Konfidenzintervall für My
Werbung

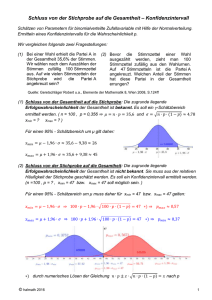
(c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt Konfidenzintervall für My - Sigma bekannt Worum geht es in diesem Modul? Von der Punktschätzung zur Intervallschätzung Konstruktion eines Intervalls um einen Punktschätzwert Verbesserter Ansatz Theoretische Herleitung eines Intervalls für My 1. Schritt: Schwankungsintervall für den Mittelwert 2. Schritt: Konfidenzintervall für My 3. Schritt: Herleitung der Formel für das Konfidenzintervall für My Interpretation des Konfidenzintervalls Zwischenbilanz Simulation Konfidenzniveau Allgemeine Formel für die Breite des Konfidenzintervalls Zusammenhang zwischen Standardabweichung und Präzision Zusammenhang zwischen Konfidenzniveau und Präzision Zusammenhang zwischen Stichprobenumfang und Präzision Bestimmung des Stichprobenumfangs bei vorgegebener Präzision Worum geht es in diesem Modul? Wie schon kurz im angesprochen, gibt es neben den Punktschätzern eine weitere Form von Schätzern: die Intervallschätzer. Wir werden in diesem Modul die Idee der Intervallschätzung erläutern. Im zweiten Schritt wird dann ein Intervallschätzer für bei Normalverteilung und bekanntem zunächst graphisch und anschließend theoretisch hergeleitet. Abschließend werden die Eigenschaften dieses Schätzintervalls untersucht. Von der Punktschätzung zur Intervallschätzung Bisher haben wir ausschließlich Punktschätzer betrachtet. Ein erwartungstreuer Punktschätzer trifft den tatsächlichen Parameterwert im Durchschnitt - keinesfalls jedoch in jedem Einzelfall; das zeigen auch die bisher angestellten Simulationen. Die Standardabweichung des Schätzers ist zwar ein generelles Maß für die Abweichung von Schätzer und tatsächlichem Parameterwert, aber auch sie gibt im konkreten Einzelfall keine Auskunft über die Abweichung. Letztendlich gaukelt die Punktschätzung eine "Pseudogenauigkeit" vor: Wir geben den geschätzten Parameterwert punktgenau an und das, obwohl wir - insbesondere im stetigen Fall - den wahren Parameterwert sehr selten exakt treffen werden. Allerdings Page 1 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt werden "gute Schätzer" Schätzwerte liefern, die sich im Rahmen akzeptabler Genauigkeit nah um den wahren Parameterwert scharen. Man kann eine Punktschätzung mit dem Versuch vergleichen, eine winzige Fliege (den wahren Parameterwert) mit einer Stecknadel (dem Punktschätzer) zu treffen. Der erfahrene Fliegenjäger würde der Stecknadel eine Fliegenklatsche vorziehen... in der Statistik wäre ein Intervall die Entsprechung. Beispiel: Simulations-Beispiel Die Exponentialverteilung (vgl. )gilt als geeignetes Modell, um die Dauer von Telefongesprächen zu modellieren. Wir betrachten Stichproben, in denen jeweils die Dauer von Telefongesprächen genau erfasst wurde. In der Grafik sind jeweils die Schätzwerte ( ) angegeben. Das wahre sei exakt 0.5, d.h. wir erwarten, dass ein Telefongespräch im Mittel 2 Minuten dauert ( ). Visualisierung der sich aus k=25 Stichproben ergebenden Schätzwerte für den Parameter "Lambda" der Exponentialverteilung; es sind drei Mal dieselben Schätzwerte in unterschiedlicher Skalierung dargestellt Hat es auf den oberen beiden Abbildungen noch den Anschein, als würde der wahre Parameterwert zumindest von einem Schätzwert exakt getroffen, so wird unten (bei weiterer Ausschnittsvergrößerung) deutlich, dass kein Schätzwert das wahre exakt trifft. Das ist bei kontinuierlichem Parameterraum auch fast unmöglich. Stattdessen liegen die Schätzwerte in einem Intervall um das wahre Beispiel ungefähr in dem Intervall Page 2 herum; im . Dieses Intervall korrespondiert mit (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt einer Schätzung der durchschnittlichen Gesprächsdauer von (in Minuten). Sie können diese Simulation zu Telefonatdauer ( a57.spf ) im Statistiklabor nachvollziehen und modifizieren. Fassen wir zusammen: Während keiner der 25 Punktschätzwerte der tatsächliche Wert von exakt trifft, liegt in dem konstruierten Intervall. Die Intervall-Schätzung ist in gewisser Hinsicht "ungenauer", weil wir statt eines Punktes ein Intervall als Ergebnis der Schätzung erhalten; dafür überdeckt das Intervall den wahren Parameterwert tatsächlich. Vorteilhaft am Intervall ist außerdem, dass seine Breite unmittelbar Informationen über die Präzision der Schätzung gibt - bei einem Punktschätzer müssen solche Informationen (z.B. Standardfehler) ggf. separat angegeben werden. Konstruktion eines Intervalls um einen Punktschätzwert Wenden wir uns dem Schätzproblem für den Parameter zu. Verschiedene Punktschätzer für der Normalverteilung (vgl. ) kennen wir bereits aus dem . Im Folgenden orientieren wir uns an dem besten Schätzer für , den wir kennen, nämlich Wir wollen versuchen, ein sinnvolles Intervall für die Schätzung von . zu konstruieren. Um die Idee hinter der Intervallschätzung zu verdeutlichen, wollen wir dazu zunächst eine Simulation anstellen: Es werden Stichproben vom Umfang Standardnormalverteilung Parameterwert ist also aus der gezogen. Der tatsächliche ; in der Simulation schwanken die Schätzungen allerdings zwischen -0.24 und 0.20. Die Abweichung vom wahren Wert ist also im Simulationsexperiment betragsmäßig nie größer als 0.24. Sollte das immer gelten, so könnte man um jeden Schätzwert ein Intervall der Breite legen und behaupten, der - im praktischen Fall unbekannte - Parameterwert läge in diesem Intervall. Für die 50 Werte aus unserer Simulation stimmt das natürlich: Intervalle um k=50 Schätzerwerte für den Parameter My der Normalverteilung aus Stichproben vom Umfang n=100; die größte Abweichung vom wahren Wert My=0 (mit einem Pfeil gekennzeichnet) bestimmt die Breite der Intervalle Einführung des Konfidenz-Niveaus Leider ist es keinesfalls sicher, dass dieses Vorgehen auch für alle Folgeschätzungen zum Erfolg führt. Es ist durchaus möglich, dass - wenn wir unser Simulationsexperiment weiter führen - eine der nächsten Stichproben zu einem Schätzwert führt, der noch extremer von dem zu schätzenden Parameterwert abweicht als jeder unserer ersten 50 Schätzwerte, so dass das um ihn gebildete Intervall der Breite den zu schätzenden Parameterwert nicht enthält. Im haben wir die Dichtefunktion von hergeleitet. Wir können also die Wahrscheinlichkeit dafür ausrechnen, dass ein Schätzwert auftritt, der betragsmäßig Page 3 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt größer als 0.24 ist. Die Wahrscheinlichkeit für das Ereignis ist zwar gering (), aber größer als 0. Würde das Ereignis auftreten, so überdeckte unser Intervall den wahren Parameterwert nicht. Würden wir stattdessen den Versuch unternehmen, ein Intervall zu konstruieren, welches für alle denkbaren Schätzwerte das wahre überdeckt, so würde dieses Intervall zwangsläufig den gesamten Parameterraum überdecken ( bis ). Schließlich ist für jedes noch so große immer positiv - die Schätzung wäre sinnlos (denn es ist trivial, dass das wahre immer in liegt). Der Versuch, ein Intervall zu konstruieren, das den wahren Wert von immer einschließt, ist also eine Sackgasse. Wir müssen daher das "immer" relativieren, etwa zu "fast immer", oder noch besser: wir könnten uns vornehmen, die Intervallbreite so festzulegen, dass auf lange Sicht ein festgelegter Anteil der Intervalle, wir bezeichnen ihn als Konfidenzniveau , den zu schätzenden Parameterwert überdeckt, während der Anteil der Intervalle das nicht tut. Natürlich würden wir in der Nähe von 1 wählen, vielleicht 0.95 oder 0.99. Verbesserter Ansatz Wir führen das begonnene Simulationsexperiment weiter, beispielsweise, bis wir Schätzwerte haben (um der Aussage auf lange Sicht gerecht zu werden). Dann sortieren wir die Beträge der 10000 Abweichungen zwischen Schätzer und zu schätzendem Parameterwert nach aufsteigender Größe und suchen uns, um zu realisieren, den Wert heraus, der von 95% der Beträge unterschritten bzw. von 5% überschritten wird. Wenn wir nun für jeden einzelnen der 10000 Fälle das vom bis zum reichende Intervall bilden, dann werden ca. 95% der Intervalle den zu schätzenden Parameterwert überdecken, ca. 5% nicht. Die Abbildung veranschaulicht diese Methode. Schätz-Intervall, welches auf Basis von k=10000 Stichproben vom Umfang n=100 aus N(0,1) so abgegrenzt wurde, dass 95% der Schätzwerte umschlossen werden und 5% nicht. Zwar können wir nicht mit Sicherheit behaupten, dass ein beliebig aus den 10000 Intervallen herausgegriffenes Intervall den zu schätzenden Parameterwert überdeckt und damit eine richtige Aussage macht (im Gegenteil: gerade dieses Intervall könnte den Parameterwert nicht überdecken und damit eine Fehlaussage liefern). Aber wir könnten behaupten, dass jedes der 10000 Intervalle aus einer langen Serie möglicher Intervalle stammt, von denen 95% den zu schätzenden Parameterwert überdecken und damit eine richtige Aussage liefern, während nur 5% den zu schätzenden Parameterwert nicht überdecken und damit eine Fehlaussage liefern. Basierend auf unserem Simulationsexperiment ergeben sich folgende Intervallgrenzen in Abhängigkeit von : Konfidenzniveau Schätzintervall 0.165 0.196 0.257 Page 4 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt Theoretische Herleitung eines Intervalls für My Das erste Problem des "immer" haben wir durch die Vorgabe des Konfidenzniveaus gelöst. Ein zweites Problem scheint aber zunächst größer zu sein: Die Breite des zum Konfidenzniveau gehörenden Intervalls haben wir durch ein umfangreiches Simulationsexperiment gefunden. Tatsächlich ist das unnötig: Wir brauchen weder mit bekanntem Parameterwert noch überhaupt zu simulieren, weil sich ein Intervall zu einem vorgegebenen Konfidenzniveau aufgrund statistischer Überlegungen aus jeder einzelnen Stichprobe errechnen lässt. Dazu machen wir die Voraussetzung, dass die beobachteten Merkmalswerte in unserer Stichprobe, , unabhängige Realisierungen einer normalverteilten Zufallsvariablen mit dem Erwartungswert und der Varianz sind. Außerdem setzen wir im ersten Schritt voraus, dass die Varianz bekannt ist; im zweiten Schritt lassen wir diese - unrealistische - Voraussetzung fallen. Kurz gesagt stellen wir unter den Voraussetzungen der Unabhängigkeit, der Normalverteilung und bekannter Varianz die Frage nach dem Schätz-Intervall für den Erwartungswert . Analog zum "Konfidenzniveau" nennen wir dieses Schätz-Intervall "Konfidenzintervall". Die Herleitung erfolgt in drei Schritten. 1. Schritt: Schwankungsintervall für den Mittelwert Wir finden das Konfidenzintervall für den Parameter der Normalverteilung, indem wir zunächst die umgekehrte Frage beantworten, nämlich die nach einem Intervall für aus einer Stichprobe aus einer Normalverteilung mit gegebenem und gegebenem . Wir wissen bereits: Wenn normalverteilt ist wie , dann ist ebenfalls normalverteilt, und zwar wie - vgl. . Daraus folgt, dass die standardisierte Zufallsvariable standardnormalverteilt ist: . Veranschaulichung des (1-Alpha)-Niveaus an der Dichtefunktion der Standardnormalverteilung Das zentrale Schwankungsintervall für zur vorgegebenen Wahrscheinlichkeit ist definiert durch . Durch Zerlegung der Doppelungleichung finden wir die Intervallgrenzen: Für die p-Quantile der standardisierten Normalverteilung gilt , so dass für auch geschrieben werden kann. Wir erhalten das zentrale ()-Schwankungsintervall für , , für das die Wahrscheinlichkeitsaussage Page 5 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt gilt (vgl. ). Aus dem zentralen Schwankungsintervall für können wir leicht ein zentrales Schwankungsintervall für gewinnen, indem wir für den Ausdruck in unsere letzte Gleichung einsetzen. Es ergibt sich . Durch Auflösen nach erhalten wir . Das Intervall ist das zentrale ()-Schwankungsintervall für . 2. Schritt: Konfidenzintervall für My Mithilfe der Gleichung können wir jetzt also ein Intervall für zum Niveau konstruieren, so dass auf lange Sicht ( ) Prozent unserer Schätzungen in diesem Intervall liegen werden und Prozent nicht. Das löst die Frage nach dem Intervall für bei gegebenem , aber nicht unsere - umgekehrte - Frage nach dem Intervall für bei gegebenem . Erinnern wir uns: Beim Schätzen ist der tatsächliche Parameterwert unbekannt - wir wollen also versuchen, um unseren Schätzer ein Intervall zu konstruieren, in dem mit einer bestimmten Wahrscheinlichkeit liegt. Wie kommen wir von dem Schwankungsintervall für zum Schwankungs- bzw. Konfidenzintervall für ? Die folgende Überlegung bringt uns ans Ziel: Wir wollen das zentrale ()-Schwankungsintervall für nicht für ein bestimmtes , sondern für verschiedene grafisch angeben. Dazu tragen wir an der Abszisse eines Koordinatensystems und an der Ordinate die untere und obere Grenze des Schwankungsintervalls ab. Wenn wir die Maßeinheiten der beiden Koordinaten gleich wählen, dann bilden die beiden Grenzlinien der Schwankungsintervalle gemäß unserer Gleichung Page 6 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt parallele Geraden, die gegenüber der Diagonalen um den Betrag nach unten bzw. nach oben verschoben sind. Grafische Bestimmung der Grenzen des Schwankungsintervalls für den Mittelwert Für jedes gewählte können wir nun das zentrale Schwankungsintervall für ablesen; die Abbildung verdeutlicht dies exemplarisch für (rot eingezeichnet). Um zum Schwankungsintervall für zu kommen, benutzen wir die Abbildung nun umgekehrt: wir kennen nicht, haben aber aus der Stichprobe das arithmetische Mittel bestimmt und tragen ihn auf der Ordinate unserer Abbildung ab. Wir fragen uns nun, bei welchen Werten von der von uns gefundene Wert im zentralen Schwankungsintervall gelegen hätte. Grafische Bestimmung der Grenzen des Schwankungsintervalls für den Parameter My Die Antwort ist einfach: Ziehen wir eine Waagerechte durch , dann ergibt der Schnittpunkt mit offenbar das kleinste (wir nennen es ), für das gerade noch in dem - fett eingerahmten - Schwankungsintervall liegt. Umgekehrt ergibt der Schnittpunkt mit das größte (wir nennen es ), für das gerade noch - in dem fett eingezeichneten - Schwankungsintervall liegt. Anders gesagt: Das Intervall enthält alle Werte , für die das gegebene )-Schwankungsintervall gelegen hätte. Wir nennen im zentralen ( ein zweiseitiges symmetrisches ()-Konfidenzintervall für . 3. Schritt: Herleitung der Formel für das Konfidenzintervall für My Wie können wir nun die Formel finden, die unserer Grafik zugrunde liegt? Ganz einfach, indem wir die bereits bekannte Gleichung nach auflösen: Aus folgt und aus folgt . Also ergibt sich . Damit sind wir schon am Ziel! Die folgende Animation gibt noch einmal einen Überblick über die Überlegungen, die uns zu dieser Gleichung geführt haben. : Flashanimation ' Animation Konfidenz-Schätzung ' siehe Online-Version öffnen Interpretation des Konfidenzintervalls Page 7 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt Solange die Zufallsvariable noch nicht den sich aus der Stichprobe ergebenden Wert angenommen hat, sind die Grenzen des untersuchten Konfidenzintervalls, und , Zufallsvariablen; das zufällige Intervall zwischen ihnen überdeckt mit der Wahrscheinlichkeit den Erwartungswert . Setzt man in der Gleichung des Konfidenzintervalls für die Zufallsvariable Stichprobenwert den ein, dann ergeben sich die Grenzen des konkreten Konfidenzintervalls für . Die Wahrscheinlichkeitsaussage gilt natürlich in dem Moment nicht mehr, in dem wir die Zufallsvariable durch ihren konkreten Wert ersetzt. Denn dann stehen in der Bestimmungsgleichung des Konfidenzintervalls zwei Zahlenwerte als Grenzen, so dass das Intervall zwischen ihnen den unbekannten, aber festen Wert entweder überdeckt oder nicht. Obwohl das konkrete Konfidenzintervall aus einer Wahrscheinlichkeitsaussage zur Wahrscheinlichkeit hervorgegangen ist, werden wir im Einzelfall nur sagen können, dass es den Erwartungswert überdeckt oder auch nicht. Wir werden aber erwarten, dass der Anteil von ()-Konfidenzintervallen, die auf der Basis verschiedener Stichproben abgegrenzt wurden, den unbekannten Erwartungswert überdecken, der Anteil dagegen nicht. Satz - Konfidenzintervall für bei Normalverteilung und bekannter Varianz : Ist eine konkrete Stichprobe vom Umfang aus einer Normalverteilung (d.h. sind Realisierungen der Zufallsvariablen , die unabhängig identisch normalverteilt sind) mit bekannter Varianz und unbekanntem Erwartungswert und ist der arithmetische Mittelwert der Stichprobe, dann ist mit ein zweiseitiges symmetrisches Konfidenzintervall für zum Konfidenzniveau Page 8 ; dabei (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt ist das ( )-Quantil der standardisierten Normalverteilung. Beispiel: Preisvergleich Ein namhafter Hersteller von Spiegelreflex- und Kleinbildkameras hat beschlossen, auch das Marktsegment "höherwertige Digitalkameras" zu besetzen. Man hofft auf eine erfolgreiche Verwertung der Kernkompetenz "Know-how rund um hochwertige Optiken" und das Image als Markenhersteller. Die Vertriebsstrukturen weichen allerdings erheblich ab: Die Käufer digitaler Photoapparate sind internet- und technikaffinitiv. Es herrscht eine hohe Preiselastizität, viele Geräte werden über schwer kontrollierbare Versandhändler abgesetzt. Für die Hersteller ist es dadurch schwierig, die gewünschten Endverbraucherpreise durchzusetzen. Preisdifferenzen bei digitalen Photoapparaten (Quellen: www.canon.de, www.guenstiger.de) Um sich mit dem Markt vertraut zu machen, sollen die Endverbraucherpreise eines etablierten Konkurrenzproduktes analysiert werden. Dazu wird eine Stichprobe vom Umfang aus einer sehr umfangreichen Liste ( ) entsprechender Händler gezogen - bei den Händlern in der Stichprobe ( dfb.txt ) werden Angebote für das Konkurrenzprodukt eingeholt. Es ergibt sich . Das Konfidenzintervall für den durchschnittlichen Endverbraucherpreis soll berechnet werden (Konfidenzniveau ; es wird angenommen, dass die Endverbraucherpreise normalverteilt sind; die Standardabweichung betrage ). mit: ,,,. Es ergibt sich: Zum Konfidenzniveau 95% erhalten wir für den "Straßenpreis" das Konfidenzintervall . In Zusammenhang mit Konfidenzintervallen trifft man oft auf falsche Interpretationen der Aussage, die ein solches Intervall macht. Während solche Fehler in der Praxis gelegentlich unbemerkt bleiben, gilt das für Klausuren nur in den wenigsten Fällen! Daher soll an dieser Stelle noch einmal auf ein häufiges Missverständnis eingegangen werden: In Bezug auf das Beispiel Preisvergleich würden sich einige Personen zu der folgenden (falschen) Aussage hinreißen lassen: "Das wahre liegt mit der Wahrscheinlichkeit 95% in dem Intervall ." Wir unterscheiden die allgemeine Konstruktionsgleichung (1) für ein Konfidenzintervall, in der die Intervallgrenzen Zufallsvariablen sind und das sog. "realisierte" oder "konkrete" Konfidenzintervall (2), welches wir erhalten, wenn Daten einer konkreten Stichprobe in die Konstruktionsgleichung eingesetzt wurden. (1) Vor der Beobachtung : es gilt: Page 9 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt (2) Realisiertes Konfidenzintervall : es gilt nicht: Wo ist der Unterschied? Die roten (groß geschrieben) sind Zufallsvariablen, die blauen (klein geschrieben) sind Realisierungen dieser Zufallsvariablen. Das realisierte Intervall hat zwei konkrete Zahlenwerte als Grenzen, z.B. . Warum gilt die Wahrscheinlichkeitsaussage nun nicht mehr? Die Tatsache, dass wir nicht kennen, führt gelegentlich zu dem Fehlschluss, sei eine Zufallsvariable. ist aber eine, wenn auch unbekannte, Konstante. Eine Wahrscheinlichkeit dafür angeben zu wollen, dass die unbekannte Konstante von überdeckt wird, ist unsinnig. Das realisierte Intervall überdeckt entweder oder es tut es nicht! Eine Aussage zur Überdeckung in Bezug auf realisierte Intervalle macht erst auf lange Sicht Sinn: Wir erwarten, dass bei wiederholter Stichprobenziehung auf lange Sicht ungefähr 95% der realisierten Intervalle den wahren Parameterwert überdecken. Ein Beispiel soll den Denkfehler verdeutlichen: Sie möchten Lotto spielen, um Ihre Haushaltskasse aufzubessern (tatsächlich hat dies meist den gegenteiligen Effekt). Um am "Samstags-Lotto" teilzunehmen, füllen Sie schon am Freitag Ihren Lottoschein aus und geben ihn ab. Die Aussage, dass sie mit der Wahrscheinlichkeit 6 richtige getippt haben ist jetzt korrekt. Nehmen wir weiter an, Sie sind am Samstagabend unterwegs und verpassen die Ziehung der Lottozahlen. Auch wenn Sie die gezogenen Lottozahlen nicht kennen, können Sie nach der Ziehung keine Wahrscheinlichkeit für einen möglichen Gewinn mehr angeben, denn sobald die Lottozahlen feststehen, haben Sie entweder 6 richtige oder Sie haben sie nicht. Ob Sie die Gewinnzahlen kennen, spielt dabei keine Rolle. Würden Sie regelmäßig Lotto spielen, könnte man allerdings davon ausgehen, dass Sie auf lange Sicht (allerdings nur, wenn Sie einige Milliarden Jahre alt werden würden) im Durchschnitt ca. jedes 13983816te Spiel gewinnen würden. Zwischenbilanz Wir haben die theoretische Herleitung des Konfidenzintervalls für unter Normalverteilung bewältigt. Es ist nicht unbedingt erforderlich, jeden einzelnen Schritt auf Anhieb zu verstehen, schließlich werden wir die Herleitung im anhand eines weiteren Schätzproblems wiederholen. Entscheidend ist, dass die Idee, die hinter dem Konfidenzintervall steht, verinnerlicht wurde. Um dies zu erleichtern, werden wir im Folgenden noch einige Eigenschaften des Konfidenzintervalls für untersuchen. Simulation Konfidenzniveau Wir wollen eine Simulation anstellen: Es werden Stichproben vom Umfang aus der Normalverteilung erzeugt und jeweils und das zugehörige Konfidenzintervall für zum Konfidenzniveau und bestimmt. Vergleich von je k=100 Konfidenzintervallen zum Konfidenzniveau 95% bzw. 99%; n=10, Stichproben aus N(50, 10^2) 5% Page 10 Konfidenzniveau ( ) tatsächlicheÜberdeckung 95% 95% Breite 12.40 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt 1% 99% 98% 16.29 Das Konfidenzniveau wird bereits bei Wiederholungen recht stabil eingehalten. Die Intervalle werden offensichtlich breiter, wenn ein höheres Konfidenzniveau (also mehr Sicherheit) gewählt wird. Die Simulation ( f0e.spf ) können Sie im Statistiklabor nachvollziehen und modifizieren. Allgemeine Formel für die Breite des Konfidenzintervalls Die Breite des Konfidenzintervalls erhält man, indem man die Differenz aus oberer Grenze () und unterer Grenze () bildet: Die Breite des Konfidenzintervalls ist ein Maß dafür, mit welcher Präzision erfasst wird. Je breiter das Konfidenzintervall ist, desto unpräziser ist die Schätzung. Man erkennt sofort, dass die Breite von drei Größen abhängt: - von der Standardabweichung , - von bzw. dem Konfidenzniveau - vom Stichprobenumfang , . Den Einfluss dieser Größen auf die Breite des Konfidenzintervalls (bzw. die Präzision der Schätzung) werden wir im Folgenden genauer untersuchen. Zusammenhang zwischen Standardabweichung und Präzision Aus der Formel für die Breite ist der Zusammenhang leicht ersichtlich: Je größer , d.h. je mehr die Werte streuen, desto breiter ist das Konfidenzintervall, um so geringer also die Präzision, mit der erfasst wird. Der Zusammenhang ist linear. Zusammenhang zwischen Standardabweichung und Breite des Konfidenzintervalls (n=10, Konfidenzniveau 95%) Der Grund dafür ist, dass die Schätzung in einer eher homogenen Grundgesamtheit (geringe Standardabweichung ) genauer erfolgen kann als in einer Grundgesamtheit, in der die Ausprägungen des untersuchten Merkmals stark variieren. So ließe sich z.B. die tägliche Ausbringungsmenge einer Maschine mit hoher Präzision schätzen, wenn sie nur minimalen Schwankungen unterliegt. Variiert die Ausbringungsmenge dagegen stark, so wird das Konfidenzintervall breiter (die Schätzung wird unpräziser). Zusammenhang zwischen Konfidenzniveau und Präzision In der Formel für die Breite, , spiegelt sich das gewählte Konfidenzniveau im Quantil der Standardnormalverteilung Page 11 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt wieder. Den Zusammenhang verdeutlicht die Tabelle. 0.9 0.95 1.64 0.95 0.975 1.96 0.99 0.995 2.58 Je höher das Konfidenzniveau (Sicherheit der Schätzaussage) gewählt wird, desto größer ist das entsprechende Quantil der Standardnormalverteilung. Die Abbildung zeigt den Zusammenhang zwischen Konfidenzniveau und Breite des Konfidenzintervalls. Zusammenhang zwischen Konfidenzniveau und Breite des Konfidenzintervalls (n=10, Sigma=1) Mit wachsendem wächst , so dass sich das Konfidenzintervall mit wachsendem Konfidenzniveau verbreitert: Wer eine sicherere Aussage machen will, muss sich mit einer unpräziseren Aussage zufrieden geben, und umgekehrt. Die Sicherheit der Aussage und die Präzision der Aussage stehen also im Widerspruch zueinander! Diesmal ist der Zusammenhang aber nicht linear: Während die Präzision der Schätzung mit wachsendem Konfidenzniveau anfangs nur leicht abnimmt, muss man für das letzte "Quäntchen" Sicherheit einen überproportionalen Verlust an Präzision hinnehmen. Zur Erinnerung : Das Konfidenzniveau muss immer kleiner als 100% gewählt werden, sonst überdeckt das Konfidenzintervall den gesamten Parameterraum und verliert damit jegliche Aussagekraft. In der Praxis ist ein Konfidenzniveau von 95% oder 99% üblich. Zusammenhang zwischen Stichprobenumfang und Präzision Aus der Formel für die Breite des Konfidenzintervalls, , ist der Zusammenhang leicht ersichtlich: Je größer der Stichprobenumfang , desto schmaler das Konfidenzintervall und umgekehrt; allerdings steht im Nenner unter einer Wurzel, d.h. erst eine Vervierfachung des Stichprobenumfangs führt zu einer Halbierung der Breite des Konfidenzintervalls (vgl. Abbildung). Zusammenhang zwischen Stichprobenumfang und Breite des Konfidenzintervalls (Sigma=1, Konfidenzniveau 95%) Mit wachsendem Stichprobenumfang wird die Präzision der Konfidenzschätzung des unbekannten Parameterwertes immer größer. Im Grenzfall tendiert die Breite des Konfidenzintervalls gegen 0; der aus der immer größer werdenden Stichprobe gewonnene Schätzwert wird dann dem unbekannten Parameterwert der Page 12 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt Grundgesamtheit gleich. Diesem Zusammenhang kommt in der Praxis eine zentrale Bedeutung zu: Die Standardabweichung ist eine Eigenschaft der Untersuchungseinheiten bzw. des Zufallsvorgangs insgesamt und lässt sich vom Forscher nicht beeinflussen. Die Sicherheit der Schätzung (also das Konfidenzniveau) ist ebenfalls meist vorgegeben (z.B. durch den Auftraggeber einer Untersuchung); genauso verhält es sich häufig mit der Präzision der Schätzung. Schließlich wäre z.B. eine Wahlhochrechung mit einer Präzision von für eine Partei schlichtweg wertlos. Eine adäquate Wahl des Stichprobenumfangs ist i.d.R. die einzige Möglichkeit, die Anforderungen an Sicherheit der Schätzaussage und deren Präzision in Einklang zu bringen. Die Wahl des Stichprobenumfangs unterliegt in der Praxis jedoch diversen Restriktionen: Je größer der Stichprobenumfang, desto kosten- und aufwandsintensiver wird die Erhebung; ggf. können auch zeitliche Restriktionen eine Rolle spielen. Das Applet Breite des Konfidenzintervalls für MY (I1002.jar) ermöglicht einen Überblick über die hier untersuchten Zusammenhänge: Es wird davon ausgegangen, dass die in einem Intelligenztest erreichten Punkte normalverteilt sind. Für den Parameter der Normalverteilung soll in der Aufgabe Intelligenztest ( I1014.zmpf ) im Statistiklabor ein Konfidenzintervall bestimmt werden. Bestimmung des Stichprobenumfangs bei vorgegebener Präzision Gibt es eine Möglichkeit, sowohl eine hohe Sicherheit (hohes Konfidenzniveau) als auch eine gute Präzision (schmales Konfidenzintervall) zu bekommen? Oder anders gefragt, kann man bei vorgegebenem Konfidenzniveau ein Konfidenzintervall mit vorgegebener Breite bekommen? Wir setzen . Da vorgegeben ist und als Maß für die Streuung von von uns nicht beeinflusst werden kann, bleibt eine Festlegung des Stichprobenumfangs so, dass ist. Durch einige Umformungen ergibt sich . Beispiel: Körpergröße Aus Erfahrung ist bekannt, dass die Körpergröße (in cm) von männlichen Studierenden normalverteilt ist mit cm. Der Erwartungswert der Körpergröße soll mit einem Konfidenzintervall (Konfidenzniveau ) der Breite erfasst werden. Welcher Stichprobenumfang ist erforderlich? Mit ergibt sich Page 13 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt . Da nur ganzzahlig sein kann, ist der kleinste Stichprobenumfang, der den Anforderungen an Konfidenzniveau und Präzision gerecht wird. In einem Abfüllwerk werden täglich viele hundert Flaschen Bier abgefüllt. Die Werksleitung will überprüfen, ob die tatsächliche Abfüllmenge den geforderten 0,33 Litern entspricht. Für die Konfidenzschätzung ist die Präzision von der Geschäftsleitung vorgegeben worden. Bestimmen Sie in der Aufgabe Abfüllmenge ( I107b.zmpf ) im Statistiklabor den zur Einhaltung dieser Forderung mindestens benötigten Stichprobenumfang. Punktschätzer treffen den wahren Parameterwert in den seltensten Fällen exakt - bei konsistenten Schätzern erwarten wir allerdings, dass sich die Schätzwerte bei wiederholter Schätzung nah um das wahre scharen. Bei der Intervallschätzung wird ein Unsicherheitsintervall um den Punktschätzwert gelegt, das als Schätzung angegeben wird. Dieses Intervall heißt Konfidenzintervall und wird so konstruiert, dass es mit der Wahrscheinlichkeit von überdeckt. wird Konfidenzniveau genannt und ist ein Maß dafür, wie sicher die gemachten Schätzaussagen sind. Wir haben ein solches Konfidenzintervall in diesem Modul für den Parameter der Normalverteilung hergeleitet und die Eigenschaften des Konfidenzintervalls eingehend untersucht. Wir halten fest, dass... - das Konfidenzintervall umso breiter ist, je größer die Standardabweichung ist, - das Konfidenzintervall breiter wird, wenn das Konfidenzniveau (Sicherheit der Schätzung) erhöht wird, - das Konfidenzintervall schmaler wird, wenn der Stichprobenumfang vergrößert wird. Die Breite des Konfidenzintervalls beschreibt die Präzision der Schätzung; ein schmales Intervall bedeutet eine präzise Schätzung. Leider stehen Präzision der Schätzung und Sicherheit der Aussage (also Konfidenzniveau) in einem Konflikt zueinander. Höhere Sicherheit geht (bei gleichem Stichprobenumfang) immer zu Lasten der Präzision und umgekehrt. Die Präzision der Schätzung lässt sich aber durch eine Erhöhung des Stichprobenumfangs steigern, so dass bei vorgegebenem Konfidenzniveau nahezu jede gewünschte Präzision durch Wahl eines entsprechend großen Stichprobenumfangs realisiert werden kann. Die Interpretation des Konfidenzintervalls wurde ebenfalls thematisiert: Solange keine konkreten Stichprobenwerte eingesetzt werden, gilt die Wahrscheinlichkeitsaussage . Sobald für aber konkrete Werte eingesetzt werden, gilt diese Wahrscheinlichkeitsaussage nicht mehr. Wir erhalten dann ein sog. realisiertes Konfidenzintervall mit festen Grenzen - dieses überdeckt das unbekannte (aber feste) oder es überdeckt es nicht. Als wesentliche Einschränkung ist zu vermerken, dass wir als bekannt voraussetzen, was in der Praxis jedoch unrealistisch ist. Dieses Voraussetzung wird im aufgehoben. KonfidenzintervallErklärungKonfidenzintervall für MyErklärungKonfidenzniveauErklärungSchwankungsintervall ErklärungPräzision einer SchätzungErklärung (c) Projekt Neue Statistik 2003, Freie Universität Berlin, Center für Digitale Systeme Page 14 (c) Projekt Neue Statistik 2003 - Lernmodul: Konfidenzintervall für My - Sigma bekannt Kontakt: http://www.neuestatistik.de Page 15