Neuronale Netze, Teil 1
Werbung

Machine Learning
Neuronale Netze
(Mitchell Kap. 4)
Typische Anwendungen
• Große Menge von Features mit diskreten oder rellen
Werten (z.B. Input von Sensoren)
• Ergebnis kann sein:
– Diskreter oder reeller Wert
– Vektor mit diskreten oder reellen Werten
•
•
•
•
•
Möglicherweise fehlerhafte (Trainings-)Daten
Lange Lernzeiten sind akzeptabel
Schnelle Auswertung des Inputs notwendig
Form der Zielfunktion ist unbekannt
Das Ergebnis (die Zielfunktion) muss für den Benutzer
nicht nachvollziehbar sein („black-box“)
Typische Beispielanwendungen
•
•
•
•
•
•
Erkennung gesprochener Sprache
Handschrifterkennung
Bildklassifikation
Vorhersagen im Finanzbereich
Wettervorhersagen
Textklassifikation
Hintergrund
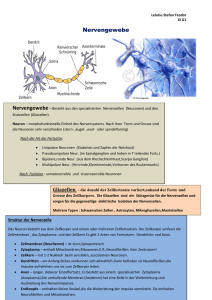
• Biologische Prozesse:
– Neuronen = Nervenzellen im Gehirn
– Funktion: Übermittlung von Information
– Erhöhung der Zellmembrandurchlässigkeit (Natriumund Kalium-Ionen) führt zu Spannungsunterschieden
– Weiterleitung des Spannungspotentials übers Axon
zum synaptischen Spalt
– Freisetzung von Neuro-Transmittern
– Lernen: das Gewicht der Verbindung zwischen zwei
Neuronen erhöht sich, wenn sie zur gleichen Zeit
aktiv sind
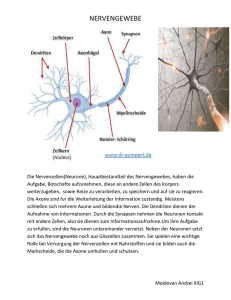
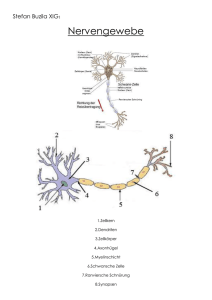
Aufbau eines Neurons
Dendriten
synaptisches
Endköpfchen
Axonhügel
AP
Axon
Zeit
Neuronenverbindungen
Informationsübertragung
Neuronale Netze
• Neuron:
• Interaktion:
Abstrakte Definition
• Neuronales Netz (U,W,A,O,net,ex):
– U ist endliche Menge von Arbeitseinheiten (=Neuronen), die einen
Eingabewert verarbeiten und einen Ausgabewert liefern
– W definiert die Netzstruktur durch Zuordnung eines Gewichts zur
Verbindung zweier Neuronen
• W: U x U -> R
– Für jedes u U ist auA die Aktivierungsfunktion, die aus externer
Aktivierung, bisherigem Aktivierungszustand und der über das Netz
vermittelten Aktivierung durch die anderen Neuronen eine neue
Aktivierung für ein Neuron u berechnet.
• au : R3 -> R
– Für jedes u U ist ou O die Ausgabefunktion:
• ou : R -> R
– Für jedes u U ist netu die Übergangsfunktion
– ex ist eine externe Eingabefunktion
– Ausserdem sei UO U die Menge der Ausgabeneuronen
Neuronale Netze
• Die grundlegende Arbeitsweise eines neuronalen Netzes
kann beschrieben werden als:
– Zunächst befindet sich ein Netz in einer Ruhephase oder einem
eingefrorenen Zustand.
– In der Aktivierungsphase werden durch die externe
Aktivierungsfunktion externe Aktivierungen der
Eingabeneuronen ermittelt.
– Es folgt nun die Arbeitsphase, in welcher die Aktivierungen durch
das Netz propagiert werden. Die Arbeitsphase ist spätestens
dann abgeschlossen, wenn das Netz erneut in eine Ruhephase
übergegangen ist, sich also die Aktivierungen nicht mehr ändern.
– Die Aktivierungspotentiale der Ausgabeneuronen werden nun als
Ausgabe des Netzes interpretiert und je nach Einsatz bzw.
Anwendung des Netzes genutzt.
Künstliche und biologische NNs
• Massive Parallelität der Neuronen
• Relativ einfache Elemente:
– Neuronen verarbeiten die Aktivierungen der Vorgängerneuronen
und die Stärke der Verbindung zu einer Ausgabe.
• Die Neuronen sind durch gewichtete Verbindungen
(biologisch: Synapsen) miteinander verbunden.
• Die Verbindungsgewichte bei künstlichen Neuronen sind
modifizierbar. Das entspricht der Plastizität der
Synapsen beim biologischen Vorbild.
• Ein Neuron ist mit sehr vielen anderen Neuronen
verbunden (hohe Konnektivität).
Künstliche vs biologische NNs
• Künstliches Netz
– viel geringere Anzahl der
Neuronen (102 - 104)
– viel geringere Anzahl von
Verbindungen
– Stärke einer Synapse wird
ausschließlich durch das
Gewicht bestimmt
– numerischer
Aktivierungswert
(Amplitudenmodulation)
– zeitliche Vorgänge der
Nervenleitung werden
vernachlässigt
• Biologisches Vorbild
– ca. 1011 Neuronen
– höhere Anzahl an
Verbindungen zwischen
den Neuronen
– Einfluß verschiedener
Neurotransmitter auf die
Stärke einer Synapse
– impulscodierte
Informationsübertragung
(Frequenzmodulation)
– verzögerte Aktivierung
Die Hebb‘sche Lernregel (1)
• Problematik der Berechnung der Gewichte
• selten existiert eine direkte Berechnungsvorschrift für die jeweiligen Anwendungen
• Bei der Methode der Berechnung der
Gewichte Rückgriff auf die Natur
• Das menschliche Gehirn ist in der Lage,
Funktionen im Laufe des Lebens zu
lernen
Die Hebb‘sche Lernregel (2)
• Im Gehirn erfolgt Lernen durch Änderung
der Synapsenstärken
• Der Psychologe Donald Hebb (1949)
stellte die Hypothese auf (bis heute nicht
experimentell nachgewiesen), daß sich die
Gewichtung der Synapse verstärkt, wenn
Neuronen vor oder nach der Synapse
gleichzeitig aktiv sind
Die Hebb‘sche Hypothese
Die synaptische Eigenschaft (Verstärken
oder Hemmen) ändert sich proportional
zum Produkt von prä- und
postsynaptischer Aktivität
Die Hebb‘sche Hypothese
(saloppe Formulierung)
Oft genutzte Neuronenverbindungen
verstärken sich
oder
Es bilden sich „Trampelpfade“
oder
Übung macht den Meister
Math. Formulierung der
Hebb‘schen Lernregel
Dwij = ·ei ·oj (Hebb‘sche Regel)
wobei wij das Gewicht von Input ei zum
Output oj
> 0 eine Konstante
Modifikation der Hebb‘schen
Regel
Dwij = ·ei · D oj (Delta-Regel)
wobei wij das Gewicht von Input ei zum
Output oj
> 0 eine Konstante
D oj die Differenz zwischen erwünschtem
Output und dem zur Zeit des Lernens
tatsächlich erzielten Output
Neuronale Netze
• Vorwärtsgerichtetes Netz
Ausgabeneuronen
Eingabeneuronen
Verdeckte Schicht
Perzeptron
• Perzeptron: einfacher Spezialfall eines
neuronalen Netzes:
– Nur 2 Ebenen: Eingabeneuronen und genau 1
Ausgabeneuron
– Keine verborgenen Schichten
– Ausgabefunktion ist die Identität oder binär
Perzeptron
• Ausgabe des Perzeptrons ist LinearKombination:
n
wx
i
i
i 0
• Wobei wi die Gewichte von ui sind und xi die i-te
Position des Eingabe-Vektors (i=1 ... n)
• wo ist der Schwellenwert (nehme an: x0 ist
konstant 1)
• Bemerkung: d.h. der Hypothesenraum ist die
Menge aller Linearkombinationen
Beispiel
• Logisches „und“
– Sei {1,-1} mögliche Eingaben (1 für wahr, -1 für falsch)
– w0 = -0.8
– w1 = w2 = 0.5
n
1 falls wixi 0
o
i 0
1sonst
Training eines Perzeptrons
• Die Gewichtsveränderung W und die
Schwellwertänderung nach der
Propagation der Eingabe eines Musters x
bei gewünschter Ausgabe t wird wie folgt
bestimmt (bei vorgegebener Lernrate ):
Perzeptron
• Man kann zeigen: Die PerzeptronLernregel konvergiert wenn
– Die Trainingsdaten linear separierbar sind
– Die Lernrate ausreichend klein gewählt
wurde
Delta-Regel
• Idee: minimiere den quadratischen Fehler
– D Trainingsmenge
– td Wert für d D
– od Ausgabe für d
Absteigender Gradient
Gradient
Damit:
Dwi (td od ) xid
d D
Algorithmus
• Jedes Trainingsbeispiel sein ein Paar
x
x, t
–
ist Inputvektor
– t ist der Zielwert
– ist die Lernrate
• Initialisiere jedes wi zu einem beliebigen, kleinen Wert
• Bis die Abbruchbedingung erfüllt ist:
– Initialisiere jedes Dwi mit 0
– Für jedes Trainingsbeispiel
x, t
• Berechne ot
• Für jedes Gewicht wi: Dwi ← Dwi + (t – ot)xi
– Für jedes wi: wi ← wi + Dwi
Delta-Regel
• Der Algorithmus konvergiert gegen eine
Hypothese mit minimalem quadratischen
Fehler
– Falls Lernrate hinreichend klein
– Auch für nicht linear separable Daten
– Auch für Trainingsdaten die Fehler enthalten
• Der Algorithmus konvergiert nicht
notwendig gegen die optimale Lösung
Aufgaben
• Definieren Sie jeweils das Perzeptron, das
folgenden logischen Operatoren
entspricht:
– „nicht (a und b)“
– „a oder b“
– „nicht a oder b“
• Wie wäre „exklusives oder“ zu definieren?