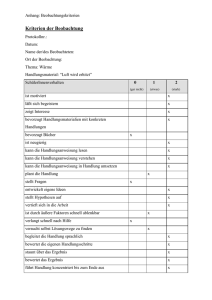
Zusammenfassung_Forschungsmethoden_v2
Werbung

Thomas Lübbeke Am Galgenberg 52 (App.9/10/2) 97074 Würzburg [email protected] Stand: 10. September 2004 Forschungsmethoden der Psychologie Zusammenfassung auf der Grundlage des Scripts zur Vorlesung von I. Totzke Ein ganz besonderes Dankeschön an dieser Stelle an den Schöpfer, die Muse, die allumfassende Gestalt des gedanklichen Überbaus – C.B.L., ohne die dieses Script nie diese unendliche Perfektion erlangt hätte! DANKE! Außerdem danke ich den Ärzten (auuus Berlin), die mir den Glauben an das Gute im Menschen gegeben haben und dafür verantwortlich sind, dass dieses Script nun jedem zur Verfügung steht. Jedem, der nur vorhat, dieses Script auswendig zu lernen, ohne den gedanklichen Hintergrund verstehen zu wollen, dem sei gesagt: „Für dich ist es nicht gemacht :-)“ 0 Inhaltsverzeichnis FORSCHUNGS-METHODEN DER PSYCHOLOGIE ZUSAMMENFASSUNG AUF DER GRUNDLAGE DES SCRIPTS ZUR VORLESUNG VON I. TOTZKE 1 0 INHALTSVERZEICHNIS 2 1 ALLGEMEINES & DEFINITIONEN 8 1.1 Methodenanwendung 1.1.1 Definition Alltag vs. Wissenschaft 1.1.2 Eigenschaften von „Methoden“ 8 8 8 1.2 Die Hypothese 1.2.1 Kriterien für Hypothesen 1.2.2 Hypothesenarten 1.2.2.1 Inhaltliche Hypothesen: 1.2.2.2 Statistische Hypothesen: 1.2.3 5 Schritte eines empirischen Forschungsprozesses 1.2.3.1 Planungsphase 1.2.3.2 Operationalisierung 1.2.3.3 Messung 1.2.3.4 Datenanalyse 1.2.3.5 Interpretation der Daten 8 9 9 9 9 9 9 9 9 10 10 1.3 Das Experiment 1.3.1 Defintion Experiment 1.3.2 Hauptmerkmale des Experiments 1.3.3 Kontrolltechniken 1.3.3.1 Experimentelle (Instrumentelle) Kontrolltechniken 1.3.3.2 Versuchsplanerische Kontrolltechniken 1.3.3.3 Statistische Kontrolltechniken 1.3.4 Logik des Experiments 1.3.5 Problemkreise Experiment 11 11 11 12 12 12 12 12 12 1.4 Der Versuch 1.4.1 Übersicht „Versuchspläne“ 1.4.2 Versuchsleiter-Artefakte 1.4.3 Funktion des Signifikanztests 13 13 13 13 1.5 Deskriptive Statistik 1.5.1 Statistische Symbole 1.5.2 Kennwerte der zentralen Tendenz (Lage) 1.5.3 Kennwerte der Dispersion (Variabilität) 1.5.4 Kennwerte der Schiefe (Abweichung von der Symmetrie) 1.5.5 Kennwerte des Exzess (Steilheit, Gipflichkeit, Kurtosis) 13 13 14 15 15 15 1.6 Variablen der Psychologie 1.6.1 UV / AV 1.6.2 Weitere Variablentypen 1.6.3 Klassifikation von Variablen 15 15 16 16 2 16 GÜTEKRITERIEN 2.1 Gütekriterien einer Messung 2.1.1 Gütekriterium: Objektivität 16 16 2 2.1.2 2.1.3 Gütekriterium: Reliabilität Gütekriterium: Validität 17 17 2.2 Stichproben 2.2.1 Zufallsstichprobe 2.2.2 Klumpenstichprobe 2.2.3 Geschichtete (stratifizierte) Stichprobe 2.2.4 Zufallsgesteuerte Stichproben: Sonderfall 2.2.5 Nicht-zufallsgesteuerte Stichproben 2.2.6 Quoten-Stichproben 2.2.7 Stichproben und Repräsentativität 2.2.8 Konfidenzintervalle und Stichprobenumfänge 17 18 18 18 19 19 19 19 20 2.3 Faktor Zeit (beeinflusst interne Validität) 2.3.1 Geschichtlichkeit: 2.3.2 Entwicklung: 2.3.3 Selektion und Messeffekte: 2.3.4 Test- und Lerneffekte: 20 20 20 20 21 2.4 21 3 Gefährdung der externen Validität FORSCHUNGSFORMEN 22 3.1 Laborforschung 22 3.2 Feldforschung 22 3.3 Labor vs. Feld 22 3.4 Web-Experimente Merkmale 3.4.1 Webexperimente (Vor- / Nachteile) 3.4.2 Verweigerung von Informationen (Drop Outs) 3.4.3 Dropout Quote 3.4.3.1 Zur Bestimmung: 3.4.3.2 3 Techniken zur Verringerung 3.4.3.2.1 High-Hurdle Technique 3.4.3.2.2 Warm-Up Technique 3.4.3.2.3 Seriousness-Check 23 23 23 24 24 24 24 24 24 3.5 Einzelfallforschung 3.5.1 Allgemeine Definition: 3.5.2 Vorteile: 3.5.3 Nachteile: 24 24 24 25 3.6 Längsschnittstudien 3.6.1 Definition: (von Baltes 1967) 3.6.2 Vorteile: 3.6.3 Nachteile: 3.6.4 Panel Forschung 3.6.4.1 Panelforschung als Beispiel einer Längsschnittstudie 3.6.4.2 Testeffekte 3.6.4.3 Weitere Nachteile: 3.6.4.4 Lösungsvorschläge 3.6.4.5 Alternierendes Panel 3.6.4.6 Rotierendes Panel 3.6.4.7 Geteiltes Panel 25 25 25 25 26 26 26 26 26 26 27 27 3.7 Querschnittstudien 3.7.1 Vorteile: 3.7.2 Nachteile: 27 28 28 3 3.8 Sekundäranalysen 3.8.1 Primäranalysen: 3.8.2 Sekundäranalysen: 3.8.2.1 Vorteile: 3.8.2.2 Nachteile: 28 28 28 28 28 4 29 4.1 BEOBACHTUNG Definition Beobachtung 29 4.2 Beobachtungssysteme (Kodierung von Beobachtung) 4.2.1 Verbalsysteme: 4.2.2 Nominalsysteme: 4.2.2.1 Zeichensysteme 4.2.2.2 Kategoriensysteme 4.2.3 Quantifizierung der Beobachtung 29 29 29 30 30 30 4.3 Beobachtungseinheit: (Empfehlungen) 4.3.1 Time-Sampling: 4.3.2 Event-Sampling 4.3.3 Ratingverfahren: 30 30 30 31 4.4 Beobachterfehler 4.4.1 Beobachterfehler durch: 4.4.2 Beobachterreliabilität 4.4.3 Verbesserung der Beobachterleistung 4.4.4 Erwartungseffekte: generell vs. speziell 4.4.5 Kappa Maß 31 31 32 32 32 33 4.5 Aspekte des Beobachtungsprozesses 4.5.1 Selbstbeobachtung: Probleme 4.5.2 Fremdbeobachtung (Aspekte) 4.5.2.1 Natürlich und künstlich 4.5.2.2 wissentlich und unwissentlich (offen und verdeckt) 4.5.2.3 Teilnehmend und nicht-teilnehmend 4.5.2.4 Direkt und indirekt (direktes Beobachten oder mittels Rückschlüsse) 4.5.2.5 Vermittelt und unvermittelt 4.5.3 Reaktive Effekte 34 35 35 35 35 36 36 37 37 4.6 38 5 Problemkreise Beobachtung BEFRAGUNG 38 5.1 Definition Befragung 5.1.1 Alltagsverständnis: 5.1.2 Wissenschaftliches Verständnis: 5.1.3 Dem Befragten muss klar sein… 38 38 38 38 5.2 Klassifikation von Befragungen 5.2.1 Ausmaß der Standardisierung 5.2.2 Autoritätsanspruch des Interviewers 5.2.3 Art des Kontakts 5.2.4 Anzahl der befragten Personen 5.2.5 Anzahl der Interviewer 5.2.6 Funktion des Interviews (Klassifizierung einer Befragung) 39 39 39 39 40 40 40 5.3 Problemkreise der Befragung 5.3.1 Aspekte der Frage: 5.3.2 Merkmale des Befragten 5.3.3 Kontext der Befragungssituation 40 40 41 41 4 5.4 Neue Befragungstechniken 41 5.5 Skalen 41 5.5.1 Numeralskala 42 5.5.2 Verbalskala 42 5.5.3 Symbolskala 42 5.5.4 Graphische Skala (Visuelle Analogskala) 43 5.5.5 Standardskala (Durch Beispiele verankerte Skala) (z.B. Checklist-Verfahren, Forced ChoiceVerfahren) 43 5.6 Verweigerung 5.6.1 Item-Non-Response 5.6.2 Unit-Non-Response 5.6.3 Verweigerungsquoten 5.6.4 Rücklaufquoten 43 43 43 43 44 6 44 MESSUNGEN 6.1 Mess-Artefakte 6.1.1 Artefakte physiologischer Herkunft 6.1.2 Bewegungsartefakte 6.1.3 Artefakte durch externe elektrische Einstreuung 44 44 44 44 6.2 Spezifitätsproblematik 6.2.1 Individualspezifische Reaktion 6.2.2 Stimulusspezifische Reaktion 6.2.3 Motivationsspezifische Reaktion 45 45 45 45 6.3 Ausgangswertgesetz von Wilder (1931): 45 6.4 Messprobleme – innere und äußere Variablen 45 7 VERSUCHSPLANUNG 45 7.1 Idee der Versuchsplanung 7.1.1 Definitionen PV / SV / FV 7.1.2 Primärvarianz: 7.1.3 Sekundärvarianz 7.1.4 Fehlervarianz (Zufallsfehler): 7.1.5 Ein Beispiel 7.1.6 Logik der Bewertung 45 46 46 46 46 47 47 7.2 Idee der Varianzanalyse 7.2.1 Modell der Varianzanalyse: 7.2.2 Statistische Prüfgröße Quadratsummen (QS) 7.2.3 Interpretation der Wirkungen 47 48 48 49 7.3 Das MAX-KON-MIN Prinzip 7.3.1 MAXimiere die Primärvarianz: 7.3.2 KONtrolliere die Sekundärvarianz: 7.3.2.1 Experimentell 7.3.2.2 Individuelle Rohdatenanalyse 7.3.2.3 Kovarianzanalytische Kontrolle (“Kovarianzanalyse“) 7.3.3 MINimiere die Fehlervarianz: 7.3.3.1 Randomisierung 7.3.3.2 Blockbildung (Parallelisierung) 7.3.3.3 Wiederholungsmessung 7.3.4 Beurteilung von Kontrolltechniken 7.3.5 Überblick Kontrolltechniken 49 49 50 50 50 50 50 51 51 51 52 52 5 7.4 Vorexperimentelle Versuchspläne 7.4.1 One-Shot Case Study (Schrotschuss-Design) 7.4.2 Einfache Vorher-Nachher-Messung (Prä-Post) 7.4.3 Statischer Gruppenvergleich (z.B. Pisa Studie) 52 52 53 53 7.5 Experimentelle Versuchspläne 7.5.1 Randomisierungspläne (Versuchspläne mit Zufallsgruppenbildung) 7.5.1.1 Zweistichprobenpläne: Zufallsgruppenplan ohne Vortest 7.5.1.2 Zufallsgruppenplan mit Vortest 7.5.1.3 Zufallsgrppenplan mit teilweisem Vortest 7.5.1.4 Mehrstichprobenversuchspläne: einfaktorieller Plan ohne Vortest 7.5.1.5 Zweifaktorieller Zufallsgruppenplan 7.5.1.6 Mehrfaktorieller Zufallsgruppenplan 7.5.1.7 Vorteile / Nachteile Zufallsgruppenpläne 7.5.2 Messwiederholungspläne (Versuchspläne mit wiederholter Messung) 7.5.2.1 Messwiederholung: Beispiel 7.5.2.2 Vorteile / Nachteile: 7.5.2.3 Ausbalancierung der Reihenfolge 7.5.3 Blockversuchspläne 7.5.4 Mischversuchspläne 7.5.5 Zusammenfassung 54 55 55 55 55 56 56 57 57 58 58 58 58 59 60 61 7.6 Quasi-experimentelle Designs 7.6.1 Zeitreihenversuchspläne 7.6.2 Versuchspläne mit unvollständiger Ausbalancierung 7.6.3 Einzelfallversuchspläne 61 62 62 62 7.7 Ex post-facto-Designs 62 7.8 Übersicht: Versuchspläne 62 7.9 Zur Übung: Womit untersuche ich was? 63 8 PRÜFUNGSFRAGEN RAUSCHE / KRÜGER: (AUS DEN LETZEN 4 KLAUSUREN) 64 8.1 Verteilungen 64 8.2 Inferenzstatistik 64 8.3 Testen 66 8.4 Induktion 66 8.5 Deskriptive Statistik 67 8.6 Logik 68 8.7 Wahrscheinlichkeit 69 8.8 Forschungsformen 8.8.1 Wissenschaftstheorie 8.8.2 Messtheorie 71 71 73 8.9 Zufallsvariable 76 8.10 Korrelationen 77 8.11 Versuchsplanung 77 6 8.12 Diverses 77 7 1 Allgemeines & Definitionen 1.1 Methodenanwendung 1.1.1 Definition Alltag vs. Wissenschaft Alltagsverständnis: Zielgerichtetes Handeln (Erreichen eines Zieles) mit Hilfe von planmäßigem und systematischem Vorgehen Wissenschaftlich: aufgrund einer (Anwendungs-) Entscheidung erfolgende Steuerung des zielgerichteten Handelns durch ein Regelsystem, das im jeweiligen Handlungsplan der Akteure repräsentiert und verfügbar ist diese methodenspezifische Handlungssteuerung ist regulativ und weitgehend adaptiv (Methoden angepasst/angemessen) und reflexiv (Regeln gerechtfertigt) 1.1.2 Eigenschaften von „Methoden“ 1. Normativer und präskriptiver (vorschreibender) Charakter 2. Die Befolgung von Regeln wird erwartet, eine Verletzung sanktioniert 3. können in hierarchischem Verhältnis zueinander stehen 1.2 Die Hypothese Eine wissenschaftliche Hypothese formuliert eine Beziehung zwischen zwei oder mehr Variablen, die für eine bestimmte Population vergleichbarer Objekte gelten soll 8 1.2.1 Kriterien für Hypothesen 1. Generalisierbarkeit (All-Satz) - wiss. Hypothese als allgemeingültige, über den Einzelfall hinausgehende Behauptung 2. Konditionalsatz (Wenn-Dann / Je-Desto) - in einer Hypothese muss eine sinnvolle Wenn-Dann Behauptung impliziert sein 3. Falsifizierbarkeit - der Konditionalsatz muss falsifizierbar sein (es muss ein widersprüchliches Ereignis denkbar sein) (keine Formulierung von „kann“ und „es gibt“ Aussagen) 1.2.2 Hypothesenarten 1.2.2.1 Inhaltliche Hypothesen: - verbale Behauptungen über kausale/nicht-kausale Beziehungen zwischen Variablen - abgeleitet aus begründeten Vorannahmen, Modellen oder Theorien - dimensionale und semantische Analyse 1.2.2.2 Statistische Hypothesen: - Zuspitzung der inhaltlichen Hypothese zu einer empirischen Vorhersage des Untersuchungsergebnisses - Formulierung von statistischen Aussagen bezogen auf Maße, die eine inhaltliche Aussage am besten wiedergeben - Def.: Annahmen über die Verteilung einer oder mehrerer Zufallsvariablen oder eines oder mehrerer Parameter dieser Verteilung - Sind nicht deterministisch, sondern probabilistisch; Hypothesen sind Wahrscheinlichkeitsaussagen 1.2.3 5 Schritte eines empirischen Forschungsprozesses 1.2.3.1 Planungsphase - Ziel: Präzisierung der Forschungsfrage, Auswahl von zu erfassenden Variablen, Formulierung von Hypothesen 1.2.3.2 Operationalisierung - Übersetzung in Techniken bzw. Forschungsoperationen - beinhaltet Angaben zur Gestaltung des Messinstruments (z.B. Fragebogen), Angaben zur Handhabung des Messinstruments (z.B. Ort des Interviews, Reihenfolge der Fragen) - Entscheidung bezüglich des Versuchsplans, der Versuchsgruppen, etc. 1.2.3.3 Messung Möglichst sorgfältige Planung vor der Versuchsdurchführung - Abschätzung des zeitlichen Ablaufs - Planung des Einsatzes und der Verwendung von Hilfspersonal, Räumen, Apparaten und ggf. auch Finanzen Regeln für das Verhalten der Versuchsleiter zur Kontrolle von sog. VersuchsleiterArtefakten - Gefahr der Beeinflussung der Untersuchungsergebnisse durch den Versuchsleiter - Kontrollmöglichkeiten 9 o o Beobachtung des Versuchsleiters durch neutrale Beobachter Standardisierung der Versuchsdurchführung Mögliche Störfaktoren einer Messung: - Durchführung der Untersuchung und Datenerhebung Situation: • Untersuchungsort • Untersuchungszeit • Atmosphäre (Leistung vs. Erleben, Technik, Ordnung, weißer Mantel) Versuchsperson: • Motivation: "Intelligente Vp", soziale Erwünschtheit, Vp-Stunden, "Gute Vp", Bewertungsangst • Erwartung: Placebo (daher: mind. Einfachblindversuch) • Prozesse in der Vp: Aktivation, Ermüdung, Lernen, Übung Versuchsleiter: • Erwartung: Rosenthal-Effekt (daher: Doppelblindversuch) • Vp-Vl-Interaktion: Sicherheit, Nervosität, Mann-Frau 1.2.3.4 Datenanalyse - Auswahl und Durchführung von Datenanalysemethoden und –verfahren 1.2.3.5 Interpretation der Daten Interpretation = Erklärung der Ergebnisse (“Warum”-Klären) Bei unerwarteten Ergebnissen mögliche Ursachen diskutieren • theoretische Annahmen • Untersuchungsaufbau, -durchführung und -auswertung • möglicherweise weitere (exploratorische) Datenanalysen anschließen (sog. hypothesenerkundender Teil) 10 Probleme: - Enge Verzahnung der einzelnen Stufen - Notwendigkeit, die einzelnen Stufen des Entscheidungsprozesses simultan zu überblicken - Fehler in vorherigen Versuchsstadien bleiben unbemerkt bzw. unkorrigiert - Dateninterpretation konzentriert sich auf Perfektion bestimmter Versuchsstadien (z.B. statistische Datenanalyse) - Keine abschließende konzeptuelle Neubewertung der Operationalisierungen von UV und AV - Frage der externen Validität nicht erörtert bzw. nicht in Form hypothetischer Schlussfolgerungen für neue Studien diskutiert - Herleitung neuer Fragestellungen orientiert sich nicht bzw. zu wenig an vorhergehenden Versuchsstadien - Es erfolgt keine wissenschaftliche Kommunikation. 1.3 Das Experiment 1.3.1 Defintion Experiment - „Unter einem Experiment versteht man einen systematischen Beobachtungsvorgang, aufgrund dessen der Untersucher das jeweils interessierende Phänomen planmäßig erzeugt sowie variiert ('Manipulation') und dabei gleichzeitig systematische und/oder unsystematische Störfaktoren durch hierfür geeignete Techniken ausschaltet bzw. kontrolliert ('Kontrolle'). Sarris (1990, S. 129) 1.3.2 Hauptmerkmale des Experiments 1. Datengewinnung über systematische Beobachtung (abhängige Variable) 2. Experimenteller Eingriff: Manipulation einer unabhängigen Variablen 3. Ausschalten bzw. Kontrolle von Störvariablen: Sicherstellen, dass nur UV Veränderungen der AV bewirkt. 11 1.3.3 Kontrolltechniken 1.3.3.1 Experimentelle (Instrumentelle) Kontrolltechniken • Anwendung bereits vor der Datenerhebung • Anwendung apparativer Techniken • z.B. Abschirmung, Eliminierung, Konstanthaltung 1.3.3.2 Versuchsplanerische Kontrolltechniken • Anwendung vor der Datenerhebung • Anwendung bestimmter Versuchsplanungsstrategien • z.B. Randomisierung, Parallelisierung, Wiederholungsmessung 1.3.3.3 Statistische Kontrolltechniken • Anwendung erst nach der Datenerhebung • z.B. allgemeine statistische Kontrolle, kovarianzanalytische Kontrolle 1.3.4 Logik des Experiments Ziel: Verifizierung einer Kausalursache Die UV ist kausal verantwortlich für die Veränderung der AV, d.h. aus der UV folgt die AV. Wenn ich zum Zeitpunkt 1 die Stufe der UV setze, tritt bei Zeitpunkt 2 notwendig die Veränderung der AV auf. Zeitfolge des Experiments: o Ursache vor Wirkung o UV vor AV Problem: • In der Zeit geschehen viele Dinge. Wie kann ich sicher sein, dass es nur die UV ist, die wirkt? Lösung: • Ich stelle Situationen her, die sich nur durch die Ausprägung der UV unterscheiden. • Verändert sich dann die AV, dann können die Ursache hierfür nur die Unterschiede in der UV gewesen sein. Vorgehen: • Systematische Manipulation der UV • Kontrolle von Störvariablen 1.3.5 Problemkreise Experiment 1. Ist es wirklich die UV, die die Veränderungen der AV verursacht? Design des Experiments, Interne Validität 2. Sind die Veränderungen der AV bedeutsam, d.h. größer als "zufällige" Schwankungen? • Planung: Max-Kon-Min-Prinzip • Prüfung: Inferenzielle Statistik 3. Für wen gelten die Ergebnisse meines Versuchs, inwieweit kann ich die Ergebnisse verallgemeinern, übertragen auf andere Personen, Situationen, Variablen? • Operationalisierung, Externe Validität 12 1.4 Der Versuch 1.4.1 Übersicht „Versuchspläne“ 1. Experimentelle Designs - systematische Manipulation relevanter Variablen - Kontrolle von Störfaktoren, die die Interpretierbarkeit und Gültigkeit der Ergebnisse beeinträchtigen könnten 2. Quasi-experimentelle Designs - systematische Manipulation relevanter Variablen - keine Kontrolle von Störfaktoren 3. Ex post-fakto-Designs - Ableitung von Kausalzusammenhängen aus nicht-manipulierten Variablen 4. Korrelative Designs - Prüfung des korrelativen Zusammenhangs zwischen zwei oder mehr Variablen 1.4.2 Versuchsleiter-Artefakte Problem der Vp-Vl-Interaktion: Abweichung des Versuchsleiterverhaltens vom geplanten Verhalten Dadurch: Gefahr der Beeinflussung des Untersuchungsergebnisses durch Versuchsleiter Kontrollmöglichkeiten: Beobachtung des Versuchsleiters durch neutrale Beobachter Standardisierung der Versuchsdurchführung Regeln für das Verhalten der Versuchsleiter zur Kontrolle von sog. VersuchsleiterArtefakten Kontrolle von Versuchsleiter-Artefakten 1. standardisierte Instruktion 2. Konstante Untersuchungsbedingungen (z.B. Beleuchtung, Geräusche, Temperatur) 3. Selbstkontrolle des Versuchsleiters (z.B. auf eigene Stimmung achten und ggf. protokollieren) 4. Verwendung sog. blinder Versuchsleiter (sind selbst nicht eingeweiht) 5. Einhalten eines zeitlichen Ablaufs 6. Untersuchungsleiter soll Vorerhebung selbst durchführen 7. Nachbefragung nach Beendigung des Hauptteils des Versuchs 8. Aufzeichnung des gesamten Versuchs per Video 9. Abweichungen vom geplanten Ablauf in einem Untersuchungsprotokoll festhalten (z.B. mögliche Zwischenfragen der Probanden) 1.4.3 Funktion des Signifikanztests 1. Als Screening-Prozedur - wo lohnt es sich genauer hinzuschauen? 2. als zufallskritische Absicherung - Ist das Ergebnis auch bei zufälliger Zuweisung wahrscheinlich, oder ist es unwahrscheinlich? 1.5 Deskriptive Statistik 1.5.1 Statistische Symbole M= Mittelwert 13 SD = SE = df = Standardabweichung Standardfehler Zahl der Freiheitsgrade Bezeichnung für die Anzahl von Werten, die innerhalb der Begrenzungen eines Systems von Werten frei variieren oder gewählt werden können. Anders formuliert: Die Anzahl der Freiheitsgrade v ist definiert als die Differenz aus dem Stichprobenumfang n und der Anzahl k der aus den n Stichprobenmeßwerten berechneten Parameter v=n-k. Freiheitsgrade werden auch als explizite Parameter verwendet, so ist v der einzige explizite Parameter der Chi-Quadrat-Verteilungsfunktion. QS = Quadratsumme N= n= Anzahl der Pbn in Gesamtstichprobe Anzahl der Pbn in Teilstichprobe Graphische Darstellung eines Boxplots: 1.5.2 Kennwerte der zentralen Tendenz (Lage) Mittelwert (arithmetisch, geometrisch, harmonisch) • Voraussetzung: Intervallskalierte Daten • Empfehlung: Ø Berechnung anderer Kennwerte (z.B. Varianz) Ø symmetrische Verteilung (insb. bei NV-Annäherung) Ø Frage nach “Schwerpunkt” der Verteilung Medianwert 14 • Voraussetzung: Ordinalskalierte Daten • Empfehlung: Ø schiefe Verteilung (insb. falls Extremwerte auf einer Seite der Verteilung betrachtet werden sollen) Ø Untersuchung der “oberen” und “unteren” Hälfte der Messwertverteilung Ø nur unvollständige Verteilung liegt vor Modalwert • Voraussetzung: Nominalskalierte Daten • Empfehlung: Ø schnellstmögliche Kenntnis des zentralen Wertes Ø grobe Schätzung der zentralen Tendenz Ø “typischer Fall einer Verteilung wird benannt 1.5.3 Kennwerte der Dispersion (Variabilität) Standardabweichung (Varianz) • wichtigstes Maße zur Kennzeichnung der Dispersion • Voraussetzung: Intervallskalierte Daten • Empfehlung: Ø wenn alle Werte in Berechnung einbezogen werden sollen Bereichsmaße (Streubreite, Interquartilbereich etc.) • Voraussetzung: Ordinalskalierte Daten • Empfehlung: Ø zur ersten Orientierung hilfreich Ø starke Ausreißerempfindlichkeit (Lösung: gestutzte Streubreite) Informationsmaß h (Entropie) • Voraussetzung: Nominalskalierte Daten 1.5.4 Kennwerte der Schiefe (Abweichung von der Symmetrie) 1.5.5 Kennwerte des Exzess (Steilheit, Gipflichkeit, Kurtosis) 1.6 Variablen der Psychologie 1.6.1 UV / AV Unabhängige Variable (UV): - vom Versuchsleiter direkt oder indirekt verändert (durch Manipulation oder Selektion) - auch: sog. Reizvariable Abhängige Variable (AV): - Ereignis, das die Folgen der Manipulation der UV beobachtet - Einfluss von Störeinflüssen ist wahrscheinlich - Versuchsleiter hat auf AV keinen direkten Einfluss - auch: sog. Reaktionsvariable Behauptung: - Abstufungen der UV verändern systematisch die AV. - Aus der Veränderung der UV folgt die Veränderung der AV 15 Funktionale Beziehung: AV = f(UV) Bei: interne Validität = 100% => keine Störvariablen 1.6.2 Weitere Variablentypen Moderierende Variable: - Beeinflussung der Wirkung der UV auf die AV - AV = (f (UV, moderierende Variable) - Moderierende Variable ist z.B. eine Organismusvariable (z.B. Alter) Kontrollvariable: - moderierende Variablen werden zu Kontrollvariablen, wenn sie bei Untersuchungen miterhoben werden Störvariable (SV): - Moderierende Variablen werden zu Störvariablen, wenn sie nicht beachtet oder sogar übersehen werden - Kontrolle der Störvariablen mittels experimenteller Techniken 1.6.3 Klassifikation von Variablen Gemäß ihrer empirischen Zugänglichkeit - manifeste Variable (direkt beobachtbar; z.B. Anzahl gelöster Testaufgaben) - latente Variable (nicht beobachtbar, liegt einer manifesten Variable als hypothetisches Konstrukt zugrunde, z.B. Intelligenz) Klassifikation von Variablen Gemäß Art der Merkmalsausprägung - dichotom (2 Abstufungen) vs. polytom (mehr als 2 Abstufungen) - natürlich (z.B. Geschlecht) vs. künstlich (z.B. Alter: jung – mittel – alt) 2 Gütekriterien 2.1 Gütekriterien einer Messung Reliabilität - Grad der Genauigkeit, irgendetwas zu messen (Streuung um die Mitte eines Ziels) Validität - Grad der Genauigkeit, wirklich das zu messen, was ich messen möchte (Streuung um eine andere Stelle auf der Zielscheibe) Objektivität - Grad der Unabhängigkeit der Ergebnisse vom Untersucher 2.1.1 Gütekriterium: Objektivität Durchführungsobjektivität - Unabhängigkeit der Ergebnisse von zufälligen oder systematischen Verhaltensvariationen des Untersuchers während des Versuchs - z.B. Versuchsleitereffekte Auswertungsobjektivität - Unabhängigkeit der Ergebnisse von Variationen des Untersuchers während der Auswertung - insb. bedeutsam bei Verfahren mit vielen Freiheitsgraden (z.B. projektive Tests, freies Interview) Interpretationsobjektivität - Unabhängigkeit der Ergebnisse von interpretierender Person - Insb. wenn ein Ergebnis unterschiedliche Schlüsse zulässt 16 Bestimmung durch: - Korrelation zwischen Ergebnissen verschiedener Untersucher 2.1.2 Gütekriterium: Reliabilität Paralleltest-Reliabilität - vergleichbare Paralleltests werden identischen Stichproben vorgegeben und deren Ergebnisse miteinander korelliert Retest-Reliabilität - ein und derselbe Test werden einer Stichprobe mehrmals vorgegeben und die Ergebnisreihen miteinander korreliert Innere Konsistenz - ein Test wird in zwei gleichwertige Hälften geteilt und die Ergebnisse beider Testhälften miteinander korreliert (Testhalbierungsmethode) - Ein Test wird in beliebig viele Testelemente geteilt und die Reliabilität über Aufgabenschwierigkeit und Trennschärfekoeffizienten bestimmt (Methode der Konsistenzanalyse) (nach Lienert und Raatz) 2.1.3 Gütekriterium: Validität Inhaltliche Validität - Genauigkeit, mit der ein zu untersuchender Inhalt (z.B. Persönlichkeitsmerkmal, Verhaltensweise) gemessen wird - Verfahren ist optimale Möglichkeit, um Inhalte zu erfassen - Bestimmungsmaß: Rating von Experten Konstruktvalidität - Genauigkeit, mit der ein zu untersuchendes Konstrukt (z.B. Eigenschaft, Fähigkeit) gemessen wird - Bestimmungsmaß: Rating von Experten Kriterienbezogene Validität - Genauigkeit, mit der ein untersuchter Aspekt mit einem unabhängig vom Test erhobenen Außenkriterium übereinstimmt - Bestimmungsmaß: Korrelation des Testergebnisses mit Außenkriterium Interne Validität - die Veränderungen der AV sind „eindeutig“ auf die Variationen der UV zurückzuführen - Annahme: Manipulationen der UV bedingen Veränderungen der AV Externe Validität - Übertragbarkeit der Ergebnisse auf Nicht-Stichprobe (Generalisierbarkeit der Ergebnisse) - Problematisch insbesondere, wenn unter “realen Bedingungen” auch andere Faktoren als in der Untersuchung eine Rolle spielen. Interne Validität ist eine notwendige, jedoch keine hinreichende Bedingung für externe Validität. 2.2 Stichproben Annahme: • Auch eine sorgfältig gezogene Stichprobe kann die Merkmalsverteilung einer Grundgesamtheit niemals exakt wiedergeben. • Daher sind Unterschiede zwischen den an mehreren Stichproben ermittelten Verteilungskennwerten zu erwarten. 17 Grundgesamtheit (Population) • Alle potenziell untersuchbaren Einheiten, die ein gemeinsames Merkmal / eine gemeinsame Merkmalskombination aufweisen Stichprobe: • Teilmenge aller Untersuchungseinheiten, die die relevanten Eigenschaften der Grundgesamtheit möglichst gut abbildet. • Globale Repräsentativität (alle Merkmale repr.) vs. spezifische Repräsentativität (ein Merkmal repr.) • Je besser die Stichprobe die Population repräsentiert, desto präziser sind die Aussagen über die Grundgesamtheit. • Je größer die Stichprobe, desto präziser sind die Aussagen über die Grundgesamtheit. 2.2.1 Zufallsstichprobe Grundprinzip: • Jedes Element der Grundgesamtheit kann mit gleicher Wahrscheinlichkeit in Stichprobe aufgenommen werden • unabhängig von weiteren Elementen Vorgehen: • zufällige Auswahl von Untersuchungseinheiten aus einer Grundgesamtheit • Beispiel: Stichprobenauswahl über Einwohnermeldeamt Empfohlener Einsatz: • Wenn über relevantes Untersuchungsmerkmal praktisch nichts bekannt ist. Problem: • Mögliche systematische Fehler im Auswahlverfahren (z.B. Tageszeit der Befragung) 2.2.2 Klumpenstichprobe Vorgehen: • Zurückgreifen auf mehrere, zufällig ausgewählten Teilmengen, die bereits vorgruppiert sind • Untersuchung aller Einheiten dieser Teilmengen • Beispiele: Alkoholikern in verschiedenen Kliniken • Untersuchung eines einzelnen Klumpen (z.B. Schulklasse) ist eine Ad-hoc-Stichprobe Empfohlener Einsatz: • aus ökonomischen Zwängen Problem: • Generalisierbarkeit hängt ab von Ähnlichkeit der Einheiten in einem Klumpen 2.2.3 Geschichtete (stratifizierte) Stichprobe Vorgehen: • Stichproben zusammenstellen, die sich bezüglich einer das Untersuchungsmerkmal moderierenden Variable unterscheiden (eigene Einteilung nach relevantem Merkmal) • Innerhalb einer Schicht soll per Zufall oder nach dem Klumpenverfahren vorgegangen werden. • proportional geschichtet: Prozentuale Verteilung der Schichtungsmerkmale der Stichprobe stimmen mit Verteilung in Grundgesamtheit überein (40% Frauen und 60% Männer in einer Population) 18 • Beispiel: Berücksichtigung des Jahreseinkommens bei der Untersuchung von Konsumgewohnheiten Empfohlener Einsatz: • Wenn bereits Kenntnisse zu moderierenden Einflüssen auf das Untersuchungsmerkmal vorliegen. • Einsatz nur, wenn Schichtungsmerkmale nicht nur mit Untersuchungsmerkmal korrelieren, sondern zugleich erhebbar sind. Problem: • Nicht Anzahl der geschichteten Merkmale bestimmt Repräsentativität der Stichprobe, sondern die Relevanz der Merkmale. • Explosion der Schichtanzahl bei mehreren Schichtungsvariablen. 2.2.4 Zufallsgesteuerte Stichproben: Sonderfall Mehrstufige Stichprobe: Vorgehen • Es werden Klumpenstichproben oder geschichtete Stichproben ausgewählt. • Stichprobenartige Untersuchung mehrerer Klumpen bzw. Schichten Einsatz: • Falls zu untersuchende Klumpen oder Schichten zu groß 2.2.5 Nicht-zufallsgesteuerte Stichproben Auswahl der Stichprobe anhand definierter Kriterien • Befragung von fotogenen Passanten in “Rush-Hour” in Einkaufspassage willkürliche Auswahl anhand subjektiver Kriterien • Einbezug von “typischen” Konsumenten bei Produktentwicklung • Konzentration auf besonders dominante Elemente der Grundgesamtheit (z.B. Einkommensmillionäre) Auswahl nach Konzentrationsprinzip 2.2.6 Quoten-Stichproben Vorgehen: • Auswahl einer Stichprobe unter Berücksichtigung der prozentualen Verteilung der relevanten Merkmale in der Gesamtpopulation • Auswahl der Einheiten innerhalb dieser Quoten bleibt i.d.R. dem Untersucher überlassen Einsatz: v.a. in Umfrageforschung Probleme: • Nur prozentuale Aufteilung der Quotierungsmerkmale wird betrachtet, i.d.R. fehlende Betrachtung von Merkmalskombinationen • Interviewer erfüllt Quote nicht nach Zufallsprinzip, sondern häufig nach Verfügbarkeitsprinzip (z.B. Vernachlässigung höherer Stockwerke) 2.2.7 Stichproben und Repräsentativität Stichprobenkennwerte repräsentieren Populationsparameter mit bestimmter Wahrscheinlichkeit Aber: Eine “repräsentative” Stichprobe gibt es im Grunde genommen nicht !!! Frage: Sind die empirischen Kennwerte adäquate Schätzwerte für die Populationsparameter? 19 Lösung: • Schätzung des Konfidenzintervalls, um Aussagen über Repräsentativität der Ergebnisse zu erlauben 2.2.8 Konfidenzintervalle und Stichprobenumfänge - Bereich eines Merkmals, in dem sich z.B. 95% aller möglichen Populationsparameter befinden, die den Stichprobenkennwert erzeugt haben können. Je größer die Stichprobe, desto kleiner das Konfidenzintervall. Vor Durchführung einer Untersuchung sollte entschieden werden, wie viele Personen benötigt werden, um Aussagen mit der gewünschten Genauigkeit machen zu können. Eine Verkleinerung des Konfidenzintervalls geht mit einer Quadrierung des benötigten Stichprobenumfangs einher. Beispiel: Halbierung des KI 4facher Stichprobenumfang 2.3 Faktor Zeit (beeinflusst interne Validität) unabhängig abhängig generell Geschichtlichkeit Selektion u. Messeffekte speziell Entwicklung Test- und Lerneffekte 2.3.1 Geschichtlichkeit: - vom Untersucher unabhängig und genereller Effekt I. besonderes Jahr - über lange Zeiträume hinweg gibt es immer wieder „zufällig“ Schwankungen - Bsp: Verringerungen der Unfallzahlen durch Tempolimiteinführung II. Kohorteneffekte - Bsp: Abnahme der kognitiven Leistungsfähigkeit mit steigendem Alter aber: Folgen früherer Lebensbedingungen? (z.B.: Erleben von Hungerjahren) 2.3.2 Entwicklung: - von Untersucher unabhängig und spezieller Effekt Beispiel I: Regelung - Regressionseffekt B (negative Rückkopplung) - Ausgangslagegesetz von Wilder: „Negative Korrelation zwischen Ausgangswert und Veränderungswert“ je weiter der Ausgangswert vom Mittelwert abweicht, desto größer ist die Veränderung Beispiel: Regulation des Pulses: Stress vor dem Versuch (hoher Puls) kein Stress während des Versuchs (nied. Puls) Beispiel II: Entwicklungseffekte - Individualentwicklung: Spontanremission bei Therapie liegt bei 60%; Pbn werden müder, hungriger, lustloser - Mortalität: Stichprobe wird gesünder, je älter sie wird (die Kranken sterben) 2.3.3 Selektion und Messeffekte: - vom Untersucher abhängig und genereller Effekt Beispiel I: Regressionseffekt A 20 Ergebnisse von fehlerhaften Messinstrumenten tendieren bei erneuter Messung zur Mitte Beispiel II: Änderung der Messinstrumente - Messfühler verstellen sich - Beobachter ermüden - 2.3.4 Test- und Lerneffekte: - vom Untersucher abhängig und spezieller Effekt Beispiel I: Lernen aus vorhergehender Untersuchung Beispiel II: Residualeffekte im Cross Over - Wirkung einer Behandlung ist trotz „Cross Over“ stets durch personenbedingte Störeinflüsse „verunreinigt“ Beispiel III: Experimentelle Mortalität - 6-Monats-Katamnese von therapeutischen Interventionen: Klienten mit Nebenwirkungen, Rückfällen, etc. kommen nicht mehr. Folge: Entscheidung, welche Veränderungen auf Behandlung zurückzuführen sind, schwer möglich 2.4 Gefährdung der externen Validität durch mögliche: 1. Reaktive Effekte der Experimentalsituation - Veränderungen des Verhaltens durch Situation - Z.B. sozial erwünschte Antworten in Interviews, Reaktanz der Pbn (entgegen der Hypothese), Demand-Effekte (zugunsten der Hypothese) 2. Interaktion von Vortest und UV - durch Vortest kann Sensitivität der Pbn gegenüber UV beeinflusst (erhöht o. verringert) und somit das Verhalten im Haupttest verändert werden (Sensibilisierung verfälscht Messung) - z.B. Kurzinterview zur Vorauswahl einer Stichprobe, anschließend experimentelle Untersuchung 21 3. Einflüsse bei Mehrfachmessungen - z.B. sukzessive Einnahme verschiedener Medikamente 4. Interaktion von Selektionseffekten und UV - Fehler bei Selektion können zur Konfundierung (Überlagerung) der Ergebnisse mit den durch die UV bedingten Veränderungen der AV führen - Bsp: Bedeutung der Wirkung eines kognitiven Trainings auf Problemlösefähigkeit kann nur schwer eingeschätzt werden, wenn in der KG intelligentere Pbn sind - Bsp: Wirkung von Nikotin, kann nicht unabhängig vom Rauchverhalten betrachtet werden 3 Forschungsformen 3.1 Laborforschung Vorteile: 1. Situation und Verhalten leichter manipulierbar 2. Störvariablen können besser kontrolliert werden 3. Schaffung optimaler Bedingungen für die Untersuchung Nachteile: 1. Die Umgebung ist ungewohnt und unnatürlich ( Gewöhnungsphase) 2. Die Personen wissen, dass die untersucht werden und verändern so u.U. ihr Verhalten 3. Übertragbarkeit der Ergebnisse auf normales Verhalten (Externe Validität) in Frage gestellt 3.2 Feldforschung Vorteile: 1. Natürliche Umgebung 2. spontanes, „normales“ Verhalten 3. besser übertragbar auf natürliches Verhalten 4. keine oder geringe Verfälschung durch „Wissen um die Studie“ Nachteile: 1. Störvariablen schlecht zu kontrollieren 2. Manipulation von Situation und Verhalten schwierig 3. Das Verhalten ist schwer zugänglich 4. die Untersuchungsbedingungen sind nicht optimal 3.3 Labor vs. Feld Allgemeiner Konsens - Laborforschung Hohe interne Validität, geringe externe Validität - Feldforschung Geringe interne Validität, hohe externe Validität ABER: - keine systematischen Vergleiche von Labor- und Feldforschung - Konsens unterliegt einer Betrachtung der Pole möglicher Labor- vs. Feldforschung Wann was? Abhängig vom aktuellen Erkenntnisstand - liegen viele Laborstudien vor, die intern valide Methoden vorschlagen, dann Feldstudie 22 3.4 Web-Experimente Merkmale Ergänzung zu klassischer Feld- und Laborforschung Unterschiede zu klassischer Laborforschung - „Versuch kommt zum Probanden“ (inkl. den dort wirkenden Störvariablen keine Kontrolle - Pbn können jederzeit Versuch abbrechen - Abhängigkeit von technischer Ausstattung der Netzwerke und Computer (Geschwindigkeit, Auflösung, Darstellbarkeit) - Untersuchung von heterogener Population und z.T. sehr großen Stichproben (n > 1000) 3.4.1 Webexperimente (Vor- / Nachteile) Vorteile: - Untersuchung heterogener Populationen (demographische und soziale Merkmale) - Zugang zu spezifischen Populationen - Hohe externe Validität (Generalisierbarkeit auf Populationen, Settings und Situationen) - Keine organisatorischen Probleme - Pbn nehmen freiwillig teil - Pbn-Motivation ist bestimmbar - Sehr große Stichproben (hohe statistische Power) - Geringe Kosten (Raum, Zeit, Ausstattung, Durchführung) - Hoher Automatisierungsgrad (Kontrolle von Vp-VL-Effekten, Demand-Effekten, Einflüsse des VL) Nachteile: - Möglichkeit einer Mehrfachteilnahme des Pbn (Lösung: Personalisierungsitems, Überprüfung der innernen Konsistenz und Zeitkonsistenz der Antworten) - v.a. mit between-Faktoren umsetzbar - Auswahlfehler bei Stichprobenzusammensetzung (Lösung: Multiple Site-Entry Technique - Fehlende VL-Vp Interaktionen (Lösung: Vorversuche zu Instruktionen und Material) - Dropout-Quote - Interne Validität gefährdet (keine Kontrolle, was nebenbei passiert) 3.4.2 Verweigerung von Informationen (Drop Outs) Item-Non-Response - Verweigerung auf einzelne Items bezogen Lösung: - alle Fragen müssen beanwortet werden Unit-Non-Response - komplette Verweigerung der Auskunft Lösung: - finanzielle Anreize - persönliche Fragen zu Versuchsbeginn - keine ladeaufwändigen Inhalte verwenden (Sounds, Bilder, Filme) 23 3.4.3 Dropout Quote 3.4.3.1 Zur Bestimmung: - Verwendung von „One-Item-One-Screen“-Design (um Abbruch zu lokalisieren) oder mindestens Multipage-Design - Vermeidung von Single-Web-Pages - „weiss nicht/will nicht“ Optionen 3.4.3.2 3 Techniken zur Verringerung 3.4.3.2.1 High-Hurdle Technique - auf die Motivation negativ wirkende Informationen (zu lang, zu schwierig) werden möglichst konzentriert am Versuchsbeginn dargeboten - auf den folgenden Seiten werden Konzentration und Bedeutung kontinuierlich reduziert Ziel: nur motivierte Versuchspersonen nehmen teil 3.4.3.2.2 Warm-Up Technique - Dropouts treten zumeist nach einigen wenigen Seiten auf Pbn orientieren sich im Versuch & entscheiden dann, ob sie endgültig teilnehmen Hauptteil des Versuchs findet erst nach einigen Webseiten statt; zuvor Instruktion, Übungsseiten 3.4.3.2.3 Seriousness-Check - Abfrage der Involviertheit der teilnehmenden Pbn zu Versuchsbeginn Bei geringem Involviertheits-Scores: - Nicht -Zulassung des Pbn vor Versuchsbeginn - Nicht-Auswertung des Pbn in Auswertephase Allgemeines Problem der internen Validität: - fehlende Kontrolle, ob der Proband (überhaupt), angemessen (oder tatsächlich) auf den Stimulus reagiert - Aufzeichnung von Computermerkmalen (Browsertyp, Betriebszeiten, Bildschirmmerkmalen (Größe, Auflösung, Farbe, Ladezeiten) 3.5 Einzelfallforschung 3.5.1 Allgemeine Definition: Eine Untersuchungseinheit - eines einzelnen Individuums (z.B. bei seltenen Krankheiten) - einer Menge von Individuen, die als Kollektiv betrachtet werden (z.B. Vereine, Kulturen - häufig mittels nicht- oder wenig standardisierter Verfahren mit dem Ziel: - detaillierte und sorgfältige Beschreibung des Phänomens - Hypothesengenerierung 3.5.2 Vorteile: - seltene Phänomene sind beschreibbar 24 - Problem der Übertragbarkeit von statistischen Gruppenkennwerten auf Einzelfälle ergibt sich nicht Bei Auswahl von Einzelfällen sind Voraussetzungen z.B. einer Zufallsstichprobe nicht notwendig Annahme: Ergebnisse (z.B. bei Prä-Post-Messungen) werden häufig so behandelt, als wären sie unabhängig voneinander. Einzelfallforschung ist bei Mehrfacherhebung stets abhängig und kann durch spezielle Verfahren kontrolliert werden 3.5.3 Nachteile: Problem der Replizierbarkeit der Ergebnisse, um eine Gesetzmäßigkeit zu beschreiben - Replikation mittels Variation der Zeit- und Personenvariable - Replikation mittels Kombinationen von Setting-, Zeit-, Probanden-, Versuchsleiterund Störvariablen Zusammenfassung von Einzelergebnissen (sog. Aggregation) ist problematisch - Möglichkeit bei vielen Einfallanalysen: Varianzanalysen mit standardisierten Zeitreihenwerten (z.B. z-Werte) Geringe Verallgemeinerbarkeit der Ergebnisse auf nicht untersuchte Elemente 3.6 Längsschnittstudien 3.6.1 Definition: (von Baltes 1967) - Dieselbe Stichprobe von Individuen wird mehrmals zu verschiedenen Zeitpunkten mit demselben oder einem vergleichbaren Messinstrument untersucht. Beispiele: - Untersuchung der kognitiven Entwicklung über den Zeitraum des Kindesalters - Einstellungsänderung durch Interventionsprogramme (z.B. AIDS-Kampagne) 3.6.2 Vorteile: - Unterschiede in den Messwerten dürfen als intraindividuelle Veränderungen interpretiert werden (Veränderung innerhalb einer Person) Unterschiede innerhalb der Stichprobe dürfen als interindividuelle Unterschiede interpretiert werden Für Auswertung von abhängigen Stichproben stehen effizientere statistische Verfahren zur Verfügung. 3.6.3 Nachteile: 1. Geschichtlichkeit - Anwendbarkeit derselben Methode über längeren Zeitraum bzw. in verschiedenen Altersgruppen fraglich (IQ Tests in unterschiedlichem Alter) - Einfluss geänderter Umweltbedingungen 2. 3. 4. 5. Entwicklung: Mortalität und Alterung der Probanden Testeffeke: Lerneffekte (z.B. d-2-Test), reaktive Effekte Konzentration i.d.R. auf eine Stichprobe Untersuchungsverfahren sind im Verlauf der Studie nicht mehr veränderbar, ohne die Vergleichbarkeit der Ergebnisse zu gefährden. 25 3.6.4 Panel Forschung 3.6.4.1 Panelforschung als Beispiel einer Längsschnittstudie • In bestimmten zeitlichen Abständen werden bei denselben Untersuchungseinheiten dieselben Merkmale erhoben Ziel: Erforschung von Wandlungsprozessen • intraindividuelle Veränderungen im Zeitablauf • interindividuelle Veränderungen im Zeitablauf Beispiele: Sozioökonomisches Panel der BRD • ca. 6000 Haushalte (Angehörige > 16 Jahre) • Angaben zu Erwerbstätigkeit, demographischen Inhalten etc. 3.6.4.2 Testeffekte Lerneffekte • abhängig von Anzahl der Panel-Erhebungen (sog. Wellen) • abhängig von zeitlichem Abstand zwischen den einzelnen Panel-Erhebungen Reaktive Effekte • Veränderung bzw. Genese von Einstellungen und Verhaltensweisen • z.B. verändertes Kaufverhalten durch erhöhtes Preisbewusstsein 3.6.4.3 Weitere Nachteile: Mortalität: Ausfall von Erhebungseinheiten • bis zu 60% der Ausgangsstichprobe • zufällige Ausfälle (z.B. Tod, Krankheit, Umzug) • systematische Ausfälle (z.B. Untersuchungsmüdigkeit, Desinteresse) Ø können mit erhobenen Merkmalen zusammenhängen Ø “Effekt der positiven Selbstauswahl” Selektionseffekte: • Bereits in der Anwerbephase stellt sich das Problem der Verweigerungsquote (> 20%) Geschichtlichkeit • bei Langzeit-Panels kann sich Bedeutungsumfang und –inhalt verändert, so dass Vergleichbarkeit der Daten fraglich ist. 3.6.4.4 Lösungsvorschläge Bildung einer sehr großen Ausgangsstichprobe, so dass bis Ende der Panel-Studie hinreichend viele Einheiten erhalten bleiben • Problem der positiven Selbstauswahl bleibt erhalten Auffüllen der ausgefallenen Einheiten • Problem des Aufrechterhaltens der Repräsentativität der Untersuchungseinheiten Anwendung verschiedener Panel-Designs 3.6.4.5 Alternierendes Panel Bildung von Subgruppen, die abwechselnd bei den Wellen untersucht werden Vorteil: Verminderung der Lern- und Testeffekte Nachteil: Notwendigkeit eines relativ großen Stichprobenumfangs, da noch Mortalität zu berücksichtigen 26 3.6.4.6 Rotierendes Panel Bildung von Subgruppen, die bei ersten Welle alle erhoben werden Bei zweiter Welle scheidet eine Subgruppe aus und wird durch eine neue Subgruppe ersetzt etc.; Gruppe 3 und 5 werden nur einmal befragt (Ø Querschnittsstudie) Vorteil: Problem der positiven Selbstauswahl wird vermindert Nachteil: Design sehr aufwändig, da bei jeder Erhebung neue Subgruppe gebildet werden muss 3.6.4.7 Geteiltes Panel Bildung von 2 Subgruppen • Eine Subgruppe läuft alle Wellen durch • Zweite Subgruppe wird nach jeder Welle durch eine neue Subgruppe ersetzt Gruppen 2 bis 5 werden nur einmal befragt (Ø Querschnittsstudie, Kontrollgruppen für Gruppe 1) Nachteil: Design sehr aufwändig, da bei jeder Erhebung neue Subgruppe gebildet werden muss 3.7 Querschnittstudien Definition von Trautner (1978) - zu einem bestimmten Zeitpunkt werden mehrere Stichproben von Individuen mit demselben oder einem vergleichbaren Messinstrument jeweils einmal untersucht. Beispiel: - Untersuchung der kognitiven Entwicklung im Kindesalter: Vergleich verschiedener Altersstufen zu einem gegebenen Zeitpunkt 27 3.7.1 Vorteile: - Kurze Durchführungsdauer der Untersuchung Geringer Personalaufwand Umfang der Stichprobe bleibt im Erhebungszeitraum konstant 3.7.2 Nachteile: - Unterschiede in Versuchsgruppen können durch Unterschiede zwischen Gruppen oder zwischen Probanden bedingt sein Unabhängige Stichproben erlauben keine Aussagen zu intraindividuellen Unterschieden Für unabhängige Stichproben stehen weniger effiziente statistische Verfahren zur Verfügung Generalisierbarkeit der Befunde über den Zeitpunkt der Untersuchung hinaus ist streng genommen nicht erlaubt. 3.8 Sekundäranalysen 3.8.1 Primäranalysen: - selbstständige Datenerhebung als wesentlicher Bestandteil des Forschungsvorhabens 3.8.2 Sekundäranalysen: - Rückgriff auf bereits existierende Datenbestände Beispiele: - Wirtschaftsforschung (Bruttoinlandsprodukt…) - Metaanalysen zur Abschätzung der Wirksamkeit verschiedener Therapieformen - Literaturreview Einfluss von Mobiltelefonieren auf Fahrzeugführung 3.8.2.1 Vorteile: - Kosteneinsparung (z.B. keine Versuchsmaterialien) - Schnelle Verfügbarkeit - Geringer Aufwand - Nachkontrollierbarkeit 3.8.2.2 Nachteile: - Daten werden i.d.R. für anderen Zweck erhoben - Qualität der Daten hängt vom Vorgehen der Untersucher ab - Mögliche Abweichung der Grundgesamtheit, Auswahl der Erhebungs- und Untersuchungseinheiten, Begriffsdefinitionen und Operationalisierungen vom eigenen Projekt - Daten sind u.U. veraltet 28 4 Beobachtung 4.1 Definition Beobachtung 1. Beobachtung ist die grundlegende Methode der Datengewinnung in den empirischen Wissenschaften 2. Beobachtung: Sammeln von Erfahrung im nicht-kommunikativen Prozess mit Hilfe sämtlicher Wahrnehmungshilfen (Laatz, 1993) 3. „Beobachtung“ umfasst die verschiedensten Methoden: Ablesen von Skalen Auswerten von Fragebögen Beobachten von Verhalten Ablesen von Testergebnissen (z.B. Reaktionszeiten) Alltagsbeobachtung - unsystematisch, naiv, ohne Theorie, willkürlich Wissenschaftliche Beobachtung - zielgerichtet, methodisch kontrolliert Dazu: Zielgerichtet: - aufgrund beschränkter Informationsverarbeitungskapazität des Beobachters - Implikation: Beobachter hat Theorie über Beobachtungsgegenstand - nur relevante Merkmale werden beobachtet Methodische Kontrolle: - Kontext der Beobachtung: (Wo, wann, warum,…) - Beobachterverhalten: Wahrnehmung ist aktiver Prozess - Speichern der Beobachtung: Zugriff auf Ergebnisse muss jederzeit möglich sein (Forderung: Entwicklung von Kategoriensystemen) - Wahrnehmung per definitionem ist subjektiv - Nachvollziehbarkeit 4.2 Beobachtungssysteme (Kodierung von Beobachtung) 4.2.1 Verbalsysteme: - möglichst genaue verbale (freie) Beschreibung von Verhaltensweisen Vorteil: umfassend, nichts vorgegeben 4.2.2 Nominalsysteme: - Kodierung von Verhaltensweisen nach einem vorgegebenen Schema. (vgl. Tagebücher) Katalog möglicher Verhaltensweisen, die möglichst genau definiert und beschrieben sind. Ein Zeichen (Code) dafür festlegen. 29 4.2.2.1 Zeichensysteme a. Zeichen schließen sich nicht gegenseitig aus, d.h. mehrere Zeichen pro Beobachtungseinheit ( mehrere Codezeichen gleichzeitig möglich!) (Unterschiedliche Verhaltensweisen können mit demselben Zeichen bezeichnet werden) b. Nicht vollständig, d.h. für manche Beobachtungseinheiten auch keine Codierung möglich. Vorteil: geringe Zahl von Beobachterkategorien Nachteil: mögliche Überlastung des Beobachters 4.2.2.2 Kategoriensysteme c. Kategorien schließen sich gegenseitig aus, d.h. pro Beobachtungseinheit nur ein Zeichen (Kategorie) d. Jedes Verhalten ist kodierbar, d.h. pro Beobachtungseinheit eine Kategorie (u.U. Einführung einer Restkategorie) e. Max. 30 Kategorien ohne Video Nachteil: evtl. deutliche Erhöhung der Kategorienzahl 4.2.3 Quantifizierung der Beobachtung Frage: Wie bestimmt man die Ausprägung des beobachteten Verhaltens? Auswahl einer Beobachtungseinheit Time-Sampling (Zeitstichprobe) - Beobachtungseinheit ist ein festes Zeitintervall - Pro Zeitintervall wird kodiert, welches Verhalten aufgetreten ist. (das zu beobachtende Verhalten wird pro Zeiteinheit mit Ja oder Nein kodiert) - Ergebnis: annähernde Informationen über Häufigkeit und Dauer eines Verhaltens Event-Sampling (Ereignisstichprobe) - Beobachtungseinheit ist eine Verhaltensweise - Von dieser wird der Beginn und das Ende festgelegt - Ergebnis: exakte Informationen über Häufigkeit und Dauer eines Verhaltens 4.3 Beobachtungseinheit: (Empfehlungen) 4.3.1 Time-Sampling: - Ergebnis: annähernde Informationen über Häufigkeit und Dauer des Verhaltens Zeitintervall sinnvoll festlegen in Abhängigkeit von Dauer und Verhaltensweisen, die beobachtet werden sollen 4.3.2 Event-Sampling - Ergebnis: exakte Informationen über Häufigkeit und Dauer des Verhaltens (je nach dem wie gut apparativ unterstützt werden kann) Bei sehr kurzen Verhaltensweisen wird die Registrierung schwierig (Lösung: Beschränkung auf wenige Verhaltensweisen, Vermeidung von Event-Sampling) Erweiterung: 30 4.3.3 Ratingverfahren: Bisher: Angaben zu Häufigkeit und Dauer eines Verhaltens Zusätzliche Information: Stärke des Verhaltens (durch Ratingverfahren) (Beispiel: Lächeln – wenig, stark, übers ganze Gesicht) mit Hilfe von Rating-Skalen 4.4 Beobachterfehler 4.4.1 Beobachterfehler durch: 1. Überschreitung der Grenzen der Leistungsfähigkeit - Ermüdung, Langeweile, Aufmerksamkeitsschwankung, Überlastung 2. Unklarheit über Ziel der Beobachtung - Beobachter muss selbst Auswahl bezüglich zu beobachtendes Verhalten treffen 3. Unklare Definitionen der Kategorien - Beobachter muss individuell Kategorien präsentieren / präzisieren 31 4. Mangelndes Training der Beobachter - mangelnde Beherrschung des Kategoriensystems - Abweichung des Beobachterverhaltens vom geplanten Verhalten 4.4.2 Beobachterreliabilität Dazu: Um zu beurteilen, wie stark bestimmte Fehler die Güte einer Beobachtung einschränken, wird oft die Interrater-Reliabilität berechnet. Zur Erinnerung: Reliabilität: (Allg.) Grad der Genauigkeit, mit dem etwas gemessen wird (unabhängig davon, ob dies auch gemessen werden soll) Retest-Reliabilität (intraindividueller Vergleich) Prinzip: Übereinstimmung bei wiederholter Durchführung (Stabilität und Konsistenz) Interraterreliabilität (interindividueller Vergleich) Prinzip: Übereinstimmung verschiedener Beobachter Reliabilitätsschätzung einer Beobachtung als Güte der Übereinstimmung der Beobachter Aber: - 2 Beobachter beobachten und kodieren „perfekt“ hohe Beobachterreliabilität - 2 Beobachter beobachten perfekt, kodieren gleichermaßen „falsch“ hohe Beobachterreliabilität 4.4.3 Verbesserung der Beobachterleistung Genaues Nachvollziehen, wo die Probleme liegen Beispiel: Erwartungseffekte Beobachtertraining Verbesserung der Beobachterleistung (Feedback über Werte anderer Beobachter) Angleichung des Hintergrundwissens von Beobachtern Verbesserung der Ratertrainings (z.B. Übungsmaterial, Regelspezifikationen) Vereinfachung der Durchführung der Beobachtung Einfachere Informationsverarbeitung (keine Interpretationen) Veränderung der Skalenbeschreibung (Kombinierte Verbal-/Numeralskalen) Verwendung von Beispielen („ist gemeint“ vs. „ist nicht gemeint“) „Merkmal für Merkmal“ (anstelle eines Globalurteils) Kontrolle der Auswerteprozeduren Ausschluss von Beobachtern und/oder Beobachtungsgegenständen Verwendung von Mittelwerten über mehrere Rater (bei hinreichender Beobachterzahl) Verwendung von zusammengefassten Werten (anstelle Werten für Einzelkategorie) 4.4.4 Erwartungseffekte: generell vs. speziell Generell: Rosenthal- bzw. Pygmalion-Effekt 32 - Unbeabsichtigte Beeinflussung des Pbn durch verbales Verhalten des Beobachters (Proband in besonder schwieriger Bedingung Versuchsleiter ist besonders nett Lösung: Doppelblindversuch) Speziell: Zentrale Tendenz - häufigere Verwendung der mittleren Kategorien Milde-Tendenz - systematische Verzerrung der Kategorien in Richtung „geringerer Extremität“ Primacy-Recency-Effekt - v.a. bei Aufzeichnungen nach Ende der Beobachtungen Halo-Effekt - z.B. unzulässige Generalisierung von beobachteten Verhaltensweisen auf erwartete Persönlichkeitsmerkmale (Blondinen sind blöd) 4.4.5 Kappa Maß Definition: Es wird die beobachte Beobachter-Übereinstimmung berechnet und mit Hilfe der Kappa Formel an der zufälligen Übereinstimmung der Beobachter relativiert bzw. ins Verhältnis gesetzt. Wertebereich von: -1 bis 1 sollte größer als 0,7 sein (für gute Übereinstimmung) Berechnung: Angegeben sind meist entweder Rater X Beobachtung - Tabellen oder Kategorie X Beobachtung – Tabellen. Zunächst ist es sinnvoll die Übereinstimmung pro Beobachtungseinheit zu berechnen. Dazu ist zu überlegen, welche Anzahl von Rater – Pärchen es insgesamt gibt, und wie viele davon übereinstimmen. Die Anzahl der Pärchen insgesamt berechnet sich wie folgt: 3 Rater => 1 + 2 = 3 Pärchen 4 Rater => 1 + 2 + 3 = 6 Pärchen 5 Rater => 1 + 2 + 3 + 4 = 10 Pärchen (kommt in Aufgaben selten vor) n Rater => 1 + 2 + … + (n-1) = [n*(n-1)]:2 Pärchen (nur zur Vollständigkeit, für die Klausur nicht nötig!!!) (oder n über k mit dem Taschenrechner) Um nun eine relative Übereinstimmung zu berechnen muss man noch die Anzahl der übereinstimmenden Pärchen finden. Diese ergibt sich durch logische Überlegung. Geben z.B. von 5 Ratern 2 die Kategorie 0 an und 3 die Kategorie 1, so bilden die beiden „0 – Rater“ ein Pärchen und die 3 „1 – Rater“ bilden 3 Pärchen (1 + 2; siehe oben). Teilt man diese Zahl nun durch die Anzahl möglicher Pärchen insgesamt, so erhält man eine relative Übereinstimmung von 3 / 10 = 33.33 %. Extrembeispiel (das so sicher in keiner Klausur vorkommt): 33 10 Beobachter; 5 Kategorien Rater X Beobachtung – Tabelle: Rater 1 2 3 Beobachtung 3 1 2 4 0 5 4 Kategorie X Beobachtung – Tabelle: Kategorie 0 1 2 Beobachtung 2 4 1 3 2 4 1 6 1 7 3 8 1 9 0 10 1 1. Anzahl der Maximalen Pärchen: (10 * 9):2 = 45 2. Anzahl der Übereinstimmenden Pärchen: Kategorie 0 = 2 Rater => 1 Pärchen Kategorie 1 = 4 Rater => 6 Pärchen Kategorie 2 = 1 Rater => kein Pärchen Kategorie 3 = 2 Rater => 1 Pärchen Kategorie 4 = 1 Rater => kein Pärchen => Insgesamt stimmen 8 Pärchen überein 3. Relative Übereinstimmung berechnen: 8 : 45 = 17.77% Dieser Vorgang wird nun für jede einzelne Beobachtungseinheit durchgeführt. Am Ende berechnet man den Durchschnitt aus den einzelnen Werten und erhält somit PBeobachtet. Um nun noch PZufall zu berechnen, muss für jede Kategorie ausgezählt werden, wie oft sie von einem Rater angegeben wird (wenn dies nicht schon als Randsumme in der Kategorie X Beobachtung – Tabelle angegeben ist). Man berechne dann noch die Gesamtzahl von Einzelbeobachtungen (Anzahl der Beobachtungseinheiten * Anzahl der Rater). Nun lässt sich für jede Kategorie eine relative Häufigkeit pi = Anzahl der Nennungen der Kategorie i : Gesamtzahl der Einzelbeobachtungen berechnen. Dann ist PZufall = Summe aller pi². Beispiel: Kategorie Randsumme 0 12 1 21 2 7 - Gesamtzahl der Beobachtungen ist 12 + 21 + 7 = 40 - p0 = 12 : 40 = 0.3; p1 = 21 : 40 = 0.525; p2 = 7 : 40 = 0.175 => PZufall = (0.3)² + (0.525)² + (0.175)² = 39.625 % Die entsprechenden Werte sind nun nur noch in die Formel (s.o.) einzusetzen. 4.5 Aspekte des Beobachtungsprozesses 1. 2. 3. 4. 5. Objekt der Beobachtung (was wurde beobachtet?) Subjekt der Beobachtung (die zu beobachtende Person) Umstände der Beobachtung (Rahmen, Gruppe, einzeln, Feld, Labor, Kittel,…) Mittel der Beobachtung (Sinnesorgane, Geräte, Prozeduren) Impliziertes oder explizites theoretisches Wissen, mit dessen Hilfe die o.g. Aspekte aufeinander bezogen werden (welches Wissen hat man über die Umstände?) (nach Bunge, 1967) Beobachtungsgegenstand Selbst Fremd Beobachtungsinhalt äußeres Verhalten inneres Verhalten Erröten, Schweißausbruch Trauer, Freunde Erröten, Aktivität der Hände Trauer, Freude 34 4.5.1 Selbstbeobachtung: Probleme Der Beobachter weiß, was beobachtet werden soll. - Problem der Reaktivität, d.h. Veränderung des Beobachtergegenstandes durch die Beobachtung Der Beobachter führt gleichzeitig Tätigkeit und Beobachtung aus - Grenzen der Verarbeitungskapazität Durch Beobachtung selbst wird beobachteter Gegenstand verändert - keine Objektivität - online verändertes Verhalten - Demand-Effekt Bei retrospektiver Beobachtung: - nachträglich möglichst genau beschreiben, was während der Tätigkeit passiert ist - Beobachtungsergebnis kann durch Gedächtnisprozesse verändert werden (z.B. Verzerrungen, Auslassungen, Beeinflussung durch Emotionen) Nicht alle Phänomene beobachtbar. - z.B. automatische Prozesse, während des Schlafs Die Ergebnisse der Beobachtung sind nicht nachprüfbar. - Es ist keine Aussage über die Güte der Beobachtung möglich, sinnvoll zur Hypothesengenerierung 4.5.2 Fremdbeobachtung (Aspekte) 4.5.2.1 Natürlich und künstlich - wird das Verhalten in der natürlichen Umgebung beobachtet, wenn es spontan auftritt (Feldforschung hohe ext. Validität) - wird eine bestimmte Situation hergestellt, vielleicht sogar ein bestimmtes Verhalten provoziert? (Laborforschung hohe int. Validität) Beobachtung mit vs. ohne Instruktion (Natürlichkeit - weitere Aspekte) Problem - ohne Instruktion tritt Verhalten u.U. zufällig, erst sehr spät oder gar nicht auf - mit Instruktion tritt Verhalten unnatürlich auf Beobachtung mit vs. ohne Manipulation am beobachteten System - z.B. Markierungen von Tieren im Rudel, Blickbewegungskamera verändert Verhalten der anderen Autofahrer - Problem: Proband bemerkt nichts von Manipulation, das soziale Umfeld aber möglicherweise 4.5.2.2 wissentlich und unwissentlich (offen und verdeckt) - wissen Pbn, dass sie beobachtet werden? (Problem der Reaktivität) Lösung: Gewöhungsphase - wissen Pbn, was beobachtet wird? Täuschung, Einsatz von Videogeräten 35 Vor eigentlichem Versuch: • Warten mit zweiter Versuchsperson (Versuchsleiter hat etwas vergessen) In Wirklichkeit: • Beobachtung über Videokamera Ziel: • Untersuchung des Kennenlernprozesses Danach: • Aufklärung über Versuch, Einverständnis einholen. 4.5.2.3 Teilnehmend und nicht-teilnehmend - interagiert der Beobachter mit der Person, die er beobachtet? - kann er Einfluss nehmen auf das Verhalten der Person oder nicht? Problem in der Situation: Beobachter als Gruppenmitglied - Beobachter muss in Gruppe integriert werden - Beobachter selbst verändert aktiv den Beobachtungsgegenstand Grenzen der Verarbeitungskapazitäten - Beobachter muss sowohl Tätigkeit ausführen als auch beobachten 4.5.2.4 Direkt und indirekt (direktes Beobachten oder mittels Rückschlüsse) - wird das Verhalten selbst beobachtet (direkt) oder Spuren bzw. Auswirkungen des Verhaltens (indirekt = non-reaktiv) (z.B. leere Flaschen, abgetretende Teppiche) Non-reaktive Kennzeichen - nicht das Verhalten selbst, sondern die Spuren oder Auswirkungen des Verhaltens werden beobachtet. - häufig keine Individualzuweisung von Daten möglich - prozentuale Angaben, Personen nicht bekannt - der Zugriff auf die Daten verändert diese nicht (non-reaktiv) Beispiele: - physische Spuren, Ablagerungen, (z.B. Spuren im Schnee, Abnutzung von Stufen, abgetretene Teppiche) - Graphitti (momentaner Zustand der Jugend) - Schilder / Hinweistafeln / Hausordnungen - Archive / Verzeichnisse / Statistiken - Dokumente: privat (Tagebücher), öffentlich (Presse) - Provoziert: Wrong-number-Technik, Lost-Letter Technik Non-reaktiv: Probleme - Interpretation der Daten verlangt eine Verhaltenstheorie: welches Verhalten erzeugt die Daten? - Interpretation der Daten verlangt eine Stichprobentheorie: - wer kann die Daten erzeugt haben? Direktheit – Fehlende Verbindung 36 Echt non-reaktiv Spuren keine Individualzuweisung möglich "Aufgeweicht" non-reaktiv: • Vl hat Einfluss auf Vp • Diese weiß nicht, dass sie beobachtet wird Beispiele: • Einwegscheibe • Provozierte Daten (Lost Letter-Technik, Wrong-NumberTechnik) Versuch hat für Vp andere Bedeutung als für Vl: Cover-Stories Reaktive Messverfahren: Übliche Beobachtung 4.5.2.5 Vermittelt und unvermittelt - wird das Verhalten, das beobachtet werden soll, gespeichert (Audio/Video) oder nicht? - Ist es jederzeit zugänglich? Vermittelt (= Speicherung) Vorteile: - beliebige Abrufbarkeit des beobachteten Geschehens - unbegrenzte Speichermöglichkeiten - Wieder- bzw. Weiterverwendbarkeit der gespeicherten Daten Nachteile - ergeben sich aus Eigenschaften des Aufzeichnungsgeräts - jedes Gerät kann nur Untermenge der vorhandenen Variablen aufzeichnen (z.B. Tonband nur akustische Signale) 4.5.3 Reaktive Effekte Abschwächung reaktiver Effekte - Einführung einer Gewöhnungsphase - Täuschung der Pbn über die interessierenden Variablen des Verhaltens - Einsatz von Aufzeichnungsgeräten (z.B. Video) anstelle von menschlichen Beobachtern 37 - Coverstory (nur in der Sozialpsychologie) Versuchsperson weiß in der Regel nicht, dass sie Daten produziert (keine Interaktion Versuchsperson – Versuchsleiter) 4.6 Problemkreise Beobachtung 1. Definition des Beobachtungsgegenstandes - welches Verhalten ist interessant, entspricht der Fragestellung? 2. Erstellung und Überprüfung eines Beobachtungssystems - Übersetzung des Beobachtungsgegenstandes in ein Zeichen 3. Entscheidung für ein Quantifizierungsverfahren - Wie soll Häufigkeit, Dauer und Intensität bestimmt werden? 4. Auswahl der Beobachtungssituation 5. Training der Beobachter 6. Durchführung der Beobachtung 7. Überprüfung der Güte der Beobachtung (Reliabilität) 5 Befragung 5.1 Definition Befragung 5.1.1 Alltagsverständnis: - Befragung als verbale Kommunikation zwischen Personen 5.1.2 Wissenschaftliches Verständnis: - - - - Befragung als Informationsfluss zwischen Personen (ohne Fokussierung auf den verbalen Kanal) Systematische Vorbereitung und Durchführung Abhängigkeit des Ergebnisses von der Befragungssituation Sozialer Vorgang, d.h. Wechselwirkungen zwischen Personen Zielgerichtetheit der Befragung Verwendete Mittel (z.B. Telefoninterview) und Bedingungen der unmittelbaren räumlichen Umwelt (z.B. Ruhe vs. Stress) Normative Orientierung (d.h. Ausbildung von Verhaltenserwartungen, Soziale Erwünschtheit) Einsatz der Befragung zur Überprüfung theoretischer Zusammenhänge (UV/AV) Berücksichtigung von Merkmalen der befragten Person bei der Gestaltung des Befragungsinstruments z.B. Alter, Geschlecht, Bildungsstand, Schichtzugehörigkeit, Herkunft, ethnische Zugehörigkeit) Befragung einer Stichprobe aus der Gesamtpopulation Kontrolle der Kontextbedingungen (gleiche Befragungsinstrumente, Berücksichtigung der sozialen Beziehung zwischen Personen, Bedingungen der unmittelbaren räumlichen Umwelt Fazit: Kontrolliertheit jedes einzelnen Befragungsschritts 5.1.3 Dem Befragten muss klar sein… - über welchen Gegenstand er berichten soll - wie ist der Gegenstand beim Befragten repräsentiert? 38 - Welches Sprachsystem er verwenden soll - welche Eigenschaften besitzt die verwendete Skala? Mit welcher Intention (Urteilshaltung) er berichten soll - Bsp: sachorientierte Beschreibung vs. wertungsorientierte Stellungnahme (Fakten vs. pers. Meinung) 5.2 Klassifikation von Befragungen 5.2.1 Ausmaß der Standardisierung strukturiert – halb-stukturiert- unstrukturiert Standardisierung bedeutet: - Vorgabe der Abfolge der Fragen - Vorgabe der Wortlauts der Fragen - Stand. bedeutet NICHT Vorgabe von Antwortalternativen - Geschlossene Fragen: Vorgabe einer Reihe von Antwortmöglichkeiten - Offene Fragen: Befragter muss Frage sowohl inhaltlich beantworten als auch die Antwort selbstständig sprachlich formulieren Standardisierte Befragung v.a. geeignet - für umgrenzten Themenbereich - für Themenbereiche, für die bereits Vorwissen besteht Mittelweg: Halbstandardisierte Befragung Interviewer Leitfaden - schreibt dem Fragenden die Art und Inhalte der Befragung nicht vollkommen verbindlich vor - teilweise offene Fragen - teilweise geschlossene Fragen 5.2.2 Autoritätsanspruch des Interviewers weich – neutral – hart Weiches Interview (Beckmann) - basiert auf Prinzipien der Gesprächspsychotherapie (nicht-direktiv, empathisch, wertschätzend, selbstkongruent) - Ziel: Antworten ohne Hemmungen, reichhaltig und aufrichtig Hartes Interview (Friedmann) - autoritär-agressive Haltung des Fragenden: häufiges Anzweifeln der Antworten, schnelle Aufeinanderfolge von Fragen - Ziel: „Überrennen“ von Abwehrmechanismen Neutrales Interview (Christiansen) - Betonung der informationssuchenden Funktion der Befragung - Fragender und Befragter sind gleichwertige Partner 5.2.3 Art des Kontakts direkt/pers. – telefonisch – schriftlich Persönliche Befragung „Face-to-Face Interview“ - hoher Aufwand (z.B. Besuch in der Wohnung des Befragten) - persönliche oder Privatsphäre betreffende Inhalte können thematisiert werden Telefonische Befragung „Telefoninterview“ - schnell und preiswert 39 vom Befragten als anonymer und weniger bedrängend erlebt als persönliche Befragung - geringe Verweigerungsquote Schriftliche Befragung „Paper-and-Pencil“ - kostspielig, unkontrollierte Erhebungssituation - heterogene Rücklaufquote - 5.2.4 Anzahl der befragten Personen Einzelinterview – Gruppeninterview Einzelbefragung - bei Themenbereichen, die individuelles Eingreifen des Fragenden nötig machen (z.B. Gebiete ohne Vorwissen) - bei Themenbereichen, bei denen Gruppeneffekte auftreten können (z.B. Leistungsdruck, sozialer Druck) Gruppenbefragung - geringe Kosten, einheitliche Befragungssituation für jeweilige Gruppe - Befragte machen Angaben auf Antwortbogen 5.2.5 Anzahl der Interviewer ein Interviewer – Tandem – Hearing Ein Interviewer: - am ökonomischsten Tandem-Interview - sinnvoll bei anspruchsvollen Befragungssituationen (z.B. Erfragen des Wissens von Experten, 2. Person als Befrager, z.B. in Bewerbungsgepräch) Hearing / Board-Interviews - mehrere Personen befragen einen/mehrere Kandidaten - Möglichkeit zur gegenseitigen Ergänzung der Interviewer - Vom Befragten als belastend wahrgenommen - z.B. Personalkommissionen 5.2.6 Funktion des Interviews (Klassifizierung einer Befragung) ermittelnd – vermittelnd Informationsermittelnde Funktion - Erfassung von Fakten - Zeugeninterviews - Panel-Befragungen - Interview bei der Personalauswahl Informationsvermittelnde Funktion - Beratungsgespräche (z.B. Berufsberatung) 5.3 Problemkreise der Befragung 5.3.1 Aspekte der Frage: Zubeachten ist die Reihenfolge und Formulierung der Fragen, sowie die Formatierung der Antwortskala (Kategorienanzahl, Mittelkategorien, Verankerung, Balancierung, optische Gestaltung) 40 5.3.2 Merkmale des Befragten Motivation: - Proband will keine validen Angaben machen (“Self-Disclosure”) - Demand-Effekte - Motive zur Selbstdarstellung und Streben nach Konsistenz (“Impression Management”) - Soziale Erwünschtheit Kompetenz: - Proband kann keine validen Angaben machen (Lösung: zustäzlich ein „keine Ahnung“ Button) 5.3.3 Kontext der Befragungssituation - Art der Befragung Zweck der Befragung Merkmale des Interviewers 5.4 Neue Befragungstechniken 1. Computerunterstützte persönliche Befragung (“Computer Assisted Personal Interviewing”, CAPI) 2. Computerunterstützte telefonische Befragung (“Computer Assisted Telephone Interviewing”, CATI) 3. Computerunterstützte schriftliche Befragung • “Computer Assisted Self Interviewing”, CASI • „Computerized Self-Administered Questionnaire“, CSAQ Ø Electronic Mail Survey (EMS) Ø Disk by Mail (DBM) 4. Touchtone Data Entry (TDE) / Voice Recognition (VR) 5. Fax-Surveys 5.5 Skalen Polung der Skala • unipolar: schwach extravertiert – stark extravertiert • bipolar: extravertiert – introvertiert 41 Art der Skala: 5.5.1 Numeralskala Bewertung: - Verwendung negativer Skalenwerte umstritten - Können Urteile in Zahlen ausgedrückt werden? (Abstraktheit) - Anfälliger für Urteilseffekte als Verbalskalen + Durch verbale Verankerung der Pole präziser 5.5.2 Verbalskala Bewertung: - Durch verbale Bezeichnung u.U. unpräzise - Äquidistanz der Kategorien nicht immer sichergestellt + weniger anfällig für Urteilseffekte als Numeralskalen 5.5.3 Symbolskala z.B.: Kunin-Skala: 42 5.5.4 Graphische Skala (Visuelle Analogskala) Bewertung: - hoher Auswertungsaufwand (z.B. über künstliche Einführung von Kategorien) - Anfangs: Höhere Unsicherheit der Pbn + später: höhere Motivation der Befragten, Antwortabgabe leichter und schneller als bei Numeralskala + Feinere Abstufungen des Urteils möglich + entspricht Intervallniveau + geringe Erinnerungseffekte: Befragte können sich angegebene Position nur schwer merken 5.5.5 Standardskala (Durch Beispiele verankerte Skala) (z.B. Checklist-Verfahren, Forced Choice-Verfahren) 5.6 Verweigerung 5.6.1 Item-Non-Response - Verweigerung auf einzelne Inhalte bezogen Ursachen für Nicht-Auskunft bei einzelnen Items - Verweigerung der Auskunft - Nicht-Informiertheit - Meinungslosigkeit - Unentschlossenheit v.a. bei sehr persönlichen, intimen Fragen unsichere Personen, ältere Menschen, Personen mit geringem Sozialstatus 5.6.2 Unit-Non-Response komplette Verweigerung der Auskunft (Ablehnung der Teilnahme an Interview, keine Rücksendung des Fragebogens) Kontrollmöglichkeiten: - Auffüllen der Stichprobe - Anfangs hinreichend große Stichprobe wählen Aber: Non-Responder unterscheiden sich systematisch von Respondern - im Interview: alte Menschen, Frauen (45+), geringe Schulbildung, geringer Bildungsstatus - in schriftlicher Befragung: geringe Schulbildung, geringer Bildungsstatus, geringere Intelligenz, geringes Interesse am Forschungsthema, fehlende Beziehung zum Untersucher - 5.6.3 Verweigerungsquoten - Persönliche Befragung: 7 – 14 % (Esser, 1974) 43 Telefonische Befragung: 7 % (Downs et al. 1980) Schriftliche Befragung: 0 – 90 %(Wieken, 1974) Robinson & Agism (1950/51): Verweigerungsquote bei Freistemplung des Briefes 34%, bei Frankierung mit Briefmarke 26% - Später antwortende Personen sind zumeist in ihren Angaben unzuverlässiger Computerunterstützte Befragung: - keine Unterschiede zu o.g. Befragungsarten (Porst et al. 1994) - aber: teilweise höhere Rücklaufgeschwindigkeit (Swoboda et al (1997): Rücklaufquote bei Electronic Mail Survey 90% innerhalb von 4 Tagen - 5.6.4 Rücklaufquoten Hohe Rücklaufquoten - für Stichproben, die Umgang mit schriftlichen Texten gewohnt sind - für aktuelle, interessante Themen - für ansprechende Gestaltung (Frageformulierung, Layout, persönliches Anschreiben) - bei vorherigen Ankündigungsschreiben (2x so hoch) oder kurzen Anrufen (3x so hoch) - bei Angabe eines Rücksendedatums (Deadline): Erhöhung der Rücklaufquote und – geschwindigkeit Verwertbarkeit der Ergebnisse schriftlicher Befragung - hängt nicht von Höhe des Rücklaufs ab - entscheidend ist die Zusammensetzung der Stichprobe der Responder Möglichkeiten zur qualitativen Kontrolle von Rückläufern - Gewichtungsprozeduren bei Über-/Unterpräsentation einzelner Merkmale der Stichprobe im Vergleich zur Grundgesamtheit - Gezielte telefonische, schriftliche oder persönliche Nachbefragung der NonResponder 6 Messungen 6.1 Mess-Artefakte Def: Artefakt = aufgefangenes Signal, das anderen Ursprungs ist als das zu messende Biosignal 6.1.1 Artefakte physiologischer Herkunft - Potenzialschwankungen, Signalstörungen von begleitenden physiologischen Prozessen Lösung: bessere Elektroden, bessere elektronische Komponenten 6.1.2 Bewegungsartefakte - Lösung: optimale Platzierung der Elektroden 6.1.3 Artefakte durch externe elektrische Einstreuung - Lösung: bessere elektronische Komponenten, Verfahren der Filterung und Verstärkung 44 6.2 Spezifitätsproblematik 6.2.1 Individualspezifische Reaktion - Personen reagieren auf physiologischer Seite unabhängig vom Stimulus in einer für sie typischen Reaktionsweise 6.2.2 Stimulusspezifische Reaktion - Alle Individuen reagieren auf einen Stimulus in ähnlicher Weise 6.2.3 Motivationsspezifische Reaktion - unter einem bestimmten Motivationszustand reagieren alle Personen in ähnlicher Weise Bei biopsychologischen Untersuchungen sind diese Anteile zu berücksichtigen. 6.3 Ausgangswertgesetz von Wilder (1931): Je stärker vegetative Organe aktiviert sind, desto stärker ist ihre Ansprechbarkeit auf hemmende Reize und desto schwächer ist ihre Ansprechbarkeit auf aktivierende Reize. Statistisch: - negative Korrelation zwischen Ausgangswert und Veränderungswert ( Regressionseffekt B) - Veränderungswerte enthalten somit einen systematischen Fehler 6.4 Messprobleme – innere und äußere Variablen Äußere Variablen: - Tageszeit - Raumtemperatur (zu Versuchsbeginn) - Außentemperatur - Niedrigste rel. Luftfeuchtigkeit in den letzten 24 Stunden - Höchster Barometerstand in den letzten 24 Stunden Innere Variablen: - Motivation - Emotion, Stimmung - Lebensalter - Geschlecht - Rasse - Kulturzugehörigkeit - Intelligenz 7 Versuchsplanung 7.1 Idee der Versuchsplanung 45 7.1.1 Definitionen PV / SV / FV 7.1.2 Primärvarianz: - systematische Variation der Messwerte zurückzuführen auf die Variation der UV 7.1.3 Sekundärvarianz - systematische Variation der Messwerte Zurückzuführen auf die Variation identifizierbarer Störvariablen 7.1.4 Fehlervarianz (Zufallsfehler): - Unsystematische Variation der Messwerte Nicht auf den Einfluss der Variation der UV zurückzuführen Nicht auf den Einfluss der identifizierbaren Störvariablen zurückzuführen Varianzen addieren sich auf: PV+SV+FV = totale Varianz PV / FV > 1 - sonst kein Effekt Wenn die Primärvarianz der AV deutlich größer ist als die Fehlervarianz, dann hat die UV gewirkt 46 7.1.5 Ein Beispiel Als Zusammenhang formuliert: - Trommeln führt zu „nach Motorboot klingen“ - Sternzeichen verändern Kaufverhalten Frage: Wie prüfe ich Kausalzusammenhänge zwischen UV und AV? Antwort: - ich stelle Situationen her, die sich nur durch die Ausprägung der UV unterscheiden. - Verändert sich dann die AV, dann können die Ursache hierfür nur die Unterschiede in der UV gewesen sein 7.1.6 Logik der Bewertung Primärvarianz: - Unterschiede zwischen den beiden Gruppen aufgrund Trommelfrequenz (hohe vs. geringe Frequenz) Sekundärvarianz: - Unterschiede zwischen den beiden Untergruppen (kleiners vs. großes Lungenvolumen) in den beiden Versuchsgruppen Fehlervarianz: - Unterschiede innerhalb der vier Versuchsgruppen (unterschiedlicher Klang) 7.2 Idee der Varianzanalyse Gesucht wird ein Maß für die Veränderungen in der AV: - Differenz zwischen Versuchsgruppen geht nicht, wenn mehr als zwei Stufen der UV oder mehr als zwei UVn - Lösung: Quadratsummen als Maß der Unterschiedlichkeit Grundgedanke: Aufklärung, wie viel Variation der AV durch die UV erzeugt wird (Primärvarianz) - Gesamtvarianz wird aufgeteilt in Primärvarianz und Fehlervarianz 47 - Man vergleicht: Primärvarianz (PV) / Fehlervarianz (FV) Wenn PV „größer“ als FV, dann hat die UV gewirkt Statistisches Modell hilft bei der Entscheidung, ab wann „größer“ bedeutsam ist 7.2.1 Modell der Varianzanalyse: Statistisches Modell: (H0: PV=FV) - Erzeugen einer Verteilung von PV/FV unter der Nullhypothese - Nullhypothese: UV erzeugt keine große Variation der AV - Wenn empirisches Verhältnis PV/FV in der Verteilung unwahrscheinlich ist, dann ist das Modell der Nullhypothese nicht gut - Folge: Ablehnung der Nullhypothese, UV hat gewirkt - Was heißt unwahrscheinlich? Festlegung durch Alpha Risiko (sog. Ablehnungsbereich) Wie alle Entscheidungen kann auch eine statistische Entscheidung falsch sein: alpha-Fehler (Fehler 1. Art): H0 ablehnen, obwohl H0 gilt beta-Fehler (Fehler 2. Art): H0 beibehalten, obwohl H0 nicht gilt Konvention: alpha = 1%, alpha = 5%. Wenn das empirische Ergebnis zu den 1% / 5% unwahrscheinlichsten Ergebnisse unter dem Modell der Nullhypothese gehört, ist es unwahrscheinlich. Folge: Die Nullhypothese wird abgelehnt. Im zweifaktoriellen Beispiel: - Drei Arten von Primärvarianz: Erzeugt durch UV1 (HW1), UV2 (HW2) und Zusammenwirkung der UVn1 und 2 (WW) - Jeweils Vergleich mit Fehlervarianz - Damit drei Vergleiche, drei Entscheidungen, drei mögliche Wirkungen (PVHW1/FV, PVHW2/FV und PVWW/FV) 7.2.2 Statistische Prüfgröße Quadratsummen (QS) (Maß für die Unterschiedlichkeit): Wie unterschiedlich sind die Personen insgesamt, die ich untersucht habe? - QSTotal = QSHW1 + QSHW2 + QS WW + QS Fehler - QSHauptiwrkung / QSWechselwirkung Wie unterschiedlich sind die Gruppen unter den Stufen der UV? - QSFehler Wie unterschiedlich sind die Personen noch, wenn die Unterschiede, die durch die UVn entstanden sind, abgezogen wurden? Wert, den eine Person liefert setzt sich zusammen aus verschiedenen Einflussgrößen: Additives Modell der Varianzanalyse Im zweifaktoriellen Beispiel: Xijk = G... + Ai.. + B.j. + ABij. + Eijk Dabei bedeuten: Xijk: Messwert der Person k G...: Typischer Wert der untersuchten Stichprobe Ai..: Einfluss der Stufe i der ersten UV B.j.: Einfluss der Stufe j der zweiten UV ABij: Einfluss der Kombination UV1 und UV2 Eijk: Typischer Wert der Person: „Fehler“ 48 7.2.3 Interpretation der Wirkungen Problematisch; - Interpretation der HW bei Signifikanz der WW - Interpretation der HW hängt von der Art der WW ab Logik der Interpretation: Verändert die Wechselwirkung die Richtung der Hauptwirkung? - Wenn nein, darf die Hauptwirkung interpretiert werden - Wenn ja, darf die Hauptwirkung nicht interpretiert werden Interpretation ist damit nur möglich bei Veranschaulichung der Effekte, d.h. entweder graphisch oder in einer Tabelle Vorausgesetzt ist natürlich, dass die HW überhaupt signifikant werden. Ordinale Wechselwirkung: - beide Hauptwirkungen dürfen interpretiert werden. Die Reaktion auf die UVn ist unterschiedlich stark, aber in die gleiche Richtung Semi-disordinale oder hybride Wechselwirkung - Eine Hauptwirkung darf interpretiert werden, die andere nicht. Disordinale Wechselwirkung - nur die WW darf interpretiert werden. Bei Signifikanz: WW darf immer interpretiert werden, HW in Abhängigkeit der „Richtung“. Berechnung der Freiheitsgrade Bei Stichproben der Größe n können nur (n-1)-Abweichungen vom Gruppenmittelwert variiert werden. --- Zum weiteren Verständnis dieses Themenbereichs: s. Script der Vorlesung --S.26-42 im Script 7.3 Das MAX-KON-MIN Prinzip (Kerlinger, 1973) 7.3.1 MAXimiere die Primärvarianz: • Wähle die Stufen der UV so, dass möglichst große Unterschiede in der AV zwischen den Gruppen entstehen, die diese Stufen erhalten Kontrolltechniken • Wahl von mehreren experimentellen Bedingungen (> 2 Stufen) • Wahl von extremen experimentellen Bedingungen („Extremgruppenverfahren“) • Wahl von mehrfaktoriellen experimentellen Designs Ziel: • Effekte der UV durch die Versuchsplanung möglichst „maximal“ zum Vorschein bringen 49 7.3.2 KONtrolliere die Sekundärvarianz: • Sorge dafür, dass bekannte Störvariablen in allen Gruppen gleich wirken (interne Validität) und bestimme deren Einfluss, d.h. die Varianz, die sie erzeugen. Kontrolltechniken: 7.3.2.1 Experimentell (Abschirmung, Eliminierung, Konstanthaltung) 1. Abschirmung:• Beschränkung möglicher Störeffekte (z.B. Fenster zu) 2. Eliminierung:• Vollständige Abschirmung möglicher Störeffekte (z.B. schalltoter Raum) 3. Konstanthaltung: Gleichhaltung von Störvariablen unter verschiedenen Versuchsbedingungen (z.B. gleiches weißes Rauschen) Ziel: - Mögliche Störeffekte wirken unter verschiedenen Versuchsbedingungen gleich stark Statistisch: allgemeine statistische Kontrolle, kovarianzanalytische Kontrolle - Effekte von „Nicht-UVn“, die als Störvariablen einen systematischen Einfluss haben können, bestmöglich unter Kontrolle halten 7.3.2.2 Individuelle Rohdatenanalyse • Problem: Durchschnittswerte sind nicht die besten Repräsentanten einer Stichprobe Statistische Berechnung und graphische Veranschaulichung des Standardfehlers • Standardfehler (s/Wurzel n) sinnvoll zur Bestimmung der praktischen Signifikanz von Mittelwertsunterschieden) Überprüfung der statistischen Ausgangswerte bei Vorher-Nachher-Versuchsplänen 7.3.2.3 Kovarianzanalytische Kontrolle (“Kovarianzanalyse“) • Betrachtung von Effekten auf die AV, die nicht auf die UV zurückzuführen sind • Ziel: Bereinigung der Werte der AV bezüglich der Effekte der Störvariablen (z.B. Ausreißer eliminieren) 7.3.3 MINimiere die Fehlervarianz: • Vermeide Fehler auf Seiten der Versuchssituation (Konstanthalten der Bedingungen), der Datenerfassung (Beobachter: Reliabilität; Messinstrumente) und der Datenverarbeitung (doppelte Eingabe) Kontrolltechniken: Ziel: Auswirkungen von unbekannten Störvariablen so klein wie möglich halten 50 7.3.3.1 Randomisierung - Zufällige Zuweisung der Pbn zu den Versuchsbedingungen - Annahme: Gebildete Zufallsstichproben, die derselben Population entstammen, gleichen einander weitgehend - Prinzipielle Vergleichbarkeit der Ausgangsbedingungen und Ausgangsmesswerte Ziel: Erwartungswertgleichheit der Versuchsgruppen - Vermeidung systematischer Unterschiede bei Gruppenbildung, die einen systematischen Effekt auf die AV haben können - Kontrolle der interindividuellen Varianz (Fehlervarianz) Anwendung: - Wenn eine Vielzahl möglicher Störvariablen kontrolliert werden soll, über deren Effekt nichts Genaueres bekannt ist - Effektiv nur dann, wenn Stichproben hinreichend groß sind - bei kleinen Stichproben (mit Versuchsgruppen n <= 10) ist gleiche Zusammensetzung der Versuchsgruppen statistisch unwahrscheinlich - dann: besser Blockversuchspläne oder Wiederholungsmessungen 7.3.3.2 Blockbildung (Parallelisierung) Umwandlung möglicher Störvariablen, die einen Einfluss auf die AV haben (d.h. mit ihr korrelieren), in eine UV Beispiel: Organismusvariablen (z.B. Alter, Intelligenz) Ziel:Kontrolle der interindividuellen Varianz (Fehlervarianz) Anwendung: bei kleinen Stichproben Grundgedanke des Vorgehens: Zuordnung der Pbn zu den Versuchsbedingungen aufgrund der Merkmale, in denen man eine Einflussgröße auf die AV erwartet Vorgehen: 1. Auswahl von Pbn, die sich hinsichtlich Parallelisierungsmerkmal gleichen 2. Aufstellen einer Rangreihe (bezogen auf Ausprägung des Parallelisierungsmerkmals) 3. Bildung von “Blöcken” von Pbn mit jeweils benachbarten Rangplätzen Gedanke: Pbn eines Blocks sind sich hinsichtlich Parallelisierungsmerkmal ähnlicher als Pbn aus unterschiedlichen Blöcken - „Statistische Zwillinge“ 4. Zuordnung der Pbn eines “Blocks” zu Versuchsbedingung erfolgt dann per Zufall (“Randomisierung”) 7.3.3.3 Wiederholungsmessung Eliminierung von interindividuellen Unterschieden zwischen Bedingungen aufgrund Mehrfachmessung Ziel: Kontrolle der interindividuellen Varianz (Fehlervarianz) Vorgehen: Alle Pbn werden unter sämtlichen Versuchsbedingungen untersucht Vorteile: explizite Kenntnis über Personenvariablen, die mit AV korrelieren, nicht nötig Versuchsdurchführung sehr ökonomisch Nachteile: 51 Pbn sind keine “statischen” Einheiten, die von Messung zu Messung konstant bleiben (z.B. Lernfähigkeit) 7.3.4 Beurteilung von Kontrolltechniken 7.3.5 Überblick Kontrolltechniken Experimentelle (Instrumentelle) Kontrolltechniken • Anwendung bereits vor der Datenerhebung • Anwendung apparativer Techniken • z.B. Abschirmung, Eliminierung, Konstanthaltung Versuchsplanerische Kontrolltechniken • Anwendung vor der Datenerhebung • Anwendung bestimmter Versuchsplanungsstrategien • z.B. Randomisierung, Parallelisierung, Wiederholungsmessung Statistische Kontrolltechniken • Anwendung erst nach der Datenerhebung • z.B. allgemeine statistische Kontrolle, kovarianzanalytische Kontrolle 7.4 Vorexperimentelle Versuchspläne 7.4.1 One-Shot Case Study (Schrotschuss-Design) einmalige Nachhermessung an einer einzelnen Versuchsgruppe In Fachliteratur findet man keine ernstzunehmende Arbeit, die auf diesem Design basiert Vorteile: - 52 - gerinstmöglicher Aufwand Nachteile - fehlende experimentelle Kontrolle - keine Vergleichsmöglichkeiten der Untersuchungsbedingungen - aufgrund irreführender Plausibilität der Ergebnisse: Gefahr der missbräuchlichen Anerkennung dieses Designs - starke Gefährdung der internen Validität 7.4.2 Einfache Vorher-Nachher-Messung (Prä-Post) Zusätzliche Einführung einer Ausgangsmessung (Vorher-Messung) In der Psychologie können Vorher-Nachher-Differenzen nicht eindeutig auf die Behandlung zurückgeführt werden Vorteile: - Interindividuelle Verhaltensvariablen untersuchbar / Vielfältigkeit des Verhaltens - Zumindest Vergleich möglich, d.h. Frage nach Veränderung der AV zu untersuchen Nachteile: - Müdigkeits- oder Gewöhnungseffekte können für Ergebnis verantwortlich sein - Testeffekte aufgrund zweimaliger Testung - Fehlen eines Doppelblindversuchs, d.h. reaktive Verhaltensweisen von Pb und VL nicht kontrolliert - 7.4.3 Statischer Gruppenvergleich (z.B. Pisa Studie) Vergleich von zwei oder mehreren experimentell behandelten Gruppen Nicht mittels einer Zufallsbildung zusammengestellt, d.h. bereits existierende, vorgegebene Gruppen Vorteile: - zumindest Vergleich zwischen verschiedenen Versuchsbedingungen möglich, d.h. Frage nach Veränderung der AV zu untersuchen Nachteile: - Gleichheit der Versuchsgruppen ist nicht gewährleistet - „Reifungseffekte“ werden nicht kontrolliert Einsatz empfehlenswert, wenn Zufallsgruppenbildung nicht möglich. - 53 Bewertung vorexperimenteller Designs Vorgehen: - explizite Einführung einer experimentellen Bedingung - keine Kontrolle von Störfaktoren Ergebnisse solcher Versuche sind prinzipiell mehrdeutig - Möglichkeit von Alternativerklärungen, über die nicht entschieden werden kann Untersuchungsbefunde können durch Störvariablen verzerrt sein - Untersucher kann über Ausmaß und Richtung solcher Datenverzerrungen keine Aussagen machen Eignung - v.a. für Pilotstudien (Erkundungsexperimente) mit Ziel der Hypothesengenerierung und Entwicklung eines adäquaten Versuchsdesigns Schemata des Experiments 7.5 Experimentelle Versuchspläne Klassifikation von Versuchsplänen Anzahl der untersuchten Versuchsgruppen Ein-, Zwei-Stichproben- vs. Mehrstichproben-Plan Placebo vs. Alkohol; Placebo, wenig, viel Alkohol Anzahl der unabhängigen Variablen (UV) Einfaktorieller vs. Mehrfaktorieller Plan UV 1: Alkohol, UV 2: Geschlecht Anzahl der abhängigen Variablen (AV) Univariater vs. Multivariater Plan Alkoholwirkungen auf Sprechverhalten, Blickkontakt, Befinden Werden dieselben Pbn unter den Stufen der UV untersucht oder ähnliche Vpn oder verschiedene Vpn? Abhängige Gruppen vs. Blockplan vs. Unabhängige Gruppen Alkohol vs. Placebo: Zwei Sitzungen an zwei Abenden, Reihenfolge zufällig 54 Experimentelle Designs kausaltheoretische Vorhersage vorhanden systematische Manipulation relevanter Variablen Kontrolle von Störfaktoren, die die Interpretierbarkeit und Gültigkeit der Ergebnisse beeinträchtigen könnten. 7.5.1 Randomisierungspläne (Versuchspläne mit Zufallsgruppenbildung) • Zufällige Zuweisung der Pbn zu Versuchsgruppen, danach zufällige Zuweisung der Versuchsgruppen zu den Bedingungen • Prinzipielle Vergleichbarkeit der Ausgangsbedingungen und Ausgangsmesswerte 7.5.1.1 Zweistichprobenpläne: Zufallsgruppenplan ohne Vortest Sehr einfacher und ökonomischer Versuchsplan 7.5.1.2 Zufallsgruppenplan mit Vortest Zusätzliche Informationen durch Vorher-Messung Kontrolle von interindividuellen Messwertdifferenzen 7.5.1.3 Zufallsgrppenplan mit teilweisem Vortest Hauptvorteil gegenüber Zufallsgruppenplan mit Vortest: Abschätzbarkeit möglicher Effekte des Vortests auf Wirkung des Treatments „Solomon-Dreigruppen-Versuchsplan“ relativ selten verwendet 55 7.5.1.4 Mehrstichprobenversuchspläne: einfaktorieller Plan ohne Vortest Variation nur einer UV („Faktor“): einfaktorieller Plan Verallgemeinerung der Zweistichprobenversuchspläne auf drei der mehr Versuchsgruppen 7.5.1.5 Zweifaktorieller Zufallsgruppenplan 56 7.5.1.6 Mehrfaktorieller Zufallsgruppenplan 7.5.1.7 Vorteile / Nachteile Zufallsgruppenpläne Vorteile: Erwartete Gleichheit der Merkmale in Versuchsgruppen Vortest: Kontrolle von interindividuellen Messwertdifferenzen möglich Mehrstichproben- vs. Zweistichprobenpläne: • höhere interne Validität (breitere Analyse möglich: Max-Prinzip) • höhere externe Validität (sachrepräsentativere Analyse möglich) Multifaktorielle vs. einfaktorielle Versuchspläne: • erlauben Aussagen über Hauptwirkungen und Wechselwirkungen (Interaktionen) zwischen untersuchten Variablen Nachteile: bei kleinen Stichproben (je Gruppe n <= 10) ist gleiche Zusammensetzung der Versuchsgruppen statistisch unwahrscheinlich • dann: Blockversuchspläne oder Wiederholungsmessungen bei Mehrstichprobenversuchsplänen steigt Anzahl der Versuchsgruppen mit Anzahl der Faktoren stark an • Beispiel: Ø 3 Stufen UV 1 x 2 Stufen UV 2 = 6 Gruppen Ø 3 Stufen UV 1 x 2 Stufen UV 2 x 3 Stufen UV 3 = 18 Gruppen Interaktionen bei drei- und mehrfaktoriellen Plänen sind kaum interpretierbar 57 7.5.2 Messwiederholungspläne (Versuchspläne mit wiederholter Messung) • Untersuchung einer Versuchsgruppe zu verschiedenen Messzeitpunkten Unterscheidung von Zweistichproben- vs. Mehrstichprobenversuchsplänen Untersuchung unter zwei oder mehreren Bedingungen Beispiel: Vorhersage der Leidensfähigkeit über Leistung in 2 Statistik-Klausuren (“Zweistichproben”) vs. Leistung in 8 Vordiplom-Prüfungen (“Mehrstichproben”) Einfaktorielle, zweifaktorielle vs. mehrfaktorielle Versuchspläne einfaktoriell: Untersuchung bei einer UV mit mindestens 2 Stufen zweifaktoriell: Untersuchung bei Variation von 2 UV mit je mindestens 2 Stufen 7.5.2.1 Messwiederholung: Beispiel 7.5.2.2 Vorteile / Nachteile: Vorteile: • ökonomische Designs aufgrund geringer Probandenzahl • geringere interindividuelle Varianz als bei Einfachmessungen Ø Wirksamkeit der experimentellen Effekte leichter nachweisbar Nachteile: • Problem von sog. Carry-over-Effekten • Lösung: Ø Wahl eines hinreichend großen Zeitabstandes Ø Ausbalancierung der Reihenfolge der Versuchsbedingungen 7.5.2.3 Ausbalancierung der Reihenfolge Beispiel: 2 Versuchsgruppen mit n = 15 Pbn, 3 Bedingungen (a, b, c) Mögliche Kombinationen der Reihenfolge: • abc • acb • bac • bca • cab • cba 58 7.5.3 Blockversuchspläne • auch: Versuchspläne mit parallelisierten Gruppen • Kombination aus Designs der Zufallsgruppenbildung und der Wiederholungsmessung 1. Auswahl von Pbn, die sich hinsichtlich Parallelisierungsmerkmal gleichen 2. Aufstellen einer Rangreihe (bezogen auf Ausprägung des Parallelisierungsmerkmals) 3. Bildung von “Blöcken” von Pbn mit jeweils benachbarten Rangplätzen Gedanke: Pbn eines Blocks sind sich hinsichtlich Parallelisierungsmerkmal ähnlicher als Pbn aus unterschiedlichen Blöcken 4. Zuordnung der Pbn eines “Blocks” zu Versuchsbedingung erfolgt dann per Zufall (“Randomisierung”) “Statistische Zwillinge” Bildung statistischer Zwillinge: 59 Unterscheidung von • Zweistichproben- vs. Mehrstichprobenversuchsplänen: • Untersuchung von zwei oder mehreren parallelisierten Versuchsgruppen • Einfaktorielle, zweifaktorielle vs. mehrfaktorielle Versuchspläne: • einfaktoriell: Untersuchung bei einer UV mit mindestens 2 Stufen • zweifaktoriell: Untersuchung bei Variation von 2 UV mit je mindestens 2 Stufen Vorteil: - Erhöhung der Erwartungswertgleicheit durch Parallelisierung Nachteil: - Mehrfachmessung: Übertragungseffekte zwischen Messzeitpunkten nicht auszuschließen - Vortestvariablen, die hoch mit AV korrelieren, sind schwer aufzufinden. - Höherer Versuchsaufwand 7.5.4 Mischversuchspläne Zwei- oder mehrfaktorielle Designs, bei dem die Faktoren verschiedenen Design-Haupttypen entsprechen • Zufallsgruppenfaktor (“R” Randomisierung) • Faktor mit wiederholter Messung (“W” Wiederholung) • Blockfaktor (“O” Block) Symbolabfolge zur Charakterisierung des Versuchsplans • RO-Mischdesign, RW-Mischdesign, RWO-Mischdesign Lassen alle möglichen Faktorenkombinationen zu und sins somit äußerst flexibel für die jeweilige inhaltliche Fragestellung Beispiel: 60 7.5.5 Zusammenfassung Mit welchem Plan untersuche ich? Versuchspläne mit Zufallsgruppenbildung • Zufällige Zuweisung der Pbn zu Versuchsgruppen, danach zufällige Zuweisung der Versuchsgruppen zu den Bedingungen Versuchspläne mit wiederholter Messung • Untersuchung einer Versuchsgruppe zu verschiedenen Messzeitpunkten Blockversuchspläne • Kombination aus Designs der Zufallsgruppenbildung und der Wiederholungsmessung Mischversuchspläne • Kombination aus o.g. Designs Empfehlungen: Wenn der Zeitverlauf interessiert: • Mischversuchsplan (z.B. Alkohol und Sprechen) Wenn Patienten untersucht werden, die alle behandelt werden müssen: • abhängiger Plan im Cross-Over (z.B. Psychotherapieklienten) Wenn hoher Aufwand bei der Probandengewinnung: • Abhängiger Plan (z.B. Training auf Fahrsimulator) Wenn Testeffekte zu erwarten sind: • Unabhängiger Plan (z.B. Problemlösen und Lernerfahrungen) Wenn Wirkungen in versch. Verhaltens- und Erlebensbereichen erwartet werden: • Multivariater Plan (Therapiekontrolle) 7.6 Quasi-experimentelle Designs • systematische Manipulation relevanter Variablen • keine Kontrolle von Störfaktoren • Beispiele: Ø Zeitreihenversuchspläne mit einer Gruppe oder mit statischen Gruppen Ø Versuchspläne mit unvollständiger Ausbalancierung Ø Einzelfallversuchspläne 61 7.6.1 Zeitreihenversuchspläne Eingruppen-Zeitreihendesign Beispiel: ABAB-Plan Einfachste Lösung: Vorher- und Nachher-Messungen an einer einzelnen Gruppe unter einer Bedingung Erweiterung auf mehrere verschiedene Gruppen: MehrgruppenZeitreihendesign (mit vorgegebenen “statischen” Gruppen) Abgrenzung von Mehrgruppen-Zeitreihendesign mit Zufallsgruppenbildung als experimenteller Versuchsplan 7.6.2 Versuchspläne mit unvollständiger Ausbalancierung Annahme: Konfundierung zwischen den UVn und der gewählten Darbietungsabfolge der Bedingungen Quasi-experimentell: Versuchspläne mit unvollständigem faktoriellem Design bei der Wiederholungsmessung Methoden: • Vollständige Permutation Ø Herstellung und Durchführung aller möglichen Behandlungskombinationen • Unvollständige Permutation Ø Herstellung aller möglichen Behandlungskombinationen Ø Zufällige Auswahl einzelner Kombinationen Ø Jede Behandlungsform kommt gleich häufig vor. • Lateinisches Quadrat ( s. Krüger) Vorteile: Zeitreihenversuchspläne: Untersuchung von Prozessen Einzelfallversuchspläne: Brückenschlag zwischen Allgemeiner und Differentieller Psychologie Ausbalancierungspläne: Bestmögliche Kontrolle der Bedingungsabfolge Nachteile: Generell: Probleme des Faktors „Zeit“ (geringe interne Validität) Einzelfallversuchspläne: z.T. fehlende inferenzstatistische Verfahren, Problem der Verallgemeinerbarkeit 7.6.3 Einzelfallversuchspläne 7.7 Ex post-facto-Designs Ableitung von Kausalzusammenhängen aus nicht-manipulierten bzw. nichtmanipulierbaren Variablen Bewertung: Keine Manipulation durch den Untersucher Probandengruppen unterscheiden sich höchstwahrscheinlich nicht nur hinsichtlich UV „Handynutzung“. Ergebnisse sind streng genommen nur „korrelativ“ zu interpretieren. 7.8 Übersicht: Versuchspläne 1. Vorexperimentelle (“ungültige”) Designs 62 explizite Einführung einer experimentellen Bedingung keine Kontrolle von Störfaktoren 2. Experimentelle Designs kausaltheoretische Vorhersage vorhanden systematische Manipulation relevanter Variablen Kontrolle von Störfaktoren, die die Interpretierbarkeit und Gültigkeit der Ergebnisse beeinträchtigen könnten. 3. Quasi-experimentelle Designs systematische Manipulation relevanter Variablen keine Kontrolle von Störfaktoren 4. Ex post-facto-Designs Ableitung von Kausalzusammenhängen aus nicht-manipulierten Variablen 7.9 Zur Übung: Womit untersuche ich was? Wahrnehmungslernen: Störungen der visuellen Entwicklung innerhalb kritischer Periode führen zu dauerhafter Beeinträchtigung des Wahrnehmungslernens. Emmertsches Gesetz: Das Nachbild wird umso größer, je weiter die Vorlage, auf der man das Nachbild sieht, entfernt ist (G = R x D). Sexualsymbolismus von Freud: Runde Formen sind eher weiblich, längliche und spitze eher männlich. Geschlechter bevorzugen ihre eigene Symbolik. Gruppendruck: In einer Gruppensituation wird der Gruppendruck umso stärker, je größer die andersdenkende Gruppe ist. Dieser Effekt ist am deutlichsten bei mittlerer Diskrepanz der Urteile. Isolation: Wenn Menschen in Angst versetzt werden, tendieren sie zu mehr Sozialkontakten mit fremden Personen als wenn sie angstfrei sind. Konfundierung: Führen bestimmte physische Behandlungen von Jungtieren direkt zu Veränderungen oder ist die unterschiedliche Behandlung durch die Mutter verantwortlich? Lernen: Ist Lernen mit Verständnis besser als Lernen ohne Verständnis? Soziales Modellernen von Hilfsbereitschaft: Ähnliche Modelle führen dann zur Nachahmung, wenn diese gute Erfahrungen machen (und umgekehrt), unähnliche Modelle haben keinen Einfluss. 63 8 Prüfungsfragen Rausche / Krüger: (aus den letzen 4 Klausuren) 8.1 Verteilungen Parameter einer Normalverteilung - eindeutig bestimmt durch die Parameter und . Die Normalverteilung hat folgende Eigenschaften: arithm. Mittel, Modus und Median fallen zusammen die Kurve hat bei x=µ ihr einziges Maximum die beiden Äste der Kurve nähern sich asymptotisch der Abzisse De Fläche unter der Kurve muß natürlich gleich 1 sein Parameter einer Standardnormalverteilung Jede beliebige Zufallsvariable X mit dem Mittelwert und der Streuung lässt sich durch eine Standardisierung (z-Transformation) in eine Zufallsvariable z mit =0 und der Streuung =1 überführen. Geben Sie Schiefe und Modalität einer Normalverteilung an: Schiefe = 0; Modalität = unimodal (eingipflig) 8.2 Inferenzstatistik Bezüglich welcher Annahmen unterscheiden sich t-Test und z-Test. Beim z-Test ist die wahre Varianz bekannt. Beim t-test ist die wahre Varianz unbekannt. Wann ist eine Varianzanalyse im Gegensatz zu einem t-Test zu verwenden? t-test ist ein 2-Stichprobentest. Varianzanalyse ist die Verallgemeinerung des t-Tests auf mehr als 2 Stichproben. Nennen Sie für t-Test und Varianzanalyse je ein non-parametrisches Verfahren. H-Test für die Varianzanalyse Wilcoxon-Rangsummentest für den t-Test In einem Versuch zur Wirkung von Alkohol auf die Reaktionsgeschwindigkeit werden drei unabhängige Versuchsgruppen (eine Kontrollgruppe und zwei Experimentalgruppen) untersucht. Eine Kontrollgruppe erhält ein Placebo, in Experimentalgruppe 1 werden 0.5 Promille Blutalkohol angesteuert, in Experimentalgruppe 2 eine Blutalkoholkonzentration von 0.8 Promille. a. Stellen Sie die statistische Nullhypothese sowie je eine gerichtete bzw. ungerichtete Alternativhypothese dieses Versuchs auf. 64 H0: mtk=mt1=mt2 H1c: mtk ≠ mt1 oder/und ≠ mt2 H1c: mtk < mt1 < mt2 b. Welches inferenzstatistische Verfahren würden Sie empfehlen, um zu prüfen, ob sich die drei Versuchsgruppen „statistisch signifikant“ unterscheiden? Einfaktorielle Varianzanalyse c. Welches inferenzstatistische Verfahren würden Sie empfehlen, um zu prüfen, ob sich nur die zwei Experimentalgruppen „statistisch signifikant“ voneinander unterscheiden? t-test zwecks Mittelwertsvergleich Bei der Auswahl eines inferenzstatistischen Verfahrens müssen verschiedene Fragen gestellt werden. Nennen Sie diese Fragen. - Skaltenniveau - Anzahl der Stichproben - Unabhängige / abhängige Stichprobe Es werden der Fehler 1. Art und der Fehler 2. Art unterschieden. Definieren Sie kurz deren Bedeutung. Wie verhalten sich diese Fehler zueinander? Fehler 1. Art (): H0 Hypothese wird abgelehnt, obwohl H0 richtig ist. Fehler 2. Art (): H0 wird beibehalten, obwohl H1 richtig ist. Verhalten sich antiproportional zueinander Die inferenzstatistische Überprüfung, ob sich zwei Versuchsgruppen „statistisch signifikant“ unterscheiden, folgt einer typischen Folge von Auswertungsschritten. Beantworten Sie für jeden der Auswertungsschritte die entsprechende Frage: (a) Es wird eine Nullhypothese aufgestellt. Was wird in dieser formuliert? (1P) Die inhaltliche Frage „Hat eine Behandlung einen Einfluss?“ wird methodisch dargestellt als „Ist der Unterschied zwischen Behandlungen bedeutsam?“ Besondere Hinweise: • Bei mehreren Stichproben überprüft die ANOVA die Hypothese, ob sich mindestens zwei der k Stichproben unterscheiden • Ein signifikantes Ergebnis sagt nicht, wo der Unterschied liegt. Dies kann erst durch nachgeschaltete Einzelvergleiche überprüft werden. (b) Mit Hilfe der Nullhypothese wird eine Verteilung erstellt. Wie kommt diese Verteilung zustande? (1P) Wahrscheinlichkeitsfunktion X-Achse: mögliche Brüche PV/FV Y-Achse: Wahrscheinlichkeit dieser Brüche Eine Zufallsvariable X hat endlich oder abzählbar unendlich viele Werte, d.h. der Wertebereich hat die Gestalt {x1, x2, x3...}. Diese Zufallsvariable und auch deren Verteilung heißen diskret. Die Wahrscheinlichkeitsfunktion P(X=xi)=P(xi) ordnet jeder reellen Zahl X die Wahrscheinlichkeit zu, mit der sie von X angenommen wird. Die Wahrscheinlichkeitsfunktion sagt also aus, mit welcher Wahrscheinlichkeit eine bestimmte Ausprägung einer Zufallsvariablen bei einem Zufallsexperiment auftritt. 65 Verteilungsfunktion: Kumuliert man die Werte der Wahrscheinlichkeitsfunktion für die Werte xi, so erhält man die Verteilungsfunktion: F(t)=P(X<=xt)= P(xi) (c) Das empirische Ereignis wird in Beziehung gesetzt zur Verteilung unter (b). Auf welche Weise geschieht dies? (1P) # (d) Schließlich wird eine Entscheidung getroffen. Was wird entschieden und wie geschieht dies in der Regel? (2P) Wenn mein empirisches Ergebnis unter dem Modell der H0-Hypothese zu den 5% bzw. 1% der unwahrscheinlichsten Ergebnisse zählt, ist das Modell der H0Hypothese abzulehnen. = wir haben einen Effekt 8.3 Testen Was bedeutet „Signifikanz“ (2 P)? In der Statistik heißen Unterschiede signifikant, wenn sie mit einer bestimmten Wahrscheinlichkeit nicht durch Zufall zustande gekommen sind. Die Überprüfung der statistischen Signifikanz geschieht mit Hilfe einer Nullhypothese, die verworfen wird, wenn das zufällige Zustandekommen des Unterschiedes sehr unwahrscheinlich ist. Der Grad der zu überprüfenden Unwahrscheinlichkeit wird vorher festgelegt und mit α bezeichnet, beispielsweise α = 0.05 für 5% Irrtumswahrscheinlichkeit. 8.4 Induktion Was bedeutet eine „induktive Schlussweise“? Induktion (lat. Hinführung) bedeutet in der Logik das Verfahren, vom besonderen Einzelfall auf das Allgemeine, Gesetzmäßige zu schließen, im Gegensatz zum umgekehrten Vorgang, der Deduktion. Der Induktion liegt die Annahme zugrunde, daß, wenn sich etwas bei einer Reihe von beobachteten Ereignissen als wahr erweist, es sich bei allen gleichartigen Ereignissen als wahr erweisen wird. Die Wahrscheinlichkeit der Richtigkeit hängt dabei von der Anzahl der beobachteten Ereignisse ab. Eines der einfachsten Beispiele für ein induktives Vorgehen ist die Auswertung von Meinungsumfragen, bei denen die Antworten eines relativ geringen Prozentsatzes der Gesamtbevölkerung auf diese hochgerechnet werden. Diese Gegenüberstellung von Induktion und Deduktion geht auf den Begriff der "epagoge" bei Aristoteles zurück. http://arbeitsblaetter.stangl-taller.at/DENKENTWICKLUNG/Induktion.shtml […] Letztendlich läuft das Verifikationverfahren auf einen Induktionsschluss hinaus, bei dem vonn einer begrenzten Anzahl spezieller Ereignisse unzulässigerweise auf die Allgemeingültigkeit der Theorie geschlossen wird. 66 Welches Ziel verfolgt der „Canon of induction“ von J.St. Mill? Benötigt werden Regeln der Induktion, die möglichst hohe Plausibilität gewährleisten. Was ist die Grundfrage der Canon of Induction? (1P) Die Grundfrage des induktiven Schließens: - darf man aus der Beobachtung von Einzelfällen verallgemeinern? Nennen Sie drei Canon of Induction und geben Sie jeweils eine empirische Technik an, die sich das entsprechende Prinzip zu Eigen macht. (3P) 1. First Canon: Method of Agreement Maximieren der Begleitvarianz 2. Second Canon: Method of Difference Minimieren der Begleitvarianz 3. Third Canon: Joint Method of agreement and Prinzip der Randomisierung difference 4. Fouth Canon: Method of residues Isolation bekannter Ursachen aus den Ergebnissen 5. Fifth Canon: Method of concomitant variation Untersuchung von Funktionalitäten 8.5 Deskriptive Statistik Im Rahmen der deskriptiven Datenanalyse werden seitens der auswertenden Personen immer wieder Fehler gemacht, die typischen Fehlerklassen zugewiesen werden können. Nennen Sie zwei dieser typischen Fehler und die entsprechende Möglichkeit, wie diese Fehler kontrolliert werden können (2 P). Fehler 1. Art Alpha: möglichst klein halten Fehler 2. Art Beta: große Stichprobe nehmen und 2 (Fehlervarianz)möglichst gering halten Ein Lehrling hat in drei verschiedenen Eignungstests folgende Testwerte erhalten: x1 = 60, x2 = 30 und x3 = 110. Diese drei Tests wurden in vorherigen Untersuchungen mit folgenden Mittelwerten und Standardabweichungen gekennzeichnet: m1 = 42, s1 = 12, m2 = 40, s2 = 5, m3 = 80, s3 = 15. In welchem Eignungstest hat der Lehrling am besten abgeschnitten? Geben Sie die Formel der entsprechenden Berechnung an und führen Sie diese Berechnung durch (2.5 P). Formel: (x – m) / s = z 1)1,5 2)-2 3)2 (am besten!) Nennen Sie je ein Maß für Lage und Variabilität einer Stichprobe, das von Ausreißerwerten minimal abhängig ist. Lage: Modus / Median 67 Variabilität: Bereichsmaße (Interquartilbereich, etc.) Nennen Sie je ein Maß für Lage und Variabilität einer Stichprobe, das von Ausreißerwerten sehr stark abhängig ist. Lage: Mittelwert Variabilität: Varianz Wie verändert sich das Konfidenzintervall des Mittelwerts bei Vergrößerung des Stichprobenumfangs? Begründen Sie ihre Antwort kurz? Wird kleiner, weil durch die Vergrößerung der Stichprobe die Chance größer wird den wahren Mittelwert zu treffen. Der Mittelwert einer größeren Stichprobe ist repräsentativer. Wie verändert sich das Konfidenzintervall des Mittelwerts bei Vergrößerung der Populationsstreuung? Begründen Sie ihre Antwort kurz? Wird größer, da die die große Varianz die Treffsicherheit verringert. 8.6 Logik Definition Modus Tollens: Grundregel der Logik: Wenn gilt "aus A folgt B" und "B ist falsch", dann gilt auch "A ist falsch". Warum beruht ein Signifikanztest auf dieser Tautologie? Weil er auch die Gesetze der Logik anwendet: - Bezug zur Entscheidungsregel: o Jedes empirische Ergebnis, das in den Ablehnungbereich von H0 fällt, führt dazu, dass das durch H0 spezifizierte Modell als „Erklärung“ für das empirische Ergebnis abgelehnt wird. Beschreiben Sie kurz, was unter einer „Tautologie“ bzw. einer „Kontradiktion“ verstanden wird. Geben Sie jeweils ein aussagenlogisches Beispiel an. (2P) Eine Tautologie ist eine Aussage der Aussagenlogik, die immer wahr ist. Mit anderen Worten, eine Tautologie ist eine Aussage, die immer den Wahrheitswert wahr annimmt, unabhängig davon, wie die Variablen in der Aussage belegt sind. "Eine ungerade natürliche Zahl ist nicht durch zwei teilbar." ist als Aussage eine Tautologie, denn eine "ungerade Zahl" wird dadurch definiert, dass sie nicht durch zwei teilbar ist Laut Krüger Script: Ein aussagenlogischer Ausdruck ist eine Tautologie, wenn er bei jeder möglichen Kombination von Wahrheitswerten der beteiligten Aussagen zu einer wahren Aussage führt. Eine Kontradiktion oder auch Widerspruch ist eine Aussage der Aussagenlogik, die immer falsch ist. Mit anderen Worten, eine Kontradiktion ist eine Aussage, die immer den Wahrheitswert falsch annimmt, unabhängig davon, wie die Variablen in der Aussage belegt sind. 68 Die Aussage B:=„A und nicht A“ ist eine Kontradiktion, da B unabhängig von der Belegung von A immer den Wahrheitswert nicht wahr annimmt. Ich bin ein Lügner ist eine kontradikte Aussage, denn wenn die Aussage des Lügners wahr ist, ist sie gelogen. Laut Krüger Script: Ein aussagenlogischer Ausdruck ist eine Kontradiktion, wenn er bei jeder möglichen Kombination von Wahrheitswerten der beteiligten Aussagen zu einer falschen Aussage führt. Stellen Sie die Wahrheitstafel dar. ". Geben Sie kurz an, was in der Aussagenlogik unter den Junktoren „Konjunktion“, „Disjunktion“, „Implikation“ und „Äquivalenz“ verstanden wird. (2P) „Konjunktion“ = und „Disjunktion“ = oder „Implikation“ = wenn, dann „Äquivalenz“ = genau wenn, dann 8.7 Wahrscheinlichkeit a. Welche unterschiedlichen Definitionen der Wahrscheinlichkeit kennen Sie? Induktive Wahrscheinlichkeit Deduktive Wahrscheinlichkeit - Klassische - Axiomatische Wie werden in den unterschiedlichen Ansätzen Wahrscheinlichkeiten berechnet? 69 Worin unterscheiden sie sich? Induktiv: vom Einzelfall zum Allgemeinen Deduktiv. Vom Allgemeinen zum Einzelfall Welche Gemeinsamkeiten haben die Definitionen? # Was bedeutet das Prinzip der „Indifferenz“? Wenn wir keine hinreichenden Gründe für die Annahme haben, dass etwas wahr oder falsch ist, weisen wir den beiden Wahrheitswerten die gleiche Wahrscheinlichkeit zu. (Beispiel aus dem Script: Gibt es irgendeine Form von Leben auf dem TITAN?) Wie hängt dieses Prinzip mit der Definition von Wahrscheinlichkeit zusammen? Die Vorraussetzung für das Rechnen mit Wahrscheinlichkeiten ist auch: alle Ereignisse sind gleichwahrscheinlich. (abgeleitet aus dem Prinzip des Zufalls) Wie heißt der klassische Wahrscheinlichkeitsbegriff nach PASCAL? Deduktive Wahrscheinlichkeit: klassissch: 1. Aufzählen aller möglichen Fälle (Enumeration) = m 2. Bilden der Menge der günstigen Fälle = g 3. Bilden des Bruchs p = g/m Welche Wahrscheinlichkeiten haben bei dieser Definition die Elementarereignisse? Alle Elementarereignisse sind gleichwahrscheinlich und abzählbar. Alle haben die Wahrscheinlichkeit (px * 1-p)n-x Warum ist dieser Wahrscheinlichkeitsbegriff bei unedlichen Ereignissmengen nicht anwendbar? Weil die Trefferzahl x (und N = die Anzahl der Versuche) vorgegeben sein muss, um Pascal anzuwenden. Bei x = unendlich ist keine Rechnung möglich. weil die Menge der Ereignisse nicht abzählbar ist 70 (a) Die Wahrscheinlichkeit, in 20 Jahren noch zu leben, möge für Herrn M. p = 0.60 und für Frau M. p = 0.70 betragen. Wie groß ist die Wahrscheinlichkeit, dass Herr und Frau M. in 20 Jahren beide noch leben werden? Geben Sie die Formel an und führen Sie die Berechnung durch (2 P). 0,6*0,7=0,42 8.8 Forschungsformen 8.8.1 Wissenschaftstheorie Was versteht man unter der „ceteris paribus“-Bedingung? (1P) ceteris paribus = „alle übrigen gleich“ Alle übrigen Versuchsbedingungen lasse ich gleich Durch welches versuchsplanerische Prinzip wird diese Bedingung umgesetzt? (1P) Dies fürhrt zu den experimentellen Techniken der: o Konstanthaltung o Kontrolle der Sekundärvarianz o Randomisierung o und insbesondere der Kontrollgruppe Schreiben Sie in logischer Schreibweise, wie nach HEMPEL & OPPENHEIMER die wissenschaftliche Erklärung aufgebaut ist. Geben Sie an, wie in diesem Schema eine ex-post-Erklärung dargestellt werden kann. - Es liegt eine Consecutio (Wirkung) vor - Ein Allgemeines Gesetz (Ursache führt zur Wirkung) gilt - Also muss die Prämisse (Ursache) gelten Geben sie ein psychologisches Beispiel für eine solche ex-post-Erklärung. - MacMahon et al. (1981): Führt Kaffeekonsum zu erhöhtem Auftreten von Pankreaskarzinom? - Ex post: Korrelation zwischen erhobenem Kaffeekonsum und Krebserkrankung Nach Hempel & Oppenheimer wird bei der wissenschaftlichen Erklärung aus einer Prämisse über ein Gesetz eine Folgerung abgeleitet. Je nach Lesart dieses Schemas entstehen vier Forschungstypen, die sich auf zwei Dimensionen unterscheiden. Was ist mit der Unterscheidung „deduktiv – reduktiv“ gemeint? Deduktiv: Das allgemeine Gesetz ist bekannt → Angewandte Forschung Deduktiv: Vom Allgemeinen zum Besonderen 71 Reduktiv (induktiv): Das allgemeine Gesetz wird gesucht → Grundlagenforschung Reduktiv: Vom Besonderen zum Allgemeinen Was ist mit der Unterscheidung „progressiv – regressiv“ gemeint? Progressiv: Die Ursache wird gesetzt, der Effekt abgewartet → ex ante-Forschung Progressiv: von der Prämisse zur Consecutio Regressiv: Die Wirkung wird festgestellt, die Ursache wird gesucht → Ex post factoForschung Regressiv: von der Consecutio zur Prämisse Welchem Forschungstyp können Labor- und Feldexperimente bzw. die Ex post-facto Forschung zugeordnet werden. Welche Problematik ergibt sich bei progressiven bzw. regressiven Forschungstypen? 1. Die Problematik des reduktiven (induktiven) Schlusses Darf man aus der Beobachtung von Einzelfällen verallgemeinern? Das Problem der Induktion 2. Die Problematik des regressiven Schlusses Darf man auf zeitlich frühere Ursachen schließen? Das Problem der ex post factoForschung Forschungstypen Man unterscheidet zwischen progressiven und regressiven Ansätzen. (a) Warum sind Experimente Beispiele für progressives Vorgehen? (1P) Weil ich die Ursache setze (UV) und die Wirkung (AV) abwarte. (b) Beschreiben Sie kurz an einem Beispiel, wie man bei einem regressiven Ansatz versuchsplanerisch vorgeht. (2P) Viele Autounfälle, mögliche Ursache Telefonieren während der Fahrt (Korrelation – dazu müssen beide Variablen erhoben worden sein) (c) Wie bewerten Sie regressive Ansätze hinsichtlich ihrer internen Validität? (1P) 72 Es gibt keine Manipulation der UV, somit ist die AV nicht eindeutig auf die Veränderung der UV zurückzuführen (Kausalitätsproblem) (d) Warum setzt man dennoch regressive Ansätze ein? Geben Sie zwei Gründe an. (2P) Die behauptete Consecutio ist so negativ, dass sie nicht experimentell erzeugt werden darf. (z.b. Krebsforschung) Die Ursache für die Consecutio ist noch so wenig bekannt, dass eine experimentelle Manipulation noch nicht möglich ist. 8.8.2 Messtheorie Wie wird Messen in der mathematischen Messtheorie definiert? Messen ist die homomorphe Abbildung eines empirischen Relativs in ein numerisches Relativ Gegeben sind die Mengen A = {2,3} und B = {4,5}. Stellen Sie das kartesische Produkt A x B dar und definieren Sie darauf die Relation „größer als“. # In der Messtheorie werden vier Problemkreise diskutiert. Nennen Sie diese Probleme und geben Sie die damit verbundene Frage an. Welches Problem tritt bei Abbildungen von Relativen auf? Siehe unten! Wird ein Relativ auf ein anderes strukturgleich abgebildet, stellt sich die Frage, ob zugleich eine Abbildung der Relation stattfindet. (muss gewährleistet sein) Beim Vergleich zwischen Objekten sind zwei psychische Relationen möglich: Ununterscheidbarkeit und Ordnung. Gehen Sie von einer Menge A und drei Objekten a, b und c aus. Welche Relationen muss das Urteil „ununterscheidbar“ erfüllen (1.5 P)? A ~ A (reflexiv), A ~ B → B ~ A (symmetrisch), A ~ B und B ~ C → A ~ C (transitiv) psychische R1 ist ~ (ununterscheidbar): a R1 b genau dann, wenn f(a) = f(b) für alle a,b Є A Welche Relationen muss das Urteil „größer“ erfüllen? (1.5 P)? psychische R2 ist > (vorrangig): a R2 b genau dann, wenn f(a) > f(b) für alle a,b ~ A für alle a,b Є A - Eigenschaften: Transitivität & Konnexivität Es wird zwischen algebraischen und probabilistischen Messmodellen unterschieden. (a) Stellen Sie die Grundstruktur eines algebraischen Messmodells mit Angaben zu den beteiligten Mengen, Relationen, Relativen und Abbildungen kurz dar (3.5 P). Mengen: - Auswahl eines Gegenstandsbereichs Relativen: - Auswahl einer empirischen Anordnung, die es erlaubt, die Eigenschaften der Relationen zu prüfen (z.B. Paarvergleich) Relationen: - Aufsuchen eines numerischen Relativs mit den gleichen Struktureigenschaften Abbildungen: - Zuordnung von Funktionswerten zu den Elementen des Gegenstandsbereichs Hierbei ist es wichtig, die Klassifikationssysteme zu beherrschen. Äquivalenzrelation: kann der Mensch gleiches gleich bezeichnen? 73 Ordnungsrelation: kann er Elemente ordnen? Art des Relativs, das er abbildet (b) Stellen Sie die Grundstruktur eines probabilistischen Messmodells am Beispiel des „Law of Comparative Judgement“ kurz dar. 1. Welche Datenmatrix liegt vor (1 P)? Graphische Darstellung der Normalverteilungshypothese (repräsentierende Relationen) über den Zusammenhang zwischen der Differenz der subjektiven Skalenwerte zweier Objekte und der Wahrscheinlichkeit, dass das Subjekt b über a dominiert. # 2. Welche Annahmen werden gemacht (1 P)? - Die Psychophysik unterscheidet zwischen der Abbildung des Reizes auf das Sensorium (Empfindung) und der Abbildung der Empfindung auf das Urteil. - Die Annahme normalverteilter Fehler (Bestimmung der Absolutschwelle und der Unterschiedsschwelle) - die Normalverteilung der Urteilsverteilung und der Fehler 3. Was resultiert als Ergebnis der Analyse (1 P)? Bestimmung der Unterschiedsschwelle (c) Was ist der Unterschied zwischen beiden Ansätzen (2 P)? Repräsentationstheorem (algebraisches Modell) vs. Theorie über die Verteilung von Fehlern (probabilistisches Modell) (Die deterministischen Messmodelle sind algebraischer Natur. Hier wird geprüft, ob ein numerisches Relativ ein empirisches Relativ repräsentieren kann. Weiter prüfbar sind die Zahl der Verletzungen des Messmodells, ohne dass eine eigene Theorie der Fehler besteht. Demgegenüber zeichnen sich probabilistische Messmodelle dadurch aus, dass sie Annahmen über die Verteilung von Fehlern machen. Daraus resultiert auch, dass für die gemessenen Objekte oder Items Messwerte geschätzt werden müssen (sie sind ja wegen der Fehler nicht mehr eindeutig), wobei die Schätzung auf der Basis des Fehlermodells geschehen müssen. Probabilistische Messmodelle gehen davon aus, dass eine Messung sich immer aus einem wahren Wert und einem Fehler zusammen setzt. Prinzipiell haben probabilistische Messmodelle die gleiche Aufgabe wie die algebraischen: Untersuchung der beiden psychischen Relationen „Gleich - ungleich“ Psychometrie der Unterscheidbarkeit „größer als“ Psychometrie der Dominanz) In der folgenden Tabelle sei das Ergebnis eines Leistungstests erfasst. N Probanden bearbeiten jeweils k Aufgaben und lösen diese (= 1) oder nicht (= 0). 74 (a) Um welchen Typ eines Cartesischen Produkts handelt es sich (2 P)? Binäre A x B Relation (linkstotal und rechtseindeutig) (b) Wie heißt die empirische Relation, die hier dargestellt wird (1 P)? Aufgabe gelöst vs. Aufgabe nicht gelöst (a) Was ist unter einer homomorpher bzw. isomorpher Abbildung zu verstehen? Beschreiben Sie diese Begriffe kurz und veranschaulichen Sie graphisch den Unterschied. (2P) . Ist die Abbildung injektiv, spricht man von homomorpher Abbildung. Injektive Abbildung: Verschiedene a aus A liefern verschiedene b aus B. Abbildung ist linkstotal und eineindeutig. Ist die Abbildung bijektiv, spricht man von isomorpher Abbildung. Bijektive Abbildung: Jedem a aus A ist ein b aus B zugeordnet. Abbildung ist bitotal und eineindeutig. (b) Geben Sie je ein Beispiel für eine zulässige bzw. nicht-zulässige Transformation auf Intervallniveau. (2P) Zulässig: Jede positiv lineare Funktion y = bx + c mit b>0 Nicht zulässig: Quadrieren und Wurzel ziehen (wegen des Vorzeichenverlusts): y = x² 75 (c) Geben Sie je ein Beispiel für ein zulässiges bzw. nicht-zulässiges Lagemaß auf Ordinalniveau. (2P) Zulässig: Modus/Median Nicht zulässig: Mittelwert (d) Im Rahmen der mathematischen Messtheorie treten unterschiedliche Probleme auf, die zu lösen sind. Geben Sie für die vorherigen Teilaufgaben (a) bis (c) an, welches Problem jeweils angesprochen wird und definieren Sie dieses Problem kurz. (3P) a) Eindeutigkeitsproblem Welche anderen numerischen Relative sind ebenfalls in der Lage, diese Abbildung zu leisten? b) Bedeutsamkeitsproblem - Eine Aussage ist bedeutsam, wenn sich ihr Wahrheitswert bei einer zulässigen Transformation der Werte nicht ändert - welche Rechenoperationen dürfen mit den erhaltenen Zahlen ausgeführt werden? c) Skalierungsproblem - welche statistischen Kennwerte eine sinnvolle Aussage über die Objekte und ihre Relationen erlauben? 8.9 Zufallsvariable Führen Sie einen dreimaligen Münzwurf aus. Was ist ein „Ergebnis“, was ein „Ereignis“? Ereignis: Kopf oder Zahl ist gefallen Ergebnis: z.B. in 3 Versuchen ist 2 mal Kopf gefallen Definieren Sie eine Zufallsvariable. Eine Zufallsvariable ist eine solche Variable, die ihre Werte in Abhängigkeit vom Zufall d.h. mit einer gewissen Wahrscheinlichkeit annimmt. Die Wahrscheinlichkeiten und damit die Zufallsvariable können oft durch eine Verteilung eindeutig charakterisiert werden. Man unterscheidet diskrete und stetige Zufallsvariable . Man benutzt Zufallsvariable u.a. zur Entscheidung beim statistischen Test . Solche Zufallsvariablen heißen Teststatistik. Den Wert, den sie im konkreten Fall annimmt, nennt man Prüfgröße. Jede Regel (oder Funktion) X, die jedem Elementarereignis eines Ereignisraumes eine reelle Zahl und gleichzeitig die zu dem Elementarereignis gehörende Wahrscheinlichkeit der reellen Zahl zuordnet, heißt Zufallsvariable. Eine diskrete Zufallsvariable X liegt dann vor, wenn jedem möglichen Ereignis eines endlichen Ereignisraumes eine Zahl xi aus der Menge der Zahlen {x1, x2, x3...xk} zugeordnet wird. Eine stetige Zufallsvariable X liegt dann vor, wenn jedem möglichen Ereignis eines endlichen Ereignisraumes eine Zahl x aus einem Intervall I: a<=x<=b zugeordnet wird. 76 8.10 Korrelationen Veranschaulichen Sie grafisch (z.B. in Form eines Streudiagramms) folgende Korrelationen zwischen zwei Variablen X und Y (3 P): (a) Nullkorrelation (r = 0.0) (b) Mittelhohe positive Korrelation (r = 0.5) (c) Perfekte positive Korrelation (r = 1.0) Was prüft eine Korrelation? Die Korrelation entspricht dem mittleren Kreuzprodukt aus standardisierten Werten und ist damit unempfindlich gegen lineare Transformationen der Messwerte. Das gilt z. B. für Merkmale wie Alter und Geschlecht (organismische Variable;). 8.11 Versuchsplanung Sind experimentelle oder versuchsplanerische Kontrolltechniken bedeutsamer für die Versuchsplanung? gleichbedeutsam Bei welcher versuchsplanerischen Kontrolltechnik ist die Chance, vorhandene Effekte zu entdecken, am größten bzw. bei welcher Kontrolltechnik am kleinsten? Begründen Sie ihre Antwort kurz? Bei der Wiederholungsmessund am größten Bei der Randomisierung am kleinsten Ein Forscher möchte den Einfluss der kogntiven Leistungsgeschwindigkeit auf Lernund Gedächtnisleistungen untersuchen. Zu Beginn der Studie steht er vor der Frage, welches Versuchsdesign er wählen soll. a) Welches experimentelle Design ist zu empfehlen? Wiederholungsmessung b) Welches quasi-experimentelle Design ist zu empfehlen? Mehrgruppenzeitreihendesign? c) Welches vorexperimentelle Design ist zu empfehlen? Statischer Gruppenvergleich? 8.12 Diverses Organismische Variable - Definition: - eine spezielle, physiologische Eigenschaften (z.B. Alter, Intelligenz) betreffende, moderierende Variable, die einen Einfluss auf die AV haben könnte. Das Randomisieren als Voraussetzung für das Labor- und Feldexperiment ist nicht immer möglich. Einschränkungen ergeben sich in erster Linie aus folgendem Grund: - nicht jede interessierende UV erlaubt eine Zufallszuteilung. THE END Anregungen zur Verbesserung, Ergänzungen und Antworten auf noch offene Fragen werden gerne entgegengenommen. [email protected] 77