Multiple Regression
Werbung

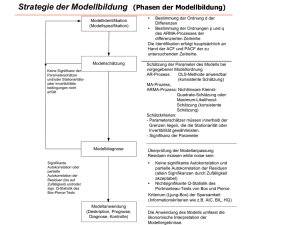
Modellprämissen der linearen Regression • Anzahl der erklärenden Variablen < Anzahl der Fälle • Linearität in den Regressionsparametern • Keine exakte Multikollinearität (keine exakte Abhängigkeit der Prädiktoren) relevant bei der multiplen Regressionsanalyse Residuendiagnostik (ei): • Residuen haben einen Erwartungswert von Null • Homoskedastizität (alle Residuen besitzen die gleiche konstante Varianz) • Normalverteilung der Residuen • Keine Autokorrelation (für jedes Residuenpaar ei und ej ist die Korrelation gleich Null) relevant bei der Analyse von Zeitreihen Linearität (Modellverstoß: keine Linearität): • Im Fall von Nichtlinearität liefert die Regressionsgerade nicht mehr die besten Schätzer (d.h. sie minimieren nicht mehr den Abstand zwischen tatsächlichen und geschätzten Werten) • Die Folge ist eine Verzerrung der Schätzwerte der Parameter, d.h. die Schätzwerte bj streben mit wachsendem Stichprobenumfang nicht mehr gegen die wahren Werte βj. Prüfung: 1. Begutachtung der Punkteverteilung im Streudiagramm (Plot) 2. Begutachtung der Partialdiagramme: Regression der bereinigten Regressoren auf das bereinigte Kriterium (Partielle Korrelation, Korrelation der Regressionsresiduen) Begutachtung der Punkteverteilung im Streudiagramm: Begutachtung der Partialdiagramme: Nach Elimination der Effekte der anderen Einflussgrößen verbleibt ein starker linearer Zusammenhang zwischen X und Y. Grundsätzliche Lösungstrategie: Transformation der unabhängigen Variablen, z.B. Quadrierung: y = a + b ∙ x2, Logarithmierung: y = a + b ∙ ln(x) (Keine exakte) Multikollinearität: • Mit zunehmender Multikollinearität werden die Schätzungen der Regressionsparameter unzuverlässiger. Dies macht sich bemerkbar am Standardfehler der Regressionskoeffizienten (sb), der größer wird. • Bei perfekter Multikollinearität ist eine Schätzung der Regressionskoeffizienten bj nicht mehr möglich. Prüfung: 1. Betrachtung der Korrelationsmatrix der unabhängigen Variablen 2. Besser: Durchführung von Regressionsanalysen jeder unabhängigen Variablen X auf die übrigen unabhängigen Variablen 3. Am besten: Berechnung der Toleranz und des VIF-Wertes Toleranz der Regressoren: Tj 1 R 2j Koeffizient der Nichtdetermination: Der Wertebereich ist [0; 1] R2j: Bestimmtheitsmaß, unter Zugrundelegung eines Regressionsmodells, in dem Xj die abhängige Variable und die übrigen X des ursprünglichen Regressionsmodells die unabhängigen Variablen bilden. • • Die Toleranz einer Variablen gibt den Varianzanteil wieder, der durch die anderen unabhängigen Variablen in der Modellgleichung nicht erklärt wird. Eine Variable mit einer geringen Toleranz wird durch die anderen unabhängigen Variablen in hohem Maße determiniert. Grenzwert der Toleranz: • R = 0,7 (Grenzwert, ab da großes Anwachsen von sb) R2 = 0,49, Tj = 1 - 0,49 = 0,51 • R = 0,8 (Grenzwert in der Praxis) R2 = 0,64, Tj = 1 - 0,64 = 0,36 Variance Inflation Factor (VIF) der Regressoren: 1 VIFj 1 R 2j VIF ist der Kehrwert (Inverse) der Toleranz. Der Standardfehler wird um den Faktor √VIF erhöht. Beispiel: Tj = 0,51 VIF = 1,96, Tj = 0,36 VIF = 2,78 Allgemein gilt: • Bei T- und VIF-Werten nahe 1 kann (nahezu) von linearer Unabhängigkeit der Regressoren ausgegangen werden. • Niedrige Toleranzwerte und hohe VIF-Werte weisen dagegen auf Multikollinearitätsprobleme hin. Lösungsstrategie: • Entfernung von Prädiktor(en) mit hoher Multikollinearität • Zusammenfassung von hoch korrelierenden Prädiktoren (z.B. Indexbildung) Erwartungswert der Residuen ist gleich Null (E(e/ε) = 0) (Modellverstoß: E(ε) ≠ 0): E(ε) = 0: • Residuen erfassen nur zufällige Effekte. D.h. Schwankungen der Residuen gleichen sich im Mittel aus. E(ε) ≠ 0 (Systematik in den Fehlertermen): • Wenn relevante Regressoren nicht berücksichtigt sind, eine falsche funktionale Form angenommen wird, die Stichprobenauswahl nicht zufällig ist, die Messwerte von Y systematisch zu hoch/niedrig gemessen werden, dann erfassen die Residuen systematische Effekte. • Folge: Der systematische Fehler geht in die Berechnung von a ein (verzerrte Schätzung), Schätzverfahren sind nicht mehr erwartungstreu und ungültig. Homoskedastizität (Varianzhomogenität der Residuen) (Modellverstoß: Heteroskedastizität): • Wenn die Streuung der Residuen in einer Reihe von Werten der prognostizierten abhängigen Variablen nicht konstant ist, d.h. wenn die Fehlerterme systematisch streuen, dann liegt Heteroskedastizität vor. • Heteroskedastizität führt zu Ineffizienz der Schätzung und verfälscht den Standardfehler des Regressionskoeffizienten. Damit wird auch die Schätzung des Konfidenzintervalls und der Testverfahren ungenau und unzuverlässig. • Möglicher Grund: Residualwerte sind abhängig von einem oder mehreren Regressoren Prüfung: • Residuenplot: Standardisierte Residuen werden gegen die standardisierten geschätzten yi-Werte geplottet. Berechnung standardisierter vorhergesagter Werte: y i' y Z y' i sy Mittelwert = 0, s = 1 Berechnung standardisierter Residuen: ei e ei 0 ei Zei se se se ei = yi - y’i se = Standardfehler des Schätzers Mittelwert = 0, s = 1 Residuenplot: Idealtypisch ist, wenn die Residuen unsystematisch um die Nulllinie schwanken. Ein statistischer Test zur Prüfung von Heteroskedastizität: Goldfeld-Quandt-Test: 1. Unterteilung der Stichprobe in zwei Unterstichproben z.B. nach: a. b. dem Zeitfaktor t bei Zeitreihen einer bestimmten Variablen bei Querschnittsdaten (z.B. Schulbildung) 2. Getrennte OLS-Regression und Vergleich der Varianzen auf signifikante Unterschiede • • Grundidee: Bestimmte Variable verursacht die Heteroskedastizität und muss beseitigt werden. Nachteil: Nur einfache Formen von Heteroskedastizität (d.h. von einer Variable ausgehend) identifizierbar. Mit dem White-Test können höhere Formen von Heteroskedastizität geprüft werden. Normalverteilung der Residuen: • Bei Verletzung der Linearitäts- oder Varianzhomogenitätsannahme kann die Normalverteilung der Residuen nicht geprüft werden. • Die Annahme ist für die Durchführung statistischer Tests (T-Test, F-Test) von Bedeutung. Hierbei wird unterstellt, dass b0 und bj normalverteilt sind. Wäre dies nicht der Fall, wären auch die Tests nicht gültig. • Aber: Je größer die Stichprobe ist, desto eher kann man von einer asymptotischen Normalverteilung der Fehler ausgehen. Prüfung: (1) Histogramm für die standardisierten Residuen mit eingezeichneter Normalverteilungskurve und (2) P-P-Diagramm der erwarteten Residuen bei Normalverteilung versus tatsächliche Residuen. - Zudem Statistische Tests zur Prüfung der Normalverteilungsannahme: Kolmogorov-Smirnov-Test, Skewness-Kurtosis Test, Shapiro-Wilk Test Histogramm für die standardisierten Residuen mit eingezeichneter Normalverteilungskurve: P-P-Diagramm der erwarteten Residuen bei Normalverteilung versus tatsächliche Residuen: Residuen weichen nicht von Normalverteilung ab: kein Verstoß Vergleich: Häufigkeitsverteilung der standardisierten Residuen mit Normalverteilungskurve. Vergleich: Kumulierte Häufigkeitsverteilung der standardisierten Residuen mit kumulierter Normalverteilung (durchgezogene Linie). (Keine) Autokorrelation: • Autokorrelation (Korrelation zwischen zwei aufeinander folgende Residualgrößen ei und ej) tritt vor allem bei Zeitreihen auf. • Die Abweichungen von der Regressionsgeraden sind dann nicht mehr zufällig, sondern von den Abweichungen der vorangehenden Werte abhängig. • Autokorrelation führt zu Verzerrungen bei der Ermittlung des Standardfehlers der Regressionskoeffizienten. Damit wird auch die Schätzung des Konfidenzintervalls verzerrt. Prüfung: • Durbin-Watson-Test Durbin-Watson-Test: Berechnung des Durbin-Watson-Wertes d: 2 ( e e ) t 2 t t 1 T d 2 e t 1 t T Wertebereich: 0 < d < 4 Es gilt: d = 0 Perfekt positive Autokorrelation d = 2 Keine Autokorrelation d = 4 Perfekt negative Autokorrelation • Die Nullhypothese (H0) lautet: Es liegt keine Autokorrelation vor (ρ = 0). • Die Alternativhypothese (H1) lautet: Es liegt Autokorrelation vor (ρ 0). Zusammenhang zwischen d und ρ : d = 0 ρ = 1 Perfekt positive Autokorrelation d = 2 ρ = 0 Keine Autokorrelation d = 4 ρ = -1 Perfekt negative Autokorrelation Berechnung: ei ρ ei 1 vi • ρ gibt die Stärke der Autokorrelation an • Anhand einer Tabelle (Kritischer Wert der Durbin-Watson-Statistik) kann der Vertrauensbereich abgelesen werden. Liegt d außerhalb dieses Bereichs, wird H0 abgelehnt.