7.8 Kovarianz und Korrelation
Werbung

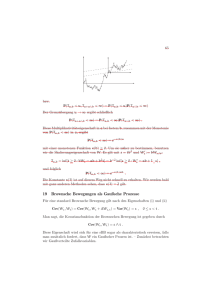
7.8 Kovarianz und Korrelation (7.8.1) E(X + Y ) = E(X) + E(Y ) Satz 7.8.1: V (X + Y ) = V (X) + V (Y ) + 2 Cov(X, Y ) Cov(X, Y ) := E(X · Y ) − E(X) · E(Y ) heißt die Kovarianz von X und Y . Satz 7.8.2: Für X, Y aus Def. 7.7.2 gilt: E(X · Y ) = Satz 7.8.3: X, Y unabhängig ⇒ 6 ⇐ m n P P ( xi yi pi,j ) i=0 j=0 Cov(X, Y ) = 0 ZV X, Y mit Cov(X, Y )=0 heißen unkorreliert Satz 7.8.4: Die ZV X1 , X2 , . . . , Xn sollen alle den gleichen Erwartungswert µ und die gleiche Varianz σ 2 besitzen. Dann gilt: a) E(X1 + X2 + . . . + Xn ) = n · µ b) Im Fall der Unabhängigkeit der ZV: V (X1 + X2 + . . . + Xn ) = n · σ 2 Def. 7.8.1: Es seien X und Y zwei beliebige ZV mit V (X), V (Y ) > 0. Dann heißt √ ) ̺(X, Y ) := √ Cov(X,Y V (X) V (Y ) der Korrelationskoeffizient von X und Y . (Maß für den linearen Zusammenhang von X und Y ) Satz 7.8.5: X, Y seien ZV aus Def. 7.8.1. Dann gilt: a) |̺(X, Y )| ≤ 1; dabei nennt man X und Y unkorreliert, schwach korreliert, stark korreliert, positiv korreliert, negativ korreliert, falls falls falls falls falls ̺(X, Y ) = 0 ist, (vgl. o.) |̺(X, Y )| nahe bei 0 aber > 0 ist, |̺(X, Y )| nahe bei 1 ist, ̺(X, Y ) > 0 ist, ̺(X, Y ) < 0 ist b) ̺(X, Y ) = +1 (bzw. -1) ⇐⇒ Y = a + bX (fast sicher) für geeignete Konstante a ∈ IR und b > 0 (bzw. b < 0) Fasst man die Messwertpaare (x1 , y1 ), (x2 , y2 ), . . . , (xn , yn ) als Realisation von einem Paar (X, Y ) von ZV auf, so ist (vergl. (6.1.6)) b1 · b2 = (xy − x · y)2 , (x2 − x2 )(y 2 − y 2 ) wobei b1 (b2 ) die Steigung der ersten (zweiten) Regressionsgerade ist, ein Schätzwert für (̺(X, Y ))2 . Damit wäre folgender Ausdruck ein Schätzwert für ̺(X, Y ): (7.8.2) ̺ˆ = √ xy−x·y √ x2 −x2 y 2 −y 2 Es gilt also: Beide Regressionsgeraden sind gleich ⇔ b2 = 1/b1 ⇔ |ˆ ̺| = 1. Außerdem gilt analog zu Satz 7.8.5b) nach (6.1.6): (7.8.3) |ˆ ̺| = 1 ⇔ b1 · b2 = 1 ⇔ Alle Punkte (xi , yi ) liegen (exakt) auf einer Geraden. 57 Allgemein gilt: (7.8.4) |ˆ ̺| ≤ 1. Zur Bedeutung von ̺: q x2 − x 2 xy − x · y q ̺ˆ = q q = · = b1 · x2 − x2 y2 − y2 x2 − x 2 y 2 − y 2 xy − x · y Ist also ̺(X, Y ) := Cov(X, Y ) σ(X) · σ(Y ) s V ar(xi ) V ar(yi ) > 0 (< 0), so sind bei größeren Messergebnissen xi bei der Messgröße X entsprechend größere (kleinere) Messergebnisse yi bei der Messgröße Y zu erwarten, und zwar umso stärker, je größer |̺| ist. 7.9 Gesetz der großen Zahl Def. 7.9.1: Eine unendliche Folge von ZV X1 , X2 , . . . , heißen eine Folge unabhängiger ZV, wenn je endlich viele der ZV unabhängig sind. Satz 7.9.1 (Tschebyscheff-Ungleichung): P (|X − E(X)| ≥ t σ(X)) ≤ 1 t2 Satz 7.9.2 (Folgerung): Unter den Voraussetzungen von Satz 7.8.4 b) gilt: P (| X1 +X2n+...+Xn − µ| ≥ α) ≤ σ2 α2 n (n ∈ IN, α > 0) Satz 7.9.3 (Starkes Gesetz der großen Zahl): a) Es sei X1 , X2 , . . . eine Folge unabhängiger ZV, die alle die gleiche Verteilung, den gleichen Erwartungswert µ und die gleiche Varianz σ 2 besitzen. Dann gilt: X1 +X2 +...+Xn n → µ für n → ∞ (fast sicher) b) A ⊂ Ω sei ein Ereignis bei einem Zufallsexperiment, das beliebig oft wiederholt wird, und P (A) sei eine Wahrscheinlichkeit. Dann gilt für die rel. Häufigkeiten (vgl. Def. 7.2.6) hn (A) → P (A) für n → ∞ (fast sicher) 7.10 Zentraler Grenzwertsatz Satz 7.10.1: Unter den Voraussetzungen von Satz 7.9.3 a) gilt: P (a ≤ X1 + X2 + . . . + Xn − n · µ √ ≤ b) → Φ(b) − Φ(a) für n → ∞, d.h. nσ ≈ Φ(b) − Φ(a) für ”große” n Bem. : Häufige Anwendung von Satz 7.10.1: Annahme, dass eine unbekannte Verteilung durch eine Normalverteilung angenähert werden kann. Diese Anmahme ist nicht immer gerechtfertigt. 58