Teil1 - schule.at
Werbung

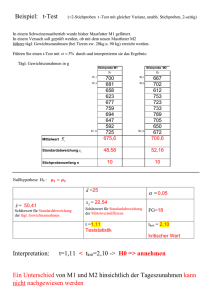
2010 TEIL1 STATISTIK NACH DER MATURA, GRUNDLAGEN Grundlage für den Übertritt in Hochschulen und Fachhochschulen Brigitte Wessenberg Das vorliegende Skriptum ist als kostenlose Lernhilfe für Absolventinnen und Absolventen gedacht, die an Hochschulen oder Fachhochschulen mit Statistik zu tun haben. Es orientiert sich an der Statistik-Broschüre der Sportuni Wien (Baca u.a.), die ohne didaktischen Hintergrund den Umfang an Statistik-Wissen für die Studierenden festlegt. Voraussetzung für das Verständnis: Mathematik-Standardwissen nach Beendigung einer Höheren Schule (AHS, BHS). Das vorliegende Skriptum behandelt KEINE Software Anwendungen (SPSS, R, EXCEL etc), sondern nur die allgemeinen Grundlagen. Es verwendet Beispiele und Aussagen aus folgenden Werken, die zahlreiche Beispiele zum weiterführenden Üben enthalten. Ingenieur-Mathematik 4, Timischl, Kaiser, Verlag E. Dorner Angewandte Statistik, Lothar Sachs, Springer-Verlag Statistik, Deborah Rumsey, Verlag Wiley-VCH Statistik, Detert/ Söhl, Verlag Hirzel Mathematik für HTL, Schärf, Oldenburg-Verlag Mathematik 8, Szirucsek ua./Verlag HPT Mathematik 4 HAK, Schneider u.a., Trauner Verlag Lehrbuch der Mathematik, Reichel u.a./HPT Verlag Mathematik 4 Oberstufe, Bürger-Fischer-Malle, HPT Verlag Mathematik für Ökonomen, Dück u.a. /Verlag Harri Deutsch www.lernstats.de ! Zu einem großen Teil wird das PDF-Skriptum von Dr. Andreas Handl „Einführung in die Statistik mit R“ 558 Seiten, herangezogen. http://www.wiwi.uni-bielefeld.de/~frohn/Mitarbeiter/Handl/statskript.pdf Dieses Skriptum ist didaktisch gut aufgebaut und bringt auch die sonst kaum je erwähnten Ableitungen und Hintergründe, sowie eine ausführliche Begleitung durch die Statistik-Freeware R. Empfehlenswert! 2 Inhalt von Teil 1, Grundlagen Univariate Datenanalyse 4 I Darstellung von univariaten Datensätzen 4 1. Qualitative Merkmale 4 2. Quantitative Merkmale 4 3. Skalierungen 5 II Lageparameter von univariaten Datensätzen 6 1. Modus 6 2. Median 6 3. Mittelwert 7 4. Quantile 7 III Beschreibung der Variabilität 9 1. Stichprobenvarianz 9 2. Standardabweichung einer Stichprobe 9 3. Spannweite10 4. Interquartilsabstand 10 5. Der Boxplot 10 6. Variationskoeffizient 11 Bivariate Zusammenhangsanalyse 12 I Empirische Kovarianz 12 II Pearson Korrelationskoeffizient 13 III Rangkorrelationskoeffizient von Spearman 14 IV Lineare Regression 15 V Kontingenz 16 1. Phikoeffizient 16 2. Cramérs V 17 VI Punktbiseriale Korrelation 17 VII Biseriale Rangkoerrelation 18 Inferenzstatistische Methoden des Schätzens 21 I Wichtige Wahrscheinlichkeitsverteilungen 21 1. Normalverteilung nach Gauß 21 2. z-Verteilung 22 3. Chi-Quadrat-Verteilung 24 4. Student t-Verteilung 25 5. F-Verteilung 27 II Konfidenzintervalle 28 1. KI für Prozentanteil 28 2. KI für Mittelwert, STABW bekannt 29 3. KI für Mittelwert, STABW nicht bekannt 30 4. KI für Standardabweichung 30 Anhang: Tabellen z-Verteilung 31 Chi-Quadrat-Verteilung 32 t-Verteilung 33 F-Verteilung 35 3 Univariate Datenanalyse Statistik beschäftigt sich mit Populationen. In der beschreibenden Statistik betrachten wir alle Merkmalsträger einer Population und stellen die Verteilung eines oder mehrerer Merkmale dar. In diesem Kapitel werden wir jeweils nur ein Merkmal betrachten. Man spricht auch von univariater Datenanalyse. I Darstellung von univariaten Datensätzen 1. Qualitative Merkmale Ausprägungen sind Kategorien nominalskaliert: ungeordnet ordinalskaliert: geordnet: a<b<c<d etc.…Häufigkeiten sind kumulierbar! 2. Quantitative Merkmale Ausprägungen sind ZAHLEN zum Berechnen… Metrisch skaliert: Intervall -, Absolut- und Verhältnisskala (möglich ist auch numerisch nominal und ordinal) BSP: diskrete Merkmale abzählbare Ausprägungen! -Frage nach Anzahl der Geschwister: Ungeordnete Urliste kann geordnet werden. Häufigkeitstabellen, kumulierbar…. Grafiken lassen sich nach bestimmten Eigenschaften einteilen: linkssteil(rechtsschief), rechst steil (linksschief), symmetrisch, bimodal (2Gipfel) BSP: nominalskaliert: -Frage nach Gründen für Studienwahl. Interesse: ja nein Erhebung der Häufigkeit für ja und für nein Qualitatives Merkmal mit 2 Merkmalausprägungen dichotom (in der Summe ergänzen sie sich zu relativer Häufigkeit 1! Daher muss man eigentlich nur eine Ausprägung untersuchen….) - Frage nach Wahlverhalten 6 verschiedenen Merkmalsausprägungen: ÖVP, SPÖ, FPÖ, BZÖ, GR, Sonstige: Keine natürliche Reihenfolge… BSP. Ordinalskaliert. (Rangskala) Wie hat die Sportveranstaltung gefallen? sehr gut, gut, mittel, eher nicht, gar nicht geordnete Merkmalsausprägungen! Die Darstellung erfolgt für beide gleich: Häufigkeitstabellen und Diagramme: Kreis, Säulen, Balken.. Wahlverhalten BSP Stetige Merkmale Ausprägungen nicht abzählbar. Unendl . viele Ausprägungen möglich. - Frage nach dem Alter: In Stichprobe Urliste, ordnen, KLASSEN bilden: Untere Grenze gehört nicht dazu, obere schon (rechts geschlossen!) Häufigkeitstabelle zu den Klassen. Darstellung im HISTOGRAMM: aneinandergrenzende Rechtecke Buchstabenverteilung in Buch 4 Details zu den Klassen: Bei der Erstellung der Klassen muss man die Untergrenze der 1. Klasse festlegen, die Zahl und die Breite der Klassen.2Arten: entweder ist untere Grenze offen, oder die obere: (1,2] (2,3] … oder [1,2) [2,3) …Nicht normiert. Im Statistik-Programm SPSS ist die untere Klassengrenze ausgeschlossen, die obere Klassengrenze eingeschlossen Meist sind die Klassenbreiten gleich groß, die Untergrenze der 1. Klasse sollte eine ganze, möglichst runde Zahl sein. Nicht mehr als etwa 20 Klassen. Richtlinie Klassenzahl ist ca. Wurzel aus n. Faustregel: Anzahl k = 1 + 3,3 log(n), Breite: B = (max(xi) - min(xi)) / k, zB n = 20, Daten von 163 bis 189, k = 5, b = (189-162,9)/5 = 5,2 Klassen: (162,9; 168] (168, 173] (173, 179] ( 179, 184] (184, 189] 3. Skalierung der Merkmale Nominalskala liegt vor, wenn begriffliche Merkmalsausprägungen durch zugeordnete Zahlen lediglich eine Verschiedenartigkeit zum Ausdruck bringen. Sie drückt die qualitativen Eigenschaften eines Merkmals aus und stellt die einfachste Form einer Skala dar. Zulässige Relationen einer Nominalskala sind nur: "gleich" oder "ungleich". Die den begrifflichen Merkmalsausprägungen zugeordneten Zahlen werden als Nominalzahlen (Schlüsselzahlen) bezeichnet und haben eine reine Bezeichnungsfunktion. Merkmale, die auf einer Nominalskala gemessen werden, heißen nominalskalierte Merkmale. Dichotomes bzw. binäres Merkmal Weist ein Merkmal nur zwei sich gegenseitig ausschließende (disjunkte) Ausprägungen auf, handelt es sich um ein dichotomes bzw. binäres Merkmal. Beispiel: Geschlecht kodiert als: männlich = 0 und weiblich = 1 Ordinalskala oder Rangskala liegt vor, wenn Merkmalsausprägungen durch zugeordnete Zahlen nicht nur eine Verschiedenartigkeit, sondern auch eine natürliche Rangfolge zum Ausdruck bringen. Sie drückt die qualitativen Eigenschaften eines Merkmals aus. Neben den Relationen der Nominalskala sind als weitere Relationen "größer als" und "kleiner als" zulässig. Abstände zwischen den Merkmalsausprägungen sind nicht quantifizierbar und besitzen keine Aussagefähigkeit. Begrifflichen Merkmalsausprägungen zugeordnete Zahlen werden als Rangzahlen bezeichnet. Merkmale, die auf einer Ordinalskala gemessen werden, heißen ordinalskalierte Merkmale. Beispiel: militärischer Dienstgrad, Zensuren, Wind- und Erdbebenstärken, Güteklassen für Produkte, Aggressivität, Intelligenz, sozialer Status Metrische Skala Eine metrische Skala (Kardinalskala) liegt vor, wenn Merkmalsausprägungen durch zugeordnete Zahlen sowohl Verschiedenartigkeit und Rangfolge als auch mess- und quantifizierbare Unterschiede zum Ausdruck bringen. Sie drückt die quantitativen Eigenschaften eines Merkmals aus. Merkmale, die auf einer metrischen Skala gemessen werden, heißen metrisch skalierte Merkmale und ihre Merkmalsausprägungen sind meist das Ergebnis eines Zähl- oder Messprozesses. 5 Die metrische Skala wird weiter unterteilt in: Intervallskala , Verhältnisskala, Absolutskala Intervallskala liegt vor, wenn die Abstände (Differenzen) zwischen Merkmalswerten messbar und plausibel interpretierbar sind. Quotienten können nicht sinnvoll gebildet werden. Intervallskalierte Merkmale besitzen keinen natürlichen Nullpunkt und keine natürliche Maßeinheit. Beispiel: Temperatur °C, Kalenderzeitrechnung, Breiten- und Längengrade der Erde Ein Temperaturanstieg von 10 Grad Celsius ist geringer als ein Temperaturanstieg von 14 Grad Celsius. Verhältnisskala liegt vor, wenn außer Abständen zwischen Merkmalsausprägungen auch Quotienten von Merkmalswerten berechenbar und plausibel interpretierbar sind. Verhältnisskalierte Merkmale besitzen einen natürlichen Nullpunkt, aber keine natürliche Maßeinheit. Beispiel: Längenmaße, Gewichtsmaße , Alter , Wertvolumen eines Warenkorbes Ein 10 kg schwerer Stein ist doppelt so schwer wie ein 5 kg schwerer Stein. Absolutskala wird eine metrische Skala genannt, die sowohl einen natürlichen Nullpunkt als auch eine natürliche Maßeinheit besitzt. Beispiel: Stückzahl II Lageparameter univariater Datensätze Zur Beschreibung wichtig: Welche Ausprägung tritt am häufigsten auf? Wo liegt das Zentrum der Verteilung? Wie dicht liegen die Beobachtungen um das Zentrum? 1. Modus: relative Häufigkeit ist am größten. Modus bei Wahlverhalten oben: SPÖ Modus bei Buchstabenverteilung in Buch Buchstabe A. usw.. 2. Median: (Lageparameter). Merkmal ist zumindest ordinalskaliert, geordneter Datensatz liegt vor. In der Mitte des geordneten Satzes liegt der Median. Für ungerades n ist er eindeutig definiert und auch für qualitative Merkmals geeignet. Bei geraden n ist es der Mittelwert der beiden in der Mitte liegenden. Das ist eindeutig nur bei quantitativen Merkmalen. -Frage nach dem Alter der Väter: 9 Daten: Median ist bei (9 + 1) /2 = 5. Stelle: 59 10 Daten: Median ist an 5. und 6. Stelle zu berechnen: (58 + 59)/2 = 58,5 Bei qualitativen Merkmalen muss man sich bei geradem n u.U. für eine Ausprägung entscheiden, wenn die beiden mittleren unterschiedlich sind. sehr gut, gut etc.… 6 In der Mitte befinden sich g und m. Man muss sich für einen davon entscheiden. Es ist hier nicht eindeutig. 3. Mittelwert: (Lageparameter) verteilt die Summe der Beobachtungen gleichmäßig auf alle Merkmalsträger. Bsp. Anzahl der Geschwister in einer Urliste: Mittelwert: Gewogenes Mittel kann über die relativen Häufigkeiten der Ausprägungen fi (f = absolute Häufigkeit / n) berechnet werden. Mit den Merkmalausprägungen ai gilt: Für die stetigen Merkmale werden die Klassenmitten zur Berechnung genommen. Man berechnet den Mittelwert von Unter- und Obergrenze jeder Klasse mi Für den Mittelwert bekommt man mit den entsprechenden relativen Häufigkeiten: Häufig zentriert man die Beobachtungen, so dass der Mittelwert auf dem Nullpunkt liegt und man die Abweichungen gut erkennen kann. Negativ: die Werte sind kleiner als der Mittelwert, positiv, sie sind größer. Die Transformation ist einfach: Jeder Einzelwert wird verschoben: und damit auch: Das Problem beim Mittelwert sind Ausreißer, sie beeinflussen das Ergebnis stark. Der Median ist dagegen nicht ausreißerempfindlich, er ist robust. Vor allem bei offenen Endintervallen unendlich kann der Mittelwert überhaupt nicht gebildet werden. 4. Quantile: Mindestens 50% aller Beobachtungen sind kleiner oder gleich dem Median xmed und auch 50% sind größer oder gleich dem Median. Ein Quantil xP sagt aus, dass p in Prozent kleiner oder gleich xp sind und (1-p) in Prozent größer oder gleich. Allgemein für die Quantile gilt bei geradem n: k = n.p, k ist eine natürliche Zahl 7 Ist n ungerade, dann ist k nicht eine natürliche Zahl. Es gilt dann: also aufgerundet auf ganz,. a) PERZENTILE sind Quantile, die in 1% -Segmente aufteilen. Näherungsweises Berechnen von Perzentilen aus einer kleinen Stichprobe, die möglicherweise aus einer normalverteilten Grundgesamtheit stammt: Orden, Median bestimmen. Differenz von Median und Minimum bedeuten 50 % Daher Schluss: Differenz … 50 % p-Perzentilanteil……..p % Perzentilanteil p-Perzentil = Median - p-Perzentil = Median + Median Minimum 50 (50 p) Maximum Median (p 50) 50 p < 50% man rechnet 50-p vom Median weg p> 50% man rechnet p-50 zum Median dazu Am Beispiel: 5 Schülerinnen: Körpergröße 1,54 / 1,70,/ 1,73/1,85/ 1,89 Median 1, 73, Minimum 1,54. Maximum 1,89 20% Perzentil = 1,73 - (1,73 – 1,54) . 30 /50 = 1,616 80% Perzentil = 1,73 + (1,89-1,73). 30 / 50 = 1,826 17% Perzentil= 1,73 - (1,73 – 1,54) . 33/50 = 1,604 62% Perzentil: 1,73+ (1,89-1,73) . 12/ 50 = 1,768 Das exakte Berechnen von Perzentilen in einer Stichprobe, die aus einer normalverteilten Grundgesamtheit stammt: p%-Perzentil muss man aus z–Tabelle nachschlagen: zB 20% -0,845 80 % 0,845 17% -0,954 62% 0,305 Dann gilt: p-Perzentil = Mittelwert + z(p). Standardabweichung 8 Im Beispiel: 5 Schülerinnen: Körpergröße 1,54 / 1,70,/ 1,73/1,85/ 1,89 Wenn ich weiß, dass es normalverteilt ist, dann kann man rechnen: x 1,742 , s 0,138 20% Perzentil = 1,742 -0,845 . 0,138 = 1,625 80% Perzentil =1,742+0,845 . 0,138 = 1,858 17% Perzentil =1,742-0,945 . 0,138 = 1,61 62% Perzentil = 1,742+0,305 . 0,138 = 1,784 Nimmt man als Mittelwert den Median, dann bekommt man: 1,613/1,847/1,598 /1,77 b) QUARTILE sind Quantile, die in 4 Sektoren aufteilen zu je 25%. Die Quantile x0,75 und x0,25 für p = 75% und 25% heißen oberes und unteres Quartil BSP: Alter der Teilnehmer einer Fortbildungsveranstaltung: Geordneter Datensatz Median ist 28, für unteres Quartil gilt p = 0,25, n = 25, k = ca.7 also x0,25 = 26, für das obere: k = 25 . 0,75 = ca.19 x0,75 = 31,5 III Beschreibung der Variabilität Neben der Lage einer Verteilung interessiert. die dicht die Beobachtungen um den Lageparameter liegen. Man spricht von STREUUNG. 1. Stichprobenvarianz s² in einer Stichprobe Das wichtigste Streuungsmaß berechnet die mittlere quadratische Abweichung vom Zentralwert.(Quadratisch deshalb, damit sich die Vorzeichen der Abweichungen nicht auswirken) In einer Stichprobe mit dem Mittelwert x gilt für die Varianz: Durch n wird dividiert, wenn man die Grundgesamtheit untersucht, die Varianz wird dann mit σ² bezeichnet 2. Standardabweichung s in einer Stichprobe Sie ist die Wurzel aus der Varianz und weist die gleiche Maßeinheit wie die Beobachtungsdaten auf. 9 auch für die Grundgesamtheit wird die Standardabweichung durch die Wurzel gerechnet und mit σ bezeichnet. BSP: Höhe von monatlichem Taschengeld bei 3 Kindern: 4,5,6 € in einer 2. Gruppe: 3,5,7 € In der 1. Gruppe gilt: s² = ½ ( 1²+0²+(-1)²) = 1 s = 1 In der 2. Gruppe s² = ½ ((-2)² + 0² + 2²) = 4 s= 2 Diese Werte lassen sich standardisieren, dh. Nullpunkt um 5 verschieben… und durch s dividieren: 1. Gruppe: 2. Gruppe: 3. Spannweite R: Differenz zwischen größtem und kleinsten Wert 4. Interquartilsabstand IQR: Differenz zwischen oberen und unteren Quartil. BSP: Bestimme Medina und IQR: Dieses Beispiel beruht auf einer Messreihe mit den folgenden 20 Datenpunkten: 9, 6, 7, 7, 3, 9, 10, 1, 8, 7, 9, 9, 8, 10, 5, 10, 10, 9, 10 und 8 5. Boxplot visualisiert die Verteilung eines quantitativen Merkmals sehr gut. 5-Zahlen-Zusammenfassung: Darstellung des Datensatzes: 5 Zahlen: Minimum, unteres Quartil, Median, oberes Quartil. Maximum Bild: 10 Zeigt an, dass die Datenverteilung unsymmetrisch und linkssteil. IQR = 5, Spannweite R = 15 6. Variationskoeffizient Der Variationskoeffizient VarK ist eine statistische Kenngröße und ist definiert als die relative Standardabweichung, d.h. die Standardabweichung dividiert durch den Mittelwert einer Zufallsvariablen X. In der Regel wird der Variationskoeffizient in Prozent angegeben, d. h. Eine Zufallsvariable mit großem Mittelwert weist im Allgemeinen eine größere Varianz auf als eine mit einem kleinen Mittelwert. Da die Standardabweichung nicht normiert ist, kann im Allgemeinen nicht beurteilt werden, ob eine Varianz groß oder klein ist. (Relativieren!) Beispiel: So schwanken beispielsweise die Preise für ein Pfund Salz, das im Durchschnitt wohl etwa 0,5 Euro kostet, im Cent-Bereich, während Preise für ein Auto, das im Mittel beispielsweise 20.000 Euro kostet, im 1000-Euro-Bereich variieren. Der Variationskoeffizient hingegen stellt eine Art Normierung der Varianz dar. Das bedeutet: Ist die Standardabweichung größer als der Mittelwert, so ist der Variationskoeffizient größer 1. 11 Bivariate Zusammenhangs-Analyse Man untersucht die Abhängigkeit von 2 Merkmalen voneinander. Bei nominal- und ordinalskalierten qualitativen Merkmalen stellt man am besten die Grafiken – Boxplot und/oder Säulendiagramm – nebeneinander. Bei quantitativen Merkmalen lässt sich der Zusammenhang auch noch durch Rechnung nachweisen und beurteilen. BSP: Zusammenhang von Noten bei Studenten: Tabelle Streudiagramm geteilt in 4 Quadranten deutet auf einen positiven linearen Zusammenhang hin: Bessere Noten Im Abitur führen zu besseren Noten im Vordiplom. I) Empirische Kovarianz covx,y Er gibt an, ob ein Zusammenhang zwischen 2 quantitativen Größen x und y existiert. Für diese Summe erhält man einen positiven Wert, wenn die meisten Punkte des Streudiagramms im ersten und im 3. Quadranten liegen, negativ dagegen, wenn sie im 2. und 4. liegen. 12 Für das Beispiel der Noten ergeben sich die folgenden Werte: Summe: 1,21 / 6 = 0,202 Die Zahl bestätigt einen positiven Zusammenhang zwischen den beiden Größen. sie sagt aber nichts aus über die Stärke des Zusammenhangs. Daher wird die Kovarianz normiert. Dies ergibt den II Pearson Korrelationskoeffizient von 2 metrisch skalierten Merkmalen oder kurz r cov x ,y sx s y wobei sx (x x)² ,s i n1 y (y y)² , i n 1 In unserem Beispiel mit den Noten sind 2 Spalten zu ergänzen: Summen: 0,473 0,093 daher r = 0,95 Interpretation: Der Pearson Korrkoeff charakterisiert auch die Stärke des Zusammenhangs. Er liegt immer zwischen -1 und +1. 1 ist er, wenn ein exakter linearer Zusammenhang mit positiver Steigung der Geraden besteht. -1 , wenn ein exakter linearer Zusammenhang mit einer negativen Steigung besteht. Liegt der Wert in der Nähe von 1 oder -1 so ist ein starker Zusammenhang anzunehmen. Es gilt ungefähr die folgende Faustregel bei nicht zu kleiner Stichprobe, zumindest größer als 5!: r >0,7 oder < -0,7 starker Zusammenhang r zwischen 0,4 und 0,7 mittlerer Zusammenhang, 0 bis 0,4 niedriger bis kein Zusammenhang. 13 III Rangkorrelationskoeffizient von Spearman bei 2 metrisch oder 2 ordinalskalierten Merkmalen Pearson gibt einen linearen Zusammenhang, Spearman dagegen einen monotonen (nicht unbedingt linear!). Monoton liegt vor, wenn für 2 beliebige Punkte (xi, yi ) und (xk,yk ) gilt, dass xi < xk mit yi < yk ( steigend) oder xi < xk mit yi > yk (fallend) also 2 zumindest ordinalskalierte Merkmale! Es werden daher die Maßzahlen jedes Merkmals durch die RÄNGE ersetzt. Der Rang ri (si ) gibt an, an der wie vielten Stelle xi in der geordneten Datenmenge steht. In unserem Notenbeispiel sind die Ränge für die Abiturnoten: r1= 2 r1 = 4 r3 = 3 r4 = 1 r5 =5 r6 = 6 die Ränge für die Diplomnoten: Bei gleich großen Werten wird ein durchschnittlicher Rang gegeben. z. an 4. und 5. Stelle ist die Zahl 6. Dann hat r4 = 4,5 und r5 = 4,5…. Der Rangkorrkoeff nach Spearmann lautet dann: Wenn es einen Zusammenhang in den Rangfolgen gibt, dann müsste gelten: ri = si das bedeutet: Ein streng monoton wachsender Zusammenhang besteht bei rS = 1. streng monoton fallend bei rS = -1 Bei 0 gibt es keinen Zusammenhang. Bsp mit den Noten: rS = 0,886 Es besteht ein guter positiver Zusammenhang der beiden Merkmale 14 IV Lineare Regression zweier metrisch-skalierter Merkmale (intervallsk) In diesem speziellen Fall, wenn ein linearer Zusammenhang zwischen 2 intervallskalierter Merkmalen besteht, so kann dieser Zusammenhang mit Hilfe einer Geradengleichung beschrieben werden. Die Gerade repräsentiert die Punktewolke im Streudiagramm. Sie beschreibt sie Abhängigkeit einer Größe von der anderen. Zielgröße in y-Achse, Einflussgröße in die x-Achse. Sie wird mit der Methode der kleinsten Fehlerquadrate berechnet. Sie lautet y = a + bx …… Bezeichnungen schwanken in der Literatur ( y = kx +d, etc…) b ist der Anstieg der Geraden, a der Abschnitt auf der y-Achse. Durch das Minimieren der Fehlerquadrate erhält man für b: b cov x ,y (xi x) (yi y) sx ² (xi x)² Mit Rückeinsetzen in die Geradengleichung y = a + bx berechnt man a: a y bx Im Falle unseres Notenbeispiels ergibt sich Abitur x 1,7 2,4 2 Vordiplom y 2,2 2,4 2,1 xi-x -0,5 0,2 -0,2 yi-y -0,1 0,1 -0,2 (xi-x)(yi-y) 0,05 0,02 0,04 (xi-x)² 0,25 0,04 0,04 b= a= 1,1 2,9 3,1 Mittelw 2,2 1,8 -1,1 -0,5 0,55 1,21 2,7 0,7 0,4 0,28 0,49 2,6 Mittelw 0,9 0,3 0,27 Summe 0,81 Summe 2,3 1,21 2,84 0,42605634 1,36267606 3 Vordiplomnote 2,5 2 1,5 1 Regressionslinie : y = 0,4261x + 1,3627 0,5 0 0 0,5 1 1,5 2 2,5 3 3,5 Abiturnote Die Gleichung der Regressionslinie kann für Vorhersagen benützt werden, wie sich y mit x auch über die gegebene Wertemenge hinaus verhält. EINSETZEN DER WERTE in die Regressionslinie! BSP: welche Note bekommt jemand im Vordiplom, wenn er beim Abitur 1,5 hat? x = 1,5 einsetzen: y = 2. Note 2 ist zu erwarten. Stimmt mit der Zeichnung überein. 15 V Kontingenz = Korrelation von 2 nominalskalierten Merkmalen Sonderfall: Kontingenz von 2 Merkmalen mit nur 2 Ausprägungen (dichotom) = Assoziation. Zur Beurteilung des Zusammenhangs stehen Assoziations- bzw. Kontingenzkoeffizienten zur Verfügung. Die wichtigsten sind Phikoeffizient und Cramers V 1. Phikoeffizient Für die Analyse des Zusammenhangs benützt man Kontingenztafeln. Bei Assoziationen genügt die sogenannte 4-Feldertafel. Umfrage ergab in einer Stichprobe bei der Fragestellung: Raucher/Nichtraucher und Mann/Frau die 2 Merkmale: x..Rauchverhalten mit 2 Ausprägungen und das Merkmal Geschlecht mit 2 Ausprägungen. Stichprobenumfang n=20 Merkmal x: 15 Raucher. Merkmal y: 7 Männer, wovon 6 Männer Raucher sind. Zusammenstellung in der 4-Feldertafel: Schema der Tafel: Merkmal x Ausprägg Gegenteil Spaltensumme Merkmal Y Auspräg Gegenteil a b c d a+c b+d Raucher Nichtraucher SP-Summe Geschlecht Mann Frau 6 9 1 4 7 13 Zeilensumme a+b c+d n im Beispiel: Rauchverh. Zl-Summe 15 5 20 Definition des Phikoeffizienten: ad bc 0,1816 (a b)(c d)(a c)(b d) Nur ein schwacher Zusammenhang sichtbar zwischen Rauchverhalten und Geschlecht in dieser Stichprobe. Im Verhältnis finden sich unter Männern mehr Raucher als bei Frauen. Der Wert + 1 und -1 würde einen vollständigen Zusammenhang darstellen, 0 keinen. +1 wäre der Fall, wenn alle Männer rauchen und keine Frau, -1, wenn alle Frauen rauchen und keine Männer. 16 2. Cramérs V ist ein sogenanntes standardisiertes Chi-quadrat χ²- Maß und ist definiert mit: n…Zahl der Beobachtungen, k Zahl des Minimum von Zeilen und Spaltenzahl. Bei 4-Feldern ist k = 2 und es gilt hier die Beziehung Φ² = χ² / n Daher ist im Falle einer 2x2-Tafel V =+ Φ… Nur positive Werte! V ad bc ² (a b)(c d)(a c)(b d) speziell nur für 2x2!!! Cramérs V = 0: es besteht kein Zusammenhang zwischen X und Y Cramérs V = 1: es besteht ein perfekter Zusammenhang zwischen X und Y Cramérs V = 0,6: es besteht ein relativ starker Zusammenhang zwischen X und Y Da Cramérs V immer positiv ist, kann keine Aussage über die Richtung des Zusammenhangs getroffen werden. Cramérs V –Kontingenzkoeffizient in unserem Beispiel Geschlecht, Rauchverhalten: 0,1816, daher geringer Zusammenhang. Cramérs V ist auch für nichtlineare Korrelationen einsetzbar, Phi nicht! VI Punktbiseriale Korrelation = Zusammenhang zwischen metrisch und nominal (dichotom) Zusammenhang zwischen einem metrisch skalierten (intervallskal) Merkmal und einem künstlich numerisch dichotomen Merkmal (0,1) Bsp: Geschlecht und Körpergröße, nach Zusammenhang zwischen Männern und Frauen untersucht. Die Formel dafür lautet: Differenz der Mittelwerte durch alle Beobachtungen gebrochen durch Stichprobenstandardabweichung, bezogen auf beide Stichproben s : Wurzel n1n2 17 Die Berechnung ergibt: Es besteht ein Zusammenhang zwischen Geschlecht und Körpergröße. Männer sind größer. VII Biseriale Rangkorrelation = Korrelation zwischen intervallskaliert (auch ordinalsskaliert) und nominal dichotom. Dieses Kapitel ist eine Zusammenfassung aus der Seite: http://www.lernstats.de/web/php/glossar.php?sub=&glossar=biseriale_korrelation Die Formel der biserialen Korrelation liefert eine Schätzung des Zusammenhangs zweier prinzipiell intervallskalierbarer normalverteilter Variablen, von denen eine jedoch nur mit dichotomisierten Daten vorliegt. rbis xP xq sx p q yˆ In Formel haben die Abkürzungen die folgende Bedeutung: Mittelwert in der intervallskalierten Variablen, berechnet nur aus den Personen, die im dichotomisierten Merkmal die ´höhere´ bzw. ´bessere´ Alternative haben (z.B. die über dem Median, oder ja-Beantworter etc.). Mittelwert in der intervallskalierten Variablen berechnet aus der Gruppe mit den ´unteren´ Alternativen (niedriger, schlechter, unter dem Median, Nein-Sager, etc.). Standardabweichung in der intervallskalierten Variablen, über alle Personen berechnet (wie bekannt!). Prozentualer Anteil der Personen mit der ´höheren´ Alternative (z.B. 0,40). Prozentualer Anteil der Personen mit der ´unteren´ Alternative (z.B. 0,60). (Wie man sofort sieht, muss gelten p+q = 1,00). Ordinate des z-Wertes, an der die Standardnormalverteilung im Verhältnis p:q aufgeteilt wird. Das klingt kompliziert und wird deshalb für Interessenten im Anschluss noch näher erläutert. Für die konkrete Berechnung können die Werte von jedermann leicht einer Tabelle entnommen werden. 18 Bsp: 50 Schüler werden zwei Tests unterzogen. Der erste Test ist ein Intelligenztest, der zweite ein Kreativtest. Von beiden Merkmalen wird angenommen, daß sie sich normal verteilen. Das Merkmal Kreativität wird in zwei Klassen aufgeteilt: über dem Median: ´hoch kreativ´, unter dem Median: ´niedrig kreativ´. Stichprobe: 50 Schüler der vierten Klasse einer Hauptschule. Merkmal 1 (kontinuierlich) : Intelligenz (x) Merkmal 2 (eigentlich kontinuierlich, aber in zwei Klassen aufgeteilt) : Kreativität (y) Die Ergebnisse werden in der folgenden Tabelle mitgeteilt, dabei bedeuten: Spalte (1) : Intelligenzquotient, Spalte (2) : Anzahl der Vpn mit dem entsprechenden Intelligenzquotienten, die als ´hoch kreativ´ eingestuft wurden, Spalte (3) : Anzahl der als ´niedrig kreativ´ eingestuften Vpn, Spalte (4) : Summe aus (1) und (2), d.h. Gesamtzahl der Vpn mit einem entsprechenden Intelligenzquotienten. Diese Tabellendarstellung kennen wir schon aus der Berechnung der biserialen Korrelation: IQ hoch kreativ (1) (2) niedrig kreativ Summe (3) (4) 100 106 111 114 115 118 119 120 122 125 0 1 2 3 5 6 7 2 2 2 1 1 4 6 3 2 1 1 1 0 1 2 6 9 8 8 8 3 3 2 np = 30 nq = 20 n = 50 Wir berechnen die folgenden Größen (bei p = hoch kreativ und q = niedrig kreativ): 117,33 113,80 4,63 0,60 0,40 Jetzt muss noch der Wert ̂ aus der Tabelle abgelesen werden. Genau passiert bei der Bestimmung von ̂ Folgendes: Wir wissen, dass unter der Kurve der Standardnormalverteilung (SNV) insgesamt eine Fläche von 1,00 liegt (sie lässt sich so definieren). Wir können nun durch die SNV eine Senkrechte genau so legen, dass sie die Fläche der SNV genau im Verhältnis von p:q aufteilt. 19 Diese Senkrechte schneidet die z-Werte in einem bestimmten Punkt, d.h. bis zu diesem bestimmten z-Wert liegen 60 % der Werte in einer SNV und darüber genau 40 %. Nun sagt die Höhe der SNV über bestimmten z-Werten etwas über die Häufigkeit des Auftretens dieser z-Werte aus (in einer theoretischen Verteilung muss es eigentlich heißen: ´über die Wahrscheinlichkeit des Auftretens´). Der von uns gesuchte ̂ -Wert ist nun die genaue Höhenangabe (=Ordinate) der SNV-Kurve über dem durch p und q bestimmten z-Wert: z = 0,25; die Ordinatenhöhe in diesem Punkt beträgt ̂ =0 ,3867 In unserem Fall ist p = .60 (also größer als q) und führt zu dem Wert: p . q/ ̂ = 0,6212 Insgesamt ergibt sich: rbis = (117,33 -113,80) / 4,63 . 0,6212 = 0,.474 In dem Beispiel zeigt sich also ein mittlerer bis geringer Zusammenhang zwischen der Kreativität und der Intelligenz von Schülern. Auch bei der biserialen Korrelation interpretieren wir den Koeffizienten ohne das Vorzeichen wegen der Beliebigkeit, mit der die Alternativklassen mit p bzw. q bezeichnet werden können. Weiterführend siehe: www.lernstats.de 20 Inferenzstatistische Methoden des Schätzens Inferenz heißt Beurteilung, Schluss. In der Schließenden Statistik geht man von Stichproben aus und schließt auf die Größen der Grundgesamtheit. Man benützt dabei die Methoden der Wahrscheinlichkeitsrechnung. I Wichtige Wahrscheinlichkeitsverteilungen Man nimmt in der schließenden Statistik fast immer an, dass alle Beobachtungen normalverteilt sind - (zumindest angenähert auch bei diskreten Merkmalen mit binomial –, hypergeometrisch und poissonverteilten Größen. Das ist bei hinreichend großen Stichproben möglich)). Daher ist das Verständnis der Normalverteilung grundlegend. 1. Die Normalverteilung N(µ,σ) nach GAUSS Die Normalverteilung beschreibt das Auftreten von stetigen Merkmalen. Der typische verlauf der WahrscheinlichkeitsDICHTE ist eine symmetrische Glockenkurve. (Dichte hat mit den Häufigkeiten des Auftretens zu tun.) Die Gleichung der Glockenkurve kann durch eine Funktion der ZUFALLSVARIABLEN beschrieben werden. Eine Zufallsvariable – meist mit Großbuchstaben bezeichnet - ist eine Funktion, die den Ergebnissen eines Zufallsexperiments Werte zuordnet. zB X (x) = 0, wenn x Kopf der Münze und 1, wenn x Zahl der Münze Die Zufallsvariable X für die Normalverteilung wird beschrieben durch die Dichtefunktion (Glocke). die auftretenden Parameter sind µ = Mittelwert und σ = Standardabweichung. Die Gleichung der Dichtefunktion: f(x) (x µ)² 1 e 2 ² 2 Die Wahrscheinlichkeit in Prozentanteilen wird durch den Inhalt der Fläche unter der Dichtefunktion repräsentiert, wobei die untere Grenze der Glocke - ∞ ist, die obere Grenze der Glocke +∞. die gesamte Fläche hat die Größe 1 (100%) ( ) = 1, Es gilt: F(x) = ∫ wobei außerhalb von µ ± 3σ praktisch keine Elemente mehr auftreten! Die Grafik zeigt die Verteilung in σ, 2σ und 3σ-Abweichungen 21 2. z-Verteilung = standardisierte Normalverteilung N(0,1) Schiebt man den Mittelwert auf 0 und reduziert σ auf 1, dann erhält man die z-Verteilung. Die Transformation erfolgt mit der Variablen z: z xi z-Transformation Die Form der Kurve ist standardisiert, die Flächen kann man für Z tabellieren. Man kommt über die Transformationsformel aber zu den Aussagen für eine reale Verteilung mit µ und σ . Die Dichtefunktion (Funktionswerte der Kurve) lautet: Die Verteilungsfunktion (Fläche unter der Kurve) erhält man mit beachte: die Fläche zählt immer von links! Form der Kurve: Symmetrisch, daher Φ (-z) = 1 - Φ (z) Tabellenwerte für Φ für die ersten Zahlen: Tabelle siehe Anhang z 0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09 0,0 5000 5040 5080 5120 5160 5199 5239 5279 5319 5359 0,1 5398 5438 5478 5517 5557 5596 5636 5675 5714 5753 0,2 5793 5832 5871 5910 5948 5987 6026 6064 6103 6141 0,3 6179 6217 6255 6293 6331 6368 6406 6443 6480 6517 0,4 6554 6591 6628 6664 6700 6736 6772 6808 6844 6879 usw dh. die Fläche von -∞ bis z = 0,4 ist 0,6554 Einheiten, das sind 65,54 % Die Fläche von -∞ bis z = -0,4 ist 1- 0,6554 = 0, 3446, das sind 34,46% 22 BSP: Die Fahrzeit eines Studenten ist z-verteilt mit µ = 40 und Varianz 4. Wie wahrscheinlich ist es, dass er nur 36 Minuten braucht. P…Abkürzung für Wahrscheinlichkeit. Aus der N(0,1) – Tabelle kann man entnehmen: Φ (2) = 0,977, daher: 2,3% wahrscheinlich, dass er nur 26 Minuten braucht. Man kann diskrete Verteilungen, insbesondere die Binomialverteilung nach Bernoulli an die Normalverteilung anpassen, wenn n groß genug ist. Dies geschieht durch die Umwandlungsformeln: µ = n. p und σ² = n. p. (1-p) BSP: Ein Würfel wird 300 mal geworfen, wie wahrscheinlich ist die Anzahl der Sechserwürfe kleiner als 40? Die Wahrscheinlichkeit beim 1. Wurf 6 zu werfen ist p = 1/6, nicht 6 zu werfen daher 5/6. P(X<40) müsste man mit 40 Schritten binomisch lösen. Hier ist die N(0,1) gut anzunähern: µ= 300. 1/6 = 50 σ² = 300 . 1/6 . 5/6 =41,67, σ= 6,455 in N(0,1) transferieren: z = (40 – 50) / 6,455= -1,55 Φ (-1,55) = 1- Φ(1,55) Tabelle = 1- 0,9394 = 0,0606 6,06 % wahrscheinlich…. Will man die Näherung genauer machen, so berücksichtigt man, dass die diskrete Verteilung nur in 1Schritten gehen kann und berechnet z genauer: √ ( ) ..Stetigkeitskorrektur durch + 0,5 bei oberer Grenze, - 0,5 bei unterer Grenze. In unserem Beispiel: z = (40,5 – 50)/ 6,455 = -1,45 Φ (-1,45) = 1- Φ(1,45) Tabelle = 1- 0,9265 = 0,0735 …. 7,35 % wahrscheinlich…. 23 3. Chi-Quadrat-Verteilung (eine Prüfverteilung) Prüfgrößen sind Vorschriften, nach denen aus einer vorliegenden Stichprobe eine Zahl, ein Wert berechnet wird. (Stichprobenmittelwert, Stichprobenvarianz, oder das Verhältnis zweier Varianzen). Wenn s² die Varianz einer zufälligen Stichprobe des Umfanges n einer normalverteilten Grundgesamtheit mit der Varianz σ² ist, dann wird die Zufallsvariable f = n-1… Freiheitsgrad, ist die Zahl der frei verfügbaren Beobachtungen, n ist die Zahl voneinander unabhängiger Beobachtungen in der Stichprobe. Man sieht die Dichtefunktionen χ² - Verteilung im Diagramm für f = 5, 10, 15 und 20 Je höher f, desto mehr nähert sich die Kurve der Grafik einer Normalverteilung an… Der Mittelwert der χ²-Verteilung : µ = f, Varianz σ² = 2f Die χ²- Tabellen für viele Freiheitsgrade und die wichtigsten Prozentzahlen 0,5%;1%; 2,5%; 5%; 10%; 50%; 95%; 97,5%; 99% Tabelle Siehe im Anhang Wahrscheinlichkeit p Freiheitsgrade 0,005 0,01 0,025 0,05 0,1 0,5 0,9 0,95 0,975 0,99 0,995 1 0,00 0,00 0,00 0,00 0,02 0,45 2,71 3,84 5,02 6,63 7,88 2 0,01 0,02 0,05 0,10 0,21 1,39 4,61 5,99 7,38 9,21 10,60 3 0,07 0,11 0,22 0,35 0,58 2,37 6,25 7,81 9,35 11,34 12,84 4 0,21 0,30 0,48 0,71 1,06 3,36 7,78 9,49 11,14 13,28 14,86 5 0,41 0,55 0,83 1,15 1,61 4,35 9,24 11,07 12,83 15,09 16,75 6 0,68 0,87 1,24 1,64 2,20 5,35 10,64 12,59 14,45 16,81 18,55 7 0,99 1,24 1,69 2,17 2,83 6,35 12,02 14,07 16,01 18,48 20,28 8 1,34 1,65 2,18 2,73 3,49 7,34 13,36 15,51 17,53 20,09 21,95 9 1,73 2,09 2,70 3,33 4,17 8,34 14,68 16,92 19,02 21,67 23,59 10 2,16 2,56 3,25 3,94 4,87 9,34 15,99 18,31 20,48 23,21 usw Wird bei zahlreichen Prüfungsverfahren eingesetzt, hauptsächlich bei nominalen 1 oder 2 Variablen (abhg oder unabhg). 24 4. Student- oder t-Verteilung (eine Prüfverteilung) Die Verteilung der Prüfgröße, die aus dem Quotienten aus der Abweichung eines Stichprobenmittelwerts vom Mittelwert der Grundgesamtheit gebildet wird, folgt bei normalverteilter Grundgesamtheit einer t-Verteilung, wenn µ und σ nicht bekannt sind und mit den Stichprobendaten geschätzt werden müssen. Die t-Verteilung ähnelt der z-Verteilung: µ = 0. Die Definition: t x z s/ n ²/ f Grafische Darstellung für f = 2,10 und100 und die Standard Normalverteilung rot Die Dichtekurve von t verläuft flacher als die z-Kurve. Die Standardabweichung ist bei kleinem f größer, nähert sich mit wachsendem n immer mehr der z-Verteilung an. σ² = f/(f-2) für f>2. Tabelliert sind die t-Werte wieder für die wichtigsten Prozentwerte, die durch die Fläche unter der Kurve repräsentiert wird. Tabelle im Anhang f t-Werte bei gegebenen % der Fläche von links 65% 70% 75% 80% 85% 90% 95% 97,5% 99% 99,5% 1 0,510 0,727 1,000 1,376 1,963 3,078 6,314 12,706 31,821 63,656 2 0,445 0,617 0,816 1,061 1,386 1,886 2,920 4,303 6,965 9,925 3 0,424 0,584 0,765 0,978 1,250 1,638 2,353 3,182 4,541 5,841 4 0,414 0,569 0,741 0,941 1,190 1,533 2,132 2,776 3,747 4,604 5 0,408 0,559 0,727 0,920 1,156 1,476 2,015 2,571 3,365 4,032 6 0,404 0,553 0,718 0,906 1,134 1,440 1,943 2,447 3,143 3,707 7 0,402 0,549 0,711 0,896 1,119 1,415 1,895 2,365 2,998 3,499 8 0,399 0,546 0,706 0,889 1,108 1,397 1,860 2,306 2,896 3,355 9 0,398 0,543 0,703 0,883 1,100 1,383 1,833 2,262 2,821 3,250 10 0,397 0,542 0,700 0,879 1,093 1,372 usw 1,812 2,228 2,764 3,169 Es gibt auch t-Werttabellen, die für die % die Fläche zwischen –t und +t angeben. Vorsicht beim Lesen der Tabelle! 25 Die t-Verteilung liefert das wichtigste Verfahren für die Überprüfung von Stichprobenwerten. - Intervallskaliert, 1 Variable, Stichprobe > 30 und normalverteilt -intervallskaliert, 2 Variable unabhängig, beide n>30, Varianzen gleich - Intervallskliert, 2 Variable, abhängig , n>30 oder die Differenzen normalverteilt Eignet sich für die Prüfung der Verteilung von Stichprobenmittelwerte auch bei sehr kleinem n. BSP: a) Es ist für f = 8 der Wert t1 zu ermitteln, für den gilt: 10% der Fläche von unter der Kurve liegen rechts von t1. b) Es sind für f = 8 die Werte t1 und t2 zu ermitteln für die gilt: 10% der Fläche liegen symmetrisch verteilt außerhalb des Intervalls 1 bis t2.. Skizze: a) Die t- Tabelle ist in Prozent-Intervallen eingeteilt. 10 % rechts bedeuten 90% links und die zugeordnete Fläche 1-α ist daher für 90% zu nehmen für f = 8: t1 = 1,397 b) In diesem Falle liegen 5% links und 5% rechts. Wir suchen die 95% Marke für f = 8, das ist t2 = 1,86. Die 5% Marke ist symmetrisch, daher t1 = -1,86 26 5. Die F-Verteilung nach Fisher (Prüfverteilung) Sie wird hauptsächlich zur Prüfung von 2 Varianzen im Vergleich benützt. Sie ist stetig und unsymmetrisch und hängt von 2 Parametern ab, den Freiheitsgraden f1 und f2 . F ist der Quotient zweier jeweils durch die zugehörige Anzahl von Freiheitsgraden geteilter ChiQuadrat-verteilter Zufallsvariablen Für f1 = n und f2 = m gilt: ² s² F(m,n) m 1 ² s2 ² n Grafische Darstellung der Funktionen Die F-Tabellen sind sehr umfangreich, weil sie für beide Parameter möglichst viele Freiheitsgrade berechnet hat. Siehe Anhang für 95% und 97,5% Die Tabelle für 95 % -Quantile sind besonders wichtig: F-Wert ist groß bei kleinem Freiheitsgrad! usw BSP: Welchen F –Wert erhalten wir als obere Begrenzung der Fläche von 95% bei m = 4 und n= 3 sowie umgekehrt bei m = 3 und n = 4. Was bei m = 6 und n = 8? 6,5; umgekehrt 9,12 ( nicht gleich!) 4,15 (kleiner bei höherem n,m ) 27 II Konfidenzintervalle = Vertrauensbereiche einer Schätzung und die Signifikanz Eine Hauptaufgabe der beurteilenden Statistik besteht darin, aus den Verhältnissen in einer Stichprobe (Sample) auf die Verhältnisse in der Grundgesamtheit (Kollektiv, Population) zu schließen. Häufig ist aus der relativen Häufigkeit in der Stichprobe für das Auftreten eines Merkmals auf die Wahrscheinlichkeit µ oder p in der Grundgesamtheit zu schließen. BSP: Wählerverhalten… Man zieht eine Zufallsstichprobe mit n Elementen und beobachtet den Mittelwert oder die relative Häufigkeit mit der interessierenden Eigenschaft. Diese so gewonnenen Werte sind dann die Schätzwert ̂ ̂ für die Grundgesamtheit, die natürlich nicht wirklich dem realen µ, p in der Grundgesamtheit genau entsprechen können. Aus diesem Grund baut man diese „Punktschätzungen“ zu je einem Intervall aus, innerhalb dessen der wahre Wert µ oder p des gesuchten Parameters mit einer vorher ausgewählten Wahrscheinlichkeit liegt. Das dazugehörige Intervall heißt Konfidenzbereich oder Vertrauensbereich für die Schätzung für das unbekannte µ, p unter Annahme von zB 95% (99%, 99,7% usw.) 1. Bestimmung des Konfidenzintervalls für den Prozentanteil p an einem Beispiel, in dem σ (Grundgesamtheit) als bekannt vorausgesetzt wird und dem Schätzwert ̂ aus der Stichprobe entspricht. x ..Zahl der Wähler n = 500 Wahlberechtigte bilden die Stichprobe. x =120 sind für FPÖ. Gesucht: Wie viel Prozent wird die FPÖ bei den Wahlen erreichen, wenn man den Prozentsatz mit 95%- iger Genauigkeit haben möchte? Es handelt sich um eine Binomialverteilung, die wir einer Normalverteilung annähern. µ = np, σ² = np(1-p) ̂ = 120 / 500 = 0,24 =x/n Daraus berechnet sich die Standardabweichung dieser Schätzung ̂ √ ( ) Wir können annehmen, dass p nicht sehr von ̂ abweicht, so dass der Schätzwert von ̂ dem σ der Grundgesamtheit entspricht. Da dieser Wert > 3 kann die Normalverteilung benützt werden: Für das Konfidenzintervall unter 95% Sicherheit gilt die Beziehung: |x-µ| z σ oder mit den Formeln für µ und σ: |x-np| z √ ( ) und z berechnet man aus: 0,95 = 2 Φ(z) – 1 z = 1,96 setzt man ein und löst die Gleichung unter Berücksichtigung des Betragstriches ( 2 Fälle + und -) so bekommt man im 1. Fall: 120 – 500 p = 1,96 √ ( ) Die Lösung dieser Gleichung p1 = 0,205 Für den 2. Fall: -120 + 500p = 1,96 √ ( ) erhält man p = 0,279 Damit ist das Intervall für den Prozentanteil der FPÖ-Wähler in der Grundgesamtheit : 20,5% bis 27,9 % in einer Aussage mit 95% Sicherheit. Die Unsicherheit beträgt 5%, man bezeichnet sie mit α= Irrtumswahrscheinlichkeit oder Signifikanz. Konfidenz = Sicherheit = 95% = 1- α 28 Will man die Sicherheit erhöhen auf 99%, Unsicherheit (Signifikanz) 1% so ändert sich in der Rechnung nur der Wert von z: 0,99 = 2 Φ(z) – 1 z = 2,326 Dies führt zu p1 = 0,1985 und p2 = 0,287 also von 19,9% zu 28,7 %. Das Vertrauensintervall wird etwas breiter, die Schätzung der Prozentanteile bei der hohen Sicherheit der Aussage ist daher nur weniger präzise möglich. Im Übrigen kann man auch durch Division durch n bei den oben genannten Beziehungen |x-µ| z σ oder mit den Formeln für µ und σ: |x-np| z √ ( ), und mit ̂ =x/n eine Umformung erreichen, die das Berechnen von p ebenfalls ermöglicht: | ̂ - p| ≤ z√ ( ) Die genaue Berechnung von p ist immer etwas mühsam. Falls man annehmen kann, dass der geschätzte Stichprobenwert ̂ = x/n nicht besonders falsch liegt, dann kann für die Berechnung des Konfidenzintervalls die folgende Näherungsformel verwendet werden: √ p= ̂ ̂( ̂) In unserem Beispiel bei z = 1,96 (95% Sicherheit) bedeutet dies: p = 0,24 ± 1,96 . 0,19 = 0,24 ± 0.037 = 0,277 und 0,2025 also von 20,3% bis 27,7% (gegenüber 20,5% und 27,9% siehe oben). Dies ist ein durchaus brauchbares Ergebnis. Die Stichprobe mit n= 500 lieferte einen guten Schätzwert x/n. 2. Vertrauensbereich für den Mittelwert µ bei bekannter Standardabweichung σ der Grundgesamtheit. Bei der Fertigung mit Automaten liegt eine normalverteilte Grundgesamtheit vor σ = 5,8 vor. Die Mittelwerte hängen von den jeweiligen Einstellungen ab, Die Stichprobe mit 49 Anlagen ergibt einen Mittelwert von ̅ Wie groß ist das Konfidenzintervall für den Mittelwert in der Grundgesamtheit bei einer Sicherheit von 95%? (Signifikanz 5%). Es gilt für die Standardabweichung in einer Stichprobe: s = | -µ| also gilt: µ= ±z √ z √ √ = 32,5 ± 1,96 . 5,8/7 = 32,5 ± 1,624 Der Mittelwert liegt mit Sicherheit von 95% im Intervall 30,9 bis 34,1. 29 3. Vertrauensbereich für den Mittelwert bei unbekannter Standardabweichung Eine endliche Stichprobe mit einigen Daten aus einer normalverteilten Grundgesamtheit wird gezogen, der Mittelwert und die Standardabweichung der Stichprobe werden berechnet. und ̂. Wenn man σ der Grundgesamtheit nicht kennt und n nicht besonders groß ist, dann wird die t-Verteilung eingesetzt. Die z-Verteilung kann nur bei großem n verwendet werden! Aus einer normalverteilten Grundgesamtheit entnimmt man die Daten: 5,6,6, 4,5 ; ̂ = Vorsicht, mit n-1 dividieren! = 0,837 n = 5 t-Verteilung f=4 Wir suchen in der t-Tabelle den Wert für f= 4 und Sicherheit 95% (Vorsicht, für die zweiseitig abgeschnittene Fläche nachschauen. In der Tafel dieses Skriptums muss man bei 95 + 2,5 nachschauen, links 2,5 rechts 2,5) dies ergibt den Wert: t = 2,78 Die Formel | -µ| Das ergibt für µ= ±t ̂ √ t ̂ √ = 5,2 ±1,04 Der Mittelwert liegt mit 95% Sicherheit im Intervall 4,16 und 6,24 (Nebenbei: was wäre, wenn wir z genommen hätten? µ= ± z = 5,2 ± 1,96 . 0,374 = 5,2 ± 0,73. Das wäre ein Intervall von 4,47 bis 5,93. Um ein 0,62 √ schmäleres Intervall! Daher fehleranfälliger!) 4. Vertrauensbereich für die Standardabweichung σ der Grundgesamtheit Aus einer Stichprobe mit n = 10 ermittelt man die Standardabweichung der Stichprobe s = 16. Es ist der 95%- Vertrauensbereich für σ zu finden. Die Varianz muss mit der χ2-Verteilung behandelt werden. χ² = f s² / σ² Wir suchen aus der Tabelle χ² für f = 9 Freiheitsgrade. die 95% ergänzen sich zu 100% mit links 2,5% und rechts 95 +2,5 = 97,5% χ²9, untere Grenze = 2,7 χ²9, obere Grenze = 19 Für das Intervall gilt die Beziehung: χ²9, untere Grenze ≤ f s² / σ² ≤ χ²9, obere Grenze | Kippen und mal fs² ergibt: fs² / χ²u ≥ σ² ≥ fs² / χ²o | Wurzel ziehen und Zahlen einsetzen: 29,21 ≥ σ ≥ 11,01. Der Vertrauensbeweis liegt für σ zwischen 11,01 und 29,21. 30 Anhang: Tabellen Die Flächen Φ der z-Verteilung: Standardnormalverteilung z= x µ , negative z-Werte: Φ(-z) = 1-Φ(+z) 31 Einige Perzentile der Chi-Quadrat-Verteilung 32 Einige Perzentile der Student-Verteilung Einseitige Fragestellung 33 Zweiseitige Fragestellung f f 34 Quantile der F-Verteilung für 95% Sicherheit 35 Quantile der F-Verteilung für 97,5% Sicherheit 36