnet seine Aktivität a = xw = x1w1 +..+ xnwn nach der Skalarprodukt-Regel und verwendet die Sprungfunktion (x< s)?0:1 als Output-Funktion. • Der Output errechnet sich also aus der Formel: o = 0 falls xw = x1w1 +..+ xnwn < s und o = 1 sonst; es entscheidet also das Vorzeichen des Skalarprodukts yv = x1w1 +..+ xnwn-s der erweiterten Vektoren y=(1,x1,..,xn) und v=(-s,w1,..,wn) über den Output. WS 2010/11 H. Werner : Datenalyse §1 : 16 xn Geometrische Interpretation • Die Gleichung wx = s beschreibt eine Hyperebene im ndimensionalen Raum, auf der der Vektor w senkrecht steht. • Der Inputraum wird dadurch in zwei Hälften geteilt, auf dessen einer Hälfte (wx < s) der Wert 0 ausgegeben wird, auf der anderen Hälfte der Wert 1. 1 x1 w WS 2010/11 x2 H. Werner : Datenalyse 0 §1 : 17 die Delta-Regel • • • Das Perceptron wird nach der sogenannten Delta-Regel output-orientiert trainiert. Beim Training werden dem Netzwerk Inputs aus einer Trainingsdatei präsentiert, für die die gewünschten (soll-) Outputs bekannt sind. Die aktuellen Ist-Outputs des Netzes werden mit den Soll-Outputs verglichen und im Fall einer Diskrepanz die Gewichte und der Schwellwert nach folgender Formel angepaßt: 1. Delta-Regel: • • • WS 2010/11 wi,neu := wi,alt + xi*(Outputsoll - Outputist) Beachte: w0= -b (bias) , x0=1 Der Faktor xi sorgt dafür, daß eine Angleichung nur erfolgt, wenn die Verbindung wi tatsächlich zu dem Output beiträgt. Outputsoll – Outputist ist der aktuelle Fehler des Netzes. H. Werner : Datenalyse §1 : 18 Korrektheit Der Perceptron Lernalgorithmus wird nun wie folgt interpretiert • Es gibt zwei Mengen Y und Z auf deren Elemente das Perzeptron mit 0 bzw. 1 antworten soll, also yv<0, zv>0 muß für ein geeignetes v gelten. • Ist y Y oder z Z ein Element, das noch nicht korrekt behandelt wird (yv>=0 , zv<=0 ), dann erzeugt die DeltaRegel ein neues vneu := valt-y , vneu := valt+z und beim nächsten Versuch mit demseben y, z ist yvneu= yvalt-yy < yvalt, bzw , zvneu= zvalt+zz > zvalt. • Das Verfahren beginnt also mit einem beliebigen erweiterten Gewichtsvektor v0 und addiert (subtrahiert) sukzessive erweiterte Inputs z , bei denen der Output noch nicht korrekt ist und wird dabei immer besser. • Der Perceptron Konvergenz Satz besagt nun, daß dieses Verfahren nach endlich vielen Schritten bei einer Lösung v endet, falls es überhaupt eine Lösung gibt. WS 2010/11 H. Werner : Datenalyse §1 : 19 Konvergenz Satz • SATZ: Wenn ein Perceptron eine Klasseneinteilung überhaupt lernen kann, dann lernt es diese mit der Delta-Regel in endlich vielen Schritten. – Problem: Wenn der Lernerfolg bei einem Perceptron ausbleibt, kann nicht direkt erkannt werden, ob 1. das Perceptron die Klassifikation prinzipiell nicht lernen kann, oder 2. der Lernalgorithmus mit seinen endlich vielen Schritten noch nicht fertig geworden ist, denn der Satz als reiner Existenzsatz gibt keinen Anhaltspunkt über eine obere Schranke für die Anzahl von Lernschritten. WS 2010/11 H. Werner : Datenalyse §1 : 20 Konvergenzbeweis • Nach Voraussetzung gibt es ein w mit wz>0 für alle zZ und wir beginnen den Algorithmus mit v0=0. (eigentlich müssen wir auch Y mit wy<0 für alle yY betrachten) • Sei a das Minimum aller wz>0 und M das Maximum aller z2. • vi = z1 +..+ z i , also ist wvi = wz1 +..+ wz i >= i*a. • Wegen (wv i)2 <= w2v i2 folgt v i2>= i2*a2/w2 • Andererseits ist für alle k <=i stets vk-1zk < 0 also vk2= (vk-1+zk)2 = vk-12 + 2*vk-1zk + zk2 < vk-12+ zk2 also ist v i2< z12+...+ zi2<i*M • Es folgt i*M > i2*a2/w2 und damit i < M*w2 / a2 Ohne Kenntnis von w kennen wir weder w2 noch a, also können wir die obere Schranke von i nicht aus dem Beweis bestimmen! WS 2010/11 H. Werner : Datenalyse §1 : 21 unlösbare Probleme • Die boolesche Funktion XOR stellt ein nicht linear separierbares Problem dar, weil sich die beiden Klassen auf Diagonalen gegenüberliegen. • Die Punkte (0,1) und (1,0) mit den Werten 1 liegen auf einer Diagonale und die beiden anderen auf der zweiten Diagonale. • Es gibt also keine Gerade, die Punkte (0,1) und (1,0) sowie (0,0) und (1,1) voneinander trennt . WS 2010/11 H. Werner : Datenalyse 1 0 0 1 §1 : 22 alternative Outputfunktion • Wähle man nun als alternative Outputfunktion die Funktion o(a) = 1-(a-1)2 • Mit den Gewichten 1 und 1 liefern (0,1) und (1,0) die Aktivität a=1 mit Output 1 und (0,0) bzw. (1,1) die Aktivitäten a=0 bzw. a=2 und damit den Output 0. • Problem: Wie trainiert man Netzwerke mit anderen Output Funktionen? WS 2010/11 H. Werner : Datenalyse 1 0 0 1 §1 : 23 zusätzliche Schichten • Mit einer Zwischenschicht lassen sich aber zwei trennende Hyperebenen definieren, zwischen denen die eine der Klassen lokalisiert werden kann. • komplexere Klassifikationen lassen sich durch Einfügen von Zwischenschichten realisieren. • Problem: Wie trainiert man mehrere Schichten? WS 2010/11 H. Werner : Datenalyse x0=1 1 0 0 1 x1 x2 w x3 x4 sr §1 : 24 Anwendungsgebiete • Mustererkennung Handschrift-Erkennung / Spracherkennung / optische Musterkassifikation / EEG-Klassifikation. • Codierung / Visualisierung Bildkompression / Sprachsynthese / Rauschfilter / Mapping z.B. in der Medizin. • Kontrolle Qualitätskontrolle (optisch, akustisch) / Robotersteuerung / Navigation / Schadens-Diagnostik / EEG-Überwachung. • Optimierung Parametervariation in Fertigungsprozessen / TSPProbleme / Scheduling-Probleme. WS 2010/11 H. Werner : Datenalyse §1 : 25