Vortrag Proseminar Datenkompression
Werbung

Vortrag Proseminar Datenkompression:
Konstruktion binärer Suchbäume:
Binäre Suchbäume:
–
–
–
–
–
–
Suche in linear geordneter Menge X = x 1,... , x n ∪ y 0,..., y n
Gesucht ist ein Wort W
Interpretation des Suchbereichs:
x i W stimmt mit W i überein
–
y i liegt Alphabetisch zwischen W i und W i 1
–
y n W liegt nach W n
–
y 1 W liegt vor W 1
–
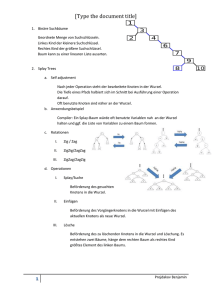
für das Problem wird Baum konstruiert
x sind innere knoten und y Blätter des Baums
ist x i im linken und x j im rechten Unterbaum eines
Baumes mit der Wurzel x k dann gilt x i x k x j
Abbildung 1: Beispiel Suchbaum
-Definition:
–
–
–
Existiert Pfad von x i nach x j über linken Baum so ist i>j
die Kosten des Punktes z , L(z) entspricht der # Knoten von der
Wurzel von B bis zu z
Für Gewichtung p sind die Kosten C B= ∑ p z L z z∈ X
-Definition:
–
–
–
–
Sei X ij= x i 1 ,..., x j ∪ y i ,..., y j eine Einschränkung des
Suchbereichs
W ij = p X ij
C ij sind die Kosten des optimalen Suchbaums B zu X ij und p
W ij sei die Wurzel des oder der Index der Wurzel des Baumes
Konstruktion von optimalen Suchbäumen:
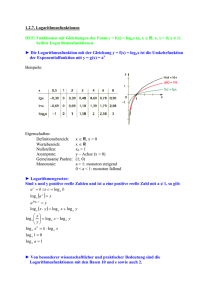
Bellmansche Optimalitätsgleichung:
C i , j =W i , j C i , R
i, j
−1
C R
i, j
, j
= min W i , j C i , k −1C k , j [ i k ≤ j]
wobei C ii=0
Algorithmus von Bellman:
–
–
–
–
Da X i , i 1= x i 1 ∪ y i , y i 1 folgt das Ri , i 1=i1 und C i , i 1=W i , i 1
Berechnung Ri , j und C i , j mit i− jl
Berechnung Ri , i l und C i , i l 0in−l
R i , i l ist einer der werte die C i , k −1C k , i l minieren und
C i , i l =W i , i l C i , R −1C R , i l
– Errechnung von W ij für konstantes i und wachsendes j
– Errechnung aller C i , k −1C k , i l (l add.)
i,il
–
–
–
i,il
2
O n
Ermittlung des Minimums dieser Werte (l-1 Vergl.)
damit erhält man Wurzel (k)
insgesamt O n3
Algorithmus von Knuth
Durch Einschränkung auf Bereich Ri , j −1≤RijRi 1, j benötigt man nur
O n 2 Rechenschritte
noch
Effiziente Konstruktion guter binärer Suchläufe:
Min-Max-Bäume:
–
–
–
–
–
Wurzel wird so gewählt das größerer Teilbaum möglichst
klein ist
wenn x k die Wurzel ist so sind W i , k −1 und W kj die
Wurzeln der Teilbäume
M k =max W i , k −1 , W kj ist das Gewicht des schweren
Teilbaums
x_r ist min-max-Wurzel wenn
M r i , j=minM i 1 i , j ,..., M j i , j
ein Suchbaum heißt min-max-Baum wenn beide
Teilbäume min-max-Wurzeln haben
Algorithmus von Mehlhorn
– Teil des Suchbereichs für den wir Wurzel eines Teilbaums
konstruieren wird durch die Parameter (i,j,w,l) beschrieben mit 3
Bedingungen
i) 0i jn
ii) W =v2−l 1 und v ∈0,1,...,2 l −1−1
iii) wqiq jw2l −1 (l # innerer Pkt. Auf Pfad von
Wurzel des Gesamtbaums bis Wurzel des Tailbaums; v gibt
an wie weit rechts der Teilbaum im Gesamtbaum liegt)
– Zu beginn sind Bedingungen erfüllt da i=0, j=n, l=1 und w=0
– allgemein soll Wurzel x k
die erfüllen: qk −1w2−l qk
– Fall 1: i+1=j dann konstruiert der Algorithmus den Baum: Wurzel x_j
mit Endpunkten: y j −1 und y j
−l
– Fall 2: i1≠ j und qiw2
x_{i+1} wird Wurzel des Suchbaums,
linker Teilbaum besteht aus y i und rechter wird mit
−l
i1, j , w2 , l1 konstruiert
x j ist Wurzel und rechter Teilbaum
– Fall 3:
i1≠ j und qiw2−l
y j und linker wird mit (i,j-1,w,l+1) erstellt
−l
– Fall 4: i+1<>j und qiw2 q j Wurzel x k wird so gewählt,
dass qk −1w2−l qk und ik j
x k =i1 besteht linker Teilbaum aus y i sonst
– wenn
erstellen mit (i,k-1,w,l+1) erstellt
y j sonst
– wenn x k = j besteht rechter Teilbaum aus
−l
erstellen mit k , j , w2 , l1 erstellt
–
Für die Kosten des konstruierten Baumes gilt:
C BH p1¿0in p x i
Verfahren von Fredman:
–
–
Berechnung q(1),...,q(n) (O(n) Add. Und Div.)
Errechnung x k für Fall 4:
−l
– k so bestimmen das qk −1w2 qk
– feststellen ob man k=l wählen kann oder k>l bzw.
k<l
– Vergleich wir q(l-1) und q(l) mit ½
–
1
2
wenn ql−1 ql dann k=l
falls q(l-1)>1/2 (q(l))<1/2 muss k<l (k>l) gewählt
werden
– Test ob K=[1/2(n+1)] wählen kann wenn ja dann
müssen die Teilbäume mit k-1 und n-k gewählt
werden
– sonst ist k in menge (1,...,[1/2(n+1)]) oder
([½(n+1]+1,...,n) zu finden
– weiter für Menge 1:
– prüfen ob k 1 , k 2 , k 4 , k 8 ,... wählen
kann bei erster postiver Antwort wird abgebrochen
h−1
– man erhält daraus menge 2
1,...,2 h
– indem man menge fortlaufend halbiert erhält man k
in h-1 fragen
der Algorithmus von Mehlhorn kann mittels des Verfahrens
von Fredman in O(n) schritten durchgeführt werden
–
–
2.Untere Schranken für die Kosten von Suchbäume:
Satz1:
–
–
–
–
für B gilt:
C(p) sind die Kosten eines optimalen Suchbaums zur a-prioriVerteilung p au dem Suchbereich X
Ergebnisfolgen e y 0 , e x 1 , e y 1 ,..., e x n , e y n dieser Suchbäume
bilden Präfixcodes auf Alphabet (0,1,2)
siehe Noiseless-Coding-Theorem: erwartete Codewortlänge
Da Kosten gleich E(c) sind C plog3−1 H p log 3−1≈0.63
L(X_k) und L(y_m) sind die Kosten für x_k und y_m
i)
∑ 2− L x 1
m
0≤m≤n
ii)
1
∑ 2− L x 2log n1
k
dies ist mit der Ungleichung von Kraft beweisbar
0≤k ≤n
Abschätzen von C(p) – H(p) mit obigen Formeln:
Sei p x := ∑ p x k und p y:= ∑ p y m und B optimaler
Suchbaum.
–
C p−H p= ∑ p x k L x k log p x k ∑ p x m L x m log p x m
= −∑ p x k log
–
− L xm
Für x ∈ℝ ist ln x ≤ x −1 und damit log x ≤ x −1 log e . Damit
abschätzen des 2. Summanden:
−∑ p x m log
–
− L xk
2
2
− ∑ p x m log
P xk
P x m
2− L x
≥−log e ∑ 2− L y − p y m ≥−log e1− p y
P x m
m
m
Nun zum Abschätzen des ersten Summanden:
−∑ p x k log
− L xk
2
=−∑ p x k log
P xk
−log e−∑
2− L x
k
− L xk
1
2
− ∑ p x k log logn1
1
2
P x k logn1
2
− p x k − p x log logn1−1
1
logn1
2
≥ −log e1− p x − p x log logn1−1
≥
–
Damit ergibt sich:
H p−H p≥−log e1− p y1− p x − p x log logn1−1
= −log e− p x log logn1−1
Daraus folgt der nächste Satz.
Satz 2:
Für alle a-priori-Verteilungen p ist
C p≥H p−log e− p x log log n1−1
Diese Schranke ist in diesen Fällen ungefähr H p – p x log H p und damit viel
besser als die Schranke aus Satz 1. Für Verteilungen mit kleiner Entropie liefert
Satz 2 jedoch keine gute untere Schranke.
Für jeden Knoten x k betrachten wir nun den Baum b, der aus x_k und dessen
Nachfolgern besteht. b enthält dabei die Knoten x i 1 ,..., x j , y i ,..., y j .
Daraus folgt pb=W ij . D. h. pb ist Wahrscheinlichkeit, dass der gesuchte
Knoten in b liegt und die Wahrscheinlichkeit das wir den Test t k durchführen.
X k ist die Zufallsvariable die wenn sie 1 ist angibt das der Test ausgeführt wird
bzw. wenn sie 0 ist das er nicht ausgeführt wird.
Daraus folgt: E X k =P X k =1= pb¿
T(B) ist Menge aller Teilbäume von B.
∑
1≤ k ≤ n
Xk
Ist die Anzahl der benötigten Tests.
X k = ∑ E X k = ∑ pb
Damit gilt: C p=C B=E 1≤∑
k ≤n
1≤ k ≤ n
b∈T B
Die Wahrscheinlichkeit des Objektes
z∈ X , wenn z in b liegt, wird mit
pb z=
p z
pb
bezeichnet, Bei einer Suche in die x k Wurzel des Teilbaumes b erreichen so ist die
Wahrscheinlichkeit das x k das gesuchte Objekt ist pb x k .
Weiterhin lassen sich auch die Wahrscheinlickeiten, ob das Objekt im linken l b oder
im rechten r b Teilbaum von b liegt, herleiten:
pl b
pb
pr b
pb
So ist die Ungewissheit über den Ausgang des Tests t k :
H b :=H
P x k pl b P r b
,
,
pb pb
pb
Daraus lässt sich folgendes Lemma ableiten:
H p=
∑
b∈T B
pb H b
Durch sorgfältigeres Abschätzen von H b lässt sich eine e wesentlich bessere unter Schranke für
die Kosten binärer Suchbäume ableite. Dazu beweisen wir zunächst dieses Lemma:
–
Für alle Wahrscheinlichkeitsverteilungen
P= p1, p2, p 3
und alle reellen Zahlen a ist .
−a
H p≤ap1log 22
Aus der Konkavität der Entropiefunktion ergibt sich:
1
,1
F p1 :=H p1 , 1− p1 1− p1 ≥H P 1 , p2 , p3
2
2
Jede Tangente von F liegt oberhalb von F und damit:
F ' p1 =log
1−P 1
P1
−1 damit gilt auch
F ' 2a 11−1 =a .
F 2 a 11−1 =a2 a 11−1log22−a ist, ergibt sich die Tangente
−a
G p1 :=ap1log22 die F im Punkt 2 a 11−1 , F 2 a 11−1 berührt.
Da
Daraus folgt
H p1, p 2, p 3 ≤F p1 ≤G p1 =ap1log22−a | a∈ℝ .
wzbw.
x k nun die Wurzel von
p x k
log22−a ist.
H b≤a
pb
Wenn
b∈T B
ist, so folgt aus dem Lemma, dass
Weiterhin lässt sich ableiten:
H p=
∑
pb≤
b∈T B
∑
1≤ k ≤ n
ap x k
∑
b∈T B
−a
−a
pb log22 =ap x C p log22 | a∈ℝ
Damit ist der Folgende Satz bewiesen:
Satz 3: Für alle a-priori-Verteilungen p gilt
C p≥sup[H p−ap x log−1 22−a | a∈ℝ]
Diese untere Schranke ist noch zu kompliziert. Wenn man die Funktion
−1
−a
f a:=H p−ap x log 22 untersucht lässt sich über das Maximum am Punkt
H p
c:=log
lässt sich folgende untere Schranke beweisen.
2p x
Satz 4: Für alle a-priori-Verteilungen p, für die H p≥ p x ist, gilt
C p≥H p− p x logH p p x log p x −loge1
Weiterhin lässt sich hier errechnen, dass mit wachsender Entropie der a-priori-Verteilung sich der
Quotient der oberen und unteren Schranke 1 annähert.