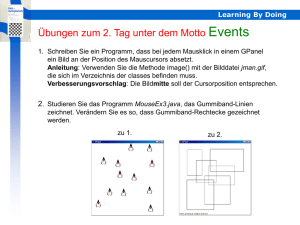
Learning Expressive Models for Word Sense Disambiguation
Werbung

Lucia Specia – Mark Stevenson – Maria das Graças V. Nunes: Learning Expressive Models for Word Sense Disambiguation Referat Galina Sîrcu Éva Mújdricza Maschinelles Lernen WS07/08, Dozent: Philipp Cimiano Ruprecht-Karls-Universität Heidelberg 23.01.2007 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 2 Einleitung: Motivation Das Papier präsentiert einen neuen Ansatz für das Disambiguierungsproblem auf Wortebene. Methode: – hybrid: • korpusbasiert + • bezieht Hintergrundwissen ein – relational: benutzt einen ILP-Algorithmus Learning Expressive Models for WSD 3 Word Sense Disambiguation Lexikalische Ambiguitäten sind eine der wichtigsten Hindernisse des erfolgreichen Sprachverstehens. → Ziel: Word Sense Disambiguation (WSD) Zum WSD wird der Kontext betrachtet. z.B. „run” – ’to move fast by using one’s feet’ – ’to direct or control’ Anwendungen der WSD: – Informationsgewinnung, Informationserschließung, maschinelle Übersetzung Learning Expressive Models for WSD 4 WSD-Systeme: 3 Ansätze für den Aufbau a) wissensbasierte Systeme: nutzen linguistisches Wissen, manual kodiert oder aus lexikalischen Quellen extrahiert. b) korpusbasierte Systeme: nehmen aus Korpora automatisch erhaltenes flaches Wissen, und induzieren das Disambiguierungsmodell mit statistischen oder maschinellen Lernalgorithmen. c) hybride Systeme: eine Mischung aus a) und b) – automatisches Erstellen von Disambiguierungsmodellen aus Korpora mit Hilfe von linguistischen Wissen. Learning Expressive Models for WSD 5 Traditionelle Methode Gängige Methoden: – korpusbasiert mit verschiedenen lexikalischen Ressourcen – mit überwachtem Training – möglichst ohne linguistisches Wissen – liefern auch gute Ergebnisse Nachteil: eingeschränkte Wissensrepräsentation und Modellierungstechniken. (herkömmliche Algorithmen zum maschinellen Lernen, bzw. Attribut-WertVektoren zur Instanzrepräsentation) → Schwierigkeiten bei tiefen Wissensquellen (d.h. direkt aus dem Korpus extrahiertes Wissen, z.B.: Wortbündel (bags-ofwords) oder Kollokationen, oder bereitgestellt von flachen Natural Language Tools wie POS-Taggers.) Learning Expressive Models for WSD 6 Traditionelle Methode Tiefes Wissen: z.B. Auswahlpräferenzen (selectional preferences) – wird entweder in einer Vektor-Repräsentation umgesetzt, die an den Lernalgorithmus angepasst ist, – oder es wird zur Ausfilterung möglicher Bedeutungen verwendet. Aber: Das führt zum Informationsverlust → tiefe Wissensquellen können ihre Wirkung im Lernprozess nicht ausüben! Folge: Die Modelle spiegeln nur das flache Wissen wider, das vom Lernalgorithmus unterstützt wird. Learning Expressive Models for WSD 7 Hybride Systeme Hybride Systeme kombinieren die Vorteile beider Strategien. – kombinieren Hintergrundwissen mit aus dem Korpus gewonnenen Merkmalen (corpus-based evidence). – nützlich bei Aufgaben, bei denen tiefes Wissen nötig ist. Linguistische Wissensquellen: WordNet, elektronische Wörterbücher, Parser. Repräsentation des tiefen Wissens über Beispiele: – Formalismus erster Ordnung (first-order formalism) + – leistungsstarke Modellierungstechnik für die Erschließung der Regeln, die auf den Beispielen und dem Hintergrundwissen basieren. • Verfahren: ILP = induktive logische Programmierung (bisher noch nicht auf WSD angewendet!) Learning Expressive Models for WSD 8 Relationale Systeme Relationale Systeme unterstützen das Einbinden von unterschiedlichem Hintergrundwissen. Die Repräsentation ist mächtig genug, kontextuelle Relationen darstellen zu können. Jedes Beispiel wird von den anderen unabhängig repräsentiert; so ist das Datenseltenheitsproblem (data sparseness problem) minimiert. z.B.: John and Anna gave Mary a present. – has_subject(verb, subject) • has_subject(give, john) • has_subject(give, anna) Learning Expressive Models for WSD 9 Hybride relationale Systeme Annahme: Die Kombination von hybriden und relationalen Methoden erhöht die Leistung des WSD-Systems. – Wenn ein sehr ausdrucksstarker Repräsentationsformalismus mit einer Reihe von (tiefen und flachen) Wissensquellen und ILP als Lerntechnik eingesetzt wird, kann man ein Modell generieren, das eine höhere Genauigkeit hat und für den Menschen einfacher interpretierbar ist, als die herkömmlichen Algorithmen für maschinelles Lernen. Learning Expressive Models for WSD 10 Hybride relationale Systeme Bisher waren die WSD-Systeme am erfolgreichsten bei Nomen. Die Disambiguierung der Verben wird unterstützt von mehr spezifischeren Wissensbasen, z.B. Relationen zwischen dem Verb und anderen Elementen im Satz. – Annahme: für die Disambiguierung der Verben eignet sich ILP. WSD wurde bisher immer wieder als eine in sich geschlossene, eigenständige Aufgabe dargestellt. Aber: Ein angemessen spezialisiertes WSD-Modul kann die Leistungsfähigkeit eines mehrsprachigen maschinellen Übersetzungssystems erhöhen. Learning Expressive Models for WSD 11 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 12 Konkrete Aufgabe Übersetzung mit WSD-Komponent: – mehrsprachiges Modul: 10 häufig vorkommende, hochambige englische Verben ins Portugiesische zu übersetzen. – einsprachiges Modul: 32 englische Verben aus dem Senseval-3-Beispiele zu disambiguieren. Dazu werden 12 syntaktische, semantische und pragmatische Merkmale als Wissensbasis genommen. – Davon werden mit Hilfe von Aleph Regeln generiert = A Learning Engine for Proposing Hypotheses: • in PROLOG • hat einen kompletten Inferenzmechanismus • iterative Schritte Learning Expressive Models for WSD 13 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 14 Zielfunktion Die Inferenzmaschine erzeugt eine symbolische Regelmenge (anhand von Beispielen, Hintergrundwissen und einer Reihe von Umgebungen (settings), die das zu lernende Prädikat spezifizieren). Die zu lernende Hypothese ist eine Klausel mit dem Kopf sense (die Bedeutung des Verbs in einem Satz) → Ziel ist es, Regeln der folgenden Form zu lernen: sense(snt, sense) ← Merkmale Die gelernte Hypothese ist leicht zu interpretieren. Die Regeln sind von verschiedener Tiefe. Learning Expressive Models for WSD 15 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 16 Merkmale / Hintergrundwissen Beispielsatz: „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ Learning Expressive Models for WSD 17 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ KS1: has_bag(snt, word) – Wortbündel (bag-of-word) – Kontext von 5 Wörtern rechts und links vom Verb, wobei Stoppwörter nicht betrachtet werden. – has_bag(snt1, mind), has_bag(snt1, not), ... KS2: has_bigram(snt, word1, word2) – Die mindestens zehn mal im Korpus vorkommenden Bigramme werden notiert. – has_bigram(snt1, back, as), has_bigram(snt1, such, a) Learning Expressive Models for WSD 18 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ KS3: has_narrow(snt, word_position, word) – Ein enger Kontext von 5 Wörtern rechts und links vom Verb. – has_narrow(snt1, 1st_word_left, mind), has_narrow(snt1, 1st_word_right, back) KS4: has_pos(snt, word_position, word) – POS-Tags von 5 Wörtern rechts und links vom Verb. – has_position(snt1, 1st_word_left, nn), has_position(snt1, 1st_word_right, rb) Learning Expressive Models for WSD 19 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ KS5: has_collocation(snt, type, collocation) – 11 Kollokationen: • erste Präposition nach rechts • erstes und zweites Wort links und rechts • erstes Nomen links und rechts • erstes Adjektiv links und rechts • erstes Verb links und rechts – has_collocation(snt1, 1st_prep_right, back), has_collocation(snt1, 1st_noun_left, mind) Learning Expressive Models for WSD 20 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ KS6: has_rel(snt, type, word) – Subjekt und Objekt (durch Minipar ermittelt) – has_rel(snt1, subject, i), has_rel(snt1, object, nil) Learning Expressive Models for WSD 21 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ KS7: has_related_pair(snt, word1, word2) – mehr als 10mal vorkommende grammatische Relationen (mit Minipar ermittelt) • Verb – Subjekt • Verb – Modifizierer/Argument • Subjekt – Modifizierer • Objekt – Modifizierer • has_related_pair(snt1, there, be) Learning Expressive Models for WSD 22 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ KS8: has_overlapping(snt, translation) – Die Bedeutung mit der höchsten Anzahl von überlappenden Wörtern aus dem Wörterbuch und dem Satz (ausschließlich Stoppwörter). – has_overlapping(snt1, voltar) Learning Expressive Models for WSD 23 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ KS9: satisfy_restriction(snt, rest_subject, rest_object) – (Mit LDOCE definierte) Selektionsbeschränkungen des Verbs. Dazu wird WordNet benutzt, wenn die Beschränkungen von der Argumentstruktur des Verbs festgelegt werden, aber man sie aus Synonymen oder Hyperonymen der Argumente ermitteln kann. – satisfy_restriction(snt1, [human], nil), satisfy_restriction(snt1, [animal, human], nil) Learning Expressive Models for WSD 24 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ K10: has_expression(snt, verbal_expression) – nur für das mehrsprachige Tool – phrasale Verben – has_expression(snt1, „come back”) Learning Expressive Models for WSD 25 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ K11: has_bag_trns(snt, portuguese_word) – nur für das mehrsprachige Tool – 5 Wörter rechts und links vom Zielverb in der portugiesischen Übersetzung. Diese werden mit Hilfe von parallelen Korpora ermittelt. – has_bag_trns(snt1, coelho), has_bag_trns(snt1, reincarnação) Learning Expressive Models for WSD 26 Merkmale / Hintergrundwissen „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.“ K12: has_narrrow_trns(snt, word_position, portuguese_word) – nur für das mehrsprachige Tool – Enger Kontext von 5 Kollokationen des Verbs in der portugiesischen Übersetzung, wobei auch die Position des Wortes in Bezug genommen wird. – has_narrrow_trns(snt1, 1st_word_right, como), has_narrrow_trns(snt1, 2nd_word_right, um) Learning Expressive Models for WSD 27 Beispiele für Regeln (mehrspr. Modul) „If there is such a thing as reincarnation, I would not mind coming back as a squirrel.” Rule_1. sense(A, voltar) :has_collocation(A, 1st_prep_right, back). Rule_2. sense(A, chegar) :has_rel(A, subj, B), has_bigram(A, today, B), has_bag_trans(A, hoje). Rule_3. sense(A, chegar) :satisfy_restriction(A, [animal, human], [concrete]); has_expression(A, 'come at'). Rule_4. sense(A, vir) :satisfy_restriction(A, [animate], nil); (has_rel(A, subj, B), (has_pos(A, B, nnp); has_pos(A, B, prp))). Learning Expressive Models for WSD 28 Erklärungen für die Beispielregeln Rule 1: Die Übersetzung des Verbs im Satz A ist voltar (‚return’), wenn als erste Präposition rechts vom Verb im Satz back steht. Rule 2: Die Übersetzung des Verbs ist chegar (‚arrive’), wenn es ein Subjekt B hat, das mit dem Wort today als Bigramm vorkommt, und wenn der teilweise übersetzte Satz das Wort hoje (‚today’) enthält. Rule 3: Die Übersetzung des Verbs ist chegar (‚reach’), wenn das Subjekt des Verbs das Merkmal [animal] oder [human] hat, und das Objekt das Merkmal [concrete] hat, oder wenn das Verb im Ausdruck come at vorkommt. Rule 4: Die Übersetzung des Verbs ist vir (‚move toward’), wenn das Subjekt des Verbs das Merkmal [animate] hat und es kein Objekt im Satz gibt, oder wenn das Verb ein Subjekt B hat, das ein Eigenname oder ein Personalpronomen ist. Learning Expressive Models for WSD 29 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 30 ILP ILP = Induktive logische Programmierung (inductive logic programming) Techniken vom maschinellen Lernen + logischer Programmierung Ziel: ausdrucksstarke Disambiguierungsregeln zu generieren, die verschiedenes Hintergrundwissen verarbeiten und auch die Beziehungen zwischen diesen erfassen können. Mit Hilfe der Logik erster Ordnung Vorteil: ILP erlaubt Repräsentation von Variablen und n-stelligen Prädikaten, d.h. relationale Beziehungen. Learning Expressive Models for WSD 31 Aleph: ein ILP-System Iterative Schritte: 1. Eine Instanz wird zufällig zum Generalisieren ausgewählt. 2. Eine spezifischere Klausel – die untere Klausel – wird gebildet mit Hilfe der inversen Implikation. Dabei wird das Wissen über das Beispiel repräsentiert. 3. Eine allgemeinere als die untere Klausel wird gesucht. 4. Die beste Klausel wird zur Hypothese hinzugefügt, und die Beispiele, die von der Klausel abgedeckt sind, werden aus der Beispielmenge entfernt. 5. Gibt es in der Trainingsmenge keine Beispiele mehr, stoppt der Algorithmus, sonst macht er mit Schritt 1 weiter. Learning Expressive Models for WSD 32 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 33 Trainings- und Testdaten: mehrsprachiges Modul Korpus: 500 Sätze wurden für die 10 Verben generiert. Der Text wurde zufällig von verschiedenen Themen und Genren ausgewählt. Dieses Korpus wurde automatisch annotiert mit der Übersetzung des Verbs mit Hilfe eines parallelen Korpus. Die automatische Annotation wurde anschließend manuell nachgebessert. Für jedes Verb wurde eine Bedeutungssammlung (sense repository) definiert: eine Menge von möglichen Übersetzungen. 80% des Korpus wurde als Trainingskorpus genommen. Learning Expressive Models for WSD 34 Trainings- und Testdaten: mehrsprachiges Modul Beispieldaten für das mehrsprachige Modul Learning Expressive Models for WSD 35 Trainings- und Testdaten: einsprachiges Modul Korpus: Zwischen 40 und 398 Beispiele wurden für die 32 Verben generiert. Jedes Verb hat zwischen 3 und 10 Bedeutungen (in 55% von Beispielen wird die häufigste Bedeutung getroffen). Die getaggten Texte und die Bedeutungssammlungen für die Verben wurden aus Senseval-3 genommen. Beide Korpora wurden lemmatisiert und nach Wortarten getaggt (mit Minipar und MXpost). Anschließend wurden die Eigennamen erkannt und ausgezeichnet: (proper_noun). Pronomen wurden unterschieden und nach ihren Klassen markiert z.B.: relative_pronoun. Learning Expressive Models for WSD 36 Trainings- und Testdaten: einsprachiges Modul 32 englische Verben Learning Expressive Models for WSD 37 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 38 Evaluierung: mehrsprachiges Modul Bessere durchschnittliche Genauigkeit (average accuracy) als die gängigen MLTechniken: Jedes Verb wurde auf der entsprechenden Testmenge getestet mit allem verfügbaren Hintergrundwissen. Learning Expressive Models for WSD 39 Evaluierung: mehrsprachiges Modul Aleph: 50 bis 96 Regeln (nicht so viel) – alle sind wichtig. Die „Hauptbedeutung”-Spalte zeigt die häufigste Übersetzung in dem Trainingsset. – Weniger mögliche Übersetzungen → höhere Genauigkeit Noch 3 andere, oft benutzte Lernalgorithmen zum Vergleich: Attribut-Wert-Vektoren (C4.5), naïve Bayes, Support Vector Machine (SVM). – Die ILP-Methode ist erheblich besser als die Baseline und auch besser als die anderen Lernalgorithmen. Die Ergebnisse wurden dadurch negativ beeinflusst, dass – diese Verben sehr viele Bedeutungen haben, – das Tagging automatisch durchgeführt wurde, – gleiche Übersetzungen sehr selten im Korpus vorkamen. Learning Expressive Models for WSD 40 Evaluierung: einsprachiges Modul Ähnliche durchschnittliche Genauigkeit wie der Stand der Technik. Ergebnisse (accuracy) für die besten auf der Senseval-3 getesteten Systeme: Learning Expressive Models for WSD 41 Evaluierung: einsprachiges Modul Syntalex-3: (Mohammad and Pedersen, 2004), basiert auf einer Kombination von gebündelten (gebagged) Entscheidungsbäumen mit wenigen POS-Merkmalen und Bigrammen. CLaC1 (Lamjiri et al., 2004): benutzt einen Naïve-BayesAlgorithmus mit einem dynamisch angepassten Kontextfenster um das Zielwort herum. MC-WSD (Ciaramita and Johnson, 2004): ein multi-class Durchschnittsperzeptron (average perceptron), das syntaktische und eingeschränkte Kontextmerkmale benutzt. Aleph: Die Ergebnisse sind sehr ermutigend. Die ILP-Methode ist viel besser als die Baseline. – Es wurde eine geringe Anzahl von Regeln benutzt: 6 bis 88. Auch hier wurde alles Hintergrundwissen eingesetzt. Learning Expressive Models for WSD 42 Übersicht Einleitung Aufgabe Zielfunktion Merkmale Lernalgorithmus Trainings- / Testdaten Evaluierung Fazit Learning Expressive Models for WSD 43 Fazit Beide Module haben gezeigt, dass man mit ILP ausdrucksstarke Regeln generieren kann, die viel Hintergrundwissen integrieren und dieses miteinander kombinieren können. – sowohl tiefes als auch flaches Hintergrundwissen wurde einbezogen! ILP wurde bisher schon erfolgreich bei POS-Tagging, Grammatikerfassung und semantischem Parsen eingesetzt. Dieses Papier hat gezeigt, dass Aleph bei der Wortbedeutungsdisambiguierung gute Ergebnisse liefert mit einer hybriden, relationalen Methode. Learning Expressive Models for WSD 44 Ausblick Sie werden ihr System auch – auf anderen Wortmengen testen – mit anderen POS-Mengen. Learning Expressive Models for WSD 45 Literatur Specia, L. & Stevenson, M. & Nunes, M. (2007): Learning Expressive Models for Word Sense Disambiguation, Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, S. 41–48. – http://acl.ldc.upenn.edu/P/P07/P07-1006.pdf (Stand: 17.11.2007) MarkStevenson: WSD (Folien) – tutorialresearch.microsoft.com/india/nlpsummerschool/data/fil es/MarkStevenson%20-%20WSD%20tutorial.pdf (Stand: 16.01.2008) Learning Expressive Models for WSD 46