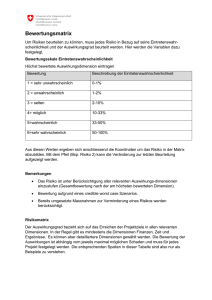
3. Kombination von Informationsqualität und - IQIK-Projekt
Werbung

UNIVERSITÄT REGENSBURG
Informationsqualität versus
Informationskompetenz
-
Ein kombiniertes Modell
Hausarbeit im Seminar
Informationsqualität
Leitung: Prof. Dr. Hammwöhner
Modul: M32.2
Wintersemester 2009/2010
Lehrstuhl für Informationswissenschaft
Institut für Information und Medien, Sprache und Kultur
Philosophische Fakultät III
Vorgelegt von:
Stefanie Bachhuber, Michael Fischbach, Daniel Lottes und Sarah Will
Matrikelnummer: XXX - Bachhuber
Matrikelnummer: XXX - Fischbach
Matrikelnummer: 1281928 - Lottes
Matrikelnummer: 1284150 - Will
Gliederung
1. EINLEITUNG .................................................................................................................... 4
2. DEFINITIONEN UND MODELLE ................................................................................ 5
2.1 MODELLE DER INFORMATIONSQUALITÄT ............................................................................. 5
2.1.1 Vergleich der Modelle der Informationsqualität ........................................................................ 5
2.1.2 DGIQ – 15 Dimensionen der Informationsqualität ................................................................. 6
2.2 MODELLE DER INFORMATIONSKOMPETENZ ......................................................................... 7
2.2.1 Informationskompetenz als Metakompetenz ............................................................................ 8
2.2.2 Seven Faces of Information Literacy ....................................................................................... 9
2.2.3 The Big6TM Skills ........................................................................................................... 10
3. KOMBINATION VON INFORMATIONSQUALITÄT UND
INFORMATIONSKOMPETENZ ....................................................................................... 12
3.1 ENTWICKLUNG EINES KOMBINIERTEN INFORMATIONSQUALITÄTSINFORMATIONSKOMPETENZ-MODELLS .................................................................................... 12
3.2 VERTIEFTE VERKNÜPFUNG VON IQ-DIMENSIONEN UND IK-SKILLS .................................. 15
4. VERWENDUNG IM RAHMEN VON
INFORMATIONSQUALITÄTSEVALUATIONEN .......................................................... 19
4.1 METRIKEN FÜR INFORMATIONSQUALITÄT........................................................................... 19
4.1.1 Harte Maße - Daniel ....................................................................................................... 19
4.1.2 Weiche Maße - Daniel ...................................................................................................... 23
4.1.3 Ambigue Maße ............................................................................................................... 27
4.2 INFORMATIONSKOMPETENZ UND WEICHE EVALUATION .................................................... 29
5. FAZIT ................................................................................................................................ 32
6. LITERATURVERZEICHNIS .......................................................................................... 33
2
Abbildungsverzeichnis
Abbildung 1: Gemeinsame Kriterien der Informationsqualitätsmodelle (Knight &
Burn (2005), S. 162) .............................................................................................. 6
Abbildung 2: IQ-Definition: 15 Dimensionen, 4 Kategorien (DCIQ 2007a) ........ 7
Abbildung 3: Informationskompetenz als Metakompetenz (Maberry & Giuntini
2008) ...................................................................................................................... 9
Abbildung 4: Bruce: Seven Faces of Information Literacy (vgl. Bruce 2003) .... 10
Abbildung 5: XXXX ............................................................................................ 22
Abbildung 6: Verwirrendender Menüpunkt in Windows XP: Über „Start“ lässt
sich das System „Herunterfahren ......................................................................... 26
3
1. Einleitung
4
2. Definitionen und Modelle
Um eine Kombination aus Informationsqualitäts- und Informationskompetenzmodell erstellen zu können, sollen zunächst bereits bestehende Modelle der jeweiligen
Disziplin vorgestellt werden. Aus diesen wird jeweils der bestmögliche Vertreter für
die Informationsqualität bzw. die Informationskompetenz gewählt um im Anschluss aufbauend auf diesen beiden Modellen ein kombiniertes Modell erstellen zu
können.
2.1 Modelle der Informationsqualität
„Defining Information Quality is a complex and multi-faceted issue ...
(Knight
& Burn 2005: 170).“ Dieses Problem beruht auf der Kontextabhängigkeit und der
meist subjektiven Beurteilung der Informationsqualität. Denn je nach Nutzer, Informationsträger und Informationsbedürfnis fällt die Bewertung der Qualität unterschiedlich aus. Um Informationsqualität dennoch universell definieren zu können
wird Hinrichs herangezogen. Nach seiner Definition ist Informationsqualität der
„Grad, in dem Merkmale eines Datenproduktes Anforderungen genügen (Hildebrand et al. 2008: 25).“ Unter den Merkmalen sind Eigenschaften wie beispielsweise
Fehlerfreiheit, Übersichtlichkeit der Darstellung und Verständlichkeit zu verstehen.
2.1.1 Vergleich der Modelle der Informationsqualität
Für die Messung der Informationsqualität gibt es unzählige und auch anerkannte
Modelle. Zwölf dieser Modelle aus den Jahren 1996 bis 2002 haben Knight und
Burn in ihrer Arbeit Developing a Framework for Assessing Information Quality on the World
Wide Web (2005) auf Kongruenz bezüglich der Dimensionen, Kategorien und Kriterien untersucht. Unter diesen Modellen befanden sich Wang & Strong (1996), Alexander & Tate (1999), Dedeke (2000) und Klein (2002).
Knight und Burn führten diese Untersuchung mit dem Ziel durch, Metriken für
Informationsqualität im Information Retrieval zu entwickeln: „IQIP – A model to
Identify, Quantify, Implement & Perfect the process of IQ dimension application
to Web Crawler quality retrieval algorithms (Knight & Burn 2005: 168).“
5
Nach Analyse der einzelnen Modelle, wurde die untenstehende Tabelle erstellt, in
der die Kriterien nach ihrem Vorkommen in den Modellen platziert wurden und
jeweils eine kurze Beschreibung nach Wang und Strong enthalten.
Abbildung 1: Gemeinsame Kriterien der Informationsqualitätsmodelle (Knight & Burn (2005), S.
162)
Mittels dieser Kriterien wurde ein Informationsmodell ausgewählt, das möglichst
viele dieser Merkmale enthält. Dies garantiert, dass sich im kombinierten IQ-IKModell ein erheblicher Teil der Informationsqualitätskriterien wieder findet.
2.1.2 DGIQ – 15 Dimensionen der Informationsqualität
Dem Modell der anwenderbezogenen Definition für Informationsbedürfnisse liegt
eine Studie von Richard Wang und Diane Strong aus dem Jahre 1996 zu Grunde.
Bei den 15 Dimensionen handelt es sich um die Forschungsergebnisse die in einer
Umfrage unter IT-Nutzern ermittelt wurden. Diese 15 Dimensionen wurden von
der DCIQ mit deutschen Begriffen, Kurzdefinitionen und praktischen Beispielen
6
versehen (vgl. DCIQ 2007b). Weiter Informationen dazu finden sich im Internet
unter www.dciq.de.
Eben dieses Modell wird auch für die spätere Untersuchung von Zusammenhängen
zwischen Informationsqualität und –kompetenz verwendet, da sich alle 20 Kriterien
aus der Studie von Knight und Burn den hier aufgeführten Dimensionen zuordnen
ließen.
Abbildung 2: IQ-Definition: 15 Dimensionen, 4 Kategorien (DCIQ 2007a)
2.2 Modelle der Informationskompetenz
„The next best thing to knowing something, is knowing where to find it.“
Samuel Johnson
In den letzten Jahrzehnten ist die Informationsflut enorm angewachsen, mitunter
ein Grund dafür ist die Entwicklung neuer Kommunikations- und Publikationsmedien, die die Vervielfältigung und Verbreitung von Information stark vereinfachen
(vgl. Kabo 2007: 12) Aus dieser Gegebenheit ist das Bedürfnis nach einer neuen
Qualifikation erwachsen: die Fähigkeit dem Informationsbedarf entsprechend relevante und aktuelle Quellen mittels geeigneter Informationsmedien zu finden (vgl.
Kabo 2007: 13). Bei dieser neuen Fertigkeit handelt es sich um die Informationskompetenz (englisch: Information Literacy). Dieser Begriff wurde erstmals von Paul
Zurkowski im Jahre 1974 in seinem Bericht an die National Commission on Libraries
and Information Science genutzt (vgl. Doyle 1994: 5).
7
Eine grundlegende Definition für Informationskompetenz kommt von der American
Library Association (ALA) von 1989:
„To be information literate, a person must be able to recognize when
information is needed and have the ability to locate, evaluate, and use
effectively the needed information (Rauchmann 2002: 8 ).“
Diese Definition fasst alle Gemeinsamkeiten der verschiedenen Sinndeutungen der
letzten Jahre zusammen. Die Mannigfaltigkeit der Sinndeutung findet ihren Ursprung in den gesellschaftlichen Entwicklungen der letzten 25 Jahre. So liegt in den
70er Jahren der Schwerpunkt der Informationskompetenz im adäquaten und autonomen Umgang mit Informationsressourcen für Problemlösungen im Alltag und
Beruf. In den 80ern rückte der effektive Umgang mit dem Computer in den Mittelpunkt und wurde in den 90er Jahren durch die Forderung nach einem kompetenten
Umgang mit den Neuen Medien und deren Inhalte analysieren und bewerten zu
können verdrängt. Gegenwärtig wird der Informationskompetenz kein primärer
Aufgabenbereich mehr zugeschrieben, man sieht sie als Metakompetenz, wobei sich
die Relevanz der einzelnen Kompetenzen nach dem Anwendungsfeld richtet (vgl.
Rauchmann 2002: 8f).
Dementsprechend ist die Informationskompetenz keine Qualifikation, die man
einmalig im Leben zu erwerben hat, durch den Wandel der Medien zeichnet sich die
Informationskompetenz durch lebenslanges Lernen und Weiterbilden aus (vgl.
Kabo 2007: 16).
2.2.1 Informationskompetenz als Metakompetenz
Die nachfolgende Grafik (Abb. 3) stammt von Sue Maberry. Sie ist Direktorin der
Library and Instructional Technology at Otis College of Art and Design (vgl. LinkedIn Corporation 2010). Mittels dieser Grafik werden die Schnittstellen der Informationskompetenz zu anderen Kompetenzen visualisiert.
8
Abbildung 3: Informationskompetenz als Metakompetenz (Maberry & Giuntini 2008)
Die Kompetenzen bedingen sich gegenseitig, so fordert die Media Literacy nach einem kritischen Umgang mit den Massenmedien, den Neuen Medien und deren Inhalten. Diese wäre jedoch nicht ohne Network Literacy möglich, die dazu befähigt
Multimedia und Hypertexte lesen und verstehen zu können. Diese wiederum setzt
beim Nutzer Computer Literacy voraus, welche ihn zu einem effektiven Umgang mit
Computern (Software und Hardware) befähigt. Um sich fehlende Qualifikation eigenständig aneignen zu können, bedarf es der Library Instruction, die die selbständige
Nutzung der Bibliothek und deren Dienstleistungsangeboten beinhaltet. Dies alles
wäre nicht ohne den drei Basiskomptenzen Lesen, Schreiben und Rechnen möglich,
welche die Traditional Alphabetic Literacy in sich birgt. Dabei handelt sich unbestritten
um die wichtigste Kompetenz, was auch an der obigen Grafik abgelesen werden
kann, in der der Traditional Alphabetic Literacy die größte Fläche der sieben Kompetenzen zu Teil wird. Um solche Rückschlüsse aus einer Darstellung ziehen zu können ist Visual Literacy erforderlich, denn diese schließt die psychischen und physischen Aspekte der Wahrnehmung ein. Letztlich fehlt noch die Cultural Literacy um
die Informationskompetenz zu vervollständigen. Sie befähigt ihren Besitzer Traditionen von unterschiedlichen Länder und Religionen zu verstehen (vgl. Heinze &
Fink 2009: 3ff).
2.2.2 Seven Faces of Information Literacy
Christine Bruce definiert ihren Ansatz aus Benutzersicht, indem sie die „Informationskompetenz als die Fähigkeit beschreibt, effektiv in der Informationsgesellschaft
zu agieren (Heinz & Fink 2009: 3).“ Für ihre Studie führte sie eine Umfrage unter
Wissenschaftlern, Bibliothekaren und IT-Experten bezüglich ihres Umgangs mit
Information durch. Als Ergebnis erhielt Bruce sieben verschiedene Wege der Inter-
9
aktion, die sich jeweils durch drei Elemente beschreiben lassen: der Informationstechnologie (grün in Abb. 4), dem Informationsgebrauch (dunkelblau in Abb. 4)
und einem dritten, wechselnden Element (vgl. Rauchmann 2002: 10). Bei diesem
wechselnden Element handelt es sich um:
1. Face:
2. Face:
3. Face:
4. Face:
5. Face:
6. Face:
7. Face:
„The IT Experience
FaceFaceThe Info Sources Experience
The Info Process Experience
The Info-Control Experience
The Knowledge Construction Experience
The Knowledge Extension Experience
The Wisdom Experience (Bruce 2002)“
So bezieht sich das erste Face auf den Zugang zur Information, worauf das Auffinden von internen und externen Informationsquellen folgt (vgl. Mutch 2008: 18). In
Face 3 steht der Prozess der Problemeingrenzung und –lösungsfindung im Mittelpunkt, welche im vierten Face abgelöst werden durch das Erkennen und Verwalten
relevanter Informationen und deren Beziehungen. Woraus im fünften Face eine
eigene Basis für das neu gewonnene Wissen erstellt wird (vgl. Bruce 2003). Das
sechste Face beschreibt eine Intuition für die Entwicklung neuer Einsichten (vgl.
Rauchmann 2002: 10) und das letzte Face beschreibt die Verbindung von Information mit Werten und persönlicher Moral und schließlich die bestmögliche Aufbereitung für weitere Personen (vgl. Bruce 2003).
Abbildung 4: Bruce: Seven Faces of Information Literacy (vgl. Bruce 2003)
2.2.3 The Big6TM Skills
Dieses Modell wurde 1990 von Michael Eisenberg und Robert Berkowitz in den
USA entwickelt (vgl. Rauchmann 2002: 20). Charakteristisch für diesen Ansatz sind
die übersichtliche Strukturierung des Ansatzes, die lineare Sichtweise des Informati-
10
onsprozesses und die Konzentration auf die kognitiven Faktoren (vgl.: Homann
2000: 1999).
Eisenberg und Berkowitz teilen den Informationsprozess in sechs Schritte auf, die
sich wiederum aus zwei Unterkategorien zusammensetzen:
1. „Task Definition
1.1 Define the information problem
1.2 Identify information needed
2. Information Seeking Strategies
2.1 Determine all possible sources
2.2 Select the best sources
3. Location and Access
3.1 Locate sources (intellectually and physically)
3.2 Find information within sources
4. Use of Information
4.1 Engage (e.g., read, hear, view, touch)
4.2 Extract relevant information
5. Synthesis
5.1 Organize from multiple sources
5.2 Present the information
6. Evaluation
6.1 Judge the product (effectiveness)
6.2 Judge the process (efficiency) (Eisenberg 2007)“
Bei diesem Modell handelt es sich um das bekannteste und auch am weitest verbreiteten Informationskompetenzmodell. Aufgrund dessen und der klaren Strukturierung und Untergliederung des Informationsprozesses soll dieses Modell im Folgenden für die Kombination von Informationskompetenz und –qualität verwendet
werden.
11
3. Kombination von Informationsqualität und Informationskompetenz
Im folgenden Kapitel beschäftigen wir uns damit, wie wir die oben besprochenen
Modelle für Informationsqualität (IQ) und Informationskompetenz (IK) verwendet
haben, um beide Konzepte zu vereinen. Da es bisher nur wenig Literatur zu
derartigen Ansätzen gibt1, haben wir uns zuerst über das Zusammenspielen von IQ
und IK in einem generischen Informationsfluss Gedanken gemacht. Das daraus
resultierende Iterative Kombinierte Informationsqualitäts-InformationskompetenzModell (IKIQIK-Modell) wird in Sektion 3.1 vorgestellt. Sektion 3.2 behandelt
dann, basierend auf diesem kombinierten Modell, die Verknüpfung der in Kapitel 2
besprochenen IQ-Dimensionen und IK-Skills. Sektion 3.3 gibt es bis jetzt noch
nicht.
3.1 Entwicklung eines kombinierten InformationsqualitätsInformationskompetenz-Modells
Als Grundlage für das IKIQIK-Modell diente das informationstheoretische Modell
von Claude E. Shannon2. Ziel war es, das von Shannon vorgestellte
Kommunikationsmodell für den breiteren Kontext von Informationssystemen zu
spezifizieren, und die Einwirkungen von Informationskompetenz und -qualität der
verschiedenen Akteure darin festzuhalten.
In Shannons Modell besteht aus fünf Komponenten: einer Informationsquelle,
einem Sender, einem Kanal, einem Empfänger, und einem Informationsziel. Die
Information wird dabei von der Quelle aus an den Sender übermittelt, welche die
Information in ein Signal umwandelt. Dieses Signal kann verschiedene Formen
annehmen, so dass zum Beispiel die gesprochene Sprache einer menschlichen
Quelle in Schallwellen übertragen wird, oder digitaler Text von einem
Informationssystem in einen digitalen Bitstrom. Der Kanal ist das Medium, über
den das Signal an den Empfänger des Informationsziels übertragen wird. Der
Empfänger leistet dann die umgekehrte Arbeit des Senders und versucht, das die
ursprüngliche Information aus dem empfangenen Signal wiederherzustellen. Sollten
bei der Übermittlung Störsignale auf den Kanal eingewirkt haben, kann diese
Wiederherstellung unter Umständen fehlschlagen oder zumindest Mängel
aufweisen. Dies kann sich zum Beispiel in einem lauten Geräuschpegel im
Hintergrund einer verbalen Kommunikation äußern, oder dem Entstehen von
1
2
u.U. Verweis auf wenige bestehende Literatur? (falls tatsächlich vorhanden)
Wo nicht anders vermerkt, bezieht sich diese Sektion durchgehend aus Shannon 1948.
12
Rauschen auf einem elektronischen Kanal. So kommt die gewünschte Information
schlussendlich – mit oder ohne Informationsverlust – beim beabsichtigten Ziel an.
Eine grafische Darstellung von Shannons Modell ist auf Abbildung 3.1 zu sehen.
Überträgt man dieses Modell nun auf den Kontext von Informationssystemen,
kann man prinzipiell zwei Iterationen dieses Prozesses feststellen: zum einen
werden Informationen von einem Informationsbereitsteller (zum Beispiel einem
Autor) in einem System bereitgestellt; zum anderen holt sich der spätere
Informationsnutzer diese Informationen aus dem System. In ersterem Falle
entspricht die Informationsquelle dem Bereitsteller, und das Ziel dem System; der
Kanal entspricht dem Medium, das der Bereitsteller nutzt, um seine Informationen
in das System einzuspeisen. In letzterem Falle dagegen entspricht die
Informationsquelle dem System, und das Ziel dem Nutzer, der sich die
Informationen aus dem System holt; der Kanal entspricht hierbei dem Medium,
durch das der Nutzer mit dem System interagiert.
Ein weiterer Prozess ist vorstellbar, wenn man den Bereitsteller der
Informationen vom Bereitsteller des Systems unterscheidet. Man stelle sich dabei
beispielsweise den Webauftritt einer Tageszeitung vor. Hier wäre der Redakteur, der
für den Inhalt der Artikel zuständig ist, ein Informationsbereitsteller; der
Webdesigner, der das Layout und den Aufbau der Website konzipiert, wäre dagegen
ein Systembereitsteller. Jedoch lässt sich dieser Prozess nicht eins zu eins auf
Shannons Modell übertragen, da nicht, wie in den oben genannten Prozessen,
Informationen an ein Ziel übermittelt werden, sondern vielmehr methodisches
Wissen3 an einem Ziel angewandt wird. Wir haben uns dennoch für die Einbindung
dieses Prozesses in das IKIQIK-Modell entschieden, da er später relevant für die
Einflüsse von IQ und IK auf den Informationsfluss sein wird. Abbildung 3.2 zeigt
ein Modell, in dem alle drei Prozesse auf das Informationssystem einwirken.
Kommen wir nun zur Einbindung von IQ und IK. IQ bezieht sich, wie bereits
in den vorhergehenden Kapiteln erörtert, immer auf das System und die darin
enthaltenen Informationen4. Ist ein System schlecht zu bedienen oder sind die
Informationen unübersichtlich dargestellt, hat dies negative Auswirkungen auf den
Informationsfluss. Der Nutzer wird sich bei einem System mit niedriger IQ
schwerer tun, die gewünschten Informationen zu finden und aus dem System
herauszuholen, ebenso wie der Systembereitsteller eher Probleme haben wird, das
System zu warten oder zu erweitern, oder der Informationsbereitsteller, weitere
3
Es wird hierbei bewusst nicht die Bezeichnung Information verwendet, da dieses methodische Wissen nicht für spätere Informationssuchende im System verfügbar ist, sondern vielmehr Teil des Systems ist. (cf. Informations-Definition?)
4
Erläuterung notwendig? Schon vorher erklärt? PSP IQ?
13
Informationen in das System einzubinden beziehungsweise für das System relevante
Informationen auszuwählen. Insofern können die Auswirkungen der IQ eines
Systems gemäß Shannons Kommunikationsmodell als Störsignale betrachtet
werden. Wirken diese Störsignale auf den Informationsfluss ein, kommt es zu
einem Informationsverlust, so wenn beispielsweise ein Nutzer den für ihn
relevanten Artikel in einem Literaturrecherchesystem nicht findet oder das System
eine ungeeignete Zusammenfassung oder Auszeichnung des Artikels bietet.
Anders als IQ bezieht sich IK immer auf menschliche Akteure; in unserem Falle
also auf den Informationsnutzer, den
Informationsbereitsteller und den
Systembereitsteller. Jeder dieser Akteure wirkt sich durch seine IK auf den
Informationsfluss aus. Ist der Informationsbereitsteller beispielsweise nicht in der
Lage, die gewünschten Informationen gut verständlich aufzubereiten, ist die
Information mangelhaft. Oder anders ausgedrückt: es kommt beim
Bereitstellungsprozess zu einem Informationsverlust. Analog dazu kann es auch bei
der Information, die ein Nutzer aus dem System zieht, zu Mängeln kommen, wenn
der Nutzer die gesuchte Information nicht richtig zu finden und zu interpretieren
weiß. Auch die IK des Systembereitstellers wird relevant, wenn dieser nicht in der
Lage ist, das System bedien- und wartbar zu gestalten – auch wenn es bei diesem
Prozess, wie oben erörtert, nicht um die Übermittlung von Informationen im
eigentlichen Sinne geht, und man deshalb auch nur schwer von einem
Informationsverlust sprechen kann. Davon abgesehen ist es jedoch bei allen drei
Prozessen möglich, die Einwirkung einer mangelhaften IK als Störsignal, gemäß
Shannons Kommunikationsmodell, zu interpretieren. Abbildung 3.3 zeigt eine
Erweiterung des in 3.2 abgebildeten Modells, das nun um die Darstellung von IQ
und IK und deren Auswirkungen ergänzt wurde.
Der letzte Schritt, der nun noch zur Vollendung des IKIQIK-Modells fehlt, ist
die Einführung von Iterationen. Eine Iteration wird beispielsweise dann benötigt,
wenn ein Nutzer Informationen aus einem System holt, um damit Informationen
für ein anderes System bereitzustellen. Ein Beispiel dafür wäre das Verfassen einer
wissenschaftlichen Arbeit: hierbei werden verschieden Quellen – Monographien,
Artikel in wissenschaftlichen Zeitschriften, Sammelbände, et cetera – zu Rate
gezogen, um selbst einen neuen Artikel zu verfassen, der seinerseits wieder
irgendwo veröffentlicht werden kann. In diesem Fall wird der Informationsnutzer
selbst zum Informationsbereitsteller in der nächsten Iteration. Ebenso kann der
Nutzer auch zum Systembereitsteller werden, wenn er beispielsweise Fachliteratur
für eine Skript- oder Programmiersprache, oder Webdesign-Guides liest, und das
dadurch gewonnene Wissen verwendet, um ein Webportal zur Literaturrecherche zu
designen und zu kodieren.
14
Gerade im Internet und in Zeiten der Social-Software verschwimmen die
Grenzen zwischen Autoren und Lesern immer mehr – man denke dabei nur an die
komplexe Entwicklung eines Wikipedia-Artikels und dessen viele teilhabende
Autoren und Leser. Aus diesem Grund wurde mit der Einführung der Iteration, wie
in Abbildung 3.4 zu sehen ist, auch die Unterscheidung zwischen reinen
Informationsnutzern und reinen Informations- und Systembereitstellern eliminiert.
Im iterativen Modell gibt es nur noch Nutzer, die auf verschiedene Arten und
Weisen auf das Informationssystem und die darin enthaltenen Informationen
einwirken.
Damit ist die letzte Ausbaustufe des IKIQIK-Modells erreicht. Das Modell ist
für jegliche Art von Interaktion mit einem Informationssystem geeignet. Es sei
vielleicht noch darauf hingewiesen, dass „Informationssystem“ hier in einem sehr
weiten Sinne zu verstehen ist, sodass beispielsweise auch ein Buch oder eine
Bibliothek als solches gesehen werden kann. Daraus ergibt sich natürlich, dass,
anders als die Abbildungen 3.2 bis 3.4 vielleicht vermuten lassen, ein System
natürlich Teil eines weiteren System sein kann, und jedes dieser Systeme und
Teilsysteme einen eigenen Systembereitsteller5 hat. Diese Rekursion wurde zwar bei
der Erstellung des Modells berücksichtigt, allerdings aus Gründen der Einfachheit
und Übersichtlichkeit nicht explizit dargestellt. Ebenso wurde bisher nicht
ausdrücklich auf die Möglichkeit hingewiesen, dass beispielsweise System- und
Informationsbereitsteller ein und die selbe Person sind. Diese und andere
Überschneidungen können natürlich ebenfalls modelliert werden, wurden aber
wieder um der Übersichtlichkeit willen nicht extra grafisch umgesetzt.
3.2 Vertiefte Verknüpfung von IQ-Dimensionen und IK-Skills
In der letzten Sektion wurden die Einwirkungen von IK und IQ auf den
Informationsfluss mit Informationssystemen anhand des IKIQIK-Modells
dargelegt, mit dem Ergebnis, dass jedes Mal, wenn ein Nutzer mit dem System
interagiert, sowohl eine eigene IK als auch die IQ des Systems auf den
Kommunikationsprozess einwirken. Die Frage ist nun, wie sich diese Einwirkungen
konkret im Informationsfluss manifestieren, beziehungsweise wann es wo zu
Problemen kommen kann. Zu diesem Zweck haben wir zwei etablierte Modelle –
5
Obwohl weiter oben ja darauf hingewiesen wurde, dass keine absolute Unterscheidung
zwischen den einzelnen Akteuren zu treffen ist, werden die Bezeichnungen „System-“ und „Informationsbereitsteller“ hier dennoch der Einfachheit halber weiterverwendet. In diesen Kontexten bezeichnen diese dann immer einen Nutzer in der Rolle des System- oder Informationsbereitstellers.
15
die 15 IQ-Dimensionen der DGIQ (vgl. DGIQ 2007) und die Big6-Skills der IK
(vgl. Eisenberg & Berkowitz 1987)6 – auf Basis des IKIQIK-Modells einander
gegenüber gestellt.
Die Big6-Skills – Task Definition, Information Seeking Strategies, Location and Access,
Use of Information, Synthesis und Evaluation – ließen sich relativ leicht in unser
kombiniertes Modell einordnen, da auch sie stark prozessorientiert sind. Einige der
Skills lassen sich daher unserem Bereitstellungsprozess von Nutzer zu System
zuordnen, während andere eher zum Beschaffungsprozess von System zu Nutzer zu
zählen sind. Zur ersten Gruppe gehören die Skills Information Seeking Strategies,
Location and Access und Use of Information, da der Nutzer hier respektive Quellen
auswählt und Informationen in ihnen sucht und aufnimmt. Kurzum: der Nutzer
beschafft sich die von ihm gewünschten Informationen. Der Skill Synthesis dagegen
gehört zur zweiten Gruppe. Hier verwendet der Nutzer die bereits gefundenen
Informationen, um diese in eine neue Form zu bringen und einen neuen Text aus
ihnen zu machen. Kurzum: der Nutzer stellt Informationen für spätere Nutzer
bereit (vgl. Eisenberg & Berkowitz 1987).
Die beiden Skills Task Definition und Evaluation sind dagegen etwas schwieriger
zuzuordnen. In erstem besteht eigentlich noch keine Interaktion mit einem
Informationssystem, da sich der Nutzer hier erst für sich eine Fragestellung
zurechtlegt und sein Problem definiert. Daher wurde dieser Skill in unserem Modell
nicht berücksichtigt. Letzterer ist, dadurch dass hier nicht nur das Endprodukt,
sondern auch der Arbeitsprozess evaluiert wird, dagegen für den Bereitstellungsund den Beschaffungsprozess gleichermaßen relevant (vgl. Eisenberg & Berkowitz
1987). Aus diesem Grund wurde der Skill Evaluation auch beiden Prozessen
zugeordnet.
Um nun festzustellen, an welcher Stelle die einzelnen IQ-Dimensionen für den
Informationsfluss relevant wurden, wurden diese mit den beiden Prozessen
zugeordneten IK-Skills abgeglichen. Die Tabellen 3.1 und 3.2 zeigt einen Überblick
über die Korrelationen von IQ-Dimensionen und IK-Skills entlang der beiden
Prozesse. Erstere bezieht sich auf den Beschaffungsprozess. Hier geht die IQ des
Systems der IK des informationssuchenden Nutzers voran. Das bedeutet, dass,
wenn das System Mängel in einer bestimmten IQ-Dimension hat, wird sich dies für
den Nutzer in den Anforderungen an bestimmte IK-Skills niederschlagen. Wenn die
Informationen im System also nicht eindeutig auslegbar sind oder unübersichtlich
dargestellt werden, wird der Nutzer Probleme beim Auffinden der gesuchte
Informationen (Location & Access) und auch beim Lesen und Verstehen der
6
Vorher schon diskutiert? Evtl. noch mal kurz drauf eingehen.
16
Informationen (Information Use) haben. Sind die Informationen dagegen für den
Nutzer nicht relevant oder nicht aktuell genug, wird sich dies noch nicht bei Location
& Access, sondern erst bei Information Use bemerkbar machen.
IQ-Dimensionen, die in einer Spalte mit dem Schlagwort „indirekt“
gekennzeichnet wurden, haben keine direkten Auswirkungen auf den
entsprechenden IK-Skill, auch wenn ein gewisser Einfluss nicht zu leugnen ist. So
wird sich beispielsweise die mangelhafte Glaubwürdigkeit oder das niedrige
Ansehen eines Systems nicht unbedingt in Problemen beim Lesen und Verstehen
seiner Informationen (Information Use) niederschlagen. Wenn man jedoch davon
ausgeht, dass sich Glaubwürdigkeit und Ansehen mitunter auch auf
systeminhärente Qualitätskriterien begründen – also dass niedriger angesehene
Systeme auch qualitativ minderwertigere Informationen enthalten, und ihr Ansehen
deswegen auch gerade so niedrig ist –, dann ist es durchaus vorstellbar, dass es
gerade bei solchen Systemen hierbei zu Problemen kommen kann. Ähnlich haben
bis auf Glaubwürdigkeit und Hohes Ansehen fast keine weiteren IQ-Dimensionen
direkte Auswirkungen auf die Auswahl des Quellen für die Informationssuche
(Information Seeking Strategies), weil sich alle anderen Dimensionen hier nur indirekt
durch Glaubwürdigkeit und Ansehen auswirken. Die einzigen Ausnahmen sind die
Zugänglichkeit und die Bearbeitbarkeit eines Systems, welche beide einen direkten
Einfluss auf die Auswahl der Quellen haben können.
Tabelle 3.2 ist im Vergleich zur ersten Tabelle etwas leichter zu lesen, weil hier ja
auch nur zwei IK-Skills betroffen sind. Beim hier dargestellten
Bereitstellungsprozess beeinflusst die IK des Nutzers – hier in der Rolle des
Informations- oder Systembereitstellers – die IQ des Systems anstatt, wie oben, die
IQ des Systems die Anforderungen an die IK des Nutzers. So hat die IK, die der
Nutzer beim Zusammenstellen und Niederschreiben der Informationen (Synthesis)
an den Tag legt, Auswirkungen auf jede der IQ-Dimensionen. Bei Glaubwürdigkeit
und Hohes Ansehen einerseits, und den Dimensionen der Kategorie Nutzung
andererseits sind diese Auswirkungen jedoch wieder nur indirekt. Erstere kann der
Nutzer nicht direkt beeinflussen, weil sie unter anderem von externen Faktoren
beeinflusst werden, beziehungsweise sich erst nach einer gewissen Zeit entwickeln
können. Letztere können nur indirekt beeinflusst werden, weil sie immer vom
jeweiligen Informationsbedürfnis des späteren Nutzers abhängen. So gibt es
beispielsweise keine absolute, allgemeingültige Relevanz oder keinen für alle
Bedürfnisse angemessenen Umfang. Der Informationsbereitsteller kann hier
lediglich klarstellen, für welche Nutzergruppen und für welche Kontexte seine
Informationen gedacht und geeignet sind, um so Missverständnissen von Seiten der
Nutzer vorzubeugen. Der IK-Skill Evaluation hat generell nur indirekte
17
Auswirkungen auf die IQ des Systems.
Eine Besonderheit, die beim Bereitstellungsprozess noch festzuhalten ist, ist,
dass sich die IK-Skills auf zwei verschiedene Akteure beziehen können: dem
Informations- und dem Systembereitsteller. Während die 15 IQ-Dimensionen der
DGIQ nicht auf eine eindeutige Trennung von System und Information ausgelegt
sind, kann eine solche Einteilung doch zumindest ansatzweise getroffen werden.
Dimensionen der Kategorie System liegen so zum Beispiel eindeutig im
Aufgabenbereich des Systembereitstellers. Das heißt, die IK des Systembereitstellers
bestimmt die Werte bei den Dimensionen Zugänglichkeit und Bearbeitbarkeit. Die
Dimensionen der Kategorie Inhalt sind dagegen eindeutig dem
Informationsbereitsteller zuzuordnen. Ebenso bezieht sich auch die IQ in der
Kategorie Nutzung hauptsächlich aus der IK des Informationsbereitstellers, auch
wenn die Aktualität und der Umfang der Informationen auch in gewisser Weise von
den technischen Möglichkeiten des Systems abhängen. Die Kategorie Darstellung
kann nur schwerlich einer einzigen Seite allein zugeordnet werden. Vor allem die
Dimension Verständlichkeit kann ebenso in den sprachlichen Fertigkeiten des
Informationsbereitstellers begründet liegen wie in der Qualität des vom
Systembereitsteller erstellten Designs.
18
4. Verwendung im Rahmen von Informationsqualitätsevaluationen
Die Vorteile der erörterten Matrix liegen in ihrer Spezifität und zugleich ihrer Flexibilität. Zum einen ist für jeden Knotenpunkt in der Matrix eine bestimmte Vorgehensweise heranzuziehen, zum anderen lässt sich diese Matrix auf die verschiedensten Informationssysteme anwenden. Dadurch ist es zwar nicht möglich eine einheitliche, für alle Systeme kompatible Evaluationsmethode zu erstellen, doch kann die
Matrix zur Fehlerdiagnose zu Rate gezogen werden. Im Einzelnen bedeutet das,
dass der Systembereitsteller ein Diagnosetool erhält, an Hand welchem er nachvollziehen kann bei welchem der folgenden Punkte Probleme bestehen:
-
Informationskompetenz des Nutzers
Informationskompetenz des Systembereitstellers
Informationskompetenz des Informationsbereitstellers
Bewertet wird hier also abhängig vom System die Kompetenz einer Person. Geht
man aber von einer solchen systematischen Analyse aus, benötigt man zunächst
Metriken bezüglich der Informationsqualität. Vorausgesetzt ist also eine Qualitätsbewertung.
4.1 Metriken für Informationsqualität
Im Begriff „Informationsqualität“ ist bereits eine wertende Komponente impliziert.
Unterstellt man dem Begriff Qualität nun auch noch Messbarkeit, so stellt sich die
Frage nach der Vorgehensweise zur Messung des Qualitätsgehalts eines Informationssystems. In diversen Arbeiten und Frameworks wurden bereits solche Metriken
diskutiert7. Dabei handelt es sich oftmals um zu spezifische Maße oder aber zu stark
verallgemeinernde Vorgehensweisen. Für eine Systemunabhängige Analyse lässt sich
jedoch eine Einteilung in drei Hauptgruppen vornehmen:
4.1.1 Harte Maße
Zu diesen Maßen zählen Kriterien wie Fehlerfreiheit, Aktualität, einheitliche Darstellung,
Zugänglichkeit und Bearbeitbarkeit. All diesen Punkten ist gemeinsam, dass sie sich
durch Zahlen ausdrücken lassen.
7
Vgl. Eppler (2003: 287ff).
19
Fehlerfreiheit
Ganz allgemein lässt sich die Anzahl der Fehler in einem Dokument im Verhältnis
zur Größe des Dokuments betrachten. Von gänzlicher Fehlerfreiheit lässt sich
demzufolge erst sprechen, wenn die Anzahl der Fehler gleich Null ist („Alles oder
Nichts“-Ansatz). Allerdings lässt sich die Fehlerfreiheit auch relativiert als Abstandsfunktion ausdrücken8:
„Alles oder Nichts“-Ansatz:
Sei w1 ein Attributwert im Informationssystem und wR der entsprechende Attributwert in der Realwelt. Sei zudem d(w1 , wR) ein domänenspezifisches, auf das
Intervall [ 0 ; 1 ] normiertes Abstandsmaß zur Bestimmung der Abweichung zwischen w1 und wR.
𝑑1(𝑤1, 𝑤𝑅 ): = {
0, 𝑓𝑎𝑙𝑙𝑠 𝑤1 = 𝑤𝑅
1, 𝑓𝑎𝑙𝑙𝑠
𝑠𝑜𝑛𝑠𝑡
Abstandsmaß – durch den Parameter a (a ∈ 𝐼𝑅 +) kann eine Gewichtung der relativen Abweichung von w1 und wR durchgeführt werden:
𝑎
|𝑤1 − 𝑤𝑅 |
𝑑1(𝑤1, 𝑤𝑅 ) ≔ (
)
𝑚𝑎𝑥{|𝑤1|, |𝑤𝑅 |}
Was bei einer Evaluation als Fehler gewertet wird ist natürlich stark kontextabhängig. Stvilla gibt beispielsweise an, dass man bei der Evaluation einer Website die
toten Links zählen kann.9 Zu berücksichtigen gilt es, dass hier das Verständnis von
„Fehler“ immer im Bezug zu einem abhängigen System steht. Erst so wird ein Fehler als solcher kenntlich (Beziehung zwischen w1 und wR wobei sich wR auf ein
System bezieht). Dieses Kriterium unterscheidet die Fehlerfreiheit von anderen
Kategorien wie der Objektivität, die auf Grund ihrer starken Kontextabhängigkeit
und individuellen Interpretierbarkeit nicht systemabhängig gemessen werden können.
8
9
Vgl. im Folgenden Heinrich (2008: 58)
Vgl. Stvilla (2007: 20)
20
Aktualität
Die Aktualität oder „currency“ ist ein Kriterium welches den Wert einer Information maßgeblich beeinflusst. Aus Informationsphilosophischer Sicht muss Information sogar aktuell sein, da sie sonst ihren Informationscharakter verliert. Nur Neuigkeiten können informativ sein.10 Für das Kriterium der Aktualität bedeutet das eine
binäre Betrachtungsweise. Im Unterschied zur Fehlerfreiheit wäre hier ein Abstandsmaß sinnlos, da Aktualität im logischen Sinne ein Superlativ ist.11
Eine wissenschaftliche Erkenntnis beispielsweise ist nur so lange aktuell wie sie
noch nicht in das Standardrepertoire aufgenommen oder verworfen wurde. Vergessen werden darf allerdings nicht, dass Aktualität vom Subjekt abhängig gemacht
werden kann. In diesem Zusammenhang muss allerdings eine Unterscheidung zwischen Mikro- und Makrozeitgeschichtlichem Geschehen durchgeführt werden.
Ausgangspunkt ist hier die These, dass in einem Makrozeitgeschichtlichem Raum
Informationen in einen kulturellen oder geschichtlichen Konsens übergehen, während Information in einem kurzen Zeitraum als aktuell oder nicht aktuell interpretiert werden kann. Als Beispiel sei der Bericht eines Fernsehsenders über den Anschlag vom 11.September angeführt, welcher 20 Minuten später auch im Radio
übertragen wird: In beiden Fällen kann die Information aktuell sein, solange sie
vom Subjekt noch nicht wahrgenommen wurde. Nach 2 Jahren allerdings reiht sich
ein solches Ereignis in einen geschichtlich dokumentierten Kontext und wandelt
sich somit zu kulturellem Wissen.
Als Methode zur Überprüfung der Aktualität von Informationen schlagen Zhu und
Gauch vor, den timestamp eines Dokumentes zu verwenden.12 An Hand der letzten
Modifikation soll so die Aktualität ermittelt werden. Zwar ist damit keine einheitliche Formel erzeugbar, durch die (domänenabhängige) binäre Unterscheidbarkeit
handelt es sich aber dennoch um ein hartes Maß.
Einheitliche Darstellung
Das Kriterium der einheitlichen Darstellung muss differenziert betrachtet werden.
Zum einen kann es auf inter- und zum anderen auf intratextueller Ebene relevant
sein. Deshalb macht es Sinn, den Evaluationskontext mit einzubeziehen. In einem
Recherchesystem wie Beispielsweise dem Regensburger OPUS13 setzt man eine
10
Vgl. Kuhlen (2004: 11)
Ausgangspunkt ist hier nicht der Umgangssprachliche Gebrauch des Wortes nach
welchem auch Steigerungen wie „aktueller“ möglich sind.
12
Vgl. Zhu (200: 288ff)
13
http://www.opus-bayern.de/uni-regensburg/
11
21
intertextuelle Einheitlichkeit voraus. Alle Links die auf Dokumente auf dem Server
verweisen werden nach dem gleichen Schema dargestellt.
Abbildung 5: XXXX
Abweichungen würden die Übersichtlichkeit und damit die Usability des Systems
verschlechtern. Auch bei einer intratextuellen Analyse sind die formellen Kriterien
ausschlaggebend. Zu Ihnen zählen etwa Inhaltsverzeichnis, Abstract, Zusammenfassung, Absätze, Seitenzahlen und Formatierung.14 Auch hier beeinträchtigen Abweichungen oder Fehlen von Komponenten die Übersichtlichkeit. Da auch die einheitliche Darstellung als „Alles oder Nichts“-Ansatz oder als Abstandsmaß abgebildet werden kann, kann man die gleichen Maße wie für die Fehlerfreiheit verwenden.
Zugänglichkeit
Ob Informationen zugänglich sind oder nicht hängt vom System und den damit
verknüpften Restriktionen oder Rechten für bestimmte Nutzergruppen ab. Aber
auch Usability und die Informationskompetenz eines Nutzers sind von Belang. Ist
ein System schlecht bedienbar, baut es indirekt Restriktionen gegenüber dem Nutzer auf. Folglich steht die Zugänglichkeit eines System in direktem Bezug zur seiner
Persistenz und Fehlerfreiheit. Aber auch externe Faktoren können eine Rolle spie14
In Abhängigkeit von der Textsorte
22
len. Wird beispielsweise online nach einer großen Datei – etwa einem Video - recherchiert, so können sich die Zugriffszeiten von Nutzer zu Nutzer unterscheiden.
In der Tat kann also die eigene Verbindungsgeschwindigkeit den Ausschlag geben.
Ein weiteres Beispiel für einen externen Faktor stellt ein entliehenes Buch einer
Bibliothek dar. Dabei ist es im System der Bibliothek so vorgesehen, dass Bücher
verliehen sein können. Gleichzeitig ist es unterdessen für andere Nutzer nicht zugänglich. Auf kognitiver Ebene ist anzumerken, dass sich auch die Komplexität
eines Textes auf die Zugänglichkeit auswirken kann. Allerdings handelt es sich hier
eher um den Zugang zu einem bestimmten Themenbereich als zu einem System.
Für die Evaluation einer Website schlagen Eppler und Muenzenmayer vor, die
„broken links“ bzw. „broken anchors“ zu zählen.15 Wünschenswert wäre hier - wie
bereits erwähnt – ergänzend die Zugriffszeiten des Servers zu messen und mit ähnlichen Seiten zu vergleichen. Außerdem können etwa Vorgangsabbrüche etc. in
einer Log-Datei dokumentiert und anschließend analysiert werden.
Bearbeitbarkeit
Ähnlich wie die Aktualität ist auch die Bearbeitbarkeit ein eindeutiges Kriterium.
Dabei basiert sie wie die Zugänglichkeit auf Rechten und Restriktionen. Wang
spricht bei dieser Kategorie übrigens sowohl von „flexibility“ 16 als auch von
„security“17 und ist sich wohl selbst nicht mit einer eindeutigen Bezeichnung wohl
selbst nicht ganz sicher. Ob Dokumente editierbar sind oder nicht, hängt tatsächlich
nur vom System und den vergebenen Rechten ab. Bei diesem Kriterium gibt es
wohl die größten Unterschiede - je nach Konzeption des Systems. Von Wikipedia
bis zum Buch muss eine Abgrenzung auch durch die beabsichtigte Nutzung erfolgen. Ein Buch ist für den normalen Leser kaum editierbar18. Für den Autor hingegen muss die Bearbeitbarkeit gewährleistet sein, wenn er eine weitere Auflage des
Buches veröffentlichen will.
4.1.2 Weiche Maße
Im Gegensatz zu den harten Maßen lassen sich weiche Maße nicht direkt aus einem
Dokument oder Informationssystem extrahieren. Für die Bestimmung weicher Maße ist der „Umweg“ über den Menschen notwendig. Deshalb müssen für die Krite-
15
Vgl. Eppler (2002: 187ff)
Wang (1996: 92)
17
Wang (1997: 39)
18
Abgesehen von Schwärzungen oder Randnotizen
16
23
rien Relevanz, Vollständigkeit, angemessener Umfang, eindeutige Auslegbarkeit und Verständlichkeit Erhebungen in anderer Form stattfinden.
Relevanz
Um die Relevanz einer Information zu beurteilen, ist immer der Kontext in dem sie
steht zu berücksichtigen. In diesem Punkt stimmen alle Informationsqualitätsmodelle überein.19 Messbar machen wollen Naumann und Rolker die Relevanz durch
wiederholte Nutzerbefragungen.20 Eine andere Methode der Bewertung wäre ein
Expertenreview. In jeder Hinsicht kann Relevanz aber nur als subjektives Kriterium
erfasst werden, welches sich nur nach statistischer Signifikanz dem Bild der Allgemeinheit bzw. der Experten annähern kann.
Vollständigkeit
Zunächst erweckt die Vollständigkeit den Eindruck eines hart messbaren Kriteriums. Im Bezug auf Datenqualität geben Heinrich und Klier eine Formel für Vollständigkeit an21:
Vollständigkeit in Bezug auf Datenqualität:
NULL ist Platzhalter für Nichtbefüllung (also eine mögliche Lücke)
(𝑠𝑒𝑚𝑎𝑛𝑡. )ä𝑞𝑢𝑖𝑣𝑎𝑙𝑒𝑛𝑡
𝑄𝑉𝑜𝑙𝑙𝑠𝑡(𝑤) ≔ {0 𝑓𝑎𝑙𝑙𝑠 𝑤 = 𝑁𝑈𝐿𝐿 𝑜𝑑𝑒𝑟 𝑤 𝑧𝑢 𝑁𝑈𝐿𝐿
𝑠𝑜𝑛𝑠𝑡
Allerdings wird bei näherem Betrachten schnell klar, dass es Vollständigkeit per se
in einem Informationskontext nur in seltenen Fällen geben kann. Denn ob ein Text
vollständig ist oder nicht, kann nur der Nutzer beurteilen, dem zum Verständnis
einer Informationseinheit oder der Bedienung eines Systems Wissen fehlen kann.
Somit ist auch bei diesem Kriterium eine Nutzerbefragung obligatorisch.
Angemessener Umfang & Verständlichkeit
Die Kriterien des angemessenen Umfangs und der Verständlichkeit werden hier in
einem Punkt zusammengelegt, weil sich die beiden Kriterien gegenseitig bedingen.
Auch sie sind stark Kontextabhängig: Eine domänenspezifische Sichtweise muss bei
einer Evaluation dieser Punkte immer berücksichtigt werden. Handelt es sich bei19
Vgl. Knight (2005: 160ff)
Vgl. Naumann (2000: 160)
21
Heinrich (2008: 54)
20
24
spielsweise um Fachliteratur, so muss Fachsprache nicht näher erörtert werden –
die Verständlichkeit des Textes ist dann vorausgesetzt. Ist aber im Umkehrschluss
ein Text welcher etwa in einer Tageszeitung steht unverständlich, so muss ist der
Umfang des Textes mit hoher Wahrscheinlichkeit unangemessen. Ein Glossar, eine
Legende oder grafische Hilfsmittel können dann Abhilfe schaffen.
Schon der deutschen Definition „angemessenem Umfangs“ nach Rohweder22 ist die
Verständlichkeit inhärent:
„Informationen sind von angemessenem Umfang, wenn die Menge der verfügbaren Informationen den gestellten Anforderungen genügt.“23
Geht man vom Textverständnis als priorisierte „gestellte Anforderung“ aus, so wird
die implizit geforderte Verständlichkeit dieser Definition schnell ersichtlich. Da sich
die beiden Kriterien immer auf eine bestimmte Zielgruppe konzentrieren, muss dies
bei einer Befragung auch berücksichtigt werden.
Eindeutige Auslegbarkeit
Das Gegenstück zur Begrifflichkeit der „eindeutigen Auslegbarkeit“ ist die Möglichkeit einer ambiguen Interpretationsweise. Eine solche kann nur auftreten, wenn
man Informationen außerhalb eines normierten Systems betrachtet. Im dezimalen
Zahlensystem ergibt die Summe aus 3 und 8 immer 11. Eine Normierung fällt genau dann schwer, wenn sprachliche Mittel ein solches System aufweichen. Metaphorik, Hyperbeln oder gewollte Zweideutigkeit sind Stilmittel, die genau das erreichen wollen oder zumindest können. Es gilt also zu differenzieren, ob eine mehrdeutige Auslegbarkeit eines Textes oder einer Information gewollt ist oder nicht. Ist
eine Information eindeutig zweideutig, so kann man ihr nicht gleichzeitig Fehlerhaftigkeit vorwerfen. Dies gilt für die inhaltliche Ebene.
Auf Seiten des Systems gilt es klarzustellen, ob etwa Navigationselemente für Verwirrung sorgen können.
22
23
Basierend auf den 15 Qualitätsdimensionen nach Wang & Strong
Rohweder (2007: 2)
25
Abbildung 6: Verwirrendender Menüpunkt in Windows XP: Über „Start“ lässt sich das System
„Herunterfahren
Eine intendierte Irreführung des Systemerstellers ausgeschlossen kann man solche
Fehler am besten über eine Nutzerbefragung ermitteln. Nützlich können hier thinking-alouds sein, weil der Endnutzer dabei kritische Punkte direkt vermitteln kann.
Objektivität
Der Begriff „Objektivität“ kann, abhängig vom jeweiligen Kontext, sehr unterschiedlich interpretiert und gewertet werden. Im Nachrichtenjournalismus steht eine
sachliche, auf Fakten beruhende Berichterstattung in der Regel klar im Vordergrund, jedoch gibt es ebenso zahlreiche Informationsformen, in denen ein persönlicher Standpunkt von zentralem Interesse sein kann. Zudem kann die Bewertung, ob
eine Information wertfrei, unvoreingenommen und unparteiisch und präsentiert
wird, abhängig vom jeweiligen Rezipienten sehr unterschiedlich ausfallen. Schließlich ist jeglicher Information ein gewisses Maß an Subjektivität zu Eigen.
In vielen Fällen kann es eventuell gar nicht möglich sein, festzustellen, in welchem
Maße Informationen wirklich hinreichend objektiv aufbereitet wurden, oder ob –
wie oftmals im Fall von Suchmaschinen beispielsweise durch Werbeanreize – die
Aggregation, Darstellung, Präsentation und Gewichtung von Informationen nicht
doch durch externe Faktoren beeinflusst wurde.
26
Die demnach durchaus potentiell schwierige Erfassung der Objektivität von Information wird in der Regel nur in Form von Expertenreviews erfolgen – dabei sollte
zumindest festgestellt werden können, ob die untersuchte Information auf nachvollziehbaren Fakten beruht und ob die Informationen offensichtlich von einem
persönlichen Standpunkt beeinflusst sind.24 Naumann zieht hier einen Bogen zur
„Nachprüfbarkeit“ (Verifiability) von Information und schlägt vor, das Maß an Objektivität abhängig vom Grad der Nachweisbarkeit der Informationen bzw. der präsentierten Fakten anzulegen.25
4.1.3 Ambigue Maße
Abhängig vom zu bewertenden System gibt es Maße, welche sich nicht eindeutig als
hart oder weich klassifizieren lassen. Für Wertschöpfung, hohes Ansehen, Glaubwürdigkeit
und Übersichtlichkeit können in bestimmten Kontexten harte Meßverfahren existieren, in Bezug auf ein anderes System mögen lediglich Nutzerbefragungen oder Expertenreviews eine Messung dieser Informationsqualitätsdimensionen ermöglichen.
Es gilt deshalb immer mit Blick auf das zu untersuchenden System zu entscheiden,
welche Meßverfahren verwendet werden können.
Wertschöpfung
Die Informationsqualitätsdimension Wertschöpfung (engl. value added) kann sich einerseits auf eine monetäre Zielfunktion beziehen, die durch die Nutzung von Information potentiell gesteigert werden kann; anderseits jedoch auch lediglich das Ausmaß
beschreiben, in dem eine Information im Rahmen eines konkreten Informationsbedürfnisses von persönlichem Nutzen für jemanden ist.26 Folglich steht Wertschöpfung
unabhängig von einer konkreten Interpretation in engem Zusammenhang mit dem
Kriterium Relevanz.27
Ob eine Information „wertvoll“ ist, ist demnach immer vom Informationsnutzer
und dessen Informationsbedürfnis abhängig. Aus der Perspektive eines Unternehmens als Nutzer der Information wäre diese folglich dann wertvoll, wenn durch sie
ein Wettbewerbsvorteil erreicht oder Umsatz/Gewinn erwirtschaftet werden kann.28
Geht man jedoch von einem Nutzer außerhalb eines ökonomischen Kontextes aus,
erfolgt durch eine Information genau dann ein Mehr an Wertschöpfung, wenn sie
Vgl. Naumann & Rolker (2000:160), vgl. Naumann (2002:35).
Vgl. Naumann (2002:34f.)
26 Vgl. Rohweder et al. (2008:28).
27 Vgl. Rohweder et al. (2008:27).
28 Vgl. Wang & Strong (1996:14).
24
25
27
für den Informationskonsumenten einen (produktiven) Nutzen hat. Die Messung
der Wertschöpfung von Information kann somit analog zur Relevanz einerseits durch
Befragung von Nutzern nach ihrem persönlichen Gewinn durch die Information
erfolgen; anderseits im unternehmerischen Kontext auch durch konkrete Zahlen
messbar gemacht werden, wenn Wertschöpfung mit einer „quantifizierbaren Steigerung einer monetären Zielfunktion“29 gleichgesetzt werden kann:
„Der Wertschöpfungsbeitrag der Information bemisst sich dann an der Differenz zwischen
dem Wert der Zielfunktion, der ohne die Information erreichbar wäre, und dem Wert, der
durch die Nutzung der Information erreichbar ist.“30
Je nach Art der Evaluation und Nutzungskontext der evaluierten Information kann
Wertschöpfung somit entweder als hartes oder als weiches Maß verstanden werden.
Hohes Ansehen & Glaubwürdigkeit
Hohes Ansehen sowie die Glaubwürdigkeit einer Informationsquelle können sich sowohl auf die Information selbst und dessen Autor, als auch auf das System, in dem
die Information eingebettet ist, beziehen. Während sich das hohe Ansehen einer Informationsquelle auf „länger andauernde […] positive Erfahrungen“31 mit dieser
Quelle bezieht; meint die Glaubwürdigkeit eher die allgemeine Zuverlässigkeit und
Vertrauenswürdigkeit der Quelle. In bestimmten Kontexten können diese Dimensionen über objektive Indikatoren messbar gemacht werden, jedoch existieren – insbesondere im World Wide Web – ebenso Informationsräume, in denen aus Mangel
an Metriken nur eine subjektive Bewertung von Ansehen und Glaubwürdigkeit über
Nutzerbefragungen möglich ist, was beide Dimensionen als ambigue Maße klassifiziert.
Im wissenschaftlichen Kontext können hohes Ansehen und Glaubwürdigkeit beispielsweise mit Hilfe des Impact Factors einer Zeitschrift, Journal Rankings, sowie der Zitierhäufigkeit eines Autors oder einer Institution quantifizierbar gemacht werden. Außerhalb der Wissenschaft können Zertifikate, Qualifikationen oder Zugehörigkeit zu
etablierten und anerkannten Institutionen Ansatzpunkte für das Ausmaß dieser
Qualitätsdimensionen einer Informationsquelle darstellen.32 Im Word Wide Web
könnte zudem theoretisch die Anzahl der Links auf ein Informationsobjekt als Maß
herangezogen werden – diese muss jedoch nicht zwangsläufig mit hohem Ansehen
Rohweder et al. (2008:28).
Rohweder et al. (2008:42).
31 Rohweder et al. (2008:40).
32 Vgl. Rohweder et al. (2008:34).
29
30
28
oder Glaubwürdigkeit korrelieren. In der Regel wären Nutzerbefragungen solchen
tendenziell unsicheren Maßen vorzuziehen.33
Übersichtlichkeit
Die Dimension Übersichtlichkeit lässt sich gleichermaßen auf die Information selbst
und deren inhaltliche Darstellung, sowie auf die Art und Weise, wie die Information
in welchem Umfang in das umgebende System eingebettet ist, beziehen. Auch dieses Kriterium lässt sich oftmals nur mit Hilfe der Nutzer bewerten:34 die Definition
der Deutschen Gesellschaft für Informationsqualität beschreibt Informationen als
übersichtlich, „wenn genau die benötigten Informationen in einem passenden und
leicht fassbaren Format dargestellt sind“35.Dies setzt wiederum ein subjektives Informationsbedürfnis voraus, womit die Bewertung der Übersichtlichkeit durch Nutzerbefragung einer objektiven Metrik vorzuziehen wäre.
Im Rahmen von Informationsqualitätsbewertungen im Kontext des World Wide
Web ließen sich dennoch ebenso sämtliche Maße aus den Bereichen Usability, Accessibility oder Information Architecture heranziehen, um Übersichtlichkeit auch objektiv
messbar zu machen, wie beispielsweise die Verfügbarkeit von globalen und lokalen
Navigationsgruppen, Designkonsistenz, die Anzahl von Informationselementen
innerhalb eines definierten Bereichs, der Hierarchisierungsgrad der Webseite, sowie
der Einsatz strukturierender und gliedernder Elemente wie Überschriften, Hervorhebungen, Trennlinien et cetera. Je nach Bewertungskontext sind hier ist hier ebenso zwischen harten oder weichen Meßverfahren zu entscheiden.
4.2 Informationskompetenz und weiche Evaluation
Während in Kapitel 3 bereits auf die grundlegenden Zusammenhänge zwischen
Informationsqualität und Informationskompetenz eingegangen wurde, stellt sich
nun die Frage, welche Rolle die Informationskompetenz im Rahmen einer Informationsqualitätsbewertung spielen kann.
Im vorherigen Kapitel wurde bereits auf die unterschiedlichen Möglichkeiten, IQ
messbar zu machen, eingegangen. Einige IQ-Dimensionen unabhängig vom Nutzer
und Verwendungskontext messbar und lassen sich folglich als „harte Maße“ klassifizieren; andere IQ-Kriterien, welche als „weiche Maße“ bezeichnet werden sollen,
lassen keine objektive Bewertung zu und können nur über Expertenreviews
und/oder Nutzerbefragungen erfasst werden. Darüber hinaus gibt es Dimensionen,
Vgl. Naumann & Rolker (2000:160).
Vgl. Naumann & Rolker (2000:160).
35 Rohweder et al. (2007:7).
33
34
29
welche beide je nach Bewertungskontext entweder objektiv messbar oder nur subjektiv bewertbar sind.
Folglich kann festgestellt werden, dass der Nutzer der Information bei der Bewertung durch harte Maße keine Rolle spielt und somit seine Informationskompetenz
hier ebenso keinen Einfluss hat. Wenn in Bezug auf die Dimensionen Fehlerfreiheit,
Aktualität, einheitliche Darstellung, Zugänglichkeit und Bearbeitbarkeit jedoch im Zuge der
objektiven Bewertung Mängel festgestellt werden konnten, lässt dies wiederum
Rückschlüsse auf potentielle Mängel in der Informationskompetenz des Informationsautors und des Systembereitstellers zu. Sind die Informationen nicht fehlerfrei,
nicht (mehr) aktuell oder inhaltlich uneinheitlich dargestellt, ist anzunehmen, dass es
seitens des Informationserstellers Mängel in der IK bei der Synthese der Information gab. Wenn die Informationen im System uneinheitlich dargestellt sind, gilt dies
analog für den Systembereitsteller. Da für Mängel in der Zugänglichkeit und Bearbeitbarkeit in der Regel andere Faktoren – wie Urheberrechtsansprüche oder Gewinnstreben – verantwortlich sind, ist bei diesen systembezogenen Dimensionen in der
Regel kein unmittelbarer Zusammenhang mit der IK des Systembereitstellers herzustellen.
Bei der Bewertung durch weiche Maße spielt jedoch die Informationskompetenz
des Nutzers eine zentrale Rolle. Da er derjenige ist, der die Bewertung der einzelnen
IQ-Dimensionen vornimmt, hat seine IK immer auch Einfluss auf das Ergebnis
dieser Bewertung. Unterschiedliche Fähigkeiten in Bezug auf die Informationskomptenz können Einfluss darauf haben, ob eine Informationsquelle bezüglich
Relevanz, Vollständigkeit, angemessenem Umfang, eindeutiger Auslegbarkeit und Verständlichkeit (sowie einzelner ambiguer Maße in spezifischen Kontexten) positiv oder negativ
bewertet werden. Um die Beeinflussung der Ergebnisse durch die unterschiedlichen
Informationskompetenzen der Nutzer nachvollziehen und gegebenenfalls in die
Evaluation mit einfließen lassen zu können, sollte im Rahmen von subjektiven IQBewertungen auf der Basis von Nutzerbefragungen oder Expertenreviews immer
auch versucht werden, die Informationskompetenz des Nutzers / des Experten mit
zu erfassen.
Zur Evaluation oder Messung von Informationskompetenz gibt es bereits einige
wenige Ansätze, der Großteil davon beinhaltet jedoch oftmals umfassende mündliche Befragungen oder umfangreiche Testszenarien; Vorschläge zur schriftlichen
Evaluation von IK haben in der Regel „Schulaufgabencharakter“ und sind zur Erfassung zusätzlicher Informationen im Rahmen einer solchen IQ-Bewertung zu
30
ausführlich.36 Es ist davon auszugehen, dass ein Fragenkatalog, mit dessen Hilfe
Rückschlüsse auf die Informationskompetenz des Nutzers gezogen werden kann,
individuell an den jeweiligen IQ-Bewertungskontext anzupassen ist.
Hier könnte es bereits hilfreich sein, neben den üblichen demographischen Angaben zu Alter, Ausbildung und Profession auch den Erfahrungsgrad des Nutzers im
getesteten Systemumfeld (Internet, Bibliothek, Zeitschriften, et cetera) sowie den
untersuchten Informationsarten (bibliographische Informationen, wissenschaftliche
Informationen, Nachrichten, Texte im Internet etc.) zu erfassen. In speziellen Kontexten wie dem studentischen Umfeld wären weitere Fragen, wie beispielsweise
nach der Erfahrung mit informationskompetenzrelevanten Veranstaltungen oder
Recherchefähigkeiten, denkbar.
Im Zuge einer solchen Erfassung der Fähigkeiten und Kenntnisse der Nutzer könnten Gruppen von Nutzern ähnlicher „IK-Level“ gebildet und daraus sogenannte
Personas37 erstellt werden, um eventuelle Korrelationen zwischen der Informationskompetenz einer Nutzergruppe und deren Informationsqualitätsbewertungen aufdecken zu können. In der Folge könnten für verschiedene Benutzergruppen unterschiedliche Gewichtungen erfolgen, um beispielsweise die Bewertung seitens eines
Information Professionals stärker zu gewichten, als die eines Nutzers ohne einen derartigen beruflichen Hintergrund. Dies darf natürlich nicht bedeuten, dass das Urteil
eines Nutzers mit geringerem IK-Level als weniger wert erachtet wird. Je nach Bewertungskontext und untersuchter IQ-Dimension kann gerade diese Bewertung
essentiell sein, um Mängel im System oder der Information selbst aufzudecken.
Letztlich darf eine solche Gewichtung niemals ohne Berücksichtigung aller Nutzergruppen, die mit dem System interagieren, geschehen.
Schließlich darf auch im Falle der weichen Maße der Einfluss der IK des Informationsautors sowie des Systembereitstellers nicht vergessen werden. Wenn auch die
Möglichkeit besteht, dass gewisse Nutzergruppen aufgrund von Mängeln in der IK
negative IQ-Bewertungsurteile abgeben, muss die Verantwortung zur Verbesserung
von Mängeln in der IQ letztlich in jedem Fall beim Ersteller der Information sowie
dem Bereitsteller des umgebenen Systems liegen.
36
37
Vgl. Gendina (2008), vgl. Kennedy (1998), vgl. Cameron, Wise & Lottridge (2007).
Vgl. Cooper (2003).
31
5. Fazit
32
6. Literaturverzeichnis
Cameron, Lynn; Wise, Steven L. & Susan M. Lottridge (2007). The Development
and Validation of the Information Literacy Test. In: College and Reseach
Libraries
68(3),
S.
229-236.
<http://www.tcc.edu/welcome/collegeadmin/oie/soa/documents/ILT_dev
elopment_article.pdf>(letzter Zugriff 14. April 2010).
Cooper,
Alan
(2003).
The
Origin
Of
Personas.
<
http://www.cooper.com/journal/2003/08/the_origin_of_personas.html>
(letzter Zugriff am 14. April 2010).
DGIQ (2007). IQ-Definitionen. In: Deutsche Gesellschaft für Informations- und
Datenqualität.
<http://dgiq.de/_data/pdf/IQ-Definition/IQDef_Visual.pdf> (letzter Zugriff: 31. März 2010).
Eisenberg, Michael & Robert Berkowitz (1987). The Big6TM-Skills. In: The Big Six.
Information
&
Technology
Skills
for
Student
Achievement.
<http://www.big6.com/files/Big6Handouts.pdf> (letzter Zugriff: 31. März
2010).
Eppler, Martin J. (2003). Managing information quality: Increasing the value of information in
knowledge-intensive products and processes. Berlin, Germany: Springer-Verlag.
Eppler, Martin J. & Muenzenmayer Peter (2002). Measuring information quality in
the web context: A survey of state-of-the-art instruments and an application
methodology. Proceedings of 7th International Conference on Information Quality.
Gendina, Natalia I. (2008). Could Learners Outcomes in Information Literacy Be
Measured: Pluses and Minuses of Testing? In: World Library and Information
Congress:
74th
IFLA
General
Conference
and
Council.
<http://archive.ifla.org/IV/ifla74/papers/134-Gendina-en.pdf>
(letzter
Zugriff 14. April 2010).
Kennedy, Cathleen (1998). Measuring Information Literacy: The "Tool Literacy" Variable.
<http://www.eric.ed.gov/ERICDocs/data/ericdocs2sql/content_storage_01
/0000019b/80/1a/90/31.pdf>(letzter Zugriff 14. April 2010).
Kuhlen, Rainer (2004). Information. In: Kuhlen, Rainer.; Seeger, Thomas (Hrsg.).
Handbuch Grundlagen von Information und Dokumentation. München: Saur-Verlag.
33
Knight, Shirlee-ann & Burn, Janice (2005). Developing a Framework for Assessing
Information Quality on the World Wide Web. In: Information Science Journal.
Ausgabe 8, S. 159-172.
Heinrich, Bernd & Klier, Mathias (2008). Datenqualitätsmetriken für ein
ökonomisch orientiertes Qualitätsmanagement. In: Mielke, Michael et al.
(Hrsg.) (2008). Daten- und Informationsqualität. Auf dem Weg zur Information
Excellence. Wiesbaden: Vieweg+Teubner Verlag.
Naumann, F. & Rolker, C. (2000). Assessment methods for information quality
criteria. In: Proceedings of 5th International Conference on Information Quality.
Naumann, F. (2002). Quality-Driven Query Answering for Integrated Information Systems.
Lecture Notes In Computer Science, Vol. 226. Berlin: Springer.
Rohweder, J et al. (2007). Informationsqualität – Definitionen, Dimensionen und
Begriffe. Projektgruppe „Normen und Standards“. Deutsche Gesellschaft für
Informationsund
Datenqualität.
<http://www.dgiq.de/_data/pdf/IQDefinition/IQ-Definitionen.pdf> (letzter Zugriff: 13.April 2010)
Rohweder, J et al. (2008). Informationsqualität – Definitionen, Dimensionen und
Begriffe. In: Mielke, Michael et al. (Hrsg.) (2008). Daten- und
Informationsqualität. Auf dem Weg zur Information Excellence. Wiesbaden:
Vieweg+Teubner Verlag.
Shannon, Claude Elwood (1948). A Mathematical Theory of Communication. In:
Former Bell Labs Computing and Mathematical Sciences Research. <http://cm.belllabs.com/cm/ms/what/shannonday/shannon1948.pdf> (letzter Zugriff: 25.
März 2010).
Stvilla, Besiki et. al. (2007). A Framework for Information Quality Assessment. Graduate
School of Library and Information Science. University of Illinois at UrbanaChampaign.
<
http://mailer.fsu.edu/~bstvilia/papers/stvilia_IQFramework_p.pdf> (letzter
Zugriff: 11.April.2010).
Wang, R & Wand, Y (1996). Anchoring Data Quality in Ontological Foundations.
In: Communications of the ACM.
Wang, R & Strong, D (1996). Beyond accuracy: What data quality means to data
consumers. In: Journal of Management Information Systems 12(4). S. 5-33.
Wang, R & Strong, D (1997). 10 Potholes in the Road to Information Quality. In:
IEEE Computer. Band 30. Ausgabe 8.
34
Zhu, X (2000). Incorporating quality metrics in centralized/distributed information
retrieval on the World Wide Web. Proceedings of the 23rd annual international
ACM SIGIR conference on Research and development in information retrieval. Athen.
35