Statistik
Werbung

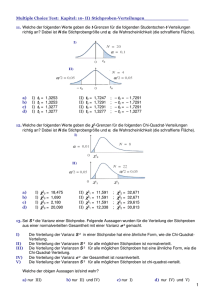
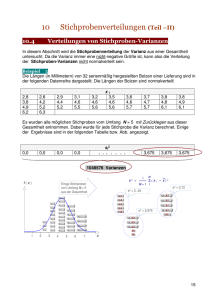
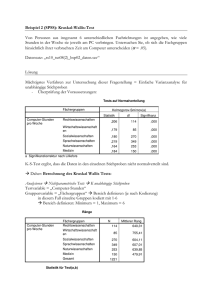
EINFÜHRUNGSKURS STATISTIK Modul 0008 Warum eigentlich Statistik? • Deskriptive Statistik • Beschreiben der Daten • Suchen nach Trends /Mustern • Induktive Statistik • Ziel: Verallgemeinerung der Ergebnisse • Rückschlüsse auf Grundgesamtheit/Population durch Erhebung einer repräsentativen Stichprobe Ablauf statistischer Untersuchungen Ablauf statistischer Untersuchungen • Wieviele Proben benötige ich? • Welche Stichprobeneinheit soll verwendet werden? • Skalierung • Welches räumliche Probennahmemuster soll verwendet werden? • z.B. bei Beprobung einer Fläche • Welches zeitlich Probennahmemuster soll verwendet werden? • Adäquate Intervalle Populationen und Stichproben Definition Population Stichprobe Grundgesamtheit Teilmenge einer Grundgesamtheit latein Symbole griechisch Mittel m Standardabweichung s s Stichproben • Verbundene Stichproben • z.B. wiederholte Messungen am gleichen Versuchsobjekt • Stichprobe zu einem Zeitpunkt kann Einfluss auf Stichprobe eines anderen Zeitpunkts haben • Unverbundene Stichproben • Stichproben haben keinen Einfluss aufeinander • z.B. unterschiedliche Populationen, Vergleich unterschiedlicher Individuen Datentypen Informationsgehalt Merkmale / Variablen • Experimente werden normalerweise so gestaltet, um den Einfluss eines oder mehrerer Faktoren auf eine Variable zu untersuchen • Feldarbeit kann nie vollständig kontrolliert werden: Verschiedene Faktoren können Einfluss auf Variable haben • see “Nearly right or precisely wrong” by Randolph and Nuttall (1994) Systematische Fehler/Trend (Bias) • Auftretender, meist störender systematischer Effekt mit einer Grundtendenz, der von den wahren Ergebnissen abweicht • Schätzung von Fischpopulationen mit Netzen einer bestimmten Maschenweite: kleine Fische können immer entkommen • Fangen von Säugetieren: manche Individuen sind “trap happy”, manche sind “trap shy” Deskriptive Statistik • Eine Methode um Daten zusammenzufassen und darzustellen • Heiko hat 2006 über 68.000 Zecken gesammelt • H.G. Andrewartha hat in 14 Jahren über 3.000.000 Fransenflügler auf Rosen gezählt • Große Datenmengen müssen zusammengefasst werden • Eine numerische Darstellung wird für eine genaue Beschreibung der Daten benötigt • Excel, SPSS, R, … Darstellung von Daten Darstellung von Daten Histogramm Säulendiagramm Scatterplot Boxplot Häufigkeitsverteilungen Parameter einer Verteilung • Lagemaße • Mittelwerte • Median • Modalwert • Quantile • Streuungsmaße • Spannweite (Minimum bis Maximum) • Varianz • Standardabweichung • Konfidenzintervall (e.g. a=5%=95%KI) Zentrale Tendenz & Streuung Lagemaße - Mittelwerte • Arithmetisches Mittel (am häufigsten verwendet) AM=1/nSxi • Geometrisches Mittel (für logarithmierte Daten, z.B. Populationswachstum) • Harmonisches Mittel (Mittelwert von Verhältnissen, z.B. Fahrzeit) • AM>GM>HM Weitere Lagemaße • Median (der Wert, der bei einer Auflistung von Zahlenwerten in der Mitte steht) 4, 1, 37, 2, 1 Median = 2 (1, 1, 2, 4, 37) • Modalwert (Dichtemittel) • 2, 2, 3, 5, 5, 5, 9, 9, 15 • Quantil, Quartil • Die geordnete Reihe der Merkmalsausprägungen wird in gleichgroße Teile zerlegt Streuungsmaße • Spannweite • Maximale Differenz zwischen zugrunde liegenden Daten • Mindestens Ordinaldaten notwendig • Varianz • Mittlere quadratische Abweichung der einzelnen Datenwerte vom arithmetischen Mittelwert. • Standardabweichung • Als Standardabweichung bezeichnet man die Wurzel aus der Varianz. Dieses Streuungsmaß besitzt die selbe Einheit wie die Daten und der Mittelwert Wahrscheinlichkeitsverteilung • Einige Verteilungen, die natürlich vorkommen • Normalverteilung • Poissonverteilung • Binomialverteilung • Negative Binomialverteilung Normalverteilung • Häufigste Verteilung für stetige Variablen • Lagemaß: Mittelwert • Streuungsmaß: Varianz • Anforderung um parametrische Tests durchzuführen Bei einer Normalverteilung sind Mittelwert und Median gleich Poissonverteilung • Einparametrige, diskrete statistische Verteilung • “Verteilung der seltenen Ereignisse • Anzahl von Tieren, die auf einem km Straße getötet werden • Anzahl der Personen aus 10 preussischen Armeen, die über den Zeitraum von 20 Jahren durch Pferdetritte getötet werden Binomialverteilung • Zweiparametrige, diskrete statistische Verteilung • Genau zwei Ausprägungsmöglichkeiten des Merkmals möglich: z.B. weiblich & männlich, verheiratet und ledig Negative Binomialverteilung • Eine gruppierte Anzahl Darmwürmer pro Igel (aggregierte) Verteilung, die oft verwendet wird um eine Überdispersion z.B. in Parasitenpopulationen anzugeben. • Die Varianz ist normalerweise größer als der Mittelwert • Bsp.: Anzahl von Zecken/ Igel auf 20 Igeln) Hypothesen und Testen von Hypothesen • Hypothesen • Signifikanzniveau • Konfidenzintervall • Typ I - und Typ II - Fehler • Ein- und zweiseitige Tests Das Prinzip der Hypothesen • Die Nullhypothese (H0) sagt, dass es keine Unterschiede gibt • Wird H0 abgelehnt, wird die Alternativhypothese H1 akzeptiert Statistische Tests untersuchen die Wahrscheinlichkeit ob einer der Hypothesen “richtig” oder “falsch” ist Ablauf eines statistischen Tests • Aufstellen der Forschungsfrage Entwicklung eines • • • • • • Experiments zum testen der Hypothese Formulieren von H0 und H1: klares Verständnis für Erwartungen Entscheidung für einen geeigneten statistischen Test und Signifikanzniveau (normalerweise p < 0.05) Sammeln der Daten um Hypothese zu testen Kontrolle der Probenverteilung: wenn nötig alternativer Test oder Datentransformierung Testanalyse: Berechnung des p-Wertes Statistische Entscheidung p < 0,05 => Verwerfen der H0 und Annehmen der H1 p ≥ 0,05 Beibehalten der Nullhypothese (H0) • Interpretation der Ergebnisse Signifikanzniveau & Konfidenzintervall =Irrtumswahrscheinlichkeit α α/2 = Konfidenzintervall & Co. • Konfidenzintervall: Der Bereich in dem der Parameter der Grundgesamtheit mit einer gewissen Wahrscheinlichkeit liegt • Konfidenzintervalle lassen sich nur bestimmen wenn die Verteilung der Grundgesamtheit bekannt ist • Ein Mittelwert ist wenig wert, wenn man nichts über die Verteilung der Daten weiß > Standardabweichung (s) Maß für die Streuung der Werte einer Zufallsvariablen um ihren Erwartungswert > Standardfehler (Streuungsmaß - (s/sqrt(n))) Durchschnittliche Abweichung des geschätzten Parameterwertes vom wahren Parameterwert Testauswahl: Welche Kriterien nutzen wir? • Skalenniveau das für die Daten passt • Sind die Daten verbunden oder unverbunden? • Sind die Daten normalverteilt? • Anzahl der untersuchten Variablen • Anzahl der Vergleichsgruppen der Variablen • Können eine oder mehrere Faktoren die Werte der Variable beeinflussen? • (univariate oder multivariate Analyse) Kreuztabelle • tabellarische Darstellung der gemeinsamen Häufigkeitsverteilung zweier Variablen • Eignet sich vor allem für kategorielle Daten • 2 x 2 Tabelle • m x n Tabelle • z.B. Vergleich von Prävalenzen Produkt A Produkt B Summe weiblich männlich Summe 660 440 1100 340 560 900 1000 1000 2000 Frage 1 Trevor möchte wissen ob das Verhältnis der Anzahl von männlichen zu weiblichen Zecken, die er im Garten gesammelt hat, gleich ist. 2x2 Tabelle Variable I II Total + a b a+b - c d c+d Total a+c b+d Männchen (m) Weibchen (f) Total Beobachtet (o) 42 38 80 Erwartet (e) 40 80 40 c2 1= (om-em)2/em + (of-ef)2/ef Freiheitsgrade (df) = Anzahl untersuchten Gruppen -1 c2 mit 1df ist signifikant wenn α=5% wenn größer als >3.84 c2 1= 0.2 nicht signifikant Frage 2 Trevor möchte wissen ob das Verhältnis von männlichen zu weiblichen Zecken an zwei unterschiedlichen Fangtagen im März das Gleiche ist. Männchen Weibchen Total 31. März 42 38 80 14. März 33 35 68 Total 75 73 148 c21=n(lad-bcl-n/2)2/(a+b)(c+d)(a+c)(b+d) n/2 =Yates Korrektur für kleine Stichproben Eine alternative Methode bei kleinen Stichproben ist der Fisher’s exact test http://www.quantpsy.org/chisq/chisq.htm http://daten-consult.de/forms/cht2x2.html http://www.quantpsy.org/chisq/chisq.htm Frage 3 Trevor möchte wissen ob das Verhältnis von Männchen zu Weibchen aus dem Garten im März das gleiche ist wie an zwei Sammeltagen im April. n x m Tabelle Variable 1 2 Total A n11 n21 R1 B n12 n22 R2 C n13 n23 R3 Total C1 C2 N Männchen Weibchen Total 17. März 75 73 148 25. April 13 6 19 27. April 13 5 18 Total 101 84 185 c22=4,64; p=0,098 df=(c-1)(r-1) Achtung: es gibt keinen signifikanten Unterschiede zwischen den Apriltagen. Vereinigt man die Daten der beiden Apriltage und vergleicht sie mit März c21=4,54; p=0,032 SEHR WICHTIG! • Plane dein Experiment von Anfang an immer mit den statistischen Tests im Hinterkopf • Viele Daten werden gesammelt ohne die spätere statistische Auswertung zu berücksichtigen oft nutzlos! Typ 1 und Typ 2 Fehler • Typ 1: wir lehnen H0 ab, obwohl sie wahr ist. Wenn a=0,05 dann lehnen wir H0 in 5% der Fälle ab, obwohl sie wahr ist. a, die Wahrscheinlichkeit, mit der wir H0 ablehnen, wird so definiert. • Typ 2: wir akzeptieren H0 obwohl sie falsch ist. Die Wahrscheinlichkeit einen Typ 2 Fehler zu machen ist b. 1-b ist die Wahrscheinlichkeit H0 abzulehnen obwohl sie in Wirklichkeit richtig ist. Ein- oder zweiseitige Tests t-Test und andere • tdf= 1- 2/Standardfehler • Vergleich von Mittelwerten • Zwei unabhängige Stichproben • Gleiche Varianz (Mann-Whitney U-test) • Ungleiche Varianz • Abhängige Stichproben (Wilcoxon signed-ranks test) • Transformationen • * nicht-parametrische Tests Freiheitsgrade • Stichprobengröße kann die Verteilung der Daten beeinflussen • Je mehr Individuen, desto eher sind die geschätzten Parameter nah an der Realität (Grundgesamtheit). • Dieser Einfluss wird in der Statistik mit aufgenommen (df) • Für eine Population ist df=n, für eine Stichprobe n-1 Frage • Miriam möchte wissen, ob sich die Anzahl von Retikulozyten bei männlichen und weiblichen Igeln unterscheidet • Eventuell saisonal abhängig Mai 2007 für den Test • Zwei Mittelwerte (Männchen, Weibchen) • Stichproben sind unabhängig voneinander Gruppenstatistiken VAR00004 VAR00002 1,00 2,00 N 13 15 Mittelwert 508,8462 486,4000 Standardab weichung 284,59470 114,95453 Standardfe hler des Mittelwertes 78,93237 29,68113 Test bei unabhängigen Stichproben Levene-Test der Varianzgleichheit VAR00004 Varianzen sind gleich Varianzen sind nicht gleich F Signifikanz 6,017 ,021 T-Test für die Mittelwertgleichheit T ,281 ,266 df Sig. (2-seitig) 26 ,781 15,370 ,794 95% Konfidenzintervall der Differenz Mittlere Standardfehle Differenz r der Differenz Untere Obere 22,4462 79,93357 -141,860 186,75195 22,4462 84,32845 -156,919 201,81174 Die Annahmen des t-Tests • Beobachtungen müssen unabhängig voneinander sein • Stichproben müssen zufälllig aus einer normal verteilten Population genommen werden (ggf. Transformation) • Populationen haben (normalerweise) die gleiche Varianz (nicht zwingend notwendig) • Variablen müssen mindestens intervallskaliert sein Was machen, wenn die Daten nicht zum Test passen? • Parametrische Tests • Annahme der Normalverteilung • Die tatsächlichen Werte werden verwendet • Nicht-parametrische Tests • Keine bestimmte Verteilung wird angenommen • Daten werden für den Test klassifiziert (verlieren damit an Information) Parametrisch vs. nicht-parametrisch • Vorteile von parametrischen Tests • Die wahre Verteilung der Daten wird in den Test mit einbezogen vorhandene Informationen werden genutzt • Vorhandene Tests können komplexe Interaktionen zwischen Variablen einschätzen • Vorteile von nicht-parametrischen Tests • Können verwendet werden wenn die Stichprobengröße gering ist • Können für Daten verwendet werden, die nicht normalverteilt sind (auch nicht transformiert werden können) • Können auch für nominale oder ordinale Daten verwendet werden Nicht-parametrischer Test für zwei Stichproben • Mann-Whitney U-test • Zwei unabhängige Stichproben • Wilcoxon-Vorzeichen-Rang-Test • Zwei abhängige Stichproben Beide verwenden klassifizierte Daten Frage • Miriam möchte wissen, ob die Anzahl von Retikulozyten sich bei männlichen und weiblichen Igeln unterscheiden • Eventuell saisonal abhängig Mai 2007 für den Test • Zwei Mittelwerte (Männchen, Weibchen) Stichproben sind unabhängig voneinander Ränge VAR00003 VAR00002 1,00 2,00 Ges amt N 14 19 33 Mittlerer Rang 13,93 19,26 Statistik für Testb Mann-Whitney-U Wilcoxon-W Z Asymptotische Signifikanz (2-seitig) Exakte Signifikanz [2*(1-seitig Sig.)] VAR00003 90,000 195,000 -1,566 ,117 ,123 a a. Nicht für Bindungen korrigiert. b. Gruppenvariable: VAR00002 Rangsumme 195,00 366,00 Gruppenstatistiken VAR00004 VAR00002 1,00 2,00 N 13 15 Mittelwert 508,8462 486,4000 Standardab weichung 284,59470 114,95453 Standardfe hler des Mittelwertes 78,93237 29,68113 Test bei unabhängigen Stichproben Levene-Test der Varianzgleichheit VAR00004 Varianzen sind gleich Varianzen sind nicht gleich F Signifikanz 6,017 ,021 T-Test für die Mittelwertgleichheit T ,281 ,266 df Sig. (2-seitig) 26 ,781 15,370 ,794 95% Konfidenzintervall der Differenz Mittlere Standardfehle Differenz r der Differenz Untere Obere 22,4462 79,93357 -141,860 186,75195 22,4462 84,32845 -156,919 201,81174 Varianzanalyse (ANOVA) • Einfach (Einfaktorielle) • z.B. Hämoglobinkonzentration/Igel in drei verschiedenen Gruppen • Mehrfaktoriell: mehr als eine unabhängige Variable • Zwei oder mehr Faktoren können das Ergebnis eines Experiments beeinflussen: die Interaktionen zwischen den unabhängigen Faktoren können bestimmt werden • z.B. Stichproben von 100 Bulinus Schnecken, die sich unter verschiedenen Temperatur- und pH- Bedingungen entwickelt haben 1 380 376 360 368 372 366 374 382 2 350 356 358 376 338 342 366 350 344 364 3 354 360 362 352 366 372 362 344 342 358 351 348 348 4 376 344 342 372 374 360 Breite des Scutums von Haemaphysalis laporis palustris Larven von 4 Kaninchen(mm) Deskriptive Statistik n 1 2 3 4 8 10 13 6 372,3 354,4 355,3 361,3 11,91 8,91 15,26 Standard7,36 abweichung ANOVA (Analysis of Variance) Quelle der df Abweichungen Sums of Mean F squares squares P Zwischen Gruppen 3 1.807,7 602,6 0,004 Innerhalb der Gruppen Total 33 3.778,0 114,5 36 5.585,7 5,26 Interpretation • Wir finden Unterschiede zwischen den Gruppen aber wo? • Weitere Tests können dies überprüfen (Post-hoc Tests): • Least significant difference (LSD) • Tukey’s HSD Wo sind die Unterschiede? • LSD und Tukey’s HSD zeigen beide: • 1=4 aber 1> 2 und 3 • 2=3, 4 aber 2>1 • 3= 2,4 aber 3>1 • 4=1, 2, 3 Hintergrund • Annahmen: wie für den t- Test • Abhängige (Zielvariable) und unabhängige Variablen (Einflussvariable/Faktor) • Der Faktor beeinflusst die Zielvariable • z.B. wie beeinflusst eine bestimmte Dosis eines Medikaments den Blutdruck? Der Blutdruck hängt von der Dosis ab, aber nicht umgekehrt Nicht-parametrische Tests für mehr als zwei Stichproben • Kruskal-Wallis Test • Für k unabhängige Stichproben • Friedman-Test • Für k abhängige Daten • Beide nutzen klassifizierte Daten Korrelation • Pearson Korrelation (r) • Verwendet tatsächlichen Werte • Rangkorrelation nach Spearman (rs) • Verwendet klassifizierte Daten • Bestimmtheitsmaß (r2) • Zwischen 0 und 1 • Zusammenhang zwischen der abhängigen und den unabhängigen Variablen 160 Retikulozyten 140 120 100 80 60 VAR00003 40 20 0 0 200 VAR00004 400 600 800 1000 Retikulozyten Konz. 1200 Korrelationen VAR00004 VAR00003 VAR00004 VAR00003 Korrelation nach Pears on 1 ,796** Signifikanz (2-s eitig) . ,000 N 28 28 Korrelation nach Pears on ,796** 1 Signifikanz (2-s eitig) ,000 . N 28 33 **. Die Korrelation is t auf dem Niveau von 0,01 (2-s eitig) s ignifikant. Korrelationen Spearman-Rho VAR00004 VAR00003 VAR00004 VAR00003 Korrelations koeffizient 1,000 ,850** Sig. (2-s eitig) . ,000 N 28 28 Korrelations koeffizient ,850** 1,000 Sig. (2-s eitig) ,000 . N 28 33 **. Die Korrelation is t auf dem 0,01 Niveau s ignifikant (zweis eitig). Regression • Linear • Nicht-linear • Transformationen wie für den t-Test und die ANOVA Bsp.: Kurvenförmige Regression http://www.methodenberatung.uzh.ch/index.html Fragen?