Diagnose Statistische Diagnose Statistische Diagnose Statistische
Werbung

Diagnose
Statistische Diagnose
Einordnung:
Kernfrage bzgl. der Modellierung:
Diagnose ∈ Problemklasse “Analyse”
Wieviel ist bekannt über das zu diagnostizierende System?
Begriffe der Diagnose:
• System.
Black box
Gray box
White box
Ausschnitt aus der realen Welt.
Hier: System zeigt Fehlverhalten bzw. einen Fehler.
• Symptom.
Beobachtbare Ausprägung einer Eigenschaft eines Systems,
die durch einen Fehler im System verursacht wird.
Wenn wenig bekannt ist, haben wir es mit einem Black-Box-Modell
bzw. assoziativem Modell zu tun.
Input
Output
Einfach: Abweichung vom Normalverhalten.
...
...
• Diagnose I.
Zustand eines Systems, der alle Symptome erklärt.
Black box
Hier: Diagnose = Fehler(zustand) bzw. Menge von
Fehler(zuständen)
Modellierung:
• Diagnose II.
Prozess zur Bestimmung einer Diagnose (im Sinne von I).
• statistische Verfahren
• neuronale Netze
• Methoden der Identifikation
• Hypothese.
Diagnosekandidat, mögliche Diagnose (im Sinne von I).
c
STEIN
2000-2004
V-1 Statistical Diagnosis: Bayes
• ...
c
STEIN
2000-2004
V-2 Statistical Diagnosis: Bayes
Statistische Diagnose
Statistische Diagnose
Problemstellung und Rahmen für Modellierung seien vorgegeben.
Arzt: “Das Medikament wird Sie mit einer Wahrscheinlichkeit von
90% heilen.”
Frage: Welche Problemlösungsmethode ist geeignet?
Was könnte damit gemeint sein?
Problemlösungsmethoden für
Analyseaufgaben
1. Er hat das Medikament bei 20 PatientInnen ausprobiert und 18
wurden geheilt.
statistische
Diagnose
fallbasierte
Diagnose
assoziative
Diagnose
funktionsbas.
Diagnose
verhaltensbas.
Diagnose
2. Er glaubt, daß, wenn er immer mehr PatientInnen mit diesem
Medikament behandeln würde, sich die relative Häufigkeit der
Erfolge bei genügend großer PatientInnen-Zahl bei 0.9
stabilisieren wird.
StrukturLogik-
Ursache/
Wirkungs-
Fehler-
modell
Verhaltens-
3. Er hält 90 Euro für den fairen Einsatz einer Wette, bei der er
100 Euro bekommt, wenn Sie geheilt werden.
Regel-
Fuzzy-
4. Ein statistischer Test mit der Irrtums-Wahrscheinlichkeit 10%
hat die Wirksamkeit des Medikamentes bewiesen.
Black-Box-
[Hennig, Univ. Hamburg]
V-3 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-4 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Statistische Diagnose
Entwicklung des Wahrscheinlichkeitsbegriffs
Prinzip:
Definition 27 (Zufallsexperiment, Zufallsbeobachtung)
Aus einer Menge vorhandener Fälle werden mit Hilfe statistischer
Methoden Aussagen über die typische Verteilung möglicher
Diagnosen abgeleitet.
Ein Zufallsexperiment ist ein – im Prinzip – beliebig oft
wiederholbarer Vorgang mit folgenden Eigenschaften:
• Anordnung.
• Aussagen quantifizieren den Zusammenhang zwischen
Symptomen und Diagnosen
• Aussagen umfassen oft a-Priori-Wahrscheinlichkeiten und
bedingte Wahrscheinlichkeiten
➜ Für gegebene Symptomkonstellationen können
Wahrscheinlichkeiten möglicher Diagnosen berechnet werden
➜ Wahrscheinlichste Diagnose (= Lösung) kann ausgewählt
werden.
Durch eine Beschreibung festgelegte reproduzierbare
Gegebenheit.
• Prozedur.
Ein festgelegtes Vorgehen innerhalb der Anordnung zur
Durchführung des Experiments.
• Unvorhersagbarkeit des Resultats.
Werden Anordnung und Prozedur nicht künstlich geschaffen, so
spricht man von natürlichen Zufallsexperimenten bzw. von
Zufallsbeobachtungen.
Grundlage wichtiger statistische Ansätze:
1. Theorem von Bayes
Bemerkungen:
2. Dempster-Shafer-Theorie
Der Vorgang kann mehrmalig mit demselben System oder einmalig mit
gleichartigen Systemen durchgeführt werden.
Auch Zufallsexperimente laufen kausal im Sinne von Ursache und Wirkung ab.
Die Zufälligkeit des Ergebnisses beruht nur auf dem Fehlen von Informationen
über die Ursachenkette.
V-5 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Entwicklung des Wahrscheinlichkeitsbegriffs
V-6 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Entwicklung des Wahrscheinlichkeitsbegriffs
Definition 28 (Ergebnisraum)
Empirisches Gesetz der großen Zahlen:
Eine Menge Ω = {ω1, ω2, . . . , ωn } heißt Ergebnisraum eines
Zufallsexperiments, wenn jedem Versuchsausgang höchstens ein
Element ω ∈ Ω zugeordnet ist. Die Elemente von Ω heißen
Ergebnisse.
Es gibt Ereignisse, deren relative Häufigkeit nach einer hinreichend
großen Anzahl von Versuchen ungefähr gleich einem festen
Zahlenwert ist.
Motivation zum klassischen Wahrscheinlichkeitsbegriff:
Definition 29 (Ereignisraum)
• Laplace-Experiment.
Jede Teilmenge A eines Ergebnisraums Ω heißt Ereignis. Ein
Ereignis A tritt genau dann ein, wenn ein Ergebnis ω vorliegt mit
ω ∈ A. Die Menge aller Ereignisse P(Ω) heißt Ereignisraum.
Hierunter versteht man ein Zufallsexperiment, bei dem auf
Basis einer Analyse der Anordnung und Prozedur
angenommen werden kann, daß alle Ergebnisse gleich
wahrscheinlich sind.
• Laplace-Wahrscheinlichkeiten.
Definition 30 (wichtige Ereignistypen)
Sei Ω ein Ergebnisraums, A ⊆ Ω und B ⊆ Ω zwei Ereignisse. Dann
sei vereinbart:
So bezeichnet man die Wahrscheinlichkeiten der Ergebnisse
eines Laplace-Experiments. Bei n Ergebnissen beträgt die
Wahrscheinlichkeit jedes Ergebnisses 1/n.
• ∅ heißt unmögliches Ereignis.
• Laplace-Annahme.
• Ω heißt sicheres Ereignis.
Hierunter versteht man die Annahme, daß es sich bei einem
Experiment um ein Laplace-Experiment handelt.
• Ω \ A =: A heißt Gegenereignis zu A.
• |A| = 1 ⇔ A heißt Elementarereignis.
• A ⊆ B ⇔ A heißt Teilereignis von B bzw. “A zieht B nach sich”.
• A = B ⇔ (A ⊆ B ∧ B ⊆ A).
• A ∩ B = ∅ ⇔ A und B sind unvereinbar (ansonsten vereinbar).
V-7 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-8 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Entwicklung des Wahrscheinlichkeitsbegriffs
Definition 31 (klassischer oder Laplace’scher Wahrscheinlichkeitsbegriff)
Wird jedem Elementarereignis aus Ω die gleiche
Wahrscheinlichkeit zugeordnet, so gilt für die Wahrscheinlichkeit
P (A) eines Ereignisses A:
P (A) =
|A| Anzahl der für A günstigen Elementarereignisse
=
|Ω|
Anzahl aller möglichen Elementarereignisse
Entwicklung des Wahrscheinlichkeitsbegriffs
Axiomatische Definition des Wahrscheinlichkeitsbegriffs:
1. Postulierung einer Funktion, die jedem Element des
Ereignisraums eine Wahrscheinlichkeit zuordnet.
2. Formulierung grundlegender Eigenschaften dieser Funktion in
Form von Axiomen.
Definition 32 (Wahrscheinlichkeitsmaß)
Bemerkungen:
• Strenggenommen handelt es sich hierbei nicht um eine Definition.
Warum nicht?
• Trifft die Laplace-Annahme nicht zu, so können die Wahrscheinlichkeiten
nur als relative Häufigkeiten bei der Durchführung vieler Versuche geschätzt
werden.
• Motiviert durch das empirische Gesetz der großen Zahlen wurde versucht,
den Wahrscheinlichkeitsbegriff frequentistisch, über den (fiktiven) Grenzwert
der relativen Häufigkeit zu definieren (hier insbesondere v. Mises, 1951).
Dieser Versuch scheiterte, weil dieser Grenzwert – im Gegensatz zu
Grenzwerten in der Infinitesimalrechnung – nicht nachweisbar ist.
Sei Ω eine Menge, genannt Ergebnisraum, und sei P(Ω) die Menge
aller Ereignisse, genannt Ereignisraum. Dann heißt eine Funktion
P : P(Ω) → R, die jedem Ereignis A ∈ P(Ω) eine relle Zahl P (A)
zuordnet, Wahrscheinlichkeitsmaß, wenn sie folgende
Eigenschaften besitzt:
1. P (A) ≥ 0
(Axiom I)
2. P (Ω) = 1
(Axiom II)
3. A ∩ B = ∅ ⇒ P (A ∪ B) = P (A) + P (B)
(Axiom III)
[Kolmogorow 1933]
Bemerkungen:
• Die drei Axiome heißen auch das Axiomensystem von Kolmogorow.
• P (A) wird als “Wahrscheinlichkeit für das Eintreffen von A” bezeichnet.
• Es ist nicht definiert, wie die Wahrscheinlichkeiten P verteilt sind.
• Allgemein nennt man eine Funktion, welche die drei Bedingungen der
Definition erfüllt, ein nicht-negatives, normiertes und additives Maß.
c
STEIN
2000-2004
V-9 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-10 Statistical Diagnosis: Bayes
Entwicklung des Wahrscheinlichkeitsbegriffs
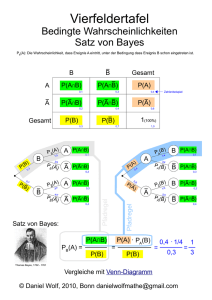
Bedingte Wahrscheinlichkeiten
Definition 33 (Wahrscheinlichkeitsraum)
Definition 34 (bedingte Wahrscheinlichkeit)
Sei Ω ein Ergebnisraum, P(Ω) ein Ereignisraum und P : P(Ω) → R
ein Wahrscheinlichkeitsmaß. Dann heißt das Paar hΩ, P i bzw. das
Tripel hΩ, P(Ω), P i Wahrscheinlichkeitsraum.
Seien hΩ, P(Ω), P i ein Wahrscheinlichkeitsraum und A, B ∈ P(Ω)
zwei Ereignisse. Die Wahrscheinlichkeit, daß A eintritt, wenn man
bereits weiß, daß B eingetreten ist, ist definiert durch
P (A | B) =
Satz 4 (Folgerungen der Axiome von Kolmogorov)
1. P (A) + P (A) = 1
2. P (∅) = 0
(aus Axiomen II und III)
P (A ∩ B)
,
P (B)
falls P (B) > 0
P (A | B) heißt bedingte Wahrscheinlichkeit für A unter der
Bedingung B.
(aus 1. mit A = Ω)
Bemerkung:
3. Monotoniegesetz des Wahrscheinlichkeitsmaßes:
A ⊆ B ⇒ P (A) ≤ P (B)
Die bedingte Wahrscheinlichkeit P (A | B) erfüllt für variables A und festes B die
Axiome von Kolmogorov und stellt ein Wahrscheinlichkeitsmaß dar.
(aus Axiomen I und II)
4. P (A ∪ B) = P (A) + P (B) − P (A ∩ B)
(aus Axiom III)
5. Seien A1, A2 . . . , Am paarweise unvereinbar, dann gilt:
P (A1 ∪ A2 ∪ . . . ∪ Am ) = P (A1) + P (A2) + . . . + P (Am)
V-11 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-12 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Bedingte Wahrscheinlichkeiten
Bedingte Wahrscheinlichkeiten
Wichtige Folgerungen aus der Definition der bedingten
Wahrscheinlichkeit:
1. P (A ∩ B) = P (B) · P (A | B)
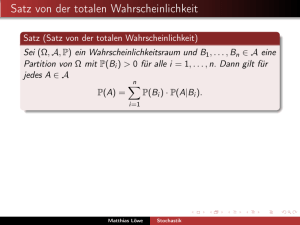
Satz 5 (totale Wahrscheinlichkeit)
Seien hΩ, P(Ω), P i ein Wahrscheinlichkeitsraum, B1, . . . , Bm
disjunkte Ereignisse mit Ω = B1 ∪ . . . ∪ Bm , P (Bi) > 0, i = 1, . . . , m
und A ∈ P(Ω). Dann gilt:
(Multiplikationsregel)
2. P (A ∩ B) = P (B ∩ A) = P (A) · P (B | A)
P (A) =
m
X
i=1
P (Bi) · P (A | Bi)
3. P (B) · P (A | B) = P (A) · P (B | A)
⇔ P (B | A) =
P (A ∩ B)
P (B) · P (A | B)
=
P (A)
P (A)
Beweis 1
4. P (A | B) = 1 − P (A | B)
P (A) = P (Ω ∩ A)
= P ((B1 ∪ . . . ∪ Bm) ∩ A)
Bemerkung:
= P ((B1 ∩ A) ∪ . . . ∪ (Bm ∩ A))
Im allgemeinen gilt P (A | B) 6= 1 − P (A | B).
=
m
X
i=1
m
X
=
i=1
m
X
=
i=1
P (Bi ∩ A)
P (A ∩ Bi )
P (Bi) · P (A | Bi)
2
c
STEIN
2000-2004
V-13 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-14 Statistical Diagnosis: Bayes
Unabhängigkeit von Ereignissen
Satz von Bayes
Definition 35 (stochastische Unabhängigkeit von zwei Ereignissen)
Satz 6 (Bayes)
Seien hΩ, P(Ω), P i ein Wahrscheinlichkeitsraum und A, B ∈ P(Ω)
zwei Ereignisse. A und B heißen stochastisch unabhängig (bei P )
genau dann, wenn gilt:
Seien hΩ, P(Ω), P i ein Wahrscheinlichkeitsraum, B1, . . . , Bm
disjunkte Ereignisse mit Ω = B1 ∪ . . . ∪ Bm , P (Bi) > 0, i = 1, . . . , m
und A ∈ P(Ω) mit P (A) > 0. Dann gilt:
P (A ∩ B) = P (A) · P (B)
“Produktregel”
P (Bi | A) =
P (Bi) · P (A | Bi)
m
X
i=1
P (Bi) · P (A | Bi)
Bemerkung:
Mit 0 < P (B) < 1 gelten folgende Äquivalenzen:
Beweis 2
P (A ∩ B) = P (A) · P (B)
Aus der Multiplikationsregel für P (A | Bi) und P (Bi | A) folgt:
⇔ P (A | B) = P (A | B)
⇔ P (A | B) = P (A)
P (Bi | A) =
Definition 36 (stochastische Unabhängigkeit von m Ereignissen)
Seien hΩ, P(Ω), P i ein Wahrscheinlichkeitsraum und A1, . . . , Am
∈ P(Ω) Ereignisse. A1 , . . . , Am heißen gemeinsam stochastisch
unabhängig (bei P ) genau dann, wenn für alle Teilmengen
{Ai1 , . . . , Aik } aus {A1, . . . , Am} mit i1 < i2 < . . . < ik und 2 ≤ k ≤ m
die Produktregel gilt:
P (A ∩ Bi ) P (Bi) · P (A | Bi )
=
P (A)
P (A)
Anwendung des Satzes der totalen Wahrscheinlichkeit für P (A) im
Nenner des Bruches gibt die Behauptung.
2
Bemerkungen:
• P (Bi ) heißt a-Priori-Wahrscheinlichkeit von B i.
• P (Bi | A) heißt a-Posteriori-Wahrscheinlichkeit von B i .
P (Ai1 ∩ . . . ∩ Aik ) = P (Ai1 ) · . . . · P (Aik )
V-15 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-16 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Satz von Bayes
Satz von Bayes
Anwendung von Bayes zur Diagnose:
Verallgemeinerung auf mehrere Ereignisse.
Aus Wahrscheinlichkeiten für Kausalzusammenhänge
P (<symptom> | <ursache>) und Ursachen P (<ursache>) kann
mittels Bayes die Wahrscheinlichkeit P (<ursache> | <symptom>) in
einer “Diagnosesituation” berechnet werden.
• Seien B1, . . . , Bm Ereignisse.
• Dann bezeichne P (A | B1, . . . , Bm ) die Wahrscheinlichkeit für A
unter der Voraussetzung, daß alle Bi eingetreten sind.
Schreibweisen auch: P (A | B1 ∧ . . . ∧ Bm), P (A | B1 ∩ . . . ∩ Bm)
• P (A | B1, . . . , Bm) heißt bedingte Wahrscheinlichkeit für A unter
den Bedingungen Bi.
Bemerkungen:
• Diagnosen entsprechen Ursachen.
• Diagnosen und Symptome werden als Ereignisse aufgefaßt.
Ereignisse sind Teilmengen eines Ergebnisraums Ω = {ω1, . . . , ωn }. Wie Ω
tatsächlich aussieht, wird in der statistischen Diagnostik oft nicht betrachtet.
Grund: Hier ist die wichtigste Begriffsebene (Knowledge level) auf den
Konzepten “Diagnose” bzw. “Hypothese” und “Symptom” aufgebaut.
Anwendung auf die Diagnose:
• Situation des Kausalzusammenhangs S1, . . . , Sk | D :
Es wird (wurde in der Vergangenheit) immer wieder festgestellt,
daß in der Situation D die Symptome S1, . . . , Sk beobachtet
werden können.
Man könnte sich den Ergebnisraums Ω als Menge von Vektoren ωi
vorstellen, wobei jeder Vektor ωi einer Zufallsbeobachtung des Systems
entspricht. Z. B. könnte ωi Informationen über Blutwerte,
Herz-Kreislaufwerte etc. beinhalten.
• Diagnosesituation D | S1 , . . . , Sk :
Umkehrung der Situation des Kausalzusammenhangs.
Beobachtet werden die Symptome S1 , . . . , Sk . Gesucht ist die
Wahrscheinlichkeit dafür, daß D vorliegt.
➜ Wenn sich Daten zur Berechnung von P (D) und
P (S1, . . . , Sk | D) akquirieren lassen, läßt sich P (D | S1, . . . , Sk )
mit dem Satz von Bayes berechnen.
c
STEIN
2000-2004
V-17 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-18 Statistical Diagnosis: Bayes
Satz von Bayes
Satz von Bayes
Gegeben sind:
Wird weiterhin vorausgesetzt:
• Menge von Diagnosen: Di, i = 1, . . . , m
•
• Menge von Symptomen: Sj , j = 1, . . . , k
m
X
i=1
P (Di) = 1
(die Menge der Diagnosen ist vollständig)
• P (Di, Dj ) = 0,
Mit Bayes folgt:
P (Di | S1 , . . . , Sk ) =
1 ≤ i, j ≤ m, i 6= j
(die Diagnosen schließen sich gegenseitig aus)
P (Di) · P (S1, . . . , Sk | Di)
P (S1, . . . , Sk )
dann gilt:
• P (S1, . . . , Sk ) =
Bemerkungen:
1. Der Aufbau einer Datenbasis, um verläßliche Werte für P (S 1 , . . . , Sk | Di )
schätzen zu können, ist in der Praxis unmöglich. Ausweg durch folgende
Annahme (“Naive Bayes Assumption”):
P (S1 , . . . , Sk | Di ) =
k
Y
P (Sj | Di )
“Unter dem Ereignis (der Bedingung) Di sind die Ereignisse S1 , . . . , Sk
stochastisch unabhängig.”
(Satz der totalen Wahrscheinlichkeit)
• P (S1, . . . , Sk ) =
D∈{Di |i=1,...,m}
P (Di ) ·
k
Y
m
X
i=1
P (Di) ·
k
Y
j=1
P (Sj | Di)
und insgesamt:
2. Die Wahrscheinlichkeit P (S1 , . . . , Sk ) ist eine Konstante und braucht nicht
bekannt zu sein, um das unter der “Naive Bayes Assumption”
wahrscheinlichste Ereignis DN B aus {Di | i = 1, . . . , m} zu bestimmen:
argmax
P (Di) · P (S1, . . . , Sk | Di)
(“Naive Bayes Assumption”)
j=1
DN B =
m
X
i=1
P (Di) ·
P (Di | S1, . . . , Sk ) =
m
X
i=1
P (Sj | Di )
k
Y
P (Sj | Di)
j=1
k
Y
P (Di) ·
j=1
P (Sj | Di)
j=1
Bemerkung:
Die Formel ermöglicht nicht nur eine Bestimmung der Rangordnung zwischen
den Di , sondern auch die Berechnung ihrer a-Posteriori-Wahrscheinlichkeiten.
Beachte aber die gemachten Voraussetzungen.
V-19 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-20 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Diagnose mit Bayes
Diagnose mit Bayes
Beispiel:
Fortsetzung Beispiel. Modellierung:
Eine Krankheit D liege bei 0.8% der Bevölkerung vor. Ein Bluttest
liefert in 98% aller Fälle ein „positives“ Ergebnis, falls die Krankheit
tatsächlich vorliegt.
Liegt die Krankheit nicht vor, liefert der Test trotzdem noch zu 3%
ein „positives“ Ergebnis. Die Frage ist nun, wie wahrscheinlich es
ist, daß ein Patient an D erkrankt ist, wenn der Bluttest „positiv“
ausgeht.
• A-Priori-Wahrscheinlichkeit für das Vorliegen der Krankheit:
P (D+) = 0.008
• A-Priori-Wahrscheinlichkeit für die Abwesenheit der Krankheit:
P (D−) = 0.992
• Bedingte Wahrscheinlichkeit für ein positives Ergebnis, unter
der Annahme, daß die Krankheit vorliegt: P (S+ | D+) = 0.98
• Bedingte Wahrscheinlichkeit für ein positives Ergebnis, unter
der Annahme, daß die Krankheit nicht vorliegt:
P (S+ | D−) = 0.03
P (D i ) ·
Rangordnung der Diagnosen gemäß fallender Werte
k
Y
P (Sj | Di ).
j=1
1. P (D− ) · P (S+ | D− ) = 0.992 · 0.03 = 0.0298
2. P (D+ ) · P (S+ | D+ ) = 0.008 · 0.98 = 0.0078
P (Di ) ·
A-Posteriori-Wahrscheinlichkeiten gemäß
m
X
i=1
P (S+ ) =
m
X
P (Di ) ·
i=1
k
Y
k
Y
P (Sj | Di )
j=1
k
Y
P (Di ) ·
.
P (Sj | Di )
j=1
P (Sj | Di ) = 0.0298 + 0.0078 = 0.0376 ≈ 3, 8%
j=1
• P (D− | S+ ) = 0.0298/0.0376 ≈ 79%
• P (D+ | S+ ) = 0.0078/0.0376 ≈ 21%
c
STEIN
2000-2004
V-21 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-22 Statistical Diagnosis: Bayes
Diagnose mit Bayes
Diagnose mit Bayes
Für einen Diagnoseansatz nach Bayes müssen umfangreiche,
gesicherte Datenmengen vorliegen. Entweder
• a-Priori-Wahrscheinlichkeiten für Diagnosen, P (Di), sowie
bedingte Wahrscheinlichkeiten P (Sj | Di)
oder
• eine Menge von Fällen C, die einen Zusammenhang zwischen
Diagnosen und Symptomen beschreiben:
C = {(Di, S) | i ∈ {1, . . . , m}, S ⊆ {S1, . . . , Sk }}
Die Anwendung von Bayes’ Formel zur Verarbeitung von Wissen
über Diagnosen und Symptome ist problematisch:
• Closed-World-Assumption: Die Menge der Diagnosen Di muß
vollständig sein.
• Single-Fault-Assumption: Die Diagnosen müssen sich
gegenseitig ausschließen, d. h. es darf nur eine Diagnose
zutreffen.
• Vereinfachtes Modell: Die Symptome Sj dürfen nur von den
Diagnosen abhängen und müssen untereinander unabhängig
sein.
• Welt ändert sich langsam: Die statistischen Daten müssen über
einen längeren Zeitraum (relativ) konstant bleiben.
Vorgehensweise:
1. Schätzung der a-Priori-Wahrscheinlichkeiten und der bedingten
Wahrscheinlichkeiten aus C.
2. Schätzung der a-Posteriori-Wahrscheinlichkeiten für die
einzelnen Diagnosen, P (Di | S1, . . . , Sk ), unter der Annahme,
daß die gegebenen Symptome S1, . . . , Sk vorliegen.
3. Auswahl der Diagnose mit der höchsten a-PosterioriWahrscheinlichkeit.
V-23 Statistical Diagnosis: Bayes
Diese Anforderungen sind in den meisten Fällen verletzt.
➜ Der Satz von Bayes ist oft nicht direkt anwendbar.
➜ In vielen Systemen werden Varianten des Satzes von Bayes
verwendet.
Bemerkung:
Je mehr Annahmen verletzt sind, desto fließender die Grenze zwischen
statistischen Verfahren und heuristischen Verfahren.
c
STEIN
2000-2004
V-24 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
Interpretation des Konzeptes “Wahrscheinlichkeit”
Beispiel: “Mit einer Wahrscheinlichkeit von 60% hat ein Patient mit den
Symptomen Fieber, Husten und Schwäche eine TBC.”
1. objektivistische Interpretation
• Wahrscheinlichkeit ist ein objektives Merkmal materieller Prozesse, die
unabhängig vom Beobachter stattfinden.
• Ein Wahrscheinlichkeitsurteil entspricht einem Wahrnehmungsurteil und
kann mehr oder weniger richtig sein.
Es gibt einen “wahren Wert” für die Wahrscheinlichkeit, daß ein Patient mit
den Symptomen Fieber, Husten und Schwäche TBC hat. Die Aussage “Mit
einer Wahrscheinlichkeit von 60%” kann diesem wahren Wert mehr oder
weniger gut entsprechen.
2. frequentistische Interpretation
• Wahrscheinlichkeit ist eine Beschreibung von Beobachtungen im Sinne
der Angabe der relativen Häufigkeit bezogen auf eine Referenzmenge.
• Wahrscheinlichkeit ist der Grenzwert der relativen Häufigkeit des
Auftretens eines Ereignisses für n → ∞.
Von 100 Patienten, die die Symptome Fieber, Husten und Schwäche gezeigt
haben, hatten 60 Patienten eine TBC. Die relative Häufigkeit “60%” nähert
sich der tatsächlichen Wahrscheinlichkeit mit zunehmendem n an. Sie wird
bei 100.000 Patienten eher der Wahrscheinlichkeit entsprechen als bei 100
Patienten.
Subjektivistische Verwendung von Bayes
Subjektivistische Deutung als Lernen aus Erfahrung:
• Ausgangspunkt sind bedingte Wahrscheinlichkeiten P (Aj | Bi)
für das Eintreffen von beobachtbaren Ereignissen
(Symptomen) Aj als Folge anderer, nicht beobachtbarer
Ereignisse (Systemzustände, Diagnosen) Bi.
• Die a-Priori-Wahrscheinlichkeiten P (Bi) der Systemzustände
seien unbekannt und sollen zunächst als gleichverteilt
angenommen werden.
1. Wird nun Ereignis Aj beobachtet, so lassen sich mit der Formel
von Bayes die a-Posteriori-Wahrscheinlichkeiten P (Bi | Aj ) der
Systemzustände Bi ausrechnen.
2. Die a-Posteriori-Wahrscheinlichkeiten P (Bi | Aj ) können als
neue Schätzung der a-Priori-Wahrscheinlichkeiten P (Bi) der
Systemzustände interpretiert werden: Lernen durch Erfahrung.
3. Eventuell weiter bei 1.
Bemerkung:
3. subjektivistische Interpretation
• Wahrscheinlichkeit ist Ausdruck eines subjektiven Grades an Gewissheit
bzw. Sicherheit.
• Ein Wahrscheinlichkeitsurteil kann somit nicht “objektiv” richtig oder
falsch sein, aber es besitzt subjektive Validität.
Je öfter der Zyklus aus Beobachtung eines Ereignisses und Aktualisierung der
a-Posteriori-Wahrscheinlichkeiten durchlaufen wird, um so exakter ist das
erworbene Wissen über die Welt – hier: Wissen darüber, welcher
Systemzustand Bi vorliegen mag.
Die Aussage ”Mit einer Wahrscheinlichkeit von 60%” ist ein Maß für die
subjektive Sicherheit des Arztes. D. h., in 60% aller vergleichbaren Fälle
würde der Arzt die richtige Diagnose TBC stellen.
[Sachse 04, TU Berlin]
c
STEIN
2000-2004
V-25 Statistical Diagnosis: Bayes
Subjektivistische Verwendung von Bayes
Beispiel:
c
STEIN
2000-2004
V-26 Statistical Diagnosis: Bayes
Subjektivistische Verwendung von Bayes
Fortsetzung Beispiel.
Gegeben sind drei Würfel, ein Laplace-Würfel W, ein RiemerU-Würfel und ein Riemer-L-Würfel:
1. Beobachtung: “3 fällt”.
a-Priori-Wahrscheinlichkeiten: P (W ) = P (L) = P (U ) = 1/3
Es ist bekannt: P (3 | W ) = 0.17, P (3 | L) = 0.21, P (3 | V ) = 0.1
2
➜ a-Posteriori-Wahrscheinlichkeiten (nach Bayes):
4
6
4
4
4
W
6
2
2
U
P (W | 3) =
L
=
Es wird gewürfelt, die Zahlen genannt, aber nicht der verwandte
Würfel gezeigt. Angenommen, es wird dreimal gewürfelt, zuerst 3,
dann 1 und schließlich 5. Welche Hypothesen sind zu entwickeln?
Aufgrund von Experimenten mit U- und L-Würfeln sind folgende
Wahrscheinlichkeitsverteilungen für die 3 Würfel bekannt:
W
L
U
Laplace-Würfel
L-Würfel
U-Würfel
1
0.17
0.01
0.24
2
0.17
0.14
0.06
P (W ) · P (3 | W )
P (W ) · P (3 | W ) + P (L) · P (3 | L) + P (U ) · P (3 | U )
3
0.17
0.21
0.10
4
0.17
0.40
0.10
5
0.17
0.14
0.06
6
0.17
0.10
0.44
0.33 · 0.17
≈ 0.35
0.33 · 0.17 + 0.33 · 0.21 + 0.33 · 0.1
P (L | 3) = . . . ≈ 0.35
P (U | 3) = . . . ≈ 0.21
2. Beobachtung: “1 fällt”.
Neue a-Priori-Wahrscheinlichkeiten sind die alten
a-Posteriori-Wahrscheinlichkeiten: P (W ) = 0.35, P (L) = 0.44, P (U ) = 0.21
Es ist bekannt: P (1 | W ) = 0.17, P (3 | L) = 0.01, P (3 | V ) = 0.21
➜ a-Posteriori-Wahrscheinlichkeiten:
P (W | 1) ≈ 0.52, P (L | 1) ≈ 0.04, P (U | 1) ≈ 0.44
3. Beobachtung: “5 fällt”.
[LearnLine NRW 2002]
a-Priori-Wahrscheinlichkeiten: P (W ) = 0.52, P (L) = 0.04, P (U ) = 0.44
➜ a-Posteriori-Wahrscheinlichkeiten:
P (W | 5) ≈ 0.73, P (L | 5) ≈ 0.05, P (U | 5) ≈ 0.22
V-27 Statistical Diagnosis: Bayes
c
STEIN
2000-2004
V-28 Statistical Diagnosis: Bayes
c
STEIN
2000-2004