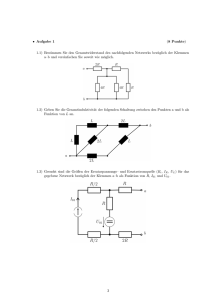
6 Vektorräume mit Skalarprodukt
Werbung

6
Vektorräume mit Skalarprodukt
Der Begriff der linearen Abhängigkeit ermöglicht die Definition, wann zwei Vektoren “parallel” sind oder drei Vektoren “in einer Ebene” liegen. Reale Vektoren im physikalischen
Raum V haben aber auch Längen und schließen Winkel miteinander ein. Dies ist Folge
einer zusätzlichen Struktur dieses Vektorraums, die durch den Begriff des Skalarprodukts
zweier Vektoren begründet wird.
Das Standard-Skalarprodukt im Rn , definiert durch
a1
b1
a · b ≡ ... · ... := a1 b1 + ... + an bn ,
an
bn
(487)
haben wir zur anschaulichen Interpretation von Begriffen, etwa der Determinante als
Volumen eines Parallelepipeds, bereits mehrmals benutzt.
6.1
6.1.1
Skalarprodukte
Geometrische Motivation
Im physikalischen Raum V wird für je zwei Vektoren a und b, mit Längen |a|, |b| ∈ R
und Zwischenwinkel γ (mit 0 ≤ γ ≤ π), ein Skalarprodukt a · b definiert als
a · b := |a||b| cos γ = ±|a||ba |.
(488)
Hier ist ba der Vektor der Projektion von b auf die Richtung von a,
a
ba :=
|b| cos γ,
|a|
(489)
und ± das Vorzeichen von cos γ. Das Skalarprodukt ist kommutativ (Eigenschaft S1),
und positiv definit (S3),
a · a ≡ |a|2 ≥ 0,
a · b = b · a,
(490)
wobei a · a = 0 genau dann, wenn a = 0.
(491)
Außerdem ist es im rechten (und somit auch im linken) Argument linear (S2),
a · (λb + µc) = a · (λb) + a · (µc) ≡ λa · b + µa · c
(λ, µ ∈ R).
(492)
a · (b + c) = a · b + a · c folgt aus der anschaulichen Beziehung (b + c)a = ba + ca .
Die Eigenschaften (S1–3) werden der Definition von Skalarprodukten in abstrakten
Vektorräumen zugrunde gelegt. Um auch den Fall K = C einzuschließen, müssen sie
etwas modifiziert werden.
84
6.1.2
Allgemeine Definition
Def.: Es sei V ein beliebiger Vektorraum über dem Körper K ∈ {R, C}.
Ein Skalarprodukt ist eine Abbildung V ×V → K, die jedem geordneten Paar von Vektoren
a, b ∈ V eine Zahl (a, b) ≡ a · b ∈ K zuordnet und dabei folgende Eigenschaften hat (mit
a, b, c ∈ V und λ, µ ∈ K):
(S1) Hermitezität (Charles Hermite, 1822–1901),
(b, a) = (a, b)∗ ;
(493)
(S2) Linearität im zweiten Argument,
(a, λb + µc) = λ(a, b) + µ(a, c) ;
(494)
(a, a) ≥ 0,
(495)
(S3) Positive Definitheit,
wobei (a, a) = 0 dann und nur dann gilt, wenn a = 0.
Im Fall K = R heißt das Skalarprodukt reell, im Fall K = C heißt es unitär.
Entsprechend heißt V ein euklidischer bzw. ein unitärer Vektorraum.
Die Menge V = Cn ist ein Vektorraum über K = C,
a1
a1 + b1
b1
..
..
λ ... :=
,
+ . :=
.
an
an + bn
bn
an
Bsp. 1a:
a1
..
.
wenn man definiert
λa1
.. (λ ∈ C). (496)
.
λan
Wie in den Übungen gezeigt wird, ist ein Skalarprodukt in Cn gegeben durch
b1
a1
.. ..
∗
∗
. · . := a1 b1 + ... + an bn ∈ C.
bn
an
Als Beispiel mit n = 2 berechnen wir
3+4i
1+2i
= (1 − 2 i )(3 + 4 i ) + (2 + i )(5 + 2 i ) = 19 + 7 i .
·
5+2i
2− i
(497)
(498)
Das Skalarprodukt eines Vektors mit sich selbst ist tatsächlich ≥ 0,
3+4i
3+4i
·
= (3 − 4 i )(3 + 4 i ) + (5 + 2 i )(5 − 2 i ) = 25 + 29 = 54. (499)
5− 2i
5− 2i
85
Bem.: Mit (S1) und (S2) ist ein Skalarprodukt im ersten Argument antilinear,
(λa + µb, c) = λ∗ (a, c) + µ∗ (b, c) .
(500)
(Soweit in der Physik; in der Mathematik wird Linearität im ersten Argument festgelegt!)
Im Fall K = R gilt (a, b)∗ ≡ (a, b), und das Skalarprodukt ist nach (S1) kommutativ,
(a, b) = (b, a), und in beiden Argumenten linear.
B = {v1 , ..., vn } sei eine Basis von V . Für die Vektoren
a=
n
X
ai vi ,
b=
i=1
n
X
bi vi
(501)
i=1
berechnen wir unter Ausnutzung der Eigenschaften (S1) und (S2) das Skalarprodukt,
(a, b) =
n
X
i=1
ai vi ,
n
X
j=1
bj vj =
n
X
a∗i bj (vi , vj )
i,j=1
=
n
X
gij a∗i bj .
(502)
i,j=1
Man nennt G = (gij ) die Matrix des Skalarprodukts bezüglich der Basis B,
gij := (vi , vj ),
(503)
gelegentlich auch den metrischen Tensor des Skalarprodukts bezüglich B.
Bsp. 1b: Im Vektorraum P2 (R) betrachten wir das Skalarprodukt (Übungen!)
Z 1
(f, g) :=
dt f (t)g(t).
(504)
0
Für die Polynome a(t) = t2 − 4t + 3 und b(t) = 2t2 + t − 5 ergibt sich also
Z 1
Z 1
117
2
2
(a, b) =
dt (t −4t+3)(2t +t−5) =
dt (2t4 −7t3 −3t2 +23t−15) = −
. (505)
20
0
0
Bezüglich der Basis B = {1, t, t2 } =: {v1 (t), v2 (t), v3 (t)} lautet der metrische Tensor
Z 1
1 21 31
g11 g12 g13
g21 g22 g23 = 1 1 1 .
(506)
gij =
dt vi (t)vj (t)
⇒
2
3
4
1
1
1
0
g31 g32 g33
3
4
5
Mit (a1 , a2 , a3 ) = (3, −4, 1) und (b1 , b2 , b3 ) = (−5, 1, 2) folgt also
(a, b) = g11 a1 b1 + g12 a1 b2 + ... + g33 a3 b3
a1 b2 + a2 b1 a1 b3 + a2 b2 + a3 b1 a2 b3 + a3 b2 a3 b3
+
+
+
= a1 b1 +
2
3
4
5
3 + 20 6 − 4 − 5 1 + 8 2
117
= −15 +
+
+
+ = −
.
2
3
4
5
20
86
(507)
6.1.3
Die Ungleichung von Cauchy-Schwarz
Satz: Der Vektorraum V sei euklidisch oder unitär. Dann gilt für alle a, b ∈ V
|(a, b)|2 ≤ (a, a)(b, b).
(508)
(Gleichheit gilt genau dann, wenn {a, b} linear abhängig ist.)
Beweis: OBdA sei b 6= 0. Für beliebiges λ ∈ C gilt
0 ≤ (a − λb, a − λb) = (a, a) − λ∗ (b, a) − λ(a, b) + λ∗ λ(b, b).
Speziell für λ =
(b,a)
(b,b)
(509)
ergibt sich direkt die Behauptung.
Bsp. 2a: Im Fall V = Rn mit Standard-Skalarprodukt erhalten wir
2
(a · b) ≤ (a · a)(b · b)
n
X
⇔
k=1
ak bk
2
≤
n
X
i=1
a2i
n
X
j=1
a2j .
(510)
Bsp. 2b: (Quantenmechanik!) Die stetigen Funktionen f : [0, 1] → C, t 7→ f (t) einer
reellen Variable t bilden einen (∞-dimensionalen) Vektorraum V über K = C. Durch
Z 1
(f, g) :=
dt f ∗ (t)g(t)
(511)
0
wird in V ein unitäres Skalarprodukt erklärt (Übungen!). Folglich gilt
Z 1
Z 1
2 Z 1
∗
2
dt f (t)g(t) ≤
dt |f (t)|
dt |g(t)|2
0
0
(512)
0
Als Beispiel betrachten wir die Funktionen f (t) = t5 und g(t) = t8 ,
Z 1
Z 1
2 Z 1
1
1
1 1
1
5 8
10
= 2 ≡
=
.
dt t t ≤
dt t16 ≡
dt t
196
14
11 17
187
0
0
0
87
(513)
6.1.4
Norm
Def.: Sei V ein Vektorraum mit Skalarprodukt. Die Norm (oder der Betrag/die “Länge”)
eines Vektors a ∈ V wird definiert als
p
(514)
|a| := (a, a).
Satz: Sei V ein VR mit Skalarprodukt. Dann gilt für a, b ∈ V die Dreiecksungleichung,
|a + b| ≤ |a| + |b|.
(515)
Beweis: Allgemein gilt
|a + b|2 ≡ (a + b, a + b) = |a|2 + (a, b) + (b, a) + |b|2 = |a|2 + 2Re(a, b) + |b|2 . (516)
Wegen Re(z) ≤ |z|, für beliebige z ∈ C folgt
|a + b|2 ≤ |a|2 + 2|(a, b)| + |b|2 ≤ (|a| + |b|)2 ,
(517)
wobei im zweiten Schritt die Ungleichung von Cauchy-Schwarz benutzt wurde,
|(a, b)| ≤ |a||b|.
(518)
Wegen der Ungleichung von Cauchy-Schwarz kann man in beliebigen euklidischen Vektorräumen den Winkel γ zwischen je zwei Vektoren a und b definieren durch
cos γ :=
(a, b)
.
|a||b|
(519)
Bsp. 2c: Im Rn mit dem Standard-Skalarprodukt ist der Winkel γ zwischen der Raumdiagonale und einer der Achsen gegeben durch
1
1
1
1 0
1
cos γ = √ .. · .. = √ .
(520)
n . .
n
1
0
Es gilt also γ = 45◦ (n = 2), γ ≈ 54.7◦ (n = 3), γ = 60◦ (n = 4), sowie limn→∞ γ = 90◦ .–
Zwischen den beiden Polynomen a = t2 − 4t + 3 und b = 2t2 + t − 5 aus Bsp. 1b, mit
(a, b) =
p
1√
(a, a)(b, b) cos γ =
8816 cos γ,
15
ließe sich ein Winkel γ mit cos γ ≈ −0.935 definieren!
88
(521)
6.1.5
Orthonormierte Basen (ON–Basen)
Def.: Zwei Vektoren a, b ∈ V heißen zueinander orthogonal, wenn gilt
(a, b) = 0.
(522)
Bem. 1: Der Nullvektor 0 ∈ V ist zu jedem Vektor a ∈ V orthogonal.
Bem. 2: Sind die Vektoren v1 , ..., vk paarweise orthogonal,
(vi , vj ) = 0 für alle i, j ∈ {1, ..., k} mit i 6= j,
(523)
und ist vi 6= 0Pfür alle i ∈ {1, ..., k}, so ist {v1 , ..., vk } linear unabhängig.
Beweis: Sei ki=1 λi vi = 0. Dann folgt für jedes j ∈ {1, ..., k},
k
k
X
X
λi (vj , vi ) = λj (vj , vj ),
0 = (vj , 0) = vj ,
λi vi =
i=1
(524)
i=1
und also, wegen vj 6= 0, λj = 0.
Def.: Eine Basis {v1 , ..., vn } eines Vektorraums V mit Skalarprodukt heißt orthonormiert
oder ON-Basis, wenn die Basisvektoren auf 1 normiert und paarweise orthogonal sind,
|vi | = 1,
(vi , vj ) = 0 für alle i, j ∈ {1, ..., n} mit i 6= j.
(525)
Dies läßt sich mit Hilfe des Kronecker-Symbols δij kompakter formulieren,
(vi , vj ) ≡ gij = δij
für alle i, j ∈ {1, ..., n}.
(526)
Der metrische Tensor G von (, ) bezüglich einer ON-Basis ist also die Einheitsmatrix E.
Lemma 1: Sei B = {v1 , ..., vn } eine ON-Basis von V und a ∈ V beliebig. Dann gilt
a=
n
X
ai vi ,
mit:
ak = (vk , a).
(527)
i=1
Der k-te Koeffizient ak von a bezüglich B ist also genau das Skalarprodukt von vk mit a.
Beweis:
n
n
X
X
ai (vk , vi ) = ak .
(vk , a) = vk ,
ai vi =
(528)
| {z }
i=1
Lemma 2: Mit b =
(a, b) ≡
Pn
j=1 bj vj
n
X
i=1
ai vi ,
i=1
δki
folgt weiter
n
X
j=1
bj vj =
n
X
i,j=1
89
a∗i bj
(vi , vj ) =
| {z }
δij
n
X
i=1
a∗i bi .
(529)
6.1.6
Das Schmidtsche Orthogonalisierungsverfahren
Sei {v1 , ..., vn } eine Basis von V . Wir wollen daraus eine ON-Basis {e1 , ..., en } konstruieren (und dadurch zeigen, daß dies immer möglich ist). Im ersten Schritt wählen wir
e1 :=
v1
.
|v1 |
(530)
Nun fahren wir induktiv fort. Sei also {e1 , ..., ek } orthonormiert, wobei ei , mit 1 ≤ i ≤ k,
jeweils eine Linearkombination von {v1 , ..., vi } ist. Dann ist der Vektor
′
vk+1
= vk+1 −
k
X
j=1
(ej , vk+1 )ej 6= 0
(531)
verschieden von 0, da hier von vk+1 eine Linearkombination der Vektoren {v1 , ..., vk }
′
subtrahiert wird. Insbesondere ist vk+1
orthogonal zu ei für alle i ∈ {1, ..., k}, denn
′
(ei , vk+1
)
= (ei , vk+1) −
k
X
= (ei , vk+1) −
k
X
(ei , (ej , vk+1 )ej )
j=1
j=1
(ej , vk+1) (ei , ej ) = 0.
| {z }
(532)
δij
Eine orthonormierte Menge {e1 , ..., ek+1} ergibt sich also mit der Wahl
ek+1 :=
′
vk+1
.
′
|vk+1
|
(533)
Damit ist die Konstruktion der ON-Basis {e1 , ..., en } klar.
R1
Bsp. 3: Für {v1 , v2 , v3 } = {1, t, t2 } ⊂ P2 (R) findet man bezüglich (f, g) = 0 dtf (t)g(t)
√
√
e1 ≡ e1 (t) = 1,
e2 ≡ e2 (t) = 3(2t − 1),
e3 ≡ e3 (t) = 5(6t2 − 6t + 1). (534)
Für die Polynome a ≡ a(t) = t2 − 4t + 3 und b ≡ b(t) = 2t2 + t − 5 aus Bsp. 1b/2c findet
man mit ai = (ei , a) bzw. bi = (ei , b) folgende Darstellungen (Übungen!):
√
√
√
√
3
5
3
5
23
4
e2 (t) +
e3 (t),
b(t) = − e1 (t) +
e2 (t) +
e3 (t). (535)
a(t) = e1 (t) −
3
2
30
6
2
15
Ihr Skalarprodukt ergibt sich jetzt tatsächlich nach der Formel aus Abschnitt 6.1.5 zu
√ √
√ √
3
X
4 23
−920 − 135 + 2
117
3 3
5 5
(a, b) ≡
ai bi = −
−
+
=
=−
.
(536)
3
6
2
2
30
15
180
20
i=1
90
6.2
Skalarprodukt und lineare Selbstabbildungen
Notation: Zu einer komplexen (n × m)-Matrix A, mit den Elementen aij , definieren wir
die adjungierte Matrix A† durch
A† := (AT )∗
a†ij := a∗ji .
⇔
(537)
Insbesondere ist das Adjungierte eine komplexen Spalte a ∈ Cn die Zeile
a† := (a∗1 , . . . , a∗n ).
(538)
Sind alle Elemente von A reell, so ist natürlich A† ≡ AT .
Bsp.:
1+2 i 2−3 i
A=
5
6i
6.2.1
:
1−2 i
5
A =
2+3 i −6 i
†
,
2+ i
a=
−3 i
:
a† = (2− i , 3 i ). (539)
Unitäre Selbstabbildungen
Im physikalischen Raum V sei eine lineare Selbstabbildung f : V → V, x 7→ y = f(x)
dadurch festgelegt, daß jeder Bildvektor y gegen seinen Urvektor x mit dem gleichen
Winkel φ um eine starr vorgegebene Achse e verdreht ist. Dann ist anschaulich klar,
daß y die gleiche Länge hat wie x, und daß je zwei Bildvektoren y1 und y2 den gleichen
Winkel einschließen wie die entsprechenden Urvektoren x1 und x2 . Es gilt also
y1 · y2 ≡ f(x1 ) · f(x2 ) = x1 · x2 ,
für alle x1 , x2 ∈ V,
(540)
mit dem üblichen geometrischen Skalarprodukt in V. Man nennt f eine Drehung.
Lineare Selbstabbildungen f : V → V mit der Eigenschaft (540) heißen orthogonal. Es
sind die sog. Drehspiegelungen, bei denen zusätzlich zur Drehung eine (Raum-) Spiegelung
am Ursprung 0 erfolgen kann. Wir wollen dies nun verallgemeinern.
Def.: Sei V ein Vektorraum mit unitärem (bzw. reellem) Skalarprodukt.
Eine lineare Selbstabbildung f : V → V heißt unitär (bzw. orthogonal), wenn gilt
(f(a), f(b)) = (a, b),
für alle a, b ∈ V .
Bem.: Ist V endlich-dimensional, so gilt für eine unitäre Abbildung f : V → V :
(a) |f(v)| = |v| für alle v ∈ V ;
(b) f(v) = λv ⇒ |λ| = 1 (alle Eigenwerte von f haben den Betrag 1);
(c) f ist ein Isomorphismus, also invertierbar.
91
(541)
Satz: f : V → V ist bereits unitär, wenn für eine ON-Basis {v1 , ..., vn } von V gilt:
(f(vi ), f(vj )) = δij
für alle i, j ∈ {1, ..., n}.
(542)
(Trivialerweise gilt dies umgekehrt für jede ON-Basis, wenn f unitär ist.)
Beweis: Für zwei beliebige Vektoren a, b ∈ V ,
a=
n
X
ai vi ,
b=
i=1
n
X
bj vj ,
(543)
j=1
folgt sofort (Lemma 2 aus Abschnitt 6.1.5!)
n X
n
X
(f(a), f(b)) =
a∗i bj
i=1 j=1
(f(v ), f(v )) =
| i {z j }
δij
n
X
a∗i bi = (a, b).
(544)
i=1
Wir betrachten einen Vektor x ∈ V und seinen Bildvektor y = f(x) ∈ V ,
x=
n
X
xi vi ,
y=
n
X
yj vj ,
(545)
j=1
i=1
wobei B = {v1 , ..., vn } eine ON-Basis von V sei. Die Matrix A von f ist definiert durch
x1
y1
x := ... , y := ...
(546)
⇒
y = A ◦ x.
xn
yn
Die k-te Spalte von A enthält also die Koeffizienten des Vektors f(vk ) bezüglich B,
f(vk ) =
n
X
Aik vi .
(547)
i=1
Ist also f unitär, (f(vk ), f(vℓ )) = δkℓ , so sollten die Spalten von A paarweise orthonormal
sein, m.a.W.: eine ON-Basis des Cn bilden,
n
X
A∗ik Aiℓ
= δkℓ
i=1
⇔
n
X
i=1
A†ki Aiℓ ≡ (A† ◦ A)kℓ = δkℓ
⇔
A† ◦ A = E.
(548)
Tatsächlich gilt der
Satz: Die invertierbare Matrix A, durch die eine unitäre Abbildung f : V → V bezüglich
einer ON-Basis {v1 , ..., vn } dargestellt wird, hat die Eigenschaft A−1 = A† .
Beweis: Da f unitär ist, gilt
δkℓ ≡ (f(vk ), f(vℓ ))
n X
n
n
n
X
X
X
=
A∗ik Ajℓ (vi , vj ) =
A∗ik Aiℓ =
A†ki Aiℓ = (A† ◦ A)kℓ .
| {z }
i=1 j=1
δij
i=1
92
i=1
(549)
6.2.2
Lineare Funktionale
Def.: Unter einem linearen Funktional auf dem Vektorraum V versteht man eine lineare
Abbildung f : V → K von V in den Grundkörper K. Statt f, g, ... schreiben wir α, β, ...,
α : V → K,
x 7→ α(x) ∈ K.
(550)
Linearität: Für λ, µ ∈ K und x1 , x2 ∈ V muß gelten α(λx1 + µx2 ) = λα(x1 ) + µα(x2 ).
Bsp. 1a: Zwei lineare Funktionale α, β : V → R auf V = P2 (R) sind etwa gegeben durch
Z 3
α : x ≡ x(t) 7→ α(x) :=
dt t2 x(t),
β : x ≡ x(t) 7→ β(x) := x(t = 0.8). (551)
0
Für x ≡ x(t) = pt2 + qt + r folgt α(x) = 48.6p + 20.25q + 9r und β(x) = 0.64p + 0.8q + r.
Wie man sich leicht klarmacht (Übungen!), bildet die Menge aller linearen Funktionale
auf V selbst einen Vektorraum, den sog. Dualraum V † von V . Zwischen diesen Räumen
besteht eine enge Beziehung: Bezüglich einer (ON-) Basis von V werden die Elemente von
V selbst durch Spalten, diejenigen von V † durch (1 × n)-Matrizen, also Zeilen dargestellt.
Ehe wir den entsprechenden Satz beweisen, wollen wir dies noch etwas genauer betrachten.
Die Matrix A von α ∈ V † bezüglich einer Basis B = {v1 , ..., vn } von V ist eine Zeile,
α(x) = A ◦ x,
A ≡ (A11 , ..., A1n ) = (α(v1 ), ..., α(vn )),
(552)
P
wobei x ∈ Cn die aus den Komponenten xk von x = nk=1 xk vk gebildete Spalte ist.
A ist das Adjungierte a† einer durch α (und B) eindeutig bestimmten Spalte a ∈ Cn ,
a1
A∗11
α(v1 )∗
..
A = a† ,
a ≡ ... = ... =
(553)
.
.
∗
∗
an
A1n
α(vn )
Wir können also schreiben α(x) = a† ◦ x. Ist insbesondere B eine ON-Basis, so gilt
α(x) ≡ a† ◦ x = (a, x),
(554)
mit dem Vektor a ∈ V , der bezüglich B durch a dargestellt wird. Es deutet sich an:
Satz: Sei V ein Vektorraum mit Skalarprodukt. Dann gibt es zu jedem α ∈ V † genau
ein a ∈ V , und umgekehrt zu jedem a ∈ V genau ein α ∈ V † , sodaß gilt
α(x) = (a, x),
für alle x ∈ V .
93
(555)
Beweis: Sei {v1 , ..., vn } eine ON-Basis von V . Mit den n Zahlen α(vk ) ∈ C setzen wir
a :=
n
X
α(vk )∗ vk .
(556)
k=1
Dann gilt für beliebiges x =
α(x) =
Pn
n
X
k=1 xk vk
∈ V , wobei xk = (vk , x) ist, tatsächlich
xk α(vk ) =
k=1
n
X
(vk , x)α(vk ) = (a, x).
(557)
k=1
Sei umgekehrt α(x) = (b, x), mit einem b ∈ V . Speziell für x = a − b folgt dann
0 = (a, x) − (b, x) = (a − b, a − b)
⇔
a−b=0
⇔
b = a.
(558)
Def.: Das dem Vektor a ∈ V durch die Bedingung
α(x) = (a, x),
für alle x ∈ V
(559)
eindeutig zugeordnete lineare Funktional α ∈ V † heißt das Adjungierte a† von a.
Bsp. 1b: Wir betrachten das Funktional β aus Bsp. 1a und das Skalarprodukt
Z 1
(x, y) :=
dt x(t)y(t)
(560)
0
in P2 (R). Mit b ≡ b(t) := 1.2t2 + 2.4t − 0.6 gilt für x ≡ x(t) = pt2 + qt + r tatsächlich
Z 1
Z 1
(b, x) =
dt b(t)x(t) =
dt (1.2t2 + 2.4t − 0.6)(pt2 + qt + r)
0
0
= ...
= 0.64p + 0.8q + r = f (0.8) ≡ β(x).
(561)
Es gilt also β = b† .
Bem.: In der Quantenmechanik ist folgende Schreibweise (nach P.A.M. Dirac) üblich:
x = |xi,
β ≡ b† = hb|,
also: β(x) = hb|xi.
94
(562)
6.2.3
Die zu f : V → V adjungierte Abbildung f † : V → V
Sei a ∈ V ein fester Vektor und f : V → V eine Selbstabbildung. Dann wird durch
β(x) := (a, f(x)),
∀x∈V
(563)
eine Abbildung β : V → K festgelegt. Diese ist ein lineares Funktional, β ∈ V † , denn
β(λx1 + µx2 ) = (a, f(λx1 + µx2 )) = (a, λf(x1 ) + µf(x2 )) = λβ(x1 ) + µβ(x2).
(564)
Nach Abschnit 6.2.2 gibt es also ein durch a eindeutig bestimmtes b ∈ V , sodaß gilt
β(x) ≡ (a, f(x)) = (b, x),
∀ x ∈ V.
(565)
M.a.W.: Durch die Bedingung
(a, f(x)) = (g(a), x),
∀x∈V
(566)
wird eindeutig eine Abbildung g : V → V, a 7→ b = g(a) festgelegt. Sie ist linear, denn
(g(λa1 + µa2 ), x) = (λa1 + µa2 , f(x)) = λ∗ (a1 , f(x)) + µ∗ (a2 , f(x))
= λ∗ (g(a1 ), x) + µ∗ (g(a2 ), x)
= (λg(a1 ) + µg(a2 ), x).
(567)
Def.: Die zu einer gegebenen Abbildung f : V → V durch die Bedingung
(v, f(x)) = (f † (v), x),
∀x∈V
(568)
eindeutig festgelegte Abbildung f † : V → V heißt die zu f adjungierte Abbildung.
Satz: Die Abbildung f : V → V werde bezüglich der ON-Basis B = {v1 , ..., vn } durch
die Matrix A dargestellt. Dann wird f † bezüglich B durch die Matrix A† dargestellt.
Beweis: Die gesuchte Matrix von f † sei M ,
f † (vℓ ) =
n
X
Mjℓ vj .
(569)
j=1
Wegen f(vk ) =
Pn
i=1
Aik vi folgt dann
†
Aℓk = (vℓ , f(vk )) = (f (vℓ ), vk ) =
n
X
Mjℓ vj , vk =
j=1
n
X
∗
∗
Mjℓ
(vj , vk ) = Mkℓ
.
j=1
Es folgt also A = M † ⇔ M = A† , und die Behauptung ist bewiesen.
95
(570)
6.2.4
Unitäre und selbstadjungierte Abbildungen
Def.: Die Abbildung f : V → V heißt selbstadjungiert, wenn gilt f † = f.
Bem.: Während die Matrix U einer unitären Abbildung f : V → V (bezüglich einer
ON-Basis von V ) invertierbar ist, mit der Eigenschaft (“unitär”)
U † = U −1 ,
(571)
so ist die Matrix H einer selbstadjungierten Abbildung charakterisiert durch
H † = H.
(572)
Solche Matrizen heißen hermitesch. (Reelle hermitesche Matrizen sind symmetrisch.)
Bsp. 2a: Eine unitäre und eine hermitesche (2 × 2)-Matrix U bzw. H sind etwa,
1
1 i
1 i
,
H=
U=√
.
(573)
i 1
−i 1
2
Bem.: Alle Eigenwerte λ einer selbstadjungierten Abbildung f sind reell.
Beweis: Sei nämlich f(v) = λv und (v, v) = 1. Dann folgt
λ = (v, λv) = (v, f(v)) = (f † (v), v) ≡ (f(v), v) = (λv, v) = λ∗ ,
q.e.d.
(574)
Dasselbe gilt natürlich insbesondere auch für die Eigenwerte einer hermiteschen Matrix.
Bsp.: Die allgemeine hermitesche (2 × 2)-Matrix lautet
a
x+ iy
(a, b, x, y ∈ R).
H=
x − iy
b
(575)
Man beachte, daß die Diagonalelemente Hii , auch im Fall (n × n), alle reell sein müssen!
Das charakteristische Polynom,
PH (λ) = λ2 − (a + b)λ + [ab − (x2 + y 2)],
hat tatsächlich nur reelle Nullstellen,
i
p
1h
λ1,2 = (a + b) ± (a − b)2 + 4(x2 + y 2) .
2
(576)
(577)
Dies gilt natürlich erst recht im speziellen Fall y = 0 einer symmetrisch-reellen Matrix!
96
6.2.5
ON-Basis aus Eigenvektoren
Eigenvektoren v1 und v2 einer selbstadjungierten Abbildung f zu verschiedenen Eigenwerten λ1 bzw. λ2 sind zueinander orthogonal, denn
λ2 (v1 , v2 ) = (v1 , f(v2 )) = (f(v1 ), v2 ) = λ∗1 (v1 , v2 ) ≡ λ1 (v1 , v2 ),
(578)
was wegen λ2 6= λ1 nur mit (v1 , v2 ) = 0 vereinbar ist.
Auch bei einer unitären Abbildung f, mit f † = f −1 , sind Eigenvektoren zu verschiedenen Eigenwerten λ1 = e i φ1 bzw. λ2 = e i φ2 (mit φ1 , φ2 ∈ R) zueinander orthogonal,
e i φ2 (v1 , v2 ) = (v1 , f(v2 )) = (f −1 (v1 ), v2 ) = (e− i φ1 v1 , v2 ) = e i φ1 (v1 , v2 ),
(579)
was wiederum wegen φ2 6= φ1 nur mit (v1 , v2 ) = 0 vereinbar ist.
Satz: Sei V ein endlich-dimensionaler Vektorraum über K ∈ {C, R} mit Skalarprodukt.
Sei außerdem f : V → V eine selbstadjungierte oder eine unitäre Selbstabbildung.
Dann gibt es eine ON-Basis von V , die aus Eigenvektoren von f besteht.
Auf den Beweis wollen wir hier verzichten.
Dieser Satz hat fundamentale Bedeutung in der Quantenmechanik, wo er auf gewisse
∞-dimensionale Vektorräume, sog. Hilbert-Räume verallgemeinert wird.
Eine dem Satz analoge Aussage gilt natürlich für hermitesche oder unitäre Matrizen:
Satz: Sei A eine komplexe (oder auch reelle) (n × n)-Matrix, die entweder hermitesch
oder unitär ist. Dann existiert eine ON-Basis {v 1 , ..., vn } des Cn aus Eigenvektoren von
A. Im hermiteschen Fall sind alle Eigenwerte λ1 , ..., λn reell,
A† = A :
A ◦ v k = λk vk ,
λ∗k = λk ,
(580)
im unitären Fall sind sie im allg. komplex, haben dafür aber immer den Betrag 1,
A† = A−1 :
A ◦ v k = λk vk ,
λk = e i φk
(φk ∈ R).
(581)
Bsp. 2b: Die unitäre Matrix U aus Bsp. 2a hat die orthogonalen Eigenvektoren
1
1
, v2 =
,
(582)
v1 =
1
−1
√
zu den unimodularen komplexen Eigenwerten λ1,2 = 21 2(1 ± i ) ≡ e±π i /4 , mit |µ1,2 | = 1.
Dagegen hat die hermitesche Matrix H aus Bsp. 2a reelle Eigenwerte λ1 = 0 und λ2 = 2;
die Eigenvektoren sind aber ebenfalls orthogonal,
1
1
v1 =
, v2 =
.
(583)
i
−i
97
Bsp. 3: Für die Physik besonders wichtig ist der Spezialfall einer symmetrisch-reellen
Matrix, die ja auch hermitesch ist. Als Beispiel diene die symmetrische (3 × 3)-Matrix
25
2
−8
34 −10 .
A= 2
(584)
−8 −10 31
Wie man leicht nachrechnet, sind drei paarweise orthogonale Eigenvektoren gegeben durch
2
2
1
1
1
1
(585)
v1 = 1 , v 2 = −2 , v 3 = 2 .
3
3
3
2
−1
−2
Sie bilden offensichtlich eine ON-Basis des R3 , und die zugehörigen Eigenwerte sind reell,
λ1 = 18,
6.2.6
λ2 = 27,
λ3 = 45.
Zusammenfassung
Drei Kategorien mathematischer Objekte:
1. Vektoren a, b, c, ... ∈ V .
2. Lineare Selbstabbildungen f, g, h, ... : V → V .
3. Lineare Funktionale α, β, γ, ... : V → K.
Zuenander adjungiert sein können: 1 ↔ 3, 2 ↔ 2, 3 ↔ 1.
Wählt man in V eine Basis {v1 , ..., vn }:
1. Spalten a, b, c, ... ∈ Kn .
2. (n × n)-Matrizen F , G, H, ....
3. Zeilen a† , b† , c† , ....
98
(586)
6.3
6.3.1
Hauptachsentransformation
Einführung: Quadratische Funktionen
Wir betrachten eine quadratische Funktion mit zwei reellen Variablen x und y,
f (x, y) = −23x2 + 72xy − 2y 2.
(587)
Zur graphischen Veranschaulichung denke man an jedem Punkt der xy-Ebene je einen Stab
vertikal (in z-Richtung) aufgestellt, dessen Länge gleich dem jeweiligen Funktionswert
f (x, y) ist. [Im Fall f (x, y) < 0 muß der Stab “nach unten” zeigen.] Die freien Enden
dieser Stäbe bilden eine gekrümmte, 3-dimensionale Fläche, den 3D-Plot der Funktion.
Wie sieht dieser aus?
Die Nullstellen von f in der xy-Ebene folgen aus der Gleichung −2y 2 +72xy−23x2 = 0,
√
√
(36 ± 25√2) x (x ≥ 0),
y1,2 = 36x ± 25 2|x| =
(588)
(18 ± 25 2)|x| (x ≤ 0).
√
Dies sind die beiden Geraden y(x) = (36 ± 25 2)x, also y ≈ 71.35x und y ≈ 0.65x.
Sie schneiden sich im Ursprung (x, y) = (0, 0) und schließen den Winkel ≈ 55◦ ein.
Sie teilen die xy-Ebene in vier Sektoren auf, abwechselnd mit f (x, y) > 0 bzw. f (x, y) < 0.
Damit ist qualitativ klar, daß der 3D-Plot eine Sattelfläche sein muß.
Ein klareres Bild läßt sich gewinnen, wenn wir in der xy-Ebene zu verdrehten Koordinatenachsen übergehen. Dann gehen die “alten” Koordinaten x und y eines Punktes,
zur Spalte r zusammengefaßt, über in die “neuen” Koordinaten x′ und y ′ , bzw. r ′ ,
′ x
U11 U12
x
′
.
(589)
◦
r =U ◦r
=
⇔
y
U21 U22
y′
Die Spalten der Trafo-Matrix U sind die Koeffizienten der “alten” Basisvektoren ex und
ey , dargestellt als LKen der “neuen”, ex′ und ey′ . Da U eine reine Drehung beschreibt,
müssen diese Spalten zueinander orthogonale Einheitsspalten, die Matrix U selbst also
orthogonal (d.h.: reel-unitär) sein, U −1 = U T .
Für die genannte Funktion f erweist sich folgende orthogonale Matrix als hilfreich,
1
3 4
.
(590)
U=
5 −4 3
Mit der inversen Matrx U −1 = U T ergibt sich zunächst
′ 1 3x′ − 4y ′
1 3 −4
x
x
=
.
◦
≡
y′
y
5 4 3
5 4x′ + 3y ′
99
(591)
Setzt man dies in der quadratischen Funktion f (x, y) für x und y ein,
(3x′ − 4y ′)2
(3x′ − 4y ′ )(4x′ + 3y ′)
(4x′ + 3y ′)2
f˜(x′ , y ′ ) = −23
+ 72
−2
,
25
25
25
(592)
so treten nur noch rein-quadratische Terme aber kein gemischter Term ∼ x′ y ′ mehr auf,
f˜(x′ , y ′) = 25x′2 − 50y ′2.
(593)
Die neuen Achsen {ex′ , ey′ } heißen daher die Hauptachsen der quadratischen Funktion.
Wir werden sehen, daß jede quadratische Funktion (mit n Variablen) durch geeignete
Verdrehung der n Koordinatenachsen, Hauptachsentransformation genannt, auf diese reinquadratische Form gebracht werden kann.
Im einfachsten Fall n = 2 lautet eine Funktion in rein-quadratischer Form
f (x, y) = ax2 + by 2 .
Ihr 3D-Plot ...
100
(594)
6.3.2
Bilinearformen
Def.: Eine Bilinearform (BF) auf dem Vektorraum V (mit oder ohne Skalarprodukt) ist
eine Funktion Φ : V × V → R, die jedem geordneten Paar von Vektoren x, y ∈ V eine
Zahl Φ(x, y) ∈ R zuordnet und dabei in beiden Argumenten linear ist,
Φ(λx1 + µx2 , y) = λΦ(x1 , y) + µΦ(x2 , y),
Φ(x, λy1 + µy2 ) = λΦ(x, y1 ) + µΦ(x, y2 ).
(595)
Die BF heißt symmetrisch, wenn zusätzlich gilt Φ(x, y) = Φ(y, x).
Bsp. 1a: Jedes (reelle) Skalarprodukt (x, y) in V bildet eine symmetrische BF auf V ,
Φ(x, y) := (x, y) ≡ (y, x).
(596)
Bsp. 1b: Im Fall V = R2 ist eine BF Φ : R2 × R2 → R gegeben durch
x y 1
1
= 2x1 y1 − 5x2 y2 .
,
Φ(x, y) ≡ Φ
y2
x2
(597)
Dies ist zwar symmetrisch aber kein Skalarprodukt, denn es ist etwa Φ([11 ], [11 ]) = −3 < 0.
Bem.: Sei B = {v1 , ..., vn } eine Basis von V . Dann gilt für eine BF allgemein
Φ(x, y) ≡ Φ
n
X
i=1
xi vi ,
n
X
yj vj =
j=1
n
X
i,j=1
xi yj Φ(vi , vj ) ≡
n
X
Aij xi yj .
(598)
i,j=1
Jede BF Φ : V × V → R auf einem n-dimensionalen Vektorraum V wird also bezüglich
einer Basis B von V durch eine (n × n)-Matrix A = (Aij ) beschrieben, mit
Aij = Φ(vi , vj ).
(599)
Dabei ist Φ genau dann symmetrisch, wenn die Matrix A es ist.
Bsp. 1c: Eine nicht-symmetrische BF Φ : R2 × R2 → R und ihre Matrix bezüglich der
Standardbasis des R2 sind
2
X
2 3
Φ(x, y) = 2x1 y1 + 3x1 y2 + 7x2 y1 − 8x2 y2 =
Aij xi yj ,
A=
. (600)
7 −8
i,j=1
Bsp. 1d: Im ∞-dimensionalen Vektorraum der auf [a, b] stetigen Funktionen ist eine BF
allgemein gegeben durch
Z b Z b
Φ(x, y) =
ds
dt A(s, t) x(s)y(t),
(601)
a
a
mit einer für Φ charakteristischen stetigen Funktion A(s, t) der zwei Variablen s und t.
Diese bilden eine Verallgemeinerung die diskreten Matrixindizes i und j.
101
6.3.3
Quadratische Formen
Def.: Jede BF Φ : V × V → R, (x, y) 7→ Φ(x, y) definiert durch die Vorschrift
Q(x) := Φ(x, x)
(602)
eine Funktion Q : V → R, x 7→ Q(x), die zu Φ gehörende quadratische Form (qF).
Solange nicht anders betont, ist hier immer V = Rn und B die Standardbasis des Rn .
Bem.: Aus der qF Q(x) läßt sich die BF Φ(x, y) nicht eindeutug rekonstruieren.
Wegen x1 x2 = x2 x1 führen etwa die beiden BFen
Φ(x, y) = 2x1 y1 + 5x1 y2 + 5x2 y1 − 8x2 y2 ,
Ψ (x, y) = 2x1 y1 + 3x1 y2 + 7x2 y1 − 8x2 y2
(603)
auf ein- und dieselbe qF
Q(x) ≡ Φ(x, x) = 2x21 + 10x1 x2 − 8x22 = Ψ (x, x).
(604)
Zur Erzeugung von qFen kann man sich daher auf symmetrische BFen (wie Φ im aktuellen
Beispiel) beschränken. Die beliebige BF Ψ (mit Matrix M ) erzeugt die gleiche qF
n
X
n
n
X
X
Mij + Mji
Q(x) ≡ Ψ (x, x) =
Mij xi xj =
xi xj =:
Aij xi xj ,
2
i,j=1
i,j=1
i,j=1
(605)
wie die symmetrische BF Φ mit der symmetrischen Matrix
A :=
1
M + MT
2
⇔
Aij :=
Mij + Mji
= Aji .
2
(606)
Wir können uns also bei qFen auf symmetrische Matrizen A beschränken. Folglich gibt
es neben der Standardbasis B = {e1 , ..., en } im Rn auch eine ON-Basis B1 = {v1 , ..., vn }
aus Eigenvektoren von A. Jeder beliebige Vektor x ∈ Rn hat die beiden Darstellungen
x = x1 e1 + ... + xn en = ξ1 v1 + ... + ξn vn .
(607)
Die neuen Koordinaten ξk sind mit den xi verknüpft durch eine unitäre Trafo-Matrix U ,
ξk =
n
X
Uki xi
i=1
⇔
ξ = U ◦ x.
(608)
Wegen U −1 = U † = U T (die unitäre Matrix U ist reell, also orthogonal) gilt umgekehrt
xi =
n
X
k=1
T
Uik
ξk
⇔
102
x = U T ◦ ξ.
(609)
Wir setzen dies in der qF Q(x) für xi und xj ein,
Q(x) =
n
X
Aij xi xj =
i,j=1
=
n
X
i,j=1
n
X
Aij
n
X
T
Uik
ξk
k=1
n
X
n
X
T
Ujℓ
ξℓ
ℓ=1
T
Uki Aij Ujℓ
ξk ξℓ =
k,ℓ=1 i,j=1
n X
k,ℓ=1
U ◦ A ◦ UT
kℓ
ξk ξℓ . (610)
Als Transformierte von A auf die ON-Basis B1 aus Eigenvektoren ist A′ = U ◦ A ◦ U T die
Diagonalmatrix mit den Eigenwerten λ1 , ..., λn auf der Diagonalen,
= λk δkℓ
U ◦ A ◦ UT
⇒
kℓ
Q(x) =
n
X
λk ξk2 .
(611)
k=1
Damit haben wir folgenden Satz bewiesen,
Satz (Hauptachsen-Trafo): Jede quadratische Form Q : Rn → R, x 7→ Q(x),
Q(x) =
n
X
(612)
Aij xi xj ,
i,j=1
läßt sich auf Hauptachsen transformieren. D.h.: Man kann im Rn eine ON-Basis B1 so
wählen, daß Q(x) als Funktion der Koordinaten ξk von x bezüglich B1 die Form
Q(x) =
n
X
λk ξk2
(613)
k=1
annimmt, mit n Parametern λ1 , .., λn .
B1 besteht aus den Eigenvektoren von A, die Parameter λk die zugehörigen Eigenwerte.
Bsp.: Wir betrachten eine quadratische Form auf V = R3 ,
Q(x) =
4x21
+
3x22
+
2x23
− 4x1 x2 + 4x2 x3 =
n
X
Aij xi xj .
(614)
i,j=1
Ihre (symmetrische!) Matrix A = (Aij ) hat die Eigenwerte λ1 = 0, λ2 = 3 und λ3 = 6,
4 −2 0
A = −2 3 2 ,
(615)
det A − λE = −λ(λ − 3)(λ − 6).
0
2 2
Drückt man also in Q(x) die xi durch die Koordinaten ξk von x bezüglich der (noch nicht
berechneten!) normierten Eigenvektoren von A aus, so muß sich also ergeben
Q(x) ≡ λ1 ξ12 + λ2 ξ22 + λ3 ξ32 = 3ξ22 + 6ξ32 .
103
(616)
Aus dieser Darstellung lesen wir ab, daß Q(x) ≥ 0 für alle x ∈ R3 , daß aber bei x = 0
trotzdem kein Minimum vorliegt. Man sagt in diesem Fall, Q sei positiv semidefinit (s.u.).
Zu den Eigenwerten λ1 = 0, λ2 = 3 bzw. λ3 = 6 gehören die normierten Eigenvektoren
1
2
2
1
1
1
v1 = 2 ,
v2 = 1 ,
lvv3 = −2 .
(617)
3
3
3
−2
2
−1
Sie bilden die Spalten der inversen Trafo-Matrix U −1 = U T ,
1 2 2
1
U T = 2 1 −2 .
3
−2 2 −1
(618)
Der Vektor x = ξ1 v1 + ξ2 v2 + ξ3 v3 hat also bezüglich der Standardbasis die Koordinaten
1
x1 = (ξ1 + 2ξ2 + 2ξ3 ),
3
1
x2 = (2ξ1 + ξ2 − 2ξ3 ),
3
1
x3 = (−2ξ1 + 2ξ2 − ξ3 ).
3
(619)
Setzt man diese Ausdrücke in Q(x) = 4x21 + 3x22 + 2x23 − 4x1 x2 + 4x2 x3 ein, so ergibt sich
nach mühsamem Ausmultiplizieren tatsächlich das einfache Ergebnis Q(x) = 3ξ22 + 6ξ32 .
Def.: Seien λ1 , ..., λn die Eigenwerte der symmetrischen Matrix A. Dann heißt die qF
Q(x1 , ..., xn ) =
n
X
Aij xi xj
i,j=1
(1)
(2)
(3)
(4)
(5)
positiv definit, wenn die Menge Λ := {λ1 , ..., λn } nur positive Zahlen,
positiv semidefinit, wenn Λ positive Zahlen und Null(en),
negativ definit, wenn Λ nur negative Zahlen,
negativ semidefinit, wenn Λ negative Zahlen und Null(en),
indefinit, wenn Λ positive und negative Zahlen enthält.
104
(620)