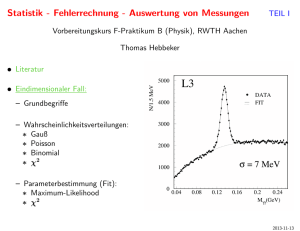
fehlerrechnung
Werbung

Einführung zur Fehlerrechnung Messen einer physikalischen Größe • erfolgt direkt durch Vergleich mit einem zuvor definierten Maßstab oder indirekt über eine wohlbekannte Beziehung unter Verwendung einer oder mehrerer einfacher zugänglicher Größen. • Jede gemessene Größe enthält unvermeidbar einen Messfehler. Deshalb werden nur die signifikanten Stellen einer physikalischen Größe angegeben. • In der numerischen Darstellung einer physikalischen Größe ist die letzte Stelle signifikant, d.h. die nächste Stelle ist um eine halbe Stelle ungewiß. • ACHTUNG: Auch angegebene Nullen sind signifikant! • Beispiel: Die Angabe x = 2,0 m bedeutet: 1,95 m x 2,05 m Angabe einer Messgröße • • • • x xu Allgemeine Ergebnisangabe: Beispiel: v = (3,770,04) m/s Der wahre Wert xW ist nicht identisch mit dem Mittelwert x Der Wert xW liegt mit einer gewissen Wahrscheinlichkeit (nicht mit Sicherheit) im durch die Messunsicherheit u bestimmten Intervall: xu xu x • Bei n Messungen xi, i = 1....n wird für Mittelwert eingesetzt: 1 n x x n i 1 i x der arithmetische Methode der kleinsten Quadrate • Die Beziehung für den Mittelwert folgt aus der von Gauß entwickelten Methode der kleinsten Quadrate: • Der Mittelwert wird so definiert, dass die Summe der Quadrate der Abweichungen vom Mittelwert ein Minimum wird: 2 n x i 1 i x Min • Aus dem Nullsetzen der ersten Ableitung folgt mit d 2 x x 2 x i x 0 x i nx i dx i i i • Die Beziehung für den Mittelwert: (gleichgewichteter Messwerte) 1 n x xi n i 1 WICHTIG!!! • Der Mittelwert wird nicht genauer, als der Messfehler angegeben. • Die Messunsicherheit wird nur auf eine Stelle genau angegeben. • Richtig: s = (3,14 0,02) m • Falsch: s = (3,1416 0,021) m Zielstellung der Fehlerrechnung • Die Zielstellung der Fehlerrechnung ist die Bestimmung der Messunsicherheit u • Die Messunsicherheit u setzt sich zusammen aus einem systematischen und zufälligen Anteil: u = |eS| + |eZ| • Die Angabe der Messunsicherheit erfolgt entweder als • absoluter Fehler: x xu • relativer Fehler: u x oder als Fehlerarten • Entsprechend ihrer Ursache unterscheidet man: • • grobe Fehler : sind durch ‘sauberes’ Experimentieren auszuschließen konstante Fehler : können durch Differenzmessung ausgeschlossen werden • systematische Fehler : sind ihre Ursachen bekannt, können sie durch Korrekturrechnung ‘herausgerechnet’ werden. Diese „Korrekturfehler“ verändern den Betrag des Mittelwertes. Es bleibt ein systematischer Restfehler bestehen, der, bedingt durch die Genauigkeit der Messinstrumente, in den Gesamtfehler eingeht. • zufällige Fehler : siehe folgende Folie • Zufällige Fehler sind statistische Fehler und können durch eine hohe Zahl von wiederholten Messungen minimiert werden. Die mittlere quadratische Abweichung vom Mittelwert einer n-fach gemessenen Größe ist durch die (empirische) Standardabweichung bzw. Streuung gegeben: n • • • • 2 x x i i 1 n 1 Die Standardabweichung heißt auch mittlerer Fehler der Einzelmessung. Bei einer großen Zahl von Messungen hängt der Betrag von nicht von n ab. Den mittleren Fehler des Mittelwertes nennt man Vertrauensbereich. Er hängt von n ab und wird folgendermaßen ermittelt: Der Student‘sche Faktor t kann für n > 6, besser n > 10, gleich 1 gesetzt werden. Der Vertrauensbereich ist der Beitrag des zufälligen Fehlers eZ zur Messunsicherheit, vorausgesetzt n > 6. st n Messunsicherheit u=ez+es • Der Vertrauensbereich s ist der Beitrag des zufälligen Fehlers eZ zur Messunsicherheit. • Der systematische Restfehler eS ist der Anteil des systematischen Fehlers an der Messunsicherheit u. Lineare Fehlerfortpflanzung • Fehler pflanzen sich fort. Haben wir einen Zusammenhang y = f(x1,..,xi,..,xn), so gilt für das dy = (y/xi)dxi (Taylorentwicklung in linearer Näherung), bzw. nach dem Übergang zu den Differenzen (der Betrag ist notwendig, da sich Fehler nie gegenseitig aufheben): uy i • f ( x i ) u xi x i Für Summen y(x,z) =ax + bz folgt daraus: u y au x bu z Es addieren sich die absoluten Fehler der Größen x und z, gewichtet mit den Vorfaktoren a und b. • Für Produkte der Art y = cx/z erhält man aus der linearen Abschätzung uy ux uz y x z • Es addieren sich die relativen Fehler der Einzelgrößen. • Im Falle von Potenzfunktionen y = xnzm erhält man uy ux uz n m y x z • Es addieren sich die relativen Fehler der Größen x und z – gewichtet mit den Beträgen der Exponenten n bzw. m. • Die oberen Näherungsformeln eignen sich gut für Fehlerabschätzungen. Für genauere Rechnungen (bei großer Zahl von Messwerten) benutzt man das Gauß‘sche Fehlerfortpflanzungsgesetz: Gauß‘sches Fehlerfortpflanzungsgesetz • • Die lineare Fehlerfortpflanzung wird in der Regel zur Fehlerabschätzung für systematische Fehler und bei einer sehr geringen Zahl von Messwerten auch im Falle zufälliger Fehler angewendet. Da insbesondere gilt n (negative Abweichungen sind genauso u 0 i i 1 wahrscheinlich, wie positive), geht man zu den Quadraten der Abweichungen über: 2 f ( x i ) 2 uy u xi i 1 x i n • Trägt man alle Änderungen der Funktion f in einem linearen Vektorraum mit den Koordinaten xi auf, so ergibt sich der Gesamtbetrag aller Abweichungen uy durch pythagoräische Summation der einzelnen Abweichungen ui gewichtet mit dem partiellen Anstieg der Funktion f. • Beispiel: Zylindervolumen 2 V d h 4 2 uV 2u d u h V d h 2 Varianz und Zuverlässigkeit • • Die empirische Standardabweichung, Streuung oder Varianz ist ein Maß für die Genauigkeit des Messverfahrens. Sie gibt an, in welchem Intervall der n-te Messwert (mit einer Wahrscheinlichkeit von 68%) zu erwarten ist. Der Vertrauensbereich ist ein Maß für die Zuverlässigkeit der Messung. Bei n Messwerten xi errechnet man mittels des Fehlerfortpflanzungsgesetzes den Fehler der Funktion x x / n , wobei xi den Fehler hat: i i s i n n 2 • Will man eine höhere statistische Sicherheit, so muss man s mit dem Student‘schen Faktor für die gewünschte Wahrscheinlichkeit multiplizieren. Geradenausgleich • Ein physikalischer Zusammenhang sei durch eine Gerade y(x) gegeben. Einfachster Fall: Gerade durch den Nullpunkt y = ax Gemessen werden n Wertepaare yi(xi), gesucht ist der Anstieg a sowie sein Fehler ua. Unter Anwendung der Methode der kleinsten Quadrate 2 n y i 1 i n ax i i2 Minimum i 1 xy a x i i i 2 i erhält man den Anstieg a zu i und den zufälligen Fehler von a unter Anwendung des Gauß‘schen Fehlerfortpflanzungsgesetzes zu 2 sa • n 1 x i i 2 i i Den allgemeinen Fall y = ax + b sowie die Verfahren zur Linearisierung von Funktionen studiere man in der ausgehändigten Skripte. Allgemeiner Fall y = ax + b: 2 n y i 1 a i n ix i y i ix i iy i D x y x y x b 2 i i i i i i i i i D D n x 2 i i x ax i b Minimum sa s y sb s y 2 i i sy n D x 2 i i D 2 i i n2 Gauß‘sche Normalverteilung • Die Gauß‘sche Normalverteilung spiegelt die Statistik der zufälligen Fehler wider: x x 2 1 ( x ) exp 2 2 2 x • • • Sie hat ein Maximum beim Wert . Sie ist symmetrisch bezüglich . Für x besitzt sie einen Wendepunkt und ist schmal für kleine . • Die Normierung ist x x dx 1 • Das Integral x2 w x dx x1 gibt die Wahrscheinlichkeit an, einen Messwert x im Intervall x1xx2 zu finden. • Das Integral x w x dx 0,683... x gibt an, dass die Wahrscheinlichkeit, einen einzelnen Messwert innerhalb der durch die Standardabweichung definierten Grenzen zu finden, 68,3..% beträgt. • Das folgende Integral berechnet den Mittelwert von x x xx dx Streuung • xx Wir gehen über zu Die Fehlerverteilungsfunktion lautet dann: 2 1 ( v) exp 2 2 2 • Die mittlere quadratische Abweichung bzw. Streuung erhält man dann mittels der Beziehung für den quadratischen Mittelwert 2 2 d • Für den linearen Mittelwert erhält man erwartungsgemäß d 0 Fehlerfunktion • Das Integral () d heißt Gauß‘sche Fehlerfunktion. Fehlerfunktion Diskrete Messwerte h(xi): relative Häufigkeit des Messwertes xi xi H( x ) h ( x i ) Mittelwerte Stetige Zufallsgröße x mit der Wahrscheinlichkeitsdichte (x) x x(x )dx Stichproben der Klassen xj mit den absoluten Häufigkeiten k(xj) 1 N x x jk x j n j1 Diskrete Zufallsgröße x mit der relativen Häufigkeit h(xi) x x i h(x i ) 1 Stichprobe der Elemente xi vom Umfang n 1 n x xi n i 1