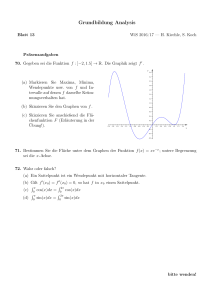
Mathematischer Vorkurs für Studienanfänger
Werbung

Rechnen in Naturwissenschaft und Technik: Mathematischer Vorkurs für Studienanfänger 8.-19.10.2007, Geb. C6 3, gr. Hörsaal K. Kruse L. Santen W. Zimmermann Kontakt: K. Kruse, Theoretische Physik, UdS, Geb. E2 6 [email protected] http://www.uni-saarland.de/fak7/kruse/index.html 1 Die Mathematik stellt am Anfang des Physikstudiums oft eine große Hürde dar. Ähnliches gilt für das Studium der Ingenieurswissenschaften und in geringerem Umfang auch für das der anderen Naturwissenschaften. Die Mathematikausbildung in der Schule sollte Ihnen aber ein gutes Fundament vermittelt haben, von dem aus Sie diese Hürde überwinden können. Dieser Vorkurs soll Ihnen dabei helfen, die in der Schule erworbenen Mathematikkenntnisse aufzufrischen, und damit den Einstieg in die universitäre Mathematik erleichtern. Mit der Wiederholung des Ihnen bekannten mathematischen Stoffs sollen Sie auch in die studentische Arbeitsweise eingeführt werden. Diese erfordert zunächst eine große Selbstdisziplin. Aus diesem Grund sind die Vormittage zum Selbststudium vorgesehen. Setzen Sie sich in Gruppen zusammen und arbeiten die angegebenen Seiten des Skripts durch. An den Nachmittagen findet eine Übung statt, in der Sie im Beisein von Tutoren Aufgaben lösen können, die zu dem für den Vormittag vorgesehenen Stoff passen. Wie tief Sie jeweils in ein Problem oder ein Thema eintauchen, ist ganz allein Ihnen überlassen. Bedenken Sie aber, dass Sie ohne solide mathematische Grundkenntnisse eher früher als später in Ihrem Studium auf große Probleme stoßen werden. Für diesen Vorkurs stehen uns zwei Wochen zur Verfügung, in denen wir den Stoff der Oberstufe Revue passieren lassen werden. Natürlich ist es nicht möglich, ihn sich in dieser Zeit komplett neu zu erarbeiten. Auch ist das vorliegende Skript nicht als Lehrbuch gedacht. Sollten Sie mal eine Lücke feststellen oder sollte Ihnen die Darstellung des einen oder anderen Punkts anders vorkommen als in der Schule, dann lassen Sie sich dadurch nicht abschrecken. Nehmen Sie sich in diesem Fall ihr Schulbuch zur Hand und arbeiten sie den entsprechenden Punkt dort durch. Gehen Sie dann zurück zum Skript und setzen sich an die entsprechenden Übungsaufgaben. Gerade für die Mathematik gilt, dass nur durch das selbständige Lösen vieler Aufgaben die nötige Souverenität im Umgang mit Konzepten und Rechentechniken erworben werden kann. 2 Inhaltsverzeichnis 1 Funktionen und Ableitungen 1.1 Funktionen . . . . . . . . . 1.2 Umkehrfunktionen . . . . . 1.3 Grenzwerte und Stetigkeit . 1.4 Gewöhnliche Ableitungen . . 1.5 Höhere Ableitungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 5 8 9 9 12 2 Folgen, Reihen, die Exponentialfunktion und eine Differentialgleichung 2.1 Folgen und Reihen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.1 Arithmetische Folgen und Reihen . . . . . . . . . . . . . . . . . 2.1.2 Geometrische Folgen und Reihen . . . . . . . . . . . . . . . . . 2.2 Die Exponentialfunktion . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3 Differentialgleichungen und die Exponentialfunktion . . . . . . . . . . . 2.4 Einige Rechenregeln für die Exponentialfunktion . . . . . . . . . . . . . 2.5 Der natürliche Logarithmus . . . . . . . . . . . . . . . . . . . . . . . . 14 14 14 15 16 20 22 22 3 Komplexe Zahlen und weitere elementare Funktionen 3.1 Wo treten komplexe Zahlen auf? . . . . . . . . . . . . . . 3.2 Die vier Grundrechenarten mit komplexen Zahlen . . . . 3.2.1 Addition und Subtraktion . . . . . . . . . . . . . 3.2.2 Multiplikation . . . . . . . . . . . . . . . . . . . . 3.2.3 Division . . . . . . . . . . . . . . . . . . . . . . . 3.3 Komplex konjugierte Zahl . . . . . . . . . . . . . . . . . 3.4 Betrag und Argument komplexer Zahlen . . . . . . . . . 3.5 Komplexe Zahlen und die Exponentialfunktion . . . . . . 3.6 Die Polardarstellung komplexer Zahlen . . . . . . . . . . 3.7 de Moivres Theorem . . . . . . . . . . . . . . . . . . . . 3.8 Trigonometrische Funktionen . . . . . . . . . . . . . . . 3.9 Additionstheoreme . . . . . . . . . . . . . . . . . . . . . 3.10 Die n-te Wurzel von 1 . . . . . . . . . . . . . . . . . . . 3.11 Der komplexe Logarithmus . . . . . . . . . . . . . . . . . 3.12 Hyperbolische Funktionen . . . . . . . . . . . . . . . . . 3.13 Hyperbolische Umkehrfunktionen – Areafunktionen . . . . . . . . . . . . . . . . . . . 24 24 26 26 26 27 27 27 28 28 30 30 32 34 35 36 37 4 Funktionen und Ableitungen II 4.1 Ableitungen von Umkehrfunktionen . . . . . . . . . . . . . . . . . . . . 4.2 Ableitungen der trigonometrischen und der hyperbolischen Funktionen 4.3 Anwendungsbeispiel für den tanh(x) . . . . . . . . . . . . . . . . . . . 4.4 Regel von l’Hospital . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.5 Taylor-Entwicklung von Funktionen in Potenzreihen . . . . . . . . . . . 4.6 Das Newton-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 38 38 40 41 42 43 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 Integralrechnung 5.1 Das bestimmte Integral . . . . . . . . . . 5.2 Das unbestimmte Integral . . . . . . . . 5.3 Integration durch Ansehen . . . . . . . . 5.4 Integration trigonometrischer Funktionen 5.5 Integration durch Substitution . . . . . . 5.6 Logarithmische Integration . . . . . . . . 5.7 Partielle Integration . . . . . . . . . . . 5.8 Integration durch Partialbruchzerlegung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 45 46 48 48 49 50 50 52 6 Vektoren 6.1 Koordinatendarstellung von Vektoren . . . . . 6.1.1 Länge eines Vektors . . . . . . . . . . . 6.1.2 Elementare Rechenregeln für Vektoren 6.2 Schnitte zweier Geraden . . . . . . . . . . . . 6.3 Polarkoordinaten . . . . . . . . . . . . . . . . 6.4 Skalarprodukt . . . . . . . . . . . . . . . . . . 6.5 Vektorprodukt im R3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 53 55 55 56 59 60 61 7 Lineare Systeme 7.1 Drehungen von Vektoren . . . . . 7.2 Matrix-Multiplikation . . . . . . . 7.3 Transponierte und inverse Matrix 7.4 Eigenwerte und Eigenvektoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 63 64 65 67 8 Wahrscheinlichkeitsrechnung 8.1 Wahrscheinlichkeiten . . . . . . . . . . . . . . . . 8.2 Eigenschaften der Wahrscheinlichkeit . . . . . . . 8.3 Bedingte Wahrscheinlichkeiten . . . . . . . . . . . 8.4 Permutationen und Kombinationen . . . . . . . . 8.5 Kontinuierliche Zufallsvariablen und Verteilungen 8.6 Statistische Größen . . . . . . . . . . . . . . . . . 8.7 Die Gauß-Verteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69 69 69 69 71 73 74 75 9 Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77 4 1 1.1 Funktionen und Ableitungen Funktionen Funktionsverläufe begegnen uns tagtäglich in Nachrichten- und Informationssendungen im Fernsehen oder in Zeitungen zur Darstellung empirischer Daten. Häufig werden die Ergebnisse von Meinungsumfragen oder die Entwicklung von Börsenkursen als Funktion der Zeit durch Graphen dargestellt. Formal ist eine Funktion eine eindeutige Zuordnung von Elementen einer Definitionsmenge zu Elementen einer Bildmenge. Hier bedeutet eindeutig“, dass jedem Element der Definitionsmenge genau ein Element ” der Bildmenge zugeordnet wird, so ist zum Beispiel die Größe eines Menschen eine Funktion seines Alters, denn er hat zu jedem Zeitpunkt nur eine Größe. Die Größe der Menschen überhaupt in Abhängigkeit ihres Alters ist dagegen keine Funktion, denn zwei Menschen desselben Alters können verschieden gross sein. Formal schreibt man für eine Funnktion f f : D → B (1) x "→ f (x) . Hier ist f der Funktionsname, D die Definitions-, B die Bildmenge und x "→ f (x) die Abbildungsvorschrift. Häufig ergeben sich D und B aus dem Zusammenhang und es wird nur die Abbildungsvorschrift angegeben, z.B. f (x) = x. Nicht jeder Funktionsverlauf ist analytisch durch eine einfache Formel darstellbar. Dies setzt nämlich ein Verständnis der mit der Formel beschriebenen Vorgänge voraus. Nach dem Stand der Dinge verstehen wir die komplizierten Ursachen und Beweggründe z.B. der Bevölkerungsentwicklung noch nicht, auch nicht die Entwicklung der Börsenkurse. Demzufolge können wir für deren zeitliche Entwicklung immer nur bis zur Gegenwart die Daten aufzeichnen und keine Formel angeben, um damit deren Entwicklungen auch vorherzusagen. Im folgenden geht es um typische und analytisch darstellbare Gesetzmäßigkeiten, wie sie bei vielen naturwissenschaftlichen und technischen Vorgängen auftreten. Beginnen wir mit besonders einfachen Beispielen. Fährt ein Fahrzeug am Ort y0 mit konstanter Geschwindigkeit v los und behält diese bei, dann befindet es sich zur Zeit t am Ort y = y0 + vt . (2) Dieser einfache und lineare (gerade) Funktionsverlauf ist in Abb. 1a für y0 = 0, 1 und v = 1 (durchgezogene Linie) und für y0 = 1, 0 mit entgegengesetzter Geschwindigkeit v = −1 dargestellt (gestrichelt). Auch Funktionsverläufe mit der Form einer Parabel y = x2 , wie in Abb. 1b zu sehen, sind in Wissenschaft und Technik weit verbreitet. Abbildung 1c zeigt einen Funktionsverlauf, der sich aus einem linearen und einem parabolischen Anteil zusammensetzt: y = b + ax + x2 . Ein wichtiges Beispiel für eine Polynomfunktion höheren Grades ist 5 (3) 2 a) y 2 c) b) 1 y y = x 2 y 1 1 0 0 0 −1 0 1 t 2 −1 0 1 −1 x 0 1 x Abbildung 1: Elementare Funktionen: Im Teil (a) sind es zwei Geraden nach Gl.(2) und Parametern wie im Text. In (b) ist die Parabel f (x) = x2 dargestellt und in (c) ist ein Verlauf nach Gl. (3) dargestellt, wobei a = −1 (durchgezogen) und a = 1.5 (gestrichelt) sowie in beiden Fällen b = 0. y 2 1 − 1.5 − 1.0 − 0.5 0.5 1.0 1.5 x −1 Abbildung 2: Die Polynomfunktion fp (x) = −ax2 + x4 für a = −2 (Strichpunktlinie), a = 0 (gestrichelt) und a = 2 (durchgezogen) . f (x) = −ax2 + x4 . (4) Diese einfache Polynomfunktion begegnet ihnen z.B. während des Studiums in der Mechanik, der Thermodynamik und Statistik und in der Festkörperphysik. Man stelle sich z.B. vor, der Funktionsverlauf in Abb. 2 entspräche einer Muldenform in dem ein Kügelchen losgelassen wird. Das Kügelchen wird dem niedrigsten Punkt der Kurve zustreben. Dies ist einmal x = 0 für a < 0 und x ̸= 0 für a > 0. Bestimmen Sie als Übung den Wert x ̸= 0. Nicht nur Summen verschiedener Potenzen xn einer Variablen x sind als Funktionen von Bedeutung. Manche Funktionen haben die Variable x im Exponenten, wie z.B. für eine positive reelle Zahl b die Funktion f (x) = bx . Die berühmteste und zugleich wichtigste Funktion dieser Art ist die Exponentialfunktion ex auch ex = exp(x) geschrieben. Die Zahl e hat den Wert e = 2.7182818 . . ., welchen wir uns später im Abschnitt 2 mit einer Reihendarstellung noch beschaffen werden. Der Funktionsverlauf von ex ist zur Erinnerung in Abb. 3 dargestellt. Die Exponentialfunktion tritt in vielerlei Zusammenhängen auf, wie z.B bei der Zinses– 6 10 y 8 x y=e 6 y 4 2 1 y = ln ( x ) 2 0 0 −1 0 1 2 0 x 2 4 6 x 8 10 Abbildung 3: Zwei weitere elementare Funktionen. Links ist die Exponentialfunktion ex = exp(x) dargestellt und rechts ist ihre Umkehrfunktion ln(x) gezeigt. zinsrechnung, bei der Rentenrechnung oder beim Bakterienwachstum. Aber auch bei sehr vielen anderen funktionalen Zusammenhängen tritt die Exponentialfunktion auf. Wie wir noch in vielen Beispielen sehen werden, ist die Exponentialfunktion ganz zentral bei sogenannten linearen Systemen (deren Bedeutung später erklärt wird). Ähnlich universelle Funktionen sind die trigonometrischen Funktionen sin und cos, welche beide in Abb. 4 dargestellt sind. f (t) = A sin(ωt) beschreibt beispielsweise die kleinen Auslenkungen eines Uhrenpendels als Funktion der Zeit t, wobei ω die Kreisfrequenz der Schwingung mit Periode T ist: ω = 2π/T . Beide Funktionen lassen sich durch die Exponentialfunktion ausdrücken, wie im Abschnitt 3.8 beschrieben werden wird. Auch die Anwendung der trigonometrischen Funktionen ist nicht auf ein Beispiel be- 1 y 0 −1 0 5 10 15 x Abbildung 4: Die durchgezogene Kurve ist f (x) = cos(x) und die gestrichelte Line ist f (x) = sin(x). 7 Abbildung 5: Ein Beispiel für eine Funktion, die von zwei Variablen abhängt. Die Funktion beschreibt hier eine etwas seltsame Fläche, deren analytischer Ausdruck im Bild angegeben ist. schränkt. Wie die Exponentialfunktion begleiten sie diese durch die Mechanik, Elektrizitätslehre und Elektrodynamik, Quantenphysik etc. Dahinter steckt, daß viele grundlegende Differentialgleichungen linear sind, welche sin(ωt), cos(ωt) als Lösungen besitzen. Neben Funktionen von einer Variablen sind auch Funktionen von mehreren Variablen vorstellbar und von Bedeutung: Flächen über einer Ebene, wie z.B. in Abb. 5, sind Funktionen von zwei Variablen, f (x, y); die Temperatur T in einem Raum hängt von wenigstens 4 veränderlichen ab, den drei Raumkoordinaten x, y, z und der Zeit t, T = T (x, y, z, t). In den bisher angeführten Beispielen war die Definitionsmenge durch ein oder mehrere Intervalle bestimmt. Sie kann aber auch durch eine diskrete Menge gegeben sein. Zum Beispiel kann man jedem Menschen ein Geburtsdatum zuordnen. Die Definitionsmenge kann auch beide Formen mischen: Betrachten wir ein Gas in einem Volumen. Jedem Gasteilchen (i = 1, ..., N ) kann zu j edem Zeitpunkt des Beobachtungszeitraums (tϵ[0, T ]) ein Ort zugeordnet werden. 1.2 Umkehrfunktionen Wenn man eine Funktion y = f (x) kennt, dann möchte man oft auch x durch die Variable y, also durch eine Funktion x = g(y) ausdrücken. Man nennt dann g(y) die Umkehrfunktion zu f (x). Dieses geht offensichtlich nur dann, wenn die Funktion eineindeutig ist: nicht nur das jedem Element der Definitionsmenge genau ein Element der 8 g f x 0 0 x Abbildung 6: Stetigkeit. Bildmenge zugeordnet wird sondern auch umgekehrt - jedem Element der Bildmenge wird genau ein Element der Definitionsmenge zugeordnet. Die Verkettung der Funktion mit ihrer Umkehrfunktion liefert die Identität, g ◦ f = I, d.h., ein Element wird durch diese Operation auf sich selbst abgebildet, g(f (x)) = x. Für die lineare Funktion f (x) = ax mit a ̸= 0 ist die Umkehrfunktion g(y) = a1 y, denn f (g(y)) = a a1 y = y. Für die quadratische Funktion f (x) = bx2 , b > 0, existiert keine Umkehrfunktion, falls die Definitions- und Bildmenge R sind. Werden für ! die beiden nur die positiven reellen ! Zahlen einschließlich 0 gewählt, dann ist g(y) = y/b, ! 2 denn f (g(y)) = by /b = y 2 = y. Die Umkehrfunktion der in Abb. 3 gezeigten Exponentialfunktion ist der Logarithmus ln(x), welche ebenfalls in Abb. 3 gezeigt ist. 1.3 Grenzwerte und Stetigkeit Die beiden in Abb. 6 gezeigten Funktionen unterscheiden sich qualitativ. Während f in einer Linie durchgezogen werden kann, hat g Sprünge. Die Eigenschaft von f bezeichnet man als Stetigkeit. Sie bedeutet, daß limx→x0 f (x) = f (x0 ) für alle x0 gilt. In dieser Beziehung bezeichnet limx→x0 f (x) den Grenzwert von f wenn x gegen x0 geht. Anschaulich heißt das, daß je dichter Sie x bei x0 wählen, desto dichter liegt f (x) bei f (x0 ). Bei geeigneter Wahl von x aus einer Umgebung von x0 unterschreitet der Abstand von f (x) zu f (x0 ) jeden beliebigen von Ihnen vorgegebenen Wert. 1.4 Gewöhnliche Ableitungen Eine Funktion f (x) heißt differenzierbar an der Stelle x0 , falls der Grenzwert lim x→x0 f (x) − f (xo ) = f ′ (x0 ) x − x0 (5) existiert. f ′ (x0 ) nennt man die Ableitung der Funktion f (x) im Punkt x0 . Es gibt dafür auch andere und oft benutzte äquivalente Schreibweisen: " df "" ′ f (x0 ) = = fx (x0 ) . (6) dx "x=x0 9 Handelt es sich bei der Variablen x um die Zeit t, so ist für die Ableitung einer Funktion g auch die Schreibweise g ′(t0 ) = ġ(t0 ) üblich. Da f ′ (x) für eine differenzierbare Funktion an jeder Stelle des Definitionsbereichs berechnet werden kann, ist f ′ (x) selbst wieder eine Funktion. Betrachten wir ein Beispiel. Der zurückgelegte Weg eines Teilchens nach der Zeit t und der Anfangsposition y0 zur Zeit t = 0 sei durch Gl. (2) gegeben. Die Ableitung (t0 ) 0 = limt→t0 t−t v = v ist offensichtlich die von t unabhängige f ′ (t) = limt→t0 f (t)−f t−t0 t−t0 Geschwindigkeit v des Teilchens. Nehmen wir als zweites Beispiel die Parabel f (x) = ax2 : ax2 − ax20 (x + x0 )(x − x0 ) = lim a = lim a(x + x0 ) = 2ax0 . x→x0 x→x0 x→x0 x − x0 x − x0 lim (7) Die Ableitung der Parabel f (x) = ax2 an der Stelle x ist also f ′ (x) = 2ax (8) und hängt selbst wieder von x ab. (x0 ) gibt die Steigung der Geraden, die durch (x, f (x)) Der Differenzenquotient f (x)−f x−x0 und (xa , f (x0 )) geht an, siehe Abb. 7. Die Ableitung f ′ (x0 ) gibt entsprechend die Steigung der Tangente an die Funktion f im Punkt (x0 , f (x0 )) an. Sie wird durch die Gleichung T (x; x0 ) = f (x0 ) + f ′ (x0 )(x − x0 ) (9) beschrieben. Die Ableitung f ′ (x0 ) wird auch als Steigung von f in x0 bezeichnet. Die Tangente T (x; x0 ) stellt eine lineare Näherung (Approximation) der Funktion f in x0 dar. Wie gut diese Näherung ist, können wir am Besipiel der Parabel betrachten. Sei f (x) = x2 , x0 = 1 und x1 = 1.1. Dann ist T (x1 ; x0 )−f (x1 ) = 12 +2.1(1.1−1)−(1.1)2 = 1 + 0.2 − 1.21 = −0.01. Der Fehler durch die Näherung beträgt also nur etwa 1%. Das Differential der Funktion y = f (x) ist dy = f ′ (x)dx . (10) Wegen y = f (x) ist für das Differential auch die Schreibweise df (x) üblich. Mit dem Differential werden also infinitesimale Veränderungen einer Größe beschrieben und mit infinitesimalen Veränderungen anderer Größen in Verbindung gesetzt. Es ist insbesondere in der Thermodynamik von großer Bedeutung, tritt aber auch in anderen Zusammenhängen in der Physik auf. Wir wenden uns nun einfachen Ableitungsregeln zu, die es uns ersparen werden, Ableitungen über den häufig umständlich zu berechnenden Grenzwert (5) auszurechnen. Aus der Definition der Ableitung ergibt sich sofort, dass sie eine lineare Operation ist. Die Ableitung einer Summe von zwei Funktionen ist also die Summe der Ableitungen der beiden Funktionen, (f + g)′(x) = f ′ (x) + g ′(x), und bei der Multiplikation mit einer Konstanten α kann diese vor die Ableitung gezogen werden, (αf )′(x) = αf ′(x). 10 y=f(x) y ∆ y=f(x+dx)-f(x) dy dx x x+dx x Abbildung 7: ∆y ist also die Änderung von y = f (x) entlang des Wegstückes ∆x = dx. dy ist die Änderung von y entlang der Tangente. D.h. dy ist die Tangentenapproximation (lineare Approx.) zu ∆y und der Unterschied zwischen ∆y und dy verschwindet für ∆x → 0. Oftmals ist f (x) aus anderen Funktionen zusammengesetzt, z.B. als Produkt f (x) = g(x) h(x) zweier differenzierbarer Funktionen. Die Parabel ist ein sehr einfaches Beispiel mit g(x) = h(x) = x. Der Differentialquotient ist f (x + ∆x) − f (x) ∆x→0 ∆x g(x + ∆x)h(x + ∆x) − g(x)h(x) = lim ∆x→0 ∆x g(x + ∆x)h(x + ∆x) − g(x)h(x + ∆x) + g(x)h(x + ∆x) − g(x)h(x) = lim ∆x→0 ∆x ′ ′ = g (x) h(x) + g(x) h (x) (11) f ′ (x) = lim Also gilt (g h)′ (x) = g ′ (x) h(x) + g(x) h′ (x) (12) Wenn man diese Produktregel auf f (x) = x2 anwendet, folgt f ′ (x) = x·x′ +x′ ·x = 2x wie oben. ′ Als ein weiteres Beispiel betrachten wir f (x) = x3 . Die Ableitung ist f ′ (x) = (x3 ) = ′ x2 (x)′ + (x2 )′ x = x2 + x(2x) = 3x2 . Es liegt nun folgende Vermutung nahe: (xn ) = nxn−1 . Gezeigt haben wir es für n = 1, 2, 3. Nehmen wir an, dass wir die Formel bis zu ′ einem Wert n gezeigt hätten, (xn )′ = nxn−1 . Dann gilt (xn+1 )′ = (xn x)′ = (xn+1 ) = (xn )′ x + xn (x)′ = (n + 1)xn . Also gilt diese Aussage auch für n + 1 und daher für jedes n (dieses Beweisschema nennt man vollständige Induktion): d(xn ) = nxn−1 dx . (13) Damit kann man nun auch die Ableitung der Funktion in Gl. (4) leicht berechnen: fp′ (x) = −2ax + 4x3 . 11 Neben Produkten von Funktionen gibt es auch Quotienten von Funktionen f (x) = g(x)/h(x). Auch deren Ableitungen können wieder durch Ableitungen der Teilfunktionen dargestellt werden, siehe unten. Als letztes lassen Sie uns die Ableitungen zusammengestzter Funktionen f (x) = g(h(x)) berechnen. Ein Beispiel ist f (x) = g(h(x)) = h2 (x) mit h(x) = 2x + b. Bei deren Ableitung nach x geht man schrittweise vor. Mit y = g(h(x)) kann man für die Differenzen ∆y auch schreiben durch Erweiterung des Bruches ∆x ∆y ∆y ∆h = ∆x ∆h ∆x . (14) Geht dann ∆x → 0, so strebt für eine differenzierbare und damit stetige Funktion h auch ∆h → 0. Damit kann der Grenzwert ∆x → 0 ∆y ∆h ∆y = lim · lim ∆x→0 ∆x ∆h→0 ∆h ∆x→0 ∆x lim (15) gebildet werden und es folgt die Regel für die Ableitung einer Verkettung von Funktionen dg(h(x)) dg(h) dh(x) = . (16) dx dh dx Damit folgt für das Beispiel df dx = dh2 dx = dh2 dh dh dx = 2h · 2 = 4(2x + b). Ableitungsregeln d dx (f + g) (x) = d dx (αf (x)) d (f dx g)(x) d f (x) dx + d g(x) dx Summenregel d = α dx f (x) #d $ d = dx f (x) g(x) + f (x) dx g(x) d f (x) dx g(x) = d f (g(x)) dx = ( dxd f (x))g(x)−f (x) dxd g(x) g 2 (x) für g(x) ̸= 0 df (g) dg(x) dg dx (α ∈ R) Produktregel Quotientenregel Kettenregel Die Ableitungen der Exponential- und Logarithmusfunktionen sowie der trigonometrischen Funktionen berechnen wir im Abschnitt 4. 1.5 Höhere Ableitungen Oftmals ist die Ableitung h(x) = f ′ (x) einer Funktion f (x) wieder differenzierbar, d.h. es existiert der Grenzwert h(x) − h(x0 ) = h′ (x0 ) . x→x0 x − x0 lim 12 (17) Der Ausdruck h′ (x0 ) wird als die zweite Ableitung von f an der Stelle x0 bezeichnet. Hierfür verwendet man die Schreibweisen f ′′ (x0 ) = d2 f |x=x0 dx2 . (18) Die zweite Ableitung bestimmt die geometrische Krümmung einer Kurve, wie z.B. die Parabel f (x) = ax2 verdeutlicht: f ′′ (x) = a. Die n-te Ableitung wird entsprechend über dn f (n−1) (x + ∆x) − f (n−1) (x) (n) f (x) = f (x) = lim ∆x→0 dxn ∆x definiert, wobei f (1) (x) = f ′ (x), f (2) (x) = f ′′ (x) usw. 13 (19) 2 Folgen, Reihen, die Exponentialfunktion und eine Differentialgleichung In diesen Abschnitt beschäftigen wir uns mit der in den Natur- und Ingenieurswissenschaften laufend vorkommenden und auch in der Mathematik zentralen Exponentialfunktion. Bevor wir jedoch die Zahl e berechnen und uns Beispielen zuwenden in denen die Exponentialfunktion auftritt, frischen wir unser Wissen zu Folgen und Reihen ein wenig auf. 2.1 Folgen und Reihen Zahlenfolgen haben große Bedeutung, welche z.B. darauf beruht, daß viele Zahlen wie z.B. die Zahl e und andere Ausdrücke sich nicht exakt angeben lassen, sondern nur durch geeignete Zahlenfolgen approximieren lassen. Auch bei vielen Beispielen aus Physik und Technik ist das Ergebnis der Grenzwert einer Zahlenfolge oder die Summe einer Zahlenfolge. Eine Folge ist hierbei zunächst nichts anderes als eine Funktion, deren Definitionsbereich die natürlichen Zahlen N sind. 2.1.1 Arithmetische Folgen und Reihen Gewöhnlich werden die Glieder einer Folge in der Form an angegeben, wobei an die Zahl ist, die der natürlichen Zahl n zugeordnet wird. Beispiele sind an = n oder bn = n1 . Letztere konvergiert für n → ∞ gegen den Wert 0, d.h. limn→∞ bn = 0. Eine Reihe %N ist eine Folge, die durch Summen der Glieder einer Folge gebildet wird SN = n=1 an . Arithmetische und geometrische Folgen und Reihen, denen wir uns im folgenden zuwenden, sind von besonderer Bedeutung. Ein sehr einfaches Beispiel einer Reihe ist die Summe der Folge natürlicher Zahlen 1, 2, 3, . . . : SN =: N & k = 1 + 2 + 3+ ... k=1 Welchen Zahlenwert ergibt diese Summe? Probieren wir: 1 + 2 = 3 = 6 = 3·4 ; 1 + 2 + 3 + 4 = 10 = 4·5 . . . Demzufolge scheint zu gelten 2 2 N & k=1 k= N(N + 1) 2 . 2·3 ; 2 1+2+3 = (20) Wir können dies überprüfen, indem wir wieder das Schema der vollständigen Induktion verwenden. Für N = 1, 2, 3, 4 haben wir die Vermutung bereits bestätigt. Nehmen wir an, wir hätten die Formel bis zu einem gewissen Wert N überprüft. Wir zeigen nun, 14 dass sie dann auch für N + 1 gilt: N +1 & k = k=1 N & k + (N + 1) = k=1 N(N + 1) + (N + 1) = 2 N(N + 1) + 2N + 2 N 2 + 3N + 2 (N + 1)(N + 2) = = . 2 2 2 Im 2. Schritt haben wir die Annahme, dass wir die Formel bereits für N überprüft haben, genutzt. Damit gilt die Formel für alle natürlichen Zahlen N. Bei dem vorhergehenden Beispiel handelt es sich um eine arithmetische Reihe. Allgemein sind diese dadurch bestimmt, dass die Differenz zweier beliebiger aufeinanderfolgender Glieder eine Konstante d ist, d.h. = an+1 − an = d , (21) für alle n. Weitere Beispiele sind 1, 3, 5, 7, . . . (also d = 2) oder 1, 21 , 0, − 12 , . . . (also d = − 21 ). Die Summenformel für arithmetische Zahlenfolgen ist SN = N & N (a1 + aN ). 2 aν = ν=1 2.1.2 (22) Geometrische Folgen und Reihen Bei einer geometrischen Zahlenfolge an ist der Quotient zweier aufeinanderfolgender Glieder konstant, d.h. an+1 = q. an Die Folge an = ( 21 )n−1 mit n = 1, . . . , N erfüllt das Kriterium der geometrischen Zahlenfolge, denn an+1 /an = 1/2. Aber auch jede andere Folge aus Potenzen einer Zahl b, wie an = bn−1 , erfüllt dieses Kriterium. Nun wollen wir die Glieder der zugehörigen geometrischen Reihe berechnen. Es ist a0 + a1 + a2 + . . . aN −1 = a0 (1 + q + q 2 + q 3 + . . . + q N −1 ) N & = a0 q n−1 = a0 SN . (23) n=1 Multiplizieren wir die Reihe SN mit q und subtrahieren davon wieder SN , erhalten wir qSN − SN = (q − 1)SN = q N − 1 oder SN = N & ν=1 q ν−1 1 − qN = . 1−q 15 (24) y 5.0 2.5 x − 1.0 − 0.5 0.5 1.0 Abbildung 8: Die Funktion f (x) = 1/(1 − x) Ist zusätzlich q < 1, so konvergiert q n gegen 0: limn→∞ q n → 0. In diesem Fall konvergiert auch die Reihe. Es ist lim SN = lim N →∞ N →∞ N & q n−1 = n=1 1 1−q (25) für |q| < 1. Die geometrische Reihe ist ein Beispiel für die Reihendarstellung einer Funktion f (x) = 1 1−x , siehe Abb. 8. Ein konkretes Zahlenbeispiel für die geometrische Reihe ist: (n ∞ ' ∞ & & 1 4 1 #1$ = 3 . =4 = 4 n (−3) −3 1 − −3 n=0 n=0 (26) (27) Ein völlig anderes Ergebnis liefert dagegen folgende Summe: ∞ & 1 = ζ(a) . a n n=1 (28) Dies ist die Riemannsche Zeta-Funktion, die hier aber nicht weiter diskutiert werden soll. 2.2 Die Exponentialfunktion Enorm viele Prozesse in Natur und Gesellschaft, bei denen eine gewisse Größe y im Laufe der Zeit ab- oder zunimmt, sind Wachstums- oder Schrumpfungsprozesse, deren 16 Änderung von y proprotional zum aktuellen Wert y(t) ist. Zum Beispiel ist die absolute Änderung einer Bakterienpopulation proportional zur momentanen Größe der Population - eine größere Zahl produziert mehr Nachkommen. Schreitet man um einen kleinen Zeitschritt ∆t voran, so wächst oder fällt die Funktion um ∆y(t). Diese kleine Änderung ∆y(t) = y(t + ∆t) − y(t) ist auch noch proportional zum Zeitschritt ∆t, also insgesamt ∆y(t) = y(t + ∆t) − y(t) = αy(t) · ∆t , (29) wobei α eine vom aktuellen System abhängige Proportionalitätskonstante ist und Auskunft über die Stärke des Wachstums oder der Schrumpfung gibt. Dieser Zusammenhang gilt nicht nur für Bakterienpopulationen. Liegt eine vorgegebene Menge radioaktiver Elemente vor, dann zerfallen absolut gesehen umso weniger Elemente pro Zeiteinheit je weniger radioaktive Elemente vorhanden sind. Wenn man sein Kapital anlegt, dann ist der Zuwachs pro Zeiteinheit auch umso größer, je größer das eingesetzte Kapital ist. Dies sind alles ähnliche Wachstums- oder Schrumpfungsprozesse. Die Frage ist nun, ob man mit Hilfe dieses lokal gültigen Änderungsgesetzes nicht auch den Endzustand eines längerdauernden Prozesses bis zu einem beliebigen Zeitpunkt T berechnen kann. Hierzu unterteilen wir das Intervall [0, T ] in k = 0, 1, . . . , m Teilintervalle mit den Intervallgrenzen tk = k∆t und ∆t = T /m. Setzen wir yk = y(tk ), so erhalten wir folgende Näherungsgleichungen. ' ( T y1 ≈ 1+α y0 , m ( ' (2 ' T T y1 = 1 + α y2 ≈ 1+α y0 , m m .. . ' (m T y0 , y(T ) = ym ≈ 1+α m T m ) y0 den Endzustand y(T ) umso besser beschreiben wird, je kleiner ∆t = Da (1 + α m T /m und je größer also m gewählt wurde, gilt ' (m T y(T ) = lim 1 + α y0 . m→∞ m Mathematiker beginnen an dieser Stelle berechtigterweise damit, über die Existenz dieses Limes nachzudenken. Wir fangen einfach an, ihn auszurechnen. Dazu fromen wir ym noch etwas um, indem wir (m ' ((m/αT )·(αT ) )' (m/αT *αT ' T T T 1+α = 1+α = 1+α m m m 17 (30) schreiben und uns um die innere Klammer kümmern. Insbesondere benötigen wir (n ' m 1 , wobei n= . (31) lim 1 + n→∞ n αT Wie kann man diesen Ausdruck berechnen? Wie groß muß n werden, damit man den Ausdruck hinreichend genau bekommt? Der Grenzübergang n → ∞ ist auch mit Rechenmaschinen schwer. Ein analytischer Zugang für den Grenzübergang ist daher sehr nützlich. Erinnern wir uns hierzu an die Binomischen Formeln aus der Schule: (a + b)2 = a2 + 2ab + b2 . Diese Gesetze sind auch für die n − te Potenz des Binoms erweiterbar. Hier verwenden wir das Ergebnis ' ( n n−2 2 n n 0 n−1 1 (a + b) = a b + na b + a b 2 ' ( ' ( n n−k k n 0 m a b + ab , (32) ...+ k n um den Ausdruck (31) umzuformen. Die Klammern sind dabei eine Abkürzung für ' ( n! n ≡ , (33) k k!(n − k)! wobei das Symbol n! für das Produkt von n Zahlen n! = 1 · 2 · . . . · n steht und n Fakultät genannt wird. Die Fakulät ist eine sehr schnell wachsende Funktion: 2! = 2, 3! = 6, 4! = 24, 5! = 120, 6! = 720, 7! = 5040, 8! = 40320, 9! = 362880, 10! = 3628800, . . . . In guter Näherung läßt sich n! durch die Stirling-Formel ausdrücken √ n! ≈ 2πn nn e−n , (34) √ Diese Formel ergibt 10! = 3598697.76838632 und der relative Fehler ist (10! − 20 π · 1010 · e−10 )/10! ∼ 0.0083, also bereits bei n = 10 kleiner als 1%. Setzen wir nun die Formel (32) ein und formen den Ausdruck (31 ) wie folgt um (n ' ( ' ( ' ' ( 1 n 1 n 1 n 1 + + + ... 1+ = 1+ 2 n 1 n 2 n 3 n3 ' ( n n! und = , 2 2!(n − 2)! ' ( n 1 n! (n)! (n − 1) (n) 11 = = 2 n2 2!(n − 2)! n n 2!(n)! n n 1 n−1 1 = ( ) ≈ für n → ∞ , 2! n 2! 18 ' ( n 1 3 n3 = ≈ usw. n! 1 (n − 3)! (n − 2)(n − 1)n = 3 3!(n − 3)! n 3!(n − 3)! n·n·n 1 für n → ∞ 3! Der gesuchte Ausdruck in Gleichung (31) kann also durch eine Reihe, die sogenannte Exponentialreihe, ausgedrückt werden, ' (n ∞ & 1 1 lim 1 + = = e = 2.7182818 . . . (35) n→∞ n k! k=0 Nun stellt sich die Frage, bis zu welchen Wert n man die Exponentialreihe aufsummieren muß, damit der Fehler so klein wie gewünscht wird. Eine Möglichkeit hierzu wäre, für die Reihe einfach ein kleines Computerprogramm zu schreiben und dies bis zu verschiedenen Werten von n aufzusummieren. Mit der folgenden Abschätzung geht es aber noch schneller. Trennen wir nun die unendliche Reihe in zwei Teile, n & 1 + rn+1 e= k! mit rn+1 ∞ & 1 = , k! (36) k=n+1 k=0 wobei rn+1 das Restglied genannt wird. Dessen Größe können wir abschätzen ' ( 1 1 1 1+ + + ... rn+1 = (n + 1)! n + 2 (n + 2)(n + 3) ' ( 1 1 1 < 1+ + + ... (n + 1)! (n + 2) (n + 2)2 (k ∞ ' ∞ ' (k & & 1 1 1 1 < = (n + 1)! k=0 n + 2 (n + 1)! n=0 2 = 1 1 (n + 1)! 1 − 1 2 1 < 1 gilt, haben wir im vorletzten Schritt das Ergebnis für die geometrische Da n+2 Reihe (25) eingesetzt. Insgesamt gilt also rn+1 < 2 . (n + 1)! (37) Nun haben wir eine bequeme Methode zur Berechnung von e und wir kennen nun auch den Fehler, der z.B. für n = 15 r16 < 2 < 10−13 16! beträgt. Folgende Zahlenbeispiele sollen nochmals verdeutlichen, daß die Exponentialreihe viel schneller konvergiert als der Ausdruck in (31). 19 n Sn := n % k=0 2 4 6 12 105 107 1 k! 2,5 2,7083333333 2,7180555555 2,7182818282 - # $n an := 1 + n1 2.25 2,4414062500 2,5216263717 2,6130352901 2,7181459268 2,7182816925 Mit Gl. (30) und x = αT gilt offensichtlich + x ,n = ex lim 1 + n→∞ n (38) und man nennt die x-te Potenz von e die Exponentialfunktion, wobei ebenso die Schreibweise exp(x) =: ex , gängig ist. Die Exponentialfunktion ist positiv und monoton wachsend wie auch bereits in Abb. 3 zu sehen war. Kommen wir zum Ausgangsproblem zurück. Wir können die Größe y nun auch für größere Zeiten berechnen y(T ) = eαT y0 , (39) wobei y0 der Anfangszustand ist. Mit dem bisher Besprochenen und nach der Ersetzung 1 → x, sowie der Wiederholung der Rechenschritte folgt nun auch die Reihendarstellung der Exponentialfunktion + + x , 'm( + x ,2 'm( + x ,3 x ,m x e = lim 1 + = 1+m + + + ... m→∞ m m 2 m 3 m ∞ & 1 k = x = exp(x) . (40) k! n=0 2.3 Differentialgleichungen und die Exponentialfunktion In Abschnitt 1.4 haben wir gesehen, daß die Ableitung einer Parabel y ′ = (x2 )′ = 2x √ ist. Die Umkehrfunktion der Parabel ist x = y (für x > 0). Faßt man die beiden √ Gleichungen zusammen, so folgt y ′ = 2 y. Wenn eine Ableitung selbst wieder durch die ursprüngliche Funktion ausgedrückt wird, spricht man von einer Differentialgleichung. 20 10 y 8 −x x y=e y=e 6 4 2 0 −2 −1 0 1 x 2 Abbildung 9: Die Funktionen ex und e−x . Führen wir nun in Gl. (29) den Grenzprozeß ∆t → 0 aus, so folgt die Differentialgleichung d y(t) = αy(t) (41) dt und mit Gl. (39) auch d y(t) = αy(t) = eαt y0 . dt Setzen wir noch α = 1, so ergibt sich mit d y(t) = y(t) = et y0 dt auch d t e = et . dt (42) Für beliebige Werte von α finden wir d αt e = αeαt . dt (43) und für die n-malige Ableitung der Exponentialfunktion dn αt e = αn eαt . dtn (44) Die Differentialgleichung (41) heißt linear, weil y in der Gleichung nur linear vorkommt und z.B. keine Potenz oder eine Wurzel von y. Es ist eine Differentialgleichung erster Ordnung, da nur die erste Ableitung vorkommt. Wie dieses einfache Beispiel bereits 21 zeigt, haben lineare Differentialgleichungen mit konstanten Koeffizienten Exponentialfunktionen als Lösung. Es lassen sich sehr viele Gesetzmäßigkeiten, wenn auch manchmal nur als Näherung, durch lineare Differentialgleichungen beschreiben. Aus diesen Gründen ist die Exponentialfunktion ein ständiger Begleiter in den Naturwissenschaften. 2.4 Einige Rechenregeln für die Exponentialfunktion Für eine reelle Zahl u gilt mit natürlichen Zahlen n1 und n2 als Exponenten un1 un2 = un1 +n2 . (45) Wieder ein Beispiel zur Erinnerung: 23 · 22 = 8 · 4 = 32 bzw. 2(2+3) = 25 =32. Dies gilt für die Zahl e ebenso und zwar auch für beliebige reelle Zahlen x, y im Exponenten exp(x) exp(y) = exp(x + y) . (46) Werden also zwei Exponentialfunktionen miteinander multipliziert, so addieren sich die Argumente. Lassen Sie uns diesen Zusammenhang beweisen f (x) = ex erfüllt die Gleichung f ′ = f . Aber auch f (x) = ex+y erfüllt die Gleichung f ′ = f , allerdings jetzt mit der Anfangsbedingung f (0) = c(y) = ey bei x = 0. Damit gilt für alle Werte von x die Relation ex+y = c(y)ex = ey ex . Hiermit kann man auch sofort auf folgende nützliche Regel schließen exp(−x) = 1 exp(x) (47) und ebenso (ex )n = ex · ex · . . . ex = enx . (48) Letzteres gilt nicht nur für natürliche Zahlen, sondern ebenso für reelle Zahlen r im Exponenten (exp(x))r = (ex )r = erx = exp(rx) 2.5 (49) Der natürliche Logarithmus Die Umkehrfunktion der Exponentialfunktion x = ey heißt natürlicher Logarithmus und definitionsgemäß sind die beiden Gleichungen x = ey und y = ln x (50) zueinander äquivalent. Entsprechend gilt x = eln x . Mit der Identität eln(xy) = xy = eln(x) · eln(y) = enx + ny 22 (51) folgt eine wichtige Rechenregel: ln(xy) = ln(x) + ln(y) . (52) Bei einem wichtigen Problem der Physik vieler Teilchen (Statistische Physik) steht man z.B. vor dem Problem, welchen Wert der Ausdruck za − 1 a→o a (53) R = lim hat Auch hier sind Exponential-Funktion und der Logarithmus sehr hilfreich. Wir wissen bereits z = eln z . Dies bedeutet z a = (eln z )a = ea ln z . (54) Benutzen wir noch die Reihenentwicklung der Exponentialfunktion, so bekommen wir für R ea ln z − 1 = a→o a 2 z)2 z 1 + a ln + a (ln + ...− 1 1! 2! = lim a→o a a2 (ln z)2 a ln z + 2! = lim a→0 a = ln z R = lim Ähnlich gelagerte Probleme wie z a kommen immer wieder vor. 23 (55) 3 Komplexe Zahlen und weitere elementare Funktionen √ √ 2 oder 2 = 1.4142.. waren schon den Griechen bekannt. Aber Die Wurzeln wie 4 = √ was macht man mit −1 ? Man trifft auf diese Wurzel aus einer negativen Zahl bei der Suche nach der Lösung der scheinbar sehr einfachen Gleichung x2 + 1 = 0. Um mit derartigen Problemen umzugehen, sind komplexe Zahlen der Ausweg. Komplexe Zahlen √ wurden aber nicht nur wegen des Problemes mit −1 eingeführt. Vielmehr erfuhren durch deren Einführung im 16. Jahrhundert die Analysis und die Algebra eine große Vereinfachung. Außerdem werden durch die komplexen Zahlen ganz verschiedene Teile der Mathematik miteinander in Verbindung gesetzt. Auch die Beschränkung auf die reelle Zahlenachse wird abgestreift. Dadurch werden viele Dinge überschaubarer. Eine berühmte Relation ist die Euler-Beziehung eix = cos x + i · sin x , (56) durch welche auf einen Schlag Zusammenhänge zwischen scheinbar ganz verschiedenen Funktionen aufgedeckt werden. Die volle Entfaltung findet diese Idee in der Funktionentheorie, in der Funktionen von komplexen Zahlen untersucht werden. 3.1 Wo treten komplexe Zahlen auf? Obwohl komplexe Zahlen in sehr vielen Bereichen auftreten, begegnen sie uns am natürlichsten als Wurzeln von Polynomen. Polynome treten laufend bei der Berechnung von Eigenwerten von Matrizen auf. Wie in Abschnitt 7.4 gezeigt wird, werden die Eigenwerte z einer 2 × 2 Matrix durch eine quadratische Gleichung bestimmt: Sie hat die beiden Lösungen1 z2 − b z + c = 0 . z1/2 = . √ 1 b ± b2 − 4c . 2 (57) (58) Wenn der Ausdruck unter der Wurzel positiv ist, also b2 −4c > 0 gilt, so sind die beiden Lösungen reelle Zahlen. Für b2 − 4c < 0 steht man allerdings wieder wie oben vor dem Problem, was die Wurzel einer negativen Zahl ist. Verdeutlichen wir uns nochmals mit dem Zahlenbeispiel b = 4 und c = 5 in Abb. 10, was das eigentliche Problem ist. Dort ist die Funktion f (z) f (z) = z 2 − 4z + 5 für reelle Werte von z = x gezeigt. Man sieht, daß f (x) keine Nullstelle besitzt. 1 Zur Erinnerung: Gleichung (57) kann umgeschrieben werden in (z − b/2)2! + c − b4 /4 = 0 bzw. 2 2 2 (z − b/2) ! = b /4 − c. Zieht man daraus die Wurzel, so folgt z − b/2 = ± b /4 − c bzw. z = b/2 ± b2 /4 − c . 24 y 4 2 y = x −4x+5 2 0 0 1 2 3 4 x Abbildung 10: Die Funktion f (x) = x2 − 4x + 5. Dasselbe Polynom kann sich aber z.B. bei der Berechnung der Schwingungsfrequenz (auch Eigenfrequenz) eines Pendels oder eines elektrischen Schwingkreises, oder auch bei der sogenannten Stabilitätsanalyse nichtlinearer und chaotischer Systeme (z.B. bei der Analyse des Räuber-Beute-Verhaltens von Luchs und Schneehase etc.) und vielen anderen Problemen ergeben. Dort wird man auf die Berechnung einer Determinate einer Matrix A geführt, die selbst wieder verschwinden soll: Also D = det(A) = 0 ist gefragt. Nehmen wir ein Beispiel für eine Matrix, wie sie typischerweise bei derartigen Fragestellungen auftritt ' ( z−2 1 A= , (59) −1 z − 2 dann führt die Bedingung D = det(A) = 0 auf D = (z − 2)2 + 1 = z 2 − 4z + 5 = 0 . (60) Während wir bei der Funktion f (x) evtl. damit leben können, daß diese keine Nullstelle hat, sind wir bei der Berechnung der Schwingungsfrequenz eines Schwingkreises etc. darauf angewiesen, daß Polynome wie in (60) eine Lösung haben. Um mit diesem Problem fertig zu werden, wird die imaginäre Einheit i eingeführt. √ −1 = +i bzw. i2 = −1 . (61) √ In Ingenieurbüchern schreibt man auch oft −1 = j, weil dort i als Symbol für den Strom verwendet wird. Mit dieser Vereinbarung läßt sich nun auch für b2 − 4c < 0 eine Lösung angeben . √ 1 z1/2 = b ± i 4c − b2 . (62) 2 Ganz allgemein schreiben wir komplexe Zahlen in der Form z = x + iy , 25 (63) wobei x und y reelle Zahlen sind. Man nennt x den Realteil und y den Imaginärteil √ von z. In dem vorigen Beispiel ist x = b/2 und y = ± 4c − b2 /2. Man schreibt für den Real- und den Imaginärteil auch x = Re(z) und y = Im(z). (64) Wenden wir uns nun den elementaren Rechenregeln komplexer Zahlen zu. 3.2 3.2.1 Die vier Grundrechenarten mit komplexen Zahlen Addition und Subtraktion Die Addition zweier komplexer Zahlen z1 und z2 ergibt im allgemeinen wieder eine komplexe Zahl. Dabei werden die Realteile xi und die Imaginärteile yi separat addiert. z1 + z2 = (x1 + iy1 ) + (x2 + iy2 ) = (x1 + x2 ) + i(y1 + y2 ) . (65) Dies hat eine gewisse Ähnlichkeit zu Vektoren, wo die Addition komponentenweise ausgeführt wird siehe Abschnitt 6. Man kann sich auch sofort überzeugen, daß aus der Gültigkeit des Assoziativ- und Kommutativgesetzes für die Addition reeller Zahlen, diese Gesetze ebenso für komplexe Zahlen folgen. z1 + z2 = z2 + z1 (Kommutativgesetz) z1 + (z2 + z3 ) = (z1 + z2 ) + z3 (Assoziativgesetz) 3.2.2 (66) (67) Multiplikation Die Multiplikation zweier komplexer Zahlen ergibt gewöhnlich auch wieder eine komplexe Zahl. Das Produkt wird erhalten, indem man alles ausmultipliziert und sich daran erinnert, daß i2 = −1 gilt. z1 z2 = (x1 + iy1 )(x2 + iy2 ) = x1 x2 + ix1 y2 + iy1 x2 + i2 y1 y2 = (x1 x2 − y1 y2 ) + i(x1 y2 + x2 y1 ) (68) Das Produkt der beiden Zahl z1 = 3 + 2i und z2 = −1 − 4i ist demnach z1 z2 = (3 + 2i)(−1 − 4i) = −3 − 2i − 12i − 8i2 = 5 − 14i Wie für reelle Zahlen, so gelten auch für die Multiplikation komplexer Zahlen das Kommutativ- und das Assoziativgesetz z1 z2 = z2 z1 (z1 z2 )z3 = z1 (z2 z3 ) . 26 (69) 3.2.3 Division Der Quotient zweier komplexer Zahlen ist z3 = x1 + iy1 z1 = z2 x2 + iy2 . Dies möchte man natürlich wieder in der Form z3 = x3 + iy3 mit x3 , y3 ϵR darstellen und erweitert hierfür einfach den Quotienten mit (x2 − iy2 ). z1 (x1 + iy1 )(x2 − iy2 ) (x1 x2 + y1 y2 ) + i(x2 y1 − x1 y2 ) = = z2 (x2 + iy2 )(x2 − iy2 ) x22 + y22 x1 x2 + y1 y2 x2 y1 − x1 y2 = +i 2 2 x2 + y2 x22 + y22 3.3 (70) Komplex konjugierte Zahl Zu einer komplexen Zahl z = x+ iy wird noch die komplex konjugierte Zahl z ∗ = x−iy definiert. Es gelten einige nützliche Rechenregeln. Für z = x + iy gilt (z ∗ )∗ = z z + z ∗ = 2x z − z ∗ = 2iy 3.4 (71) Betrag und Argument komplexer Zahlen Da jede komplexe Zahl z = x + iy als geordnetes Paar reeller Zahlen betrachtet werden kann, lassen sich solche Zahlen durch Punkte in der xy-Ebene, der sogenannten komplexen Ebene (Argand Diagramm) darstellen. Eine komplexe Zahl die z.B. durch den Punkt P = (3, 4) in der xy-Ebene repräsentiert wird, kann daher als (3, 4) oder 3 + 4i gelesen werden. Für jede komplexe Zahl gibt es genau einen Punkt in der Ebene, und umgekehrt entspricht jedem Punkt der Ebene genau eine komplexe Zahl. Manchmal bezeichnet man die x und y-Achse als relle bzw. imaginäre Achse und die komplexe Ebene als z-Ebene. Der Abstand des Punktes (x, y) vom Ursprung (0, 0) entspricht der Länge des Vektors ⃗r = (x, y), was wir als den Betrag der komplexen Zahl interpretieren. ! (72) | z |= x2 + y 2 . Anders geschrieben | z |= √ z · z∗ = ! (x + iy)(x − iy) (73) Mit dem Argument einer komplexen Zahl arg(z) wird der Winkel φ = arg z in Abb. 11 bezeichnet y (74) arg(z) = arctan( ) . x 27 y P(x,y) r φ x Abbildung 11: Punkt P (x, y) in der komplexen Ebene Durch Konvention wird dieser Winkel entgegen des Uhrzeigersinnes positiv gewählt. Betrachten Sie z = 2 − 3i. Der Betrag dieser komplexen Zahl ist ! √ | z |= 22 + (−3)2 = 13 und ihr Argument 3 arg(z) = arctan(− ) ∼ −56, 3◦ = −0.98279 2 3.5 Komplexe Zahlen und die Exponentialfunktion √ Nachdem wir mit der Wurzel einer negativen √ Zahl −1 = i umzugehen gelernt haben, stellt sich die Frage, was machen wir mit i und ähnlichen Ausdrücken? Hierfür wird sich die Exponentialfunktion mit einer komplexen Zahl im Argument als nützlich erweisen. Daher ist es an dieser Stelle ganz passend, daß wir bisher bei der Exponentialfunktion exp(x) noch wenig über das Argument x angenommen haben. Die Reihendarstellung (40) gilt nämlich auch für komplexe Zahlen ∞ & zk e = . k! k=0 z (75) Dies wird ihnen in der Mathematik noch genauer erklärt. 3.6 Die Polardarstellung komplexer Zahlen Im folgenden wählen wir ω = iφ mit reeller Variable φ. In diesen Fall ist dann ω rein imaginär und exp(ω) = exp(iφ). Wir nutzen nun die Reihendarstellung (75) der 28 Exponentialfunktion aus und schreiben davon die ersten Summanden hin i φ+ 1! i exp (−iφ) = 1 − φ + 1! exp (iφ) = 1 + i2 2 i3 3 φ + φ + ... 2! 3! 2 i 2 i3 3 φ − φ + ... 2! 3! , . (76) Nutzen wir noch die Regel i2 = −1, so bekommen wir mit i2 2 i4 4 φ + φ + . . .) 2! 4! φ2 φ4 + + . . .) = 2(1 − 2! 4! exp (iφ) + exp (−iφ) = 2(1 + (77) wieder eine reelle Zahl! Offensichtlich sind für reelles φ die komplexen Zahlen z = eiφ und z = e−iφ konjugiert komplex zueinander, also z ∗ = (eiφ )∗ = e−iφ . Demzufolge gilt z + z ∗ = eiφ + e−iφ = 2 Re{eiφ } z − z ∗ = eiφ − e−iφ = 2 Im{eiφ } . (78) Für den Betrag von eiφ folgt mit der Regel (72) |z|2 = |eiφ |2 = zz ∗ = eiφ e−iφ = eiφ−iφ = e0 = 1 Offensichtlich beschreibt eiφ einen Kreis mit Radius 1 in der komplexen Ebene. Mit z = x + iy = eiφ sieht man aus Abb. 11 daß x = cos φ und y = sin φ. Daraus folgt die Eulersche Formel cos φ + i sin φ = eiφ . (79) Hier sieht man nun auch, daß es sich z.B. für z = iφ = iωt bei eiωt um eine Schwingung handelt. Die Exponentialfunktion in dieser Schreibweise ist daher bei der Untersuchung schwingender Systeme unentbehrlich. Insbesondere folgt man sofort eiπ = −1, eiπ/2 = i und ei0 = ei2π = 1. Mit der Darstellung (79) kann man auch leicht eine altbekannte Formel neu ableiten 1 = |z|2 = (cos φ + i sin φ)(cos φ − i sin φ) = cos2 φ + sin2 φ = 1 . Darüberhinaus läßt sich jede komplexe Zahl in dieser sogenannten Polardarstellung z = reiφ schreiben, wobei r und φ reell sind. Das Argument arg(z) = φ ist in dieser Darstellung trivial abzulesen. 29 Die Multiplikation und Division komplexer Zahlen wird in Polardarstellung ausgesprochen einfach. Das Produkt der komplexen Zahlen z1 = r1 eiφ1 und z2 = r2 eiφ2 ist mit den Regeln (46) für die Exponentialfunktion z1 z2 = r1 eiφ1 r2 eiφ2 = r1 r2 ei(φ1 +φ2 ) . (80) Daraus folgen auch unmittelbar |z1 z2 | = |z1 | · |z2 | und arg(z1 z2 ) = arg(z1 ) + arg(z2 ). Insbesondere ist auch die Division komplexer Zahlen in Polardarstellung sehr einfach z1 r1 eiφ1 r1 iφ1 −iφ2 r1 i(φ1 −φ2 ) = = e e = e iφ z2 r2 e 2 r2 r2 . (81) Die Beziehungen |z1 /z2 | = |z1 |/|z2 | und arg(z1 /z2 ) = arg z1 − arg z2 folgen. 3.7 de Moivres Theorem Ein recht wichtiges Theorem für sin und cos folgt aus der einfachen Identität (eiφ )n = einφ . Schreibt man dies in der sin und cos Darstellung, so ist dies äquivalent mit # $n (cos φ + i sin φ)n = eiφ = einφ = cos(nφ) + i sin(nφ) , (82) 3.8 Trigonometrische Funktionen Diese Verwandtschaft zwischen der Exponentialfunktion und den trigonometrischen Funktionen werden Sie auf Schritt und Tritt durch Ihr Naturwissenschaftler- oder Ingenieurleben begleiten. Die Moivres Theorem läßt sich vorzüglich benutzen, um eine Reihe von Beziehungen für trigonometrische Funktionen abzuleiten und zu berechnen. Beginnen wir mit den komplexen Darstellungen von sin und cos 1 iφ (e + e−iφ ) 2 1 iφ (e − e−iφ ) , (83) sin φ = 2i welche unmittelbar aus (79) und (78) folgen. Mit Gl. (76) erhält man auch Reihendarstellungen für cos und sin cos φ = cos φ = sin φ = ∞ & k=0 ∞ & k=0 1 2k φ (2k)! 1 φ2k+1 (2k + 1)! (84) . (85) Entsprechend folgt auch für tan und cot eine Exponentialdarstellung. sin φ 1 eiφ − e−iφ tan φ = = , cos φ i eiφ + e−iφ cos φ eiφ + e−iφ cot φ = = i iφ . sin φ e − e−iφ 30 (86) Ersetzt man nun φ = nΘ, so folgt auch für den n-fachen Winkel Θ zusammen mit z = eiΘ ' ( $ 1 n 1 # inΘ 1 −inΘ e +e = z + n cos(nΘ) = 2 2 z ' ( # $ 1 1 1 inΘ −inΘ n e −e = z − n (87) sin(nΘ) = 2i 2i z Anwendungsbeispiele 1) Überlagerung zweier Schwingungen gleicher Frequenz ω, welche gegeneinander Phasenverschoben sind. Die Gesamtschwingung ist dann f (t) = A1 sin(ωt + ϕ1 ) + A2 sin(ωt + ϕ2 ) $ # $0 1 / # i(ωt+ϕ1 ) A1 e − e−i(ωt+ϕ1 ) + A2 ei(ωt+ϕ2 ) − e−i(ωt+ϕ2 ) = 2i $ 1 # $ 1 i(ωt+ϕ1 ) # = e A1 + A2 ei(ϕ2 −ϕ1 ) − e−i(ωt+ϕ1 ) A1 + A2 e−i(ϕ2 −ϕ1 ) 2i 2i $ 1 i(ωt+ϕ1 ) # i(ϕ2 −ϕ1 ) e A1 + A2 e + konj. komplex = 2i Nun kann man den Vorfaktor umschreiben und man erhält mit # $ −η A1 + A2 ei(ϕ2 −ϕ1 ) = A eiϕ (88) wieder eine komplexe Zahl, die sich leicht mit den bisherigen Regeln berechnen läßt. Das Endsignal hat also die gleiche Frequenz, aber eine andere Amplitude und ist phasenverschoben f (t) = A cos(ωt + ϕ) . (89) 2) Betrachten wir einen Verstärker mit einem Input-Signal x(t) = x0 cos(ωt) und der Eigenschaft, daß der Output mit dem Input wie folgt zusammenhängt y(t) = B(x + f x2 ) = B(x0 cos(ωt) + x20 cos2 (ωt)) . (90) Um daran zu erkennen, welche Frequenzen im Output sind, muß man z.B. ausrechnen wie cos2 (ωt) mit der ursprünglichen Frequenz zusammenhängt. Das Input- und Outputsignal ist für ein Zahlenbeispiel in Abb. 12 gezeigt. 3) Ein anderes Problem von großer Bedeutung betrifft die Überlagerung von zwei Schwingungen mit zwei leicht verstimmten Frequenzen: f (t) = A1 cos((ω + ∆ω)t + ϕ1 ) + A2 cos(ωt + ϕ2 ) . (91) Das Resultat ist eine Schwebung siehe Abb. 13. In der Akustik ist dieses Phänomen gut hörbar. 31 1 x 0 0 5 10 15 t Abbildung 12: Modellverstärker für den Input x(t) = 0.2 sin(t) (durchgezogene Linie) und dem Output y(t) = 0.3 sin(t) + 0.5 sin2 (t). Ein ähnliches Verhalten zeigen auch nichtlineare optische Frequenzverdoppler. y 0 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95100 105 110 115 120 125 130 135 140 145 150 t Abbildung 13: Eine Überlagerung zweier leicht verstimmter Schwingungen y = cos(x) + cos(1.1 x). Das Ergebnis ist eine Schwebung. 3.9 Additionstheoreme Was ist z.B. mit Winkelsummen sin(x + y), die einem ständig über den Weg laufen? Diese lassen sich mit Gl. (83) auch in Produkte von sin und cos umschreiben. Hierfür sind die Exponentialdarstellung und die Euler Formel (79) besonders hilfreich. sin(x + y) = $ 1 # i(x+y) e − e−i(x+y) 2i . (92) Von exp(i(x + y)) brauchen wir nur den Imaginärteil und zur Umformung dieses Ausdruckes verwenden wir die Produktregel für Exponentialfunktionen und die EulerFormel (79) ei(x+y) = eix eiy = (cos x + i sin x)(cos y + i sin y) = i(sin x cos y + cos x sin y) + cos x cos y − sin x sin y 32 (93) Subtrahieren wir hiervon noch exp(−i(x + y)) so bleibt nur der Imaginärteil übrig. Insgesamt bekommen wir dadurch sin(x + y) = sin x cos y + cos x sin y . (94) Oder man steht vor dem Problem sin 3Θ und cos 3Θ durch Potenzen von cos Θ und sin Θ auszudrücken. Nutzen wir hierzu das Theorem von de Moivre. Wir erhalten cos 3Θ + i sin 3Θ = (cos Θ + i sin Θ)3 = (cos3 Θ − 3 cos Θ sin2 Θ) + i(3 sin Θ cos2 Θ − sin3 Θ). Vergleichen wir die die Real- und Imaginärteile auf beiden Seiten, so bekommen wir cos 3Θ = cos3 Θ − 3 cos Θ sin2 Θ = cos3 Θ − 3 cos Θ(1 − cos2 Θ) = 4 cos3 Θ − 3 cos Θ (95) und sin 3Θ = 3 sin Θ cos2 Θ − sin3 Θ = 3 sin Θ(1 − sin2 Θ) − sin3 Θ = 3 sin Θ − 4 sin3 Θ . (96) Ein weiteres Beispiel ist cos3 Θ, das wir mit z = eiΘ und Gl. (78) leicht berechnen können 1 1 (z + )3 3 2 z 1 1 1 3 (z + 3z + 3 + 3 ) = 8 z z 1 3 1 3 1 = (z + 3 ) + (z + ) 8 z 8 z 3 1 cos(3Θ) + cos Θ = 4 4 cos3 Θ = (97) Potenzen von sin x und cos x führen offensichtlich zu höheren harmonischen wie cos(3x) und umgekehrt lassen sich höhere harmonische Funktionen durch Potenzen der Grundfrequenz ausdrücken. An dem oben genannten nichtlinearen Verstärker wird dann eine Frequenzmischung deutlich. Auf diese und ähnliche Weise lassen sich eine Reihe weiterer nützlicher Beziehungen ableiten. 33 Einige nützliche Formeln sin(x ± y) = sin x cos y ± cos x sin y cos(x ± y) = cos x cos y ∓ sin x sin y x−y x+y cos cos x + cos y = 2 cos 2 2 x+y x−y cos x − cos y = −2 sin sin 2 2 x+y x−y cos sin x − sin y = 2 sin 2 2 x+y x−y sin x + sin y = 2 sin cos 2 2 tan x = sin x/ cos x 2 tan x sin(2x) = 2 sin x cos x = 1 + tan2 x cos(2x) = cos2 x − sin2 x = 2 cos2 x − 1 sin(3x) = 3 sin x − 4 sin3 x 1 (1 − cos 2x) sin2 (x) = 2 1 (1 + cos 2x) cos2 (x) = 2 1 sin(x) cos(y) = {sin(x − y) + sin(x + y)} 2 ' ( ' ( n n n n−2 2 cos(nx) = cos x − cos x sin x + cosn−4 x sin4 x . . . 2 4 1 1 − cos x x sin = ± 2 2 1 x 1 + cos x cos = ± 2 2 2 1 = sin x + cos2 x 3.10 (98) (99) (100) (101) (102) (103) (104) (105) (106) (107) (108) (109) (110) (111) (112) (113) (114) Die n-te Wurzel von 1 Die Gleichung z 2 = 1 hat die beiden bekannten Lösungen z = ±1. Nachdem uns die komplexen Zahlen bekannt sind, können wir auch alle Lösung von z n = 1 beschaffen. Nach dem Fundamentalsatz der Algebra gibt es für jedes Polynom n-ten Grades n Lösungen. Wir wissen auch schon, daß e2iπk = cos(2πk) + i sin(2πk) = 1 (115) falls k ∈ Z Demzufolge können wir schreiben z n = e2ikπ 34 (116) oder z = e2iπk/n . (117) Dies bedeutet, die Lösungen von z n = 1 sind z1,2,...,n = 1, e2iπ/n , . . . , e2i(n−1)π/n , (118) wobei wir hier k = 0, 1, 2, . . . , n − 1 verwenden. Größere Werte von k ergeben keine neuen Lösungen, sondern sind nur eine Duplizierung der vorhandenen Lösungen. Betrachten wir als Beispiel die Lösungen der Gleichung z 3 = 1. Wenden wir nun Formel (118) an, so erhalten wir z1 = 20i , z2 = e2iπ/3 , z3 e4iπ/3 . Für k = 3, also z4 = e6iπ/3 = e2iπ = 1 = z1 , nur eine Wiederholung von z1 . Es ist auch keine Überraschung, daß wir auch |z|3 = |z 3 | finden, da alle Wurzeln auf dem Einheitskreis liegen und damit den Betrag 1 haben. 3.11 Der komplexe Logarithmus Die Umkehrfunktion der Exponentialfunktion exp(x) = y ist der Logarithmus x = ln y (119) falls x, yϵR siehe Abschnitt 2.5. Der Funktionsverlauf wurde in Abb. 3 gezeigt. Der Logarithmus ist auch die Umkehrfunktion der Exponentialfunktion für komplexe Zahlen. Für den Logarithmus einer komplexen Zahl z schreiben wir w = ln z mit z = ew (120) Jetzt können wir die Regeln für die Exponentialfunktion ausnutzen, um den Logarithmus eines Produktes komplexer Zahlen z1 · z2 = ew1 ew2 = ew1 +w2 (121) ln(z1 z2 ) = w1 + w2 = ln(z1 ) + ln(z2 ) . (122) zu berechnen Nehmen wir eine komplexe Zahl auf dem Einheitskreis, so wissen wir bereits, daß z = eiφ = ei(φ+2πk) . (123) Diese Vieldeutigkeit wirkt sich auch auf den Logarithmus aus und es folgt ln z = ln r + i(φ + 2π) . (124) Um die Vieldeutigkeit zu vermeiden, schränkt man das Argument arg(z) = φ auf −π < φ ≤ π ein und nennt ln(z) bei dieser Einschränkung den Hauptwert. Und was ist ln(−i)? Hier schreiben wir zuerst −i in Exponentialform um + π , # $ ln(−i) = ln ei(−π/2+2nπ) = i − + 2πn , (125) 2 mit einer natürlichen Zahl n. Dies bedeutet ln(−i) = −i π2 , 3i π2 , . . . Für den Hauptwert gilt ln(−i) = − π2 i. 35 3.12 Hyperbolische Funktionen Was bedeutet eigentlich cos(iφ) oder sin(iφ)? Mit dieser Wahl eines rein imaginären Argumentes im cos und sin werden die Exponente von e in Gl. (83) reell und es folgt eine neue Klasse von Funktionen: 1 −φ cos(iφ) = (e + e+φ ) =: cosh φ 2 1 −φ (e − e+φ ) =: sinh φ . (126) i sin(iφ) = 2 Die beiden Funktionen cosh φ und sinh φ bezeichnet man als ”Cosinus Hyperbolicus” oder ”Hyperbelcosinus” bzw. ”Sinus Hyperbolicus” oder ”Hyperbelsinus”. Diese hyperbolischen Funktionen sind die komplexen Analoga zu den trigonometrischen Funktionen. Neben den beiden fundamentalen Funktionen gibt es in Analogie zu den trigonometrischen Funktionen die verbleibenden hyperbolischen Funktionen ex − e−x sinh x = x cosh x e + e−x cosh x ex + e−x coth x = = x sinh x e + e−x 1 2 sechx = = x cosh x e + e−x 2 1 = x cosechx = sinh x e − e−x tanh x = , (127) siehe Abb. 14. Folgende Beziehungen zwischen trigonometrischen und Hyperbelfunktionen sind noch ganz hilfreich cosh x i sinh x cos x i sin x = = = = cos(ix) sin(ix) cosh(ix) sinh(ix) . (128) Ähnlich zu den Relationen zwischen verschiedenen trigonometrischen Funktion lassen sich auch Hyperbelfunktionen durch andere Hyperbelfunktionen ausdrücken. Gehen wir von cos2 x + sin2 x = 1 aus und benutzen (128) so folgt mit cosh2 x = cos2 (ix) und sinh2 x = − sin2 (ix) cosh2 x − sinh2 x = 1 . (129) Einige andere Identitäten können ebenso abgeleitet werden. sech2 x cosech2 x sinh(2x) cosh(2x) = = = = 1 − tanh2 x coth2 x − 1 2 sinh x cosh x cosh2 x + sinh2 x 36 (130) 5.0 y 5.0 y 5.0 y cosech x 2.5 2.5 cosh x coth x sinh x 2.5 −2 sech x −2 −1 1 x −1 1 x 2 −2 −1 1 −2.5 −2.5 −5.0 −5.0 tanh x 2 2 x Abbildung 14: Graphen der verschieden hyperbolischen Funktion deren analytische Darstellung im Text angegeben ist. 3.13 Hyperbolische Umkehrfunktionen – Areafunktionen Die Umkehrfunktion von y = sinh x nennen wir x = arsinh y. Wir sind nun an der expliziten Form dieses Ausdruckes interessiert. Hierfür drückt man ex durch Linearkombinationen von cosh x und sinh x aus. ex = ! cosh x + sinh x = 1 + sinh2 x + sinh x ! = 1 + y2 + y . (131) Wenden wir auf beide Seiten den Logarithmus an, so folgt der explizite Ausdruck für die Umkehrfunktion ! x = arsinh(y) = ln( 1 + y 2 + y) . (132) Auf ähnliche Weise erhält man ! x = arcosh(y) = ln( y 2 − 1 + y). (133) für |y| > 1. Die Umkehrfunktion von tanh(x) nennen wir analog artanh(y) und die explizite Form ist ' ( 1+y 1 (134) x = artanh(y) = ln 2 1−y 37 4 Funktionen und Ableitungen II In diesem Abschnitt werden weitere Ableitungsregeln wiederholt. Zunächst berechnen wir die Ableitungen der Funktionen aus dem vorigen Abschnitt. Darüberhinaus betrachten wir Reihendarstellungen dieser Funktionen sowie ein numerisches Verfahren, um Ableitungen zu berechnen. 4.1 Ableitungen von Umkehrfunktionen Neben einer Reihe von Funktionen sind nun schon eine Reihe von Umkehrfunktionen definiert worden. Wir zeigen jetzt, wie sich die Ableitung einer Umkehrfunktion aus der Ableitung der zugehörigen Funktion berechnen läßt. Sei y = f (x) und x = g(y) die zugehörige Umkehrfunktion. Dann ist f (g(y)) = y. Die Ableitung dieser Gleichung führt unter Benutzung der Kettenregel auf df dg d f (g(y)) = dy dg dy d = y dy = 1 Also ist g ′ (y) = 1 f ′ (g(y)) . (135) (136) Lassen Sie uns ein einfaches Beispiel betrachten. Sei f (x) = x/2 − 2. Dann ist g(y) = 2y + 4. Es gilt df/dx = 1/2 und dg/dy = 2. Also ist g ′ (y) = 1/f ′ (g(y)). Auch die Ableitung des Logarithmus läßt sich auf diese Weise erhalten: d ln x/dx = 1/ exp(y)|y=ln x = 1/x. 4.2 Ableitungen der trigonometrischen und der hyperbolischen Funktionen Die Ableitungen der trigonometrischen Funktionen berechnen unter Berücksichtigung von Gl. (83) sich zu $ $ d 1 d # ix 1 # ix sin x = e − e−ix = ie + ie−ix dx 2i dx 2i = cos x $ 1 # ix $ d 1 d # ix e + e−ix = i e − i e−ix cos x = dx 2 dx 2 $ 1 # ix = − e − e−ix 2i = − sin x , 38 (137) (138) die der Hyperbolfunktionen analog zu $ 1 d # x d sinh x = e − e−x = dx 2 dx = cosh x $ d 1 d # x cosh x = e − e−x = dx 2 dx = sinh x . $ 1# x e + e−x 2 (139) $ 1# x e + e−x 2 (140) Damit können wir die Ableitung der anderen trigonometrischen und hyperbolischen Funktionen berechnen, z.B. sinh2 x d sinh′ x sinh x cosh′ x = 1 − tanh x = − dx cosh x cosh2 x cosh2 x 1 = 1 − tanh2 x = . cosh2 x (141) Wir zeigen nun noch an einigen Beispielen, wie die Ableitungen der Umkehrfunktionen der trigonometrischen und der hyperbolischen Funktionen berechnet werden. Beginnen wir mit arsinh. Die zugehörige ursprüngliche Funktion ist x = sinh y. Nach Gl. (136) gilt 1 1 d arsinhx = = ′ dx sinh (arsinhx) cosh(arsinhx) 1 = 2 1 + sinh2 (arsinhx) = √ 1 1 + x2 . (142) (143) (144) Auf dieselbe Art erhält man die Ableitung von artanhx: 1 1 d artanh x = = ′ 2 dx tanh (artanh x) 1 − tanh (artanh x) 1 = 1 − x2 39 (145) (146) Im folgenden finden Sie eine Zusammenstellung einiger wichtiger Ableitungen: f (x) f ′ (x) Anmerkungen xq q xq−1 qϵR eax a eax ln x 1/x cos x − sin x sin x cos x 1 cos2 (x) tan(x) −1 sin2 (x) cot(x) = (1 + tan2 (x)) = − (1 + cot2 (x)) (1 − tanh2 (x)) = tanh(x) − sinh12 x coth(x) arcsin(x) arccos(x) arctan(x) arccot(x) √ 1 1−x2 1 − √1−x 2 1 1+x2 1 − 1+x 2 artanh(x) √ 1 1+x2 √ 1 x2 −1 1 1−x2 arcoth(x) 1 1−x2 arsinh(x) arcosh(x) 4.3 1 cosh2 (x) −1 ≤ x ≤ 1 x>1 |x| < 1 |x| > 1 Anwendungsbeispiel für den tanh(x) Betrachten Sie die nicht-lineare Differentialgleichung 0 = u(x) + ξ 2 d2 u(x) − u3 (x) . 2 dx2 (147) Diese beschreibt in dieser oder in leicht veränderter Form Phänomene in Magneten (Sprünge in der magnetischen Diplostärke), Defektstrukturen in Supraleitern oder Phasensprünge in der Konvektion (beispielsweise in Wolkenstraßen) und in anderen selbstorganisierenden chemischen oder biologischen Systemen. Es ist eine nichtlineare Differentialgleichung und diese Gleichung hat die hyperbolische Funktion u(x) = tanh(x/ξ) als Lösung. Dies können wir mit dem bisher gelernten Stoff leicht nachprüfen, indem man den tanh(x/ξ) zweimal nach x ableitet. Die erste 40 Abbildung 15: Ableitung ist oben bereits ausgeführt worden und leiten wir diese noch einmal ab und bekommen dadurch ' (( ' ( ' 1 d x x d2 2 tanh = 1 − tanh 2 dx ξ ξ dx ξ ' ( ' ( 2 x d x = − 2 tanh tanh ξ ξ dx ξ ' (' ' (( x x 2 2 1 − tanh (148) = − 2 tanh ξ ξ ξ Setzt man diese Ableitung ein und sammelt die Vorfaktoren von tanh(x/ξ) und tanh3 (x/ξ) so verschwinden diese Vorfaktoren und damit ist gezeigt, daß tanh(x/ξ) eine Lösung von (147) ist. Für x → ±∞ strebt tanh(x/ξ) → ±1. Die Breite des Übergangsbereiches von −1 nach +1 wird durch die ”Länge” ξ bestimmt, welche in jedem der erwähnten Systeme eine andere Bedeutung hat, siehe Abb. 15. 4.4 Regel von l’Hospital Jetzt wollen wir noch daran erinnern, dass Ableitungen auch helfen können, Grenzwerte zu berechnen. Sind zwei Funktionen f (x) und g(x) in einer Umgebung von x0 ∞ differenzierbar und ist limx→x0 f (x)/g(x) von der Form 00 “ bzw. ∞ “, dann ist ” ” f (x) f ′ (x) = lim ′ x→x0 g(x) x→x0 g (x) lim , falls der letzte Grenzwert existiert. Ein Beispiel hierfür ist die Funktion sich für x → 0 das Problem 0/0 ergibt cos x sin x = lim =1 . x→0 x→0 x 1 lim 41 (149) sin x , x bei der (150) 4.5 Taylor-Entwicklung von Funktionen in Potenzreihen Mit der geometrischen Reihe und der Exponentialreihe haben wir bereits im Abschnitt 2 Darstellungen von Funktionen durch Potenzreihen kennengelernt. Wir werden jetzt sehen, daß jede differenzierbare Funktion wenigstens lokal durch eine Potenzreihe dargestellt werden kann. Die zugrundeliegende Idee ist, daß wenn ich alle Ableitungen einer Funktion f im Punkt x0 kenne, dann kenne ich f auch in einer Umgebung von x0 . Nehmen wir an, wir wollen eine Funktion f (x) in Form einer Potenzreihe mit Koeffizienten an für alle n = 0, 1, 2, 3, . . . darstellen: f (x) = ∞ & an xn . (151) n=0 k Für die Exponentialreihe wissen wir, dass an = xk! . Wie finden wir für eine beliebige Funktion f die Koeffizienten durch formale Operationen an dieser Funktion? Nun, wir differenzieren f (x) einmal, zweimal, dreimal etc. nach x, und setzen dann x = 0. Hierbei sei f (n) die n-te Ableitung von f (x) nach x. Wir finden Folgendes: f (0) f (0) f (2) (0) f (3) (0) f (4) (0) = = = = = .. . (n) f (0) = (1) a0 a1 2 · a2 3 · 2 · a3 4 · 3 · 2 · a4 n! an . (152) Damit folgt die neue Darstellung der Funktion f (x) = ∞ & f (n) (0) n=0 n! xn = f (0) + f ′ (0)x + 1 ′′ f (0)x2 + . . . 2! , (153) die sogenannte Taylor-Reihe von f . Natürlich sind wir nicht auf diese Entwicklung um den Ursprung x = 0 fixiert. Durch schlichte Verschiebung des Ursprungs nach x = b erhalten wir die Taylor-Reihe für f (x) um den Punkt x = b: f (x) = ∞ & f (n) (b) n=0 n! (x − b)n = f (b) + f ′ (b)(x − b) + 1 ′′ f (b)(x − b)2 + . . . 2! (154) Wir haben damit ein wirksames Verfahren gefunden, um nahezu beliebige Funktionen durch einfache Summen von Potenzen auszudrücken. Wir können diese Taylor-Reihen 42 y f(x) x2 x1 x0 x Abbildung 16: Illustration des Newton-Verfahrens zur näherungsweisen Bestimmung von Nullstellen. Für nähere Erläuterungen, siehe Text. näherungsweise nach einer endlichen Anzahl von Termen abbrechen. Solche Potenzreihen sind beispielsweise auch sehr einfach zu integrieren. Betrachten wir als Beispiel die Entwicklung von ln(1 + x) in der Nähe von x = 0. Wir finden ln(1 + x) |x=0 = ln(1) = 0 1 "" 1 ′ ln (1 + x) |x=0 = = " 1 + x x=0 2 " 1 1 " ′′ =− ln (1 + x) |x=0 = − " 2 (1 + x) x=0 2 .. . (155) (156) (157) (158) Also ist ln(1 + x) = 12 x − 41 x2 + . . . Diese Entwicklung kann offensichtlich nur dann sinnvolle Ergebnisse liefern, wenn x > −1 (tatsächlich muß |x| < 1 gelten). Ein zweites Beispiel liefert ln(1 + x2 ): ln(1 + x2 ) |x0 ln′ (1 + x2 ) |x=0 ln′′ (1 + x2 ) |x=0 = ln(1) = 0 2x "" =0 = " 1 + x2 x=0 2(1 + x2 ) − 4x2 "" = =2 " (1 + x2 )2 x=0 .. . (159) (160) (161) (162) Also ist ln(1 + x2 ) = x2 + . . . Diese Entwicklung gilt für alle x ∈ R. 4.6 Das Newton-Verfahren Wir wollen jetzt noch ein Näherungsverfahren zur Nullstellenbestimmung vorstellen, welches die Taylor-Entwicklung benutzt. Oftmals sind Stellen x∗ gesucht, an der eine 43 Funktion f verschwindet, f (x∗ ) = 0. Allerdings lassen sich die Nullstellen nur selten exakt angeben, wie z.B. bei der quadratischen Gleichung x2 + bx + c = 0. Man ist dann auf Näherungsverfahren angewiesen. Das bekannteste ist wohl das folgende von Newton angegebene Näherungsverfahren. Das Newton-Verfahren nutzt die TaylorEntwicklung der Funktion f (x) an einer Stelle f (xi ) aus und gibt eine Vorschrift an, wie man sich an x∗ durch mehrmalige Iterationen herantastet. Als Startpunkt wird der Funktionswert an einer Stelle x0 benötigt und deren Ableitung f ′ (x0 ). Damit kann die Tangentengleichung T0 (x) = f (x0 ) + f ′ (x0 )(x − x0 ) (163) aufgestellt werden und man kann die Nullstelle x1 der Tangentenfunktion T0 (x1 ) = 0 bestimmen f (x0 ) , (164) x1 = x0 − ′ f (x0 ) siehe Abb. 16. Im nächsten Schritt wird f (x1 ) und f ′ (x1 ) berechnet und es ergibt sich mit T1 (x) = f (x1 ) + f ′ (x1 )(x − x0 ) (165) die Nullstelle x2 von T1 aus x2 = x1 − f (x1 ) f ′ (x1 ) . (166) Man fährt nun solange mit dem Iterationsschema xi+1 = xi − f (xi ) f ′ (xi ) (167) fort, bis die Unterschiede zwischen xi+1 und xi und der Wert f (xi ) so klein sind wie gewünscht. Der Startwert sollte bei diesem Verfahren schon gut geschätzt werden. Die Funktion f muß außerdem in dem Intervall, in dem die Nullstelle und der Schätzwert liegen, monoton sein (steigend oder fallend). Wenn die Funktion f (x) zwei nahe benachbarte Nullstellen besitzt oder wenn zwischen zwei Nullstellen eine Polstelle liegt, ist eine gute Wahl des Schätzwertes besonders wichtig. 44 5 Integralrechnung Zur Formulierung (nicht nur physikalischer) Gesetze spielt neben der Differentialrechnung auch die Integralrechnung eine bedeutende Rolle. 5.1 Das bestimmte Integral Über das Integral berechnet man die Fläche unter einer Kurve. Formal schreibt man für die Fläche I unter der Funktion f im Intervall [a, b] 3 b I= f (x)dx (168) a Da in Gl. (168) die untere Grenze x = a und die obere Grenze x = b festgelegt (bestimmt) sind, spricht man von einem bestimmten Integral. Die Funktion f wird in diesem Zusammenhang Integrand genannt. Eine Näherung des Integrals folgt durch Unterteilung des Intervalles [a, b] in n Teilintervalle der Breite ∆x = (b − a)/n, der anschließenden Berechnung der Funktion f (x) an den Stellen xk = a + k∆x (k = 1, 2, 3, . . . , n) und der Berechnung der Summe n & f (xk )∆x , (169) k=1 siehe Abb. 17. Bei numerischen Berechnungen von Integralen mit dem Computer wird eine ähnliche Diskretisierung und Summenbildung vorgenommen. Der bei der Näherung der Fläche durch kleine Rechtecke begangene Fehler läßt sich bei analytischen Betrachtungen durch Verkleinerung von ∆x oder entsprechend einer Erhöhung von n minimieren. Tatsächlich ist das Riemannsche Integral über den Grenzwert ∆x → 0 in der Summe (169) definiert. Beachten Sie, dass bei numerischen Rechnungen auf dem Computer Rundungsfehler der einfachen Verkleinerung von ∆x zur Verbesserung der Genauigkeit Grenzen setzen. Wir wollen nun die Fläche unter der Parabel f (x) = x2 im Intervall [a,b] berechnen, 4b I = 0 x2 dx. Hierfür unterteilen wir die Fläche unter der Kurve f (x) = x2 zwischen 0 und b in n Rechtecke der Breite h. Die Fläche des k-ten Rechteckes ist (kh)2 h = k 2 h3 . %n−1 Aufsummation aller Rechtecke liefert mit Hilfe der Summenformel k=0 k 2 = n(n − 1)(2n − 1)/6 die Gesamtfläche A= n−1 & k=0 2 3 3 k h =h n−1 & 1 k 2 = h3 n(n − 1)(2n − 1) . 6 k=0 Da h = b/n, läßt sich A weiter umformen ' (' ( ' 3( 1 1 b3 n b 1− 2− . (n − 1)(2n − 1) = A= n3 6 6 n n 45 y=f(x) dx a xi x i+1 x b Abbildung 17: Das Integral als Fläche unter einer Kurve f (x) zwischen a und b. Im Limes n → ∞ strebt der Wert der Fläche gegen A → b3 . 3 Nun listen wir noch einige Regeln für bestimmte Integrale auf, die sich unmittelbar aus der Summendarstellung (169) ableiten lassen 3b αf (x)dx = α a 3a f (x)dx a f (x)dx = − 3c 3b b f (x)dx = a [f (x) + g(x)]dx = a 5.2 f (x)dx 3b a 3b 3b f (x)dx + f (x)dx a 3c 3b f (x)dx + 3b g(x)dx . b a (170) a Das unbestimmte Integral Die Integration kann auch als inverse Operation der Differentiation aufgefaßt werden. Ist F ′ (x) = f (x), so heißt F (x) eine Stammfunktion von f (x). Prüfen wir dies kurz nach und betrachten hierzu das Integral mit variabler Obergrenze x F (x) = 3x f (u)du . a 46 (171) Jetzt berechnen wir F (x + ∆x) F (x + ∆x) = x+∆x 3 f (u)du = a = F (x) + 3x f (u)du + a x+∆x 3 f (u)du x x+∆x 3 f (u)du . x Damit erhält man 1 F (x + ∆x) − F (∆x) = ∆x ∆x x+∆x 3 f (u)du . x Für kleines ∆x unterscheidet sich f (u) mit u ∈ [x, x + ∆x] kaum von f (x) und das Integral kann durch f (x)∆x genähert werden. Im Limes ∆x → 0 wird diese Näherung exakt und man erhält dF = f (x) (172) F ′ (x) = dx oder auch ⎡ x ⎤ 3 d ⎣ f (u)du⎦ = f (x) . (173) dx a Diese Rechnung zeigt, daß die Integration als die inverse Operation zur Differentiation betrachtet werden kann. Die Konstante a in (173) ist allerdings beliebig. Dies bedeutet, die Ableitung besitzt keine eindeutige Umkehrung. Jene Funktion F , die Gl. (172) erfüllt, wird auch das unbestimmte Integral von f genannt, wobei F bis auf eine Integrationskonstante c bestimmt ist: F (x) = 3x f (u)du + c (174) a 4 Häufig schreibt man einfach F = f (u)du + c. Auch das bestimmte Integral kann durch die Stammfunktion F (x) ausgedrückt werden: 3b a f (x)dx = 3b x0 f (x)dx − 3a x0 f (x)dx = F (b) − F (a) . (175) wobei F ′ = f . Dieses ist der Hauptsatz der Differential- und Integralrechnung. Während bei der Differentiation durch wiederholte Anwendung von Produkt- und Summenregel das entgültige Resultat für die Ableitung folgt, ist dies bei der Integration 47 nicht immer möglich. Für viele elementare Funktionen f (x) lassen sich die Stammfunktionen F (x) zwar berechnen, wie wir gleich sehen. Im allgemeinen lassen sich aber keine geschlossenen Ausdrücke für Stammfunktionen angeben. In diesen Fällen bleibt man auf die numerische Berechnung eines Integrals angewiesen. 5.3 Integration durch Ansehen Für eine Reihe von Funktionen f (x) kann die Stammfunktion F (x) einfach durch rückwärtslesen der Formeln in den Gleichung (137) ermittelt werden. Wir 4notieren in der Tabelle die Ausgangsfunktion f (x) und aus dem unbestimmten Integral f (x)dx = F (x) + c nur die Stammfunktion F (x) ohne die Konstante c . f(x) F(x) xn 1 xn+1 n+1 1 x ln |x| 1 a e(ax) sin(ax) n ̸= −1 x ̸= 0 e(ax) − a1 cos(ax) cos(ax) 1 a sin(ax) 1 cos2 (ax) 1 a tan(ax) 1 sin2 (ax) - a1 cot(ax) √ 1 1−x2 1 1+x2 arcsin(x) 1 1−x2 artanh(x) = 1 2 sinh(x) sinh(x) cosh(x) 1 sinh2 (ax) √ 1 1+x2 √ 1 x2 −1 x ̸= (2k + 1)π/a |x| < 1 arctan(x) cosh(x) 1 cosh2 (ax) 5.4 Anmerkungen 1 a ln 1+x 1−x |x| < 1 tanh(ax) − a1 coth(ax) √ # $ arsinh(x) = ln x + 1 + x2 √ # $ arscosh(x) = ln | x + x2 − 1 | |x| > 1 Integration trigonometrischer Funktionen 4 4 Integrale vom Typ sinn (x)dx und cosn (x)dx können durch geeignete trigonometrische Umformungen berechnet werden. Hierzu zwei Beispiele: eines für gerades und eines 48 für ungerades n. In beiden Fällen wird der Integrand so umgeformt, ss der Integrand die Ableitung einer Potenz von4 sin oder cos ist. Betrachten wir zunächst I = sin5 x dx. Wir nutzen zu dessen Berechnung sin2 x = 1 − cos2 x aus. Damit folgt 3 3 4 I = sin x sin x dx = (1 − cos2 x)2 sin x dx 3 = (1 − 2 cos2 x + cos4 x) sin x dx 3 = (sin x − 2 sin x cos2 x + sin x cos4 x)dx = − cos x + 1 2 cos3 x − cos5 x + c , 3 5 (176) d wobei wir im letzten Schritt einfach dx cos3 x = −3 sin x cos2 x etc. verwendet haben. 4 Betrachten wir nun I = cos4 x dx. Dieses Integral wird berechnet, indem wir cos2 x = 1 (1 + cos 2x) ausnutzen. 2 3 3 1 2 2 I = (cos x) dx = (1 + cos 2x)2 dx 4 3 $ 1# 1 + 2 cos(2x) + cos2 (2x) dx . (177) = 4 Benutzt man zusätzlich cos2 (2x) = 12 (1 + cos 4x), so folgt : 3 9 1 1 1 I = + cos(2x) + (1 + cos(4x)) dx 4 2 8 1 1 1 1 x + sin(2x) + x + sin(4x) + c = 4 4 8 32 3 1 1 = x + sin(2x) + sin(4x) + c . 8 4 32 5.5 (178) Integration durch Substitution Durch Substitution kann oft ein kompliziertes Integral in ein einfacheres und manchmal schon bekanntes Integral umgeformt werden. Zu erkennen, welche Substitution gerade geeignet 4ist, √ ist oft eine Frage der Erfahrung. 2x + 1dx. Obwohl das Integral sehr einfach aussieht, zählt es nicht zu Sei I = den elementaren bisher bekannten Integralen. Durch die Substitution z = 2x + 1 wird √ dz eine neue Variable eingeführt. Damit ist der Integrand nun z. Wegen dx = 2 können 1 wir im Integral dx = 2 dz ersetzen. 3 3 √ 1 √ 2x + 1dx = zdz I = 2 1 3/2 1 = z + c = (2x + 1)3/2 + c . (179) 3 3 49 5.6 Logarithmische Integration d ln[f (x)] = f ′ (x)/f (x). Dies beAus dem Abschnitt über Differentiation wissen wir dx deutet natürlich 3 ′ f (x) dx = ln f + c (180) f (x) Mit dieser Kenntnis kann man folgendes Integral leicht berechnen, an dessen Integranden zu erkennen ist, daß der Zähler proportional zur Ableitung des Nenners ist. 3 6x2 + 2 cos x I= dx = 2 ln(x3 + sin x) + c . (181) 3 x + sin x 5.7 Partielle Integration Die partielle Integration ist die Analogie zur Differentiation eines Produktes. Das Prinzip ist, eine komplizierte Funktion in ein Produkt zweier oder mehrerer Funktionen aufzuspalten, von denen die Stammfunktionen schon bekannt sind. Hierzu gehen wir von der Produktregel (12) aus d dv du (uv) = u + v dx dx dx . Durch Integration dieser Gleichung finden wir uv|ba = 3b dv u dx + dx a 3b du v dx dx a und durch Umstellen folgt die häufig gebrauchte Form 3b dv u dx = uv|ba − dx a 3b du v dx . dx (182) a 4 Berechnen wir mit dieser Regel zunächst I = x sin x dx. Hierzu identifizieren wir dv u = x und dx = sin x. Damit folgt v = − cos x und du = 1. Nutzt man dies zusammen dx mit Regel (182), so folgt 3 I = x(− cos x) − (1)(− cos x)dx = −x cos x + sin x + c . Nicht immer ist die Identifikation der u und v so offensichtlich, wie das 4 Funktionen 3 −x2 folgende Beispiel verdeutlicht, I = x e dx. Hier identifizieren wir u = x2 und 2 2 dv 1 = xe−x . Dann haben wir v = − 2 e−x und du = 2x und bekommen dx dx 3 1 2 −x2 1 1 2 2 2 I =− x e − (−x)e−x dx = − x2 e−x − e−x + c , 2 2 2 50 2 dv = xe−x ausgenutzt haben. wobei wir im letzten Schritt nochmals dx Ein weiterer Trick ist 4 manchmal, die 1 als Faktor des Produktes dvzu identifizieren. Betrachten Sie I = ln x, dx. Hier identifizieren wir u = ln x und dx = 1. Damit ist v = x und du = 1/x und wir bekommen dx 3 ' ( 1 I = (ln x)(x) − xdx = x ln x − x + c . x Bei Integranden der Gestalt xn eax für n ∈ N kann der Exponent n durch partielle Integration erniedrigt werden: 3 3 1 n ax n n ax xn−1 eax dx . In = x e dx = x e − a a Dadurch erhält man die Rekursionsformel 1 n In = xn cax − In−1 a a , (183) 4 die In sukzessive auf I0 = eax dx = a1 eax zurückführt. Mit In hat man auch Stammfunktionen für xn eax cos bx und xn eax sin bx für a, b ∈ R. Ist c = a + ib, so gilt 3 3 n ax x e cos bxdx = ReIn , xn eax sin bx dx = ImIn . (184) 4√ Betrachten wir nun 1 − x2 dx . Mit dem angeführten Trick der 1 erhalten wir 3 √ 3 √ x(−2x) 2 2 √ 1 − x · 1dx = x 1 − x − dx 2 1 − x2 3 3 √ 1 − x2 dx 2 − √ dx = x 1−x + √ 1 − x23 1 − x2 √ √ 1 − x2 dx . = x 1 − x2 + arcsin x − Die gleichen Terme auf der linken und rechten Seite können nun zusammengefaßt werden und es folgt somit 3 √ , 1+ √ 2 2 x 1 − x + arcsin x 1 − x dx = 2 für x ∈ [−1; 1]. Ebenso berechnet man 3 √ , 1+ √ 1 + x2 dx = x 1 + x2 + arsinh x 2 3 √ , 1+ √ 2 2 x − 1 dx = x x − 1 − arcosh x 2 wobei im letzten Fall x ∈ [1; ∞]. 51 , 5.8 Integration durch Partialbruchzerlegung Bei dieser Methode versucht man einen Integranden, der in der Form eines komplizierten Bruchs vorliegt, in eine Summe von zwei oder mehreren einfachen Brüchen zu zerlegen, deren Stammfunktionen möglichst schon bekannt sind. Man bestimmt dazu die reellen Nullstellen des Nenners und zerlegt den Bruch als Summe von4 Brüchen mit nur einer Nullstelle im Nenner. Wir illustrieren das an dem Beispiel: x21+x dx. Die B . MultiplikatiNullstellen sind x = 0 und x = −1. Wir schreiben daher x21+x = Ax + x+1 on mit x bzw. x + 1 und Auswertung der so entstandenen Gleichungen bei x = 0 bzw. x = −1 liefert: 1 B =A+ x+1 x+1 1 A(x + 1) = +B x x x=0 =⇒ A = 1 x=−1 =⇒ B = −1 . (185) 1 geschrieben werden und wir Damit kann der Integrand in der Form x21+x = x1 − x+1 erhalten ( 3 3 ' 1 1 1 dx = − dx x2 + x x x+1 = ln x − ln(x + 1) + c ( ' x +c . (186) = ln x+1 52 6 Vektoren Viele physikalische Größen lassen sich durch eine Zahl zusammen mit einer physikalischen Dimension charakterisieren. Beispiele sind die Masse (m = 78 kg), die Energie (E = 10 J), die Temperatur (T = - 177◦ C) oder die Zeit (t = 3 s). Solche Größen nennt man skalare Größen. Andere physikalische Größen wie etwa die Kraft, die Geschwindigkeit, die Beschleunigung usw. sind durch eine Richtung und einen Betrag gegeben, wobei der Betrag wieder eine skalare Größe ist. Eine derartig gerichtete Größe beschreibt man ganz praktisch und intuitiv durch einen Pfeil. Um eine Größe formal als Vektor zu kennzeichnen sind verschiedene Konventionen gebräuchlich, z.B. ⃗v , v. Das n-fache einer Kraft oder einer Geschwindigkeit wird durch einen Pfeil in gleicher Richtung, aber mit der n-fachen Länge veranschaulicht, die Gegenkraft durch einen Pfeil gleicher Länge, aber entgegengesetzter Richtung. Formal schreibt man ⃗k2 = n⃗k1 , bzw. ⃗k2 = −⃗k1 . Greifen zwei Kräfte ⃗k1 und ⃗k2 in einem Punkt P an, so bewirken sie insgesamt dasselbe wie eine einzige Kraft. Die resultierende Kraft ⃗kres ergibt sich geometrisch durch die skizzierte Parallelogrammkonstruktion in Abb. 18. Dieses definiert die Vektoraddition ⃗kres = ⃗k1 + ⃗k2 . 6.1 Koordinatendarstellung von Vektoren Eine gerichtete Größe durch einen Pfeil darzustellen, ist plausibel. Um damit auch vernünftig rechnen zu können, muß man einem Pfeil Zahlen zuordnen. Hierzu müssen erst einmal Vereinbarungen getroffen werden. Wenn sie in einer Stadt jemandem die Lage einer in der Nähe liegenden Straße beschreiben, ist es häufig ganz praktisch, dies mit Hilfe der Anzahl von Abzweigungen zu machen: an der dritten Kreuzung nach links abzweigen und dann die vierte Querstraße. Beschreiben sie die Lage eines Objektes in einem Raum, so liegt es nahe, dies wie folgt zu tun: von der Raumecke an der Eingangstür 2 Meter an der linken Wand entlang und dann zu dieser Wand senkrecht 3 Meter nach rechts. Treffen sie die Vereinbarung, ss die Wegstrecke nach rechts zuerst vor der Wegstrecke nach links genannt wird, so können sie die Lage nun durch das Zahlenpaar (3, 2) Meter angeben. Wenn sie dies mit der gemachten Vereinbarung richtig lesen, ist eigentlich über die Lage des Objektes alles gesagt. Jetzt können sie noch die Richtung an der linken Wand entlang die kres k1 a) k2 b) Abbildung 18: a) Ein Vektor für eine gerichtete Größe. b) Überlagerung von Vektoren. 53 3 y (3,2) 2 k 1 1 2 3 x Abbildung 19: Die Koordinaten (x = 3, y = 2) im kartesischen (x, y)-Koordinatensystem geben die Lage des Punktes P an. Andererseits beschreibt das Zahlenpaar auch den Vektorpfeil ⃗r , der bei (0, 0) startet und bei (3, 2) endet. y-Richtung nennen und die an der rechten Wand entlang x-Richtung und die Lage wie in Abb. 19 veranschaulichen. Formal können sie die x- und y-Richtung wieder durch Vektoren angeben, also ⃗ex und ⃗ey . Dann ist ⃗k = x⃗ex + y⃗ey für geeignete Zahlen x und y. Die Zahlen x und y nennt man die Koordinaten des Vektors ⃗k in dem durch ⃗ex und ⃗ey aufgespannten Koordinatensystem. Die Vektoren ⃗ex und ⃗ey sind dessen Basis. Es sind viele verschiedene Koordinatensysteme möglich. Tatsächlich definieren zwei beliebige Vektoren ⃗e1 und ⃗e2 ein Koordinatensystem in der Ebene, solange ⃗e1 ̸= α⃗e2 für alle α ∈ R. Hat man sich auf ein Koordinatensystem geeinigt, so reicht die Angabe der Koordinaten zur Bestimmung eines Vektors: ⃗k = (x, y). Ganz analog liegt es im dreidimensionalen Raum nahe, anstelle eines ebenen Koordinatensystemes ein Koordinatensystem mit drei Raumachsen x, y und z einzurichten und einen Punkt P im Raum bzw. einen Vektor ⃗r vom Ursprung zum Punkt P durch ein ⎛ ⎞ x ⎜ ⎟ ⎜ ⎟ Zahlentripel (x, y, z) zu beschreiben. Manchmal ist es bequemer ⃗r = ⎜ y ⎟ zu schrei⎝ ⎠ z ⎛ ⎞ x ⎜ ⎟ ⎜ ⎟ ben. Tatsächlich gibt es einen formalen Unterschied zwischen (x, y, z) und ⎜ y ⎟, der ⎝ ⎠ z hier aber nicht von Bedeutung ist. Besondere Koordinatensysteme sind die kartesischen Koordinatensysteme. Für diese stehen jeweils zwei Basisvektoren senkrecht aufeinander und jeder Basisvektor hat die Länge 1. Wir beschränken uns zunächst auf solche Koordinatensysteme. 54 k2 k1 k1 k2 Abbildung 20: Addition von Vektoren bzw. deren Verschiebung ist vertauschbar. 6.1.1 Länge eines Vektors Für die Länge oder Norm eines Vektors schreibt man |r|. Es entspricht dem Abstand eines Punktes P welcher durch r beschrieben wird vom Ursprung. Dessen Abstand läßt sich in der Ebene mit den Regeln zur Berechnung der Hypothenuse eines Dreieckes bestimmen. ! (187) | r |= x2 + y 2 Analog ist die Norm eines Vektors in 3 Dimensionen ! | r |= x2 + y 2 + z 2 und für einen Vektor in N Dimensionen r = (x1 , x2 , . . . , xN ) ist die Länge A B N B& x2i . | r |= C (188) (189) i=1 6.1.2 Elementare Rechenregeln für Vektoren ⎞ ⎛ ⎞ ⎛ x2 x1 ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ⎜ Die Addition zweier Vektoren r1 = ⎜ y1 ⎟ und r2 = ⎜ y2 ⎟ sieht in Komponenten⎠ ⎝ ⎠ ⎝ z2 z1 schreibweise so aus ⎛ ⎞ x + x2 ⎜ 1 ⎟ ⎜ ⎟ r1 + r2 = ⎜ y 1 + y 2 ⎟ . (190) ⎝ ⎠ z1 + z2 Es ist daraus unmittelbar einsichtig, daß die Reihenfolge der Addition beliebig ist. Die Summe ergibt immer den gleichen Endpunkt, was man sich leicht wie in Abb. 20 veranschaulichen kann. Es gilt also für Vektoren wie für reelle Zahlen das Kommutativgesetz. r1 + r2 = r2 + r1 55 . (191) A v a B b g O Abbildung 21: Parameterdarstellung einer Geraden. Es gibt ein neutrales Element 0 : r+0=r (192) und die Multiplikation eines Vektors mit einer Zahl a entspricht einer Multiplikation der Komponenten des Vektors, ⎛ ⎞ ax ⎜ ⎟ ⎜ ⎟ ar = ⎜ ay ⎟ , (193) ⎠ ⎝ az was einer Verlängerung gleichkommt: |ar| = a|r| (a > 0). Ausserdem gilt für Vektoren auch das Assoziativgesetz. (a + b) + c = a + (b + c) . 6.2 (194) Schnitte zweier Geraden Seien A und B zwei verschiedene Punkte mit Ortsvektoren a und b und sei g die Gerade durch A und B, so sind die Punkte von g durch die Ortsvektoren a + t(b − a) mit t ∈ R gegeben. Hierfür schreibt man g = {a + tv | tϵR} (195) wobei v = b − a. Man nennt g die Gerade durch den Punkt a mit Richtungsvektor v in Parameterdarstellung. Betrachten wir nun zwei Geraden g = {a + x1 b | x1 ϵR} und f = {c + x2 d | x2 ϵR}. 56 (196) Ist b = 0 und d = 0 so schneiden sich beide Geraden offensichtlich bei x1 = x2 = 0. Sind aber b ̸= 0 und d ̸= 0, dann schneiden sich beiden Geraden nur, wenn die Bedingung a + x1 b = c + x2 d (197) für geeignete Werte x1 und x2 erfüllt ist. Diese Bedingung bedeutet nichts weiter, als ss beide Geraden einen gemeinsamen Punkt haben. Aus dieser Bedingung können wir bei gegebenen Vektoren a, b, c, d die notwendigen Werte für x1 und x2 berechnen. Schreiben wir die Vektoren in Komponentendartstellung ⎛ ⎞ ⎛ ⎞ ⎛ ⎞ ⎛ ⎞ a1 b1 c1 d1 ⎠, ⎠, ⎠, ⎠ a=⎝ b=⎝ c=⎝ d=⎝ (198) a2 b2 c2 d2 so wird offensichtlich, daß die Vektorgleichung (197) eigentlich zwei gekoppelte lineare Gleichungen für die noch Unbekannten x1 und x2 bedeutet: x1 b1 − x2 d1 = c1 − a1 x1 b2 − x2 d2 = c2 − a2 . (199) Identifiziert man a11 = b1 , a12 = −d1 , a21 = b2 , a22 = −d2 , f1 = c1 − a1 , f2 = c2 − a2 , so läßt sich Gl.(199) umschreiben in a11 x1 + a12 x2 = f1 a21 x1 + a22 x2 = f2 . Dies läßt sich nochmals kompakter als Matrix-Gleichung schreiben ⎛ ⎞⎛ ⎞ ⎛ ⎞ a a x f ⎝ 11 12 ⎠ ⎝ 1 ⎠ = ⎝ 1 ⎠ . a21 a22 x2 f2 Mit der weiteren Abkürzung für die Koeffizientenmatrix ⎛ ⎞ a11 a12 ⎠ A=⎝ a21 a22 (200) (201) (202) kann Gl. (201) in die Form Ax = f (203) gebracht werden, an der man auf den ersten Blick gar nicht mehr erkennt, um wieviele gekoppelte lineare Gleichungen es sich handelt. Damit hat sich hier im Falle des zweidimensionalen Raumes - zwei Unbekannte x1 und x2 - neben dem Vektor mit der Matrix noch eine weitere Rechengröße aufgedrängt. Analog können auch größere Systeme linearer Gleichungen in Matrixform geschrieben werden. 57 Durch den Vergleich von Gl. (203) mit Gl. (200) erkennen wir, wie das Produkt einer Matrix A mit einem Vektor ausgeführt wird. Erstens erkennt man an Gl. (203), daß Ax, also (Matrix × Vektor), wieder ein Vektor ist. In der ersten Zeile dieses resultierenden Vektors stehen die ausmultiplizierten Faktoren der ersten Zeile der Matrix mit dem Vektor x, nämlich a11 x1 + a12 x2 , und das Produkt der zweiten Zeile der Matrix mit dem Vektor x, a21 x1 + a2 x2 , steht in der zweiten Komponente. Multiplikationen von mehrkomponentigen Vektoren mit entsprechenden Matrizen werden auf dieselbe Weise ausgeführt. Wir versuchen nun das Gleichungssystem (199) bzw. (201) zu lösen und x1 und x2 zu bestimmen. Hierfür eliminieren wir erst einmal x2 , indem wir die erste Gleichung in (200) mit a22 und die zweite aus (200) mit a12 multiplizieren und dann beide voneinander subtrahieren. Dies ergibt (a11 a22 − a21 a12 )x1 = a22 f1 − a12 f2 . (204) Entsprechend gibt a21 · (Zeile 1) - a11 · (Zeile 2) (a12 a21 − a11 a22 )x2 = a21 f1 − a11 f2 . (205) Der Vorfaktor von x1 bzw. x2 in den beiden vorangegangen Gleichungen ist die Determinante der Matrix A aus Gl. (203) det(A) = D = a11 a22 − a21 a12 . (206) Damit sehen wir, daß die beiden Gleichungen (204) und (205) gerade dann lösbar sind, wenn die Determinante D verschieden von Null ist - ansonsten würden wir ja durch 0 dividieren. Diese Lösbarkeitsbedingung gilt auch in 3 und höheren Dimensionen, die Berechnung der Determinante ist allerdings komplizierter. Für D ̸= 0 sind die beiden Lösungen 1 (a22 f1 − a12 f2 ) D 1 (a11 f2 − a21 f1 ) = D x1 = x2 . (207) Ist die Determinante Null, so sind obige Gleichungssysteme entweder unlösbar oder die Menge der Lösungspunkte (x1 , x2 ) enthält mindestens eine Gerade. Ist das Gleichungssystem (203) andererseits homogen, d.h. f = 0, dann gibt es zwei Möglichkeiten. Falls D ̸= 0, dann gibt es nur die Lösung x = 0. Falls die Determinate verschwindet, dann gibt es Lösungen x ̸= 0 dieses homogenen Gleichungsystems. 58 y a α x Abbildung 22: Vektor a = r(cos α, sin α) in Polarkoordinaten. 6.3 Polarkoordinaten Neben kartesischen Koordinaten (x, y) kann in der Ebene ein durch die Pfeilspitze des Vektors a gekennzeichneter Punkt auch durch den Abstand vom Ursprung, also der Länge des Vektors r = |a|, und dem Winkel α zwischen dem Vektor und der x-Achse beschrieben werden. Dies sind ebenfalls zwei Zahlen, r und α, wie die Anzahl der Komponenten des Vektors a = (a1 , a2 ). Aus diesen Polarkoordinaten erhält man die kartesische Koordinaten über die Beziehung ⎛ ⎞ cos α ⎠ , a = r⎝ (208) sin α wobei −π ≤ α < π. Wegen cos2 α + sin2 α = 1 gilt dann nach Konstruktion für die Länge |a| = r. In drei Dimensionen sind das Analogon die Kugelkoordinaten (gegeben durch die Länge und 2 Winkel). Polarkoordinaten von Vektoren in der Ebene sind eng mit der Polardarstellung von komplexen Zahlen verbunden, siehe 3.6. Tatsächlich kann man jeden Vektor r = (x, y) mit kartesischen Koordinaten x und y mit der komplexen Zahl x + iy identifizieren. Eine weitere Darstellung von r ist also r = reiφ . Betrachtet man noch einen zweiten Vektor ⎛ ⎞ ⎛ ⎞ b1 cos β ⎠ = rb ⎝ ⎠ b=⎝ (209) b2 sin β mit rb = |b| und −π ≤ β < π, so stellt sich z.B. die Frage, welchen Winkel diese beiden Vektoren a und b einschließen? 59 6.4 Skalarprodukt Die Multiplikation eines Vektors mit einer Zahl führt zu einer Verlängerung desselben, siehe Abschnitt 6.1.1. Für das Produkt zweier Vektoren kann man sich verschiedene Möglichkeiten vorstellen. Das Skalarprodukt zweier Vektoren so definiert, ss das Ergebnis eine reelle Zahl, ein Skalar, ist. Das Skalarprodukt ermöglicht die Definition eines Winkels ϕ zwischen zwei Vektoren. Definition Skalarprodukt. Für N-dimensionale Vektoren a und b ist a·b = N & ai bi . (210) i=1 Zum Skalarprodukt sagt man in der Literatur auch häufig Inneres Produkt. Mit dem Skalarprodukt definiert man den Winkel zwischen a und b über a · b = |a| |b| cos ϕ . (211) Mit a in Polardarstellung, a= r(cos α, sin α), und b = (1, 0) ist diese Definition unmittelbar einsichtig: a · b = r cos α. Dreht man beide Vektoren um einen Winkel β, verändert aber den Winkel zwischen beiden nicht, dann sind die Lagen beider Vektoren a = r(cos(α, β), sin(α + β)) und b = (cos β, sin β) und das Skalarprodukt von beiden Vektoren muß unverändert bleiben. Man kann dies unmittelbar nachrechnen: ⎛ ⎞ ⎛ ⎞ cos(α + β) cos β ⎠·⎝ ⎠ a·b = r⎝ sin(α + β) sin β = r [cos(α + β) cos β + sin(α + β) sin β] = r [(cos α cos β − sin α sin β) cos β + (cos α sin β + sin α cos β) sin β] / 0 = r cos α cos2 β + sin2 β = r cos α . (212) Im dritten Schritt der Rechnung wurden Additionstheoreme für trigonometrische Funktionen verwendet. Regeln für das Skalarprodukt S1 S2 S3 a·b= b·a a · (αb) = αa · b a · (b + c) = a · b + a · c 60 kommutativ assoziativ distributiv 6.5 Vektorprodukt im R3 Im Gegensatz zum Skalerprodukt ergibt das Vektorprodukt einen Vektor. Der Begriff des Vektorprodukts hat nur im dreidimensionalen Raum Bedeutung. Definition Vektorprodukt. Für Vektoren ⎛ ⎞ ⎛ ⎞ a b ⎜ 1 ⎟ ⎜ 1 ⎟ ⎜ ⎟ ⎜ ⎟ a = ⎜ a2 ⎟ , b = ⎜ b2 ⎟ ⎠ ⎝ ⎠ ⎝ a3 b3 nennt man den Vektor ⎛ a b − a3 b2 ⎜ 2 3 ⎜ c := a × b = ⎜ a3 b1 − a1 b3 ⎝ a1 b2 − a2 b1 ⎞ ⎟ ⎟ ⎟ ⎠ (213) (214) das Vektorprodukt, Kreuzprodukt oder äußere Produkt von a und b. Man kann zur Übung leicht nachrechnen, daß a·c = 0 und b·c = 0 gilt, also c senkrecht auf a und b steht. Andere in der Literatur benutzte Notationen sind [a, b], [ab] oder ab. Die Vektoren a, b, c bilden ein positiv orientiertes Dreibein, d.h. liegen im Raum wie Daumen, Zeigefinger und Mittelfinger der rechten Hand (Dreifingerregel). Eine nützliche Eigenschaft ist, daß die Länge von c dem Flächeninhalt des von a und b aufgespannten Parallelogramms entspricht. Es ist also |c| = |a| · |b| · sin ϕ, (215) wo 0 ≤ ϕ < π der Winkel zwischen den Vektoren a und b ist. Das kann man schnell nachrechnen indem man die Quadrate davon betrachtet. |a|2 |b|2 sin2 ϕ = |a|2 |b|2 (1 − cos2 ϕ) = |a|2 |b|2 − (a · b)2 = (a21 + a22 + a23 )(b21 + b22 + b23 ) − (a1 b1 + a2 b2 + a3 b3 )2 = (a2 b3 − a3 b2 )2 + (a3 b1 − a1 b3 )2 + (a1 b2 − a2 b1 )2 = |a × b|2 (216) Aus der Definition ergeben sich auch noch folgende leicht nachrechenbare Regeln für das Vektorprodukt V1 V2 V3 V4 b × a = −a × b a × (b + c) = (a × b) + (a × c) a × (rb) = r(a × b) (a × b) · a = 0 und (a × b) · b = 0 61 (217) Für das angegebene Vektorprodukt gilt also das Kommutativgesetz, nicht. Stattdessen gilt das in (V1) angegebene Gesetz. Auch das Assoziativgesetz gilt nicht. Jedoch gilt das Distributivgesetz (V2) und damit eine der wichtigsten Regeln für eine Multiplikation in einem Bereich, in dem auch eine Addition definiert ist. Das Vektorprodukt tritt in Physik und Technik bei der Beschreibung des Drehimpulses, der Bewegung eines starren Körpers sowie bei der Bewegung eines Elektrons in einem Magnetfeld auf. 62 7 Lineare Systeme Viele Probleme der Physik führen auf lineare Gleichungssysteme. In diesem Abschnitt wird deren Verbindung mit Matrizen aufgezeigt. Dies geschieht am Beispiel von Systemen aus zwei Gleichungen. 7.1 Drehungen von Vektoren Mit der Translation wurde bereits im vorigen Abschnitt eine einfache Transformation eines Vektors beschrieben: r1 → r2 = r1 + v. Eine weitere Transformation, welche die Länge des Vektors unverändert läßt, ist die Rotation um eine Winkel φ, r1 → r2 = D(φ)r1 wie Abb. 23 dargestellt. Diese Drehung läßt sich kompakt in der Polardarstellung komplexer Zahlen beschreiben r1 = reiφ1 r2 = reiφ2 . (218) Wenn r2 aus r1 durch eine Drehung hervorgeht, dann ist der Drehwinkel φ sofort offensichtlich φ = φ2 − φ1 , mit r2 = r1 eiφ . (219) In kartesischen Koordinaten führt dieses Ergebnis auf zwei Gleichungen für die einzelnen Komponenten x2 = cos(φ) x1 − sin(φ) y1 y2 = sin(φ) x1 + cos(φ) y1 (220) (221) . y r2 r1 φ φ1 x Abbildung 23: Drehung eines Vektors in der Ebene um den Winkel φ. 63 In Matrix-Schreibweise umformuliert werden diese Gleichungen zu ⎛ ⎞ ⎛ ⎞⎛ ⎞ x cos φ − sin φ x ⎝ 2 ⎠=⎝ ⎠⎝ 1 ⎠ y2 + sin φ cos φ y1 (222) Dies kann noch kompakter in der Form r2 = D(φ)r1 , geschrieben werden, wobei ⎛ D(φ) = ⎝ cos ϕ − sin φ + sin φ cos ϕ ⎞ . (223) det D(φ) = cos2 φ + sin2 φ = 1 . (224) Die Determinante der Drehmatrix D(φ) ist ⎠ Dieses Ergebnis gilt allgemein: für alle Matrizen D, die Vektoren im Raume drehen und die Länge unverändert lassen, gilt det D = 1. Wird im dreidimensionalen Raum die Drehachse als die z-Achse gewählt, so ist die Darstellung der Drehung in drei Dimensionen ⎞ ⎛ ⎞ ⎛ x x ⎜ 2 ⎟ ⎜ 1 ⎟ ⎟ ⎜ ⎟ ⎜ ⎜ y2 ⎟ = Dz (φ) ⎜ y1 ⎟ ⎠ ⎝ ⎠ ⎝ z1 z2 ⎞⎛ ⎞ ⎛ cos φ − sin φ 0 x ⎟⎜ 1 ⎟ ⎜ ⎟ ⎟⎜ ⎜ (225) = ⎜ + sin φ cos φ 0 ⎟ ⎜ y1 ⎟ ⎠ ⎝ ⎠⎝ 0 0 1 z1 analog zu der Drehung in der Ebene. 7.2 Matrix-Multiplikation Wenn wir nun nach der Drehung um den Winkel φ noch eine weitere Drehung um den Winkel θ mit der Drehmatrix D(θ) ausführen möchten, so werden wir mit der Multiplikation von Matrizen konfrontiert. Wird nämlich nach der ersten Drehung r2 = D(φ)r1 noch die zweite Drehung mit der Drehmatrix D(θ) ausgeführt, so führt dies auf r3 = D(θ)r2 = D(θ)D(φ)r1 . Da die Drehung auch in einem Schritt r3 = D(θ + φ)r1 möglich ist, ergibt sich offensichtlich die Matrix der Gesamtdrehung als das Produkt der beiden Matrizen für die Einzeldrehungen D(θ + φ) = D(θ)D(φ). Allgemein läßt 64 sich das Produkt C von zwei 2 × 2-Matrizen A und B explizit für die Matrixelemente Aij , Bij , Ci,j mit i, j = 1, 2 angeben Cij = 2 & Aik Bkj . (226) k=1 Konkret gilt für D(φ) und D(θ) unter Benutzung der Regel für die Matrixmultiplikation und den Additionstheoremen für sin und cos ⎛ ⎞ cos θ cos φ − sin θ sin φ − cos θ sin φ − sin θ cos φ ⎠ D(θ + φ) = ⎝ sin θ cos φ + cos θ sin φ − sin θ sin φ + cos θ cos φ ⎛ ⎞ cos(θ + φ) − sin(φ + θ) ⎠ . = ⎝ (227) sin(θ + φ) cos(θ + φ) Die zusammengesetzte Drehung ist wie erwartet tatsächlich auch in dieser Darstellung eine Addition der Drehwinkel. Es folgt sofort, ss hier D(θ)D(φ) = D(φ)D(θ). Im allgemeinen jedoch kommutieren zwei Matrizen unter der Multiplikation nicht! 7.3 Transponierte und inverse Matrix Zur jeder n×n Matrix A gibt es eine transponierte Matrix AT . Diese wird aus A erzeugt, indem die Matrixelemente an der Diagonale gespiegelt werden. Die Transponierte der in Gl. (235) definierten Drehmatrix ist ⎛ ⎞ cos φ sin φ ⎠ DT = ⎝ (228) − sin φ cos φ Eine Matrix heißt invers zur⎛Matrix⎞A, wenn das Produkt mit dieser die Einheits1 0 ⎠. Es gilt IA = AI = A. Die folgende Matrixmatrix I ergibt, wobei I = ⎝ 0 1 −1 Bestimmungsgleichung für A A−1 A = I (229) ist bei 2 × 2 Matrizen äquivalent zu 4 linearen Gleichungen für die 4 Matrixelemente von A−1 . Diese sollen nun berechnet werden. Ist die Ausgangsmatrix ⎛ ⎞ a b ⎠ A = ⎝ (230) c d 65 so werden die Elemente der inversen Matrix ⎛ ⎞ v v 1 2 ⎠ A−1 = ⎝ v3 v4 (231) nach Gl. (229), also durch die Gleichungen ⎛ ⎞⎛ ⎞ ⎛ ⎞ v v a b 1 0 ⎝ 1 2 ⎠⎝ ⎠=⎝ ⎠ v3 v4 c d 0 1 (232) oder av1 + cv2 = 1 , av3 + cv4 = 0 , bv1 + dv2 = 0 bv3 + dv4 = 1 . (233) bestimmt. Eliminiert man zuerst v3 und v1 so folgen unmittelbar zwei Ausdrücke für v4 und v2 , womit auch gleich v3 und v1 bestimmt werden können. Insgesamt bekommt man für die inverse Matrix ⎛ ⎞ d −b 1 ⎝ ⎠ . (234) A−1 = ad − bc −c a Für obige Drehmatrix ist damit ⎛ D−1 = DT = ⎝ cos φ sin φ − sin φ cos φ ⎞ ⎠ . (235) Die Äquivalenz D−1 = DT zeichnet die Drehmatrizen aus. Diese Eigenschaft zusammen mit det D = 1 definiert die sogenannten orthogonalen Matrizen. Unter Benutzung der inversen Matrix kann das lin. Gleichungssystem (203) leicht gelöst werden: x = A−1 f . (236) Da die Inverse von A nur existiert, falls det A ̸= 0, finden wir hier die Lösbarkeitsbedingung aus 6.2 wieder. 66 7.4 Eigenwerte und Eigenvektoren Die Drehmatrizen in drei Dimensionen lassen Vektoren entlang der Drehachse offensichtlich unverändert. Zum Beispiel läßt die Matrix aus Gl. (225) den Vektor ez = (0, 0, 1) unverändert, Dz (φ)ez = ez unabhängig vom Wert φ. Allgemeiner nennt man Vektoren, die bei Multiplikation mit einer Matrix ihre Richtung nicht ändern, Eigenvektoren der Matrix. Der Betrag, um den sich ihre Länge ändert, nennt man den zugehörigen Eigenwert. Formal werden die Eigenvektoren r und Eigenwerte λ einer Matrix A durch die Eigenwertgleichung Ar = λr bestimmt. Für eine 2 × 2-Matrix hat sie die Form ⎛ ⎞⎛ ⎞ ⎛ ⎞ a b x x ⎝ ⎠⎝ ⎠ = λ⎝ ⎠. c d y y Bringt man alles auf eine Seite, so nimmt dies die Form ⎛ ⎞⎛ ⎞ ⎛ ⎞ a−λ b x 0 ⎠⎝ ⎠ = ⎝ ⎠ = 0 (A − λI)r = ⎝ c d−λ y 0 (237) (238) (239) an. Diese Gleichung hat nur dann Lösungen x, y ̸= 0, wenn die Determinante der Matrix sf A − λI verschwindet. Die Gleichung det (A − λI) = 0 führt auf ein Polynom 2. Grades in λ (a − λ)(d − λ) − cb = λ2 − (a + d)λ + ad − cb = 0 . (240) Die beiden Lösungen dieses quadratischen Polynomes sind die beiden Eigenwerte der Matrix A , ! 1+ a + d ± (a + d)2 − 4(ad − cb) λ1,2 = 2 , ! 1+ = a + d ± (a − d)2 + 4cb) (241) 2 Diese sind reell, wenn (a − d)2 + 4cb > 0. Andernfalls sind die beiden Eigenwerte komplex konjugiert zueinander. Die Vektoren r1,2 , die für λ1,2 die Eigenwertgleichung Ar1,2 = λ1,2 r1,2 (242) erfüllen sind die beiden Eigenvektoren. Da auch ein gestreckter Vektor αr mit α ∈ R diese Eigenwertgleichung erfüllt, ist eine Komponente des Eigenvektors frei wählbar. Wählt man x1,2 = 1, so folgt als Bestimmungsgleichung für die zweite Komponente y1,2 = λ1,2 − a . b 67 (243) Häufig werden Eigenvektoren auf die Länge 1 normiert. Die Eigenwerte orthogonaler Matrizen sind zueinander orthogonal. Sind die Eigenwerte komplex, so werden auch die Eigenvektoren komplex. Beispiel 1: a = 1, b = 2, c = 2, d = 1. Die Eigenwerte sind in diesem Fall λ1 = 3 und λ = −1. Für die korrespondierenden normierten Eigenvektoren finden wir ⎛ ⎞ ⎛ ⎞ 1 1 1 1 ⎠ . r1 = √ ⎝ ⎠ , r2 = √ ⎝ (244) 2 2 1 −1 Es ist an diesem Beispiel zu sehen, daß diese beiden Eigenvektoren orthogonal zueinander sind r1 · r2 = 0, obwohl die Matrix selbst nicht orthogonal ist. Beispiel 2: a = 1, b = 2, c = −2, d = 1. In diesem Falle sind die beiden Eigenwerte komplex: λ1 = 1 + 2i und λ = 1 − 2i. Die Eigenvektoren hierzu sind ⎛ ⎞ ⎛ ⎞ 1 1 1 1 ⎠ . r1 = √ ⎝ ⎠ , r2 = √ ⎝ (245) 2 2 i −i 68 8 Wahrscheinlichkeitsrechnung 8.1 Wahrscheinlichkeiten Bei vielen Experimenten läßt sich der Ausgang nicht mit Bestimmtheit vorhersagen. Dennoch weisen sie eine gewisse Regulation auf. Dies ist z.B. beim Würfeln der Fall: Man erwartet, dass in etwa 61 der Fälle der Wurf die 6 ergibt. Bei dieser Art von Ereignissen A können wir also eine Wahrscheinlichkeit P (A) angeben, mit der das Ereignis eintritt. Für P (A) gilt P (A) = nnAS wobei nA die Anzahl der Ereignisse A angibt und nS die Gesamtzahl aller möglichen Ereignisse S und ns , nA ≫ 1. 8.2 Eigenschaften der Wahrscheinlichkeit Unabhängig von dem betrachteten System besitzen die Wahrscheinlichkeiten folgende Eigenschaften: (i) Für ein beliebiges Ereignis A im Konfigurationsraum F gilt 0 ≤ P (A) ≤ 1 (246) (ii) Für die Gesamtwahrscheinlichkeit aller möglichen Ereignisse S gilt P (S) = nS =1 nS (247) (iii) Die Zahl der Ereignisse bei denen A oder B auftritt ist nA∪B = nA + nB − nA∩B , (248) wobei nA∩B die Zahl der Ereignissen angibt bei denen A und B gemeinsam auftreten. Damit gilt für die Wahrscheinlichkeit P (A ∪ B) = P (A) + P (B) − P (A ∩ B) (249) Lassen Sie uns für (iii) ein Beispiel betrachten. Wir suchen die Wahrscheinlichkeit dafür, aus einem Skat-Kartenspiel zufällig ein Pik oder einen Buben zu ziehen. Da es 8 Pik-Karten, 4 Buben und einen Pik-Buben gibt, gilt nS = 32; nP = 8; nB = 4; nB∩P = 1 und damit P (P ∪ B) = P (P ) + P (B) − P (P ∩ B) = 8/32 + 4/32 − 1/32 = 11/32. 8.3 Bedingte Wahrscheinlichkeiten Bislang haben wir nur Wahrscheinlichkeiten betrachtet, die die relative Häufigkeit angeben, ss Ereignis A eintritt. Häufig ergeben sich aber auch Fragestellungen, bei denen man die Wahrscheinlichkeit dafür sucht, ss Ereignis B eintritt unter der Bedingung, 69 ss vorher A eingetreten ist. Man spricht dann von einer bedingten Wahrscheinlichkeit. Um bei dem Kartenbeispiel zu bleiben: Was ist die Wahrscheinlichkeit dafür zwei Asse hintereinander aus einen Kartenstapel zu ziehen? Solche bedingten Wahrscheinlichkeiten schreiben wir in der Form P (B|A). Wie berechnet man bedingte Wahrscheinlichkeiten? Die Wahrscheinlichkeit, ss A und B auftreten, sei gegeben durch P (A ∩ B) = P (B ∩ A). Dann gilt P (A ∩ B) = P (A) P (B|A) = P (B) P (A|B) . (250) Also gilt für die bedingte Wahrscheinlichkeit P (A ∩ B) P (B) P (A|B) = und P(B|A) = P(B ∩ A) P(A) . (251) Für den Fall, dass sich zwei Ereignisse ausschließen gilt: P (A|B) = 0 = P (B|A) (252) Lassen Sie uns diese Ergebnisse auf das Beispiel mit den zwei Assen anwenden. Bei einem solchen Experiment muß man zwischen zwei Fällen unterscheiden. Im ersten Fall wird die erste gezogene Karte wieder zurückgelegt bevor die zweite gezogen wird (Sampling mit Ersetzen), im zweiten Fall nicht (Sampling ohne Ersetzen). In unserem Beispiel erhält man (i) mit Zurücklegen 1 64 ; (253) 1 3 3 · = 8 31 248 . (254) P (A ∩ B) = P (A) P (B|A) = P (A)2 = (ii) ohne Zurücklegen P (A ∩ B) = P (A) P (B|A) = Von statistischer Unabhängigkeit zweier Ereignisse spricht man, wenn P (A|B) = P (A). Daraus folgt sofort, ss in diesem Fall P (A ∩ B) = P (A)P (B) . Eine nützliche Eigenschaft ist die folgende Normierungsbedingung & P (B) = P (A) P (B|A) (255) (256) A falls die Summe über alle Ereignisse A läuft. Aus der Identität P (A) P (B|A) = P (A∩B) = P (B) P (A|B) folgt direkt das Bayes’sche Theorem: P (A) P (A|B) = P (B|A) , (257) P (B) 70 welches die Basis für einen ganzen Zweig der Statistik bildet. Bevor wir den Nutzen des Theorems an einem Beispiel illustrieren, stellen wir noch eine Umformulierung des Theorems vor. Sie ist immer dann nützlich, wenn die Einzelwahrscheinlichkeit P (B) nicht bekannt ist. Aus der Normierungsbedingung erhalten wir P (B) = P (A) P (B|A) + P (A) P (B|A) , (258) wobei P (A) die Wahrscheinlichkeit ist, ss A nicht eintritt. Damit lautet dann (257): P (A|B) = P (A) P (B|A) P (A) P (B|A) + P (A)P (B|A) . (259) Betrachten wir als Beispiel einen Bluttest, der mit 99,99 % Wahrscheinlichkeit ein positives Ergebnis aufweist, wenn ein Patient infiziert ist. Für nichtinfizierte Menschen ist der Test mit Wahrscheinlichkeit 0.02% positiv. Die Krankheit tritt in einer Gruppe von 10.000 Menschen einmal auf. Nun wird zufällig ein Mensch ausgewählt und positiv getestet. Wie groß ist die Wahrscheinlichkeit, dass er tatsächlich infiziert ist? Sei P (A) die Wahrscheinlichkeit der Infektion und P (B) die Wahrscheinlichkeit 9999 1 , P (A) = 1 − P (A) = 10000 , für einen positiven Test. Dann gilt also P (A) = 10000 9998 2 P (B|A) = 1 − P (B|A) = 10000 und P (B, A) = 10000 . Damit folgt durch Anwendung von Bayes’ Theorem für die Wahrscheinlichkeit einer Infektion bei einem positiven Test P (A) P (B|A) P (A) P (B|A) + P (A) P (B|A) 1/10000 · 9998/10000 = (1/10000 · 9998/10000) + (9999/10000 · 2/10000) 1 . (260) ≈ 3 Trotz der großen Zuverlässigkeit des Tests, ist die Unsicherheit nach dem Test also immer noch sehr groß. Dies liegt darin begründet, ss die Krankheit so selten auftritt. P (A|B) = 8.4 Permutationen und Kombinationen Zur Berechnung von Wahrscheinlichkeiten ist es also nötig, die Häufigkeit zu bestimmen, mit der ein Ereignis auftritt. Häufig kann dieses Problem in der folgenden Form formuliert werden: Man betrachte n Objekte, die alle paarweise verschieden sind. Auf wie viele Arten kann man die Objekte auf n Plätze verteilen? Anders gefragt: wieviele Permutationen dieser Objekte gibt es? Das Ergebnis lässt sich einfach herleiten: Bei der Anordnung des ersten Objekts gibt es n Möglichkeiten, bei der Anordnung des zweiten bleiben (n − 1) Möglichkeiten usw., so ss sich insgesamt n(n − 1)(n − 1) . . . 2 · 1 = n! verschiedene Möglichkeiten ergeben. Wenn wir nur k ≤ n Objekte ohne Zurücklegen aus den n Objekten auswählen, so gibt es insgesamt n! n(n − 1)(n − 2) . . . (n − k + 1) = ≡ Pkn (261) (n − k)! 71 Varianten, die alle zu derselben Menge von ausgewählten Objekten führen. Mit Zurücklegen gibt es nk Varianten. Mit diesen Überlegungen können wir nun bestimmen, wie groß ist die Wahrscheinlichkeit dafür ist, ss in einer Gruppe von k Personen zwei am gleichen Tag Geburtstag haben. Die Gesamtzahl aller möglichen Geburtstagskombinationen ist nk = 365k , die Anzahl der Kombinationen ohne Überschneidungen (entspricht dem Fall ohne Zurücklegen) ist Pkn . Daraus erhalten wir für die gesuchte Wahrscheinlichkeit P Pkn 365! = k 365 (365 − k)! 365k √ # $n Mit der Stirling-Formel n! ≈ 2πn ne erhalten wir 1−P = −k P ≈1−e ' 365 365 − k . (365−4+0.5 (262) (263) Für k = 23 gilt bereits P > 12 und für k = 50 gilt p ≈ 0.97! Wenn die Reihenfolge der Anordnung keine Rolle spielt, so gilt für die Zahl der Möglichkeiten: ⎛ ⎞ n h! ≡ Ckn = ⎝ ⎠ , (264) (n − k)!k! k wobei 0 ≤ k ≤ n. Damit erhalten ⎛ wir ⎞ dann auch sofort den verallgemeinerten binomin n % ⎝ ⎠ ak bn−k : die Binomialkoeffizienten Ckn geben schen Lehrsatz (a + b)n = k=0 k an, auf wieviele Arten man k a’s und n − k b’s anordnen kann. Abbildung 24: kumulative Wahrscheinlichkeitsfunktion 72 8.5 Kontinuierliche Zufallsvariablen und Verteilungen Bisher haben wir nur Systeme betrachtet, die eine diskrete Menge von Ereignissen besitzen. Die Zufallsvariable X kann in diesem Fall nur die Werte X1 , . . . , Xn mit den Wahrscheinlichkeiten P1 , . . . , Pn annehmen. Wir können eine Wahrscheinlichkeitsfunktion definieren, die die folgende Gestalt hat ⎧ ⎨ P falls x = X i i f (x) = P (X = x) = . (265) ⎩ 0 sonst Die Wahrscheinlichkeitsfunktion ist normiert, denn es gilt auch die kumulative Wahrscheinlichkeitsfunktion & F (x) = P (X ≤ x) = f (xi ) n % f (xi ) = 1. Wir können i=1 (266) xi ≤x definieren, die beide in Abb. 24 für das Beispiel eines Würfels illustriert sind. Diese Funktionen bringen kaum Vorteile, wenn man sich auf diskrete Zufallsvariablen beschränkt, sind aber von großer Bedeutung bei kontinuierlichen Zufallsvariablen. Wenn die Wertemenge einer Zufallsvariable nicht mehr abzählbar ist, werden die Wahrscheinlichkeiten über eine Wahrscheinlichkeitsdichte f (x) bestimmt. Für diese gilt, ss die Wahrscheinlichkeit, dass die Zufallsvariable χ zwischen x und x + dx liegt, durch P (x < χ ≤ x + dx) ≡ f (x)dx gegeben ist. Außerdem gilt die Normierungsbedingung 4∞ f (x)dx = 1, denn es ist sicher, ss irgendein Ereignis eintritt. Ist χ auf das Intervall −∞ 4x [x1 , x2 ] beschränkt, so gilt x12 f (χ)dχ = 1. Die Wahrscheinlichkeit, ss χ einen Wert im 4b Intervall [a, b] annimmt ist P (a ≤ χ ≤ b) = a f (x)dx. Die kumulative Verteilung ist durch 3 x F (x) = P r(χ ≤ x) = f (χ)dχ (267) x1 gegeben. Also ist P (a ≤ χ ≤ b) = F (b) − F (a). Lassen Sie uns noch anmerken, ss die Wahrscheinlichkeitsdichte auch von mehr als einer Variablen abhängen kann. In diesem Fall ist P (x = xi ; y = yj ) = f (xi , yj ) , (268) P (x < χ ≤ x + dx, y < η ≤ y + dy) = f (x, y)dxdy . (269) bzw. Bei statistischer Unabhängigkeit der Variablen χ und η faktorisiert die Verteilungsfunktion, d.h. f (x, y) = g(x)h(y). 73 8.6 Statistische Größen Sei g eine Funktion der Zufallsvariable χ, die eine Wahrscheinlichkeitsdichte f besitze. Dann ist der Erwartungswert E[g] von g definiert über ⎧ ⎨ % g(x )f (x ) für eine diskrete Verteilung i i i E[g] = . (270) 4 ⎩ g(x)f (x)dx für eine kontinuierliche Verteilung Aus dieser Definition lassen sich folgende Eigenschaften des Erwartungswertes leicht ableiten: (i) Falls a eine Konstante ist, gilt E[a] = a. (ii) Für eine beliebige Konstante gilt a E[ag] = aE[g]. (iii) Falls g(x) = h(x) + k(x), so ist auch E[g] = E[h] + E[k] Der Erwartungswert der Funktion g(x) = x wird auch der Mittelwert der Verteilung f genannt. Also ⎧ ⎨ % x f (x ) für diskrete Verteilungen i i i ⟨x⟩ = . (271) 4 ⎩ xf (x)dx für kontinuierliche Verteilungen Andere Schreibweisen sind E(x) oder [x]. Der Mittelwert einer Verteilung gibt häufig den typischen Wert der zugehörigen Zufallsvariable an. Neben den Mittelwert wird eine Verteilung auch oft durch den Median xmed charakterisiert. Das ist der Wert für den P (χ ≤ xmed ) = 1/2. Bei Zufallsprozessen ist es auch wichtig, die Fluktuationen um den Mittelwert zu charakerisieren. Üblicherweise wird dazu die Varianz verwendet. Sie wird definiert als ⎧ ⎨ % (x − ⟨x⟩)2 f (x ) für diskrete Verteilungen i i i 2 E[(x − ⟨x⟩) ] = . (272) 4 ⎩ (x − ⟨x⟩)2 f (x)dx für kontinuierliche Verteilungen Eine alternative Notation ist σ 2 oder auch V [x]. Ein weiteres Maß für die Fluktuationen ist die mittlere absolute Abweichung 3 Eabs = E[|x − ⟨x⟩|] = |x − ⟨x⟩|f (x) dx . (273) Betrachten wir ein Beispiel aus der Atomphysik. Die Wahrscheinlichkeit, ein Elektron im Wasserstoffatom im Volume dV zu finden ist durch ψ ∗ ψdV gegeben, wobei ψ(x, y, z) die quantenmechanische Wellenfunktion bezeichnet. Bei der Lösung der Schrödingergleichung für dieses Problem stellt sich heraus, ss die Wahrscheinlichkeit nur vom Abstand zum Atomkern abhängt. Es ist ψ = Ae−r/a0 . Für die radiale Wahrscheinlichkeitsdichte ergibt sich denn insgesamt 2 −2r/a0 P (r < R ≤ r + dr) = GA2 eHI J4πr G HI drJ ψψ∗ 74 V olumen (274) Die Konstante A bestimmen wir aus der Normierungsbedingung A2 3∞ e−2r/a0 4πr 2 dr = 1 . (275) 0 Dieses Integral können wir durch partielle Integration lösen. Es folgt A = 2 −2r/a0 f (r) = 4a−3 0 r e . 1 , πa30 so ss (276) Der mittlere Abstand des Elektrons vom Kern ist somit ⟨r⟩ = 3∞ 0 4 rf (r)dr = 3 a0 3∞ r 3 c−2r/a0 dr = 3a0 2 . (277) 0 Schließlich können wir noch die Varianz σ 2 berechnen σ 2 3∞ = (r − ⟨r⟩)2 f (r) dr (278) 0 4 = 3 a0 Mit ⟨r⟩ = 8.7 3a0 2 ergibt sich σ 2 = 3∞ (r 4 − 2r 3 ⟨r⟩ + r 2 ⟨r⟩2 )e−2r/a0 dr . (279) 0 3a20 . 4 Die Gauß-Verteilung Sehr viele Systeme werden durch die Gauß-Verteilung beschrieben. Diese hat die Form ( ' 1 (x − x0 )2 (280) fσ (x) ≡ √ exp − 2σ 2 2πσ 2 mit dem Mittelwert x0 und der Varianz σ 2 . Eine besondere Eigenchaft der Gauß-Verteiliung f σ ist der schnelle asymptotische Abfall. Zum Beispiel treten Fluktuationen der Größe 10σ nur mit einer Wahrscheinlichkeit kleiner als 2 × 10−23 auf. Die Bedeutung der Gauß-Verteilung ergibt sich aus dem zentralen Grenzwertsatz: Seien χi mit i = 1, 2, . . . , n unabhängige Zufallsvariablen, die durch die Wahrscheinlichkeitsdichten fi (x) beschrieben werden. Diese können alle verschieden sein. Die Mittelwerte 2 der Verteilungen seien m% i und die Varianzen σi . n Die Zufallsvariable ζ = ( i=1 χi ) /n besitzt die folgenden Eigenschaften % (i) E(ζ) = ( ni=1 mi )/n = m 75 2 (ii) V [ζ] ≡ σ = ' n % i=1 σi2 ( /n2 (iii) Für n → ∞ ist die zugehörige Wahrscheinlichkeitsdichte eine Gauß-Verteilung mit Erwartungswert m und Varianz σ 2 . Damit werden unkorrelierte Summen von Zufallsvariablen unter sehr allgemeinen Bedingungen durch Gauß-Verteilungen beschrieben. 76 9 Literatur Da die hier behandelte Mathematik nicht wesentlich über die Schulmathematik hinausgeht, sollten Sie alles Wesentliche in Ihren Schulbüchern finden. Falls Sie schon etwas weiterlesen möchten, so seien Ihnen die folgenden beiden Bücher empfohlen: • S. Großmann, Mathematischer Einführungskurs für die Physik, B.G. Teubner Verlag, Wiesbaden Das Buch ist von einem Physiker geschrieben und bietet ausführliche Erklärungen der Methoden, ohne größere mathematische Beweise. • K. Jähnich, Mathematik. Geschrieben für Physiker, Springer-Verlag, Heidelberg Die beiden Bände behandeln einen Großteil der Mathematik, wie sie im Grundstudium gelehrt wird. Dabei wird ein guter Mittelweg zwischen mathematische Strenge und dem Bedürfnis der Physiker nach anwendbarem Wissen gefunden. Der Autor ist Mathematiker. Es sei darauf hingewiesen, dass kein Buch allen Wünschen und Bedürfnissen gerecht werden kann. Bevor Sie sich eines anschaffen, sollten Sie ausprobieren, wie Sie mit ihm zurechtkommen. Darüberhinaus ist es empfehlenswert, sich ein Nachschlagewerk anzuschaffen. Unter Physikern erfreut sich die folgende Formelsammlung großer Beliebtheit • I. Bronstein, K. Semendjajew, Taschenbuch der Mathematik, Verlag Harri Deutsch, Frankfurt Dort sind nahezu alle Regeln gesammelt, die irgendwo in Mathematikvorlesungen besprochen werden und mehr. 77