Grundbegriffe und Kennwerte
Gliederung
• Deskriptive Statistik
• Grundbegriffe
–
–
–
–
–
Merkmale
Variable
Operationalisierung
Skalenniveaus
Fragebogenformate
• Datensätze in SPSS
• Kennwerte
– Häufigkeiten
– Maße der zentralen Tendenz
– Maße der Dispersion
02_grundbegriffe_kennwerte
1
Deskriptive Statistik
• Definition:
„Unter deskriptiver Statistik versteht man ein Gruppe
statistischer Methoden zur Beschreibung statistischer Daten
anhand statistischer Kennwerte, Graphiken, Diagrammen oder
Tabellen.“ (Leonhart, 2004)
• Deskriptive Statistik bezieht sich immer auf eine Stichprobe, d.h.
auf die Personen, die tatsächlich untersucht bzw. beobachtet
wurden.
• Die Inferenzstatistik zieht dagegen aus den in einer Stichprobe
erhobenen Daten Schlüsse auf die zugrunde liegende Population.
02_grundbegriffe_kennwerte
2
Grundbegriffe der Datenerhebung
• Bei einer Datenerhebung geht es darum, bestimmte
Merkmalsausprägungen der untersuchten Einheiten zu messen.
• Was sind Merkmale?
• Was sind Einheiten?
• Was ist eine Messung?
02_grundbegriffe_kennwerte
3
Deskriptive Statistik
Beispiel 1: Merkmale von Psychologiestudierenden:
• Geschlecht
• Alter
• Größe
• Wohnort
• Ängstlichkeit
• Extravertiertheit
• Statistikkenntnisse
02_grundbegriffe_kennwerte
4
Merkmale
Beispiel 2: Merkmale von Therapiemaßnahmen:
• Anzahl der therapeutischen Sitzungen (25 vs. 100)
• Therapeutisches „Setting“ (z.B. Einzel- vs. Gruppentherapie)
• Eingesetzte therapeutische Methoden (z.B. Gesprächsterapie vs.
Verhaltenstherapie)
• Motivation des Klienten
• Motivation des Therapeuten
• …
Eine statistische Erhebung von Merkmalen muss nicht auf Basis
von Personen erfolgen.
02_grundbegriffe_kennwerte
5
Merkmale
Qualitative vs. Quantitative Merkmale
• Qualitative Merkmale beschreiben die Zugehörigkeit einer
Person oder eines Objektes zu einer Kategorie.
• Quantitative Merkmale beschreiben die Ausprägung eines
Merkmals auf einem Kontinuum.
• Beispiele …
– Qualitativ: Geschlecht, Wohnort
– Quantitativ: Alter, Ängstlichkeit
02_grundbegriffe_kennwerte
6
Merkmale
Manifeste vs. Latente Merkmale
• Manifeste Merkmale können (im Prinzip) direkt beobachtet oder
gemessen werden.
• Latente Merkmale können nur indirekt zu erfasst werden. Diese
Merkmale sind meist nur unzureichend operational definiert, so
dass ihre Messung indirekt durch korrespondierender manifeste
Merkmale geschieht.
• Beispiele …
– Manifest: Geschlecht, Körpergröße
– Latent: Persönlichkeitseigenschaften
02_grundbegriffe_kennwerte
7
Deskriptive Statistik
Klassifikation von Merkmalen:
Manifest
Latent
Qualitativ
• Geschlecht
• Wohnort
• …
• Persönlichkeitstypus
(z.B. „Choleriker“)
• …
Quantitativ
• Alter
• Gewicht
• …
• Persönlichkeitseigenschaft
(z.B. Extraversion)
• …
02_grundbegriffe_kennwerte
8
Messung
Vom Merkmal zur Variable
• Um ein Merkmal exakt zu erfassen, muss eine präzise
Operationalisierung (Messvorschrift) vorliegen.
• Die Operationalisierung definiert, wie unterschiedliche
Ausprägungen eines Merkmals erfasst (kodiert) werden
• Die Kodierung der Merkmalsausprägungen erfolgt in der Regel in
Zahlen.
• Man spricht nun von einer Variable, die die Information enthält.
• Ein Messung ist also eine Zuordnung von Zahlen zu Objekten
gemäß den Regeln einer Operationalisierung.
02_grundbegriffe_kennwerte
9
Operationalisierung
Beispiele für Operationalisierungen
• Die Variable „sex“ soll das Geschlecht erfassen. Es wird für Frauen der
Wert 1 und für Männer der Wert 2 verwendet.
• Die Variable „alter“ soll das Alter der untersuchten Personen in Jahren
erfassen.
• Die Variable „alter“ soll das Alter von Säuglingen in Monaten erfassen.
• Die Variable „opt“ soll den selbst eingeschätzten Optimismus auf einer
Skala von -2 (überhaupt nicht optimistisch) bis +2 (extrem optimistisch)
erfassen.
• Die Variable „angst“ soll die Ängstlichkeit erfassen. Diese wird
gemessen als die Zeitdauer in Sekunden, bis eine Spinne angefasst
wird.
02_grundbegriffe_kennwerte
10
Variablen
Klassifikation von Variablen: Diskret vs. Kontinuierlich
• Diskrete Variablen: Die Anzahl der möglichen Werte ist
abzählbar.
• Kontinuierliche Variablen: Die möglichen Werte liegen auf einem
Kontinuum.
• Beispiele …
02_grundbegriffe_kennwerte
11
Merkmale und Variablen
Merkmal
qualitativ oder manifest
quantitativ ?
oder latent ?
diskret oder
kontinuierlich
Geschlecht
Alter
Wohnort
qualitativ
quantitativ
qualitativ
manifest
manifest
manifest
diskret
?
diskret
Optimismus
quantitativ
latent
diskret
quantitativ
latent
kontinuierlich
(Rating 1 bis 5)
Ängstlichkeit
(Zeit bis zur
Handlung)
02_grundbegriffe_kennwerte
12
Skalenniveaus
Möglichkeiten, das Konstrukt „Ängstlichkeit“ zu operationalisieren:
• „Mutprobe“ (z.B. bungee jump)
– Erfolg: angst=„0“
– Misserfolg: angst=„1“
• „Experten-Rating“ (Einschätzung)
–
–
–
–
nicht ängstlich („0“)
wenig ängstlich („1“)
eher ängstlich („2“)
klinisch relevante Angststörung („3“)
Die Art der Operationalisierung
beeinflusst das Skalenniveau und
damit die Möglichkeiten der
statistischen Auswertung!
• Ergebnis eines Ängstlichkeitsfragebogens
– Werte von 0-40
• „Mutprobe“
– Zeit bis zur erfolgreichen Handlung (0 bis ? Sekunden)
02_grundbegriffe_kennwerte
13
Skalenniveaus
Vier Skalenniveaus:
(1) Nominalskala
(2) Ordinalskala
(3) Intervallskala
(4) Verhältnisskala
• Die Messgenauigkeit und Aussagekraft der Daten steigt mit dem
Skalenniveau.
• Es sollte daher versucht werden, Daten auf einem möglichst
hohem Skalenniveau zu erfassen.
02_grundbegriffe_kennwerte
14
Skalenniveaus
Die Nominalskala
• Es werden „Namen“ (Zahlenwerte) für jede Merkmalsausprägung
vergeben.
• Beispiel: Geschlecht („m“ / „w“)
• Zwei Annahmen müssen berücksichtigt werden:
1.
2.
Exklusivität: Unterschiedliche Merkmalsausprägungen werden
unterschiedlichen Zahlen zugeordnet.
Exhaustivität: Jeder beobachteten Merkmalsausprägung eine Zahl
zugeordnet.
• Man spricht von einer homomorphen Abbildung, d.h. aus der
Variablen kann immer auf das Merkmal zurückgeschlossen
werden.
02_grundbegriffe_kennwerte
15
Skalenniveaus
Die Nominalskala
• Aussagekraft von Variablenwerten:
– Information über Gleichheit / Verschiedenheit der Merkmalsausprägung
(Keine Aussagen zu größer/kleiner Relationen möglich!)
• Mögliche Transformationen:
– Die Variablenwerte können willkürlich vorgegeben und auch nachträglich
geändert werden.
– Es sind alle eineindeutigen Transformationen erlaubt
– Beispiel:
weiblich = 1;
männlich = 2
oder weiblich = 2;
männlich = 1
oder weiblich = 100; männlich = 200;
02_grundbegriffe_kennwerte
16
Skalenniveaus
Die Ordinalskala
• Bei der Ordinalskala (Rangskala) geben die Variablenwerte
Aufschluss über die Rangfolge der Merkmalsträger bezüglich des
gemessenen Merkmals
• Beispiel: Schulabschluss
„0“=kein SA, „1“=Haupts., „2“=Reals., „3“=Gymnasium)
• Zusätzliche Annahme für die Operationalisierung:
3.
Die zugeordneten Zahlen repräsentieren eine Rangreihe der
Merkmalsausprägung.
02_grundbegriffe_kennwerte
17
Skalenniveaus
Die Ordinalskala
• Aussagekraft von Variablenwerten:
– Information über Gleichheit / Verschiedenheit der Merkmalsausprägung
– Größer / Kleiner Relationen
• Mögliche Transformationen:
– Erlaubt sind nur noch alle monotonen Transformationen.
– Beispiele
• y=x+3
• y = 2x
• y = log(x)
02_grundbegriffe_kennwerte
18
Skalenniveaus
Die Intervallskala
• Bei der Intervallskala geben die Variablenwerte Aufschluss über
die Abstände zwischen Merkmalsausprägungen.
• Beispiel: Ergebnisse eines Intelligenztests
(IQ (Peter) = 115; IQ(Anne) = 130 Differenz 15 Punkte )
• Zusätzliche Annahme für die Operationalisierung:
4.
Gleich große Intervalle zwischen Zahlenwerten der Variable
repräsentieren gleich große Abstände in der Merkmalsausprägung.
02_grundbegriffe_kennwerte
19
Skalenniveaus
Die Intervallskala
• Aussagekraft von Variablenwerten:
– Information über Gleichheit / Verschiedenheit der Merkmalsausprägung
– Größer / Kleiner Relationen
– Größe von Unterschieden
• Mögliche Transformationen:
– Erlaubt sind nur noch alle linearen Transformationen (y = ax+b).
– Beispiele
• y = x - 100
• y = 0.1 x
02_grundbegriffe_kennwerte
20
Skalenniveaus
Die Verhältnisskala
• Die Verhältnisskala kann vor allem bei der Messung
physikalischer Größen (Länge, Gewicht, Zeit) angenommen
werden.
• Beispiel: Reaktionszeit (ms)
• Zusätzliche Annahme für die Operationalisierung:
5.
Die Skala hat einen definierten Null-Punkt.
02_grundbegriffe_kennwerte
21
Skalenniveaus
Die Verhältnisskala
• Aussagekraft von Variablenwerten:
–
–
–
–
Information über Gleichheit / Verschiedenheit der Merkmalsausprägung
Größer / Kleiner Relationen
Größe von Unterschieden
Verhältnis von Merkmalsausprägungen (z.B. doppelte Reaktionszeit)
• Mögliche Transformationen:
– Erlaubt sind nur noch alle multiplikativen Transformationen (y = ax).
– Beispiele
• y = 0.001 ∙ x (Umrechnung von Millisekunden in Sekunden)
• y = 24 ∙ x (Umrechnung von Jahren in Monate)
02_grundbegriffe_kennwerte
22
Skalenniveaus
Skalenniveau
Beispiele
Mögliche
Aussagen
Erlaubte Transformationen
Nominalskala
Geschlecht,
Diagnosen
Gleichheit /
Verschiedenheit
Eineindeutige
Transformationen
Ordinalskala
Schulbildung,
Ratings
Größer / Kleiner
Relationen
Monotone Transformationen
Intervallskala
IQ,
Gleichheit von
Persönlichkeits- Differenzen
merkmale
Verhältnisskala Alter,
Reaktionszeit
02_grundbegriffe_kennwerte
Gleichheit von
Verhältnissen
Lineare Transformationen
Multiplikative
Transformationen
23
Skalenniveaus
• Das Skalenniveau hängt ab:
1. Von dem erhobenen Merkmal
2. Von der Operationalisierung der Messung
• Beispiele:
Geschlecht ist immer Nominalskaliert, da das Merkmal an sich keine
Rangreihe oder Intervalle definiert.
Ängstlichkeit kann jedoch nominal-, ordinal-, oder intervallskaliert
erhoben werden (s.o.)
• Durch die Art der Messung kann das Skalenniveau sinken.
02_grundbegriffe_kennwerte
24
Skalenniveaus
Niveau eines Merkmals vs. Niveau der Variablen
• Beispiel 1: Zeit bis zum Anfassen der Spinne
– Peter: 10 Sekunden; Martin: 20 Sekunden
– Also: „Martin hat doppelt so lange gezögert wie Peter.“ (Zeit ist verhältnisskaliert)
– Also: „Martin ist doppelt so ängstlich wie Peter“
– Das ergibt keinen Sinn
– Ängstlichkeit kann vermutlich nicht auf Verhältnisskalenniveau gemessen
werden.
• Für (latente) psychologische Konstrukte wird in aller Regel nur
Intervallskalenniveau angenommen.
02_grundbegriffe_kennwerte
25
Skalenniveaus
Niveau eines Merkmals vs. Niveau der Variablen
• Beispiel 2: Reaktionszeit
– Viele psychologische Studien beruhen auf Reaktionszeiten
– Die Zeit ist verhältnisskaliert
– Aber: Unterschiede zwischen 500 ms und 600 ms sind „psychologisch
bedeutsamer“ als Unterschiede zwischen 1500 ms und 1600 ms
– Daher werden Reaktionszeiten vor der Auswertung manchmal
logarithmiert
– Nun gilt:
• ln(600) - ln(500) = 6.40 – 6.22 = 0.18
• ln(1600) - ln(1500) = 7.38 – 7.31 = 0.07
– Eine Logarithmierung ist eigentlich nur für ordinalskalierte Variablen
zulässig.
– Dennoch wird angenommen, dass die logarithmierten Zeiten besser das
intervallskalierte Konstrukt (z.B. Aufmerksamkeit) abbilden.
02_grundbegriffe_kennwerte
26
Skalenniveaus
Das Skalenniveau von Fragebogen
• Oft ist das Skalenniveau umstritten:
– z.B. Schulnoten (ordinal oder intervall?)
– z.B. „Ratings“ (ordinal oder intervall?)
• Für einzelne Fragebogenitems kann man nur von einem
Ordinalskalennieveau ausgehen
• Bei einer Aggregation von vielen „Items“ (Summenbildung) wird
meist von einem Intervallskalenniveau ausgegangen.
• Für psychologische Untersuchungen ist das Intervallskalenniveau
von besonderer Bedeutung, da viele statistische Verfahren nur
bei intervallskalierten Daten eingesetzt werden können.
02_grundbegriffe_kennwerte
27
Unterschiedliche Fragebogenformate
Zweistufige Antworten
Trifft nicht zu
Trifft zu
Bei allem sehe ich stets die positive Seite.
1
0
Ich blicke immer mit Zuversicht in die Zukunft
1
0
Auch in unsicheren Zeiten rechne ich im allgemeinen damit, dass sich
alles zum Besten wendet.
1
0
Alles in allem erwarte ich, dass mir mehr gute als schlechte Dinge
widerfahren.
1
0
02_grundbegriffe_kennwerte
28
Unterschiedliche Fragebogenformate
-2
-1
0
1
2
Ich blicke immer mit Zuversicht in die Zukunft
-2
-1
0
1
2
Auch in unsicheren Zeiten rechne ich im allgemeinen damit,
dass sich alles zum Besten wendet.
-2
-1
0
1
2
Alles in allem erwarte ich, dass mir mehr gute als schlechte
Dinge widerfahren.
-2
-1
0
1
2
02_grundbegriffe_kennwerte
Trifft eher zu
Trifft eher nicht zu
Bei allem sehe ich stets die positive Seite.
Unbestimmt
Trifft gar nicht zu
Trifft voll und ganz zu
Mehrstufige Ratingskalen
29
Unterschiedliche Fragebogenformate
Bipolare Ratingskalen
Zufrieden
2
1
0
1
2
Ärgerlich
Gut
2
1
0
1
2
Schlecht
Ausgeruht
2
1
0
1
2
Schlapp
Gelassen
2
1
0
1
2
Angespannt
Ruhig
2
1
0
1
2
Unruhig
02_grundbegriffe_kennwerte
30
Zusammenfassung Grundbegriffe
• Die deskriptive Statistik dient der Beschreibung einer Stichprobe.
• Grundlage jeder Statistik ist ein Datensatz. Dieser entsteht durch
die Messung von Merkmalen der Mitglieder dieser Stichprobe.
• Dabei spielt die Operationalisierung der Merkmale eine
entscheidende Rolle.
• Die Daten können auf unterschiedlichen Skalenniveaus vorliegen:
– Noninalskala, Ordinalskala, Intervallskala, Verhältnisskala
• Grundsätzlich sollte versucht werden, bei einer Messung ein
möglichst hohes Skalenniveau zu erreichen.
• Bei der Erfassung vieler psychologischer Merkmale kann ein
Intervallskalenniveau erreicht werden.
02_grundbegriffe_kennwerte
31
Datensätze in SPSS
02_grundbegriffe_kennwerte
32
Datensätze in SPSS
02_grundbegriffe_kennwerte
33
Datensätze in SPSS
Erstellen eines neuen Datensatzes
• Definieren der Variablen (Variablenansicht)
–
–
–
–
–
Name (kurzer Bezeichner)
Typ (meist: Numerisch = Zahl oder String = Text)
evtl.: Variablenlable und Wertelable
wichtig: Wert für missings (fehlende Werte) definieren!
Messniveau (Skalenniveau): Nominal, ordinal, oder Metrisch
• Eingabe der Daten (Datenansicht)
– Jede Zeile ist ein Fall (eine Versuchsperson)
– Bei fehlenden Angaben immer den Wert für missings eintragen!
02_grundbegriffe_kennwerte
34
Statistische Kennwerte
• Daten können auf viele unterschiedliche Arten dargestellt
werden.
• Es gehört zu den Kompetenzen eines Statistikers zu entscheiden,
welche Art der Darstellung geeignet ist.
• Sinnvoll ist immer eine Zusammenfassung des ursprünglichen
Datensatzes.
• Gleichzeitig soll aber auch möglichst viel Information über das
erhobene Merkmal erhalten bleiben.
• Dies erfolgt z.B. durch die Darstellung von
– Häufigkeiten
– Maßen der Zentrale Tendenz
– Maßen der Dispersion
02_grundbegriffe_kennwerte
35
Häufigkeiten
• Eine Urliste enthält alle Werte einer Stichprobe
• Beispiel Geschlecht: (w, w, w, m, m, w, w, w, w, m, w, m, …)
• Zur Darstellung der Geschlechterverteilung fasst man diese
Urliste zusammen:
• Berechnung der Prozente:
02_grundbegriffe_kennwerte
Prozent
AnzKategorie
100
AnzGesam t
36
Häufigkeiten in SPSS
Befehle in SPSS
• Grundsätzlich gibt es zwei Möglichkeiten, Befehle aufzurufen
(1) Das Menu
• Vorteil: Einfache Bedienung, wenn man sich nicht gut auskennt
• Nachteil: Wenn man das Ergebnis nochmal braucht, muss man alles von neuem
anklicken.
(2) Das Syntaxfenster
• Öffnen mit Datei > Neu > Syntax
• Dann können Befehle direkt eingetippt werden.
• Vorteil: Man kann die Syntax speichern, und alle Berechnungen später erneut
ausführen
• Nachteil: Man muss die Befehle kennen
• Sie müssen den Syntax nicht für die Klausur lernen.
• ABER: Ich empfehle jedem regelmäßigem SPSS Nutzer, sich mit der SPSS Syntax
vertraut zu machen.
02_grundbegriffe_kennwerte
37
Häufigkeiten in SPSS
Häufigkeiten über das Menu berechnen
• Analysieren > Deskriptive Statistik > Häufigkeiten
02_grundbegriffe_kennwerte
38
Häufigkeiten in SPSS
Häufigkeiten über das Menu berechnen
• Die interessierenden Variablen aus der Liste (links) in das
Auswahlfeld (rechts) schieben
• … und OK anklicken
02_grundbegriffe_kennwerte
39
Häufigkeiten in SPSS
Häufigkeiten über den Syntax berechnen
• Ein Syntaxfester öffnen
• Den Befehl eingeben:
– frequency sex.
– fre sex.
• Den Befehl ausführen:
– Strg. R („run“)
– oder den blauen Pfeil
anklicken
02_grundbegriffe_kennwerte
40
Häufigkeiten in SPSS
Häufigkeiten – SPSS Ausgabe
02_grundbegriffe_kennwerte
41
Häufigkeiten in SPSS
Häufigkeiten – SPSS Ausgabe
02_grundbegriffe_kennwerte
42
Häufigkeiten in SPSS
Häufigkeiten – SPSS Ausgabe
Bundesland
Gültig
Baden-Württemberg
Bayern
Hessen
Saarland
Nordrhein-Westfalen
Rheinland-Pfalz
Niedersachsen
Berlin
Thüringen
Mecklenburg-Vorpommern
Bremen
außerhalb Deutschlands
Gesamt
Fehlend
-1
Gesamt
02_grundbegriffe_kennwerte
Häufigkeit
53
7
8
2
7
3
3
2
2
2
1
4
94
Prozent
54,1
7,1
8,2
2,0
7,1
3,1
3,1
2,0
2,0
2,0
1,0
4,1
95,9
4
4,1
98
100,0
Gültige
Kumulierte
Prozente
Prozente
56,4
56,4
7,4
63,8
8,5
72,3
2,1
74,5
7,4
81,9
3,2
85,1
3,2
88,3
2,1
90,4
2,1
92,6
2,1
94,7
1,1
95,7
4,3
100,0
100,0
43
Kategorisierung
• Oft hat ein Merkmal zu viele Ausprägungen, um für jede einzelne
die Häufigkeit anzugeben.
• In diesem Fall kann es sinnvoll sein, Kategorien zu bilden.
• Regeln für die Bildung von Kategorien:
–
–
–
–
–
Kategorien sind disjunkt (keine Überlappung)
Kategorien sind direkt benachbart (keine Lücken)
An den Rändern sind „offene“ Kategorien erlaubt
Alle geschlossenen Kategorien sind gleich breit
Je größer eine Stichprobe, desto mehr und desto schmalere Kategorien
werden gebildet, in der Regel nicht mehr als 20.
– Faustregel für die Anzahl der Kategorien (Leonhard, 2004):
•
•
•
•
Bei N Probanden:
Bei 20 Probanden:
Bei 100 Probanden:
Bei 1000 Probanden:
02_grundbegriffe_kennwerte
m = 1 + 3.32 · log (N)
m = 1 + 3.32 ∙ log (20) = 1 + 3.32 ∙ 1.3 ≈ 4
m = 1 + 3.32 ∙ log (100) = 1 + 3.32 ∙ 2.0 ≈ 8
m = 1 + 3.32 ∙ log (100) = 1 + 3.32 ∙ 3.0 ≈ 10
44
Kategorisierung
Kenntnisse in der Statistik
Häufigkeit
Gültig
02_grundbegriffe_kennwerte
0
0.1
2
5
10
15
20
23
25
30
35
36
40
50
55
60
62
65
70
80
Gesamt
8
1
2
7
17
6
12
1
2
12
1
1
10
10
1
1
1
1
2
2
98
Prozent
8,2
1,0
2,0
7,1
17,3
6,1
12,2
1,0
2,0
12,2
1,0
1,0
10,2
10,2
1,0
1,0
1,0
1,0
2,0
2,0
100,0
Gültige
Prozente
8,2
1,0
2,0
7,1
17,3
6,1
12,2
1,0
2,0
12,2
1,0
1,0
10,2
10,2
1,0
1,0
1,0
1,0
2,0
2,0
100,0
Kumulierte
Prozente
8,2
9,2
11,2
18,4
35,7
41,8
54,1
55,1
57,1
69,4
70,4
71,4
81,6
91,8
92,9
93,9
94,9
95,9
98,0
100,0
45
Kategorisierung
Selbsteinschätzung der Statistikkenntnisse (Kategorisiert)
Kategorie
Prozent
Kumuliert
0 ≤ x < 10
18.40%
18.40%
10 ≤ x < 20
23.40%
41.80%
20 ≤ x < 30
15.30%
57.10%
30 ≤ x < 40
14.30%
71.40%
40 ≤ x < 50
10.20%
81.60%
50 ≤ x < 60
11.30%
92.90%
7.10%
100.00%
60 ≤ x
02_grundbegriffe_kennwerte
46
Maße der Zentralen Tendenz
• Maße der zentralen Tendenz geben an, wie ein Merkmal bei den
meisten Mitgliedern einer Stichprobe bzw. in dieser Stichprobe
im Durchschnitt ausgeprägt ist.
• Es gibt dafür unterschiedliche Maße der zentralen Tendenz
– Modalwert (für alle Skalentypen)
– Median (für mindestens ordinalskalierte Daten)
– Mittelwert (für mindestens intervallskalierte Daten).
02_grundbegriffe_kennwerte
47
Der Modalwert
• Der Modalwert (Modus, Mo) ist derjenige Wert aus einer
Verteilung, welcher am häufigsten besetzt ist.
• Es kann auch mehrere Modalwerte geben.
– SPSS gibt dann nur den kleinsten Wert aus.
• Bei kategorisierten Daten wird die Mitte der am häufigsten
besetzten Kategorie angegeben.
• Die Angabe des Modalwertes ist besonders bei nominalskalierten
Daten sinnvoll.
02_grundbegriffe_kennwerte
48
Der Modalwert
Beispiele:
02_grundbegriffe_kennwerte
Wert
0
0.1
2
5
10
15
20
23
25
30
35
36
40
50
55
60
62
65
70
80
Häufigkeit
8
1
2
7
17
6
12
1
2
12
1
1
10
10
1
1
1
1
2
2
Kategorie
Prozent
0 ≤ x < 10
18.40%
10 ≤ x < 20
23.40%
20 ≤ x < 30
15.30%
30 ≤ x < 40
14.30%
40 ≤ x < 50
10.20%
50 ≤ x < 60
11.30%
60 ≤ x
7.10%
49
Der Modalwert in SPSS
Den Modalwert über das Menu berechnen
• Analysieren > Deskriptive Statistiken > Häufigkeiten…
• Auswahl „Statistiken …“
• Auswahl „Modalwert“
02_grundbegriffe_kennwerte
50
Der Modalwert in SPSS
Den Modalwert über den Syntax berechnen
frequencies age
/format notable
/statistics modus.
•
•
•
•
Ergänzende Unterbefehle in der Syntax werden immer mit
einem „/“ eingeleitet.
Ganz am Ende des Kommandos steht ein Punkt.
„/format notable“ unterdrückt die normale Häufigkeitstabelle
„/statistics modus” gibt den Modalwert aus.
02_grundbegriffe_kennwerte
51
Der Modalwert in SPSS
Modalwert – SPSS Ausgabe
02_grundbegriffe_kennwerte
52
Der Median
Der Median
• Der Median (Md) ist derjenige Wert, der die geordnete Reihe der
Messwerte in die oberen und die unteren 50 Prozent aufteilt.
Somit ist die Anzahl der Messwerte über und unter dem Median
gleich.
• Man benötigt ordinalskalierte Daten, um eine „geordnete Reihe“
bilden zu können.
02_grundbegriffe_kennwerte
53
Der Median
Der Median – Berechnung
• Für ungerade N nimmt man den Wert in der Mitte der
geordneten Liste:
– Liste: 20, 21, 23, 27, 35
– Md = 23
– Allgemein: Md x N 1
2
• Für gerade N nimmt man den Mittelwert der beiden in der Mitte
stehenden Werte:
– Liste: 20, 21, 23, 27, 35, 36
– Md = (23+27) / 2 = 25
xN xN
– Allgemein:
02_grundbegriffe_kennwerte
Md
2
2
1
2
54
Der Median
Beispiel:
02_grundbegriffe_kennwerte
55
Der Median in SPSS
Den Median über das Menu berechnen
• Analysieren > Deskriptive Statistiken > Häufigkeiten
• Auswahl „Statistiken …“
• Auswahl „Median“
02_grundbegriffe_kennwerte
56
Der Median in SPSS
Den Median über den Syntax berechnen
frequencies age
/format notable
/statistics median.
•
•
•
•
•
Ergänzende Unterbefehle in der Syntax werden immer mit
einem „/“ eingeleitet.
Ganz am Ende des Kommandos steht ein Punkt.
„/format notable“ unterdrückt die normale Häufigkeitstabelle
„/statistics median” gibt den Median aus.
Man kann auch Kennwerte kombinieren:
–
“/statistics median, modus.”
02_grundbegriffe_kennwerte
57
Der Median in SPSS
Median – SPSS Ausgabe
02_grundbegriffe_kennwerte
58
Der Median
Der Median bei kategorisierten Daten
• Bei kategorisierten Daten wird berücksichtigt, wie viel Prozent
der Stichprobe oberhalb und unterhalb der Kategorie mit dem
Median liegen.
• Berechnung:
–
–
–
–
uG:
KB
fk
cum fk-1:
02_grundbegriffe_kennwerte
0.5 N cum f k 1
Md uG
KB
fk
Untere Grenze der Kategorie, in der der Median liegt.
Breite der Kategorie
Häufigkeit in der Kategorie k, in der der Median liegt
kumulierte Häufigkeit der Kategorie k-1, d.h. die Summe der
Häufigkeiten aller Kategorien unter dem Median.
59
Der Median
Berechnung
0.5 N cum f k 1
Md uG
KB
fk
0.5 98 42
Md 20
10
15
20 0.47 10
Kategorie
f
cumf
0 ≤ x < 10
18
18
10 ≤ x < 20
24
42
20 ≤ x < 30
15
57
30 ≤ x < 40
14
71
40 ≤ x < 50
11
82
50 ≤ x < 60
11
93
60 ≤ x
7
100
20 4.7
24.7
02_grundbegriffe_kennwerte
60
Das arithmetische Mittel
Das arithmetische Mittel
• Der arithmetische Mittel (Mittelwert, „Durchschnitt“, x ) ist das
häufigste Maß der zentralen Tendenz.
• Das arithmetische Mittel darf nur für intervallskalierte Daten
berechnet werden.
02_grundbegriffe_kennwerte
61
Das arithmetische Mittel
Das arithmetische Mittel – Berechnung
• Das arithmetische Mittel ist die Summe aller Messwerte geteilt
durch deren Anzahl N.
x
N
x
i 1 i
N
02_grundbegriffe_kennwerte
Zum Rechnen mit dem
Summenzeichen siehe auch
Leonhart (2004, S. 421f)
62
Das arithmetische Mittel
Beispiel:
95
x
19
5
02_grundbegriffe_kennwerte
Vp
lot
1
16
2
23
3
12
4
19
5
25
63
Das arithmetische Mittel in SPSS
Das arithmetische Mittel über das Menu berechnen
• Analysieren > Deskriptive Statistiken > Deskriptive Statistik…
• Variable auswählen
• OK
02_grundbegriffe_kennwerte
64
Das arithmetische Mittel in SPSS
Das arithmetische Mittel über den Syntax berechnen
descriptives lot.
oder
descriptives lot
/statistic mean.
oder
descriptives age, lot, stat_k
/statistic mean.
oder
frequency age, lot, stat_k
/format notable
/statistic mean.
02_grundbegriffe_kennwerte
65
Das arithmetische Mittel in SPSS
Das arithmetische Mittel– SPSS Ausgabe
frequency age, stat_k, lot
/format notable
/statistic mean.
descriptives age, stat_k, lot
/statistic mean.
02_grundbegriffe_kennwerte
66
Vergleich der Maße der Zentralen Tendenz
frequencies age, freiburg
/format notable
/statistics modus median mean.
•
•
•
Alter: Mittelwert > Median > Modus
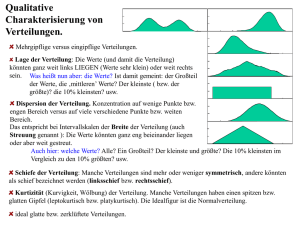
Einstellung zu Freiburg: Modus > Median > Mittelwert
Warum?
02_grundbegriffe_kennwerte
67
Vergleich der Maße der Zentralen Tendenz
02_grundbegriffe_kennwerte
68
Vergleich der Maße der Zentralen Tendenz
Linkssteile Verteilung
Rechtssteile Verteilung
AM Median Modus
Modus Median AM
Symmetrische Verteilung
02_grundbegriffe_kennwerte
Modus Median AM
69
Das gewichtete arithmetische Mittel (GAM)
Das gewichtete arithmetische Mittel (GAM)
• Problem: Wie berechnet man das arithmetische Mittel, wenn
man nur Mittelwerte aus verschiedenen Gruppen kennt?
• Beispiel: Die Studienmotivation von Psychologiestudierenden des
1.Semesters soll bestimmt werden. Ein Fragebogen wird in den
drei Tutorien vorgegeben. Die Tutorinnen melden folgende
Ergebnisse zurück:
– Gruppe 1: M = 12
– Gruppe 2: M = 10
– Gruppe 3: M = 8
• Wichtig: Die Gruppengrößen müssen beachtet werden!
02_grundbegriffe_kennwerte
70
Das gewichtete arithmetische Mittel (GAM)
Berechnung:
n x
GAM
n
k
i 1 i
k
i 1
i
i
Gruppe 1: M=12; N=50
Gruppe 2: M=10; N=20;
Gruppe 3: M=8; N=10;
02_grundbegriffe_kennwerte
n1 x1 n2 x2 n3 x3
GAM
n1 n2 n3
50 12 20 10 10 8
50 20 10
600 200 80
80
880
80
11
71
Zusammenfassung: Maße der zentralen Tendenz
• Eine einfache Form der Zusammenfassung ist die Darstellung der
Häufigkeiten oder Prozente.
• Der Modalwert ist der Wert einer Verteilung, der am häufigsten
vorkommt.
• Der Median ist der Wert, der eine Stichprobe in die oberen 50%
und unteren 50% aufteilt.
• Der Mittelwert ist die Summe aller Werte geteilt durch die
Anzahl der Werte.
• Die Maße der zentralen Tendenz lassen auch Rückschlüsse auf
die Verteilungsform zu.
• Sollen Mittelwerte aus Mittelwerten berechnet werden, müssen
die Gruppengrößen berücksichtigt werden (GAM).
02_grundbegriffe_kennwerte
72
Maße der Dispersion
• Die Maße der zentralen Tendenz geben Auskunft über die „Mitte“
einer Verteilung.
• Maße der Dispersion beziehen sie dagegen auf die „Variabilität“
einer Verteilung, d.h. darauf, wie sehr sich die Werte
unterscheiden.
• Beispiel: Schulnoten in zwei Klassen
– Gruppe 1: 3, 3, 3, 3, 3, 3, 3
– Gruppe 2: 1, 2, 3, 3, 3, 4, 5
– Modalwert (=3), Median (=3) und Mittelwert (=3) unterscheiden nicht
zwischen beiden Gruppen!
– Dennoch gibt es natürlich Unterschiede zwischen den Verteilungen.
02_grundbegriffe_kennwerte
73
Maße der Dispersion
Maße der Dispersion:
• Spannweite
• Interquartilabstand
• Varianz
• Standardabweichung
• Schiefe, Exzess
02_grundbegriffe_kennwerte
74
Spannweite (Range)
• Die Spannweite wird auch als Variationsbreite oder Range
bezeichnet.
• Unterschiedliche Definitionen für kontinuierliche und diskrete
Variablen:
– Für kontinuierliche Variablen:
Range = maximaler Wert – minimaler Wert.
– Für diskrete Variablen:
Range = maximaler Wert – minimaler Wert +1
(bzw.: Range = Anzahl der Kategorien)
• Bewertung
– Eher geringe Aussagekraft über die Verteilung, da nur 2 Werte
berücksichtigt werden (der Kleinste und der Größte)
– Hohe Empfindlichkeit gegenüber Ausreißerwerten.
02_grundbegriffe_kennwerte
75
Spannweite (Range)
Beispiel: Wie groß ist der „Range“?
Minimum
Maximum
Range
Geschlecht
1
2
2
Alter
18
49
31
Bundesland
1
11
11
Kenntnisse „Freiburg“
5
90
85
02_grundbegriffe_kennwerte
76
Spannweite (Range)
• In SPSS kann der Range über den Befehl „Häufigkeiten“
ausgegeben werden.
– Anwählen: Statistiken > Spannweite
• Syntax:
frequency age, stat_k, lot
/format notable
/statistic range.
• Achtung: SPSS verwendet immer die Formel für kontinuierliche
Variablen!
02_grundbegriffe_kennwerte
77
Interquartilabstand
• Als Quartilgrenzen werden die drei Punkte einer Verteilung
bezeichnet, welche die geordnete Liste von Werten in vier
Bereiche mit jeweils 25% der Stichprobe einteilen.
– 25% (1. QG) 25% (2. QG) 25% (3. QG) 25%
• Die 2. Quartilgrenze entspricht damit dem Median
• Beispiel: In einem Assessment-Center erhalten die 12 Teilnehmer
folgende Gesamtbeurteilungen (Max. 50 Punkte möglich):
– 24, 28, 30, 31, 34, 35, 36, 37, 37, 41, 42, 43
Q1=30.5
02_grundbegriffe_kennwerte
Q2=35.5
Q3=39
78
Interquartilabstand
• Der Abstand zwischen dem 1. und dem 3. Quartil wird als
„Interquartilabstand“ bezeichnet.
• Es ist ein Maß für den „Kernbereich“ einer Verteilung.
• Im Interquartilbereich liegen 50% der Stichprobe.
• Berechnung: IQA = Q3 – Q1
– IQA = 39 – 30.5 = 8.5
• Vorteil: Der IQA ist weniger anfällig gegenüber Ausreißern als die
Spannweite.
• Voraussetzung für die Bildung von Quartilen ist ein Ordinalskalenniveau.
02_grundbegriffe_kennwerte
79
Interquartilabstand
• In SPSS kann man sich die Quartilgrenzen mit dem Befehl
„Häufigkeiten“ ausgeben lassen:
• Im Menu „Analysieren > Deskriptive Statistiken > Häufigkeiten“
aufrufen.
• Dann unter Statistiken „Quartile“ auswählen.
02_grundbegriffe_kennwerte
80
Interquartilabstand
• In der Syntax:
frequency age, stat_k, lot
/format notable
/percentiles 25, 50, 75.
• Perzentile sind „hundertstel“ der Verteilung
• 25 Hundertstel entsprechen 1 Viertel
– 1. Qurtil = Perzentil 25
– 2. Quartil = Perzentil 50
– 3. Quartil = Perzentil 75
02_grundbegriffe_kennwerte
81
Interquartilabstand
• SPSS Ausgabe:
• IQA = 26.5 – 20.0 = 6.5
02_grundbegriffe_kennwerte
82
Zentrale Momente
• Als zentrales Moment wird der Abstand der Messwerte vom
Mittelwert bezeichnet.
• Dabei unterscheidet man verschiedene „Ordnungen“:
– Zentrales Moment 1. Ordnung:
( xi x )
– Zentrales Moment 2. Ordnung:
( xi x )2
„Varianz“
– Zentrales Moment 3. Ordnung:
( xi x )3
„Schiefe“
– Zentrales Moment 4. Ordnung:
( xi x )4
„Exzess“
02_grundbegriffe_kennwerte
83
Varianz
• Das wichtigste Maß für die Dispersion ist die Varianz.
• Bei der Berechnung der Varianz wird jeder einzelne Wert
berücksichtigt.
• Die Varianz gibt an, wie weit jede individuelle Merkmalsausprägung vom Mittelwert der Verteilung entfernt ist.
• Dabei wird die Summe des zentralen Moments 2. Ordnung über
alle Probanden einer Stichprobe durch die Anzahl der Probanden
dividiert:
x x
N
s
2
x
i 1
2
i
N
• Voraussetzung für die Berechnung der Varianz ist
Intervallskalenniveau.
02_grundbegriffe_kennwerte
84
Varianz
Beispiel: Berechnung der Varianz für folgende Variable:
Vp
1
2
3
4
5
x
4
2
2
2
5
x-M
(x-M)²
1
1
-1
1
-1
1
-1
1
2
4
1. Berechnen Sie den Mittelwert
2. Bilden Sie für jede
Merkmalsausprägung die Differenz
zum Mittelwert
3. Quadrieren Sie die Differenzen
4. Bilden Sie die Summe
5. Teilen Sie die Summe durch N
8
s 1 .6
5
2
x
02_grundbegriffe_kennwerte
85
Varianz
Varianz in der Stichprobe und in der Population
• Die Formel für die Varianz, die wir bisher kennengelernt haben,
gilt für die Berechnung der Varianz in einer Stichprobe.
• In aller Regel will man etwas über die Varianz eines Merkmals in
der gesamten Population erfahren.
• Die Varianz ist aber kein „erwartungstreuer Schätzer“, d.h. wenn
man viele Stichproben untersucht, dann entspricht der
Mittelwert der Varianzen dieser Stichproben nicht der Varianz der
gesamten Population.
• Die Stichprobenvarianz unterschätzt die Populationsvarianz.
• Diese Abweichung ist umso stärker, je kleiner die Stichprobe ist.
02_grundbegriffe_kennwerte
86
Varianz
Varianz in der Population
• Die Formel für die Populationsvarianz korrigiert die
Unterschätzung der Varianz in der Stichprobe:
2
(
x
x
)
i1 i
N
ˆ x2
N 1
• Unterschiede zu der Formel für s²:
– Wir verwenden nun ein griechisches Sigma (statt s), um zu verdeutlichen,
dass wir uns auf die Population beziehen.
– Das ^ wird verwendet, um zu zeigen, dass die Populationsvarianz nur
geschätzt werden kann.
– Im Nenner steht N-1 (statt N). Dadurch wird das Ergebnis der Formel
etwas größer.
02_grundbegriffe_kennwerte
87
Varianz
Zurück zum Beispiel:
• Stichprobenvarianz:
x x
N
s
2
x
i 1
2
i
N
8
1.6
5
• Populationsschätzer:
2
x
x
i1 i
N
ˆ
2
x
02_grundbegriffe_kennwerte
N 1
8
2.0
4
88
Standardabweichung
• Die Varianz ist durch die Bildung der Quadrate schwer zu
interpretieren.
• Daher wird aus ihr oft die Standardabweichung berechnet,
indem wieder die Quadratwurzel aus der Varianz gezogen wird.
• Voraussetzung für die Berechnung der Standardabweichung ist
wiederum Intervallskalenniveau.
02_grundbegriffe_kennwerte
89
Standardabweichung
• In der Stichprobe:
2
x
x
i 1 i
N
s x s x2
N
• Populationsschätzer:
2
i 1 xi x
N
ˆ x ˆ x2
02_grundbegriffe_kennwerte
N 1
90
Schiefe
• Zusätzliche Information über die Form einer Verteilung liefert die
Schiefe.
• Man unterscheidet
Rechtssteile Verteilung
02_grundbegriffe_kennwerte
Linkssteile Verteilung
91
Schiefe
• Die Schiefe wird aus dem zentralen Moment 3. Ordnung
berechnet:
x x
N
a3
3
i 1
i
N s x3
• Es gilt dabei:
– a3<0 rechtssteile Verteilung
– a3=0 symmetrische Verteilung
– a3>0 linkssteile Verteilung
02_grundbegriffe_kennwerte
92
Exzess (Kurtosis)
• Weitere Information über die Form einer Verteilung liefert der
Exzess (Kurtosis).
• Man unterscheidet
Breitgipflige Verteilung
02_grundbegriffe_kennwerte
Schmalgipflige Verteilung
93
Exzess (Kurtosis)
• Der Exzess wird aus dem zentralen Moment 4. Ordnung
berechnet:
x x
N
a4
4
i 1
i
N s
4
x
3
• Es gilt dabei:
– a4<0 breitgipflige Verteilung
– a4=0 „Normalverteilung“
– a4>0 schmalgipflige Verteilung
02_grundbegriffe_kennwerte
94
Kennwerte in SPSS
• Varianz, Standardabweichung, Schiefe und Exzess können in SPSS
über die Befehle „Häufigkeiten“ oder „Deskriptive Statistiken“
berechnet werden.
• Syntax für den Befehl Häufigkeiten:
frequencies freiburg psycho stat
/format notable
/statistic mean variance stddev skewness kurtosis.
frequencies freiburg_k psycho_k stat_k
/format notable
/statistic mean variance stddev skewness kurtosis.
02_grundbegriffe_kennwerte
95
Kennwerte in SPSS
SPSS Ausgabe:
02_grundbegriffe_kennwerte
96
Kennwerte und Skalenniveaus
Maß
Skalenniveau
mindestens:
Häufigkeit / Prozente
Nominal
Modalwert
Nominal
Median
Ordinal
Quartile
Ordinal
Arithmetisches Mittel
Intervall
Varianz
Intervall
Standardabweichung
Intervall
Schiefe
Intervall
Exzess
Intervall
02_grundbegriffe_kennwerte
97
Zusammenfassung Dispersionsmaße
• Wichtige Maße der Dispersion sind der Range, der
Interquartilabstand, die Varianz und die Standardabweichung.
• Bei Varianz und Standardabweichung muss beachtet werden, ob
ein Maß für die Stichprobe oder für eine Population berechnet
wird.
• Weiteren Aufschluss über die exakte Verteilungsform liefern die
Schiefe und der Exzess.
• Bei der Berechnung statistischer Kennwerte muss beachtet
werden, ob das entsprechende Skalenniveau gegeben ist.
02_grundbegriffe_kennwerte
98