Kapitel 19 Modelle mit diskreten abhängigen Variablen
Werbung

Kapitel 19
Modelle mit diskreten abhängigen
Variablen
19.1
Vorbemerkungen
Bisher sind wir stets davon ausgegangen, dass die abhängige Variable y intervallskaliert ist. Zusätzlich haben wir meist angenommen, dass die Störterme εi normalverteilt sind.
Sehr häufig ist diese Annahme aber nicht erfüllt und die abhängige Variable ist in
irgendeiner Form ‘beschränkt’. In solchen Fällen spricht man von “Limited Dependent Variables” (LDV). In diesem Kapitel werden wir einige solcher Fälle und die
damit einhergehenden Probleme diskutieren.1
Zum Beispiel haben wir bisher Dummy-Variablen (auch bekannt als binäre, dichotome oder qualitative Variablen) ausschließlich als erklärende Variablen (auf der
rechten Seite der Regressionsgleichungen) zugelassen. Solche qualitative Variablen
können aber auch als abhängige Variable interessieren, z.B. kauft ein Kunde mit
bestimmten Charakteristika ein Produkt oder kauft er es nicht, lässt sich jemand
scheiden oder nicht, geht eine Firma in Konkurs oder nicht, usw.
Es gibt zahlreiche Arten von diskreten abhängigen Variablen, die wichtigsten Fälle
sind:
• Binäre abhängige Variablen: z.B. Kaufentscheidungen (ja/nein), Konkurse,
→ lineares Wahrscheinlichkeitsmodell, Probit- / Logit Modelle;
• Ordinale abhängige Variablen: z.B. Schulnoten, Zustimmungsgrade, . . .
→ Ordered Probit- / Logit Modelle;
• Nominale abhängige Variablen: z.B. Wahl eines Schultyps, eines Transportmittels, . . .
→ Multinominale Logit Modelle;
• ‘Zensierte’ oder ‘gestutzte’ abhängige Variablen (censored or truncated ): z.B.
Arbeitsangebot kann nicht negativ sein, Einkommen über einer bestimmten
Höhe werden in der Einkommenssteuerstatistik nicht einzeln ausgewiesen, . . .
→ z.B. Tobit-Modelle
1
Dieses Kapitel folgt eng dem Lehrbuch von Long (1997).
1
2
Empirische Wirtschaftsforschung
• Zähldaten: z.B. Anzahl der Kinder einer Frau, Zahl der Regierungswechsel in
einer Periode, . . .
Solche Daten treten häufig auf, wenn individuelles Verhalten beobachtet wird, deshalb werden Schätzverfahren für solche Daten üblicherweise der Mikroökonometrie
zugerechnet. Da in diesen Fällen die Annahmen des klassischen linearen Regressionsmodells meist verletzt sind, wurden für diese Daten eigene Modelle entwickelt, die
häufig auf der Maximum Likelihood Methode beruhen. Bevor wir uns aber ausführlich mit diesen Methoden beschäftigen, werden wir uns vorher noch kurz mit einem
sehr einfachen Modell befassen, nämlich der Anwendung von OLS bei abhängigen
Dummy Variablen.
19.2
Das
Lineare
(LPM)
Wahrscheinlichkeitsmodell
Beim Linearen Wahrscheinlichkeitsmodell (Linear Probability Model, LPM) wird das
Modell mit einer binären abhängigen Variable einfach mit OLS geschätzt.2
Angenommen wir interessieren uns dafür, welche Personen sich nach einer Verkaufsveranstaltung entschließen das Produkt zu kaufen, oder genauer, wie welche persönliche Charakteristika die Kaufwahrscheinlichkeit beeinflussen. Dazu könnten wir eine
Zufallsstichprobe ziehen und die Personen befragen, ob sie das Produkt gekauft haben (y), sowie nach den interessierenden Charakteristika wie z.B. Einkommen (I),
Alter (A), Bildungsniveau (E). Das Modell lautet
yi = β1 + β2 Ii + β3 Ai + β4 Ei + εi
wobei
(
1 wenn Person i das Produkt gekauft hat,
yi =
0 wenn Person i das Produkt nicht gekauft hat.
Natürlich können auch erklärende Variablen qualitativ sein, z.B. das Geschlecht.
Wenn wir mit x′i die i-te Zeile der X Matrix bezeichnen (xi ist also ein Spaltenvektor,
und x′i ein 1 × k Zeilenvektor mit den Daten für Beobachtungseinheit i) können wir
das Modell schreiben als
yi = x′i β + εi
Dieses Modell kann prinzipiell mit OLS geschätzt werden (auch wenn dies Probleme
mit sich bringt, mehr dazu später).
Abbildung 19.1 zeigt das lineare Wahrscheinlichkeitsmodell (LPM) für den bivariaten Fall. Die Punkte zeigen die Realisationen von y (yi = 0 oder yi = 1). Die durchgezogene (blaue)( Linie ist das Ergebnis einer OLS-Regression und zeigt ybi = βb1 + βb2 xi .
Die entsprechende PRF beschreibt den bedingten Erwartungswert E(yi | xi ) = β1 +
β2 xi .
2
Man kann zeigen, dass das LPM eng mit der statistischen Diskriminanzanalyse verwandt ist
(siehe z.B. Maddala and Lahiri, 2009, 332f).
3
Empirische Wirtschaftsforschung
Dieser Erwartungswert hat eine interessante Interpretation. Da y nur zwei Werte
annehmen kann, 0 oder 1, ist der bedingte Erwartungswert
E(yi | x′i ) = [1 × Pr(yi = 1| x′i )] + [0 × Pr(yi = 0| x′i)] = Pr(yi = 1| x′i )
wobei Pr die Wahrscheinlichkeit bezeichnet, mit der das Ereignis eintritt.
Der Erwartungswert der binären Variable kann also als bedingte Wahrscheinlichkeit
interpretiert werden, mit der das Ereignis yi = 1 für gegebene x′i eintritt. Also gilt
Pr(yi = 1) = ybi = x′i β
Dies erklärt den Namen des LPM.
Im LPM können die marginalen Effekte wie üblich interpretiert werden
∂ Pr(yi = 1)
∂y
=
= βh
∂xh
∂xh
d.h. βh gibt an, wie eine marginale Änderung der Variable xh die Eintrittswahrscheinlichkeit des Ereignisses beeinflusst. Wenn D eine Dummyvariable ist und der
Vektor xi die restlichen erklärenden Variablen enthält ist wie üblich die Differenz
der Erwartungswerte zu bilden
∆ Pr(yi = 1) = E(yi | x′i , Di = 1) − E(yi | x′i , Di = 0)
E(y|x)
y
Daten:
y x
0 8
0 15
0 24
0 33
0 42
1 47
1 58
1 73
1 82
1 96
1.0
b
b
b
b
b
ε1
rs
0.5
ε0
0.0
−0.2
b
0
b
b
b
b
50
x∗
100
x
Abbildung 19.1: Das ‘Linear Probability Model’
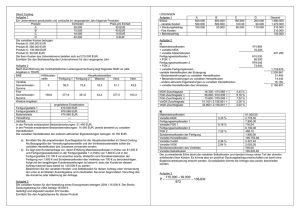
Beispiel: Ein bekanntes Beispiel für die Analyse einer diskreten abhängigen Variable stammt von Fair (1978). Dieser wertete das mittels Fragebögen erhobene
‘Seitensprungverhalten’ seiner verheirateten Mitbürger aus. Da wir diesen Datensatz noch öfters verwenden werden sind in Tabelle 19.1 die deskriptiven Statistiken
der Variablen zusammengefasst.
Tabelle 19.2 zeigt die Anwendung einer einfachen OLS-Regression auf diese Daten,
d.h. das Lineare Wahrscheinlichkeitsmodell, und Abbildung 19.2 das Histogramm
der gefitteten Werte, d.h. der prognostizierten Wahrscheinlichkeiten.
4
Empirische Wirtschaftsforschung
Tabelle 19.1: Deskriptive Statistik zu Fair, Ray C. (1978), “A Theory of Extramarital Affairs”, Journal of Political Economy, Vol 86 No 1, 45-61.
Variable
EMA
Sex
Age
YMar
Kids
Relig
Educ
Occ
RMar
Mean Max.
0.250
1
Min. Std. Dev. Description
0
0.433 Extramarital Affairs,
0 = no, 1 = yes,
0.476
1
0
0.500 0 = female, 1 = male ,
32.488
57 17.5
9.289 Age
8.178
15 0.125
5.571 No. of years married
0.715
1
0
0.452 Children, 0 = no, 1 = yes
3.116
5
1
1.168 How religious,
5 = very, 1 = anti
16.166
20
9
2.403 Education,
from 9 (low) to 20 (high)
4.195
7
1
1.819 Occupation (1 - 7)
3.932
5
1
1.103 Rate marriage, from 5 = very
happy to 1 = very unhappy
n = 601, Survey data of first time married people.
Tabelle 19.2: Das Lineare Wahrscheinlichkeitsmodell (OLS)
Dependent Variable: EMA
Method: Least Squares
Included observations: 601
White Heteroskedasticity-Consistent Standard Errors & Covariance
Variable
C
SEX
AGE
YMAR
KIDS
RELIG
EDUC
OCC
RMAR
Coefficient Std. Error
t-Stat.
b1
0.7361
0.1631
4.5143
b2
0.0452
0.0412
1.0960
b3 −0.0074
0.0032 −2.3466
b4
0.0160
0.0056
2.8382
b5
0.0545
0.0463
1.1771
b6 −0.0537
0.0153 −3.5001
b7
0.0031
0.0085
0.3613
b8
0.0059
0.0117
0.5061
b9 −0.0875
0.0170 −5.1364
R-squared
0.1066 Log likelihood
Adjusted R-squared
0.0945 Akaike info criterion
S.E. of regression
0.4122 Schwarz criterion
Sum squared resid
100.5637 F-statistic
Durbin-Watson Stat.
0.2227 Prob(F-statistic)
Prob.
0.0000
0.2735
0.0193
0.0047
0.2396
0.0005
0.7180
0.6130
0.0000
-315.5469
1.0800
1.1459
8.8293
0.0000
5
Empirische Wirtschaftsforschung
70
Series: EMA_F
Sample 1 601
Observations 601
60
50
40
30
20
10
0
-0.00
0.25
Mean
Median
Maximum
Minimum
Std. Dev.
Skewness
Kurtosis
0.249584
0.238449
0.636909
-0.115100
0.141414
0.250231
2.631197
Jarque-Bera
Probability
9.678037
0.007915
0.50
Abbildung 19.2: Histogram der prognostizierten Wahrscheinlichkeiten
19.2.1
Probleme mit dem linearen Wahrscheinlichkeitsmodell
Das lineare Wahrscheinlichkeitsmodell ist verblüffend einfach und – wie die Praxis
zeigt – in vielen Fällen erstaunlich robust, weshalb es oft vernünftig ist zur ersten
Orientierung mit einem solchen Modell zu beginnen. Leider hat es auch einige Nachteile:
• Die prognostizierten Wahrscheinlichkeiten können größer als Eins oder kleiner als Null sein, was natürlich der Definition einer Wahrscheinlichkeit widerspricht. Abbildung 19.2 mit dem Histogram der prognostizierten Werte zeigt,
dass in dem Beispiel von Fair (1978) eine Reihe negativer Seitensprungwahrscheinlichkeiten vorhergesagt werden.
• Die unterstellte lineare Funktionsform ist häufig unrealistisch. Wenn z.B. bestimmt werden soll, mit welcher Wahrscheinlichkeit Frauen berufstätig sind,
unterstellt das LPM, dass ein erstes Kind einer Frau den gleichen Einfluss auf
die Wahrscheinlichkeit für die Berufstätigkeit hat wie ein viertes Kind.
• Heteroskedastizität: Man kann zeigen, dass die Varianz einer binären Variable
yi mit Mittelwert µ immer µ(1 − µ) ist.3
Im Regressionsmodell ist der bedingte Erwartungswert E(yi | x′i ) = x′i β. Die
bedingte Varianz von y ist deshalb von X abhängig
var(yi | x′i ) = Pr(yi = 1| x′i )[1 − Pr(yi = 1| x′i )] = x′i β(1 − x′i β)
d.h. das Modell ist heteroskedastisch. Deshalb ist das LPM nicht effizient und
die Standardfehler sind verzerrt. Dieses Problem lässt sich durch die Anwendung eines FGLS Schätzers4 (Feasible Generalized Least Squares), oder – noch
einfacher – durch heteroskedastie-konsistente (White-) Standardfehler zumindest wesentlich mildern.
3
Warum? Sei y eine Dummy Variable mit E(y) = µ. Per Definition gilt var(y) = E(y − µ)2 =
E(y ) − 2µ E(y) + µ2 . Da y nur die Werte 0 und 1 annehmen kann gilt y 2 = y. Einsetzen von
E(y) = µ gibt var(y) = µ − µ2 = µ(1 − µ).
p
4
Man schätzt die gefitteten Werte ŷi , berechnet daraus die Gewichte wi = ŷi (1 − ŷi ), und
regressiert yi /wi auf xi /wi .
2
6
Empirische Wirtschaftsforschung
• Die Störterme sind nicht normalverteilt: Die Störterme sind die Differenz
zwischen realisierten Werten und dem bedingten Erwartungswert εi = yi −
E(yi | xi ). In Abbildung 19.1 (Seite 3) ist der Störterm für einen Wert x∗ eingezeichnet. Da y nur 0 oder 1 sein kann, ist der entsprechende Störterm entweder
ε1 = 1 − E(y| x∗) oder ε0 = 0 − E(y| x∗). Diese Störterme können deshalb nicht
normalverteilt sein. Dies beeinflusst zwar nicht die Unverzerrtheit des OLS
Schätzers, aber die Teststatistiken sind in kleinen Stichproben ungültig.
Einige der Probleme des LPM lassen sich beseitigen, wenn man eine Funktion wählt
die sicher stellt, dass der bedingte Erwartungswert – d.h. die Wahrscheinlichkeit –
im [0,1] Intervall liegt
Pr(yi = 1| x′i ) = E(yi | x′i ) = F (x′i β)
wobei x′i β Indexfunktion genannt wird und F eine Transformationsfunktion ist, die
folgende Eigenschaft erfüllt:
F (−∞) = 0.
dF (x)
≡ f (x) ≥ 0
dx
F (∞) = 1,
(dies impliziert 0 < F (z) < 1 ∀ z ∈ x)
Eine solche Funktion F kann natürlich niemals linear sein, sondern wird meist Sförmig angenommen. Deshalb sind die marginalen Effekte nicht konstant, weshalb
die Parameter dieser Modelle – wie wir später sehen werden – deutlich schwieriger
zu interpretieren sind als die des LPM.
LPM
y
b
1.0
b
b
b
b
Logit
0.5
b
0.0
−0.2
0
b
b
b
b
50
x∗
100
x
Abbildung 19.3: Vergleich LPM- und Logit Modell
19.3
Eine Interpretation: Latente Variablen
Ein wesentliches Problem des LPM besteht darin, dass die prognostizierten Wahrscheinlichkeiten nicht im [0, 1] Intervall liegen müssen, sowie, dass konstante mar-
7
Empirische Wirtschaftsforschung
ginale Effekte häufig theoretisch unplausibel sind. Deshalb liegt es nahe eine Funktionsform zu wählen, die diese Probleme vermeidet. Meistens wird eine S-förmige Funktionsform gewählt wie in Abbildung 19.3. In diesem Abschnitt werden wir
versuchen eine plausible Begründung für eine solche Funktionsform zu geben, und
anschließend werden wir uns mit der Schätzung und Interpretation der Parameter
beschäftigen.
Für das Verständnis ist es am einfachsten, wenn wir uns vorstellen, dass die beobachtbare binäre Variable y von einer zugrundeliegenden unbeobachtbaren intervallskalierten Variable y ∗ ‘erzeugt’ wird. Falls die abhängige Variable y z.B. angibt, ob
jemand eine Kauf getätigt hat oder nicht, könnte die latente intervallskalierte Variable y ∗ interpretiert werden als ‘Kaufneigung’; oder wenn y angibt, ob eine Firma
zahlungsunfähig wurde, könnte y ∗ als ‘Liquidität’ oder etwas ähnliches interpretiert
werden.
Eine solche ‘dahinterliegende’ unbeobachtbare Variable wird latente Variable genannt. Wir werden im weiteren solche latente Variablen mit einem hochgestellten ∗
kennzeichnen.
Das Strukturmodell sei
yi∗ = x′i β + εi
mit
(
1 wenn yi∗ > τ,
yi =
0 wenn yi∗ ≤ τ.
wobei τ einen (beliebigen) Schwellenwert (treshold oder cutoff point) bezeichnet.
Meist wird τ = 0 angenommen, da sich die Wahl eines anderen (beliebigen) Schwellenwerts bei der Schätzung nur auf den Wert des Interzepts auswirkt, welches aber
nur selten von Interesse ist.
Die Wahrscheinlichkeit, dass für ein gegebenes xi die abhängige Variable yi den
Wert 1 annimmt, kann für τ = 0 als Wert der Verteilungsfunktion an der Stelle x′i β
berechnet werden, denn
Pr(yi = 1| x′i ) =
=
=
=
=
Pr(y ∗ > 0| x′i )
Pr(x′i β + εi > 0| x′i )
Pr(εi > −x′i β| x′i )
Pr(εi ≤ x′i β| x′i )
F (x′i β| x′i )
(der letzte Schritt folgt aus der Symmetrie der Normalverteilung).
Diese Herleitung wird in Abbildung 19.4 grafisch veranschaulicht.
Man beachte, dass auch für E(y ∗ | x′i ) > τ und deshalb E(y| x′i ) = 1 das tatsächlich
beobachtete yi gleich Null sein kann (d.h. yi = 0), wenn nämlich εi hinreichend
negativ ist.
Wir werden außerdem später sehen, dass σ in diesen Modellen nicht berechnet werden kann (d.h. nicht identifizierbar ist), sondern nur das Verhältnis β/σ.
8
Empirische Wirtschaftsforschung
y∗
E(y ∗ |x)
y=1
xi β
y=0
τ
τ =0
Dichte
xi
Pr(y = 1)
Pr(y = 0)
Pr(y = 1)
x
Pr(y = 1)
= F (xβ)
Pr(y = 0)
Pr(y = 0)
0
xi β
y∗
y = xβ + ε
∗
Pr(y = 1) = Pr(xβ + ε > 0)
0
0
ε = y − xβ
−ε = xβ − y ∗
−xi β
∗
Pr(y = 1) = Pr(ε > −xβ)
xi β
Pr(y = 1) = Pr(ε ≤ xβ) = F (xβ)
Abbildung 19.4: Latente Variable Pr(yi = 1| xi ) = F (βxi )
Die obere Grafik von Abbildung 19.5 (Seite 9) zeigt die Verteilung des Störterms ε
für 5 verschiedene x. Die schraffierte Fläche gibt die auf x bedingte Eintrittswahrscheinlichkeit Pr(yi = 1| xi ) an, die in der unteren Abbildung aufgetragen ist. Dies
ist offensichtlich eine Verteilungsfunktion.
19.4
Probit- und Logit Modelle
Benötigt wird also eine Transformationsfunktion F die sicherstellt, dass F (x′i β) in
das Intervall [0, 1] fällt. Die beiden am häufigsten verwendeten Funktionen, die diese
Annahme erfüllen, sind die Verteilungsfunktionen der Normal- und der logistischen
Verteilung.
• Probit: verwendet für F die Verteilungsfunktion der Standardnormalverteilung:
2
Z x′i β
Z x′i β
1
−z
′
Pr(yi = 1) = Φ(xi β) =
φ(z)dz =
exp
dz
2
−∞
−∞ 2π
9
Empirische Wirtschaftsforschung
y∗
8
y=1
7
E(y ∗ |x)
6
5
τ
τ
4
y=0
3
2
1
0
0
1
2
3
4
5
6
7
8
9
10
0
1
2
3
4
5
6
7
8
9
10
x
Pr(y = 1|x)
1
0.5
0
Abbildung 19.5: Interpretation als latente Variable : die schraffierte Fläche
der oberen Abbildung ist als Verteilungsfunktion in der unteren
Abbildung dargestellt.
wobei Φ (Phi) die Verteilungsfunktion (cdf für ‘Cumulative Distribution Function’ ) und φ (phi) die Dichtefunktion (pdf für ‘Probability Density Function’ )
der Standardnormalverteilung ist.
• Logit: basiert auf der Verteilungsfunktion (cdf) der logistischen Verteilung:
Pr(yi = 1) = Λ(x′i β) =
exp(x′i β)
1 + exp(x′i β)
wobei Λ (Lambda) die Verteilungsfunktion (cdf) der standard-logistischen Verteilung mit Mittelwert 0 und Varianz π 2 /3 ist. Die Dichtefunktion (pdf) der
logistischen Verteilung ist nebenbei erwähnt
λ(x′i β) =
exp(x′i β)
[1 + exp(x′i β)]2
10
Empirische Wirtschaftsforschung
Die Schätzung beider Modelle erfolgt mittels Maximum Likelihood.
Die Wahrscheinlichkeit
Pr(yi = 1| x′i ) = F (x′i β)
wobei F im Probit Modell die cdf Φ und im Logit Modell die cdf Λ ist (vgl. Abbildung
19.4, Seite 8).
Pr(yi = 1| x′i ) = F (x′i β)
Pr(yi = 0| x′i ) = 1 − F (x′i β)
Wenn die Stichprobenziehungen unabhängig sind (i.i.d. sampling) ist die gemeinsame Wahrscheinlichkeit
Y
Y
Pr(y1 , y2 , . . . , yn | X) =
[1 − F (x′i β)]
[F (x′i β)]
{i,yi =0}
{i,yi =1}
Da die beobachteten yi Ausprägungen eines Binomialprozesses sind ist die Likelihood
Funktion für n Beobachtungen
n
Y
y
1−y
L(β| y, X) =
[F (x′i β)] i [1 − F (x′i β)] i
i=1
Die Log-Likelihood Funktion ist das Produkt der individuellen Likelihoodbeiträge
ln Li
n
X
ln L =
{yi ln [F (x′i β)] + (1 − yi ) ln [1 − F (x′i β)]}
i=1
Man beachte, dass der Wert dieser Log-Likelihood Funktion nie positiv sein kann,
da 0 ≤ F (·) ≤ 1 impliziert, dass ln[F (·) ≤ 0] und ln[1 − F (·) ≤ 0].
Die Bedingungen erster Ordnung sind
n ∂ ln L X yi fi
−fi
!
=
+ (1 − yi )
x′i = 0
∂β
Fi
(1 − Fi )
i=1
wobei fi = dFi /d(x′i β) die Dichtefunktion (pdf) ist, also φ für das Probit und λ
für das Logit Modell. Die Parameter β dieses Modells können mit Hilfe iterativer
Verfahren geschätzt werden.
Die Log-Likelihood Funktion könnte z.B. in EViews (oder jedem anderen geeigneten
Programm5 einfach maximiert werden (hier für das Probit)
logl LL1 ’ Log-Likelihood Objekt LL1 anlegen
’ OLS Schätzungen als Startwerte setzen
eq1.ls y c x
LL1.append @logl logl1
LL1.append xb = c(1) + c(2)*x
LL1.append logl1 = EMA*log(@cnorm(xb)) + (1-EMA)*log(1-@cnorm(xb))
LL1.ml
show LL1
(EMA ist die abhängige Dummyvariable ‘Extramarital Affairs’) aber selbstverständlich sind entsprechende Routinen einfacher mit dem Befehl eqname.probit list of
variables aufgerufen werden.
5
Für R Beispiele siehe z.B. Kleiber
wwz.unibas.ch/fileadmin/wwz/redaktion/statistik/downloads/Lehre/Mikro/Folien/Binary.pdf
11
Empirische Wirtschaftsforschung
Beispiel: Tabelle 19.3 und 19.4 zeigen Probit- bzw. Logitschätzungen für die bereits früher zitierte Arbeit von Fair (1978) über außerehelicher Beziehungen (für die
Definition der Variablen siehe Seite 4).
Tabelle 19.3: Probit-Schätzung von Fair (1978)
Dependent Variable: EMA
Method: ML - Binary Probit (Quadratic hill climbing)
Sample: 1 601
Included observations: 601
Convergence achieved after 5 iterations
Covariance matrix computed using second derivatives
Variable
Coefficient
C
b0
0.7794
SEX
b1
0.1735
AGE
b2
−0.0246
YMAR
b3
0.0543
KIDS
b4
0.2166
RELIG
b5
−0.1855
EDUC
b6
0.0113
OCC
b7
0.0137
RMAR
b8
−0.2718
Mean dependent var
0.249584
S.E. of regression
0.410279
Sum squared resid
99.65088
Log likelihood
−305.198
Restr. log likelihood −337.6885
LR statistic (8 df)
64.98107
Probability(LR stat) 4.87E − 11
Obs with Dep=0
451
Obs with Dep=1
150
Std. Error
z-Stat.
Prob.
0.5125
1.5206
0.1289
0.1380
1.2570
0.2092
0.0104 −2.3598
0.0186
0.0188
2.8893
0.0040
0.1652
1.3117
0.1901
0.0516 −3.5926
0.0004
0.0295
0.3816
0.7029
0.0414
0.3301
0.7414
0.0535 −5.0826
0.0000
S.D. dependent var
0.433133
Akaike info criterion
1.045584
Schwarz criterion
1.111453
Hannan-Quinn criter.
1.071224
Avg. log likelihood
−0.507817
McFadden R-squared
0.096215
Total obs
601
Achtung: Der Maximum Likelihood Schätzansatz bricht zusammen, wenn für eine
Linearkombination x′i β ∗ der erklärenden Variablen gilt
(
yi = 0 wenn x′i β ∗ < 0, und
yi = 1 wenn x′i β ∗ > 0
Dies bedeutet, dass in einer graphischen Abbildung die Beobachtungen durch eine
Gerade (oder Hyperebene) perfekt getrennt werden können. Dieses Problem ist als
Perfect Classifier Problem oder (Quasi-)Vollständige Separation bekannt (siehe z.B.
Davidson and MacKinnon, 2003, 458).
12
Empirische Wirtschaftsforschung
Tabelle 19.4: Logit-Schätzung von Fair 1978
Dependent Variable: EMA
Method: ML - Binary Logit (Quadratic hill climbing)
Sample: 1 601
Included observations: 601
Convergence achieved after 5 iterations
Covariance matrix computed using second derivatives
Variable
C
b0
SEX
b1
AGE
b2
YMAR
b3
KIDS
b4
RELIG
b5
EDUC
b6
OCC
b7
RMAR
b8
Mean dependent var
S.E. of regression
Sum squared resid
Log likelihood
Restr. log likelihood
LR statistic (8 df)
Probability(LR stat)
Obs with Dep=0
Obs with Dep=1
19.5
Coefficient
1.3773
0.2803
−0.0443
0.0948
0.3977
−0.3247
0.0211
0.0309
−0.4685
0.249584
0.409947
99.48925
−304.7552
−337.6885
65.86657
3.25E − 11
451
150
Std. Error
z-Stat.
Prob.
0.8878
1.5514
0.1213
0.2391
1.1723
0.2416
0.0182 −2.4252
0.0156
0.0322
2.9419
0.0034
0.2915
1.3642
0.1730
0.0898 −3.6179
0.0003
0.0505
0.4168
0.6770
0.0718
0.4308
0.6668
0.0909 −5.1531
0.0000
S.D. dependent var
0.433133
Akaike info criterion
1.044111
Schwarz criterion
1.10998
Hannan-Quinn criter.
1.06975
Avg. log likelihood
−0.50708
McFadden R-squared 0.097526
Total obs
601
Identifizierbarkeit und Vergleich der Koeffizienten von Probit- & Logitmodellen
Wir haben bereits früher gezeigt (siehe latente Variablen), dass
Pr(y = 1| x) = Pr(y ∗ > 0| x)
= Pr(xβ + εi > 0| x)
= Pr(εi > −xβ| x)
Man kann nun einfach eine Standardisierung vornehmen, indem man εi durch σ
dividiert (εi /σ ist standardnormalverteilt mit Mittelwert 0 und Standardabweichung
13
Empirische Wirtschaftsforschung
1)
Pr(yi =
1| x′i )
β
εi
> −x′i
= Pr
σ
σ
εi
β
= Pr
≤ x′i
σ
σ
β
= F x′i
σ
Dies führt zur Likelihood Funktion
Y
yi 1−yi
n β
′β
′β
L
| y, X =
F xi
1 − F xi
σ
σ
σ
i=1
bzw. Log-Likelihood Funktion
n X
′β
′β
ln L =
yi ln F xi
+ (1 − yi ) ln 1 − F xi
σ
σ
i=1
Man beachte, dass β und σ hier immer nur gemeinsam als β/σ auftreten. Deshalb
kann nur das Verhältnis β/σ berechnet werden, nicht aber die getrennten Werte β
und σ. Man sagt, β und σ sind nicht einzeln identifiziert, sodern nur das Verhältnis
β/σ ist identifiziert.
Intuitiv kann man sich vorstellen, dass die latente Variable y ∗ im Strukturmodell
yi∗ = xi β + εi nicht beobachtbar ist, deshalb kann die Varianz von y ∗ nicht aus den
beobachteten Daten berechnet werden.
Tatsächlich kann man eine beliebige Varianz σ annehmen und dazu den entsprechenden Koeffizientenvektor β̃ berechnen. Aus Einfachkeitsgründen hat es sich eingebürgert, für das Probitmodell eine Varianz von Eins (σP2 = 1) und für das Logitmodell eine Varianz π 2 /3 (σL2 = π 2 /3) anzunehmen. Der Grund für diese Annahmen
liegt einzig und alleine in der damit zu erzielenden Einfachheit. Also
• Probit: Standardnormalverteilung mit µ = 0 und var(ε) = 1
εi ∼ N(0, 1)
• Logit: Standard-logistische Verteilung mit µ = 0 und var(ε) = π 2 /3
εi ∼ L(0, π 2 /3)
(L bezeichne die logistische Verteilung)
Abbildung 19.6 zeigt die Dichte und Verteilungsfunktionen dieser beiden Verteilungen.
Die geschätzten Koeffizienten werden sich deshalb im Logit- und Probitmodell unterscheiden
β̂L
β̂P
√
↔ p
1
π 2 /3
14
Empirische Wirtschaftsforschung
Dichtefunktionen:
0.5
0.4
0.3
0.2
0.1
0
−4
−3
−2
−1
0
1
2
3
4
0
1
2
3
4
Verteilungsfunktionen:
1.0
0.5
0
−4
−3
−2
−1
Standardnormalverteilung
Standardlogistische Verteilung
Standardisierte logist. Verteilung
Abbildung 19.6: Standardnormale & standard-logistische Verteilung
Deshalb würden wir näherungsweise erwarten, dass
p
β̂L ≈ π 2 /3 β̂P ≈ 1.81β̂P
Nach Amemiya (1981) sollte man eher einen Wert von 1.6 verwenden, da für diesen
Wert die Verteilungsfunktionen am ähnlichsten sind (vgl. Long, 1997, 47f)
β̂L ≈ 1.6β̂P
Diese Approximation funktioniert für Wahrscheinlichkeiten zwischen 0.1 und 0.9
recht gut.
Für einen Vergleich der Koeffizienten des Logit Modells mit den Koeffizienten des
linearen Wahrscheinlichkeitsmodells (LPM) empfiehlt Amemiya die Logit Koeffizienten mit 0.25 zu multiplizieren (vgl. Vogelvang 2005, S. 244; Greene 2003, S. 676).
15
Empirische Wirtschaftsforschung
Als grobe Faustregel gilt (Cameron & Trivedi 2005, 473)
β̂Logit ≃ 4 β̂OLS
β̂Probit ≃ 2.5 β̂OLS
β̂Logit ≃ 1.6 β̂Probit
Tabelle 19.5 zeigt die geschätzten Koeffizienten und deren p-Werte (Prob.) für das
LPM, Probit- und Logitmodell.
Tabelle 19.5: Vergleich der Modelle Fair (1978)
Variable
C
SEX
AGE
YMAR
KIDS
RELIG
EDUC
OCC
RMAR
LPM
0.7361
0.0452
-0.0074
0.0160
0.0545
-0.0537
0.0031
0.0059
-0.0875
Prob.
0.0000
0.2735
0.0193
0.0047
0.2396
0.0005
0.7180
0.6130
0.0000
Probit
0.7794
0.1735
-0.0246
0.0543
0.2166
-0.1855
0.0113
0.0137
-0.2718
Prob.
0.1284
0.2087
0.0183
0.0039
0.1896
0.0003
0.7028
0.7413
0.0000
Logit
1.3773
0.2803
-0.0443
0.0948
0.3977
-0.3247
0.0211
0.0309
-0.4685
Prob.
0.1208
0.2411
0.0153
0.0033
0.1725
0.0003
0.6769
0.6666
0.0000
Wichtig ist, dass dadurch zwar die geschätzten Parameter in einem gewissen Sinne
‘willkürlich’ sind (d.h. von der identifizierenden Annahme über die Varianz abhängig
sind), dass dies aber keine Auswirkungen auf die Wahrscheinlichkeiten (predicted
probabilities) hat.
Dies kann für das Logit Modell einfach gezeigt werden. Die Verteilungsfunktion für
die standardisierte logistische Verteilung (d.h. mit µ = 0 und σ 2 = 1) ist
√
exp[(π/
3) ε]
√
Λs (ε) =
1 + exp[(π/ 3) ε]
(diese standardisierte logistische Verteilungsfunktion ist in Abbildung 19.6 punktiert
eingezeichnet).
Wenn wir das Strukturmodell durch σ dividieren
yi+
x′ β εi
= i +
σ
σ
σ
hat εi /σ eine standardisierte logistische Verteilung
ε exp √π3 εσi
i
Λs
=
π εi
σ
√
1 + exp
3 σ
√
da σ = π/ 3 ist aber
16
Empirische Wirtschaftsforschung
Λs
ε i
σ
=
exp (εi )
= Λ(εi )
1 + exp (εi )
Deshalb hängt die geschätzte Eintrittswahrscheinlichkeit eines Ereignisses Pr(yi =
1| x) nicht von der Annahme über die Varianz von εi ab! Gleiches gilt für das Probit
Modell.
19.6
Interpretation der Parameter
Während die Schätzung der Modelle weitgehend von der entsprechenden Software
übernommen wird und deshalb kaum Probleme bereitet ist die Interpretation der
Ergebnisse deutlich komplexer als im Fall der linearen Regression. Abbildungen 19.7
und 19.8 verdeutlichen das Problem. Bei einer linearen Regression (Abbildung 19.7)
sind die marginalen Effekte konstant und eine Dummy-Variable führt zu einer einfachen Parallelverschiebung der Regressionsgerade im Ausmaß des Koeffizienten der
Dummy. Wie aus Abbildung 19.8 ersichtlich ist gilt dies nicht für nicht-lineare Modelle. Tatsächlich gehört eine kompakte Darstellung der Ergebnisse zu den schwierigeren Teilen einer Probit- oder Logit Analyse.
yi = β1 + β2xi + β3 Di
y
D=0
D=1
β2
β2
β3
x1
β3
β2
β2
x2
x
Abbildung 19.7: Interpretation der Parameter des linearen Regressionsmodells (LPM)
Die Abbildungen 19.9 und 19.10 zeigen die Funktion
Pr(yi = 1| x′i) = F (β1 + β2 xi )
für unterschiedliche β1 , bzw. β2 . Man beachte, dass eine Erhöhung des Interzepts
β1 zu einer Linksverschiebung führt (der Grund dafür sollte aus Abbildung 19.5
ersichtlich sein).
17
Empirische Wirtschaftsforschung
yi = f (α1 + α2 xi + α3 Di ) =
exp(α1 +α2 xi +α3 Di )
[1+exp(α1 +α2 xi +α3 Di )]
y
D=0
D=1
δ4
δ6
δ2
δ3
δ5
δ1
x1
x2
x
Abbildung 19.8: Interpretation der Parameter des Logit Modells
Pr(y = 1)
1.0
0.5
β1
β1
β1
β1
β1
= −10
= −5
=0
= +5
= +10
(β2 = 1)
0
−30 −25 −20 −15 −10 −5
0
5
10
15
20
25
Abbildung 19.9: Parameter β1 des Logit Modells
Abbildung 19.11 zeigt den multivariaten Fall
Pr(yi = 1| x′i ) = F (β1 + β2 xi1 + β3 xi2 )
19.6.1
Interpretation unter Verwendung der berechneten
Wahrscheinlichkeiten
Man kann nun die Schätzergebnisse verwenden um für bestimmte Werte von x′i die
entsprechenden Wahrscheinlichkeiten zu berechnen.
c i = 1| x′ ) = F (x′ β̂) = 1 − F (−x′ β̂)
Pr(y
i
i
i
18
Empirische Wirtschaftsforschung
β2
β2
β2
β2
β2
Pr(Y = 1)
1.0
= 0.1
= 0.3
=1
=2
= −0.5
(β1 = 0)
0.5
0
−30 −25 −20 −15 −10 −5
0
5
10
15
20
25
Abbildung 19.10: Parameter β2 des Logit Modells
1
0.75
PHY=1»XL
4
0.5
0.25
2
0
0
-4
X2
-2
-2
0
X1
2
-4
4
Abbildung 19.11: Das multivariate Logit Modell
Für jedes Individuum existiert eine individuelle Wahrscheinlichkeit, d.h. die Wahrscheinlichkeiten sind beobachtungsspezifisch. Man kann nun einfach über die Wahrscheinlichkeiten aller Individuen mitteln, zum Beispiel kann man aus den Daten von
Fair (1978) mit Hilfe einer Logit-Schätzung eine mittlere Seitensprungwahrscheinlichkeit von 0.24958 berechnen. Dies ist der Mittelwert der gefitteten Wahrscheinlichkeiten. In EViews erhalten Sie diesen Mittelwert z.B. mit
equation eq1.logit ema c sex age ymar kids relig educ occ rmar
eq1.fit ema_fit
coef(1) m1 = @mean(ema_fit)
show m1
Man kann alternativ aber auch die Wahrscheinlichkeiten im Mittelwert der jeweiligen
19
Empirische Wirtschaftsforschung
c i = 1| x̄′) = F (x̄′ β̂). Dafür erhält man aus den Fair (1978)
x berechnen, d.h. Pr(y
Daten einen Wert von 0.22246.
Diesen Wert können Sie in EViews z.B. berechnen, indem Sie aus der Equation
Toolbar View - Representations wählen, den Output mit Substituted Coefficients mit
Copy & Paste in ein Programm-Fenster kopieren und dort Variablennamen mit
@mean(varname) ersetzen; für dieses Beispiel6
coef(1) m2 = 1-@LOGIT(-(1.3772582 + 0.280286652*@mean(SEX)
0.0442550229*@mean(AGE) + 0.0947730223*@mean(YMAR)
0.397672133*@mean(KIDS) - 0.324720635*@mean(RELIG)
0.0210508638*@mean(EDUC) + 0.0309197089*@mean(OCC)
0.468454261*@mean(RMAR)))
show m2
+
+
-
_
_
_
_
Interessanter sind jedoch häufig die Bereiche der Wahrscheinlichkeiten für unterschiedliche Werte von x. Die minimale und maximale Wahrscheinlichkeit in der
Stichprobe ist definiert als
c i = 1| x′ ) = min F (x′ β̂)
min Pr(y
i
i
i
c i=
max Pr(y
1| x′i )
= max F (x′i β̂)
i
Dies sind die Werte für das Individuum mit der höchsten und das Individuum
mit der niedrigsten Wahrscheinlichkeit. In EViews erhalten Sie diese einfach aus
den oben berechneten gefitteten Werten z.B. mit ema_min1 = @min(ema_fit) bzw.
ema_max1 = @max(ema_fit). Die Werte für das Fair-Beispiel finden Sie in der ersten
Zeile von Tabelle 19.6.
Man kann auch den Bereich der Wahrscheinlichkeiten für die minimalen (bzw.
maximalen) Wert jeder einzelnen x-Variable berechnen, ungeachtet dessen, ob es
tatsächlich ein Individuum mit solchen extremen Merkmalsausprägungen in der
Stichprobe gibt. Dabei ist das Vorzeichen der geschätzten βbh zu berücksichtigen
(
(
bh ≥ 0,
min
x
wenn
β
maxi xki wenn βbh ≥ 0,
i
ki
←
− =
→
−
x
xh =
h
maxi xki wenn βbh < 0
mini xki wenn βbh < 0
− die zu verwendenden Werte von x für die Berechnung der minimalen
wobei ←
x
h
ih
→
und −
x h die Werte für die Berechnung der maximalen Wahrscheinlichkeit bezeichnet.
In der zweiten Zeile von Tabelle 19.6 finden sich die entsprechenden minimalen und
maximalen Wahrscheinlichkeiten
−) = F (←
−β̂)
c = 1| ←
Pr(y
x
x
und
−
→
c = 1| →
Pr(y
x ) = F (−
x β̂)
Man beachte, dass diesen Wahrscheinlichkeiten vermutlich kein Individuum der
Stichprobe entspricht, und dass die so berechneten Wahrscheinlichkeiten sehr empfindlich auf Ausreißer reagieren.
6
Das ‘underline’ Zeichen am Zeilenende (!) erlaubt einen Befehl über mehrere Zeilen zu schreiben.
20
Empirische Wirtschaftsforschung
Diese Bereiche der Wahrscheinlichkeiten sind nützlich, um das Ausmaß der NichtLinearität abzuschätzen. Wenn diese gefitteten Wahrscheinlichkeiten z.B. alle zwischen 0.2 und 0.8 liegen können sie vermutlich durch ein lineares Modell möglicherweise einigermaßen gut angenähert werden. Ebenso, wenn der Bereich zwischen
minimalen und maximalen Wert sehr klein ist.
Tabelle 19.6: Bereich der gefitteten Wahrscheinlichkeiten für das Logit Modell
(nach Fair 1978)
Variable
c i = 1| xi )
Pr(y
c i = 1| xmin / max )
Pr(y
SEX
AGE
YMAR
KIDS
RELIG
EDUC
OCC
RMAR
Min.
0.03173
0.00755
0.20025
0.08817
0.11768
0.17713
0.13435
0.19746
0.20585
0.14782
Max.
0.72473
0.92735
0.2489
0.35707
0.35325
0.24265
0.36260
0.23673
0.23783
0.53047
Diff.
0.69300
0.91980
0.04866
0.26890
0.23556
0.06551
0.22824
0.03927
0.03198
0.38265
Als nächstes kann man den Einfluss der einzelnen erklärenden Variablen untersuchen, indem man für jedes xh den minimalen und maximalen Wert einsetzt und
für alle anderen Variablen jeweils den Mittelwert einsetzt (x̄ ist ein Vektor mit den
Durchschnitten aller x Variablen außer der Variable xh ). Die Differenzen
c = 1| x̄, max xh ) − Pr(y
c = 1| x̄, min xh )
Diffh = Pr(y
sind für unser Beispiel in Tabelle 19.6 ab Zeile 3 angegeben. Eine kleine Differenz
bedeutet, dass eine Veränderung dieser Variable keinen großen Einfluss auf die prognostizierten Wahrscheinlichkeiten hat. Schließlich ist es wichtig, ob die maximalen
und minimalen Werte in einen Bereich fallen, in denen die Kurve einigermaßen linear
ist, oder in einen Bereich starker Nicht-Linearität.
Häufig ist es nützlich, die Wahrscheinlichkeiten über einen Bereich einer Variablen
graphisch darzustellen. Obwohl in unserem Beispiel das Geschlecht keinen signifikanten Erklärungsbeitrag leistet – und deshalb nicht interpretiert werden sollte –
wollen wir im Moment davon absehen um die Methode zu demonstrieren.
Abbildung 19.12 zeigt die gefittetet Wahrscheinlichkeiten getrennt für Männer und
Frauen (d.h. für SEX = 1 bzw. SEX = 0) über das Alter, wobei für alle anderen
Variablen der Mittelwert eingesetzt wurde. Offensichtlich nehmen die Wahrscheinlichkeiten für beide Geschlechter mit dem Alter ab, aber auch der Unterschied zwischen Männern und Frauen wird kleiner. In Abbildung 19.13 wird dasselbe über
die Ehejahre gezeigt (für das Alter und alle anderen Variablen wird der Mittelwert
eingesetzt). Hier wird der Unterschied zwischen Männern und Frauen offensichtlich
nicht geringer, sondern nimmt mit den Ehejahren sogar zu. Man beachte aber, dass
die gewählte Funktionsform keine Änderung des Vorzeichens zulässt.
21
Empirische Wirtschaftsforschung
Wir haben bisher jeweils die Mittelwerte für die ‘anderen’ erklärenden Variablen
eingesetzt. Wenn die Verteilung der Variablen sehr schief ist kann man überlegen
anstelle des Mittelwertes den Median heranzuziehen. Besondere Vorsicht ist angebracht, wenn sich unter den erklärenden Variablen weitere Dummies befinden. Da
der Mittelwert von Dummies nicht wirklich interpretierbar ist sollte man sich in
diesem Fall überlegen, ob man die Ergebnisse für jede Dummy-Kombination einzeln
darstellt.
.40
.35
Probability
.30
.25
Female
Male
.20
.15
.10
.05
15
20
25
30
35
40
45
50
55
60
AGE
Abbildung 19.12: Unterschiedliche
Seitensprungwahrscheinlichkeiten
von
Männern und Frauen in Abhängigkeit vom Alter (alle
anderen Variablen im Mittelwert)
.40
.35
Probability
.30
.25
Female
Male
.20
.15
.10
0
2
4
6
8
10
12
14
16
Years married
Abbildung 19.13: Beispiel: Unterschiedliche Seitensprungwahrscheinlichkeiten
von Männern und Frauen in Abhängigkeit von den Ehejahren
(alle anderen Variablen im Mittelwert)
22
Empirische Wirtschaftsforschung
19.6.2
Marginale Effekte
Im einfachen linearen Regressionsmodell können die Koeffizienten unmittelbar als
marginale Effekte interpretiert werden. Man könnte versucht sein dies auch für die
latente Variable y ∗ zu tun, da
yi∗ = x′i β + εi
mit
∂y ∗
= βh
∂xh
Das Problem besteht darin, dass die latente Variable y ∗ nicht beobachtbar ist, weshalb auch deren Varianz unbekannt ist; wir haben bereits festgestellt, dass βh nicht
identifiziert ist, sondern nur βh /σ.
Deshalb müssen wir uns auf die marginale Änderung von Pr(yi = 1| x′i) konzentrieren. Bekanntlich ist
Pr(yi = 1| x′i ) = F (x′i β)
und der marginale Effekt ist
∂F (x′i β)
∂F (x′i β) ∂x′i β
∂ Pr(yi = 1| x′i )
=
=
= f (x′i β)βh
′
∂xh
∂xh
∂xi β ∂xh
wobei f (x′i β) der Wert der Dichtefunktion an der Stelle x′i β ist. Deshalb hängt der
marginale Effekt Vom Wert aller x Variablen ab und ist nicht konstant!
Das Problem kann in Abbildung 19.11 veranschaulicht werden. Die Ableitung
∂ Pr(y = 1| x1 , x2 )/∂x1 gibt die Steigung einer Tangente in einem Punkt (xi1 , xi2 ) an,
die parallel zur x2 Achse verläuft (d.h. für ein fixes x2 ). Im Punkt (x1 = 0, x2 = −4)
verläuft diese Tangente sehr flach, eine Änderung von x1 hat in diesem kaum Auswirkungen auf die Eintrittswahrscheinlichkeit. Im Punkt x1 = 0, x2 = 0 sind hingegen
die Auswirkungen einer Änderung von x1 viel größer.
Nebenbei bemerkt ist das Verhältnis zweier marginaler Effekte konstant
∂ Pr(y=1| x)
∂xh
∂ Pr(y=1| x)
∂xl
=
βh
βl
aber selten von Interesse und schwer interpretierbar.
Meistens werden deshalb durchschnittliche marginale Effekte berechnet, wobei man
entweder den Mittelwert über alle Beobachtungen berechnen kann (average, d.h.
man berechnet für jede Beobachtung den marginalen Effekt und bildet anschließend
den Mittelwert)
n
∂P (y = 1| x)
1X
=
f (x′i β)βh
∂xh
n i=1
oder die Effekte im Mittelwert der erklärenden Variablen (at mean) (d.h. man berechnet den marginalen Effekt im Mittelwert der erklärenden Variablen)
∂ Pr(y = 1| x̄)
= f (x̄′ β)βh
∂xh
23
Empirische Wirtschaftsforschung
Tabelle 19.7: Logit-Schätzung (Fair 1978)
Dependent Variable: EMA
Method: ML - Binary Logit (Quadratic hill climbing)
Variable
C
SEX
AGE
YMAR
RELIG
RMAR
Coefficient Std. Error
t-Stat.
b0
1.9476
0.6123
3.1806
b1
0.3861
0.2070
1.8651
b2 −0.0439
0.0181 −2.4321
b3
0.1113
0.0298
3.7323
b4 −0.3271
0.0895 −3.6563
b5 −0.4672
0.0893 −5.2329
McFadden R-squared
0.094048 Log likelihood
Prob.
0.0015
0.0627
0.0153
0.0002
0.0003
0.0000
-305.9295
Tabelle 19.8: Marginale Effekte (Fair 1978)
Variable
SEX
AGE
YMAR
RELIG
RMAR
Logit
Average At Means
0.0645
0.0671
-0.0073
-0.0076
0.0186
0.0194
-0.0547
-0.0569
-0.0781
-0.0812
Probit
Average At Means
0.0642
0.0678
-0.0071
-0.0075
0.0184
0.0194
-0.0536
-0.0566
-0.0785
-0.0829
Tabelle 19.7 zeigt eine kürzere Logit-Schätzung für das Fair Beispiel (1978) und
Tabelle 19.8 die entsprechenden marginalen Effekte für das Logit- und das Probit
Modell.
Ein marginaler Effekt von ‘Geschlecht’ (Sex) ist natürlich sinnlos, da es sich um
eine Dummy Variable handelt! Für Dummy Variablen werden deshalb diskrete
Änderungen berechnet, also
∆P = Pr(y = 1| x̄, D = 1) − Pr(y = 1| x̄, D = 0)
Für das obige Logit Modell, und wenn für alle anderen Variablen wieder der Mittelwert angenommen wird, erhält man für das Geschlecht den diskreten Effekt
∆ Pr(EMA = 1| x̄, Sex) = 0.261264 − 0.193796 = 0.067468
Tip: In EViews kann im Equation-Menü unter View / Representations folgende
Gleichung mit Copy/Paste kopiert werden:
EMA = 1 −@LOGIT(−(1.948 + 0.386 ∗ SEX −0.044 ∗ AGE + 0.111 ∗ YMAR −0.327 ∗
RELIG − 0.467 ∗ RMAR))
Der diskrete Effekt von ‘Sex’ im Mittelwert aller anderen Variablen wird berechnet
als Differenz von
EMA1 = 1 − @LOGIT(−(1.948 + 0.386 ∗ SEX − 0.044 ∗ @mean(AGE) + 0.111 ∗
Empirische Wirtschaftsforschung
24
@mean(YMAR) − 0.327 ∗ @mean(RELIG) − 0.467 ∗ @mean(RMAR)))
und
EMA0 = 1 − @LOGIT(−(1.948 − 0.044 ∗ @mean(AGE) + 0.111 ∗ @mean(YMAR) −
0.327 ∗ @mean(RELIG) − 0.467 ∗ @mean(RMAR))).
In Stata können die marginalen Effekte ‘at means’ einfach mit dem postestimation
mfx Befehl berechnet werden; mit der Option at(atlist) können sie an einer beliebigen Stelle berechnet werden. Mit dem ado-Befehl margeff können auch die ‘average
marginal effects’ berechnet werden. Seit Version 12 von Stata steht der mächtigere
Befehle margins zur Verfügung.
Für R existiert ein Package effects. für nähere Hinweise siehe Kleiber and Zeileis
(2008, Chap. 5).
Die Auswirkungen von diskrete Änderungen sind manchmal auch für NichtDummy Variablen zweckmäßig, da die Unterschiede von marginalen und diskreten
Änderungen in nicht-linearen Modellen beträchtlich sein können, und da sie häufig
einfacher zu interpretieren sind.
∆ Pr(y = 1| x̄)
= Pr(y = 1| x̄, xh + δ) − Pr(y = 1| x̄, xh )
∆xh
Am häufigsten wird als diskrete Änderung δ entweder eine Einheit von xh (unit
change) oder eine Standardabweichung von xh (standard deviation change) angenommen werden.
Es hat sich außerdem eingebürgert die diskreten Änderungen symmetrisch um den
Mittelwert von xh anzunehmen, also x̄h ± δ/2, oder konkret
• Centered Unit Change
∆ Pr(y = 1, x̄)
1
1
= Pr y = 1| x̄, xh +
− Pr y = 1| x̄, xh −
∆xh
2
2
• Centered Standard Deviation Change
∆ Pr(y = 1, x̄)
sh sh = Pr y = 1| x̄, xh +
− Pr y = 1| x̄, xh −
∆xh
2
2
wobei sh die Standardabweichung von xh ist.
• Dummy Variable:
∆ Pr(y = 1, x̄)
= Pr (y = 1| x̄, xh = 1) − Pr (y = 1| x̄, xh = 0)
∆xh
Tabelle 19.9 zeigt diese zentrierten diskreten Effekte für das Fair Beispiel.
Insbesondere kann es manchmal sehr anschaulich sein, die Wahrscheinlichkeiten und
deren Änderungen für bestimmte ‘typische’ Repräsentanten anzugeben. Der Phantasie sind dabei kaum Grenzen gesetzt.
25
Empirische Wirtschaftsforschung
Tabelle 19.9: Diskrete Effekte im Logit & Probit Modell (Fair 1978)
Logit
Centered
Centered
Unit Change StDev Change
SEX
AGE
YMAR
RELIG
RMAR
0.109
0.137
0.057
0.029
0.041
0.222
0.046
0.020
Probit
Centered
Centered
Unit Change StDev Change
SEX
AGE
YMAR
RELIG
RMAR
-0.008
0.019
-0.057
-0.083
Dummy
0 to 1
0.184
Dummy
0 to 1
0.068
-0.070
0.108
-0.066
-0.091
Besondere Vorsicht ist geboten bei Interaktionseffekten in Probit- oder Logitmodellen
E(yi |x′i ) = F (β1 + β2 xi2 + β3 xi3 + β4 xi2 xi3 )
dann ist
∂ E(yi |x′i )
= (β2 + β4 xi3 )F ′
∂xi2
und
∂ 2 E(yi |x′i )
= β4 F ′ + (β2 + β4 xi3 )F ′′
∂xi2 ∂xi3
Offensichtlich können hier Interaktionseffekte auftreten, selbst wenn β4 = 0, und das
Vorzeichen des Koeffizienten des Interaktionseffekts β4 muss nicht einmal mit dem
Vorzeichen des Interaktionseffekts übereinstimmen. Außerdem kann die statistische
Signifikanz des Interaktionseffekts nicht mehr mit einem einfachen t-Test getestet
werden.
Ai and Norton (2003) zeigen diese Probleme auf und bieten Lösungsansätze.
19.6.3
Chancenverhältnisse (‘Odds Ratios’) im Logit Modell
Im Logit Modell gibt es im Unterschied zum Probit Modell eine relativ einfache
Interpretation der Koeffizienten.
Die Chance (engl. odds) ist definiert als
Odds:
Pr(yi = 1| x′i )
Pr(yi = 1| x′i )
=
Pr(yi = 0| x′i )
1 − Pr(yi = 1| x′i )
26
Empirische Wirtschaftsforschung
und gibt an, wie oft yi = 1 relativ zu yi = 0 passiert. Dieser Wert kann zwischen
Null und ∞ liegen.
Angenommen, die Wettervorhersage sagt mit einer Wahrscheinlichkeit von 3/4 für
den nächsten Tag Regen vorher. Dann ist die Wahrscheinlichkeit dafür, dass es nicht
regnet, gleich 1/4, und die Chance (Odds), dass es regnet, ist deshalb drei, weil
Odds:
Pr(yi = 1| x′i )
=
Pr(yi = 0| x′i )
3
4
1
4
=3
Der Logarithmus des Verhältnisses von Eintrittswahrscheinlichkeit zu NichtEintrittswahrscheinlichkeit (pi /(1 − pi )) ist als das Logit bekannt.
Man kann zeigen, dass
pi
Pr(yi = 1| x′i )
ln
≡ ln
= x′i β
1 − Pr(yi = 1| x′i )
1 − pi
wobei wir pi := Pr(yi = 1| x′i ) nur für eine einfachere Schreibweise einführen.
Beweis:
exp(x′i β)
1 + exp(x′i β)
1
=
1
+1
exp(x′ β)
pi ≡ Pr(yi = 1| x′i ) =
i
=
1
1 + exp(−x′i β)
Also ist
mit
1
= 1 + exp(−x′i β)
pi
1
1
pi
−1= −
= exp(−x′i β)
pi
pi pi
pi
= exp(x′i β)
1 − pi
pi
ln
= x′i β
1 − pi
∂ ln
pi
1−pi
= βh
∂xh
Dieser marginale Effekt ist zwar konstant, aber wieder schwer interpretierbar.
Zur Vereinfachung führen wir für die Chance pi /(1 − pi ) das Symbol Ω ein und
definieren
pi
ln(Chance) = ln Ω(x) ≡ ln
= x′i β
1 − pi
und betrachten insbesondere die Variable xh . Die Chance ist also
Ω(x, xh ) = exp (xβ)
= exp (β1 + β2 x1 + · · · + βh xh + · · · βh xh )
= exp(β1 ) exp(β2 x1 ) · · · exp(βh xh ) · · · exp(βh xh )
Empirische Wirtschaftsforschung
27
Wenn wir nun zur Variablen xh eine Konstante δ addieren folgt
Ω(x, xh + δ) = exp(β1 ) exp(β2 x1 ) · · · exp(βh (xh + δ)) · · · exp(βh xh )
= exp(β1 ) exp(β2 x1 ) · · · exp(βh xh ) exp(βh δ) · · · exp(βh xh )
Das Verhältnis der Chancen, genannt das Chancenverhältnis (‘odds ratio’ ), ist also
exp(β1 ) exp(β2 x1 ) · · · exp(βh xh ) exp(βh δ) · · · exp(βh xh )
Ω(x, xh + δ)
=
Ω(x, xh )
exp(β1 ) exp(β2 x1 ) · · · exp(βh xh ) · · · exp(βh xh )
= exp(βh δ)
Wenn sich also xh um δ ändert, ändert sich das Chancenverhältnis ceteris paribus
um den Faktor exp(βh δ). Die prozentuelle Änderung der Chance ist
Ω(x, xh + δ) − Ω(x, xh )
× 100 = [exp(βh δ) − 1] × 100
Ω(x, xh )
Für δ kann man verschiedene Werte wählen, z.B. 1 (v.a. für Dummies), oder auch
eine Standardabweichung von xh . Der Vorteil dieses Maßes besteht darin, dass es
konstant und unabhängig von allen x Variablen ist.
In unserem Fair Beispiel (siehe Tabelle 19.7) nimmt die erwartete Chance mit jedem
zusätzlichen Altersjahr also um ca. 4.3% ab [(exp(−0.0439 × 1) − 1) × 100 ≈ −4.3].
Vorsicht: Das Chancenverhältnis ist keine Wahrscheinlichkeit, eine Interpretation
wie ‘Erhöht man die erklärende Variable um eine Einheit, erhöht sich die Eintrittswahrscheinlichkeit um . . . ’ ist falsch!
19.7
Tests und Güte der Anpassung
Sowohl im Probit als auch im Logit Modell können Wald, LR- und LM Tests wie
üblich durchgeführt werden.
Insbesondere Liklihood-Ratio (LR) Tests sind einfach durchzuführen:
LR = −2[ln(LR ) − ln(LU )] ∼ χ2q
wobei ln(LU ) der Wert der Log-Likelihood Funktion eines nicht restringierten Modells und ln(LR ) der Wert der Log-Likelihood Funktion eines restringierten Modells
ist.
EViews (wie die meisten anderen Programme) geben standardmäßig den Wert der
Log-Likelihood Funktion des geschätzten Modells sowie den Wert der Log-Likelihood
Funktion einer Schätzung nur auf die Konstante (Restr. log likelihood) aus.
Mit Hilfe dieser Werte kann man einen LR-Test durchführen, ob die erklärenden Variablen gemeinsam einen Erklärungsbeitrag leisten (LR statistic (# df)). Dieser
Test entspricht dem üblichen F -Test des linearen Regressionsmodells.
28
Empirische Wirtschaftsforschung
19.7.1
McFadden Pseudo-R2
Das Pseudo-Bestimmtheitsmass von McFadden vergleicht den maximalen Wert der
Log-Likelihood-Funktion des interessierenden Modells mit dem maximalen Wert der
Log-Likelihood-Funktion eines Modells, das keine erklärenden Variablen, sondern
nur die Konstante enthält.
ln LM
ln LC
wobei ln LM der Wert der Log-Likelihood-Funktion des geschätzten Modells und
ln LC der Wert der Log-Likelihood-Funktion einer Schätzung nur auf die Konstante
ist. Man beachte, dass ln(LR ) < ln(LU ) und dass der Wert der log-Likelihood Funktion nie positiv werden kann (warum?), weshalb das McFadden Pseudo-R2 immer
zwischen Null und Eins liegt.
2
Pseudo-RMcF
= 1−
19.8
Spezifikation in binären Modellen
Eine korrekte Spezifikation ist bei Maximum-Likelihood Schätzung von binären Modellen besonders wichtig, da bei Fehlspezifikation von F (x′i β) die Schätzfunktionen
in aller Regel nicht konsistent sind.
Ein großer Teil der Spezifikationstests im OLS-Modell beruhte auf einer Analyse der
geschätzten Residuen. Dies wäre einfach, wenn die Residuen des latenten Modells
yi∗ = x′i β + εi zur Verfügung stünden, aber da y ∗ eine latente Variable ist, ist dies
nicht der Fall.
Allerdings können Residuen als Differenz zwischen den beobachteten (binären) yi
und
ci [yi = 1|x′ ] = F (x′ β̂) = Pr
ci
Pr
i
i
berechnet werden. Da eine Bernoulli verteilte Variable mit Mittelwert Pr eine Varianz Pr(1 − Pr) hat können diese Residuen standardisiert werden
ci
yi − Pr
ε̂i = q
c i (1 − Pr
ci )
Pr
Wenn diese Residuen gegen die Beobachtungsnummer geplottet werden können eventuelle Ausreißer erkannt werden.
Für das OLS Modell garantieren die Bedingungen erster Ordnung, dass die geschätzten Residuen ε̂ orthogonal auf die x-Variablen stehen.
Aus den Bedingungen erster Ordnung für die ML-Schätzung kann man die generalisierten Residuen (‘generalized residuals’ ) herleiten
ε̂i =
yi − F (x′i β̂)
x′i β̂(1
−
x′i β̂)
f (x′i β̂)
Diese generalisierten Residuen können ebenfalls Hinweise auf Ausreißer geben, sind
aber nicht normalverteilt.
29
Empirische Wirtschaftsforschung
Ein spezielles Problem in binären Modellen stellt Heteroskedastizität dar. Man kann
einfach zeigen, dass die bedingte Varianz von Probit- oder Logitmodellen immer von
der erklärenden x Variablen abhängt, also heteroskedastisch ist, denn
var(yi |xi ) = F (x′i β)[1 − F (x′i β)]
Wenn wir hier von Heteroskedastizität sprechen, so beziehen wir uns auf die latente
Variabel yi∗ = x′i β + εi mit homoskedastischen Störtermen εi = σi2 (x).
Wenn die Störterme dieser Gleichung für die latente Variable heteroskdastisch sind,
sind die Koeffizientenschätzungen verzerrt und nicht länger konsistent.
Deshalb empfiehlt es sich darauf zu testen. Davidson and MacKinnon (2003, 464f)
schlagen einen Test vor, der die Nullhypothese einer konstanten Varianz gegen die
Alternativhypothese
var(εi ) = [exp(zi γ]2
testet, wobei zi ein 1 ×q Vektor mit Variablen ist, von denen die Heteroskedastizität
abhängt, und γ ein q × 1 Vektor mit unbekannten Parametern ist.
Nach Davidson and MacKinnon (2003) (vergleiche auch Greene (2002, 681f)) kann
ein (asymptotischer) Test auf Heteroskedastizität auf der Grundlage einer Hilfsregression durchgeführt werden, nämlich
q
ci
yi − Pr
ci (1 − Pr
ci )
Pr
=
k
X
h=1
q
X f (−x′ β̂)(x′ β̂))
f (−x′i β̂)
i
b
q
q i
xih βh +
zij aj
c i (1 − Pr
ci )
ci (1 − Pr
ci )
j=1
Pr
Pr
c die gefitteten Wahrscheinlichkeiten sind (also ŷ) und f eine geeignete
wobei Pr
Dichtefunktion ist.
Die erklärte Quadratsumme (d.h. die Quadratsumme der gefitteten Werte) ist asymptotisch χ2 verteilt mit q Freiheitsgraden (q ist die Anzahl der Variablen in z).
Das folgende Beispiel (aus den EViews ‘Example Files’, siehe EViews Hilfe) zeigt
die Durchführung des Test anhand eines Beispiels aus Greene.
’ Test for Heteroskedasticity for Probit Model
’ Example 21.3 (p. 675) of Greene, William H. (2003) Econometric Analysis,
’ 5th edition, Prentice-Hall.
’create workfile
wfcreate probit u 32
’read data from Greene
series gpa
series tuce
series psi
series grade
gpa.fill 2.66,2.89,3.28,2.92,4,2.86,2.76,2.87,3.03,3.92,2.63,3.32,3.57, _
3.26,3.53,2.74,2.75,2.83,3.12,3.16,2.06,3.62,2.89,3.51,3.54,2.83,3.39, _
2.67,3.65,4,3.1,2.39
tuce.fill 20,22,24,12,21,17,17,21,25,29,20,23,23,25,26,19,25,19,23, _
25,22,28,14,26,24,27,17,24,21,23,21,19
30
Empirische Wirtschaftsforschung
psi.fill 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1
grade.fill 0,0,0,0,1,0,0,0,0,1,0,0,0,1,0,0,0,0,0,1,0,1,0,0,1,1,1,0,1,1,0,1
equation eq1.binary(d=n) grade c gpa tuce psi
eq1.makeresids(s) brmr_y
’ [s] -> standardized residuals
eq1.forecast p_hat ’ predicted probabilities
eq1.forecast(i) Xb
’ [i] -> forecast index
series fac=@dnorm(-xb)/@sqrt(p_hat*(1-p_hat))
group brmr_x fac (gpa*fac) (tuce*fac) (psi*fac)
equation eq2.ls brmr_y brmr_x (psi*(-xb)*fac)
eq2.forecast brmr_yf
scalar lm_test = @sumsq(brmr_yf)
’ lm_test = 1.548017
scalar p_val = 1-@cchisq(lm_test,1) ’ p_val = 0.213428
In diesem Fall muss die Nullhypothese konstanter Varianz nicht verworfen werden,
da eine LM-Statistik = 1.548017 mit einem p-Wert = 0.213428 berechnet wird.
Sollten in einem Modell Hinweise auf Heteroskedastizität gefunden werden kann
versucht werden ein Modell mit
εi ∼ N(0, σi2 )
mit
σi2 = [exp(zi γ]2
zu schätzen, aber dies geht über den Rahmen dieser Einführung hinaus.7
In Stata steht dafür der Befehl hetprob zur Verfügung.
Generell gelten alle Ergebnisse nur asymptotisch und man sollte deshalb mindestens
100 (oder besser 1000) Beobachtungen zur Verfügung haben.
Übungsbeispiel: Auf http://www.uibk.ac.at/ cb0189/data/cps88.zip finden Sie
einen Datensatz von Johnston/DiNardo über Union Participation (in Ascii, EViews
und Stata Format). Die Beschreibung und Definition der Variablen finden Sie in der
Readme-Datei.
1. Suchen Sie eine geeignete Spezifikation, um die Mitgliedschaft in den Gewerkschaften zu erklären.
2. Vergleichen Sie für diese Spezifikation die Schätzungen eines LPM, Probit- und
Logit Modells.
3. Berechnen Sie den ‘Bereich’ der gefitteten Wahrscheinlichkeiten für das Modell
und für mindestens zwei erklärende Variablen (entsprechend zu Tabelle 19.6
im Manuskript oder Table 3.4 in Long (1997, 66)). Führen Sie dies (und die
folgenden beiden Aufgaben) nur für das Probit oder Logit Modell durch.
7
Eine ausprogrammiertes Beispiel dazu findet man in den EViews ‘Example Files’ : Probit with
heteroskedasticity, HPROBIT.PRG, http://www.uibk.ac.at/econometrics/dl/logl.html.
Empirische Wirtschaftsforschung
31
4. Fertigen Sie eine Grafik für das Probit oder Logit Modell an, die die Wahrscheinlichkeit einer Mitgliedschaft in Abhängigkeit von einer intervallskalierten
Variable für zwei Gruppen (also die zwei Ausprägungen einer Dummy Variable) zeigt (wie z.B. Abb. 19.12 bzw. 19.13 im Manuskript; oder Figure 3.10
(3.11) in Long (1997, 67)).
5. Berechnen Sie für mindestens zwei Variablen die marginalen Effekte (sowohl
die durchschnittlichen als auch im Mittelwert; vgl. Tabelle 19.8 im Manuskript
oder Table 3.7 in Long (1997, 74)).
6. Berechnen Sie für mindestens eine Variable das Chancenverhältnis (odds ratio)
und interpretieren Sie dieses.
32
Empirische Wirtschaftsforschung
19.9
Das Ordinale Probit Modell (Ordered Probit
Model )
Ordinalen Daten begegnet man häufig in Fragebögen, wenn z.B. fünf Antwortmöglichkeiten zwischen ‘sehr gut’ und ‘sehr schlecht’ vorgegeben sind.
Am einfachsten ist das ordinale Probit Modell vermutlich wieder mit Hilfe latenter
Variablen zu verstehen. Wir stellen uns vor, dass die konkrete Ausprägung (z.B.
Antwort auf die Frage nach dem Ausmaß der Zustimmung 1 – 5) von einer unbeobachteten Variable y ∗ (z.B. einem Nutzenindex) abhängt. Welche Antwort von
den vorgegebenen Möglichkeiten gewählt wird hängt von Schwellenwerten ab. Aufgrund des ordinalen Charakters müssen die Abstände zwischen den Schwellenwerten
keineswegs gleich groß sein!
Angenommen das latente Modell erfülle alle Gauss-Markov Annahmen und die
Störterme seien normalverteilt (n.i.d., normally and independently distributed )
yi∗ = x′i β + εi ,
εi ∼ n.i.d.(0, 1)
Abbildung 19.14 zeigt die (unbeobachtbare!) latente Variable y ∗, die von einer Variable x (z.B. Alter) abhängt, und darunter die beobachtbare Variable y, die nur
diskrete Ausprägungen zwischen 1 und 5 zulässt.
Die der Grafik zugrunde liegenden Daten wurde mittels des folgenden EViewsProgramms erzeugt:
wfcreate(wf=ordered) u 50
rndseed 123
series trend = @trend
series ylat = -0.5 + 0.25*trend +
’ scat ylat @trend
series y = na
smpl @all if ylat > 10
y = 5
smpl @all if ylat > 8 and ylat <=
y = 4
smpl @all if ylat > 4 and ylat <=
y = 3
smpl @all if ylat > 1 and ylat <=
y = 2
smpl @all if ylat <= 1
y = 1
smpl @all
@rnorm
10
8
4
equation eq_ylat.ls ylat c trend
equation eq_y.ls y c trend
equation eq_ordered.ordered y c trend
Dieses Programm liefert unten stehenden Output. Die entsprechenden Regressionsgeraden für das latente und OLS-Modell sind auch in Abbildung 19.14 eingezeichnet.
33
Empirische Wirtschaftsforschung
b
b
yi∗
Latente Variable:
= −0.5 + 0.25xi + εi
y
b
b
b
b
b
10
τ4
b
b
b
b
b
b
b
8
b
b
b
b
b
b
b
b
b
τ3
b
b
b
b
6
b
b
b
b
4
b
τ2
b
b
b
b
b
b
2
b
b
b
b
τ1
b
b
b
b
b
b
0
b
b
0
4
8
12
16
20
24
28
32
36
40
44
x
48
Beobachtbare Variable:
y
10
8
6
b
4
b
b
2
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
b
0
0
4
8
12
16
20
24
28
32
36
40
44
48
x
Abbildung 19.14: Latente und beobachtete Variable in einem ordinalen Probit
Modell
Dependent Variable: YLAT
Method: Least Squares
Included observations: 50
Variable
C
TREND
Coefficient Std. Error
βb1 −0.246
0.296
βb2
0.245
0.010
R-squared
Adjusted R-squared
S.E. of regression
Sum squared resid
Durbin-Watson Stat.
0.920
0.919
1.063
54.198
2.178
t-Stat.
−0.831
23.549
Prob.
0.410
0.000
Log likelihood
Akaike info criterion
Schwarz criterion
F-statistic
Prob(F-statistic)
-72.962
2.998
3.075
554.541
0.000
OLS-Schätzung mit der beobachtbaren ordinalen Variable:
34
Empirische Wirtschaftsforschung
Dependent Variable: Y
Method: Least Squares
Included observations: 50
Variable
C
TREND
Coefficient Std. Error
b
β1
0.951
0.131
b
β2
0.080
0.005
t-Stat.
7.267
17.295
Prob.
0.000
0.000
R-squared
0.862 Log likelihood
Adjusted R-squared
0.859 Akaike info criterion
S.E. of regression
0.469 Schwarz criterion
Sum squared resid
10.578 F-statistic
Durbin-Watson Stat. 1.780 Prob(F-statistic)
-32.116
1.365
1.441
299.134
0.000
Eine ‘naive’ OLS-Schätzung liefert offensichtlich ganz andere Ergebnisse und ist
keine gute Näherung für das ‘wahre’ latente Modell yi∗ = −0.5 + 0.25xi + εi . Die
Ergebnisse wären bestenfalls ähnlich, wenn die Abstände zwischen den Schwellenwerten gleich groß wären, aber dies ist keine typische Eigenschaft ordinaler Daten.
Darüber hinaus sind die Störterme einer einfachen OLS-Regression auf eine ordinale
Variable heteroskedastisch.
Wie wir gleich sehen werden kann dieses Modell mit Maximum Likelihood geschätzt
werden. Der EViews Output einer solchen Schätzung ist
Dependent Variable: Y
Method: ML - Ordered Probit (Quadratic hill climbing)
Included observations: 50
Number of ordered indicator values: 5
Convergence achieved after 7 iterations
Covariance matrix computed using second derivatives
Variable
TREND
LIMIT 2:
LIMIT 3:
LIMIT 4:
LIMIT 5:
Coefficient Std. Error
b
β2
0.260
0.049
c2
1.941
0.544
c3
4.555
0.934
c4
9.239
1.771
c5 11.198
2.124
Log likelihood
LR statistic (1 df)
Probability(LR stat)
LR index (Pseudo-R2)
19.9.1
z-Stat.
5.341
3.566
4.875
5.218
5.273
Prob.
0.000
0.001
0.000
0.000
0.000
-27.324 Restr. log likelihood
98.693 Akaike info criterion
0.000 Schwarz criterion
0.6436
-76.67033
1.293
1.484
Wahrscheinlichkeit der beobachtbaren Ausprägungen
Wir wollen im folgenden normalverteilte Störterme unterstellen, obwohl die Überlegungen analog auch für das Logit Modell gültg sind.
35
Empirische Wirtschaftsforschung
Einfachheitshalber beginnen wir mit nur drei mögliche Ausprägungen. Die Beziehung zwischen der beobachteten Variable yi und der latenten Variable yi∗ sei
∗
0 wenn yi < τ1 ,
yi = 1 wenn τ1 ≤ yi∗ < τ2 ,
2 wenn yi∗ ≥ τ2 .
wobei τj Schwellenwerte (thresholds oder cutoff points) sind, wobei τ2 > τ1 etc. gelte.
y∗
y=5
τ4
E(y ∗ | x)
y=4
τ3
y=3
τ2
y=2
τ1
x1
x2
x3
x
y=1
Abbildung 19.15: Eintrittswahrscheinlichkeiten im ordinalen Probit Modell für 4
Schwellenwerte
Die Wahrscheinlichkeit für yi = 1 ist
Pr(yi = 1| x′i ) = Pr(τ1 ≤ yi∗ < τ2 | x′i )
Einsetzen von y ∗ = x′i β + εi gibt
Pr(yi = 1| x′i ) = Pr(τ1 ≤ x′i β + εi < τ2 | x′i )
Subtraktion von x′i β in der Klammer
Pr(yi = 1| x′i ) = Pr(τ1 − x′i β ≤ εi < τ2 − x′i β| x′i )
Die Wahrscheinlichkeit, dass eine Zufallsvariable einen Wert zwischen diesen Schwellenwerten annimmt, ist gleich der Differenz der Werte der Verteilungsfunktion an
diesen beiden Stellen
Pr(yi = 1| x′i ) = Pr(εi < τ2 − x′i β) − Pr(εi ≤ τ1 − x′i β)
= F (τ2 − x′i β) − F (τ1 − x′i β)
Dies kann natürlich für yi = m, gegeben X, verallgemeinert werden:
Pr(yi = m| x′i ) = F (τm − x′i β) − F (τm−1 − x′i β)
36
Empirische Wirtschaftsforschung
Für das erste Intervall fällt der zweite Term der rechten Seite weg, da das erste
Intervall bei −∞ beginnt, also F (−∞ − x′i β) = 0. Das letzte Intervall M erstreckt
sich bis +∞, also gilt analog
Pr(yi = M| x′i ) = F (∞ − x′i β) −F (τM −1 − x′i β) = 1 − F (τM −1 − x′i β)
|
{z
}
1
Für z.B. vier beobachtete Ausprägungen erhält man analog
Pr(yi
Pr(yi
Pr(yi
Pr(yi
19.9.2
= 1| x′i )
= 2| x′i )
= 3| x′i )
= 4| x′i )
=
=
=
=
F (τ1 − x′i β)
F (τ2 − x′i β) − F (τ1 − x′i β)
F (τ3 − x′i β) − F (τ2 − x′i β)
1 − F (τ3 − x′i β)
Schätzung
Die Wahrscheinlichkeit irgendeinen Wert von y
ist
Pr(yi = 1| x′i , β, τ )
..
.
pi = Pr(yi = m| x′i , β, τ )
..
.
Pr(y = M| x′ , β, τ )
i
i
bei der i-ten ‘Ziehung’ zu erhalten
wenn y = 1,
..
.
wenn y = m,
..
.
wenn y = M.
Wenn die Beobachtungen unabhängig sind ist die Likelihood Funktion
L(β, τ | y, X) =
n
Y
pi
i=1
bzw. für die einzelnen Ausprägungen
L(β, τ | y, X) =
=
M Y
Y
Pr(yi = m| x′i , β, τ )
m=1 yi =m
M Y
Y
m=1 yi =m
F (τm − x′i β) − F (τm−1 − x′i β)
Q
wobei yi =m das Produkt aller Fälle bedeutet, in denen das beobachtete y den Wert
m hat.
Die Loglikelihood Funktion ist deshalb
ln L(β, τ | y, X) =
M X
X
m=1 yi =m
ln [F (τm − x′i β) − F (τm−1 − x′i β)]
Mit Hilfe numerischer Methoden können die Werte von β̂ und τ̂ gefunden werden,
die diese Funktion maximieren.
37
Empirische Wirtschaftsforschung
19.9.3
Identifikation
Da die latente Variable y ∗ per Definition unbeobachtbar ist können weder Varianz
noch Mittelwert von y ∗ geschätzt werden. Für die Varianz wird deshalb im LogitModell var(εi | X) = π 2 /3 und im Probit-Modell var(εi | X) = 1 angenommen. Aber
dies reicht im Ordered Probit Modell noch nicht aus um alle β und τ zu identifizieren.
Um dies zu zeigen wollen wir uns zur Vereinfachung auf das bivariate Modell y ∗ =
β1 + β2 x + u und ‘wahre’ Schwellenwerte τm beschränken, von denen wir annehmen,
dass sie die beobachteten Daten erzeugen. Wir definieren zwei alternative Parameter
β1+ = β1 − γ
und
+
τm
= τm − γ
wobei γ eine beliebige Konstante ist.
Man kann nun zeigen, dass die Wahrscheinlichkeit für y = m für die wahren und
alternativen Parameter gleich ist
Pr(y = m| x) = F (τm − β1 − β2 x) − F (τm−1 − β1 − β2 x)
= F ([τm − γ] − [β1 − γ] − β2 x) − F ([τm−1 − γ] − [β1 − γ] − β2 x)
+
+
= F (τm
− β1+ − β2 x) − F (τm−1
− β1+ − β2 x)
mit anderen Worten, die Daten enthalten nicht genügend Information um das Interzept β1 und alle Schwellenwerte zu schätzen, bzw., das Modell ist nicht identifiziert.
Zwei identifizierende Annahmen sind in der Literatur gebräuchlich:
• Annahme τ1 = 0
• Annahme β1 = 0
Welche dieser Möglichkeiten man wählt ist im Prinzip gleichgültig und beeinflusst
b die Eintrittswahrscheinlichkeiten oder die Sinicht die Schätzung der restlichen β,
gnifikanztests. EViews wählt z.B. automatisch β1 = 0.
Für eine Diskussion siehe z.B. http://www.stata.com/support/faqs/stat/ologit_con.html.
19.9.4
Interpretation
Für die Interpretation der geschätzten Koeffizienten gilt ähnliches wie für das Probit Modell. Ein Koeffizient kann unmittelbar als marginaler Effekt auf die latente
Variable y ∗ interpretiert werden, da
y ∗ = Xβ + ε mit
∂y ∗
= βh
∂xh
Da die latente Variable y ∗ häufig keine unmittelbare Interpretation hat, und deren
Varianz außerdem nicht beobachtbar ist, ist dies selten sehr hilfreich.
Aussagekräftiger sind häufig prognostizierte Wahrscheinlichkeiten
c i = m| x′ ) = F (τ̂m − x′ β̂) − F (τ̂m−1 − x′ β̂)
Pr(y
i
i
i
38
Empirische Wirtschaftsforschung
Von diesen können wieder Mittelwerte oder Extremwerte berechnet werden, sie
können über Bereiche von exogenen Variablen geplottet werden oder tabellarisch
dargestellt werden, wie wir es schon für das Logit Modell gezeigt haben (vgl. z.B.
Long, 1997, 127ff).
Ebenso können marginale Effekte der prognostizierten Wahrscheinlichkeiten berechnet werden
∂F (τm − x′i β) ∂F (τm−1 − x′i β)
∂ Pr(yi = m| X)
=
−
∂xh
∂xh
∂xh
′
= βh f (τm−1 − xi β)) − βh f (τm − x′i β)
= βh [f (τm−1 − x′i β)) − f (τm − x′i β)]
wobei f (·) wieder die Dichtefunktion bezeichnet.
Man beachte, dass das Vorzeichen des marginalen Effektes nicht gleich dem Vorzeichen von βh sein muss, da [f (τm−1 − Xβ)) − f (τm − Xβ)] positiv oder negativ sein
kann.
Da diese marginalen Effekte wieder von den X abhängen kann wieder der Durchschnitt der marginalen Effekte aller Beobachtungen (‘average’ )
Avg.
∂ Pr(yi = m| X)
∂xh
i
1X h
′
′
βh f (τm−1 − xi β̂) − f (τm − xi β̂)
=
n i=1
n
oder die marginalen Effekte in den Mittelwerten der x-Variablen (‘at mean’ ) berechnet werden
∂ Pr(y = m| x̄)
= βh [f (τm−1 − x̄′ β) − f (τm − x̄′ β)]
∂xh
Für Dummy Variablen sind natürlich wieder diskrete Änderungen heranzuziehen,
aber auch für andere Variablen kann dies manchmal anschaulicher sein.
Literaturverzeichnis
Ai, C. and Norton, E. C. (2003), ‘Interaction terms in logit and probit models’,
Economics Letters 80(1), 123 – 129.
URL:
http://www.sciencedirect.com/science/article/B6V84-48CFVPF1/2/bcb7f777a652c51e50ed120c730430b1
Davidson, R. and MacKinnon, J. G. (2003), Econometric Theory and Methods, Oxford University Press, USA.
Fair, R. C. (1978), ‘A theory of extramarital affairs’, The Journal of Political Economy 86(1), 45–61.
Greene, W. H. (2002), Econometric Analysis (5th Edition), 5th edn, Prentice Hall.
Kleiber, C. and Zeileis, A. (2008), Applied Econometrics with R (Use R!), 2008 edn,
Springer.
Empirische Wirtschaftsforschung
39
Long, J. S. (1997), Regression Models for Categorical and Limited Dependent Variables (Advanced Quantitative Techniques in the Social Sciences), 1 edn, Sage
Publications, Inc.
Maddala, G. S. and Lahiri, K. (2009), Introduction to Econometrics, 4 edn, Wiley.