Datenbanken
Werbung

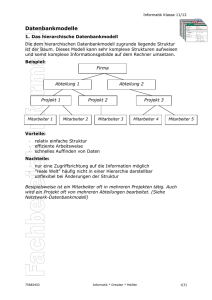
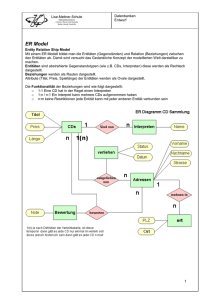
Datenbanken Wozu eine Datenbank? Kernaufgaben von Datenbanksystemen sind die Speicherung und Verwaltung von großen Datenbeständen. Beispiel einer Datenbank S-Nr Vor- Nachname name Geschlecht Straße PLZ Ort Klasse AG 1 Peter Lustig m Löwenzahn weg 3 823456 Gartensta 10 dt Schach 2 Peter Lustig m Löwenzahn weg 3 823456 Gartensta 10 dt Astrono mie 3 Anja Meyer w Meisenweg 1 823457 Nesthaus en 8 Badmint on 4 Anja Meyer w Meisenweg 1 823457 Nesthaus en 8 Theater Probleme • Falls ein Schüler mehrere AGs besucht, müssen mehrere Datensätze angelegt werden mit vollständiger Adresse • Ein Schüler besitzt mehrere Schülernummern • Werden mehrere Datensätze für einen Schüler angelegt, können Inkonsistenzen entstehen, falls die Adresse einmal falsch eingegeben wird Probleme • Beim Ändern von Schülerdaten (z.B. Adresse) müssen alle Datensätze berücksichtigt werden. Wird einer übersehen, kommt es zu einer Änderungsanomalie . • Beim Löschen von Schülern kann es ebenfalls zu Inkonsistenzen kommen, man spricht von einer Löschanomalie. • Soll eine neue AG angelegt werden, kann dies nur in Verbindung mit einem Schüler geschehen (Einfügeanomalie). Vermeidung von Anomalien durch Umstrukturierung der Daten; Regeln 1. Folgende Daten sollen gespeichert werden: Schülernummer, Vorname, Nachname, Geschlecht, Straße, PLZ, Ort, Klasse, AG 2. Ein Schüler kann verschiedene AGs besuchen. Eine AG kann von mehreren Schülern besucht werden. 3. Für einen Schüler wird eine Adresse erfasst. In einem Ort können mehrere Schüler wohnen. Dateisysteme Eigenschaften von Dateisystemen • Daten werden in unterschiedlichen Dateien gespeichert • Jede Anwendung greift auf eigene Dateien zu • Dateien sind unabhängig und können somit nicht verknüpft werden Probleme bei Dateisystemen (1) • Redundanz – Daten werden mehrfach in unterschiedlichen Dateien gespeichert. Das verschwendet Speicher. • Inkonsistenz – Werden Daten in einer Datei geändert, so müssen entsprechende Daten in anderen Dateien geändert werden. Das kann zu Fehlern führen. • Daten-Programm-Abhängigkeit – Wird die Datenstruktur geändert, müssen auch die Programme geändert werden. Probleme bei Dateisystemen (2) • Inflexibilität – Neue Anwendungen, die bereits vorhandene Daten nutzen, können nur schwer realisiert werden – Schwierig wird es auch, wenn Daten aus mehreren Dateien benötigt werden. • Mehrbenutzerbetrieb, Synchronisation – Bei gleichzeitigem Zugriff besteht die Gefahr des gegenseitigen Überschreibens von Daten • Datensicht – Unterschiedliche Anwender benötigen unterschiedliche Ansichten der Daten • Datensicherheit – Nicht jeder darf alle Daten sehen! Datenschutz! Ziele der Datenorganisation • Datenunabhängigkeit – Unabhängigkeit vom Anwendungsprogramm – Unabhängigkeit der logischen von der physischen Datenorganisation – Physische Datenunabhängigkeit • • • • • • • • Redundanzfreiheit Datenintegrität Benutzerfreundlichkeit Mehrfachzugriff, Synchronisation Datenschutz Datensicherheit Flexibilität Effizienz Was ist ein Datenbanksystem? Definition: Datenbanksystem Unter einem Datenbanksystem stellt man sich ein System vor, das es erlaubt große Datenmengen abzuspeichern, nach beliebigen Kriterien Daten wieder zu finden und Daten zu verändern. Beispielsweise möchte man, wenn man die Daten über alle Schüler einer Schule abgespeichert hat, die Anfrage stellen können: "Liste alle Schüler auf, die nicht in Augsburg wohnen und 18 Jahre alt sind." Aufbau und Konzept eines Datenbanksystems Datenbanksysteme werden im Folgenden als ein Organisationsmittel betrachtet, das folgende Aufgaben in einer Organisation abdeckt: • Die Daten der Organisation sind für alle Benutzer in einer gemeinsamen Datenbasis (der Datenbank) abgespeichert. • Viele Benutzer mit unterschiedlichen Anforderungen arbeiten mit diesen Daten. Das Datenbanksystem übernimmt den Zugriff und die Darstellung der gewünschten Daten. • Das Datenbanksystem kontrolliert den Zugang zu den Daten, es zeigt Daten nur berechtigten Benutzern. Aufbau und Konzept eines Datenbanksystems Was ist eine Datenbank? Definition: Datenbank Eine Datenbank ist eine integrierte Ansammlung von Daten, die Benutzern verschiedener Anwendungen als gemeinsame Basis für die Pflege und Gewinnung von Informationen dient. Aufbau einer Datenbank • Die Abspeicherung der Daten geschieht mit Hilfe von Tabellen. • Dabei entspricht eine Zeile der Tabelle einem Datensatz und eine Spalte der Tabelle einem Datenfeld. • Die Datensätze werden von verschiedenen Benutzern nach unterschiedlichen Kriterien sortiert. • Die Reihenfolge der Eingabe der Datensätze keine Rolle. Datenbank Eine Datenbank bietet die Möglichkeit des gleichzeitigen Zugriffs auf mehrere Dateien bzw. Tabellen (Vielfachzugriff), um Daten aus den unterschiedlichen Dateien (Tabellen) miteinander zu verknüpfen (Flexibilität), und auf diese Weise zusätzliche Informationen aus den bereits bestehenden Dateien (Tabellen) zu gewinnen. Hinzu kommt die Möglichkeit der komfortablen Beantwortung von Anfragen des Benutzers mit Hilfe einer integrierten Abfragesprache. Möglichkeiten eines Datenbanksystems Der Zugriff auf die Datenbank erfolgt ausschließlich über den "Filter" des Datenbank-Management-Systems (z. B. dBase, Oracle, Paradox, MS-Access). Ein Datenbanksystem ermöglicht dem Benutzer, über ein DBMS • die Struktur einer Datenbasis aufzubauen (Datendefinition), • Daten zu pflegen: Datensätze eingeben, ändern und löschen (Datenmanipulation), • Informationen aus der Datenbasis zu gewinnen (Datenabfrage), • Zugangs- und Zugriffsrechte zu verwalten (Datenkontrolle) und • Daten zu sichern, zu exportieren und zu importieren (Datenübertragung). Datenbankebenen im ANSIArchitekturmodell Datenbankebenen im ANSIArchitekturmodell Die Beschreibung einer Datenbank erfolgt nach diesem Konzept auf drei verschiedenen Ebenen, die jeweils durch eine andere Sichtweise geprägt sind: • Externe Ebene • Konzeptionelle Ebene • Interne Ebene Konzeptionelle Ebene • Der Kern dieser Architektur ist die konzeptionelle Ebene (auch konzeptuelle Ebene). Hier wird der Teil der Realität, den das Datenbanksystem (DBS) nachbilden soll, in seiner logischen Gesamtheit beschrieben. In dieser Ebene werden alle Daten und ihre Beziehungen zueinander modelliert. Darüber hinaus ist sie unabhängig von den hardwaremäßigen Gegebenheiten und den Anforderungen einzelner Benutzer. • Beispiel: Auf der konzeptionellen Ebene ist für ein Gehaltsabrechnungsprogramm z.B. festzulegen, dass es die Datensätze "Mitarbeiter" gibt, die die Personalnummer, den Namen, das Gehalt usw. enthalten. Ferner ist festzuhalten, in welcher Beziehung einzelne Mitarbeiter zueinander stehen (z.B. Abteilungsleiter) oder in welchem Bereich der Firma ein Mitarbeiter beschäftigt ist (z.B. Materiallager). Interne Ebene • Über bzw. unter der konzeptionellen Ebene liegen die interne und die externe Ebene. In der internen Ebene wird die Organisation der Daten und ihrer Zugriffspfade auf den physischen Speicher festgelegt. In dieser Ebene werden Fragen geklärt, wie: Welche Daten werden zu welchen Einheiten (Datensätzen) zusammengefasst und wie schnell wird darauf zugegriffen? • Beispiel: Auf der internen Ebene ist für das Gehaltsabrechnungsbeispiel zu definieren, in welcher Reihenfolge die Felder "Personalnummer", "Name", "Gehalt" usw. des Datensatzes "Mitarbeiter" gespeichert werden, welche Länge sie haben und wie die Daten codiert werden. Des Weiteren sind hier Angaben über die Dateiorganisation und die Zugriffsmechanismen zu den Daten (z.B. Hash-Verfahren, Binärbaum) notwendig. Externe Ebene • Die externe Ebene legt fest, welche Daten bestimmte Benutzer bzw. Programme sehen und bearbeiten können. Dabei kann es zu jedem Anwendungsprogramm ein eigenes externes Schema geben, welches die für das Anwendungsprogramm wichtigen Daten der Datenbank in der Weise definiert, wie sie das Programm als Eingabe erwartet. • Beispiel: Auf der externen Ebene ist für das Gehaltsabrechnungsbeispiel z.B. zu definieren, dass für die Statistiker von den Personaldaten nur das Gehalt (die Statistik soll anonym bleiben) und die Abteilung benötigt werden. Datenbankmodelle • • • • • Hierarchisches Datenbankmodell Netzwerkdatenbankmodell Relationales Datenbankmodell Objektorientiertes Datenbankmodell Objektrelationales Datanbankmodell Relationales Datenbankmodell • Das relationale Datenbankmodell wurde von Edgar F. Codd in den 1960ern/70ern entwickelt und ist ein mengenorientiertes Datenbankmodell. Die Firma Oracle veröffentlichte wenige Jahre später die erste funktionierende Datenbank, die nach diesem System funktionierte. • Das Relationale Datenbankmodell stellt man sich allgemein als 2dimensionale Tabelle vor. Es wird über Schlüssel definiert (Primärschlüssel) und verknüpft (Fremdschlüssel). Die Darstellung erfolgt sehr häufig im Entity-Relationship-Modell nach Chen. • Edgar F. Codd legte seinerzeit 12 Regeln fest, denen eine relationale Datenbank entsprechen sollte. (siehe Normalisierung) • Das relationale Datenbankmodell ist heute das am häufigsten verwendete Modell überhaupt, da es sich sehr einfach darstellen lässt. Der Nachteil dieses Modells liegt allerdings darin, dass unter Umständen durch eine große Anzahl an Tabellen Informationen weit verstreut sein können. Die goldenen Regeln der Relationalität Regel 1 (Darstellung von Information) Alle Informationen in relationalen Datenbanken müssen logisch in Tabellen dargestellt sein, insbesondere – Daten – Definitionen von Tabellen und Attributen – Integritätsbedingungen und die Aktion bei deren Verletzung (siehe Regel 10) – Sicherheitsinformationen (z.B. Zugangsberechtigungen) Regel 2 (Zugriff auf Daten) Jeder Wert einer relationalen Datenbank muss logisch durch eine Kombination von Tabellenname, Primärschlüssel und Attributname (Spaltenname) auffindbar sein. Dies bedeutet, dass in einer Tabelle an jedem Schnittpunkt einer Zeile mit einer Spalte nur ein Wert stehen darf. Die goldenen Regeln der Relationalität Regel 3 (Systematische Behandlung von Nullwerten) Nullwerte stellen in Attributen, die nicht Teil eines Primärschlüssels sind, eine fehlende Information dar und werden durchgängig gleich, insbesondere unabhängig vom Datentyp des Attributes, behandelt. (Man kann also nicht in numerischen Feldern bei fehlenden Daten das Feld leerlassen, und bei Textfeldern das Zeichen -- einfügen. Fehlende Informationen werden heute meist mit NULL bezeichnet.) Regel 4 (Struktur einer Datenbank) Die Datenbankstruktur wird in derselben logischen Struktur wie die Daten gespeichert, also in Tabellen. Dazu muss die Struktur aller Tabellen, die zu einer Datenbank gehören, in einer Tabelle (dem Katalog) zugänglich sein. Diese Forderung bedingt, daß sich eine Änderung im Katalog automatisch in einer geänderten Datenbankstruktur auswirkt! Die goldenen Regeln der Relationalität Regel 5 (Die Abfragesprache) Ein relationales System enthält mindestens eine befehlsgesteuerte Abfragesprache, die mindestens die folgenden Funktionen unterstützt: – Datendefinition – Definition von Views (logische Sichten der Datenbank, die der Benutzer aus den Attributen der Basistabellen erstellt und mit den gewohnten Operatoren manipulieren kann) – Definition von Integritätsbedingungen – Definition von Transaktionen (Eine Transaktion ist eine Folge von Befehlen, die eine Datenbank von einem konsistenten Zustand in einen anderen überführen. Eine Transaktion muss entweder vollständig durchgeführt oder, bei einem Abbruch, vollständig zurückgesetzt werden.) – Definition von Berechtigungen Eine weit verbreitete Abfragesprache ist SQL. Die goldenen Regeln der Relationalität Regel 6 (Aktualisieren von Views) Alle Views, die theoretisch aktualisiert werden können, können auch vom System aktualisiert werden. (Beispiel: Hat man zwei Spalten A und B mit Zahlen, so kann man sich eine weitere Spalte definieren, die A*B enthält. Ändert man einen Wert in dieser Spalte, so kann daraus nicht der Wert der Spalten A und B bestimmt werden, da im allgemeinen aus dem Produkt zweier Zahlen diese zwei Zahlen nicht bestimmt werden können. Dieses View kann also theoretisch nicht aktualisiert werden.) Problem: Im Allgemeinen kann nicht entschieden werden, ob ein View theoretisch aktualisiert werden kann Regel 7 (Abfragen und Editieren ganzer Tabellen) Abfrage- und Editieroperationen müssen als Operanden ganze Tabellen und nicht nur einzelne Sätze erlauben. Die goldenen Regeln der Relationalität Regel 8 (Physikalische Unabhängigkeit) Der Zugriff auf die Daten durch den Benutzer muss unabhängig davon sein, wie die Daten gespeichert werden oder wie physikalisch auf sie zugegriffen wird. Dies bedeutet, dass Anwendungen nur auf die logische Struktur des Systems zugreifen dürfen. (Beispiel: Die Daten dürfen auf einem Datenträger durchaus hierarchisch gespeichert sein. Nur die logische Struktur der Datenbank muß relational sein. Ändert der Datenbankverwalter die physikalische Struktur, darf der Anwender davon nichts mitbekommen.) Regel 9 (Logische Unabhängigkeit der Daten) Anwendungen und Zugriffe dürfen sich logisch nicht ändern, wenn Tabellen so geändert werden, dass alle Informationen erhalten bleiben (z.B. beim Aufspalten einer Tabelle in zwei Tabellen) Die goldenen Regeln der Relationalität Regel 10 (Unabhängigkeit der Integrität) Alle Integritätsbedingungen müssen in der Abfragesprache definierbar sein und in Tabellen dargestellt werden. Das System muss mindestens die folgenden Integritätsbedingungen prüfen: – Vollständigkeitsintegrität (Entity Integrity, Existential Integrity), d.h. ein Primärschlüssel muss eindeutig sein und darf insbesondere keinen Nullwert enthalten. – Beziehungsintegrität (Referentielle Integrität, Referential Integrity), d.h. zu jedem Fremdschlüsselwert existiert ein Primärschlüsselwert. Regel 11 (Verteilung der Daten) Anwendungen für eine nicht-verteilte Datenbank dürfen sich beim Übergang zu einer verteilten Datenbank logisch nicht ändern. (Beispiel: Wenn die oben beschriebenen Tabellen in einem Netzwerk auf zwei verschiedenen Rechnern gespeichert sind, darf sich bei der Anwendung nichts ändern, wenn die Tabellen irgendwann auf demselben Rechnern gespeichert werden.) Die goldenen Regeln der Relationalität Regel 12 (Unterlaufen der Abfragesprache) Unterstützt ein relationales Datenbanksystem neben der High-LevelAbfragesprache eine Low-Level-Abfragesprache, so darf diese die Integritätsbedingungen der High-Level-Sprache nicht unterlaufen. (Beispiel: Die Low-Level Abfragesprache darf z.B. nicht direkt auf die physikalischen Eigenschaften der gespeicherten Daten zugreifen.) ER-Modell ER-Modell • Basiert auf einem Artikel von Peter Pin-Shan Chen aus dem Jahre 1976 • „ER“ steht für Entity-Relationship • Entity = Objekt, Relationship = Beziehung • Das ER-Modell veranschaulicht grafisch die Beziehung von Objekten ER-Modell • Ein ER-Modell ist ein abstraktes Abbild der Wirklichkeit (=Miniwelt) • Aspekte werden weggelassen, vereinfacht oder zusammengefasst • Abstraktionsmechanismen sind – Klassifikation (Zusammenfassung von Objekten zu Klassen mit für für die Miniwelt relevanten Attributen) – Aggregation (Bestehende Klassen werden zu einer Oberklasse zusammengefasst) – Generalisierung oder Spezialisierung Entität Definition: Entität Eine Entität (engl. entity) ist eine eindeutig identifizierbare Einheit (Objekt) des betrachteten Modells. Das Identifizierungsmerkmal wird als Schlüssel bezeichnet. Eine Entität kann sein: • Ein Gegenstand (z.B. der Raum mit der Nr. 37) • Eine Person (z.B. der Schüler Hans Mustermann) • Ein abstraktes Konzept (z.B. der Kurs Informatik) • Ein Ereignis (z.B. eine mündliche Prüfung) Entitätsmenge Unter einer Entitätsmenge (entity set) versteht man eine konkrete Sammlung von Entitäten gleichen Typs (z.B. alle Schülerinnen und Schüler einer Schule). Die einzelnen Entitäten einer Entitätsmenge unterscheiden sich in verschiedenen Werten der Attribute (z.B. die Namen der Schüler). Zur grafischen Darstellung von Entitätsmengen werden Rechtecke verwendet Schwache Entitäten In den meisten Fällen sind Entities autonom und innerhalb der Entitätsmange eindeutig identifizierbar. Es gibt aber auch die Möglichkeit, dass Entities nur in Kombination mit dem Schlüssel eines dominanten Entity-Types identifizierbar sind. Solche Entitäten bezeichnet man als abhängig oder schwach. Beispiele für schwache Entitäten sind: • Die Bankverbindung eines Kunden, der eine Einzugsermächtigung erteilt hat. Beim Löschen des Kunden ist auch die Einzugsermächtigung zu löschen. • Eine Klasse einer Schule. Eine Klasse existiert nur an einer Schule und wird zum Teil auch durch die Attribute des Objekts Schule definiert. Schwache Entitäten werden in Grafiken als doppelte Rechtecke dargestellt. Zum übergeordneten Element zeigt ein Pfeil: Schwache Entität: Beispiel Subtyp und Supertyp Definition: Subtyp & Supertyp Ein Subtyp ist eine Untermenge von übergeordneten Objekten eines Supertyps. Sub- bzw. Supertypen stellen deshalb eine Besonderheit von Objekttypen dar, um Informationen hierarchisch abzubilden. Da es sich bei einem Einzelobjekt der spezialisierten Menge und der generalisierten Menge um "dasselbe" Einzelobjekt handelt, gelten alle Eigenschaften – insbesondere die Identifikation – und alle Beziehungen des generalisierten Einzelobjektes auch für das spezialisierte Einzelobjekt. Subtyp und Supertyp: Beispiele • Schüler (Merkmale: Name, Geschlecht, Wohnort,…) • Mittelstufenschüler (ist ein Schüler, erhält Noten von 1 bis 6) • Oberstufenschüler (ist ein Schüler, erhält in Kursen jedoch Punkte) Subtyp und Supertyp Attribute und Schlüssel Definition: Attribute und Schlüssel Attribute sind Informationsobjekte, die Objekttypenbeschreiben oder identifizieren. Attribute, die einen Objekttyp eindeutig identifizieren bezeichnet man als Schlüssel bzw. Schlüsselattribut. Objekt mit Attributen Beziehung zwischen Entitäten Definition: Beziehung Beziehungen sind Assoziationen zwischen Objekttypen und können grammatikalisch in der Regel durch Verben in einer Textbeschreibung ausgemacht werden. • Mehrere Entitäten können zueinander in Beziehung stehen. Beziehungen können zweistellig sein oder mehr als zwei Entitäten einbeziehen. • Da Beziehungen wechselseitig sind, ist die Richtung bei der Betrachtung von Bedeutung. • Zur grafischen Darstellung von Beziehungen verwendet man eine Raute. Die Verbindungen zu den entsprechenden Entitätsmengen werden durch Linien repräsentiert. Beispiele Beziehungsrichtung 1 Schüler belegt einen Kurs Beziehungsrichtung 2 Ein Kurs enthält Schüler Ein Kurs wird von einem Lehrer Lehrer unterrichtet einen Kurs unterrichtet Abteilung besteht aus Mitarbeiter gehört zu Abteilung Mitarbeitern Mitarbeiter hat Vorgesetzten Vorgesetzter hat Mitarbeiter Kunde bestellt Artikel Artikel wird von Kunde bestellt Beispielgrafik Kardinalität und Optionalität Beziehungen zwischen Objekttypen enthalten unterschiedliche Merkmale wie Kardinalität und Optionalität. Kardinalität legt fest, wie viele Objekte des einen Objekttyps in Beziehung zu einem Objekt des anderen Objekttyps stehen und umgekehrt. Optionalität legt fest, ob ein Objekt eines Objekttypsimmer in Beziehung zu einem anderen Objekt stehen muss, oder ob es optional ist. 1:1 Beziehung Jedes Entity vom Typ E1 steht höchstens mit einem Entity vom Typ E2 in Beziehung und umgekehrt. Die Grafik veranschaulicht eine 1:1 - Beziehung: Ein Lehrer kann einen Kurs leiten. bzw. Ein Kurs wird von einem Lehrer geleitet. 1:n Beziehung Jedes Entity vom Typ E2 steht höchstens mit einem Entity vom Typ E1 in Beziehung, es können aber mehrere aus E2 zum selben Entity aus E1 eine Beziehung haben. n:1-Beziehungen sind natürlich ganz analog definiert. Die Grafik veranschaulicht eine 1:n - Beziehung: Eine Klasse (kann) mehrere Schüler enthalten. bzw. Ein Schüler gehört zu einer Klasse. n:m Beziehung Jedes Entity aus E1 kann zu mehreren aus E2 eine Beziehung haben, und jedes Entity aus E2 zu mehreren aus E1. Die Grafik veranschaulicht eine n:m - Beziehung: Lehrer unterrichten Klassen. bzw. Eine Klasse kann von mehreren Lehrern unterrichtet werden. Aufgabe Entwirf ein Entity Relationship Modell für eine Musik/CDDatenbank. Die folgenden Informationen sollen sich verwalten lassen: Interpret / Band, Songtitel, Länge des Songs, Komponist, Erscheinungsjahr des Songs, Kennnummer der zug. CD, Titel der CD, die Songs auf einer CD. Man soll herausfinden können, ob eine Band einen Song auf mehreren CDs veröffentlicht hat (das ist oft der Fall). Man soll herausfinden können, ob ein Song von mehreren Interpreten veröffentlicht wurde (das ist nicht nur bei Bob Dylan der Fall). Man soll alle Songs einer CD finden können auch wenn die CD ein Sampler mit verschiedenen Interpreten ist. Normalisierung Anforderungen an Relationen Tabellen (Relationen) sollten letztlich so geplant werden, dass • logische Widersprüche (Inkonsistenzen, Anomalien) in der Datenbasis und • Datenredundanz (Mehrfachspeicherung gleicher Daten) vermieden sowie • eine höchstmögliche Flexibilität und schneller Zugriff gewährleistet werden. Normalisierung • Vermeidung redundanter Daten im Relationenmodell mittels Normalisierung • Normalisierung führt zu Vorgaben, die von Tabellen erfüllt werden müssen • Normalformen • Normalisierung ist weitere Technik zur Erstellung relationaler Datenbanken Normalisierung von Tabellen • Durch Normalisierung werden Tabellen in weitere Tabellen aufgeteilt, um redundante Daten zu vermeiden. • Es dürfen keine Informationen verloren gehen, so dass ein späteres Zusammensetzen der geteilten Tabellen über Fremd- und Primärschlüssel zur ursprünglichen Tabelle führen • Normalisierung nach Erstellen des Relationenmodells zur Überprüfung Durchführung einer Normalisierung • Schritt 1: Entfernung von Wiederholgruppen • Schritt 2: Entfernung redundanter Daten Funktionale Abhängigkeit • Das Attribut Farbe ist von dem Attribut Bezeichnung abhängig. Die Umkehrung gilt jedoch nicht. • Man sagt: Das Attribut Farbe ist von dem Attribut Bezeichnung funktional abhängig: formal: Bezeichnung Farbe Funktionale Abhängigkeit in der Mathematik • Die Funktion y=2x liefert für jeden x-Wert genau einen y-Wert. • Der y-Wert ist von dem x-Wert funktional abhängig Volle funktionale Abhängigkeit von Attributen • Die Attribute Bezeichnung und Geschmack bilden den Primärschlüssel • Es gilt: Bezeichnung, Geschmack Farbe • Es gilt auch: Bezeichnung Farbe • Es gilt jedoch nicht: Geschmack Farbe Volle funktionale Abhängigkeit von Attributen Man spricht von voller funktionaler Abhängigkeit, wenn jedes NichtschlüsselAttribut nur durch den gesamten Primärschlüssel eindeutig bestimmt werden kann. Minimaler Primärschlüssel Die Forderung nach voller funktionaler Abhängigkeit steht in unmittelbarem Zusammenhang mit der Forderung nach einem minimalen Primärschlüssel. Transitive Abhängigkeit von Attributen Aus Bezeichnung Typ und TypRäder folgt Bezeichnung Räder Transitive Abhängigkeit von Attributen • Die Attribute Bezeichnung, Typ und Räder sind transitiv abhängig, da: • Wenn eine Vespa ein Motorroller ist und jeder Motorroller zwei Räder hat, dann hat auch die Vespa zwei Räder. Oder allgemeiner: Wenn A den Wert von B bestimmt und B den Wert von C bestimmt, dann bestimmt auch A den Wert von C. Zusammenfassung 1. Ein Attribut A ist von einem Attribut B funktional abhängig, wenn zu jedem Wert von B eindeutig der Wert von A bestimmt werden kann. 2. Von voller funktionaler Abhängigkeit spricht man, wenn ein Attribut A von einer Attributkombination B komplett funktional abhängig ist, und nicht nur von einem Teil dieser Attributkombination. 3. Transitive Abhängigkeit zwischen zwei Attributen A und C liegt vor, wenn ein Attribut A von einem Attribut B eindeutig bestimmt wird, das Attribut B aber wiederum von einem Attribut C eindeutig bestimmt wird. Normalformen Bis 1978 wurden von E. F. Codd drei Normalformen aufgestellt, die entsprechend als erste, zweite und dritte Normalform bezeichnet werden. Es gibt noch vier weitere Normalformen, die jedoch in der Praxis nicht so relevant sind, da Probleme, die durch diese Normalformen beseitigt werden, nur selten vorkommen. NF² (Non-First-Normal-Form) Als NF² wird jede unnormalisierte Relation bezeichnet, sozusagen eine Relation, die nicht einmal der ersten Normalform genügt. 1. Normalform Eine Relation (Tabelle) ist in der ersten Normalform (1. NF), wenn die Werte der Attribute elementar (atomar) sind, d.h. pro Datenfeld darf nur maximal ein Wert enthalten sein (Nullwerte sind erlaubt!) Atomar oder nicht atomar? • Geburtsdatum gilt als atomar • Bilder, Videosequenzen und Tonfolgen können als atomare Attribute gespeichert werden --> keine Möglichkeit, bestimmte Teil-Inhalte abzufragen (Tonfolge etc.) • Mengen, Folgen und Array gelten als nicht atomar • Atomar bedeutet, dass der Wert als Ganzes zu sehen ist und keine Teile des Wertes getrennt verarbeitet werden sollen Beseitigung von Mehrfachattributen 1. Das Mehrfachattribut wird innerhalb des Datensatzes in mehrere Einfachattribute zerlegt, d.h. der Datensatz erhält mehr Attribute. 2. Wenn das Mehrfachattribut eine Liste von typgleichen Daten enthält, wird jedem Wert der Liste eine eigener Datensatz zugeordnet. Ausgangsrelation in 1. NF • Erweiterung des Primarschlüssels • Folge: Datenredundanzen Fehlermöglichkeiten der 1. NF • Einfüge-Anomalie – Fall 1: Zur bestehenden Prüfungsfachnummer erfolgt ein weiterer Eintrag mit anderer Prüffachbezeichnung – Fall 2: Zur selben Matrikelnummer erfolgt ein Eintrag mit anderem Studentennamen – Fall 3: Der Eintrag eines Studenten, der noch kein Prüfungsfach gewählt hat liefert Nullwerte in der Prüfungsfachnummer, da dies aber Teil des Primärschlüssels ist, darf dies nicht sein. Es verletzt die Integrität. Fehlermöglichkeiten der 1. NF • Änderungs-Anomalie – Fall 4: Wenn der Name des Professors / der Professorin sich ändert, muss dies in allen Zeilen geschehen! – Fall 5: Den einzelnen Prüfungsfächern werden neue Prüfer zugeordnet. Überall! • Lösch-Anomalie – ... Gehen Daten unwiederbringlich verloren, wenn ein Tupel gelöscht wird? 2. Normalform Die zweite Normalform bezieht sich ausschließlich auf Tabellen, deren Primärschlüssel aus mehreren Attributen zusammengesetzt ist: Eine Relation ist in der zweiten Normalform (2.NF), wenn sie sich in der 1.NF befindet und jedes nicht zum Primärschlüssel gehörige Attribut voll von diesem abhängig ist. Tabelle in 2. NF ??? • • • • Primärschlüssel: Mnr und PrüfFachNr Name ist von MNr abhängig, nicht jedoch von PrüfFachNr PrüfFachBezeichnung ist von PrüfFachNr abhängig, nicht jedoch von MNr Weder Name noch PrüfFachBezeichnung sind voll funktional vom Primärschlussel abhängig. Relationen in 2. Normalform In allen entstandenen Relationen sind alle NichtPrimärschlüssel-Attribute voll funktional abhängig von den jeweiligen Primarschlüsseln! Hinweise • Gesamtinformation ist nicht geändert worden • Verbindung zwischen Relationen durch korrespondierende Attribute (Attribute, die in mehreren Relationen als Primär- bzw. Fremdschlüssel auftauchen = Globale Attribute) • Redundanzen weitgehend beseitigt, jedoch nicht vollständig! 3. Normalform • Die dritte Normalform bezieht sich auf funktionale Abhängigkeiten zwischen Nichtschlüssel- Attributen. • Eine Relation befindet sich dann in der dritten Normalform (3.NF), wenn sie sich in der 1.NF und in der 2.NF befindet und wenn alle Nichtschlüssel-Attribute ausschließlich vom Primärschlüssel funktional abhängig sind, und nicht transitiv über ein Nichtschlüssel-Attribut. Relationen in 3. Normalform? Das Attribut ProfName kommt mehrmals vor, obwohl mit ProfNr der Name des Professors schon gegeben wäre. Diese Redundanzen von Attributen, die nicht zum Primärschlüssel gehören, beseitigt die Überführung in die 3. Normalform. Relationen in 3. NF Reicht die 3. Normalform? Oft reicht die 3. Normalform, um redundanzfreies, konsistentes und realitätsgetreues Datenmodell zu erstellen. Unter bestimmten Voraussetzungen können jedoch auch bei Relationen, die sich in der 3. Normalform befinden, Anomalien auftreten und zwar, wenn • die Relation mehrere Schlüsselkandidaten hat (Prüfungsfachnr. vs. Prüffachbezeichnung) • die Schlüsselkandidaten zusammengesetzt sind, also aus mehr als einem Attribut bestehen • die Schlüsselkandidaten sich mit dem Primärschlüssel überlappen, d.h. mindestens ein Attribut mit dem Primärschlüssel gemeinsam haben. Weitere Normalformen (werden hier nicht thematisiert) Aufgabe Jemand hat eine CD-Sammlung und möchte diese in einer Datenbank speichern. Eine Inventur ergab die oben abgebildete Tabelle. Überführe die Tabelle in die 3. Normalform!