Pseudonymisierung medizinischer Datenbanken
Werbung

..
..
....
...........
..
............
...
...
..
Pseudonymisierung
medizinischer
Datenbanken
..
...
....
............
Bachelorarbeit
Katharina Rudert
............
....
...
..
Lehrstuhl für Informatik 6
(Datenmanagement)
Department Informatik
Technische Fakultät
Friedrich AlexanderUniversität
Erlangen-Nürnberg
..
.
..
..
..
..
..
..
..
..
...
..
.
...
...
...
...
...
..
....
..
.
.
....
.
...
....
...
....
......
.....
.......
......
........
.......
.
.
.
.
.
.
.........
.
.............
.........
......................................................
Pseudonymisierung
medizinischer
Datenbanken
Bachelorarbeit im Fach Informatik
vorgelegt von
Katharina Rudert
geb. 25.08.1988 in Erlangen
angefertigt am
Department Informatik
Lehrstuhl für Informatik 6 (Datenmanagement)
Friedrich-Alexander-Universität Erlangen-Nürnberg
Betreuer: Univ.-Prof. Dr.-Ing. habil. Richard Lenz
Dipl.-Inf. Gregor Endler
Beginn der Arbeit: 15.11.2012
Abgabe der Arbeit: 15.04.2013
Erklärung zur Selbständigkeit
Ich versichere, dass ich die Arbeit ohne fremde Hilfe und ohne Benutzung anderer als der
angegebenen Quellen angefertigt habe und dass diese Arbeit in gleicher oder ähnlicher
Form noch keiner anderen Prüfungsbehörde vorgelegen hat und von dieser als Teil einer
Prüfungsleistung angenommen wurde. Alle Ausführungen, die wörtlich oder sinngemäß
übernommen wurden, sind als solche gekennzeichnet.
Der Universität Erlangen-Nürnberg, vertreten durch den Lehrstuhl für Informatik 6
(Datenmanagement), wird für Zwecke der Forschung und Lehre ein einfaches, kostenloses, zeitlich und örtlich unbeschränktes Nutzungsrecht an den Arbeitsergebnissen der
Bachelorarbeit einschließlich etwaiger Schutzrechte und Urheberrechte eingeräumt.
Erlangen, den 15.04.2013
(Katharina Rudert)
Kurzfassung
Pseudonymisierung medizinischer Datenbanken
Um private Daten veröffentlichen zu können, ohne dass die Identität der zugehörigen
Personen rekonstruiert werden kann, werden Pseudonymisierung- und Anononymisierungsverfahren eingesetzt.
Im Folgenden werden vorhandene Konzepte zur Pseudonymisierung und kAnonymisierung vorgestellt und kathegorisiert. Desweiteren befasst sich diese Arbeit
mit Überlegungen zu einem Programm, dass es dem Anwender erlaubt Datenbankschemata frei konfigurierbar zu pseudonymisieren und zu k-anonymisieren. Im Gegensatz
zu Arbeiten von Noumeir [29] bestimmt der Anwender dabei, welche Attribute und
Tabellen bearbeitet werden sollen und inwieweit sie irreversibel pseudonymisiert oder
k-anonymisiert werden sollen.
Abstract
Pseudonymisierung medizinischer Datenbanken
Pseudonymization and k-anonymization is to provide medical data for research purpose
and to protect the data owner’s privacy at the same time.
This works aims for delivering medical data to researchers and thus protecting the
privacy of the patients. Existing works will be introduced and categorized. A programm
called p1 is build to change the medical data into anonymous data. The user of p1 can
choose which table and attributes to protect and on which level to protect them.
In contrast to existing works of Pommerening or Noumeir this works enables the user
to control the progress of pseudonymization and k-anonymization.
Inhaltsverzeichnis
1 Einleitung
1
2 Hintergrund
2.1 Komponenten der Pseudonymisierungs- und Anonymisierungssysteme
2.2 Verschlüsselung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2.1 Symmetrische & asymmetrische Verschlüsselung . . . . . . . .
2.2.2 Challenge Response . . . . . . . . . . . . . . . . . . . . . . . .
2.3 Anonymisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3.1 De-Identifizierung . . . . . . . . . . . . . . . . . . . . . . . . .
2.3.2 Anonymisierung . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4 Pseudonymisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
3
3
5
5
6
7
7
7
8
.
.
.
.
.
.
.
.
.
.
.
.
13
13
13
13
15
16
21
21
23
25
27
30
32
3 Verwandte Arbeiten
3.1 Überblick . . . . . . . . . .
3.2 Anonymisierende Ansätze .
3.2.1 Kalam . . . . . . . .
3.2.2 Grosskreutz . . . . .
3.2.3 Samarati & Sweeney
3.3 Pseudonymisierende Ansätze
3.3.1 Peterson . . . . . . .
3.3.2 Neubauer . . . . . .
3.3.3 Caumanns . . . . . .
3.3.4 Noumeir . . . . . . .
3.3.5 Pommerening . . . .
3.4 Einordnung . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
4 Implementierung
35
4.1 Fachkonzept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
I
4.2
4.3
Programmarchitektur . . . . . . . . . . . . . .
4.2.1 Übersicht . . . . . . . . . . . . . . . .
4.2.2 Module . . . . . . . . . . . . . . . . .
Implementierungsdetails . . . . . . . . . . . .
4.3.1 Die Klasse DataField . . . . . . . . .
4.3.2 Der Speicherplan . . . . . . . . . . . .
4.3.3 Die Integritätsbedingungen . . . . . . .
4.3.4 Referenzen und die Klasse Encryption
5 Evaluation
5.1 Laufzeiten . . . . . . . . .
5.1.1 Theoretische Zeiten
5.1.2 Gemessene Zeiten .
5.1.3 Fazit . . . . . . . .
5.2 Sicherheit . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
39
39
41
44
45
46
49
49
.
.
.
.
.
53
55
55
57
62
63
6 Diskussion
67
6.1 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Appendices
A Dokumentation des Programmes p1
A.1 Vorbereitungen . . . . . . . . . . . .
A.1.1 Benötigte Dateien . . . . . . .
A.1.2 Oracle und der Instant Client
A.2 Anwenden . . . . . . . . . . . . . . .
A.2.1 Programmaufruf . . . . . . .
A.3 Aufgaben der Module . . . . . . . . .
A.3.1 Middleware . . . . . . . . . .
A.3.2 InputConverter . . . . . . . .
A.3.3 DataBaseFunctionality . . . .
A.3.4 PseudoLogic . . . . . . . . . .
A.3.5 KAnoLogic . . . . . . . . . .
A.3.6 Encryption . . . . . . . . . .
A.3.7 DataField . . . . . . . . . . .
A.4 Austausch von Modulen . . . . . . .
A.4.1 Abhängigkeiten der Module .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
71
71
71
73
75
75
76
77
78
79
85
86
87
88
89
89
A.5 Das Programm bauen . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A.5.1 Hardware und Software Voraussetzungen . . . . . . . . . . . . . .
A.5.2 Makefile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Literaturverzeichnis
90
90
91
93
Abbildungsverzeichnis
2.1
2.2
2.3
Kategorisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Das Challenge Response Verfahren nach [9] . . . . . . . . . . . . . . . . .
Eigenschaften und Unterschied zwischen primärem und sekundärem Gebrauch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.1
3.2
3.3
3.4
Schema Kalam [23] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Schema Grosskreutz [18] . . . . . . . . . . . . . . . . . . . . . . . . . . .
Generalisierungsdomänen und Hierarchie nach Samarati [38, 37] . . . . .
Beispiele für generalisierte Tabellen mit Anzahl der Generalisierungsschritte [38] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.5 Aufteilung der Tabellen nach Peterson [31] . . . . . . . . . . . . . . . . .
3.6 Sicherungsschichten nach Neubauer [28] . . . . . . . . . . . . . . . . . . .
3.7 virtuelles Dateisystem nach Caumanns [9] . . . . . . . . . . . . . . . . .
3.8 Schema für reversible Pseudonymisierung nach Noumeir [29] . . . . . . .
3.9 Schema für One-Way Pseudonymisierung nach Noumeir [29] . . . . . . .
3.10 Einfaches Schema für reversible Pseudonymisierung nach Pommerening
[33] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.11 Verarbeitungssystem von medizinischen Daten für den sekundären Gebrauch nach Pommerening [32] . . . . . . . . . . . . . . . . . . . . . . . .
4.1
4.2
4.3
4.4
4.5
4.6
4.7
4.8
Anwendungsmöglichkeiten des Programms zur Pseudonymisierung von
sensiblen Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Programmaufruf für eine Pseudonymisierung . . . . . . . . . . . . . . . .
Programmaufruf für eine k-Anonymisierung . . . . . . . . . . . . . . . .
Klassendiagramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Funktionalität der Middleware . . . . . . . . . . . . . . . . . . . . . . .
Funktionalität der PseudoLogic . . . . . . . . . . . . . . . . . . . . . . .
Funktionalität der KAnoLogic . . . . . . . . . . . . . . . . . . . . . . . .
Variablen und Operationen in der Klasse DataField . . . . . . . . . . . .
4
6
11
14
16
17
19
22
24
26
28
29
31
32
36
37
39
40
41
43
44
46
V
4.9
Schema zum Holen und Abspeichern von Spalten einer Tabelle . . . . . .
48
5.1
5.2
54
5.7
5.8
Datenbankschema für Messungen und Tests . . . . . . . . . . . . . . . .
Gemessene Laufzeiten anhand von 1000 Tupeln für Attribute vom Datentyp Int, Varchar und Date . . . . . . . . . . . . . . . . . . . . . . . .
Gemessene Laufzeiten für eine Pseudonymisierung mit Referenzen mit
wachsender Anzahl an zu referenzierender Attributen im Vergleich zur
Pseudonymisierung desselben Attributes ohne Referenzen . . . . . . . . .
Gemessene Laufzeiten für eine reine Pseudonymisierung, eine Pseudonymisierung mit Referenzen und eine k-Anonymisierung mit wachsender
Anzahl an zu referenzierender Tabellen . . . . . . . . . . . . . . . . . . .
Gemessene Laufzeiten für eine reine Pseudonymisierung, eine Pseudonymisierung mit Referenzen und eine k-Anonymisierung mit wachsender
Anzahl an Datensätzen . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Gemessene Laufzeiten für unterschiedliche k-Anonymisierungen mit bis
zu drei angegebenen Attributen auf 1000 Datensätzen . . . . . . . . . . .
Abfrage Ergebnis für Listing 5.1 . . . . . . . . . . . . . . . . . . . . . . .
Abfrage Ergebnis für Listing 5.1 mit Tabelle Patient_Pseudo . . . . . . .
62
64
65
A.1
A.2
A.3
A.4
A.5
A.6
A.7
A.8
A.9
Entwurfsmuster . . . . . . . . . . . . . . . . . . . . .
Variablen und Operationen der Middleware . . . . .
Operation des InputConverters . . . . . . . . . . . .
Variablen und Operationen der Klasse DBF . . . . . .
Variablen und Operationen der Klasse PseudoLogic .
Variablen und Operationen der Klasse KAnoLogic . .
Operationen der Klasse Encryption . . . . . . . . . .
Variablen und Operationen in der Klasse DataField .
Abhängigkeiten der Module untereinander . . . . . .
77
78
79
80
85
87
87
89
90
5.3
5.4
5.5
5.6
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
58
59
59
61
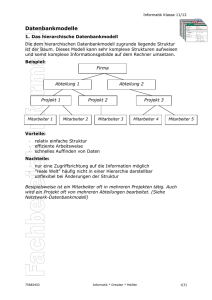
1 Einleitung
Heutzutage werden immer mehr personenbezogene Daten über das Internet verarbeitet
und verwendet. Statistische Recherchen, Forschungsprojekte und Unternehmen benutzen
solche Daten. Mit der Zunahme dieser Datenverarbeitung wächst auch das Verlangen
nach dem Schutz der Privatsphäre.
Was genau unter Privatsphäre verstanden wird, ist kulturell sehr unterschiedlich, wie
zum Beispiel Sweeney [42] feststellt. Wo amerikanische Studenten ihre Universität nicht
berechtigt sahen ihre E-Mails zu lesen, hatten taiwanesische Studenten keine Einwände
dagegen. In Europa wurde 1995 eine Richtlinie [10] erlassen, die sich mit der Verarbeitung medizinischer Daten befasst. Forschungsgruppen und Unternehmen, die medizinische Daten für ihre Zwecke benutzen wollen, dürfen das erst, wenn die Daten dieser EU
Richtlinie entsprechen.
Ziel dieser und verwandter Arbeiten ist es sensible Daten zu anonymisieren. Dadurch
können zum Beispiel Softwarehersteller ihre Produkte an realen Daten testen. Auch
werden Langzeitstudien und Beobachtungen zum Beispiel im Pharmaziebereich ohne
Einwilligung der Datenbesitzer ermöglicht.
Um solche Daten mit realem Hintergrund verwenden zu dürfen, gibt es zwei Möglichkeiten. Einmal die direkte Verwendung der Daten ohne irgendeine weitere Verarbeitung.
Hierfür muss die Genehmigung des Patienten vorliegen. Diese Zustimmung muss vom
Patienten für jedes Forschungsprojekt neu erfolgen. Um dieses Problem zu umgehen,
gibt es eine zweite Möglichkeit, die versucht die sicherheitsrelevanten Daten zu depersonalisieren. Es darf folglich nach Bearbeitung der Daten nicht mehr möglich sein die
Person zu identifizieren, auf die sich die Daten beziehen. Der Vorteil ist, dass die Zustimmung des Patienten zur Nutzung seiner Daten nicht mehr erforderlich ist. Ein Nachteil
ist, dass Patienten nicht mehr über die Forschungsergebnisse informiert werden können.
Für den Fall, dass anhand von Testergebnissen einzelne Patienten informieren werden
sollen, werden die Daten pseudonymisiert, was bedeutet, dass eine Rückführung auf den
Patienten unter kontrollierten Umständen möglich ist.
Die Vielzahl vorhandener Ansätze im medizinischen Bereich zeigen die Komplexität
und Aktualität dieses Themas. Die elektronische Gesundheitskarte (eGK) [8] zum Bei-
1
1 Einleitung
spiel verwendet das Prinzip der Pseudonymisierung um das Sicherheitsrisiko bei zentraler
Datenhaltung zu reduzieren. Durch die zentrale Datenhaltung können Verwaltungskosten reduziert und Verwaltungsarbeit erleichtert werden.
Diese Projekte haben große Bedeutung für die medizinische Forschung. Denn nicht
nur Softwarehersteller und andere Hersteller medizinischer Produkte profitieren von
pseudonymisierten Datensätzen, sondern auch die Forschung. Eine pseudonymisierte
Datenbank, die die Privatsphäre eines jeden Patienten schützt, ermöglicht es auf realen Daten zu forschen. In der Forschung, zum Beispiel in der Krebsregistratur [32] in
Rheinland-Pfalz, werden ebenfalls Pseudonyme verwendet, um Privatsphäre zu schützen
und gleichzeitig Datensätze untereinander zuordbar zu halten.
Die Schwierigkeiten in der Umsetzung einer solchen pseudonymisierten Datenbank
liegen in der Rechtslage [10]. Da jederzeit der Schutz der Privatsphäre des Patienten
gegeben sein muss, kann die Pseudonymisierung nur auf Seiten der medizinischen Datenhersteller, also der Kliniken und Ärzte, geschehen oder auf eine Trusted Third Party
ausgelagert werden. Eine Trusted Third Party ist eine dritte Partei, die die Verarbeitung
der Daten übernimmt [33].
In diesem Kontext steht das Projekt MEDITALK der Universität Erlangen Nürnberg
und der Firma Astrum IT [14, 13]. MEDITALK beschäftigt sich damit, mehrere heterogene und autonome medizinische Datenbanken und Anwendungen mit einander zu
vereinen. Dieses medizinische Verbundzentrum übernimmt dann die Verwaltungsaufgaben der einzelnen Ärzte. Hinzu kommt, dass dieses Zentrum die Patienten Verteilung
auf die einzelnen Ärzte dynamisch regeln kann und so den Ärzten ermöglicht innerhalb ihres Budgets zu bleiben. Meine Arbeit ist Teil des Projekts und beschäftigt sich
mit der Pseudonymisierung und Anonymisierung der medizinischen Daten auf Seiten
der Ärzte und Kliniken. Der Anwendungsbenutzer übergibt seine Datenbank und erhält
eine pseudonymisierte und anonymisierte Kopie der Daten, die an Forschungsprojekte
ausgegeben werden kann. Je nach Anwendung des Programms können Datensätze aus
mehreren medizinischen Datenbeständen nach Bearbeitung weiterhin einander zugeordnet werden.
Im Gegensatz zu den schon erschienenen Forschungsarbeiten zu dieser Thematik ermöglicht dieser Ansatz eine konfigurierbare Sonderbehandlung spezieller Attribute. Er
erlaubt außerdem eine benutzerdefinierte k-Anonymisierung.
2
2 Hintergrund
Zum tieferen Verständnis der Materie soll erläutert werden, was unter De-Identifizierung,
Anonymisierung und Pseudonymisierung verstanden wird. Die Begriffe werden im normalen Sprachgebrauch häufig missverständlich verwendet.
2.1 Komponenten der Pseudonymisierungs- und
Anonymisierungssysteme
Alle vorgestellten Systeme zum Schutz sensibler Daten bestehen aus den folgenden
Bausteinen. Es ist wichtig, sich Überlegungen zu Datenbezug und -verarbeitung, Datenbankaufteilung, -struktur sowie Verschlüsselungsarten zu machen. Bild 2.1 zeigt die
möglichen Zusammensetzungen für solche Lösungen.
Die Quellen, aus denen die Daten bezogen werden, können eine einzige oder mehrere
örtlich verteilte Datenbanken sein. Zum Beispiel vereinigen mehrere Kliniken und Arztpraxen ihre Daten, um Verwaltungsarbeit auszulagern oder Forschungsarbeit auf ihren
Daten zu ermöglichen. Da die meisten Quellen aus unterschiedlichen Datenbanksystemen bestehen, nimmt bei Verarbeitung mehrerer Quellen die Komplexität des Systems
zu.
Beim Zusammenführen von Daten derselben Person aus mehreren Datenbanken kann
es zu Problemen hinsichtlich der Datenzuordnung kommen. Meistens arbeiten diese verschiedene Datenbanken mit unterschiedlichen Attributen, um den Patienten zu identifizieren. Auch haben sie eventuell unterschiedliche Schreibweisen des Namens des Patienten gespeichert. Datensätze können unter Umständen nicht automatisiert einander
zugeordnet werden, obwohl sie demselben Patienten gehören. Das Verschlüsseln solcher
Datensätze erschwert diese Zuordnung noch weiter.
Record Linkage beschäftigt sich mit dem Problem der Zuordnung von Datensätzen
aus verschiedenen Quellen [40]. Die einfachste Lösung für dieses Problem ist eine Standardverschlüsselungsmethode und einen Standardidentifizierer für alle betrachteten Datenbanken einzuführen. Dadurch stimmen die Identifizierer exakt überein und können
3
2 Hintergrund
Bild 2.1: Kategorisierung
einander zugeordnet werden. Bei Abweichungen in der Schreibweise können Datensätze
allerdings nicht mehr zugeordnet werden, da Verschlüsselungsmethoden ein unterschiedliches Ergebnis produzieren.
Probabilistic Record Linkage [19] ermöglicht es Datensätze ohne exakte Übereinstimmung einander zuzuordnen. String Matching Functions werden verwendet, um die Datensätze zu verbinden, ohne diese zu entschlüsseln. Anhand von euklidischen Distanzen
kann ermittelt werden, wie wahrscheinlich Datensätze zueinander gehören.
Die Anonymisierung der Daten kann intern in der Quelldatenbank erfolgen. Das funktioniert natürlich nur, wenn die Daten aus nur dieser einen Datenbank verarbeitet werden. Die interne Verarbeitung bringt den Vorteil, dass die Daten nicht erst über das
Internet oder über andere Wege, wie transportable Speichermedien, übertragen werden
müssen. Die Sicherheitsvorkehrungen für die Übertragung entfallen somit.
Eine andere Möglichkeit ist es, die Daten an eine dritte vertrauenswürdige Organisation zu übergeben. (Im Bild und im folgenden als TTP, Trusted Third Party bezeichnet.)
Diese TTP wandelt dann die Daten soweit um, dass sie den Datenschutzbestimmungen
4
2.2 Verschlüsselung
entsprechen. Pommerening [32] schlägt vor, diese TTP mit einem Arzt zu besetzen, da
dieser von Beruf aus alle nötigen Rechte im Umgang mit medizinischen Daten besitzt.
Die Anonymitätsstufen teilen sich in De-Identifikation, Anonymisierung und Pseudonymisierung auf. Genaueres dazu findet sich in den Abschnitten 2.3 und 2.4.
Die bearbeiteten und ursprünglichen Daten können auf unterschiedliche Arten gespeichert werden. Die anonymisierte oder pseudonymisierte Datenbank kann auf eine
einzige oder mehrere DB angelegt werden. Die ursprünglichen Daten bleiben meist in
der Ursprungsdatenbank. Mehrere Datenbanken können vor Datenverlust schützen, Latenzzeiten verringern und Durchsatzraten steigern.
Ebenso kann die Datenbankstruktur aus einer oder mehreren Tabellen bestehen. Ein
reversibles Pseudonymisierungsverfahren benötigt immer zwei Tabellen. Eine Tabelle
speichert die identifizierenden Daten oder die Schlüssel, die eine Umkehrung der Pseudonyme möglich machen, und eine Tabelle beinhaltet die pseudonymisierten Daten. Bei
einem irreversiblem Pseudonymisierungsverfahren wird nur eine Tabelle, die die bearbeiteten Daten enthält, benötigt.
2.2 Verschlüsselung
Verschlüsselung ist ein wichtiger Bestandteil aller Ansätze zur Pseudonymisierung. Deswegen soll hier kurz erläutert werden, wie Verschlüsselung funktioniert und was die
gängigsten Verfahren dazu sind.
2.2.1 Symmetrische & asymmetrische Verschlüsselung
Verschlüsselungsarten können in symmetrische, asymmetrische und hybride Verschlüsselungen aufgeteilt werden.
Bei symmetrischen Algorithmen berechnet sich der Chiffrierschlüssel aus dem Dechiffrierschlüssel und umgekehrt. Diese beiden Schlüssel sind meistens identisch. Es gibt zwei
unterschiedliche Arten von symmetrischen Algorithmen: Die Einen ent- und verschlüsseln jedes Bit einzeln. Die Anderen bearbeiten Blöcke bestehend aus einer Menge von
Bits. Der Nachteil bei symmetrischen Verschlüsselungsverfahren ist, dass die verschlüsselten Nachrichten nur solange geheim bleiben, wie der Schlüssel geheim gehalten wird.
Ein einfaches Beispiel dafür ist die Caesar-Verschlüsselung. Es wird mit einer anderen
Person vereinbart für jeden Buchstaben im Alphabet einfach den nächsten zu nehmen.
5
2 Hintergrund
Zum Beispiel wird aus Nina Ojob. Nachrichten werden dann entschlüsselt, indem jeder
Buchstabe durch den Buchstaben im Alphabet davor ersetzt wird.
Bei asymmetrische Algorithmen ist der Chiffrierschlüssel öffentlich bekannt, weswegen
sie auch Public-Key-Algorithmen genannt werden. Der Dechiffrierschlüssel unterscheidet sich folglich vom Chiffrierschlüssel und wird auch privater Schlüssel genannt. Nur
die Person mit dem Dechiffrierschlüssel kann mit dem Chiffrierschlüssel verschlüsselte
Nachrichten entschlüsseln.
Die hybride Verschlüsselung kombiniert den Vorteil der Geschwindigkeit bei der symmetrischen Verschlüsselung mit der höheren Sicherheit der asymmetrischen Verschlüsselung. Genaueres zu den Verschlüsselungsarten lässt sich in [39] nachlesen.
2.2.2 Challenge Response
Eine weitere Möglichkeit der Verschlüsselung ist das Challenge Response Verfahren (siehe Bild 2.2).
Bild 2.2: Das Challenge Response Verfahren nach [9]
Der Server an dem sich die Person authentifizieren möchte, verschickt eine Zufallszahl an diese Person (1). Die Person nimmt diese Zufallszahl und ihr Passwort und
verschlüsselt beides mit einer beiden Seiten bekannten Hashfunktion oder einer andersartigen Verschlüsselung. Das Ergebnis wird an den Server zurückgeschickt (2). Der Server
berechnet gleichzeitig die selbe Aufgabe (3) und vergleicht das Ergebnis mit dem der
Person (4). Sind beide Ergebnisse identisch, wurde die Person erfolgreich authentifiziert
(5). Challenge Response bietet Sicherheit vor möglichen Angreifern, die Nachrichten
mithören können, da keine Passwörter in Klartext verschickt werden.
6
2.3 Anonymisierung
2.3 Anonymisierung
2.3.1 De-Identifizierung
Als erster Schritt in der Anonymisierung erfolgt die De-Identifikation der Daten. Unter
De-Identifikation versteht sich nach Noumeir [29, 42] das Löschen von Daten, die die
Patienten identifizieren, im folgenden Patienten Identifizierer genannt. Als Identifizierer gelten Name, Adressen und Sozialversicherungsnummern. Bei Verwendung verteilter
Systeme sind auch Attribute wie Krankenhaus IDs, Identifizierer. Anstellen des Löschens
dieser identifizierenden Daten, können sie auch durch falsche Werte ersetzt werden.
2.3.2 Anonymisierung
“Anonym” heißt nach Noumeir [29], dass die Daten nicht nur de-identifiziert sind, sondern auch jeglicher Individualität entbehren, mit der einzelne Personen wiedererkannt
werden könnte. Anders formuliert, setzen anonymisierte Daten voraus, dass niemand
durch Manipulation oder geschickten Verlinken von Datensätzen den ursprünglichen
Besitzer des Datensatzes herausfinden kann [42]. De-identifizierte Daten entsprechen also noch nicht den anonymisierten Daten. Denn mit De-identifizierten Daten ist es unter
Umständen noch möglich, Rückschlüsse auf Personen zu ziehen.
Zum Beispiel lassen sich unter Umständen die Daten einer Patientin anhand zweier
Geburtstermine und der zugehörigen Klinik identifizieren. Auch andere herausstehende
Merkmale können zur Rückverfolgung von Patientendaten dienen. Um diese Rückschlüsse zu verhindern, empfiehlt es sich, nicht nur Anonymität garantieren zu können, sondern
sogar sogenannte k-Anonymität.
2.3.2.1 k-Anonymisierung
Wenn in den Daten zu jedem Attribut mindestens k gleiche Werte vorliegen, wird von
k-Anonymität gesprochen.
Es kann passieren, dass Rückschlüsse auf die Patienten zu den Daten gezogen werden können, obwohl alle identifizierenden Daten gestrichen wurden. Das geschieht durch
Kombination von Attributen. Solch eine identifizierende Kombination von Attributen
wird Quasi-Identifizierer genannt [18]. k-Anonymisierung ist dann gegeben, wenn alle Quasi-Identifizierer von mindestens k-Datensätzen erfüllt werden. Es müssen folgich
mehr als k Personen existieren, für die diese Kombination zutrifft. Es kann passieren,
7
2 Hintergrund
dass, wenn mehrere Abfragen auf Daten miteinander kombiniert werden, Rückschlüsse
auf einzelne Personen gezogen werden können, obwohl die Daten anonymisiert wurden.
Um k-Anonymität zu erreichen, gibt es unter Anderen die Möglichkeiten der Generalisierung und der Unterdrückung [4, 22, 18].
Bei der Generalisierung werden Attribute solange verallgemeinert, bis mindestens k
Datensätze für jeden einzelnen Wert existieren. Bei Postleitzahlen können zum Beispiel
gering besiedelte Gegenden zusammengefasst werden. Für die Gebiete 91090 bis 91099
wird etwa 91090 eingetragen. Dasselbe funktioniert bei Gewichtsangaben. Zum Beispiel kann das Gewicht in Fünferschritten angegeben werden. Durch die Generalisierung
entsteht allerdings ein nicht unerheblicher Qualitätsverlust der Daten hinsichtlich des
Informationsgehaltes.
Unterdrückung basiert darauf, herauszufinden, wo weniger als k-Tupel für QuasiIdentifizierer existieren und diese dann zu löschen. Da dadurch Datensätze aus der
Datenbank entfernt werden, verringert sich ebenfalls die Genauigkeit der Informationen.
Weitere Möglichkeiten, k-Anonymisierung zu erreichen, sind sogenannte Scrambling,
Swapping oder Noise-Adding Methoden [37, 15, 2, 16, 21, 24, 25]. Der Verlust an Informationen ist hier jedoch höher als bei Generalisierung und Unterdrückung.
k-Anonymisierung ist NP-schwer [5]. Existierende Approximationsalgorithmen, die
durch Generalisierung und Unterdrückung k-Anonymität herstellen, finden sich in [42,
43, 38].
2.4 Pseudonymisierung
Wenn Daten nur vorübergehend anonym sein sollen, wird ein anderes Konzept als die
Anonymisierung benötigt. Wenn Patienten über sie betreffende Forschungsergebnisse
informiert werden sollen, benötigt es
Die Reversion der Anonymität wird verschieden begründet. Ein Grund ist die Möglichkeit die betreffenden Patienten über mögliche Ergebnisse zu informieren oder Nachfragen bei ihnen zu tätigen. Ein weiterer ist, bei zentraler Haltung von sensiblen Daten
nur autorisierten Personen Zugang zu einer Datenmenge geben zu können [9, 8]. Dies
funktioniert indem die Daten verschlüsselt werden. Eine sicherere Variante kann sein, die
sensiblen Daten von allgemeinen, nicht zurück verfolgbaren Daten zu trennen und die
Verbindung zwischen ihnen, das Pseudonym, zu verschlüsseln. Im Falle einer medizinischen Datenbank sind die identifizierenden Daten sensibel und die medizinischen Daten
8
2.4 Pseudonymisierung
ungefährlich, da sie meistens keiner Person zugeordnet werden können und somit nur
Krankheitsfälle darstellen. Caumanns erstellt zum Beispiel mit Hilfe von Pseudonymen
eine Zugangsberechtigungssystem zu Patientenakten in Deutschland [9, 8].
Auch in der Langzeitforschung kommen Pseudonyme zum Einsatz [29, 32]. Wenn
Daten über einen längeren Zeitraum betrachtet werden, sollen nachträglich hinzugefügte
Datensätze in Verbindung mit den früheren gebracht werden können.
Wenn die Assoziation zwischen den Patientensätzen nicht verloren gehen soll, werden
Pseudonyme eingesetzt [33].
Pseudonyme müssen somit eindeutige, aber nicht zurück verfolgbare Identitäten sein.
Sie können nach Pommerening [33] in zwei verschiedene Arten aufgeteilt werden:
• Irreversible (One-way) Pseudonyme, die nicht rückgängig gemacht werden können,
aber Verlinkung von Datensätzen ermöglichen.
• Reversible Pseudonyme, die Reidentifikation der zum Datensatz zugehörigen Person erlauben.
Welche Art der Pseudonymisierung eingesetzt wird, hängt von der Art und den Anforderungen des jeweiligen Projektes ab.
Es gibt verschiedene Ansätze um Daten in pseudonymisierte Daten umzuwandeln,
siehe 3.3.1 bis 3.3.4. Zwei Gemeinsamkeiten gibt es für alle Ansätze:
Ein oder mehrere identifizierende Attribute müssen in ein Pseudonym umgewandelt
werden. Das kann zum Beispiel eine Patienten ID, oder die Sozialversicherungsnummer
sein. Der Rest der sensiblen Attribute wird in der pseudonymisierten Datenmenge nicht
aufgeführt.
Als zweites werden für eine reversible Pseudonymisierung mindestens zwei Tabellen
benötigt. In diesen Tabellen werden zum einen die Identifizierenden, durchaus auch vollständigen Daten mit dem Pseudonym gespeichert. In die zweite Tabelle kommen nur
die medizinischen relevanten Daten, ebenfalls mit dem Pseudonym. Das Pseudonym ist
damit der Fremdschlüssel der medizinischen Tabelle auf die Tabelle mit den Identifizierenden Daten. Beide Tabellen können einzeln verschlüsselt und in unterschiedlichen
Datenbanken gespeichert werden.
Eine Methode zur Pseudonymerstellung sind Hashfunktionen. Ein Attribut, zum Beispiel die Patienten ID, ist Eingabewert der Hashfunktion. Ergebnis der Funktion ist das
Pseudonym. Es besteht die Gefahr der Kollision beim hashing, das heißt, dass durch die
Pseudonymisierung Homonyme produziert werden. Um Kollision zu vermeiden, werden
kollisionsarme Algorithmen angewendet.
9
2 Hintergrund
Ein anderer Ansatz ist, die Pseudonyme quasi aus dem Wörterbuch zu vergeben. Bei
diesem Ansatz werden solange Pseudonyme geraten, bis ein noch unbelegtes Pseudonym
gefunden wurde. Dieses wird dann verwendet. Eine Variation ist, die Pseudonyme nicht
zu raten, sondern der Reihe nach zu vergeben. Nach Samarati besteht hierbei das Problem, das auch schon durch die Kenntnis der zeitlichen Einordnung der Entstehung des
Datensatzes Informationen ausgelesen werden können, die eventuell die Anonymität verletzten. Von einer inkrementellen Vergabe von Nummern als Pseudonyme wird deshalb
abgeraten [38].
Um die Pseudonyme reversibel zu machen, muss einer von den folgenden zwei Faktoren
gespeichert werden. Die eine Möglichkeit ist, die Verbindung zwishen Patientenidentifizierer und Pseudonym zu sichern. Die Sicherung der Verbindung kann in der Tabelle mit
den identifizierenden Daten des Patienten geschehen, oder in einer gesonderten Tabelle.
Diese Verbindung muss zusätzlich gesichert werden und darf nur mit Einverständnis des
Patienten erstellt werden [33].
Eine andere Möglichkeit ist, die Parameter einer umkehrbaren Hashfunktion zu speichern. Auch diese Parameter müssen verschlüsselt werden, um die nötige Sicherheit zu
garantieren.
Um nicht reversible Pseudonyme zu erstellen, wird die Verbindung zwischen Patienten
und Pseudonym nicht gespeichern. Um ein One-Way Pseudonym von höherer Sicherheit
zu generieren, kann eine sogenannte One-Way Hashfunktion verwendet werden. Diese
Hashfunktionen erschweren erschöpfendes Suchen, neigen allerdings besonders häufig zu
Kollisionen [11].
Ein Problem aller Methoden zur Erstellung von Pseudonymen ist der Realwelteinfluss.
Durch leichte Abweichungen in den identifizierenden Daten können unterschiedliche Ergebnisse als Pseudonym entstehen. Die Daten wären damit nicht mehr verknüpfbar.
Abweichungen in der Schreibweise von Namen oder Rechtschreibfehler zum Beispiel
würden es unmöglich machen die Datensätze, die ursprünglich derselben Person zugeordnet waren, wieder miteinander in Verbindung zu bringen. Privacy Protecting Record
Linkage [40] beschäftigt sich mit diesem Problem und ermöglicht es, Daten aus heterogenen Datenbanken zu sammeln und zusammengehörige Datensätze unter demselben
Pseudonym zusammenzufassen.
Pseudonymisierung beruht, je nach gewünschten Eigenschaften, auf Verschlüsselung
oder Anonymisierung, siehe Bild 2.3. Für eine reversible Pseudonymisierung werden
Verschlüsselungmethoden gebraucht und somit die Eigenschaften einer Verschlüsselung
10
2.4 Pseudonymisierung
übernommen. Irreversible Pseudonymisierung beinhaltet die Eigenschaft der Irreversibilität der Anonymisierung und die Verknüpfbarkeit der Verschlüsselung.
Bild 2.3: Eigenschaften und Unterschied zwischen primärem und sekundärem Gebrauch
Hinsichtlich der Verwendung der Pseudonymisierung kann in primären und sekundären Gebrauch unterschieden werden.
Unter primären Gebrauch wird die Verwendung der Daten im medizinischen Umfeld
verstanden. Dazu gehört zum Beispiel die Berechnung von Arztkosten, oder die Einsichtnahme in Behandlungsfälle. Hierbei greifen hauptsächlich Ärzte oder Verwaltungsangestellte auf die Daten zu. Verwaltungsangestellte sollten dabei eine beschränkte Sicht
auf Details der Daten haben. Die Pseudonyme sind reversibel und einzelne Datensätze
derselben Person untereinander verknüpfbar.
Der Sekundäre Gebrauch medizinischer Daten umfasst statistische Auswertungen,
Forschungsprojekte und weitere Projekte. Diese weiteren Projekte haben kein Zugriffsrecht auf persönliche Daten, wollen jedoch auf realen medizinischen Daten arbeiten. Die
Daten werden dafür deidentifiziert und anonymisiert, um die Privatsphäre des Patienten
zu schützen. Die so bearbeiteten Daten werden außerhalb der ursprünglichen Datenbank
verwendet. Die Pseudonyme sind meist irreversibel, können aber auch reversibel sein.
11
2 Hintergrund
Datensätze einer Person erscheinen auch in den pseudonymisierten Daten zueinander
zugehörig.
12
3 Verwandte Arbeiten
Im Folgenden werden dem Thema verwandte Arbeiten und Ansätze erläutert.
3.1 Überblick
Existierende Ansätze unterschieden sich nicht nur in den Bausteinen aus dem vorherigen Kapitel 2.1, sondern auch in ihren Zielen. Anonymisierende Ansätze verfolgen alle
das Ziel die Datensätze nicht rückverfolgbar zu halten. Pseudonymisierende Ansätze
dagegen lassen sich nach primären und sekundären Gebrauch unterscheiden, siehe Kapitel 2.4. Den Schutz der Privatsphäre haben alle nachfolgend vorgestellten Ansätze
gemeinsam. Im Folgenden werden die Ansätze, mit Schwerpunkt auf Anonymisierung
oder Pseudonymisierung unterteilt, vorgestellt.
3.2 Anonymisierende Ansätze
Folgende Ansätze wurden aufgrund ihrer Einfachheit, überzeugenden Darbietung und
der Nähe zu meinen Zielen ausgewählt. Kalam kombiniert Anonymisierung mit Pseudonymisierung, um Record-Linkage zu ermöglichen. Grosskreutz und Sweeney dagegen
versuchen höchstmögliche k-Anonymität mit minimalem Datenverlust zu garantieren.
Alle Ansätze befassen sich mit dem Schutz der Patientenidentität in medizinischen Daten, die für den sekundären Gebrauch freigegeben werden sollen. Es gibt noch weitere
anonymisierende Ansätze [4, 22], die den vorgestellten ähneln, sich aber mit anderen
Datenbankformaten und -inhalten befassen.
3.2.1 Kalam
Kalam [23, 12] anonymisiert medizinische Daten aus einer einzelnen Quelle. Ausgegangen
wird von einzelnen Krankenhäusern, die intern für jedes einzelne Forschungsprojekt ihre
Datenbank anonymisieren und verschlüsselt an das Projekt schicken. Es werden hierbei
nur Daten von Patienten vergeben, die ihr Einverständnis dafür gegeben haben.
13
3 Verwandte Arbeiten
Es wird von einem Krankenhaus mit drei verschiedenen Datenbanktypen ausgegangen:
administrative, medizinische und verschiedene anonyme Datenbanken. In der medizinischen Datenbank werden die medizinische Daten, in der administrative Datenbank die
patientenidentifizierende Daten gelagert. Medizinische und identifizierende Daten sind
mithilfe eines Pseudonyms verknüpft. Jedes Projekt bekommt eine eigene anonyme Datenbank.
Bild 3.1 erläutert den Ablauf der Erstellung einer anonymisierten Datenbank für ein
Projekt a.
Bild 3.1: Schema Kalam [23]
Jeder Patient besitzt einen permanenten Patienten Identifizierer, im Folgenden und
im Bild ID-Pat genannt. Diese ID-Pat ist zum Beispiel auf einer sogenannten Smartcard
gespeichert. Um einem Projekt a den Zugriff auf medizinische Daten zu gewähren, muss
der Patient einwilligen. Die Einwilligung erfolgt über die Smartcard, also über die IDPat auf der Karte. Mit der ID-Pat und der Projekt ID (im Bild ID-Proj) des Projektes
a wird ein anonymer Identifizierer pro Person und pro Projekt erstellt. Ausgeführt wird
dies durch eine One-Way Hashfunktion.
Um Verwirrung durch Daten aus mehreren Kliniken zu vermeiden, wird das Ergebnis noch mit dem öffentlichen Schlüssel der Klinik verschlüsselt. Im Bild als KS-Hosp
bezeichnet.
14
3.2 Anonymisierende Ansätze
Anhand dieser KS-Hosp und der Kombination aus ID-Pat und Projekt ID wird die
anonyme Datenbank erstellt und anschließend verschlüsselt an das Projekt a geschickt.
Mit Hilfe eines weiteren Schlüssels der Klinik (KP-Hosp) kann Projekt a die Daten
wieder entschlüsseln und mit ihnen arbeiten.
Wenn Projekt a seine Ergebnisse an einen Endnutzer [23] weitergeben möchte, wird
noch einmal anonymisiert und es werden eventuell Datensätze gelöscht. Endnutzer sind
zum Beispiel die Presse oder Verleger.
Ein Vorteil dieses Ansatzes ist, dass durch die Kombination aus Projekt ID und Patienten ID die Projekte zusammengehörige Datensätze erkennen können. Es ist möglich
mehrere Daten, die zu demselben Patienten gehören, auch in der anonymisierten Datenbank wieder in Verbindung miteinander zu bringen. Der Nachteil jedoch ist, dass für
jedes neue Projekt wieder die Zustimmung, also die Smartcard des Patienten erforderlich ist. Ein weiterer Nachteil ist nach Neubauer [27] der fehlende Backup Mechanismus
bei Verlust der Smartcard. Bei Verlust der Smartcard ist die Patienten ID unwiderruflich verloren und somit der Zugang zu den Patientenakten nicht mehr möglich. Hinzu
kommt, dass das System nicht gegen einen internen Angreifer geschützt ist. Ein Angestellter kann einen Patienten mit seinen Daten in Verbindung setzen, wenn er die ID-Pat
der Smartcard in Erfahrung gebracht hat.
3.2.2 Grosskreutz
Grosskreutz [18] beschäftigt sich mit der Informationsgewinnung aus nicht zwingend
medizinischen Datenbanken ohne Verletzung der Privatsphäre des Datenbesitzers. Die
Verarbeitung von Daten mit Schutz der Privatsphäre wird Privacy-Preserving Data
Mining genannt. In einer zentralen Datenbank, einer Trusted Third Party zugehörig,
werden Daten aus mehreren Quellen gesammelt und anschließend verarbeitet. Diese
anonymisierten Daten werden dann an Forschungsprojekte freigegeben. Das Bild 3.2
erläutert das Konzept Grosskreutzs.
In der zentralen Datenbank wird eine k-Anonymisierung anhand von Generalisierung
und Unterdrückung durchgeführt.
Grosskreutz weist darauf hin, dass Ergebnisse aus Data Mining ebenfalls der kAnonymisierung entsprechen müssen. Unter Umständen besteht sonst die Gefahr, dass
auch aus den Abfrageergebnissen Rückschlüsse auf Patienten gezogen werden.
Dieser Ansatz eignet sich nicht für Langzeitstudien, da immer nur eine Momentaufnahme in der anonymisierten Datenbank zu finden ist. Record Linkage zwischen nacheinander erstellten anonymisierten Datenbanken ist nicht möglich, da für jede neue Datenbank
15
3 Verwandte Arbeiten
Bild 3.2: Schema Grosskreutz [18]
anders verschlüsselt wird. Auch die Qualität der Abfrageergebnisse, verschlechtert sich
je nach Grad der k-Anonymisierung.
Grosskreutz nennt neben dem obigen Anonymisierungsansatz noch weitere interessante Ansätze zum verteilten Data Mining, die für meine Zwecke aber nicht von Belang sind,
da es sich um Berechnungen über mehrere verteilte Datenbestände handelt. Mehrere
Teilnehmer versuchen dabei Informationen aus ihrem Datenbestand und dem Datenbeständen weiterer Teilnehmer zu gewinnen, ohne dass die Datenbestände den anderen
zugänglich gemacht werden müssen. Da in unserem Fall die Forschungsgruppen keine
eigenen Datenbankbestände haben, die in ein Gesamtergebnis einfließen sollen, könne
sie nicht an einem verteilten Data Mining teilnehmen. Sie können höchstens von dem
Ergebnis profitieren.
3.2.3 Samarati & Sweeney
Samarati beschäftigt sich mit der Theorie der Minimierung der Generalisierung [38, 37]
und Sweeney mit der praktischen Umsetzung dieser Theorie [43, 42]. Ihr Programm
Datafly [42] anonymisiert medizinische Daten.
Um die Generalisierungschritte zu minimieren führt Samarati Begriffe wie Generalisierungsdomänen und Generalisierungshierarchien ein.
Eine Generalisierungsdomäne umfasst demzufolge die Menge der vorhandenen Möglichkeiten ein Attribut zu verallgemeinern (siehe Bild 3.3).
16
3.2 Anonymisierende Ansätze
Bild 3.3: Generalisierungsdomänen und Hierarchie nach Samarati [38, 37]
Eine Domäne für Postleitzahlen ist die Menge {. . . , 91095, 91096, 91097, . . . }. Weitere
Domänen für dieses Beispiel sind {. . . , 91070, 91080, 91090, . . .},{. . . , 91000, 91100, . . .}
Beim Ehestand könnte eine Domäne aus {verheiratet, ledig, verwitwet, geschieden} bestehen und eine weitere Domäne nur noch aus {irgendwann − verheiratet, niemals −
verheiratet}. Alle Attribute haben die Domäne {unbekannt} gemeinsam. In dieser Domäne werden keine Werte mehr eingetragen, der Datenverlust ist hier am größten.
Die Generalisierungshierarchie gibt an, wie die Domänen miteinander in Beziehung stehen. Die Höhe der Hierarchie ist gleich den möglichen Generalisierungsschritten, die für das Attribut vorgenommen werden können. In dem
Beispiel zum Ehestand steht {verheiratet, ledig, verwitwet, geschieden} unter
{irgendwann − verheiratet, niemals − verheiratet}, denn verwitwet, verheiratet
und geschieden kann in irgendwann − verheiratet zusammengefasst werden. ledig
kann zu niemals − verheiratet verallgemeinert werden. Die nächste Domäne und letzte
in diesem Beispiel ist dann die Domäne {unbekannt}, die irgendwann − verheiratet
17
3 Verwandte Arbeiten
und niemals − verheiratet vereint. Das Attribut Ehestand kann also nur zweimal
generalisiert werden, bevor alle Information in den Daten verloren gegangen sind.
Bei der Postleitzahl kann von der Domäne mit Genauigkeit von fünf Ziffern bis zu der
Domäne unbekannt fünfmal in Zehnerschritten generalisiert werden, bevor die Daten
unbrauchbar sind. Die Generalisierungsschritte gehen von der exakten Postleitzahl über
9109*, 910**, 91***, 9**** bis 00000, also bis unbekannt. Es ist möglich mehr oder
weniger Generalisierungschritte zu erhalten, wenn mit einem anderen Zahlenabstand
generalisiert wird.
Je nachdem in welcher Reihenfolge die Attribute generalisiert werden können unterschiedlich viele Generalisierungsschritte benötigt werden, um zu einem zufriedenstellenden Ergebnis zu kommen. Samarati nennt die unterschiedliche Ausführungsreihenfolge
Generalisierungsstrategie [37]. Im Bild 3.4 oben rechts sind die möglichen Strategien für
unser Beispiel dargestellt.
Ausgehend von dem ursprünglichen Zustand der Attribute kann als erstes Ehestand
oder Postleitzahl generalisiert werden. Im Bild bedeutet {E1, P 0}, dass der Ehestand
E einmal generalisiert wurde. P 0 gibt an, dass die Postleitzahl null mal generalisiert
wurde, sich also noch in ihrem Ursprungszustand befindet. Wenn von der Ursprungstabelle aus erst die Postleitzahl generalisiert wurde, {E0, P 1}, gibt es zwei weiterführende
Möglichkeiten zur Generalisierung. Eine Möglichkeit wäre die Postleitzahl ein weiteres
mal zu generalisieren {E0, P 2}. Eine andere Möglichkeit besteht in der Generalisierung
des Ehestands {E1, P 1}. Sobald der Ehestand sich im Zustand E2 befindet, also dreimal generalisiert wurde, kann nur noch die Postleitzahl generalisiert werden. E2 besitzt
keinerlei Informationen mehr.
In demselben Bild wird dargestellt, wie unterschiedlich die Ergebnisse anhand der sequentiellen Ausführung der Generalisierung ausfallen. Die ursprüngliche Tabelle enthält
die Attribute Postleitzahl und Ehestand aus dem vorherigen Beispiel. Die vier weiteren
Tabellen auf dem Bild zeigen vier mögliche Generalisierungsstrategien, die noch weiter generalisiert werden können. Eine davon ist {E1, P 0}. Bei dieser Tabelle wurde der
Ehestand einmal generalisiert und die Postleitzahlen nicht bearbeitet. Es können weiterhin mehrere Datensätze anhand der Postleitzahl identifiziert werden. Diese Tabelle
garantiert nur 1-Anonymität.
Die Tabelle {E0, P 1} hat dieselbe Anonymität. Es gibt nur einen Datensatz mit der
Postleitzahl 1960. Hier würde es sich anbieten, nicht durch weiteres Generalisieren die
Datenqualität zu verschlechtern, sondern den einzelnen Datensatz zu streichen. Das
18
3.2 Anonymisierende Ansätze
Bild 3.4: Beispiele für generalisierte Tabellen mit Anzahl der Generalisierungsschritte
[38]
19
3 Verwandte Arbeiten
Problem dabei ist zu erkennen, wann eine Unterdrückung mehr Vorteile bietet, als eine
weitere Generalisierung.
In Tabelle {E1, P 1} wurde die vorherige Tabelle {E0, P 1} noch im Ehestand generalisiert. Auch hier sticht wieder der Datensatz mit der Postleitzahl 91060 heraus. Es
wird somit unnötig die Qualität der Daten reduziert. Um eine Anonymität höher als
1-anonym zu erhalten muss nochmal generalisiert, oder der Datensatz mit Postleitzahl
91060 gelöscht werden.
Die Tabelle {E0, P 2} wurde zweimal nach dem Attribut Postleitzahl generalisiert. Zu
jedem Datensatz gibt es in dieser Tabelle einen identischen Zweiten. Diese Generalisierungsstrategie garantiert also 2-Anonymität.
Bei einer schlecht gewählten Strategie werden mehr Generalisierungsschritte benötigt
um k-Anonymität herzustellen. Für jede weitere Generalisierung wird der Inhalt der
nächst höher gelegenen Domäne verwendet.
Um die minimale Generalisierung der Tabelle zu berechnen, werden sogenannte Distance Vectors eingeführt. Diese messen sowohl den Abstand zwischen Tupeln, als auch
Tabellen, anhand der Anzahl der benötigten Generalisierungsschritte. Ein Distance Vector gibt an, wie viele Generalisierungsschritte T upeli von T upelj entfernt ist. Für Tabellen wird ebenso ein Distance Vector berechnet. Mithilfe dieser Vektoren kann eine
minimale Generalisierung gefunden werden. Eine Generalisierung einer Tabelle ist nach
Samarati [38] dann minimal, wenn die Tabelle k-anonym ist und es keine andere Generalisierung dieser Tabelle gibt, die k-anonym ist und einen geringeren Datenqualitätsverlust hat.
Der Vorteil bei Samarati und Sweeney liegt in der Veröffentlichung von privaten Daten,
ohne dass aus ihnen mithilfe von fremden Datenquellen zugehörige Personen rekonstruiert werden können. Bei einer reinen Pseudonymisierung bleiben unter Umständen Daten erhalten, die alleine betrachtet nicht zur Identifizierung eines Patienten ausreichen.
Werden diese jedoch mit fremden Quellen, wie etwa Telefonbüchern oder Behördenauskünften, kombiniert, kann es zu einer Identifizierung kommen. Durch die Generalisierung
aller Quasi Identifizierer ist es möglich dieses Problem einzugrenzen.
Der Nachteil an der Generalisierung ist der Informationsverlust. Dieser lässt sich nur
mit hohem Aufwand reduzieren.
20
3.3 Pseudonymisierende Ansätze
3.3 Pseudonymisierende Ansätze
Bei pseudonymisierenden Ansätzen erfolgt eine Unterteilung im Verwendungszweck. Die
Ansätze von Neubauer [26, 28], Caumanns [9, 8], Peterson [31] und Bleumer [6] beschäftigen sich hauptsächlich mit der primären Verwendung medizinischer Daten. Das heißt,
sie widmen sich der Aufgabe medizinische Daten, sowohl in Hinsicht auf Abrechnung
als auch auf Zugangskontrolle, zu verwalten. Hier soll nur Neubauer, Caumanns und
Peterson näher erklärt werden, da sie neben dem primären Gebrauch gewollt oder auch
ungewollt die Möglichkeit für sekundären Gebrauch bereitstellen. Bleumer beschäftigt
sich nur oberflächlich mit der technischen Seite des Problems, bietet aber interessante
Einblicke in das medizinische Verwaltungssystem.
Pommerening [33, 32, 35, 34] und Noumeir [29] behandeln beide Pseudonymisierung
im sekundären Gebrauch. Beide Arbeiten sind auf Langzeitforschung ausgelegt und begründen damit den Gebrauch von Pseudonymen. Gemeinsamkeiten liegen im Auslagern
der Pseudonymisierung in eine Trusted Third Party und in Überlegungen zu One-Way
Pseudonymen und reversiblen Pseudonymen.
3.3.1 Peterson
Bei dem Ansatz von Peterson [31] handelt es sich um ein Patent zu einem Verschlüsselungssystem für unmittelbaren Zugang zu medizinischen Datensätzen. Besonders berücksichtigt wird, dass der Patient die volle Kontrolle über seine Daten behält. Die
medizinischen Daten kommen aus einer oder mehreren Quellen und werden in einer zentralen Datenbank verarbeitet. Diese zentrale Datenbank übernimmt die Funktion einer
Trusted Third Party und teilt die Daten auf drei Tabellen auf. Bild 3.5 veranschaulicht
diese Aufteilung.
Die Patiententabelle enthält alle den Patienten identifizierenden Daten. Hinzu kommen ein eindeutiger globaler Schlüssel, ein eindeutiger persönlicher Schlüssel (im Folgenden und im Bild PEK, nach Personal Encryption Key, genannt), das Passwort des
Patienten und ein sogenannter Server Side Key. Der Server Side Key (im Folgenden und
im Bild SSK) übernimmt die Funktion des Fremdschlüssels auf die Sicherheitstabelle.
Die Sicherheitstabelle besitzt demnach diesen eindeutigen SSK. Weitere Attribute der
Tabelle sind die persönliche Verschlüsselungsmethode, ein Server Side Encryption Key
(im Folgenden und im Bild SSEK), eine Server Side Verschlüsselungsmethode und eine
Zeilennummer. Diese Zeilennummer ist der Fremdschlüssel auf die Datentabelle.
21
3 Verwandte Arbeiten
Bild 3.5: Aufteilung der Tabellen nach Peterson [31]
Die Datentabelle enthält die medizinischen Daten. Alle Daten, die aus den externen Quellen in die zentrale Datenbank überführt werden, werden nach diesem Schema
abgespeichert.
Um einen neuen Benutzer in dieses System aufzunehmen, erstellt die zentrale Datenbank den globalen Schlüssel und den SSK. Danach muss der neue Benutzer solange einen
PEK raten, bis dieser dem erwünschten Format entspricht und noch nicht vergeben ist.
Das Format des PEK muss dem des globalen Schlüssels entsprechen und eindeutig sein.
Nachdem der neue Benutzer ein geeignetes Passwort gewählt hat, ist er fertig registriert und bekommt eine Smartcard mit seinem globalen Schlüssel.
Mit seinen Schlüssel auf der Karte und dem Passwort kann sich der Benutzer jetzt an
der Datenbank anmelden und seine Daten anzeigen lassen.
Für den Fall, dass der Benutzer seine Karte verliert oder zerstört, kann er sich immer
noch mit seinem PEK und dem Passwort anmelden. Der globale Schlüssel wird dann
erneuert und auf eine neue Smartcard gespeichert.
Wenn jemand in Besitz des globalen Schlüssels oder des PEKs kommt, kann er die
medizinischen Daten auslesen. Nur zum Verändern der Daten wird das Passwort gebraucht.
Für Forschungszwecke kann die dritte Tabelle, die Datentabelle entnommen werden,
was von Peterson aber nicht vorgesehen ist.
22
3.3 Pseudonymisierende Ansätze
Als Nachteil sieht Neubauer [27] die Speicherung aller notwendigen Schlüssel in der
Datenbank. Ein Angreifer, der sich Zugriff auf die Datenbank verschafft, kann so alle
Informationen entschlüsseln, auslesen und sogar ändern. Eine weitere Sicherheitslücke
ist das Erstellen des PEK. Nachdem solange ein weiterer PEK eingegeben wird, bis ein
unbelegter gefunden ist, kann beobachtet werden, welche schon vergeben sind.
3.3.2 Neubauer
Neubauers Model PIPE (Pseudonymization of Information for Privacy in e-Health) [26,
28, 27] baut auf einer Datenbank mit zwei Tabellen auf. Es wird davon ausgegangen,
dass eine oder mehrere Quellen in das erwünschte Format umgewandelt und in der
Datenbank abgespeichert wurden. Die Verschlüsselung erfolgt hybrid.
Die Daten werden in zwei Tabellen von identifizierenden Daten und pseudonymisierten
medizinischen Daten aufgeteilt. Um diese Tabellen vor Angreifern zu schützen, führt
Neubauer eine Schichtenarchitektur ein, siehe Bild 3.6.
• Authentification Layer: Mithilfe eines asymmetrischen Schlüsselpaares und eines
PIN Codes wird der Benutzer authentifiziert und darf die nächste Schicht betreten.
Teile des Schlüssels werden auf einer Smartcard gespeichert.
• Permission Layer: Um diese Schicht passieren zu dürfen, benötigt es eines asymmetrischen Schlüsselpaares und eines symmetrischen Schlüssels aus der Datenbank.
• Concealed Data Layer: In dieser Schicht sind die Pseudonyme versteckt, wobei
jeder Datensatz mit einem bis mehreren Pseudonymen verbunden sein kann. Der
Patient ist Eigentümer seiner Daten und besitzt deswegen das sogenannte RootPseudonym. Hier werden die Pseudonyme mithilfe des symmetrischen Schlüssels
des Eigentümers und eines Algorithmus berechnet.
Die Smartcard wird hauptsächlich zu Patientenerkennung und für die Verbindungssicherheit verwendet. Alle restlichen Verschlüsselungen laufen auf dem Rechner, der die
Datenbank beinhaltet. Damit diese Verschlüsselungen sicher sind, besitzt dieser Rechner ein Hardware Secure Modul, das die Verschlüsselungen ausführt und gegen sowohl
logische, als auch physische Attacken geschützt sind [3]. Ein Hardware Secure Modul
hat einen Prozessor der auf kryptographische Aufgaben ausgelegt ist und ein sicheres
Metallgehäuse.
Es gibt drei verschiedene Rollen, die an die Datenbankbenutzer vergeben werden:
Besitzer, Vertrauenswürdiger und Autorisierter. Der Besitzer hat Zugang zu allen Daten
23
3 Verwandte Arbeiten
Bild 3.6: Sicherungsschichten nach Neubauer [28]
und hält das Root-Pseudonym. Er kann vertrauenswürdige Personen ernennen, die die
zweite Rolle repräsentieren. Für die Rolle des Vertrauenswürdigen werden beispielsweise
Verwandte und Ehegatten vorgeschlagen. Vertrauenswürdige haben wie der Besitzer
Zugang zu allen Daten. Die dritte Rolle sind sogenannte Autorisierte, denen bestimmte
Bereiche der Daten zugewiesen werden, zum Beispiel Ärzte, denen das Recht auf Einsicht
in bestimmte Teile der medizinischen Daten gegeben wird. Diese Rollen werden vom
Besitzer vergeben und können auch wieder entzogen werden.
Um das Suchen in den Daten zu erleichtern werden von den Entwicklern bestimmte
Indexe mit Schlüsselwörtern vorgegeben. Diese Schlüsselwörter enthalten grobe Werte,
damit dadurch nicht auf Daten zurückgeschlossen werden kann. Schlüsselwörter können
zum Beispiel Dokumententypen, Krankheitstypen und Datumsangaben sein.
Bei Verlust der Smartcard werden die benötigten Informationen zur Rekonstruktion aus der Smartcard des Vertrauenswürdigen gewonnen. Für den Fall, das die Rolle
24
3.3 Pseudonymisierende Ansätze
des Vertrauenswürdigen nicht vergeben wurde, gibt es immer noch die Möglichkeit, die
fehlenden Schlüssel über die Systemadministratoren zu rekonstruieren. Die Administratoren haben natürlich keinen Zugriff auf Daten und Schlüssel, sondern hüten sogenannte
geteilte Geheimnisse. Nach Shamirs Schwellen Verfahren [41] können Schlüssel über mehrere zufällig ausgesuchte Administratoren verteilt aufgehoben werden. Um den Schlüssel
wieder zu rekonstruieren, benötigt es eine gewisse Anzahl an Administratoren, die aber
selber keine Kenntnis von den Schlüsseln haben, die sie aufheben.
3.3.3 Caumanns
Seit 2011 wird in Deutschland Schritt für Schritt die Krankenversichertenkarte für gesetzlich Versicherte durch die elektronische Gesundheitskarte (im Folgenden eGK) abgelöst. Das Konzept der eGK entstand im Fraunhofer Institut im Auftrag des deutschen
Gesundheitsministeriums [20].
Anwendungen dieser Karte, wie das elektronische Rezept, reduzieren gezielt Kosten im
Gesundheitswesen. Andere Teile der Anwendungen verbessern die Zusammenarbeit zwischen den Ärzten, Krankenhäusern und den Apotheken. Dazu zählen eine elektronische Patientenakte, Verwaltungsinformationen, Arzneimitteldokumentationen und ein
Notfalldatensatz für jeden Patienten. Der Notfalldatensatz besteht aus unverschlüsselten medizinischen Daten, wie Unverträglichkeiten oder Blutgruppe, die im Notfall von
Notärzten ausgelesen werden.
Mehrere heterogene Quellen, bestehend aus Arzt- und Klinikakten, werden zur Verwendung an ein gemeinsames Kommunikationsnetz angeschlossen. Um existierende IT
Lösungen der Leistungserbringer nicht migrieren zu müssen, gibt es kein zentrales System, sondern alle schon vorhandenen Systeme werden gekapselt angekoppelt. Die Pseudonymisierung erfolgt durch die Einbindung der medizinischen Daten in ein virtuelles
Dateisystem.
Genaueres zum Konzept der eGK findet sich bei Caumanns [9, 8]. Die dort beschriebene Lösungsarchitektur besteht aus mehreren Schichten, von denen die Zugangs- und
Integrationsschicht am interessantesten für die Pseudonymisierung ist. Diese Schicht
beschäftigt sich mit kryptographischen Methoden und Berechtigungsmanagement.
Caumanns entkoppelt das Auffinden, Zugreifen und Entschlüsseln von Daten. Die
Ent- und Verschlüsselung erfolgt über hybride Verschlüsselungsverfahren mithilfe der
Smartcard. Das Zugreifen, also die Authentifizierung und Autorisierung erfolgt über
ein Challenge-Response Verfahren, dass Caumanns ’Ticket Toolkit’ nennt. Das virtuelle
Dateisystem übernimmt die Funktion des Auffindens von Daten.
25
3 Verwandte Arbeiten
Die Sicherheit der Daten wird durch hybride Verschlüsselung garantiert. Alle Daten
werden mithilfe der Karte asynchron verschlüsselt und signiert. Das Challenge Response
Verfahren zur Authentifizierung erfolgt wie in Kapitel 2.2.2 beschrieben.
Alle angeschlossenen Datenbanken werden als virtuelles hierarchisches Dateisystem
betrachtet, siehe Bild 3.7.
Bild 3.7: virtuelles Dateisystem nach Caumanns [9]
Jedes Datenobjekt besitzt eine nicht geheime Objekt ID und eine verschlüsselte Daten
ID. Die Daten ID wird zusammen mit der Zufallszahl des Challenge Response Verfahrens verschlüsselt und durch eine Hashfunktion geschützt. Dadurch werden Brute Force
Attacken verhindert.
Außerdem gehört zu jedem Objekt ein allgemein gehaltener Text, der keine Rückschlüsse auf Patienten zu lässt, und eine Parent ID. Das Wurzelverzeichnis, der Root
Ordner, hat als Objekt ID die Krankenversichertennummer des Patienten und die Parent
ID 0. Die untergeordneten Datenobjekte haben alle eine wahlfreie Objekt ID und eine
26
3.3 Pseudonymisierende Ansätze
Parent ID, die auf die unverschlüsselte Daten ID des nächsthöher gelegenen Ordners
verweist.
Dadurch, dass die Daten ID eines jeden Objektes verschlüsselt vorliegt, ist es unmöglich die Eltern eines Objektes zu finden. Derjenige, der die Daten ID des Objektes
entschlüsseln kann, kann somit alle untergeordneten Objekte ansehen. Es ist also möglich abwärts und nicht aufwärts zu traversieren. Der große Vorteil dadurch ist, dass die
Objekt ID des Wurzelknotens nicht geheim gehalten werden muss. Ein Nachteil ist, dass
das ganze Dateisystem traversiert werden muss, um einen bestimmten Patientendatensatz zu finden.
Der Patient bleibt bei diesem Konzept Besitzer seiner Daten. Er entscheidet, wer
Zugriff bekommt. Die Zugriffserteilung kann durch die Gesundheitskarte, über Eingabe
einer PIN oder auf andere Weise geschehen. Wenn der Zugriff auf einen Datensatz für
einen Arzt verweigert wird, kann dieser Arzt auch nicht erkennen, dass Daten gesperrt
wurden, da er nicht sieht, dass der Datensatz überhaupt existiert.
Mit den Besitzrechten an seinen Daten ist es dem Patienten möglich Rollen an andere
zu verteilen. Er hat die Möglichkeit über Terminals, die im gesamten Bundesgebiet verteilt werden sollen, auf seine Daten zuzugreifen und diese zu editieren oder Zugriffsrechte
zu verwalten.
3.3.4 Noumeir
Noumeir [29] widmet sich der Pseudonymisierung medizinischer Daten für den sekundären Gebrauch. Ziel von Noumeir ist eine zentrale Datenbank für Forschungszwecke,
die über die Zeit mit weiteren medizinischen Daten gefüllt wird. Weitere Datensätze eines Patienten sind anhand der Pseudonymisierung mit alten Daten desselben Patienten
verlinkbar.
Aus mehreren Quellen werden Daten in eine Forschungsdatenbank abgeführt. Die Daten durchlaufen zwei Trusted Third Partys, wobei die erste anonymisiert und die zweite
pseudonymisiert. Fertig anonymisierte und pseudonymisierte Daten werden in einer Datenbank außerhalb aller medizinischen Quellen gespeichert. Um die Pseudonymisierung
bei Bedarf rückgängig machen zu können, hält die zweite TTP eine Tabelle mit der
Verbindung Patient - Pseudonym oder die Umkehrfunktion der Hashfunktion mit den
zugehörigen Parametern. Diese Tabelle und alle anderen Daten sind hybrid verschlüsselt.
Der Patient muss der Verarbeitung seiner Daten zu Forschungszwecken zustimmen.
Dabei kann er bestimmen, ob seine Daten reversibel pseudonymisiert werden sollen. Die-
27
3 Verwandte Arbeiten
se Reversibilität kann er mit Konditionen verknüpfen. Er kann zum Beispiel bestimmen,
dass nach einem bestimmten Zeitraum seine Daten irreversibel gehalten werden müssen.
Noumeirs Langzeitstudien beschäftigen sich mit radiologischen Aufnahmen, deshalb
arbeitet er mit dem DICOM Standard [1]. Der Digital Imaging and Communications
in Medicine Standard schreibt vor, wie Bildmaterial gespeichert und ausgetauscht werden kann. Fast alle bildgebenden Verfahren in der Medizin, wie zum Beispiel digitales Röntgen, Magnetresonanztomographie oder Computertomographie, benützen diesen
Standard.
DICOM besagt auch, welche Attribute geschützt werden müssen. Die DICOM Attribute, welche in [1] als schützenswert eingestuft werden, werden anonymisiert oder
pseudonymisiert. Objektidentifizierer, wie zum Beispiel global eindeutige IDs, sollen die
Hierarchie zwischen den Datensätzen erhalten. In seinem Konzept verwendet Noumeir
die Patienten ID als globalen Objektidentifizierer. Mithilfe der Patienten ID wird durch
eine Hashfunktion ein Pseudonym erstellt.
Um Datensätze nicht zweimal zu importieren, muss die Datenbank sich merken können, welche schon importiert wurden. Um das zu erreichen wird ein sogenanntes ’Manifest’ verwendet. Manifeste sind Bestandteile des DICOM Konzepts. Ein Manifest enthält
Referenzen auf andere DICOM Objekte. Für jede exportierte Studie wird ein Manifest
erstellt. Wenn die Forschungsdatenbank nun ein solches Manifest von einer Klinik erhält,
kann entschieden werden, ob die Daten zu importieren sind, oder schon vorhanden sind.
Bild 3.8 zeigt den Ablauf für die reversible Pseudonymisierung von Daten.
Bild 3.8: Schema für reversible Pseudonymisierung nach Noumeir [29]
28
3.3 Pseudonymisierende Ansätze
Die Daten der Klinik werden verschlüsselt an die Erste der zwei Trusted Third Partys
übergeben. Diese TTP anonymisiert die Daten bis auf die Patienten ID. Danach werden die Daten an die zweite TTP übertragen. Hier wird das Pseudonym anhand der
Patienten ID errechnet. Die Patient ID wird dann mithilfe einer Hashfunktion in ein
Pseudonym übersetzt.
Für reversible Pseudonyme, wird eine Tabelle erstellt, die entweder die Umkehrfunktion der Hashfunktion mit Parametern speichert, oder die direkte Verbindung zwischen
Patient und Pseudonym. Über geheime Schlüssel kann dann anhand dieser Tabelle der
Patient über das Pseudonym wieder ausgelesen werden.
Wenn der Patient der Reversibilität seines Pseudonyms nicht zustimmt, verändert sich
der Aufbau geringfügig. Bild 3.9 beschreibt die Konstruktion einer Forschungsdatenbank,
die Langzeitforschung ermöglicht, aber keinerlei, auch keinen gewollten, Rückschluss auf
den Patienten bietet.
Bild 3.9: Schema für One-Way Pseudonymisierung nach Noumeir [29]
Die Anonymisierung und Pseudonymisierung erfolgt wie bei der reversiblen Pseudonymisierung in zwei TTPs aufgeteilt. Damit das Pseudonym nicht mehr auf den Patienten
umgerechnet werden kann, wird auf die Speicherung der Parameter oder der Verbindung
Patient - Pseudonym verzichtet.
Somit kann die Option freigehalten werden, sowohl mit reversiblen als auch mit irreversiblen Pseudonymen in derselben Datenbank zu arbeiten.
Nachdem die zweite TTP durchlaufen wurde, werden die anonymisierten und pseudonymisierten Daten verschlüsselt an die Forschungsprojekte vergeben. Den Projekten
bleibt es frei, jederzeit einen weiteren Snapshot der stetig wachsenden Forschungsdatenbank zu beziehen.
29
3 Verwandte Arbeiten
Wenn eine One-Way Pseudonymisierung gewünscht ist, wird die Pseudonymisierung
ebenfalls mit einer Hashfunktion durchgeführt. Noumeir verwendet als Hashfunktion
den kollisionsarmen Secure Hash Algorithm SHA [11].
Hashfunktionen sind nicht immer sicher gegen Wörterbuch Attacken. Ein möglicher
Angreifer könnte mithilfe einer erschöpfenden Suche an die ID des Patienten zu gelangen.
Natürlich ist es immer noch möglich den Patienten allein anhand seiner Bilddaten zu
identifizieren.
Positiv an diesem Ansatz ist es, dass sowohl anonymisiert als auch pseudonymisiert
wird. Ein alleiniges Austauschen einer Patienten ID gegen ein Pseudonym garantiert
noch lange nicht die Anonymität des Patienten.
3.3.5 Pommerening
Pommerening bietet ein komplexeres Konzept für Langzeitstudien an medizinischen Daten. Mithilfe zweier außerklinischer Stationen wird die Dienstgüte der Daten hinsichtlich
Richtigkeit, Vollständigheit und Konsistenz [?] aus verteilten Quellen gesteigert und sicher gestellt. Die begutachteten, geprüften Daten werden in einer zentralen Datenbank
gespeichert auf die Forschungsgruppen Zugriff beantragen können.
Pommerening [33] verweist, wie Noumeir, auf zwei Arten Pseudonyme, reversible oder
irreversible Pseudonyme.
Für irreversible Pseudonyme generiert eine Trusted Third Party aus der Patienten
ID ein Pseudonym, speichert jedoch die Umkehrung nicht. Genau wie bei Noumeir,
werden alle identifizierenden Daten bis auf die Patienten ID entfernt, bevor die ID zum
Pseudonym umgewandelt und die medizinischen Daten verschlüsselt an die Forschung
geschickt werden.
Für reversible Pseudonyme kommt eine weitere TTP zum Einsatz, siehe Bild 3.10.
Die PID (PID steht für Patienten ID) Service genannte TTP erstellt für jeden Patienten eine geheime Patienten ID, die dann an die Pseudonymisierungsservice genannte
TTP geschickt wird. Der PID Service entspricht der TTP, die auch bei den irreversiblen
Pseudonymen zum Einsatz kommt. Der Pseudonymisierungsservice verwandelt dann die
Patienten ID in ein Pseudonym um. Diese TTP speichert auch die Verbindung zwischen
Patienten ID und Pseudonym.
Da die Liste mit den Verbindungen zwischen Patienten ID und Pseudonymen ein sehr
attraktives Ziel für mögliche Angreifer ist, wird die Patienten ID von der ersten TTP
geheim vergeben. Falls jemand widerrechtlich an die Patienten ID kommt, kann er diese
immer noch nicht mit einen Patienten in Verbindung bringen.
30
3.3 Pseudonymisierende Ansätze
Bild 3.10: Einfaches Schema für reversible Pseudonymisierung nach Pommerening [33]
Um die Datenqualität sichern zu können und die Möglichkeit für Rückfragen an Ärzte
bereitzustellen, verfeinert Pommerening das Konzept in [32]. Die medizinischen Daten
werden aus lokalen Datenquellen in eine zentrale Datenbank, die von einer TTP geleitet
wird, abgeführt (siehe Bild 3.11).
Kliniken und Ärzte schicken Daten, etwa Behandlungsberichte, an das Trusted Office.
Dieses prüft die Datensätze auf Vollständigkeit und Plausibilität. Wenn nötig, holt das
Office zusätzliche Informationen zu einem Datensatz von dem zugehörigen Arzt. Die
Daten bekommen einen Zusatz, zum Beispiel zu welchem Krankheitsbild sie gehören.
Fertig verarbeitet werden sie pseudonymisiert und an das Registration Office geschickt.
Die Schlüssel zur Rückverfolgung des Pseudonyms werden in einer zusätzlichen Trusted
Third Party, dem Supervising Office, außerhalb der Forschungsdatenbank untergebracht.
Wenn nach einem gewissen Zeitraum keine Rückfragen des Registration Office erfolgt
sind, werden die Daten im Trusted Office gelöscht.
Das Registration Office erhält nur pseudonymisierte Daten und speichert diese permanent. Wenn bei der Verlinkung von Datensätzen Ungereimtheiten auftreten, werden
diese an das Trusted Office berichtet, welches dann beim zugehörigen Arzt Erkundungen
einholt.
Pseudonymisierung bedeutet in diesem Fall, dass die identifizierenden Daten RSA [11]
verschlüsselt werden. Das Supervising Office hält die Schlüssel, um die identifizierenden
Daten wieder zu entschlüsseln.
31
3 Verwandte Arbeiten
Bild 3.11: Verarbeitungssystem von medizinischen Daten für den sekundären Gebrauch
nach Pommerening [32]
Die medizinische Daten werden dann wie gewohnt über ein Pseudonymisierungssystem
an die Forschungsdatenbank weitergegeben.
Der Patient kann und soll nicht in der Lage sein sein eigenes Pseudonym umzuwandeln.
Das wird mit dem Recht begründet, dass ein Arzt einen Fall bekannt machen darf, ohne
den Patienten zu informieren.
3.4 Einordnung
Mein Ansatz greift die Ideen von Noumeir und Pommerening bezüglich irreversibler
Pseudonyme auf und erweitert sie um eine gesonderte Behandlung spezifischer Attribu-
32
3.4 Einordnung
te. Desweiteren wird eine durch den Anwender definierte k-Anonymisierung ermöglicht.
Die Anonymität der bearbeiteten Daten kann durch den Anwender problemorientiert
geregelt werden. Es wird außerdem die Möglichkleit offen gelassen, den Informationsverlust bei der k-Anonymisierung nach Samarati und Sweeney zu minimieren [37, 38].
33
4 Implementierung
In den folgenden Unterkapiteln wird mein Ansatz zu einem Dienst, der sensible Daten
pseudonymisieren und anonymisieren kann zu den existierenden Ansätzen eingeordnet.
Es wird erklärt, welchem Entwurfsmuster das erarbeitete Programm folgt und wie einzelne Aspekte implementiert wurden.
4.1 Fachkonzept
Die Aufgabe des erarbeiteten Programms, im Folgenden auch als p1 bezeichnet, ist es
Daten zu pseudonymisieren und optional zu anonymisieren. Das Anwendungsfalldiagramm in Bild 4.1 zeigt die verschiedenen Möglichkeiten das Programm zu verwenden.
In allen Anwendungsfällen wird Tabelle für Tabelle in der Datenbank eine Kopie der
zu bearbeitenden Daten erstellt. Die Tabellenkopien werden erst mit den Originaldaten
befüllt, die anschließend pseudonymisiert oder k-anonymisiert werden. Die Pseudonymisierung ist irreversibel, die Datensätze sind aber dennoch weiterhin einander zuordbar.
Die pseudonymisierten oder k-anonymisierten Daten können dann sicher an eine zentrale
Stelle übermittelt werden, die die Sammlung solcher Daten übernimmt. Eine Reversion
der Daten ist nicht vorgesehen.
Bei Programmaufruf kann angeben werden, ob für bestimmte Attribute nach der
Pseudonymisierung leserliche Ergebnisse vorliegen sollen. Zum Beispiel kann ein Attribut mit der Referenz Vorname versehen werden. Alle Werte des Attributes werden dann
durch lesbare Vornamen ausgetauscht. Die Funktion des Pseudonyms, also die Zuordbarkeit, bleibt trotzdem gegeben. Die mögliche Referenzen umfassen bis jetzt Vor- und
Nachnamen, Land, Stadt, Straße und Titel. Neue Referenzen einzuführen ist Dank der
Modulariät des Programms leicht möglich.
Das Bild 4.2 beschreibt die benötigten und optionalen Eingaben sowie die Resultate
des Programms für eine Pseudonymisierung.
Unabhängig davon, ob pseudonymisiert oder anonymisiert werden soll, benötigt das
Programm als Eingabe einen Benutzernamen, das zugehörige Passwort und den DataSource Name der Datenbank für die Datenbankanbindung. Als weitere Eingabe werden
35
4 Implementierung
Bild 4.1: Anwendungsmöglichkeiten des Programms zur Pseudonymisierung von
sensiblen Daten
36
4.1 Fachkonzept
Bild 4.2: Programmaufruf für eine Pseudonymisierung
die zu pseudonymisierenden Tabellen sowie eine Aufzählung der zu schützenden Attribute angegeben. Optional kann der Datenbesitzer eine Referenzliste für ein lesbares
Pseudonymisierungsergebnis angeben.
Der Aufbau der Dateien an zu schützenden Tabellen und Attributen folgt dem gleichem Schema. In beiden Fällen werden .txt Dateien angelegt, in denen die Namen
getrennt durch Zeilenumbrüche eingetragen werden. Ein Beispiel für den Aufbau einer
Datei, die die Tabellennamen enthält, ist der folgende Abschnitt:
Patient
SurgeryUnit
Diagnosis
37
4 Implementierung
Die Trennung von Attributen und zugehörigen Tabellen in zwei Dateien erfolgt, um
unnötige Redundanz zu verhindern. Das Programm sucht sich die Verbindung zwischen
Tabellen und Attributen aus den Metainformationen der Datenbank.
Das Format der Datei, die die Referenzliste enthält, ähnelt den für die Dateien mit
Tabellen und Attributen. Es wird in die .txt Datei erst das zu schützende Attribut
geschrieben, gefolgt von einem ’=’ und der entsprechenden Referenz. Mögliche Referenzen sind: firstName, lastName, title, street, country und city. Ein Beispiel für eine
Referenzdatei sieht wie folgt aus:
Vorname=firstName
Name=lastName
Adr=city
Alle im Datenbankschema angegebenen Tabellen werden kopiert und nur die Attribute
pseudonymisiert, die in der Aufzählung zu schützender Attribute vorkommen. Die Beziehungen zwischen den Tabellen sind vernachlässigbar, da alle zu pseudonymisierenden
Attribute mit den selben Verschlüsselungsfunktionen übersetzt werden und so eine Verknüpfung ohne explizites Wissen über diese Verknüpfung zwischen den Tabellen erhalten
bleibt. Die Integritätsbedingungen, die die einzelnen Attribute laut Datenbankschema
erfüllen müssen, können ebenfalls ignoriert werden, da sie vor dem Pseudonymisieren gegeben sein müssen und nicht verändert werden. Näheres dazu findet sich im Unterkapitel
4.3.3.
Das Programm liefert keine sichtbare Ausgabe sondern erstellt nur Kopien der zu
pseudonymisierenden Tabellen in der selben Datenbank.
In Bild 4.3 sind die benötigten Eingaben zum Ausführen einer k-Anonymisierung
dargestellt.
Die Eingaben für die Datenbankanbindung sind die selben wie bei einem Programmaufruf für eine Pseudonymisierung. Bei einer k-Anonymisierung werden die zu bearbeitenden Tabellen sowie die zu beachtenden Attribute in denselben Format wie bei einer
Pseudonymisierung angegeben. Weiterhin wird eine ganzzahlige Zahl k übergeben.
38
4.2 Programmarchitektur
Bild 4.3: Programmaufruf für eine k-Anonymisierung
4.2 Programmarchitektur
4.2.1 Übersicht
Das Programm zur Pseudonymisierung und k-Anonymisierung von medizinischen Datenbanken folgt nicht direkt einem Entwurfsmuster.
Das Bild 4.4 zeigt die Module meines Programms und ihr Zusammenspiel untereinander. Die Module für die Datenbankanbindung, für das Einlesen der Eingaben und für
die Verschlüsselung der Attributwerte sind nach der Schablonenmethode konzipiert [17].
39
4 Implementierung
Bild 4.4: Klassendiagramm
Das Modul Middleware besitzt die main Methode, in der die Programmeingaben
mithilfe des InputConverter Moduls bearbeitet werden. Die Middleware öffnet auch die
Datenbankverbindung mithilfe des Moduls DataBaseFunctionality, im Folgenden und
im Code mit DBF abgekürzt, bevor sie je nach Programmaufruf die Module PseudoLogic
und/oder KAnoLogic aufruft. Bei Aufruf der PseudoLogic und der KAnoLogic wird das
erstellte Datenbankobjekt sowie die konvertierten Eingaben mit übergeben.
PseudoLogic übernimmt die Pseudonymisierung der, von der Middleware übergebenen, Tabellen. Das Modul verwendet dafür die Module DBF und Encryption. DBF
stellt alle gewünschten Datenbankoperationen zu Verfügung. Das Modul Encryption
übernimmt die Verschlüsselungsaufgaben und das Austauschen von referenzierten Attributen.
Im Modul KAnoLogic werden alle Tabellen mit Blick auf die Anzahl gleicher Werte
eines Attributs betrachtet. Das bei Programmaufruf übergebene k dient dabei als Grenz-
40
4.2 Programmarchitektur
wert, ab wann eine Spalte in einer Tabelle bearbeitet wird. Die KAnoLogic verwendet
für die Datenbankoperationen ebenfalls das Modul der DBF.
Sowohl PseudoLogic als auch KAnoLogic arbeiten mit der Klasse DataField. Mithilfe
dieser Klasse werden Werte eines Attributs aus der Datenbank zwischengespeichert.
Ganze Spalten einer Tabelle können so mithilfe der DBF aus der Datenbank ausgelesen
und in einer Liste von DataFields abgespeichert werden. Details zur Umsetzung der
Klasse DataField befinden sich im Unterkapitel 4.3.1.
4.2.2 Module
Im Folgenden sollen die Einzelteile des Programms p1 vor allem im Hinblick auf ihre
Aufgaben und ihre Bedeutung näher betrachtet werden.
Die Middleware ist der Zugangspunkt zu p1, da sie die main und keine anderen Funktionen besitzt. Das Aktivitätsdiagramm in Bild 4.5 zeigt die Aufgaben der Middleware.
Bild 4.5: Funktionalität der Middleware
Die Middleware konvertiert die Eingaben und erstellt ein Datenbankobjekt. Mithilfe dieses Datenbankobjektes können Datenbankfunktionen aufgerufen und ausgeführt
werden.
41
4 Implementierung
Es erfolgt eine Aufteilung je nach Eingaben des Programmaufrufers in sechs mögliche
Fälle. Der erste Fall ist ein Programmaufruf mit fehlerhafter Anzahl an Parametern,
woraufhin das Programm abgebrochen wird.
Die anderen fünf Fälle unterscheiden sich in der Anzahl an Eingaben. Hat der Programmaufrufer nur die Option -p sowie eine Liste mit Tabellen und eine Liste zu schützender Attribute übergeben, wird eine Pseudonymisierung durchgeführt und das Programm erfolgreich beendet. Wurde zusätzlich mithilfe der Option -ref beim Programmaufruf eine Referenzliste übergeben, pseudonymisiert p1 mit Referenzen. Wird bei Übergabe neben den oben genannten Eingaben mithilfe der Option -k auch eine Zahl k und
zwei weitere Listen mit Tabellennamen und Attributen mitgegeben, so wird pseudonymisiert und anschließend k-anonymisiert. Desweiteren ist es möglich Eingaben für eine
Pseudonymisierung mit anschließender k-Anonymisierung oder Eingaben für eine reine
k-Anonymisierung zu geben.
Die Klasse PseudoLogic übernimmt das Pseudonymisieren mit und ohne Referenzen.
Das Aktivitätsdiagramm in Bild 4.6 zeigt die Funktionalität der Klassen.
Die PseudoLogic bekommt von der Middleware die Datenbankverbindung, eine Liste
an Tabellennamen, eine Liste an zu schützenden Attributen und eventuell Referenzen
übergeben. Anhand der Liste von Tabellennamen kopiert die PseudoLogic die Tabellen.
Es folgt eine Schleife über alle Tabellen, in der für jede Tabelle alle zu pseudonymisierenden Spalten bearbeitet werden. Für jede dieser Spalten werden die Daten geholt und
je nach gesetzten Optionen verschlüsselt oder ausgetauscht und anschließend zurück
in die Tabellenkopie gespeichert. Sind alle Tabellen abgearbeitet, ist die Aufgabe der
PseudoLogic beendet.
Das Programm kehrt zurück in die Middleware und ruft von dort, falls erwünscht, die
Klasse KAnoLogic auf. Die Klasse KAnoLogic übernimmt die Aufgabe alle angegebenen
Tabellen zu k-anonymisieren. Genau wie die PseudoLogic betrachtet sie allerdings nur
die Attribute, die der Programmaufrufer in der Liste zu schützender Attribute angegeben
hat. Das Aktivitätsdiagramm in Bild 4.7 zeigt den internen Ablauf in der KAnoLogic.
Die KAnoLogic bekommt von der Middleware die Datenbankverbindung, die Liste zu
bearbeitender Tabellennamen, die Liste zu schützender Attribute und die Zahl k, um
die k-anonymisiert werden soll, übergeben. Für jede Tabelle wird als Erstes ermittelt,
ob schon eine Kopie von ihr vorliegt. Danach wird für jede zu schützende Spalte in der
Tabelle die Häufigkeit gleicher Attributwerte in der aktuellen Spalte gezählt. Ist die Zahl
größer als k, werden die nächsten Spalten oder die nächste Tabelle betrachtet. Ist die
Zahl kleiner als k muss generalisiert werden. Das Generalisieren erfolgt in der jetzigen
42
4.2 Programmarchitektur
Bild 4.6: Funktionalität der PseudoLogic
43
4 Implementierung
Bild 4.7: Funktionalität der KAnoLogic
Implementierung durch Division durch zwei, wobei die Nachkommastellen ignoriert werden. Für den Sonderfall, dass k gleich eins ist, können Datensätze unterdrückt werden.
Voraussetzung dafür ist es jedoch, dass zuverlässig Primärschlüssel erkannt werden können, da in einer Spalte mit Primärschlüsseln, nie mehr eine Häufigkeit größer eins an
Vorkommen des einzelnen Wertes herrscht. Eine Unterdrückung hätte dann zur Folge,
dass der ganze Inhalt der Tabelle gelöscht wird, da die KAnoLogic erst aufhört zu anonymisieren, wenn das Ergebnis größer als k oder gleich null ist. Es fehlt außerdem an einer
Strategie, ab wann eine Unterdrückung hinsichtlich der Bearbeitungszeit von Vorteil ist
und ab wann durch sie mehr Informationen verloren gehen. Aus diesem Gründen wird
in der jetzigen Implementierung von p1 auf die Unterdrückung verzichtet.
4.3 Implementierungsdetails
Im Verlauf dieses Unterkapitels wird der Aufbau der Klasse DataField erklärt.Weiterhin
wird erläutert, wie das Holen und Rückspeichern von ganzen Datenspalten aus der Datenbank funktioniert. Zum Abschluss betrachten wir, warum Integritätsbedingungen
wie etwa Primärschlüssel und Fremdschlüssel im Programm nicht gesondert behandelt
44
4.3 Implementierungsdetails
werden. In den Beispielen und Erklärung wird vor allen C++ als Programmiersprache
betrachtet, da die konkrete Implementierung in C++ geschrieben ist.
4.3.1 Die Klasse DataField
Um Daten aus der Datenbank holen und bearbeiten zu können, wird in p1 die Klasse
DataField zum Zwischenspeichern verwendet.
Eine Datenbank kann viele verschiedene Datentypen besitzen, die unter Umständen
in C++ sowie in anderen Programmiersprachen nicht darstellbar sind. Ein weiteres
Problem mit diesen Datentypen ist, dass erst zur Laufzeit entschieden wird, welchen
Typ ein Attribut besitzt.
Vorweg drei Überlegungen, wie dieses Problem der Zwischenspeicherung gelöst werden
könnte.
Als erste Möglichkeit gibt es in C++ seit dem C++11 Standard die auto Variable.
Diese Variable nimmt den Datentyp von den Werten, mit denen sie befüllt wird, an.
Allerdings wird dieser Typ beim kompilieren ermittelt und nicht erst zur Laufzeit. Die
auto Variable löst das Problem also nicht.
Als Zweites gibt es die Möglichkeit den Datentyp eines Attributs mithilfe der C++
Funktion typeid oder einer Datenbankabfrage zu ermitteln. Dieser Datentyp kann
zusammen mit den einzelnen Werten in der Klasse DataField gespeichert werden.
DataField besitzt dann die privaten Variablen dataType und value, sowie die passenden Zugriffsfunktionen. Die Variable value benötigt immer den passenden Datentyp,
je nachdem welcher Typ in ihr gespeichert werden soll. Das geht unter C++ nur mithilfe von void Pointern, da Daten von jedem beliebigen Typ in einem void Pointer
gespeichert werden können. Zum Auslesen dieser Daten muss nur der Typ bekannt sein,
nach dem der void Pointer gecastet wird. Der große Nachteil bei diesem Ansatz ist,
dass Pointer außerhalb der Funktionen, in denen sie erstellt wurden, nicht mehr existieren. Ein Vorteil wäre, dass so gut wie alle Datentypen bedient werden können. Ein
daraus resultierendes Problem wäre, dass nicht alle Verschlüsselungsmethoden mit allen
Datentypen gut zurechtkommen.
Die dritte Überlegung ist die, die auch in p1 umgesetzt wurde. Es gibt von den großen
Datenbankanbietern Interfaces um mithilfe von C++ auf ihre Datenbank zuzugreifen.
Für Oracle und C++ heißt das, in dieser Implementierung auch verwendete, Interface
Oracle C++ Callable Interface (kurz OCCI). Diese Interfaces ordnen ihren Datenbankinternen Datentypen C++ Typen zu.
45
4 Implementierung
Wenn diese Zuordnungen betrachtet werden, stellt sich heraus, dass sehr viele Datentypen auf int, long, char, string oder double abgebildet werden. Es gibt allerdings
auch Abbildungen auf weniger häufig vorkommende C++ Datentypen. Zum Beispiel
gibt es in Oracle Datenbanken den Datentyp BLOB (BLOB steht für Binary Large Object). Mit diesem Datentyp werden Bild- oder Audiodateien gespeichert. Mithilfe von
OCCI werden BLOBs in den C++ Datentyp Blob umgewandelt.
Die Idee bei der dritten Überlegung ist es alle möglichen datenbankinternen Datentypen auf drei C++ Datentypen herunterzubrechen. Die Klasse DataField bekommt drei
Variablen vom Typ int, string, double und eine weitere Variable vom Typ string,
in der der Datentyp gespeichert wird. Datentypen wie BLOB lassen sich natürlich nicht
in eine der drei Variablen abspeichern, allerdings ist es auch schwer solche Datentypen
zu pseudonymisieren. Es wird folglich davon ausgegangen, dass auch nur Attribute mit
pseudonymisierbaren Datentypen angegebene werden.
Bild 4.8: Variablen und Operationen in der Klasse DataField
Das Klassendiagramm in Bild 4.8 zeigt die endgültige Fassung der Klasse DataField.
4.3.2 Der Speicherplan
Um das reibungslose Holen und Zurückspeichern von Datenspalten aus einer Tabelle
zu gewährleisten, stellt die DataBaseFunctionality zwei Methoden zur Verfügung. Die
Idee hinter diesen Methoden soll hier kurz erklärt werden.
46
4.3 Implementierungsdetails
Als Voraussetzung für das Bearbeiten von ganzen Spalten, wird beim Kopieren der
Originaltabellen der Kopie ein neues Attribut vom Typ Integer hinzugefügt. Dieses neue
Attribut nennt sich PseudonymID. Es wird davon ausgegangen, dass die Originaltabelle
kein Attribut mit diesem Namen enthält. Anhand dieser PseudonymID können Datensätze entnommen und wieder zurück gespeichert werden. Die PseudonymID wird nach
dem Erstellen mit Zahlen von 1 bis zur Anzahl der Datensätze in der Originaltabelle
befüllt. Das Attribut übernimmt also die Funktion eines Primärschlüssels.
Ein Nachteil dieser PseudonymID ist, dass anhand ihrer Zahl sichtbar ist, in welcher
zeitlichen Abfolge der Datensatz eingefügt wurde. Dieser Nachteil ist allerdings vernachlässigbar, da immer eine komplette Tabelle pseudonymisiert wird und nicht mehrere Datensätze über einen größeren Zeitraum. Es lässt sich allerdings anhand dieser
PseudonymID sagen in welcher Reihenfolge Daten in die Tabelle gespeichert wurden.
Um dies auch noch zu umgehen ist es vorstellbar, die PseudonymID nach Bearbeitung
der Daten zu entfernen. Bis jetzt wurde davon allerdings Abstand genommen, da bei einer Hintereinanderausführung von Pseudonymisierung und k-Anonymisierung diese ID
wiederverwendet wird.
Um die Werte eines Attributs aus einer Tabelle auszulesen, wird die Methode
getColumnData aus der DBF Klasse verwendet. Diese Methode erwartet den Tabellennamen und den Namen des Attributs als Eingabeparameter. Sie erstellt anhand dieser
Parameter eine Liste an DataFields, die mit den Werten des angegebenen Attributs aus
der Tabelle befüllt wird. Diese Werte werden aus der Tabelle mithilfe einer SQL Anweisung entnommen, die die Daten in Reihenfolge der PseudonymID ordnet. Zu sehen
ist dieser Vorgang im oberen Teil des Bildes 4.9. Die Liste entnommener Daten ist als
vector im Bild gekennzeichnet. Der Datensatz mit der PseudonymID 1 wird als erstes
entnommen und an der Stelle mit dem Index 0 in die Liste eingefügt. Der zweite Datensatz hat die PseudonymID 2 und wird in die Liste mit Index 1 eingefügt. Der letzte
Datensatz hat folglich die PseudonymID Anzahl_T upel_in_der_T abelle und wird an
Stelle (Anzahl_T upel_in_der_T abelle) − 1 in die Liste eingefügt.
Das Zurückspeichern übernimmt die Funktion storeColumnData aus der DBF Klasse.
Sie ist im Bild 4.9 im unteren Bereich dargestellt. Die Funktion erwartet die weiterverarbeitete Liste an DataFields, die beim Aufruf von getColumnData zurückgegeben
wurde. Der Wert eines DataFields wird anhand seines Indexes in der Liste und der
PseudonymID zurück gespeichert. Das DataField mit dem Index 0 in der Liste wird in
den Datensatz mit PseudonymID 1 gespeichert und so weiter.
47
4 Implementierung
48
Bild 4.9: Schema zum Holen und Abspeichern von Spalten einer Tabelle
4.3 Implementierungsdetails
4.3.3 Die Integritätsbedingungen
Fast alle Datenbanktabellen enthalten Integritätsbedingungen, die ihre Attribute betreffen, allen voran Primär- und Fremdschlüssel. Beim Kopieren einer Tabelle in meinem
Programm werden die Integritätsbedingungen der Originaltabelle nicht mit übernommen. Auch wird beim Speichern der bearbeiteten Daten nie überprüft, ob eventuelle
Integritätsbedingungen verletzt werden. Dies ist auch nicht nötig.
Es wird davon ausgegangen, dass alle eventuell existierenden Integritätsbedingungen
in der Originaltabelle erfüllt sind. Durch das Kopieren der Originaldaten werden diese
Daten nicht verändert. Primärschlüssel müssen nicht beachtet werden, da keine weiteren
Datensätze hinzugefügt werden, sondern nur vorhandene verändert werden.
Die einzigen Methoden die diese Daten verändern, sind die Verschlüsselungsmethoden und Austauschmethoden der Encryption Klasse. Die Verschlüsselungsmethode erzeugt für gleiche Eingabe immer die selbe Ausgabe. Genauso verhält es sich mit der
Austauschmethode für referenzierte Strings. Es wird für die gleiche Eingabe die selbe
Ausgabe erzeugt.
Fremdschlüssel sind also weiterhin noch zuordbar, da alle Tabellen mit der selben
Methode bearbeitet werden.
Bei einer k-Anonymisierung von Attributen mit Integritätsbedingungen können diese
verletzt werden und Fremdschlüsselbeziehungen verloren gehen. Hier liegt es in der Hand
des Anwenders zu entscheiden, ob dies toleriert werden kann.
4.3.4 Referenzen und die Klasse Encryption
In der Klasse Encryption werden mithilfe der Methode changeDataFieldValue Stringwerte gegen neue leserliche Werte ausgetauscht. In der konkreten Implementierung wird
dafür je nach gewünschter Referenz eine andere .txt Datei eingelesen. Diese Dateien
bestehen aus den neuen Werten, getrennt durch einen Zeilenumbruch. Es ist also möglich
durch das Einlesen einer ganzen Zeile schnell einen Austauschwert zu erhalten.
In diese Dateien können beliebige Werte eingetragen werden. In der jetzigen Implementierung sind Namen aus den Scheibenweltromanen des Autors Terry Pratchett enthalten
[7, 36].
Damit auch alle gleichen Eingabewerte denselben Austauschwert erhalten, wird
in der Methode changeDataFieldValue die HashEncryption-interne Methode
changeStringValue aufgerufen. Die Methode changeStringValue wendet folgendes Konzept an. Mit dem Eingabewert wird eine Zahl ermittelt, die als Zeilennummer
49
4 Implementierung
zum Auslesen des Austauschwertes aus der gewünschten Datei dient. Das Listing 4.1
zeigt den Code, der den Eingabestring in eine Nummer umwandelt und anschließend
die Zeile mit dieser Nummer ausliest.
Der Eingabestring value wird in einen char Pointer umgewandelt. Dieser Pointer
wird durchlaufen und jeder einzelne char in eine Integerzahl gecastet. Diese Zahlen
werden zusammengezählt und anschließend als Zeilennummer verwendet.
Da diese Zahl eventuell größer als die vorhandenen Zeilen in der Datei ist, wird sie
modulo der Anzahl vorhandener Zeilen genommen. Dadurch ist es möglich, dass unterschiedliche Eingabewerte denselben Ausgabewert erhalten. Je mehr Zeilen die Referenzdateien enthalten, desto unwahrscheinlicher wird das allerdings.
Nachteile an dieser Implementierung sind, dass Zeichenketten mit den selben Buchstaben in unterschiedlichen Reihenfolgen den selben Wert und somit den selben Austauschwert erhalten. Außerdem entsteht ein hoher Rechenaufwand, da für jeden Attributwert die Referenzdatei zweimal durchlaufen wird. Die Schleife, die die Anzahl an
Zeilen in der Referenzdatei zählt, sollte in den InputConverter ausgelagert werden.
50
4.3 Implementierungsdetails
1
2
3
4
5
6
7
8
9
10
11
12
13
// ch angeSt ringVa lue bekommt einen Wert value uebergeben
// und tauscht ihn durch einen neuen Wert aus der Referenzdatei
// unter path aus .
string HashEncryption :: c hangeS tringV alue ( string value , string path )
const
{
// Anhand der chars im value string wird eine Zahl q ermittelt ,
// die fuer gleiche strings gleich bleibt .
const char * m = value . c_str () ;
int q =0;
while (* m ) {
q +=( int ) * m ;
m ++;
}
14
// stream zum oeffnen der Pseudonymdatei
ifstream stream ;
// return string
string s ;
// Name der Pseudonymdatei
string file = path + " . txt " ;
// Anzahl Zeilen in der Datei
int count =0;
15
16
17
18
19
20
21
22
23
// Anzahl der Zeilen in der Datei ermitteln
// open aus - std = c ++11
stream . open ( file , ifstream :: in ) ;
if ( stream . is_open () ) {
while ( getline ( stream , s ) ) count ++;
24
25
26
27
28
29
// Pointer an den Anfang der Datei zurücksetzen
stream . seekg (0 , stream . beg ) ;
30
31
32
// q . te Zeile aus der Pseudonymdatei auslesen
q = q % count ;
while (q >0) {
getline ( stream , s ) ;
q - -;
}
stream . close () ;
return s ;
33
34
35
36
37
38
39
40
}
41
42
// type ist keine existierende Referenz
return " NOREF " ;
43
44
45
}
Listing 4.1: Methode changeStringValue aus der Klasse HashEncryption
51
5 Evaluation
Im Folgenden soll die Laufzeit des Programms p1 sowohl theoretisch berechnet als auch
gemessen werden. Des weiteren wird untersucht wie sich kombinierte Anfragen auf die
Datensicherheit hinsichtlich der Personen Identifizierung auswirken.
Um diese Kapitel zu verstehen wird hier kurz das verwendete Datenbankschema vorgestellt (Bild 5.1). Die Messungen zur Laufzeit des Programmes p1 benutzen ausschließlich
die Tabelle Patient. Die Tabelle Patient besitzt zehn Attribute darunter die Adresse, zusammengesetzt aus state, city, street und zipcode, den Name des Patienten,
firstname und lastname, das Geburtsdatum, dateOfBirth, eine ID und einen für uns
unwichtigen hash Wert.
Die Tabelle SurgeryUnit beinhaltet die Adresse, zusammengesetzt wie in der Tabelle
Patient, eine ID und eine Beschreibung, description, der beteiligten klinischen Einrichtung. Die Tabelle HealthServiceProvider besitzt die Informationen über beteiligte
Ärzte und anderes medizinisches Personal. In ihr ist die Adresse des Arztes, der Name,
lastname und firstname, der Arzttyp, typ, eine ID, das Gültigkeitsdatum der Arztlizenz, validUntil, und die Information, ob der Arzt von außerhalb stammt, isExtern,
gespeichert.
Die Tabelle Appointment speichert Behandlungen, indem sie mithilfe von Fremdschlüsseln auf den Patienten, das medizinische Personal und die medizinische Einrichtung verweist. Zusätzlich wird in dieser Tabelle das Datum der Behandlung und eine
eindeutige ID gespeichert.
Die bei einer Behandlung gestellte Diagnose wird in der Tabelle Diagnosis abgelegt.
Ihre Fremdschlüssel speichern die Beziehung zwischen Patient, medizinischem Personal
und medizinischer Einrichtung. Weitere Attribute sind ICDCode und ICDText [30], sie
beinhalten die gestellte Diagnose. Das Datum der Diagnose wird in datum gespeichert.
Die Attribute classification und location beinhalten weitere Informationen über
die Diagnose.
53
5 Evaluation
Bild 5.1: Datenbankschema für Messungen und Tests
54
5.1 Laufzeiten
5.1 Laufzeiten
Es werden grob die theoretischen Laufzeiten des Programms p1 berechnet sowie eine
Messreihe zur Laufzeitentwicklung bei Veränderung mehrere Parameter erstellt.
5.1.1 Theoretische Zeiten
Von der main Methode im Modul Middleware ausgehend werden die Zeiten betrachtet,
die nötig sind um zu pseudonymisieren und zu k-anonymisieren. Es erfolgt keine genauere Zeiteinteilung der unterschiedlichen Datenbankoperationen oder C++ interner
Funktion. Jede Operation bekommt die Zeiteinheit 1 zugewiesen.
Die Middleware benötigt konstante Zeit, da sie nur Objekte, zum Beispiel das Objekt
zur Datenbankanbindung, erstellt und die PseudoLogic sowie die KAnoLogic aufruft.
Wird die PseudoLogic betrachtet, pseudonymisiert sie ohne gesetzter Referenzen im
schlechtesten Fall in folgender Zeit:
AT · OA + AT · (OA + OA · AA · (T + T + T ))
= 2 · AT · OA + 3 · AT · OA · AA · T
Wobei AT für die Anzahl der bei Programmaufruf angegebenen Tabellen und AA für
die Anzahl der angegebenen Attribute steht. OA verdeutlicht die Anzahl der Attribute,
die die aktuelle Tabelle besitzt. T kennzeichnet die Anzahl der Tupel, die in der aktuellen
Tabelle vorhanden sind. OA und T schwanken je nach verwendeten Tabellen. Die Angabe
zählt für eine Pseudonymisierung ohne Referenzen.
Bei einer Pseudonymisierung ohne Referenzen wird in der PseudoLogic für jede bei
Programmaufruf angegebene Tabelle die copyTable Funktion aufgerufen, die alle Attribute der Tabelle durchläuft. Das benötigt zusammen AT ·OA. Des weiteren wird für jede
angegebene Tabelle die pseudomize Funktion aufgerufen. Die Funktion pseudomize holt
sich eine Liste mit allen Attributen der aktuellen Tabelle (OA) und geht für jedes dieser
Attribute die angegebenen Attribute durch (OA · AA). Für jede Übereinstimmung eines
Attributs aus der Tabelle und eines angegebenem Attributs werden alle zugehörigen Tupel aus der Datenbank geholt (T ), anschließend verarbeitet (T ) und zurück gespeichert
(T ). Die Pseudonymisierung ohne Referenzen liegt in O(AT · OA · AA).
Bei einer Pseudonymisierung mit Referenzen kommen die Variablen AR, Anzahl der
Referenzen und LS, Länge des zu verändernden Strings und AZ als Anzahl Zeilen in
55
5 Evaluation
einer Referenzdatei hinzu. Wobei davon auszugehen ist, das LS vernachlässigt werden
kann. Bei einer Pseudonymisierung mit Referenzen sieht die Laufzeit im worst case wie
folgt aus:
AT · OA + AT · (OA + OA · AA(T + AR + T · (LS + AZ + AZ) + T ))
= 2 · AT · OA + 2 · AT · OA · AA · T + AT · OA · AA · AR + AT · OA · AA · T · LS+
2 · AT · OA · AA · T · AZ
Hier kommt zur normalen Pseudonymisierung hinzu, dass für jedes zu schützende
Attribut überprüft wird welche Referenz gesetzt ist. Dies geschieht in der Zeit von AR.
Im Gegensatz zur einfachen Verschlüsselung der Daten benötigt das Austauschen von
Werten im schlimmsten Fall eine Zeit von (LS + AR + AR). Die Zeit kommt Zustande,
indem eine Zahl über die Länge des zu verändernden String erstellt wird (LS), alle
Zeilen in der Referenzdatei gezählt werden (AZ) und anschließend im schlechtesten Fall
nochmal alle Zeilen der Referenzdatei durchlaufen werden (AZ), um den Austauschwert
zu ermitteln.
Die KAnoLogic benötigt zur Laufzeitberechnung dieselben Variablen wie oben für die
Pseudonymisierung beschrieben. Die Laufzeit ermittelt sich für den worst case wie folgt:
AT · OA + AT · AA · OA · (OA + OA + T · (T + T ) · (OA + OA)))
= AT · OA + 2 · AT · AA · OA2 + 4 · AT · AA · OA2 · T 2
Die Laufzeit ergibt sich aus dem Nachschlagen der Attribute der aktuellen Tabelle
für jede angegebene Tabelle (AT · OA). Des weiteren wird für jede Tabelle und jedes
Attribut in der Tabelle die angegebenen Attribute verglichen (AT ·AA·OA) und für jede
Übereinstimmung der minimal vorkommende Wert gesucht (OA + OA). Danach muss
so oft generalisiert werden, bis der minimale vorkommende Wert größer oder gleich
k ist. In der jetzigen Implementierung erfolgt das Generalisieren in linear quadratisch
konvergenten Schritten. Es wird vereinfachend davon ausgegangen, das nicht mehr als T
mal pro Attribut generalisiert werden muss. Das Generalisieren erfordert eine Zeit von
(T + T ) um alle Tupel eines Attributes auszulesen und zurückzuspeichern.
Im besten Fall, nämlich dann, wenn nichts zu anonymisieren ist, beläuft sich die Zeit
für die k-Anonymisierung immer noch auf:
56
5.1 Laufzeiten
AT · (OA + AA · OA · (OA + OA))
= AT · OA + 2 · AT · AA · OA2
Die k-Anonymisierung liegt im worst case in O(AT · AA · OA2 T 2 ) und im besten Fall
in O(AT · AA · OA2 ).
5.1.2 Gemessene Zeiten
In diesem Unterkapitel sollen gemessene Programmlaufzeiten dargestellt und erläutert
werden. Gemessen wurde auf einen Linux Rechner mit 64-bit Prozessor, siehe Unterkapitel A.5.1.
Als Erstes wurde die Zeit gemessen die es benötigt, um ein Attribut im Hinblick
auf den Datentyp zu pseudonymisieren. In Bild 5.2 sind die Zeiten dargestellt die das
Programm p1 benötigt Attribute vom Typ Int, Varchar und Date in der Tabelle Patient
mit 1000 Datensätzen zu pseudonymisieren.
Gemessen wurde jeweils fünfmal an zwei verschiedenen Tagen. Der Durchschnitt ist
in Bild 5.2 aufbereitet. Werden die Attribute verglichen, besteht der einzige nennbare
Unterschied zwischen ihnen, dass ein Attribut vom Typ Int für eine Pseudonymisierung
doppelt solange wie ein Attribut von Typ Varchar oder Date. Bei Pseudonymisierung von
mehreren Attributen des Typs Int gleicht sich die Laufzeit allerdings wieder an die der
anderen Datentypen an. Die nachfolgenden Messungen werden deshalb ohne gesonderte
Betrachtung von unterschiedlichen Datentypen ausgeführt. Bei einer k-Anonymisierung
sind Datentypen mit der jetzigen Implementierung irrelevant, da Varchar und Date nur
ein einziges mal generalisiert werden und sie somit für weiterführende Messungen nicht
in Frage kommen.
Aus demselben Bild 5.2 kann auch die Veränderung der Laufzeit hinsichtlich der Anzahl der Attribute entnommen werden. Aus den gemessenen Zeiten lässt sich schließen,
dass die Laufzeit für jedes weitere zu pseudonymisierende Attribut linear um vier bis
fünf Sekunden steigt. Für genauere Aussagen müssten jedoch noch mehr Messungen
erfolgen.
Das nächste Bild 5.3 zeigt die Messergebnisse, wenn für die Tabelle Patient mit 1000
Datensätzen ein String Attribut, in diesem Fall firstname, mit Referenz pseudonymisiert wird. Das Bild stellt außerdem die Unterschiede in den Laufzeiten bei Veränderung
der Anzahl der zu pseudonymisierenden Attributen und zwischen reiner Pseudonymisierung und Pseudonymisierung mit Referenzen dar.
57
5 Evaluation
Bild 5.2: Gemessene Laufzeiten anhand von 1000 Tupeln für Attribute vom Datentyp
Int, Varchar und Date
58
5.1 Laufzeiten
Bild 5.3: Gemessene Laufzeiten für eine Pseudonymisierung mit Referenzen mit
wachsender Anzahl an zu referenzierender Attributen im Vergleich zur
Pseudonymisierung desselben Attributes ohne Referenzen
Der Mehraufwand für die Referenzierung benötigt circa eine Sekunde Rechenzeit.
Dementsprechend verhält sich die Laufzeit bei Anstieg der angegebenen Attribute wie
bei einer reinen Pseudonymisierung. Es wird ein Mehraufwand an Zeit von vier bis fünf
Sekunden für jedes angegebene Attribut benötigt.
Bild 5.4: Gemessene Laufzeiten für eine reine Pseudonymisierung, eine
Pseudonymisierung mit Referenzen und eine k-Anonymisierung mit
wachsender Anzahl an zu referenzierender Tabellen
59
5 Evaluation
Im Bild 5.4 sind die Messergebnisse für Pseudonymisierung, Pseudonymisierung mit
Referenzen und k-Anonymisierung mit k gleich fünf aufbereitet. Diesmal wurden die
Laufzeit hinsichtlich angegebener Tabellen betrachtet. Es wurde die Tabelle Patient
mit 1000 Datensätzen verwendet. Die Pseudonymisierung mit Referenzen erfolgte wie in
obiger Messung mithilfe des Attributs firstname, dass um Vergleichbarkeit mit reiner
Pseudonymisierung zu erhalten mit steigernder Anzahl angegebener Tabellen dementsprechend öfters pseudonymisiert wurde. Für alle Ausführungsvarianten war nur dieses
eine Attribut gegeben. Die k-Anonymisierung arbeitet mit dem Attribut Int, da alle
Varchar und Date Typen in der jetzigen Implementierung nie mehr als einen Generalisierungschritt benötigen und somit nicht repräsentativ sind.
Sowohl bei der Pseudonymisierung mit Referenzen als auch bei der reinen Pseudonymisierung lassen sich Unstimmigkeiten bei einerseits drei angegebenen Tabellen andererseits zwei angegebenen Tabellen erkennen. Durch mehr Messungen vor allen über mehr
angegebene Tabellen hinaus, lassen sich folgenden Vermutungen erklären.
Die reine Pseudonymisierung benötigt für jede weitere angegebene Tabelle einen linearen Mehraufwand, ohne Inbetrachtnahme der Unstimmigkeit für zwei angegebene
Tabellen, von 4,5 Sekunden. Eine Pseudonymisierung mit Referenzen braucht ebenfalls
circa 4,5 Sekunden mehr für jede zusätzlich angegebene Tabelle. Der Unterschied in der
Laufzeit einer reinen Pseudonymisierung im Vergleich zu einer mit Referenzen ist auch
hier, bei Betrachtung unterschiedlich vieler verarbeiteter Tabellen, konstant. Pseudonymisierung mit Referenzen benötigt circa zwei Sekunden mehr als reine Pseudonymisierung.
Bei einer k-Anonymisierung lässt sich ebenfalls ein linearer Anstieg beobachten. Für
jede weitere angegebene Tabelle werden circa 22 Sekunden benötigt, um diese zu verarbeiten. Für genauere Aussagen bräuchte es hier jedoch mehr Tests.
Mit demselben Bild 5.4 können Laufzeiten für Pseudonymisierung mit denen für kAnonymisierung verglichen werden. Da Pseudonymisierung und k-Anonymisierung unterschiedliche Funktionalitäten sind und beide Eigenschaften durch unterschiedliche Module implementiert wurden, ist es nicht weiter verwunderlich, dass sich die Zeiten unterscheiden. Es ist zu sehen, dass die k-Anonymisierung deutlich mehr Zeit beansprucht
als die Pseudonymisierung (siehe 2.3).
Eine weitere Messung verdeutlicht den Unterschied in der Laufzeit für unterschiedliche eine Anzahl an Datensätzen (Bild 5.5). Die Tabelle Patient wurde mit jeweils
1000, 10.000 oder 100.000 Datensätzen pseudonymisiert und k-anonymisiert. Aus den
60
5.1 Laufzeiten
Bild 5.5: Gemessene Laufzeiten für eine reine Pseudonymisierung, eine
Pseudonymisierung mit Referenzen und eine k-Anonymisierung mit
wachsender Anzahl an Datensätzen
Messungen lässt sich entnehmen, das die Laufzeit sowohl für die Pseudonymisierung als
auch für die k-Anonymisierung nicht linear mit Anzahl der Datensätze wächst.
Für die k-Anonymisierung wurden ebenfalls Messungen mit den gleichen Parametern
ausgeführt (Bild 5.6). Für die Tabelle Patient mit 1000 Datensätzen wurden bis zu drei
Attribute angegeben (id, hash, insuranceNumber). Die Attribute wurden 1-, 5- und
10-anonymisiert. Da die Attribute unterschiedlich viel zeit zum k-anonymisieren benötigen, sind folgende Messergebnisse ungenau. Es lassen sich jedoch trotzdem Tendenzen
erkennen.
Bei einer k-Anonymisierung mit k gleich eins verdoppeln sich die benötigten Zeiten
pro weiterem zu anonymisierenden Attribut. Bei k-Anonymisierungen mit k gleich von
und zehn steigt die Laufzeit für jedes weitere zu anonymisierende Attribut um grob
betrachtet circa zwei Minuten an. Der Anstieg der Laufzeit hinsichtlich gleichbleibender
Attributanzahl und steigender Werte für k veringert sich mit steigendem k. Auch hier
ist davon auszugehen, dass weitere Messungen mehr Aufschluß geben können.
61
5 Evaluation
Bild 5.6: Gemessene Laufzeiten für unterschiedliche k-Anonymisierungen mit bis zu drei
angegebenen Attributen auf 1000 Datensätzen
5.1.3 Fazit
Bei Zunahme der angegebenen zu pseudonymisierenden Attribute oder Tabellen steigt
der Zeitbedarf für das Pseudonymisieren steigt nur linear mit Anzahl der zu pseudonymisierenden Attribute oder Tabellen an. Wird mit Referenzen pseudonymisiert ergibt
sich ein konstanter Mehraufwand an Zeit im Vergleich zu reiner Pseudonymisierung.
Dasselbe lässt sich bei der k-Anonymisierung beobachten. Trotz diesem linearen Wachstum steigen die Laufzeiten bei Zunahme der Tupel oder bei kombinierter Zunahme von
Attributen und Tabellen sehr stark.
Es ist sinnvoll sich je nach Einsatzgebiet Gedanken zu machen, ob eine Beschleunigung des Programms erwünscht wäre oder ob die Laufzeiten toleriert werden können.
Vorstellbar ist, dass bei kleineren Datenbeständen über Nacht pseudonymisiert und kanonymisiert wird. Wenn pseudonymisierte und k-anonymisierte Datenbestände nur in
großen zeitlichen Abständen generiert werden sind die Laufzeiten des Programmes vernachlässigbar.
Soll jedoch in kürzeren Zeitabständen eine erneute Pseudonymisierung und kAnonymisierung der Datenbestände erfolgen ist zu überlegen, ob nicht mithilfe von
Parallelisierung und den Ansätzen von Sweeney und Samarati die Laufzeiten deutlich
verbessert werden können. Näheres zu Verbesserungsvorschlägen ist in Kapitel 6.1 nachzulesen.
62
5.2 Sicherheit
5.2 Sicherheit
Im Folgenden soll die Auswahl der zu bearbeitenden Attribute, sowie die Sicherheit der
Daten hinsichtlich der gewählten Attribute betrachtet werden. Da das Programm p1
alle erdenklichen Freiheiten hinsichtlich der Konfigurierbarkeit der Pseudonymisierung
und der k-Anonymisierung bietet, liegt viel Verantwortung bezüglich der Auswahl der
zu pseudonymisierenden und zu k-anonymisierenden Attribute beim Anwender.
Um die Identifizierung einzelner Personen in den Datenbeständen zu verhindern,
gibt es ein Minimum an einzuhaltenden Regeln. Noumeir [29] empfiehlt, dass für DeIdentifikation Name, Adressen sowie identifizierende Nummern der beteiligten Personen
unkenntlich gemacht werden müssen. Des weiteren kann auch der DICOM Standard
berücksichtigt werden [1].
In Bild 5.1 wurden alle zu pseudonymisierenden Attribute des Beispielschemas markiert.
Des weiteren sind die Attribute markiert, die pseudonymisiert werden müssen oder
wenn nicht pseudonymisiert wird dann zumindest k-anonymisiert werden müssen. Alle
markierten Attribute müssen jedoch bearbeitet werden um ein Minimum an Sicherheit
zu garantieren.
Die k-Anonymisierung des Programmes p1 stellt in der jetzigen Implementierung nur
die Möglichkeit einzelne Attribute hinsichtlich k Vorkommen zu prüfen und zu bearbeiten. Das ganze Tupel jeweils k mal vorliegen kann nicht geprüft werden. Es ist p1 folglich
nicht möglich Quasi-Identifizierer zu berücksichtigen. Wenn es zu Sicherheitsproblemen
bezüglich der Identifikation von Personen kommt, dann anhand gänzlich unbearbeiteter
oder nur k-anonymisierter Attribute.
Diese minimale Auswahl an zu pseudonymisierenden und zu k-anonymisierenden Attributen reicht aufgrund von Quasi-Identifizierern nicht aus um Anonymität garantieren
zu können. Wenn in der Beispieldatenbank nach einer Diagnose mit dem im Internet
nachgeschlagenen ICDCode für Kaiserschnittgeburten, ’O82’, gesucht wird, ergibt sich bei
einem Datensatz von 100.000 Patienten ein Ergebnis von sechs Tupeln. Alle sechs Kaiserschnitte fanden an einem anderen Tag statt. Wenn das Geburtsdatum des Kindes der
gesuchten Person bekannt ist, ist es durch obige Anfrage möglich diese Person zu identifizieren und weitere zugehörige Diagnosen auszulesen. Deswegen sollten auch Zeitangaben
pseudonymisiert werden, solange die k-Anonymisierung nicht für Quasi-Identifizierer implementiert wurde. Im Folgenden sollen zwei SQL Anfragen hinsichtlich der Häufigkeit
der Attributwerte in der Tabelle Patient das Ergebnis einer k-Anonymisierung mit k
63
5 Evaluation
gleich 10 darstellen. Es wird die Tabelle Patient mit 1000 Datensätzen anhand des
Attributs insuranceNumber betrachtet.
Die SQL Abfrage in Listing 5.1 ergibt, dass für dieses Attribut nur unterschiedliche
Werte existieren (siehe Bild5.7).
1
2
3
4
5
SELECT COUNT ( insuranceNumber ) AS c o u n t _ i n s u r a n c e N u m b e r
FROM Patient
GROUP BY insuranceNumber
ORDER BY c o u n t _ i n s u r a n c e N u m be r ASC
;
Listing 5.1: SQL Anfrage zur Häufigkeit der Attributwerte
Bild 5.7: Abfrage Ergebnis für Listing 5.1
Nach der k-Anonymisierung wird dieselbe Anfrage aus Listing 5.1 mit der Tabelle
Patient_Pseudo durchgeführt. Das Ergebnis dieser Anfrage ist in Bild 5.8 dargestellt.
Wie zu erwarten gibt es jetzt mindestens zehn Vorkommen des selben Attributwertes.
64
5.2 Sicherheit
Bild 5.8: Abfrage Ergebnis für Listing 5.1 mit Tabelle Patient_Pseudo
65
6 Diskussion
Im Vergleich zu Kalam [23, 12] ist das Programm p1 weniger komplex und es entfallen
sämtliche Sicherheitsvorkehrungen wie etwa die Autorisierung durch den Patienten. Der
Vorteil zu Kalam ist, dass ohne das Mitwirken des Patienten pseudonymisiert und kanonymisiert werden kann. Im Gegensatz zu Grosskreutz [18] werden die Daten direkt
vor Ort pseudonymisiert und anonymisiert, was den Vorteil bringt, dass die Übermittlung der Daten nicht gesichert werden muss. Die Verlinkbarkeit bei Grosskreutz ist auch
in p1 gegeben. Samarati und Sweeney [38, 37, 43, 42] dagegen besitzen den Vorteil, dass
sie mit ihrem Ansatz den Informationsverlust beim Generalisieren mindern, was p1 in
seiner jetzigen Fassung noch nicht kann.
Am nähesten verwandt ist p1 mit dem Ansatz von Noumeir. Alle Vorteile Noumeirs, die Irreversibilität sowie die Datensicherheit bleiben in p1 erhalten und werden um die benutzerspezifische Konfigurierbarkeit der Pseudonymisierung sowie der kAnonymisierung erweitert. Im Gegensatz zu der Anonymisierung bei Noumeir bietet p1
eine k-Anonymisierung.
6.1 Ausblick
Das vorliegende Programm liefert eine exemplarische Implementierung von einem System zur Pseudonymisierung und k-Anonymisierung. Module können gegen komplexere
und funktionalere ausgetauscht werden. Zum Beispiel könnte die HashEncryption gegen sichere Verfahren wie etwa MD5 oder SHA-3 [11] ersetzt werden. Desweiteren kann
nach Anpassung des InputConverter Moduls, die Eingabe der zu pseudonymisierenden Tabellen und Attribute durch andere Schemata, wie zum Beispiel XML, getauscht
werden.
Eine weitere Aufgabe wäre die Parallelisierung des Codes. Es bietet sich an die Abarbeitung der Tabellen und Attribute auf mehrere Prozessoren aufzuteilen. Parallelisierung
ist sowohl bei der Pseudonymisierung als auch bei der k-Anonymisierung möglich. Bis
jetzt werden in beiden Fällen die Tabellen, sowie die zugehörigen Attribute, sequenziell
erfasst. Vorstellbar ist, die Tabellen auf threads aufzuteilen, da die Bearbeitung der ein-
67
6 Diskussion
zelnen Datenfelder unabhängig voneinander erfolgt. Auch eine weitere Aufteilung nach
Attributen sowie eine weitere Aufteilung innerhalb der Datensätze der einzelnen Attribute ist denkbar, da programmintern immer nur ein Datensatz unabhängig von allen
anderen bearbeitet wird. Die Pseudonymisierung parallel zur k-Anonymisierung laufen
zu lassen ist jedoch nicht möglich, da es zu Konflikten hinsichtlich der gleichzeitigen
Bearbeitung einzelner Datensätze kommt.
Des weiteren kann die k-Anonymisierung mithilfe der Ideen von Samarati und Sweeney
[38, 37, 43, 42] zur Minimalisierung der Generalisierung verbessert werden. Mit diesen
Ansatz kann der Datenverlust hinsichtlich des Informationsgehaltes beim Anonymisieren
der Daten verringert werden.
68
Anhang
69
A Dokumentation des Programmes p1
A.1 Vorbereitungen
Bevor das Programm ausgeführt oder neu kompiliert und gelinkt werden kann, muss
Folgendes beachtet werden. Alle Dateien die zum Ausführen und Kompilieren nötigt
sind werden in A.1.1 beschrieben.
Neben den Dateien muss auch eine Version des Oracle Instant Client, sowie weitere
Pakete von Oracle auf dem Rechner installiert sein. Näheres zu diesem nicht trivialen
Thema unter A.1.2.
A.1.1 Benötigte Dateien
Die benötigten Dateien lassen sich unterscheiden in die, die zum Ausführen des Programms benötigt werden und die, die zum neu kompilieren und linken des Programmes
gebraucht werden.
Die folgende Liste an Dateien ist nötig, um das Programm auszuführen:
• p1
• city.txt
• country.txt
• firstName.txt
• lastName.txt
• street.txt
• title.txt
• tnsnames.ora
• oic11.env
71
A Dokumentation des Programmes p1
Die texttt.txt Dateien enthalten Austauschwerte für die Pseudonymisierung mit Referenzen aus der Scheibenwelt von Terry Pratchett [7, 36]. Sie können gegen gleichartig
formatierte Listen anderer Namen, Orte und so weiter ausgetauscht werden.
Folgende Dateien werden benötigt um das Programm neu zu kompilieren und zu
linken:
• DataField.h
• DBF.h
• Encryption.h
• HashEncryption.h
• InputConverter.h
• KAnoLogic.h
• OracleDBF.h
• PseudoLogic.h
• TXTInputConverter.h
• DataField.cpp
• HashEncryption.cpp
• KAnoLogic.cpp
• Middleware.cpp
• OracleDBF.cpp
• PseudoLogic.cpp
• TXTInputConverter.cpp
• pMake
• tnsnames.ora
• oic11.env
Alle Dateien müssen in denselben Ordner abgespeichert werden.
72
A.1 Vorbereitungen
A.1.2 Oracle und der Instant Client
Für die Datenbankanbindung im Programm wird der Oracle Instant Client benötigt,
der das Oracle C++ Callable Interface zur Verfügung stellt.
Mehr Hilfe zum Thema Oracle C++ Callable Interface (kurz OCCI) und dem Instant
Client oder beim Benutzen eines anderen Betriebssystem gibt Mark Williams:
http://oradim.blogspot.de/2009/08/getting-started-with-occi-linux-version.html
Der Instant Client und zwei weitere Pakete werden von der Oracle Seite geladen. Die
Addresse lautet:
http://www.oracle.com/technetwork/topics/linuxx86-64soft-092277.html
Der Instant Client der jetzigen Implementierung besitzt die Version: ’Instant Client
für Linux x86-64 Version 11.2.0.3.0’. Abweichende Versionen sollten kein Problem darstellen. Es muss jedoch darauf geachtet werden, dass alle drei Pakete die gleiche Version
aufweisen. Die Namen der drei .zip Pakete sind die folgenden:
• instantclient-basic-linux.x64-11.2.0.3.0.zip
• instantclient-sqlplus-linux.x64-11.2.0.3.0.zip
• instantclient-sdk-linux.x64-11.2.0.3.0.zip (Basic verspricht zwar OCCI,
das sdk Packet wird jedoch benötigt)
Die drei Pakete werden im home Verzeichnis entzippt. Das Ergebnis sollte wie folgt
ausschauen: ~/instantclient_11_2
Als nächstes werden zwei Links über die Konsole mit den folgenden zwei Befehlen
angelegt:
ln -s ./libclntsh.so.11.1 ./libclntsh.so
ln -s ./libocci.so.11.1 ./libocci.so
Dann wird das tnsnames.ora File aus der Datenbank in das instantclient_11_2 Verzeichnis kopiert oder dort neu angelegt. Die Datei tnsnames.ora für die Oracle Datenbank des Lehrstuhls ist in Listing A.1 dargestellt.
73
A Dokumentation des Programmes p1
1
2
# tnsnames . ora Network Configuration File : / opt / oracle / product / <
version >/ network / admin / tnsnames . ora
# Generated by Oracle configuration tools .
3
4
5
6
7
8
9
10
11
12
13
# unsere neue Hauptdatenbank 29.04.2009
ORA11G61 =
( DESCRIPTION =
( ADDRESS_LIST =
( ADDRESS = ( PROTOCOL = TCP ) ( HOST = faui61 . informatik . uni erlangen . de ) ( PORT = 1522) )
)
( CONNECT_DATA =
( SERVICE_NAME = ora11g61 )
)
)
Listing A.1: tnsnames.ora
Die Datei oic11.env wird in das Verzeichnis abgelegt, in dem das Programm laufen
soll. Dort wird sie in einer bash shell mit dem folgenden Kommando ausgeführt:
. ./oic11.env
Listing A.2 stellt den Inhalt der Datei oic11.env dar.
1
2
3
4
5
6
export ORACLE_BASE =~
export ORACLE_HOME = $ORACLE_BASE / i ns ta nt cl ie nt _1 1_ 2
export LD_LIBRARY_PATH = $ORACLE_HOME
export TNS_ADMIN = $ORACLE_HOME
export NLS_LANG = AMERICAN_AMERICA . UTF8
export PATH = $ORACLE_HOME :/ usr / local / bin :/ bin :/ usr / bin :/ usr / X11R6 / bin
:~/ bin
Listing A.2: oic11.env
Wenn mit der csh gearbeitet wird, kann das richtige Setzen der Umgebung bei Mark
Williams nachgeschlagen werden.
Ob die Einträge richtig gesetzt sind wird mithilfe des folgenden Kommandos ermittelt:
env |grep -i oracle
Eventuell muss bei jedem neuen Anmelden oder Starten des Rechners die Datei
oic11.env neu ausgeführt werden, da das System unter Umständen die Daten zurücksetzt.
Das sdk Paket liefert mehrere Testprogramme mit. Unter instantclient_11_2/sdk/demo/
finden sich diese Beispielprogramme.
74
A.2 Anwenden
Zum Übersetzen dieser Programme werden ein paar Compiler und Linker Flags benötigt. Im Listing A.3 ist ein Makefile dargestellt, dass das Testprogramm occidml.cpp
übersetzt.
1
2
3
p : occidml . cpp
g ++ -o p occidml . cpp - I$ ( ORACLE_HOME ) / sdk / include \
- L$ ( ORACLE_HOME ) - lclntsh - locci
Listing A.3: Makefile zur occidml.cpp
Wie p1 zu kompilieren und zu linken ist, findet sich im Unterkapitel A.5.
A.2 Anwenden
A.2.1 Programmaufruf
Um das Programm benützen zu können, muss der Aufrufer über create, insert, delete,
update und query Rechte der Datenbank verfügen. Das Programm p1 wird auf einer
Linux Konsole aufgerufen. Das Aufrufschema ist für eine Pseudonymisierung folgendes:
./p1 Benutzername Passwort DSN -p TabellenDatei AttributDatei [-ref
Referenzdatei]
Für eine k-Anonymsisierung wird das Programm so aufgerufen:
./p1 Benutzername Passwort DSN -k TabellenDatei AttributDatei Zahl_k
Es können auch Pseudonymisierung und k-Anonymisierung kombiniert werden:
./p1 Benutzername Passwort DSN -p TabellenDatei AttributDatei [-ref
Referenzdatei] -k TabellenDatei AttributDatei Zahl_k
Wobei p1 das Binary des Programmes bezeichnet. Der Benutzername, das Passwort
und der Data Source Name (DSN) der Datenbank sowie die Datei mit den zu pseudonymisierenden Tabellen und die zu schützenden Attribute sind zwingend anzugeben. Das
Kürzel -p kennzeichnet die Pseudonymisierung, -k die k-Anonymisierung. Die Referenzdatei bei der Pseudonymisierung ist eine optionale Angabe. Der Aufbau der Tabellen
und Attribut Dateien folgt dem gleichem Schema. In beiden Fällen werden .txt Dateien angelegt in denen die Namen getrennt durch Zeileumbrüche eingetragen werden.
Ein Beispiel für den Aufbau einer Datei, die die Tabellennamen enthält ist der folgende
Abschnitt:
Patient
SurgeryUnit
75
A Dokumentation des Programmes p1
Diagnosis
Die Trennung von Attributen und zugehörigen Tabellen in zwei Dateien erfolgt, um
unnötige Redundanz zu verhindern. Das Programm sucht sich die Verbindung zwischen
Tabellen und Attributen aus den Metainformationen der Datenbank.
Um eine Pseudonymisierung mit leserlichen Ergebnissen zu bekommen, muss die Option -ref gefolgt von einer .txt Datei angegeben werden. Das Format dieser Datei ähnelt
den für die Dateien mit Tabellen und Attributen. Es wird in die .txt Datei erst das
zu schützende Attribut geschrieben, gefolgt von einem ’=’ und der entsprechenden Referenz. Mögliche Referenzen sind: firstName, lastName, title, street, country und city.
Es ist dabei unbedingt auf Groß- und Kleinschreibung der Referenzen zu achten, da
sonst das Programm die Referenzen nicht erkennt. Auch sind überflüssige Leerzeichen
zu vermeiden, da sie ebenfalls zu fehlerhaften Verhalten führen können. In den Dateien
mit Tabellennamen und Attributnamen ist die Groß- und Kleinschreibung irrelevant.
Ein Beispiel für eine Referenzdatei sieht wie folgt aus:
Vorname=firstName
Name=lastName
Adr=city
Mit der Option -k gefolgt von einer ganzzahligen Zahl werden die Daten zusätzlich
anonymisiert. Wenn diese Option nicht gegeben ist, wird folglich auch nicht anonymisiert.
Die Reihenfolge der Argumente ist wichtig, da das Programm die Argumente anhand
ihrer Reihenfolge erkennt. Es ist durchaus möglich zu pseudonymisieren und zu anonymisieren ohne eine Referenz angegeben zu haben.
Alle Dateien für den Programmaufruf müssen sich im selben Ordner befinden, wie das
Programm.
A.3 Aufgaben der Module
Jedes Modul besitzt eigene von den anderen Modulen gekapselte Aufgaben, die im folgenden näher erläutert werden sollen. Als kurzer Überblick dient das Bild A.1.
Die main befindet sich im Modul Middleware. Die Middleware spricht je
nach Aufruf die PseudoLogic und KAnoLogic an und verwendet außerdem das
DataBaseFunctionality und InputConverter Modul. Die PseudoLogic benötigt
76
A.3 Aufgaben der Module
Bild A.1: Entwurfsmuster
zum pseudonymisieren das Modul der DataBaseFunctionality (im Bild und im Folgenden DBF) und die Encryption. Für die KAnoLogic ist ebenfalls das DBF Modul
wichtig. Die folgenden Unterkapitel erklären das Verhalten und die Schnittstellen der
einzelnen Module.
A.3.1 Middleware
Die Middleware beherbergt die main des Programmes und ist damit der Startpunkt.
Ihre Aufgabe kann im Pseudocode folgend beschrieben werden:
- Für alle übergebenen Dateien aus der Eingabe konvertiere die Dateien.
- Öffne eine Datenbankverbindung
- Je nach Eingabe Optionen:
77
A Dokumentation des Programmes p1
- Führe die Pseudonymisierung aus
- Führe Pseudonymisierung mit Referenzen aus
- Führe Pseudonymisierung mit Anonymisierung aus
- Führe Pseudonymisierung mit Referenzen und Anonymisierung aus
Das UML Klassendiagramm in Bild A.2 stellt die Klasse der Middleware da.
Bild A.2: Variablen und Operationen der Middleware
Die Variablen mit Typ TXTInputConverter und OracleDBF halten jeweils ein Objekt ihrer Klasse. _k enthält die Zahl in der k-anonymisiert werden soll. Die Listen vector<string> _tableNameList und _columnToProtectList werden von dem
InputConverter mit den Namen der zu pseudonymisierenden Tabellen und der zu schützenden Attribute befüllt. Diese Listen werden zusammen mit der Datenbankverbindung
an die PseudoLogic und KAnoLogic im Konstruktor übergeben. Genaueres dazu in den
Unterkapiteln PseudoLogic A.3.4 und KAnoLogic A.3.5.
_cRef und _rRef sind ebenfalls Ergebnisse des InputConverters und stellen die Referenzliste dar. In _cRef sind die Attribute und in _rRef die zugehörigen Referenzen
gespeichert. Wenn keine Referenz gegeben ist bleiben beide leer.
A.3.2 InputConverter
Der InputConverter wandelt die bei Programmaufruf übergebenen Dateien in
vector<string> Listen um. Mithilfe der convert Methode werden die Middlewareinternen Listen erstellt. Die einzige Funktion convert dieser Klasse bekommt einen
Dateipfad übergeben und ein flag, dass die Art der Datei bestimmt. Mögliche flags sind:
table, columnName, cRef und rRef. Durch table wird signalisiert, dass es sich um die
78
A.3 Aufgaben der Module
Datei handelt, die die zu pseudonymisierenden Tabellen enthält. Das flag columnName
steht für die Datei mit den zu schützenden Attributen. Die Datei mit den Referenzen
durchläuft convert einmal mit dem flag cRef (kurz für columnReference) und einmal
mit dem flag rRef (kurz für referenceReference). Mit cRef werden nur die Attribute aus
der Referenzdatei in eine vector<string> Liste eingelesen. Bei Konvertierung mit rRef
werden nur die Referenzen in einem vector<string> gespeichert. Aufgrund derselben
Auslese- und Speicherreihenfolge, wird bei Zugriff über _cRef.at(i) und _rRef.at(i)
auf die zugehörigen Werte zugegriffen. Dadurch wird eine unkomplizierte Zuordnung
und spätere Verarbeitung der Werte gewährleistet.
In Bild A.3 ist die Funktionalität der Klasse InputConverter dargestellt.
Bild A.3: Operation des InputConverters
A.3.3 DataBaseFunctionality
Die DataBaseFunctionality Klasse (kurz: DBF) erstellt eine Verbindung zur gewünschten Datenbank und führt alle nötigen Datenbankoperationen aus. Bild A.4 zeigt das
Klassendiagramm der DBF.
Die konkrete Implementierung hierzu ist die OracleDBF. Mit ihr wird eine Oracle
11gR2 Datenbank angebunden. Im Folgenden werden Aufgaben der DBF näher erklärt.
Für jede Funktion sind außerdem die mit ihr verbundenen SQL Anfragen und Befehle beispielhaft anhand der Tabelle Diagnosis erklärt. Alle SQL Anweisungen wurden
mithilfe von sqlplus auf syntaktische und logische Korrektheit geprüft.
Der Konstruktor öffnet die Verbindung zu der Datenbank. Der Destruktor schließt
diese Verbindung wieder.
79
A Dokumentation des Programmes p1
Bild A.4: Variablen und Operationen der Klasse DBF
A.3.3.1 copyTable
Die Funktion copyTable kopiert die Tabelle mit dem übergebenen Namen. Im einzelnen
erstellt die Funktion die Tabelle neu auf den Namen alterTabellenName_Pseudo. Es
wird davon ausgegangen, dass die angesprochenen Datenbanken keine schon existierenden Tabellen mit der Endung _Pseudo besitzen.
Bevor die neu erstellte Tabelle mit den ursprünglichen Daten befüllt wird, werden die
Datentypen der einzelnen Spalten betrachtet. Besitzt eine Spalte den Datentyp DATE
wird dieser in den Typ VARCHAR umgewandelt. Der Grund dafür ist, dass das Auslesen
und Verändern eines DATE Wertes zwar leicht möglich ist, aber das Rückspeichern in
die Tabelle nicht. Beim Rückspeichern kommt es zu dem Problem, dass der veränderte
Wert nicht mehr das Format eines DATE Typen aufweist. Um dieses Problem ohne viel
Aufwand zu umgehen, werden alle Spalten mit DATE Werten umgewandelt.
80
A.3 Aufgaben der Module
Danach kann die Tabellenkopie mit den Daten der Ursprungstabelle befüllt werden.
Anschließend wird eine neue Spalte mit Datentyp INT und dem Namen PseudonymID
hinzugefügt. Hier wird davon ausgegangen, dass es in der ursprünglichen Tabelle kein Attribut mit diesem Namen gibt. Die Spalte wird mit Zahlen von 1 bis Anzahl vorhandener
Datensätze gefüllt. Sie dient als Primärschlüssel für die Funktionen storeColumnData
und getColumnData. Mithilfe dieses Primärschlüssels wird garantiert, dass die entnommenen Daten korrekt zurück gespeichert werden können. Näheres dazu bei der Beschreibung von getColumnData und storeColumnData
Die SQL Anweisungen in Listing A.4 erklären beispielhaft anhand der Tabelle Diagnosis, was in der Funktion copyTable ausgeführt wird.
1
2
3
4
-- 1. Tabellenschema kopieren
CREATE TABLE Diagnosis_Pseudo
AS ( SELECT * FROM Diagnosis WHERE 1=2)
;
5
6
-- 2. fuer alle Spalten vom Typ DATE : Typ auf VARCHAR aendern
7
8
9
10
11
-- 3. Kopie mit Inhalt der Originaltabelle befuellen
INSERT INTO Diagnosis_Pseudo
( SELECT * FROM Diagnosis )
;
12
13
14
15
16
-- 4. Spalte PseudonymID hinzufuegen
ALTER TABLE Diagnosis_Pseudo
ADD ( PseudonymID int )
;
17
18
19
20
21
-- 5. Spalte PseudonymID mit fortlaufenden Nummern befuellen
UPDATE Diagnosis_Pseudo
SET PseudonymID = ROWNUM
;
Listing A.4: SQL Anweisungen in der Funktion copyTable
A.3.3.2 getColumnNameList
getColumnNameList liefert eine Liste mit den Namen der Spalten der übergebenen Tabelle. Der Name der Tabelle muss in Großbuchstaben geschrieben sein, damit die SQL
Anweisung Ergebnisse liefert. Die Funktion transform aus der algorithm Bibliothek
stellt sicher, das alle übergebenen Tabellennamen durchgehend großgeschrieben sind. Die
Funktion getColumnNameList wird sowohl von der PseudoLogic als auch der KAnoLogic
benutzt um den Tabellen die zu schützenden Attribute zuzuordnen.
81
A Dokumentation des Programmes p1
Die Funktion verwendet die SQL Abfrage in Listing A.5.
1
2
3
4
5
-- 1. Liste mit Spaltennamen der Tabelle DIAGNOSIS ausgeben lassen
SELECT column_name
FROM all_tab_columns
WHERE table_name = ’ DIAGNOSIS ’
;
Listing A.5: SQL Abfrage in der Funktion getColumnNameList
A.3.3.3 getColumnDataType
Die Funktion getColumnDataType wird von den DBF Klassen intern verwendet. Die
copyTable Funktion benötigt sie, um den Datentyp der einzelnen Spalten der Tabelle zu
ermitteln und gegebenenfalls auszutauschen. Genaueres zum Tauschen der Datentypen
siehe copyTable A.3.3.1.
Die Funktion getColumnDataType benutzt die Oracle interne Tabelle all_tabColumns
um den Datentyp der gewünschten Spalte zu erfahren. Die SQL Abfrage in Listing A.6
erklärt das beispielhaft an der Tabelle Diagnosis und der Spalte id.
1
2
3
4
5
6
-- 1. Datentyp der Spalte ’id ’ aus der Tabelle Diagnosis ermitteln
SELECT data_type
FROM all_tab_columns
WHERE table_name = ’ DIAGNOSIS ’
AND column_name = ’ ID ’
;
Listing A.6: SQL Anweisung in der Funktion getColumnDataType
Die SQL Abfrage liefert nur dann Ergebnisse, wenn sowohl der Spaltenname als auch
der Tabellenname in Großbuchstaben geschrieben wurden. Um dies zu garantieren werden beide Namen vorher Mithilfe der transform Methode aus der algorithm Bibliothek
konvertiert.
Nachdem der Datentyp ermittelt wurde, wird einer der drei möglichen programminternen Datentypen als Rückgabeparameter zurückgeliefert. Programminterne Datentypen
sind INT, DOUBLE und STRING. Warum es nur diese drei Typen gibt, ist in 4.3.1
nachzulesen.
A.3.3.4 getMinAttributeFrequency
Die Funktion getMinAttributeFrequency liefert die geringste Anzahl der unterschiedlichen Werte eines Attributs. Zum Beispiel liefert sie eine zwei, wenn es mindestens ein
82
A.3 Aufgaben der Module
Attributwert in der angegebenen Tabelle und Spalte gibt, das nur zweimal vorkommt.
Alle anderen Werte kommen dann häufiger vor als zweimal. In einer Spalte die Identifikationsnummern beherbergt, liefert diese Funktion immer 1, da dies die geringste
Anzahl gleichwertiger Attribute ist. Die KAnoLogic Klasse verwendet diese Funktion
um ein Attribut auf k-Anonymität zu prüfen.
Die SQL Abfrage in der Funktion ist in Listing A.7 dargestellt. Die Tabelle heißt in
dem Codebeispiel Diagnosis_Pseudo und die Spalte, also das Attribut, dessen Häufigkeit gezählt wird, heißt id.
1
2
3
4
5
SELECT COUNT ( id ) AS c
FROM Diagnosis_Pseudo
GROUP BY id
ORDER BY c ASC
;
Listing A.7: SQL Abfrage in der Funktion getMinAttributeFrequency
A.3.3.5 removeRowWithLeastFrequency
Die Funktion removeRowWithLeastFrequency ist die Folgefunktion zu der Funktion
getMinAttributeFrequency. Sie ist in der aktuellen Implementierung nicht mehr vorgesehen, siehe Kapitel 4.2.2, soll aber trotzdem kurz erläutert werden. Die Funktion
löscht aus der Pseudonymtabelle der angegebenen Tabelle die Zeilen mit den am seltensten vorkommenden Wert. Diese Funktion kann von der Klasse KAnoLogic benutzt
werden und zwar, wenn getMinAttributeFrequency 1 zurücklieferte. Der Gedanke dahinter ist, dass in diesem Fall schneller k-Anonymität erreicht werden kann, wenn anstatt
zu generalisieren die entsprechende Zeile gelöscht wird. Hier besteht Verbesserungsbedarf, da im Falle eines Attributes mit Primärschlüsselfunktion solange alle Datensätze
gelöscht werden, bis gar kein Datensatz mehr übrig bleibt. Aus diesem Grund wird diese
Funktion in p1 nicht verwendet. Die Klasse KAnoLogic generalisiert deswegen nur und
unterdrückt nicht. Unterdrückung kann erfolgen, wenn vorher sichergestellt wird, dass
es wirklich nur einige wenige einzelne Werte und viele gleiche Werte in einem Attribut
gibt.
A.3.3.6 getColumnData & storeColumnData
Das Holen der Daten aus der Datenbank und das Abspeichern übernehmen die Funktionen getColumnData und storeColumnData. Daten werden spaltenweise aus der Da-
83
A Dokumentation des Programmes p1
tenbank entnommen und in der PseudoLogic oder KAnoLogic verarbeitet. Das richtige
Rückspeichern der Werte ist möglich, da die Reihenfolge der aus der Datenbank gelieferten Werte von dem Attribut PseudonymID abhängt. Anhand dieses in der copyTable
Funktion hinzugefügte Attribut ist es möglich, gezielt Daten zu holen und zu speichern. Bild 4.9 beschreibt das Holen der Daten, das Zwischenspeichern in eine Liste aus
DataFields und das Rückspeichern.
Die Indizierung des Vectors ist mit der PseudonymID verbunden. Die PseudonymID
wurde im Falle der Oracle Datenbank mit ROWNUM befüllt. ROWNUM ist die Nummerierung der Datensätze intern in Oracle. Besonders zu beachten ist, dass die durch
ROWNUM befüllte PseudonymID bei 1 beginnt, der vector jedoch, wie alle Listen und
Arrays in C++ schon bei 0. In der Funktion storeColumnData wird deshalb eine zusätzliche Variable int ii eingefügt, die immer eins höher ist als die Laufvariable der
Schleife i. Mithilfe von ii und i werden dann die Daten in der Liste an der Stelle i
in den DAtensatz mit der PseudonymID ii geschrieben. Diese zwei Variablen könnten
auch in einer zusammengefasst werden, übersichtlicher ist es jedoch mit zwei.
Die SQL Abfrage für die Funktion getColumnData, beispielhaft anhand der Tabelle
Diagnosis_Pseudo und der Spalte id dargestellt, ist in Listing A.8 dargestellt.
1
2
3
4
5
-- 1. Auslesen der Daten der Spalte ’id ’ aus der Tabelle
Diagnosis_Pseudo
SELECT id
FROM Diagnosis_Pseudo
ORDER BY PseudonymID ASC
;
Listing A.8: SQL Datenabfrage in der Funktion getColumnData
In Listing A.9 sind die zwei unterschiedlichen SQL Anweisungen zum Zurückspeichern
aus der Funktion storeColumnData am Beispiel der Tabelle Diagnosis_Pseudo und der
Spalten id vom Typ INT und der Spalte ’location’ vom TYP VARCHAR verdeutlicht.
84
A.3 Aufgaben der Module
1
2
3
4
5
-- 1. Zurueckspeichern eines Wertes vom typ INT
UPDATE Diagnosis_Pseudo
SET id = 12
WHERE PseudonymID = 13
;
6
7
8
9
10
11
-- 2. Zurueckspeichern eines Wertes vom Typ VARCHAR
UPDATE Diagnosis_Pseudo
SET location = ’ Bla ’
WHERE PseudonymID = 1
;
Listing A.9: SQL Anweisung in der Funktion storeColumnData
A.3.4 PseudoLogic
Aufgabe der PseudoLogic ist es die Attribute, die geschützt werden sollen auszulesen
und zu verschlüsseln oder durch eine lesbare Verschlüsselung zu ersetzen. Der Ablauf
dazu lässt sich in Pseudocode beschreiben:
- Für alle Tabellen in der Tabellenliste
- kopiere die Tabelle mit Inhalt
- für alle zu schützenden Attribute in der Tabelle
- hole eine Liste mit allen Daten zu diesem Attribut
- sind Referenzen gegeben?
- ja: Daten bearbeiten
- nein: Daten verschlüsseln
- Daten abspeichern
Das Bild A.5 zeigt die Klasse PseudoLogic.
Bild A.5: Variablen und Operationen der Klasse PseudoLogic
85
A Dokumentation des Programmes p1
Dem Konstruktor muss Datenbankverbindung und die Listen mit den Tabellennamen
und zu schützenden Attributen übergeben werden. Mit der Funktion execute werden
die Tabellen kopiert und anschließend die Funktion pseudomizeTable für jede zu bearbeitende Tabelle aufgerufen. Die Funktion pseudomizeTable benötigt den aktuellen
Tabellennamen um arbeiten zu können. Sie holt mit dem Tabellennamen aus der Datenbank eine Liste mit den zugehörigen Namen der Spalten. Diese Liste wird durchgegangen
und jeder Spaltenname mit der Liste der zu schützenden Attribute verglichen. Bei identischem Namen wird der komplette Inhalt der Spalte, als Liste von DataFields aus der
Datenbank geholt und entweder verschlüsselt oder lesbar verändert. Das verschlüsseln
erfolgt über ein HashEncryption Objekt. Näheres zu der Arbeitsweise von Encryption
Objekten findet sich in dem Unterkapitel A.3.6. Die Liste mit DataFields wird in der
Variablen _rowData zwischengespeichert. Anschließend wird die ganze Liste wieder in
die Datenbank zurück gespeichert.
Wenn keine Referenz erwünscht ist wurden keine Werte in _cRef und _rRef eingelesen.
Dies kann über die Größe des vectors geprüft werden. Wenn der vector eine Größe von
0 aufweist, wurde keine Referenz angegeben und es muss verschlüsselt werden.
A.3.5 KAnoLogic
Die KAnoLogic übernimmt die Aufgabe die fertig pseudonymisierten Tabellen zu kanonymisieren. Das in der Eingabe übergebene k, wird im Konstruktor angeben, genauso
wie die Datenbankverbindung db, die Listen zu Tabellennamen und zu den schützenswerten Attributen.
Die Funktion execute übernimmt das Anonymisieren, indem sie jede Tabelle einzeln
durchgeht und bei zu schützenden Attributen die Häufigkeit der Vorkommen der einzelnen Werte zählt. Ist diese Häufigkeit größer k wird das nächste Attribut betrachtet.
Ist sie kleiner als k wird generalisiert mithilfe der Funktion generalize. Ist die Häufigkeit gleich 1 kann der Wert mit der Funktion surpress unterdrückt werden. In der
Implementierung wird allerdings darauf verzichtet, da Primärschlüssel nicht zuverlässig
erkannt werden. Für nähere Informationen siehe A.3.3.5.
Die Implementierung von generalize ist hier bewusst einfach gehalten und kann
leicht ausgetauscht werden. Die Funktion generalize holt sich in meiner Implementierung die Daten des entsprechenden Attributs aus der Datenbank und verändert sie
je nach Datentyp. Daten vom Typ String werden gegen ’NONE’ ausgetauscht. Int und
Double Werte werden nach Int gecastet und halbiert. Durch die Umwandlung in einen
86
A.3 Aufgaben der Module
Int Datentyp gehen alle Nachkommastellen verloren. Surpress würde die Zeile mit dem
einzeln vorkommenden Wert des Attributs löschen.
Das Klassendiagramm in Bild A.6 zeigt KAnoLogic.
Bild A.6: Variablen und Operationen der Klasse KAnoLogic
A.3.6 Encryption
Die Encryption Klasse bekommt ein DataField übergeben, dass sie verändert. Bild A.7
zeigt das UML Klassendiagramm der Encryption Klasse.
Bild A.7: Operationen der Klasse Encryption
Die Methode changeDataFieldValue verändert den Wert des DataFields in einen
lesbaren neuen Wert. Alle alten Werte die gleich sind, werden dabei in den selben neuen
87
A Dokumentation des Programmes p1
Wert umgewandelt. Das heißt, wenn der Name Hans in Edward umgewandelt wird, gilt
das auch für alle folgenden Hans. Die Funktion bekommt dafür das DataField und eine
Referenz übergeben. Mögliche Referenzen sind: firstName, lastName, title, city, street
und country. Die Groß- und Kleinschreibung der Referenzen spielt dabei für die fehlerlose
Verarbeitung eine Rolle.
In der konkreten Umsetzung der Encryption wird in der changeDataFieldValue
die private Funktion changeStringValue aufgerufen. Für die Umwandlung wird dort
zunächst eine Datei mit Austauschwerten zu der gesetzten Referenz geöffnet. Diese Dateien sollten sich im selben Ordner wie das Programm befinden. Die Namen der Dateien
lauten firstName.txt, lastname.txt und so weiter. Alle Referenzdateien sind auch
in Unterkapitel A.1.1 aufgezählt. Aus diesen Dateien wird dann ein Referenzwert gelesen und zurückgeliefert, den die changeDataFieldValue in das überlieferte DataField
speichert. Dabei wird für gleiche Namen immer der selben Referenzwert geliefert, somit
bleiben auch nach der Veränderung der Werte die Daten untereinander zuordbar.
Die Funktion encryptDataFieldValue ermittelt den Datentyp des DataField und
verschlüsselt entsprechend den Wert. Daten vom Typ String werden mithilfe der C++
Funktion hash aus der Bibliothek locale verändert. Daten vom Typ Double und Int
wird ihrem aktuellen Wert derselbe modulo 13 aufsummiert. Auch hier werden für gleiche
Werte die selben Pseudonyme generiert.
A.3.7 DataField
Die Klasse DataField übernimmt die Speicherung eines einzelnen Wertes aus einer
beliebigen Tabelle.
Die Datenbanktypen werden in drei verschiedene Datentypen unterteilt. Dementsprechend werden im DataField drei Variablen für diese Typen angelegt: int _iValue,
string _sValue und double _dValue. Eine weitere Variable _dataType speichert die
Art des gespeicherten Wertes.
Zu jeder Variable gibt es Getter und Setter, siehe A.8.
88
A.4 Austausch von Modulen
Bild A.8: Variablen und Operationen in der Klasse DataField
A.4 Austausch von Modulen
A.4.1 Abhängigkeiten der Module
Die folgende Graphik verdeutlicht die Abhängigkeiten der Module untereinander (Bild
A.9). Aus diesen Abhängigkeiten folgt, welche Module betrachtet und verändert werden
müssen, wenn ein Modul gegen eine andere Implementation ausgetauscht wird.
89
A Dokumentation des Programmes p1
Bild A.9: Abhängigkeiten der Module untereinander
A.5 Das Programm bauen
Das Programm wurde mit g++ kompiliert und gelinkt. Im folgenden werden Compiler
Version und zugehöriges Makefile erläutert.
A.5.1 Hardware und Software Voraussetzungen
Unter folgenden Soft- und Hardwarevoraussetzungen compiliert, linkt und läuft das
Programm p1 fehlerfrei:
• Betriebssystem: Linux Version 3.4.28-2.20-desktop GNU/Linux
• openSUSE 12.2 (x86_64)
• Version 12.2
• CODENAME = Mantis
• Prozessorkennung: x86_64
• g++ Version 4.7
Andere Umgebungen oder Compiler wurden nicht getestet.
90
A.5 Das Programm bauen
A.5.2 Makefile
Das Makefile in Listing A.10 lässt erst alle Dateien zu Objectsfiles kompilieren und bindet
diese dann zusammen. Der Datenbankzugriff erfolgt über das Oracle C++ Callable
Interface (kurz OCCI). Wichtig für das Verwenden von OCCI sind folgende flags beim
kompilieren und linken:
• −I$(ORACLE_HOM E)/sdk/include sagt dem Compiler, wo die notwendigen
Bibliotheken von OCCI zu finden sind.
• −L$(ORACLE_HOM E) − locci − lclntsh liefert dem Linker die notwendigen
Informationen zu OCCI.
• −std = c + +11 ist das Flag, dass dem Compiler angibt, das in c++ Standard 11
gecodet wurde.
91
A Dokumentation des Programmes p1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
OBJS = TX TInput Conver ter . o HashEncryption . o OracleDBF . o \
DataField . o PseudoLogic . o KAnoLogic . o Middleware . o
CC = g ++
DEBUG = -g
# ORACLE_HOME =/ opt / oracle / product /11 gR2 / client
CFLAGS = - std = c ++11 - Wall -c $ ( DEBUG ) - I$ ( ORACLE_HOME ) / sdk / include
# Beim oben angegebenen ORACLE_HOME benoetigt der Linker
# noch ein / lib hinter dem $ ( ORACLE_HOME )
LFLAGS = - Wall $ ( DEBUG ) - L$ ( ORACLE_HOME ) - locci - lclntsh
p1 : $ ( OBJS )
$ ( CC ) $ ( LFLAGS ) $ ( OBJS ) -o p1
TXT InputC onvert er . o : TX TInput Conver ter . cpp \
TXT InputC onvert er . h InputConverter . h
$ ( CC ) $ ( CFLAGS ) TXTI nputCo nverte r . cpp
DataField . o : DataField . cpp DataField . h
$ ( CC ) $ ( CFLAGS ) DataField . cpp
KAnoLogic . o : KAnoLogic . cpp KAnoLogic . h DBF . h \
DataField . h
$ ( CC ) $ ( CFLAGS ) KAnoLogic . cpp
PseudoLogic . o : PseudoLogic . cpp PseudoLogic . h DBF . h \
DataField . h Encryption . h
$ ( CC ) $ ( CFLAGS ) PseudoLogic . cpp
HashEncryption . o : HashEncryption . cpp HashEncryption . h \
Encryption . h DataField . h
$ ( CC ) $ ( CFLAGS ) HashEncryption . cpp
OracleDBF . o : OracleDBF . cpp OracleDBF . h DataField . h
$ ( CC ) $ ( CFLAGS ) OracleDBF . cpp
Middleware . o : Middleware . cpp OracleDBF . h TXT InputC onvert er . h \
PseudoLogic . h KAnoLogic . h
$ ( CC ) $ ( CFLAGS ) Middleware . cpp
clean :
\ rm *. o *~ p1
Listing A.10: pMake
92
Literaturverzeichnis
[1] Digital Imaging and Communications in Medicine (DICOM), Supplement 55: Attribute level confidentiality (including de-identification), 2002.
[2] D. Agrawal and C.C. Aggarwal. On the design and quantification of privacy preserving data mining algorithms. In Proceedings of the twentieth ACM SIGMODSIGACT-SIGART symposium on Principles of database systems, pages 247–255.
ACM, 2001.
[3] J. Attridge. An overview of hardware security modules. SANS Institute, Information Security Reading Room, 2002.
[4] M. Atzori, F. Bonchi, F. Giannotti, and D. Pedreschi. Anonymity preserving pattern
discovery. The VLDB journal, 17(4):703–727, 2008.
[5] R.J. Bayardo and R. Agrawal. Data privacy through optimal k-anonymization. In
Data Engineering, 2005. ICDE 2005. Proceedings. 21st International Conference
on, pages 217–228. IEEE, 2005.
[6] G. Bleumer and M. Schunter. Datenschutzorientierte Abrechnung medizinischer
Leistungen. Datenschutz und Datensicherheit, 2(21):24–35, 1997.
[7] Andrew M Butler. An unofficial companion to the novels of Terry Pratchett. Greenwood World Publishing, 2007.
[8] J. Caumanns, H. Weber, A. Fellien, H. Kurrek, O. Boehm, J. Neuhaus, J. Kunsmann, and B. Struif. Die eGK-Lösungsarchitektur Architektur zur Unterstützung der Anwendungen der elektronischen Gesundheitskarte. Informatik-Spektrum,
29(5):341–348, 2006.
[9] Jörg Caumanns. Der Patient bleibt Herr seiner Daten - Realisierung des eGKBerechtigungskonzepts über ein ticketbasiertes, virtuelles Dateisystem. InformatikSpektrum, 29:323–331, 2006.
93
Literaturverzeichnis
[10] E. U. Directive. 95/46/EC of the European Parliament and of the Council of 24
October 1995 on the Protection of Individuals with Regard to the Processing of
Personal Data and on the Free Movement of such Data, 1995.
[11] Claudia Eckert. IT-Sicherheit: Konzepte-Verfahren-Protokolle. Oldenbourg Wissenschaftsverlag, 2011.
[12] A. El Kalam, Y. Deswarte, G. Trouessin, and E. Cordonnier. Smartcard-based
anonymization. Smart Card Research and Advanced Applications VI, pages 49–66,
2004.
[13] Gregor Endler. Data quality and integration in collaborative environments. In
SIGMOD/PODS and ACM, editors, Proceedings of the SIGMOD/PODS 2012 PhD
Symposium, pages 21–26, New York, NY, USA, 2012.
[14] Gregor Endler, Michael Langer, Jörg Purucker, and Richard Lenz. An Evolutionary
Approach to IT Support in Medical Supply Centers. In Gesellschaft für Informatik e.V. (GI), editor, Informatik 2011, GI-Edition-Lecture Notes in Informatics
(LNI), 2011.
[15] V. Estivill-Castro and L. Brankovic. Data swapping: Balancing privacy against
precision in mining for logic rules. DataWarehousing and Knowledge Discovery,
pages 796–797, 1999.
[16] A. Evfimievski, R. Srikant, R. Agrawal, and J. Gehrke. Privacy preserving mining
of association rules. Information Systems, 29(4):343–364, 2004.
[17] E. Gamma, R. Helm, J. Vlissides, and R. Johnson. Entwurfsmuster. Pearson
Deutschland GmbH, 2009.
[18] H. Grosskreutz, B. Lemmen, and S. Rüping.
Informatik-Spektrum, 33(4):380–383, 2010.
Privacy-preserving data-mining.
[19] T.N. Herzog, F.J. Scheuren, and W.E. Winkler. Data quality and record linkage
techniques. Springer, 2007.
[20] Fraunhofer Institut and Herbert Prof. Dr. Weber. Die Spezifikation der Lösungsarchitektur zur Umsetzung der Anwendungen der elektronischen Gesundheitskarte.
2005.
94
Literaturverzeichnis
[21] M.Z. Islam and L. Brankovic. A framework for privacy preserving classification
in data mining. In Proceedings of the second workshop on Australasian information security, Data Mining and Web Intelligence, and Software InternationalisationVolume 32, pages 163–168. Australian Computer Society, Inc., 2004.
[22] V.S. Iyengar. Transforming data to satisfy privacy constraints. In Proceedings of the
eighth ACM SIGKDD international conference on Knowledge discovery and data
mining, pages 279–288. ACM, 2002.
[23] Anas Abou El Kalam, Yves Deswarte, Gilles Trouessin, and Emmanuel Cordonnier.
A generic approach for healthcare data anonymization. In Vijay Atluri, Paul F.
Syverson, and Sabrina De Capitani di Vimercati, editors, WPES, pages 31–32.
ACM, 2004.
[24] H. Kargupta, S. Datta, Q. Wang, and K. Sivakumar. On the privacy preserving
properties of random data perturbation techniques. In Data Mining, 2003. ICDM
2003. Third IEEE International Conference on, pages 99–106. IEEE, 2003.
[25] K. Muralidhar and R. Sarathy. Security of random data perturbation methods.
ACM Transactions on Database Systems (TODS), 24(4):487–493, 1999.
[26] Thomas Neubauer and Andreas Ekelhart. An evaluation of technologies for the
pseudonymization of medical data. In Proceedings of the 2009 ACM symposium on
Applied Computing, SAC ’09, pages 857–858, New York, NY, USA, 2009. ACM.
[27] Thomas Neubauer and Johannes Heurix. A methodology for the pseudonymization
of medical data. I. J. Medical Informatics, 80(3):190–204, 2011.
[28] Thomas Neubauer and Mathias Kolb. An evaluation of technologies for the pseudonymization of medical data. In Roger Lee, Gongzu Hu, and Huaikou Miao, editors,
Computer and Information Science 2009, volume 208 of Studies in Computational
Intelligence, pages 47–60. Springer Berlin / Heidelberg, 2009.
[29] Rita Noumeir, Alain Lemay, and Jean-Marc Lina. Pseudonymization of radiology
data for research purposes. J. Digital Imaging, 20(3):284–295, 2007.
[30] World Health Organization. The ICD-10 classification of mental and behavioural
disorders: clinical descriptions and diagnostic guidelines. World Health Organization, 1992.
95
Literaturverzeichnis
[31] R.L. Peterson. Encryption system for allowing immediate universal access to medical records while maintaining complete patient control over privacy, 2003.
[32] K. Pommerening, M. Miller, I. Schmidtmann, and J. Michaelis. Pseudonyms for
cancer registries. Methods of Information in Medicine, pages 112 – 121, 1996.
[33] K. Pommerening and M. Reng. Secondary use of the EHR via pseudonymisation.
Studies in health technology and informatics, pages 441–446, 2004.
[34] K. Pommerening, M. Reng, P. Debold, and S. Semler. Pseudonymisierung in der
medizinischen Forschung-das generische TMF-Datenschutzkonzept. 2005.
[35] Klaus Pommerening. Medical requirements for data protection. In IFIP Congress
(2), pages 533–540, 1994.
[36] Terry Pratchett and Stephen Briggs. The Streets of Ankh-Morpork. Trans-World,
1993.
[37] P. Samarati. Protecting respondents identities in microdata release. Knowledge and
Data Engineering, IEEE Transactions on, 13(6):1010–1027, 2001.
[38] P. Samarati and L. Sweeney. Generalizing data to provide anonymity when disclosing information. In PROCEEDINGS OF THE ACM SIGACT SIGMOD SIGART
SYMPOSIUM ON PRINCIPLES OF DATABASE SYSTEMS, volume 17, pages
188–188. ASSOCIATION FOR COMPUTING MACHINERY, 1998.
[39] Bruce Schneier. Applied Cryptography: Protocols, Algorithms, and Source Code in
C. John Wiley & Sons, Inc., New York, NY, USA, 2nd edition, 1995.
[40] R. Schnell, T. Bachteler, and J. Reiher. Privacy-preserving record linkage using
bloom filters. BMC Medical Informatics and Decision Making, 9(1):41, 2009.
[41] A. Shamir. How to share a secret. Communications of the ACM, 22(11):612–613,
1979.
[42] L. Sweeney. Datafly: a system for providing anonymity in medical data. Database
Security XI: Status and Prospects, Elsevier, Amsterdam, 1998.
[43] L. Sweeney. k-anonymity: A model for protecting privacy. International Journal of
Uncertainty, Fuzziness and Knowledge-Based Systems, 10(05):557–570, 2002.
96