Erforschung der Motivationselemente des Konsumenten
Werbung

Mathematik
M5 Folgen und Reihen
Arithmetische Folge/Reihe
Folge
(Sobald Veränderungen im Exponent => GF)
= Sequenz von Werten
an = a1 + (n – 1) d (Bildungsgesetz)
endlich:
unendlich:
<a1, a2, a3>
<a1, a2, ...>
f:nan, n |N*3
f:nan, n |N*
=>Startwert ist immer erstes Glied der Folge
sn =
Bildungsgesetz
an = f(n) ist nicht rekursiv!
Rekursion
Vorschrift:
Basis:
Beispiel:
ergibt
Bildung:
Def: an+1 – an = d
Geometrische Folge/Reihe
Def:
an+1 = f(an), n |N*
a1 = 3
an+1 = 2 an, n |N*, a1 = 3
<3, 6, 12, 24, ...>
a1 = 3
a2 = 3 2
a3 = 3 2 2
a4 = 3 2 2 2
an = 3 2n–1
n
n (n – 1)
(a1 + an) = n a1 +
d
2
2
an+1
=q
an
an = a1 qn–1 (Bildungsgesetz)
sn = a1
qn – 1
,q1
q–1
Summe unendliche geom. Reihe
a1
s=
, |q| < 1
1–q
Multiplikator =
a1
s
Reihe
Monotonie / Beschränktheit
= Summen einer Folge
an+1 an
an+1 an
an s
an s
an smax an smin
endlich:
a1 + a2 + a3
unendlich:
a1 + a2 + ...
monoton wachsend
monoton fallend
nach oben beschränkt
nach unten beschränkt
beschränkt
Summe der ersten n Glieder
n
sn =
∑ (ai)
s: reele Zahl
i=1
Summe aller Glieder (unendliche Summe)
∞
s =
∑ (ai)
i=1
an => n-tes Glied
< an> => Folge
3. + 4. Semester
Christian Meyer
Seite 1 / 18
Grenzwert
Stetige Verzinsung
offene -Umgebung von a: U(a) = ]a – , a + [
Zinseszins mit jährlicher Verzinsung (ZiZi)
Jährl. effektive Wachstumsrate
Def: a ist Grenzwert von <an>, wenn in jeder noch so
kleinen Umgebung von a, alle bis auf endlich viele a n
liegen.
lim an = a
n∞
Kn = K0 (1 +
peff n
) , peff = effektiver Jahreszins
100
Zinseszins mit m-jährlicher Verzinsung:
1
k p
1
und
Kn = K0 (1 + k )m n m
100
k
p
m 100
Jede Folge, die monoton und beschränkt ist, hat einen
Grenzwert.
Zinseszins mit stetiger Verzinsung
Häufungswerte: Folge schwankt zwischen n Werten
Kn = K0 e0.01 ps n , ps = stetiger/nominaler Jahresz.
Nullfolge: Grenzwert = 0
=> ist KEIN Grenzwert
konvergiert: Folge hat Grenzwert
divergiert: Folge hat keinen Grenzwert
Umrechnung:
peff = 100 (e0.01 ps – 1)
Stetige Rendite / stetige od. nominale Wachstumsrate
ps = 100 ln (1 +
Grenzwert berechnen:
Bei Potenzen:
immer mit dem Kehrwert der höchsten Potenz
multiplizieren
Wenn ein Nenner eine Nullfolge ist, gibt es
keinen Grenzwert
Wenn Zähler und Nenner eine Nullfolge sind,
KANN es einen Grenzwert geben (beide Fkt.
Müssen gleichschnell nach 0 laufen)
Grenzwertsätze
lim (c an ) =
<an ± bn> gilt
lim
an
bn
=ca
c lim ( an )
n∞
lim (an ± bn)=
lim ( an ) ± lim ( bn ) = a ± b
n∞
n∞
n∞
lim an
lim bn
n∞
lim ( an ) lim ( bn)
n∞
Standardabweichung darf nur von ps berechnet
werden!
Zur Bestimmung von Wachstumsraten:
n∞
<an bn > gilt lim (an bn) =
Renditeberechnung mit Anfangs- und Endwert NUR
wenn keine Dividenden ausgeschüttet wurden.
Rendite
n∞
=> gilt nur, wenn a und b konvergent sind
<c an> gilt
Durchschnittliche Rendite
= geom. Mittel von peff (5% = 1.05)
= arithm. Mittel von ps
Renditen
Gegeben
<an> mit lim an = a und <bn> mit lim bn = b
n∞
peff
)
100
n∞
=ab
reff 100 n a1 a 2 ...a n wobei z.B. 1.1 für 10%
stetige Rendite
reff
rs 100 ln
100
n
rs 100 ln a1 a2 ... an
-stetige Rendite ist arithmetisches Mittel der stetigen
Renditen:
n
rs
3. + 4. Semester
Christian Meyer
r
k 1
sk
n
Seite 2 / 18
M6 Finanzmathematik
Renten
Abschreibungen
Einzahlung von r Franken, n Jahre lang, peff
Jahreszins. sn:RentenENDwert
I0 = Anschaffungswert
In = Schrottwert / Liq. Erlös
At = Abschreibungsbetrag
im Jahr t
It = Zeitwert im Jahr t (Restwert)
A = Annuität
n = Nutzungsdauer in Jahre
t = Jahr
p
q = 1 + 100
q 1
p
100
nachschüssiger Rentenendwert
qn – 1
sn = r
q–1
Lineare Abschreibung
Jedes Jahr wird ein fester Betrag (A) abgeschrieben.
I0 – In
A=
(AF)
n
vorschüssiger Rentenendwert
qn – 1
sn' = r q
q–1
It = I0 – t A
Digitale / arithm. degressive Abschreibung
nachschüssiger Rentenbarwert
r qn – 1
B= n
q
q–1
Im ersten Jahr werden n Einheiten, im zweiten (n – 1)
Einheiten, im n-ten Jahr 1 Einheit abgeschrieben.
2 (I0 – In)
E=
(AF)
n (n + 1)
vorschüssiger Rentenbarwert
r
qn – 1
B' =
n
–
1
q
q–1
Zeitwerte It liegen auf einer Geraden
E: Summe der Abschreibungsbeiträge bis zum n-ten Jahr
At = (n – t + 1) E (Veränderung Abschr.Wert)
Zahlung Ende Jahr: postnumerando / nachschüssig
Zahlung zu Periodenbeginn: vorschüssig
E
1
It = t2 – E (n + ) t + I0
2
2
Sparkassenformel
Kapital K0 zum Zeitpunkt 0,
Einzahlung/Entnahme von r Franken, n Jahre lang,
peff Jahreszins.
It liegt auf einer nach oben geöffneten Parabel mit
Scheitelpunkt:
1
s (n +
/ ... )
2
Geometrisch degressive Abschreibung
Jedes Jahr werden p% vom Zeitwert des Vorjahres
abgeschrieben.
p
At = I0
100
It = I0 (1 –
nachschüssiger Endwert
qn – 1
)
Kn = K0 qn ± (r
q–1
E K q n sn
vorschüssiger Endwert
Kn' = K0 qn ± (r q
qn – 1
)
q–1
E ' K q n s'n
p n
)
100
+ Einzahlung
- Entnahme
I
p 1 n n 100
I0
(Zeitwerte It liegen auf einer Exponentialkurve.)
Die Abschreibungsbeträge und die Zeitwerte bilden
eine geometrische Folge.
3. + 4. Semester
Christian Meyer
Seite 3 / 18
M6 Ewige Rente
Barkredit
Kapital K0 zum Zeitpunkt 0,
n Jahre lang, peff Jahreszins.
Methode der mittleren Kreditfrist
Es wird nur soviel Rente ausbezahlt, wie Zins
vorhanden ist, das Kapital wird nicht aufbebraucht:
Kp
r=
100
Mittlere Kreditfrist MK =
nachschüssiger Barwert:
r
B=
q–1
Jährlicher Aufwand => immer nachschüssig
vorschüssiger Barwert:
rq
B' =
q–1
bei gleichen Raten:
∑ der Kreditfristen
Anzahl Raten
bei gleichen Raten und gleichen Zahlungsabständen:
erste Frist + letzte Frist
MK =
2
Höhe einer Monatsrate:
K
MK K p
r =
+
n
n 1200
Angewandter Zinssatz:
1200 (n r – K)
p =
MK K
Tilgung
Die Schuld K ist in n nachschüssigen Annuitäten
abzutragen.
=> Raten und Tilgungen immer nachschüssig
Modell "HSW Luzern"
Höhe einer Monatsrate:
K qn (q – 1)
r =
n
(q – 1) (12 + 5.5 [q – 1])
Annuität = Zins + Tilgungsbetrag
Gleichbleibende Tilgung (Ratentilgung)
Tilgung T =
K
n
Gleichbleibende Annuität
(Annuitätentilgung)
Fester Zinssatz:
Annuität A = K qn
q–1
qn– 1
Zinssatz wechselt nach w Jahren:
q1 = Zins bis und mit Jahr w (5 % = 1.05)
q2 = Zins ab Jahr w bis Jahr n
K q1w q2n–w
A=
w
q1 – 1
q2n–w – 1
q2n–w +
q1 – 1
q2 – 1
Angewandter Zinssatz:
Mit dem Solver die folgende Gleichung nach q
auflösen:
q–1
=0
r (12 + 5.5 [q – 1]) – K qn n
q –1
Annuitätenmethode
Monatliche Verzinsung der Schuld wird unterstellt. Der
Kredit wird in gleichen Monatsraten getilgt.
Monatszinsatz:
Folgende Gleichung mit Solver nach q auflösen:
q–1
r = K qn
qn– 1
Jahreszinsssatz:
Nominaler Jahreszins aus Monatszinsatz:
pjs = 12 PM
Effektiver Jahreszins aus Monatszinsatz:
PM 12
pjeff = [ (1 +
) – 1] 100
100
Beispiel: Kredithöhe 20'000.–, rückzahlbar in 30
Monaten zu Fr. 803.55, beginnend 1 Monat nach
Kreditaufnahme.
Gesucht: nominaler und effektiver Jahreszinssatz
FINZ ANNU
#R/J = 12 = Anzahl Raten pro Jahr
END = Nachschüssig!
#R= n = Anzahl Raten
BARW = -K = negative Kredithöhe
RATE = Monatsrate
ENDW = 0
I%J ps = nominaler/stetiger Jahreszinssatz
(ps in Speicher ablegen)
FINZ II'
3. + 4. Semester
Christian Meyer
Seite 4 / 18
Annuitätenmethode
DISK12 #I/J ps NOM% EFF% peff = 16.075
Die Investition ist vorteilhaft, wenn
Einzahlungsannuität > Auszahlungsannuität.
Höhe einer Monatsrate:
q–1
r = K qn
qn– 1
Taschenrechner verwendet Monatszinssatz PM =
PJ/12
FINZ Z-STR
CLEAR DATA wichtig!
...alle Einzahlungen eingeben inklusive Ln...
ÄQ.R Einzahlungsannuität
Dynamische Investitionsrechnung
Bei der dynamischen Investitionsrechnung wird nur in
die Zukunft gerechnet. Werte aus der Vergangenheit
werden nie berücksichtigt, weil man diese nicht mehr
beeinflusenkann.
FINZ Z-STR
CLEAR DATA wichtig!
...alle Auszahlungen eingeben inklusive I0...
ÄQ.R Auszahlungsannuität
Kapitalwertmethode
(Net Present Value Method)
Die Investition ist vorteilhaft, wenn K0 > 0 ist.
n
et – at
Ln
K0 = ∑ (
) + n – I0
qt
q
t=1
FINZ Z-STR
CLEAR DATA wichtig!
...
NBW K0
Methode des internen Ertragssatzes
(Internal Rate of Return Method)
Die Investition ist vorteilhaft, wenn der interne
Ertragssatz mindestens so hoch ist, wie die geforderte
Zielrendite.
Der interne Ertragsatz ist derjenige
Kalkulationszinssatz, für den der Kapitalwert = 0 ist.
FINZ Z-STR
CLEAR DATA wichtig!
...
IZF% Interner Zinsfuss
Spezialfall ewige Rente:
e–a
p = 100
I0
Spezialfall gleiche Nettoeinzahlungen und Ln = I0:
e–a
p = 100
I0
Spezialfall Es gibt nur 2 Zahlungen:
Ln
)– 1]
p = 100 [ n(
I0
Mehr als ein oder kein interner Ertragssatz
Ökonomisch unnütz, stattdessen auf
Kapitalwertmethode ausweichen.
3. + 4. Semester
Christian Meyer
Seite 5 / 18
7.3 Extremwerte, Wendepunkte
M7 Differentialrechnung
M7.2 Ableitungsregeln
Ableitungen der Funktion
f(x) = c
f'(x) = 0
f(x) = x
f'(x) = 1
f(x) = xn
f'(x) = n xn – 1 , n |Q*
f(x) = x–n
f'(x) = –n x–n – 1
f'(x0) = 0
Horizontale Tangente
f'(x0) = 0 f''(x0) < 0
Lokales Maximum
f'(x0) = 0 f''(x0) > 0
Lokales Minimum
f''(x0) = 0 f'''(x0) 0
Wendepunkt
Im Wendepunkt ist die Steigung des Graphen
bezüglich seiner Umgebung von x0 maximal oder
minimal.
f''(x) > 0 : Graph ist nach links gekrümmt
f''(x) < 0 : Graph ist nach rechts gekrümmt
7.2B Faktorregel
f(x) = c g(x) f'(x) = c g'(x)
M7.4 Ökonomische Anwendungen
7.4A Produktionsfunktion
7.2C Summenregel
f(x) = g(x) ± h(x) f'(x) = g'(x) ± h'(x)
7.2D Ganz-Rationalen Funktion
f(x) = anxn + an–1xn–1 + ... + a2x2 + a1x + a0
f(x) = n anxn–1 + (n–1) an–1xn–2 + ... + 2 a2x + a1
7.2E Produktregel
f(x) = g(x) h(x) f'(x) = g'(x) h(x) + g(x) h'(x)
7.2F Quotientenregel
Z(x)
Z' N – Z N'
f(x) =
f'(x) =
N(x)
N2
Klassisches Ertragsgesetz
Bei wachsendem Faktoreinsatz steigt der
Ertragszuwachs zunächst. Nach erreichen eines
bestimmten Optimums (Wendepunkt) sinkt der
Ertragszuwachs bei wachsendem Faktoreinsatz.
Optimum ist beim Wendepunkt
Neoklassische Produktionsfunktion
Die Grenzerträge sind immer positiv nehmen aber
stets ab.
x'(r) ist immer > 0
x''(r) ist immer < 0
7.4B Kosten
7.2H Logarithmus- und der Exponentialfunktion
1
1
=
f(x) = ln x = loge x f'(x) =
x
x ln e
1
x ln a
f(x) = loga x
f'(x) =
f(x) = ex
f'(x) = ex
f(x) = ax
f'(x) = ax ln a
Linearer Kostenverlauf
K'(x) ist immer > 0 und ist konstant
K''(x) ist immer = 0
Progressiver Kostenverlauf
K'(x) ist immer > 0 und ist wachsend
K''(x) ist immer > 0
Wenn der Verlauf einer Parabel entspricht dann:
K'(x) ist immer > 0 und ist konstant
K''(x) ist immer > 0 und ist konstant
7.2I Kettenregel
f(x) = g( h(x) ) = g(v) f'(x) = g'(v) h'(x)
Degressiver Kostenverlauf
K'(x) ist immer > 0 und ist abnehmend
K''(x) ist immer < 0
7.2G Differentiale
Schreibweise (Sprich "dy nach dx"):
dy
y'(x) =
dx
Bedeutet, dass y von x abhängt:
Die Gleichung muss somit nach y aufgelöst sein.
Alle Variablen ausser x werden als konstante Werte
betrachtet.
Typischer Kostenverlauf
K'(x) ist immer > 0
K''(x) ist < 0 von x=0 bis zum Wendepunkt xw
= 0 am Wendepunkt xw
> 0 vom Wendepunkt xw bis x=∞
mathematisch ökonomische Definition der
Grenzkosten:
K'(x) = lim K(x + ∆x) – K(x) = lim ∆K
∆x0
∆x0
∆x
∆x
K'(x) gibt näherungsweise den Kostenzuwachs an,
wenn x um 1 Einheit erhöht wird.
3. + 4. Semester
Christian Meyer
Seite 6 / 18
Der Wendepunkt des Graphen von K ist dort, wo
die Grenzkosten K' minimal sind.
Der Graph der Grenzkostenfunktion K' schneidet
den Graphen der Durchschnittskosten k in dessen
Minimum. (= Betriebsoptimum)
Der Graph der Grenzkostenfunktion K' schneidet
den Graphen der durchschnittlichen variablen
Kosten kv in dessen Minimum. (=Betriebsminimum).
7.C Gewinnmaximierung
Monopolist
Das Gewinnmaximum ist dort, wo Steigung der
Kosten = Steigung des Erlös.
K'(x) = E'(x)
7.E Elastizität
dy
x
dx
y(x)
y(x) gibt näherungsweise an, um wieviel Prozent sich
die abhängige Variable y ändert, wenn die
unabhängige Variable x um 1 Prozent verändert wird.
y(x) =
Nachfragefunktion
Preiselastizität der Nachfage
x = Nachfrage
p = Preis
dx
p
x(p) =
dp
x(p)
Angebotsfunktion
Preiselastizität des Angebots
x = Angebot
p = Preis
dx
p
x(p) =
dp
x(p)
bzw. G'(x) = 0 und G''(x) < 0
Die Steigung des Gewinns ist:
G'(x) = E'(x) – K'(x)
Vollkommene Konkurrenz
Der Erlös ist eine Gerade, weil wir den Preis nicht
beinflussen können.
Das Gewinnmaximum ist dort, wo Steigung der
Kosten = Erlös bzw. wo Grenzkosten = Verkaufspreis.
K'(x) = E(x)
Die Steigung des Gewinns ist:
G'(x) = E'(x) – K'(x)
Produktionsfunktion
Produktionselastizität
x = Output
r = Input des Produktionsfaktors
dx
r
x(r) =
dr
x(r)
Konsumfunktion
Einkommenselastizität des Konsums
C = Konsum
Y = Einkommen
dC
Y
C(Y) =
dY
C(Y)
7.D Marginale Konsum- und Sparquote
Konsumfunktion
Y = C+S
C = Konsum eines Haushaltes
S = Ersparnis des Haushaltes
Y = Einkommen des Haushaltes
Marginale Konsumquote
Die marginale Konsumquote gibt näherungsweise an,
um wieviel sich der Konsum des Haushaltes ändert,
wenn das Einkommen um eine Einheit erhöht wird.
dC
=
dY
Marginale Sparquote
Die marginale Sparquote gibt näherungsweise an, um
wieviel sich die Ersparnis des Haushaltes ändert,
wenn das Einkommen um eine Einheit erhöht wird.
dS
=
dY
Die marginalen Konsum- und Sparquote ergänzen
sich zu 1!
Kostenfunktion
Kostenelastizität
K = Kosten
x = Produktionsmenge
dK
x
K(p) =
dx
K(x)
K(p) = K'(x)
x
1
K'(x)
Grenzk.
=
=
= K'(x)
K(x)
k(x) k(x) Durchschnk.
Im Betriebsoptimum ist K' = k, somit = 1
7.F Optimale Bestellmenge
xopt = √
200 M F
ep
M = Bedarfsmenge pro Planperiode
F = Fixe Kosten pro Bestellung
e = Stückkosten
p = Zins und Lagerkosten in % für das im Lager
gebundene Kapital: 20 % = 0.2
Anzahl Bestellungen:
M
Anz =
xopt
3. + 4. Semester
Christian Meyer
Seite 7 / 18
S5 Regression
und Korrelation
Nichtlineare Regression,
nichtlinearer Trend
Methode der kleinsten Quadrate
Quadratische Regression durch Einpassen einer
Parabel mit der folgenden Gleichung:
y = ax2 + bx + c
Eine Gerade wird so gelegt, dass die
Standardabweichung minimal ist.
Regressionsgerade: y = a x + b
mx = arithmetisches Mittel aller x
my = arithmetisches Mittel aller y
n
∑ (xi yi) – n mx my
a =
i=1
n
∑ (xi2) – n mx2
i=1
b = my – a mx
STAT LISTE
*NEU NAME X INPUT
*NEU NAME Y INPUT
LISTE Name wählen X
...X-Werte eingeben...
LISTE Name wählen Y
...Y-Werte eingeben...
RECH MEHR KURV
X-Variable wählen X
Y-Variable wählen Y
MEHR MODL LIN
KORR Korrelationskoeffizient
M a
B b
Summe der Abstandsquadrate
Die Regressionsgerade wird so gewählt, dass die
Summe der Abstandsquadrate zwischen den y
Punkten der Streupunkte und den ^y Punkten der
Gerade minimal ist.
n
Summe =
∑ (yi - ^yi)2
i=1
Regression n-ten Grades
Gleichungssystem mit 3 Unbekannten lösen:
a ∑xi2 + b ∑xi +c n = ∑yi
a ∑xi3 + b ∑xi2 +c ∑xi = ∑xi yi
a ∑xi4 + b ∑xi3 +c ∑xi2 = ∑xi2 yi
Exponentielle Regression
Einpassen einer Exponentialkurve mit der folgenden
Gleichung:
y = b em x
Nicht lösbar mit einfachem Gleichungssystem, daher
logarithmisches Diagramm verwenden, und Gleichung
in Gerade für Methode der kleinsten Quadrate
umformen. (Dieses Verfahren liefert allerdings keine
optimal eingepasste Regressionskurve).
y = b em x ln y = ln b + m x
MODL EXP
Logarithmische Regression
Einpassen einer logarithmischen Kurve mit der
Gleichung
y = b + m ln(x)
MODL LOG
Regression mit Potenzkurve
Einpassen einer Potenzkurve Kurve mit der Gleichung
y = b + xm
Nicht lösbar mit einfachem Gleichungssystem, daher
logarithmisches Diagramm verwenden, und Gleichung
in Gerade für Methode der kleinsten Quadrate
umformen. (Dieses Verfahren liefert allerdings keine
optimal eingepasste Regressionskurve).
MODL POT
3. + 4. Semester
Christian Meyer
Seite 8 / 18
Korrelationskoeffizient
5.6 Portfolio-Analyse
Masszahl für die Streuung von Punkten um die
Regressionsgerade. Bei nichtlinearen
Zusammenhängen ist er unbrauchbar.
Der Korrelationskoeffizient ist gleich der Kovarianz
dividiert durch das Produkt der
Standardabweichungen von X und Y.
Geht nur mit stetigen Renditen!
n
Die Portefeuille-Rendite ist das gewogene arithm.
Mittel der einzelnen Renditen ri.
n
Portfolio-Rendite rp = ∑ (zi ri)
∑ (xi yi) – n mx my
=
√
i=1
n
n
i=1
i=1
i=1
n
{ [ ∑ (xi2) – n mx2] [ ∑ (yi2) – n my2] }
wobei ∑ (zi) = 1
i=1
-1 ≤ ≤ 1
Die Standardabweichung sp des Portefeuilles
(Portefeuille-Risiko) berechnet sich aus den einzelnen
Standardabweichungen und den Kovarianzen mit
Hilfe der Formel:
Verlauf der Regressionsgeraden:
>0
von unten links nach oben rechts
<0
von oben links nach unten rechts
= NaN horizontal keine Aussage über
Zusammenhang möglich!
n–1
n
∑ (zi2 si2) + 2
sp2 =
i=1
Bedeutung von
|| = 1
funktionaler Zusammenhang
0.9 ≤ || < 1
starker Zusammenhang
0.5 ≤ || < 0.9 schwacher Zusammenhang
|| < 0.5
kein Zusammenhang
{
n
∑ [ ∑ (zi zj Cov(i, j) ) ] }
i=1
j>i
Varianz-Zerlegung
Varianz = Standardabweichung im Quadrat = s2
n
s2
∑ (yi – my)2
=
i=1
n
Vergleich von Rängen
Diese Formel ist nur anwendbar, wenn es sich um
Ränge handelt, d. h. die Streupunkte sind lückenlos
von 1 durchnummeriert.
s = 1 –
Durch die Regressionsgerade erklärte Varianz
= Varianz der Regressionsgeraden: s^y2
n
2
s^y =
∑ (^yi – my)2
i=1
n
n
6
∑ (xi yi)2
n (n2 – 1) i=1
Durch die Regressionsgerade nicht erklärbare
Varianz:
Die Kovarianz
n
∑ (yi – ^yi)2
2
Zeigt das "Miteinander-Variieren" von Y und X.
Gibt an, ob sich tendenziell bei grösseren x-Werten
auch die y-Werte vergrössern (Cov > 0) oder sich
diese tendenziell verkleinern (Cov < 0).
n
1
Cov(X, Y) = sXY = ( ∑ (xi yi) – n mx my )
n
i=1
snicht =
i=1
n
Totale Varianz = Varianz der Streupunkte:
n
sY2
=
∑ (yi – my)2
i=1
n
n
für den Taschenrechner:
n
Cov(X, Y) =
∑ (xi yi)
i=1
n
n
–
n
∑ (xi)
∑ (yi)
i=1
i=1
n2
sY2
=
n
∑ (^yi – my)2
i=1
sY2 =
+
∑ (yi – ^yi)2
i=1
n
n
2 sY2
+
durch Regr.gerade
erklärte Varianz
(1 – 2) sY2
durch Regr.gerade
nicht erkl. Varianz
Zusammenhang mit Korrelationskoeffizient:
durch die Regr.gerade erklärte Varianz
1 = 2 +
totale Varianz
Schwerpunkt der Regressionsgeraden:
S(mx / my)
Der Schwerpunkt hat die Eigenschaft, dass
∑(yi - my) = 0 und ∑(xi - mx) = 0.
3. + 4. Semester
Christian Meyer
Seite 9 / 18
Beta-Faktor
Bestimmtheitmass
Das Bestimmtheitsmass gibt an, welcher Anteil der
Varianz durch die Regressionskurve erklärt wird.
0 ≤ R2 ≤ 1
A =
R2 = 1 Alle liegen Punkte auf der eingepassten
Regressionskurve
R2 gilt nur für
lineare Regression
logarithmische Regression
polynomische Regression
n
R2
=1–
Der Beta-Faktor einer Anlage A bezüglich des
Marktes M (einer Aktie A bezüglich des Aktienindexes
A).
∑ (yi – ^yi)2
i=1
Cov(M, A)
s M2
=
MA sA
sM
Der Beta-Faktor ist die Steigung der
Regressionsgeraden: Steigt die Marktrendite um 1, so
steigt die Aktienrendite tendenziell um .
Hat nichts mit Elastizität zu tun!
Elastizität erklärt einen einzigen Punkt auf einer
Regressionsgeraden
Beta-Faktor macht Aussage über ganze
Regressionsgerade.
sY2 n
n
∑ (yi – ^yi)2
R2 = 1 –
i=1
n
∑ (yi – my)2
i=1
Bei einer linearen Regression ist R2 = 2.
Weiterhin gilt:
1 – R2 = Durch Regressionskurve nicht erklärte
Varianz.
R2 für Aktie A im Markt M:
RA2 =
A2 sM2
sA2
3. + 4. Semester
Christian Meyer
Seite 10 / 18
S6 Zeitreihenanalyse
S7
Wahrscheinlichkeitsrechnu
ng
Komponenten einer Zeitreihe
Trend
Grundrichtung
langfristige Entwicklungsrichtung
glatte Komponente
S7.1 Kombinatorische Grundlagen
Name
Saisonkomponente / Konjunkturkomponente
Wellenförmige Komponente
Saisonale Schwankungen innerhalb eines Jahres
Restkomponente
Einmalige und zufällige Einflüsse
Verbundenheiten
Additive Verbundenheit
Saisonfigur wird zum Trend hinzu addiert
Saisonfigur ist unabhängig vom Trend
Multiplikative Verbundenheit
Saisonfigur wird zum Trend hinzu multipliziert
WiederReihenholung
folge
Permutation ohne
ja
Auswahl von n versch. Elementen
Formel
Variation
ohne
ja
Anordnung von k aus n versch.
Elementen
=
Variation
mit
ja
Anordnung von k aus n versch.
Elementen
= nk
Kombination ohne
nein
Auswahl von k aus n versch.
Elementen
=
n!
(n – k)! k!
=
(
=
(
= n!
n!
(n – k)!
Ermittlung des Trends
Methode der kleinsten Quadrate
liefert die Trendgerade
)
n
)
n–k
n tief k
Methode der gleitenden Durchschnitte
Glättung der Zeitreihe mittels benachbarter Werte.
Die Ordnung muss der Anzahl Werte der Saisonfigur
entsprechen.
Nachteile:
geglättete Zeitreihe ist kürzer als die ursprüngliche
Trend ist nicht durch Funktionsgleichung
beschrieben
Extrapolation nicht möglich
Gl. D. 3. Ordnung
Der erste und letzte Wert geht verloren
a1 + a2 + a3
g2 =
3
n
k
n tief k = (
n
n!
k Faktoren abw. von n
)=
=
k
k Faktoren aufw. von 1
(n – k)! k!
n
( )=1
0
0
( )=1
0
n
n
( )=(
)
k
n–k
Gl. D. 4. Ordnung
Die 2 ersten und 2 letzten Werte geht verloren
0.5 a1 + a2 + a3 + a4 + 0.5 a5
g3 =
3
Saisonbereinigung
Saisonfigur durch Subtraktion oder Division aus
Zeitreihe entfernen.
3. + 4. Semester
Christian Meyer
Seite 11 / 18
S7.2 Wahrscheinlichkeit
Wahrscheinlichkeit P =
Anz. günstige Fälle
Anz. gleichmögliche Fälle
S7.3 Häufigkeits- und
Wahrscheinlichkeitsverteilungen
Erwartungswert
n
Additionssatz
=
Wahrscheinlichkeit, dass A oder B eintritt:
P(A B) = P(A) + P(B) – P(A B)
pi = Wahrscheinlichkeit des Wertes
i=1
Standardabweichung
Multiplikationssatz
Wahrscheinlichkeit, dass A und B eintritt, wenn A und
B voneinander unabhängig sind:
P(A B) = P(A) P(B)
Wahrscheinlichkeit dass A und B eintreten, wenn B
von A abhängig ist:
P(A B) = P(A) P(A / B) '/' steht für 'ohne'
Lotto
Gewinnchance =
∑ (xi pi)
1
45
( )
6
=√
n
( ∑ [ (xi – )2 pi ] )
i=1
Binomialverteilung
Ziehen mit zurücklegen, oder Stichprobe < 5 %
n = Anz. Experimente
k = Anz. eingetretene Ereignisse
p = Wahrsch. das Ereignis eintritt
n
P(X=k) = ( ) pk (1 – p)n – k
k
Für die Binomialverteilung gilt:
=np
= √ (n p (1 – p) )
6
45 – 6
)
)(
n
6–n
n richtige Zahlen =
45
(
)
6
(
Urne mit schwarzen und weissen Kugeln
ks = Anzahl schwarze Kugeln
kw = Anzahl weisse Kugeln
n = ks + kw = Anzahl Kugeln insgesamt
kw
( )
4
P(4 weisse Kugeln) =
n
( )
4
Beispiel
Flugzeug mit 3 Triebwerken: n = 3
Wahrsch. für Ausfall eines Triebwerks: k = 0.01
P(0 Ausfälle) = (
(
P(X=k) = e-
kw
ks
)
)(
2
3
n
(
)
2+3
1
4
P(9 gleichfarbige
35 =
36
Karten) =
( )
(
)
8
9
Weil es egal ist, welche Karte zuerst gezogen wird,
müssen wir uns nur auf die Wahrscheinlichkeit für die
nachfolgenden 35 Karten konzentrieren.
1
36
( )
9
Hier ist nicht mehr egal, welche Karte zuerst gezogen
wird.
3. + 4. Semester
k
k!
=
=√
Karten ziehen
P(9 Eicheln) =
3
) 0.010 (1 – 0.01)3 = 0970299
0
Poissonverteilung
P(min. 1 schw. Kugel) = 1 - P(4 weisse Kugeln)
P(2 weisse Kugeln
und 3 schw. Kugeln) =
Die Binomialverteilung kann durch die
Standardnormalverteilung angenähert werden, wenn
9
n>
p (1 – p)
Beispiel
Das Spital erwartet 1.2 Notfälle pro Tag: = 1.2.
Maximal 1 von 500 Notfällen müssen durch die
Notfallstation abgedeckt sein: P(X=k)=99.8%.
Wieviele Plätze braucht die Notfallstation?
P(0 Notfälle=k) = ... %
...
P(5 Notfälle=k) = ...%
P(...) solange addieren, bis die gewünschte Fläche
gefüllt ist.
P(0 bis 5 Notfälle=k) = 99.85 %
Die Notfallstation braucht 5 Plätze um 499 von 500
Fällen abzudecken.
Christian Meyer
Seite 12 / 18
Normalverteilung
Die Normalverteilung basiert auf der Dichtefunktion
(Graph siehe Standardnormalverteilung).
Portfolio-Analyse ist nur zulässig mit stetigen
Renditen!
x–
1
e–0.5 (
√ (2 )
= Erwartungswert
= Standardabweichung
f(x) =
)2
b
P(X=k) = ∫ f(x)dx
a
X = Klasse von a bis unter b
a = Untergrenze der Klasse
b = Obergrenze der Klasse
LÖSE NORMAL berechnet jedoch
z
F(z) = ∫ f(x)dx
–∞
Um P(X=k) zu erhalten, muss man deshalb zuerst die
standardnormalverteilte Zufallsvariable z je aus a und
b berechnen. Dann muss man F(za) von F(zb)
abziehen.
Standardnormalverteilung
Entspricht der Normalverteilung, wobei = 0 und
= 1 gesetzt sind.
-z
+z
-3
-2
-1
0
1
2
3
Umrechnen der Zufallsvariable X in die
standardnormalverteilte Zufallsvariable z:
X–
z=
Tabelle 1: Fläche von -z bis +z
z
1
1.96
2
F[z] 68.269%
95%
95.5%
2.58
99%
3
99.73%
Tabelle 2. Fläche von -∞ bis z
z
0
1.65
1.96
F[z]
50%
95%
97.5%
2.35
99%
2.58
99.5%
Satz 1: X1, X2, ..., Xn seien unabhängige
normalverteilte Zufallsvariablen, die alle den
Erwartungswert und die Standardabweichung
besitzen. Dann ist die Zufallsvariable X = X1+X2+...+Xn
normalverteilt und hat den Erwartungswert n und
die Standardabweichung √(n) .
Satz 2: X1, X2, ..., Xn seien unabhängige normalverteilte Zufallsvariablen. 1, 2, ..., n sind die
Erwartungswerte, 1, 2, ..., n die
Standardabweichungen. Dann ist die Zufallsvariable X
= X1+X2+...+Xn normalverteilt und hat den
Erwartungswert = 1 + 2 + ... + n und die
Standardabweichung = √(12 + 22 + ... + n2).
3. + 4. Semester
Christian Meyer
Seite 13 / 18
S8 Schliessende Statistik
S8.1B Vertrauensbereiche für das
arithmetische Mittel
N = Grösse der Grundgesamtheit
= arithmetisches Mittel der Grundgesamtheit
= Standardabweichung der Grundgesamtheit
Quantitativer Fall
Mit der zu z gehörenden Wahrscheinlichkeit liegt das
arithmetische Mittel mx einer Stichprobe im Intervall
von
s
N–n
)
mx = (z
√n √ N – 1
n = Grösse der Stichprobe
mx = arithmetisches Mittel der Stichprobe
s = Standardabweichung der Stichprobe
S8.1 Vertrauensbereiche
Eine Stichprobe wird genommen um eine Aussage
über den der Gesamtmenge zu machen.
Weil die Stichprobe kleiner als die Gesamtmenge ist,
kann nur mit einer gewissen Wahrscheinlichkeit
getroffen werden.
Ist n kleiner als 5 % von N, so ist
N–n
√( N – 1 ) 1
S8.1A Der zentrale Grenzwertsatz
Ziehen mit Zurücklegen
Sind X1, X2, ..., Xn unabhängige Zufallsvariablen, die
alle dieselbe Verteilungsfunktion
(Wahrscheinlichkeitsverteilung) und somit denselben
und 2 besitzen, so ist die Zufallsvariable
X1 + X2 + ... + Xn
mX =
n
mit wachsendem n immer besser normalverteilt mit
dem Erwartungswert und der Varianz
2
X2 =
n
(mX = arithmetisches Mittel von X)
Ziehen ohne Zurücklegen
Sind X1, X2, ..., Xn abhängige Zufallsvariablen (X2 ist
abhängig von X1 usw.), die alle dieselbe
Verteilungsfunktion (Wahrscheinlichkeitsverteilung)
und somit denselben und 2 besitzen, so ist die
Zufallsvariable
X1 + X2 + ... + Xn
mX =
n
mit wachsendem n immer besser normalverteilt mit
dem Erwartungswert und der Varianz
N–n
2
X2 =
n
N–1
(mX = arithmetisches Mittel von X)
N = Gesamtmenge
n = Auswahl
3. + 4. Semester
Grosse Stichprobe
Mit der zu z gehörenden Wahrscheinlichkeit enthält
das Intervall
s
N–n
)
Vertrauensbereich = mx (z
√n √ N – 1
das arithmetische Mittel der Grundgesamtheit
Kleine Stichprobe
Für im Verhältnis zur Grundgesamt kleinen
Stichproben (n < 5 % von N) gilt:
s
)
Vertrauensbereich = mx (z
√n
mx = Arithmetisches Mittel von n
= Arithmetisches Mittel von N
Formulierung
"Das Intervall mx ... enthält mit 95-%iger
Sicherheit".
"Mit 99.7-%iger Sicherheit enthält das Intervall von
... bis ... den durchschnittlichen Anteil ... aller ...".
Wir stellen fest
je grösser die Sichherheit, desto breiter der
Vertrauensbereich
je grösser die Stichprobe, desto schmaler der
Vertrauensbereich
je grösser die Standardabweichung der Stichprobe,
desto grösser der Vertrauensbereich
für kleine Stichproben gilt: die Grösse der
Grundgesamtheit hat keinen Einfluss auf den
Vertrauensbereich
Halbiert man den maximalen Fehler (den
Vertrauensbereich) so vervierfacht sich die
Stichprobengrösse
Christian Meyer
Seite 14 / 18
Qualitativer Fall
S8.1C Stichprobengrösse
Wir interessieren uns für die relative Häufigkeit, mit
der ein bestimmtes Merkmal auftritt.
Standardabweichung der Grundgesamtheit:
Wie gross muss die Stichprobengrösse mindestens
sein, wenn mit mit einer Sicherheit von p %, nicht
mehr als ±F Elemente daneben liegen möchte?
s= √( A (1 – A) )
z = p via Tabelle 1 umrechnen
A = Anteil des gesuchten Merkmals in der
Grundgesamtheit
0≤A≤1
Quantitativer Fall
Grosse Stichprobe
Stichprobengrösse n =
Da der Anteil von A der Grundgesamtheit nicht
bekannt ist, ersetzen wir A durch den Anteil a der
Stichprobe (A wird durch a geschätzt).
Grosse Stichprobe
Für grosse Stichproben (n 5 % von N) muss wegen
des bei der Stichprobe üblichen "Ziehens ohne
Zurücklegen" ein Korrekturfaktor verwendet werden.
N–n
a (1 – a
Vertrauensbereich = a (z √(
) √( N – 1 ) )
n
Kleine Stichprobe
Für im Verhältnis zur Grundgesamtheit kleine
Stichproben (n < 5 % von N) gilt:
Mit der zu z gehörenden Wahrscheinlichkeit enthält
das Intervall von
a (1 – a
Vertrauensbereich = a (z √(
))
n
den Anteil A der Grundgesamtheit
N
F2 (N – 1)
+1
z2 2
Kleine Stichprobe
Stichprobengrösse n =
z2 2
F2
Schätzen
Dummerweise ist der Grundgesamtheit nicht
bekannt, es muss deshalb geschätzt werden:
Bei normalverteilten Grössen liegen zwischen ± 3
99.7 % (also nahezu 100 %) der Werte. Dividiert man
die Spannweite durch 6 (Drei-Sigma-Regel), so kriegt
man einen Schätzwert für .
Qualitativer Fall
Kleine Stichprobe
Stichprobengrösse n =
z2 2
F2
mit
= √( A (1 – A) )
Schätzen
Sind keine Richtwerte für bekannt, so verwendet
man die Tatsache, dass höchstens 0.5 sein kann.
3. + 4. Semester
Christian Meyer
Seite 15 / 18
S8.2 Testen von Hypothesen
Frage
Trifft eine Vermutung gegenüber einer
Grundgesamtheit zu?
Logischer Ablauf eines Hypothesen-Tests
Die Vermutung über eine Grundgesamtheit soll
indirekt bestätigt werden.
Die Nullhypothese H0 wird als "Gegenhypothese"
aufgestellt. Ziel ist H0 zu widerlegen.
Planung des Zufallsexperiments: Wahl der
Testgrösse, deren Wert durch das
Zufallsexperiment bestimmt werden kann.
Signifikanzniveau wählen, Verwerfungsbereich
bestimmen, Entscheidungsregel aufstellen.
Zufallsexperiment durchführen, Wert der
Testgrösse bestimmen.
Wert der Testgrösse fällt in Verwerfungsbereich:
H0 verwerfen (Möglichkeit eines Fehlers 1. Art)
Wert der Testgrösse fällt nicht in Verwerfungsb:
H0 ist nicht widerlegt und wird somit bis auf
weiteres beibehalten (Möglichkeit eines Fehlers 2.
Art)
Fehler 1. Art
Die Nullhypothese ist richtig, wird aber trotzdem
verworfen.
Die Wahrscheinlichkeit für einen Fehler 1. Art ist = .
Fehler 2. Art
Die Nullhypothese ist falsch, wird aber nicht
verworfen.
Die Wahrscheinlichkeit für einen Fehler 2. Art ist = .
ist schwer oder überhaupt nicht berechenbar.
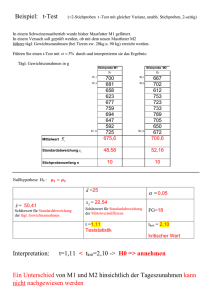
S8.2A Tests bezüglich
Einstichprobentest
Frage
Ist in einer Grundgesamtheit das arithmetische Mittel
verschieden von einem vermuteten Wert 0?
Nullhypothese H0: = 0
Stichprobe:
Grösse: n ≥ 100
Arithmetisches Mittel: mx
Standardabweichung: s
Nullhypothese H0: Ausschuss = 1%.
Testgrösse:
(mx – 0) √n mx – 0
z=
=
s
s
√n
Irrtumswahrscheinlichkeit :
5 % = signifikant
1 % = hochsignifikant
Einseitiger Test
Alternativhypothese HA: > 0 bzw. < 0
Beispiel:
Vermutet wird, dass der Ausschuss > 1 % ist.
Verwerfungsbereich V: X > 4 (d. h. >2 % von N).
Verwerfungsbereich (Tabelle 1):
= 5 %:
|z| > 1.65
= 1 %:
|z| > 2.33
Gesamtmenge N=sehr gross.
Stichprobe n=200.
Anzahl fehlerhafte Teile in Stichprobe: X = 6.
= 1 – P(X ≤ 4) = 1 – [P(0)+P(1)+P(2)+P(3)+P(4)]
LÖSE BINOM
200 N
0.01 P (=1 %)
0 K PROB 0.1339... STO
1 K PROB 0.2706... STO
2 K PROB 0.2720... STO
3 K PROB 0.1813... STO
4 K PROB 0.0902... STO
RCL 1 0.9482...
1 – +/- 0.0517... (= 5.2%)
Verwerfungsbereich (Tabelle 2):
= 5 %:
|z| > 1.96
= 1 %:
|z| > 2.58
1
+1
+1
+1
+1
Weil X in den Verwerfungsbereich fällt, kann die
Nullhypothese verworfen werden.
Formulierung
Es ist signifikant zum Niveau = 5,2 %, dass der
Ausschussanteil grösser ist als 1 %.
3. + 4. Semester
Zweiseitiger Test
Alternativhypothese HA: ≠ 0
Zweistichprobentest
Frage
Haben zwei Grundgesamtheiten verschiedene
arithmetische Mittel 1 und 2?
Nullhypothese H0: 1 = 2?
Alternativhypothese HA: 1 2
zwei voneinander unabhängig gezogene Stichproben:
Grösse: n1 ≥ 100, n2 ≥ 100
Arithmetisches Mittel: mx1, mx2
Standardabweichungen: s1, s2
Testgrösse:
mx1 – mx2
z=
s2
s2
√( n11 + n22
Christian Meyer
)
Seite 16 / 18
Verwerfungsbreich (Tabelle 2):
= 5 %:
|z| > 1.96
= 1 %:
|z| > 2.58
8.2B Tests bezüglich p
Einstichprobentest
Frage: Ist in einer Grundgesamtheit der Anteil p eines
Merkmals verschieden von seinem vermuteten Wert
p0?
Nullhypothese H0: p = p0
Stichprobe:
Grösse: n >
9
p0 (1 – p0)
Anteil des Merkmals in der Stichprobe: a
Testgrösse:
(a – p0) √n
z=
, mit = √( p0 (1 – p0) )
Einseitiger Test
Alternativhypothese HA: p > p0 bzw. p < p0
Verwerfungsbereich (Tabelle 1):
= 5 %:
|z| > 1.65
= 1 %:
|z| > 2.33
Zweiseitiger Test
Alternativhypothese HA: p ≠ p0
Verwerfungsbereich (Tabelle 2):
= 5 %:
|z| > 1.96
= 1 %:
|z| > 2.58
Zweistichprobentest
Frage
Haben zwei Grundgesamtheiten verschiedene Anteile
p1 und p2 eines Merkmals?
Nullhypothese H0: p1 = p2
Alternativhypothese HA: p ≠ p0
zwei voneinander unabhängig gezogene Stichproben:
(n1 + n2) p > 5
(n1 + n2) (1 – p) > 5
n1 ≥ 50 n2 ≥ 50
wobei:
p=
a1 n1 + a2 n2
n1 n2
Grösse: n >
9
p0 (1 – p0)
Anteil des Merkmals in der Stichproben: a1, a2
Testgrösse:
z=
a1 – a2
√(p (1 – p) (
1
n1
+
1
n2 ) )
Verwerfungsbereich (Tabelle 2):
= 5 %:
|z| > 1.96
= 1 %:
|z| > 2.58
3. + 4. Semester
Christian Meyer
Seite 17 / 18
Den kritischen Wert c entnimmt man der 2-Tabelle.
Ist S > c, so wird die Nullhypothese H0 verworfen.
8.2C Chiquadrat Anpassungstest
Definition
Sind X1, X2, X3, ..., Xv unabhängige
standardnormalverteile Zufallsvariablen ( = 0, = 1),
so heisst die Zuvallsvariable 2 = X12, X22, X32, ..., Xv2
chiquadratverteilt mit Freiheitsgraden.
Frage: Sind zwei Grundgesamtheiten annähernd
gleich verteilt?
Gleichverteilung
Nullhypothese H0: Grundgesamtheit ist gleichverteilt
Alternativhypothese HA:
Grundgesamtheit ist nicht gleichverteilt.
Testgrösse:
k
(fi – fthi)2
S= ∑
fthi
i=1
k
S=
∑
i=1
(beobachtete Häuf. – theoretische Häuf.)2
theoretische Häuf
Geht nur, wenn die theoretischen Häufigkeiten > 5
sind! Ansonsten müssen benachbarte Klassen
zusammengelegt werden.
Berechnung Anzahl Freiheitsgrade :
=k–m–1
k = Anzahl Klassen (beim Würfel: 6)
m = Anzahl Parameter der
Wahrscheinlichkeitsverteilung
Gleichverteilung (kein Parameter): m = 0
Binomialverteilung (Parameter p): m = 1
Poissonverteilung (Parameter ): m = 1
Normalverteilung (Parameter , ): m = 2
Den kritischen Wert c entnimmt man der 2-Tabelle.
Ist S > c, so wird die Nullhypothese H0 verworfen.
8.2D Chiquadrat Unabhängigkeitstest
Frage
Sind zwei qualitative Merkmale unabhängig
voneinander?
Testgrösse:
k
m
S= ∑ ∑
i=1 j=1
S= ∑
(fij – fthij)2
fthij
(beobachtete Häuf. – theoretische Häuf.)2
theoretische Häuf
Berechnung Anzahl Freiheitsgrade :
= (k – 1) (m – 1)
k = Anzahl Ausprägungen des einen Merkmals
m = Anzahl Ausprägungen des anderen Merkmals
3. + 4. Semester
Christian Meyer
Seite 18 / 18