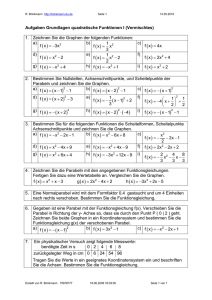
Visualisierung I 9. Darstellung von Graphen
Werbung

Visualisierung I
9. Darstellung von Graphen
Vorlesung: Mi, 9:00 – 11:00, INF 368 – 532
Übung: Do, 14:00 – 16:00, INF 350 – OMZ R U011
JProf. Dr. Heike Jänicke – http://www.iwr.uni-heidelberg.de/groups/CoVis/
Inhaltsverzeichnis
1. Einführung
2. Visuelle Wahrnehmung
3. Datentypen und Datenrepräsentation
4. Skalardaten
5. Statistische Graphiken
6. Interaktion und Datenexploration
7. Vektordaten
8. Tensordaten
9. Darstellung von Graphen
Visualisierung I – 9. Graphen
2
Inhaltsverzeichnis
9. Darstellung von Graphen
5. Zeichenalgorithmen für Bäume
1. Traversieren von Bäumen
2. Wetherell Shannon Algorithmus
3. Reingold Tilford Algorithmus
4. H-förmiges Layout
5. Radiales Layout
6. Kraftbasierte Ansätze für allgemeine Graphen
7. Manipulation von Darstellungen
1. Clustering
2. Hierarchisches Clustering
3. Relevanzbasierte Ansätze
Visualisierung I – 9. Graphen
3
Inhaltsverzeichnis
9. Darstellung von Graphen
5. Zeichenalgorithmen für Bäume
1. Traversieren von Bäumen
2. Wetherell Shannon Algorithmus
3. Reingold Tilford Algorithmus
4. H-förmiges Layout
5. Radiales Layout
6. Kraftbasierte Ansätze für allgemeine Graphen
7. Manipulation von Darstellungen
1. Clustering
2. Hierarchisches Clustering
3. Relevanzbasierte Ansätze
Visualisierung I – 9. Graphen
4
Traversieren von Bäumen
●
Traversieren eines Baumes bezeichnet das Durchlaufen seiner Knoten. Hierbei gibt
es verschiedene Strategieen:
–
pre-order oder Hauptreihenfolge (W–L–R): Es wird zuerst die Wurzel
betrachtet, dann linke Teilbaum durchlaufen und abschließend der rechte.
–
in-order oder symmetrische Reihenfolge (L–W–R): Es wird zuerst der linke
Teilbaum durchlaufen, anschließend wird die Wurzel betrachtet und zuletzt der
rechte Teilbaum durchlaufen.
–
post-order oder Nebenreihenfolge (L–R–W): Es wird zuerst der linke, dann der
rechte Teilbaum durchlaufen und abschließend die Wurzel betrachtet.
–
level-order oder Breitensuche: Beginnend bei der Wurzel, werden die Ebenen
von links nach rechts durchlaufen.
1
2
3
5
4
7
4
6
2
7
Visualisierung I – 9. Graphen
1
3
6
3
5
7
1
6
2
4
5
5
Zeichnen von Bäumen
●
●
●
Der Algorithmus von Reingold und Tilford [E. M. Reingold and J. S. Tilford, „Tidier
Drawing of Trees“, IEEE Trans. Software Eng., vol7, no2, pp. 223-228, 1981] erzeugt
eine klassische Baumstruktur für Bäume mit ausgezeichneter Wurzel mit einem
typischen Divide-and-Conquer Ansatz.
Dabei soll die Zeichnung eines Unterbaums nicht von Knoten außerhalb dieses
Unterbaums beeinflusst werden.
Die vier wesentlichen Ästhetikkriterien sind:
1. Knoten einer Ebene des Baumes liegen auf einer Geraden und die Geraden,
die eine Ebene beschreiben sind parallel. (Implizit ist gemeint, dass sich Kanten
nicht schneiden.)
2. Ein „linker“ Kindknoten soll links des Elternknoten positioniert werden, ein
„rechter“ recht davon.
3. Ein Elternknoten soll mittig zu seinen Kindern liegen.
4. Ein Baum und seine gespielte Versionen sollen Zeichnungen ergeben die
diesen Zusammenhang widerspiegeln; Unterbäume sollen gleich gezeichnet
werden, egal an welcher Position im Baum sie auftreten.
Visualisierung I – 9. Graphen
6
Zeichnen von Bäumen – Beispiel
Ursprünglicher Algorithmus, der die
ersten drei Kriterien beachtet.
Visualisierung I – 9. Graphen
Baumzeichnung mit dem
Reingold Tilford Algorithmus
7
Wetherell Shannon Algorithmus
Der Algorithmus von Reingold und Tilford verbessert den Baumzeichenalgorithmus von
Wetherell und Shannon (ersten drei Ästhetikkriterien), der wie folgt funktioniert:
●
●
Speichere in jedem Knoten seine Ebene im Baum, dies gibt die y-Koordinate des
Knoten.
Durchlaufe den Baum in Post-Order (L-R-W) und weise dabei jedem Knoten eine xKoordinate zu. Hierzu gibt es folgende Regeln:
–
Ist der Knoten ein Blatt so weise ihm die nächste freie Position auf seiner
Ebene zu (letzte Position mit Knoten + 2).
–
Ist der Knoten ein innerer Knoten unterscheide:
●
●
●
–
hat er nur ein linkes Kind, weise ihm die x-Koordinate seines
Kindes + 1 zu.
hat er nur ein rechtes Kind, weise ihm die x-Koordinate seines
Kindes - 1 zu.
hat er zwei Kinder, weise ihm das Mittel deren beider xKoordinaten zu.
Ist der Knoten ein innerer Knoten und hat nicht mindestens den Abstand 2
zum Vordermann in seiner Ebenen, so verschiebe den gesamten
Unterbaum entsprechend.
Visualisierung I – 9. Graphen
8
Reingold Tilford Algorithmus
●
●
●
Der Reingold Tilford Algorithmus ist ein heuristischer Ansatz. Dabei werden die
beiden Unterbäume eines Knotens zunächst unabhängig gezeichnet und
anschließend so nah wie möglich aneinandergeschoben.
Die Heuristik wird wieder in einem Post-order Durchlauf angewendet:
–
Wenn man sich vorstellt, dass an jedem Knoten T die beiden Unterbäume
bereits gezeichnet wurden und aus Papier entlang ihrer Kontur ausgeschnitten
wurden.
–
Die Wurzeln der beiden Unterbäume werden nun überlagert. Man durchläuft die
Ebenen, die von den beiden Unterbäumen überdeckt werden und schiebt sie so
weit auseinander, dass sie einander nicht mehr überlagern.
–
Die beiden Unterbäume werden abschließend relativ zu ihrem Vater angordnet.
In einem abschließenden Pre-order Durchlauf werden die relativen Verschiebungen
an die Kinder weitergegeben und die entgültigen Positionen berechnet.
Visualisierung I – 9. Graphen
9
H-förmiges Layout
●
Man kann Bäume auch H-förmig auslegen [P. Eades, „Drawing Free Trees“, Bulletin
of the Inst. For the Combinatorics and Its Applications, pp. 10-36, 1992]. Auch dies ist
ein Divide-and-Conquer Ansatz.
Visualisierung I – 9. Graphen
10
Radiales Layout
●
Eine weitere Divide-and-Conquer Variante legt einen Baum mit Wurzel radial aus. Die
Wurzel kommt ins Zentrum. Alle Knoten einer Ebene liegen auf konzentrischen
Kreisen. Ferner vermeidet der Algorithmus Überschneidungen durch Festlegen der
Sektoren für die Teilbäume. Man kann die letzte Bedingung auch abschwächen, um
im Mittel gute Ergebnisse zu erhalten [I.Herman, G. Melancon, M. M. De Ruiter, and
M. Delest, „Latour-A Tree Visualization System“, Proc. Symp. Graph Drawing GD'99,
pp. 392-399, 1999. A more detailed version in: Reports of the Centre for Math. And
Computer Sciens, Report number INS-R9904, available at:
http://www.cwi.nl/InfoVisu/papers/LatourOverview.pdf, 1999]
Visualisierung I – 9. Graphen
11
Eigenschaften der Algorithmen
●
●
Alle besprochenen Baumauslegealgorithmen sind vorhersagbar, d. h. bei gleichem
Input liefern sie den gleichen Output und isomorphe Teilbäume werden gleich
behandelt.
Diese in der Visualisierung sehr sinnvolle Eigenschaft weisen kraftbasierte Ansätze in
der Regel nicht mehr auf, da es meistens mehrere lokale Minima gibt.
Visualisierung I – 9. Graphen
12
Inhaltsverzeichnis
9. Darstellung von Graphen
5. Zeichenalgorithmen für Bäume
1. Traversieren von Bäumen
2. Wetherell Shannon Algorithmus
3. Reingold Tilford Algorithmus
4. H-förmiges Layout
5. Radiales Layout
6. Kraftbasierte Ansätze für allgemeine Graphen
7. Manipulation von Darstellungen
1. Clustering
2. Hierarchisches Clustering
3. Relevanzbasierte Ansätze
Visualisierung I – 9. Graphen
13
Kraftbasierte Ansätze
●
Kraftbasierte Methoden orientieren sich an einem physikalischen Modell mit Kräften
bzw. potentieller Energie, die minimiert werden. Da sie intuitiv zu verstehen, relativ
einfach zu implementieren sind und zugleich oft gute Ergebnisse liefern, sind sie sehr
beliebt. Ein einfache Illustration findet sich im Bild.
http://vimeo.com/4356593
Visualisierung I – 9. Graphen
14
Feder-Kraft-Modell
●
Der einfachste Ansatz nutzt elektrische Kräfte und Federn, wobei jeder Knoten v als
positiv geladenes Teilchen und jede Kante e = {u, v} als Feder mit vorgegebener
Ruhelänge luv modelliert wird. Die Kraft auf einen Knoten v ist
F v = ∑ f uv
{u , v}
∑
g uv
u , v ∈V ×V
wobei fuv die Kraft auf v durch die Feder zwischen u und v ist und guv eine elektrische
Abstoßung von v durch u modelliert.
●
Genauer gilt
2
p
−
p
k
pu − pv
1
u
v
uv
F v = ∑ k uv d pu , pv −l uv
∑
2
d
p
,
p
{u , v }
u , v ∈V ×V d p u , p v d p u , p v
u
v
mit den Zeichnungspositionen pu, pv und dem euklidischen Abstand d (pu, pv) sowie
den Federkonstanten kuv(1) und der ladungsbasierten Abstoßungsstärke kuv(2).
Visualisierung I – 9. Graphen
15
Berechnung des Kraftminimums
●
Zum Finden des Kraftminimums kann eine Vielzahl numerischer Verfahren verwendet
werden. Ein häufig genutzter intuitiver Ansatz ist:
1) Plaziere die Knoten zufällig in der Ebene
2) Berechne die Kraft F(v) für alle Knoten v.
3) Bewege jeden Knoten v ein kleines Stück in Richtung F(v).
4) Wenn die Kräfte nicht annähernd Null sind und das Maximum an
Iterationen nicht erreicht ist, gehe zu 2).
●
Alternative, schnellere Ansätze liefert beispielsweise die Numerik gewöhnlicher
Differentialgleichungen.
Visualisierung I – 9. Graphen
16
Kraft-basierte Ansätze – Anwendungen
Visualisierung I – 9. Graphen
17
Einschränkungen für kraftbasierte Ansätze
Die kraftbasierten Methoden lassen sich gut mit Einschränkungen wie
●
festgelegte Positionen einiger Knoten,
●
fixierte Teilgraphen
●
vorgegebener Rahmen für den Graphen
●
durch Energie ausdrückbare Beschränkungen (z.B. unterschiedliche Abstände
zwischen Knoten)
verbinden.
Visualisierung I – 9. Graphen
18
Finden eines guten Minimums
●
●
Kraftbasierte Methoden benötigen oft viel Rechenaufwand. Daher sind effiziente
Minimierungsmethoden nötig. Entweder wird der Zufall bemüht (Simulated Annealing,
Behandlung steifer Differentialgleichungen, Kombinatorische Vorbehandelung) oder
es werden geeignete Heuristiken verwendet.
Weitere Details ergeben sich aus dem Buch von [Battista, Eades, Tamassia, Tollis.
Graph Drawing. Prentice Hall, Upper Saddle River, NJ, USA, 1999] der dort zitierten
Literatur und den Proceedings der Graph Drawing Conference Series.
Visualisierung I – 9. Graphen
19
Inhaltsverzeichnis
9. Darstellung von Graphen
5. Zeichenalgorithmen für Bäume
1. Traversieren von Bäumen
2. Wetherell Shannon Algorithmus
3. Reingold Tilford Algorithmus
4. H-förmiges Layout
5. Radiales Layout
6. Kraftbasierte Ansätze für allgemeine Graphen
7. Manipulation von Darstellungen
1. Clustering
2. Hierarchisches Clustering
3. Relevanzbasierte Ansätze
Visualisierung I – 9. Graphen
20
Clustering
●
●
Insbesondere wenn der Graph zu groß für die Darstellung ist, kann man ihn auch
vereinfachen. Dies erfolgt in der Regel durch ein Clustering der Knoten. Man
unterscheidet dabei zwei Grundprinzipien:
–
Structural clustering, bei dem nur aufgrund der Struktur des Graphen
zusammengefasst wird.
–
Content-based clustering, bei dem die Semantik, insbesondere der Knoten,
mit berücksichtigt wird.
Fast alle Verfahren basieren auf structural clustering, da es einfacher umzusetzen ist
und der Ansatz auf jeden Graphen unabhängig von der Anwendungsdomäne
angewendet werden kann.
Visualization of a 160-vertex relaxed caveman graph [228] with m
= 1415 edges computed by starting with random initial positions for
each vertex and using a spring-force algorithm to iteratively move
them to the final locations [203]. The graph was generated with a
model that introduced a clear eight-cluster structure, but no
information on the clustering was given to the spring-force
algorithm. However, the natural grouping by balancing the “springs”
of the edges matches the inherent cluster structure.
[Schaeffer, Graph Clustering, Computer Science Review, 2007]
Visualisierung I – 9. Graphen
21
Hierarchisches Clustering
●
●
●
●
Clustering kann auch verwendet verschiedene Abstraktionsebenen des Graphen zu
erzeugen.
Auf der feinsten Ebene sind alle Knoten und Kanten sichtbar.
Auf höheren Ebenen werden jeweils mehrere Knoten oder Cluster zu einem Cluster
der nächsten Ebene zusammengefasst. Zwischen Clustern wird eine Kante
eingezeichnet, wenn eine Kante zwischen Elementen der Cluster existiert.
Durch interaktives Anclicken lassen sich Knoten expandieren.
Visualisierung I – 9. Graphen
22
●
●
●
Oft besteht ein Graph aus verschieden wichtigen Einheiten. Somit kann die
Darstellung des Graphen vereinfacht werden, indem z.B. weniger wichtige Strukturen
unterdrückt werden.
Hierzu muss den Knoten und Kanten ein Relevanzwert zugeordnet werden, der im
Regelfall vom Nutzer bestimmt wird. Häufig werden vordefinierte Kriterien, wie die
Anzahl der Nachbarknoten, oder assoziierte Skalarwerte die sich aus der jeweiligen
Anwendung ergeben verwendet.
Für die Repräsentation gibt es drei verschiedene Ansätze:
–
Ghosting, also unwichtige Kanten und Knoten in den Hintergrund treten
lassen.
–
Hiding, also unwichtige Elemente weglassen.
–
Grouping, also unwichtige Elemente zusammenfassen.
Visualisierung I – 9. Graphen
23
Referenzen
Die Erklärungen folgen den Beschreibungen in:
●
A. C. Telea. Data Visualization: Principles and Practice, A K Peters, Ltd., 2008.
●
R. Diestel. Graphentheorie, Springer, 3. Auflage, 2006
●
G. Di Battista, P. Eades, T. Tamassia, I. G. Tollis. Graph Drawing: Algorithms for the
Visualization of Graphs, Prentice Hall, 1999
Visualisierung I – 9. Graphen
24