Teilbereich Datenbanken
Werbung

Vorlesung Datenverarbeitung II
Teilbereich Datenbanken
SS 2008
Prof.Dr.Kühn
Die Vorlesungskopien sollen die Studierenden entlasten – sie enthalten nicht den gesamten klausurrelevanten Stoff und ersetzen nicht den Besuch der
Vorlesung
Einführung: Kapitelinhalt
Die Vorlesung befasst sich mit der Speicherung und Verwaltung großer
Datenmengen
Einleitende Fragen:
• Was versteht man unter einer Datenbank
• Welche Arten von Daten gibt es und welche werden hier betrachtet
• Wie lassen sich diese Daten prinzipiell auf Datenträgern speichern
(Dateiorganisation)
• Welche Zugriffsarten können prinzipiell benötigt werden
• Wie kann die Speicherung für die gewünschten Zugriffe optimiert werden
• Welche Vorteile bietet ein zusätzliches Datenverwaltungsprogramm (DBMS)
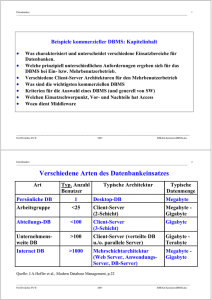
• Was charakterisiert eine Datenbank im Vergleich mit Dateien
• Welche neuen Probleme können auftreten
• Welche prinzipiellen Anforderungen muss ein DBMS erfüllen
• Welche prinzipiell unterschiedlichen Typen von DBMS gibt (gab) es
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
1.1 Datenbanken: Überblick
Datenbanken bestehen aus einer Ansammlung vieler verschiedener Daten,
auf die über ein Verwaltungsprogramm zugegriffen werden kann.
Unterscheidungskriterien:
Was wird gespeichert
formatierte Daten
unformatierte Daten
Für welchen Zweck
operativen Einsatz: OLTP
Managementinformation: OLAP
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Datenbanken (formatierte Daten / OLTP)
¾
Datenbanken dienen zur langfristigen Speicherung von Daten
¾
Die Daten sind für viele Programme / Benutzer zugänglich
¾
Die Daten können nach vielen Gesichtspunkten ausgewertet werden
¾
Die Datenverwaltung und der Zugang erfolgt über ein eigenes
Verwaltungsprogramm, das Datenbankmanagementsystem (DBMS)
¾
Die Speicherung der Daten entspricht einer Vielzahl von verknüpften
Dateien
Die verschiedenen möglichen Organisationsformen für die Daten
entsprechen denen von Dateien
¾
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
1.2 Datenspeicherung
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Zur physischen Speicherung und Plattenzugriff
Seite (Block):
Transfereinheit zwischen Platte und Pufferbereich im Arbeitsspeicher;
Größe vom Betriebssystem bestimmt;
typische Größen: 512 Byte; 2 Kbyte (2048 B); o.a.
Eine Seite enthält einen Header (Adresse Vorgängerseite, Adresse
Nachfolgerseite, Sonstiges) und einen oder mehrere Datensätze.
Datentransfer: (Richtwerte)
Suchen+Übertragen des ersten Blockes: ca. 10 msec.
Übertragen anschließender Blöcke: jeweils ca.1 ms.
Die Anzahl der Plattenzugriffe ist häufig entscheidend für die Programmlaufzeit
Æ minimieren erwünscht!
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Dateiorganisationsformen (formatierte Daten):
Voraussetzung: Es werden Datensätze mit jeweils gleichem Satzaufbau gespeichert:
Es gibt genau ein Schlüsselfeld.
Es gibt nur begrenzte Möglichkeiten, die Datensätze auf der Platte zu organisieren:
1. Sequentielle Speicherung (sortiert)
2. Serielle Speicherung (unsortiert)
2a) Serielle Datei ohne Indexdatei
2b) Serielle Datei mit Indexdatei
(Indexdatei unsortiert,
sortiert,
Baumstruktur*)
3. Hash-Speicherung
*: wird hier nicht näher besprochen
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Zu 1: Sequentielle Speicherung
Die Datensätze werden sortiert nach dem Inhalt des Schlüsselfeldes gespeichert.
Die Sortierung erleichertert die Suche nach einem Satz mit einem bestimmten
Schlüsselwert.
Neu aufgenommene Datensätze werden „einsortiert“.
Zu 2: Serielle Speicherung
Die Datensätze werden in der Reihenfolge der Erfassung („zufällige Reihenfolge“,
unsortiert) gespeichert, ohne den Inhalt des Schlüsselfeldes zu berücksichtigen.
Bei der Suche nach einem Satz mit einem bestimmten Schlüsselwert muss von Anfang an
gesucht werden.
Um die Satzsuche zu beschleunigen kann eine zusätzliche Hilfsdatei (Indexdatei)
eingerichtet werden (s.u.).
Neu aufgenommene Datensätze werden gespeichert „wo Platz ist“, häufig am Dateiende.
Zu 3: Hashdatei
Der Speicherort jedes Datensatzes innerhalb der Datei wird aus dem Inhalt seines
Schlüsselfeldes berechnet.
Auf einen Satz mit einem bestimmten Schlüsselwert kann nach Rechnung direkt zugegriffen
werden.
So ergibt sich auch der Speicherort für jeden neuen Datensatz.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Bearbeitung von Dateien
• Fortlaufendes Lesen, Satzreihenfolge beliebig (unsortiert)
• Fortlaufendes Lesen, Satzreihenfolge sortiert nach Schlüsselwert
• Wahlfreies Lesen (Satz mit einem bestimmten Schlüsselwert)
• Speichern eines Satzes
• Ändern eines bestimmten Satzes (Schlüsselwert bekannt)
• Löschen eines bestimmten Satzes (Schlüsselwert bekannt)
Die gewählte Dateiorganisationsform hat Einfluss darauf, wie schnell Datensätze
gespeichert, gelöscht bzw. gefunden werden können (wahlfreier Zugriff).
Die Zeit wird hierbei v.a. durch die Anzahl der benötigten Plattenzugriffe bestimmt
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Die serielle Speicherung: Beispiel Studentendatei
Studentendatei={Student}
Satzaufbau: Student=(MNr,Name,Vorname,Idat,Fachb,Stdg,Fsem)
Idat=[SS|WS] JJJJ; Immatrikulationsdatum,
JJJJ=Jahr, Fachb=Fachbereich, Stdg=Studiengang,FSem=Fachsemester*
zu speichernder Inhalt:
1237 Zendt
Sybille SS2004
W
W-B 7
1437 Kant
Egon
SS2005
W
W-B 5
1234 Müller Egon
WS2003 W
W-D 8
1340 Eder
Martin SS2005
W
IM-B 5
1451 Weber
Elke
WS2006 W
IM-M 2
1235 Bauer
Maria
WS2003 W
IM-B 8
1320 Ehrig
Klaus
SS2004
W
W-D 7
1450 Schulz
Peter
WS2005 W
IM-B 4
..............
Es soll eine Datei erstellt werden.
derzeit umfasst sie 500 Datensätze zu je 400 Byte; Block-(Seiten-) größe: 512 Byte
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Serielle Datei (unsortiert) (1 Satz pro Block Æ 500 Blöcke)
2a) Hauptdatei (Datendatei)
1237
Zendt
Sybille
W
W-B
5
Eder
Martin SS2004
IM-M 2
1235
Klaus SS2004 W
4
…
…
SS2004
1234
W
Bauer
W-D
…
W
Müller
IM-B
Maria
7
W-B
Egon
5
WS2003
1450
7
WS2003
1451
W
Schulz
1437
W
Weber
IM-B
Peter
Kant
W-D
Elke
8
WS2005
Egon
8
WS2005
1320
W
SS2005
1340
W
Ehrig
IM-B
Tabellenform: eine andere Darstellungsform derselben Datei
(die Datensätze sind natürlich weiterhin fortlaufend gespeichert)
1237
1437
1234
1340
….
Zendt
Kant
Müller
Eder
….
Sybille
Egon
Egon
Martin
SS2004
SS2005
WS2003
SS2004
W
W
W
W
W-B
W-B
W-D
IM-B
7
5
8
5
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Aufgabe:
Auf die besprochene Studentendatei soll zugegriffen werden.
a) Es sollen alle Datensätze gelesen werden (unsortiert)
b) Es soll der Datensatz mit der Matrikelnummer 1320 gelesen werden
c) Es soll ein Datensatz mit der Matrikelnummer 1350 gelesen werden (nicht
vorhanden)
d) Es soll ein neuer Datensatz gespeichert werden:
(1370, Esser, Klaus, SS2008, W, IM-B, 1)
wieviele Plattenzugriffe werden jeweils benötigt, wenn die Datei organisiert ist als
1. serielle Datei (ohne Index)
2. serielle Datei plus unsortierte Indexdatei
3. serielle Datei plus sortierte Indexdatei
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Wahlfreier Zugriff auf eine serielle Datei ist (zeit-)aufwendig.
Deshalb: Einrichten einer Indexdatei als „Zugriffshilfe“:
Zusätzliche Indexdatei für das Feld MNr
Satzaufbau:
MNr
Eintrag in die Indextabelle
Eintragslänge z.B. 8 Byte
wievielter Satz=SatzNr
Varianten:
2a) zusätzliche Indextabelle, unsortiert
1237 1
....
oder
1437 2
....
1234 3
....
1340 4
...
1451 5
...
1235 6
...
1320 7
...
1450 8
...
.....
...
.....
1437 2
...
1450 8
...
1451 5
...
.....
...
....
2b) zusätzliche Indextabelle, sortiert
1234 3
....
1235 6
....
1237 1
....
1320 7
...
1340 4
...
Umfang dieser Indexdatei: (Annahmen: Eintragslänge 8 B, Blockgröße 512 B; s.o.)
512:8 Æ64 Einträge pro Block Æ8 Blöcke
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Vorgehen bei der Erstellung einer Datei:
1. Satzaufbau festlegen (Feldnamen, Datentypen, Reihenfolge)
2. Dateiorganisationsform festlegen
3. Datensätze laden
4. Bearbeiten
Die Wahl der Dateiorganisation wird bestimmt durch
1. Umfang der Datei
2. die häufigsten geplanten Bearbeitungen
Insbesondere ist zu überlegen, ob das Anlegen einer Indexdatei (2b) die
Gesamtbearbeitung beschleunigt.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
1.3 Charakteristika von Datenbanken
Unterschiede Dateien / Datenbanken
¾ In einer Datei werden jeweils (beliebig viele) Datensätze mit einheitlicher
Struktur gespeichert (Studentendatei, Prüfungsdatei).
In einer Datenbank werden Datensätze unterschiedlicher Struktur
gespeichert (sowohl Studenten- als auch Prüfungsdaten)
¾ Bei Dateien muss der Benutzer „logisch zusammengehörige“
Datensätzen aus verschiedenen Dateien selbst heraussuchen.
Bei einer Datenbank werden entsprechende Datensätze auf Anforderung
vom System gesucht und geliefert.
¾ In Dateien findet man häufig Datenredundanz.
In einer Datenbank erfolgt die Speicherung nahezu redundanzfrei
¾ Die Datenspeicherung in einer Datei wird vom Ersteller für seine Zwecke
optimiert. Die Datei wird von wenigen Anwendern verwendet
Die Datenspeicherung in einer Datenbank muss für viele Anwender
„passen“.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Datenbanken
¾ Es werden viele Datensätze unterschiedlicher Struktur gespeichert
¾ Zwischen diesen Datensätzen können vielerlei Beziehungen bestehen
¾ Die Daten sind für viele Programme / Benutzer zugänglich
¾ Die Daten können nach vielen Gesichtspunkten ausgewertet werden
¾ Die Datenverwaltung und der Zugang erfolgt nur über ein eigenes
Verwaltungsprogramm, das Datenbankmanagementsystem
(DBMS)
- dieses DBMS benötigt dafür bestimmte Komponenten
- das DBMS legt für seine Arbeit zusätzliche Verwaltungsdaten an
(data dictionary, repository,...).
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Komponenten eines DBMS
Komponente zum Erstellen der DB:
Datendefinitionssprache: DDL
Speicherstruktursprache: SSL
Komponente zur Datenmanipulation
Datenmanipulationssprache: DML
Komponente für die Benutzerverwaltung
Datenkontrollsprache: DCL
Komponente für Mehrbenutzerzugriffe:
Transaktionskontrollsprache TCL und
Transaktionsmonitor
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Vorteile und Probleme von Datenbanken:
Vorteile
• Datenunabhängigkeit der
Programme
-->
• Beziehungen werden
durch DBMS verwaltet
-->
• nur kontrollierte
Redundanz
-->
• viele Abfragemöglichkeiten
durch spezielle Sprachen
-->
Mögliche Probleme
• sehr unterschiedliche
Anforderungen
-->
• viele Benutzer in
unterschiedlichen Positionen
-->
• Systemabsturz gefährdet
Datenintegrität
-->
• gleichzeitiger Zugriff
gefährdet Datenintegrität
-->
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
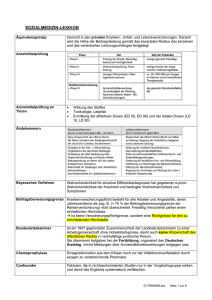
Typen von Datenbanksystemen
¾ Hierarchische DBMS: seit ca.1960
¾ Netzwerk-DBMS: seit ca.1970
¾ Relationale DBMS:
seit ca.1980
¾ Objektorientierte DBMS:
seit ca.1990
Gemeinsamkeiten
• Speicherung von Daten
• Verwaltung v. Beziehungen
• Strukturänderungen
möglich
• alles vom DBMS verwaltet
Unterschiede
• Welche Datentypen gibt es
• wie werden Beziehungen hergestellt
• Flexibilität bzgl. Änderungen der
Datenbankstruktur
• Flexibilität bzgl. ungeplanten
Abfragen
• Effizienz bei vorgesehenen Abfragen
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Relationales Datenmodell:
Datentypen:“rein“ relationale Systeme: Zahlen, Texte, Datum
inzwischen erweitert („objektrelational“), abhängig vom Anbieter
Flexibilität bzgl. Strukturänderungen: gut; besser als bei früheren Systemen
Flexibilität bzgl. ungeplanten Abfragen: gut; besser als b. früheren Systemen
Effizienz bzgl. vorhergesehenen Abfragen: aufgrund der Vorgehensweise
langsamer als bei früheren Systemen; wird durch inzwischen viel schnellere
HW kompensiert
Beziehungen: In einer relationalen Datenbank wird (wie bei der
Dateiorganisation) der Zusammenhang zwischen verschiedenen
Datensatzmengen durch gleiche Feldinhalte hergestellt
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
Beispiel
An einer Hochschule sind Studentendaten u. Studiengänge gespeichert
Student (MNr,Name,Vorname,Idat,Fachb,Stdg,FSem)
Studiengang (Stdg, Studiengangsname, Abschluss)
Student
MNr
1237
1340
1320
...
Studiengang
Name
Zendt
Eder
Ehrig
…
Stdg
IM-B
IM-M
W-M
…
Vorname
Sybille
Martin
Klaus
…
Idat
Fachb
SS2004
W
SS2005
W
SS2004
W
Stdg
W-B
IM-B
W-D
FSem
7
5
7
Studiengangsname
Abschluss
International Management Bachelor of Science
International Management
Master of Science
Wirtschaftsingenieurwesen Master of Science
…
…
Die beiden Tabellen können über den Inhalt des Feldes „Stdg“ (Studiengang)
miteinander verknüpft werden.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc
•
•
•
•
•
•
•
Einführung: Zusammenfassung
Gegenstand der Vorlesung sind Datenbanken für formatierte Daten und operative
Auswertungen (OLTP-Systeme)
Die Speicherung der Daten erfolgt üblicherweise in unsortierten Dateien, evt. mit
Indextabellen für der schnelleren Zugriff. In Spezialfällen sind andere
Speicherungsformen möglich.
Datenbanken haben Vorteile gegenüber Dateien (insbesondere bzgl. der Datenintegrität),
aber aufgrund der großen Datenmengen, der vielen gleichzeitigen Nutzer und der
unterschiedlichen Anforderungen treten neue Probleme auf.
Das Antwortzeitverhalten aufgrund hoher Anforderungen wird über die Art der
Datenspeicherung und Indextabellen sowie eigene Anfrageoptimierer des DBMS
beeinflusst.
Die Mehrbenutzerverwaltung ist Aufgabe des DBMS, wobei das Transaktionskonzept
eine entscheidende Rolle spielt.
Es gibt unterschiedliche Typen von DBMS (hierarchische, relationale, objektorientierte).
Es können verschiedene Datentypen gespeichert werden und die Verwaltung der Daten
und ihrer Beziehungen ist technisch unterschiedlich gelöst
Heute spielen im kommerziellen Bereich nur die relationalen Datenbanken eine Rolle
(evt. mit objektorientierten Erweiterungen)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Prof. Dr.Kühn
2008
IMB-K1-Einfuehrung.doc