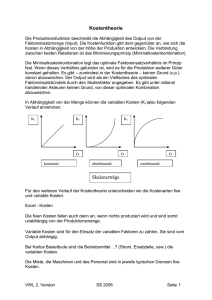
PowerPoint-Präsentation - Universität Koblenz · Landau
Werbung

APPLIED MARKET RESEARCH 1 MARKET RESEARCH …IST AUCH EIN PROZESS Definitionsphase Vorbereitung: Worauf will ich Antworten? Und wie bekomme ich sie? Im Feld: Wie sieht der Blick in die Realität aus? • Formulierung des Forschungsproblems • Bestimmung der Erhebungsziele • Desk Research Designphase • Informationsquellen (Primär-/Sekundärerhebung) • Messinstrumente/Operationalisierung • Grobplanung der Datenauswertung • Erhebungseinheiten (Voll-/Teilerhebung, Stichprobenumfang) • Arbeits-, Zeit- und Kostenplanung • Pre-Tests Feldphase • Durchführung • Kontrolle und Dokumentation der Datenerhebung • Eingreifen vs. Standardisierung Analysephase Nachbereitung: Was sind die Antworten? • Vorbereitung der Datenauswertung (Digitalisierung, Kodierung, Logikchecks) • Auswertung und Interpretation Kommunikationsphase • Forschungsbericht • Präsentation 2 MARKET RESEARCH …IST AUCH EIN PROZESS Definitionsphase • Formulierung des Forschungsproblems • Bestimmung der Erhebungsziele • Desk Research Vorbereitung Designphase • Informationsquellen (Primär-/Sekundärerhebung) • Messinstrumente/Operationalisierung • Grobplanung der Datenauswertung • Erhebungseinheiten (Voll-/Teilerhebung, Stichprobenumfang) • Arbeits-, Zeit- und Kostenplanung • Pre-Tests Feldphase Im Feld • Durchführung • Kontrolle und Dokumentation der Datenerhebung • Eingreifen vs. Standardisierung Analysephase Nachbereitung • Vorbereitung der Datenauswertung (Digitalisierung, Kodierung, Logikchecks) • Auswertung und Interpretation Kommunikationsphase • Forschungsbericht • Präsentation 3 MARKET RESEARCH PLAN DER VERANSTALTUNG + EINFÜHRUNG IN DIE VERANSTALTUNG + WAS IST MARKET RESEARCH – UND (WOZU) BRAUCHE ICH DAS? + DATEN SAMMELN + + Definitionsphase, Designphase, Feldphase: Wo die Fragen und Daten herkommen? DR. JAN RUTENBERG Leiter Kundenmanagement & Marktforschung sowie Regal- & Flächenmanagement + DATEN AUSWERTEN + + Analysephase: Wie kommt man von Daten zu Ergebnissen? INSIGHTS GENERIEREN UND KOMMUNIZIEREN + Kommunikationsphase: Wie werden aus Ergebnissen „Insights“? 4 DATEN AUSWERTEN (1) Daten aufbereiten (2) Daten beschreiben: Deskriptive Statistiken (3) Daten testen I: Was ist stat. Signifikanz und wozu brauche ich das überhaupt? (4) Daten testen II: Methoden zur Aufdeckung von Zusammenhängen (5) Daten testen III: Methoden zur Aufdeckung von Gruppenunterschieden 5 (1) Daten aufbereiten Bildquelle: http://www.werbetechnik.schule.bremen.de/ 6 Literatur Backhaus, Klaus, Erichson, Bernd, Plinke, Wulff & Weiber, Rolf (2006). Multivariate Analysemethoden, 11. Auflage, Berlin-Heidelberg-New York etc.: Springer, S.4-6. Berekoven, Ludwig, Eckert, Werner & Ellenrieder, Peter (2004). Marktforschung. Methodische Grundlagen und praktische Anwendung, 10. Auflage, Wiesbaden: Gabler, S.197-202. Bortz, Jürgen (2005). Statistik für Human- und Sozialwissenschaftler, 6. Aufl., Heidelberg: Springer, S.15-47. Fahrmeir, Ludwig, Künstler, Rita, Pigeot, Iris & Tutz, Gerhard (2004). Statistik, 5. Aufl., Berlin-Heidelberg-New York etc.: Springer, S.14-74. Handl, Andreas (2002). Multivariate Analysemethoden: Theorie und Praxis unter besonderer Berücksichtigung von S-Plus, Berlin-Heidelberg-New York etc.: Springer, S.13-21. 7 ANALYSEPHASE DATENAUFBEREITUNG Fragebogen Bearbeiten Kodieren Säubern/ Checken Transformieren Datenanalyse Darstellung der Ergebnisse, Interpretation und Präsentation/ Darstellung 8 ANALYSEPHASE DATENAUFBEREITUNG 9 ANALYSEPHASE DATENAUFBEREITUNG 10 ANALYSEPHASE DATENAUFBEREITUNG Fragebogen Bearbeiten Kodieren Säubern/ Checken Transformieren Datenanalyse Darstellung der Ergebnisse, Interpretation und Präsentation/ Darstellung 11 ANALYSEPHASE DATENAUFBEREITUNG Kodieren + In der Regel notwendig bei + Kategorisieren offener Antworten + Nicht-nummerischen Antworten Zahlen/Kategorien zuweisen + Zusammenfassen (komplexer) Antworten Wie viele Snickers essen Sie normalerweise am Tag? 27 Anzahl Kategorie Code 0 bis 3 wenig 0 4 bis 10 mittel 1 über 10 viel 2 k.A. „missing“ 99 12 ANALYSEPHASE DATENAUFBEREITUNG Kodieren + In der Regel notwendig bei + Kategorisieren offener Antworten + Nicht-nummerischen Antworten Zahlen/Kategorien zuweisen + Zusammenfassen (komplexer) Antworten Wie alt bist Du? 18-30 31-40 41-55 56 und älter Was ist Deine Lieblingsfarbe? braun gelb 1 2 lila bordeaux 2 3 13 ANALYSEPHASE DATENAUFBEREITUNG Kodieren + In der Regel notwendig bei + Kategorisieren offener Antworten + Nicht-nummerischen Antworten Zahlen/Kategorien zuweisen + Zusammenfassen (komplexer) Antworten Was ist Deine Lieblingsfarbe? braun gelb lila bordeaux Antwort Kategorie Code braun erdfarben 1 gelb erdfarben 1 lila rötlich 2 bordeaux rötlich 2 k.A. „missing“ 99 Vergessen Sie den Kodierungsplan nicht! 14 ANALYSEPHASE DATENAUFBEREITUNG Transformieren + Rohdaten so anpassen, dass die gewünschten Auswertungen möglich werden, beispielsweise durch das Zusammenführen von Antworten in eine Variable, + Multi-Item Messungen eines Konstrukts + Zusammenfassende Kennzahlen Sie wollen wissen, wie viele Schokoladenriegel der Proband am Tag insgesamt ist. Wie viele Snickers essen Sie normalerweise am Tag? Wie viele sonstige Schokoladenriegel essen Sie normalerweise am Tag? 27 28 1 15 ANALYSEPHASE DATENAUFBEREITUNG Transformieren 16 + + + Darstellungformen Lageparameter Streuungsparameter (2) Daten beschreiben: Deskriptive Statistiken Bildquelle: http://www.werbetechnik.schule.bremen.de/ 17 ANALYSEPHASE DATEN BESCHREIBEN + Wahl einer geeigneten Betrachtungsform, die die in den Daten steckende Struktur möglichst gut erkennen lässt oder der Fragestellung entspricht + Häufige Darstellungsformen von Daten: + Buchstaben vom Ende unseres Alphabets kennzeichnen Variablen, häufig bspw. X + Die zu einer Variable X zugehörigen Beobachtungswerte werden mit dem entsprechenden Kleinbuchstaben bezeichnet (x) + Unterschiedliche Beobachtungswerte x für ein Merkmal X werden von 1 bis n indiziert (x1, x2, …, xn), wobei n den Stichprobenumfang, die Anzahl an Beobachtungen für das Merkmal X, repräsentiert. + In der Regel wird dem Index auch ein Buchstabe zugeordnet, zum Beispiel i. + Bei n Beobachtungen kann der Index i die Werte von 1 bis n annehmen (i = 1,2, …, n) + Lateinische Buchstaben werden dabei kursiv gesetzt, griechische nicht + vor und nach allen Operatoren (bspw. „+“, „=“) wird ein Leerzeichen eingefügt + Bei Werten, die nicht größer als eins werden können, wird oftmals die Null vor dem Komma weggelassen (bspw. „p = .01“). 18 ANALYSEPHASE DATEN BESCHREIBEN Urliste x1 x2 x3 x4 x5 x6 x7 x8 x8 x10 21 33 41 52 61 28 34 43 53 68 x11 x12 x13 x14 x15 x16 x17 x18 x19 x20 27 36 41 52 34 48 58 38 45 58 x21 x22 x23 x24 x25 x26 x27 x28 x29 x30 37 47 57 34 48 57 33 45 46 41 19 ANALYSEPHASE DATEN BESCHREIBEN Häufigkeitstabellen + Eine Häufigkeitstabelle zeigt, wie häufig eine Merkmalsausprägung – also ein bestimmter tatsächlich beobachteter Wert – in einer Menge von erhobenen Daten vorkommt. Sie liefert somit Informationen über die Häufigkeitsverteilung der erfassten Daten. 20 ANALYSEPHASE DATEN BESCHREIBEN Häufigkeitstabellen + Eine Häufigkeitstabelle zeigt, wie häufig eine Merkmalsausprägung – also ein bestimmter tatsächlich beobachteter Wert – in einer Menge von erhobenen Daten vorkommt. Sie liefert somit Informationen über die Häufigkeitsverteilung der erfassten Daten. 21 ANALYSEPHASE DATEN BESCHREIBEN Säulendiagramm bzw. Stabdiagramm (bei diskreten Merkmalen) + Auf der horizontalen Achse werden die tatsächlich beobachteten Werte yi des Merkmals Y eingetragen. + Die absoluten oder relativen Häufigkeiten bestimmen die Länge der senkrechten Linien über jedem beobachteten Wert yi 22 ANALYSEPHASE DATEN BESCHREIBEN Histogramm (bei kontinuierlichen Merkmalen) + Auf der horizontalen Achse werden die tatsächlich beobachteten Werte yi des Merkmals Y eingetragen. Dabei werden Klassen gebildet. + Die absoluten oder relativen Häufigkeiten bestimmen die Länge der senkrechten Linien über jedem beobachteten Wert yi 23 ANALYSEPHASE DATEN BESCHREIBEN Streckenzugdiagramm (bei kontinuierlichen Merkmalen) 24 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken (Beschreibende Kennzahlen) + Situation + Fragestellung + Datenlage + Lageparameter + + + Modus + Median + Mittelwert Streuungsparameter + Spannweite + Varianz + Standardabweichung Zusammenfassende Darstellung 25 ANALYSEPHASE DATEN BESCHREIBEN Situation Eine Befragung von Absolventen des Studiengangs BWL in Göttingen, Hannover und Mannheim sollte Aufschluss über die jeweiligen Studiendauer in Semestern bringen. Im ersten Auswertungsschritt gilt es die Daten und ihre Häufigkeitsverteilung durch Grafiken und geeignete Kennzahlen zu beschreiben. 26 ANALYSEPHASE DATEN BESCHREIBEN Fragestellung Erläutern und berechnen Sie einzelne Lage- und Streuungsparameter auf Grundlage der erfassten Stichprobendaten. Gehen Sie bei der Erläuterung auch auf das Kriterium des Skalenniveaus ein. Abschließend geben Sie bitte eine kurze Beurteilung der Aussagekraft der Lage- und Streuungsmaße. 27 ANALYSEPHASE DATEN BESCHREIBEN Datenlage Die Untersuchung führte zu folgendem Ergebnis (Urliste): 1) Universität Göttingen Person 1 2 3 4 5 6 7 8 9 10 11 Semester 8 11 9 10 8 9 12 10 11 12 10 2) Universität Hannover Person 1 2 3 4 5 6 7 8 9 10 11 Semester 7 9 11 10 10 15 10 15 20 20 38 3) Universität Mannheim Person 1 2 3 4 5 6 7 8 9 10 11 Semester 9 7 9 7 10 7 10 9 7 10 10 28 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken (Beschreibende Kennzahlen) + Lage- und Streuungsparameter (stets bezogen auf eine Variable/Merkmal) sind Kennzahlen zur Beschreibung empirischer Merkmalsverteilungen + Sie sollten folgende Kriterien erfüllen: + + große Aussagekraft bei möglichst geringem Informationsverlust, + Sachverhalt muss angemessen repräsentiert werden Wichtige Lageparameter + + + + Modus, Median, (arithmetischer) Mittelwert Wichtige Streuungsparameter + + + Spannweite, Varianz, Standardabweichung 29 ANALYSEPHASE DATEN BESCHREIBEN Säulendiagramme der Studiendauern von Absolventen Universität Göttingen Universität Hannover 3 3 2 4 2 1 Universität Mannheim 5 Häufigkeit 4 Häufigkeit 4 3 2 1 1 0 0 8 9 10 11 Studiendauer in Semestern 12 0 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 Studiendauer in Semestern 7 8 9 10 Studiendauer in Semester 30 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Lageparameter + Frage nach einer typischen Eigenschaft der betrachteten Häufigkeitsverteilung + Sollen Auskunft darüber geben, wo der „Schwerpunkt“ des Datenbündels liegt + Unterschiedliche Möglichkeiten der Anwendung von Lageparametern in Abhängigkeit vom Skalenniveau der Daten (1) Modus (Modalwert) + Wert eines Datenbündels mit der größten Häufigkeit + da eine Verteilung mehrgipflig (bi- bzw. multimodal) sein kann, können einer Verteilung auch mehrere Modi zugeordnet sein + notwendiges Skalenniveau: schon bei nominalskalierten Variablen zu ermitteln + Aussagekraft: bietet wenig Informationen hinsichtlich der numerischen Verteilung der Werte; insbesondere daher schlechte Eignung bei schiefen Verteilungen 31 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Lageparameter (1) Modus (Modalwert) 1) Universität Göttingen Person 1 2 3 4 5 6 7 8 9 10 11 Semester 8 11 9 10 8 9 12 10 11 12 10 Modus = 10 2) Universität Hannover Person 1 2 3 4 5 6 7 8 9 10 11 Semester 7 9 11 10 10 15 10 15 20 20 38 Modus = 10 3) Universität Mannheim Person 1 2 3 4 5 6 7 8 9 10 11 Semester 9 7 9 7 10 7 10 9 7 10 10 Modus = 7; 10 32 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Lageparameter (2) Median (Zentralwert) + Ist der mittlere Wert (50%-Punkt) innerhalb der Rangwertreihe des betrachteten Merkmals + Teilt die Reihe aller Merkmalswerte in zwei Hälften (mindestens 50% der Merkmalswerte liegen unter dem Zentralwert) + Bei einer Reihe mit einer geraden Anzahl von Elementen wird das arithmetische Mittel der beiden mittleren Werte genommen + Notwendiges Skalenniveau: mindestens Ordinalskala + Aussagekraft: + Bezieht als ein Maß der zentralen Tendenz im Gegensatz zum Modalwert die ganze Verteilung mit ein, wobei die Berechnung bei nominalskalierten Variablen nicht möglich ist + Lässt sich auch bei Verteilungen mit offenen Randklassen berechnen + (relative) Stabilität gegenüber extremen Merkmalsausprägungen + Bietet (relativ) wenig Informationsgehalt, da für den Median insbesondere die Anzahl der Messwerte eine große Rolle spielt 33 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Lageparameter (2) Median (Zentralwert) 1) Universität Göttingen Person 1 5 3 6 4 8 11 2 9 7 10 Semester 8 8 9 9 10 10 10 11 11 12 12 Median = 10 2) Universität Hannover Person 2 3 4 1 5 6 7 8 9 10 11 Semester 7 9 10 10 10 11 15 15 20 20 38 Median = 11 3) Universität Mannheim Person 2 4 6 9 1 3 8 5 7 10 11 Semester 7 7 7 7 9 9 9 10 10 10 10 Median = 9 34 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Lageparameter (3) (arithmetischer) Mittelwert + Lagemaß zur Kennzeichnung von metrischen (mindestens intervallskalierten) Daten + Wird berechnet, indem die Summe der Einzelwerte (xi) i = 1,…,n des Datenbündels durch die Anzahl der Beobachtungen (n) dividiert wird n x i x i 1 n + notwendiges Skalenniveau: setzt metrisches Skalenniveau voraus + Aussagekraft: reagiert auf Ausreißer und auf Schiefe der Verteilung 35 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Lageparameter (3) (arithmetischer) Mittelwert 1) Universität Göttingen Person 1 2 3 4 5 6 7 8 9 10 11 Semester 8 11 9 10 8 9 12 10 11 12 10 Mittelwert = 10 2) Universität Hannover Person 1 2 3 4 5 6 7 8 9 10 11 Semester 7 9 11 10 10 15 10 15 20 20 38 Mittelwert = 15 3) Universität Mannheim Person 1 2 3 4 5 6 7 8 9 10 11 Semester 9 7 9 7 10 7 10 9 7 10 10 Mittelwert = 8,6 36 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Lageparameter (3) (arithmetischer) Mittelwert »Sollen wir das arithmetische Mittel als durchschnittliche Körpergröße nehmen und den Gegner erschrecken, oder wollen wir ihn einlullen und nehmen den Median?« 37 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Worin unterscheiden sich Mittelwert und Median? Universität Göttingen Universität Hannover Universität Göttingen Universität Mannheim Universität Hannover 4 4 3 3 Universität Mannheim 5 2 1 Häufigkeit Säulendiagramm Häufigkeit Häufigkeit 4 2 3 2 1 1 0 0 8 9 10 11 Studiendauer in Semestern Median Mittelwert 12 0 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 Studiendauer in Semestern 7 8 9 10 Studiendauer in Semester 10 11 9 10 15 8,6 38 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Worin unterscheiden sich Mittelwert und Median? + Extreme Beobachtungswerte haben einen großen Einfluss auf den Mittelwert; der Median gibt in diesem Fall die Lage der Verteilung besser wieder + Bei symmetrischen Verteilungen nimmt der Mittelwert den gleichen Wert an wie der Median + Bei einer rechtsschiefen (oder linkssteilen) Verteilung ist der Mittelwert immer größer als der Median; für linksschiefe (oder rechtssteile) Verteilungen gilt entsprechend das Gegenteil 39 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Streuungsparameter + Erfassen, wie eng bzw. weit die einzelnen Merkmalswerte über den Bereich der Merkmalsskala verteilt sind + Geben an, wie gut eine Verteilung durch einen Lageparameter charakterisiert werden kann (1) Spannweite (Range) + Differenz zwischen größtem (xmax) und kleinstem (xmin) Merkmalswert + Notweniges Skalenniveau: zur Kennzeichnung der Streuung bei mindestens ordinalem Skalenniveau + Aussagekraft: im allgemeinen als alleinige Maßzahl zur Verdeutlichung der Streuung nicht gut geeignet, da die Spannweite stark von den betrachteten Werten abhängig ist 40 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Streuungsparameter (1) Spannweite (Range) 1) Universität Göttingen Person 1 5 3 6 4 8 11 2 9 7 10 Semester 8 8 9 9 10 10 10 11 11 12 12 Spannweite = 4 2) Universität Hannover Person 2 3 4 1 5 6 7 8 9 10 11 Semester 7 9 10 10 10 11 15 15 20 20 38 Spannweite = 31 3) Universität Mannheim Person 2 4 6 9 1 3 8 5 7 10 11 Semester 7 7 7 7 9 9 9 10 10 10 10 Spannweite = 3 41 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Streuungsparameter (2) Varianz (mittlere quadratische Abweichung) + Summe der quadrierten Abweichungen der einzelnen Werte xi eines Datenbündels vom Mittelwert x , dividiert durch die Anzahl der Beobachtungen n + Berechnung: x x ² n i i 1 n s² + Notwendiges Skalenniveau: setzen metrisches Skalenniveau der Variablen voraus + Aussagekraft: + Maß dafür, wie weit die einzelnen Werte im Durchschnitt vom Mittelwert x entfernt liegen + durch die Quadrierung erhalten Beobachtungswerte mit einer großen Differenz von x ein stärkeres Gewicht 42 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Streuungsparameter (2) Varianz (mittlere quadratische Abweichung) 1) Universität Göttingen Person 1 2 3 4 5 6 7 8 9 10 11 Semester 8 11 9 10 8 9 12 10 11 12 10 Varianz = 1,82 2) Universität Hannover Person 1 2 3 4 5 6 7 8 9 10 11 Semester 7 9 11 10 10 15 10 15 20 20 38 Varianz = 70 3) Universität Mannheim Person 1 2 3 4 5 6 7 8 9 10 11 Semester 9 7 9 7 10 7 10 9 7 10 10 Varianz = 1,69 43 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Streuungsparameter (3) Standardabweichung + Quadrat-)Wurzel aus der Varianz eines Datenbündels + Berechnung: + Notweniges Skalenniveau: nur für metrische Daten anwendbar + Aussagekraft: + Eignet sich zur Kennzeichnung von Fehlerintervallen um das arithmetische Mittel + Durch die Wurzelberechnung wird die Quadrierung der Abweichungen "rückgängig gemacht", so dass s die gleiche Maßeinheit hat wie die Datenwerte selbst 44 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Streuungsparameter (3) Standardabweichung 1) Universität Göttingen Person 1 2 3 4 5 6 7 8 9 10 11 Semester 8 11 9 10 8 9 12 10 11 12 10 Standardabweichung= 1,35 2) Universität Hannover Person 1 2 3 4 5 6 7 8 9 10 11 Semester 7 9 11 10 10 15 10 15 20 20 38 Standardabweichung = 8,37 3) Universität Mannheim Person 1 2 3 4 5 6 7 8 9 10 11 Semester 9 7 9 7 10 7 10 9 7 10 10 Standardabweichung = 1,30 45 ANALYSEPHASE DATEN BESCHREIBEN Deskriptive Statistiken: Streuungsparameter (3) Standardabweichung + Für Normalverteilungen gilt: + zwischen den Werten x+s und xs liegen ca. 2/3 aller Fälle (genau 68,26%) + oder umgekehrt: die Wahrscheinlichkeit dafür, dass ein Messwert um mehr als eine Standardabweichungseinheit vom Mittelwert abweicht ist kleiner als 32% 46 ANALYSEPHASE DATEN BESCHREIBEN Zusammenfasende Darstellung Skalenniveau Lageparameter Nominal Ordinal Metrisch Modus ☺ ☺ ☺ ☺ ☺ Median ☺ Arithmetischer Mittelwert Streuungsparameter Spannweite (☺) ☺ Varianz ☺ Standardabweichung ☺ 47 (3) Daten testen I: Was ist stat. Signifikanz und wozu brauche ich das überhaupt? Bildquelle: http://startistik.csd.univie.ac.at/ 48 ANALYSEPHASE DATEN TESTEN + statistische Kennwerte aus einer Stichprobe reflektieren nicht unbedingt die Grundgesamtheit 22 19 23 22 22 24 37 26 28 41 22 37 21 33 26 28 43 21 38 33 22 21 19 27 31 33 35 19 21 25 38 38 22 21 19 27 31 33 35 19 21 25 41 23 22 37 19 22 22 22 21 20 19 21 19 33 21 19 28 19 21 20 Stichprobe (Mx = 22) Grundgesamtheit (Mx = 26) + Inwieweit lässt sich von den Verhältnissen in der Stichprobe auf die betreffende Grundgesamtheit schließen? (Zulässigkeit und Zuverlässigkeit eines Induktionschlusses) 49 ANALYSEPHASE DATEN TESTEN + + Lösung: Berechnung der Wahrscheinlichkeit, dass der Wert in der Stichprobe/der Unterschied zwischen zwei Stichproben zufällig zustande gekommen ist + Formulierung von Hypothesen und Überprüfung + Die Nullhypothese H0 beinhaltet diejenige Aussage, welche falsifiziert werden soll, während die Alternativhypothese H1 die Aussage enthält, die man aufzeigen möchte Für die praktische Durchführung eines Hypothesentestes ist die Alternativhypothese eher von nebensächlicher Bedeutung. Sie dient lediglich dazu, den Ablehnungsbereich der »Prüfgröße« zu lokalisieren 50 ANALYSEPHASE DATEN TESTEN Hypothesen + + einseitig gerichtete Hypothesen + H0-Hypothese: Der Absatz von Tiefkühlpizza zu Sonderangebotspreisen ist nicht höher im Vergleich zum Absatz von Tiefkühlpizza zu Normalpreisen. + H1-Hypothese: Der Absatz von Tiefkühlpizza zu Sonderangebotspreisen ist höher im Vergleich zum Absatz von Tiefkühlpizza zu Normalpreisen. zweiseitig gerichtete Hypothesen + H0-Hypothese: Es besteht kein Unterschied in der Absatzzahl zwischen dem Angebot von Tiefkühlpizza zu Sonderpreisen und zu Normalpreisen. + H1-Hypothese: Bezüglich der Absatzzahl besteht ein Unterschied zwischen dem Angebot von Tiefkühlpizza zu Sonderpreisen und zu Normalpreisen. 51 ANALYSEPHASE DATEN TESTEN Fehlerarten + beim Prüfen von Hypothesen können zwei Fehler gemacht werden: + Die Nullhypothese wird verworfen, obwohl sie richtig ist (Fehler 1. Art) + Die Nullhypothese wird beibehalten, obwohl sie falsch ist (Fehler 2. Art) + Mit dem Signifikanzniveau α wird die Wahrscheinlichkeit bezeichnet, mit der man einen Fehler 1. Art riskieren will + die Wahrscheinlichkeit für einen Fehler 1. Art entspricht der Irrtumswahrscheinlichkeit p + die Gefahr einem Fehler 2. Art (β-Fehler) zu erliegen, ist umso kleiner, je deutlicher die berechnete Irrtumswahrscheinlichkeit die Signifikanzgrenze übersteigt 52 ANALYSEPHASE DATEN TESTEN Fehlerarten + die Gefahr einem Fehler 2. Art (β-Fehler) zu erliegen, ist umso kleiner, je deutlicher die berechnete Irrtumswahrscheinlichkeit die Signifikanzgrenze übersteigt 53 ANALYSEPHASE DATEN TESTEN Signifikanzniveau + α = 0,1% Nullkommaeins-prozentige Wahrscheinlichkeit, die Nullhypothese zu verwerfen, obwohl die richtig ist (“bei 1000 identischen Tests, maximal einmal ein Fehler erster Art”, sehr konservativ) + α = 1% Ein-prozentige Wahrscheinlichkeit, die Nullhypothese zu verwerfen, obwohl die richtig ist (“bei 100 identischen Tests, maximal einmal ein Fehler erster Art”, konservativ) + α = 5% Fünf-prozentige Wahrscheinlichkeit, die Nullhypothese zu verwerfen, obwohl die richtig ist (“bei 100 identischen Tests, maximal fünf Mal ein Fehler erster Art”, weniger konservativ) 54 ANALYSEPHASE DATEN TESTEN Fehlerarten + wird über die Richtung der Alternativhypothese eine Aussage gemacht, dann wird die Hypothese mit einem einseitigen Test geprüft, andernfalls mit einem zweiseitigen Test + im Fall eines zweiseitigen Tests liegt der Ablehnungsbereich zu gleichen Teilen an beiden Enden der Standardnormalverteilungs-kurve + die sich beim einseitigen Test ergebende Irrtumswahrscheinlichkeit p ist kleiner als die beim zweiseitigen Test (nämlich halb so groß) 55 ANALYSEPHASE DATEN TESTEN Testen + Annahme- und Ablehnungsbereiche bei einseitiger Fragestellung + Annahme- und Ablehnungsbereich bei zweiseitiger Fragestellung 56 ANALYSEPHASE DATEN TESTEN Vorgehensweise beim Signifikanztest + Ermittlung der Wahrscheinlichkeit für eine Prüfgröße unter der Bedingung H0 + Auf der Grundlage der erhobenen Stichprobendaten wird ein standardisierter Kennwert (die Prüfgröße) ermittelt + Häufig verwendete Prüfgrößen 2 (in Abhängigkeit von Fragestellung, Verteilungsannahmen c und Skalenniveau) sind: t, , F + Für diese Kennzahl sind bei einem gegebenen Test zum gewählten Signifikanzniveau Ablehnungsschwellen festgelegt, die den Bereich der möglichen Werte der Prüfgröße in einen Ablehnungs- und einen Annahmebereich der Nullhypothese H0 unterteilen + Die Ablehnungsschwellen werden aus der Verteilung der Teststatistik unter der Bedingung der Gültigkeit von H0 bestimmt + Liegt die Prüfgröße im Ablehnungsbereichs, so wird H0 abgelehnt, sonst wird H0 angenommen 57 ANALYSEPHASE DATEN TESTEN Vorgehensweise beim Signifikanztest + Vergleich des p-Wertes mit dem Signifikanzniveau α + ist p < α, dann ist die Wahrscheinlichkeit für einen Fehler erster Art kleiner als vorher akzeptiert + ist p > α, dann ist die Wahrscheinlichkeit für einen Fehler erster Art größer als vorher akzeptiert + H0 wird dann zugunsten der Alternative verworfen, wenn die Irrtumswahrscheinlichkeit p kleiner als das Signifikanzniveau α ist + + Der p-Wert gibt dabei die Wahrscheinlichkeit an, unter H0 den beobachteten Prüfgrößenwert oder einen in Richtung der Alternative extremeren Wert zu erhalten ein sehr kleiner p-Wert bedeutet, dass es unter H0 sehr unwahrscheinlich ist, den Prüfgrößenwert zu beobachten; dies spricht dafür, H0 zu verwerfen 58 ANALYSEPHASE DATEN TESTEN Chi-Square Tests Prüfgröße As ymp. Sig. Vorgehensweise beim Signifikanztest Value df (2-sided) Pearson Chi-Square Likelihood Ratio Linear-by-Linear As sociation N of Valid Cases 18.563 a 20.190 2 2 .000 .000 18.243 1 .000 “Sig.”, p-Wert 100 a. 0 cells (.0%) have expected count less than 5. The minimum expected count is 6.00. Age ANOVA Sum of Squares Between Groups 1656.490 W ithin Groups 25952.260 Total 27608.750 df 1 98 99 Mean Square 1656.490 264.819 F 6.255 Sig. .014 One-Sample Test Test Value = 25 Age t 7.036 df 99 Sig. (2-tailed) .000 Mean Difference 11.750 95% Confidence Int erval of the Difference Lower Upper 8.44 15.06 59 DATEN AUSWERTEN (1) Daten aufbereiten (2) Daten beschreiben: Deskriptive Statistiken (3) Daten testen I: Was ist stat. Signifikanz und wozu brauche ich das überhaupt? (4) Daten testen II: Methoden zur Aufdeckung von Zusammenhängen (5) Daten testen III: Methoden zur Aufdeckung von Gruppenunterschieden 60 MARKET RESEARCH …IST AUCH EIN PROZESS Definitionsphase • Formulierung des Forschungsproblems • Bestimmung der Erhebungsziele • Desk Research Vorbereitung Designphase • Informationsquellen (Primär-/Sekundärerhebung) • Messinstrumente/Operationalisierung • Grobplanung der Datenauswertung • Erhebungseinheiten (Voll-/Teilerhebung, Stichprobenumfang) • Arbeits-, Zeit- und Kostenplanung • Pre-Tests Feldphase Im Feld • Durchführung • Kontrolle und Dokumentation der Datenerhebung • Eingreifen vs. Standardisierung Analysephase Nachbereitung • Vorbereitung der Datenauswertung (Digitalisierung, Kodierung, Logikchecks) • Auswertung und Interpretation Kommunikationsphase • Forschungsbericht • Präsentation 61 + + + 2 Kreuztabellierung und c -Test Korrelationsanalysen (und Kausalität) Regressionsanalysen (4) Daten testen II: Methoden zur Aufdeckung von Zusammenhängen Bildquelle: Stahel (2002) 62 Literatur Kreuztabellen Bortz, Jürgen (1999). Statistik für Sozialwissenschaftler, 5. Aufl., Berlin u.a.: Springer, S. 150-172; S.218-220 und S.224-226 Fahrmeir, Ludwig; Künstler, Rita; Pigeot, Iris & Tutz, Gerhard (2004). Statistik, 5. Aufl., Berlin-Heidelberg-New York etc. : Springer, S. 411-420 und S. 109-127 Zöfel, Peter (2003). Statistik für Wirtschaftswissenschaftler, München-Boston-San Francisco etc: Pearson, S. 177-187 63 Literatur Korrelationsanalysen Berekoven, Ludwig, Eckert, Werner & Ellenrieder, Peter (2004). Marktforschung. Methodische Grundlagen und praktische Anwendung, 10. Auflage, Wiesbaden: Gabler, S.204-206. Bortz, Jürgen (2005). Statistik für Human- und Sozialwissenschaftler, 6. Aufl., Heidelberg: Springer, S.203-207 und S.232-234. Fahrmeir, Ludwig, Künstler, Rita, Pigeot, Iris & Tutz, Gerhard (2004). Statistik, 5. Aufl., Berlin-Heidelberg-New York etc.: Springer, S.134-145 und S.147-152. Zöfel, Peter (2003). Statistik für Wirtschaftswissenschaftler, München-Boston-San Francisco etc: Pearson, 64 Literatur Regressionsanalysen Skiera, Bernd & Albers, Sönke (2000). Regressionsanalyse, in: Herrmann, Andreas & Homburg, Christian (Hg.) Marktforschung, Wiesbaden: Gabler, S. 203-236 Vertiefung: Backhaus, Klaus, Erichson, Bernd, Plinke, Wulff & Weiber, Rolf (2006). Multivariate Analysemethoden, Berlin, Heidelberg, New York: Springer, S. 45-117 Was tun bei Verletzung der Vorraussetzungen? von Auer, Ludwig (2005). Ökonometrie, Berlin, Heidelberg, New York: Springer, S. 241-498 65 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN 2 Kreuztabellierung und c -Test + Situation + Fragestellung + Verfahren der Datenanalyse im Überblick + Bivariate Analyse + Die Kreuztabellierung + + Die Kreuztabelle + Bedingte Häufigkeiten Kontingenzmaße + c 2-Koeffizient + Φ -Koeffizient + Kontingenzkoeffizient 66 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Situation Der Marketingleiter des Pizzaherstellers interessiert sich für den Zusammenhang zwischen Geschlecht und Kaufabsicht der Tiefkühlpizza Alberta, um die Marke strategisch besser ausrichten zu können. Eine Befragung von insgesamt N = 1229 Personen zu ihrer Kaufabsicht der Tiefkühlpizza sollte Aufschluss über die Frage geben. Die Kaufabsicht der Tiefkühlpizza wurde anhand der Ausprägungen „niedrig“ und „hoch“ bei unterschiedlichen Probanden ermittelt. 67 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Fragestellung Werten Sie die Befragungsdaten dahingehend aus, ob es einen signifikanten Zusammenhang zwischen Geschlecht und Kaufabsicht gibt. Formulieren Sie zu diesem Zweck die dem Test zugrunde liegende Nullhypothese und ermitteln Sie die empirische Prüfgröße. Wie lautet Ihre Entscheidung über die Forschungshypothese? Falls es einen signifikanten Zusammenhang gibt, wie beurteilen Sie die Stärke des Zusammenhangs? 68 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Datenlage Folgende Daten wurden auf Basis der Befragungen erhoben: Alter Kauffrequenz von Pizza selten oft Kaufabsicht Kaufabsicht 19-30 Jahre 31-50 Jahre Männer Frauen Männer Frauen ∑ ∑ hoch 156 72 114 180 522 714 niedrig 48 48 48 48 192 hoch 78 45 101 72 296 niedrig 39 136 30 14 219 ∑ 321 301 293 314 1229 ∑ 622 607 515 1229 69 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Verfahren der Datenanalyse im Überblick Modus Lagemaße Median Mittelwert Univariate Verfahren Spanne Streumaße Varianz Standardabweichung Kreuztabellierung Anzahl Variablen Korrelation Dependenzanalysen Regressionsanalyse Conjointanalyse Bi- und Multivariate Verfahren Varianzanalyse Faktorenanalyse Interdependenzanalysen Multidim. Skalierung Clusteranalyse 70 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Bivariate Datenanalyse + Im Mittelpunkt steht hierbei die Frage nach einer möglichen Beziehung zwischen zwei betrachteten Merkmalen + Man unterscheidet zwischen: + + Assoziationsanalysen, die ungerichtete Beziehungen untersuchen und 2. Regressionsanalysen, die sich mit gerichteten Abhängigkeiten befasst + Im Bereich der Assoziationsanalyse bei nominaler Skalierung der Merkmale ist die Kreuztabellierung zu nennen + Im Bereich der Assoziationsanalyse bei metrischer Skalierung der Merkmale ist die Berechnung des Korrelationskoeffizienten zu nennen 71 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kreuztabellierung + Zur Veranschaulichung und Herausarbeitung von Zusammenhängen zwischen zwei (oder auch mehreren) Variablen dient die Kreuztabelle bzw. Kontingenztafel + Es werden in einer Matrix für alle möglichen Kombinationen der Merkmalsausprägungen zweier Merkmale, die (absoluten bzw. relativen) Häufigkeiten angegeben + Zur Darstellung des Zusammenhangs wird nur das Nominalskalenniveau bzw. Ordinalskalenniveau der Merkmale benutzt, auch wenn die Merkmale ein höheres Messniveau aufweisen + Auf Basis der Kreuztabellierung lassen sich dann Maße für die Stärke des Zusammenhangs zwischen den beiden Merkmalen herausarbeiten 72 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Vorgehensweise zur Erstellung einer Kreuztabelle + Ausgangspunkt sind zwei Merkmale X und Y mit den möglichen Ausprägungen: a1,…,ak für X und b1,…, bm für Y + man bildet die Häufigkeiten hoij = h(aoi,boj) mit der die möglichen Kombinationen (ai,bj), i = 1,…,k; j = 1,…,m, auftreten + die sich daraus ergebene Häufigkeitstabelle heißt Kreuztabelle oder Kontingenztafel + Kreuztabellen werden durch Zeilen- und Spaltensummen ergänzt + die Zeilensummen ergeben die Randhäufigkeiten des Merkmals X und werden abgekürzt durch: hoi. = hoi1 + … + hoim, i = 1,…, k + die Spaltensummen ergeben die Randhäufigkeiten des Merkmals Y und werden abgekürzt durch: h.oj = ho1j + … + hokj, j = 1,…, m 73 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN (k x m)-Kreuztabelle der absoluten Häufigkeiten: b1 … bm a1 ho11 … ho1m ho1. a2 ho21 … ho2m ho2. ak hok1 … hokm hok. h.o1 … h.om n + hoii = ho (ai,bj) absolute Häufigkeit der Kombination (ai, bj) + ho1.,...,hok. Randhäufigkeiten von X + h.o1,...,h.om Randhäufigkeiten von Y + da die Prozentangaben häufig anschaulicher sind, betrachtet man auch die relativen Häufigkeiten, die sich ergeben, indem man die Beobachtungen durch n dividiert 74 ANALYSEPHASE DATENAUFBEREITUNG 75 ANALYSEPHASE DATENAUFBEREITUNG 76 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kreuztabelle mit absoluten Häufigkeiten hoii und Randsummen Geschlecht (Y) Kaufabsicht (X) ∑ ∑ männlich (b1) weiblich (b2) hoch (a1) 449 (ho11) 369 (ho12) 818 (ho1.) niedrig (a2) 165 (ho21) 246 (ho22) 411 (ho2.) 614 (h.o1) 615 (h.o2) 1229 (n) 77 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Bedingte Häufigkeiten + ein Zusammenhang zwischen Merkmalen ist allein durch die Betrachtung der absoluten und relativen Häufigkeiten noch nicht ersichtlich + zur besseren Beurteilung der Häufigkeiten ist eine Prozentuierung mit Bezug auf die Zeilensummen bzw. Spaltensummen sinnvoll + die Zeilenprozenturierung ist ein Hilfsmittel zum Vergleich der Zeilenkategorie; die Spaltenprozentuierung entsprechend zum Vergleich der Spaltenkategorie 78 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kreuztabelle mit Spaltenprozentuierung Geschlecht (Y) Kaufabsicht (X) ∑ ∑ männlich (b1) weiblich (b2) hoch (a1) 449 (ho11) 73,1% 369 (ho12) 60% 818 (ho1.) niedrig (a2) 165 (ho21) 26,9% 246 (ho22) 40% 411 (ho2.) 614 =100% (h.o1) 615 =100% (h.o2) 1229 (n) 73,1% der männlichen Probanden geben eine hohe Kaufabsicht an, aber nur 60% der weiblichen Studierenden. 79 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN c2 -Koeffizient + Mithilfe einer c - Analyse kann überprüft werden, ob es signifikant auffällige Kategoriekombinationen gibt 2 + Fragestellung: Unterscheiden sich die absoluten (beobachteten) Häufigkeiten hoii signifikant von den erwarteten Häufigkeiten heij? + Wenn die Merkmale X und Y unabhängig sind, sollten die tatsächlich beobachteten Häufigkeiten von den zu erwarteten Häufigkeiten kaum abweichen + Erwartete Häufigkeiten sind diejenigen, die sich unter Zugrundelegung der gegebenen Randsummen bei Gleichverteilung ergeben (Produkt aus zugehöriger Zeilen- und Spaltensumme, dividiert durch Gesamtsumme) + Berechnung der quadrierten standardisierten Residuen und Aufsummierung über alle Felder der Kreuztabelle zur Prüfgröße c 2 c 2 k m i 1 j 1 h oij heij ² heij mit df = (k-1)(m-1) Freiheitsgraden 81 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN c2-Koeffizient > c + Ho-Hypothese wird verworfen, wenn c + Sind X und Y unabhängig, dann ist c 2= 0 + c 2 nimmt mit wachsendem Stichprobenumfang zu 2 emp 2 tab 2 ohne zusätzliche Überlegungen lässt sich nicht feststellen, wie groß c sein muss, um auf einen Zusammenhang hinzuweisen + der c 2-Test ist an die Voraussetzung geknüpft, dass die erwarteten Häufigkeiten größer als 5 sind; in 20% der Fälle sind Werte < 5 erlaubt 82 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kreuztabelle mit beobachteten und erwarteten Häufigkeiten Geschlecht (Y) Kaufabsicht (X) ∑ heij ∑ männlich (b1) weiblich (b2) hoch (a1) 449 (ho11) 408,7 (he11) 369 (ho12) 409,3 (he12) 818 (ho1.) niedrig (a2) 165 (ho21) 205,3 (he21) 246 (ho22) 205,7 (he22) 411 (ho2.) 614 (h.o1) 615 (h.o2) 1229 (n) Ho-Hypothese: Es besteht kein Zusammenhang zwischen dem Geschlecht und der Kaufabsicht. 83 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN 2 Berechnung der Prüfgröße c k m c 2 i 1 j 1 h oij heij ² heij c 2 = 449 408,7 ² 369 409,3² 165 205,3² 246 205,7 ² 23,8 408,7 409,3 205,3 df p = .05 p = .01 p = .001 1 3,841 6,635 10,828 2 5,991 9,210 13,816 205,7 c 2-Tabelle + H0 kann verworfen werden, da die Prüfgröße größer ist als der kritische Tabellenwert 2 der c Tabelle + Zwischen Geschlecht und Kaufabsicht existiert ein (höchst) signifikanter Zusammenhang (p < .001). 84 ANALYSEPHASE DATENAUFBEREITUNG 85 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Berechnung der Prüfgröße c 2 Chi-Square Tests Test statistik Pearson Chi-Square Likelihood Ratio Linear-by-Linear As sociation N of Valid Cases Value 18.563 a 20.190 18.243 Sig. 2 2 As ymp. Sig. (2-sided) .000 .000 1 .000 df 100 a. 0 cells (.0%) have expected count less than 5. The minimum expected count is 6.00. + H0 kann verworfen werden, da die Prüfgröße größer ist als der kritische Tabellenwert 2 der c Tabelle + Zwischen Geschlecht und Kaufabsicht existiert ein (höchst) signifikanter Zusammenhang (p < .001). 86 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Φ -Koeffizient + Um die Stärke des Zusammenhangs zwischen zwei dichotomen Variablen aufzudecken, kann der Φ–Koeffizient ermittelt werden Φ= + c2 n θ nimmt Werte zwischen 0 (minimaler Zusammenhang) und 1 (maximaler Zusammenhang) an + Das Vorzeichen des Φ–Koeffizienten hängt von der Anordnung der Merkmalsalternativen im 4-Felder-Schema ab eine inhaltliche Interpretation kann deshalb nur aufgrund der angetroffenen Häufigkeiten erfolgen 87 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Zur Interpretation des Φ-Koeffizient Interpretation 0 0-0,25 0,25-0,66 0,66-1 1 + schwacher Zusammenhang mittlerer Zusammenhang starker Zusammenhang perfekter Zusammenhang da es einen signifikanten Zusammenhang gibt, kann auch eine Aussage über die Stärke des Zusammenhangs zwischen Geschlecht und Kaufabsicht getroffen werden θ + kein Zusammenhang χ² n 23,8 0,14 1229 zwischen Geschlecht und Kaufabsicht besteht betragsmäßig ein schwacher Zusammenhang dahingehend, dass Männer eine höhere Kaufbereitschaft haben 88 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kontingenzkoeffizient + Maß zur Charakterisierung der Stärke des Zusammenhangs zweier mindestens nominalskalierter Merkmale + Auch für Variablen mit mehr als zwei Ausprägungen geeignet + Ist der c -Test signifikant, gibt der Kontingenzkoeffizient den Grad der Abhängigkeit beider Merkmale wieder c2 K= n+c 2 + K ist nur positiv definiert und bewegt sich zwischen 0 und 1 (wobei 1 nicht erreicht werden kann) + K = 0 bei Unabhängigkeit der beiden Variablen + Kmax ist abhängig von der Zeilen- und Spaltenzahl K max + 2 k 1 k soll K genau zwischen 0 und 1 liegen, so muss er normiert werden; der normierte Kontingenzkoeffizient hängt nicht mehr von der Dimension der Kontingenztafel ab K Kko rr K max 89 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationsanalysen + Situation + Fragestellung + Datenlage + Funktionstypen + Korrelationen + Korrelationskoeffizient nach Bravais-Pearson + Rangkorrelationskoeffizient nach Spearman + Rangkorrelationskoeffizient nach Kendall + Zusammenfassung + Probleme 90 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Situation Den Marketingleiter des Pizzaherstellers interessiert die Frage nach dem Zusammenhang zwischen Verkaufspreis und Absatzmenge von Tiefkühlpizzen im Monat. Zu diesem Zweck wurde die Absatzmenge bei unterschiedlichen Preisen der Tiefkühlpizza im Monat ermittelt. 91 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Fragestellung Stellen Sie die erfassten Daten zunächst mit Hilfe eines Streudiagramms dar. Liefert Ihnen das Streudiagramm bereits erste Hinweise auf einen möglichen Zusammenhang. Beschreiben Sie den Zusammenhang mithilfe von Korrelationskoeffizienten, wobei Sie einen linearen Zusammenhang zwischen den Werten unterstellen sollten. Gehen Sie bei Ihren Berechnungen davon aus, dass die beiden Merkmale der Stichprobe normalverteilt sind. 92 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Datenlage Tiefkühlpizza A B C D E F G H I J Preis in Euro 5,10 1,80 2,10 2,05 1,99 1,90 2,20 1,95 2,50 2,25 Absatzmenge im Monat 110 1200 100 43 910 1000 760 970 685 860 93 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Ausgewählte Grundformen linearer Funktionen Beispiel: Beispiel: Zusammenhang zwischen Zahl der Vertreterbesuche und Höhe des Verkäuferumsatzes Zusammenhang zwischen Preis und Absatzmenge Beispiel: Zusammenhang zwischen Preis A und Preis B verschiedener Güter 94 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Ausgewählte Grundformen nicht-linearer Funktionen Beispiel: Beispiel: Zusammenhang zwischen Artikelanzahl und Zahlungsbereitschaft Zusammenhang zwischen Mund-zuMund Propaganda und Ausbreitung einer Werbe-botschaft Beispiel: Beispiel: Zusammenhang zwischen Preis und Absatz bei bestimmten Gütern Zusammenhang zwischen Vertraut-heit und Attraktivität eines Produktes Beispiel: Beispiel: Werbewirkungsfunktion Trendprognose zum Absatz eines Automobils 95 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Streuungsdiagramme + Streu(ungs)diagramme sind grafische Hilfsmittel, die die Anordnung der Beobachtungspunkte veranschaulichen + Jedes xi/yi - Beobachtungspaar wird in ein x/y-Koordinatensystem eingetragen + Es lässt sich ein erster Eindruck gewinnen, ob und wie stark zwei Merkmale zusammenhängen + Funktionstypen können abgeleitet werden 96 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Streuungsdiagramme Bildquelle: Stahel (2002) 97 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationen + Als Korrelation bezeichnet man den wechselseitigen Zusammenhang zwischen Größen + Korrelation bedeutet nicht das Vorhandensein von Kausalität. + Besteht eine Korrelation zwischen X und Y, so gibt es mindestens drei alternative Möglichkeiten einer Kausalitätsbeziehung: + + X bewirkt Y, + Y bewirkt X und + X und Y werden durch Z bewirkt (Scheinkorrelation). die Korrelationsanalyse liefert ein Maß für die Stärke des Zusammenhangs; erfasst jedoch nur monotone bzw. lineare Zusammenhänge 98 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationen + Die Stärke des Zusammenhangs wird durch den Korrelationskoeffizienten r gemessen + Der Korrelationskoeffizient r liegt stets in den Grenzen von -1 bis +1 + Für die Stärke des Zusammenhangs ist allein der Betrag des Korrelationskoeffizienten maßgebend + das Vorzeichen gibt an, ob der Zusammenhang gleichläufig (+) oder gegenläufig (–) ist Korrelationskoeffizient │r│≤ 0.25 Einstufung schwache Korrelation 0.25 <│r│≤ 0.66 mittlere Korrelation 0.66 <│r│< 1 starke Korrelation │r│= 1 perfekte Korrelation 99 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationen Vermutung: Zwischen den Variablen Preis und Verkaufsmenge besteht ein linearer und gegenläufiger Zusammenhang; je höher der Verkaufspreis umso geringer die Absatzmenge. 100 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson + Korrelationskoeffizient nach Bravais-Pearson dient der Beschreibung des Zusammenhangs zwischen metrisch skalierten und normalverteilten Variablen + Misst die Stärke des linearen Zusammenhangs, es gilt: n rxy xi x yi y i 1 x x y y n i i 1 + xy s ² s xs y ²n i i 1 Erläuterung: + sx bzw. sy stehen für die Standardabweichungen der Merkmale X bzw. Y + sxy bezeichnet die empirische Kovarianz (COV) n s 1 / n x x y y xy i i i1 101 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson Zur Kovarianz: y + + + um einen Zusammenhang zwischen zwei Merkmalen zu erfassen, beschreibt man die Lage eines Beobachtungspunktes mit Bezug zu dem Schwerpunkt des Streudiagramms Punkte im ersten und dritten Quadranten deuten auf einen positiven Zusammenhang hin; Punkte im zweiten und vierten Quadranten auf einen negativen Zusammenhang IV I x x x x x y x x x x x x x x x / y x x x x x x x III x II x formal wird dies für jeden Punkt durch das Produkt (xi - x )(yi - y ) erfasst 102 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson Zur Kovarianz: + y Es gilt: Quadrant 1: xi x; yi y ( xi x)( yi y) 0 Quadrant 2: xi x; yi y ( xi x)( yi y) 0 Quadrant 3: Quadrant 4: xi x; yi y ( xi x)( yi y) 0 xi x; yi y ( xi x)( yi y) 0 IV I x x x x x y x x x x x x x x x / y x x x x x x x III x + Liegen die Punkte hauptsächlich in den Quadranten 1 und 3, so ist die Summe der Produkte stark positiv. + Liegen die Punkte hauptsächlich in den Quadranten 2 und 4, so ist die Summe der Produkte stark negativ. + Sind die Punkte gleichmäßig verteilt, so heben sich positive und negative Summanden weitgehend auf und die Summe der Produkte wird weitgehend Null. II x 103 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson Zur Kovarianz: + Kovarianz: durchschnittliche Summe von Abweichungsprodukten + Die Kovarianz gibt die Tendenz an, in welche Richtung die Merkmale variieren + sxy > 0 mit x steigt (tendenziell) auch y (und umgekehrt) + sxy < 0 hohe Werte der einen Zufallsvariablen gehen mit niedrigen Werten der anderen Zufallsvariablen einher + sxy = 0 x und y sind unabhängig + Kovarianzen deuten (ggf.) auf lineare Abhängigkeiten hin. Sie sind von den Maßeinheiten der Merkmale abhängig! + Wertebereich: bis 104 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson + Normierung der Kovarianz: Korrelationskoeffizienten nach Bravais-Pearson (Produkt-Moment-Korrelation) rxy + Division der Kovarianz durch die Standardabweichungen beider Merkmale ( = Eliminierung der Streuung der einzelnen Verteilungen) + Wertebereich von rxy -1 bis +1 + rxy > 0 die Merkmale variieren tendenziell in der gleichen Richtung + rxy < 0 die Merkmale variieren tendenziell in entgegengesetzter Richtung + rxy = 0 kein (linearer) Zusammenhang! 105 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson + Die statistische Absicherung des Korrelationskoeffizienten nach Bravais-Pearson gegen Null erfolgt über die t-verteilte Prüfgröße. t + rxy n 2 1 rxy ² bei df = n-2 Freiheitsgraden Der Korrelationskoeffizient ist dann signifikant, wenn die Prüfgröße größer ist als der kritische Wert der t-Verteilung. 106 ANALYSEPHASE DATENAUFBEREITUNG 107 ANALYSEPHASE DATENAUFBEREITUNG 108 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson + Folgende Ergebnisse liefert die Berechnung des Korrelationskoeffizient nach Bravais-Pearson: N Korrelation Preis Preis Abs atzmenge Korrelation nach Pears on Sig. (2-s eitig) N Korrelation nach Pears on Sig. (2-s eitig) N Abs atzmenge 1 -,631 10 ,050 10 -,631 1 ,050 10 10 rxy Statistische Absicherung • rxy = -0,631 • Im vorliegenden Fall liegt mit α =.05 ein nicht signifikanter Wert vor 109 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson 110 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson + rxy drückt den linearen Zusammenhang zweier Variablen aus + Konsequenz: einzelne Ausreißer, d.h. einzelne extreme Datenpunkte, können einen starken, unerwünschten Effekt auf den numerischen Wert von rxy haben; hohe Korrelationen können als gering erscheinen und umgekehrt. + Lösung: Ermittlung von Rangkorrelationskoeffizienten, die von Ausreißern wesentlich weniger beeinflusst werden, da ihre Ermittlung auf den Rängen der Beobachtungen basiert. 111 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Korrelationskoeffizient nach Bravais-Pearson 112 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Rangkorrelationskoeffizient nach Spearman + drückt die Stärke des monotonen Zusammenhangs zweier Variablen aus + wird zwischen zwei Variablen berechnet, die mindestens ordinalskaliert sind; für metrisch skalierte Variablen, bei Unsicherheit hinsichtlich der Normalverteilungsanahme + Basiert auf Rangzahlen, die den Messwerten zugeordnet sind + Für beide Variablen wird eine Rangreihe der Werte erstellt, + Dem höchsten Wert wird der Rangplatz 1 verliehen; bei gleichen Werten werden gemittelte Rangplätze vergeben + die Differenz di der zugehörigen Rangplatzpaare wird bestimmt + es gilt: n rs 1 + 6 di ² i 1 n(n² 1) die Absicherung erfolgt über die t-verteilte Prüfgröße bei df = n – 2 Freiheitsgraden t rs n 2 1 rs ² 113 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Rangkorrelationskoeffizient nach Spearman + Wertebereich von rs -1 bis +1 + Gehen mit steigenden x-Werten auch steigende y-Werte einher, so nimmt rs tendenziell einen großen Wert an + sind die Rangzahlen bei den Merkmalen beider Variablen völlig gleich, so nimmt rs den Wert 1 an (die Rangpaare liegen auf einer Geraden mit positiver Steigung liegen) + bei entgegengesetzt laufenden Rangzahlen wird rs = -1 (die Rangpaare liegen auf einer Geraden mit negativer Steigung) 114 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Rangkorrelationskoeffizient nach Spearman + + Interpretation des Ergebnisses rs = -.685 + starker Zusammenhang + rs < 0 gegenläufiger monotoner Zusammenhang Es zeigt sich ein mittlerer gegenläufiger Zusammenhang zwischen Preis und Absatzmenge: Je höher der Preis einer Tiefkühlpizza, umso niedriger ist die verkaufte Menge an Tiefkühlpizzen. 117 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Zusammenfassung von Zusammenhangsmaßen + Die Rangkorrelation kann nur dann berechnet werden, wenn die beteiligten Variablen mindestens ordinalskaliert sind + Die Korrelation i.e.S (Korrelation nach Bravais-Pearson) allerdings nur für metrische Variablen. Y X nominal ordinal metrisch nominal Kontingenz Kontingenz Kontingenz ordinal Kontingenz Rang-Korrel. Rang-Korrel. metrisch Kontingenz Rang-Korrel. Korrelation i.e.S. 118 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Grenzen von Zusammenhangsmaßen + die Korrelation i.e.S gilt: Einzelne Fälle können einen starken Einfluss auf den Korrelationskoeffizienten ausüben. + Korrelationen lassen sich für alle Funktionstypen berechnen + allerdings werden nur monotone bzw. lineare Zusammenhänge erfasst. 119 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Grenzen von Zusammenhangsmaßen + Kausalzusammenhänge können nicht erfasst werden + Scheinkorrelationen (Korrelation zwischen Merkmalen, die inhaltlich nicht gerechtfertigt ist) können auftreten + Zusammenhänge ergeben sich dann, wenn ein mit beiden beobachtbaren Merkmalen hochkorreliertes drittes Merkmal übersehen wird und unberücksichtigt bleibt. + Bleibt ein entscheidendes Merkmal unberücksichtigt, kann dies zudem vorhandene Korrelationen verschleiern oder hinsichtlich des Vorzeichens umkehren 120 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kausalität r = .62 121 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kausalität + Mögliche Erklärungen für die Korrelation (1) Die Anzahl der Störche beeinflusst tatsächlich die Geburtenrate kausal. (2) Die Geburtenrate beeinflusst das die Anzahl der Störche. (3) Der Zusammenhang zwischen der Anzahl der Störche und der Geburtenrate wird durch eine dritte Variable bestimmt. (4) Der Zusammenhang zwischen Anzahl der Störche und Geburtenrate ist rein zufällig. + Es lassen sich also einige unterschiedliche Erklärung für eine hohe statistische Korrelation zwischen zwei Variablen finden. + Nicht immer ist die einfachste oder offenkundigste Erklärung auch die richtige. + Tatsächlich zeigt die Praxis, dass allzu oft vorschnell von einer Korrelation auf einen Kausalzusammenhang geschlossen wird, ohne weitere, nötige Belege für diese Interpretation anzubringen. Eine statistische Korrelation kann zwar eine kausale Beziehung nahelegen. Sie alleine reicht aber nicht aus, um Kausalität zu begründen. 122 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Kausalität + Ein solcher Schluss ist nur dann folgerichtig, wenn diese Kriterien erfüllt werden: + Vorliegen einer statistischen Korrelation. Ein statistischer Zusammenhang ist eine notwendige Bedingung für eine kausale Beziehung. Dabei ist aber zu beachten, dass auch nicht-lineare Zusammenhänge zwischen zwei Variablen bestehen können, die bspw. durch die Produkt-Moment Korrelation nicht erfasst werden. In unserem Beispiel konnten wir aber eine substantielle Korrelation zwischen dem Umsatz und den Werbeausgaben errechnen. + Die unabhängige Variable findet zeitlich vor der abhängigen Variablen statt. Als unabhängige Variable wird diejenige Variable bezeichnet, die einen Einfluss auf die abhängige Variable ausübt. Die Veränderungen in der unabhängigen Variablen müssen logischer weise vor der Veränderung in der abhängigen Variable stattfinden. + Es gibt keine Drittvariablen, die sowohl die unabhängige als auch die abhängige Variable gleichzeitig beeinflussen. Hierfür muss sorgfältig recherchiert werden und möglichst viele Variablen zusätzlich untersucht werden, die einen Einfluss auf beide Variablen ausüben könnten. + Es gibt eine inhaltliche Erklärung für den kausalen Zusammenhang. Bevor eine Korrelation kausal interpretiert werden kann, muss immer auch eine Erklärung für die Richtung des Zusammenhangs existieren. 123 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Regressionsanalysen + Situation und Problemstellung + Schritte der linearen Regressionsanalyse + Formulierung des Modells + Schätzung der einfachen Regressionsfunktion + Prüfung der einfachen Regressionsfunktion + Schätzung der multiplen Regressionsfunktion + Prüfung der multiplen Regressionsfunktion + Voraussetzungen der Regressionsanalyse + Grenzen der Regression 124 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Situation und Problemstellung Der Verkaufsleiter eines Margarineherstellers ist mit dem mengenmäßigen Absatz seiner Marke nicht zufrieden. Er stellt zunächst fest, dass der Absatz zwischen seinen Verkaufsgebieten differiert: Die Werte liegen zwischen 921 Kartons und 2.585 Kartons. Der Mittelwert beträgt 1.806,8. Er möchte wissen, warum die Werte so stark differieren und deshalb prüfen, von welchen Faktoren, die er beeinflussen kann, im wesentlichen der Absatz abhängt. Zu diesem Zweck nimmt er eine Stichprobe von Beobachtungen aus zehn etwa gleich großen Verkaufsgebieten. Er sammelt für die Untersuchungsperiode Daten über die abgesetzte Menge, den Preis, die Ausgaben für Verkaufsförderung sowie die Anzahl der Vertreterbesuche. 125 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Situation und Problemstellung Die Untersuchung soll nun die Antwort auf die Frage geben, ob die genannten Einflussgrößen sich auf die Absatzmenge auswirken. Es soll zunächst eine der in Frage kommenden Variablen (hier: die Besuche) herausgegriffen werden. Im Folgenden sollen auch die weiteren Einflussgrößen (Preis, die Ausgaben für Verkaufsförderung sowie die Anzahl der Vertreterbesuche) in die Untersuchung einbezogen werden. 126 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse + Die Folgende Daten erhielt der Verkaufsleiter aus der Stichprobe: Nr. Menge Kartons Preis pro Karton pro Periode (Menge) (Menge) Ausgaben für Zahl der Verkaufsförderung Vertreterbesuche (Ausgaben) (Besuche) 1 2585 12,50 2000 109 2 1819 10,00 550 107 3 1647 9,95 1000 99 4 1496 11,50 800 70 5 921 12,00 0 81 6 2278 10,00 1500 102 7 1810 8,00 800 110 8 1987 9,00 1200 92 9 1612 9,50 1100 87 10 1913 12,50 1300 79 127 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse (1) Formulierung des Modells (2) Schätzung der Regressionsfunktion (3) Prüfung der Regressionsfunktion 128 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Formulierung des Modells + Zunächst geht es darum, das sachlich zugrunde liegende Ursache-Wirkungsmodell in Form einer linearen Regressionsbeziehung zu bestimmen + Hier: Der Verkaufsleiter vermutet aufgrund seiner Erfahrung, dass die Absatzmenge von der Zahl der Vertreterbesuche abhängig ist + Der vermutete Zusammenhang zwischen der Absatzmenge und Zahl der Vertreterbesuche muss der Grundprämisse der Linearität entsprechen. + Linearitätsprämisse der Regressionsanalyse: Y konstant X j 129 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Formulierung des Modells + Für zwei Variablen lässt sich ein Streudiagramm der Beobachtungswerte erzeugen, das erkennen lässt, ob eine lineare Beziehung unterstellt werden kann 130 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der einfachen Regressionsfunktion + Gesucht ist die genaue Lage einer linearen Funktion im Koordinatensystem (x,y), die man Regressionsgerade nennt. + Zwei Parameter bestimmen die Lage einer Geraden + das konstante Glied b0, Schnittpunkt mit der Ordinate (x = 0) + der Regressionskoeffizient b1, der die Neigung der Geraden bestimmt: b1 + Y X die gesuchte Regressionsfunktion lautet: yˆ bo b1 x Kriterium (AV) Prädiktor (UV) 131 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der einfachen Regressionsfunktion + Ein möglicher Verlauf der Regressionsgeraden 132 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der einfachen Regressionsfunktion + + Die der Regressionsanalyse zugrundeliegende Frage lautet: + „Welcher Anteil aller Abweichungen der Beobachtungswerte von ihrem gemeinsamen Mittelwert lässt sich durch den unterstellten linearen Einfluss der unabhängigen Variablen (Vertreterbesuche) erklären und welcher Anteil verbleibt als unerklärte Residuen?“ + Hier: Lässt sich die gesamte Abweichung von 778,20 Mengeneinheiten bei Beobachtung 1 durch die Zahl der Vertreterbesuche von 109 erklären, oder ist sie auch durch andere Einflussgrößen maßgeblich bestimmt worden? Die Zielsetzung der Regressionsanalyse besteht darin, eine lineare Funktion zu ermitteln, die möglichst viel von den Abweichungen erklärt und somit möglichst geringe Residuen übrig lässt. 135 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der einfachen Regressionsfunktion + Wenn man die Residuen explizit in die Regressionsgleichung einbezieht, erhält man folgende Gleichung Y bo b1 x e + Will man den Zusammenhang zwischen Absatzmenge und Zahl der Vertreterbesuche schätzen, dann gelingt dies umso besser, je kleiner die ek sind. + Es wird ein Rechenverfahren benötigt, das die Parameter der Regressionsgeraden so schätzt, dass die Streuung der Stichprobenwerte um die Gerade möglichst klein wird. Es wird die Summe der quadrierten Residuen minimiert (KQS - Kleinste-Quadrate-Schätzung) 136 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der einfachen Regressionsfunktion + Grafische Veranschaulichung 138 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der einfachen Regressionsfunktion + Eingesetzt in (1) und (2) erhält man b1 10 1.724.403 936 18.068 18,88105 2 10 89.370 (936) b0 1.806,8 18,88105 93,6 39,5337 + Die gesuchte Regressionsgleichung lautet demnach yˆ k 39,5337 18,88105 xk 141 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der einfachen Regressionsfunktion + Die Regressionsfunktion erlaubt die Schätzung der Absatzmenge für jede Zahl von Vertreterbesuchen + Bsp.: Zahl der Vertreterbesuche 110 (Fall 7) yˆ 39.5337 18,88105 110 2.116,45 Beobachtet wurden 1.810. Das Residuum beträgt demnach e7 = -306,45 + Die Regressionsfunktion zeigt an, um wie viel sich die geschätzte Menge ändern wird, wenn die Zahl der Vertreterbesuche um eine Einheit geändert wird + In diesem Beispiel zeigt der Regressionskoeffizient b1 an, dass die geschätzte Menge um 18,88105 Einheiten zunehmen wird, wenn die Zahl der Vertreterbesuche um eine Einheit steigt 142 ANALYSEPHASE DATENAUFBEREITUNG 143 ANALYSEPHASE DATENAUFBEREITUNG 144 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Prüfung der einfachen Regressionsfunktion + Nachdem die Regressionsfunktion geschätzt wurde, ist deren Güte zu überprüfen, d.h. es ist zu klären, wie gut sie als Modell der Realität geeignet ist + Globale Prüfung der Regressionsfunktion: ob und wie gut die abhängige Variable Y durch das Regressionsmodell erklärt wird + Prüfung der Regressionskoeffizienten (nicht behandelt): ob und wie gut einzelne Variablen des Regressionsmodells zur Erklärung der abhängigen Variablen beitragen 145 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Prüfung der einfachen Regressionsfunktion + + Globale Prüfung der Regressionsfunktion anhand folgender Gütemaße + das Bestimmtheitsmaß (wird behandelt) + die F-Statistik (nicht behandelt) + der Standardfehler (nicht behandelt) Bestimmtheitsmaß + misst die Güte der Anpassung der Regressionsfunktion an die empirischen Daten („goodness of fit“). + die Basis hierfür bilden die Residualgrößen 146 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Prüfung der einfachen Regressionsfunktion + Analog zu der beschriebenen Zerlegung der Gesamtabweichung einer Beobachtung gilt folgende Zerlegung der Gesamtstreuung aller Beobachtungen Gesamtstreuung = erklärte Streuung + nicht erklärte Streuung K (y k 1 K k K y ) ( yˆ k y ) ( yk yˆ k ) 2 2 2 k 1 k 1 + Auf Basis der Streuungszerlegung lässt sich das Bestimmtheitsmaß berechnen. + Es wird mit R2 bezeichnet und ergibt sich aus dem Verhältnis von erklärter Streuung zur Gesamtstreuung 149 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Prüfung der einfachen Regressionsfunktion + Bestimmtheitsmaß K R2 ( yˆ k y)2 (y k y)2 k 1 K k 1 K oder R2 1 (y k 1 K (y k 1 + k k erklärte Streuung Gesamtstre uung yˆ k ) 2 y)2 1 nicht erklärte Streuung Gesamtstre uung Das Bestimmtheitsmaß ist eine normierte Größe, dessen Wertebereich zwischen null und eins liegt. Es ist um so größer, je höher der Anteil der erklärten Streuung an der Gesamtstreuung ist. + R2 = 1 gesamte Streuung erklärt + R2 = 0 gesamte Streuung nicht erklärt 150 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Prüfung der einfachen Regressionsfunktion + Ergebnis R2 1 + 1.188.684,94 0,3455 1.816.255,60 Das Ergebnis besagt, dass 34,55% der gesamten Streuung auf die erklärende Variable Besuche und 65,45% auf in der Regressionsgleichung nicht erfasste Einflüsse zurückzuführen sind. 152 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + Der Verkaufsleiter ist mit einer Varianzaufklärung (vgl. Bestimmtheitsmaß) von 34.6 % gar nicht zufrieden.* + Immerhin bedeutet dies, dass er 65.4 % der Schwankungen des Absatzes auch dann nicht erklären (und beeinflussen) kann, wenn er die Vertreterbesuche berücksichtigt. + Deshalb beschließt er, daneben zwei weitere Einflussgrößen in dem Modell zu betrachten: + + den Preis der Margarine und + die Ausgaben für Verkaufsförderung Er ist davon überzeugt, dass neben den Vertreterbesuchen auch diese beiden Größen Einfluss auf den Absatz nehmen. * Peterson, Robert A., Albaum, Gerald & Beltramini, Richard F. (1985). A Meta-Analysis of Effect Sizes in Consumer Behavior Experiments, in: Journal of Consumer Research, Vol. 12 (1985), No. 1, pp. 97-103, finden, dass im Durchschnitt bei veröffentlichten, signifikanten (α = .05) emp. Ergebnissen zum Käuferverhalten zwischen 1970-1982 nur etwa 11 % der AV durch die UVs aufgeklärt wurde. 153 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + Diese Entscheidung verändert das der Regressionsanalyse zu Grunde liegende Modell: 154 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + Der Regressionsansatz hat dann folgende (allgemeine) Form Yˆ b0 b1 x1 b2 x2 ... b j x j ... bJ xJ + Auch bei der multiplen Regressionsanalyse lautet die Aufgabe, die Parameter b0, b1, b2, ..., bj so zu bestimmen, dass die Summe der Abweichungsquadrate (nicht erklärte Streuung) minimiert wird e y K k 1 2 K 2 k k 1 k (b0 b1 x1k b2 x2 k ... b j x jk ... bJ xJk ) min! 155 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + Für die weiteren Variablen ergibt sich folgendes Modell: yˆ bo b1 Besuche b2 Preis b3 Ausgaben + Die Lösung der Zielfunktion und Bestimmung der Regressionskoeffizienten führt zu einem sog. System von Normalgleichungen, dessen Lösung einen größeren Aufwand als im Fall der linearen Einfachregression verursacht. 156 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + Für die weiteren Variablen ergibt sich folgendes Modell: yˆ bo b1 Besuche b2 Preis b3 Ausgaben + Die Lösung der Zielfunktion und Bestimmung der Regressionskoeffizienten führt zu einem sog. System von Normalgleichungen, dessen Lösung einen größeren Aufwand als im Fall der linearen Einfachregression verursacht. + Auf Grundlage der Daten in der Ausgangstabelle ergibt sich folgende Regressionsfunktion yˆ 6,87 11,09 Besuche 9,93 Preis 0,66 Ausgaben 157 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + Die multiple Regressionsfunktion erlaubt erneut die Schätzung der Absatzmenge + + Bsp.: Zahl der Vertreterbesuche 110 (Fall 7) Es ergibt sich ein neuer Schätzwert für die Absatzmenge von 1.816,35. Das Residuum beträgt nur noch -6,35 Erweiterung: + Für die multiple Regressionsanalyse ist es interessant, die Einflussstärke der unabhängigen Variablen für die Erklärung der abhängigen Variablen zu erkennen + Durch Umformung der Regressionskoeffizienten kann eine direkte Vergleichbarkeit der numerischen Werte hergestellt werden 158 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + Der standardisierte Regressionskoeffizient errechnet sich wie folgt j bj + Standardabweichung von X j Standardabweichung von Y Die Schätzung der Standardabweichung erfolgt nach folgendem Ausdruck K sx + + (x k 1 k x )2 K 1 Die Standardabweichung der Variablen X und Y betragen in unserem Beispiel + sMenge = 449,228 + sBesuche = 13,986 demnach ergibt sich als Wert für Besuche 11,09 13,99 0,345 449,228 159 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Schätzung der multiplen Regressionsfunktion + + Analog ergeben sich für die Ausgangsdaten mit zehn Beobachtungen und den drei unabhängigen Variablen + sBesuche = 13,986 + sPreis = 1,547 + sAusgaben = 544,289 Besuche 0,345 Preis 0,034 Ausgaben 0,794 Es zeigt sich, dass die Variable Besuche den höchsten unstandardisierten Regressionskoeffizienten, die Variable Ausgaben jedoch den höchsten standardisierten Regressionskoeffizienten aufweist - und damit den höchsten Erklärungsbeitrag liefert. yˆ 6,87 11,09 Besuche 9,93 Preis 0,66 Ausgaben 160 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Prüfung der multiplen Regressionsfunktion + Bei der multiplen Regressionsfunktion ist zu überprüfen, wie gut sie als Modell der Realität geeignet ist. + Globale Prüfung der Regressionsfunktion: ob und wie gut die abhängige Variable Y durch das Regressionsmodell erklärt wird K r2 ( yˆ k 1 K (y k 1 k y)2 k y) 2 erklärte Streuung Gesamtstre uung r2 = .926 + Das Ergebnis besagt, dass 92,6% der gesamten Streuung auf die erklärenden Variablen Preis, Ausgaben für die Verkaufsförderung sowie Anzahl Vertreterbesuche und 7,4% auf in der Regressionsgleichung nicht erfasste Einflüsse zurückzuführen sind. + Durch die Berücksichtigung der weiteren Einflussgrößen hat sich das Bestimmtheitsmaß und damit die Güte der Anpassung erheblich verbessert. + Test von r2; F-Statistik H0: r2 = 0; also: keine Varianzaufklärung durch die UVs H1: r2 > 0; 161 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Linearen Regressionsanalyse: Interpretation der Regressionsanalyse yˆ 6,87 11,09 Besuche 9,93 Preis 0,66 Ausgaben Besuche 0,345 Preis 0,034 Ausgaben 0,794 + Ist das Bestimmtheitsmaß r2 > 0 ? Für welche Prädiktoren gilt: βn > 0 ? + Sind die Voraussetzungen der Regressionsanalyse erfüllt? (folgt) + Sind die Vorzeichen der Regressionskoeffizienten plausibel? Welche Aussagen bzgl. des Zusammenhangs lassen sich bereits so ableiten? + Interpretation der Größe der (stand.) Regressionskoeffizienten 163 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Voraussetzungen der Regressionsanalyse + Metrisches Messniveau sowohl für die abhängigen als auch für die unabhängigen Variablen. + Zwischen der abhängigen Variablen und den einzelnen unabhängigen Variablen muss jeweils eine lineare Beziehung bestehen. + Die Variablen müssen additiv verknüpft sein, d.h. der Gesamteinfluss der unabhängigen Variablen auf die abhängige Variable muss gleich der Summe der Einzeleinflüsse sein. + Es darf keine Multikollinearität vorliegen, d.h. die unabhängigen Variablen müssen untereinander unabhängig sein, dürfen also nicht miteinander korrelieren. + Die Residuen sind normalverteilt (ek ~ N(0,σ2)) 164 ANALYSEPHASE AUFDECKUNG VON ZUSAMMENHÄNGEN Grenzen der Regressionsanalyse Regressionsmodell im Regressionsmodell nicht (direkt) abbildbar sind: + intervenierende Variable AV + Interaktionen UV + Schätzer für unabhängige Variable UV + usw. UV => führt zur Kausalmodellierung 165 + + + Student´s t-Test t-Test für abhängige Stichproben Varianzanalysen (5) Daten testen III: Methoden zur Aufdeckung von Gruppenunterschieden Bildquelle: http://www.minitab.com/ 166 Literatur t-Test Bortz, Jürgen (2005). Statistik für Human- und Sozialwissenschaftler, 6. Aufl., Heidelberg: Springer, S.107-123. Fahrmeir, Ludwig, Künstler, Rita, Pigeot, Iris & Tutz, Gerhard (2004). Statistik, 5. Aufl., Berlin-Heidelberg-New York etc.: Springer, S.411-420 und S.434-473. Zöfel, Peter (2003). Statistik für Wirtschaftswissenschaftler, München-Boston-San Francisco etc: Pearson, S.87-102 und S.126-150. 167 Literatur Varianzanalyse Herrmann, Andreas & Seilheimer, Christian (2000). Varianz- und Kovarianzanalyse, in: Herrmann, Andreas & Homburg, Christian (Hg.) Marktforschung, Wiesbaden: Gabler, S. 265-294 Vertiefung: Backhaus, Klaus, Erichson, Bernd, Plinke, Wulff & Weiber, Rolf (2006). Multivariate Analysemethoden, Berlin, Heidelberg, New York: Springer, S. 119-152 Speziell zu Effektstärken und Stichprobengrößen: Bortz, Jürgen & Döring, Nicola (2003). Forschungsmethoden und -evaluation, Berlin, Heidelberg, New York: Springer, S. 603-612 168 ANALYSEPHASE GRUPPENUNTERSCHIEDE Kriterien für die Auswahl des richtigen Tests + + Es gibt drei Kriterien, die bei Tests auf signifikante Unterschiede relevant sind: + Unabhängige – abhängige Stichproben + Vergleich von zwei Stichproben – Vergleich von mehr als zwei Stichproben + Intervallskalierte, normalverteilte Werte – ordinalskalierte oder nicht normalverteilte Werte Tests bei intervallskalierten und normalverteilten Variablen + Anwendung parametrischer Tests + Hypothesen über bestimmte Parameter der Verteilung sollen getestet werden + Gehen davon aus, dass die beobachteten Stichprobendaten einer Grundgesamtheit entstammen, in der die Variablen Intervallskalenniveau und eine bestimmte Wahrscheinlichkeitsverteilung (Normalverteilung) aufweisen Anzahl der Stichproben Art der Abhängigkeit Test 2 unabhängig Student´s t-Test >2 unabhängig einfaktorielle Varianzanalyse 2 abhängig t-Test für abhängige Stichproben 169 ANALYSEPHASE GRUPPENUNTERSCHIEDE Student‘s t-Test + Situation + Fragestellung + Datenlage + Schritte des Student‘s t-Test + t-Test für gepaarte Stichproben 170 ANALYSEPHASE GRUPPENUNTERSCHIEDE Situation Der Verkaufsleiter eines Pizzaherstellers ist mit dem mengenmäßigen Absatz seiner Marke Alberta nicht zufrieden. Ein Marktforschungsinstitut wird von ihm damit beauftragt zu untersuchen, wie stark ein Sonderangebot kurzfristig den Absatz von Tiefkühlpizza der Marke Alberta steigert. Zu diesem Zweck wird in einem Ladengeschäft stichprobenartig an jeweils 10 Tagen der Absatz des Produktes bei Normalpreisen und der Absatz des Produktes bei Sonderpreisen erhoben. 171 ANALYSEPHASE GRUPPENUNTERSCHIEDE Fragestellung Im Folgenden gilt es mit geeigneten statistischen Testverfahren zu untersuchen, ob sich beide Gruppen (hier: Normalpreis G1 und Sonderpreis G2) bezüglich der abgesetzten Stückzahl an Tiefkühlpizza bei einer Ablehnungswahrscheinlichkeit von 5%, signifikant voneinander unterscheiden. Gehen Sie hierbei davon aus, dass die Werte in beiden Stichproben normalverteilt sind. Formulieren Sie zunächst die relevanten Hypothesen für das vorliegende Testproblem Erweiterung: Wählen Sie in einem zweiten Schritt ein nicht-parametrisches Prüfverfahren, um zu ermitteln, ob der Unterschied zwischen beiden Gruppen signifikant ist. 172 ANALYSEPHASE GRUPPENUNTERSCHIEDE Datenlage Normalpreis Tag Sonderpreis Absatz (Stück) 1 0 4 2 1 5 3 2 4 4 5 3 5 0 2 6 2 5 7 2 4 8 3 5 9 2 3 10 5 2 173 ANALYSEPHASE GRUPPENUNTERSCHIEDE Student‘s t-Test + Vergleich zweier unabhängiger Stichproben hinsichtlich ihrer Mittelwerte, wobei die Werte der beiden Stichproben normalverteilt sein müssen + Je nachdem, ob sich die Varianzen in den beiden Stichproben signifikant unterscheiden (Varianzheterogenität), oder nicht, gibt es zwei verschiedene Formeln für eine t-verteilte Prüfgröße t + Man berechnet zunächst die Prüfgröße s ² majo r F s ² mino r mit smajor als größere und sminor als kleinere der beiden Standardabweichungen + Die Prüfgröße F ist F-verteilt mit df = (nmajor - 1, nminor - 1) + Varianzheterogenität wird bei Signifikanz auf der Stufe p < .05 angenommen 174 ANALYSEPHASE GRUPPENUNTERSCHIEDE Student‘s t-Test + im Fall der Varianzhomogenität gilt: t + (n1 1) s1² (n 2 1) s 2² n1 n 2 2 n1n 2 n1 n 2 mit df = n1 + n2 – 2 Freiheitsgraden im Fall der Varianzheterogenität gilt: t + x1 x 2 x1 x 2 mit s1² s 2² n1 n 2 df n1 n 2 2 2 Freiheitsgraden die Nullhypothese kann nicht verworfen werden, wenn der berechnete t-Wert geringer ist als der tabellierte kritische Wert (bei gegebener Anzahl der Freiheitsgrade) 175 ANALYSEPHASE GRUPPENUNTERSCHIEDE Student‘s t-Test + + + Im Schnitt unterscheiden sich die Absatzzahlen der Tiefkühlpizza zum Normalpreis im Vergleich zu den Absatzzahlen zum Sonderpreis Es soll mit dem (Student‘s) t-Test überprüft werden, ob dieser Mittelwertsunterschied statistisch signifikant ist Nullhypothese H0 : Es besteht kein Unterschied in der Absatzzahl zwischen dem Angebot von Tiefkühlpizza zu Sonderpreisen und zu Normalpreisen (d.h. der Mittelwertsunterschied in der Stichprobe ist zufällig zustande gekommen/nicht auf die Grundgesamtheit übertragbar). Normalpreis Tag Sonderpreis Absatz (Stück) 1 0 4 2 1 5 3 2 4 4 5 3 5 0 2 6 2 5 7 2 4 8 3 5 9 2 3 10 5 2 Mittelwert 2,2 3,7 176 ANALYSEPHASE GRUPPENUNTERSCHIEDE Student‘s t-Test + Im ersten Schritt ist zu entscheiden, ob Varianzhomogenität oder Varianzheterogenität vorliegt (F-Test): 10 10 x 2,2² sG2 1 F i 1 10 x 3,7² i i s G2 2 2,76 s ² major i 1 10 1,21 s ² minor s ² majo r 2,76 = 2,28 1 , 21 s ² mino r df1 df2 + 1 2 3 4 5 6 7 8 9 10 8 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39 3,35 9 5,12 4,26 3,86 3,63 3,48 3,37 3,29 3,23 3,18 3,14 F-Tabelle für p = .05 Wie die F-Tabelle ausweist, ist dies bei (9;9) Freiheitsgraden ein nicht signifikanter Wert; Varianzhomogenität ist also gegeben. 177 ANALYSEPHASE GRUPPENUNTERSCHIEDE Student‘s t-Test + Zweiter Schritt: Bestimmung der Prüfgröße t + Im Fall der Varianzhomogenität gilt t 2,2 3,7 100 2,38 20 9 * 2,76 9 *1,21 18 df α = .05 α = .01 18 1,734 2,552 19 1,729 2,539 t-Tabelle + Nach der t-Tabelle ist dies bei df = 10+10-2 Freiheitsgraden ein signifikanter Wert, da t > tkrit. + Die Nullhypothese kann daher verworfen werden. 178 ANALYSEPHASE DATENAUFBEREITUNG 179 ANALYSEPHASE DATENAUFBEREITUNG 180 ANALYSEPHASE GRUPPENUNTERSCHIEDE t-Test für abhängige Stichproben + Vergleich zweier abhängiger Stichproben hinsichtlich ihrer Mittelwerte, wobei die Differenzen zusammengehöriger Messwertpaare aus einer normalverteilten Grundgesamtheit stammen müssen + Prüfgröße + t d n ist t-verteilt mit df = n - 1 Freiheitsgraden s Errechnung des Mittelwerts d der Differenzen di n ∑ di d= i=1 n + + und deren Standardabweichung s die Nullhypothese kann nicht verworfen werden, wenn der berechnete t-Wert geringer ist als der tabellierte kritische Wert (bei gegebener Anzahl der Freiheitsgrade) 181 ANALYSEPHASE DATENAUFBEREITUNG 182 ANALYSEPHASE DATENAUFBEREITUNG 183 ANALYSEPHASE GRUPPENUNTERSCHIEDE Varianzanalyse + Problemstellung + Auswertung der Daten des Experimentes mittels einfaktorieller Varianzanalyse + Entwicklung des einfaktoriellen Untersuchungsdesigns + Schritte der einfaktoriellen Varianzanalyse + Voraussetzungen der Varianzanalyse + Zusammenfassung der wesentlichen Schritte 184 ANALYSEPHASE GRUPPENUNTERSCHIEDE Situation Der Leiter einer Supermarktkette möchte die Wirkung verschiedener Arten der Warenplatzierung auf die Absatzmenge überprüfen. Er wählt dazu Margarine in der Becherverpackung aus. Es stehen drei Möglichkeiten der Regalplatzierung offen: Unabhängige Variable (Faktor): Warenplatzierung I Platzierung nur im Normalregal der Frischwarenabteilung II Platzierung im Normalregal der Frischwarenabteilung und Zweitplatzierung im Fleischmarkt III Platzierung im Kühlregal der Frischwarenabteilung 185 ANALYSEPHASE GRUPPENUNTERSCHIEDE Aufgabenstellung Entwickeln Sie in einem ersten Schritt eine geeignete experimentelle Versuchsanordnung, mit deren Hilfe sich die Frage beantworten lässt, ob die unterschiedlichen Absatzergebnisse in den drei Supermärkten auf die Variation der Warenplatzierung zurückzuführen sind 186 ANALYSEPHASE GRUPPENUNTERSCHIEDE Entwicklung des einfaktoriellen Untersuchungsdesigns Aus den insgesamt vorhandenen Supermärkten werden drei weitgehend vergleichbare Supermärkte des Unternehmens ausgewählt (Quasi-Experiment). In einem Zeitraum von 5 Tagen wird in jedem der drei Supermärkte jeweils eine Form der Margarinepräsentation durchgeführt („Normalregal“, „Zweitplatzierung“ und „Kühlregal“). Die Auswirkungen der Maßnahmen werden jeweils in der Größe „kg Margarineabsatz pro 1000 Kassenvorgänge“ erfasst. Platzierung Normalregal n1 Zweitplatzierung n2 Kühlregal n3 187 ANALYSEPHASE GRUPPENUNTERSCHIEDE Entwicklung des einfaktoriellen Untersuchungsdesigns + Man erhält drei Stichproben mit jeweils genau fünf Beobachtungswerten, die Teilstichproben haben also den gleichen Umfang. Tag 1 Tag 2 Tag 3 Tag 4 Tag 5 Supermarkt 1 „Normalregal“ 47 39 40 46 45 Supermarkt 2 „Zweitplatz.“ 68 65 63 59 67 Supermarkt 3 „Kühlregal“ 59 50 51 48 53 Kg Margarineabsatz pro 1000 Kassenvorgänge in drei Supermärkten in Abhängigkeit von der Platzierung 188 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Mittelwerte des Margarineabsatzes in den drei Supermärkten Mittelwert pro Supermarkt Supermarkt 1 „Normalregal“ y1 =43,4 Supermarkt 2 „Zweitplatz.“ y2 =64,4 Supermarkt 3 „Kühlregal“ y3 =52,2 Gesamtmittelwert y = 53,33 Folgende Notationen werden eingeführt: y = Beobachtungswert mit gk g = Kennzeichnung einer Faktorstufe als Ausprägung einer unabhängigen Variablen (g = 1, 2 ...,G) k = Kennzeichnung des Beobachtungswertes innerhalb einer Faktorstufe (k= 1, 2 ..., K) = Mittelwert der Beobachtungswerte einer Faktorstufe yg = Gesamtmittelwert aller Beobachtungswerte y 189 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Die Fragestellung der einfaktoriellen Varianzanalyse lautet: Hat die Warenplatzierung einen Einfluss auf den Absatz? + Grundprinzip der Varianzanalyse (Streuungszerlegung): + die dargestellte Analyse basiert auf folgendem Grundmodell der einfachen Varianzanalyse y gk g gk g gk Gesamtmittelwert der Grundgesamtheit, Schätzer= Wirkung der Stufe g des Faktors, die sich durch Abweichung vom Gesamtmittelwert der Grundgesamtheit bemerkbar macht, Schätzer= y yg y nicht erklärte Einfluss der Zufallsgrößen in der Grundgesamtheit 190 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Grundprinzip der Varianzanalyse (Streuungszerlegung): + Der Prognosewert für den Margarineabsatz, wenn kein Einfluss der Warenplatzierung vorhanden wäre, ist y . + Nimmt man einen Einfluss der Warenplatzierung auf den Absatz an, dann ist der Prognosewert für den Margarineabsatz je nach Art der Platzierung y1 , y 2 oder y3 . + Die Abweichungen vom Prognosewert ( y gk - y g ) sind auf zufällige äußere Einflüsse zurückzuführen und somit nicht erklärt. 191 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Grundprinzip der Varianzanalyse: 192 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Grundprinzip der Varianzanalyse GesamtErklärte abweichung Abweichung Summe der qua- = Summe der quadrierten Gesamtdrierten Abweiabweichung chungen zwischen den Faktorstufen G K ( y gk y )2 g 1k 1 SSt(otal) = = Nicht erklärte Abweichung + Summe der quadrierten Abweichungen innerhalb der Faktorstufen G K ( y g y )2 g 1 SSb(etween) . + + G K ( y gk y g )2 g 1k 1 SSw(ithin) 193 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Ermittlung der Abweichungsquadrate: SSt SSb SSw G K ( y gk y ) 2 g 1k 1 G K ( y g y) 2 g 1 G K ( y gk y g ) 2 g 1k 1 Normal- (47-53,33)2= 40,11 (43,4-53,33)2= 98,67 (47-43,4)2= 12,96 regal +(39-53,33)2= 205,44 +(43,4-53,33)2= 98,67 +(39-43,4)2= 19,36 +(40-53,33)2= 177,78 +(43,4-53,33)2= 98,67 +(40-43,4)2= 11,56 +(46-53,33)2= 53,78 +(43,4-53,33)2= 98,67 +(46-43,4)2= 6,76 +(45-53,33)2= 69,44 +(43,4-53,33)2= 98,67 +(45-43,4)2= 2,56 (68-53,33)2= 215,11 (64,4-53,33)2= 122,47 (68-64,4)2= 12,96 +(64,4-53,33)2= 122,47 +(65-64,4)2= 0,36 +(63-53,33)2= 93,44 +(64,4-53,33)2= 122,47 +(63-64,4)2= 1,96 +(59-53,33)2= 32,11 +(64,4-53,33)2= 122,47 +(59-64,4)2= 29,16 +(67-53,33)2= 186,78 +(64,4-53,33)2= 122,47 +(67-64,4)2= 6,76 (52,2-53,33)2= 1,28 (59-52,2)2= 46,24 +(50-53,33)2= 11,11 +(52,2-53,33)2= 1,28 +(50-52,2)2= 4,84 +(51-53,33)2= 5,44 +(52,2-53,33)2= 1,28 +(51-52,2)2= 1,44 +(48-53,33)2= 28,44 +(52,2-53,33)2= 1,28 +(48-52,2)2= 17,64 +(53-53,33)2= 0,11 +(52,2-53,33)2= 1,28 +(53-52,2)2= 0,64 SSt= 1287,33 SSb= 1112,13 SSw= 175,20 Zweit- platzierung +(65-53,33)2= 136,11 Kühlregal (59-53,33)2= 32,11 194 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Ermittlung der Varianzen: SS Zahl der Beobachtungen 1 + Varianz = + Mittlere quadratische (Gesamt-) Abweichung MSt = + SSt = G * K 1 1287,33 91,95 15 1 Mittlere quadratische Abweichung zwischen den Faktorstufen SSb 1112,13 556,07 = G 1 3 1 + Mittlere quadratische Abweichung innerhalb der Faktorstufen MSb = MSw = SSw = G * ( K 1) 175,20 14,60 3(5 1) 195 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Statistische Prüfung des Einflusses des Faktors (Waren-platzierung) auf die abhängige Variable (Margarineabsatz): + Ausgangspunkt der Prüfung ist die Nullhypothese (H0): „Es bestehen bezüglich des Margarineabsatzes keine Unterschiede in der Wirkung durch die Art der Warenplatzierung.“ H0: 1 2 3 0 + Die Alternativhypothese H1 lautet: „Es besteht bezüglich des Margarineabsatzes ein Unterschied in den Wirkungen alternativer Arten der Warenplatzierung.“ H1: 0 196 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + + Es werden MSb und MSw in folgende Beziehung gesetzt Femp = MS B MSW Femp = 556,07 38,09 14,6 mit Femp = empirischer F-Wert + + + Die Prüfung erfolgt anhand eines Vergleichs des empirischen F-Wertes mit dem theoretischen F-Wert lt. Tabelle. + Die Tabelle der theoretischen F-Werte zeigt für jeweilige Vertrauenswahrscheinlichkeit einen Prüfwert. + Seine Höhe hängt von der Zahl der Freiheitsgrade (df) im Zähler (Spalten der Tabelle) und der Zahl der Freiheitsgrade im Nenner (Zeilen der Tabelle) ab. 197 ANALYSEPHASE GRUPPENUNTERSCHIEDE Schritte der einfaktoriellen Varianzanalyse + Das Signifikanzniveau von 1% und df = 2 im Zähler und df = 12 im Nenner führt zu einem theoretischen F-Wert von 6,93. Freiheitsgrade des Zählers + + Freiheitsgrade des Nenners 1 2 11 9,65 7,21 12 9,33 6,93 Empirischer und theoretischer F-Wert werden verglichen. Ist der empirische Wert größer als der theoretische, dann kann die Nullhypothese verworfen werden. + wenn: Femp. > Ftheo. H0 ist zu verwerfen + hier: 38,09 > 6,93 H0 ist zu verwerfen D.h. mit einer Vertrauenswahrscheinlichkeit von 99% kann der Schluss gezogen werden, dass die Platzierungsarten einen unterschiedlichen Einfluss auf die Absatzmenge haben. 198 ANALYSEPHASE DATENAUFBEREITUNG 199 ANALYSEPHASE DATENAUFBEREITUNG 200 ANALYSEPHASE DATENAUFBEREITUNG 201 ANALYSEPHASE GRUPPENUNTERSCHIEDE Voraussetzungen der Varianzanalyse + Formulierung einer Hypothese über den Wirkungszusammenhang der unabhängigen und der abhängigen Variablen. + Unabhängige Daten können auf nominalen, abhängige müssen auf metrischen Skalenniveau erhoben werden. + Die Restgrößen wirken sich bis auf zufällige Schwankungen in allen Stichprobenzellen gleich aus (sog. Varianzhomogenität). + Die Werte in der Grundgesamtheit sind normalverteilt. + Die Additivität der Einflussgrößen, d.h. der Einfluss eines Faktors auf die Ergebnisvariable ist unabhängig vom Einfluss weiterer Faktoren oder auch Restgrößen. + Strukturgleichheit, d.h. die in die Untersuchung gelangten Teilstich-proben haben die gleiche Struktur der absatzbeeinflussenden Größen wie die Grundgesamtheit. 206 MARKET RESEARCH PLAN DER VERANSTALTUNG + EINFÜHRUNG IN DIE VERANSTALTUNG + WAS IST MARKET RESEARCH – UND (WOZU) BRAUCHE ICH DAS? + DATEN SAMMELN + + Definitionsphase, Designphase, Feldphase: Wo die Fragen und Daten herkommen? DR. JAN RUTENBERG Leiter Kundenmanagement & Marktforschung sowie Regal- & Flächenmanagement + DATEN AUSWERTEN + + Analysephase: Wie kommt man von Daten zu Ergebnissen? INSIGHTS GENERIEREN UND KOMMUNIZIEREN + Kommunikationsphase: Wie werden aus Ergebnissen „Insights“? 207 INSIGHTS GENERIEREN UND KOMMUNIZIEREN 208 MARKET RESEARCH …IST AUCH EIN PROZESS Definitionsphase • Formulierung des Forschungsproblems • Bestimmung der Erhebungsziele • Desk Research Vorbereitung Designphase • Informationsquellen (Primär-/Sekundärerhebung) • Messinstrumente/Operationalisierung • Grobplanung der Datenauswertung • Erhebungseinheiten (Voll-/Teilerhebung, Stichprobenumfang) • Arbeits-, Zeit- und Kostenplanung • Pre-Tests Feldphase Im Feld • Durchführung • Kontrolle und Dokumentation der Datenerhebung • Eingreifen vs. Standardisierung Analysephase Nachbereitung • Vorbereitung der Datenauswertung (Digitalisierung, Kodierung, Logikchecks) • Auswertung und Interpretation Kommunikationsphase • Forschungsbericht • Präsentation 209 Ergebnisse berichten Bildquelle: http://www.portaltideelbe.de/ 210 KOMMUNIKATIONSPHASE ERGEBNISSE BERICHTEN Regeln für die Ergebnispräsentation + Wissenschaftliche Arbeiten haben unter Beachtung von fach- und disziplinspezifischen Regeln nach dem neuesten Stand der Forschung durchgeführt zu werden. Dies setzt voraus, dass man sich vor Beginn der wissenschaftlichen Untersuchung die notwendigen methodischen und theoretischen Fähigkeiten aneignet. + In Publikationen, Vorträgen, Präsentationen von Ergebnissen anderer Art sowie Gutachten und Auftragsforschung sind wirtschaftliche und andere Interessenkonflikte offen zu legen. + Ab 24 Folien pro Sekunde ist es ein Film. Als Faustregel kann gelten: 2-3 Minuten pro Folie. + Ihr Publikum liest Ihre Ergebnisse zum ersten Mal. Zudem sind Sie meist viel tiefer in der Materie als Ihr Zielpublikum. Leiten Sie den Leser also durch den Text. Uns lassen Sie ihm ein wenig Zeit, alle Informationen auch aufzunehmen. + PPPPP 211 KOMMUNIKATIONSPHASE ERGEBNISSE BERICHTEN Wichtige Bestandteile + Abstract/Kurzzusammenfassung mit den wichtigsten Ergebnissen + Management Summary zusätzlich mit den wichtigsten Informationen für die Praxis + Hintergrund/Hinführung zum Thema, in der die Fragestellung in die Forschung eingeordnet wird und deren Relevanz dargelegt wird + Stand der Forschung und theoretische Grundlagen: Was wissen wir zu der Frage aus der Literatur? Was ist noch unbekannt? Und welche Vermutungen kann man aus der Theorie dazu aufstellen (Begründung!)? + Methoden, Organisation und Ablauf, sowie die Resultate wissenschaftlicher Forschungstätigkeit sind zu dokumentieren, zu sichern und aufzubewahren! + Ergebnisse + Diskussion der Ergebnisse + Fazit, Implikationen für Forschung und Praxis sowie Limitationen 212 VIELEN DANK UND VIEL ERFOLG BEI DER KLAUSUR 213