PowerPoint-Präsentation
Werbung

521.202 / SES.125
Parameterschätzung
Varianzfortpflanzung
Torsten Mayer-Gürr
Torsten Mayer-Gürr
Diskrete Zufallsvariable
Eine diskrete Zufallsvariable X nimmt endlich viele oder abzählbar unendlich viele Werte an.
-
Werte:
x1 , x2 ,, xn ,
-
Wahrscheinlichkeit:
f ( x1 ), f ( x2 ),, f ( xn ),
P( X xi ) f ( xi )
Dichtefunktion, Wahrscheinlichkeitsdichte, Wahrscheinlichkeitsverteilung,
probability density function (pdf)
f ( xi ) 0
n
und
f (x ) 1
i 1
i
bzw.
f (x ) 1
i 1
i
Verteilungsfunktion
F ( xi ) P( X xi ) f ( xk )
k i
Torsten Mayer-Gürr
09.12.2015
2
Binomialverteilung
Wahrscheinlichkeit bei 60-maligen Würfeln x mal eine 1 oder 2 zu Würfeln
Torsten Mayer-Gürr
09.12.2015
3
Dichtefunktion und Verteilungsfunktion
Dichtefunktion,
probability density function (pdf)
Verteilungsfunktion,
cummulative density function (cdf)
F ( xi ) P( X xi ) f ( xk )
f ( xi ) P( X xi )
Torsten Mayer-Gürr
k i
09.12.2015
4
Erwartungswert und Varianz
Torsten Mayer-Gürr
Erwartungswert und Varianz
Konkrete Messreihe
Theoretischer Wert
Mittelwert
1 n
m xi
n i 1
Gewichteter Mittelwert
1 n
m xi wi
mit
W i 1
Schätzung der Varianz
Erwartungswert
n
n
W wi
E{ X } xi f ( xi )
i 1
i 1
n
f (x ) 1
i 1
i
Varianz
n
E{( X ) } ( xi ) 2 f ( xi )
2
n
1
ˆ
( xi m) 2
n 1 i 1
2
Torsten Mayer-Gürr
2
i 1
E{ X 2 } 2
09.12.2015
6
Diskrete Zufallsvariable
Eine diskrete Zufallsvariable X nimmt endlich viele oder abzählbar unendlich viele Werte an.
-
Werte:
x1 , x2 ,, xn ,
-
Wahrscheinlichkeit:
f ( x1 ), f ( x2 ),, f ( xn ),
P( X xi ) f ( xi )
kontinuierliche Zufallsvariable X
Idee: Anzahl der Ereignisse n gegen unendlich, Wert des einzelnen Ereignisses gegen null.
Torsten Mayer-Gürr
09.12.2015
7
Binomialverteilung
Dichtefunktion,
probability density function (pdf)
Verteilungsfunktion,
cummulative density function (cdf)
F ( xi ) P( X xi ) f ( xk )
f ( xi ) P( X xi )
Torsten Mayer-Gürr
k i
09.12.2015
8
Binomialverteilung
Dichtefunktion,
probability density function (pdf)
Verteilungsfunktion,
cummulative density function (cdf)
F ( xi ) P( X xi ) f ( xk )
f ( xi ) P( X xi )
Torsten Mayer-Gürr
k i
09.12.2015
9
Binomialverteilung
Dichtefunktion,
probability density function (pdf)
Verteilungsfunktion,
cummulative density function (cdf)
F ( xi ) P( X xi ) f ( xk )
f ( xi ) P( X xi )
Torsten Mayer-Gürr
k i
09.12.2015
10
Binomialverteilung
Dichtefunktion,
probability density function (pdf)
Verteilungsfunktion,
cummulative density function (cdf)
F ( xi ) P( X xi ) f ( xk )
f ( xi ) P( X xi )
Torsten Mayer-Gürr
k i
09.12.2015
11
Binomialverteilung
Dichtefunktion,
probability density function (pdf)
Verteilungsfunktion,
cummulative density function (cdf)
F ( xi ) P( X xi ) f ( xk )
f ( xi ) P( X xi )
k i
Wahrscheinlichkeit
eines Einzelereignisses geht gegen null
Verteilungsfunktion
einer stetigen Zufallsvariable
x
F ( x) P( X x)
f (t ) dt
Torsten Mayer-Gürr
09.12.2015
12
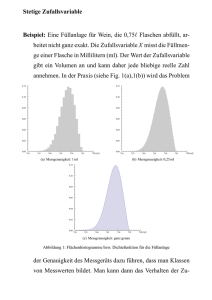
Stetige Zufallsvariable
Eine stetige Zufallsvariable X hat eine nicht-negative integrierbare Dichtefunktion mit
x
F ( x)
f (t ) dt
dF ( x)
f ( x)
dx
wobei F ( x) P( X x) die Verteilungsfunktion von X ist
Dichtefunktion
f ( x) 0
f (t ) dt 1
Wahrscheinlichkeit
x
P( X x) F ( x)
f (t ) dt
b
P(a X b) F (b) F (a ) f (t ) dt
a
a
P( X a ) F (a ) F (a ) f (t ) dt 0
a
Torsten Mayer-Gürr
09.12.2015
13
Stetige Zufallsvariable
Eine stetige Zufallsvariable X hat eine nicht-negative integrierbare Dichtefunktion mit
x
F ( x)
f (t ) dt
dF ( x)
f ( x)
dx
wobei F ( x) P( X x) die Verteilungsfunktion von X ist
Dichtefunktion
f ( x) 0
f (t ) dt 1
Wahrscheinlichkeit
x
P( X x) F ( x)
f (t ) dt
b
P(a X b) F (b) F (a ) f (t ) dt
a
a
P( X a ) F (a ) F (a ) f (t ) dt 0
a
Torsten Mayer-Gürr
09.12.2015
Pail14
Erwartungswert und Varianz
Erwartungswert (diskret)
Erwartungswert (stetig)
n
E{ X } xi f ( xi )
E{ X } x f ( x) dx
i 1
Varianz (diskret)
Varianz (stetig)
n
E{( X ) } ( xi ) f ( xi )
2
2
E{( X ) } ( x ) 2 f ( x) dx
2
2
i 1
2
Erwartungswertoperator
E{} () f ( x) dx
Torsten Mayer-Gürr
09.12.2015
15
Kontinuierliche Verteilungen:
Normalverteilung
Torsten Mayer-Gürr
Normalverteilung
Definition: Die Zufallsvariable X bezeichnet man als normalverteilt mit den
Parametern 𝜇 und 𝜎 2 , abgekürzt geschrieben 𝑋~𝑁(𝜇, 𝜎 2 ), wenn ihre Dichte 𝑓(𝑥)
gegeben ist durch
2
2
1
f ( x, , )
e ( x ) / 2 für x
2
Verteilungsfunktion:
1
F ( x)
2
x
( t )
e
2
/ 2 2
dt
Erwartungswert:
E{ X } x f ( x) dx
Varianz:
E{( X ) } ( x ) 2 f ( x) dx 2
2
Torsten Mayer-Gürr
09.12.2015
17
Standardisierte Normalverteilung
Transformation:
- Zentrierung der Verteilung (Verschiebung entlang der x-Achse)
- Normierung der Verteilung (Division durch die Standardabweichung)
X ~ N ( , 2 )
Y
1
X ~ N (0,1)
Dichte der standardisierten Normalverteilung
1 12 x2
f ( x)
e
2
Verteilungsfunktion
1
P( X x) F ( x)
2
Torsten Mayer-Gürr
x
e
1
y2
2
dy
09.12.2015
18
Tabelle
Torsten Mayer-Gürr
09.12.2015
19
3-Sigma Regel
P( X ) F
(N )
( ) F
(N )
( )
( norm )
F ( norm )
F
Transformation
y :
1
x
F ( norm ) 1 F ( norm ) 1
0.841 0.159
0.683 68%
P( 1 X 1 ) 68.3%
P( 2 X 2 ) 95.5%
P( 3 X 3 ) 99.7%
Pail
Torsten Mayer-Gürr
09.12.2015
20
Mehrdimensionale
Zufallsvariablen
Torsten Mayer-Gürr
Zweidimensionale Zufallsverteilung
Zweidimensionale stetige Zufallsvariable
x y
F ( x, y )
f ( x, y) dy dx
Wahrscheinlichkeit (Verteilungsfunktion)
P ( X x, Y y ) F ( x, y )
Dichtefunktion
Pail
f ( x, y ) 0
f ( x, y) dy dx 1
Torsten Mayer-Gürr
09.12.2015
22
Zweidimensionale Zufallsverteilung
Zweidimensionale stetige Zufallsvariable
x y
F ( x, y )
f ( x, y) dy dx
Wahrscheinlichkeit (Verteilungsfunktion)
P ( X x, Y y ) F ( x, y )
Dichtefunktion
Pail
f ( x, y ) 0
f ( x, y) dy dx 1
Torsten Mayer-Gürr
09.12.2015
23
Zweidimensionale Zufallsverteilung
Zweidimensionale stetige Zufallsvariable
x y
F ( x, y )
f ( x, y) dy dx
Wahrscheinlichkeit (Verteilungsfunktion)
P ( X x, Y y ) F ( x, y )
P ( X x ) F ( x, )
x
x
f ( x, y) dy dx f
x
( x) dx
Pail
Randverteilung f x ( x)
f ( x, y) dy
Torsten Mayer-Gürr
09.12.2015
24
Bedingte Wahrscheinlichkeit
Definition: Als bedingte Wahrscheinlichkeit P(A|B) des Ereignisses A unter der
Bedingung, dass B eingetroffen ist, bezeichnet man das Verhältnis
P( A | B)
P( A und B)
P( B)
15 rote, 5 blaue Kugeln
P( A und B) P( A | B) P( B)
Wie groß ist die Wahrscheinlichkeit, nach einer roten
ein blaue Kugel ohne zurücklegen zu ziehen?
rote Kugel:
P( A)
15
20
blaue Kugel: P( B | A)
5
19
P( A und B) P( A) P( B | A)
Torsten Mayer-Gürr
09.12.2015
15 5
19,7%
20 19
25
Bedingte Wahrscheinlichkeit
Definition: Als bedingte Wahrscheinlichkeit P(A|B) des Ereignisses A unter der
Bedingung, dass B eingetroffen ist, bezeichnet man das Verhältnis
P( A | B)
P( A und B)
P( B)
P( A und B) P( A | B) P( B)
Bedingte Dichte
f ( x | y)
f ( x, y )
f y ( y)
f ( x, y ) f ( x | y ) f y ( y )
mit der Randverteilung
f y ( y)
f ( x, y) dx
Sind die Ereignisse A und B voneinander unabhängig, gilt:
P( A und B) P( A) P( B)
Zwei Zufallsvariablen sind genau dann voneinander unabhängig, falls gilt
f ( x, y ) f x ( x ) f y ( y )
Torsten Mayer-Gürr
09.12.2015
26
Erwartungswert &
Varianz/Kovarianz
(Tafel)
Torsten Mayer-Gürr
Varianzfortpflanzung
(Tafel)
Torsten Mayer-Gürr
Mehrdimensionale Zufallsverteilung
Mehrdimensionale stetige Zufallsvariable
x1 x2
F ( x1 , x2 ,, xn )
xn
f (t , t ,, t ) dt dt
1
2
n
n
2
dt1
Wahrscheinlichkeit (Verteilungsfunktion)
P( X 1 x1 , X 2 x2 ,, X n xn ) F ( x1 , x2 ,, xn )
Dichtefunktion
Pail
f ( x1 , x2 ,, xn ) 0
f ( x , x ,, x ) dx dx
1
2
n
n
2
dx1 1
Torsten Mayer-Gürr
09.12.2015
29
Zufallsvektor
Torsten Mayer-Gürr
Varianz / Kovarianz
Zufallsvektor
x
x y
z
Erwartungswert
Varianz-Kovarianzmatrix
x
E{x} μ y
z
x2 xy xz
2
Σ{x} Σ x yx y yz
2
zx zy z
Mit der Dichte
f ( x ) f ( x, y , z ) 0
und
f (x) dx 1
Varianz
x2 E{( X x )( X x )} E{ X 2 } x2
y2 E{(Y y )(Y y )} E{Y 2 } y2
f ( x, y, z ) dxdydz 1
Kovarianz
xy E{( X x )(Y y )} E{ XY } x y
Kovarianz Operator
Σ{x} E{( x μ)(x μ)T }
Torsten Mayer-Gürr
09.12.2015
31
Gravity Recovery and Climate Experiment
JPL
Torsten Mayer-Gürr
09.12.2015
32
Korrelationen
Torsten Mayer-Gürr
09.12.2015
33
Korrelationen
Torsten Mayer-Gürr
09.12.2015
34
Korrelationen
Varianz-Kovarianzmatrix
112
2
11
2
11
Σ{x}
2
11
2
11
2
11
Torsten Mayer-Gürr
09.12.2015
35
Korrelationen
Varianz-Kovarianzmatrix
112
12
Σ{x} 13
Torsten Mayer-Gürr
09.12.2015
12
112
12
13
13
12
112
12
13
13
12
112
12
13
13
12
112
12
13
12
112
36
Polares Anhängen
Polares Anhängen
x
Gemessen
s 10 m 4 mm
t 40 gon 1 mgon
( x, y )
s
t
y
Torsten Mayer-Gürr
09.12.2015
37
Varianz / Kovarianz
Lineare Transformation
y Bx c
nx1
Zufallsvektor
mx1
Zufallsvektor
nx1
konstanter Vektor
n x m konstante Koeffizientenmatrix
Erwartungswert
E{y} E{Bx c} BE{x} c
Kovarianzmatrix
Σ{y} Σ{Bx c} BΣ{x}BT
Torsten Mayer-Gürr
09.12.2015
38
Kovarianzfortpflanzung
Kovarianzfortpflanzung
Σ{y} Σ{Bx c} BΣ{x}B
Torsten Mayer-Gürr
09.12.2015
T
39
Kovarianzfortpflanzung
Beispiel: Differenz zweier Streckenmessungen
s1 253 cm 12 (4 mm) 2
s2 153 cm 22 (3 mm) 2
s 153
x 1
cm
s2 253
12 12 (4 mm) 2
Σ x
2
0
12
2
s s1 s2
(s ) Bx
mit
s s1 s2 ?
B 1 1
0
(3 mm) 2
(4 mm) 2
BΣ{x}B 1 1
0
T
0 1
2
(3 mm) 1
Varianz der Differenz
2s 12 22 (5 mm) 2
Torsten Mayer-Gürr
09.12.2015
40
Kovarianzfortpflanzung
Beispiel: Mittelwert
1 n
1
1
1
s si s1 s2 sn
n i 1
n
n
n
s1
s
x 2
sn
s Bx
12
2
2
Σx
diag( 12 , 22 ,, n2 )
2
n
1
mit B
n
1
1
n
n
s2 BΣ{x}BT
1 2
( 1 22 n2 )
2
n
Bei gleicher Varianz
1
1
2 ( 12 22 n2 ) 2 n 2
n
n
2
s
Torsten Mayer-Gürr
s
1
s
n
09.12.2015
41
Polares Anhängen
Polares Anhängen
x
Gemessen
s 10 m 4 mm
t 40 gon 1 mgon
( x, y )
Polares Anhängen
s
x s cost /
t
y s sin t /
mit
200gon
y
s 10 m
x
t
40
gon
12 12 (0,004 m) 2
Σ x
2
12 2 0 m gon
x s cost / 8,090 m
y
y
s
sin
t
/
5
,
878
m
Torsten Mayer-Gürr
0 m gon
2
(0,001gon )
Lineare Transformation?
y Bx c
09.12.2015
Kovarianzmatrix
Σ{y} BΣ{x}BT
42
Polares Anhängen
1. Gemessen:
s 10 m
x
t
40
gon
3. Berechnet:
x s cost /
y
y
s
sin
t
/
5. Kovarianzmatrix
Σ{y} BΣ{x}BT
2. Kovarianzmatrix:
12 12 (0,004 m) 2
Σ x
2
12 2 0 m gon
0 m gon
2
(0,001gon )
4. Jakobimatrix
y x s x t cost / s / sin t /
B
x y s y t sin t / s / cost /
0,8090 0,0923 m/gon
0
,
5878
0
,
1271
m/gon
5. Kovarianzmatrix
0,8090 0,0923 m/gon (0,004 m) 2
Σ{y}
0
,
5878
0
,
1271
m/gon
0 m gon
1,0481 10 5 m 2
5
2
0,7596 10 m
Torsten Mayer-Gürr
0,8090
0,5878
0 m gon
2
0
,
0923
m/gon
0
,
1271
m/gon
(0,001gon )
0,7596 10 5 m 2
5
2
0,5544 10 m
Ergebnis
x 8,090 m 3,2 mm
y 5,878 m 2,4 mm
09.12.2015
43
Drehung des
Koordinatensystems
Torsten Mayer-Gürr
Polares Anhängen
Polares Anhängen
x
x
( x, y )
y
s
t
y
Torsten Mayer-Gürr
09.12.2015
45
Drehmatrizen
Drehmatrix
cos
Q( )
sin
sin
cos
Inverse Drehung
cos
Q ( ) Q( )
sin
1
sin
QT ( )
cos
Allgemein: Orthogonale Matrix
(Rotation mit evtl. Spiegelung)
Q 1 QT
QT Q I
QQT I
Torsten Mayer-Gürr
09.12.2015
46
Polares Anhängen
Polares Anhängen
x
x'
( x, y )
y'
s
t
y
Drehung um Winkel t
y ' Qy
mit
Kovarianzmatrix
Σ{y '} QΣ{y}QT
QAΣ{x}AT QT
cos t sin t
Q
sin
t
cos
t
Torsten Mayer-Gürr
09.12.2015
47
Polares Anhängen
Drehung um Winkel t
y ' Qy
Nebenrechnung
cost / sin t / cost / s / sin t /
QA
sin t / cost / sin t / s / cost /
mit
cost / sin t /
Q
sin t / cost /
0
1
0
s
/
Kovarianzmatrix
Σ{y '} QΣ{y}QT
QAΣ{x}AT QT
0 s2 0 1
0
1
2
0
s
/
0
s
/
0 t
s2
0
2
s t
Torsten Mayer-Gürr
0
09.12.2015
48
Polares Anhängen
Polares Anhängen
x
Gemessen
x'
s 10 m 4 mm
t 40 gon 1 mgon
( x, y )
y'
s
Polares Anhängen
x s cost /
t
y s sin t /
mit
200gon
y
Kovarianzmatrix
x' s2
Σ{ }
y' 0
2
s t
0
Durch Drehung des Koordinatensystems
kann man unkorrelierte Zufallsvariablen
erhalten!
b
r
Torsten Mayer-Gürr
09.12.2015
49
Fehlerellipse
Torsten Mayer-Gürr
Beispiel: Strecke zwischen
Koordinaten
Torsten Mayer-Gürr
Varianzfortplanzung im GaußMarkoff Modell (Tafel)
Torsten Mayer-Gürr