3 Deskriptive Statistik in R (univariat)
Werbung
")
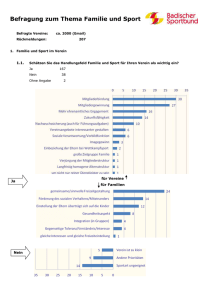
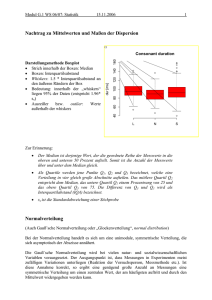
Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R 3 Deskriptive Statistik in R (univariat) Markus Burkhardt ([email protected]) Inhalt 3.1 Ziel ................................................................................................................................................. 1 3.2 Häufigkeiten .................................................................................................................................. 1 3.3 Deskriptive Kennziffern I – Lagemaße ........................................................................................... 2 3.4 Streuungsmaße ............................................................................................................................. 5 3.5 Standardisierung: z-Werte ............................................................................................................ 7 3.6 Weiterführende Deskriptive Statistik ............................................................................................ 8 3.8 Literatur ......................................................................................................................................... 9 3.1 Ziel In diesem Kapitel zeigen wir Ihnen die Grundtechniken der deskriptiven Datenanalyse in R. Ziel einer deskriptiven Analyse ist es, Variablen bzw. Datenreihen so zu beschreiben, dass möglichst viele Information in einer möglichst kleinen Menge an Zahlen ausgedrückt wird. Letztlich geht es also darum nicht die gesamte Zahlenreihe zu berichten, sondern einzelne Kennziffern die etwas über die Beschaffenheit der Zahlenreihe aussagen. Allerdings ist die Aussagekraft stets an bestimmte Bedingungen geknüpft – wie das Skalenniveau oder die Verteilung der Daten. Genau diese Bedingungen können Gegenstand der explorativen Datenanalyse. Die deskriptiven Kennziffern bieten des Weiteren die Grundlage für grafische Explorationsverfahren, die wir im nächsten Kapitel vorstellen 3.2 Häufigkeiten Das Auszählen von Häufigkeiten ist wohl die einfachste Form der deskriptiven Statistik. Ob diese Art der Analyse sinnvoll ist, hängt natürlich von der Struktur Ihrer Daten ab. Insbesondere für nominal- und ordinalskalierte Daten bieten sich Häufigkeitsanalysen an. Aber auch für intervallskalierte Daten kann eine Häufigkeitsanalyse sinnvoll sein. Wir führen zunächst eine Häufigkeitsanalyse für das Geschlecht in der Datei bsp01 durch, um herauszufinden, wie viele Männer und Frauen in unserem Beispieldatensatz vorhanden sind. Die Grundlage für Häufigkeitsanalysen bietet die Funktion table().Das Ergebnis wird in der R-Console ausgegeben (Abb. 1). Die table() Funktion schließt standardmäßig NA-Werte aus. > table(bsp01$sex) female male 58 42 Abbildung 1. Häufigkeitstabelle in R. 1 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R Durch die Eingabe mehrere Objekte, erhalten Sie mehrdimensionale Tabellen. Eine solche Darstellung, kann die Häufigkeit des Geschlechts in Abhängigkeit der Körpergröße sein. Dazu sollte die Körpergröße für eine bessere Übersichtlichkeit kategorisiert werden. Beispielsweise wollen wir die Körpergröße in zwei Kategorien einteilen, Menschen die kleiner als zwei Meter sind und Menschen die größer als zwei Meter sind. Die Funktion cut() bildet neue Kategorien. Wenn Sie sich die Hilfe zu dieser Funktion ansehen help(cut), sehen Sie, dass die Argumente x und breaks definiert werden müssen. (Die anderen Argumente sind vordefiniert. Sie können aber natürlich auch diese Werte spezifisch einstellen.) Dem Argument x weisen Sie Ihr Objekt zu, welches in kategorisiert werden soll und dem Argument breaks die Grenzwerte in Form einer Variable (Abb. 2). Wenn Sie eine Tabelle als Objekt speichern, sehen Sie, dass auch Tabellen eine eigene Objekt-Klasse in R sind. Für diese Klasse gibt es einige weitere sehr nützliche Funktionen. Wenn Sie lediglich an dem häufigsten Wert (dem Modalwert), nicht aber an der gesamten Häufigkeitstabelle interessiert sind, können Sie die Funktion which.max() anwenden. Diese gibt den Index des größten Wertes eines R-Objektes zurück. Im Falle eines Objektes der Klasse table, die entsprechende Kategorie. Allerdings wird bei mehreren Maxima nur das jeweils Erste Maximum ausgegeben. Mit Hilfe von barplot() können Sie sehr schnell eine Häufigkeitsverteilung grafisch darstellen (wir gehen auf diese Funktion ausführlicher im nächsten Kapitel ein). Die Funktion prop.table() ermöglicht es Ihnen, relative Anteile darzustellen. Natürlich können Sie auch arithmetische Operationen oder Indizierungen in Tabellen vornehmen (Beispiele in Abbildung 2). Einen guten Überblick über den Umgang mit Tabellen gibt auch die Internetseite: http://www.statmethods.net/stats/frequencies.html # Häufigkeitsanalyse mit der Funktion table() # Häufigkeitstabelle für das Geschlecht table(bsp01$sex) # Kategorisierung der Variable height in 2 Gruppen, # von 0 bis einschließlich 200 und größer 200 bis 250 # mit entsprechenden lables height_kategorien <- cut(x=bsp01$height, breaks=c(0,200,250), labels=c("kleiner/gleich 200 cm", "groesser 200 cm") ) # Mehrdimensionale Tabelle aus Geschlecht und der kategoriserten Körpergröße table(bsp01$sex, height_kategorien) # Grafische Darstellung von Häufigkeiten barplot(table(bsp01$sex)) # relative Häufigketien prop.table(table(sex)) # in Prozent prop.table(table(sex))*100 # Aufsteigende Sortierung mit sort() sort(table(bsp01$sex), decreasing=FALSE) # Modalwert which.max(table(bsp01$sex)) Abbildung 2. Häufigkeitsanalysen mit der Funktion table(). 3.3 Deskriptive Kennziffern I – Lagemaße Deskriptive Kennziffern lassen sich in Lagemaße (wo liegt die Verteilung bzw. wo konzentriert sie sich) und Streuungsmaße (wie breit ist die Verteilung bzw. wie stark konzentriert sich) unterscheiden. 2 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R Sie kennen bereits die Funktion des arithmetischen Mittelwertes1 mean(). Der Mittelwert ist vermutlich das am häufigsten berichtete Lagemaß der deskriptiven Datenanalyse (Formel 1). (1) Allerdings verlangt die sinnvolle Verwendung des Mittelwerts zwei Voraussetzungen: Zum einen müssen die Daten mindestens Intervallskalenniveau besitzen, zum anderen sollte der Mittelwert aus einer weitgehend symmetrischen Verteilung stammen. Ein Beispiel für eine asymmetrische Verteilung geben Sedlmeier und Renkewitz (2013) aus der Arbeit von Pedersen, Miller, PutchaBhagavatula und Yang (2002). Auf die Frage: „Was wäre Ihre ideale Anzahl an Sexualpartnern in den nächsten 30 Jahren?“ gaben Männer im Mittel 7,7 Partner und Frauen 2,8 Partner an. Diese Unterschiede scheinen zunächst einmal zu gängigen Geschlechterstereotypen zu passen. Allerdings zeigen Pedersen et al. (2002), dass diese Mittelwertsunterschiede weniger durch geschlechtsspezifische Sexualstrategien, sondern vielmehr durch die Asymmetrie der Antwortverteilung zustande kommen. Wir haben die Daten einmal nachgestellt2 (Abb. 3). Sie können erkennen, dass der Mittelwert der Männer vor allem durch die 3 Männer beeinflusst wird, die 99 als Antwort gaben. In diesem Fall, ist der Mittelwert also nicht gut geeignet, um die Datenreihe der idealen Anzahl an Sexualpartnern für Männer zu beschreiben. Zwei gute Alternativen sind im vorliegenden Fall der getrimmte Mittelwert und der Median. Abbildung 3. Asymmetrische Verteilung adaptiert nach Pedersen et al. (2002) mit Mittelwert. Beachten Sie, dass die Skalierung der x-Achse nur bis zum Wert 20 sinnvoll gewählt ist. 1 Wir bezeichnen den arithmetischen Mittelwert im Folgenden kurz als Mittelwert. Da wir nicht die Originalwerte vorliegen haben gibt es leichte Abweichungen zwischen unseren Daten und den Originaldaten. Unsere Daten können heruntergeladen werden: http://www.tu-chemnitz.de/hsw/psychologie/professuren/method/homepages/mb/pedersen_2002.txt. 2 3 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R Der getrimmte Mittelwert ist ein Mittelwert aus einem Anteil um die Daten in der Mitte. In der Funktion mean() können sie dem Argument trim einen Wert zwischen null und eins zuweisen, um den Anteil an Daten zu bestimmen, der von jedem Ende der Verteilung abgeschnitten werden soll (Abb. 4). Eine Alternative zum Mittelwert stellt die Berechnung des Medians – dem Wert in der Mitte aller (aufsteigend oder absteigend sortierten) Werte dar. Der Vorteil dieser Kennziffer ist, dass sie relativ robust gegenüber einzelnen extremen Werten ist. Bei einer Zahlenreihe von: {1; 2; 5; 8; 12; 15; 20; 27; 30; 100} beträgt der Median 13,5 (da dieser Wert in der Mitte liegt)3. Der Mittelwert hingegen liegt bei 22, also deutlich oberhalb des Medians. Zur Berechnung des Medians in R wird die Funktion median() genutzt. Die Mitte aller Werte lässt sich auch als den Punkt beschreiben, der eine Datenreihe in zwei Teile teilt, sodass unterhalb des Medians 50% der Daten, und oberhalb des Medians 50% der Daten liegen (Abbildung 4). Ausgehend von dieser Überlegung, können wir auch die Mitte der Daten unterhalb des Medians berechnen. Dieser Wert wird 25% Quantil4 genannt, da 25% der Daten unterhalb dieses Wertes und 75% oberhalb dieses Wertes liegen. Entsprechend können beliebige Quantile berechnet werden, am geläufigsten sind das 25% Quantil, Median und 75% Quantil. Diese werden durch die summary() oder etwas variabler mit quantile()und dem Argument probs bestimmt. Beachten Sie bei der Quantilberechnung, dass mehrere Algorithmen in R implementiert sind (siehe dazu help(quartile)) und mit dem Argument type definiert werden. Die Auswirkungen der verschiedenen Quantilalgorithmen nehmen mit zunehmender Stichprobengröße ab und sind im Bezug auf sozialwissenschaftlicher Datenanalyse als eher unbedeutend zu bewerten. Abbildung 4. Mittelwerte, getrimmte Mittelwerte, Median und Quartile einer Zahlenreihe. 3 Bei einer geraden Anzahl an Elemente innerhalb einer Variablen wird in der Regel der Mittelwert zwischen den beiden in der Mitte liegenden Elementen genutzt. 4 Zum Teil wird das 25% Quantil auch als unteres Quartil, das 75% Quantil als oberes Quartil bezeichnet. 4 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R In Abbildung 5 haben wir exemplarisch die Berechnung der deskriptiven Kennziffern für die Daten von Pedersen et al. (2002) vorgenommen. In Abbildung 6 veranschaulichen wir nochmal die verschiedenen Lageparameter bei der unsymmetrischen Verteilung der erwünschten Sexualpartner für die untersuchten Männer. # Herunterladen der Daten (Kapitel 1) von http://www.tu-chemnitz.de/hsw/psychologie/professuren/method/homepages/mb/pedersen_2002.txt attach(pederseon_2002) # Deskriptive Statistik nur für die Gruppe der Männer (des_m) des_m <- subset(desired, sex=="male") # Mittelwert mean(des_m) # getrimmter Mittelwert # hier der Mittelwert ohne die oberen und unteren 10% der Daten mean(des_m, trim=.1) # hier der Mittelwert ohne die oberen und unteren 25% der Daten mean(des_m, trim=.25) # Median median(des_m) # 25% und 75% Quantil quantile(des_m, probs=.25) quantile(des_m, probs=.75) # Zusammenfassung der deskriptiven Statistik mit summary() summary(des_m) Abbildung 5. Quellcode für Lagemaße der Daten von Pedersen 2002. Abbildung 6. Veranschaulichung der Lageparameter bei unsymmetrischer Verteilung. 3.4 Streuungsmaße Streuungsmaße geben an, wie breit die Verteilung der Daten ist bzw. wie stark sich diese Verteilung konzentriert. Für intervallskalierte Variablen wird häufig auf die Varianz bzw. die Standardabweichung zurück gegriffen. Diese werden durch die Funktionen var() bzw. sd() berechnet. Auch hier ist die Angabe v. a. dann sinnvoll, wenn normalverteilte Werte vorliegen. Varianz ist ein Mittelwert, der ausdrückt, wie weit die einzelnen Werte im Durchschnitt vom Mittelwert entfernt sind. Die „Entfernung“ wir dabei durch die Summe der quadrierten Abweichungen gemessen (Formel 2 und 3). 5 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R Varianz (2) Standardabweichung (3) Der Nachteil der Varianz ist, dass im Ergebnis quadrierte Einheiten vorliegen, die inhaltlich kaum interpretierbar sind. Die Standardabweichung als Quadratwurzel der Varianz (Formel 3) löst dieses Problem. Wenn Sie die Funktionen var() bzw. sd() in einem Script selbst programmieren, werden Sie feststellen, dass R und Sie nicht zum selben Ergebnis kommen. Das liegt daran, dass die R Funktionen auf der korrigierten Stichprobenvarianz beruhen. Die korrigierte Stichprobenvarianz spielt im Bereich der Inferenzstatistik eine entscheidende Rolle, weshalb R diese ausgibt (Formel 4 und 5). Es ist ersichtlich, dass die Unterschiede in der Varianz vor allem bei sehr kleinen Stichproben (geringes n) auftreten. korrigierte Stichprobenvarianz (4) korrigierte Standardabweichung (5) Alternative Streuungsangaben für nicht intervallskalierte Variablen sind der Interquartilsabstand oder die Spannweite. Die Berechnung des Interquartilsabstand, der Differenz des 75% Quantils und des 25% Quantils, erfolgt mit der Funktion IQR(). Die Spannweite (die Differenz zwischen größten und kleinsten Wert der Datenreihe) wird Ihnen nicht direkt angegeben. Sie können sich aber mit der Funktion range() das Minimum und das Maximum der Variable ausgeben lassen. In Abbildung 7 stellen wir die Verwendung einiger Streuungsmaße am IQ unserer Beispieldatei bsp01 vor. In Abbildung 8 zeigen wir Ihnen verschiedene Verteilungen mit zugehöriger Standardabweichung. # Berechnung von Streuungsmaßen der Variable IQ des Dataframe attach(bsp01) # Varianz und Standardabweichung des IQ var(IQ) sd(IQ) # Interquartilsabstand und Range IQR(IQ) range(IQ) # Spannweite max(IQ)-min(IQ) bsp01 # Vergleich empirische Varianz vs. korrigierte Stichprobenvarianz # empirische Varianz sum((IQ-mean(IQ))^2/length(IQ)) # korrigierte stichprobenvarianz var(IQ) detach(bsp01) Abbildung 7. Berechnung von Streuungsmaßen mit R. 6 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R Abbildung 8. Verschiedene Verteilungen mit gleichem Mittelwert und unterschiedlichen Standardabweichungen (SD). 3.5 Standardisierung: z-Werte Die Lage und Streuungsmaße die Sie bisher kennengelernt, haben sind in ihrer Größe abhängig von der jeweiligen Einheit der zugrundeliegenden Daten. Es kann natürlich vorkommen, dass Sie Werte gleicher Gegenstandsbereich miteinander vergleichen wollen, die unterschiedlich skaliert sind oder aber Sie wollen die relativen Abstände bzgl. einer gegebenen Verteilung bewerten. Zur Veranschaulichung betrachten wir das folgende Beispiel (der dazugehörige Quellcode findet sich in Abbildung 9). Die mittlere Körpergröße von Männern sollte in einer repräsentativen Stichprobe größer sein als die Körpergröße von Frauen. Betrachten wir die Mittelwerte der Männer (x = 182 cm) und der Frauen (x = 164) in unserem Beispieldatensatz, sehen wir diese Unterschiede im Mittelwert. Was wir aber nicht wissen ist, ob eine Frau mit 182 cm Körpergröße relativ zu den anderen Frauen größer ist als ein Mann mit der Größe von 200 cm relativ zu den anderen Männern. Um diese Frage zu beantworten helfen sogenannte Standardisierungsverfahren. Standardisierungen bieten die Möglichkeit Daten zu vergleichen, die ursprünglich unterschiedliche Skalierungen haben oder, wie in unserem Beispiel, aus unterschiedlichen Populationen stammen. Es gibt mehrere standardisierte Skalen (z.B. IQ –Werte oder Abiturnoten) die geläufigste und grundlegendste ist jedoch die z-Standardisierung. Diese wird in R über die Funktion scale() ausgeführt. Die z- Standardisierung erfolgt, indem jeder einzelne Messwert durch die Standardabweichung geteilt wird (Formel 6). Die neuen Daten haben dabei die Eigenschaft, dass der Mittelwert gleich null und die Standardabweichung gleich 1 ist. Jeder einzelne Messwert kann nun auch relativ zu jedem anderen Messwert mit ursprünglich anderer Skalierung verglichen werden. 7 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R (6) # Mittelwerte der Körpergröße von Männer und Frauen height_male <- subset(height, sex=="male") height_female <- subset(height, sex=="female") mean(height_male) mean(height_female) # z-Standaradisierung z_height_male <- scale(height_male) z_height_female <- scale(height_female) # Mittelwert z_Standardisierter Werte ist 0 (gerundet auf 4 Kommastellen) round(mean(z_height_male),4) round(mean(z_height_female),4) # Standardabweichung von 1 round(sd(z_height_male),4) round(sd(z_height_female),4) # Wie groß ist eine Frau von 182 cm relativ zu den anderen Frauen? (182-mean(height_female))/sd(height_female) # Wie groß ist ein Mann von 200 cm relativ zu den anderen Männern? (200-mean(height_male))/sd(height_male) ## relativ zur jeweiligen Bezugsgruppe ist eine Frau von 182 cm ## größer als ein Mann von 200 cm Körpergröße Abbildung 9. Quellcode für die z-Standardisierung. 3.6 Weiterführende Deskriptive Statistik Es gibt eine ganze Reihe weitere Funktionen der deskriptiven Statistik. Wir haben einige in Tabelle 1 ohne Anspruch auf Vollständigkeit zusammengestellt. Sie werden im Laufe Ihrer Nutzung von R merken, dass Sie mit den gängigen Lage und Streuungsmaßen ziemlich viel erreichen können, wenn Sie diese in eigenen Funktionen (Kapitel 5) nutzen. In verschiedenen Paketen finden Sie weitere Funktionen. Auch hier lohnt sich die Such im Internet. Tabelle 1. Wichtige Funktionen der deskriptiven Statistik. Statistische Funktionen in R mean median var sd quantile min max which.min which.max table IQR range summary length Beschreibung Mittelwert Median korrigierte Stichprobenvarianz Standardabweichung Quantil Minimum Maximum Welcher Wert bildet das Minimum Welcher Wert bildet das Maximum Häufigkeitstabelle Interquartilabstand Spannweite Zusammenfassung deskriptiver Kennziffern Anzahl der Elemente 8 Markus Burkhardt - EDA in R: 3 Deskriptive Statistik in R 3.7 Literatur Pedersen, W. C., Miller, L., Putcha-Bhagavatula, A. D., & Yang, Y. (2002). Evolved Sex Differences in the Number of Partners Desired? The Long and the Short of It. Psychological Science (Wiley Blackwell), 13(2), 157. Sedlmeier, P. & Renkewitz, F. (2013). Forschungsmethoden und Statistik: Ein Lehrbuch für Psychologen und Sozialwissenschaftler (2. überarbeitete und erweiterte Auflage). München, Pearson. 9